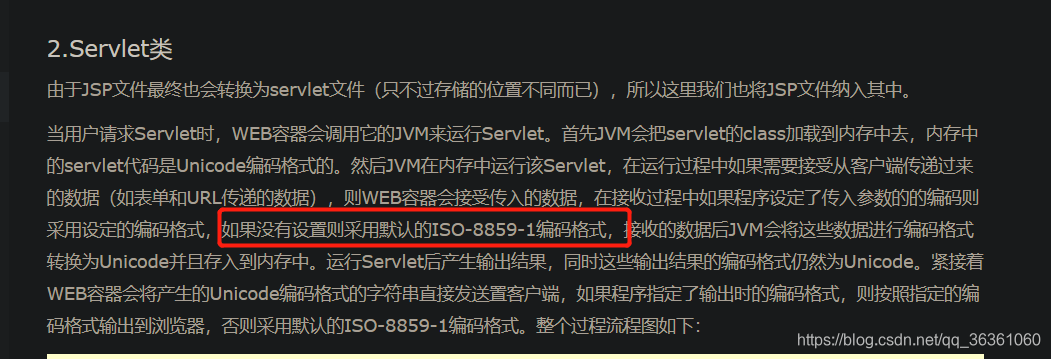
一、Java编码转换过程
一个普通Java程序的生命周期
- 第一步:编程人员在一定的操作系统上选择合适的编辑器软件实现Java源代码并以.java扩展名的形式保存在保存在操作系统本地
- 第二步:编译源代码生成相应的Class二进制文件(javac命令)
- 第三步:加载Class文件运行程序(java命令)
- 第四步:人机交互
在中文win10操作系统环境下说明:
第一步:我们在win10系统中用编辑软件编写一个java源程序,比如使用记事本编写,记事本在保存时默认采用操作系统默认支持的编码格式保存形成一个.java源文件(中文win10操作系统默认编码格式为GBK),也可以保存时手动设置编码
查看操作系统默认编码java代码:System.getProperty(“file.encoding”);
验证file.encoding属性默认值是否与操作系统默认编码一致: 更改操作系统为UTF-8,测试结果为UTF-8
第二步:我们使用JDK的javac.exe编译源代码时,如果未使用-encoding 参数(这个是编译javac命令的参数,第一步的file.encoding属性是java命令的参数,两个没关系)源程序的编码格式,则javac.exe会获取操作系统默认的编码格式,即编译源程序执行javac A.java等价于javac -encoding file.encoding,编译器根据指定的encoding编码去读取解析A.java文件二进制流最终编码为modified UTF-8格式的Class文件
第三步:使用java命令运行程序,加载Class文件到JVM内存中,此时内存中编码格式为UTF-16
第四步:人机交互输入输出
以Console为例:
默认使用file.encoding编码格式对用户输入串进行编码再转化为UTF-16内码格式保存入内存(用户可以设置输入流的编码格式),程序运行后产生的字符串UTF-16编码再回交给JVM,由JRE将字符串再转换为file.encoding编码格式(用户可以设置输出流的编码格式)传递给操作系统显示并输出到界面上。
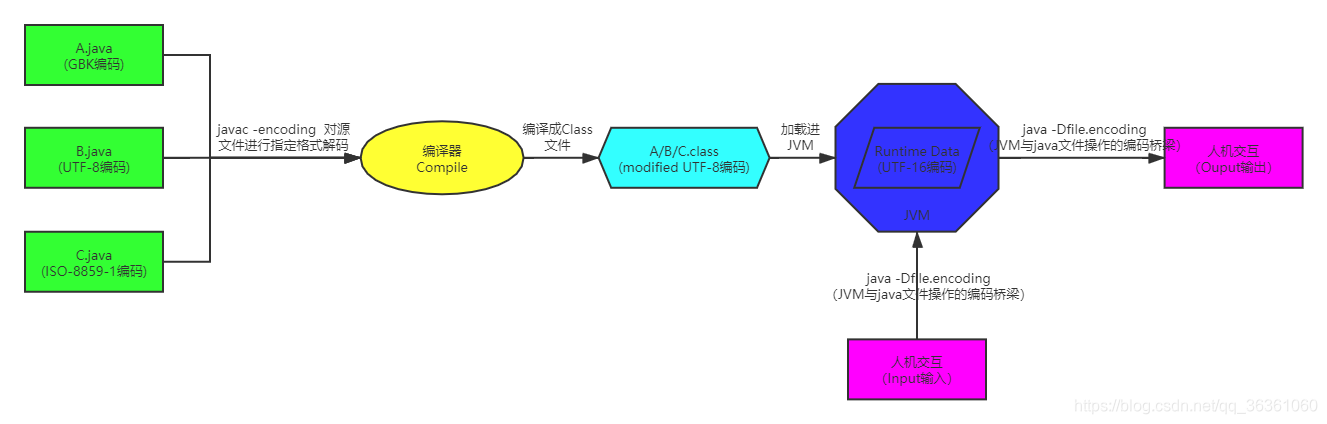
以一次HTTP请求响应为例:
用户从浏览器端发起一个HTTP请求,存在编码的地方有URL、Cookie、Parmer等。服务器端接收到HTTP请求后解析,其中URI、Cookie、Parmer参数需要解码,服务端可能需要读取数据库数据、本地或网络中其他地方的文件数据等,这些地方都可能存在编码解码,当Servlet处理完请求数据后,会将这些数据再编码通过Socket流的方式发送到用户请求的浏览器,经过浏览器解码展现。过程如图所示:
浏览器端:谷歌浏览器89.0.4389.114版本. 服务端:SpringBoot2.4.4搭建的Demo项目
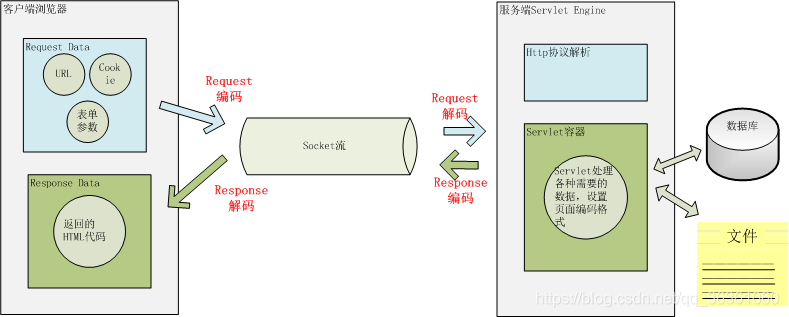
