selenium和爬虫之间的关联?
selenium之前还有一个基于Webkit的无界面浏览器phantomjs,它们都是一个用于Web应用程序自动化测试的工具。只不过Selenium直接运行在浏览器中,就像真正的用户在操作一样,所以数据提取方面很轻松,phantomjs差不多被selenium淘汰了。
selenium作用:
1、非常便捷的捕获到任意形式的数据,因为page_source属性可以返回所有当前页面被加载出来的页面数据,不管你动不动态加载,真正实现了可见即可容易得,但是爬取数据效率相对要低一点。
2、帮我们实现模拟登录,有些大型的网站确实不好模拟。就可以用selenium。
selenium捕获动态加载数据:
selenium在python中的使用方法:
1、下载chromedriver,是基于浏览器的selenium驱动程序,作用是让selenium能启动谷歌浏览器,一定要和你自己浏览器(一般都用谷歌)的版本对应上。在谷歌地址栏输入chrome://version/可以查看谷歌浏览器版本,第一行就能看到。然后再去http://chromedriver.storage.googleapis.com/index.html下载对应的谷歌浏览器的驱动软件即可。
2、pip install selenium

案例:爬取药监总局的前三页的企业名称,药监总局的页面数据都是ajax动态加载出来的:先爬第一页(首页)
http://125.35.6.84:81/xk/
使用selenium的代码如下:
# 爬药监总局第一页
from selenium import webdriver
from lxml import etree
# 我没有把驱动程序加到环境变量,所以要指定绝对路径
bro = webdriver.Chrome(executable_path='../chromedriver_win32/chromedriver.exe')
url = 'http://125.35.6.84:81/xk/'
bro.get(url)
# page_source属性可以返回所有当前页面被加载出来的页面数据
page_text = bro.page_source
# 解析企业名称(动态加载数据)
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="gzlist"]/li')
for li in li_list:
name = li.xpath('./dl/@title')[0]
print(name)
# 关闭浏览器
bro.quit()
运行之后,浏览器会自动打开:
药监总局每一页的url栏都是定死的http://125.35.6.84:81/xk/,我们点击页码的时候,它是后台ajax请求动态生成的数据。使用selenium的好处就是,我不需要管你是ajax还是不是ajax,我直接按浏览器上显示的页面(elements)解析就行了,page_source拿到的就是elements(包括了ajax请求到的)。
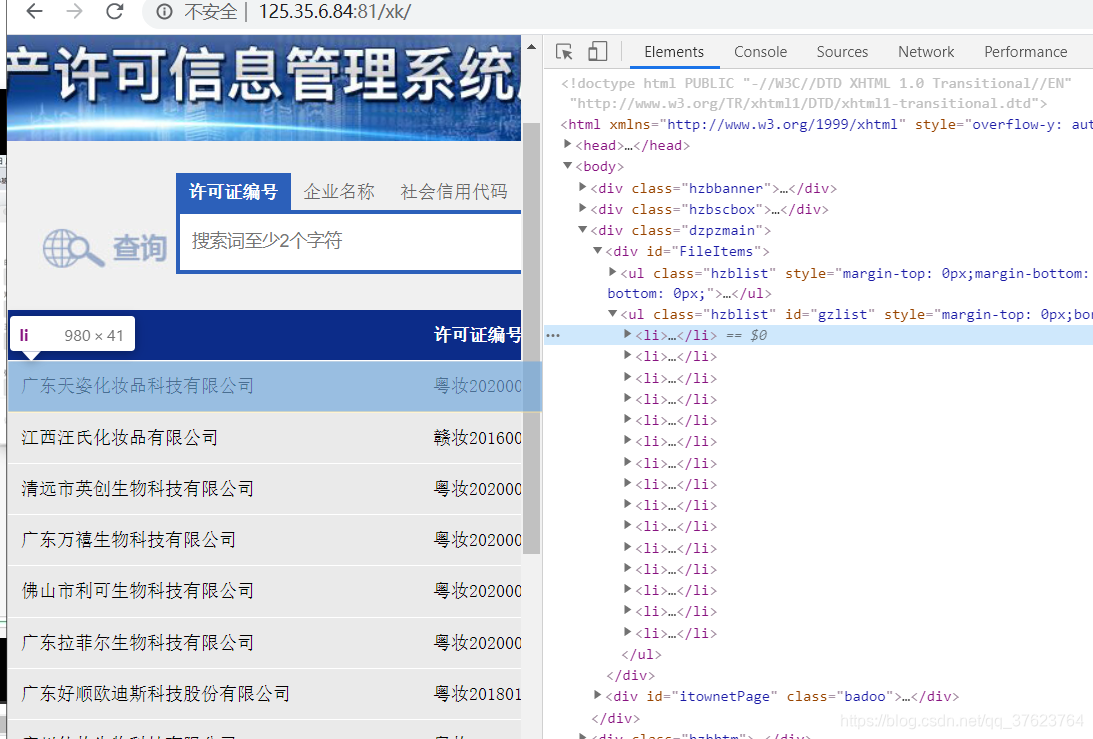
这是第一页(首页)数据:
那怎样爬前三页数据呢?

