本部分主要为机器学习理论入门_决策树算法,书籍参考 “ 统计学习方法(第二版)”。
学习目标: 熟悉决策树基础知识:树、熵、信息增益、基尼指数;熟悉决策树构建步骤;熟悉3种典型决策树算法;熟悉决策树算法优缺点。
一、决策树介绍
1.1 基本原理
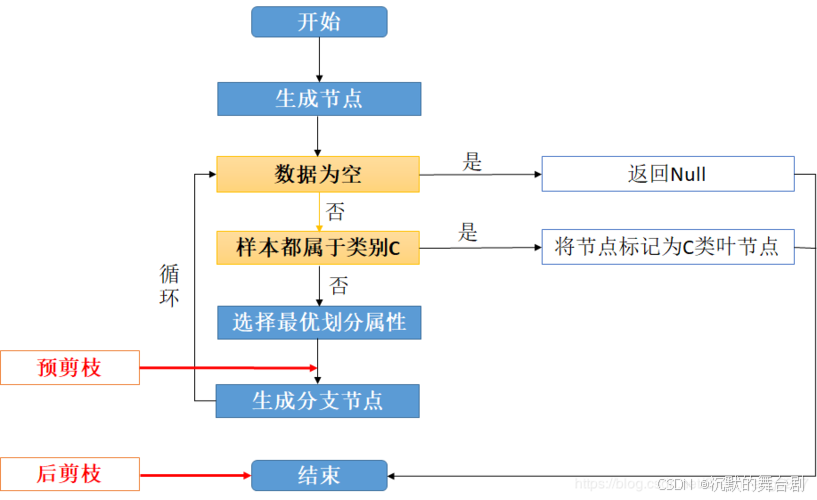
决策树( Decision Tree) 又称为判定树,是数据挖掘技术中的一种重要的分类与回归方法,它是一种以树结构(包括二叉树和多叉树)形式来表达的预测分析模型。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
一般,一棵决策树包含一个根节点,若干个内部结点和若干个叶结点。
叶结点对应于决策结果,其他每个结点对应于一个属性测试。每个结点包含的样本集合根据属性测试的结果划分到子结点中,根结点包含样本全集,从根结点到每个叶结点的路径对应了一个判定的测试序列。决策树学习的目的是产生一棵泛化能力强,即处理未见示例强的决策树。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
决策树算法采用树形结构,使用层层推理来实现最终的分类。决策树由下面几种元素构成:
- 根节点:包含样本的全集
- 内部节点:对应特征属性测试
- 叶节点:代表决策的结果
预测时,在树的内部节点处用某一属性值进行判断,根据判断结果决定进入哪个分支节点,直到到达叶节点处,得到分类结果。
这是一种基于 if-then-else 规则的有监督学习算法,决策树的这些规则通过训练得到,而不是人工制定的。
决策树是最简单的机器学习算法,它易于实现,可解释性强,完全符合人类的直观思维,有着广泛的应用。
1.2 实例应用
eg.
