文章目录
- AIGC 前沿
- (1) Gemini 1.5 Pro(谷歌新一代多模态大模型)
- (2) Sora(文本生成视频大模型)
- (3) EMO(阿里生成式AI模型)
- (4) Playground v2.5(文生图大模型)
- (5) VSP-LLM(唇语识别)
- (6) Ideogram1.0 (文生图大模型)
- (7) LTX studio(生成式AI电影制作平台)
- (8) Claude3(LLM)
- (9) Open Sora(文生视频大模型)
- (10) Yi-9B(LLM)
- (11) Stable Diffusion 3(LVM)
- (12) CARES Copilot1.0(多模态手术大模型)
- (13) Figure 01通用机器人(Figure AI + OpenAI)
- (14) Devin(AI软件工程师助手)
- (15) BEHAVIOR-1K(李飞飞团队—具身智能基准)
- (16) MM1大模型(苹果公司多模态大模型)
- (17) AesopAgent(达摩院—智能体驱动的进化系统)
- (18) CogView3(文生图大模型)
- (19) AutoDev(微软团队全自动 AI 驱动软件开发框架)
- (20) VLOGGER(Google图生音频驱动视频方法)
- (21) TextMonkey(Monkey多模态大模型在文档领域的应用)
- (22) Open-Sora 1.0(文生视频大模型)
- (23) Grok-1(马斯克开源大语言模型)
- (24) Blackwell GB200(英伟达新一代AI加速卡)
- (25) Kimi(Moonshot AI 智能助手)
- (26) Suno v3(音乐ChatGPT时刻)
- (27) Mora(Sora的通才视频生成模型)
- (28) Mistral 7B v0.2
- (29) DBRX(LLM)
- (30) Grok-1.5(LLM)
- (31) Voice Engine(OpenAI音频模型)
- (32) Jamba(Mamba + Transformer)
- (33) StreamingT2V(文生视频)
- (34) SAFE + LongFact(DeepMind根治大模型幻觉问题)
- (35) SWE-agent(AI程序员)
- (36) Stable Audio 2.0(音乐ChatGPT 2.0)
- (37) COIG-CQIA(中文指令调优数据集)
- (38) Command R+(LLM)
- (39) MoD(谷歌更新Transformer架构)
- (40) Open-Sora-Plan(国产Sora)
- (41) Grok-1.5V(马斯克-多模态模型)
- (42) GPT-4 Turbo(GPT-4升级)
- (43) Mistral-8×22B(MoE再升级)
- (44) Llama-3(Meta LLM)
- (45) Eurux-8x22B(面壁智能)
- (46) MEGALODON(Meta 上下文长度不受限的神经网络架构)
- (47) Phi-3 Mini(微软-最强小参数大模型)
- (48) 日日新5.0(商汤大模型5.0版)
- (49) 中文版Llama3
- (50) Qwen1.5-110B(国产Llama3)
- (51) Vidu(国产Sora)
- (52) Video Mamba Suite(Mamba视频领域应用)
- (53) KAN(全新神经网络架构)
- (54) Meshy 3(文本生成3D模型)
- (55) MemGPT(LLM记忆管理框架)
- (56) Vim(Vision Mamba(Mamba高性能视觉版))
- (57) InternVL 1.5(上海AI Lab多模态大语言模型 )
- (58) 通义千问2.5(阿里巴巴 )
- (59) xLSTM(LSTM强势升级)
- (60) Cone(激活函数)
- (61) Agent Hospital(清华大学)
- (62) DeepSeek-V2(深度求索-第二代MoE模型)
- (63) Lumina-T2X(多模态DiT架构大一统)
- (64) GPT-4o(OpenAI多模态模型-o代表omini,全能)
- (65) 豆包大模型(抖音大模型)
- (66) Project Astra(谷歌对标GPT-4o)
- (67) Chameleon(meta对标GPT-4o)
- (68) MiniCPM-Llama3-V 2.5(面壁智能“小钢炮”)
- (69) Copilot+ PC(微软集成GPT-4o)
- (70) CogVLM2(智谱AI多模态模型)
- (71) Baichuan4(百川智能升级LLM)
- (72) 前沿人工智能安全承诺(Frontier AI Safety Commitments)
- (73) TransformerFAM(Transformer架构升级)
- (74) YOLOv10(清华大学升级YOLO)
- (75) Aya 23(Cohere大模型)
- (76) Llama3-V(Llama3多模态模型)
- (77) SuperCLUE-Long(中文原生长文本测评基准)
- (78) Viva(类Sora免费模型)
- (79) ChatTTS(语音合成项目)
- (80) Mamba-2(大模型新架构Mamba升级)
- (81) GLM-4 9B(智谱开源LLM)
- (82) Seed-TTS(字节语音合成)
- (83) QWen2(阿里大模型)
- (84) VideoReTalking(数字人对口型)
- (85) Stable Diffusion 3 Medium(文生图更新)
- (86) Dream Machine(Luma AI文生视频)
- (87) Nemotron-4 340B(Nvidia开源模型)
- (88) Gen-3
- (89) Open-Sora(Open-Sora再升级)
- (90) Claude 3.5 Sonnet(Claude升级)
- (91) ChatTTS v3(ChatTTS升级)
- (92) 盘古大模型5.0
- (93) Falcon2
- (94) Glyph-ByT5-v2(清华、北大+微软)
- (95) LLM Leaderboard v2(大语言模型评估框架)
- (96) 豆包MarsCode(字节跳动智能编程助手)
- (97) Gemma 2(Google升级Gemma)
- (98) Cambrian-1(LeCun和谢赛宁团队多模态模型)
- (99) 讯飞星火4.0(科大讯飞升级模型)
- (100) CriticGPT(OpenAI)
- (101) AIGVBench-T2V(文生视频基准测评)
- (102) Gen-3 Alpha(Runway)
- (103) Step-2、Step-1.5V、Step-1X(阶跃星辰开源大模型)
- (104) InternVL 2.0 “书生·万象”(上海人工智能实验室)
- (105) CodeGeeX4-ALL-9B(智谱AI)
- (106) TTT(全新LLM架构)
- (107) Chameleon(Meta多模态模型)
- (108) PVG(Prover-Verifier-Games)(OpenAI全新训练框架)
- (109) GPT-4o mini(OpenAI模型更新)
- (110) Still-Moving(DeepMind文生视频模型定制通用框架)
- (111) DCLM-7B(苹果开源LLM)
- (112) Mobile-Agent-v2(阿里巴巴魔搭团队)
- (113) Llama 3.1 405B(Meta)
- (114) Mistral Large 2 123B(决战Llama3.1)
- (115) CogVideoX(智谱视频生成模型)
- (116) FLUX.1(文生图多模态模型)
- (117) SAM 2(Meta SAM升级)
- (118) Qwen2-Audio(阿里巴巴 最新语音模型)
- (119) Tora(阿里巴巴 视频生成模型)
- (120) Qwen2-Math(阿里巴巴 专业数学语言模型)
- (121) Falcon Mamba 7B(纯Mamba架构的大模型)
- (122) Gemini Live(谷歌对标GPT-4o)
- (123) Exaone 3.0(LG开源大模型)
- (124) Nemotron-4-Minitron(Nvidia LLM)
- (125) VITA(腾讯优图多模态大模型)
- (126) mPLUG-Owl3(阿里巴巴多模态大模型)
- (127) ADAS(自动化设计智能体系统)
- (128) Phi-3.5(微软小型LLM)
- (129) Transfusion(Meta多模态架构-Diffusion+Transformer)
- (130) Jamba-1.5(Transformer-Mamba)
- (131) Qwen2-VL(阿里对标GPT-4o)
- (132) GLM-4-Plus(智谱AI)
AIGC 前沿
(1) Gemini 1.5 Pro(谷歌新一代多模态大模型)
2024.02.16 谷歌新一代多模态大模型Gemini 1.5 Pro,在性能上超越OpenAI的GPT-4 Turbo,堪称业界最强大模型。
推荐文章: “打假”Sora,谷歌Gemini 1.5 Pro第一波评测出炉|甲子光年
官网链接: https://openai.com/sora
(2) Sora(文本生成视频大模型)
2024.02.16 Sora文本生成视频的大模型。它所展现出来的能力几乎可以“碾压”目前全球能实现文本生成视频的大模型 包 括 Runway、Pika、Stable Video Diffusion等20多个产品。
用户仅需输入简短一句话,Sora就可生成一段长达60秒的视频,远远超过市面上同类型级别的AI视频生成时长。在此之前,AI视频模型生成时长几乎在10秒以内,而“明星模型” Runway和Pika等也仅有3到4秒。
推荐文章: Sora到底有多强? | 微软最新Sora综述
官网链接: Gemma Open Models
(3) EMO(阿里生成式AI模型)
2024.02.28 生成式AI模型EMO(Emote Portrait Alive)。EMO仅需一张人物肖像照片和音频,就可以让照片中的人物按照音频内容“张嘴”唱歌、说话,且口型基本一致,面部表情和头部姿态非常自然。
推荐文章: 阿里EMO模型,一张照片就能造谣
官网链接: https://humanaigc.github.io/emote-portrait-alive/
(4) Playground v2.5(文生图大模型)
2024.02.28 Playground在去年发布Playground v2.0之后再次开源新的文生图模型Playground v2.5。相比上一个版本,Playground v2.5在美学质量,颜色和对比度,多尺度生成以及以人为中心的细节处理有比较大的提升。
推荐文章: 超过Midjourney v5.2的开源文生图大模型Playground v2.5来了
官网链接: https://playground.com/
(5) VSP-LLM(唇语识别)
2024.02.28 一种通过观察视频中人的嘴型来理解和翻译说话内容的技术,也就是识别唇语。该技术能够将视频中的唇动转化为文本(视觉语音识别),并将这些唇动直接翻译成目标语言的文本(视觉语音翻译)。不仅如此,VSP-LLM还能智能识别和去除视频中不必要的重复信息,使处理过程更加快速和准确。
推荐文章: VSP-LLM:可通过观察视频中人的嘴型来识别唇语
官网链接: https://github.com/sally-sh/vsp-llm
(6) Ideogram1.0 (文生图大模型)
2024.02.29 Ideogram发布了最新的Ideogram1.0图像生成模型,该模型具有强大的文字生成能力和提示词理解能力。Ideogram1.0在文本渲染准确性方面实现了飞跃。
推荐文章:Ideogram 1.0图像生成模型发布 文字生成能力更强大了
官网链接:https://top.aibase.com/tool/ideogram-ai
(7) LTX studio(生成式AI电影制作平台)
2024.02.29 生成式AI电影制作平台—LTX Studio,用户只需要输入文本就能生成超25秒的微电影视频,同时可对镜头切换、角色、场景一致性、摄像机、灯光等进行可视化精准控制。
推荐文章: 效果比Sora惊艳,著名AI平台大动作!文本生成超25秒视频,带背景音乐、转场等效果
官网链接: https://ltx.studio
(8) Claude3(LLM)
2024.03.04 Claude3是由Anthropic发布的最新的AI大模型系列,同时,Claude3是多模态大模型 ,具有强大的“视觉能力”。Claude3 Opus已经在部分行业行为准则中的表现优于OpenAI的GPT-4和谷歌的Gemini Ultra,如本科生水平知识(MMLU)、研究生级别专家推理(GPQA)和基础数学(GSM8K)。
推荐文章: OpenAI劲敌出现!Claude3正式发布,超越GTP-4?
官网链接: https://www.anthropic.com/claude
(9) Open Sora(文生视频大模型)
2024.03.01 北大团队联合兔展发起了一项Sora复现计划——Open Sora
推荐文章: 北大与兔展智能发起复现Sora,框架已开源
官网链接:
https://pku-yuangroup.github.io/Open-Sora-Plan/blog_cn.html
https://github.com/PKU-YuanGroup/Open-Sora-Plan
(10) Yi-9B(LLM)
2024.03.06 李开复旗下AI公司零一万物的最新力作——Yi-9B大模型正式对外开源发布。这款具有90亿参数的大模型,在代码和数学能力上达到了前所未有的高度,同时保持了对消费级显卡的良好兼容性,为广大开发者和研究人员提供了前所未有的便利性和强大功能。
Yi-9B作为Yi系列中的新成员,被誉为“理科状元”,特别加强了在代码和数学方面的学习能力。相较于市场上其他类似规模的开源模型,如Mistral-7B、SOLAR-10.7B、Gemma-7B等,Yi-9B展现出了最佳的性能表现。特别值得一提的是,Yi-9B既提供了浮点数版本(BF 16),也提供了整数版本(Int8),使其能够轻松部署在包括RTX 4090和RTX 3090在内的消费级显卡上,大大降低了使用门槛和成本。
推荐文章: 零一万物开源Yi-9B大模型,消费级显卡可用,代码数学历史最强
官网链接: https://github.com/01-ai/Yi
(11) Stable Diffusion 3(LVM)
2024.03.06 Stable Diffusion 3采用了与 Sora 相同的 DiT(Diffusion Transformer)架构,一经发布就引起了不小的轰动。与之前的版本相比,Stable Diffusion 3 生成的图在质量上实现了很大改进,支持多主题提示,文字书写效果也更好了(明显不再乱码)。
Stability AI 表示,Stable Diffusion 3 是一个模型系列,参数量从 800M 到 8B 不等。这个参数量意味着,它可以在很多便携式设备上直接跑,大大降低了 AI 大模型的使用门槛。
在最新发布的论文中,Stability AI 表示,在基于人类偏好的评估中,Stable Diffusion 3 优于当前最先进的文本到图像生成系统,如 DALL・E 3、Midjourney v6 和 Ideogram v1。不久之后,他们将公开该研究的实验数据、代码和模型权重。
推荐文章:
Stable Diffusion 3论文终于发布,架构细节大揭秘,对复现Sora有帮助?
突发!Stable Diffusion 3,可通过API使用啦
论文链接: https://stabilityai-public-packages.s3.us-west-2.amazonaws.com/Stable+Diffusion+3+Paper.pdf
(12) CARES Copilot1.0(多模态手术大模型)
2024.03.11 CARES Copilot是由中国科学院香港创新院AI中心研发的一个可信赖、可解释、面向医疗垂直领域并能与智能医疗设备高度集成的大模型系统。CARES Copilot 1.0实现了图像、文本、语音、视频、MRI、CT、超声等多模态的手术数据理解。支持超过100K上下文的长窗口理解和高效分析,能理解超过3000页的复杂手术教材,对于年轻医生的培训和教学具有极高的实用价值。此外,该系统能通过深度检索功能,快速精确地提取手术教材、专家指南、医学论文等专业文档的信息,确保其提供的答案具有高度的可信度和可追溯性。经测试,系统能在一秒钟内完成百万级数据的快速检索,同时保持95%的准确率。该系统已在多家医院的不同科室进行了内部测试和迭代优化。
推荐文章: CARES Copilot 1.0多模态手术大模型发布,可实现轻量化部署
官网链接: /
(13) Figure 01通用机器人(Figure AI + OpenAI)
2024.03.13 Figure 01通用机器人由Figure AI和OpenAI合作完成。展示视频中,Figure AI人形机器人具有视觉能力并能表述所见画面,它伸手拿起桌上的苹果,并解释了这么做的原因,人类的提问后,这台人形机器人“思索”2~3秒后便能顺畅作答,手部动作速度则接近人类。据视频介绍,机器人采用了端到端神经网络。
该人形机器人由OpenAI提供了视觉推理和语言理解,Figure AI的神经网络则提供快速、灵巧的机器人动作。人形机器人将摄像机的图像输入和麦克风接收的语音文字输入OpenAI提供的视觉语言大模型(VLM)中,该模型可以理解图像和文字。Figure机载相机以10hz的频率拍摄画面,随后神经网络以200hz的频率输出24个自由度动作。画面中的人形机器人不依赖远程操作,行为都是学习而得的。
推荐文章: 与OpenAI合作13天后,Figure人形机器人展示与人类对话能力
官网链接: /
(14) Devin(AI软件工程师助手)
2024.03.13 一家成立不到两个月但拥有十名天才工程师的初创公司Cognition推出了一款名为Devin的人工智能(AI)助手,可以协助人类软件工程师完成诸多开发任务。Devin不同于现有其他AI编码者,它可以从零构建网站、自行部署应用、修复漏洞、学习新技术等,人类只需扮演一个下指令和监督的角色。
这是第一个真正意义上完全自主的AI软件工程师,一亮相即掀起轩然大波,因为人们担心:人类程序员是不是真要失业了?
