本文主要从文章贡献、主要创新点以及计算资源等方面介绍相关论文。
创作不易,点赞收藏,谢谢!如有交流需要,请关注工V号“笔名二十七画生”。
一、数据集
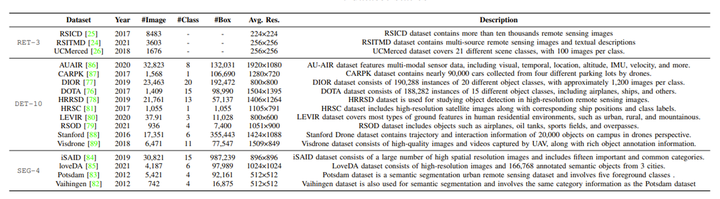
光学遥感领域的数据集现状,包含3个多模态数据集、10个检测数据集以及4个分割数据集。
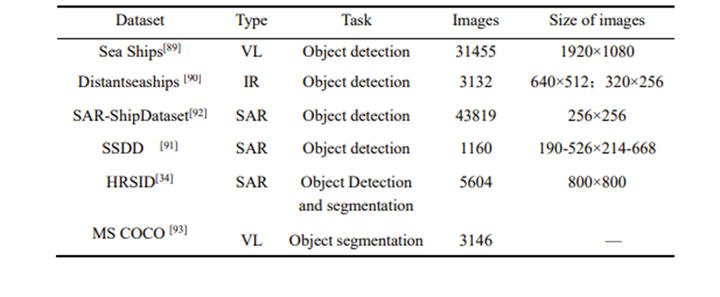
(合成孔径雷达)SAR图像数据集现状
RSGPT: A Remote Sensing Vision Language Model and Benchmark [1]
大规模语言模型(LLMs)的出现,以GPT-4为代表,显著推动了人工通用智能(AGI)的快速发展,引发了人工智能2.0的革命。在遥感领域,越来越多的人对开发针对该领域数据分析的大型视觉语言模型(VLMs)产生了兴趣。然而,目前的研究主要围绕视觉识别任务展开,缺乏对齐和适用于训练大型VLMs的大规模图像-文本数据集,这对于有效地训练这些模型以应用于遥感领域带来了重大挑战。在计算机视觉领域,最近的研究表明,在小规模、高质量的数据集上对大型视觉语言模型进行微调可以获得卓越的视觉和语言理解性能。这些结果与从头开始训练大量数据的最先进的VLMs(如GPT-4)相当。受到这个迷人的想法的启发,在这项工作中,贡献如下:
1.建立了一个高质量的遥感图像字幕数据集(RSICap),以促进遥感领域大型VLMs的开发。
2.为了促进在遥感领域进行VLMs的评估,我们还提供了一个基准评估数据集,称为RSIEval。
3.基于在新创建的RSICap数据集上对InstructBLIP 进行微调,开发了一个遥感生成预训练模型(RSGPT)。通过仅微调InstructBLIP的Q-Former网络和线性层,可以迅速学习以数据有效的方式将遥感图像的视觉特征与LLMs对齐。
具体来说:
(1). 遥感图像字幕数据集(RSICap)
RSICap包含了2585个的字幕。该数据集为每张图像提供了详细的描述,人工注释包括场景描述(如住宅区、机场或农田)以及物体信息(如颜色、形状、数量、绝对位置等)。

该图展示的不同数据集遥感图像内容的描述情况,从图中可以看出RSICap数据集描述的内容更加丰富,包含主题、形状、相对与绝对位置以及颜色数量等。

该图展示的是RSICap数据集的定量分析,包含描述长度的概率密度函数、自然段数量的概率密度函数以及RSICap的相关内容的统计。总体上个人感觉服从一个正太分布的趋。势
(2).基准评估数据集RSIEval
该数据集包括人工注释的字幕和视觉问答对,可以全面评估VLMs在遥感环境下的性能。