用户在浏览器地址栏请求一个存在中文的URL,如图:
上图中Path请求路径和QueryString请求参数中都出现了中文,可以看到经过浏览器编码后Path请求路径和QueryString请求参数中的“李”编码为“%E4%B8%AD”,查阅上一节字符编码可知 “中”的UTF-8编码十六进制为0xE4B8AD,为什么会有“%”符号?查阅URL的编码规范 RFC3986可知:谷歌浏览器编码URL是将非ASCII字符按照某种编码格式编码成16进制数字然后每个16进制数表示的字节前加上“%”,就形成了上面的URL格式,大家可以自行测试下中文IE和火狐浏览器编码
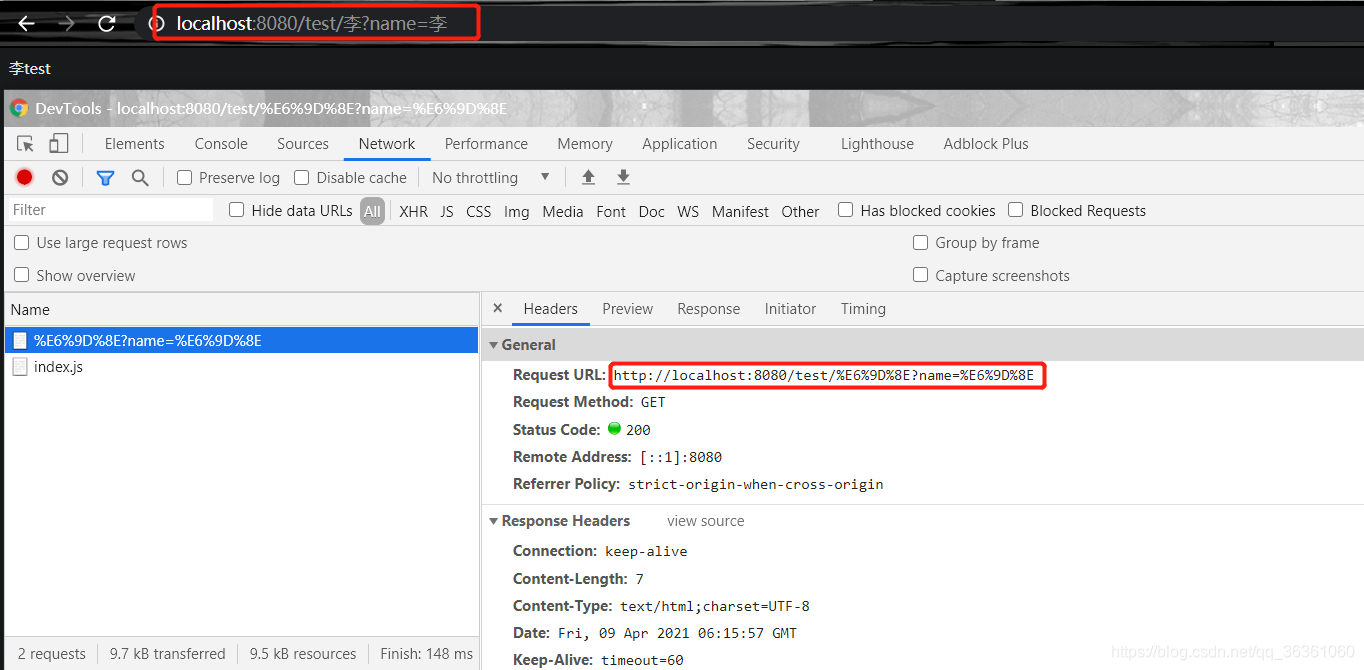
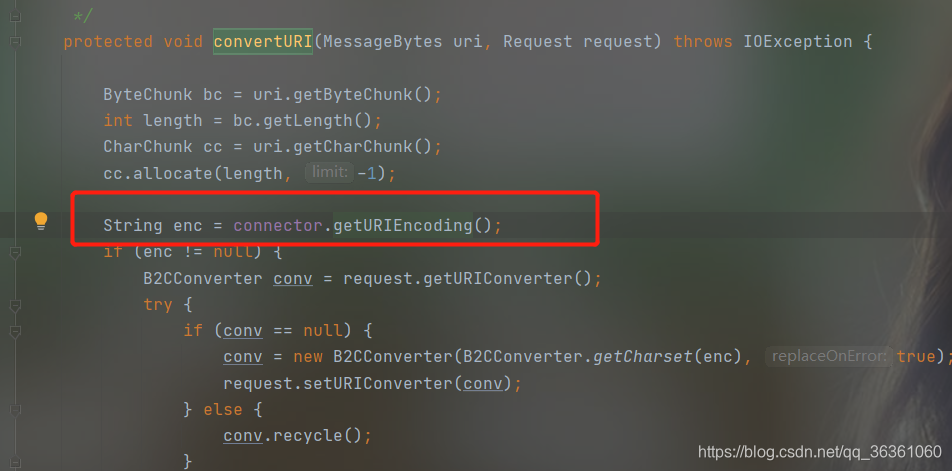
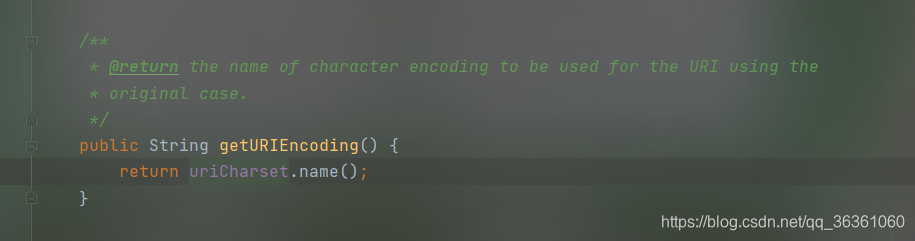
服务端解析请求的URL是在Http11InputBuffer类中的parseRequestLine方法中,该方法将传过来的URL的byte[]设置到org.apache.coyote.Request 的相应的属性中,这里的URL仍然是byte格式,字符转换是在org.apache.catalina.connector.CoyoteAdapter的convertURI方法中完成的如图
可知服务端默认解析Path请求路径为UTF-8编码,接下来分析如何解析QueryString,GET方式HTTP请求的QueryString参数是作为Parameters传递的,可以通过request.getParameter获取参数值,对应的解码在第一次调用该方法时进行,request.getParameter方法被调用时会调用Request 的parseParameters 方法,这个parseParameters方法会对GET/PSOT请求方式传递的参数进行解码操作,默认是字符编码是UTF-8(该Springboot Demo项目启动时默认配置),也可以服务端手动设置编码(request.setCharacterEncoding(“iso-8859-1”))且需要配置Connector对象的useBodyEncodingForURI属性,如

package com.example.demo.api;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;
import javax.servlet.http.HttpServletRequest;
@RestController
public class TestController {
@GetMapping("/test/{path}")
public String get(@PathVariable("path") String path, HttpServletRequest request) throws Exception {
