在提升大语言模型(LLM)推理能力时,拒绝采样(Rejection Sampling)和 马尔可夫搜索树(Markov Search Tree)是两个超强的技术。
拒绝采样 Rejection sampling🎯
- 概念
模型生成多个候选答案,然后过滤掉不符合条件的,只保留“好”的结果。 - 原理
- LLM 生成一堆候选答案(比如推理路径或解决方案)
- 通过评分函数(比如正确性、逻辑性)评估每个候选答案。
- 不符合条件的答案被拒绝,最终选出最好的一个。
- 优点
- 简单实现起来超简单
- 适用于各种任务,比如数学题、代码生成
- 只保留高质量的输出,结果更可靠
- 缺点
- 生成很多样本,大部分都被丢弃,计算成本高
- 任务越复杂,需要的样本量指数级增长
- 结果质量完全取决于评分函数的好坏
- 应用场景
- 解数学题:生成多个答案,选出正确的那个
- 代码生成:生成多个代码片段,选出能编译通过的。
马尔可夫搜索树 🌳
- 概念
马尔可夫搜索树是一种结构化搜索方法,LLM 会探索一个推理路径树,每个节点代表一个状态(比如部分解决方案),边代表动作(比如逻辑步骤)。搜索过程由策略引导,优先探索有潜力的路径 - 原理
- 逐步构建树结构,每次扩展最有潜力的节点
- 通过启发式函数(比如成功的可能性或目标一致性)引导搜索。
- 直到找到满意的解决方案或资源耗尽为止
- 优点
- 集中资源探索有潜力的路径,减少浪费
- 系统化地探索复杂推理空间,更有条理
- 可以结合领域知识,提升搜索效果
- 缺点
- 需要精心设计树结构和启发式函数。
- 维护和扩展树结构可能消耗较多资源。
- 如果启发式函数设计不好,可能会卡在次优路径上。
- 应用场景
- 解决谜题或证明定理,探索不同的推理链。
- 规划任务:生成分步计划(比如机器人或游戏)
RFT和SFT
1. RFT和SFT的区别
什么是RFT?
RFT(Rejection sampling Fine-Tuning)和SFT(Supervised Fine-Tuning)是两种用于微调机器学习模型的方法,特别是在自然语言处理领域。
SFT是一种常见的微调方法,主要步骤如下:
-
数据收集:收集大量的标注数据,这些数据通常由人类专家根据特定任务进行标注。
-
模型训练:使用这些标注数据对预训练模型进行微调,使其在特定任务上表现更好。
-
评估和优化:通过验证集评估模型性能,并根据结果进行优化。
SFT的优点是相对简单直接,只需要高质量的标注数据即可。然而,SFT也有一些局限性,比如对标注数据的质量和数量要求较高。
RFT是一种更为复杂的微调方法,主要步骤如下:
-
数据生成:首先使用预训练模型生成大量的候选输出。
-
筛选过程:通过某种筛选机制(如人工评审或自动评分系统)从这些候选输出中挑选出高质量的样本。
-
模型训练:使用筛选后的高质量样本对模型进行微调。
RFT的关键在于筛选过程,这个过程可以显著提高数据的质量,从而提升模型的性能。筛选机制可以是人工的,也可以是基于某种自动化评分系统的。
区别
- 数据来源:
-
