遥感数据处理系列
一些项目及科研中遇到的小需求,一方面记录自己的学习历程,另一方面帮助大家学习。本系列文章的开发环境为:ArcGIS 10.2.2 + Python 2.7、ENVI 5.3 + IDL 8.5
ArcPy批量计算栅格数据平均值
GLDAS数据下载及处理(NC转TIF)
ArcGIS批量裁剪栅格数据
ArcPy批量栅格重采样
ArcPy批量裁剪栅格数据
文章目录
前言
使用ArcGIS的开发包函数进行栅格数据平均值计算会导致结果影像异常值增多?IDL可以,那万能的Python + ArcPy可不可以呢?祭出ArcPy~在文章IDL批量计算栅格数据平均值中提到:使用ArcPy的GetRasterProperties_management函数进行栅格数据平均值计算会导致结果像元异常值增加。这是因为时序数据中只要有一景影像的像元为NoData,则该输出像元即为NoData。本文将使用ArcPy的RasterToNumPyArray和NumPyArrayToRaster来实现求解有效像元平均值的平均栅格计算方法。
一、栅格数据平均值
1. 原理简介
使用ArcGIS的GetRasterProperties_management进行栅格数据平均值计算时,出现异常值的原因如下图所示:
解决的思路为求解有效像元的平均值,尝试使用逐像元计算,定义一个sum存储每个像元的累加值,定义一个count存储每个像元的累加次数,二者除一下,就是Average了。
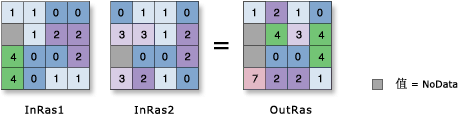
计算栅格数据平均值主要使用ArcPy的RasterToNumPyArray和NumPyArrayToRaster函数。
1.1 RasterToNumPyArray函数
函数使用:
RasterToNumPyArray (in_raster, {lower_left_corner}, {ncols}, {nrows}, {nodata_to_value})
常用参数简介:
in_raster:
要转换为 NumPy 数组的输入栅格
lower_left_corner:
可从 in_raster 中的左下角提取处理块以转换为数组。x 值和 y 值采用地图单位。若未指定值,则将使用输入栅格的原点。
ncols:
in_raster 中要转换为 NumPy 数组的 lower_left_corner 中的列数。若未指定值,则将使用输入栅格的列数。
nrows:
in_raster 中要转换为 NumPy 数组的 lower_left_corner 中的行数。若未指定值,则将使用输入栅格的行数。
nodata_to_value:
在生成的 NumPy 数组中分配 in_raster NoData 值的值。若未指定值,则将使用 in_raster 的 NoData 值。
RasterToNumPyArray 函数直接用就可,其余皆为可选参数:
array = arcpy.RasterToNumPyArray( in_raster )
1.2 NumPyArrayToRaster函数
计算结束后的数组可通过NumPyArrayToRaster函数存储为栅格数据。
函数使用:
NumPyArrayToRaster (in_array, {lower_left_corner}, {x_cell_size}, {y_cell_size}, {value_to_nodata})
常用参数简介:
in_array:
-> 要转换为栅格的 NumPy 数组。需要二维或三维 NumPy 数组。
lower_left_corner:
-> 定义地图单位中输出栅格左下角的点对象。默认情况下,左下角的坐标将设置为 (0.0, 0.0)。
x_cell_size:
-> x 方向的像元大小用地图单位指定。输入可为指定的像元大小(类型:双精度)值或栅格
-> 指定数据集后,该数据集的 x 像元大小将用在输出栅格的 x 像元大小中
-> 如果只确定了 x_cell_size 而没有确定 y_cell_size,则将会产生具有指定大小的方形像元
-> 如果 x_cell_size 和 y_cell_size 都未指定,则 x 和 y 像元大小的默认值均为 1.0
y_cell_size:
-> 同x_cell_size的用法
value_to_nodata:
-> 在输出栅格中分配到 NoData 的 NumPy 数组值。如果没有为 value_to_nodata 指定任何值,则在生成的栅格中不会有任何 NoData 值。
注意:函数中未包括投影信息的选择,需要在代码中设置一下,一般与输入影像相同。代码为:
arcpy.env.outputCoordinateSystem = in_raster
2. 代码
文件组织架构:
输入:
一个含有若干栅格数据的文件夹 inws(本例为“.tif”格式)
代码实例:
# -*- coding: UTF-8 -*-
import arcpy, sys, os, glob
from arcpy.sa import *
import numpy
'''
批量计算平均栅格(一级目录):
对输入文件夹下的数据 计算平均值,结果存放于输出文件夹
需要修改:
inws:输入路径(必选)
outws:输出路径(必选)
nameT:这里要进行下规范化,文件名的易读性(可选)
'''
arcpy.CheckOutExtension('Spatial')
# 输入路径 应该注意,中文路径,会导致读不出文件
inws = r"F:\LE-monthly\MonthGroup\2008\1"
# 输出路径
outws = r"F:\LE-monthly\Monthly\2008"
# 利用glob包,将inws下的所有tif文件读存放到rasters中
rasters = glob.glob(os.path.join(inws, "*.tif"))
r = Raster(rasters[0]) # 打开栅格
array = arcpy.RasterToNumPyArray(r) # 转成Numpy方便对每个像元进行处理
rowNum, colNum = array.shape # 波段、行数、列数
sum = numpy.zeros(shape=array.shape) # 存储累加值
