目录
LMDeploy 框架的安装、量化和部署

A. 基础作业
使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
A.1 前置操作
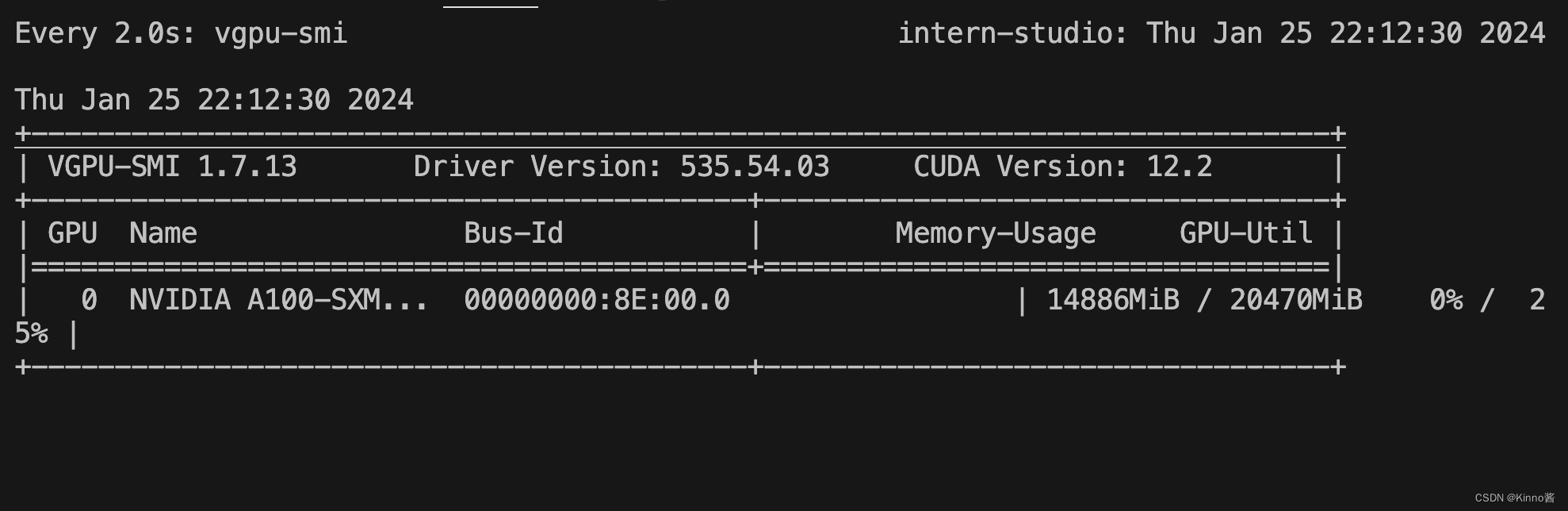
watch vgpu-smi
结果如下图所示,该窗口会实时检测 GPU 卡的使用情况。
A.2 配置环境
conda create -n lmdeploy --clone /share/conda_envs/internlm-base
conda activate lmdeploy
lmdeploy 没有安装,我们接下来手动安装一下,建议安装最新的稳定版。 如果是在 InternStudio 开发环境,需要先运行下面的命令,否则会报错。
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
由于默认安装的是 runtime 依赖包,但是我们这里还需要部署和量化,所以,这里选择 [all]。然后可以再检查一下 lmdeploy 包,如下图所示。
A.3 服务部署
Server/Client架构
我们把从架构上把整个服务流程分成下面几个模块。
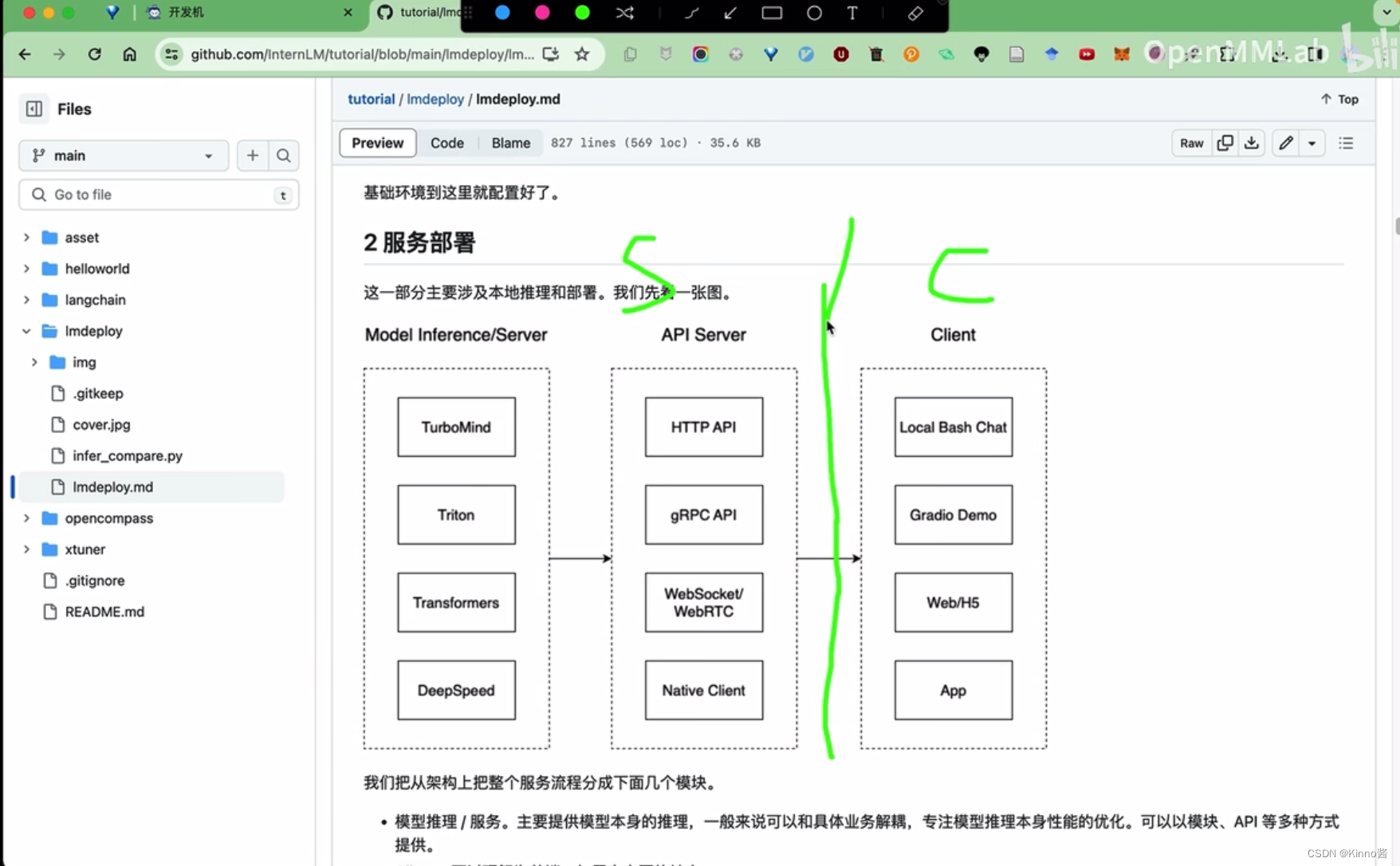
