前言
在分布式专题的开篇,我们曾提到,如今成熟的互联网架构,对于分库分表的应用必不可少!
从本节开始,我们聊一聊分库分表之MyCat,看看MyCat如何突破数据库性能瓶颈,MyCat的实战应用以及MyCat企业级高可用方案。
本文适合日常工作中接触的系统数据量比较小,不清楚分库分表的意义与实际操作的同学。
MyCat共计分为三节,分别是:
本节重点:
➢ 理解分库分表的意义
➢ 理解数据切分的不同方式,以及带来的问题与解决方案
➢ 通过实际案例掌握Mycat 特性
为什么要分库分表
对于应用来说,如果数据库性能出现问题,要么是无法获取连接,是因为在高并发的情况下连接数不够了。要么是操作数据变慢,数据库处理数据的效率除了问题。要么是存储出现问题,比如单机存储的数据量太大了,存储的问题也可能会导致性能的问题。
数据库性能瓶颈主要原因
归根结底都是受到了硬件的限制,比如CPU,内存,磁盘,网络等等。但是我们优化肯定不可能直接从扩展硬件入手,因为带来的收益和成本投入比例太比。
所以我们先来分析一下,当我们处理数据出现无法连接,或者变慢的问题的时候,我们可以从哪些层面入手。
我们拿某电商系统的数据库设计为例:
上图为A公司最原始的数据库设计方案。
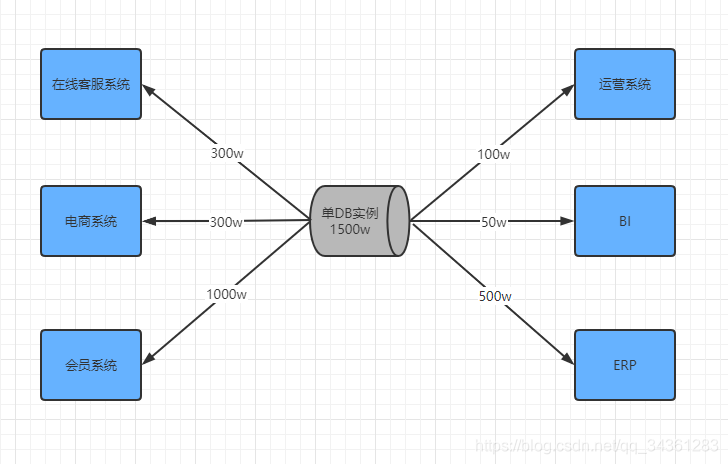
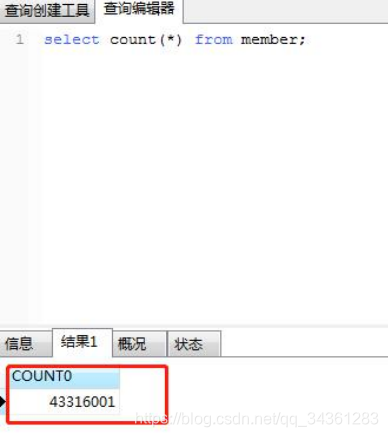
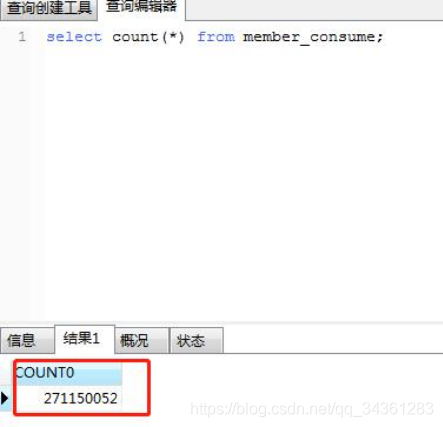
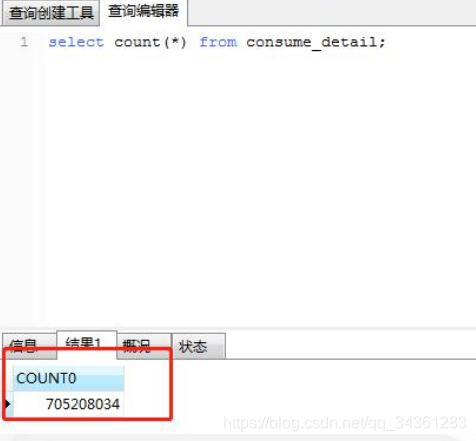
我们再看A公司核心单表的数据量:
会员表:4300w+
会员订单表:2.7亿+
订单商品表:7亿+
这样的数据库设计显然是不合理的:
- 数据库连接(连接实例)
在单数据库实例下,无法同时满足各个子系统高峰时并发访问,并且会随着时间的推移,活动的上线等业务,满足需求的能力也渐行渐远。
- 表数据量(空间存储)
表空间:通常MySql的单表数据量在1000w~1500w之间,数据行数控制在500w行以内(具体的性能测试在此不做细谈)。而上面案例展示的单表则远超1500w。
硬盘级索引:如果命中不了,则会全表的扫描;命中索引,我们知道索引是硬盘级的,它是存储在硬盘里面,那么就会有大量的IO操作。
- 硬件资源限制(QPS\TPS)
- 内存大小
- 机械硬盘&固态硬盘
数据性能优化方案
通过上面的案例我们不难分析,这样的数据库设计是需要优化的
SQL 与索引
因为SQL 语句是在我们的应用端编写的,所以第一步,我们可以在程序中对 SQL 语句进行优化,最终的目标是用到索引。这个是容易的也是最常用的优化手段。
关于SQL优化部分,我们在前面已经讲过:
MySql 性能优化 - 01 - MySql索引机制
MySql 性能优化 - 02 - MySql运行机理
MySql 性能优化 - 03 - 深入理解InnoDB
MySql 性能优化 - 04 - MySql调优
表与存储引擎
第二步,数据是存放在表里面的,表又是以不同的格式存放在存储引擎中的,所以我们可以选用特定的存储引擎,或者对表进行分区,对表结构进行拆分或者冗余处理, 或者对表结构比如字段的定义进行优化。
架构
第三步,对于数据库的服务,我们可以对它的架构进行优化。
如果只有一台数据库的服务器,我们可以运行多个实例,做集群的方案,做负载均衡。
或者基于主从复制实现读写分离,让写的服务都访问 master 服务器,读的请求都访问从服务器,slave 服务器自动master 主服务器同步数据。
或者在数据库前面加一层缓存,达到减少数据库的压力,提升访问速度的目的。
为了分散数据库服务的存储压力和访问压力,我们也可以把不同的数据分布到不同的服务节点,这个就是分库分表(scale out)。
注意主从(replicate)和分片(shard)的区别: 主从通过数据冗余实现高可用,和实现读写分离。分片通过拆分数据分散存储和访问压力。
配置
第四步,是数据库配置的优化,比如连接数,缓冲区大小等等,优化配置的目的都是为了更高效地利用硬件。
操作系统与硬件
最后一步操作系统和硬件的优化。
从上往下,成本收益比慢慢地在增加。所以肯定不是查询一慢就堆硬件,堆硬件叫做向上的扩展(scale up)。
什么时候才需要分库分表呢?我们的评判标准是什么?
如果是数据量的话,一张表存储了多少数据的时候,才需要考虑分库分表? 如果是数据增长速度的话,每天产生多少数据,才需要考虑做分库分表?