RSIEval 中的图像-问答三元组示例。这些问题和答案非常多样化,图中显示的示例包括存在、数量、颜色、绝对位置、相对位置、全色/彩色图像、图像分辨率和视觉推理,以及它们对应的开放式答案。问题类型在括号中表示,并以绿色突出显示。
(3).RSGPT
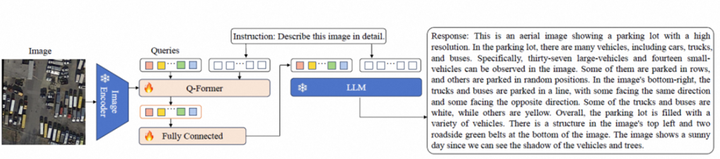
RSGPT由一个图像编码器、一个感知指令的Q-Former(微调)、一个全连接层(微调)和一个大型语言模型LLM组成。Q-Former用来增强视觉特征和文本特征的对齐表示,线性层将Q-Former的输出特征投影到LLM的输入特征中,最后LLM根据视觉信息和文本提示生成最终响应。
4.训练与测试成本

普通人还是不要卷了,需要8卡A100的GPUs(A100单卡显存为80G)
二、单模态大模型
1.RingMo: A Remote Sensing Foundation Model With Masked Image Modeling [2]
深度学习方法促进了遥感 (RS) 图像解释的快速发展。最广泛使用的训练范式是利用 ImageNet 预训练模型来处理指定任务的 RS 数据。然而,存在 自然场景与RS场景之间的领域差距,以及 RS模型泛化能力差 等问题。开发具有通用 RS 特征表示的基础模型是有意义的。由于有大量未标记的数据可用,自监督方法在遥感方面比全监督方法具有更大的发展意义。然而,目前大多数自监督方法都使用 对比学习,其性能对数据增强、附加信息以及正负对的选择很敏感。 该文献贡献如下:
1.利用 生成式自监督学习 对 RS 图像的好处,提出了一个名为 RingMo 的遥感基础模型框架;
2. 根据RS图像的特性设计了一种自监督方法,改善了以往掩码策略在复杂RS场景中可能忽略密集小目标的情况。(我觉得这一点比较有意思)
3.在没有人为监督的情况下,我们收集了200万张图像的RS数据集,这些图像来自卫星和航空平台,涵盖了六大洲不同的物体和场景。这样的数据集包含了大量不同的RS图像,提高了基础模型对不同场景的适应性。
具体如下:
(1).生成式自监督基础模型框架
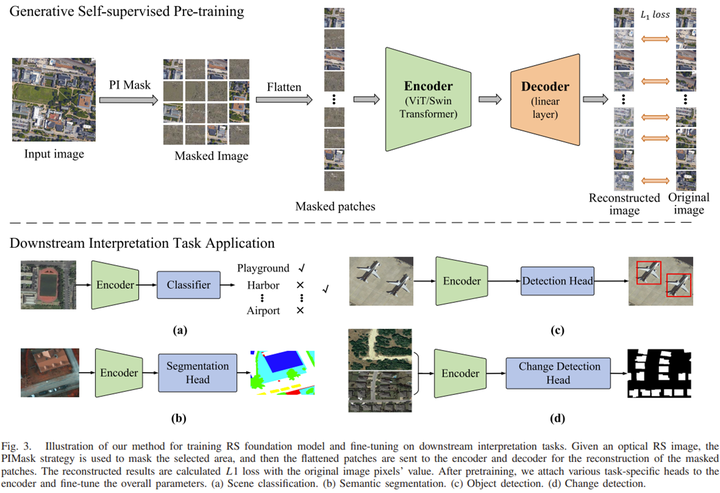
所提出的 RingMo 训练方法通过生成式自监督学习来学习遥感表示。
这种建模是一种典型的自动编码方法,它从原始信号的部分观察中重建。为了避免丢失小物体的特征信息,本文设计了PIMask策略。给定输入图像,PIMask 实现 区域选择和掩码生成。与其他自动编码器一样,本文的方法有一个编码器,可以提取掩码图像的隐藏表示,然后用于重建掩码区域的原始信号。学习到的编码器应该对各种光学遥感下游任务有用。在这项工作中,主要考虑了两种经典的视觉 Transformer 架构:ViT 和 Swin Transformer 。重建目标 指定要预测的原始信号的形式,L1回归损失 用于计算重建结果与像素值的差异。
(2).不完全掩码图像重建