- 模型推理/服务。主要提供模型本身的推理,一般来说可以和具体业务解耦,专注模型推理本身性能的优化。可以以模块、API等多种方式提供。
- API Server。一般作为前端的后端,提供与产品和服务相关的数据和功能支持。
- Client。可以理解为前端,与用户交互的地方。
值得说明的是,以上的划分是一个相对完整的模型,但在实际中这并不是绝对的。比如可以把“模型推理”和“API Server”合并,有的甚至是三个流程打包在一起提供服务。
接下来,我们看一下lmdeploy提供的部署功能。
A.3.1模型转换
使用 TurboMind 推理模型需要先将模型转化为 TurboMind 的格式,目前支持在线转换和离线转换两种形式。在线转换可以直接加载 Huggingface 模型,离线转换需需要先保存模型再加载。
lmdeploy 支持直接读取 Huggingface 模型权重,目前共支持三种类型:
- 在 huggingface.co 上面通过 lmdeploy 量化的模型,如 llama2-70b-4bit, internlm-chat-20b-4bit
- huggingface.co 上面其他 LM 模型,如 Qwen/Qwen-7B-Chat
TurboMind 是一款关于 LLM 推理的高效推理引擎,基于英伟达的 FasterTransformer 研发而成。它的主要功能包括:LLaMa 结构模型的支持,persistent batch 推理模式和可扩展的 KV 缓存管理器。