如果是应用的访问情况的话,查询超过了多少时间,有多少请求无法获取连接,才需要分库分表?这是一个值得思考的问题。
架构演进与分库分表
知其然也要知其所以然,关于读写分离与分库分表的历史演进过程,不妨回忆这篇:分布式专题-漫谈分布式架构01-分布式架构的演进过程
在本节,我们将终结剩下的两部分MySql优化方案,即 读写分离、分库分表。

单应用单数据库
以某个消费金融核心系统,这个是一个典型的单体架构的应用。同学们应该也很熟悉,单体架构应用的特点就是所有的代码都在一个工程里面,打成一个war 包部署到tomcat,最后运行在一个进程中。
这套消费金融的核心系统,用的是Oracle 的数据库,初始化以后有几百张表,比如客户信息表、账户表、商户表、产品表、放款表、还款表等等。
为了适应业务的发展,我们这一套系统不停地在修改,代码量越来越大,系统变得越来越臃肿。为了优化系统,我们搭集群,负载均衡,加缓存,优化数据库,优化业务代码系统,但是都应对不了系统的访问压力。
所以这个时候系统拆分就势在必行了。我们把以前这一套采购的核心系统拆分出来很多的子系统,比如提单系统、商户管理系统、信审系统、合同系统、代扣系统、催收系统,所有的系统都依旧共用一套Oracle 数据库。
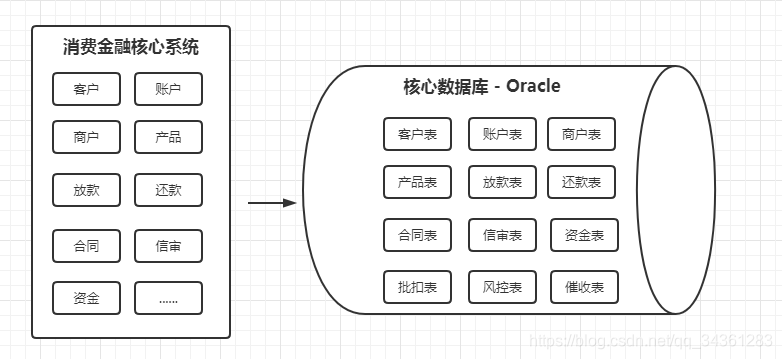
多应用单数据库
对代码进行了解耦,职责进行了拆分,生产环境出现问题的时候,可以快速地排查和解决。
这种多个子系统共用一个DB 的架构,会出现一些问题。
第一个就是所有的业务系统都共用一个DB,无论是从性能还是存储的角度来说,都是满足不了需求的。随着我们的业务继续膨胀,我们又会增加更多的系统来访问核心数据库,但是一个物理数据库能够支撑的并发量是有限的,所有的业务系统之间还会产生竞争,最终会导致应用的性能下降,甚至拖垮业务系统。
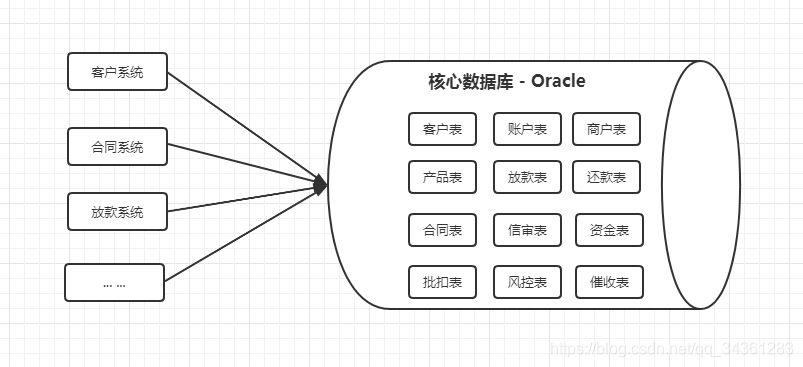
多应用独立数据库
所以这个时候,我们必须要对各个子系统的数据库也做一个拆分。这个时候每个业务系统都有了自己的数据库,不同的业务系统就可以用不同的存储方案。
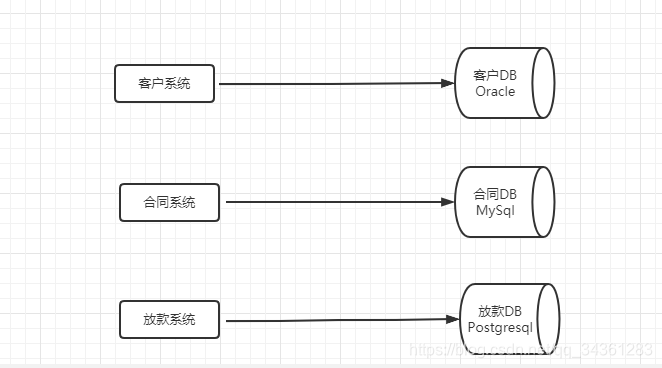
所以,分库其实是我们在解决系统性能问题的过程中,对系统进行拆分的时候带来的一个必然的结果。现在的微服务架构也是一样的,只拆应用不拆分数据库,不能解决根本的问题。
什么时候分表?
当我们对原来一个数据库的表做了分库以后,其中一些表的数据还在以一个非常快的速度在增长,这个时候查询也已经出现了非常明显的效率下降。
所以,在分库之后,还需要进一步进行分表。当然,我们最开始想到的可能是在一个数据库里面拆分数据,分区或者分表,到后面才是切分到多个数据库中。
分表主要是为了减少单张表的大小,解决单表数据量带来的性能问题。
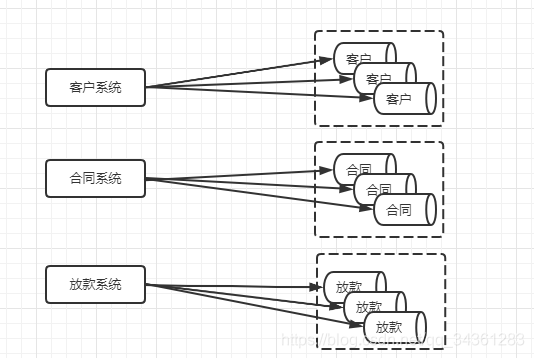
我们需要清楚的是,分库分表会提升系统的复杂度,如果在近期或者未来一段时间内必须要解决存储和性能的问题,就不要去做超前设计和过度设计。就像我们搭建项目, 从快速实现的角度来说,肯定是从单体项目起步的,在业务丰富完善之前,也用不到微服务架构。
如果我们创建的表结构合理,字段不是太多,并且索引创建正确的情况下,单张表存储几千万的数据是完全没有问题的,这个还是以应用的实际情况为准。当然我们也会对未来一段时间的业务发展做一个预判。
读写分离
区别读、写多数据源方式进行数据的存储和加载。
数据的存储(增删改)一般指定写数据源,数据的读取查询指定读数据源(读写分离会基于主从复制)
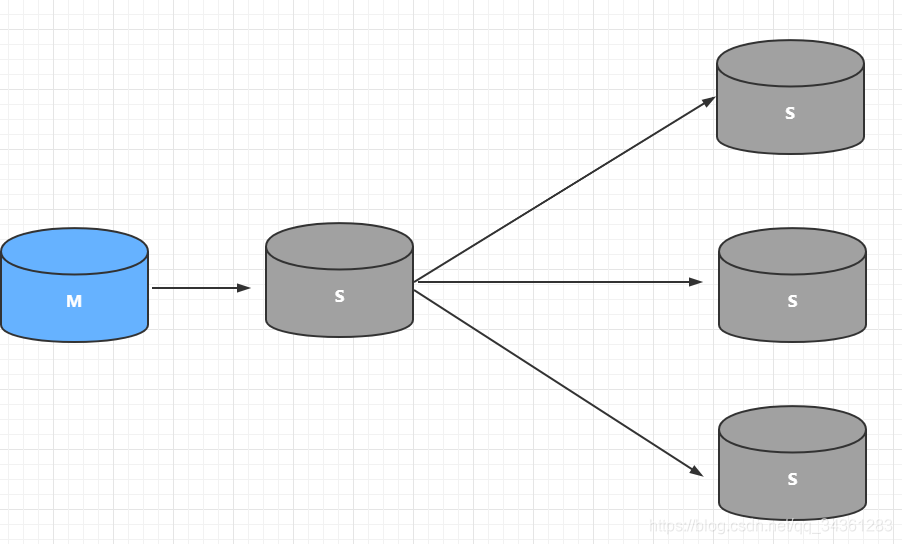
图解读写分离:
从主从形式上可以划分为:
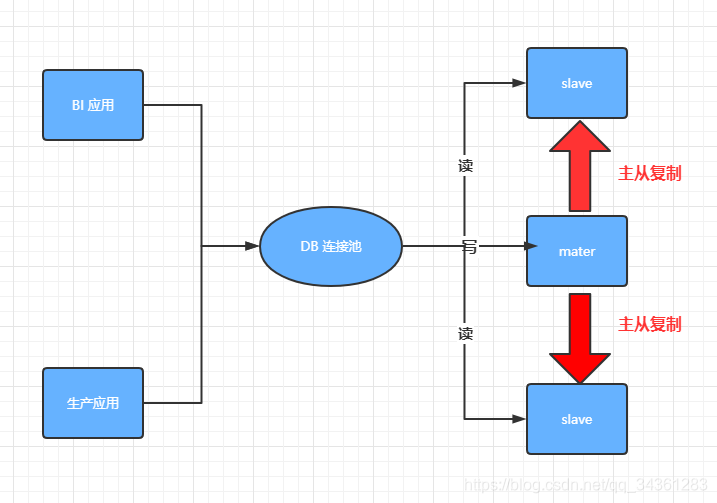
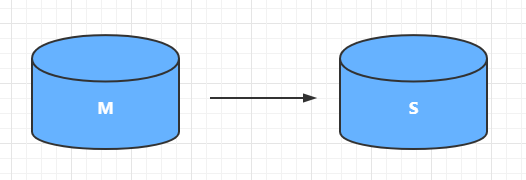
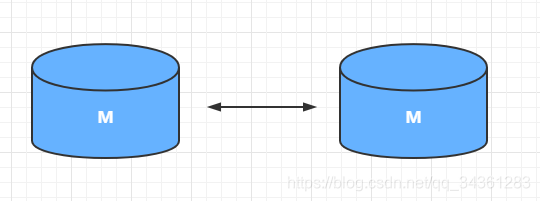
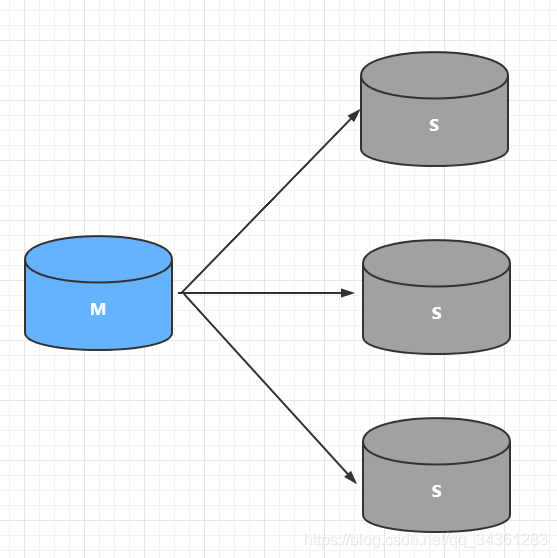
下图M:mater (主)、S:slave(从)
-
一主一从
-
互为主从
-
一主多从
-
级联主从
读写分离能够解决哪些问题?