添加图片注释,不超过 140 字(可选)
大多数MIM方法常用的掩码策略是 随机掩码,如图4所示。随机选择一定比例的图像块,然后完全掩码。这种方法在自然图像中很有用。然而,遥感影像的应用存在一些问题。特殊的成像机制导致 更复杂的背景 和 小尺度物体。使用 随机掩码策略 很容易忽略许多完整的小目标。如图 4 右侧红色块所示,随机掩模策略完全丢失了掩码patches中的小目标信息,这影响了基础模型重建小目标,增加了图像重建的难度。因此,本文设计了一种名为 PIMask 的新掩码策略来解决这个问题。本文没有完全屏蔽图像块,而是在屏蔽块中随机保留一些像素。采用这种掩码策略,可以有效地保留小目标的一些像素信息。就像图 4 中的蓝色块一样,本文增加了掩码块的数量以保持总掩码比率不变。
(3).训练与测试成本

训练采用NVIDIA Tesla V100(16GB,目前来看还可以接受,但是没给出具体用了几块卡)好处是支持mindspore框架
2.Advancing plain vision transformer toward remote sensing foundation model [3]
深度学习在很大程度上影响了遥感影像分析领域的研究。然而,大多数现有的遥感深度模型都是用ImageNet预训练权重初始化的,其中自然图像不可避免地与航拍图像相比存在较大的域差距,这可能会限制下游遥感场景任务上的微调性能。为此,京东探索研究院联合武汉大学、悉尼大学借助迄今为止最大的遥感场景标注数据集MillionAID,从头开始训练包括卷积神经网络(CNN)和已经在自然图像计算机视觉任务中表现出了良好性能的视觉Transformer(Vision Transformer)网络,首次获得了一系列基于监督学习的遥感预训练基础骨干模型。并进一步研究了ImageNet预训练(IMP)和遥感预训练(RSP)对包括语义分割、目标检测在内的一系列下游任务的影响。该文章主要贡献如下:
1.基于具有代表性的无监督掩码图像建模方法MAE对网络进行预训练来研究Plain ViT作为基础模型的潜力。
2.提出了一种新颖的旋转可变大小窗口注意力方法(我认为比较有意思的一点)来提高Plain ViT的性能。它可以生成具有不同角度、大小、形状和位置的窗口,以适应遥感图像中任意方向、任意大小的目标,并能够从生成的窗口中提取丰富的上下文信息,从而学习到更好的物体表征。
具体来说:
(1).可变尺寸窗口注意(VSA)

这篇文章第二个创新点来源于2022这篇ECCV的文章,提出了可变尺寸窗口注意(VSA)来从数据中学习自适应窗口配置。具体来说,基于每个默认窗口中的token,VSA 使用了一个窗口回归模块来预测目标窗口的大小和位置。通过对每个注意头独立采用 VSA,可以建立长期依赖关系模型。

在上图的基础上,引入了相对参考窗口的偏移量、尺度缩放因子以及旋转角度
(2).整体网络结构
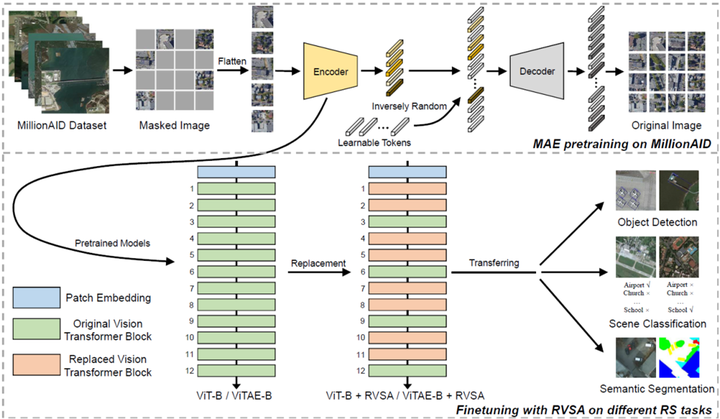
设计出符合遥感图像特点的旋转可变窗口注意力机制来代替Transformer中的原始完全注意力。
(3).训练与测试成本

