处理文本数据
我们讨论过表示数据属性的两种类型的特征:连续特征与分类特征,前者用于描述数量,后者是固定列表中的元素。在许多应用中还可以见到第三种类型的特征:文本。举个例子,如果我们想要判断一封电子邮件是合法邮件还是垃圾邮件,那么邮件内容一定会包含对这个分类任务非常重要的信息。或者,我们可能想要了解一位政治家对移民 问题的看法。这个人的演讲或推文可能会提供有用的信息。在客户服务中,我们通常想知 道一条消息是投诉还是咨询。我们可以利用消息的主题和内容来自动判断客户的目的,从而将消息发送给相关部门,甚至可以发送一封全自动回复。
文本数据通常被表示为由字符组成的字符串。在上面给出的所有例子中,文本数据的长度都不相同。这个特征显然与前面讨论过的数值特征有很大不同,我们需要先处理数据,然后才能对其应用机器学习算法。
1、用字符串表示的数据类型
在深入研究表示机器学习文本数据的处理步骤之前,我们希望简要讨论你可能会遇到的不同类型的文本数据。文本通常只是数据集中的字符串,但并非所有的字符串特征都应该被当作文本来处理。字符串特征有时可以表示分类变量。在查看数据之前,我们无法知道如何处理一个字符串特征。
你可能会遇到四种类型的字符串数据:
- 分类数据
- 可以在语义上映射为类别的自由字符串
- 结构化字符串数据
- 文本数据
分类数据(categorical data)是来自固定列表的数据。比如你通过调查人们最喜欢的颜色来收集数据,你向他们提供了一个下拉菜单,可以从 “红色” “绿色” “蓝色” “黄色” “黑色” “白色” “紫色” 和 “粉色” 中选择。这样会得到一个包含 8 个不同取值的数据集, 这 8 个不同取值表示的显然是分类变量。你可以通过观察来判断你的数据是不是分类数据(如果你看到了许多不同的字符串,那么不太可能是分类变量),并通过计算数据集中的唯一值并绘制其出现次数的直方图来验证你的判断。你可能还希望检查每个变量是否实际对应于一个在应用中有意义的分类。调查过程进行到一半,有人可能发现调查问卷中将 “black”(黑色)错拼为 “blak”,并随后对其进行了修改。因此,你的数据集中同时包含 “black” 和 “blak”,它们对应于相同的语义,所以应该将二者合并。
现在想象一下,你向用户提供的不是一个下拉菜单,而是一个文本框,让他们填写自己最喜欢的颜色。许多人的回答可能是像 “黑色” 或 “蓝色” 之类的颜色名称。其他人可能会出现笔误,使用不同的单词拼写(比如 “gray” 和 “grey” ),或使用更加形象的具体名称 (比如 “午夜蓝色”)。你还会得到一些非常奇怪的条目。xkcd 颜色调查(https://blog.xkcd. com/2010/05/03/color-survey-results/)中有一些很好的例子,其中有人为颜色命名,给出 了如 “迅猛龙泄殖腔” 和 “我牙医办公室的橙色“。”我仍然记得他的头皮屑慢慢地漂落到我张开的下巴” 之类的名称,很难将这些名称与颜色自动对应(或者根本就无法对应)。从文本框中得到的回答属于上述列表中的第二类,可以在语义上映射为类别的自由字符串 (free strings that can be semantically mapped to categories)。可能最好将这种数据编码为分类变量,你可以利用最常见的条目来选择类别,也可以自定义类别,使用户回答对应用有意义。这样你可能会有一些标准颜色的类别,可能还有一个 “多色” 类别(对于像 “绿色与红色条纹” 之类的回答)和 “其他” 类别(对于无法归类的回答)。这种字符串预处理过程可能需要大量的人力,并且不容易自动化。如果你能够改变数据的收集方式,那么我们强烈建议,对于分类变量能够更好表示的概念,不要使用手动输入值。
通常来说,手动输入值不与固定的类别对应,但仍有一些内在的结构(structure),比如地址、人名或地名、日期、电话号码或其他标识符。这种类型的字符串通常难以解析,其处理方法也强烈依赖于上下文和具体领域。对这种情况的系统处理方法超出了本书的范围。
最后一类字符串数据是自由格式的文本数据(text data),由短语或句子组成。例子包括推文、聊天记录和酒店评论,还包括莎士比亚文集、维基百科的内容或古腾堡计划收集的 50 000 本电子书。所有这些集合包含的信息大多是由单词组成的句子。为了简单起见,我们假设所有的文档都只使用一种语言:英语。在文本分析的语境中,数据集通常被称为语料库(corpus),每个由单个文本表示的数据点被称为文档(document)。这 些术语来自于信息检索(information retrieval,IR)和自然语言处理(natural language processing,NLP)的社区,它们主要针对文本数据。
2、示例应用:电影评论的情感分析
作为本章的一个运行示例,我们将使用由斯坦福研究员 Andrew Maas 收集的 IMDb (Internet Movie Database,互联网电影数据库)网站的电影评论数据集。这个数据集包含评论文本,还有一个标签,用于表示该评论是 “正面的”(positive)还是 “负面的” (negative)。IMDb 网站本身包含从 1 到 10 的打分。为了简化建模,这些评论打分被归纳为一个二分类数据集,评分大于等于 7 的评论被标记为 “正面的”,评分小于等于 4 的评论被标记为 “负面的”,中性评论没有包含在数据集中。我们不讨论这种方法是否是一种好的数据表示,而只是使用 Andrew Maas 提供的数据。
将数据解压之后,数据集包括两个独立文件夹中的文本文件,一个是训练数据,一个是测试数据。每个文件夹又都有两个子文件夹,一个叫作 pos,一个叫作 neg。
pos 文件夹包含所有正面的评论,每条评论都是一个单独的文本文件,neg 文件夹与之类似。scikit-learn 中有一个辅助函数可以加载用这种文件夹结构保存的文件,其中每个子文件夹对应于一个标签,这个函数叫作 load_files。我们首先将 load_files 函数应用于训练数据:
from sklearn.datasets import load_files
reviews_train = load_files("E:\\practice\\python\\aclImdb\\train\\")
# load_files 返回一个 Bunch 对象,其中包含训练文本和训练标签
text_train, y_train = reviews_train.data, reviews_train.target
print("type of text_train: {}".format(type(text_train)))
# type of text_train: <class 'list'>
print("length of text_train: {}".format(len(text_train)))
# length of text_train: 25000
print("text_train[6]:\n{}".format(text_train[6]))
'''
text_train[6]:
b"This movie has a special way of telling the story, at first i found it rather odd as it jumped through time and I had no idea whats happening.<br /><br />Anyway the story line was although simple, but still very real and touching. You met someone the first time, you fell in love completely, but broke up at last and promoted a deadly agony. Who hasn't go through this? but we will never forget this kind of pain in our life. <br /><br />I would say i am rather touched as two actor has shown great performance in showing the love between the characters. I just wish that the story could be a happy ending."