# 爬药监总局前三页
import time
from selenium import webdriver
from lxml import etree
bro = webdriver.Chrome(executable_path='../chromedriver_win32/chromedriver.exe')
url = 'http://125.35.6.84:81/xk/'
bro.get(url)
# page_source属性可以返回所有当前页面被加载出来的页面数据
page_text = bro.page_source
all_page_text = [page_text]
# 控制点击下一页的次数
for i in range(3):
# 进行下一页按钮的定位并且对下一页进行点击
next_page_tag = bro.find_element_by_xpath('//*[@id="pageIto_next"]')
next_page_tag.click()
# 用来观看自动化的点击效果
time.sleep(2)
all_page_text.append(bro.page_source)
# 解析企业名称(动态加载数据)
for page_text in all_page_text:
tree = etree.HTML(page_text)
li_list = tree.xpath('//*[@id="gzlist"]/li')
for li in li_list:
name = li.xpath('./dl/@title')[0]
print(name)
# 关闭浏览器
time.sleep(2)
bro.quit()
我们发现selenium使用非常简单,除了不需要考虑ajax以外,完全不用考虑反爬,因为它就是开启的一个可自动控制的真实浏览器。虽然效率有点低,但是准确度高,掌握一下page_source属性使用和怎样用方法定位浏览器上的按钮即可,如:使用xpath定位,使用id,class定位都可以。
selenium模拟登录:就别整古诗网那种简单的了,去看看12306的登录
https://kyfw.12306.cn/otn/login/init
见到图片验证,那肯定要找打码平台,还是使用我们前面破古诗文登录页时,使用的超级鹰,前面我们破解古诗文是通过解析拿到验证码图片url,再拿到图片存到本地,进行打码,然后把结果带上请求登录接口即可登录。那现在,我们用selenium做模拟登录,还可以用同样的方法吗?(重点)