训练采用A100GPU(80g)
3.Rsprompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model [4]
借助大量的训练数据(SA-1B),Meta AI Research 提出的基础 "Segment Anything Model"(SAM)表现出了显著的泛化和零样本能力。尽管如此,SAM 表现为一种类别无关的实例分割方法,严重依赖于先验的手动指导,包括点、框和粗略掩模。此外,SAM 在遥感图像分割任务上的性能尚未得到充分探索和证明。
1.本文考虑基于 SAM 基础模型设计一种自动化实例分割方法,该方法将语义类别信息纳入其中,用于遥感图像。2.受提示学习启发,本文通过学习生成合适的提示来作为 SAM 的输入。这使得 SAM 能够为遥感图像生成语义可辨别的分割结果,该方法称之为 RSPrompter。
具体来说:

除了提出的 RSPrompter 之外,还介绍了其他三种基于 SAM 的实例分割方法进行比较,如下图(a)、(b) 和 (c) 所示。文章评估了它们在遥感图像实例分割任务中的有效性并启发未来的研究。这些方法包括:外部实例分割头、分类掩码类别和使用外部检测器,分别称为SAM-seg、SAM-cls 和 SAM-det。
RSPrompter是一种用于遥感图像实例分割的提示学习方法,利用了SAM基础模型。RSPrompter的目标是学习如何为SAM生成提示输入,使其能够自动获取语义实例级掩码。相比之下,原始的SAM需要额外手动制作提示,并且是一种类别无关的分割方法。
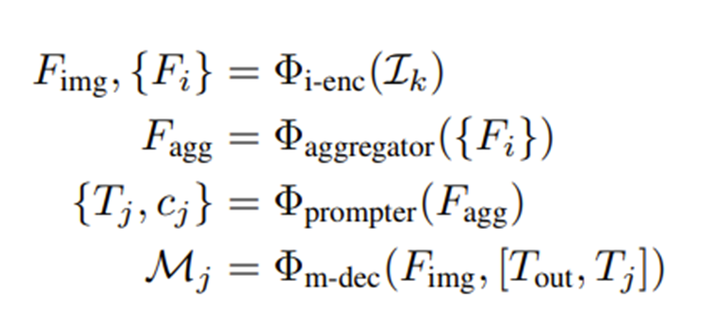
图像通过冻结的SAM图像编码器处理,生成Fimg和多个中间特征图Fi。Fimg用于SAM解码器获得prompt-guided掩码,而Fi则被一个高效的特征聚合和prompt生成器逐步处理,以获取多组prompt和相应的语义类别。为设计prompt生成器,本文采用两种不同的结构,即锚点式和查询式。
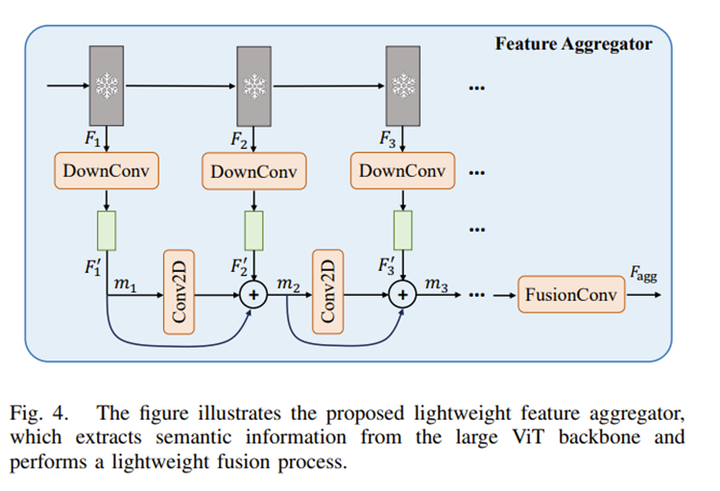
SAM是基于提示的类别无关的分割模型,为了在不增加prompter计算复杂度的情况下获得语义相关且具有区分性的特征,本文引入了一个轻量级的特征聚合模块。如下图所示,该模块学习从SAM ViT骨干网络的各种中间特征层中表示语义特征。
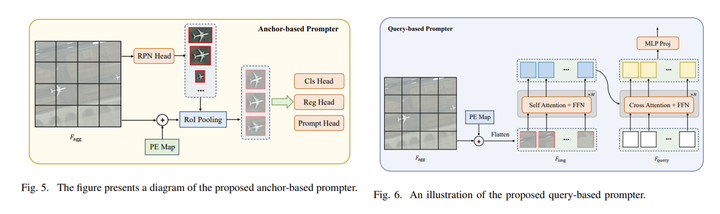
两种提示生成器。
首先,我们使用基于锚点的区域建议网络 (RPN),其次,我们获取单个对象的视觉特征表示通过RoI Pooling[20]从位置编码特征图中得出。从视觉特征中,我们推导出三个感知头:语义头、定位头,以及提示头。语义头确定特定对象类别,而定位头建立生成的提示表示与目标实例掩码之间的匹配条件,即基于贪婪匹配关于本地化(联合交集或 IoU)。提示head 生成 SAM 所需的提示嵌入掩码解码器。
基于查询的提示器主要包括内部轻量级 Transformer 编码器和解码器。这编码器用于提取高级语义特征从图像中,而解码器用于转换将可学习的查询预设到必要的提示嵌入中SAM 通过与图像特征的交叉注意力交互。
3.训练与测试成本(没给出)
4.SpectralGPT: Spectral Foundation Model [5]
基础模型最近引起了人们的极大关注,因为它有可能以一种自我监督的方式彻底改变视觉表征学习领域。虽然大多数基础模型都是为了有效地处理各种视觉任务的RGB图像而定制的,但在光谱数据方面的研究存在明显的差距,光谱数据为场景理解提供了有价值的信息,特别是在遥感(RS)应用中。为了填补这一空白,我们首次创建了一个通用的RS基础模型,名为SpectralGPT,该模型专门用于使用新型3D generative pretrained transformer(GPT)处理光谱RS图像。与现有基础模型相比,SpectralGPT贡献如下:
1.以渐进式训练方式适应不同尺寸、分辨率、时间序列和区域的输入图像,充分利用广泛的遥感大数据;
2.利用3D token生成空间光谱耦合;
3.通过多目标重建捕获光谱序列模式;
4.在100万张光谱RS图像上进行训练,生成超过6亿个参数的模型。
具体来说:
(1).整体网络结构

