Centos Linux 安装单机 Hadoop(HDFS)
视频教程链接:https://www.bilibili.com/video/BV1we4y1z7VT/
1. Hadoop 简介

Hadoop 是一个开源的分布式计算和存储框架,是 Apache 基金会开发的,包含3个核心组件:
-
HDFS:全称是 Hadoop Distributed File System,即 Hadoop 分布式文件系统。可以将将大文件、大批量文件分块存储到大量服务器组成的集群上。
-
MapReduce:分布式运算框架,可以基于它编写 MapReduce 应用程序,对大规模数据集(大于1TB)进行并行运算;
-
Yarn:分布式资源调度管理器,可以运行 MapReduce 应用程序。
2. 准备工作
2.1. 拥有一台 Centos Linux 机器
参考文章:
《VMware 安装 Centos 7 Linux 虚拟机》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/839c494401839c52b7642c9380920001
2.2. Linux 安装好 JDK、配置好环境变量
参考文章:
《Centos Linux 安装 JDK 8、配置环境变量》(含b站视频教程链接):
https://www.hanshuixin.com/app/blog/detail/839c494401839e49fa8a2c9380920002
2.3. 下载 Hadoop 安装包
Hadoop 官网:
Hadoop 安装包下载链接(官网,下载慢):
https://dlcdn.apache.org/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
Hadoop 安装包下载链接(清华大学开源软件镜像站,下载快):
https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz
3. 安装
3.1. 上传安装包、解压、放到安装位置
将安装包 hadoop-3.3.4.tar.gz 上传到 /root/ 目录。
# 进入到root目录
cd /root
# 解压
tar -zxvf hadoop-3.3.4.tar.gz
# 创建安装目录
mkdir /usr/local/hadoop
# 将解压后的hadoop挪到创建的安装目录
mv /root/hadoop-3.3.4/ /usr/local/hadoop/
# 进入到安装目录
cd /usr/local/hadoop/hadoop-3.3.4/
# 查看
ll
3.2. 修改 Hadoop 配置文件
这里做“单节点-伪分布式”配置,可以参考官网配置:
https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-common/SingleCluster.html
3.2.1. 修改 core-site.xml
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/core-site.xml