- 数据库连接
- 硬件资源限制
分库分表
对数据的库表进行拆分,用分片的方式对数据进行管理。
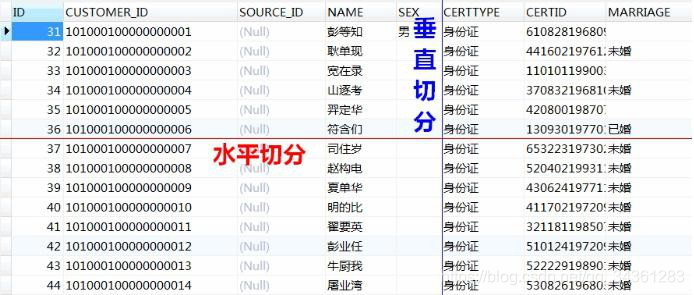
从维度来说分成两种,一种是垂直,一种是水平。
- 垂直切分:基于表或字段划分,表结构不同。我们有单库的分表,也有多库的分库。
- 水平切分:基于数据划分,表结构相同,数据不同,也有同库的水平切分和多库的
切分。
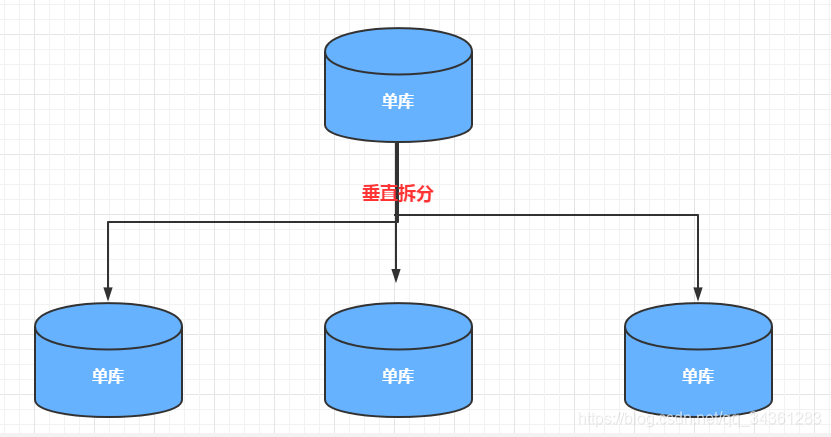
垂直拆分
垂直分表有两种,一种是单库的,一种是多库的。
- 单库垂直分表
单库分表,比如:商户信息表,拆分成基本信息表,联系方式表,结算信息表,附件表等等。 - 多库垂直分表
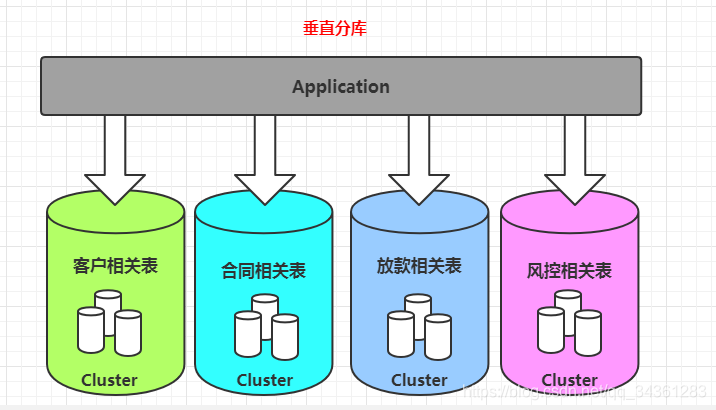
多库垂直分表就是把原来存储在一个库的不同的表,拆分到不同的数据库。比如:消费金融核心系统数据库,有很多客户相关的表,这些客户相关的表,全部单独存放到客户的数据库里面。合同,放款,风控相关的业务表也是一样的。
图解垂直拆分:
垂直拆分能够解决哪些问题?
- 数据库连接
- 硬件资源限制
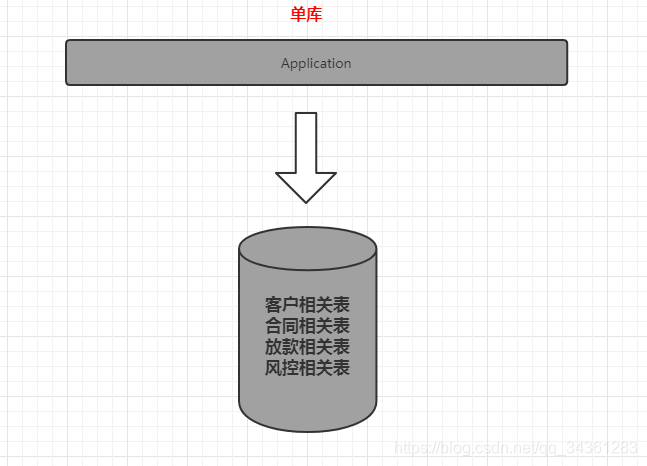
经过垂直分库:
当我们对原来的一张表做了分库的处理,如果某些业务系统的数据还是有一个非常快的增长速度,比如说还款数据库的还款历史表,数据量达到了几个亿,这个时候硬件限制导致的性能问题还是会出现,所以从这个角度来说垂直切分并没有从根本上解决单库单表数据量过大的问题。在这个时候,我们还需要对我们的数据做一个水平的切分。
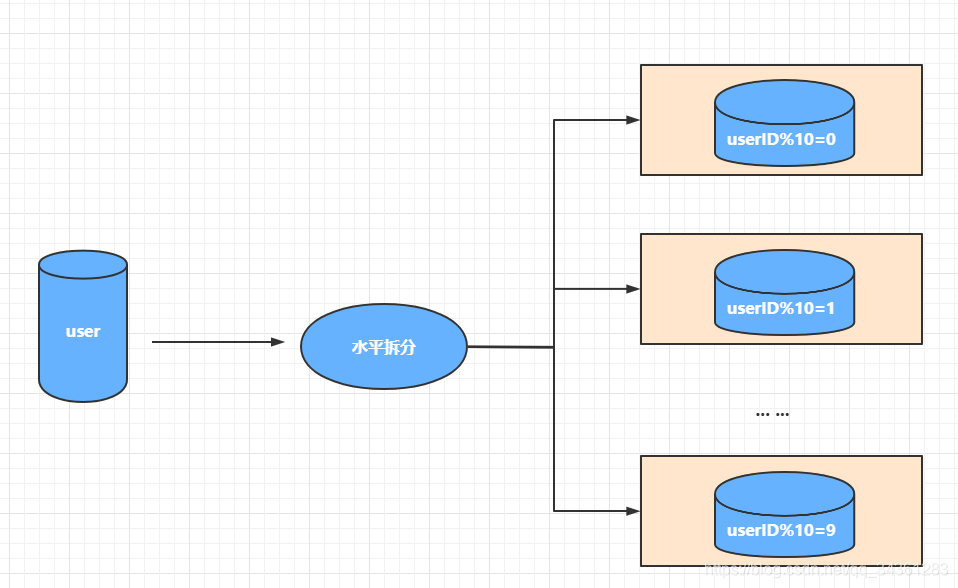
水平拆分
当我们的客户表数量已经到达数千万甚至上亿的时候,单表的存储容量和查询效率都会出现问题,我们需要进一步对单张表的数据进行水平切分。水平切分的每个数据库的表结构都是一样的,只是存储的数据不一样,比如每个库存储 1000 万的数据。
水平切分也可以分成两种,一种是单库的,一种是多库的。
- 单库水平分表
- 多库水平分表
图解水平拆分:
水平拆分能够解决哪些问题?