添加图片注释,不超过 140 字(可选)
1.在预训练阶段,SpectralGPT从头开始在一个数据集上训练模型(例如,fMoW-S2,包含712,874张图像),采用(3D)张量的随机权重初始化。随后,模型在更多数据集上进行渐进式训练(例如,BigEarthNet-S2,包含354,196张图像),这些数据集具有不同的图像大小、时间序列信息和地理区域。
2.SpectralGPT采用MAE架构构建,并引入了3D掩码,其中90%的标记被掩盖。
(2)训练与测试成本
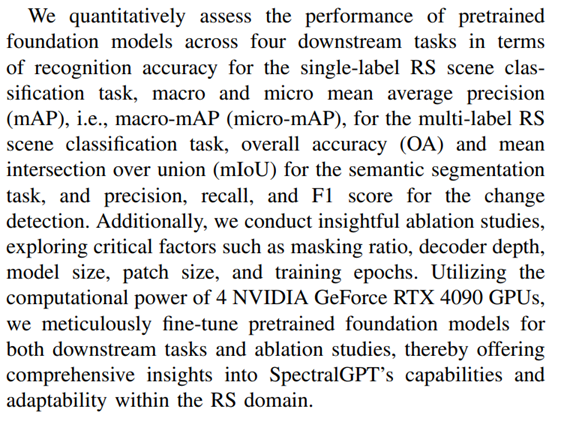
4块4090的显存(24GB)
三、多模态大模型
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing [6]
首先介绍一下,CLIP模型,CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,与CV中的一些对比学习方法如moco和simclr不同的是,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。如下图所示,CLIP包括两个模型:Text Encoder和Image Encoder,其中Text Encoder用来提取文本的特征,可以采用NLP中常用的text transformer模型;而Image Encoder用来提取图像的特征,可以采用常用CNN模型或者vision transformer。最后经过训练之后实现zero-shot分类。