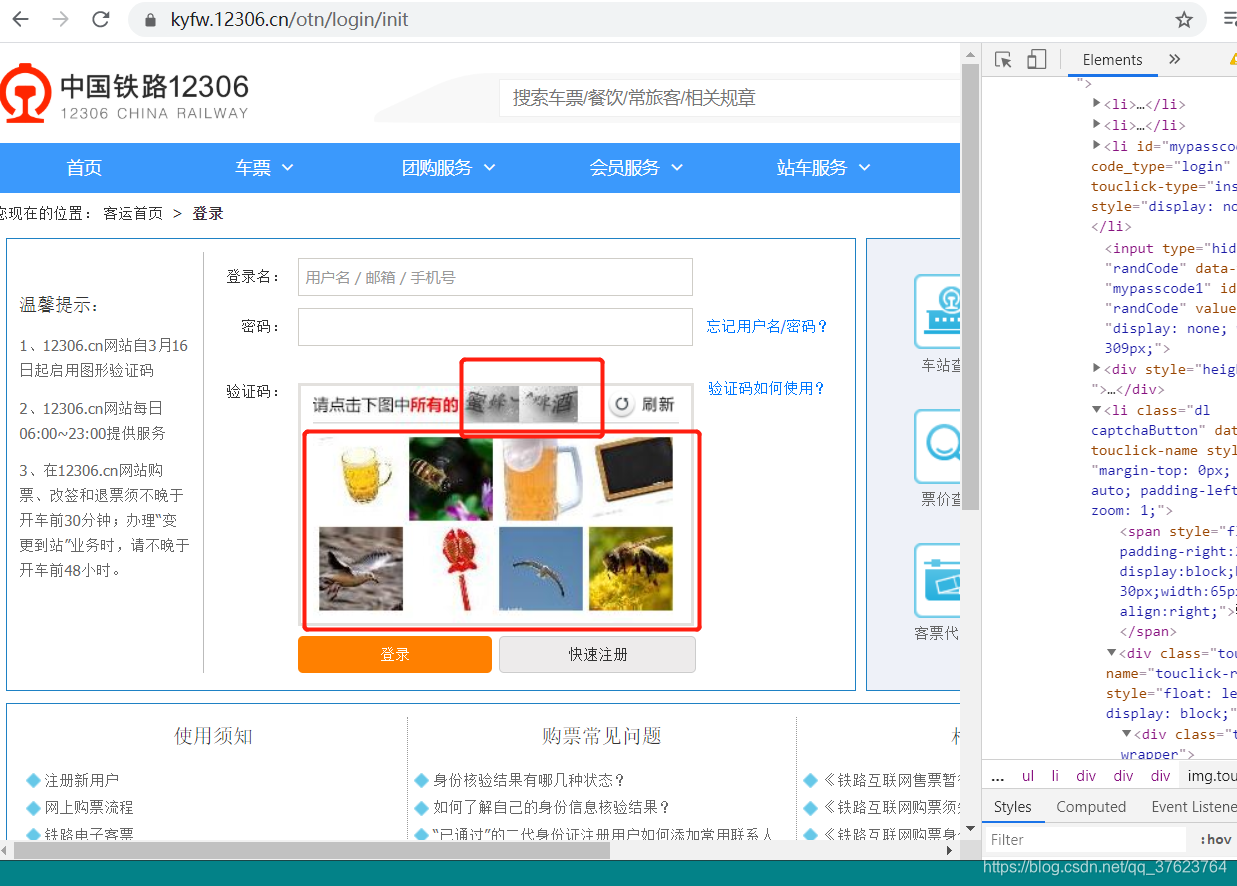
肯定是不行,这样理解:前面古诗文,我们是全程在模拟登录,做到了只请求一次登陆页面,拿到打码结果马上请求登录接口,而使用selenium,会自动打开浏览器登陆页面,相当于拿了一次验证码图片,我们再去单独请求验证码url拿图片来打码,就相当于是第二次请求验证码图片了,那这两次的验证码图片肯定是不一样的。所以归根结底原因就是selenium会自动打开浏览器。所以不能单独去请求,要截屏,selenium第一次打开浏览器我们就截屏,把截到的验证码图片拿给超级鹰打码,就能保证打码图片跟第一次打开浏览器时的验证码图片一致。
先下载个截屏python包:
pip install Pillow
from PIL import Image
代码如下有详细步骤:
from PIL import Image # 使用进行截图裁剪
bro = webdriver.Chrome(executable_path='../chromedriver_win32/chromedriver.exe')
url = 'https://kyfw.12306.cn/otn/login/init'
# 打开浏览器页面
bro.get(url)
# 为了保证验证码图片可以被刷新出来(验证码图片肯定是个后台ajax)
time.sleep(2)
# 定位到用户名标签
username_tag = bro.find_element_by_id('username')
# 模拟你自己输入用户名
username_tag.send_keys('你的用户名')
# 定位到密码标签
password_tag = bro.find_element_by_id('password')
# 模拟你自己输入密码
password_tag.send_keys('你的密码')
# 验证码识别处理:验证码应该被截屏截取下来而不应该单独再发一次请求
bro.save_screenshot('./main.png') # 表示登陆页面整张图片
# 在main.png里边进行验证码的局部图片进行精确踩点截取
# 必须将验证码图片的左下角和右下角两点坐标读到(人家源码这样写的)
code_img_tag = bro.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img')
location = code_img_tag.location # 拿到验证码图片标签在页面中的左下角x,y坐标
size = code_img_tag.size # 当前标签(验证码图片)的长宽