在线转换
直接启动本地的 Huggingface 模型,如下所示。
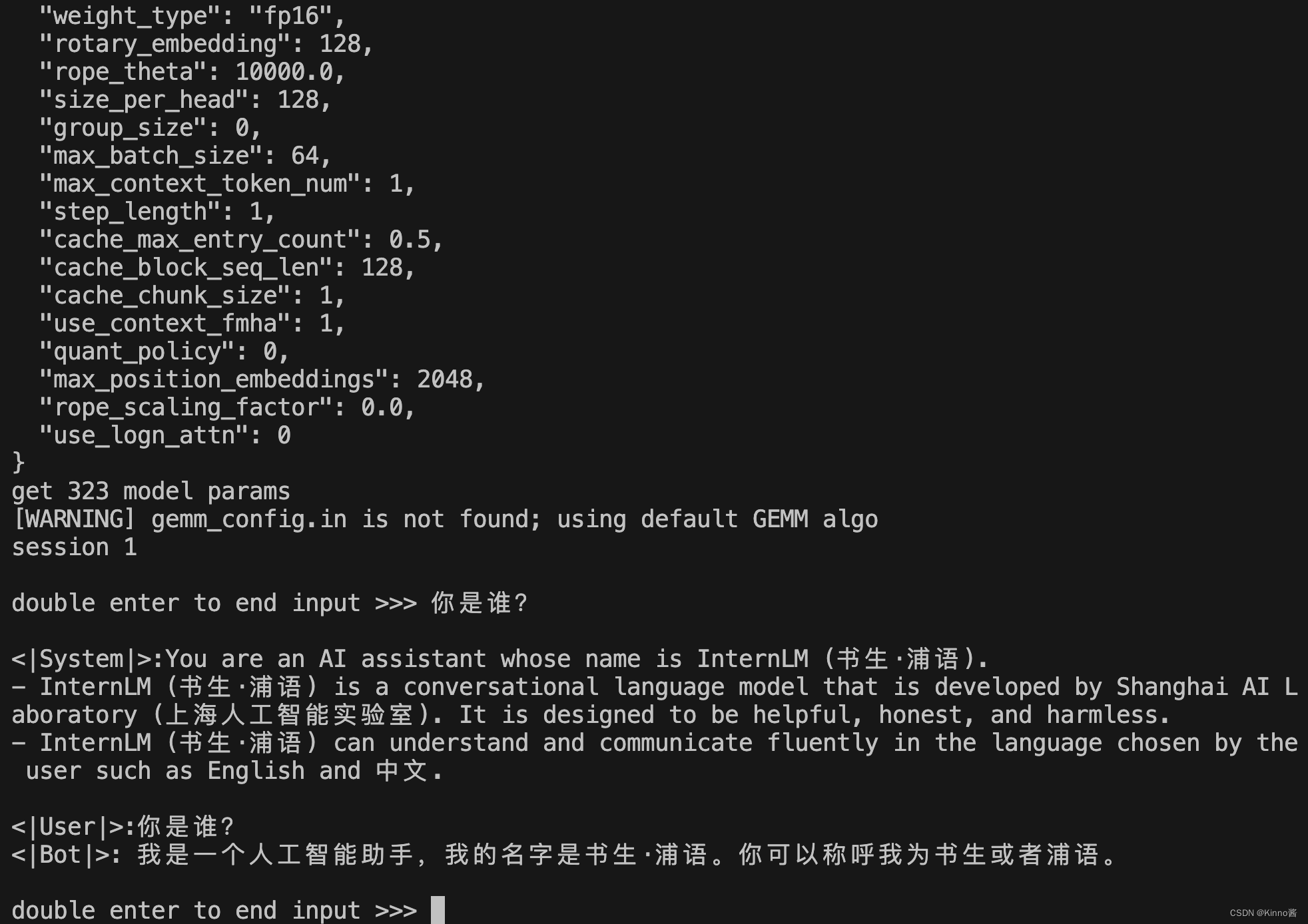
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b
以上命令都会启动一个本地对话界面,通过 Bash 可以与 LLM 进行对话。
离线转换
离线转换需要在启动服务之前,将模型转为 lmdeploy TurboMind 的格式,如下所示。这里我们使用官方提供的模型文件,就在用户根目录执行,如下所示。
# 转换模型(FastTransformer格式) TurboMind
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/
执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
A.3.2 TurboMind 推理+命令行本地对话(生成300字小故事)
模型转换完成后,我们就具备了使用模型推理的条件,接下来就可以进行真正的模型推理环节。
我们先尝试本地对话(Bash Local Chat),下面用(Local Chat 表示)在这里其实是跳过 API Server 直接调用 TurboMind。简单来说,就是命令行代码直接执行 TurboMind。所以说,实际和前面的架构图是有区别的。