添加图片注释,不超过 140 字(可选)
添加图片注释,不超过 140 字(可选)
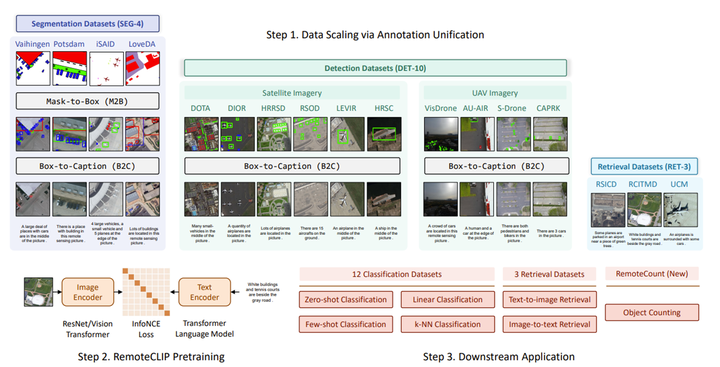
RemoteCLIP 将 异 构 注 释 转 换 为 基 于 Box-to-Caption 和 Mask-to-Box 转 换 的 统 一 图 像-字幕数据格式,构建了一个大规模图像文本对 预训练数据集。步骤1:RemoteCLIP在多样化的遥感数据集上进行训练,涵盖了10个目标检测数据集、4个遥感语义分割数据集和三个遥感图像文本数据集。步骤2:我们基于CLIP模型执行持续预训练,使其专门用于遥感领域。步骤3:我们在16个下游数据集上进行全面评估,包括新创建的RemoteCount数据集,以展示RemoteCLIP的强大能力和泛化能力。
训练与测试成本

4块3090TI显卡(24GB)
四、其他视觉领域大模型
1.Segment Anything in Medical Images [7]
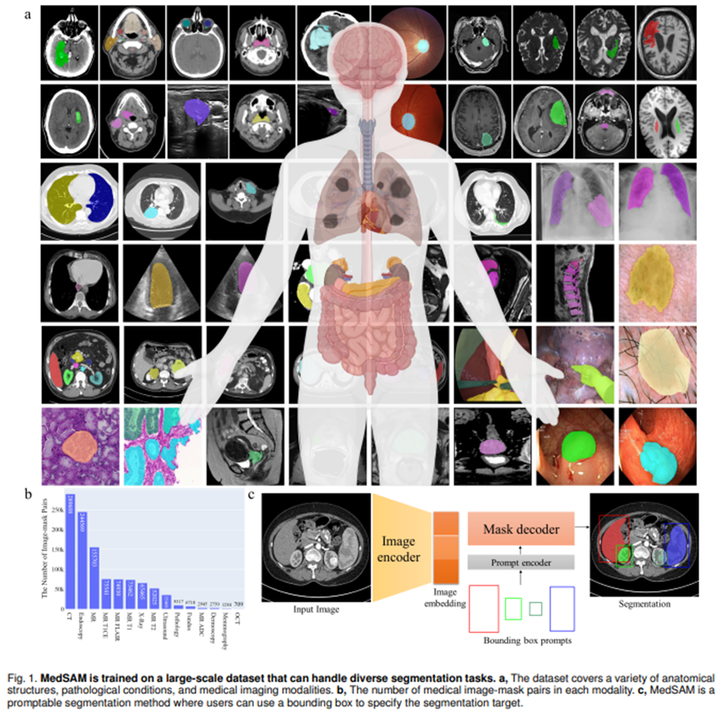
MedSAM:通过在大规模医学分割数据集上微调 SAM,创建了一个用于通用医学图像分割的扩展方法 MedSAM。这一方法在 21 个 3D 分割任务.The model was trained on 20 A100 (80G) GPUs with 100 epochs and the last checkpoint was selected as the final model.和 9 个 2D 分割任务上优于 SAM。
2.AutoSAM: Adapting SAM to Medical Images by Overloading the Prompt Encoder [8]

AutoSAM:为SAM的提示生成了一个完全自动化的解决方案,基于输入图像由AutoSAM辅助提示编码器网络生成替代提示。AutoSAM 与原始的 SAM 相比具有更少的可训练参数。

添加图片注释,不超过 140 字(可选)
3.Learnable Ophthalmology SAM [9]