# 裁剪的矩形区域(传入左下角,右上角的坐标值)
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
# 先打开整张页面的图片
i = Image.open('./main.png')
# crop就是裁剪
frame = i.crop(rangle)
# 保存裁剪的验证码图片到本地
frame.save('./code.png')# code.png就是验证码图片
# TODO:这个位置放超级鹰打码的代码
# 点击登录按钮
bro.find_element_by_id('loginSub').click()
# 3秒后退出浏览器,为了让你看清楚自动输入过程
time.sleep(3)
bro.quit()
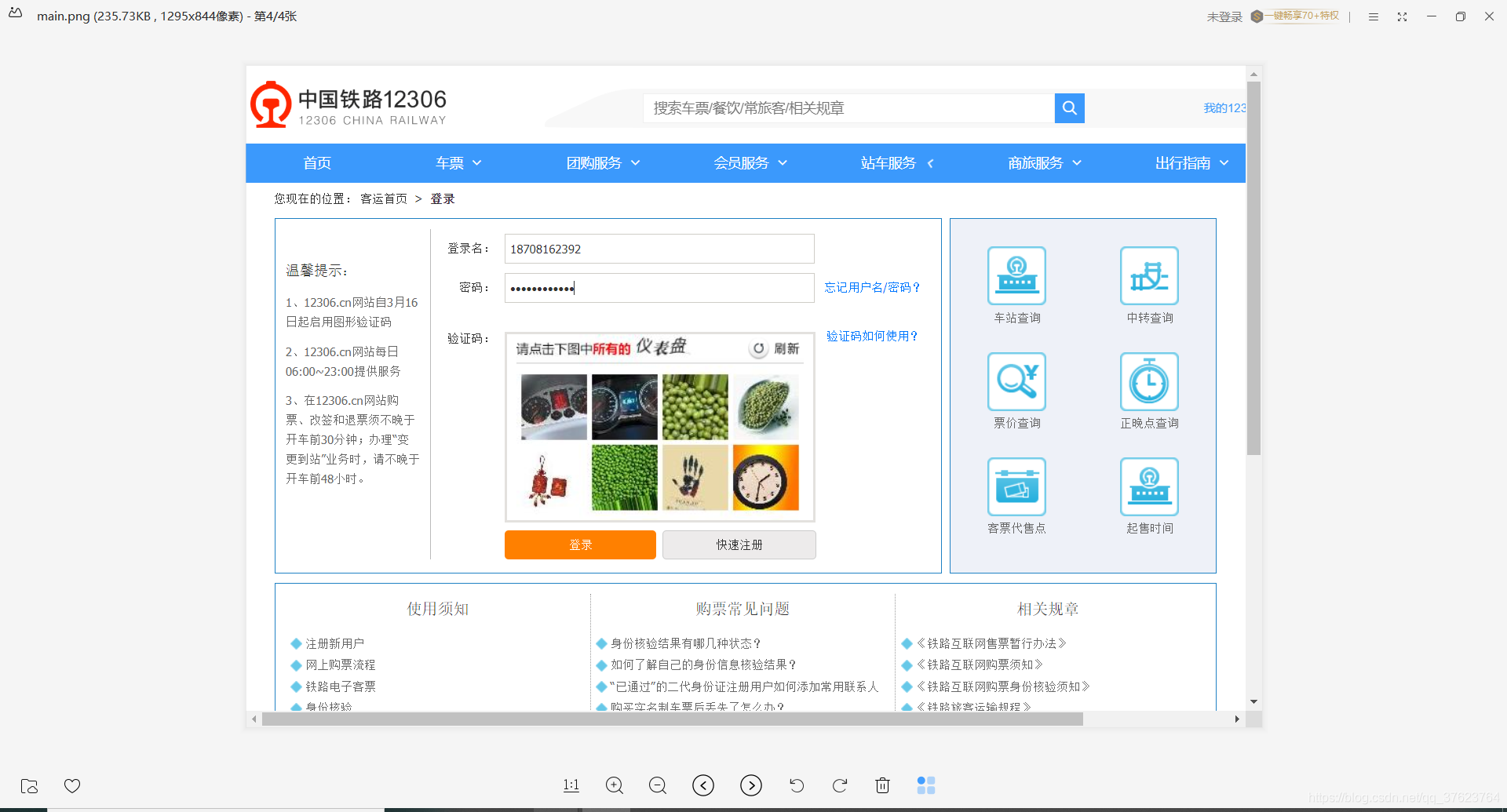
运行结果:这是全屏图片main.png
这是裁剪的验证码图片:code.png
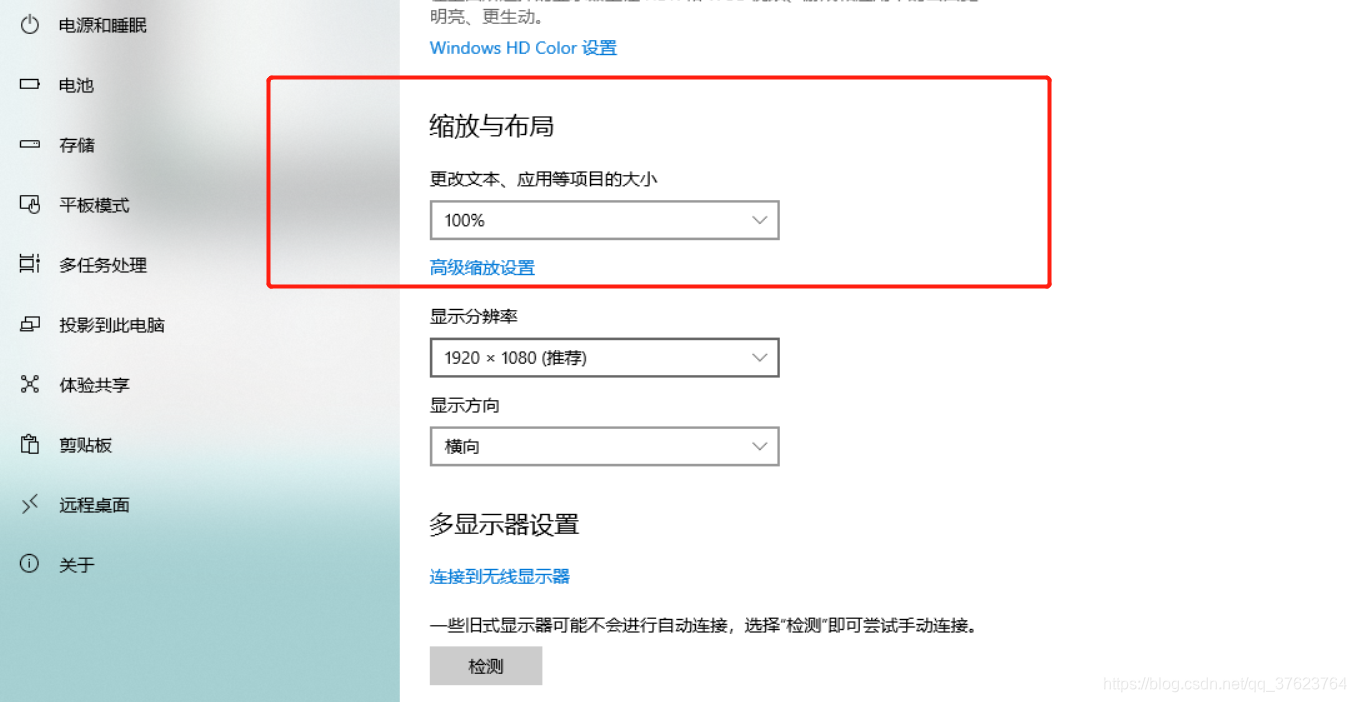
程序是没有问题,问题就出现在拿验证码的坐标没拿对:注意事项:进行在全屏中裁剪验证码图片时,必须要让你的电脑缩放比例为100%。如图:
再次运行:打码成功(这次就不贴上全屏图对比是否一致了)
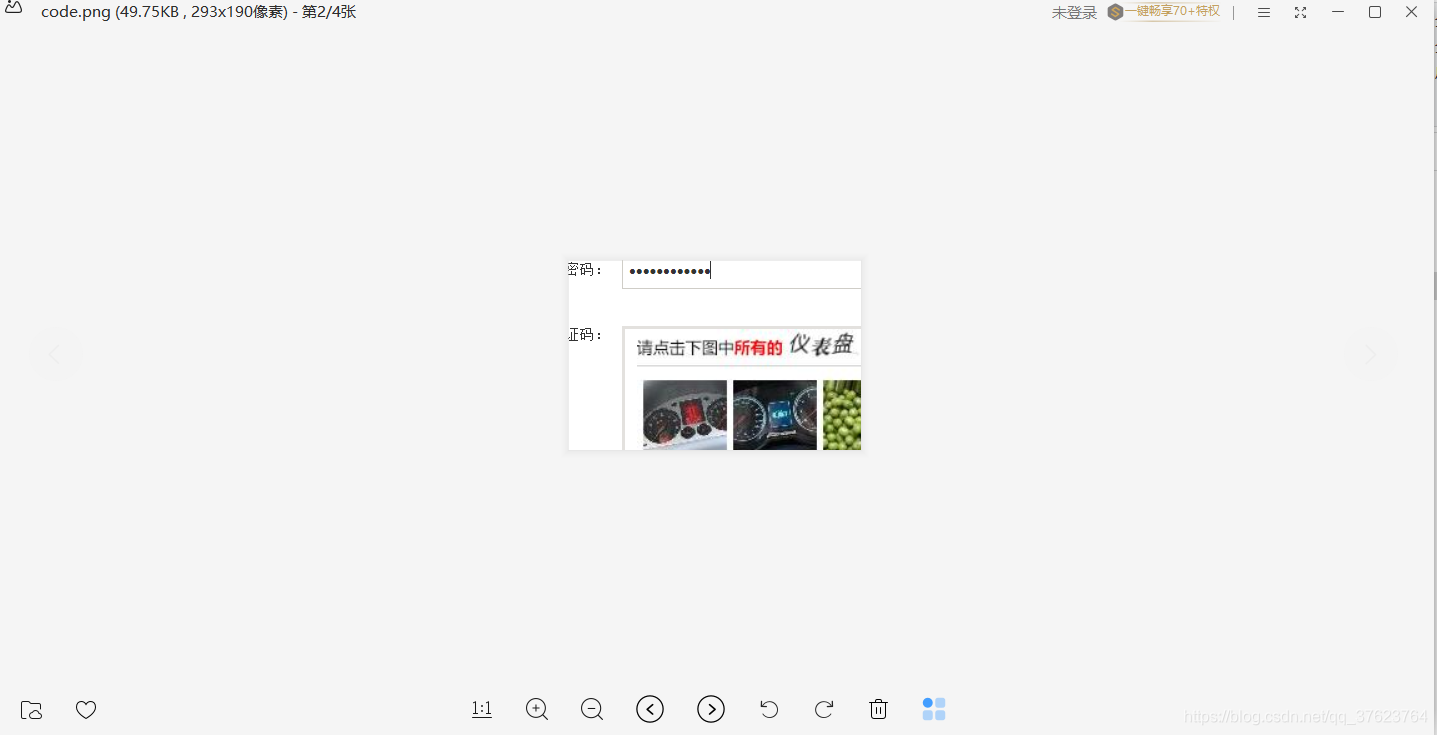
拿到验证码图片,我们马上调用封装好的超级鹰的打码方法,放在上面代码的TODO位置:
9004返回的形式是x1,y1|x2,y2…用管道符来分隔,当然如果只有一张图片符合要求,就不需要管道符了。

下载封装好的超级鹰打码的示例代码:在里边封装了一个返回图片验证码结果的函数transform_code_img,调用这个即可打码,记得填上自己的username和password以及softID(要充值积分才能用,一块就行了)
result = transform_code_img('./code.png',9004)
print(result)
到时把超级鹰返回的坐标给到selenium进行自动点击时,要给selenium形如[[x1,y1],[x2,y2]]才行,不能直接拿x1,y1|x2,y2给selenium,所以还要进行一步转换:
把超级鹰返回的x1,y1|x2,y2转换为[x1,y1],[x2,y2]放进一个列表:
# 需要将x1,y1|x2,y2转化成[[x1,y1],[x2,y2]]
all_list = [] # 转化后的形如这样的[[x1,y1],[x2,y2]]