'''
你可以看到,text_train 是一个长度为 25 000 的列表,其中每个元素是包含一条评论的字符串。我们打印出索引编号为 1 的评论。你还可以看到,评论中包含一些 HTML 换行符。虽然这些符号不太可能对机器学习模型产生很大影响,但最好在继续下一步之前清洗数据并删除这种格式:
text_train = [doc.replace(b"<br />", b" ") for doc in text_train]
收集数据集时保持正类和反类的平衡,这样所有正面字符串和负面字符串的数量相等:
print("Samples per class (training): {}".format(np.bincount(y_train)))
# Samples per class (training): [12500 12500]
我们用同样的方式加载测试数据集:
reviews_test = load_files("E:\\practice\\python\\aclImdb\\test\\")
text_test, y_test = reviews_test.data, reviews_test.target
print("Number of documents in test data: {}".format(len(text_test)))
# Number of documents in test data: 25000
print("Samples per class (test): {}".format(np.bincount(y_test)))
# Samples per class (test): [12500 12500]
text_test = [doc.replace(b"<br />", b" ") for doc in text_test]
我们要解决的任务如下:给定一条评论,我们希望根据该评论的文本内容对其分配一个 “正面的” 或 “负面的” 标签。这是一项标准的二分类任务。但是,文本数据并不是机器学习模型可以处理的格式。我们需要将文本的字符串表示转换为数值表示,从而可以对其应用机器学习算法。
3、将文本数据表示为词袋
用于机器学习的文本表示有一种最简单的方法,也是最有效且最常用的方法,就是使用词袋(bag-of-words)表示。使用这种表示方式时,我们舍弃了输入文本中的大部分结构,如章节、段落、句子和格式,只计算语料库中每个单词在每个文本中的出现频次。舍弃结构并仅计算单词出现次数,这会让脑海中出现将文本表示为 “袋” 的画面。
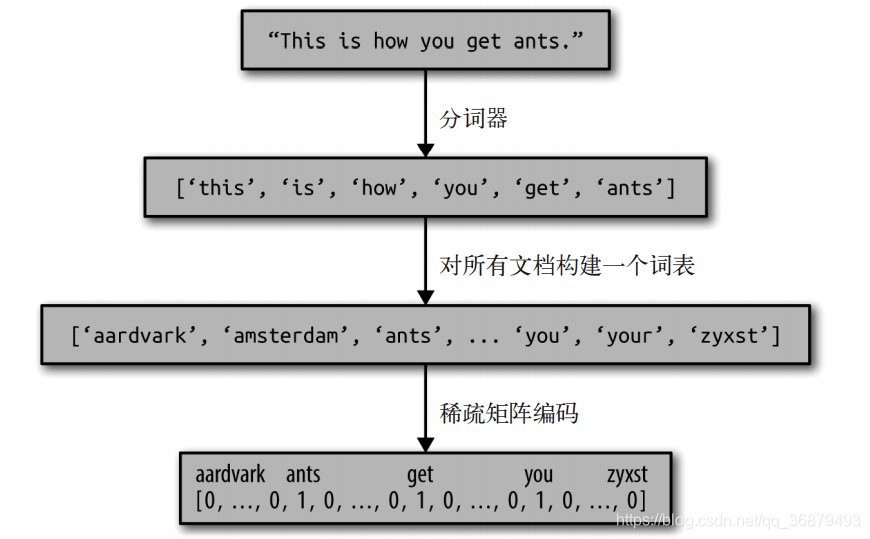
对于文档语料库,计算词袋表示包括以下三个步骤。
- 分词(
tokenization)。将每个文档划分为出现在其中的单词 [ 称为词例(token)],比如按空格和标点划分。 - 构建词表(
vocabulary building)。收集一个词表,里面包含出现在任意文档中的所有词, 并对它们进行编号(比如按字母顺序排序)。 - 编码(
encoding)。对于每个文档,计算词表中每个单词在该文档中的出现频次。
在步骤 1 和步骤 2 中涉及一些细微之处,我们将在本章后面进一步深入讨论。目前,我们来看一下如何利用 scikit-learn 来应用词袋处理过程。下图展示了对字符串 "This is how you get ants." 的处理过程。其输出是包含每个文档中单词计数的一个向量。对于词表中的每个单词,我们都有它在每个文档中的出现次数。也就是说,整个数据集中的每个唯一单词都对应于这种数值表示的一个特征。请注意,原始字符串中的单词顺序与词袋特征表示完全无关。
3.1、将词袋应用于玩具数据集
词袋表示是在 CountVectorizer 中实现的,它是一个变换器(transformer)。我们首先将它应用于一个包含两个样本的玩具数据集,来看一下它的工作原理:
bards_words =["The fool doth think he is wise,",
"but the wise man knows himself to be a fool"]
我们导入 CountVectorizer 并将其实例化,然后对玩具数据进行拟合,如下所示:
from sklearn.feature_extraction.text import CountVectorizer
vect = CountVectorizer()
vect.fit(bards_words)
拟合 CountVectorizer 包括训练数据的分词与词表的构建,我们可以通过 vocabulary_ 属性来访问词表:
print("Vocabulary size: {}".format(len(vect.vocabulary_)))
# Vocabulary size: 13
print("Vocabulary content:\n {}".format(vect.vocabulary_))
'''
Vocabulary content:
{'the': 9, 'fool': 3, 'doth': 2, 'think': 10, 'he': 4, 'is': 6, 'wise': 12, 'but': 1, 'man': 8, 'knows': 7, 'himself': 5, 'to': 11, 'be': 0}
'''
词表共包含 13 个词,从 “be” 到 “wise”。
我们可以调用 transform 方法来创建训练数据的词袋表示:
bag_of_words = vect.transform(bards_words)
print("bag_of_words: {}".format(repr(bag_of_words)))
# bag_of_words: <2x13 sparse matrix of type '<class 'numpy.int64'>'
with 16 stored elements in Compressed Sparse Row format>
词袋表示保存在一个 SciPy 稀疏矩阵中,这种数据格式只保存非零元素。这个矩阵的形状为 2×13,每行对应于两个数据点之一,每个特征对应于词表中的一个单词。 这里使用稀疏矩阵,是因为大多数文档都只包含词表中的一小部分单词,也就是说,特征数组中的大部分元素都为 0。想想看,与所有英语单词(这是词表的建模对象)相比,一篇电影评论中可能出现多少个不同的单词。保存所有 0 的代价很高,也浪费内存。要想查看稀疏矩阵的实际内容,可以使用 toarray 方法将其转换为 “密集的” NumPy 数组(保存所有 0 元素):
print("Dense representation of bag_of_words:\n{}".format(bag_of_words.toarray()))
'''
Dense representation of bag_of_words:
[[0 0 1 1 1 0 1 0 0 1 1 0 1]
[1 1 0 1 0 1 0 1 1 1 0 1 1]]
'''
我们可以看到,每个单词的计数都是 0 或 1。bards_words 中的两个字符串都没有包含相同的单词。我们来看一下如何阅读这些特征向量。第一个字符串("The fool doth think he is wise,")被表示为第一行,对于词表中的第一个单词 “be”,出现 0 次。对于词表中的第二个单词 “but”,出现 0 次。对于词表中的第三个单词 “doth”,出现 1 次,以此类推。通过观察这两行可以看出,第 4 个单词 “fool”、第 10 个单词 “the” 与第 13 个单词 “wise” 同时出现在两个字符串中。
3.2、将词袋应用于电影评论
上一节我们详细介绍了词袋处理过程,下面我们将其应用于电影评论情感分析的任务。 前面我们将 IMDb 评论的训练数据和测试数据加载为字符串列表(text_train 和 text_ test),现在我们将处理它们:
vect = CountVectorizer().fit(text_train)
X_train = vect.transform(text_train)
print("X_train:\n{}".format(repr(X_train)))
'''
X_train:
<25000x74849 sparse matrix of type '<class 'numpy.int64'>'
with 3431196 stored elements in Compressed Sparse Row format>
'''
X_train 是训练数据的词袋表示,其形状为 25 000×74 849,这表示词表中包含 74 849 个 元素。数据同样被保存为 SciPy 稀疏矩阵。我们来更详细地看一下这个词表。访问词表的另一种方法是使用向量器(vectorizer)的 get_feature_name 方法,它将返回一个列表,每个元素对应于一个特征:
feature_names = vect.get_feature_names()
print("Number of features: {}".format(len(feature_names)))
# Number of features: 74849
print("First 20 features:\n{}".format(feature_names[:20]))
'''
First 20 features:
['00', '000', '0000000000001', '00001', '00015', '000s', '001', '003830', '006', '007', '0079', '0080', '0083', '0093638', '00am', '00pm', '00s', '01', '01pm', '02']
'''
print("Features 20010 to 20030:\n{}".format(feature_names[20010:20030]))
'''
Features 20010 to 20030:
['dratted', 'draub', 'draught', 'draughts', 'draughtswoman', 'draw', 'drawback', 'drawbacks', 'drawer', 'drawers', 'drawing', 'drawings', 'drawl', 'drawled', 'drawling', 'drawn', 'draws', 'draza', 'dre', 'drea']
'''
print("Every 2000th feature:\n{}".format(feature_names[::2000]))
'''
Every 2000th feature:
['00', 'aesir', 'aquarian', 'barking', 'blustering', 'bête', 'chicanery', 'condensing', 'cunning', 'detox', 'draper', 'enshrined', 'favorit', 'freezer', 'goldman', 'hasan', 'huitieme', 'intelligible', 'kantrowitz', 'lawful', 'maars', 'megalunged', 'mostey', 'norrland', 'padilla', 'pincher', 'promisingly', 'receptionist', 'rivals', 'schnaas', 'shunning', 'sparse', 'subset', 'temptations', 'treatises', 'unproven', 'walkman', 'xylophonist']