SFT:依赖于预先标注好的高质量数据。
-
RFT:通过生成大量候选输出,然后筛选出高质量样本。
- 数据质量控制:
-
SFT:数据质量主要依赖于标注过程的质量控制。
-
RFT:通过筛选机制来确保数据质量,即使初始生成的数据质量不高,也可以通过筛选提高。
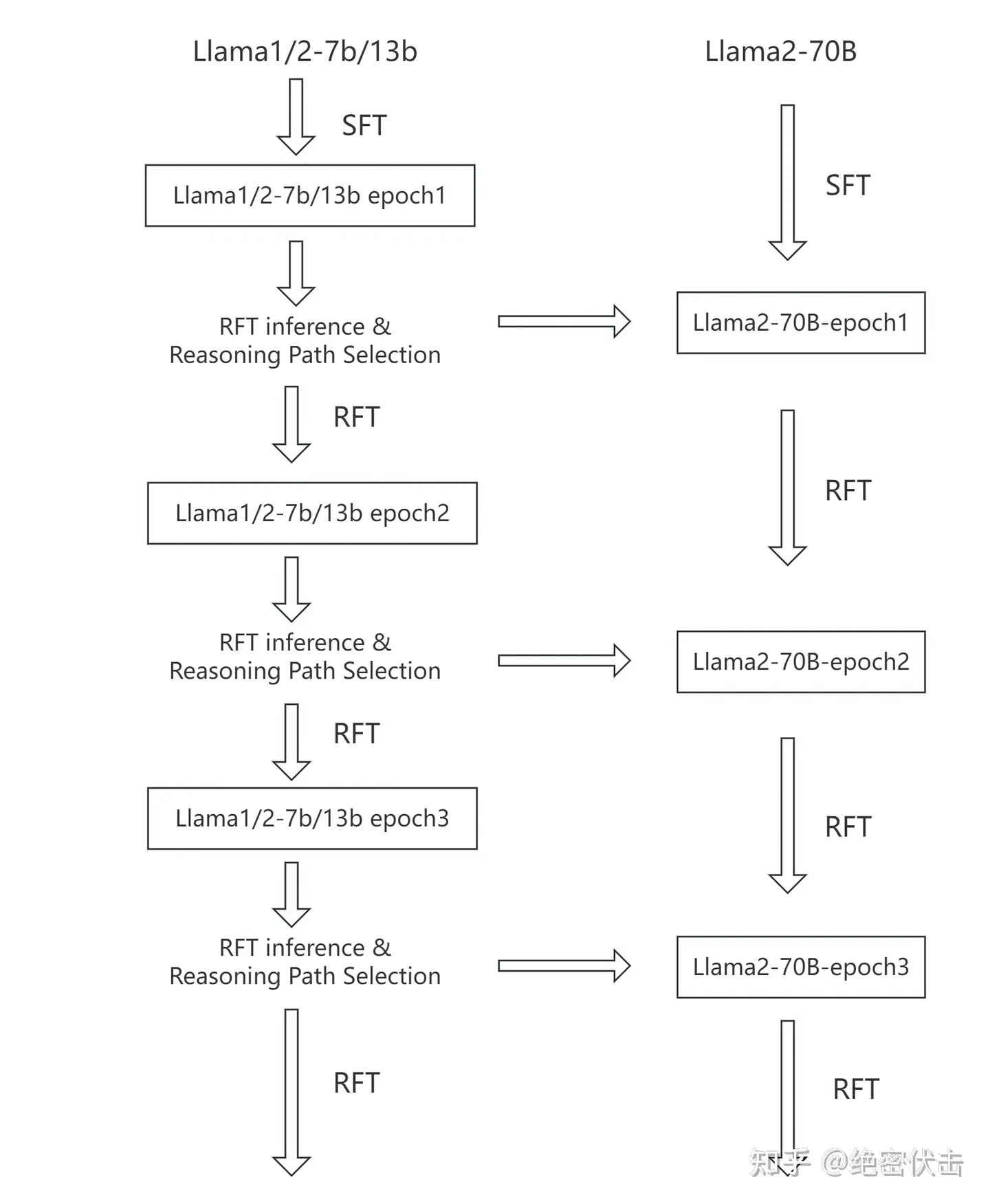
2. 如何将RFT用于数学推理任务?
RFT的核心思想是利用已有的监督模型来生成新的数据样本,如果将其用于数学推理任务,那么可以通过选择正确的推理路径来增强模型的训练数据集。
-
生成候选推理路径:使用一个已经通过监督微调(SFT)训练好的模型来生成针对训练集中每个问题的多个候选推理路径。这些路径包括一系列计算步骤,旨在解决问题。
-
筛选正确路径:从生成的候选路径中筛选出那些能够正确推导出问题答案的推理路径。
-
去重和多样化:进一步从筛选出的正确路径中选择具有不同计算过程或表达方式的路径,以增加数据集的多样性。这有助于模型学习不同的解决问题的方法。
-
微调:使用这些经过筛选和去重的推理路径作为新的训练数据,对原始的监督模型进行进一步的微调。
-
提高泛化能力:通过引入多样化的推理路径,RFT旨在提高模型在未见过的问题上的泛化能力。
将RFT用于数学推理任务,可以利用模型自身生成的数据来增强其推理能力,同时避免了昂贵的人工标注成本。这种方法特别适用于那些难以通过增加监督数据量来提升性能的场景,因为它允许模型从未充分利用的训练数据中学习新的推理策略。
和SFT相比较,RFT具有以下几点优势:
-
数据增强的有效性:RFT通过拒绝采样的方式,使用监督模型生成并收集正确的推理路径作为额外的微调数据集。这种方法可以在不增加人工标注工作量的情况下,增加数据样本,从而提高模型性能。
-
推理路径的多样性:RFT特别强调通过增加不同的推理路径来提高LLMs的数学推理能力。这意味着RFT能够提供多种解决问题的方法,有助于模型在面对新问题时有更好的泛化能力。
-
对性能较差模型的提升效果:论文中提到,RFT对于性能较差的LLMs提升更为明显。这表明RFT可能是一种更为有效的改进手段,特别是对于那些需要显著提高推理能力的模型。
-
组合多个模型的优势:RFT可以通过组合来自多个模型的拒绝样本来进一步提升性能。这种方法使得LLaMA-7B在GSM8K数据集上的准确率从SFT的35.9%显著提高到49.3%。
-
计算资源的经济性:尽管RFT在生成样本时可能需要较多的计算资源,但在训练阶段相比从头开始预训练一个LLM来说,它是一种更为经济的方法。这使得RFT成为一种可行的、成本效益更高的改进模型性能的手段。
-
减少过拟合:RFT通过引入多样化的推理路径,有助于减少模型在训练数据上的过拟合,特别是在大型模型中。
Reference
[1] RFT(拒绝采样微调):提升大模型推理能力
[2] Scaling Relationship on Learning Mathematical Reasoning with Large Language Models