if '|' in result: # 有多个符合要求的图片
list1 = result.split('|')
count1 = len(list1)
for i in range(count1):
xy_list = []
x = int(list1[i].split(',')[0])
y = int(list1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else: # 只有一个图片符合要求,没有管道符
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
现在就可以调用selenium中的方法按这个all_list中的坐标进行自动化点击:
# 动作链,比如点击事件
from selenium.webdriver import ActionChains
for postion in all_list:
x = postion[0]
y = postion[1]
# x,y就是要点击的坐标
ActionChains(bro).move_to_element_with_offset(code_img_tag,x,y).click().perform()
# 一秒点一次符合要求的图片
time.sleep(1)
最终代码,整个自动化模拟登录包括打码:
from selenium.webdriver import ActionChains # 动作链,比如点击
from PIL import Image # 进行截图裁剪
bro = webdriver.Chrome(executable_path='../chromedriver_win32/chromedriver.exe')
url = 'https://kyfw.12306.cn/otn/login/init'
# 打开浏览器页面
bro.get(url)
# 为了保证验证码图片可以被刷新出来(验证码图片肯定是个后台ajax)
time.sleep(2)
# 定位到用户名标签
username_tag = bro.find_element_by_id('username')
# 模拟你自己输入用户名
username_tag.send_keys('你的12306账号')
# 定位到密码标签
password_tag = bro.find_element_by_id('password')
# 模拟你自己输入密码
password_tag.send_keys('你的12306密码')