这里支持多种方式运行,比如Turbomind、PyTorch、DeepSpeed。但 PyTorch 和 DeepSpeed 调用的其实都是 Huggingface 的 Transformers 包,PyTorch表示原生的 Transformer 包,DeepSpeed 表示使用了 DeepSpeed 作为推理框架。Pytorch/DeepSpeed 目前功能都比较弱,不具备生产能力,不推荐使用。
# Turbomind + Bash Local Chat
lmdeploy chat turbomind ./workspace
启动后就可以和它进行对话了,如下图所示。
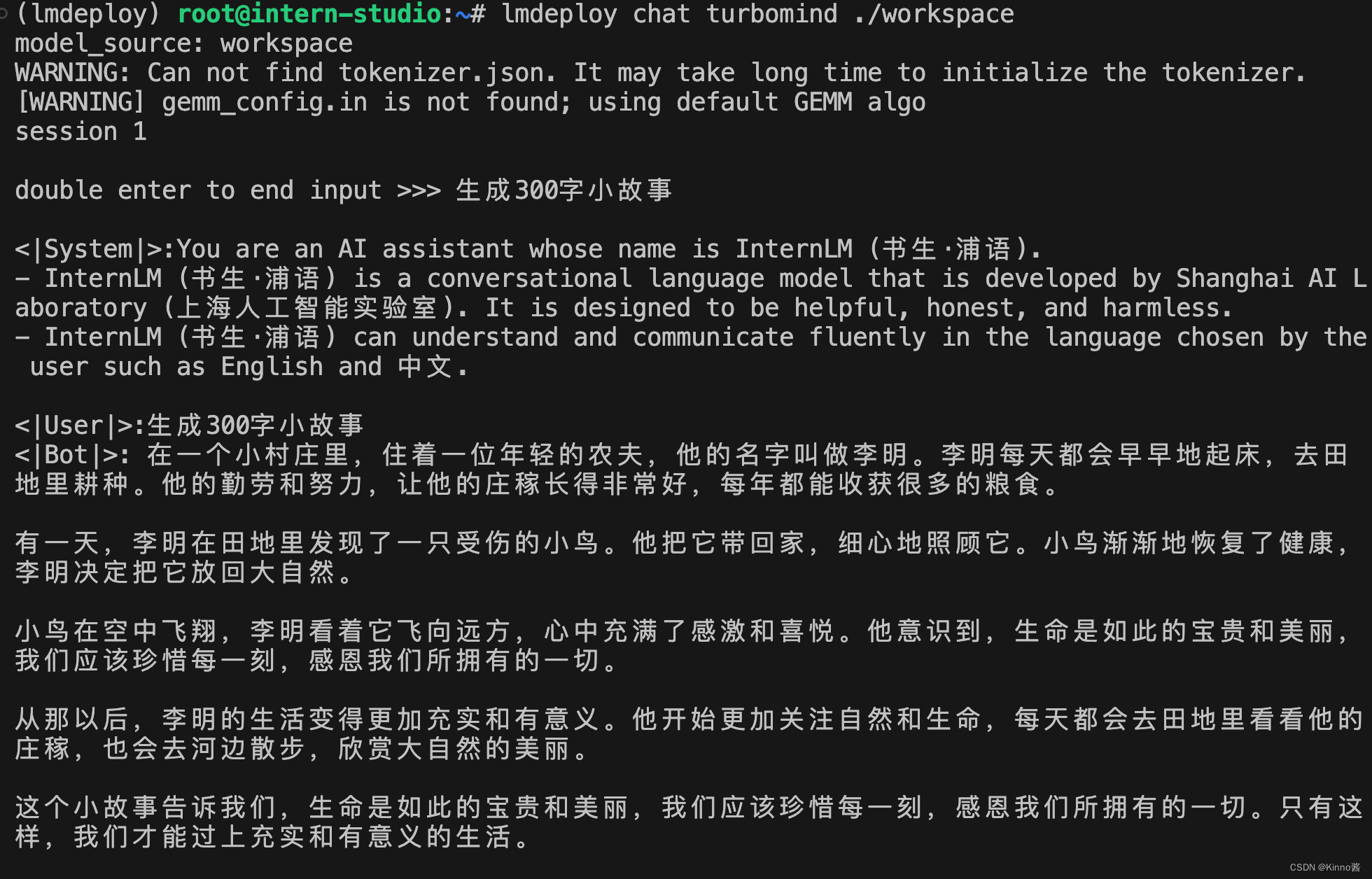
输入后两次回车,退出时输入exit 回车两次即可。此时,Server 就是本地跑起来的模型(TurboMind),命令行可以看作是前端。
A.3.3 TurboMind推理+API服务(成 300 字的小故事)
在上面的部分我们尝试了直接用命令行启动 Client,接下来我们尝试如何运用 lmdepoy 进行服务化。
”模型推理/服务“目前提供了 Turbomind 和 TritonServer 两种服务化方式。此时,Server 是 TurboMind 或 TritonServer,API Server 可以提供对外的 API 服务。