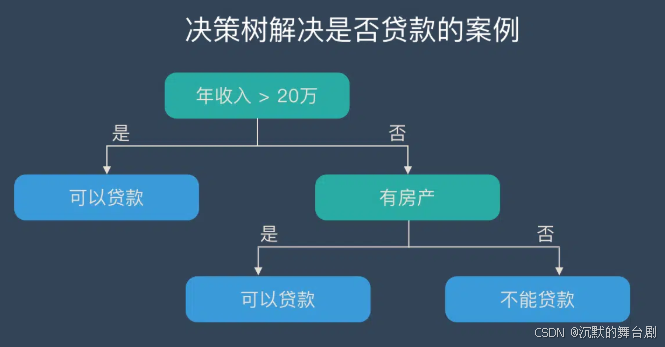
下面来看一个实际的例子。银行要用机器学习算法来确定是否给客户发放贷款,为此需要考察客户的年收入,是否有房产这两个指标。领导安排你实现这个算法,你想到了最简单的线性模型,很快就完成了这个任务。
首先判断客户的年收入指标。如果大于20万,可以贷款;否则继续判断。然后判断客户是否有房产。如果有房产,可以贷款;否则不能贷款。
这个例子的决策树如下图所示:
以上便是决策树算法的核心思想,但是具体落实到实现上还是有一些东西的。
二、决策树构建
2.1 熵、信息增益、信息增益率、基尼系数
熵是衡量信息的不确定性或混乱程度的指标,信息的不确定性越大,熵越大。
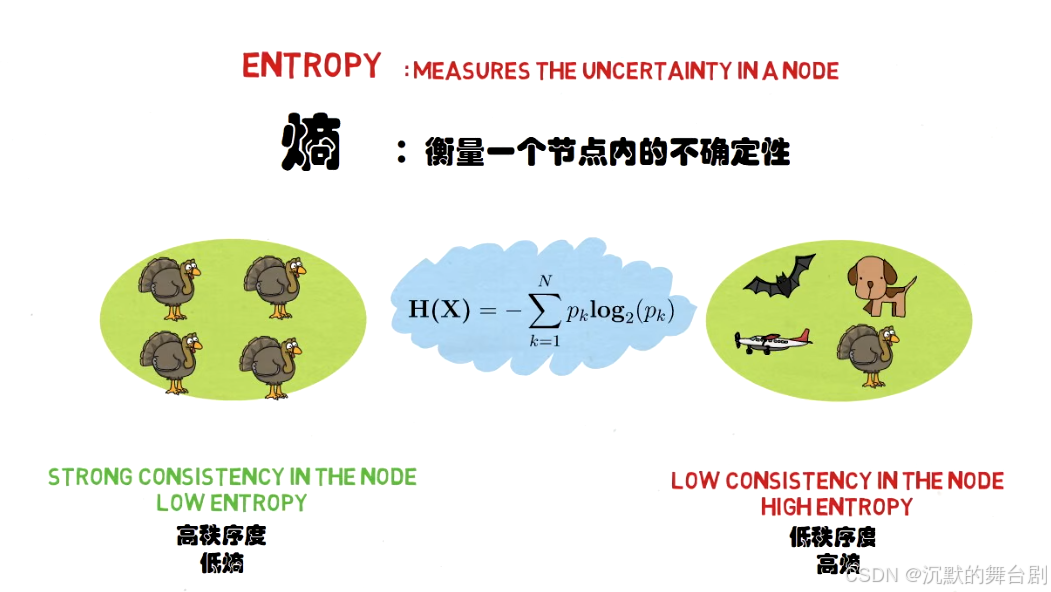
熵:物理意义是体系混乱程度的度量。
- 信息熵
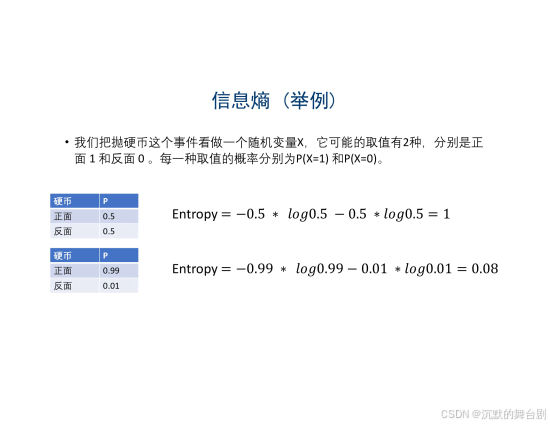
信息熵:表示事物不确定性的度量标准,可以根据数学中的概率计算,出现的概率就大,出现的机会就多,不确定性就小(信息熵小)。


- 条件熵

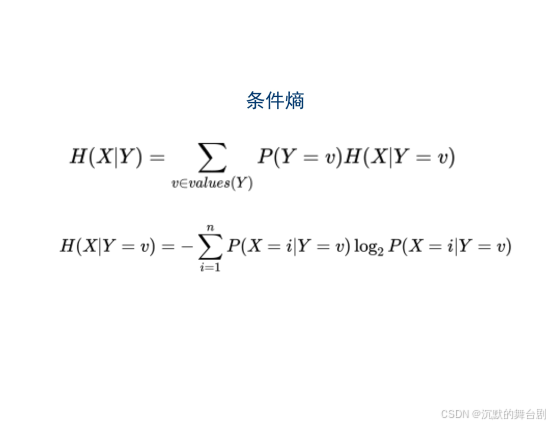
- 信息增益
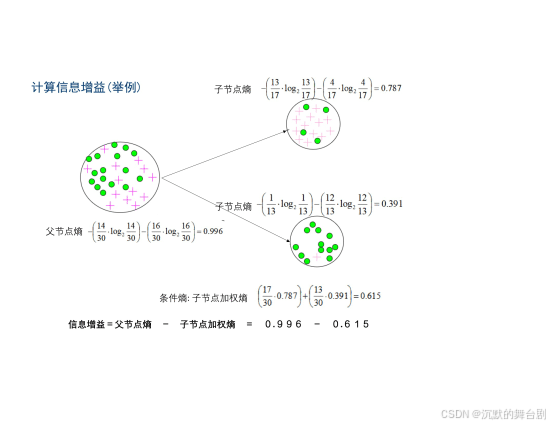
所谓的信息增益是指特征A对训练数据集D的信息增益g(D,A)定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:

- 信息增益率
信息增益率 = 信息增益 / 分裂熵
数据集D信息增益率的公式为:
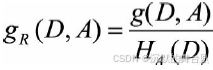
其中,分裂熵H(D)的公式为:
当A的取值越多时,分裂熵越大,信息增益率越小,达到了惩罚的目的。
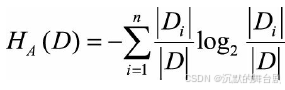
需要注意的是,增益率可能会对数目少的特征有所偏好,因此C4.5采用了启发式的方法:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选出信息增益率最高的。
- 基尼系数
分类树采用了基尼指数作为类别选择的依据。基尼纯度越小,代表数据集的纯度越高,分类效果越好。
特征p的基尼值公式如下:
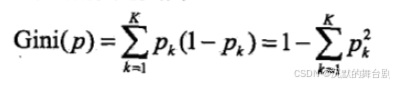
特别的,当特征只有两个类别时,基尼指数为:
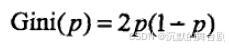
对于特征A,若其将数据集分为D1和D2两部分,则其基尼指数为:
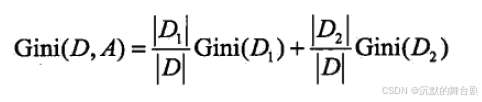
在候选集中,选择那个使得划分后基尼指数最小的属性作为最优的划分属性。
熵和基尼指数的关系如下图:
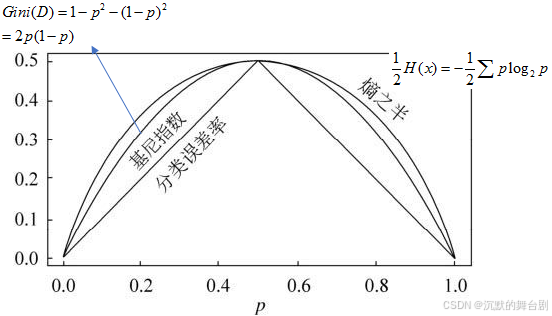
可以看出基尼指数近似于熵。
2.2 三种典型决策树算法

- ID3 算法
ID3 是最早提出的决策树算法,他就是利用信息增益来选择特征的。
ID3算法使用 信息增益 作为分裂的规则,信息增益越大,则选取该分裂规则。多分叉树。信息增益可以理解为,有了x以后对于标签p的不确定性的减少,减少的越多越好,即信息增益越大越好。

ID3算法可用于划分标称型数据集,没有剪枝的过程,为了去除过度数据匹配的问题,可通过裁剪合并相邻的无法产生大量信息增益的叶子节点(例如设置信息增益阀值)。使用信息增益选择属性,其实是有一个缺点,那就是它偏向于具有大量值的属性——就是说在训练集中,某个属性所取的不同值的个数越多,那么越有可能拿它来作为分裂属性,而这样做有时候是没有意义的,另外ID3不能处理连续分布的数据特征,于是就有了C4.5算法。CART算法也支持连续分布的数据特征。