request.setCharacterEncoding("iso-8859-1");
String name = request.getParameter("name");
System.out.println(name);
return "path: " + path + "; name: " + name;
}
}
package com.example.demo.api;
import org.springframework.boot.web.embedded.tomcat.TomcatServletWebServerFactory;
import org.springframework.boot.web.server.WebServerFactoryCustomizer;
import org.springframework.stereotype.Component;
@Component
public class CustomizationBean implements WebServerFactoryCustomizer<TomcatServletWebServerFactory> {
@Override
public void customize(TomcatServletWebServerFactory factory) {
factory.addConnectorCustomizers(connector -> connector.setUseBodyEncodingForURI(true));
}
}
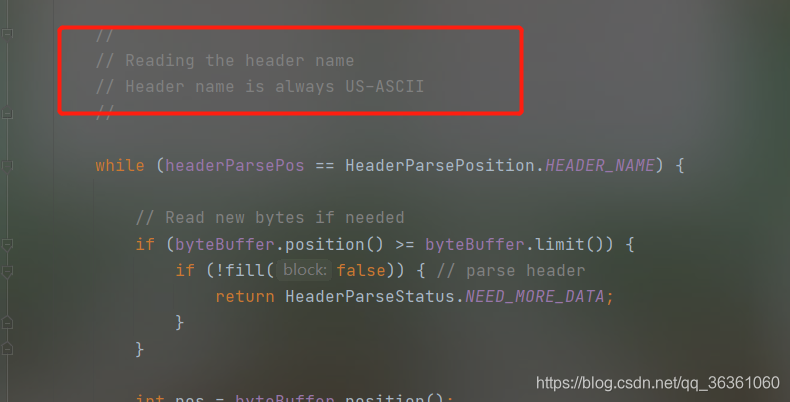
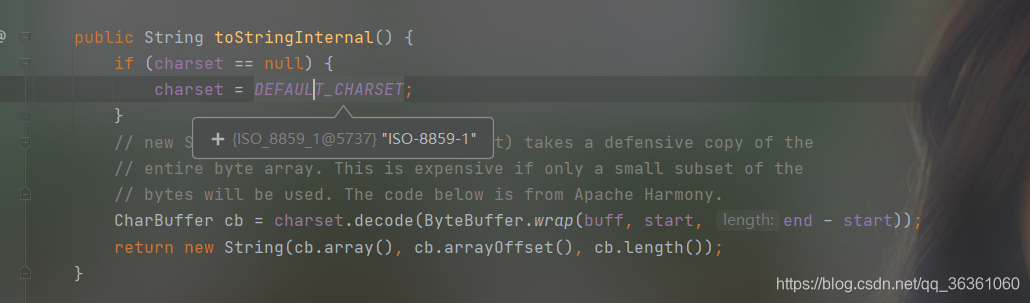
客户端的一个HTTP请求除了上面的URL一般还会在请求头Header中传递其他参数如Cookie,可以Postman设置请求头断点调试源码可知相应的请求头解码操作在request.getHeader方法时进行的,调用Http11InputBuffer的parseHeader()方法,Header项Name名称默认使用ASCII编码,Header项的Value值则调用MessageBytes 的 toString方法,该方法从byte[]到char[]的转化使用默认编码为ISO-8859-1,而我们也不能设置Header的其他编码方式,所以如果设置Header中有非ASCII字符则会有乱码(如果Header中一定要传递非ASCII字符,可以先将这些字符用URLEncoder先编码再添加到Header中,这样浏览器与服务器传递的过程就不会丢失信息,服务端访问时再按照相应的字符编码解码)