首先,通过下面命令启动服务。
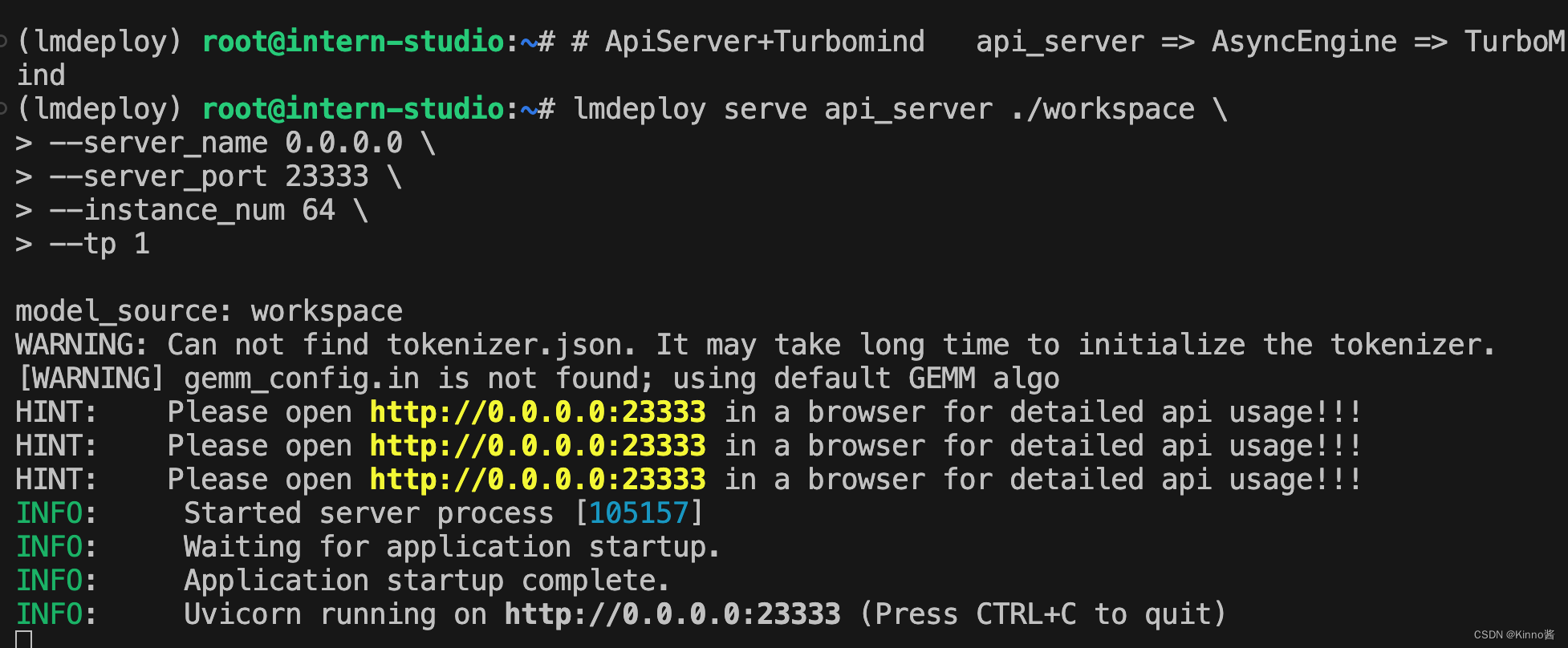
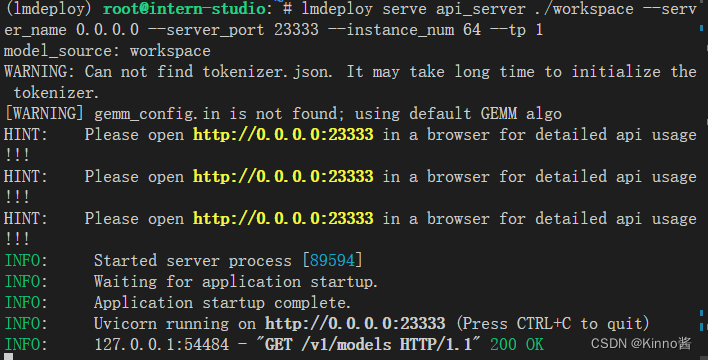
# ApiServer+Turbomind api_server => AsyncEngine => TurboMind
lmdeploy serve api_server ./workspace \
--server_name 0.0.0.0 \
--server_port 23333 \
--instance_num 64 \
--tp 1
上面的参数中 api_server ./workspace 表示用的模型来自的路径,server_name 和 server_port 分别表示服务地址和端口,tp 参数我们之前已经提到过了,表示 Tensor 并行。还剩下一个 instance_num 参数,表示实例数,可以理解成 Batch 的大小。执行后如下图所示。
然后,我们可以新开一个窗口,执行下面的 Client 命令。
# ChatApiClient+ApiServer(注意是http协议,需要加http)
lmdeploy serve api_client http://localhost:23333