在眼科的多目标分割:通过学习新的可学习的提示层对SAM进行了一次微调,从而准确地分割不同的模态图像中的血管或病变或视网膜层。

采用A100显卡(80G)
4.FASTER SEGMENT ANYTHING: TOWARDS LIGHTWEIGHT SAM FOR MOBILE APPLICATIONS [10]
考虑到sam的image encoder参数太多,不适合移动设备,论文的目的也就是用一个轻量级的image encoder替换原先比较重的image encoder模块。作者分析对比了蒸馏sam2个模块的方法,最终提出了一种解耦蒸馏的方法。
作者将其两个子任务:蒸馏image encoder和微调mask decoder,对于mask decoder参数,采用复制和冻结的方法,可以避免mask decoder受image encoder的影响,作者称这种蒸馏方法为半耦合蒸馏方法。
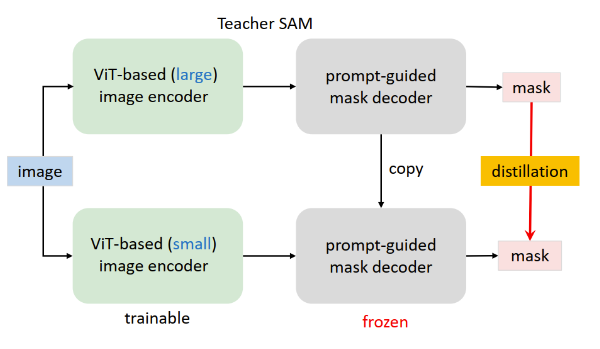
半解耦蒸馏方法
然而作者发现这种方法依然有问题,因为prompt是随机选择的,导致mask解码也是可变的,从而增加了优化难度,最后作者提出了解耦蒸馏的方法,直接蒸馏image embedding,该方法还有一个好处训练时时可以采用简单的MSE loss,而不需要sam原来的Focal Loss和Dice Loss。
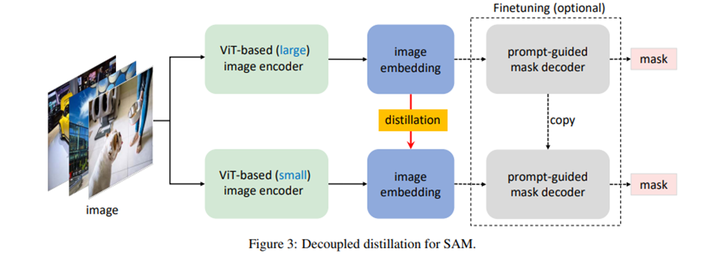
完全解耦蒸馏。MobileSAM:将原始 SAM 中的图像编码器 ViT-H 的知识蒸馏到一个轻量化的图像编码器中,该编码器可以自动与原始 SAM 中的 Mask 解码器兼容。训练可以在不到一天的时间内在单个 GPU 上完成,它比原始 SAM 小60多倍,但性能与原始 SAM 相当。

