不知道从什么时候开始,各大技术社区,技术群聊流行着 “用Rust重写!” ,放一张图(笑死…
这不, 随着大模型技术的流行,大家都在探索如何让大模型自动完成仓库级别(全程序)的代码重构,代码变换(Refactor,Transformer)

最近有很多类似的工作,将一个语言的工程项目转换为另一个语言工程项目。
- 字节在代码重构方面的探索
- C to Rust
- ICSE’23: Concrat: An Automatic C-to-Rust Lock API Translator for Concurrent Programs
- Context-aware Code Segmentation for C-to-Rust Translation using Large Language Models
- Towards Translating Real-World Code with LLMs: A Study of Translating to Rust
- Java to ArkTS
- ASE’24: LLM-Based Java Concurrent Program to ArkTS Converter
- ArkTS就是鸿蒙应用开发语言, TypeScript的一个超集

本文阅读: ICSE’25 “Using Large Language Models for inferring Checked C annotations”
原文是利用LLM去完成全程序代码重构,即: 将C语言项目的源代码转换成C语言的一个方言CheckedC,该C语言方言是内存安全的。
本文不关注它重构或者转换(Refactor/Transformer)的具体细节,而是关注整个Whole Program Transformer框架,具体细节可以查看原文。
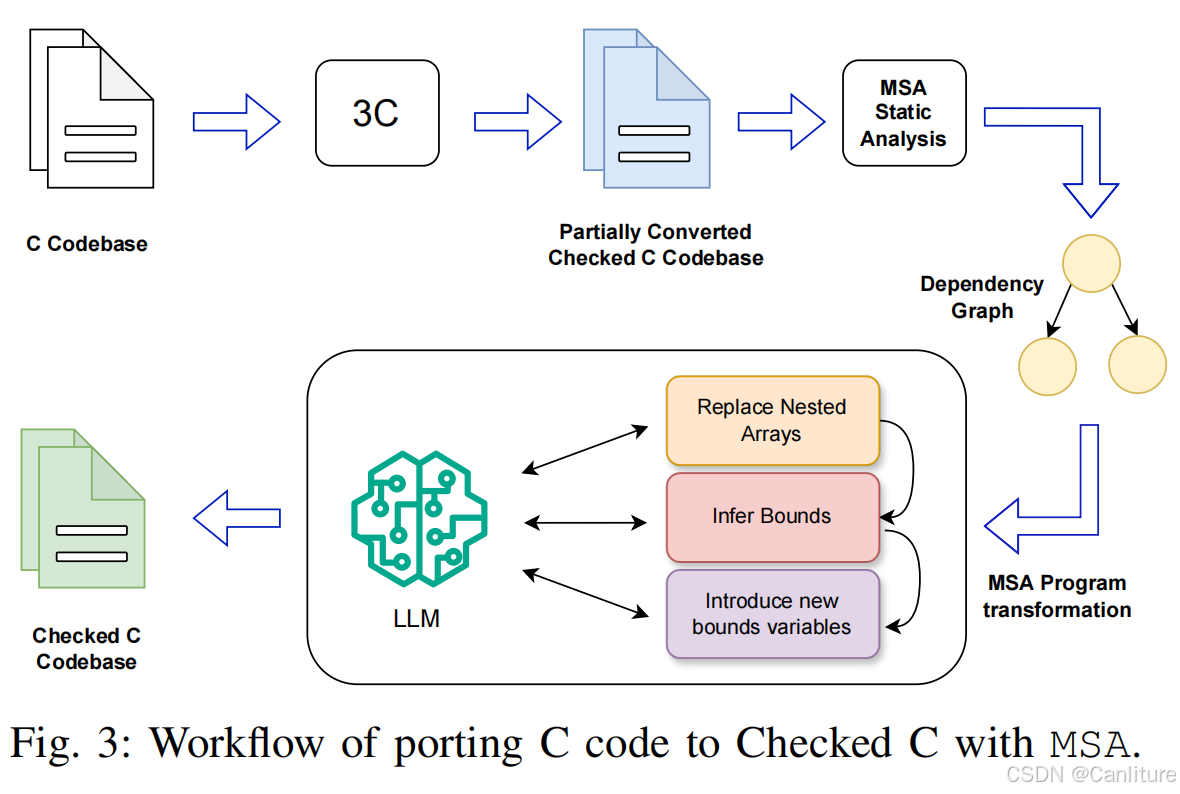
1. 依赖图构造 (Dependency Graph Generation)
核心方法学就是:渐进式代码分析(模块化代码分析). 推荐看我之前推荐的一篇文章:SOAP’24 Interleaving Static Analysis and LLM Prompting
由于大模型上下文窗口的限制,我们不可能把所有的工程文件一股脑扔给LLM,而是将大的任务拆分成更小的任务,每个任务的上下文大小就足够小,可以交给大模型去完成。
SOAP'24 Interleaving Static Analysis and LLM Prompting中提到的拆分方法是按函数级别去拆分,即构造函数调用图,然后对调用图拓扑排序,自底向上进行LLM与静态分析交互的代码分析。
但是在代码重构这个领域,按函数级别去拆分仍然不够,因为我们期望将程序中每个元素,包括数据结构,类型定义,宏定义,全局变量定义等也进行重构,很显然单纯构造全程序函数调用图仍然不够。
于是,在之前的函数调用图之上进行扩展。
- 如果一个函数内用到了某个类型,那么该函数也应该有一条边连接到这个类型的定义。
- 如果一个函数内用到了某个全局变量,那么该函数也应该有一条边连接到这个全局变量的定义。
- 类似地, 可以递归地进行边的连接:
最后的依赖图大概长这样:
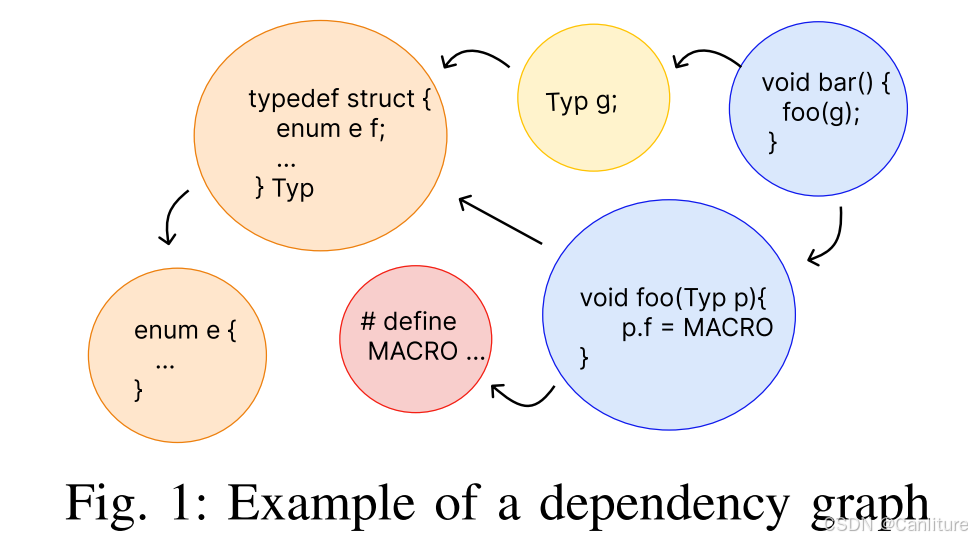
下面给出依赖图的具体定义:
依赖图的节点为程序中所有的top-level declarations。例如:
- 函数: 函数签名 + 函数体
- 类型声明: struct, union, enum
- 全局变量声明
- 宏定义
依赖图的边为有向边: n1 -> n2表示n1中用到了n2
- n1为函数。n1 -> n2,如果
- n2为n1中被调用的函数。
- 对于函数指针调用,直接连接n1到这个函数指针的类型声明
- n2为n1中出现的所有类型,全局变量,宏定义。
- n2为n1中被调用的函数。
- n1类型定义。n1 -> n2,如果
- n2为n1中出现的所有类型和宏定义
- n1全局变量声明。n1 -> n2,如果
- n2为n1中一定用到的类型或者宏定义
- n1为宏定义
- 宏定义没有出边
宏定义作者目前并没有太考虑.
2. 通用全程序变换框架 (Generic Whole-Program Transformation)
作者给出了一个通用的全程序变换算法框架:

算法的输入为:依赖图,Prompt模板。
其中,根据Transformation的不同,框架输入的具体Prompt就不同。下面是Prompt模板。

CheckedC Preamble 给大模型介绍CheckedC相关知识,例如内置的注解,语法规则等。(In-Context Learning)
模板中提供了几个模板变量,待具体问题去实例化这些变量:
- {{Task definition}}:描述LLM要执行的具体任务
- {{Task example}}:Few-shot learning,举几个例子。
- {{prelude}}:In-Context Learning,给它提供额外的相关的上下文。
- {{code}}:被变换的源代码文本
- {{refactor_history}}:之前的重构历史
- {{task_specific_code_elements}}:具体的任务
整个框架的工作流:
3. 实例化框架
之前介绍了作者的给出的算法框架,以及Prompt模板。作者将这个框架实例化为3个任务。即:在这个通用框架上扩展了3个任务实例:
- Replacing Nested Arrays with Structs
- Inferring Bounds Annotations
- Annotating Globals and Struct Fields
三个任务的Prompt分别是:



4. 实验结论
算法框架的有效性验证
- 不提供CheckedC知识背景,即使是小程序,LLM也不能推到出注解。
- 模块化分析更加高效得完成大小规模程序的全程序的代码变换。
- 最好让LLM一次分析一个函数,然后提供给它相关的依赖作为上下文
真实代码库的实验效果
- MSA能够推导出86%的3C无法推到出的指针注解
- MSA算法能够应用到要求复杂代码推理的真实代码场景
作为还拿vsftpd项目为例,与人工编辑作代码重构的对比,这里不展开了。详见原文。