- 表数据量大的问题
- 数据库连接
- 硬件资源限制
单库水平分表
银行的交易流水表,所有进出的交易都需要登记这张表,因为绝大部分时候客户都是查询当天的交易和一个月以内的交易数据,所以我们根据使用频率把这张表拆分成三张表:
- 当天表:只存储当天的数据。
- 当月表:在夜间运行一个定时任务,前一天的数据,全部迁移到当月表。用的是
insert into select,然后delete。 - 历史表:同样是通过定时任务,把登记时间超过 30 天的数据,迁移到history 历史表(历史表的数据非常大,我们按照月度,每个月建立分区)。
费用表:
消费金融公司跟线下商户合作,给客户办理了贷款以后,消费金融公司要给商户返费用,或者叫提成,每天都会产生很多的费用的数据。为了方便管理,我们每个月建立一张费用表,例如fee_detail_202101……fee_detail_202102。
但是注意,跟分区一样,这种方式虽然可以一定程度解决单表查询性能的问题,但是并不能解决单机存储瓶颈的问题。
多库水平分表
另一种是多库的水平分表。比如客户表,我们拆分到多个库存储,表结构是完全一样的。
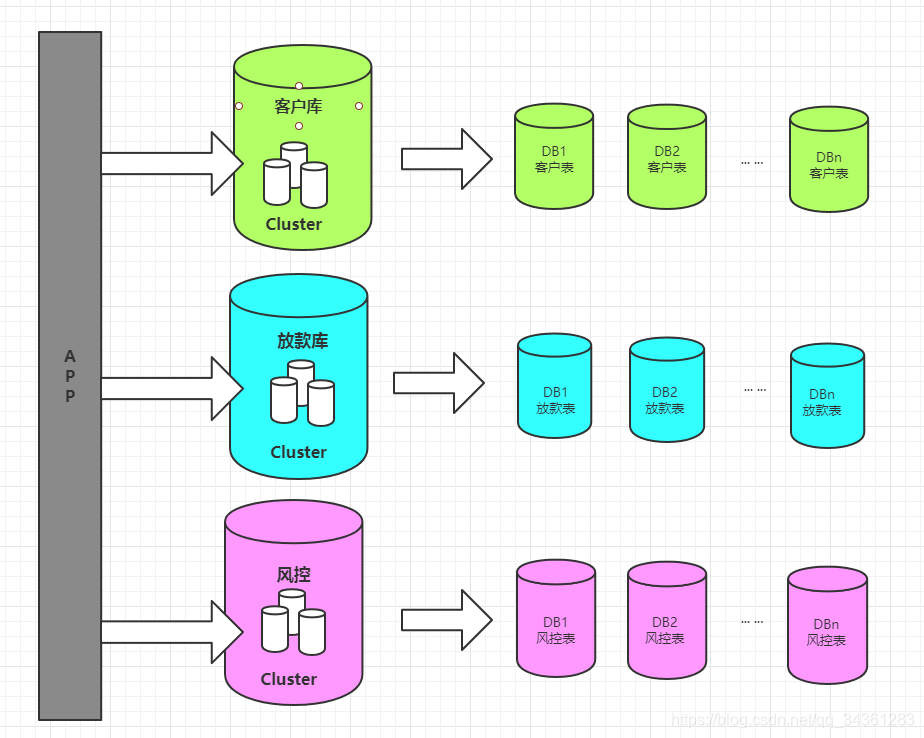
一般我们说的分库分表都是跨库的分表。
既然分库分表能够帮助我们解决性能的问题,那我们是不是马上动手去做,甚至在项目设计的时候就先给它分几个库呢?先冷静一下,我们来看一下分库分表会带来哪些问题,也就是我们前面说的分库分表之后带来的复杂性。
多案分库分表带来的问题
跨库关联查询
比如查询在合同信息的时候要关联客户数据,由于是合同数据和客户数据是在不同的数据库,那么我们肯定不能直接使用join 的这种方式去做关联查询。
我们有几种主要的解决方案:
- 字段冗余
比如我们查询合同库的合同表的时候需要关联客户库的客户表,我们可以直接把一些经常关联查询的客户字段放到合同表,通过这种方式避免跨库关联查询的问题。 - 数据同步:比如商户系统要查询产品系统的产品表,我们干脆在商户系统创建一张产品表,通过
ETL或者其他方式定时同步产品数据。 - 全局表(广播表) 比如行名行号信息被很多业务系统用到,如果我们放在核心系统,每个系统都要去关联查询,这个时候我们可以在所有的数据库都存储相同的基础数据。
ER表(绑定表)
我们有些表的数据是存在逻辑的主外键关系的,比如订单表order_info,存的是汇总的商品数,商品金额;订单明细表order_detail,是每个商品的价格,个数等等。或者叫做从属关系,父表和子表的关系。他们之间会经常有关联查询的操作,如果父表的数据和子表的数据分别存储在不同的数据库,跨库关联查询也比较麻烦。所以我们能不能把父表和数据和从属于父表的数据落到一个节点上呢?