count = numpy.zeros(shape=array.shape) # 存储 有效像元计数器
Average = numpy.zeros(shape=array.shape) # 存储 平均值
# 循环rasters中的所有影像,进行按掩模提取操作
for ras in rasters:
rmm = Raster(ras) # 打开栅格
array = arcpy.RasterToNumPyArray(rmm) # 转成Numpy方便对每个像元进行处理
# 逐像元计算
for i in range(0, rowNum):
for j in range(0, colNum):
if array[i][j] > 0 : # 判断有效值
sum[i][j] += array[i][j] # 累加
count[i][j] += 1 # 计数器
continue
Average = sum / count # 平均值计算
# 保存栅格
lowerLeft = arcpy.Point(r.extent.XMin, r.extent.YMin) # 左下角点坐标
cellWidth = r.meanCellWidth # 栅格宽度
cellHeight = r.meanCellHeight
nameT = os.path.basename(rasters[0])
outname = os.path.join(outws, nameT) # 合并输出文件名+输出路径
arcpy.env.overwriteOutput = True # 覆盖输出文件夹已有内容
arcpy.env.outputCoordinateSystem = rasters[0] # 输出坐标系与输入相同
AvgRas = arcpy.NumPyArrayToRaster(Average, lowerLeft, cellWidth, cellHeight, r.noDataValue) # 转换成栅格
AvgRas.save(outname) # 保存
print os.path.basename(rasters[0]) + " ---- 完成"
上例可实现对输入路径文件夹下的所有栅格数据的平均栅格计算。
二、多文件夹场景
2.1 二级目录
一年有十二个月,每月中的个数不一,先把相同月份的LE数据放到一个文件夹下,本例适用于年内的12个月的月均栅格计算。
文件组织架构:
代码如下:
# -*- coding: UTF-8 -*-
import arcpy, sys, os, glob
import numpy
from arcpy.sa import *
'''
批量计算平均栅格(二级目录):
对输入文件夹下的数据 计算平均值,结果存放于输出文件夹
需要修改:
inws:输入路径(必选)
outws:输出路径(必选)
nameT:这里要进行下规范化,文件名的易读性(可选)
'''
arcpy.CheckOutExtension('Spatial')
numpy.seterr(all='ignore')
# 输入路径 应该注意,中文路径,会导致读不出文件
inws = r"F:\LE-monthly\MonthGroup\2010"
# 输出路径
outws = r"F:\LE-monthly\Monthly\2010"
path_list = os.listdir(inws) # 一级目录中的 文件夹列表
# 进入二级目录
for i in range(len(path_list)):
path = inws + "\\" + path_list[i] # 二级目录的路径
# 利用glob包,将inws下的所有tif文件读存放到rasters中
rasters = glob.glob(os.path.join(path, "*.tif"))
r = Raster(rasters[0]) # 打开栅格
array = arcpy.RasterToNumPyArray(r) # 转成Numpy方便对每个像元进行处理
rowNum, colNum = array.shape # 行数、列数
sum = numpy.zeros(shape=array.shape) # 存储累加值
count = numpy.zeros(shape=array.shape) # 存储 有效像元计数器
Average = numpy.zeros(shape=array.shape) # 存储 平均值
# 循环rasters中的所有影像,进行按掩模提取操作
for ras in rasters:
rmm = Raster(ras) # 打开栅格
array = arcpy.RasterToNumPyArray(rmm) # 转成Numpy方便对每个像元进行处理
# 逐像元计算
for row in range(0, rowNum):
for col in range(0, colNum):
if array[row][col] > 0: # 判断有效值
sum[row][col] += array[row][col] # 累加
count[row][col] += 1 # 计数器
continue
Average = sum / count # 平均值计算
# 保存栅格
lowerLeft = arcpy.Point(r.extent.XMin, r.extent.YMin) # 左下角点坐标
cellWidth = r.meanCellWidth # 栅格宽度
cellHeight = r.meanCellHeight
nameT = os.path.basename(rasters[0])
outname = os.path.join(outws, nameT) # 合并输出文件名+输出路径
arcpy.env.overwriteOutput = True # 覆盖输出文件夹已有内容
arcpy.env.outputCoordinateSystem = rasters[0] # 输出坐标系与输入相同
AvgRas = arcpy.NumPyArrayToRaster(Average, lowerLeft, cellWidth, cellHeight, r.noDataValue) # 转换成栅格
AvgRas.save(outname) # 保存
print path_list[i] + " --- OK!"