添加以下 3 项:
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<!-- 自定义 hadoop 的工作目录 -->
<value>/usr/local/hadoop/hadoop-3.3.4/tmp</value>
</property>
<property>
<name>hadoop.native.lib</name>
<!-- 禁用Hadoop的本地库 -->
<value>false</value>
</property>
3.2.2. 修改 hdfs-site.xml
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/hdfs-site.xml
添加以下 1 项:
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.2.3. 修改 yarn-site.xml
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/yarn-site.xml
添加以下 3 项:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<!-- yarn web 页面 -->
<value>0.0.0.0:8088</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<!-- reducer获取数据的方式 -->
<value>mapreduce_shuffle</value>
</property>
3.2.4. 修改 mapred-site.xml
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/mapred-site.xml
添加以下 1 项:
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.2.5. 修改 hadoop-env.sh
vi /usr/local/hadoop/hadoop-3.3.4/etc/hadoop/hadoop-env.sh
在文件末尾添加:
# 将当前用户 root 赋给下面这些变量
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
# JDK 安装路径,参考 cat /etc/profile |grep JAVA_HOME
export JAVA_HOME=/usr/local/java/jdk1.8.0_341
# Hadop 安装路径下的 ./etc/hadoop 路径
export HADOOP_CONF_DIR=/usr/local/hadoop/hadoop-3.3.4/etc/hadoop
3.3. 配置 Hadoop 环境变量
# 编辑系统配置文件
vi /etc/profile
在末尾添加以下内容:
export HADOOP_HOME=/usr/local/hadoop/hadoop-3.3.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