'''
如你所见,词表的前 10 个元素都是数字,这可能有些出人意料。所有这些数字都出现在评论中的某处,因此被提取为单词。大部分数字都没有一目了然的语义,除了 “007”,在 电影的特定语境中它可能指的是詹姆斯 • 邦德(James Bond)这个角色。从无意义的 “单词” 中挑出有意义的有时很困难。进一步观察这个词表,我们发现许多以 “dra” 开头的英语单词。你可能注意到了,对于 “draught”、“drawback” 和 “drawer”,其单数和复数形式都包含在词表中,并且作为不同的单词。这些单词具有密切相关的语义,将它们作为不同的单词进行计数(对应于不同的特征)可能不太合适。
在尝试改进特征提取之前,我们先通过实际构建一个分类器来得到性能的量化度量。我们将训练标签保存在 y_train 中,训练数据的词袋表示保存在 X_train 中,因此我们可以在这个数据上训练一个分类器。对于这样的高维稀疏数据,类似 LogisticRegression 的线性模型通常效果最好。
我们首先使用交叉验证对 LogisticRegression 进行评估:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
scores = cross_val_score(LogisticRegression(), X_train, y_train, cv=5)
print("Mean cross-validation accuracy: {:.2f}".format(np.mean(scores)))
# Mean cross-validation accuracy: 0.88
我们得到的交叉验证平均分数是 88%,这对于平衡的二分类任务来说是一个合理的性能。 我们知道,LogisticRegression 有一个正则化参数 C,我们可以通过交叉验证来调节它:
from sklearn.model_selection import GridSearchCV
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10]}
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
# Best cross-validation score: 0.89
print("Best parameters: ", grid.best_params_)
# Best parameters: {'C': 0.1}
我们使用 C=0.1 得到的交叉验证分数是 89%。现在,我们可以在测试集上评估这个参数设 置的泛化性能:
X_test = vect.transform(text_test)
print("Test score: {:.2f}".format(grid.score(X_test, y_test)))
# Test score: 0.88
下面我们来看一下能否改进单词提取。CountVectorizer 使用正则表达式提取词例。默认使用的正则表达式是 "\b\w\w+\b"。如果你不熟悉正则表达式,它的含义是找到所有包含至少两个字母或数字(\w)且被词边界(\b)分隔的字符序列。它不会匹配只有一个字母的单词,还会将类似 “doesn’t” 或 “bit.ly” 之类的缩写分开,但它会将 “h8ter” 匹配为一个单词。然后,CountVectorizer 将所有单词转换为小写字母,这样 “soon” “Soon” 和 “sOon” 都对应于同一个词例(因此也对应于同一个特征)。这一简单机制在实践中的效果很好,但正如前面所见,我们得到了许多不包含信息量的特征(比如数字)。减少这种特征的一种方法是,仅使用至少在 2 个文档(或者至少 5 个,等等)中出现过的词例。仅在一个文档中出现的词例不太可能出现在测试集中,因此没什么用。我们可以用 min_df 参数来设置词例至少需要在多少个文档中出现过:
vect = CountVectorizer(min_df=5).fit(text_train)
X_train = vect.transform(text_train)
print("X_train with min_df: {}".format(repr(X_train)))
# X_train with min_df: <25000x27271 sparse matrix of type '<class 'numpy.int64'>'
with 3354014 stored elements in Compressed Sparse Row format>
通过要求每个词例至少在 5 个文档中出现过,我们可以将特征数量减少到 27 271 个,正如 上面的输出所示——只有原始特征的三分之一左右。我们再来查看一些词例:
print("First 50 features:\n{}".format(feature_names[:50]))
'''
First 50 features:
['00', '000', '007', '00s', '01', '02', '03', '04', '05', '06', '07', '08', '09', '10', '100', '1000', '100th', '101', '102', '103', '104', '105', '107', '108', '10s', '10th', '11', '110', '112', '116', '117', '11th', '12', '120', '12th', '13', '135', '13th', '14', '140', '14th', '15', '150', '15th', '16', '160', '1600', '16mm', '16s', '16th']
'''
print("Features 20010 to 20030:\n{}".format(feature_names[20010:20030]))
'''
Features 20010 to 20030:
['repentance', 'repercussions', 'repertoire', 'repetition', 'repetitions', 'repetitious', 'repetitive', 'rephrase', 'replace', 'replaced', 'replacement', 'replaces', 'replacing', 'replay', 'replayable', 'replayed', 'replaying', 'replays', 'replete', 'replica']
'''
print("Every 700th feature:\n{}".format(feature_names[::700]))
'''
Every 700th feature:
['00', 'affections', 'appropriately', 'barbra', 'blurbs', 'butchered', 'cheese', 'commitment', 'courts', 'deconstructed', 'disgraceful', 'dvds', 'eschews', 'fell', 'freezer', 'goriest', 'hauser', 'hungary', 'insinuate', 'juggle', 'leering', 'maelstrom', 'messiah', 'music', 'occasional', 'parking', 'pleasantville', 'pronunciation', 'recipient', 'reviews', 'sas', 'shea', 'sneers', 'steiger', 'swastika', 'thrusting', 'tvs', 'vampyre', 'westerns']
'''
数字的个数明显变少了,有些生僻词或拼写错误似乎也都消失了。我们再次运行网格搜索来看一下模型的性能如何:
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
# Best cross-validation score: 0.89
网格搜索的最佳验证精度还是 89%,这和前面一样。我们并没有改进模型,但减少要处理的特征数量可以加速处理过程,舍弃无用的特征也可能提高模型的可解释性。
如果一个文档中包含训练数据中没有包含的单词,并对其调用
CountVectorizer的transform方法,那么这些单词将被忽略,因为它们没有包含在字典中。 这对分类来说不是一个问题,因为从不在训练数据中的单词中学不到任何内容。但对于某些应用而言(比如垃圾邮件检测),添加一个特征来表示特定文档中有多少个所谓 “词表外” 单词可能会有所帮助。为了实现这一点,你需要设置min_df,否则这个特征在训练期间永远不会被用到。
4、停用词
删除没有信息量的单词还有另一种方法,就是舍弃那些出现次数太多以至于没有信息量的单词。有两种主要方法:使用特定语言的停用词(stopword)列表,或者舍弃那些出现过于频繁的单词。scikit-learn 的 feature_extraction.text 模块中提供了英语停用词的内置列表:
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
print("Number of stop words: {}".format(len(ENGLISH_STOP_WORDS)))
# Number of stop words: 318
print("Every 10th stopword:\n{}".format(list(ENGLISH_STOP_WORDS)[::10]))
'''
Every 10th stopword:
['they', 'of', 'who', 'found', 'none', 'co', 'full', 'otherwise', 'never', 'have', 'she', 'neither', 'whereby', 'one', 'any', 'de', 'hence', 'wherever', 'whose', 'him', 'which', 'nine', 'still', 'from', 'here', 'what', 'everything', 'us', 'etc', 'mine', 'find', 'most']
'''
显然,删除上述列表中的停用词只能使特征数量减少 318 个(即上述列表的长度),但可能会提高性能。我们来试一下:
# 指定 stop_words="english" 将使用内置列表
# 我们也可以扩展这个列表并传入我们自己的列表
vect = CountVectorizer(min_df=5, stop_words="english").fit(text_train)
X_train = vect.transform(text_train)
print("X_train with stop words:\n{}".format(repr(X_train)))
'''
<25000x26966 sparse matrix of type '<class 'numpy.int64'>'
with 2149958 stored elements in Compressed Sparse Row format>
'''
现在数据集中的特征数量减少了 305 个(27271-26966),说明大部分停用词(但不是所有)都出现了。我们再次运行网格搜索:
grid = GridSearchCV(LogisticRegression(), param_grid, cv=5)
grid.fit(X_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
# Best cross-validation score: 0.88
使用停用词后的网格搜索性能略有下降——不至于担心,但鉴于从 27 000 多个特征中删除 305 个不太可能对性能或可解释性造成很大影响,所以使用这个列表似乎是不值得的。 固定的列表主要对小型数据集很有帮助,这些数据集可能没有包含足够的信息,模型从数据本身无法判断出哪些单词是停用词。作为练习,你可以尝试另一种方法,即通过设置 CountVectorizer 的 max_df 选项来舍弃出现最频繁的单词,并查看它对特征数量和性能有什么影响。
5、用 tf-idf 缩放数据
另一种方法是按照我们预计的特征信息量大小来缩放特征,而不是舍弃那些认为不重要的特征。最常见的一种做法就是使用词频 - 逆向文档频率(term frequency–inverse document frequency,tf-idf)方法。这一方法对在某个特定文档中经常出现的术语给予很高的权重,但对在语料库的许多文档中都经常出现的术语给予的权重却不高。如果一个单词在某个特定文档中经常出现,但在许多文档中却不常出现,那么这个单词很可能是对文档内容的很好描述。scikit-learn 在两个类中实现了 tf-idf 方法:TfidfTransformer 和 TfidfVectorizer,前者接受 CountVectorizer 生成的稀疏矩阵并将其变换,后者接受文本数据并完成词袋特征提取与 tf-idf 变换。tf-idf 缩放方案有几种变体,你可以在维基百科上阅读相关内容(https://en.wikipedia.org/wiki/Tf-idf)。单词 w 在文档 d 中的 tf-idf 分数在 TfidfTransformer 类和 TfidfVectorizer 类中都有实现,其计算公式如下所示:
t
f
i
d
f
(
w
,
d
)
=
t
f
l
o
g
(
N
+
1
N
w
+
1
)
+
1
tfidf(w,d)=tf \quad log(\frac{N+1}{N_w+1})+1
tfidf(w,d)=tflog(Nw+1N+1)+1
其中 N 是训练集中的文档数量,Nw 是训练集中出现单词 w 的文档数量,tf(词频)是单词 w 在查询文档 d(你想要变换或编码的文档)中出现的次数。两个类在计算 tf-idf 表示之后都还应用了 L2 范数。换句话说,它们将每个文档的表示缩放到欧几里得范数为 1。利用这种缩放方法,文档长度(单词数量)不会改变向量化表示。
由于 tf-idf 实际上利用了训练数据的统计学属性,所以我们将使用管 道,以确保网格搜索的结果有效。这样会得到下列代码:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.pipeline import make_pipeline
pipe = make_pipeline(TfidfVectorizer(min_df=5, norm=None),
LogisticRegression())
param_grid = {'logisticregression__C': [0.001, 0.01, 0.1, 1, 10]}
grid = GridSearchCV(pipe, param_grid, cv=5)
grid.fit(text_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
# Best cross-validation score: 0.89
如你所见,使用 tf-idf 代替仅统计词数对性能有所提高。我们还可以查看 tf-idf 找到的最重要的单词。请记住,tf-idf 缩放的目的是找到能够区分文档的单词,但它完全是一种无监督技术。因此,这里的 “重要” 不一定与我们感兴趣的 “正面评论” 和 “负面评论” 标签相关。首先,我们从管道中提取 TfidfVectorizer:
vectorizer = grid.best_estimator_.named_steps["tfidfvectorizer"]
# 变换训练数据集
X_train = vectorizer.transform(text_train)
# 找到数据集中每个特征的最大值
max_value = X_train.max(axis=0).toarray().ravel()
sorted_by_tfidf = max_value.argsort()
# 获取特征名称
feature_names = np.array(vectorizer.get_feature_names())
print("Features with lowest tfidf:\n{}".format(feature_names[sorted_by_tfidf[:20]]))
'''
Features with lowest tfidf:
['poignant' 'disagree' 'instantly' 'importantly' 'lacked' 'occurred'
'currently' 'altogether' 'nearby' 'undoubtedly' 'directs' 'fond' 'stinker'
'avoided' 'emphasis' 'commented' 'disappoint' 'realizing' 'downhill'
'inane']
'''
print("Features with highest tfidf: \n{}".format(feature_names[sorted_by_tfidf[-20:]]))
'''
Features with highest tfidf:
['coop' 'homer' 'dillinger' 'hackenstein' 'gadget' 'taker' 'macarthur'
'vargas' 'jesse' 'basket' 'dominick' 'the' 'victor' 'bridget' 'victoria'
'khouri' 'zizek' 'rob' 'timon' 'titanic']
'''
tf-idf 较小的特征要么是在许多文档里都很常用,要么就是很少使用,且仅出现在非常长的文档中。有趣的是,许多 tf-idf 较大的特征实际上对应的是特定的演出或电影。这些术语仅出现在这些特定演出或电影的评论中,但往往在这些评论中多次出现。例如,对于 “pokemon”、“smallville” 和 “doodlebops” 是显而易见的,但这里的 “scanners” 实际上指的也是电影标题。这些单词不太可能有助于我们的情感分类任务(除非有些电影的评价可 能普遍偏正面或偏负面),但肯定包含了关于评论的大量具体信息。
我们还可以找到逆向文档频率较低的单词,即出现次数很多,因此被认为不那么重要的单词。训练集的逆向文档频率值被保存在 idf_ 属性中:
sorted_by_idf = np.argsort(vectorizer.idf_)
print("Features with lowest idf:\n{}".format(feature_names[sorted_by_idf[:100]]))
'''
Features with lowest idf:
['the' 'and' 'of' 'to' 'this' 'is' 'it' 'in' 'that' 'but' 'for' 'with'
'was' 'as' 'on' 'movie' 'not' 'have' 'one' 'be' 'film' 'are' 'you' 'all'
'at' 'an' 'by' 'so' 'from' 'like' 'who' 'they' 'there' 'if' 'his' 'out'
'just' 'about' 'he' 'or' 'has' 'what' 'some' 'good' 'can' 'more' 'when'
'time' 'up' 'very' 'even' 'only' 'no' 'would' 'my' 'see' 'really' 'story'
'which' 'well' 'had' 'me' 'than' 'much' 'their' 'get' 'were' 'other'
'been' 'do' 'most' 'don' 'her' 'also' 'into' 'first' 'made' 'how' 'great'
'because' 'will' 'people' 'make' 'way' 'could' 'we' 'bad' 'after' 'any'
'too' 'then' 'them' 'she' 'watch' 'think' 'acting' 'movies' 'seen' 'its'
'him']
'''
正如所料,这些词大多是英语中的停用词,比如 “the” 和 “no”。但有些单词显然是电影评论特有的,比如 “movie”、“film”、“time”、“story” 等。有趣的是,“good”、“great” 和 “bad” 也属于频繁出现的单词,因此根据 tf-idf 度量也属于 “不太相关” 的单词,尽管我们可能认为这些单词对情感分析任务非常重要。
6、研究模型系数
最后,我们详细看一下 Logistic 回归模型从数据中实际学到的内容。由于特征数量非常多 (删除出现次数不多的特征之后还有 27 271 个),所以显然我们不能同时查看所有系数。但 是,我们可以查看最大的系数,并查看这些系数对应的单词。我们将使用基于 tf-idf 特征训练的最后一个模型。
下面这张条形图给出了 Logistic 回归模型中最大的 25 个系数与最小的 25 个系数,其高度表示每个系数的大小:
mglearn.tools.visualize_coefficients(
grid.best_estimator_.named_steps["logisticregression"].coef_,
feature_names, n_top_features=40)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2TWV0WVi-1609125450294)(素材/在tf-idf特征上训练的Logistic回归的最大系数和最小系数.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvZmI2MmQ1MTAyYzg1NzMzM2RhOWUyNDU3YmQyMWQzZjQucG5n)
左侧的负系数属于模型找到的表示负面评论的单词,而右侧的正系数属于模型找到的表示正面评论的单词。大多数单词都是非常直观的,比如 “worst”(最差)、“waste”(浪费)、“disappointment”(失望)和 “laughable”(可笑)都表示不好的电影评论,而 “excellent”(优秀)、“wonderful”(精彩)、“enjoyable”(令人愉悦)和 “refreshing” (耳目一新)则表示正面的电影评论。有些词的含义不那么明确,比如 “bit”(一点)、 “job”(工作)和 “today”(今天),但它们可能是类似 “good job”(做得不错)和 “best today”(今日最佳)等短语的一部分。