# 验证码识别处理:验证码应该被截屏截取下来而不应该单独再发一次请求
bro.save_screenshot('./main.png') # 表示登陆页面整张图片
# 在main.png里边进行验证码的局部图片进行精确踩点截取
# 必须将验证码图片的左下角和右下角两点坐标读到(人家源码这样写的)
code_img_tag = bro.find_element_by_xpath('//*[@id="loginForm"]/div/ul[2]/li[4]/div/div/div[3]/img')
location = code_img_tag.location # 拿到验证码图片标签在页面中的左下角x,y坐标
size = code_img_tag.size # 当前标签(验证码图片)的长宽
# 裁剪的矩形区域(传入左下角,右上角的坐标值)
rangle = (int(location['x']),int(location['y']),int(location['x']+size['width']),int(location['y']+size['height']))
# 先打开整张页面的图片
i = Image.open('./main.png')
# crop就是裁剪
frame = i.crop(rangle)
frame.save('./code.png')# code.png就是验证码图片
# 超级鹰打码
result = transform_code_img('./code.png',9004)
# 9004返回的形式是x1,y1|x2,y2.....用管道符来分隔
print(result)
# 需要将x1,y1|x2,y2转化成[[x1,y1],[x2,y2]]
all_list = [] # 转化后的形如这样的[[x1,y1],[x2,y2]]
if '|' in result: # 有多个符合要求的图片
list1 = result.split('|')
count1 = len(list1)
for i in range(count1):
xy_list = []
x = int(list1[i].split(',')[0])
y = int(list1[i].split(',')[1])
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
else: # 只有一个图片符合要求,没有管道符
x = int(result.split(',')[0])
y = int(result.split(',')[1])
xy_list = []
xy_list.append(x)