服务端程序与数据库Mysql交互,通过JDBC数据库驱动程序连接,从JDBC驱动程序发送到Mysql服务器的所有字符串都是从本地Java的Unicode格式自动转换为客户端字符编码(Mysql8.0默认字符集已从latin1即ISO-8859-1更改为utf8mb4),连接时会自动检测到Mysql客户端和我们服务端之间的字符编码(前提是未设置Connector / J连接属性 characterEncoding并且 connectionCollation未设置),要覆盖客户端自动检测到的编码,请使用characterEncoding服务器连接URL中的属性,(例服务端配置数据源时 url: jdbc:mysql:/localhost:3306/test?characterEncoding=UTF-8)Mysql其他相关的字符编码暂不扩展
服务端处理数据完成后通过Response返回给客户端浏览器,这个过程先要经过编码再到浏览器进行解码,过程中的编码字符集可以通过response.setCharacterEncoding 来设置,它将会覆盖request.getCharacterEncoding 的值,并且通过 Header 的 Content-Type 返回客户端,浏览器接受到返回的 socket 流时将通过 Content-Type 的 charset 来解码,如果返回的 HTTP Header 中 Content-Type 没有设置 charset,那么浏览器将根据 Html 的 中的 charset 来解码。如果也没有定义的话,那么浏览器将使用默认的编码来解码。
二、JVM运行时参数file.encoding、sun.jnu.encoding
file.encoding:设置用于Java程序的文件的编码格式
查找Java源码可知只有4个类调用了file.encoding属性如图
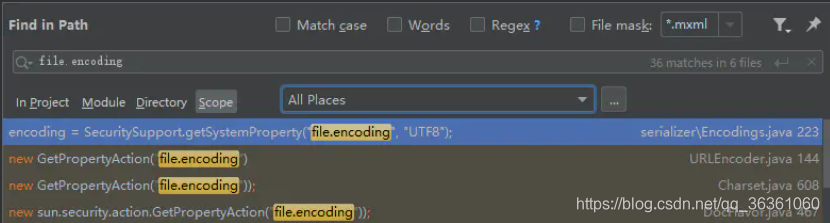
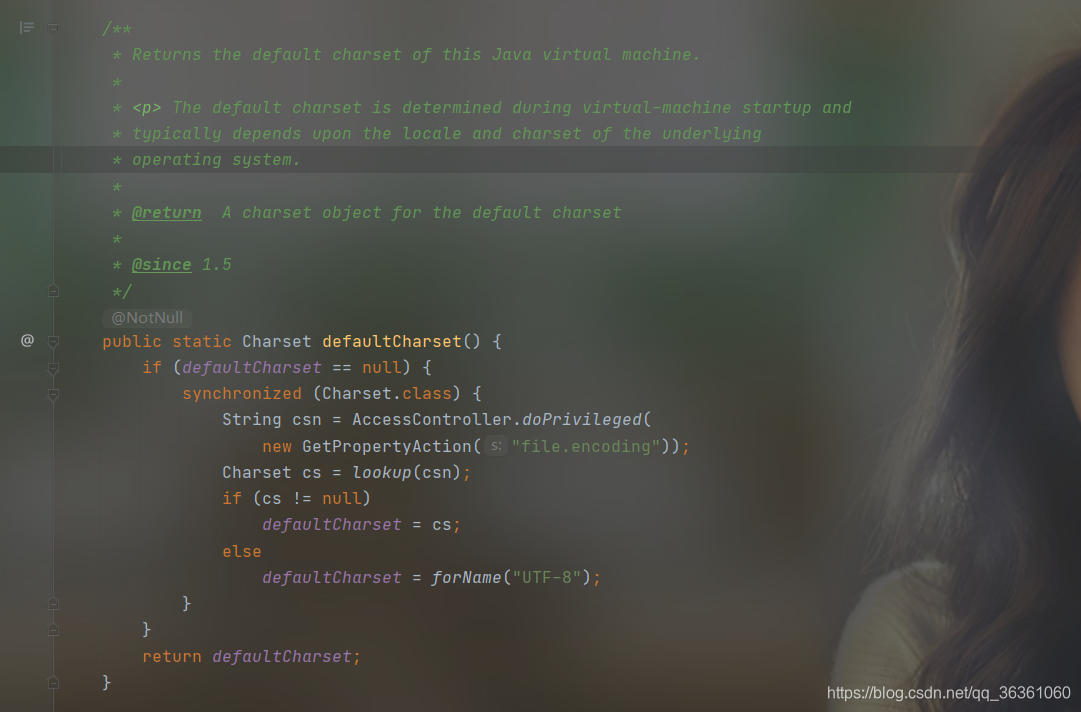
- java.nio.Charset.defaultCharset()
从上面的注释中可以知道,默认字符集是在JVM启动时决定的,依赖于JVM所在的操作系统的区域及字符集,从代码中可以看到默认字符集就是从file.encoding 这个属性中获取的。这里的默认字符集会影响到程序运行时字符串、IO流读写等的默认编码。
注意源码中的defaultCharset只能被初始化一次,后面获取都是从cache(lookup的函数)里读出来的(即file.encoding运行时不可被更改,JVM启动后设置系统配置System.setProperty(“file.encoding”, “UTF-8”)不会影响到默认字符集的编码) - URLEncoder.encode(String) Web环境中最常遇到的编码使用
- com.sun.org.apache.xml.internal.serializer.Encoding.getMimeEncodings(String) 影响对无编码设置的xml文件的读取
- javax.print.DocFlavor 影响打印的编码
sun.jnu.encoding:设置命令行参数、主类名称、环境变量的编码
三、相关概念
Modified UTF-8
在通常用法下,Java程序语言在通过InputStreamReader和OutputStreamWriter读取和写入串的时候支持标准UTF-8。但是,Java也支持一种非标准的变体UTF-8,供对象的序列化(DataInput和DataOutput的实现类也使用这种稍作修改的UTF-8来编码字符串(readUTF(DataInput in)))、Java本地界面和在class文件中的存储字符串时使用的modified UTF-8。除此之外我们一般使用中基本不会获取到modified UTF-8编码的字符串。
JVM 规范中提到的modified UTF-8: Chapter 4. The class File FormatString content is encoded in modified UTF-8. Modified UTF-8 strings are encoded so that code point sequences that contain only non-null ASCII characters can be represented using only 1 byte per code point, but all code points in the Unicode codespace can be represented. Modified UTF-8 strings are not null-terminated. The encoding is as follows: …
modified UTF-8 大致和 UTF-8 编码相同,主要有以下三个不同点:
- 空字符(null character,U+0000)使用双字节的0xc0 0x80,而不是单字节的0x00。
- 仅使用1字节,2字节和3字节格式,而UTF-8支持更多的字节
- 基本多文种平面之外的补充字符以代理对(surrogate pairs)的形式表示
使用双字节表示空字符保证了在已编码字符串中没有嵌入空字节。因为C语言等语言程序中,单字节空字符是用来标志字符串结尾的。当已编码字符串放到这样的语言中处理,一个嵌入的空字符将把字符串一刀两断。
modified UTF-8在没有超过3个字节表示的时候和UTF-8一致,但是超过3个字节即超过基本平面后会使用代理对的形式表示。之所以这样设计的原因是因为Java中的字符为16位长即默认编码是UTF-16,为了保持良好的向后兼容性。
最开始Unicode只有一个可以用16位长完全表示的基本多文种平面,所以Java中的字符(char)为16位长,一个char可以存所有的字符。后来Unicode增加了很多辅助平面,两个字节存不下那些字符,但是为了向后兼容Java不可能更改它的基本语法实现,于是对于超过U+FFFF的字符 (就是所谓的扩展字符)就需要用两个16位长数据来表示, modified UTF-8由UTF-16格式的代理码元来代替原先的Unicode码元作为字符编码表的码元。每个代理码单元由3个字节(就是一个modified UTF-8编码出来的最大字节长)表示。所以在Java内部数据是统一使用modified UTF-8进行编码的,这个编码解码出来的码元是UTF-16编码出来的2字节。JVM把UTF-16编码出来的16位长的数据(2字节,操作系统用8位长的数据,即1字节)作为最小单位进行信息交换。这样的话既不改变原来JVM中的编码规则,又减少了很多扩展字符从UTF-8转码到UTF-16时的运算量,保证了一个已编码的modified UTF-8字符串可以一次编为一个UTF-16码,而不是一次一个Unicode码位,使得所有的Unicode字符都能在Java上显示。但带来的缺点就是使用modified UTF-8进行解码解出来的数据时UTF-16编码编出来的数据,而UTF-16处理扩展字符需要两个16位字长表示即使用两个代码码元共同表示一个Unicode位,原本使用UTF-8编码只需要4个字节就能存储一个Unicode码位,使用modified UTF-8却需要6个字节来存储两个代码码元。
总结:modified UTF-8是对UTF-16的再编码,modified UTF-8和UTF-8是两种完全不同的编码,所以JVM无需解码UTF-16的数据,modified UTF-8代码码元会处理这个映射关系
四、FAQ
1、运行时UTF-16指的是什么?
答:"运行时UTF-16"指的是Java语言的内建数据类型之一的char类型规定是UTF-16 code unit(注意不是UTF-16 code point),并且许多内建API都使用char来做为参数/返回值类型,例如String的chatAt(int)方法,这样从外界进入Java世界的字符/字符串数据,无论原本编码是什么,一旦转换为java.lang.String表示,就会变为UTF-16编码处理,到最后输出的时候在转换为外界期望的编码输出。这样的好处是在Java内部,处理可以统一在UTF-16一种编码下,简化程序需要考虑的情况(但具体JVM实现可以在保持String是UTF-16的表象基础上,在内部做进一步的优化,例如可以实际用1字节的Latin(扩展ASCII编码)存储那些没有超出Latin编码范围的字符串, 请参考HotSpot的JEP 254: Compact Strings)
与此相对的另一种情况就是一个编程语言的标准库里的String类型的每个实例都携带编码信息,数据在进入该编程语言环境时不需要转换编码,Ruby(>=1.9)就是这样的情况,这样的好处是进入/离开时都不需要转换编码,但是缺点就是当两个String实例进行交互的时候(例判断a.contains(b)),这个过程就需要涉及临时编码的转换,各种String操作都必须知道如何转换编码,实现起来就相对复杂一些。
2、JVM运行时为什么使用UTF-16,而不是用UTF-8呢?
答:个人观点认为历史原因。在Unicode最初之际,由于只有一个16位长的基本多文种平面,即只有0~65535的空间,两个字节刚好够用,所以UTF-16相比UTF-8是有很多优势的,当时很多比较主流的VM或OS都是用UTF-16作为默认字符编码,例如WindowsNT和Java的Runtime Data,这也解释了为什么Java中char是两个字节。
但是到2001年,在Unicode3.0标准中加入了很多扩展字符,整个Unicode字符集增大到90000多个字符,2个字节放不下,UTF-16是变长编码的事也被人想起来了。从此UTF-16的地位就变的很尴尬,一方面存储空间利用率不高,另一方面变长编码无法直接访问其中的码元,但是完全放弃UTF-16成本太高,所以现在JVM的运行时数据依然是UTF-16编码的。由于成本问题不能放弃UTF-16,但是UTF-8的兼容性和流行程度又使得JVM必须做点什么来保证其内部数据不会被编码方式影响,于是就有了这个modified UTF-8
3、中文GBK与UTF-8字符转换Demo
package com.example.demo;
import java.io.UnsupportedEncodingException;
public class Demo {
public static void main(String[] args) {
String str = gbkToUtf8("中国");
System.out.println(str);
System.out.println(utf8Togbk(str));
}
/**
* 中文字符串转换为UTF-8字符串输出
*
* @param str
* @return
*/
public static String gbkToUtf8(String str) {
StringBuffer sb = new StringBuffer("");
for (int i = 0, size = str.length(); i < size; i++) {
String s = str.substring(i, i + 1);
try {
byte[] bytes = s.getBytes("UTF-8");
if (bytes.length == 3) {
// 表示是中文,中文在UTF-8中占三个字节
sb.append(gbkToUtf8(bytes));
} else {
sb.append(s);
}
} catch (Exception e) {
e.printStackTrace();
}
}
return sb.toString();
}
private static String gbkToUtf8(byte[] bytes) {
StringBuffer sb = new StringBuffer();
String s = Integer.toBinaryString(bytes[0]);
s = s.substring(s.length() - 8);// 得到是32位的二进制字符串,只取后8位
sb.append(s.substring(s.length() - 4));// 去掉前4位
s = Integer.toBinaryString(bytes[1]);
s = s.substring(s.length() - 8);// 得到是32位的二进制字符串,只取后8位
sb.append(s.substring(s.length() - 6));// 去掉前2位
s = Integer.toBinaryString(bytes[2]);
s = s.substring(s.length() - 8);// 得到是32位的二进制字符串,只取后8位
sb.append(s.substring(s.length() - 6));// 去掉前2位
String utf8 = "\\u"
+ Integer.toHexString(Integer.valueOf(sb.toString(), 2));
return utf8;
}
/**
* UTF-8字符串转换为中文字符串输出 \\u开头及后4位是对应的中文
*
* @param utf8
* @return
*/
public static String utf8Togbk(String utf8) {
int length = utf8.length();
int index = 0;
StringBuffer sb = new StringBuffer();
while (index < length) {
if (length - index < 2) {
sb.append(utf8.charAt(index));
index++;
} else if ("\\u".equals(utf8.substring(index, index + 2))) {
index += 2;
String s = utf8.substring(index, index + 4);
char ch = (char) Integer.parseInt(s, 16);
try {
s = new String((ch + "").getBytes("gbk"), "gbk");
sb.append(s);
index += 4;
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}
} else {
sb.append(utf8.charAt(index));
index++;
}
}
return sb.toString();
}
}
运行结果:
\u4e2d\u56fd
中国
4、十六进制Hex与字节Byte数组的转换
十六进制(Hex):由0-9,A-F组成,字母不区分大小写,与十进制对应关系是:0-9对应0-9,A-F对应10-15
字节(Byte):java中一个字节为8个二进制位
十六进制与字节转换原理:每个二进制位有两种状态0和1,因此两个二进制位有4种状态,分别为00, 01, 10, 11,三个二进制位有8种状态,分别为000,001, 010, 011, 100, 101, 110, 111,四个二进制位有16种状态,0000,0001…1110,1111. 一个十六进制(Hex)正好对应4个二进制位,一个字节有8位,即一个字节可表示为2个十六进制数
package com.example.demo;
import java.nio.charset.StandardCharsets;
import java.util.Arrays;
public class Test {
private static final char[] HEX_CHAR = {'0', '1', '2', '3', '4', '5',
'6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f'};
public static void main(String[] args) throws Exception {
byte[] bytes = "中国NB".getBytes(StandardCharsets.UTF_8);
System.out.println("字节数组为:" + Arrays.toString(bytes));
System.out.println("方法1: " + toHex1(bytes));
System.out.println("方法2: " + toHex2(bytes));
System.out.println("方法3: " + toHex3(bytes));
System.out.println("方法4: " + toHex4(bytes));
System.out.println("==================================");
String str = "e4b8ade59bbd4e42";
System.out.println("转换后的字节数组:" + Arrays.toString(toBytes(str)));
System.out.println(new String(toBytes(str), "utf-8"));
}
/**
* byte[] to hex string 方法1
*
* @param bytes
*/
private static String toHex1(byte[] bytes) {
StringBuffer sb = new StringBuffer();
for (int i = 0; i < bytes.length; i++) {
String hex = Integer.toHexString(bytes[i] & 0xFF);
if (hex.length() < 2) {
sb.append(0);
}
sb.append(hex);
}
return sb.toString();
}
/**
* byte[] to hex string 方法2
*
* @param bytes
*/
private static String toHex2(byte[] bytes) {
// 一个byte为8位,可用两个十六进制位标识
char[] buf = new char[bytes.length * 2];
int a = 0;
int index = 0;
for (byte b : bytes) {
// 使用除与取余进行转换
if (b < 0) {
a = 256 + b;
} else {
a = b;
}
buf[index++] = HEX_CHAR[a / 16];
buf[index++] = HEX_CHAR[a % 16];
}
return new String(buf);
}
/**
* byte[] to hex string 方法3
*
* @param bytes
*/
public static String toHex3(byte[] bytes) {
char[] buf = new char[bytes.length * 2];
int index = 0;
for (byte b : bytes) {
// 利用位运算进行转换,可以看作方法二的变种
buf[index++] = HEX_CHAR[b >>> 4 & 0xf];
buf[index++] = HEX_CHAR[b & 0xf];
}
return new String(buf);
}
/**
* byte[] to hex string 方法4
*
* @param bytes
*/
public static String toHex4(byte[] bytes) {
StringBuilder buf = new StringBuilder(bytes.length * 2);
for (byte b : bytes) {
// 使用String的format方法进行转换
buf.append(String.format("%02x", new Integer(b & 0xff)));
}
return buf.toString();
}
/**
* 16进制字符串转换为byte[]
*
* @param str
* @return
*/
public static byte[] toBytes(String str) {
if (str == null || str.trim().equals("")) {
return new byte[0];
}
byte[] bytes = new byte[str.length() / 2];
for (int i = 0; i < str.length() / 2; i++) {
String subStr = str.substring(i * 2, i * 2 + 2);
bytes[i] = (byte) Integer.parseInt(subStr, 16);
}
return bytes;
}
}
运行结果:
字节数组为:[-28, -72, -83, -27, -101, -67, 78, 66]
方法1: e4b8ade59bbd4e42
方法2: e4b8ade59bbd4e42
方法3: e4b8ade59bbd4e42
方法4: e4b8ade59bbd4e42
==================================
转换后的字节数组:[-28, -72, -83, -27, -101, -67, 78, 66]
中国NB
五、参考资料
注意:
Tomcat8开始默认编码格式为UTF-8,之前版本默认编码格式为ISO-8859-1;

Mysql8.0开始默认字符编码为utf8mb4,之前版本默认字符集是Latin1即ISO-8859-1

大家在网上查阅博客时需要有自己主观判断,例部分文章编写可能年代久远,可能部分措辞与技术更替有出入。例如这样的文章就有点问题了
Java 语言中一个字符占几个字节?
JVM规范class文件格式
GBK,UTF-8,UTF-16之间的转换
字符、编码和Java中的编码
深入浅出了解Java程序中的乱码
java运行时参数file.encoding和sun.jnu.encoding详解
Java中文编码及各种编码互转和Java判断文件编码
Mysql官方更新文档
Mysql官方文档连接字符集
https://zh.wikipedia.org/wiki/UTF-8