在图像编码上进行解耦知识蒸馏,采用单张GPU进行训练,不到一天训练结构。
5.Fast Segment Anything[11]
SAM被认为是里程碑式的视觉基础模型,它可以通过各种用户交互提示来引导图像中的任何对象的分割。SAM利用在广泛的SA-1B数据集上训练的Transformer模型,使其能够熟练处理各种场景和对象。SAM开创了一个令人兴奋的新任务,即Segment Anything。由于其通用性和潜力,这个任务具备成为未来广泛视觉任务基石的所有要素。然而,尽管SAM及其后续模型在处理segment anything任务方面展示了令人期待的结果,但其实际应用仍然具有挑战性。显而易见的问题是与SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求。与卷积模型相比,ViT以其庞大的计算资源需求脱颖而出,这对于其实际部署,特别是在实时应用中构成了障碍。这个限制因此阻碍了segment anything任务的进展和潜力。
鉴于工业应用对segment anything模型的高需求,本文设计了一个实时解决方案,称为FastSAM,用于segment anything任务。本文将segment anything任务分解为两个连续的阶段,即全实例分割和提示引导选择。第一阶段依赖于基于卷积神经网络(CNN)的检测器的实现。它生成图像中所有实例的分割掩码。然后在第二阶段,它输出与提示相对应的感兴趣区域。通过利用CNN的计算效率,本文证明了在不太损失性能质量的情况下,可以实现实时的segment anything模型。 本文希望所提出的方法能够促进对segment anything基础任务的工业应用。贡献可总结如下:
1.引入了一种新颖的实时基于CNN的Segment Anything任务解决方案,显著降低了计算需求同时保持竞争性能。
2.本研究首次提出了将CNN检测器应用于segment anything任务,并提供了在复杂视觉任务中轻量级CNN模型潜力的见解。
3.通过在多个基准测试上对所提出的方法和SAM进行比较评估,揭示了该方法在segment anything领域的优势和劣势。
下图展示了FastSAM网络架构图。该方法包括两个阶段,即全实例分割和提示引导选择。前一个阶段是基础阶段,第二个阶段本质上是面向任务的后处理。与端到端的Transformer方法不同,整体方法引入了许多与视觉分割任务相匹配的人类先验知识,例如卷积的局部连接和感受野相关的对象分配策略。这使得它针对视觉分割任务进行了定制,并且可以在较少的参数数量下更快地收敛。
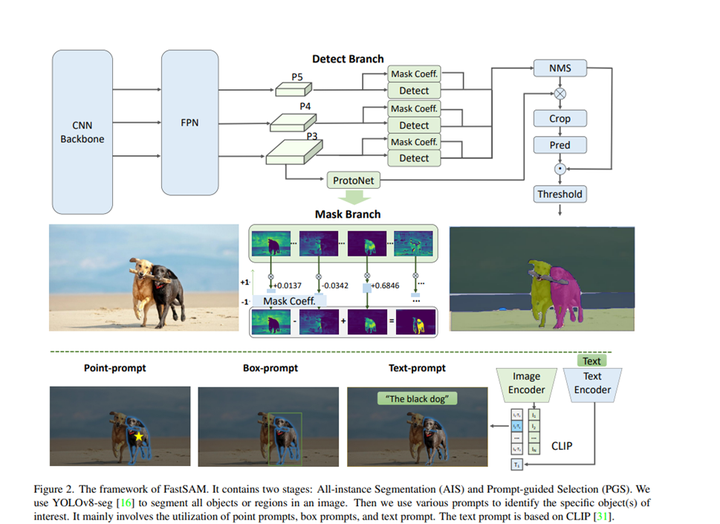
添加图片注释,不超过 140 字(可选)
FastSAM包含两个阶段:全实例分割(AIS)和提示引导选择(PGS)。先使用YOLOv8-seg 对图像中的所有对象或区域进行分割。然后使用各种提示来识别感兴趣的特定对象。主要涉及点提示、框提示和文本提示的利用。
训练与测试要求

测试用3090(24G)
参考文献
[1] Hu Y, Yuan J, Wen C, et al. RSGPT: A Remote Sensing Vision Language Model and Benchmark[J]. arXiv preprint arXiv:2307.15266, 2023.
[2]X. Sun et al., "RingMo: A Remote Sensing Foundation Model With Masked Image Modeling," in IEEE Transactions on Geoscience and Remote Sensing, vol. 61, pp. 1-22, 2023, Art no. 5612822, doi: 10.1109/TGRS.2022.3194732.
[3]Wang D, Zhang Q, Xu Y, et al. Advancing plain vision transformer toward remote sensing foundation model[J]. IEEE Transactions on Geoscience and Remote Sensing, 2022, 61: 1-15.
[4]Chen K, Liu C, Chen H, et al. Rsprompter: Learning to prompt for remote sensing instance segmentation based on visual foundation model[J]. arXiv preprint arXiv:2306.16269, 2023.
[5]Hong D, Zhang B, Li X, et al. SpectralGPT: Spectral Foundation Model[J]. arXiv preprint arXiv:2311.07113, 2023.
[6]Liu F, Chen D, Guan Z, et al. RemoteCLIP: A Vision Language Foundation Model for Remote Sensing[J]. arXiv preprint arXiv:2306.11029, 2023.
[7]Ma J, Wang B. Segment anything in medical images[J]. ar**v preprint ar**v:2304.12306, 2023.
[8]Shaharabany T, Dahan A, Giryes R, et al. AutoSAM: Adapting SAM to Medical Images by Overloading the Prompt Encoder[J]. ar**v preprint ar**v:2306.06370, 2023.
[9]Qiu Z, Hu Y, Li H, et al. Learnable ophthalmology sam[J]. ar**v preprint ar**v:2304.13425, 2023.
[10]Zhang C, Han D, Qiao Y, et al. Faster Segment Anything: Towards Lightweight SAM for Mobile Applications[J]. ar**v preprint ar**v:2306.14289, 2023.
[11]Zhao X, Ding W, An Y, et al. Fast Segment Anything[J]. ar**v preprint ar**v:2306.12156, 2023.