推荐文章: 人类程序员真要失业?首位“AI软件工程师”亮相引爆科技圈
官网链接: /
(15) BEHAVIOR-1K(李飞飞团队—具身智能基准)
2024.02.27 来自斯坦福、得克萨斯大学奥斯汀分校等大学的研究团队推出了一项以人为本的机器人技术综合模拟基准——BEHAVIOR-1K。
BEHAVIOR-1K 包括两个部分,由 “您希望机器人为您做什么?”这一问题的广泛调查结果指导和推动。第一部分是对 1000 种日常活动的定义,以 50 个场景(房屋、花园、餐厅、办公室等)为基础,其中有 9000 多个标注了丰富物理和语义属性的物体。其次是 OMNIGIBSON,这是一个模拟环境,通过对刚体、可变形体和液体进行逼真的物理模拟和渲染来支持这些活动。
实验表明,BEHAVIOR-1K 中的活动是长视距的,并且依赖于复杂的操作技能,这两点对于最先进的机器人学习解决方案来说仍然是一个挑战。为了校准 BEHAVIOR-1K 的模拟与现实之间的差距,研究团队进行了一项初步研究,将在模拟公寓中使用移动机械手学习到的解决方案转移到现实世界中。
研究团队希望 BEHAVIOR-1K 以人为本的特性、多样性和现实性能使其在具身智能和机器人学习研究中发挥重要作用。
推荐文章: stanford Behavior-1k——包含一千种日常任务的具身智能benchmark
官网链接: /
(16) MM1大模型(苹果公司多模态大模型)
2024.03.15 苹果公司最新发布了一款名为MM1的大型多模态基础模型,拥有300亿参数,采用了MoE架构,并且超过一半的作者是华人。
该模型采用了MoE变体,并且在预训练指标和多项多模态基准测试上表现出了领先水平。研究者通过多项消融试验,探讨了模型架构、预训练数据选择以及训练程序等方面的重要性。他们发现,图像分辨率、视觉编码器损失和预训练数据在建模设计中都起着关键作用。
MM1的发布标志着苹果在多模态领域的重要进展,也为未来苹果可能推出的相关产品奠定了技术基础。该研究的成果对于推动生成式人工智能领域的发展具有重要意义,值得业界密切关注。
推荐文章: 苹果大模型MM1入场:参数达到300亿 超半数作者是华人
论文地址: https://arxiv.org/pdf/2403.09611.pdf
(17) AesopAgent(达摩院—智能体驱动的进化系统)
2024.03.15 阿里达摩院提出了一个关于故事到视频制作的智能体驱动进化系统——AesopAgent,它是智能体技术在多模态内容生成方面的实际应用。
该系统在一个统一的框架内集成了多种生成功能,因此个人用户可以轻松利用这些模块。这一创新系统可将用户故事提案转化为脚本、图像和音频,然后将这些多模态内容整合到视频中。此外,动画单元(如 Gen-2 和 Sora)可以使视频更具感染力。
推荐文章: 阿里达摩院提出AesopAgent:从故事到视频制作,智能体驱动的进化系统
论文地址: https://arxiv.org/pdf/2403.07952.pdf
(18) CogView3(文生图大模型)
2024.03.10 文生图系统的最新进展主要是由扩散模型推动的。然而,单级文本到图像扩散模型在计算效率和图像细节细化方面仍面临挑战。为了解决这个问题,来自清华大学和智谱AI 的研究团队提出了 CogView3——一个能提高文本到图像扩散性能的创新级联框架。
据介绍,CogView3 是第一个在文本到图像生成领域实现 relay diffusion 的模型,它通过首先创建低分辨率图像,然后应用基于中继(relay-based)的超分辨率来执行任务。这种方法不仅能产生有竞争力的文本到图像输出,还能大大降低训练和推理成本。
实验结果表明,在人类评估中,CogView3 比目前最先进的开源文本到图像扩散模型 SDXL 高出 77.0%,而所需的推理时间仅为后者的 1/2。经过提炼(distilled)的 CogView3 变体性能与 SDXL 相当,而推理时间仅为后者的 1/10。
推荐文章: CogView3:更精细、更快速的文生图
论文地址: https://arxiv.org/pdf/2403.05121.pdf
(19) AutoDev(微软团队全自动 AI 驱动软件开发框架)
2024.03.10 微软团队推出了全自动 AI 驱动软件开发框架 AutoDev,该框架专为自主规划和执行复杂的软件工程任务而设计。AutoDev 使用户能够定义复杂的软件工程目标,并将其分配给 AutoDev 的自主 AI 智能体来实现。这些 AI 智能体可以对代码库执行各种操作,包括文件编辑、检索、构建过程、执行、测试和 git 操作。它们还能访问文件、编译器输出、构建和测试日志、静态分析工具等。这使得 AI 智能体能够以完全自动化的方式执行任务并全面了解所需的上下文信息。
此外,AutoDev 还将所有操作限制在 Docker 容器内,建立了一个安全的开发环境。该框架结合了防护栏以确保用户隐私和文件安全,允许用户在 AutoDev 中定义特定的允许或限制命令和操作。
研究团队在 HumanEval 数据集上对 AutoDev 进行了测试,在代码生成和测试生成方面分别取得了 91.5% 和 87.8% 的 Pass@1 好成绩,证明了它在自动执行软件工程任务的同时维护安全和用户控制的开发环境方面的有效性。
推荐文章: AutoDev 1.5.3:精准的自动化测试生成、本地模型强化与流程自动化优化
论文地址: /
(20) VLOGGER(Google图生音频驱动视频方法)
2024.03.14 Google Research提出了一种从单张人物输入图像生成音频驱动人类视频的方法——VLOGGER,它建立在最近成功的生成扩散模型基础之上。
VLOGGER由两部分组成,一是随机人体到三维运动扩散模型,二是一种基于扩散的新型架构,它通过空间和时间控制来增强文本到图像模型。这有助于生成长度可变的高质量视频,并可通过人脸和身体的高级表示轻松控制。
与之前的工作相比,这一方法不需要对每个人进行训练,不依赖于人脸检测和裁剪,能生成完整的图像(不仅仅是人脸或嘴唇),并能考虑广泛的情况(如可见躯干或不同的主体身份),这对于正确合成交流的人类至关重要。研究团队还提出了一个包含三维姿势和表情注释的全新多样化数据集 MENTOR,它比以前的数据集大一个数量级(800000 identities),并且包含动态手势。研究团队在其上训练并简化了他们的主要技术贡献。
VLOGGER 在三个公共基准测试中的表现达到了 SOTA,考虑到图像质量、身份保留和时间一致性,同时还能生成上半身手势。VLOGGER 在多个多样性指标方面的表现都表明其架构选择和 MENTOR 的使用有利于大规模训练一个公平、无偏见的模型。最后,研究团队还展示了在视频编辑和个性化方面的应用。
推荐文章: VLOGGER:基于多模态扩散的具身虚拟形象合成
论文地址: https://arxiv.org/pdf/2403.08764.pdf
(21) TextMonkey(Monkey多模态大模型在文档领域的应用)
2024.03.15 TextMonkey是Monkey在文档领域的重要升级,突破了通用文档理解能力的边界,在场景文字识别、办公文档摘要生成、数学问题问答、文档版式分析,表格理解,图表问答,电子文档关键信息抽取等12项等文档权威数据集以及在国际上规模最全的文档图像智能数据集OCRBench上取得了显著突破,通用文档理解性能大幅超越现有方法。
TextMonkey能帮助我们结构化图表、表格以及文档数据,通过将图像内容转化为轻量级的数据交换格式,方便记录和提取。TextMonkey也能作为智能手机代理,无需接触后端,仅需语音输入及屏幕截图,即能够模仿人类的点击手势,能够在手机上执行各种任务,自主操控手机应用程序。
推荐文章:
华科大研发多模态大模型“猴子”升级
[全网首发中文版]TextMonkey: An OCRFree Large Multimodal Model for Understanding Document
GitHub仓库地址: https://github.com/Yuliang-Liu/Monkey
论文地址: https://arxiv.org/pdf/2311.06607.pdf
(22) Open-Sora 1.0(文生视频大模型)
2024.03.17 Colossal-AI 团队全面开源全球首个类 Sora 架构视频生成模型 「Open-Sora 1.0」,涵盖了整个训练流程,包括数据处理、所有训练细节和模型权重,携手全球 AI 热爱者共同推进视频创作的新纪元。
Colossal-AI 团队深入解读 Sora 复现方案的多个关键维度,包括模型架构设计、训练复现方案、数据预处理、模型生成效果展示以及高效训练优化策略。
推荐文章: 没等来OpenAI,等来了Open-Sora全面开源
GitHub仓库地址: https://github.com/hpcaitech/Open-Sora
(23) Grok-1(马斯克开源大语言模型)
2024.03.17 马斯克宣布开源Grok-1,这使得Grok-1成为当前参数量最大的开源大语言模型,拥有3140亿参数,远超OpenAI GPT-3.5的1750亿。有意思的是,Grok-1宣布开源的封面图为Midjourney生成,可谓“AI helps AI”。
Grok-1是一个规模较大(314B参数)的模型,需要有足够GPU内存的机器才能使用示例代码测试模型。网友表示这可能需要一台拥有628 GB GPU内存的机器。此外,该存储库中MoE层的实现效率并不高,之所以选择该实现是为了避免需要自定义内核来验证模型的正确性。
目前已开源的热门大模型包括Meta的Llama2、法国的Mistral等。通常来说,发布开源模型有助于社区展开大规模的测试和反馈,意味着模型本身的迭代速度也能加快。
推荐文章: 马斯克用行动反击 开源自家顶级大模型 压力给到OpenAI
GitHub仓库地址: https://github.com/xai-org/grok-1
官方博客: https://x.ai/blog/grok-os
模型磁力链接: https://academictorrents.com/details/5f96d43576e3d386c9ba65b883210a393b68210e
(24) Blackwell GB200(英伟达新一代AI加速卡)
2024.03.18 英伟达公司于2024年的GTC大会上宣布了下一代人工智能超级计算机的问世,同时推出了备受业界瞩目的AI加速卡——Blackwell GB200。这款加速卡的发布,标志着人工智能领域又迈出了坚实的一步,其强大的性能、成本及能耗的突破,预计将引领AI技术的全新发展。
Blackwell GB200采用了英伟达新一代AI图形处理器架构Blackwell,相较于前一代Hopper架构,其性能实现了巨大的飞跃。GB200由两个B200 Blackwell GPU和一个基于Arm的Grace CPU组成,这种独特的组合使得其在处理大语言模型推理任务时,性能比H100提升高达30倍。
推荐文章: 性能飙升30倍,能耗骤降25倍!英伟达发布Blackwell GB200!
(25) Kimi(Moonshot AI 智能助手)
2024.03.18 国内 AI 创业公司月之暗面(Moonshot AI)宣布在大模型长上下文窗口技术上取得新的突破,Kimi智能助手已支持200万字超长无损上下文,短短五个月内“长文本”输入量提升10倍,并于即日起开启产品“内测”。
月之暗面创始人杨植麟博士表示,通往通用人工智能(AGI)的话,无损的长上下文将会是一个很关键的基础技术。历史上所有的模型架构演进,本质上都是在提升有效的、无损的上下文长度。上下文长度可能存在摩尔定律,但需要同时优化长度和无损压缩水平两个指标,才是有意义的规模化。
月之暗面联合创始人 周昕宇则向钛媒体App透露,月之暗面即将在今年内推出自研的多模态大模型。同时,商业化也在快速推进。
推荐文章: 对话月之暗面:Kimi智能助手支持200万字无损输入,年内将发布多模态模型|钛媒体AGI
(26) Suno v3(音乐ChatGPT时刻)
2024.03.24 AI初创公司Suno AI重磅推出了第一款可制作「广播级」的音乐生成模型——V3,一时间在网上掀起轩然大波。仅用几秒的时间,V3便可以创作出2分钟的完整歌曲。为了激发人们的创作灵感,Suno v3还新增了更丰富的音乐风格和流派选项,比如古典音乐、爵士乐、Hiphop、电子等新潮曲风。
推荐文章:音乐ChatGPT时刻来临!Suno V3秒生爆款歌曲,12人团队创现象级AI
(27) Mora(Sora的通才视频生成模型)
2024.03.24 理海大学联手微软团队一种新型的多AI智能体框架———Mora。Mora更像是Sora的通才视频生成。通过整合多个SOTA的视觉AI智能体,来复现Sora展示的通用视频生成能力。具体来说,Mora能够利用多个视觉智能体,在多种任务中成功模拟Sora的视频生成能力,包括:
- 文本到视频生成
- 基于文本条件的图像到视频生成
- 扩展已生成视频
- 视频到视频编辑
- 拼接视频
- 模拟数字世界
推荐文章: Sora不开源,微软给你开源!全球最接近Sora视频模型诞生,12秒生成效果逼真炸裂
论文地址: https://arxiv.org/abs/2403.13248
(28) Mistral 7B v0.2
2024.03.24 这次开源的 Mistral 7B v0.2 Base Model ,是 Mistral-7B-Instruct-v0.2 背后的原始预训练模型,后者属于该公司的「Mistral Tiny」系列。
此次更新主要包括三个方面:
- 将 8K 上下文提到了 32K;
- Rope Theta = 1e6;
- 取消滑动窗口。
推荐文章: 32K上下文,Mistral 7B v0.2 基模型突然开源了
(29) DBRX(LLM)
2024.03.28 超级独角兽Databricks重磅推出1320亿参数的开源模型——DBRX。全球最强开源大模型王座易主,超越了Llama 2、Mixtral和Grok-1。MoE又立大功!这个过程只用了2个月,1000万美元,和3100块H100。采用了细粒度MoE架构,而且每次输入仅使用360亿参数,实现了更快的每秒token吞吐量。
推荐文章: 全球最强开源模型一夜易主,1320亿参数推理飙升2倍!
项目地址:
https://github.com/databricks/dbrx
https://huggingface.co/databricks
(30) Grok-1.5(LLM)
2024.03.29 马斯克发布Grok-1.5,强化推理和上下文,HumanEval得分超GPT-4继开源 Grok-1 后,xAI 刚刚官方发布了他们的最新模型 Grok-1.5。据介绍,Grok-1.5 能够进行长语境理解和高级推理,并将于近日在 xAI 平台上向早期测试者和现有 Grok 用户开放。
Grok-1.5 最显著的改进之一是其在编码和数学相关任务中的表现。在给出的测试结果中,Grok-1.5 在 MATH 基准测试中取得了 50.6% 的得分,在 GSM8K 基准测试中取得了 90% 的得分。此外,在评估代码生成和解决问题能力的 HumanEval 基准测试中,Grok-1.5 获得了 74.1% 的高分,超过了 GPT-4。
推荐文章: 马斯克发布Grok-1.5,强化推理和上下文,HumanEval得分超GPT-4
项目主页: https://x.ai/blog/grok-1.5
(31) Voice Engine(OpenAI音频模型)
2024.03.30 OpenAI在官网首次展示了全新自定义音频模型“Voice Engine”。用户只需要提供15秒左右的参考声音,通过Voice Engine就能生成几乎和原音一模一样的全新音频,在清晰度、语音连贯、音色、自然度等方面比市面上多数产品都强很多。
除了能合成音频之外,OpenAI还展示了Voice Engine很多其他际商业用途,例如,一位失去声音表达能力的女孩,在Voice Engine帮助下能像以前一样正常发音说话。
推荐文章: OpenAI首次展示音频模型Voice Engine,生成的声音太逼真了!
(32) Jamba(Mamba + Transformer)
2024.03.29 AI21 Labs 推出并开源了一种名为「Jamba」的新方法,在多个基准上超越了 transformer。
Mamba 的 SSM 架构可以很好地解决 transformer 的内存资源和上下文问题。然而,Mamba 方法很难提供与 transformer 模型相同的输出水平。
Jamba 将基于结构化状态空间模型 (SSM) 的 Mamba 模型与 transformer 架构相结合,旨在将 SSM 和 transformer 的最佳属性结合在一起。
Jamba 模型具有以下特点:
- 第一个基于 Mamba 的生产级模型,采用新颖的 SSM-Transformer 混合架构;
- 与 Mixtral 8x7B 相比,长上下文上的吞吐量提高了 3 倍;
- 提供对 256K 上下文窗口的访问;
- 公开了模型权重;
- 同等参数规模中唯一能够在单个 GPU 上容纳高达 140K 上下文的模型。
推荐文章: 打败Transformer,Mamba 时代来了?
(33) StreamingT2V(文生视频)
2024.04.01 Picsart人工智能研究所、德克萨斯大学和SHI实验室的研究人员联合推出了StreamingT2V视频模型。通过文本就能直接生成2分钟、1分钟等不同时间,动作一致、连贯、没有卡顿的高质量视频。
虽然StreamingT2V在视频质量、多元化等还无法与Sora媲美,但在高速运动方面非常优秀,这为开发长视频模型提供了技术思路。
研究人员表示,理论上,StreamingT2V可以无限扩展视频的长度,并正在准备开源该视频模型。
推荐文章: 文本直接生成2分钟视频,即将开源模型StreamingT2V
论文地址: https://arxiv.org/abs/2403.14773
Github地址: https://github.com/Picsart-AI-Research/StreamingT2V(即将开源)
(34) SAFE + LongFact(DeepMind根治大模型幻觉问题)
2024.04.03 Google DeepMind 的人工智能专家团队和斯坦福大学的研究者发布了一篇名为《衡量大型语言模型长篇事实性》(Long-form factuality in large language models)的研究论文,研究者们对长篇事实性问题进行了深度探究,并对语言模型在长篇事实性上的表现进行了全面评估。
他们推出了一套新的数据集——LongFact,其中包含了 2,280 个涵盖 38 个不同话题的引导问题;同时,提出了一个新颖的评估方法——SAFE(Self-contained Accuracy with Google Evidence),该方法运用语言模型代理人和Google搜索查询技术来进行评估。
推荐文章: 人类标注的时代已经结束?DeepMind 开源 SAFE 根治大模型幻觉问题
论文地址: https://arxiv.org/abs/2403.18802
Github地址: https://github.com/google-deepmind/long-form-factuality
(35) SWE-agent(AI程序员)
2024.04.03 自从“AI 程序员”Devin 问世之后,近期的一大趋势就是程序员们争先恐后地要让自己失业,试图抢先造出比自己更强大的程序员。
普林斯顿大学为软件工程界迎来了一位新星——SWE-agent,论文将在 4 月 10 日正式发布,目前项目已在 GitHub 上开源。
SWE-agent 的特点就是将 GPT-4 这样的大型语言模型(LLMs)转化为软件工程代理,使其能够修复真实 GitHub 仓库中的错误和问题。SWE-agent 在软件工程基准测试中的准确度与 Devin 相当,在解决 GitHub 仓库问题上的性能甚至超过了 Devin:SWE-agent 平均只需 93 秒就能修完 Bug。
完整的 SWE-bench 基准测试结果显示,SWE-agent 修复了 12.29% 的问题,Debin 则是 13.84%——但 SWE-agent 有一大优势:开源。这一成绩也表明,开源模型有能力追赶甚至超越闭源模型的性能。SWE Agent 的高精度显示了其处理复杂软件工程任务的能力。
推荐文章: 华人开源最强「AI 程序员」炸场,让 GPT-4 自己修 Bug!
Github地址: https://github.com/princeton-nlp/SWE-agent
(36) Stable Audio 2.0(音乐ChatGPT 2.0)
2024.04.04 Stability AI发布了Stable Audio 2.0。
普仅仅用一条自然语言指令,它就能以44.1 kHz的立体声质量,创作出高质量、结构完整的音乐作品。
而且,每首曲目最长可达3分钟!相比之下,Suno最长可创作2分钟,这方面可是被Stable Audio 2完爆了。
并且,Audo 2.0的音频到音频功能,目前只有Meta的MusicGen可以做到,连Suno都做不到。
模型已经在Stable Audio官网上免费开放使用了,并且很快就能通过Stable Audio API提供服务。
推荐文章: 音乐ChatGPT 2.0来了!AI作曲家被踢馆,亲测周杰伦爆款大翻车
体验地址: https://stability.ai/news/stable-audio-2-0
(37) COIG-CQIA(中文指令调优数据集)
2024.04.05 最近,大型语言模型(LLM)取得了重大进展,特别是在英语方面。然而,LLM 在中文指令调优方面仍然存在明显差距。现有的数据集要么以英语为中心,要么不适合与现实世界的中国用户交互模式保持一致。
为了弥补这一差距,一项由 10 家机构联合发布的研究提出了 COIG-CQIA(全称 Chinese Open Instruction Generalist - Quality Is All You Need),这是一个高质量的中文指令调优数据集。数据来源包括问答社区、维基百科、考试题目和现有的 NLP 数据集,并且经过严格过滤和处理。
此外,该研究在 CQIA 的不同子集上训练了不同尺度的模型,并进行了深入的评估和分析。本文发现,在 CQIA 子集上训练的模型在人类评估以及知识和安全基准方面取得了具有竞争力的结果。
推荐文章: 弱智吧:大模型变聪明,有我一份贡献
论文地址: https://arxiv.org/pdf/2403.18058.pdf
数据地址: https://huggingface.co/datasets/m-a-p/COIG-CQIA
(38) Command R+(LLM)
2024.04.05 知名类ChatGPT平台Cohere在官网发布了全新模型——Command R+。
据悉,Command R+有1040亿参数,支持英语、中文、法语、德语等10种语言。最大特色之一是,Command R+对内置的RAG(检索增强生成)进行了全面强化,其性能仅次于GPT-4 tubro,高于市面上多数开源模型。
目前,Cohere已经开源了Command R+的权重,但只能用于学术研究无法商业化。想商业应用,用户可以通过微软Azure云使用该模型或者Cohere提供的API。
推荐文章: Cohere发布RAG增强版大模型并开源权重,支持中文、1040亿参数
模型地址:
官方版:https://huggingface.co/CohereForAI/c4ai-command-r-plus
量化版:https://huggingface.co/CohereForAI/c4ai-command-r-plus-4bit
(39) MoD(谷歌更新Transformer架构)
2024.04.08 谷歌终于更新了Transformer架构。最新发布的Mixture-of-Depths(MoD),改变了以往Transformer计算模式。
它通过动态分配大模型中的计算资源,跳过一些不必要计算,显著提高训练效率和推理速度。
结果显示,在等效计算量和训练时间上,MoD每次向前传播所需的计算量更小,而且后训练采样过程中步进速度提高50%。
推荐文章: 谷歌更新Transformer架构,更节省计算资源!50%性能提升
论文地址: https://arxiv.org/abs/2404.02258
(40) Open-Sora-Plan(国产Sora)
2024.04.10 自从今年 2 月 OpenAI 发布了基于日语词汇“Sora”所开发的惊艳视频生成技术以来,该技术以其能够将简短文本描述转化为高清一分钟视频而引起了全球技术界的广泛关注。北京大学及兔展智能携手于三月启动了开源项目 Open-Sora-Plan,旨在通过开源方式再现 Sora 技术,并训练涵盖无条件视频生成、类似视频生成以及文本驱动视频生成等多个技术模块的综合模型。
日前,Open-Sora-Plan 已成功发布了 v1.0.0 版本,显著提升了视频生成效果和文本引导控制功能,目前还在训练更高分辨率(超过 1024)和更长持续时间(超过 10 秒)的视频内容。项目核心技术架构包括 Video VQ-VAE、Denoising Diffusion Transformer 以及 Condition Encoder,其中 CausalVideoVAE 架构尤为关键,它结合了变分自编码器(VAE)和矢量量化(VQ)原理,有效实现视频数据的高效压缩和重建,并且特别优化了对首帧图像的处理,使其既能单独编码静态图像又能无缝应用于视频编码,进而助力扩散模型精准捕捉视频的空间细节,提升视觉品质。
推荐文章: 国产开源Sora:Open-Sora-Plan支持华为昇腾芯片,生成10秒高清视频
GitHub地址: https://github.com/PKU-YuanGroup/Open-Sora-Plan
Hugging Face 在线演示: https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0
(41) Grok-1.5V(马斯克-多模态模型)
2024.04.15 马斯克推出的多模态模型Grok-1.5V在多项基准测试中超越GPT-4V,具有强大的文档、图标、截图和照片处理能力。通过RealWorldQA基准测试,Grok-1.5V在理解物理世界方面表现出色。未来几个月,图像、音频、视频等多模态上的理解和生成能力将有望得到重大改进。
推荐文章: 马斯克新作!Grok-1.5V多模态模型发布:数字与物理世界完美融合
官网地址: https://x.ai/blog/grok-1.5v
(42) GPT-4 Turbo(GPT-4升级)
2024.04.12 OpenAI 官方宣布,新版 GPT-4 Turbo 今天开始向所有付费ChatGPT 用户开放。知识库截止时间已经更新为 2024 年 4 月。
据介绍,字少事大的新版本在写作、数学、逻辑推理和编码等多个方面都有了显著的提升。
现在,当你使用 ChatGPT 写作时,你会发现新版本的响应速度更快,交流更加直接,而且它会更多地使用口语化的表达方式。
简言之,新版本在写作上更加贴近人类的自然语言习惯,多了一些人味,少了点 AI 味。
例如,当你需要发送短信提醒朋友回复生日晚宴的邀请时,以往 GPT 版本会像小莎士比亚一样提供满满的情绪价值,虽然情感丰富,但也显得絮絮叨叨,而现在的回复则更言简意赅,直接传达核心信息。
推荐文章: 刚刚,ChatGPT大更新,GPT-4又变聪明了
(43) Mistral-8×22B(MoE再升级)
2024.04.14 Mistral AI引发了AI领域的广泛关注,他们开源了一款拥有1760亿参数的巨型模型——Mixtral 8x22B。这款模型不仅在规模上达到了前所未有的高度,而且在多个性能基准测试中展示了卓越的能力,确立了新的行业标准。
Mixtral 8x22B继续沿用Mistral AI的专家混合(MoE)架构,这是一种将不同的网络专家集成到一个统一框架中的技术,允许模型根据任务需求动态调用最合适的专家处理数据。这种架构不仅提高了处理速度,还显著提升了模型在复杂任务上的表现。
该模型的一大创新是其高效的专家选择机制。在每个处理步骤中,模型通过一个专门设计的路由网络决定哪些专家最适合当前的任务。这种机制使得8x22B能够优化其计算资源,减少不必要的计算开销。此外,Mixtral 8x22B通过其1760亿参数和64K的上下文窗口,能够处理比以往任何模型都要长的文本输入,这对于长文本的理解和生成特别有价值。例如,在自动文档摘要或详细的故事生成任务中,该模型能够展示出更好的连贯性和文本理解能力。
推荐文章: 如何看待MistralAI开源Mistral-8×22B模型?