- C4.5 算法
他是 ID3 的改进版,他不是直接使用信息增益,而是引入“信息增益比”指标作为特征的选择依据。
C4.5算法是ID3的一个改进算法,继承了ID3算法的优点。使用信息增益率作为分裂规则(需要用信息增益除以,该属性本身的熵),此方法避免了ID3算法中的归纳偏置问题,因为ID3算法会偏向于选择类别较多的属性(形成分支较多会导致信息增益大)。多分叉树。连续属性的分裂只能二分裂,离散属性的分裂可以多分裂,比较分裂前后信息增益率,选取信息增益率最大的。
C4.5算法用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足,在树构造过程中进行剪枝;能够完成对连续属性的离散化处理;能够对不完整数据进行处理。C4.5算法产生的分类规则易于理解、准确率较高;但效率低,因树构造过程中,需要对数据集进行多次的顺序扫描和排序。也是因为必须多次数据集扫描,C4.5只适合于能够驻留于内存的数据集。
- CART(Classification and Regression Tree)
这种算法即可以用于分类,也可以用于回归问题。CART 算法使用了基尼系数取代了信息熵模型。
CART的全称为Classification And Regression Tree,即分类回归树(只能形成二叉树)。采用的是Gini指数(选Gini指数最小的特征s)作为分裂标准,同时它也是包含后剪枝操作。ID3算法和C4.5算法虽然在对训练样本集的学习中可以尽可能多地挖掘信息,但其生成的决策树分支较大,规模较大。为了简化决策树的规模,提高生成决策树的效率,就出现了根据GINI系数来选择测试属性的决策树算法CART。