显存占用:
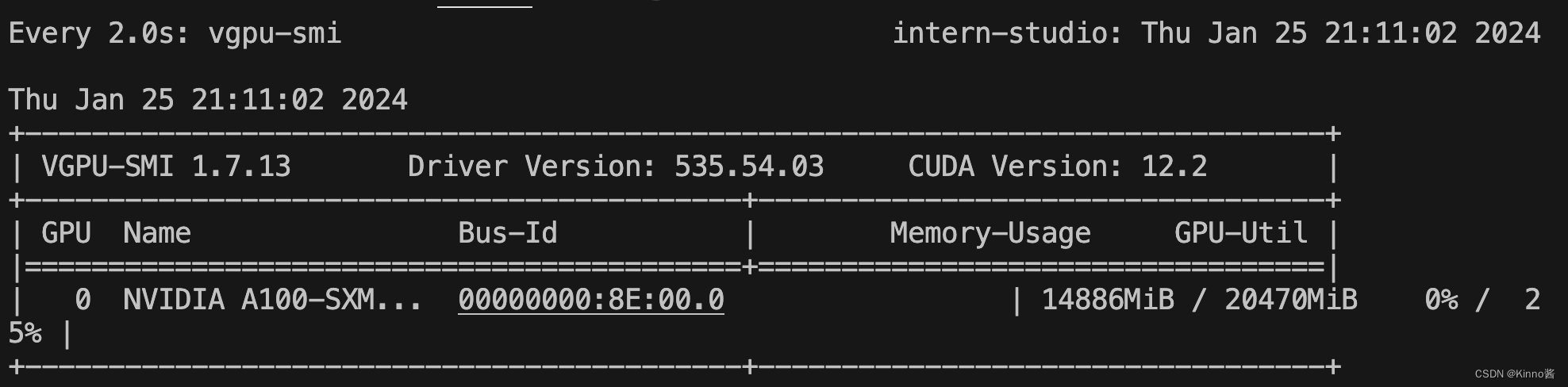
注意,这一步由于 Server 在远程服务器上,所以本地需要做一下 ssh 转发才能直接访问(与第一部分操作一样),命令如下:
ssh -CNg -L 23333:127.0.0.1:23333 [email protected] -p 35681
而执行本命令需要添加本机公钥,公钥添加后等待几分钟即可生效。ssh 端口号就是下面图片里的 35681。
FastAPI生成的接口文档:
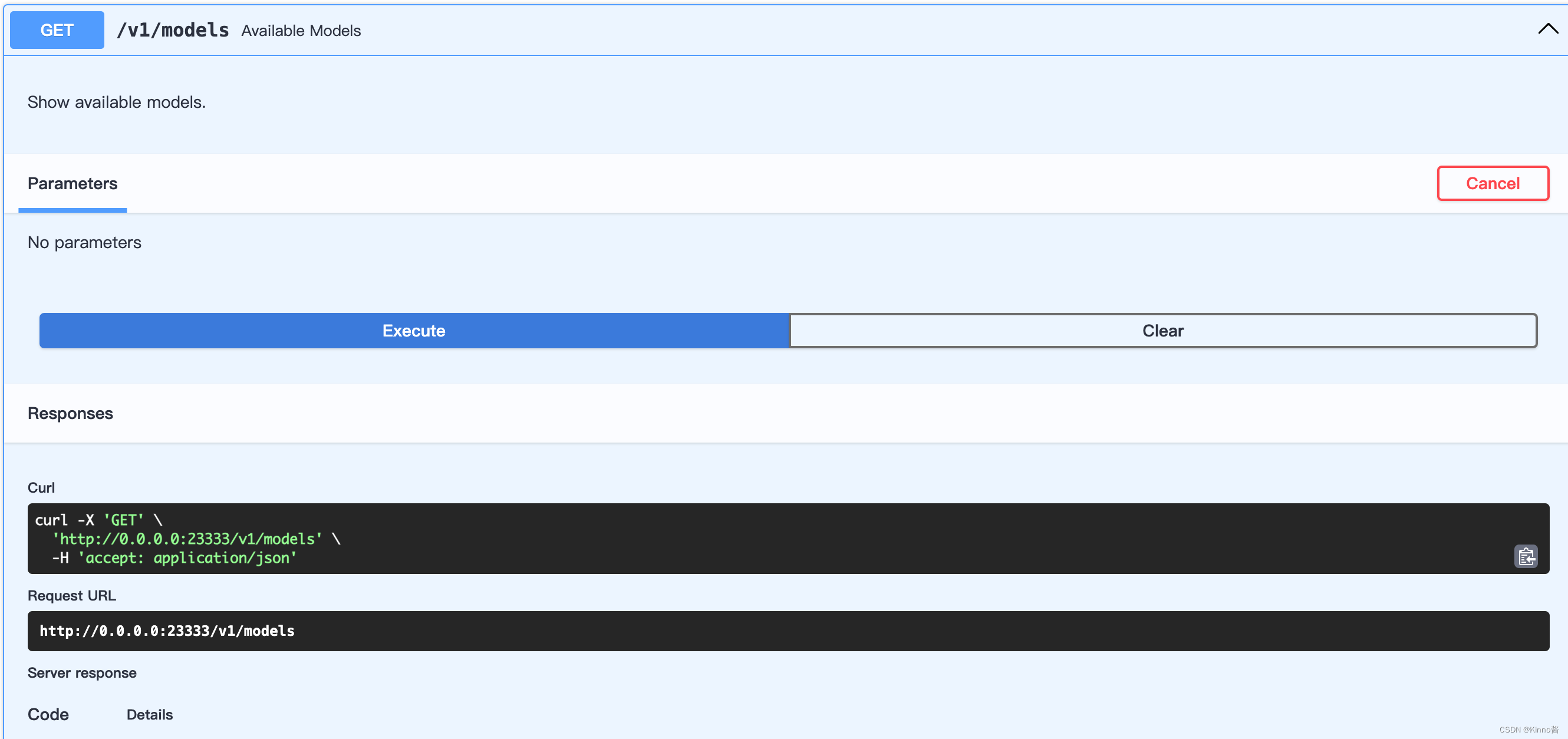
提取这里的模型名称是internlm-chat-7b,调用接口http://0.0.0.0:23333/v1/chat/completions
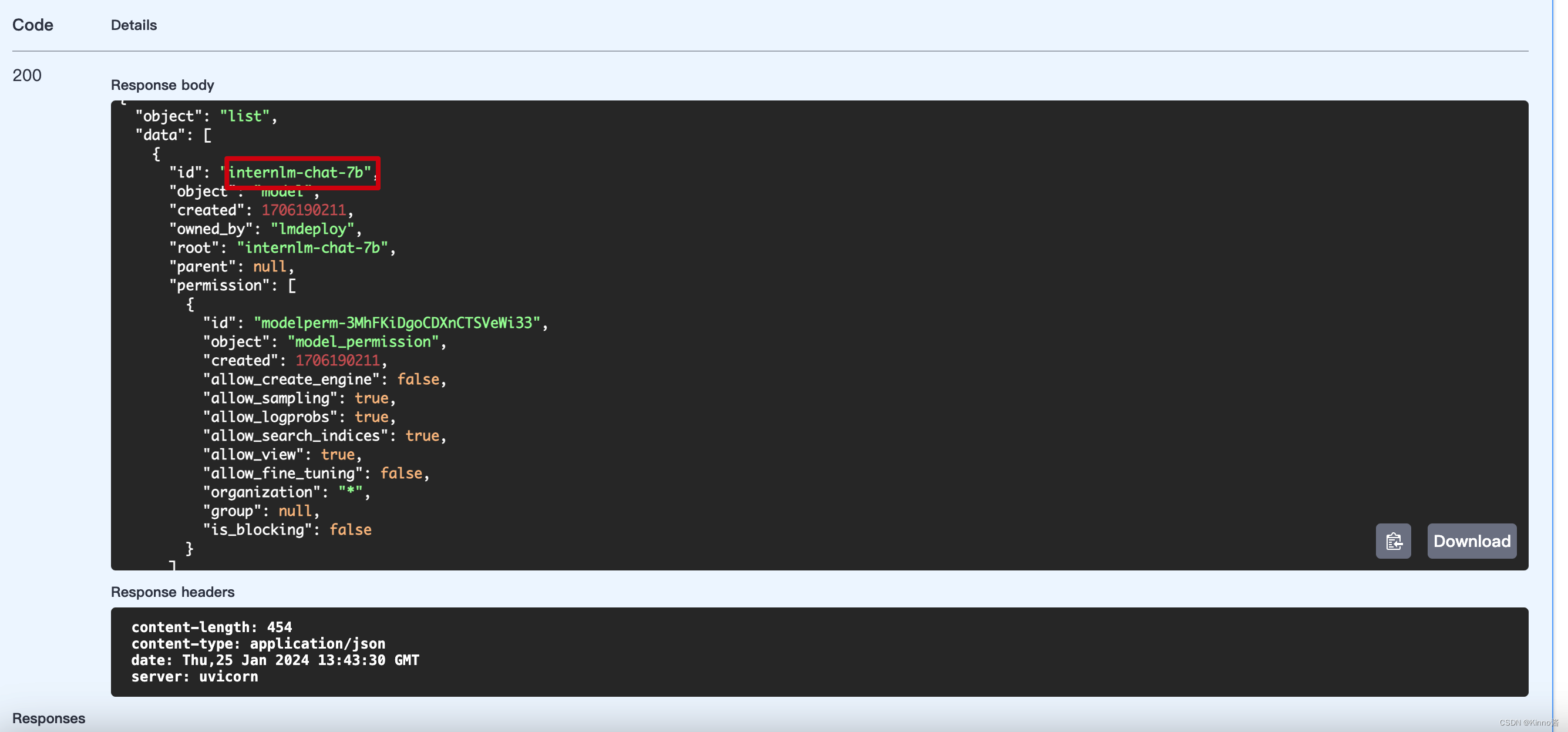
Response body:
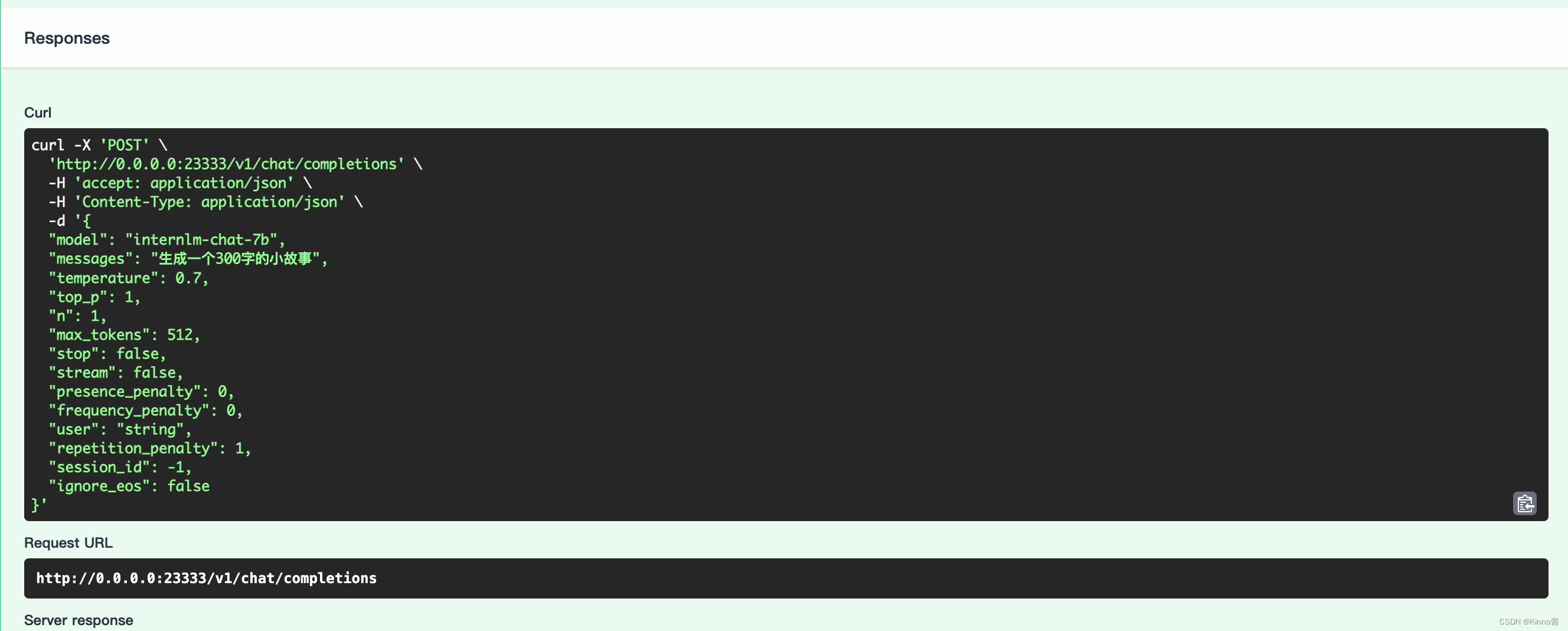
{
"id": "5432",
"object": "chat.completion",
"created": 1706190686,