Huggingface模型下载:https://huggingface.co/mistral-community
AI快站模型免费加速下载:https://aifasthub.com/models/mistralai/mixtral-8x22b
(44) Llama-3(Meta LLM)
2024.04.19 全球科技、社交巨头Meta在官网,正式发布了开源大模型——Llama-3。
据悉,Llama-3共有80亿、700亿两种参数,分为基础预训练和指令微调两种模型(还有一个超4000亿参数正在训练中)。
与Llama-2相比,Llama-3使用了15T tokens的训练数据,在推理、数学、代码生成、指令跟踪等能力获得大幅度提升。
此外,Llama-3还使用了分组查询注意力、掩码等创新技术,帮助开发者以最低的能耗获取绝佳的性能。很快,Meta就会发布Llama-3的论文。
推荐文章: 重磅!Llama-3,最强开源大模型正式发布!
开源地址: https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6
Github地址: https://github.com/meta-llama/llama3/
英伟达在线体验Llama-3: https://www.nvidia.com/en-us/ai/#referrer=ai-subdomain
(45) Eurux-8x22B(面壁智能)
2024.04.17 早在 Llama3 发布的前两天,『面壁智能』低调开源了大模型 Eurux-8x22B,包括 Eurux-8x22B-NCA 和 Eurux-8x22B-KTO。该模型主打更强大的推理性能——刷新开源大模型推理性能 SOTA,堪称开源大模型中「理科状元」。
除了开源时间早于 Llama3,Eurux-8x22B 的激活参数仅有 39B,推理速度更快,目前支持 64K 上下文,相比之下 Llama3-70B 的上下文大小为 8K。
此外,Eurux-8x22B 由 Mistral-8x22B 对齐而来,在 UltraInteract 大规模、高质量对齐数据集上训练而成,综合性能不输 Llama3-70B。
相比而言,Llama3-70B 模型则是使用了千万量级的对齐数据,这从侧面证明了 UltraInteract 数据集的优质性——数据质量胜过数据数量。
推荐文章: 『面壁智能』低调开源「理科状元」Eurux-8x22B,推理性能超越 Llama3-70B
GitHub地址: https://github.com/OpenBMB/Eurus
HuggingFace地址: https://huggingface.co/openbmb/Eurux-8x22b-nca
(46) MEGALODON(Meta 上下文长度不受限的神经网络架构)
2024.04.12 来自 Meta、南加州大学、CMU、UCSD 等公司、机构引入了 MEGALODON,一种用于高效序列建模的神经架构,上下文长度不受限制。
MEGALODON 继承了 MEGA(带有门控注意力的指数移动平均)的架构,并进一步引入了多种技术组件来提高其能力和稳定性,包括复数指数移动平均(CEMA)、时间步归一化层、归一化注意力机制和具有两个特征的预归一化(pre-norm)残差配置。
在与 LLAMA2 的直接比较中,MEGALODON 在 70 亿参数和 2 万亿训练 token 的规模上取得了比 Transformer 更好的效率。MEGALODON 的训练损失达到 1.70,处于 LLAMA2-7B (1.75) 和 13B (1.67) 之间。MEGALODON 相对于 Transformers 的改进在不同任务和模式的一系列基准测试中表现强劲。
推荐文章: Meta无限长文本大模型来了:参数仅7B,已开源
论文地址: https://arxiv.org/pdf/2404.08801.pdf
GitHub地址: https://github.com/XuezheMax/megalodon
(47) Phi-3 Mini(微软-最强小参数大模型)
2024.04.23 Phi-3-mini是微软Phi家族的第4代,有预训练和指令微调多种模型,参数只有38亿训练数据却高达3.3T tokens,比很多数百亿参数的模型训练数据都要多,这也是其性能超强的主要原因之一。
Phi-3-mini对内存的占用极少,可以在 iPhone14等同类手机中部署使用该模型。尽管受到移动硬件设备的限制,但每秒仍能生成12 个tokens数据。
值得一提的是,微软在预训练Phi-3-mini时使用了合成数据,能帮助大模型更好地理解语言架构、表达方式、文本语义理解、逻辑推理以及特定业务场景的专业术语等。
推荐文章: 微软开源最强小参数大模型—Phi-3 Mini
开源地址: https://huggingface.co/collections/microsoft/phi-3-6626e15e9585a200d2d761e3
Ollama地址: https://ollama.com/library/phi3
技术报告: https://arxiv.org/abs/2404.14219
(48) 日日新5.0(商汤大模型5.0版)
2024.04.23 商汤科技正式发布全新大模型日日新5.0(SenseChat V5),采用混合专家架构(MoE),参数量高达6000亿,支持200K的上下文窗口。据官方披露,SenseChat V5具备更强的知识、数学、推理及代码能力,综合性能全面对标GPT-4 Turbo。
据官方介绍,SenseChat V5模型能力显著提升,其背后是训练数据的全面升级与训练方法的有效提升。在数据方面,SenseChat V5采用了新一代数据生产管线,生产了10T tokens的高质量训练数据。通过多个模型进行数据的过滤和提炼,显著提升了预料质量和信息密度;基于精细聚类的均衡采样确保对世界知识覆盖的完整性。同时,SenseChat V5还大规模采用了思维型的合成数据(数千亿tokens量级),这对于模型在逻辑推理、数学和编程等方面的能力提升起到了关键作用
SenseChat V5采用了自研的多阶段训练链路,包括三阶段预训练、双阶段SFT和在线RLHF。通过在每个阶段设定更加清晰聚焦的目标,实现更敏捷的调优,也避免了不同目标之间的相互干扰。其中在预训练阶段,分阶段培养模型的基础语言和知识能力、长文建模能力、以及复杂逻辑推理能力(规模化采用合成数据);在 SFT 阶段,把任务指令遵循和对话体验优化分解到双阶段进行;在 RLHF 阶段,采用统一的多维度奖励模型和动态系统提示词对多维度偏好进行打分,从而更好地实现模型在多个维度和人类期望对齐。
推荐文章: 商汤「日日新5.0」中文基准测评出炉,总分80.03刷新最好成绩,文科能力领跑
体验地址: https://platform.sensenova.cn/home
(49) 中文版Llama3
2024.04.25 最近,Meta 推出了 Llama 3,为开源大模型树立了新的标杆。和以往的原始 Llama 模型一样,Llama 3 对中文的支持效果欠佳,经常会出现你用中文提问,它用英文或中文+英文回复的现象。因此,要想让国内用户用上该模型,开发者还需对其进行微调。
推荐文章: 中文版Llama3开源了!!
GitHub地址: https://github.com/CrazyBoyM/llama3-Chinese-chat
HuggingFace地址: https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat?continueFlag=5a1e5d88eed977ffb39d9b451be2a81d
(50) Qwen1.5-110B(国产Llama3)
2024.04.27 开源界最近属实是太疯狂了,前有Llama3-70B模型开源,后有Qwen1.5开源千亿(110B)级别参数模型。
Qwen你真的让我开始捉摸不透了,1.5系列已经从0.5B、1.8B、7B、14B、32B、72B到现在的110B、还有Code系列模型、MOE系列模型,太全了,感觉已经快把中文开源模型市场给垄断了。
模型结构与之前模型相似,采用Transformer-Decoder架构,并使用分组查询注意力(Grouped Query Attention,GQA),加速模型推理计算。模型的最大长度为32K,支持英、中、法、西、德、俄、日、韩、越等多种语言。
在基础能力上的效果全面领先72B模型,与Llama3-70B模型也是平分秋色。
并且,值得注意的是,110B的模型是Dense的模型,不是虚胖的MOE模型
推荐文章: 中国人自己的Llama:Qwen1.5开源110B参数模型
Blog地址: https://qwenlm.github.io/blog/qwen1.5-110b
HuggingFace地址: https://huggingface.co/Qwen/Qwen1.5-110B-Chat
体验地址: https://huggingface.co/spaces/Qwen/Qwen1.5-110B-Chat-demo
(51) Vidu(国产Sora)
2024.04.27 国产 AI 视频大模型 Vidu 在中关村论坛未来人工智能先锋论坛上发布。
“中国首个长时长、高一致性、高动态性视频”是 Vidu 的代名词,Vidu 模型由清华大学和生数科技联合开发,具有以下 6 大特征:模拟真实物理世界、富有想象力、具有多镜头语言、出色的视频时长、时空一致性高、理解中国元素。
- 模拟真实物理世界:展现复杂、细节丰富的场景,模拟真实世界的物理特性,符合物理规律,例如具有光影效果和人物表情等。
- 富有想象力:具备虚构场景能力,创造超现实主义画面
- 具有多镜头语言:支持实现复杂动态镜头,体现远、近、中景、特写,长镜头、追焦等效果
- 出色视频时长:一镜到底 16s 视频生成,单一大模型,端到端生成
- 时空一致性高:不同镜头之间的视频连贯,人物和场景在时空中保持一致
- 理解中国元素:可以理解、生成熊猫、龙等中国元素。
推荐文章: 国产版 Sora 横空出世,清华大学与生数科技联合发布 Vidu
申请链接地址: https://shengshu.feishu.cn/share/base/form/shrcnybSDE4Id1JnA5EQ0scv1Ph
(52) Video Mamba Suite(Mamba视频领域应用)
2024.05.01 来自南京大学、上海人工智能实验室、复旦大学、浙江大学的研究团队发布了一项开创性工作。他们全面审视了 Mamba 在视频建模中的多重角色,提出了针对 14 种模型 / 模块的 Video Mamba Suite,在 12 项视频理解任务中对其进行了深入评估。结果令人振奋:Mamba 在视频专用和视频 - 语言任务中均展现出强劲的潜力,实现了效率与性能的理想平衡。这不仅是技术上的飞跃,更是对未来视频理解研究的有力推动。
研究团队精心打造了 video-mamba-suite(视频 Mamba 套件)。该套件旨在补充现有研究的不足,通过一系列深入的实验和分析,探索 Mamba 在视频理解中的多样化角色和潜在优势。
推荐文章: Mamba再次击败Transformer!在视频理解任务中杀疯了!
论文链接: https://arxiv.org/abs/2403.09626
代码链接: https://github.com/OpenGVLab/video-mamba-suite
(53) KAN(全新神经网络架构)
2024.05.02 一种全新的神经网络架构KAN,诞生了!与传统的MLP架构截然不同,且能用更少的参数在数学、物理问题上取得更高精度。
在函数拟合、偏微分方程求解,甚至处理凝聚态物理方面的任务都比MLP效果要好。
而在大模型问题的解决上,KAN天然就能规避掉灾难性遗忘问题,并且注入人类的习惯偏差或领域知识非常容易。
来自MIT、加州理工学院、东北大学等团队的研究一出,瞬间引爆一整个科技圈:Yes We KAN!
推荐文章: 全新神经网络架构KAN一夜爆火!200参数顶30万,MIT华人一作,轻松复现Nature封面AI数学研究version=4.1.22.6014&platform=win&nwr_flag=1#wechat_redirect)
项目链接: https://kindxiaoming.github.io/pykan/
论文链接: https://arxiv.org/abs/2404.19756
(54) Meshy 3(文本生成3D模型)
2024.05.01 文本生成3D模型Meshy 3重磅发布,目前可免费试用,UI、提示词都支持中文。
本次,Meshy 3生成的3D模型更加细腻逼真,支持360度全景观超分辨率贴图、纹理、位移、法线、曲率以及物理光照渲染效果。
也就是说,用户可以像雕塑那样去生成3D模型,并且可下载fbx、obj、glb、usdz等文件格式放在不同场景中使用。
推荐文章: 支持中文,免费试用!文本生成360度,物理光照3D模型
项目链接: /
论文链接: /
免费体验地址: https://app.meshy.ai/zh/discover
(55) MemGPT(LLM记忆管理框架)
2024.05.02 根据《MemGPT:将大语言模型作为操作系统》论文,其研发灵感来自于操作系统的分层内存系统,通过在快速和慢速内存之间移动数据来提供大内存资源的外观。MemGPT系统,智能地管理不同的内存层,以有效地在LLM的有限上下文窗口内提供扩展上下文,并利用中断来管理自身与用户之间的控制流。
MemGPT的研究者写道:“大型语言模型 彻底改变了人工智能,但受到有限的上下文窗口的限制,阻碍了它们在扩展对话和文档分析等任务中的实用性。为了能够在有限的上下文窗口之外使用上下文,我们提出了虚拟上下文管理,这是一种从传统操作系统中的分层内存系统中汲取灵感的技术,该技术通过快速内存和慢速内存之间的数据移动提供大内存资源的外观。使用这种技术,我们引入了 MemGPT,这是一个智能管理不同内存层的系统,以便在 LLM 有限的上下文窗口内有效地提供扩展上下文,并利用中断来管理其自身和用户之间的控制流。我们在两个领域评估了受操作系统启发的设计,现代 LLM 的有限上下文窗口严重影响了其性能:文档分析,MemGPT 能够分析远远超出底层 LLM 上下文窗口的大型文档,以及多会话聊天,其中 MemGPT 能够分析远远超出底层 LLM 上下文窗口的大型文档。MemGPT 可以创建会话代理,通过与用户的长期交互来记忆、反映和动态发展。”
推荐文章: GitHub 8.9K Star,伯克利大学开源LLM记忆管理框架MemGPT
项目链接: https://github.com/cpacker/MemGPT
论文链接: https://arxiv.org/abs/2310.08560
免费体验地址: https://app.meshy.ai/zh/discover
(56) Vim(Vision Mamba(Mamba高性能视觉版))
2024.05.03 来自华中科技大学、地平线、智源人工智能研究院等机构的研究者提出了 Vision Mamba(Vim)。
在 ImageNet 分类任务、COCO 对象检测任务和 ADE20k 语义分割任务上,与 DeiT 等成熟的视觉 Transformers 相比,Vim 实现了更高的性能,同时还显著提高了计算和内存效率。例如,在对分辨率为 1248×1248 的图像进行批量推理提取特征时,Vim 比 DeiT 快 2.8 倍,并节省 86.8% 的 GPU 内存。结果表明,Vim 能够克服对高分辨率图像执行 Transformer 式理解时的计算和内存限制,并且具有成为视觉基础模型的下一代骨干的巨大潜力。
推荐文章: 重磅!视觉Mamba正式收录顶会ICML 2024!
论文地址: https://arxiv.org/pdf/2401.09417.pdf
项目地址: https://github.com/hustvl/Vim
(57) InternVL 1.5(上海AI Lab多模态大语言模型 )
2024.05.06 上海AI Lab 推出的 InternVL 1.5 是一款开源的多模态大语言模型 (MLLM),旨在弥合开源模型和专有商业模型在多模态理解方面的能力差距。
与开源和闭源模型相比,InternVL 1.5 在 OCR、多模态、数学和多轮对话等 18 个基准测试中的 8 个中取得了最先进的结果。
论文称,InternVL 1.5 在四个特定基准测试中超越了 Grok-1.5V、GPT-4V、Claude-3 Opus 和 Gemini Pro 1.5 等领先的闭源模型,特别是在与 OCR 相关的数据集中。
推荐文章: 上海AI Lab开源首个可替代GPT-4V的多模态大模型
论文地址: https://arxiv.org/abs/2312.14238
代码地址:
体验地址: https://internvl.opengvlab.com
(58) 通义千问2.5(阿里巴巴 )
2024.05.09 2024年5月9日,阿里云官方在AI智领者峰会中官宣了通义千问2.5版本,并开源了1100亿参数模型Qwen1.5-110B。
阿里云表示,与通义千问2.1版本相比,通义千问2.5的理解能力、逻辑推理、指令遵循、代码能力分别提升9%、16%、19%、10%;与GPT-4相比,中文语境下,通义千问2.5文本理解、文本生成、知识问答及生活建议、闲聊及对话、安全风险等多项能力赶超GPT-4。但实际使用体验还需验证。
随着通义千问2.5的发布,阿里官方晒出了一张LLM排行榜的截图,在上海AI实验室推出的权威基准OpenCompass上,通义千问2.5得分追平GPT-4Turbo,GPT-4-Turbo-1106版本和Qwen-Max-0403并列第一名。是国产大模型首次在该基准取得该项成绩。
推荐文章: 全面赶超GPT-4?阿里云发布通义千问2.5,一文带你读懂通义千问
Model地址:
(59) xLSTM(LSTM强势升级)
2024.05.08 LSTM 提出者和奠基者 Sepp Hochreiter 在 arXiv 上传了 xLSTM 的预印本论文。
论文的所属机构中还出现了一家叫做「NXAI」的公司,Sepp Hochreiter 表示:「借助 xLSTM,我们缩小了与现有最先进 LLM 的差距。借助 NXAI,我们已开始构建自己的欧洲 LLM。」
研究者增加了训练数据量,对来自 SlimPajama 的 300B 个 token 进行了训练,并比较了 xLSTM、RWKV-4、Llama 和 Mamba。他们训练了不同大小的模型(125M、350M、760M 和 1.3B),进行了深入的评估。首先,评估这些方法在推断较长语境时的表现;其次,通过验证易混度和下游任务的表现来测试这些方法;此外,在 PALOMA 语言基准数据集的 571 个文本域上评估了这些方法;最后,评估了不同方法的扩展行为,但使用的训练数据多了 20 倍。
推荐文章: 原作者带队,LSTM真杀回来了!
论文链接: https://arxiv.org/pdf/2405.04517
(60) Cone(激活函数)
2024.05.08 介绍了一类远优于几乎普遍使用的类似ReLU和Sigmoid激活函数的激活函数。提出了两种新的激活函数,称为锥形(Cone)和抛物锥形(Parabolic-Cone),它们与流行的激活函数截然不同,并且在CIFAR-10和Imagenette基准测试上的表现显著优于这些函数。锥形激活函数仅在有限区间内为正,在该区间两端点外严格为负,并在端点处变为零。
因此,对于具有锥形激活函数的神经元来说,产生正输出的输入集合是一个超条带,而不是通常情况下的半空间。由于超条带是两个平行超平面之间的区域,它允许神经元将输入特征空间更精细地划分为正类和负类,而不是无限宽的半空间。
特别是,具有锥形类激活函数的单个神经元可以学习XOR函数。本文展示了锥形和抛物锥形激活函数在基准测试中使用显著较少的神经元就能获得更高的准确度。本文提出的结果表明,许多非线性的现实世界数据集可能需要比半空间更少的超条带进行分离。锥形和抛物锥形激活函数的导数大于ReLU,并且显著加快了训练速度。
推荐文章: 超越 ReLU 和 Sigmoid | 新型激活函数锥形和抛物锥形的研究,训练速度再上一层!