对于分类树(目标变量为离散变量):使用基尼系数作为分裂规则。比较分裂前的gini和分裂后的gini减少多少,减少的越多,则选取该分裂规则,这里的求解方法只能是离散穷举。关于基尼系数,可以参考周志华的西瓜书决策树那章,讲得比较简洁,也比较易懂。“直观来说,(数据集D的基尼系数)Gini(D)反映了从数据集D中随机抽取两个样本,其类别标记不一致的概率,因此Gini(D)越小,则数据集D的纯度越高。”
具体这个的计算,我觉得有例子才好理解,下面这个红绿球的例子很好的说明了,如何根据损失函数最小(也就是基尼系数最小)来选取分裂规则。
2.3 决策树构建步骤
2.3.1 特征选择
选取有较强分类能力的特征。特征选择决定了使用哪些特征来做判断。在训练数据集中,每个样本的属性可能有很多个,不同属性的作用有大有小。因而特征选择的作用就是筛选出跟分类结果相关性较高的特征,也就是分类能力较强的特征。
在特征选择中通常使用的准则是:信息增益。
2.3.2 决策树生成
选择好特征后,就从根节点触发,对节点计算所有特征的信息增益,选择信息增益最大的特征作为节点特征,根据该特征的不同取值建立子节点;对每个子节点使用相同的方式生成新的子节点,直到信息增益很小或者没有特征可以选择为止。
典型的算法有 ID3 和 C4.5, 它们生成决策树过程相似, ID3 是采用信息增益作为特征选择度量, 而 C4.5采用信息增益比率。
- ID3算法
算法步骤如下所示:
实例实现如下所示:


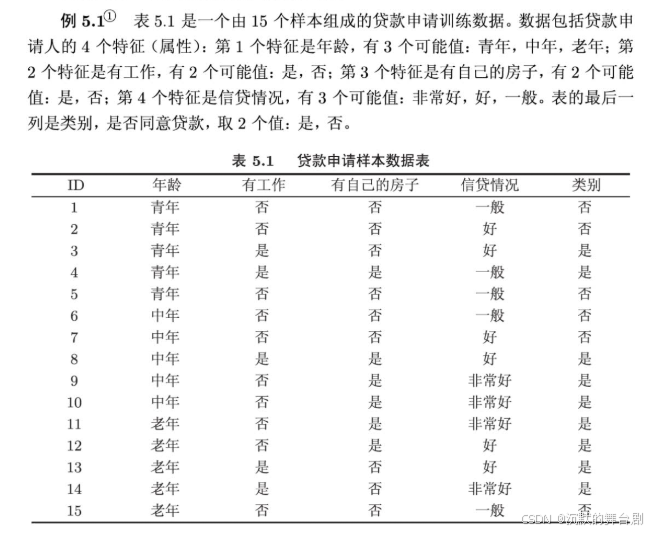
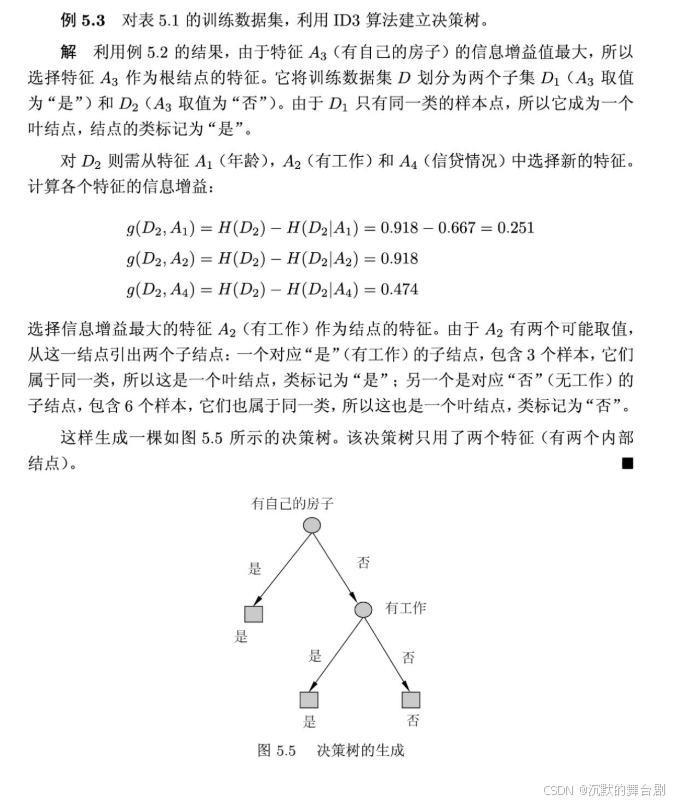
- C4.5算法
C4.5的生成算法

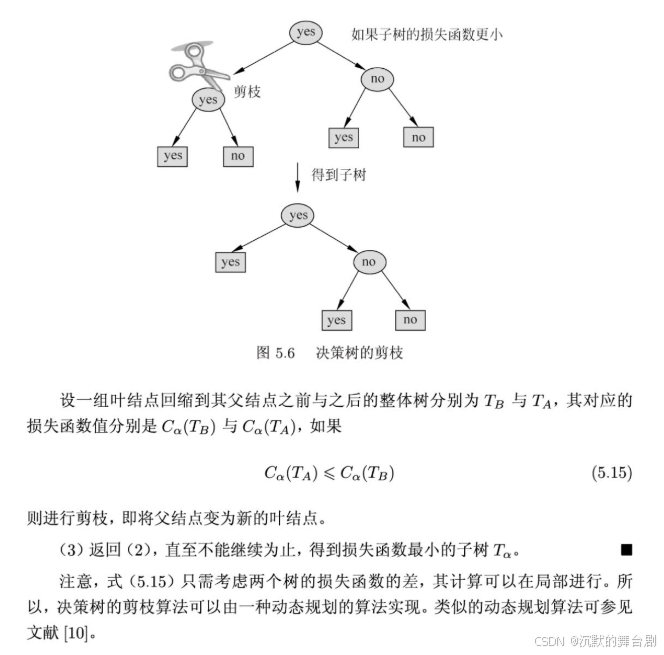
2.3.3 决策树剪枝
剪枝的主要目的是对抗「过拟合」,通过主动去掉部分分支来降低过拟合的风险。
剪枝原因是决策树生成算法生成的树对训练数据的预测很准确, 但是对于未知数据分类很差, 这就产生了过拟合的现象。涉及算法有CART算法。
懒了懒了,直接粘贴了
至于CART算法,具体看书即可