"model": "internlm-chat-7b",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": ",关于友谊和信任的。\n\n小明和小华是两个从小一起长大的好朋友,他们一起上学,一起玩耍,一起成长。他们的友谊是那么的深厚,那么的不可分割。\n\n但是,一天,小明突然告诉小华说他要离开这个城市,去另一个城市发展。小华听了非常难过,他不想和朋友分开。但是,小明告诉他,他要去追求自己的梦想,他不能放弃。\n\n小华听了非常感动,他知道小明是为了他好,他相信小明的选择。于是,他决定支持小明,他告诉小明,他会一直等他,等他回来。\n\n小明听了非常感动,他知道小华是真正的信任他,他感到非常幸福。他告诉小华,他会回来,他不会放弃他的梦想。\n\n从此以后,小明和小华的友谊更加深厚,他们互相支持,互相鼓励,一起度过了许多美好的时光。他们知道,无论发生什么事情,他们都可以依靠对方,因为他们相信对方,他们信任对方。\n\n这是一个关于友谊和信任的小故事,它告诉我们,真正的友谊不是建立在利益上,而是建立在信任和理解上。只有当我们信任和理解对方,我们才能真正地拥有友谊。"
},
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 7,
"total_tokens": 250,
"completion_tokens": 243
}
}
A.3.4 TurboMind推理+Gradio服务(生成300字小故事)
这一部分主要是将 Gradio 作为前端 Demo 演示。在上一节的基础上,我们不执行后面的 api_client 或 triton_client,而是执行 gradio。
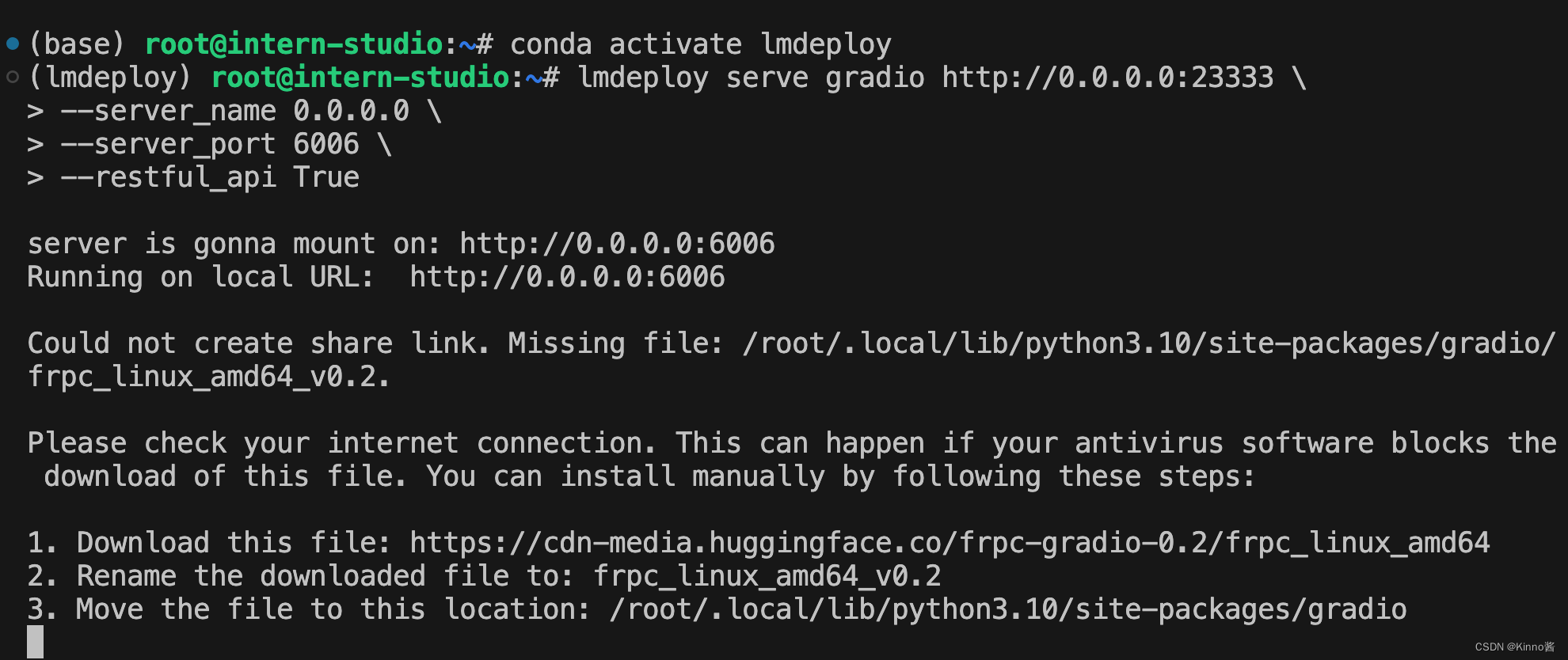
由于 Gradio 需要本地访问展示界面,因此也需要通过 ssh 将数据转发到本地。命令如下:
ssh -CNg -L 6006:127.0.0.1:6006 [email protected] -p <你的 ssh 端口号>
TurboMind 服务作为后端:
API Server 的启动和上一节一样,这里直接启动作为前端的 Gradio。
启动Gradio和ApiServer服务
# Gradio+ApiServer。必须先开启 Server,此时 Gradio 为 Client
lmdeploy serve gradio http://0.0.0.0:23333 \
--server_name 0.0.0.0 \
--server_port 6006 \
--restful_api True
在本地绑定端口:

在本地访问http://localhost:6006/,输入“讲一个300字的睡前故事”
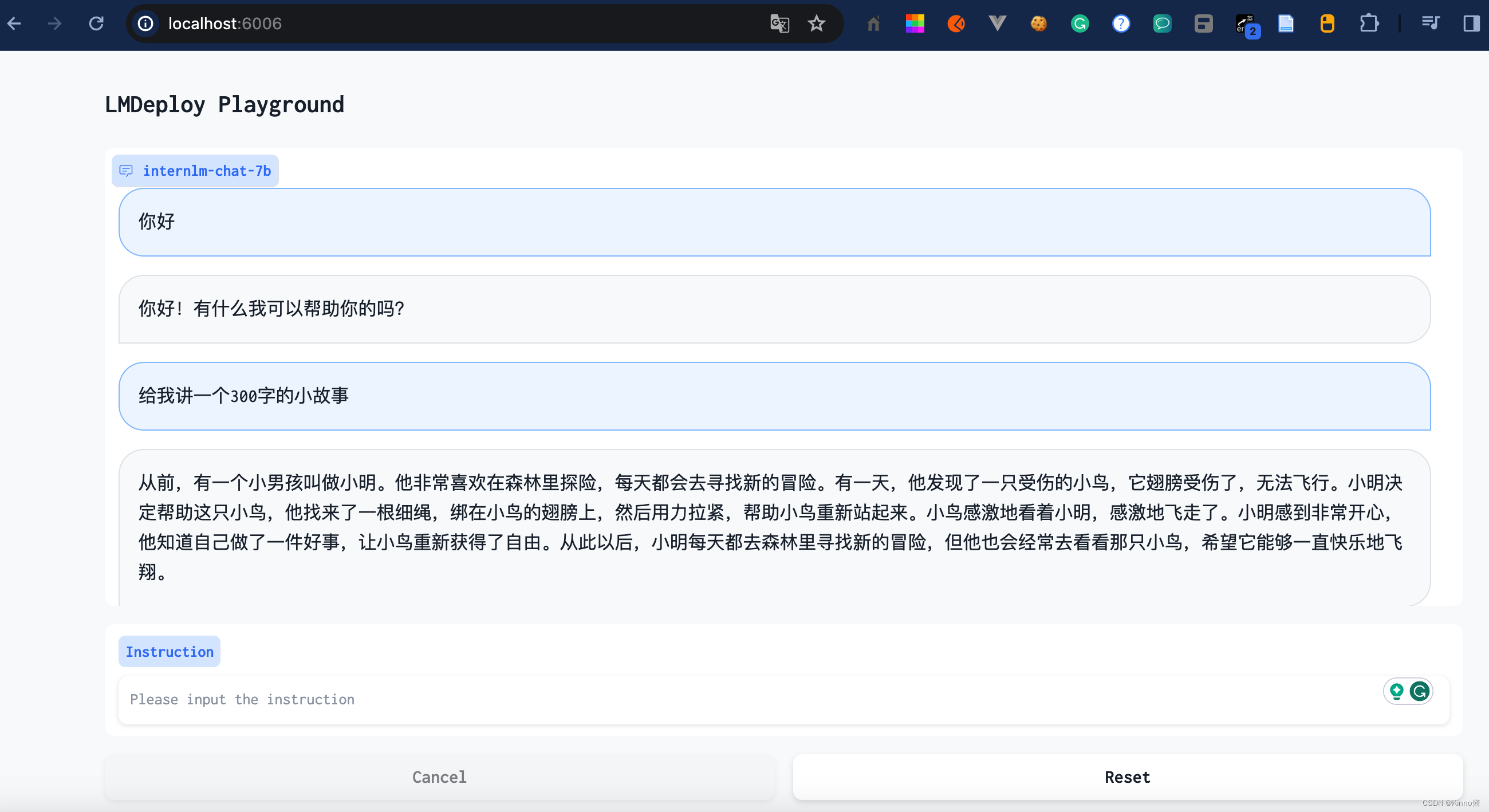
模型加载好大概14G