论文链接: https://arxiv.org/pdf/2405.04459
(61) Agent Hospital(清华大学)
2024.05.08近日,深度求索正式开源第二代MoE模型DeepSeek-V2,引起了中文技术社区的广泛关注。据官方说明,DeepSeek-V2是一个参数更多、能力更强、成本更低的模型。值得注意的是,DeepSeek-V2每百万tokens输入1元、输出2元(32K上下文),价格仅为GPT-4-Turbo的近百分之一。而且官方披露DeepSeek-V2在开源模型中最强,与GPT-4-Turbo等闭源模型在评测中处于同一梯队。
结论1:在完成SuperCLUE推理任务时,DeepSeek-v2的整体得分为74.46,表现突出。该模型与一些国际领先模型相比具有优势,比如它比Llama3-70B高出1.29分。然而,与GPT-4 Turbo相比,DeepSeek-v2仍有提升空间,低了5.68分;在国内模型中,DeepSeek-v2也显示出强劲的竞争力,仅与通义千问2.5相差了0.47分。
结论2:DeepSeek-v2在SC-Math6数学基准上得分86.39分,判定为推理等级5。成绩介于文心一言4.0(-0.79)和通义千问2.5(+0.14)之间。
结论3:DeepSeek-v2在SC-Code3代码基准上得分62.52分,与GPT-4只相差1.2分,与通义千问2.5相差在1分内。
详情介绍: 清华首个AI医院小镇来了!AI医生自进化击败人类专家,数天诊完1万名患者
论文地址: https://arxiv.org/pdf/2405.02957
(62) DeepSeek-V2(深度求索-第二代MoE模型)
2024.05.09最近,来自清华团队的研究人员开发了一个名为「Agent Hospital」的模拟医院。
在这个虚拟世界中,所有的医生、护士、患者都是由LLM驱动的智能体,可以自主交互。它们模拟了整个诊病看病的过程,包括分诊、挂号、咨询、检查、诊断、治疗、随访等环节。而在这项研究中,作者的核心目标是,让AI医生学会在模拟环境中治疗疾病,并且能够实现自主进化。
研究人员设计了,14名医生和4名护士。医生智能体被设计来诊断疾病并制定详细的治疗计划,而护理智能体则专注于分诊,支持日常治疗干预。
详情介绍: 深度求索DeepSeek-V2中文推理任务表现强劲,总分74.46,超越Llama3|SuperCLUE
模型地址:
- https://modelscope.cn/models/deepseek-ai/DeepSeek-V2-Chat
- https://modelscope.cn/models/deepseek-ai/DeepSeek-V2
- https://huggingface.co/deepseek-ai
开源地址: https://github.com/deepseek-ai/DeepSeek-V2
(63) Lumina-T2X(多模态DiT架构大一统)
2024.05.10上海 AI Lab、港中文和英伟达的研究者联合推出了 Lumina-T2X 系列模型,通过基于流(Flow-based)的大型扩散 Transformers(Flag-DiT)打造,旨在将噪声转换为图像、视频、多视图 3D 对象和基于文本描述的音频。
其中,Lumina-T2X 系列中最大的模型包括具有 70 亿参数的 Flag-DiT 和一个多模态大语言模型 SPHINX。SPHINX 是一个文本编码器,它具有 130 亿参数,能够处理 128K tokens。
基础的文本到图像模型 Lumina-T2I 利用流匹配框架,在精心整理的高分辨率真实图像文本对数据集上进行训练,只需要使用很少的计算资源就能取得真实感非常不错的结果。
Lumina-T2I 可以生成任意分辨率和宽高比的高质量图像,并进一步实现高级功能,包括分辨率外推、高分辨率编辑、构图生成和风格一致生成,所有这些都以免训练的方式无缝集成到框架中。
详情介绍: DiT架构大一统:一个框架集成图像、视频、音频和3D生成,可编辑、能试玩
模型地址: https://huggingface.co/Alpha-VLLM/Lumina-T2I/tree/main
开源地址: https://github.com/Alpha-VLLM/Lumina-T2X
论文地址: https://arxiv.org/pdf/2405.05945
(64) GPT-4o(OpenAI多模态模型-o代表omini,全能)
2024.05.14 OpenAI发布最新多模态大模型 GPT-4o(o代表omini,全能),支持文本、音频和图像的任意组合输入,并生成文本、音频和图像的任意组合输出。文本、推理和编码智能方面性能达到了GPT-4 Turbo水平,同时在多语言、音频和视觉能力方面也达到新高。据介绍,GPT-4o的速度比GPT-4 Turbo快2倍,速率限制提高5倍,最高可达每分钟1000万token,而价格则便宜了一半。
官网显示,GPT-4o的文本和图像功能将在ChatGPT更新后提供给所有用户,Plus用户的消息数量使用上限是免费版的5倍(使用上限后会切换回GPT-3.5版本)。而新版语音模式将在未来几周向Plus用户推出,同时也将会在API(应用接口)中向小范围推出对GPT-4o的新音频和视频功能的支持。
GPT-4o可以像人工智能助手一样,实现用户与ChatGPT的实时交互,不再是一问一答,也不需要其他按键操作。比如,用户可以说“Hi,ChatGPT”并提出问题,也可以在ChatGPT回答时打断它,它还可以识别用户声音中展现的情感,甚至实时根据用户的需求来使用不同情感风格的声音。
据介绍,GPT-4o的音频输入平均反应时间为0.32秒,与人类对话中的反应时间相似。
OpenAI表示,在GPT-4o之前,使用语音模式与ChatGPT对话的平均延迟时间为2.8秒(GPT-3.5)和5.4秒(GPT-4)。此前的语音模式由三个独立模型组成:一个简单模型将音频转为文本,GPT-4接收文本并输出文本,第三个简单模型将文本转回音频。这个过程也让主要的智能源GPT-4丢失了很多信息,比如不能直接观察音调、多人讲话或背景噪音,也不能输出笑声、歌声或表达情感。而GPT-4o通过在文本、视觉和音频方面训练了一个端到端新模型,所有输入和输出都由同一个神经网络处理。
详情介绍:
电影中的人工智能来了!OpenAI发布全能大模型:文图音任意组合输出,可实现人类级别响应
GPT-4o登顶中文推理基准,总分81.73,刷新数学和代码最好成绩
(65) 豆包大模型(抖音大模型)
2024.05.015 2024春季火山引擎 FORCE 原动力大会在北京正式举办。会上正式发布了字节跳动豆包大模型家族、火山方舟2.0、AI 应用及 AI 云基础设施等最新产品
为助力企业做好大模型场景落地,字节跳动自主研发的豆包大模型将通过火山引擎正式对外提供服务,企业可根据自身业务场景需求灵活选择、快速落地:
(1)豆包通用模型pro:字节跳动自研LLM模型专业版,支持 128k 长文本,全系列可精调,具备更强的理解、生成、逻辑等综合能力,适配问答、总结、创作、分类等丰富场景;
(2)豆包通用模型lite:字节跳动自研LLM模型轻量版,对比专业版提供更低 token 成本、更低延迟,为企业提供灵活经济的模型选择;
(3)豆包·角色扮演模型:个性化的角色创作能力,更强的上下文感知和剧情推动能力,满足灵活的角色扮演需求;
(4)豆包·语音合成模型:提供自然生动的语音合成能力,善于表达多种情绪,演绎多种场景;
(5)豆包·声音复刻模型:5秒即可实现声音1:1克隆,对音色相似度和自然度进行高度还原,支持声音的跨语种迁移;
(6)豆包·语音识别模型:更高的准确率及灵敏度,更低的语音识别延迟,支持多语种的正确识别;
(7)豆包·文生图模型:更精准的文字理解能力,图文匹配更准确,画面效果更优美,擅长对中国文化元素的创作;
(8)豆包·Function call模型:提供更加准确的功能识别和参数抽取能力,适合复杂工具调用的场景;
(9)豆包·向量化模型:聚焦向量检索的使用场景,为 LLM 知识库提供核心理解能力,支持多语言。
推荐文章:
字节跳动大模型首次全员亮相:一口气9个,价格低99%,没有参数规模和榜单分数
节跳动豆包大模型发布,火山引擎全栈 AI 服务助力企业智能化转型
论文链接: /
代码链接: /
(66) Project Astra(谷歌对标GPT-4o)
2024.05.15 昨天被OpenAI提前截胡的谷歌,今天不甘示弱地开启反击!大杀器Project Astra效果不输GPT-4o,文生视频模型Veo硬刚Sora,用AI彻底颠覆谷歌搜索,Gemini 1.5 Pro达到200万token上下文……谷歌轰出一连串武器,对OpenAI贴脸开大。
首先,Gemini 1.5 Pro,上下文长度将达到惊人的200万token。然后,面对昨天OpenAI GPT-4o的挑衅,谷歌直接甩出大杀器Project Astra,视觉识别和语音交互效果,跟GPT-4o不相上下。接着,谷歌祭出文生视频模型Veo硬刚Sora,效果酷炫,时长超过1分钟,打破Sora纪录。最后来了一个重磅消息:谷歌搜索将被Gemini重塑,形态从此彻底改变!我们不再需要自己点进搜索结果,而是由多步骤推理的AI Overview来代办一切。
推荐文章: 谷歌2小时疯狂复仇,终极杀器硬刚GPT-4o!Gemini颠覆搜索,视频AI震破Sora
申请入口: https://aitestkitchen.withgoogle.com/tools/video-fx
代码链接: /
(67) Chameleon(meta对标GPT-4o)
2024.05.19 GPT-4o发布不到一周,首个敢于挑战王者的新模型诞生!最近,Meta团队发布了「混合模态」Chameleon,可以在单一神经网络无缝处理文本和图像。10万亿token训练的34B参数模型性能接近GPT-4V,刷新SOTA。
与GPT-4o一样,Chameleon采用了统一的Transformer架构,使用文本、图像和代码混合模态完成训练。以类似文本生成的方式,对图像进行离散「分词化」(tokenization),最终生成和推理交错的文本和图像序列。
Meta研究团队引入了一系列架构创新和训练技术。结果表明,在纯文本任务中,340亿参数Chameleon(用10万亿多模态token训练)的性能和Gemini-Pro相当。在视觉问答和图像标注基准上,刷新SOTA,性能接近GPT-4V。不过,不论是GPT-4o,还是Chameleon,都是新一代「原生」端到端的多模态基础模型早期探索。
为了进一步评估模型生成多模态内容的质量,论文也在基准测试之外引入了人类评估实验,发现Chameleon-34B的表现远远超过了Gemini Pro和GPT-4V。相对于GPT-4V和Gemini Pro,人类评委分别打出了51.6%和60.4的偏好率。
推荐文章: Meta首发「变色龙」挑战GPT-4o,34B参数引领多模态革命!10万亿token训练刷新SOTA
申请入口: /
代码链接: /
(68) MiniCPM-Llama3-V 2.5(面壁智能“小钢炮”)
2024.05.20 杀疯了!一夜之间,全球最强端侧多模态模型再次刷新,仅用8B参数,击败了多模态巨无霸Gemini Pro、GPT-4V。而且,其OCR长难图识别刷新SOTA,图像编码速度暴涨150倍。这是国产头部大模型公司献给开发者们最浪漫的520礼物。
来自国内大模型研发实力最头部的公司面壁智能——最新打造了面壁小钢炮MiniCPM-Llama3-V 2.5。拳打GPT-4V,脚踢Gemini Pro,仅仅8B参数就能击败多模态大模型王者。这个全球最强端侧多模态模型彻底「杀疯了」!
推荐文章: 国产「小钢炮」一夜干翻巨无霸GPT-4V、Gemini Pro!稳坐端侧多模态铁王座
开源地址:
https://github.com/OpenBMB/MiniCPM-V
https://github.com/OpenBMB/MiniCPM
Hugging Face下载地址: https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
(69) Copilot+ PC(微软集成GPT-4o)
2024.05.21 微软发布了Copilot+ PC,这是全球首个专为AI设计的Windows PC,也是Windows史上最强版本。据悉,Copilot+ PC内置了OpenAI的GPT-4o模型并搭载了超强芯片,每秒能执行40多万亿次操作。可提供实时的语音、语言翻译,实时绘画、文本、图片生成等一系列超强创新功能。
Recall是该产品的一大特色功能,可以帮助用户搜索、查看过去做过的任何事情,例如,用户在PC上打开了哪些应用,使用了哪些文档等。
可以像人的大脑一样记住所有见过、碰过的东西。为了安全性,用户可以手动删除这些操作镜像。
目前,联想、宏碁、华硕、戴尔、惠普和三星著名PC厂商已经与微软签订了合作协议,6月18日将正式发布不同型号的Copilot+ PC。
微软表示,Copilot+ PC只是刚开始,他们会通过生成式AI重塑整个PC生态,从底层硬件、芯片再到开发、软件应用层等,这将是Windows平台诞生至今几十年最重要的技术变革。
推荐文章: 微软发布Copilot+ PC:集成GPT-4o,史上最强、最快Windows!
开源地址: /
(70) CogVLM2(智谱AI多模态模型)
2024.05.22 开源多模态SOTA模型再易主!Hugging Face开发者大使刚刚把王冠交给了CogVLM2,来自大模型创业公司智谱AI。CogVLM2甚至在3项基准测试上超过GPT-4v和Gemini Pro,还不是超过一点,是大幅领先。
CogVLM2整体模型参数量仅19B,却能在多项指标取得接近或超过GPT-4V的水平,此外还有几大亮点:
- 支持8K文本长度
- 支持高达1344*1344的图像分辨率
- 提供支持中英文双语的开源模型版本
- 开源可商用
推荐文章: 开源多模态SOTA再易主,19B模型比肩GPT-4v,16G显存就能跑
代码仓库: https://github.com/THUDM/CogVLM2
模型下载:
Huggingface:https://huggingface.co/THUDM
魔搭社区:https://modelscope.cn/models/ZhipuAI
始智社区:https://wisemodel.cn/models/ZhipuAI
Demo体验: http://36.103.203.44:7861
(71) Baichuan4(百川智能升级LLM)
2024.05.22 百川智能正式发布Baichuan4。
- 结论1:国内最佳成绩
在SuperCLUE综合基准上的评测中,Baichuan4以总得分80.64分刷新了国内记录。不仅如此,它在中文综合能力测试中以1.51分的领先优势超过了GPT-4-Turbo-0125,展现了其在大模型方面的强大实力。 - 结论2:分类任务表现分析
理科表现: 在理科领域,Baichuan4虽然以国内最佳成绩领先,但与GPT-4-Turbo-0125相比还有4.23分的差距,显示出进一步优化的空间。
文科表现: 在文科任务中,Baichuan4以83.13分的高分不仅领先国内,也是国际上的最高分,比GPT-4-Turbo-0125高出5.33分,验证了其在文科领域的卓越能力。 - 结论3:全面而均衡的能力展示
Baichuan4在多个领域展示了其均衡的能力,特别是在知识百科、长文本理解、工具使用、语义理解和创意生成等方面处于领先地位。这使得Baichuan4非常适合应用于知识运用、智能体、内容创作和长程对话等多种场景。然而,它在代码能力方面仍有提升的潜力。
推荐文章: 国内大模型竞争加剧!百川智能「Baichuan4」全网首测,以总分80.64刷新SuperCLUE中文基准
代码仓库: /
Demo体验: https://www.baichuan-ai.com/
(72) 前沿人工智能安全承诺(Frontier AI Safety Commitments)
2024.05.22 人工智能史上的一个重大时刻:OpenAI、谷歌、微软和智谱AI 等来自不同国家和地区的公司共同签署了前沿人工智能安全承诺(Frontier AI Safety Commitments);欧盟理事会正式批准了《人工智能法案》(AI Act),全球首部 AI 全面监管法规即将生效。
前沿人工智能安全承诺,包括以下要点:
- 确保前沿 AI 安全的负责任治理结构和透明度;
- 基于人工智能安全框架,负责任地说明将如何衡量前沿 AI 模型的风险;
- 建立前沿 AI 安全模型风险缓解机制的明确流程。
图灵奖得主 Yoshua Bengio 认为,前沿人工智能安全承诺的签署“标志着在建立国际治理制度以促进人工智能安全方面迈出了重要一步”。
作为来自中国的大模型公司,智谱 AI 也签署了这一新的前沿人工智能安全承诺
推荐文章: OpenAI、微软、智谱AI等全球16家公司共同签署前沿人工智能安全承诺
(73) TransformerFAM(Transformer架构升级)
2024.05.24 Transformer对大模型界的影响力不言而喻,ChatGPT、Sora、Stable Difusion等知名模型皆使用了该架构。
但有一个很明显的缺点,其注意力复杂度的二次方增长在处理书籍、PDF等超长文档时会显著增加算力负担。
虽然会通过滑动窗口注意力和稀疏注意力等技术来解决这一问题,在处理极长序列时仍存在局限性。
因此,谷歌的研究人员提出了全新架构TransformerFAM,可以无缝与预训练模型集成,并通过LoRA进行少量精调从而大幅度提升模型性能。
研究人员在1B、8B和24B三种参数的Flan-PaLM大语言模型上评估了Transformer FAM的性能。实验结果显示,与Transformer架构相比,TransformerFAM在长序列任务上取得了好的能力并且资源消耗更低。
推荐文章: 谷歌推出TransformerFAM架构,以更低的消耗处理长序列文本
论文地址: https://arxiv.org/abs/2404.09173
(74) YOLOv10(清华大学升级YOLO)
2024.05.25 YOLOv9刚出才3个月时间,清华大学更新YOLO系列模型,YOLOv10正式发布。
YOLOv10在YOLO系列的基础上进行了优化和改进,旨在提高性能和效率之间的平衡。首先,作者提出了连续双分配方法,以实现NMS-free训练,从而降低了推理延迟并提高了模型的性能。其次,作者采用了全面的效率-准确性驱动的设计策略,对YOLO的各种组件进行了综合优化,大大减少了计算开销,并增强了模型的能力。实验结果表明,YOLOv10在各种模型规模下都取得了最先进的性能和效率表现。例如,YOLOv10-S比RT-DETR-R18快1.8倍,同时拥有更小的参数数量和FLOPs;与YOLOv9-C相比,YOLOv10-B的延迟减少了46%,参数减少了25%,但保持了相同的性能水平。
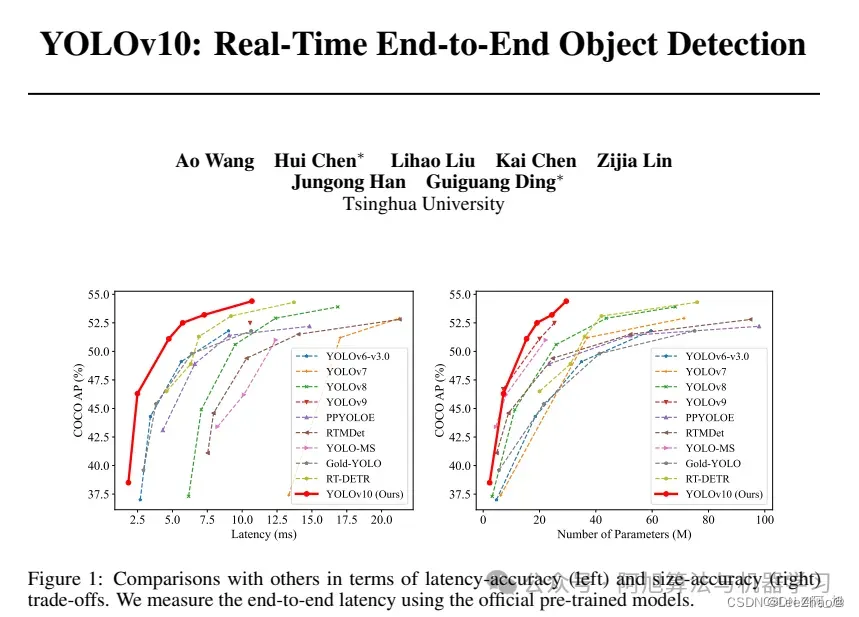
推荐文章:
YOLOv10论文解读:实时端到端的目标检测模型,检测效率大幅提升!
目标检测YOLOv10开源,实时端到端算法,检测效率大幅提升!(附论文及源码)
论文及源码地址: https://pan.baidu.com/s/16L8Sw-jMLSSUSe8aa9cJSg?pwd=dfJ3
(75) Aya 23(Cohere大模型)
2024.05.24 知名开源大模型厂商Cohere开源了新一代大模型——Aya 23。据悉,Aya 23共有80亿和350亿两种参数,支持阿拉伯语、中文(简体和繁体)、捷克语、荷兰语、英语、法语、德语、希腊语、希伯来语等23种语言,可生成文本、代码、总结内容等。
目前,Cohere已经全面开放了Aya 23的权重,在遵守CC-BY-NC、C4AI的策略下可以商业化。
在预训练方面,Aya 23基于Cohere Command系列模型,使用包括23种语言文本的数据混合进行预训练。Aya-23-35B是Cohere Command R的进一步微调版本。预训练模型采用了标准的仅解码器Transformer架构,并行注意力和FFN层、SwiGLU激活、无偏置、RoPE(旋转位置嵌入)、BPE分词器以及分组查询注意力(GQA)。
实验数据显示,在鉴别性任务上,Aya 23模型在所有未见过的任务上都表现出色,这些任务包括XWinograd、XCOPA和XStoryCloze,使用零样本评估。
推荐文章: 支持中文、开放权重,Cohere最新开源大模型Aya 23
模型地址:
https://huggingface.co/CohereForAI/aya-23-35B
https://huggingface.co/CohereForAI/aya-23-8B
(76) Llama3-V(Llama3多模态模型)
2024.05.30 Llama3席卷全球,在几乎所有基准测试中都优于GPT3.5,在部分基准测试中优于GPT4。然后GPT4o出来了,用它的多模式技巧重新夺回了宝座。然后,一个建立在Llama3之上的多模式模型Llama3-V就出现了。
Llama3-V相比当前最先进的多模态理解模型Llava,在多项指标上实现了10%-20%的提升。此外,它在不牺牲任何参数表现的前提下,展现了与闭源模型相抗衡的实力,性价比高达百倍。
- LLama3-V 的出现挑战了 GPT4-V 的主导地位,它在多模态理解方面实现了与 GPT4-V 相当或更好的性能,且成本远低。
- SigLIP 模型在处理图像方面表现出色,它能够有效地将图像信息嵌入到模型中,并且与文本信息很好地对齐。
- 系统优化对于大型模型的训练和推理至关重要,LLama3-V 通过缓存和 MPS/MLX 优化,显著提高了计算效率。
- 预训练和监督微调的策略对于模型性能的提升至关重要,LLama3-V 在这两个阶段都采用了有效的方法来更新模型权重。
- 开源模型的发展对于推动 AI 领域的进步和降低研发门槛至关重要,LLama3-V 作为一个开源模型,为社区提供了一个强大的工具。
推荐文章: 又一多模态模型开源 — Llama3-V
模型地址:
https://github.com/mustafaaljadery/llama3v
https://huggingface.co/mustafaaljadery/llama3v/tree/main
(77) SuperCLUE-Long(中文原生长文本测评基准)
2024.05.30 随着大语言模型应用的推广,越来越多的用户开始参与到模型的使用中,进而对模型的性能也提出了更多的要求。“长文本”作为用户普遍关注的热点话题,是目前国内外企业重点推进的项目,例如OpenAI推出的GPT-4 Turbo-128k;Anthropic推出的Claude3-200k。国内的企业,如月之暗面也推出了支持200万字输入的Kimi,阿里旗下的通义千问免费开放了支持1000万字的长文本处理功能。
为了衡量国内外长文本大模型的发展水平,为用户提供更为直观的、专业的长文本大模型体验报告,考量国内长文本大模型的落地实况,协助国内长文本大模型突破发展瓶颈,我们推出了中文原生长文本测评基准SuperCLUE-Long(SC-Long),旨在为长文本大模型发展现状进行量化评估。
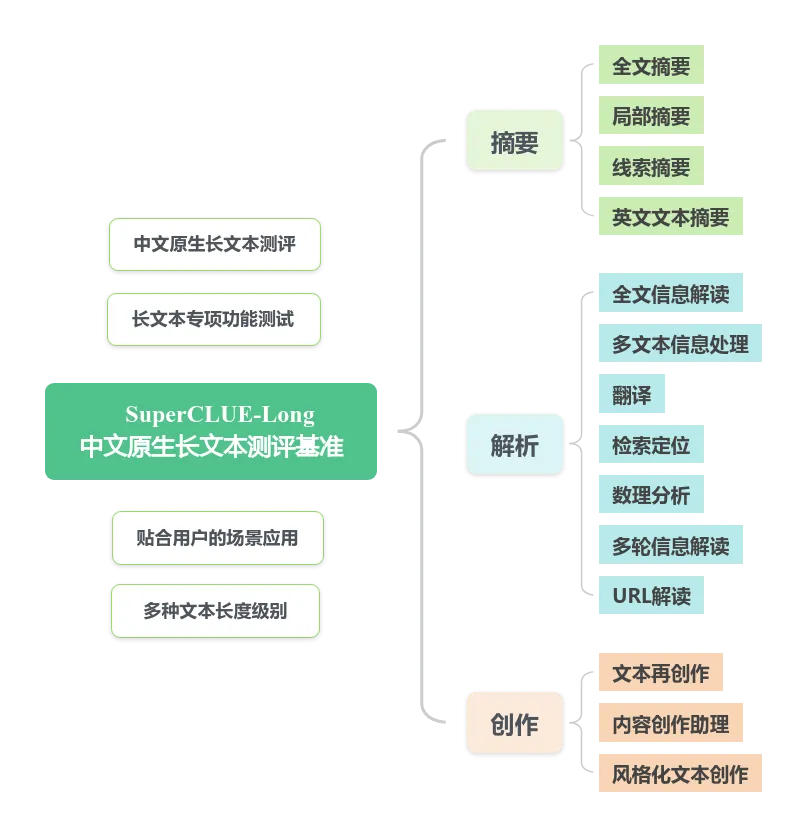
推荐文章: SuperCLUE-Long:中文原生长文本测评基准
模型地址: /
项目地址: https://github.com/CLUEbenchmark/SuperCLUE-Long
(78) Viva(类Sora免费模型)
2024.05.31 在数字化时代,视频已成为信息传播的重要媒介,而今,Viva的诞生,为视频创作带来了革命性的变革,这不仅仅是一个工具,更是一个创意无限的平台。
Viva,作为全球首个类Sora的开源应用,为视频创作者带来了全新的体验,以其免费、易用、功能强大的特点,迅速成为视频创作者的新宠。
它不仅支持文生视频和图生视频,还特别支持4K分辨率,最吸引人的是,这一切都是完全免费的。
功能特点:
- 文生视频:将文本内容转化为视频。
- 图生视频:将图片转化为视频。
- 4K分辨率:提供高清的视频输出。
- AI完善Prompt:智能提示,帮助用户自动完善输入指令。
- 画框大小调节:支持1:1、16:9和9:16的传统画框比例。
推荐文章:
全球首个类Sora的免费文生视频模型还支持4K分辨率——Viva
不只是Sora——Viva(全球首个免费文生视频模型)
模型地址: /
体验地址: https://vivago.ai/video?type=1
(79) ChatTTS(语音合成项目)
2024.06.01 ChatTTS 文本转语音项目爆火出圈,引来大家极大的关注。短短三天时间,在 GitHub 上已经斩获了 9.2 k 的 Star 量。
ChatTTS 不仅能说中文,英文也能 hold 住,还支持一些细粒度控制,它允许你加入笑声、说话间的停顿,还有语气词,可玩性很强。
它可以复刻已经逝去的人的绝版声音,想要再听到乔布斯开发布会,随时都可以。听它模仿霉霉的音色,不论是语调还是语气的变化,都挺接近本人,几乎听不出来 AI 味儿。
中英文混说也能拿捏,这口半英半中的腔调勇闯留子圈,ChatTTS 的语言能力已达到 next level。
目前 ChatTTS 支持中文和英文。最大模型使用了超过 10 万小时的中英文数据进行训练。在 HuggingFace 中开源的版本为 4 万小时训练且未 SFT 的版本。
推荐文章:
爆火ChatTTS突破开源语音天花板,3天斩获9k的Star量
AI语音:ChatTTS真有点东西啊!
代码链接: https://github.com/2noise/ChatTTS/tree/main
体验地址: https://huggingface.co/spaces/Dzkaka/ChatTTS
一键启动包下载链接: https://pan.baidu.com/s/1olSFaWT50JSRkKakyES8eg?pwd=oxwe
(80) Mamba-2(大模型新架构Mamba升级)
2024.06.03 在开源社区引起「海啸」的Mamba架构,再次卷土重来!这次,Mamba-2顺利拿下ICML。通过统一SSM和注意力机制,Transformer和SSM直接成了「一家亲」,Mamba-2这是要一统江湖了。
性能方面,Mamba-2采用了新的算法(SSD),比前代提速2-8倍,对比FlashAttention-2也不遑多让,在序列长度为2K时持平,之后便一路遥遥领先。
在Pile上使用300B token训练出的Mamba-2-2.7B,性能优于在同一数据集上训练的Mamba-2.8B、Pythia-2.8B,甚至是更大的Pythia-6.9B。
推荐文章: Mamba-2新架构出世一统江湖!普林斯顿CMU华人再出神作,性能狂飙8倍
论文地址: https://arxiv.org/pdf/2405.21060
开源代码和模型权重: https://github.com/state-spaces/mamba
(81) GLM-4 9B(智谱开源LLM)
2024.06.05 智谱AI发布新一代MaaS平台2.0,GLM-4系列模型实现性能提升并降低成本。GLM-4-9B模型首次开源,具备多模态能力,性能超越Llama-3。平台支持企业训练私有模型,LoRA微调成本仅300元。智谱AI坚持开源,推动国内模型开源走向世界。如今,平台上已经全线接入新模型,由ChatGLM3-6B升级为GLM-4-9B,堪称“最能打的小模型”,已经全面超过了 Llama3-8B-Instruct。
令人惊喜的是,第四代GLM系列开源模型GLM-4 9B,官宣开源免费用,还具备了多模态能力。同时,新发布的GLM-4-AIR性能媲美此前的最大基座模型,且价格降至1元/M token。
除了文本模型,这次一并开源了多模态模型GLM-4V-9B。最新模型采用了与CogVLM2相似的架构设计,能够处理高达1120 x 1120分辨率的输入,并通过降采样技术有效减少了token的开销。与CogVLM的不同之处在于,GLM-4V-9B并没有通过引入额外的视觉专家来增加参数量,而是采用了直接混合文本和图片数据的方式进行训练。
这种训练方法使得GLM-4V-9B模型能够同时具备强大的文本和视觉处理能力,实现了真正的多模态学习。
过去一年中,他们完成了3次基座大模型升级迭代,这次OpenDay 核心展示了面向AGI愿景的完整产品矩阵,透传出未来商业化的模式。
智谱AI正把MaaS商业模式提升到新的境界。MaaS平台2.0的诞生,将会进一步扩大智谱生态朋友圈。
推荐文章:
1毛钱1百万token,写2遍红楼梦!国产大模型下一步还想卷什么?
智谱AI GLM4开源!快速上手体验
模型链接及下载
GLM-4-9B-Chat:https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat/summary
GLM-4-9B-Chat-1M:https://modelscope.cn/models/ZhipuAI/glm-4-9b-chat-1m/summary
GLM-4-9B:https://modelscope.cn/models/ZhipuAI/glm-4-9b/summary
GLM-4v-9B:https://modelscope.cn/models/ZhipuAI/glm-4v-9b/summary
(82) Seed-TTS(字节语音合成)
2024.06.06 字节跳动团队在语音合成技术领域取得了新进展,推出了名为Seed-TTS的新型语音生成模型。该模型基于自回归Transformer架构,能够生成接近人类语音的自然且富有表现力的语音。
Seed-TTS在情绪控制方面表现出色,能够调整生成语音的情感属性,包括但不限于愤怒、快乐、悲伤、惊讶等情感,以及语调和说话风格,如正式、非正式或戏剧化等。这种精细的情绪控制使得Seed-TTS能够满足多样化的需求。该模型生成的语音不仅自然,而且具有很强的表现力,能够模拟复杂的情感和语境,特别适合用于小说朗读、视频配音等场景。
Seed-TTS在零样本学习方面也展现出了强大的能力,即便没有训练数据,也能基于简短的语音片段生成高质量的语音,这使得它在需要快速适应新语境的场合非常有用。Seed-TTS支持语音内容和说话速度的编辑,用户可以灵活调整生成的语音,以适应不同的应用场景。
推荐文章: 高度拟人化!字节王炸语音合成Seed-TTS真假难辨 小说配音的春天要来了!
体验地址: https://bytedancespeech.github.io/seedtts_tech_report/
(83) QWen2(阿里大模型)
2024.06.07 Qwen系列模型从Qwen1.5升级到Qwen2, Qwen 2.0 主要内容如下:
- 5 个尺寸的预训练和指令微调模型,包括 Qwen2-0.5B、Qwen2-1.5B、Qwen2-7B、Qwen2-57B-A14B 以及 Qwen2-72B
- 在中文英语的基础上,训练数据中增加了 27 种语言相关的高质量数据;
- 多个评测基准上的领先表现;
- 代码和数学能力显著提升;
- 增大了上下文长度支持,最高达到 128K tokens(Qwen2-72B-Instruct)。
推荐文章: 重磅发布,阿里QWen2开源,全面超越Llama3,成为开源第一大模型
相关地址:
Blog: https://https://qwenlm.github.io/blog/qwen2/wen2/
文档: https://https://qwen.readthedocs.io/en/latest/latest/
Github: https://https://github.com/QwenLM/Qwen2
modelscope: https://modelscope.cn/organization/qwenion/qwen
Huggingface: https://https://huggingface.co/Qwen
(84) VideoReTalking(数字人对口型)
2024.06.07 VideoReTalking 是一种基于深度学习的AI数字人技术,主要用于通过声音信号驱动和同步面部表情。这项技术是由西安电子科技大学、腾讯人工智能实验室和清华大学联合开发的。VideoReTalking 的主要特点是其能够根据输入的音频信号,精确控制AI数字人的面部表情,使其与声音相匹配,从而实现情感表达的同步。
VideoReTalking 的工作流程主要包括三个步骤:
- 面部视频生成:系统通过表情编辑网络对每一帧的面部表情进行修改,使其与一个标准表情模板相符,从而生成一个具有标准表情的视频。
- 音频驱动的嘴型同步:生成的标准表情视频和给定的音频一起输入到嘴型同步网络中,生成一个嘴型与音频同步的视频。
- 面部增强:最后,系统通过身份感知的面部增强网络和后处理来提高合成面部的照片真实性,使AI数字人的面部表情更加自然、逼真。
- 这项技术的优势在于其强大的声音驱动能力和高度的自动化程度。用户只需输入音频信号,系统就能自动生成与声音相匹配的面部表情,无需复杂的操作。这使得AI数字人的情感表达更加自然、流畅,大大提高了用户体验。
VideoReTalking 技术可以广泛应用于虚拟主播、智能客服、教育培训等领域。在实际应用中,为充分发挥其优势,需要注意选择合适的音频信号作为输入,并对生成的面部表情进行适当的调整和优化,以确保自然度和真实感。
推荐文章: 开源的数字人关键技术:AI对口型
代码地址: http://www.gitpp.com/digitallib/video-retalking
官方文档: https://opentalker.github.io/video-retalking/
(85) Stable Diffusion 3 Medium(文生图更新)
2024.06.13 Stable Diffusion 3 Medium(简称SD3 Medium)是Stability AI公司推出的文生图AI模型。
SD3 Medium拥有20亿参数,它的身材很“苗条”,可以完美适配你的家用电脑和笔记本。
- 照片级真实感:改善了手部和面部的常见问题,无需复杂工作流程即可生成高质量图像。
- 提示遵循:能够理解涉及空间关系、构图元素、动作和风格的复杂提示。
- 排版:在生成文本时,借助Diffusion Transformer架构,实现优秀的拼写能力。
- 资源高效:由于其低VRAM占用,可以在消费级GPU上运行,整体性能不受影响。
- 微调能力:能够从小数据集中吸收细节,适合定制化。
推荐文章: 开源文生图AI重磅更新!SD3 Medium来了!这些能力让其力压MJ!
模型地址: https://huggingface.co/stabilityai/stable-diffusion-3-medium
官方文档: https://stability.ai/news/stable-diffusion-3-medium
(86) Dream Machine(Luma AI文生视频)
2024.06.13 知名的3D建模平台Luma AI发布了他们的最新文生视频模型Dream Machine,并向所有用户免费开放使用。Dream Machine模型不仅支持文本输入,还可以使用图片作为引导来生成视频。其生成的视频在质量、动作一致性、色彩、光影、饱和度和运镜等方面可与OpenAI的Sora相媲美。
- 物理模拟支持:Dream Machine能够模拟现实世界的物理特性,如重力下落、碰撞和光影变化,这使得生成的视频更加逼真。
- 高质量视频生成:该模型能够生成高质量的视频,具有出色的动作连贯性和视觉效果。
- 免费使用:Dream Machine对所有用户免费开放,提供了一个免费体验的途径。
推荐文章: Luma AI推重磅级文生视频模型Dream Machine 炸裂程度堪比Sora
体验地址: https://lumalabs.ai/dream-machine
(87) Nemotron-4 340B(Nvidia开源模型)
2024.06.15 AIGC最赚钱的公司NVIDIA刚刚开源了超大模型Nemotron-4 340B[1],它包括三个模型:Nemotron-4-340B-Base,Nemotron-4-340B-Instruct以及Nemotron-4-340B-Reward。Nemotron-4 340B的开源协议是NVIDIA Open Model License,可以用于商用。模型可以在F8精度下用一台8卡DGX H100部署。Nemotron-4-340B模型在benchmark上的表现也相当抢眼。
Nemotron-4-340B-Instruct的一个重要特性是用于对齐训练的数据集包含98%的合成数据,所以可以用于合成数据。配合Nemotron-4-340B-Reward模型,就可以用于生成训练小模型的数据
推荐文章: 金主NVIDIA终于出手了,开源超大模型Nemotron-4 340B
模型地址: https://huggingface.co/collections/nvidia/nemotron-4-340b-666b7ebaf1b3867caf2f1911
代码地址: https://github.com/NVIDIA/NeMo-Aligner
技术报告: https://research.nvidia.com/pub
(88) Gen-3
2024.06.18 自从OpenAI公布了Sora,视频生成领域正式按下了行业加速键,许多国内外企业纷纷发力,不仅研究发布专门用于视频生成的垂直大模型,还将手里的技术封装成一个个人人能用的AIGC产品。
随着新玩家数量的剧增,这场视频生成领域的战争愈演愈烈,其中受到冲击最大的自然是老牌同类竞品模型,比如Pika、SDV、谷歌、Meta,还有刚发布第三代视频生成模型Gen-3 Alpha的Runway。
Runway深夜发布的各种演示视频展示出了电影级的画面细节,直接震惊了全体网友。Gen-3与之前的旗舰视频模型Gen-2相比,在模型生产速度和保真度方面有了重大提升,同时对生成视频的结构、风格和运动提供了细粒度的控制。
Runway表示,Gen-3 Alpha具有高保真视频、精细动作控制、逼真人物生成、多模态输入、专业创作工具、增强安全、高质量训练等特点。在这次模型的训练过程中,汇集了研究者、工程师和艺术家的集体智慧和努力。正是这种跨学科的协作精神,使得Gen-3 Alpha模型能够理解和表达多种风格和电影概念。
官方展示视频时长为10秒,人物生成中的人物面部细节和情感营造方面比较细腻,场景、风景生成中的元素、光影没有太大的违和感。友情提示,以下展示内容因为要转换为GIF,所以画质均有不同程度压缩,想看原视频的朋友可以去Runway官网复习下。
推荐文章: 视频大模型画饼哪家强?Gen-3演示效果绝杀Sora
体验地址: https://runwayml.com/blog/introducing-gen-3-alpha/
(89) Open-Sora(Open-Sora再升级)
2024.06.18 潞晨 Open-Sora 团队在 720p 高清文生视频质量和生成时长上实现了突破性进展,支持无缝产出任意风格的高质量短片,令人惊喜的是,他们选择再给开源社区带来亿点点震撼,继续全部开源。
通过他们的模型权重,能够生成各种酷炫的短片,比如海浪和海螺的亲密接触,还有那些深不可测的森林秘境。
在潞晨 Open-Sora 团队发布的这份技术报告中,他们深度剖析了本次模型训练的核心和关键。在上一个版本基础上,引入了视频压缩网络(Video Compression Network)、更优的扩散模型算法、更多的可控性,并利用更多的数据训练出了 1.1B 的扩散生成模型。
在这个"算力为王"的时代,我们深知视频模型训练的两大痛点:计算资源的巨大消耗与模型输出质量的高标准。潞晨 Open-Sora 团队以一种极简而有效的方案,成功地在成本和质量之间找到了平衡点。
Open-Sora 团队提出了一个创新的视频压缩网络(VAE),该网络在空间和时间两个维度上分别进行压缩。具体来说,他们首先在空间维度上进行了 8x8 倍的压缩,接着在时间维度上进一步压缩了 4 倍。通过这种创新的压缩策略,既避免了因抽帧而牺牲视频流畅度的弊端,又大幅降低了训练成本,实现了成本与质量的双重优化。
推荐文章: 开源模型潞晨 Open-Sora 大突破!
开源地址: https://github.com/hpcaitech/Open-Sora
(90) Claude 3.5 Sonnet(Claude升级)
2024.06.20 刚刚,被称为“OpenAI 最强竞对”的大模型公司 Anthropic 发布了 Claude 3.5 系列模型中的第一个版本——Claude 3.5 Sonnet。
Anthropic 在官方博客中表示,Claude 3.5 Sonnet 提高了智能化的行业标准,在各种评估中均优于 GPT-4o、Gemini 1.5 和 Llama-400b 等竞争对手模型和其上一代最智能的模型 Claude 3 Opus,速度和成本也与上一代中等模型 Claude 3 Sonnet 相当。
据介绍,Claude 3.5 Sonnet 的成本为 3 美元/百万输入 token,15 美元/百万输出 token,上下文窗口为 20 万 token。
现在,Claude 3.5 Sonnet 可在 Claude 网页版和 Claude iOS 应用程序上免费使用,而 Claude Pro 和 Team 计划的用户则可以更高的速率限制访问它,还可通过 Anthropic API、Amazon Bedrock 和 Vertex AI 使用。
Anthropic 表示,尽管 Claude 3.5 Sonnet 在智能方面有了飞跃,但红队评估认为,Claude 3.5 Sonnet 仍处于 ASL-2 级。
推荐文章: 刚刚,OpenAI最强竞对发布Claude 3.5 Sonnet,全面超越GPT-4o,重新定义交互方式
参考地址: https://www.anthropic.com/news/claude-3-5-sonnet
(91) ChatTTS v3(ChatTTS升级)
2024.06.22 ChatTTS增强版V3来啦!本次更新增加支持导入SRT、导入音色等功能。结合上次大家反馈的问题,修复了长文本、中英混读等问题。
推荐文章: ChatTTS增强版V3,长文本修复,中英混读,导入音色,批量SRT、TXT,代码开源
开源地址: https://github.com/CCmahua/ChatTTS-Enhanced
(92) 盘古大模型5.0
2024.06.22 华为开发者大会2024(HDC 2024)上,华为常务董事、华为云CEO张平安正式发布盘古大模型5.0,在全系列、多模态、强思维三个方面全新升级;张平安还分享了盘古大模型在自动驾驶、工业设计、建筑设计、具身智能、媒体生产和应用、高铁、钢铁、气象等领域的丰富创新应用和落地实践,持续深入行业解难题。
此外,华为诺亚方舟实验室主任姚骏、华为云CTO张宇昕分别就盘古大模型5.0技术解密和华为云全栈系统性创新发表主题演讲,详细解读华为云在AI领域的全栈创新优势。
全系列:盘古大模型5.0包含不同参数规格的模型,以适配不同的业务场景。十亿级参数的Pangu E系列可支撑手机、PC等端侧的智能应用;百亿级参数的Pangu P系列,适用于低时延、高效率的推理场景;千亿级参数的Pangu U系列适用于处理复杂任务;万亿级参数的Pangu S系列超级大模型能够帮助企业处理更为复杂的跨领域多任务。
多模态:盘古大模型5.0能够更好更精准地理解物理世界,包括文本、图片、视频、雷达、红外、遥感等更多模态。在图片和视频识别方面,可支持10K超高分辨率;在内容生成方面,采用业界首创的STCG(Spatio Temporal Controllable Generation,可控时空生成)技术,聚焦自动驾驶、工业制造、建筑等多个行业场景,可生成更加符合物理规律的多模态内容。
推荐文章: 【重磅】华为云盘古大模型5.0,正式发布!
开源地址: /
(93) Falcon2
2024.06.22 近年来,大型语言模型(LLM)领域蓬勃发展,不断涌现出新的模型和技术。其中,Meta 的 Llama 3 模型以其强大的性能和开源性,在业界引起了广泛关注。然而,来自阿联酋的技术创新研究所(TII)近日推出了新一代大模型 Falcon 2,其性能超越了 Llama 3,并展现出更多令人瞩目的亮点。
技术特点
- Falcon 2 模型系列包含两个版本:Falcon 2 11B 和 Falcon 2 11B VLM。两者均经过 5.5 万亿 token 的训练,但展现出不同的功能特性。
- Falcon 2 11B:高效易用,性能超越 Llama 3
- Falcon 2 11B 模型拥有 110 亿个参数,在性能上超越了 Meta 的 Llama 3 8B 模型,并与 Google 的 Gemma 7B 模型性能相当。
- Falcon 2 11B VLM:视觉语言模型,图像到文本转换
Falcon 2 11B VLM 是 TII 首个多模态模型,它具备了视觉语言模型 (VLM) 的能力,能够将视觉输入转换为文本输出。这意味着,模型不仅可以理解和生成文本,还能识别和解释图像,并将其转化为文字描述。这在图像理解、文档管理、内容生成等方面有着巨大的应用潜力。
推荐文章: Falcon2,110亿参数5.5万亿token,性能超越Llama 3
Huggingface模型地址: https://hf-mirror.com/tiiuae/falcon-11B
AI快站模型免费加速下载: https://aifasthub.com/models/tiiuae
(94) Glyph-ByT5-v2(清华、北大+微软)
2024.06.25 在 AI 领域,文生图技术已经取得了令人惊叹的进展,但如何将文字精准地融入图像,并支持多种语言,一直是研究人员面临的挑战。为了解决这一难题,清华大学、北京大学和微软亚洲研究院的研究人员合作推出了 Glyph-ByT5-v2,这是一个功能强大的定制多语言文本编码器,可以支持 10 种不同语言的精准视觉文本渲染。Glyph-ByT5-v2 的出现,为设计师、开发者以及普通用户提供了一个强大的工具,加速文生图技术的普及和应用,为更广泛的领域带来更智能、更便捷的设计体验。
技术特点
Glyph-ByT5-v2 采用了多项技术创新,使其在性能和功能上取得了重大突破:
- 多语言支持: Glyph-ByT5-v2 支持 10 种语言,包括英语、法语、西班牙语、德语、葡萄牙语、意大利语、俄语、中文、日语和韩语。为了实现这一目标,研究团队构建了包含 100 多万个字形文本对和 1000 万个图形设计图像文本对的多语言数据集,涵盖了上述 10 种语言。Glyph-ByT5-v2 的训练数据集规模远超其他多语言文生图模型,例如 AnyText 仅使用了 10,000 张图像来训练 5 种不同语言,这对于处理复杂的汉字、日文和韩文来说远远不够。
- 高质量数据集: 为了构建高质量的多语言数据集,研究人员采用了基于翻译的方法。他们首先利用图形渲染器生成了高质量的英语字形文本数据集,然后将其转换为其他语言的字形文本和图像。为了确保不同语言之间字形图像和图形设计图像的质量一致,研究人员在转换过程中保持了字符数量的接近。
- 步骤感知偏好学习: 为了提升视觉美学质量,Glyph-ByT5-v2 采用了最新的步骤感知偏好学习方法(Step-Aware Preference Optimization,SPO),对模型进行后训练优化。SPO 的核心思想是在模型训练过程中,根据人类对生成结果的偏好进行调整,从而提升模型的审美能力。研究团队发现,使用 SPO 对 SDXL 进行微调,能够显著提升生成图像的视觉美学效果。
- 区域式多头交叉注意力: Glyph-ByT5-v2 采用了区域式多头交叉注意力机制,可以更有效地将文本信息映射到图像空间中不同的位置,从而实现更精准的视觉文本渲染。它通过将图像分成多个区域,并针对不同的区域使用不同的文本编码器进行信息映射,从而提升文本渲染的精度和效率。
推荐文章: 清华、北大与微软推出Glyph-ByT5-v2,精准生成文字海报,支持10种语言,效果炸裂
Huggingface模型地址: https://huggingface.co/GlyphByT5/Glyph-SDXL-v2
AI快站模型免费加速下载: https://aifasthub.com/models/GlyphByT5
(95) LLM Leaderboard v2(大语言模型评估框架)
2024.06.26 评估和比较大语言模型 (LLMs) 是一项艰巨的任务。RLHF 团队在一年前就意识到了这一点,当时他们试图复现和比较多个已发布模型的结果。这几乎是不可能完成的任务:论文或营销发布中的得分缺乏可复现的代码,有时令人怀疑,大多数情况下只是通过优化的提示或评估设置来尽量提升模型表现。因此,他们决定创建一个地方,在完全相同的设置 (同样的问题,按相同的顺序提问等) 下评估参考模型,从而收集完全可复现和可比较的结果;Open LLM Leaderboard 就这样的背景下发布啦!
然而,随着排行榜的成功以及模型性能的不断提升,也带来了挑战。经过一年多的激烈使用和大量社区反馈后,我们认为是时候进行升级了!因此,我们推出了 Open LLM Leaderboard v2!
在过去的一年里,我们使用的基准测试已经被过度使用和饱和:
- 它们对模型来说变得太容易。例如,模型现在在 HellaSwag、MMLU 和 ARC 上达到了人类基准性能,这种现象被称为饱和。
- 一些较新的模型也表现出污染的迹象。这意味着这些模型可能在基准数据或与基准数据非常相似的数据上进行训练。因此,一些得分不再反映模型的一般性能,而是开始在某些评估数据集上过拟合,而不是反映所测试任务的一般性能。特别是 GSM8K 和 TruthfulQA,已包含在一些指令微调集中。
- 一些基准测试包含错误。例如,最近多个研究团队对 MMLU 进行了深入调查 (见MMLU-Redux和MMLU-Pro) ,发现了其响应中的错误并提出了新版本。另一个例子是 GSM8K 使用了特定的生成结束标记 (😃 ,这不公平地降低了许多冗长模型的表现。
因此,我们决定完全更换 Open LLM Leaderboard v2 的评估!
推荐文章: 更难、更好、更快、更强:LLM Leaderboard v2 现已发布
Huggingface模型地址: https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
(96) 豆包MarsCode(字节跳动智能编程助手)
2024.06.27 近日,字节跳动发布了一款基于豆包大模型打造的智能开发工具——豆包MarsCode,面向国内开发者免费开放。豆包MarsCode编程助手具备以智能代码补全为代表的AI功能,支持多种编程语言以及主流的IDE,旨在提升开发效率与质量。
智能编程助手:代码补全与问题修复
豆包Marsode的编程助手功能通过智能代码补全帮助开发者更快地编写代码。它不仅支持单行代码补全,还能对整个函数提供编写建议。这意味着,无论是简单的代码片段还是复杂的函数,开发者都可以依赖豆包MarsCode进行高效的代码编写。
Cloud IDE:随时随地编程
豆包MarsCode不仅是一个编程助手,还包括一个原生的云端集成开发环境(Cloud IDE)。这个云端IDE内置AI编程助手和开箱即用的开发环境,无需配置复杂的开发环境,让开发者在浏览器中即可进行编程和调试。支持的编程语言和模板包括C、C++、C#、Go、JavaScript、Java、Node.js、Rust、TypeScript等,极大地减少了环境配置时间。
项目问答与灵感启发
在需求开发场景中,豆包MarsCode通过Chat提问功能,帮助开发者分析需求、熟悉代码、编写代码和调试代码。智能代码补全功能不仅可以帮助开发者更快地输入代码,还能通过不断提供代码建议,激发开发者的灵感。
单元测试与多轮自动修复
为了保障代码质量,豆包MarsCode提供了测试用例生成功能。只需在编程助手中触发test指令,即可生成函数的测试用例。此外,AI修复功能可以通过理解报错信息、调用栈的代码以及全局项目代码,直接给出针对性的修复建议。
开源项目学习与代码推荐
在开源项目学习场景中,豆包MarsCode提供了丰富的开发模板,使开发者无需运维本地环境即可快速进入项目。借助原生集成的AI能力,开发者可以更高效地理解和上手项目。
推荐文章: 字节跳动推出“豆包MarsCode”智能编程助手:国内开发者免费使用
体验地址: https://www.marscode.cn/
(97) Gemma 2(Google升级Gemma)
2024.06.28 Google 发布了最新的开放大语言模型 Gemma 2,共涉及4 个开源模型 (2 个基础模型和 2 个微调模型) 。
Gemma 2 是 Google 最新的开放大语言模型。它有两种规模:90 亿参数和 270 亿参数,分别具有基础 (预训练) 和指令调优版本。Gemma 基于 Google DeepMind 的 Gemini,拥有 8K Tokens 的上下文长度。
Gemma 2 与第一代有许多相似之处。它有 8192 Tokens 的上下文长度,并使用旋转位置嵌入 (RoPE)。与原始 Gemma 相比,Gemma 2 的主要进展有四点:
- 滑动窗口注意力: 交替使用滑动窗口和全二次注意力以提高生成质量。
- Logit 软上限: 通过将 logits 缩放到固定范围来防止其过度增长,从而改进训练。
- 知识蒸馏: 利用较大的教师模型来训练较小的模型(适用于 90 亿模型)。
- 模型合并: 将两个或多个大语言模型合并成一个新的模型。
推荐文章: 开源真卷!Google开源Gemma 2大模型
模型地址: https://hf.co/collections/google/g-667d6600fd5220e7b967f315
(98) Cambrian-1(LeCun和谢赛宁团队多模态模型)
2024.06.27 近日,LeCun和谢赛宁团队推出了Cambrian-1,一项采用以视觉为中心的方法设计多模态大语言模型(MLLM)的研究,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。
谢赛宁刚刚发文表示,「世界不需要另一个MLLM与GPT-4V竞争。Cambrian在以视觉为核心的探索是独一无二的,这也是为什么,我认为是时候将重心从扩展大模型转移到增强视觉表征了」。
推荐文章: LeCun谢赛宁首发全新视觉多模态模型,等效1000张A100干翻GPT-4V
论文地址: https://arxiv.org/abs/2406.16860
开源代码: https://github.com/cambrian-mllm/cambrian
(99) 讯飞星火4.0(科大讯飞升级模型)
2024.06.27 科大讯飞正式对外发布讯飞星火大模型V4.0,以及在医疗、教育、商业等多个领域的人工智能应用。
随着新版本的发布,讯飞星火V4.0七大核心能力全面升级,在8个国际主流测试集中排名第一,整体超越GPT-4 Turbo,领先国内大模型。
刘庆峰称,当前,星火APP下载量已经达到了1.31亿,涌现出一批用户喜爱的应用助手。在星火大模型的加持下,部分场景下的智能硬件销量同比增长70%+,月均使用时次数超过4000万。
另外,星火V4.0大模型是基于全国首个国产万卡算力集群「飞星一号」训练而成,意味着完全自主可控。
推荐文章: 国产大模型新高度!讯飞星火4.0发布:整体超越GPT-4 Turbo,8个国际权威测试集测评第一
论文地址: /
开源代码: /
(100) CriticGPT(OpenAI)
2024.06.28 OpenAI在官网发布了,基于GPT-4的最新模型CriticGPT。
与以往模型不同的是,CriticGPT是一款面向开发人员的产品,可以增强RLHF(人类反馈强化学习)的效率培育出质量更好的训练数据。
所以,CriticGPT也被OpenAI称为“评论GPT”,主要用来审核ChatGPT输出的代码等内容,并解释内容到底错在哪里。例如,让ChatGPT用Python写一个函数,表示文件路径的字符串路径作为输入,并在“path”处返回文件的file对象。
ChatGPT很快就能给出完整代码,但是这段代码是有很大的安全漏洞,例如,使用“Startswitch()”检查文件的绝对路径是否在目录中非常不安全。
因为,用户可以通过符号链接或类似地命名目录来利用此漏洞。而CriticGPT就是专门用来查找这种错误。
推荐文章: OpenAI发布CriticGPT模型,帮助人类找出ChatGPT错误
论文地址: https://cdn.openai.com/llm-critics-help-catch-llm-bugs-paper.pdf
开源代码: /
(101) AIGVBench-T2V(文生视频基准测评)
2024.07.02 目前已经存在一些英文的文生视频基准,如VBench、FETV和EvalCrafter,可以用于评测英文文生视频模型的性能。然而,针对中文文生视频大模型的基准测试还比较缺乏,无法直接评估中文文生视频大模型的质量和效果。现如今,中文语境下的文生视频技术正处在快速发展的阶段,亟需建立一个专门针对中文大模型的基准测试。
为了推动视频生成领域的发展,量化视频生成模型的性能与用户体验,指导视频生成工具的落地与推广,第三方大模型测评机构SuperCLUE,推出AIGV视频生成能力测评基准AIGVBench。
其中针对于文生视频的能力评估,我们推出了中文专用的多层次文生视频基准测评AIGVBench-T2V。AIGVBench-T2V旨在通过一系列详尽的评估指标和测试数据集,全面衡量中文视频生成模型在生成质量、多样性及一致性等方面的性能。其设计融合了国际基准的架构及针对中文环境的特殊需求,旨在促进中文视频生成领域的研究、开发与技术创新。
推荐文章: AIGVBench文生视频测评首期结果公布,1000个AI视频对比,最高72.9分,Luma仅第3
排行榜地址: www.SuperCLUEai.com
官网地址: www.CLUEbenchmarks.com
AIGVBench登录页: www.AIGVBench.com
(102) Gen-3 Alpha(Runway)
2024.07.03 知名生成式AI平台Runway在其官方网站宣布推出新一代文生视频模型——Gen-3 Alpha。
Gen-3 Alpha 是由 Runway 推出的新一代视频生成模型,它在保真度、一致性、运动和速度方面都有所改进,并且能够进行精细的时间控制。以下是 Gen-3 Alpha 的主要特点和规格信息:
- 高保真度和一致性:Gen-3 Alpha 生成的视频具有更高的视觉保真度和时间一致性,能够生成表达丰富、逼真的人类角色,提供广泛的动作、手势和情绪,开启了新的叙事机会。
- 精确的关键帧设置和场景过渡:该模型在运动和连贯性方面有显著提升,支持多种高级控制模式,包括运动画笔 (Motion Brush)、高级摄像头控制 (Advanced Camera Controls) 和导演模式 (Director Mode)。
- 平台和规格信息:
- 费用:每秒10积分
- 支持时长:5秒(50积分),10秒(100积分)
- 无限计划中的探索模式:有
- 平台可用性:Web
- 支持输入:文本,图片(即将推出)
- 文本字符限制:500字符
- 支持分辨率:SD (720p)
- 支持的纵横比:16:9 (1280x768)
- 帧率 (FPS):24fps
通过这些特性和规格,Gen-3 Alpha 提供了更高质量的视频生成能力,适用于电影制作、广告、游戏等多个领域,极大地提升了创作者的创作自由度和表达能力。
推荐文章: Runway推出GEN3 Alpha模型!
(103) Step-2、Step-1.5V、Step-1X(阶跃星辰开源大模型)
2024.07.04 阶跃星辰在今年 WAIC 期间发布万亿参数 MoE 大模型 ——Step-2 正式版、千亿参数的多模态大模型 ——Step-1.5V,以及图像生成大模型 Step-1X。
Step-2 这个模型最早是在 3 月份和阶跃星辰公司一起亮相的,当时还是预览版。如今,它进化出了全面逼近 GPT-4 体感的数理逻辑、编程、中文知识、英文知识、指令跟随等能力。
有了这个模型做基础,阶跃星辰进一步训练出了多模态大模型 Step-1.5V。它不仅拥有强大的感知和视频理解能力,还能够根据图像内容进行各类高级推理,如解答数学题、编写代码、创作诗歌等。
《AI + 大闹天宫》的图像生成则是由另一个模型 ——Step-1X 来完成的。从生成结果中,我们能感觉到这个模型针对中国元素所做的深度优化。此外,它还有良好的语义对齐和指令遵循能力。
推荐文章: 揭秘:阶跃星辰万亿MoE+多模态大模型矩阵亮相
(104) InternVL 2.0 “书生·万象”(上海人工智能实验室)
2024.07.04 上海人工智能实验室的InternVL系列从视觉生根,进化为书生·万象多模态大模型。万象,代表作者对多模态大模型的愿景,即理解真实世界一切事物和景象,实现全模态全任务的通用智能。它涵盖图像,视频,文字,语音、三维点云等5种模态,首创渐进式对齐训练,实现了首个与大语言模型对齐的视觉基础模型,通过模型”从小到大”、数据”从粗到精"的渐进式的训练策略,以1/5成本完成了大模型的训练。它在有限资源下展现出卓越的性能表现,横扫国内外开源大模型,媲美国际顶尖商业模型,同时也是国内首个在MMMU(多学科问答)上突破60的模型。它在数学、图表分析、OCR等任务中表现优异,具备处理复杂多模态任务、真实世界感知方面的强大能力,是当之无愧的最强多模态开源大模型。
InternVL 2.0开源了多种指令微调的模型,参数从 2B 到 108B 不等,最大参数量的模型(pro版本)需要在官网申请api试用。
与最先进的开源多模态大语言模型相比,InternVL 2.0 超越了大多数开源模型。它在各种能力上表现出与闭源商业模型相媲美的竞争力,包括文档和图表理解、信息图表问答、场景文本理解和 OCR 任务、科学和数学问题解决,以及文化理解和综合多模态能力。
InternVL 2.0 使用 8k 上下文窗口进行训练,训练数据包含长文本、多图和视频数据,与 InternVL 1.5 相比,其处理这些类型输入的能力显著提高。
亮点
相比于InternVL 1.5,可以看出有一些改变:
- InternVL 2.0 更好地支持多轮对话、和多图输入的对话,可见训练上下文长度有所提升(8k上下文)
- 更好地支持了更多领域数据的输入(比如医疗影像分析能力),以及支持了更多模态的输入(比如视频输入)
- 多任务输出:支持数百种视觉代理任务的输出,比如更好地支持了Grounding任务(定位信息)
- 渐进式训练方法:引入了一种渐进式对齐训练策略,实现了第一个与大型语言模型原生对齐的视觉基础模型。通过采用渐进式训练策略,即模型从小规模逐渐扩展到大规模,数据从粗糙到精细逐步细化,以相对较低的成本完成了大型模型的训练。这种方法在资源有限的情况下展示了卓越的性能。
推荐文章: InternVL 2.0 “书生·万象” :探寻多模态大模型的能力边界
官方地址: https://internvl.intern-ai.org.cn/
Github: https://github.com/OpenGVLab/InternVL
Huggingface: https://huggingface.co/collections/OpenGVLab/internvl-20-667d3961ab5eb12c7ed1463e
(105) CodeGeeX4-ALL-9B(智谱AI)
2024.07.05 CodeGeeX4-ALL-9B 作为最新一代 CodeGeeX4 系列模型的开源版本,在 GLM-4 强大语言能力的基础上继续迭代,大幅增强代码生成能力。使用 CodeGeeX4-ALL-9B 单一模型,即可支持代码补全和生成、代码解释器、联网搜索、工具调用、仓库级长代码问答及生成等全面功能,覆盖了编程开发的各种场景。
CodeGeeX4-ALL-9B 在多个权威代码能力评测集,如 NaturalCodeBench、BigCodeBench 上都取得了极具竞争力的表现,是百亿参数量级以下性能最强的模型,甚至超过数倍规模的通用模型,在推理性能和模型效果上得到最佳平衡。
推荐文章: CodeGeeX第四代模型正式发布,同期开源!
GitHub: https://github.com/THUDM/CodeGeeX4
HuggingFace: https://huggingface.co/THUDM/codegeex4-all-9b
ModelScope: https://modelscope.cn/models/ZhipuAI/codegeex4-all-9b
WiseModel: https://wisemodel.cn/models/ZhipuAI/codegeex4-all-9b
(106) TTT(全新LLM架构)
2024.07.09 一种全新的大语言模型(LLM)架构有望代替至今在 AI 领域如日中天的 Transformer,性能也比 Mamba 更好。本周一,有关 Test-Time Training(TTT)的论文成为了人工智能社区热议的话题。
该研究的作者来自斯坦福大学、加州大学伯克利分校、加州大学圣迭戈分校和 Meta。他们设计了一种新架构 TTT,用机器学习模型取代了 RNN 的隐藏状态。该模型通过输入 token 的实际梯度下降来压缩上下文。
在机器学习模型中,TTT 层直接取代 Attention,并通过表达性记忆解锁线性复杂性架构,使我们能够在上下文中训练具有数百万(有时是数十亿)个 token 的 LLM。
作者在 125M 到 1.3B 参数规模的大模型上进行了一系列对比发现,TTT-Linear 和 TTT-MLP 均能匹敌或击败最强大的 Transformers 和 Mamba 架构方法。
TTT 层作为一种新的信息压缩和模型记忆机制,可以简单地直接替代 Transformer 中的自注意力层。
推荐文章: 彻底改变语言模型:全新架构TTT超越Transformer,ML模型代替RNN隐藏状态
论文链接: https://arxiv.org/abs/2407.04620
(107) Chameleon(Meta多模态模型)
2024.07.18 全球科技、社交巨头Meta发布了混合多模态模型Chameleon,一共有7B和34B两个版本。
Chameleon可以生成、处理混合多类型内容,包括文本、图片、图像字幕等。同时可以自动生成带图文的长篇内容,整体性能非常强劲。
根据多平台测试数据显示,Chameleon的性能超过了谷歌的Gemini Pro和OpenAI的GPT-4V等知名多模态模型。
传统的多模态大模型使用的分阶段处理策略,先分开独立处理图像和文本,然后在后续阶段将这些模态数据融合。这种方法虽然简单直观,却难以高效地捕捉和利用跨模态的复杂关联。
而Chameleon使用了一种创新处理方法,从一开始便将所有模态信息投影到一个共享的表示空间中。图像和文本数据被同等对待,共同参与模型的输入和处理过程,从而打破了模态之间的界限。
Chameleon的技术创新在于使用了一种“全tokens化”的表示方法将图像也转换成离散的tokens,使得图像和文本可以使用同一套Transformer架构进行处理。
推荐文章: Meta发布混合多模态模型—Chameleon
论文地址: https://arxiv.org/abs/2405.09818
模型申请地址: https://ai.meta.com/resources/models-and-libraries/chameleon-downloads/?gk_enable=chameleon_web_flow_is_live
(108) PVG(Prover-Verifier-Games)(OpenAI全新训练框架)
2024.07.18 7月18日凌晨,OpenAI在官网发布了最新技术研究——Prover-Verifier-Games。
随着ChatGPT在法律、金融、营销等领域的广泛使用,确保模型的安全、准确输出同时被很好理解变得非常重要。但由于神经网络的复杂和多变性,我们根本无法验证其生成内容的准确性,这也就会出现输出“黑盒”的情况。
为了解决这个难题,OpenAI提出了全新训练框架Prover-Verifier Games(简称“PVG”),例如,用GPT-3这样的小模型来验证、监督,GPT-4大模型的输出,从而提升输出准确率以及可控性。
推荐文章: OpenAI发布PVG:用小模型验证大模型输出,解决“黑盒”难题
论文地址: https://cdn.openai.com/prover-verifier-games-improve-legibility-of-llm-outputs/legibility.pdf
(109) GPT-4o mini(OpenAI模型更新)
2024.07.19 OpenAI 突然发布了他们的「最具性价比」的新一代模型 GPT-4o mini。据介绍,GPT-4o mini 将取代 GPT-3.5 Turbo,立即在 ChatGPT 免费上线,其在 MMLU 上的得分率为 82%,在 LMSYS 排行榜上的聊天偏好方面优于 GPT-4。
GPT-4o mini 不仅性能更优,价格也比 GPT-3.5 Turb 便宜了 60%,每百万输入 token 为 15 美分,每百万输出 token 为 60 美分。
OpenAI 在官方博客中表示,GPT-4o mini 将大大扩展人工智能(AI)应用的范围,使智能变得更加经济实惠。
GPT-4o mini 以其低成本和低延迟实现了各种任务,如连锁或并行多个模型调用(如调用多个应用程序接口)、向模型传递大量上下文(如完整代码库或对话历史)或通过快速、实时文本回复与客户交互(如客户支持聊天机器人)的应用。
目前,GPT-4o mini 的API支持文本和视觉,未来还将支持文本、图像、视频和音频输入和输出。该模型的上下文窗口可容纳 128K token,每个请求最多支持 16K 输出 token,知识期限到 2023 年 10 月。由于改进了与 GPT-4o 共享的 tokenizer,GPT-4o mini 处理非英语文本更加经济高效。
推荐文章: OpenAI凌晨突发「最具性价比」模型 GPT-4o mini,GPT-3.5 Turbo 已成过去式
(110) Still-Moving(DeepMind文生视频模型定制通用框架)
2024.07.20 来自 Google DeepMind 的研究团队及其合作者,提出了一个新型文生视频(T2V)模型定制通用框架——Still-Moving,其无需任何定制化视频数据。该框架适用于一种显著的 T2V 设计,即视频模型建立在 T2I 模型之上。团队假设可以访问一个仅在静态图像数据上训练的定制化 T2I 模型(例如,使用 DreamBooth 或 StyleDrop)。直接将定制化 T2I 模型的权重插入 T2V 模型中,通常会导致显著的伪影或对定制化数据的不足遵循。
为了克服这个问题,团队训练了轻量级的空间适配器,以调整由注入的 T2I 层生成的特征。重要的是,团队的适配器是在“冻结视频”(即重复图像)上训练的,这些冻结视频是从定制化 T2I 模型生成的图像样本构建的。这个训练过程由一个新颖的运动适配器模块支持,允许他们在这种静态视频上训练,同时保留视频模型的运动先验。在测试时,研究团队去除运动适配器模块,只保留训练好的空间适配器。这恢复了 T2V 模型的运动先验,同时遵循定制化 T2I 模型的空间先验。
研究团队在个性化、风格化和条件生成等多种任务上展示了他们方法的有效性。在所有评估的场景中,研究团队的方法无缝地将定制化 T2I 模型的空间先验与由 T2V 模型提供的运动先验结合起来。
推荐文章: Google DeepMind 推出文生视频模型定制通用框架 Still-Moving
论文链接: https://arxiv.org/abs/2407.08674
项目地址: https://still-moving.github.io/
(111) DCLM-7B(苹果开源LLM)
2024.07.21 苹果开源了一个全新的语言模型训练数据集 DCLM-BASELINE 和训练框架 DCLM,推动高效 LLM 训练!
• DCLM-BASELINE 在 MMLU 基准测试中达到了 64% 的准确率,超越了所有开源数据集,甚至接近了闭源模型。
• DCLM 框架提供了标准化的语料库 DCLM-Pool、高效的预训练方法以及 53 个下游任务的评估套件,帮助研究者系统化地探索数据 curation 策略。
• 研究发现,严格的数据过滤比单纯增加数据量更重要,基于模型的过滤是有效数据 curation 的关键。
• DCLM 还揭示了人工质量判断的局限性,表明基于模型的过滤更有效。
推荐文章: 苹果开源70亿参数语言模型DCLM-7B,数据集与训练框架同步开放!
官网地址: https://datacomp.ai/dclm/
HuggingFace模型地址: https://huggingface.co/apple/DCLM-7B
论文地址: https://arxiv.org/abs/2406.11794
(112) Mobile-Agent-v2(阿里巴巴魔搭团队)
2024.07.22 Mobile-Agent于今年年初发布,凭借强劲的自动化手机操作能力迅速在AI领域和手机制造商中引起广泛关注。短短五个月内,它已经在Github获得了2,000个Star。该系统采用纯视觉方案,通过视觉感知工具和操作工具完成智能体在手机上的操作,无需依赖任何系统级别的UI文件。得益于这种智能体中枢模型的强大,Mobile-Agent实现了即插即用,无需进行额外的训练和探索。近日,团队推出了新版本Mobile-Agent-v2,并列举了几大改进亮点:继续采用纯视觉方案、多智能体协作架构、增强的任务拆解能力、跨应用操作能力以及多语言支持。
作者团队在社交媒体和Github发布了一系列展示Mobile-Agent-v2在手机上实操的视频。下面的视频中展示了一个跨应用操作的实例。首先,用户需要Mobile-Agent-v2查看聊天软件中的未读消息并执行相关任务。Mobile-Agent-v2根据指令先打开了WhatsApp,查看了来自 “Ao Li” 的消息。消息内容要求在TikTok上找到一个与宠物相关的视频并分享。于是,Mobile-Agent-v2退出WhatsApp,进入TikTok开始浏览视频。在发现一个宠物猫的视频后,它点击分享按钮,将视频链接发送给了 “Ao Li”。
推荐文章: 全新Mobile-Agent-v2发布,自动化手机操作助手全面升级!
论文: https://arxiv.org/abs/2406.01014
代码: https://github.com/X-PLUG/MobileAgent
(113) Llama 3.1 405B(Meta)
2024.07.23 Llama 3.1又被提前泄露了!开发者社区再次陷入狂欢:最大模型是405B,8B和70B模型也同时升级,模型大小约820GB。除了最大的405B,Meta这次还升级了5月初发布的8B和70B模型,并将上下文长度全部提升到了128K。至此,模型版本也正式从Llama 3迭代到了Llama 3.1。
HyperWriteAI CEO Matt Schumer预言:它定将成为开源模型中的SOTA。(连70B都能和GPT-4o掰手腕,何况这还是在指令微调之前。)想象一下,一个GPT-4o级别的模型,以每秒330个token的速度运行,价格还要便宜10倍。这简直太令人兴奋了。
推荐文章: Llama 3.1磁力链提前泄露!开源模型王座一夜易主,GPT-4o被超越
论文: https://arxiv.org/abs/2406.01014
代码: https://github.com/X-PLUG/MobileAgent
(114) Mistral Large 2 123B(决战Llama3.1)
2024.07.25 紧跟着Meta的重磅发布,Mistral Large 2也带着权重一起上新了,而且参数量仅为Llama 3.1 405B的三分之一。不仅在编码、数学和多语言等专业领域可与SOTA模型直接竞争,还支持单节点部署。
Mistral Large 2在代码生成、数学和推理等方面的能力明显增强,可以与GPT-4o和Llama 3.1一较高下。
而且,模型参数量仅有123B,不到Llama 3.1 405B的三分之一,完全可以在单个节点上以大吞吐量运行。
成本效率、速度和性能的「三角形战士」,Mistral Large当之无愧——
和GPT-4o比,它开源;和Llama 3.1 450B比,它参数少;和Llama 3 70B比,它性能好。
推荐文章: Mistral新旗舰决战Llama 3.1!最强开源Large 2 123B,扛鼎多语言编程全能王
模型地址:
https://mistral.ai/news/mistral-large-2407/
https://techcrunch.com/2024/07/24/mistral-releases-large-2-meta-openai-ai-models/
https://venturebeat.com/ai/mistral-shocks-with-new-open-model-mistral-large-2-taking-on-llama-3-1/
(115) CogVideoX(智谱视频生成模型)
2024.07.26 智谱对视频生成模型进行全新升级,并正式推出新一代产品——CogVideoX。
CogVideoX的核心技术特点如下:
- 针对内容连贯性问题,智谱AI自主研发了一套高效的三维变分自编码器结构(3D VAE)。该结构能够将原始视频数据压缩至原始大小的2%,显著降低了视频扩散生成模型的训练成本和难度。结合3D RoPE位置编码模块,该技术有效提升了在时间维度上对帧间关系的捕捉能力,从而建立了视频中的长期依赖关系。
- 在可控性方面,智谱AI打造了一款端到端的视频理解模型,该模型能够为大量视频数据生成精确且内容相关的描述。这一创新增强了模型对文本的理解和对指令的遵循能力,确保生成的视频更加符合用户的输入需求,并能够处理超长且复杂的prompt指令。
- 我们的模型采纳了一种将文本、时间、空间三维一体融合的transformer架构。该架构摒弃了传统的cross attention模块,创新性地设计了Expert Block以实现文本与视频两种不同模态空间的对齐,并通过Full Attention机制优化模态间的交互效果。
- CogVideoX 模型目前已在智谱清言的PC端、移动应用端以及小程序端正式上线。所有C端用户均可通过智谱清言的AI视频生成功能「清影」(Ying),免费体验AI文本生成视频和图像生成视频的服务。
推荐文章: 人人可用,智谱 AI 推出新一代视频生成模型 CogVideoX
体验地址: https://chatglm.cn/video
(116) FLUX.1(文生图多模态模型)
2024.08.02 昨天Midjourney刚进行大更新,今天文生图片开源领域就杀出了一匹大黑马—FLUX.1。
根据其测试数据显示,性能大幅度超过了DALL·E-3、Midjourney V6闭源模型,开源SD3系列的Ultra、Medium、Turbo和SDXL被全线秒杀。
并且FLUX.1表示,文生图只是一个开始,未来还会推出文生视频模型想和Sora、Gen-3、Luma等一线产品过过招。
FLUX.1的基础架构是基于Vision Transformer,使用了流程匹配训练方法,同时使用了旋转位置嵌入和并行注意层来提高模型的性能和硬件利用效率。
FLUX.1有120亿参数,本次一共发布了三个版本:1)Pro版,通过API使用;2)dev版,这是一个非商用的指导蒸馏模型,继承了Pro版多数性能;3)schnell版,可以商用的开源模型。
虽然FLUX.1有三个版本,但在文本语义还原、图片质量、动作一致性/连贯性、多样性等方面超过了Midjourney v6.0、DALL·E 3 、SD3-Ultra等主流开闭源模型,整体性能非常强劲。此外,在文本嵌入图片方面也比这些模型表现的更好。
推荐文章: 性能秒杀SD3、DALL·E-3,开源文生图模型杀出大黑马
Github地址: https://github.com/black-forest-labs/flux
在线demo: https://replicate.com/black-forest-labs/flux-pro
(117) SAM 2(Meta SAM升级)
2024.08.02 Meta 在 SIGGRAPH 上重磅宣布 Segment Anything Model 2 (SAM 2) 来了。在其前身的基础上,SAM 2 的诞生代表了领域内的一次重大进步 —— 为静态图像和动态视频内容提供实时、可提示的对象分割,将图像和视频分割功能统一到一个强大的系统中。
Meta 多次强调了最新模型 SAM 2 是首个用于实时、可提示的图像和视频对象分割的统一模型,它使视频分割体验发生了重大变化,并可在图像和视频应用程序中无缝使用。SAM 2 在图像分割准确率方面超越了之前的功能,并且实现了比现有工作更好的视频分割性能,同时所需的交互时间为原来的 1/3。
该模型的架构采用创新的流式内存(streaming memory)设计,使其能够按顺序处理视频帧。这种方法使 SAM 2 特别适合实时应用,为各个行业开辟了新的可能性。
当然,处理视频对算力的要求要高得多。SAM 2 仍然是一个庞大的模型,也只有像 Meta 这样的能提供强大硬件的巨头才能运行,但这种进步还是说明了一些问题:一年前,这种快速、灵活的分割几乎是不可能的。SAM 2 可以在不借助数据中心的情况下运行,证明了整个行业在计算效率方面的进步。
模型需要大量的数据来训练,Meta 还发布了一个大型带注释数据库,包括大约 51,000 个真实世界视频和超过 600,000 个 masklets。与现有最大的视频分割数据集相比,其视频数量多 4.5 倍,注释多 53 倍,Meta 根据 CC BY 4.0 许可分享 SA-V。在 SAM 2 的论文中,另一个包含超过 100,000 个「内部可用」视频的数据库也用于训练,但没有公开。
与 SAM 一样,SAM 2 也会开源并免费使用,并在 Amazon SageMaker 等平台上托管。为了履行对开源 AI 的承诺,Meta 使用宽松的 Apache 2.0 协议共享代码和模型权重,并根据 BSD-3 许可分享 SAM 2 评估代码。
推荐文章: 刚刚,Meta开源「分割一切」2.0模型,视频也能分割了
官方地址: https://ai.meta.com/blog/segment-anything-2-video/
在线demo: https://sam2.metademolab.com/demo
(118) Qwen2-Audio(阿里巴巴 最新语音模型)
2024.08.10 阿里巴巴在Qwen-Audio基础之上,开源了最新语音模型Qwen2-Audio。
Qwen2-Audio一共有基础和指令微调两个版本,支持使用语音向音频模型进行提问并识别内容以及语音分析。
例如,让一位女生说一段话,然后识别她的年纪或解读她的心情;发布一段吵闹的声音,分析有哪些声音组成等。
目前,Qwen2-Audio支持中文、粤语、法语、英语、日语等主流语言和方言,这对于开发翻译、情感分析等应用非常方便。
与第一代Qwen-Audio相比,Qwen2-Audio在架构、性能等方面进行了大幅度优化和改进。在预训练阶段Qwen2-Audio采用了自然语言提示,替代了Qwen-Audio使用的复杂分层标签系统。
这一改变简化了模型的训练过程,使得模型能够更自然地理解和响应各种数据和任务,提高了模型的泛化能力能更好地理解和执行各种指令。
Qwen2 - Audio在指令跟随能力方面有了显著提升,通过增加指令调优和直接偏好优化等方法,可更准确地理解用户的指令,并根据指令提供更恰当的响应。
推荐文章: 阿里开源新语音模型,比OpenAI的Whisper更好!
Github地址: https://github.com/QwenLM/Qwen2-Audio
(119) Tora(阿里巴巴 视频生成模型)
2024.08.10 视频生成模型最近取得了显著进展,例如,OpenAI 的 Sora 和国内的Vidu、可灵等模型,通过利用 Diffusion Transformer 的扩展特性,不仅能够满足各种分辨率、尺寸和时长的预测要求,同时生成的视频更符合物理世界的表现。视频生成技术需要在一系列图像中创造一致的运动,这凸显了运动控制的重要性。
当前已有一些优秀的方法如 DragNUWA 和 MotionCtrl 已经实现了轨迹可控的视频生成,但这些方法受限于传统 U-Net 去噪模型,大多只能生成 16 帧长度、固定低分辨率的视频,难以应对长距离轨迹。此外,如果轨迹过于不规则或存在偏移过大等情况,这些方法十分容易出现运动模糊、外观失真和不自然的运动如漂移闪现等。
为了解决这些问题,阿里云提出了一种基于 DiT 架构的轨迹可控视频生成模型 Tora。Tora能够根据任意数量的物体轨迹,图像和文本条件生成不同分辨率和时长的视频,在720p分辨率下能够生成长达204 帧的稳定运动视频。值得注意的是,Tora继承了DiT的scaling特性,生成的运动模式更流畅,更符合物理世界。
推荐文章: 阿里发布轨迹可控的DiT视频生成模型—Tora
论文地址: https://arxiv.org/abs/2407.21705
项目地址: https://ali-videoai.github.io/tora_video/
(120) Qwen2-Math(阿里巴巴 专业数学语言模型)
2024.08.09 阿里巴巴开源了Qwen2_Math专注数学能力的的大模型。据官方技术博客介绍,本次开源包括Qwen2-Math和Qwen2-Math-Instruct-1.5B/7B/72B。Qwen2-Math是基于Qwen2大型语言模型构建的一系列专业数学语言模型,其数学能力显著优于开源模型甚至闭源模型(例如GPT-4o)
在一系列数学基准测试上评估了QWen2_Math的性能。如下面的结果表明,数学专用模型Qwen2-Math-72B-Instruct超过了包括GPT-4o、Claude-3.5-Sonnet、Gemini-1.5-Pro和Llama-3.1-405B在内的最先进模型。
三个广泛使用的英语数学基准测试GSM8K、Math和MMLU-STEM上评估了Qwen2-Math基础模型。此外,还评估了三个中文数学基准测试CMath、高考数学填空和高考数学问答。所有评估都通过少量样本的思考链提示进行测试。
推荐文章: 阿里重磅开源Qwen2_Math! 实操利用onnxocr+Qwen2_Math打造【AI数学老师助手】来给小孩辅导数学作业!
模型地址: https://hf-mirror.com/Qwen/Qwen2-Math-7B-Instruct
技术博客地址: https://qwenlm.github.io/blog/qwen2-math/
(121) Falcon Mamba 7B(纯Mamba架构的大模型)
2024.08.13 阿联酋技术创新研究(简称“TII”)开源了全球第一个纯Mamba架构的大模型——Falcon Mamba 7B。
根据评测数据显示,Falcon Mamba 7B的性能已经超过了Meta最新开源的Llama 3.1-8B、Mistral-7B等知名开源模型。
在处理序列时,传统的Transformer模型在生成下一个令牌时需要关注上下文中所有先前的令牌的键和值,这导致内存需求和生成时间随着上下文长度的增加而线性增长。
而像Falcon Mamba这样的状态空间语言模型,只关注和存储其循环状态,因此在生成大序列时不需要额外的内存或时间在处理长序列方面拥有很强的技术优势。
Mamba模型采用了编码器-解码器结构,编码器负责处理输入的文本,而解码器则生成输出文本。这种结构特别适合文本生成任务,因为它能够有效地将输入信息转化为流畅的输出文本。此外,Mamba模型还使用了多头注意力技术,使得它能够同时关注输入序列的不同部分,捕捉不同层次的信息。
推荐文章: TII开源第一个纯Mamba架构大模型,超过Llam3.1
开源地址: https://huggingface.co/tiiuae/falcon-mamba-7b
(122) Gemini Live(谷歌对标GPT-4o)
2024.08.14 谷歌在今天凌晨举办的“Made by Google 2024”大会上,正式发布了智能语音助手Gemini Live。
Gemini Live的功能与OpenAI在5月推出的GPT-4o语音模式类似,支持自然语言提问,能识别图像、视频和语音是一个多模态智能助手。
例如,打开Gemini Live拍摄一幅清明上河图,然后让其讲解这幅画的历史来历。在讲解的过程中,可以任意打断其对话就像朋友聊天一样。
也可以授权Gemini Live访问你的邮箱、地图和通讯录,只需要向它说”今晚8点,帮我约阿乐去有福气酒楼吃饭。”就能帮你自动完成,基本上和钢铁侠的AI助理贾维斯差不多。
Gemini Live的使用方法非常简单,长按电源按钮或对着手机直接说“Hey Google”就能开始使用。
Gemini Live除了能理解语音、图片、视频之外,还能生成图片,例如,帮我生成一张用于生日庆祝的图片,并且可以直接放在谷歌生态应用中使用。
推荐文章: 谷歌发布Gemini Live:对标GPT-4o,让每一个人都有贾维斯
开源地址: /
(123) Exaone 3.0(LG开源大模型)
2024.08.14 LG的AI研究机构开源了首个开放权重的大模型——EXAONE 3.0。
EXAONE 3.0是一个指令微调模型有78亿参数,经过了8万亿token高质量数据进行了综合训练。支持韩语和英文两种语言,尤其是对韩语的支持非常出色。
在KMMLU、KoBEST - BoolQ、KoBEST – COPA等基准测试中,高于Llama 3.1-8B、Gemma 2-9B等知名开源模型。
EXAONE 3.0使用了目前主流的解码器仅变换器架构,与传统变换器相比,摒弃了编码器部分,专注于通过解码器生成输出序列,减少了模型的复杂性,同时提高了处理长距离依赖关系的能力。
在上下文长度方面,EXAONE 3.0支持4,096 token,使得模型能够同时处理和记忆高达4,096个连续token的信息,极大地增强了其在理解语言连贯性方面的能力,在生成文本、翻译、摘要等提供了更好的生成、解读能力。
推荐文章: LG开源韩语大模型Exaone 3.0,8万亿token训练数据
开源地址: https://huggingface.co/LGAI-EXAONE/EXAONE-3.0-7.8B-Instruct
论文地址: https://arxiv.org/abs/2408.03541
(124) Nemotron-4-Minitron(Nvidia LLM)
2024.08.16 全球AI领导者英伟达(Nvidia)开源了最新大模型Nemotron-4-Minitron-4B和Nemotron-4-Minitron-8B。
据悉这两个模型是基于Meta开源的Llama-3.1 8B,但英伟达使用了两种高效的训练方法结构化剪枝和知识蒸馏。
相比从头训练,每个额外模型所需的训练token数据更少,仅需大约1000亿token,最多减少40倍,算力成本可节省1.8倍。性能却依然媲美Llama-3.1 8B、Mistral 7B、Gemma 7B等知名模型,而这些模型是在高达15万亿token数据训练而成。
推荐文章: 英伟达开源新大模型:训练数据减少40倍,算力节省1.8倍
模型地址:
4B开源地址:https://huggingface.co/nvidia/Nemotron-4-Minitron-4B-Base
8B开源地址:https://huggingface.co/nvidia/Nemotron-4-Minitron-8B-Base
(125) VITA(腾讯优图多模态大模型)
2024.08.16 GPT-4o 的卓越多模态能力和用户交互体验在实际应用中非常重要,但没有开源模型在这两个领域同时表现出色。本文介绍了 VITA,这是首个能够同时处理和分析视频、图像、文本和音频模态的开源多模态大语言模型(MLLM),并且具备先进的多模态交互体验。腾讯优图实验室在以下三个关键特性,与现有的开源 MLLM 有所区分:
- 全方位多模态理解能力:VITA 展示了强大的多语言、视觉和音频理解基础能力,并在多种单模态和多模态基准测试中表现优异。
- 非唤醒交互:VITA 可以在不需要唤醒词或按钮的情况下被激活,并对环境中的用户音频问题做出响应。
- 音频打断交互:VITA 能够实时跟踪和筛选外部查询,允许用户随时以新问题打断模型的生成,VITA 将根据新的查询做出相应的响应。
推荐文章: 腾讯优图开源多模态大模型VITA : GPT-4o的简易平替!
论文地址: https://arxiv.org/pdf/2408.05211
Demo地址: https://vita-home.github.io/
开源地址: https://github.com/VITA-MLLM/VITA
(126) mPLUG-Owl3(阿里巴巴多模态大模型)
2024.08.19 阿里的mPLUG系列在多模态大模型领域产出了多项研究工作。从mPLUG-Owl初代模型引入了视觉对齐-语言模型微调的训练模式,到mPLUG-Owl2通过模块化的模态自适应解决模态拉扯,再到mPLUG-DocOwl通过切图建模高分辨率。这一系列模型一直在探索更为高效有效的多模态大语言模型。
尽管近年包括mPLUG-Owl在内的主流多模态大模型在多种单图任务上取得了一系列进展,当前对于多模态大模型来说,多图长序列输入仍然是一个极具挑战性的场景。如图所示的多模态多轮对话、多模态RAG、长视频理解等实际应用,就对模型的多图长序列理解能力提出了很高的要求。
现有的支持多图输入的工作,主要存在两个方面的缺陷:LLaVA-Next-Interleave等工作直接将视觉特征与文本序列拼接,在多图长序列输入时会带来很高的推理成本;Flamingo等使用的cross-attention结构,虽然降低了计算成本,但造成了细粒度视觉信息的损失,限制了其在单图和多图场景的性能。
针对上述问题,阿里通义实验室的研究人员提出通用多模态大模型mPLUG-Owl3,该模型能够在支持多图长序列输入的同时,兼顾性能和效率。为实现这一点,作者提出轻量级的hyper attention模块,实现视觉和语言信息的高效自适应融合。与相似参数规模的模型相比,mPLUG-Owl3在单图、多图、视频等多达14个benchmark上表现出SOTA性能
推荐文章: 阿里开源通用多模态大模型mPLUG-Owl3:迈向多图长序列理解
论文名称: mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
论文地址: https://arxiv.org/pdf/2408.04840
开源地址:
GitHub: https://github.com/X-PLUG/mPLUG-Owl/
HF:https://huggingface.co/spaces/mPLUG/mPLUG-Owl3
魔搭:https://modelscope.cn/studios/iic/mPLUG-Owl3
(127) ADAS(自动化设计智能体系统)
2024.08.20 Agent智能体系统正在作为通用工具被广泛研究和应用,解决复杂问题通常需要由多个组件组成的复合智能体系统,而手工设计的解决方案最终会被学习到的更高效的解决方案所取代。
为此,提出了自动化设计智能体系统(ADAS:Automated Design of Agentic Systems,已开源)的新研究领域,目标是自动创建强大的智能体系统设计。
通过代码定义整个智能体系统,并由一个“元Agent”自动发现新的智能体,理论上允许ADAS算法发现任何可能的构建块和智能体系统。
自动化设计智能体系统(Automated Design of Agentic Systems):
ADAS的定义和目标
ADAS旨在自动发明新的构建块,并设计功能强大的智能体系统。智能体系统涉及使用基础模型(Foundation Models,简称FMs)作为模块,通过规划、使用工具和执行多步骤的迭代处理来完成任务。
ADAS的三个关键组成部分
自动化智能体系统设计(ADAS)的三个关键组成部分。搜索空间决定了ADAS中可以表示哪些Agent系统。搜索算法指定了ADAS方法如何探索搜索空间。评估函数定义了如何根据目标目标(如性能)评估候选Agent。
- 搜索空间(Search Space):定义了ADAS中可以表示哪些智能体系统。例如,一些研究只变异智能体的文本提示,而其他组件(如控制流)保持不变。
- 搜索算法(Search Algorithm):指定了ADAS方法如何探索搜索空间。由于搜索空间通常非常大甚至无界,需要考虑探索与利用的权衡。
- 评估函数(Evaluation Function):根据ADAS算法的应用,可能考虑不同的目标来优化,如性能、成本、延迟或智能体的安全性。评估函数定义了如何在这些目标上评估候选智能体。
推荐文章: 极限套娃,Agent自动设计Agentic系统!
论文地址: https://arxiv.org/pdf/2408.08435
开源地址: https://github.com/ShengranHu/ADAS
(128) Phi-3.5(微软小型LLM)
2024.08.21 微软继今年4月推出Phi-3系列小型语言模型后,又一鼓作气三连发布并开源其「小而美」系列 Phi-3.5模型!
本次发布的三个模型各有特色:
Mini型:Phi-3.5-mini-instruct(3.8B)
Phi-3.5 mini 具有 38 亿个参数,基于Phi-3 的数据集(合成数据和经过筛选的公开网站)构建,重点关注高质量、推理密集的数据。该模型属于 Phi-3 模型系列,支持 128K 令牌上下文长度。该模型经过了严格的增强过程,结合了监督微调、近端策略优化和直接偏好优化,以确保精确遵守指令和强大的安全措施。Phi-3.5 mini 在中文场景有所增强,但是受限于模型的大小,依然会有较多的事实错误,通过RAG的方式可以有效降低错误。
MoE型:Phi-3.5-MoE-instruct (16x3.8B)
Phi-3.5-MoE-instruct是一个MoE模型,有 16x3.8B 个参数,使用 2 位专家时有 6.6B 个活动参数。该模型使用词汇量为 32,064 的标记器。Phi-3.5-MoE-instruct在推理能力上大大增强(尤其是数学和逻辑),也非常适用于function call的场景。
多模态:Phi-3.5-vision-instruct (4.2B)
Phi-3.5-vision-instruct 多模态版本可支持 128K 上下文长度(以 token 为单位)有 4.2B 参数,主要包含图像编码器和 Phi-3 Mini 语言模型。本次Phi-3.5-vision-instruct 支持多图理解,在如下场景上有较好的效果:
- 一般图像理解;
- 光学字符识别 (OCR)
- 图表和表格理解;
- 多幅图像比较;
- 多图像或视频片段摘要
推荐文章: 多图理解,更懂中文,支持function call的Phi-3.5来了!
模型地址:
- Phi-3.5-mini-instruct:https://modelscope.cn/models/LLM-Research/Phi-3.5-mini-instruct
- Phi-3.5-MoE-instruct:https://modelscope.cn/models/LLM-Research/Phi-3.5-MoE-instruct
- Phi-3.5-vision-instruct :https://modelscope.cn/models/LLM-Research/Phi-3.5-vision-instruct
- Phi-3.5-mini-instruct-GGUF:https://modelscope.cn/models/LLM-Research/Phi-3.5-mini-instruct-GGUF
开源地址: https://github.com/microsoft/Phi-3CookBook
(129) Transfusion(Meta多模态架构-Diffusion+Transformer)
2024.08.24 Meta最新发布的Transfusion,能够训练生成文本和图像的统一模型了!完美融合Transformer和扩散领域之后,语言模型和图像大一统,又近了一步。也就是说,真正的多模态AI模型,可能很快就要来了!
Transformer和Diffusion,终于有了一次出色的融合。
自此,语言模型和图像生成大一统的时代,也就不远了!
这背后,正是Meta最近发布的Transfusion——一种训练能够生成文本和图像模型的统一方法。
推荐文章: 图像语言模型大一统!Meta新作Transfusion:将扩散和Transformer融合,多模态AI王者登场!
论文地址: https://arxiv.org/abs/2408.11039
(130) Jamba-1.5(Transformer-Mamba)
2024.08.27 Jamba-1.5,基于Jamba架构的新型指令调优大型语言模型。Jamba是一种混合Transformer-Mamba专家混合架构,能够在不同上下文长度下提供高吞吐量和低内存使用,同时保持与Transformer模型相同或更好的质量。
论文发布了两种模型尺寸:Jamba-1.5-Large,具有940亿活跃参数,以及Jamba-1.5-Mini,具有120亿活跃参数。这两种模型都针对多种对话和指令遵循能力进行了微调,并且具有256Ktoken的有效上下文长度,是开放权重模型中最大的。
为了支持成本效益高的推理,论文引入了ExpertsInt8,一种新颖的量化技术,允许在处理256K token上下文时,将Jamba-1.5-Large适配到具有8张80GB GPU的机器上,而不损失质量。在学术和聊天机器人基准测试中评估时,Jamba模型取得了优异的成绩,同时提供了高吞吐量,并在长上下文基准测试中超越了其他开放权重模型。
推荐文章: Jamba-1.5:大规模混合Transformer-Mamba模型
论文链接: https://arxiv.org/pdf/2408.12570
模型地址: https://huggingface.co/ai21labs
(131) Qwen2-VL(阿里对标GPT-4o)
2024.08.30 阿里巴巴开源了最新视觉多模态模型Qwen2-VL,根据测试数据显示,其72B模型在大部分指标超过了OpenAI的GPT-4o,Anthropic的Claude3.5-Sonnet等著名闭源模型,成为目前最强多模态模型之一。
Qwen2-VL支持中文、英文、日文、韩文等众多语言,可以在 Apache 2.0 协议下进行商业化使用。同时阿里发布了 Qwen2-VL-72B的API,帮助开发者增强或开发多模态功能的生成式AI应用。
Qwen2-VL是基于Qwen2开发而成,相比第一代Qwen-VL有以下特色功能。
可理解20分钟以上的长视频:Qwen2-VL 可理解长视频,并将其用于基于视频的问答、对话和内容创作等应用中。
例如,对于一部长达两个小时的纪录片,用户询问其中某个特定历史事件的具体时间和背景,Qwen2-VL 可以快速检索视频内容,从复杂的影像和解说中提取出关键信息,为用户提供详细准确的回答。
- Qwen2-VL还可以根据长视频的内容进行故事续写、影评撰写或者创意改编。例如,一个 30 分钟的科普长视频,Qwen2-VL 可以提取其中的核心知识,创作出一篇通俗易懂的科普文章,或者以视频中的某个情节为灵感构思出一部全新的小说。
- 可操作手机和机器人的视觉智能体:借助复杂推理和决策的能力,Qwen2-VL 可集成到手机、机器人等设备,根据视觉环境和文字指令进行自动操作。
- 能读懂不同分辨率和不同长宽比的图片:Qwen2-VL 在 MathVista、DocVQA、RealWorldQA、MTVQA等视觉理解基准测试中取得了全球领先的表现。
- 性能评估方面,阿里从大学题目、数学、文档表格多语言文字图像的理解、通用场景下的问答、视频理解、Agent进行了综合测试。
推荐文章: 阿里重磅开源Qwen2-VL:能理解超20分钟视频,媲美GPT-4o!
开源地址:
https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
https://github.com/QwenLM/Qwen2-VL
在线demo: https://huggingface.co/spaces/Qwen/Qwen2-VL
API: https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api
(132) GLM-4-Plus(智谱AI)
2024.08.29 智谱AI 在 KDD 2024 现场,重磅推出了新一代全自研基座大模型 GLM-4-Plus、图像/视频理解模型 GLM-4V-Plus 和文生图模型 CogView-3-Plus,继续瞄准通用人工智能(AGI)。
模型主要亮点如下:
- 语言基座模型 GLM-4-Plus:在语言理解、指令遵循、长文本处理等方面性能得到全面提升,保持了国际领先水平。
- 文生图模型 CogView-3-Plus:具备与当前最优的 MJ-V6 和 FLUX 等模型接近的性能。
- 图像/视频理解模型 GLM-4V-Plus:具备卓越的图像理解能力,并具备基于时间感知的视频理解能力。该模型将上线智谱大模型开放平台(bigmodel.cn),成为国内首个通用视频理解模型 API。
据介绍,GLM-4-Plus 使用了大量模型辅助构造高质量合成数据以提升模型性能;利用 PPO 有效有效提升模型推理(数学、代码算法题等)表现,更好地反映人类偏好。
在语言文本能力方面,GLM-4-Plus 和 GPT-4o 及 Llama 3.1 405B 相当。