使环境变量生效:
# 运行配置文件
source /etc/profile
# 检查 PATH 中是否包含 $HADOOP_HOME/bin:$HADOOP_HOME/sbin 对应的目录
echo $PATH
3.4. 修改hosts文件,将当前主机名配进去
# 查看当前主机名
hostname
# 此处结果为 CentOS7-1
# 修改 hosts 文件,将当前主机名配到 127.0.0.1 后面
vi /etc/hosts
# ping 当前主机名进行检测
ping CentOS7-1
3.5. 配置本机 ssh 免密登录
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
验证本机ssh到本机:
ssh [email protected]
# 不用输密码旧登录好了
3.6. 格式化 HDFS (首次启动前执行)
hdfs namenode -format
3.7. 启动 Hadoop
被执行的脚本是 /usr/local/hadoop/hadoop-3.3.4/sbin/start-all.sh,前面已经通过$HADOOP_HOME/sbin配置到环境变量中了,可以直接执行。
start-all.sh
4. 测试
4.1. HDFS 使用测试
-
在 HDFS 上创建目录
hadoop fs -mkdir /test_1/ # 查看 hadoop fs -ls / -
将本地文件上传到 HDFS
# 新建文本文件 vi test_file_1.txt # 向文本中写入字符串 123 echo 123 >> test_file_1.txt # 将文本上传到 HDFS hadoop fs -put test_file_1.txt /test_1/ # 查看文件 hadoop fs -ls /test_1/ -
查看 HDFS 上的文本文件内容
hadoop fs -cat /test_1/test_file_1.txt -
将 HDFS 上的文件下载到本地
# 先删除本地的同名文件 rm -f test_file_1.txt ll # 将 HDFS 上的文件下载到本地 hadoop fs -get /test_1/test_file_1.txt
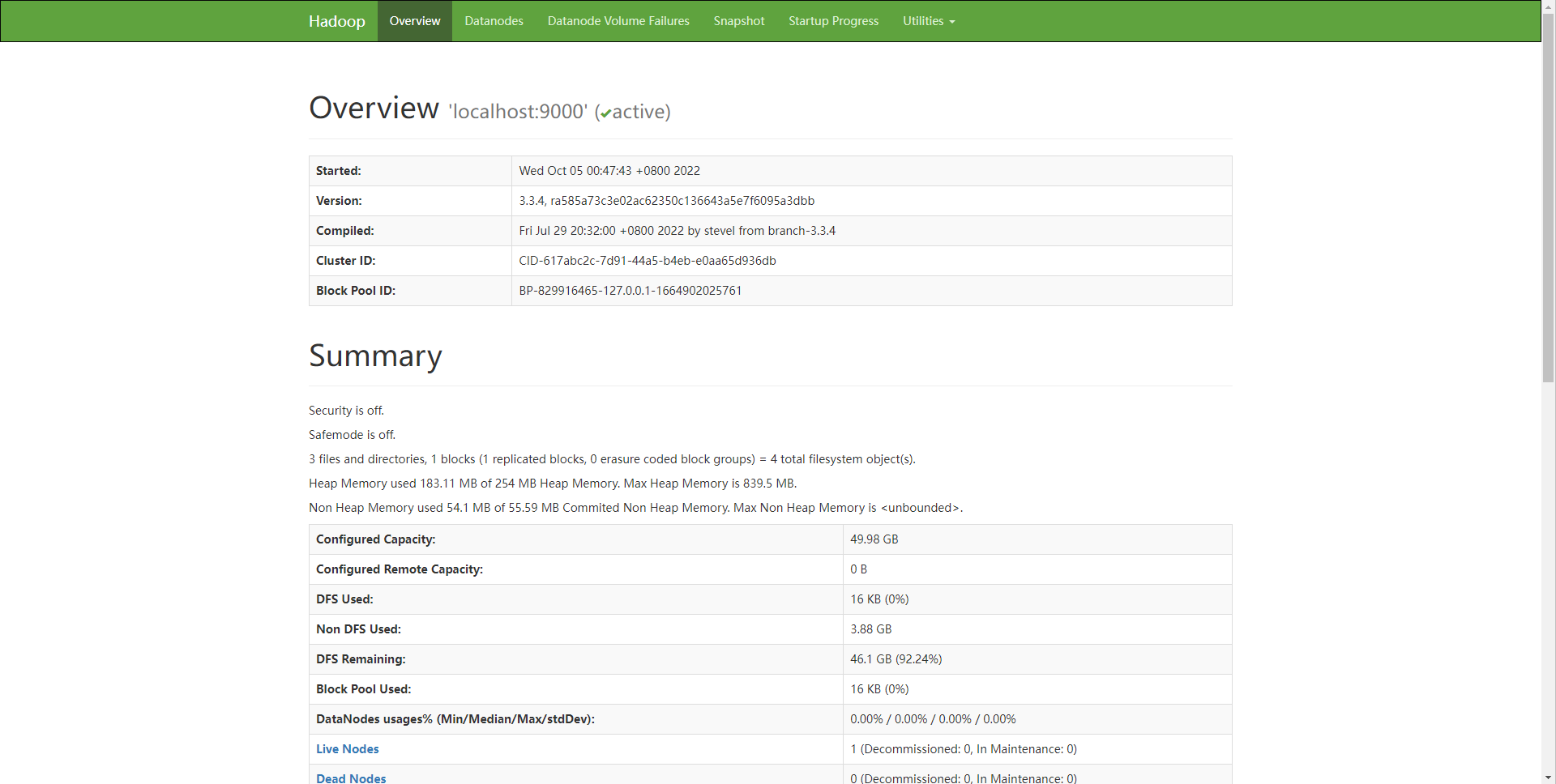
4.2. Hadoop Web 页面测试
# 防火墙放行 9870 tcp 端口
firewall-cmd --zone=public --add-port=9870/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
浏览器访问部署机器IP:9870:
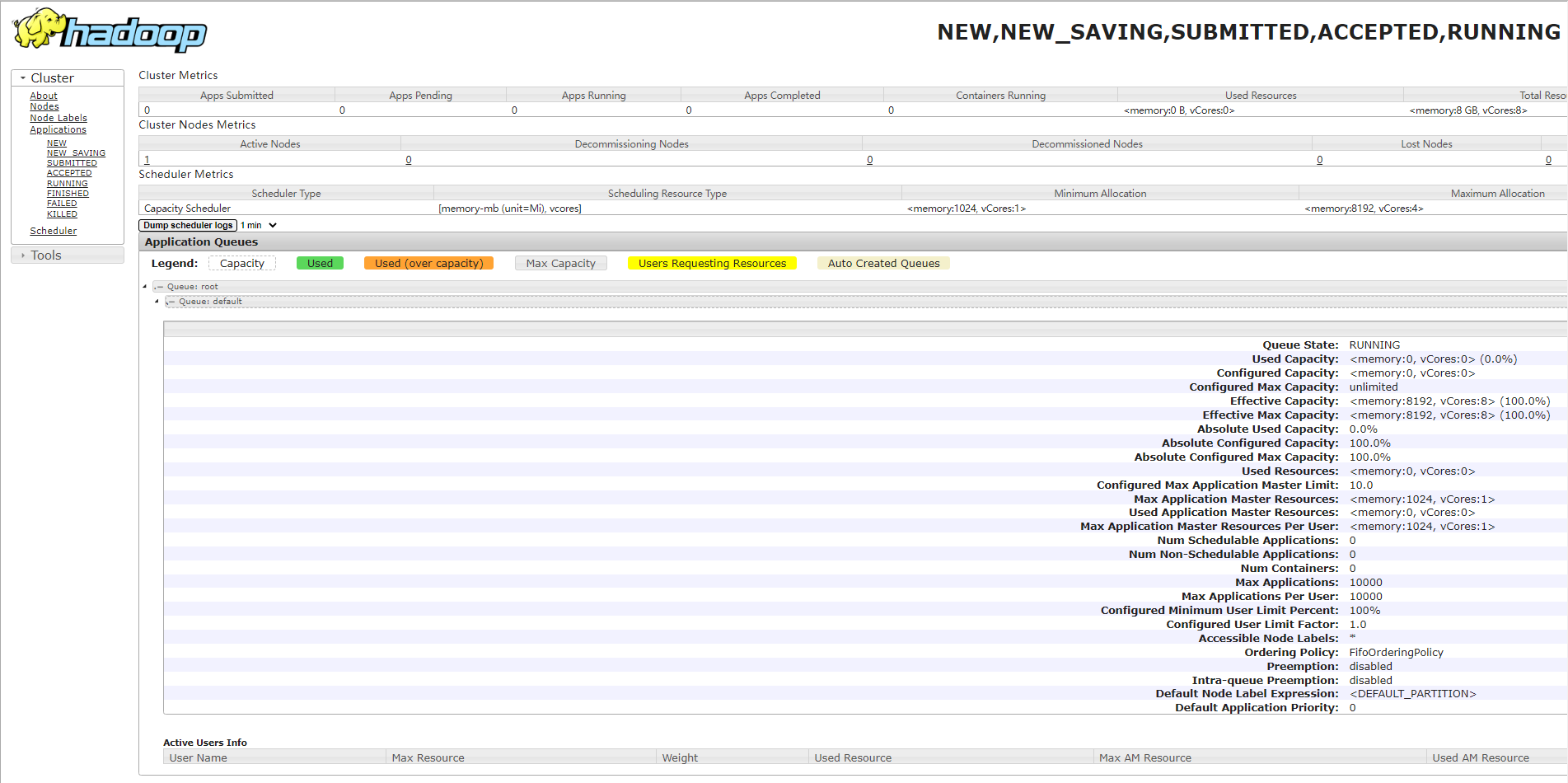
4.3. Yarn Web 页面测试
# 防火墙放行 8088 tcp 端口
firewall-cmd --zone=public --add-port=8088/tcp --permanent
# 防火墙重新加载
firewall-cmd --reload
浏览器访问部署机器IP:8088: