CornerNet(ECCV 2018)
去年暑假读到一篇ECCV 2018的文章,CornerNet,可以说是RCNN系和YOLO/SSD系垄断的基于深度学习的目标检测领域的一股清流了,想不到到现在有越来越多的这种基于关键点检测思路的研究了,于是我也决定将我看到的几篇这方面的文章梳理一下。那么这一篇博客就说说CornerNet这个搅局者吧。
CornerNet一句话解释就是将每个bounding box作为一对关键点进行检测,文章使用的关键点是左上角点和右下角点。这样做有很多好处:这是one-stage的;可以使用全卷积的网络;抛弃anchor机制(anchor的设置还是比较讲究的)。当然,想法是懂了,但问题有两个:1.如何准确地检测出关键点,应该使用怎样的特征;2.检测出关键点之后如何配对。
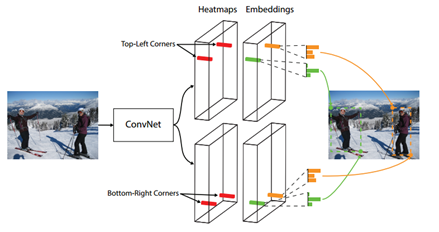
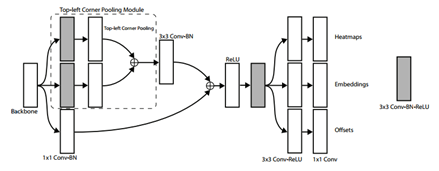
上图就是CornerNet的架构,可以看到网络主要分为三部分:特征提取;并行的两个分支分别进行左上和右下的关键点检测;关键点配对。
我们来看关键点检测是怎样的:
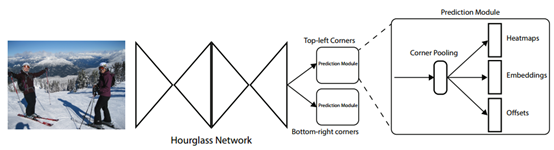
特征提取网络使用了骨骼关键点检测中常用的Hourglass网络,该网络的特点是由一个一个的hourglass模块组成的。每个hourglass会通过一系列的卷积层和maxpooling对输入的feature map进行降采样,然后再通过一系列的上采样和卷积层回到输入的尺寸。
左上和右下关键点分别有一个(组)heatmap,每个heatmap的通道数为检测物体的类别数目C,注意没有给background 的通道,尺寸和输入图片相同HxW。显然heatmap的每个通道上个每个像素值都表示原图上的对应点是该通道对应物体的corner的概率。这样的话,监督信号其实就是和原图尺寸一样0,1矩阵,是ground truth的corner的点的位置为1(positive position),其余的为0(negtive position)。在训练的时候,算法并不是将所有negtive position一视同仁的,而是减少了以positive postion为圆心一定半径内的negtive position的惩罚。最后作者搞出了下面的类似focal loss的损失函数:

上式中N是每张图片中物体的数目,y_cij是经过非归一化高斯增强的ground truth heatmap,能实现前面说的减小离positive position近的negtive position的惩罚。
在CNN中,降采样会使得原图中的(x,y)映射到特征图上的(x//n,y//n)(//表示除后下取整,n是降采样的stride),因此将heatmap中的位置信息remap到原图上时会有一定的损失,这对精确地目标检测以及小物体的检测的影响是很大的,因此文章提出为每个location预测一个offset来调整位置,这些offset的ground trouth如下:
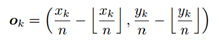
注意网络对左上和右下的heatmap分别预测一组offset map由所有类别通用,损失函数如下
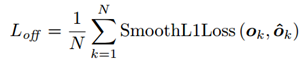
得到左上和右下关键点后,如何确定哪些点是属于一个物体的呢?其实骨骼关键点检测中也有一样的问题,检测到了所有的骨骼关键点后,哪些点是属于同一个人的。本文的方法受Associative Embedding(也是该实验室的工作。。。强不强)的启发,思想就是给每个检测到的corner预测一个embedding vector,关键是同一个物体的embedding vector应该是非常接近甚至一样的。这样再进行关键点配对的时候使用embedding vector之间的距离即可。embedding vector的训练的话,是不需要的label的,因为在意的不是具体的vector的值,而是vector之间的距离。只需要拉近(pull)同一物体corner的vector之间的距离,推远(push)不同物体corner的vector之间的距离。因此损失函数如下:
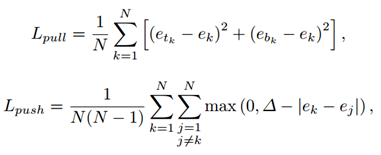
第一个式子中,N是物体的数目,e_tk和e_bk分别代表左上和右下的embedding vector,e_k是二者的平均。第二个式子就是要是不同物体的vector之间的距离超过一个margin。
直到现在,其实看起来都很顺利,如果搭好模型,依靠深度神经网络的强大的特征提取能力,模型也可能会work,但是效果一定会好吗?文章发现了一个很重要的问题:CNN提取特征依赖的是local visual evidence,但问题在于这对于识别corner可能帮助没有那么大,为什么呢?我们看下面的例子

可以看到,corner所在的位置其实是没有什么明显的local visual evidence。判断corner,我们更需要看该点所在的列和行的特征信息。因此作者提出了corner pooling,对于左上corner,则收集其右侧和下侧的信息;对于右下corner则收集左侧和上侧的信息。
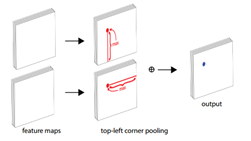
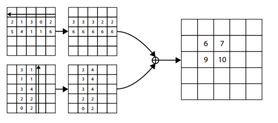
具体的计算可以用下式表示:
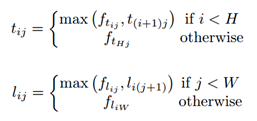
这两个corner pooling module就分别加在了两个corner的分支上
最后训练的话总的损失函数如下:
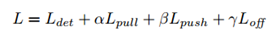
文章中α和β分别取0.1,γ取1。
虽然摆脱了anchor机制,但CornerNet在inference阶段还是要用到NMS,选择那些比较好的corner,文章中是分别选取了top-100的左上和右下的corner。
最后的实验效果也是很好的,就不放图了,而且作者也验证了corner pooling、radius penalty以及offset prediction的效果,其中offset prediction的影响是最大的。