7、多个单词的词袋(n 元分组)
使用词袋表示的主要缺点之一是完全舍弃了单词顺序。因此,“it’s bad, not good at all”(电影很差,一点也不好)和 “it’s good, not bad at all”(电影很好,还不错)这两个字符串的词袋表示完全相同,尽管它们的含义相反。将 “not”(不)放在单词前面,这只是上下文很重要的一个例子(可能是一个极端的例子)。幸运的是,使用词袋表示时有一种获取上下文的方法,就是不仅考虑单一词例的计数,而且还考虑相邻的两个或三个词例的计数。两个词例被称为二元分词(bigram),三个词例被称为三元分词(trigram),更一般的词例序列被称为 n 元分词(n-gram)。我们可以通过改变 CountVectorizer 或 TfidfVectorizer 的 ngram_range 参数来改变作为特征的词例范围。ngram_range 参数是一个元组,包含要考虑的词例序列的最小长度和最大长度。下面是在之前用过的玩具数据上的一个示例:
print("bards_words:\n{}".format(bards_words))
'''
bards_words:
['The fool doth think he is wise,', 'but the wise man knows himself to be a fool']
'''
默认情况下,为每个长度最小为 1 且最大为 1 的词例序列(或者换句话说,刚好 1 个词例)创建一个特征——单个词例也被称为一元分词(unigram):
cv = CountVectorizer(ngram_range=(1, 1)).fit(bards_words)
print("Vocabulary size: {}".format(len(cv.vocabulary_)))
# Vocabulary size: 13
print("Vocabulary:\n{}".format(cv.get_feature_names()))
'''
Vocabulary:
['be', 'but', 'doth', 'fool', 'he', 'himself', 'is', 'knows', 'man', 'the', 'think', 'to', 'wise']
'''
要想仅查看二元分词(即仅查看由两个相邻词例组成的序列),可以将 ngram_range 设置 为 (2, 2):
cv = CountVectorizer(ngram_range=(2, 2)).fit(bards_words)
print("Vocabulary size: {}".format(len(cv.vocabulary_)))
# Vocabulary size: 14
print("Vocabulary:\n{}".format(cv.get_feature_names()))
'''
Vocabulary:
['be fool', 'but the', 'doth think', 'fool doth', 'he is', 'himself to', 'is wise', 'knows himself', 'man knows', 'the fool', 'the wise', 'think he', 'to be', 'wise man']
'''
使用更长的词例序列通常会得到更多的特征,也会得到更具体的特征。bard_words 的两个短语中没有相同的二元分词:
print("Transformed data (dense):\n{}".format(cv.transform(bards_words).toarray()))
'''
Transformed data (dense):
[[0 0 1 1 1 0 1 0 0 1 0 1 0 0]
[1 1 0 0 0 1 0 1 1 0 1 0 1 1]]
'''
对于大多数应用而言,最小的词例数量应该是 1,因为单个单词通常包含丰富的含义。在 大多数情况下,添加二元分词会有所帮助。添加更长的序列(一直到五元分词)也可能有所帮助,但这会导致特征数量的大大增加,也可能会导致过拟合,因为其中包含许多非常具体的特征。原则上来说,二元分词的数量是一元分词数量的平方,三元分词的数量是一元分词数量的三次方,从而导致非常大的特征空间。在实践中,更高的 n 元分词在数据中的出现次数实际上更少,原因在于(英语)语言的结构,不过这个数字仍然很大。
下面是在 bards_words 上使用一元分词、二元分词和三元分词的结果:
cv = CountVectorizer(ngram_range=(1, 3)).fit(bards_words)
print("Vocabulary size: {}".format(len(cv.vocabulary_)))
# Vocabulary size: 39
print("Vocabulary:\n{}".format(cv.get_feature_names()))
'''
Vocabulary:['be', 'be fool', 'but', 'but the', 'but the wise', 'doth', 'doth think', 'doth think he', 'fool', 'fool doth', 'fool doth think', 'he', 'he is', 'he is wise', 'himself', 'himself to', 'himself to be', 'is', 'is wise', 'knows', 'knows himself', 'knows himself to', 'man', 'man knows', 'man knows himself', 'the', 'the fool', 'the fool doth', 'the wise', 'the wise man', 'think', 'think he', 'think he is', 'to', 'to be', 'to be fool', 'wise', 'wise man', 'wise man knows']
'''
我们在 IMDb 电影评论数据上尝试使用 TfidfVectorizer,并利用网格搜索找出 n 元分词的最佳设置:
pipe = make_pipeline(TfidfVectorizer(min_df=5), LogisticRegression())
# 运行网格搜索需要很长的时间,因为网格相对较大,且包含三元分组
param_grid = {'logisticregression__C': [0.001, 0.01, 0.1, 1, 10, 100],
"tfidfvectorizer__ngram_range": [(1, 1), (1, 2), (1, 3)]}
grid = GridSearchCV(pipe, param_grid, cv=5)
grid.fit(text_train, y_train)
print("Best cross-validation score: {:.2f}".format(grid.best_score_))
# Best cross-validation score: 0.91
print("Best parameters:\n{}".format(grid.best_params_))
'''
Best parameters:
{'logisticregression__C': 100, 'tfidfvectorizer__ngram_range': (1, 3)}
'''
从结果中可以看出,我们添加了二元分词特征与三元分词特征之后,性能提高了一个百分点多一点。我们可以将交叉验证精度作为 ngram_range 和 C 参数的函数并用热图可视化:
# 从网格搜索中提取分数
scores = grid.cv_results_['mean_test_score'].reshape(-1, 3).T
# 热图可视化
heatmap = mglearn.tools.heatmap(
scores, xlabel="C", ylabel="ngram_range", cmap="viridis", fmt="%.3f",
xticklabels=param_grid['logisticregression__C'],
yticklabels=param_grid['tfidfvectorizer__ngram_range'])
plt.colorbar(heatmap)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HvJSAjh6-1609125450296)(素材/交叉验证平均精度作为参数ngram_range和C的函数的热图可视化.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvYzIxMmIwZDk4YmM4MzAxNzEzZTQ1N2M2MDQ4MTM5ZDEucG5n)
从热图中可以看出,使用二元分词对性能有很大提高,而添加三元分词对精度只有很小贡献。为了更好地理解模型是如何改进的,我们可以将最佳模型的重要系数可视化,其中包含一元分词、二元分词和三元分词:
# 特征提取名称与系数
vect = grid.best_estimator_.named_steps['tfidfvectorizer']
feature_names = np.array(vect.get_feature_names())
coef = grid.best_estimator_.named_steps['logisticregression'].coef_
mglearn.tools.visualize_coefficients(coef, feature_names, n_top_features=40)
plt.ylim(-22, 22)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qb1h18ev-1609125450297)(素材/同时使用tf-idf缩放与一元分词、二元分词和三元分词时的最重要特征.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvNDVjZGZlNzA0MjE4NTFiMDc5YjBhZmM0MTUxNWZiNjUucG5n)
有几个特别有趣的特征,它们包含单词 “worth”(值得),而这个词本身并没有出现在一元分词模型中:“not worth”(不值得)表示负面评论,而 “definitely worth”(绝对值得) 和 “well worth”(很值得)表示正面评论。这是上下文影响 “worth” 一词含义的主要示例。
接下来,我们只将三元分词可视化,以进一步深入了解这些特征有用的原因。许多有用的二元分词和三元分词都由常见的单词组成,这些单词本身可能没有什么信息量,比如 “none of the”(没有一个)、“the only good”(唯一好的)、“on and on”(不停地)、“this is one”(这是一部)、“of the most”(最)等短语中的单词。但是,与一元分词特征的重 要性相比,这些特征的影响非常有限,正如下图所示。
# 找到三元分词特征
mask = np.array([len(feature.split(" ")) for feature in feature_names]) == 3
# 仅将三元分词特征可视化
mglearn.tools.visualize_coefficients(coef.ravel()[mask],
feature_names[mask], n_top_features=40)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T7Hc434F-1609125450298)(素材/仅将对模型重要的三元分词特征可视化.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvMzk1MTU3MjQyMzMzMzY2NjBhZDdlMThiNzA1YjNlZGUucG5n)
8、高级分词、词干提取与词形还原
如前所述,CountVectorizer 和 TfidfVectorizer 中的特征提取相对简单,还有更为复杂的方法。在更加复杂的文本处理应用中,通常需要改进的步骤是词袋模型的第一步:分词 (tokenization)。这一步骤为特征提取定义了一个单词是如何构成的。
我们前面看到,词表中通常同时包含某些单词的单数形式和复数形式,比如 “drawback” 和 “drawbacks”、“drawer” 和 “drawers”、“drawing” 和 “drawings”。对于词袋模型而言, “drawback” 和 “drawbacks” 的语义非常接近,区分二者只会增加过拟合,并导致模型无法充分利用训练数据。同样我们还发现,词表中包含像 “replace”、“replaced”、“replace ment”、“replaces” 和 “replacing” 这样的单词,它们都是动词 “to replace” 的不同动词形式或相关名词。与名词的单复数形式一样,将不同的动词形式及相关单词视为不同的词例,这不利于构建具有良好泛化性能的模型。
这个问题可以通过用词干(word stem)表示每个单词来解决,这一方法涉及找出 [ 或合并 (conflate)] 所有具有相同词干的单词。如果使用基于规则的启发法来实现(比如删除常见的后缀),那么通常将其称为词干提取(stemming)。如果使用的是由已知单词形式组成的字典(明确的且经过人工验证的系统),并且考虑了单词在句子中的作用,那么这个过程被称为词形还原(lemmatization),单词的标准化形式被称为词元(lemma)。词干提取和词形还原这两种处理方法都是标准化(normalization)的形式之一,标准化是指尝试提取一个单词的某种标准形式。标准化的另一个有趣的例子是拼写校正。
为了更好地理解标准化,我们来对比一种词干提取方法(Porter 词干提取器,一种广泛使用的启发法集合,从 nltk 包导入)与 spacy 包中实现的词形还原:
import spacy
import nltk
# 加载spacy的英语模型
en_nlp = spacy.load('en')
# 将nltk的Porter词干提取器实例化
stemmer = nltk.stem.PorterStemmer()
# 定义一个函数来对比spacy中的词形还原与nltk中的词干提取
def compare_normalization(doc):
# 在spacy中对文档进行分词
doc_spacy = en_nlp(doc)
# 打印出spacy找到的词元
print("Lemmatization:")
print([token.lemma_ for token in doc_spacy])
# 打印出Porter词干提取器找到的词例
print("Stemming:")
print([stemmer.stem(token.norm_.lower()) for token in doc_spacy])
我们将用一个句子来比较词形还原与 Porter 词干提取器,以显示二者的一些区别:
compare_normalization(u"Our meeting today was worse than yesterday, "
"I'm scared of meeting the clients tomorrow.")
'''
Lemmatization:
['our', 'meeting', 'today', 'be', 'bad', 'than', 'yesterday', ',', 'i', 'be', 'scar', 'of', 'meet', 'the', 'client', 'tomorrow', '.']
Stemming:
['our', 'meet', 'today', 'wa', 'wors', 'than', 'yesterday', ',', 'i', "'m", 'scare', 'of', 'meet', 'the', 'client', 'tomorrow', '.']
'''
词干提取总是局限于将单词简化成词干,因此 “was” 变成了 “wa”,而词形还原可以得到正 确的动词基本词形 “be”。同样,词形还原可以将 “worse” 标准化为 “bad”,而词干提取得到的是 “wors”。另一个主要区别在于,词干提取将两处 “meeting” 都简化为 “meet”。利用词形还原,第一处 “meeting” 被认为是名词,所以没有变化,而第二处 “meeting” 被认为 是动词,所以变为 “meet”。一般来说,词形还原是一个比词干提取更复杂的过程,但用于机器学习的词例标准化时通常可以给出比词干提取更好的结果。
虽然 scikit-learn 没有实现这两种形式的标准化,但 CountVectorizer 允许使用 tokenizer 参数来指定使用你自己的分词器将每个文档转换为词例列表。我们可以使用 spacy 的词形还原了创建一个可调用对象,它接受一个字符串并生成一个词元列表:
# 技术细节:我们希望使用由CountVectorizer所使用的基于正则表达式的分词器,
# 并仅使用spacy的词形还原。
# 为此,我们将en_nlp.tokenizer(spacy分词器)替换为基于正则表达式的分词。
import re
# 在CountVectorizer中使用的正则表达式
regexp = re.compile('(?u)\\b\\w\\w+\\b')
# 加载spacy语言模型,并保存旧的分词器
en_nlp = spacy.load('en', disable=['parser', 'ner'])
old_tokenizer = en_nlp.tokenizer
# 将分词器替换为前面的正则表达式
en_nlp.tokenizer = lambda string: old_tokenizer.tokens_from_list(
regexp.findall(string))
# 用spacy文档处理管道创建一个自定义分词器
# (现在使用我们自己的分词器)
def custom_tokenizer(document):
doc_spacy = en_nlp(document)
return [token.lemma_ for token in doc_spacy]
# 利用自定义分词器来定义一个计数向量器
lemma_vect = CountVectorizer(tokenizer=custom_tokenizer, min_df=5)
# 利用带词形还原的CountVectorizer对text_train进行变换
X_train_lemma = lemma_vect.fit_transform(text_train)
print("X_train_lemma.shape: {}".format(X_train_lemma.shape))
# X_train_lemma.shape: (25000, 21637)
# 标准的CountVectorizer,以供参考
vect = CountVectorizer(min_df=5).fit(text_train)
X_train = vect.transform(text_train)
print("X_train.shape: {}".format(X_train.shape))
# X_train.shape: (25000, 27271)
从输出中可以看出,词形还原将特征数量从 27 271 个(标准的 CountVectorizer 处理过程)减少到 21 596 个。词形还原可以被看作是一种正则化,因为它合并了某些特征。因此我们预计,数据集很小时词形还原对性能的提升最大。为了说明词形还原的作用,我们将使用 StratifiedShuffleSplit 做交叉验证,仅使用 1% 的数据作为训练数据,其余数据作为测试数据:
# 仅使用1%的数据作为训练集来构建网格搜索
from sklearn.model_selection import StratifiedShuffleSplit
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10]}
cv = StratifiedShuffleSplit(n_splits=5, test_size=0.99,
train_size=0.01, random_state=0)
grid = GridSearchCV(LogisticRegression(), param_grid, cv=cv)
# 利用标准的CountVectorizer进行网格搜索
grid.fit(X_train, y_train)
print("Best cross-validation score "
"(standard CountVectorizer): {:.3f}".format(grid.best_score_))
# Best cross-validation score (standard CountVectorizer): 0.721
# 利用词形还原进行网格搜索
grid.fit(X_train_lemma, y_train)
print("Best cross-validation score "
"(lemmatization): {:.3f}".format(grid.best_score_))
# Best cross-validation score (lemmatization): 0.731
在这个例子中,词形还原对性能有较小的提高。与许多特征提取技术一样,其结果因数据集的不同而不同。词形还原与词干提取有时有助于构建更好的模型(或至少是更简洁的模型),所以我们建议你,在特定任务中努力提升最后一点性能时可以尝试下这些技术。
9、主题建模与文档聚类
常用于文本数据的一种特殊技术是主题建模(topic modeling),这是描述将每个文档分配给一个或多个主题的任务(通常是无监督的)的概括性术语。这方面一个很好的例子是新闻数据,它们可以被分为 “政治” “体育” “金融” 等主题。如果为每个文档分配一个主题,那么这是一个文档聚类任务。如果每个文档可以有多个主题,那 么这个任务与无监督学习中的分解方法有关。我们学到的每个成分对应于一个主题,文档表示中的成分系数告诉我们这个文档与该主题的相关性强弱。通常来说,人们在谈论主题建模时,他们指的是一种叫作隐含狄利克雷分布(Latent Dirichlet Allocation,LDA)的特定分解方法。
9.1、隐含狄利克雷分布
从直观上来看,LDA 模型试图找出频繁共同出现的单词群组(即主题)。LDA 还要求,每个文档可以被理解为主题子集的 “混合”。重要的是要理解,机器学习模型所谓的 “主题” 可能不是我们通常在日常对话中所说的主题,而是更类似于 PCA 或 NMF所提取的成分,它可能具有语义,也可能没有。即使 LDA “主题” 具有语义,它可能也不是我们通常所说的主题。回到新闻文章的例子,我们可能有许多关于体育、政治和金融的文章,由两位作者所写。在一篇政治文章中,我们预计可能会看到 “州长” “投票” “党派” 等词语,而在一篇体育文章中,我们预计可能会看到类似 “队伍” “得分” 和 “赛季” 之类的词语。这两组词语可能会同时出现,而例如 “队伍” 和 “州长” 就不太可能同时出现。但是,这并不是我们预计可能同时出现的唯一的单词群组。 这两位记者可能偏爱不同的短语或者选择不同的单词。可能其中一人喜欢使用 “划界” (demarcate)这个词,而另一人喜欢使用 “两极分化”(polarize)这个词。其他“主题 ”可能是“ 记者 A 常用的词语” 和 “记者 B 常用的词语”,虽然这并不是通常意义上的主题。
我们将 LDA 应用于电影评论数据集,来看一下它在实践中的效果。对于无监督的文本文档模型,通常最好删除非常常见的单词,否则它们可能会支配分析过程。我们将删除至少在 15% 的文档中出现过的单词,并在删除前 15% 之后,将词袋模型限定为最常见的 10 000 个单词:
vect = CountVectorizer(max_features=10000, max_df=.15)
X = vect.fit_transform(text_train)
我们将学习一个包含 10 个主题的主题模型,它包含的主题个数很少,我们可以查看所有主题。与 NMF 中的分量类似,主题没有内在的顺序,而改变主题数量将会改变所有主题。我们将使用 “batch” 学习方法,它比默认方法(“online”)稍慢,但通常会给出更好的结果。我们还将增大 max_iter,这样会得到更好的模型:
from sklearn.decomposition import LatentDirichletAllocation
lda = LatentDirichletAllocation(n_topics=10, learning_method="batch",
max_iter=25, random_state=0)
# 我们在一个步骤中构建模型并变换数据
# 计算变换需要花点时间,二者同时进行可以节省时间
document_topics = lda.fit_transform(X)
与前面所讲的分解方法类似,LatentDirichletAllocation 有一个 components_ 属性, 其中保存了每个单词对每个主题的重要性。components_ 的大小为 (n_topics, n_words):
print("lda.components_.shape: {}".format(lda.components_.shape))
# lda.components_.shape: (10, 10000)
为了更好地理解不同主题的含义,我们将查看每个主题中最重要的单词。print_topics 函数为这些特征提供了良好的格式:
# 对于每个主题(components_的一行),将特征排序(升序)
# 用[:, ::-1]将行反转,使排序变为降序
sorting = np.argsort(lda.components_, axis=1)[:, ::-1]
# 从向量器中获取特征名称
feature_names = np.array(vect.get_feature_names())
# 打印出前10个主题:
mglearn.tools.print_topics(topics=range(10), feature_names=feature_names,
sorting=sorting, topics_per_chunk=5, n_words=10)
'''
topic 0 topic 1 topic 2 topic 3 topic 4
-------- -------- -------- -------- --------
between war funny show didn
family world comedy series saw
young us guy episode thought
real american laugh tv am
us our jokes episodes thing
director documentary fun shows got
work history humor season 10
both years re new want
beautiful new hilarious years going
each human doesn television watched
topic 5 topic 6 topic 7 topic 8 topic 9
-------- -------- -------- -------- --------
action kids role performance horror
effects action cast role house
nothing animation john john killer
budget children version actor gets
script game novel cast woman
minutes disney director plays dead
original fun both jack girl
director old played michael around
least 10 mr oscar goes
doesn kid young father wife
'''
从重要的单词来看,主题 1 似乎是关于历史和战争的电影,主题 2 可能是关于糟糕的喜剧,主题 3 可能是关于电视连续剧,主题 4 可能提取了一些非常常见的单词,而主题 6 似乎是关于儿童电影,主题 8 似乎提取了与获奖相关的评论。仅使用 10 个主题,每个主题都需要非常宽泛,才能共同涵盖我们的数据集中所有不同类型的评论。
接下来,我们将学习另一个模型,这次包含 100 个主题。使用更多的主题,将使得分析过程更加困难,但更可能使主题专门针对于某个有趣的数据子集:
lda100 = LatentDirichletAllocation(n_topics=100, learning_method="batch",
max_iter=25, random_state=0)
document_topics100 = lda100.fit_transform(X)
查看所有 100 个主题可能有点困难,所以我们选取了一些有趣的而且有代表性的主题:
topics = np.array([7, 16, 24, 25, 28, 36, 37, 41, 45, 51, 53, 54, 63, 89, 97])
sorting = np.argsort(lda100.components_, axis=1)[:, ::-1]
feature_names = np.array(vect.get_feature_names())
mglearn.tools.print_topics(topics=topics, feature_names=feature_names,
sorting=sorting, topics_per_chunk=5, n_words=20)
'''
topic 7 topic 16 topic 24 topic 25 topic 28
-------- -------- -------- -------- --------
thriller worst german car beautiful
suspense awful hitler gets young
horror boring nazi guy old
atmosphere horrible midnight around romantic
mystery stupid joe down between
house thing germany kill romance
director terrible years goes wonderful
quite script history killed heart
bit nothing new going feel
de worse modesty house year
performances waste cowboy away each
dark pretty jewish head french
twist minutes past take sweet
hitchcock didn kirk another boy
tension actors young getting loved
interesting actually spanish doesn girl
mysterious re enterprise now relationship
murder supposed von night saw
ending mean nazis right both
creepy want spock woman simple
topic 36 topic 37 topic 41 topic 45 topic 51
-------- -------- -------- -------- --------
performance excellent war music earth
role highly american song space
actor amazing world songs planet
cast wonderful soldiers rock superman
play truly military band alien
actors superb army soundtrack world
performances actors tarzan singing evil
played brilliant soldier voice humans
supporting recommend america singer aliens
director quite country sing human
oscar performance americans musical creatures
roles performances during roll miike
actress perfect men fan monsters
excellent drama us metal apes
screen without government concert clark
plays beautiful jungle playing burton
award human vietnam hear tim
work moving ii fans outer
playing world political prince men
gives recommended against especially moon
topic 53 topic 54 topic 63 topic 89 topic 97
-------- -------- -------- -------- --------
scott money funny dead didn
gary budget comedy zombie thought
streisand actors laugh gore wasn
star low jokes zombies ending
hart worst humor blood minutes
lundgren waste hilarious horror got
dolph 10 laughs flesh felt
career give fun minutes part
sabrina want re body going
role nothing funniest living seemed
temple terrible laughing eating bit
phantom crap joke flick found
judy must few budget though
melissa reviews moments head nothing
zorro imdb guy gory lot
gets director unfunny evil saw
barbra thing times shot long
cast believe laughed low interesting
short am comedies fulci few
serial actually isn re half
'''
这次我们提取的主题似乎更加具体,不过很多都难以解读。主题 7 似乎是关于恐怖电影和 惊悚片,主题 16 和 54 似乎是关于不好的评论,而主题 63 似乎主要是关于喜剧的正面评论。如果想要利用发现的主题做出进一步的推断,那么我们应该查看分配给这些主题的文 档,以验证我们通过查看每个主题排名最靠前的单词所得到的直觉。例如,主题 45 似乎是关于音乐的。我们来查看哪些评论被分配给了这个主题:
# 按主题45“music”进行排序
music = np.argsort(document_topics100[:, 45])[::-1]
# 打印出这个主题最重要的前5个文档
for i in music[:10]:
# 显示前两个句子
print(b".".join(text_train[i].split(b".")[:2]) + b".\n")
'''
b'I love this movie and never get tired of watching. The music in it is great.\n'
b"I enjoyed Still Crazy more than any film I have seen in years. A successful band from the 70's decide to give it another try.\n"
b'Hollywood Hotel was the last movie musical that Busby Berkeley directed for Warner Bros. His directing style had changed or evolved to the point that this film does not contain his signature overhead shots or huge production numbers with thousands of extras.\n'
b"What happens to washed up rock-n-roll stars in the late 1990's? They launch a comeback / reunion tour. At least, that's what the members of Strange Fruit, a (fictional) 70's stadium rock group do.\n"
b'As a big-time Prince fan of the last three to four years, I really can\'t believe I\'ve only just got round to watching "Purple Rain". The brand new 2-disc anniversary Special Edition led me to buy it.\n'
b"This film is worth seeing alone for Jared Harris' outstanding portrayal of John Lennon. It doesn't matter that Harris doesn't exactly resemble Lennon; his mannerisms, expressions, posture, accent and attitude are pure Lennon.\n"
b"The funky, yet strictly second-tier British glam-rock band Strange Fruit breaks up at the end of the wild'n'wacky excess-ridden 70's. The individual band members go their separate ways and uncomfortably settle into lackluster middle age in the dull and uneventful 90's: morose keyboardist Stephen Rea winds up penniless and down on his luck, vain, neurotic, pretentious lead singer Bill Nighy tries (and fails) to pursue a floundering solo career, paranoid drummer Timothy Spall resides in obscurity on a remote farm so he can avoid paying a hefty back taxes debt, and surly bass player Jimmy Nail installs roofs for a living.\n"
b"I just finished reading a book on Anita Loos' work and the photo in TCM Magazine of MacDonald in her angel costume looked great (impressive wings), so I thought I'd watch this movie. I'd never heard of the film before, so I had no preconceived notions about it whatsoever.\n"
b'I love this movie!!! Purple Rain came out the year I was born and it has had my heart since I can remember. Prince is so tight in this movie.\n'
b"This movie is sort of a Carrie meets Heavy Metal. It's about a highschool guy who gets picked on alot and he totally gets revenge with the help of a Heavy Metal ghost.\n"
'''
可以看出,这个主题涵盖许多以音乐为主的评论,从音乐剧到传记电影,再到最后一条评论中难以归类的类型。查看主题还有一种有趣的方法,就是通过对所有评论的 document_ topics 进行求和来查看每个主题所获得的整体权重。我们用最常见的两个单词为每个主题命名。下图给出了学到的主题权重:
fig, ax = plt.subplots(1, 2, figsize=(10, 10))
topic_names = ["{:>2} ".format(i) + " ".join(words)
for i, words in enumerate(feature_names[sorting[:, :2]])]
# 两列的条形图:
for col in [0, 1]:
start = col * 50
end = (col + 1) * 50
ax[col].barh(np.arange(50), np.sum(document_topics100, axis=0)[start:end])
ax[col].set_yticks(np.arange(50))
ax[col].set_yticklabels(topic_names[start:end], ha="left", va="top")
ax[col].invert_yaxis()
ax[col].set_xlim(0, 2000)
yax = ax[col].get_yaxis()
yax.set_tick_params(pad=130)
plt.tight_layout()
最重要的主题是主题 97,它可能主要包含停用词,可能还有一些稍负面的单词;主题 16 明显是有关负面评论的;然后是一些特定类型的主题与主题 36 和 37,这二者似乎都包含表示赞美的单词。
除了几个不太具体的主题之外,LDA 似乎主要发现了两种主题:特定类型的主题与特定评分的主题。这是一个有趣的发现,因为大部分评论都由一些与电影相关的评论与一些证明或强调评分的评论组成。
在没有标签的情况下(或者像本章的例子这样,即使有标签的情况下),像 LDA 这样的主 题模型是理解大型文本语料库的有趣方法。不过 LDA 算法是随机的,改变 random_state 参数可能会得到完全不同的结果。虽然找到主题可能很有用,但对于从无监督模型中得出的任何结论都应该持保留态度,我们建议通过查看特定主题中的文档来验证你的直觉。 LDA.transform 方法生成的主题有时也可以用于监督学习的紧凑表示。当训练样例很少时, 这一方法特别有用。
10、小结与展望
本章讨论了处理文本 [ 也叫自然语言处理(NLP)] 的基础知识,还给出了一个对电影评论进行分类的示例应用。如果你想要尝试处理文本数据,那么这里讨论的工具应该是很好的出发点。特别是对于文本分类任务,比如检测垃圾邮件和欺诈或者情感分析,词袋模型提供了一种简单而又强大的解决方案。正如机器学习中常见的情况,数据表示是 NLP 应用的 关键,检查所提取的词例和 n 元分词有助于深入理解建模过程。在文本处理应用中,对于监督任务与无监督任务而言,通常都可以用有意义的方式对模型进行内省,正如我们在本章所见。在实践中使用基于 NLP 的方法时,你应该充分利用这一能力。
近年来,NLP 还有另一个研究方向不断升温,就是使用递归神经网络(recurrent neural network,RNN)进行文本处理。与只能分配类别标签的分类模型相比,RNN 是一种特别强大的神经网络,可以生成同样是文本的输出。能够生成文本作为输出,使得 RNN 非常适合自动翻译和摘要。Ilya Suskever、Oriol Vinyals 和 Quoc Le 的一篇技术性相对较强的文章 “Sequence to Sequence Learning with Neural Networks”(http://papers.nips.cc/ paper/5346-sequence-to-sequence-learning-with-neural-networks.pdf)对这一主题进行了介绍。在 TensorFlow 网站上可以找到使用 tensorflow 框架的更为实用的教程(https://www. tensorflow.org/tutorials/seq2seq)。