比如 order_id=1001 的数据在
node1, 它所有的明细数据也放到node1;
order_id=1002 的数据在node2,它所有的明细数据都放到node2,这样在关联查询的时候依然是在一个数据库。
上面的思路都是通过合理的数据分布避免跨库关联查询,实际上在我们的业务中, 也是尽量不要用跨库关联查询,如果出现了这种情况,就要分析一下业务或者数据拆分是不是合理。如果还是出现了需要跨库关联的情况,那我们就只能用最后一种办法。
- 系统层组装
在不同的数据库节点把符合条件数据的数据查询出来,然后重新组装,返回给客户端。
分布式事务
比如在一个贷款的流程里面,合同系统登记了数据,放款系统也必须生成放款记录, 如果两个动作不是同时成功或者同时失败,就会出现数据一致性的问题。
如果在一个数据库里面,我们可以用本地事务来控制,但是在不同的数据库里面就不行了。所以分布式环境里面的事务,我们也需要通过一些方案来解决。
复习一下。
分布式系统的基础是
CAP 理论。
- C (一致性)
Consistency:对某个指定的客户端来说,读操作能返回最新的写操作。对于数据分布在不同节点上的数据来说,如果在某个节点更新了数据,那么在其他节点如果都能读取到这个最新的数据,那么就称为强一致,如果有某个节点没有读取到,那就是分布式不一致。 - A (可用性)
Availability:非故障的节点在合理的时间内返回合理的响应(不是错误和超时的响应)。可用性的两个关键一个是合理的时间,一个是合理的响应。
合理的时间指的是请求不能无限被阻塞,应该在合理的时间给出返回。合理的响应指的是系统应该明确返回结果并且结果是正确的 - P (分区容错性)
Partition tolerance:当出现网络分区后,系统能够继续工作。打个比方,这里集群有多台机器,有台机器网络出现了问题,但是这个集群仍然可以正工作。
CAP三者是不能共有的,只能同时满足其中两点。基于AP,我们又有了BASE 理论。
-
基本可用(
Basically Available):分布式系统在出现故障时,允许损失部分可用
功能,保证核心功能可用。 -
软状态(
Soft state):允许系统中存在中间状态,这个状态不影响系统可用性, 这里指的是CAP中的不一致。 -
最终一致(
Eventually consistent):最终一致是指经过一段时间后,所有节点数据都将会达到一致。
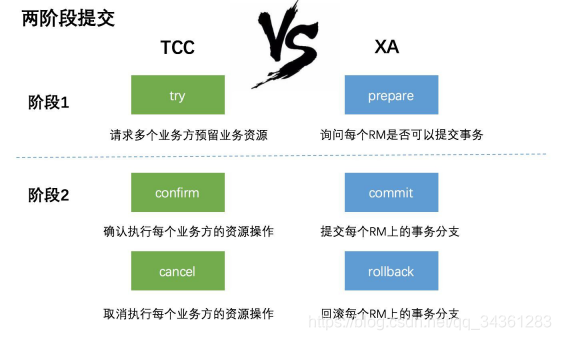
分布式事务有几种常见的解决方案
- 全局事务(比如
XA两阶段提交;应用、事务管理器(TM)、资源管理器(DB)),例如Atomikos - 基于可靠消息服务的分布式事务
- 柔性事务TCC(
Try-Confirm-Cancel)tcc-transaction
- 最大努力通知,通过消息中间件向其他系统发送消息(重复投递+定期校对)
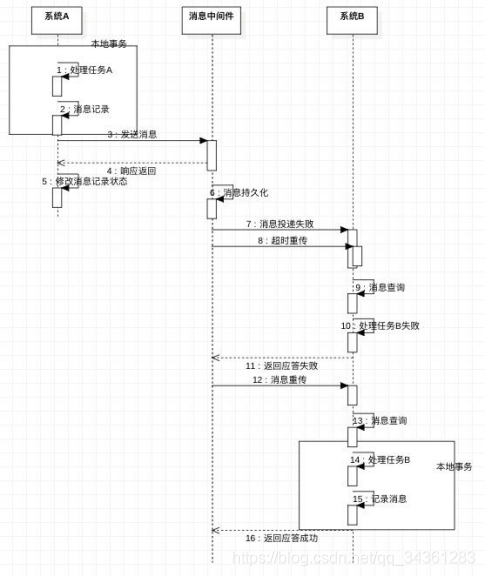
排序、翻页、函数计算问题
跨节点多库进行查询时,会出现 limit 分页,order by 排序的问题。比如有两个节点, 节点 1 存的是奇数id=1,3,5,7,9……;节点 2 存的是偶数id=2,4,6,8,10……
执行
select * from user_info order by id limit 0,10
需要在两个节点上各取出 10 条,然后合并数据,重新排序。
max、min、sum、count 之类的函数在进行计算的时候,也需要先在每个分片上执行相应的函数,然后将各个分片的结果集进行汇总和再次计算,最终将结果返回。
全局主键避重问题
MySQL 的数据库里面字段有一个自增的属性,Oracle 也有 Sequence 序列。如果是一个数据库,那么可以保证ID 是不重复的,但是水平分表以后,每个表都按照自己的规律自增,肯定会出现ID 重复的问题,这个时候我们就不能用本地自增的方式了。
全局主键避重解决方案
- UUID(
Universally Unique Identifier通用唯一识别码)
UUID 标准形式包含 32 个 16 进制数字,分为 5 段,形式为 8-4-4-4-12 的 36 个字符,例如:c4e7956c-03e7-472c-8909-d733803e79a9。
| Name | Length(Bytes) | Length(Hex Digits) | Contents |
|---|---|---|---|
| time_low | 4 | 8 | integer giving the low 32 bits of the time |
| time_mid | 2 | 4 | integer giving the middle 16 bits of the time |
| time_hi_and_version | 2 | 4 | 4-bit “version” in the most significant bits,followed by the high 12 bits of the time |
| clock_seq_hi_and_res clock_seq_low | 2 | 4 | 1-3 bit “variant” in the most significant bits,followed by the 13-15 bit clock sequence |
| node | 6 | 12 | the 48-bit node id |
M 表示 UUID 版本,目前只有五个版本,即只会出现 1,2,3,4,5,数字 N 的一至三个最高有效位表示 UUID 变体,目前只会出现 8,9,a,b 四种情况。
常见的UUID
- 基于时间和MAC 地址的UUID
- 基于第一版却更安全的DCE UUID
- 基于MD5 散列算法的UUID
- 基于随机数的UUID——用的最多,JDK 里面是 4
- 基于SHA1 散列算法的 UUID
UUID 是主键是最简单的方案,本地生成,性能高,没有网络耗时。但缺点也很明显, 由于 UUID 非常长,会占用大量的存储空间;另外,作为主键建立索引和基于索引进行查询时都会存在性能问题,在 InnoDB 中,UUID 的无序性会引起数据位置频繁变动,导致分页。
-
数据库
把序号维护在数据库的一张表中。这张表记录了全局主键的类型、位数、起始值,当前值。当其他应用需要获得全局ID 时,先 for update 锁行,取到值+1 后并且更新后返回。并发性比较差。 -
Redis
基于Redis 的INT自增的特性,使用批量的方式降低数据库的写压力,每次获取一段区间的ID 号段,用完之后再去数据库获取,可以大大减轻数据库的压力。 -
雪花算法
Snowflake(64bit)
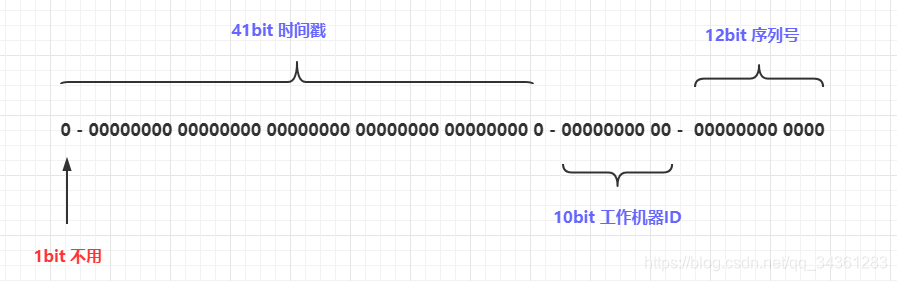
核心思想:
- 使用 41bit 作为毫秒数,可以使用 69 年
- 0bit 作为机器的 ID(5bit 是数据中心,5bit 的机器 ID),支持 1024 个节点
- 2bit 作为毫秒内的流水号(每个节点在每毫秒可以产生 4096 个 ID)
- 最后还有一个符号位,永远是 0。
优点:毫秒数在高位,生成的ID 整体上按时间趋势递增;不依赖第三方系统,稳定性和效率较高,理论上 QPS 约为 409.6w/s(1000*2^12),并且整个分布式系统内不会产生ID 碰撞;可根据自身业务灵活分配bit 位。
不足就在于:强依赖机器时钟,如果时钟回拨,则可能导致生成ID 重复。
当我们对数据做了切分,分布在不同的节点上存储的时候,是不是意味着会产生多个数据源?既然有了多个数据源,那么在我们的项目里面就要配置多个数据源。
现在问题就来了,我们在执行一条SQL 语句的时候,比如插入,它应该是在哪个数据节点上面执行呢?又比如查询,如果只在其中的一个节点上面,我怎么知道在哪个节点,是不是要在所有的数据库节点里面都查询一遍,才能拿到结果?
那么,从客户端到服务端,我们可以在哪些层面解决这些问题呢?
多数据源/读写数据源的解决方案
我们先要分析一下SQL 执行经过的流程。
DAO——Mapper(ORM)——JDBC——代理——数据库服务
客户端 DAO 层
第一个就是在我们的客户端的代码,比如 DAO 层,在我们连接到某一个数据源之前, 我们先根据配置的分片规则,判断需要连接到哪些节点,再建立连接。
Spring 中提供了一个抽象类AbstractRoutingDataSource,可以实现数据源的动态切换。
新建一个SpringBoot项目:
https://github.com/harrypottry/spring-boot-dynamic-data-source
aplication.properties定义多个数据源
server.port=8082
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.driver=com.mysql.jdbc.Driver
# 数据源1
spring.datasource.druid.first.url=jdbc:mysql://localhost:3306/ds0?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.druid.first.username=root
spring.datasource.druid.first.password=123456
# 数据源2
spring.datasource.druid.second.url=jdbc:mysql://localhost:3306/ds1?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8&useSSL=false&serverTimezone=GMT%2B8
spring.datasource.druid.second.username=root
spring.datasource.druid.second.password=123456
- 创建
@TargetDataSource注解
/**
* 多数据源注解
* <p/>
* 指定要使用的数据源
*
*/
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
@Documented
public @interface TargetDataSource {
String name() default "";
}
- 创建
DynamicDataSource继承AbstractRoutingDataSource
/**
* 扩展 Spring 的 AbstractRoutingDataSource 抽象类,重写 determineCurrentLookupKey 方法
* 动态数据源
* determineCurrentLookupKey() 方法决定使用哪个数据源
*
*/
public class DynamicDataSource extends AbstractRoutingDataSource {
private static final ThreadLocal<String> CONTEXT_HOLDER = new ThreadLocal<>();
/**
* 决定使用哪个数据源之前需要把多个数据源的信息以及默认数据源信息配置好
*
* @param defaultTargetDataSource 默认数据源
* @param targetDataSources 目标数据源
*/
public DynamicDataSource(DataSource defaultTargetDataSource, Map<Object, Object> targetDataSources) {
super.setDefaultTargetDataSource(defaultTargetDataSource);
super.setTargetDataSources(targetDataSources);
super.afterPropertiesSet();
}
@Override
protected Object determineCurrentLookupKey() {
return getDataSource();
}
public static void setDataSource(String dataSource) {
CONTEXT_HOLDER.set(dataSource);
}
public static String getDataSource() {
return CONTEXT_HOLDER.get();
}
public static void clearDataSource() {
CONTEXT_HOLDER.remove();
}
}
- 多数据源配置类
DynamicDataSourceConfig
/**
* 配置多数据源
*/
@Configuration
public class DynamicDataSourceConfig {
@Bean
@ConfigurationProperties("spring.datasource.druid.first")
public DataSource firstDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@ConfigurationProperties("spring.datasource.druid.second")
public DataSource secondDataSource(){
return DruidDataSourceBuilder.create().build();
}
@Bean
@Primary
public DynamicDataSource dataSource(DataSource firstDataSource, DataSource secondDataSource) {
Map<Object, Object> targetDataSources = new HashMap<>(5);
targetDataSources.put(DataSourceNames.FIRST, firstDataSource);
targetDataSources.put(DataSourceNames.SECOND, secondDataSource);
return new DynamicDataSource(firstDataSource, targetDataSources);
}
}
- 创建切面类
DataSourceAspect,对添加了@TargetDataSource注解的类进行拦截设置数据源。
/**
* 多数据源,切面处理类
*
*/
@Slf4j
@Aspect
@Component
public class DataSourceAspect implements Ordered {
@Pointcut("@annotation(com.test.datasource.TargetDataSource)")
public void dataSourcePointCut() {
}
@Around("dataSourcePointCut()")
public Object around(ProceedingJoinPoint point) throws Throwable {
MethodSignature signature = (MethodSignature) point.getSignature();
Method method = signature.getMethod();
TargetDataSource ds = method.getAnnotation(TargetDataSource.class);
if (ds == null) {
DynamicDataSource.setDataSource(DataSourceNames.FIRST);
log.debug("set datasource is " + DataSourceNames.FIRST);
} else {
DynamicDataSource.setDataSource(ds.name());
log.debug("set datasource is " + ds.name());
}
try {
return point.proceed();
} finally {
DynamicDataSource.clearDataSource();
log.debug("clean datasource");
}
}
@Override
public int getOrder() {
return 1;
}
}
- 在启动类上自动装配数据源配置
@Import({DynamicDataSourceConfig.class})
/**
*
*/
@MapperScan("com.test.mapper")
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
@Import({DynamicDataSourceConfig.class})
public class DynamicDSApp {
public static void main(String[] args) {
SpringApplication.run(DynamicDSApp.class, args);
}
}
- 在实现类上加上注解, 如
@TargetDataSource(name =DataSourceNames.SECOND),调用在DAO 层实现的优势:不需要依赖 ORM 框架,即使替换了 ORM 框架也不受影响。实现简单(不需要解析SQL 和路由规则),可以灵活地定制。
/**
* <p>
* 系统用户 服务实现类
* </p>
*
*/
@Service
public class SysUserServiceImpl extends ServiceImpl<SysUserMapper, SysUser> implements SysUserService {
@Override
public SysUser findUserByFirstDb(long id) {
return this.baseMapper.selectById(id);
}
@TargetDataSource(name = DataSourceNames.SECOND)
@Override
public SysUser findUserBySecondDb(long id) {
return this.baseMapper.selectById(id);
}
}
缺点:不能复用,不能跨语言。
ORM 框架层
第二个是在框架层,比如我们用MyBatis 连接数据库,也可以指定数据源。我们可以基于MyBatis 插件的拦截机制(拦截query 和update 方法),实现数据源的选择。
例如:https://github.com/colddew/shardbatis
https://docs.jboss.org/hibernate/stable/shards/reference/en/html_single/
驱动层
不管是MyBatis 还是Hibernate,还是Spring 的JdbcTemplate,本质上都是对JDBC的封装,所以第三层就是驱动层。比如 Sharding-JDBC,就是对JDBC 的对象进行了封装。JDBC 的核心对象:
- DataSource:数据源
- Connection:数据库连接
- Statement:语句对象
- ResultSet:结果集
那我们只要对这几个对象进行封装或者拦截或者代理,就可以实现分片的操作。
代理层
前面三种都是在客户端实现的,也就是说不同的项目都要做同样的改动,不同的编程语言也有不同的实现,所以我们能不能把这种选择数据源和实现路由的逻辑提取出来, 做成一个公共的服务给所有的客户端使用呢?
这个就是第四层,代理层。比如Mycat 和Sharding-Proxy,都是属于这一层。
数据库服务
最后一层就是在数据库服务上实现,也就是服务层,某些特定的数据库或者数据库的特定版本可以实现这个功能。
MyCat入门
MyCat官网导航:http://www.mycat.org.cn/
- 一个彻底开源的,面向企业应用开发的大数据库集群
- 支持事务、ACID、可以替代MySQL的加强版数据库
- 一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群
- 一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server
- 结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品
- 一个新颖的数据库中间件产品
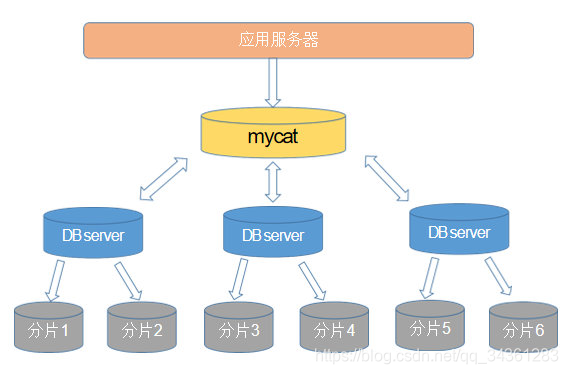
通俗点讲,应用层可以将它看作是一个数据库的代理(或者直接看成加强版数据库)
MySql主从复制
主从复制的含义
在MySQL 多服务器的架构中,至少要有一个主节点(master),跟主节点相对的, 我们把它叫做从节点(slave)。主从复制,就是把主节点的数据复制到一个或者多个从节点。主服务器和从服务器可以在不同的IP 上,通过远程连接来同步数据,这个是异步的过程。
主从复制的用途
- 数据备份:把数据复制到不同的机器上,以免单台服务器发生故障时数据丢失。
- 读写分离:让主库负责写,从库负责读,从而提高读写的并发度。
- 高可用HA:当节点故障时,自动转移到其他节点,提高可用性。
- 扩展:结合负载的机制,均摊所有的应用访问请求,降低单机IO。
案例
环境准备:
Linux1: 192.168.200.111
Linux2: 192.168.200.112
MySql 版本为5.5.8
步骤:
- Linux1 与Linux2 上分别安装MySql ,并且安装db_store与db_user表
sql脚本在本文末链接中已贴出
- 配置主从
配置文件设置Linux1 为Master ,Linux2 为Slave
Master操作
- 接入mysql并创建主从复制的用户
mysql > create user m2ssync identified by 'Qq123!@#';
- 给新建的用户赋权
mysql > GRANT REPLICATION SLAVE ON *.* TO 'm2ssync'@'%' IDENTIFIED BY 'Qq123!@#';
- 指定服务ID,开启binlog日志记录,在my.cnf中加入
server-id=137
log-bin=dbstore_binlog
binlog-do-db=db_store
- 通过命令查看Master db状态.
SHOW MASTER STATUS;
Slave操作
- 指定服务器ID,指定同步的binlog存储位置,在my.cnf中加入
server-id=101
relay-log=slave-relay-bin
relay-log-index=slave-relay-bin.index
read_only=1
replicate_do_db=db_store
my.cnf 文件默认安装在/etc/my.cnf位置,视你的mysql实际配置为准
- 接入slave的mysql服务,并配置
change master to master_host='192.168.200.111', master_port=3306,master_user='m2ssync',
master_password='Qq123!@#',
master_log_file='db_stoere_binlog',
master_log_pos=0;
-
start slave;
-
查看slave服务器状态
show slave status\G ;
- 测试访问
将Linux1机器(192.168.200.111)创建的db_store 库删掉,那么Linux2机器(192.168.200.112)的db_store库也应随之删掉:
同理,新增db_store也会保持同步,这里不再演示。
MySql基于binlog的主从复制原理
客户端对 MySQL 数据库进行操作的时候,包括 DDL 和 DML 语句,服务端会在日志文件中用事件的形式记录所有的操作记录,这个文件就是 binlog 文件(属于逻辑日志, 跟Redis 的AOF 文件类似)。
基于binlog,我们可以实现主从复制和数据恢复。
Binlog 默认是不开启的,需要在服务端手动配置。注意有一定的性能损耗。
关于MySql主从复制原理,我们前面提到过:mysql中binlog的底层原理分析
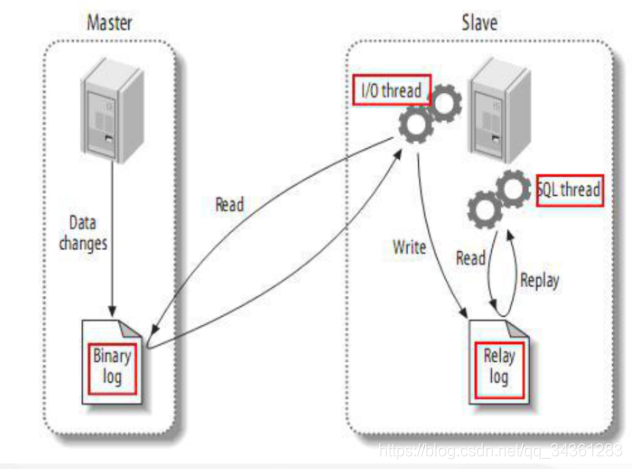
binlog实现过程
-
master将操作记录到二进制日志(binary log)中
(这些记录叫做二进制日志事件,binary log events) -
Slave通过I/O Thread异步将master的binary log events拷贝到它的中继日志(relay log);
-
Slave执行relay日志中的事件,匹配自己的配置将需要执行的数据,在slave服务上执行一遍从而达到复制数据的目的。
延迟是怎么产生的?
-
当master tps高于slave的sql线程所能承受的范围
-
网络原因
-
磁盘读写耗时
如何判断延迟?
- 使用命令:
mysql> show slave status \G;
当检查到参数 sends_behind_master为0,判断主动同步延时的参考值,是通过比较sql_thread执行的event的timestamp和io_thread复制好的event的timestamp(简写为ts)进行比较,而得到的这么一个差值。
- mk-heartbeat timestamp进行实践搓的判断
心跳检查机制,通过设置主从数据时间戳来判断。
我们怎么解决延迟问题?
-
配置更高的硬件资源
-
多线程方式:
- 把IO thread 改变成 多线程的方式
- mysql5.6 库进行多线程的方式
- GTID进行多线程的方式
- 应用程序自己去判断(mycat支持)
MyCat读写分离
案例
紧接着上面的案例,我们现在增加一台服务器:
Linux3: 192.168.200.113
使其安装与Linux1和Linux2相同版本的MySql,同时使其安装Mycat:版本为1.6.6
解压以后得到:
MyCat目录解释

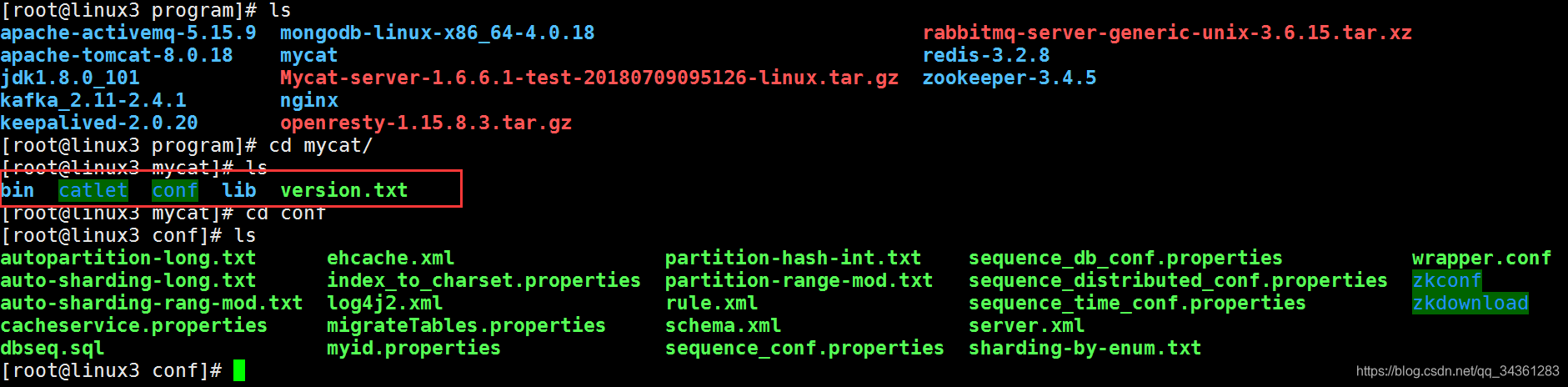
- bin 程序目录,存放了 window 版本和 linux 版本可执行文件
./mycat {start|restart|stop|status…} - conf 目录下存放配置文件