xy_list.append(y)
all_list.append(xy_list)
print(all_list)
for postion in all_list:
x = postion[0]
y = postion[1]
# x,y就是要点击的坐标
ActionChains(bro).move_to_element_with_offset(code_img_tag,x,y).click().perform()
# 一秒点一次
time.sleep(1)
# 点击登录按钮
bro.find_element_by_id('loginSub').click()
# 3秒为了让你看清楚自动输入过程
time.sleep(3)
# 登陆成功,使用page_source属性拿到登陆后的整个完整页面不管动静态加载
page_str = bro.page_source
tree = etree.HTML(page_str)
information = tree.xpath('//*[@id="J-header-logout"]//text()')
print("登陆后的页面中,登录用户信息为:\n{}".format(information))
bro.quit()
js加密,js混淆机制
https://www.aqistudy.cn/html/city_detail.html
这个网站的js加密和js混淆是比较复杂的。是个很好的例子,可能是被太多学习者爬得太厉害,服务器已经不能正常返回数据,崩了。
第一步点击搜索按钮抓包:
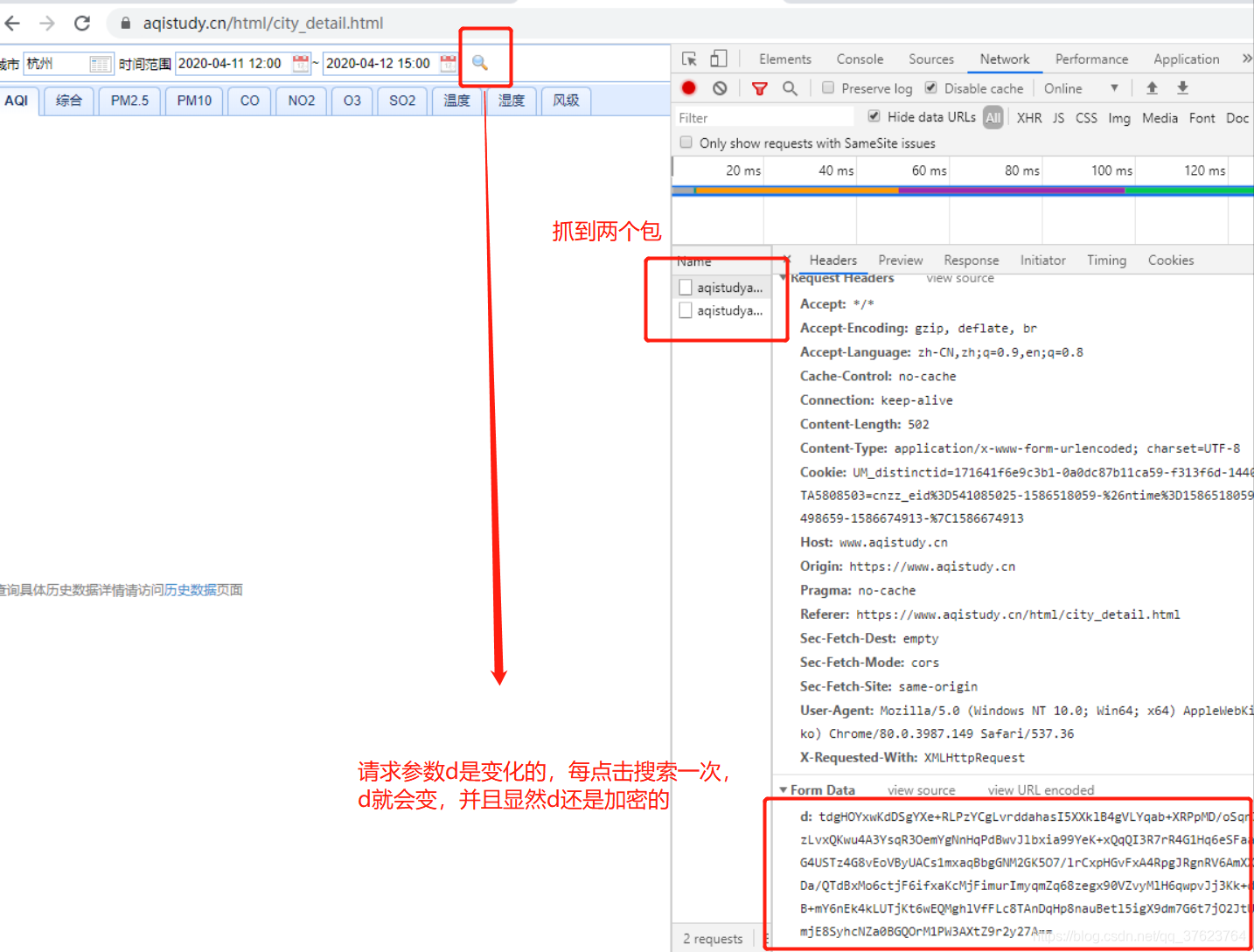
分析:
每次查询会捕获到两个一样的数据包,我们只需要破解其中一个数据包内容即可。
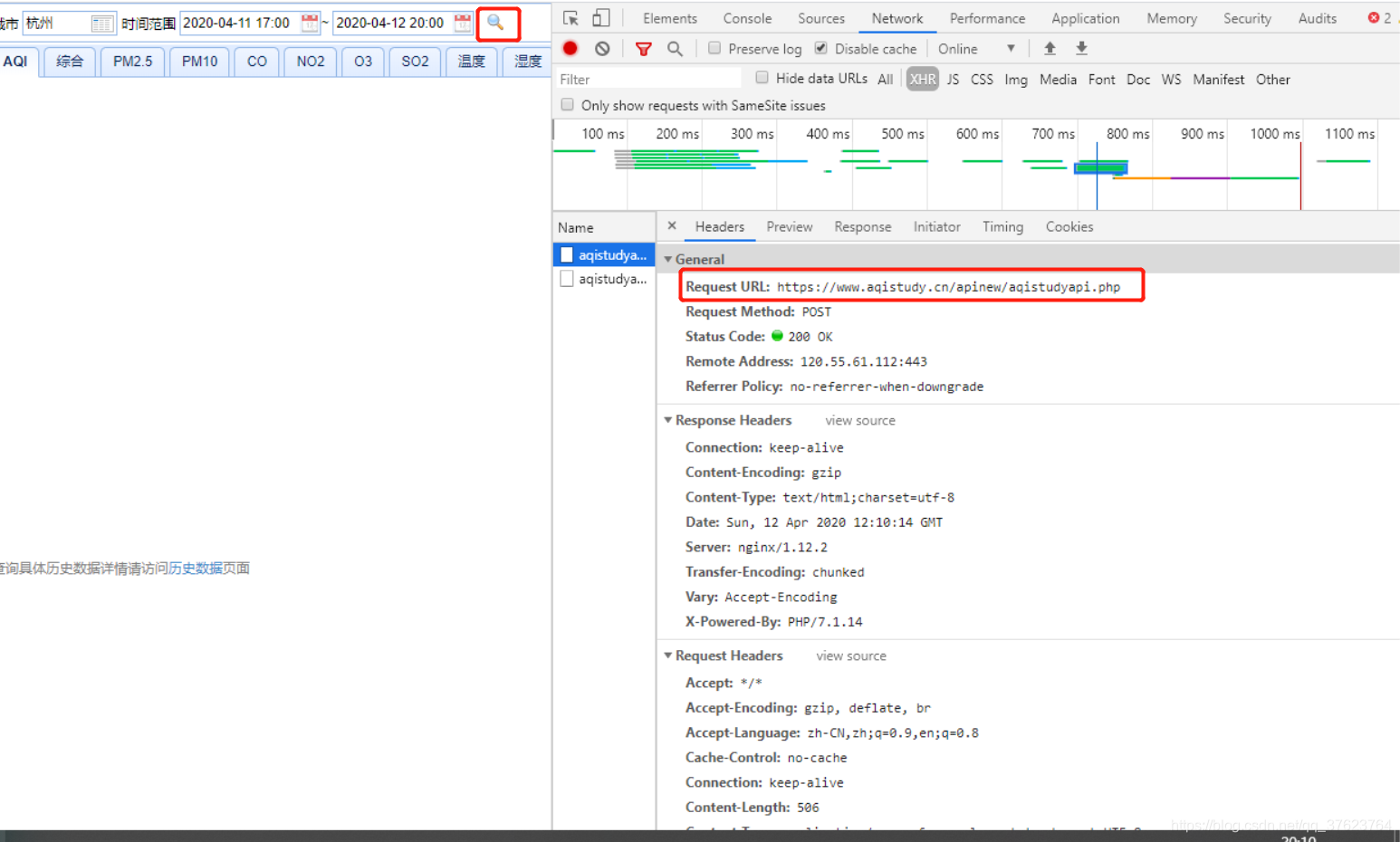
请求url:
https://www.aqistudy.cn/apinew/aqistudyapi.php
请求方式:肯定是ajax的post,因为点击搜索页面没刷新,抓包工具中也看得到X-Requested-With,还有你输入了搜索的值,基本会在请求体中传过去。
请求参数:d(一组动态变化且加密的数据值)
响应数据response就是我们想要捕获的空气指标数据,观察发现,这个response被加密了,所以我们要把response进行解密操作。
思考:
为啥response是密文,在前端能正常显示出来,谁做的解密?那肯定是前端撒。那么肯定,回来的数据包肯定有一个包是存在解密方案的,那我们怎样去找这个解密包呢?