print(" --- All project is OK! --- ")
注意:以上仅为进入二级目录的版本,三级目录有些麻烦,挨个改年份也行,哈哈哈哈(懒了,逃…
2.2 三级目录
一年有十二个月,每月中的个数不一,先把相同月份的LE数据放到一个文件夹下,然后有十年的数据,改下文件读取的逻辑,来适用于多年的计算。
文件组织架构:
代码如下:
# -*- coding: UTF-8 -*-
import arcpy, sys, os, glob, numpy
from arcpy.sa import *
'''
批量计算平均栅格(三级级目录):
对输入文件夹下的数据 计算平均值,结果存放于输出文件夹
需要修改:
inws:输入路径(必选)
outws:输出路径(必选)
nameT:这里要进行下规范化,文件名的易读性(可选)
'''
arcpy.CheckOutExtension('Spatial')
numpy.seterr(all='ignore')
# 输入路径 应该注意,中文路径,会导致读不出文件
inws = r"F:\LE-monthly\MonthGroup"
# 输出路径
outws = r"F:\LE-monthly\Monthly"
path_list = os.listdir(inws) # 第二级目录中的文件夹列表
# 进入二级目录
for i in range(len(path_list)):
path = inws + "\\" + path_list[i] # 二级目录的路径
target_path = outws + "\\" + path_list[i] # 输出路径 -- 二级目录的路径
# 重构输出文件夹文件组织形式
outFolder = target_path
isExists = os.path.exists(outFolder) # 判断路径是否存在:存在为True,不存在为False
if not isExists:
os.makedirs(outFolder) # 如果不存在则创建目录
path_list_3 = os.listdir(path) # 第三级目录中的文件夹列表
path_list_3.sort(key=int) # 数字的月份,排个序
# 进入三级目录
for third in range(len(path_list_3)):
path_3 = path + "\\" + path_list_3[third] # 三级目录的路径
# 利用glob包,将三级目录下的所有tif文件读存放到rasters中
rasters = glob.glob(os.path.join(path_3, "*.tif"))
r = Raster(rasters[0]) # 打开栅格
array = arcpy.RasterToNumPyArray(r) # 转成Numpy方便对每个像元进行处理
rowNum, colNum = array.shape # 行数、列数
sum = numpy.zeros(shape=array.shape) # 存储累加值
count = numpy.zeros(shape=array.shape) # 存储 有效像元计数器
Average = numpy.zeros(shape=array.shape) # 存储 平均值
# 循环rasters中的所有影像,进行按掩模提取操作
for ras in rasters:
rmm = Raster(ras) # 打开栅格
array = arcpy.RasterToNumPyArray(rmm) # 转成Numpy方便对每个像元进行处理
# 逐像元计算
for row in range(0, rowNum):
for col in range(0, colNum):
if array[row][col] > 0: # 判断有效值
sum[row][col] += array[row][col] # 累加
count[row][col] += 1 # 计数器
continue
Average = sum / count # 平均值计算
# 保存栅格
lowerLeft = arcpy.Point(r.extent.XMin, r.extent.YMin) # 左下角点坐标
cellWidth = r.meanCellWidth # 栅格宽度
cellHeight = r.meanCellHeight
nameT = os.path.basename(rasters[0])
outname = os.path.join(target_path, nameT) # 合并输出文件名+输出路径
arcpy.env.overwriteOutput = True # 覆盖输出文件夹已有内容
arcpy.env.outputCoordinateSystem = rasters[0] # 输出坐标系与输入相同
AvgRas = arcpy.NumPyArrayToRaster(Average, lowerLeft, cellWidth, cellHeight, r.noDataValue) # 转换成栅格
AvgRas.save(outname) # 保存
print path_list_3[third] + " --- OK!" # 三级目录处理完成
print path_list[i] + " --- OK!" # 二级目录处理完成
print(" --- All project is OK! --- ")
二级目录版本的代码,嗯,不错了。但是啊,挂机这种事情,当然是点个运行就跑路…才美妙啊。所以又回来了,添加了三级目录版本
总结
ArcPy牛皮!毕业万岁!中期快乐!
大家元旦快乐,顺利毕业,工作顺利
后记
写博客的初衷是分享我的一些经验,同时也方便自己在其他电脑上进行数据处理。帮了很多人,但评论区小伙伴也有遇到问题的,那么:知识付费,我的时间和经验正好可以解决你的问题。