- server.xml 是 Mycat 服务器参数调整和用户授权的配置文件
- schema.xml 是逻辑库定义和表
- rule.xml 是分片规则的配置文件,分片规则的具体一些参数信息单独存放为文件,也在 这个目录下
- log4j2.xml配置logs目录日志输出规则
wrapper.confJVM相关参数调整
- lib 目录下主要存放 mycat 依赖的一些 jar 文件
- logs目录日志存放日志文件
-
启动MyCat
在/bin 目录下,直接strat即可。 -
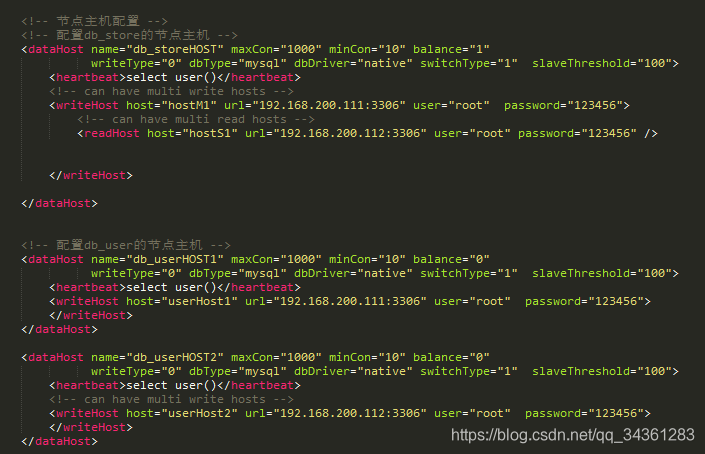
修改配置文件,关联 Master 与 Slave 节点

在/conf 目录下,修改配置文件rule.xml,schema.xml,server.xml。这里不全面展开,只展示关键配置,全部配置请参考本文末的提供的配置文件:
server.xml
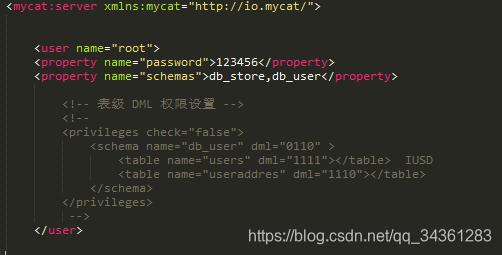
schema.xml
rule.xml

- 验证测试
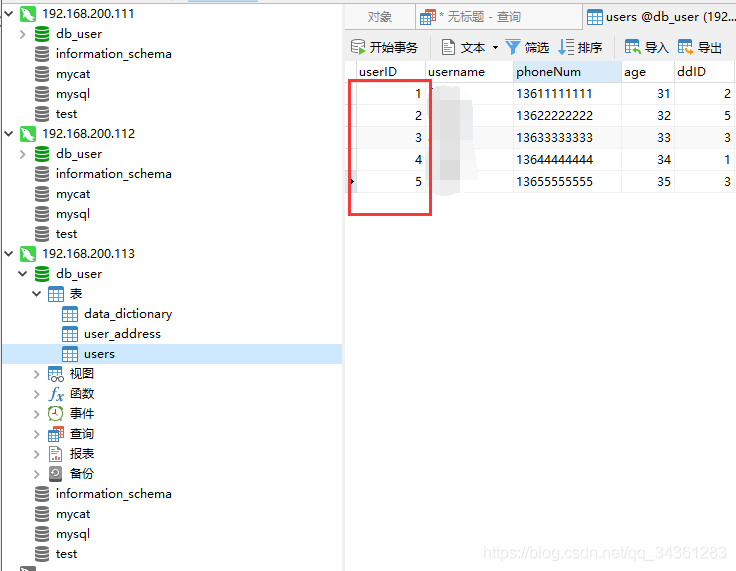
在Linux3机器的db_user插入id自增的1~5条用户数据,根据我们的分片规则,设定为奇数放在Master节点,而偶数放在Slave节点上。
- 在Linux3机器上(192.168.200.113)db_user库的user表插入五条数据
-
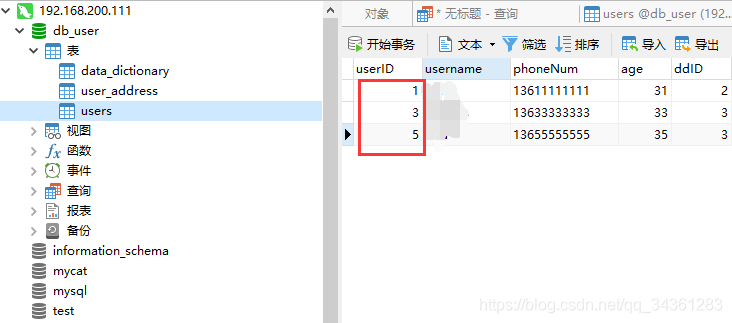
在Linux1 机器上验证(192.168.200.111)db_user库的user表数据
-
在Linux2 机器上验证(192.168.200.112)db_user库的user表数据
对应到本次的MyCat案例,整体架构图如下:
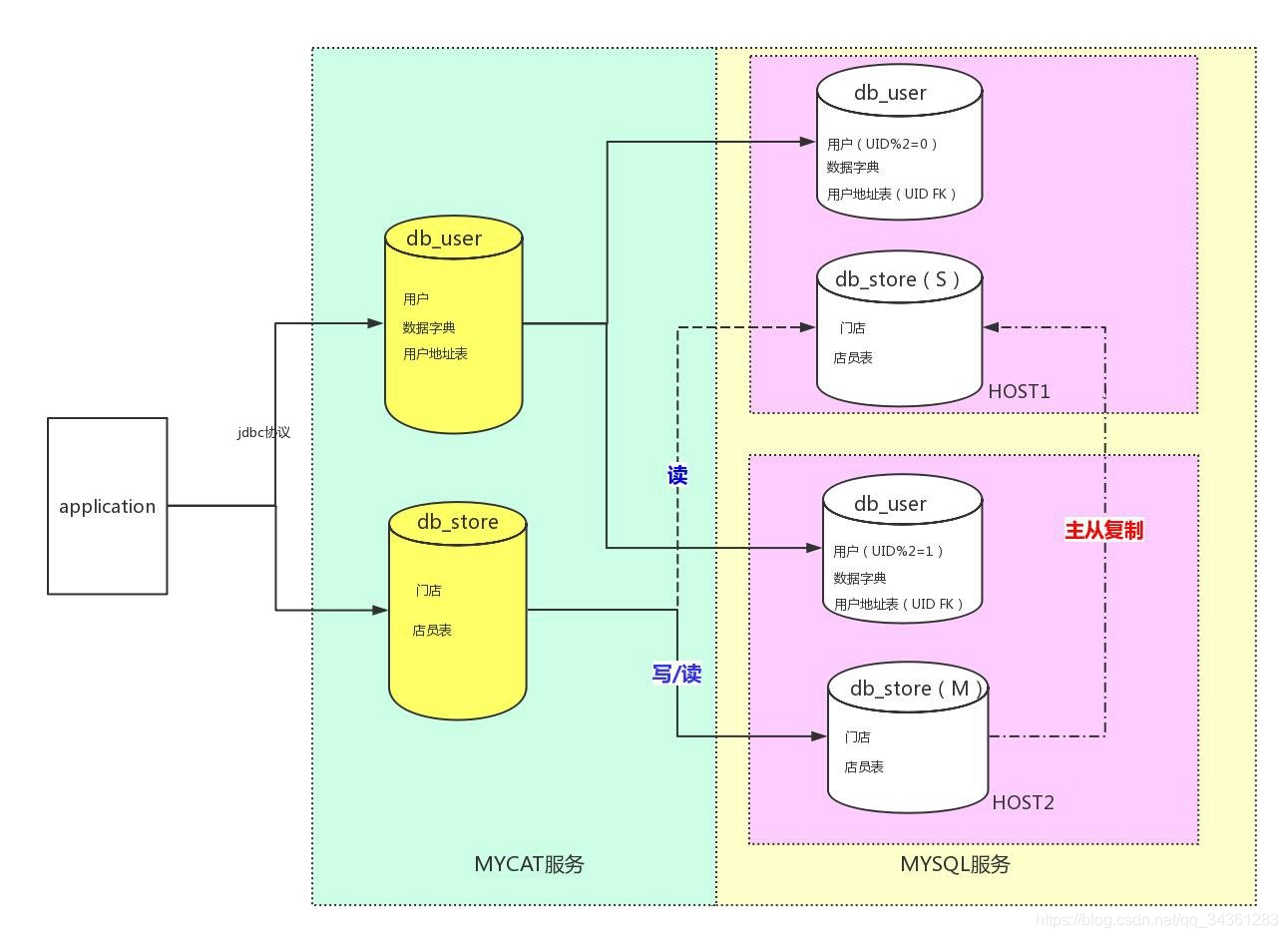
由此我们也能够理解一些MyCat的名词(对应到本次案例):
-
逻辑库
db_user db_store -
逻辑表
- 分片表
用户表
用户表按照UID取模分成两片 - 全局表
数字字典表
数据字典,比如存放用户的会员等级。 - ER表
用户地址表
每个用户,都有多个地址,ER表将按照用户的分片规则,和用户能匹配上的地址被分到同一个片上 - 非分片表
门店表,店员表
不需要分片的,数据量较小,和其他表没有关联关系
- 分片表
-
分片规则 如: userID%2(按照userID取2的模)
-
节点
节点主机(写、读节点主机)
后记
-
本节案例演示的SQL脚本及MyCat配置文件
链接:https://pan.baidu.com/s/1xg8vJz-0CyHQD57tcKM2zg
提取码: egux -
Centos 安装 MySql5.5 (tar包安装) https://www.cnblogs.com/wangxc20181130/p/10042603.html
-
Mycat官网文档(PDF版手册)
http://www.mycat.org.cn/document/mycat-definitive-guide.pdf -
spring-boot配置多数据源
https://github.com/harrypottry/spring-boot-dynamic-data-source -
数据库优化:通过Redis缓存解决问题
Redis01 - Redis的使用
Redis02 - Redis的原理分析
Redis03 - Redis的分布式
Redis04 - Redis的应用实战 -
数据库优化:通过MongoDB缓存解决问题
MongoDB01 - 应用场景及实现原理
MongoDB02 - 常用命令及配置
MongoDB03 - 手写基于MongoDB的ORM框架
MongoDB04 - 基于MongoDB实现网络云盘实战
MongoDB05 - MongoDB高可用及MongoDB4.0新特性
更多架构知识,欢迎关注本套Java系列文章:Java架构师成长之路