点击查询按钮发起的是ajax,这个ajax肯定是用原生js或其他js包来写的,那你就想,这个ajax请求代码里肯定有啥?肯定有请求url,方式,携带的请求参数,回调函数。前三个前面分析中已经拿到了。但是携带的请求参数d不能用,因为每次ajax请求d是会变化且是加密的,前面模拟古诗文网站遇到过一个变化且加密的参数__VIEWSTATE,因为它每次请求就会生成在页面的隐藏表单域中,我们能直接解析到,但是这儿的d参数,我在elements中搜不到,没办法最后只能把目光聚集到回调函数,首先,ajax请求的回调函数是个匿名函数,回调函数中的参数data就是我们想要的响应数据,而这个响应数据我们抓包看了,是加密的,所以,之所以前端正常显示数据,就是因为,回调函数中对这个密文response进行了解密操作
梳理:我们必须知道生成请求参数d的源码,才能模拟ajax请求,然后还必须知道回调函数中解密响应数据的源码,才能完成数据抓取。
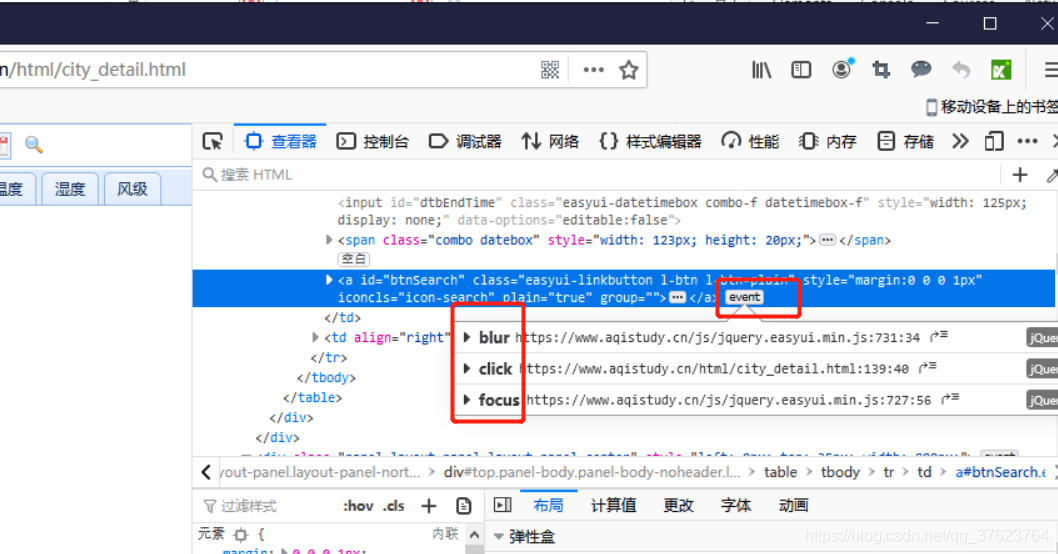
只要能找到发起这个ajax的前端代码,首先可以知道动态变化且加密的参数d是怎样生成的,然后还知道回调函数中到底是怎样解密响应数据response的。那问题又来了,我怎样去找这个ajax请求的代码呢?全局搜索可以,但是太不好找了。你想啊,ajax请求肯定是绑定在搜索按钮上的吧,那绑定也是有代码的呀,要么通过id绑,要么class绑,所以简单的思路是直接找这个绑定操作的代码。
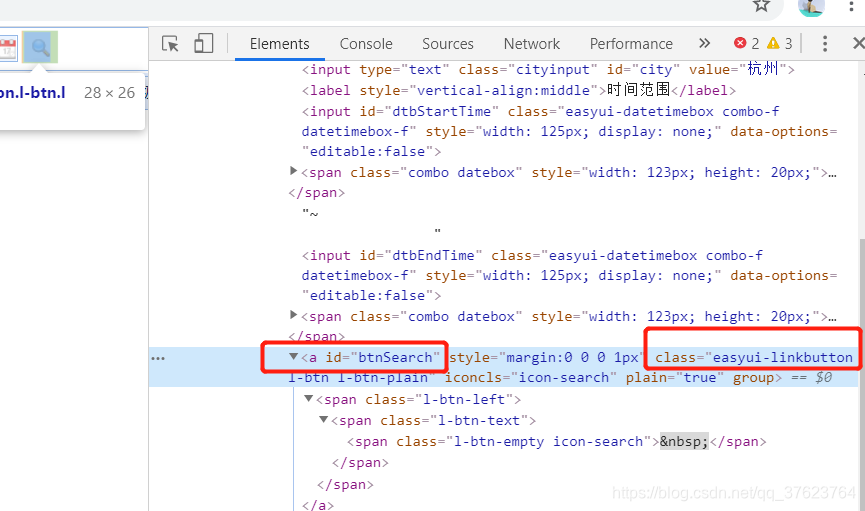
找上图的id或class,因为前端绑定事件总要绑一个,要么id要么class,最好用火狐浏览器,它可以帮我们动态的显示每个标签对应的点击事件
一下就能找到三个绑定事件,我们这里是单击搜索,肯定只要click,其实谷歌也能找到,直接全局搜上面找到的id或class。
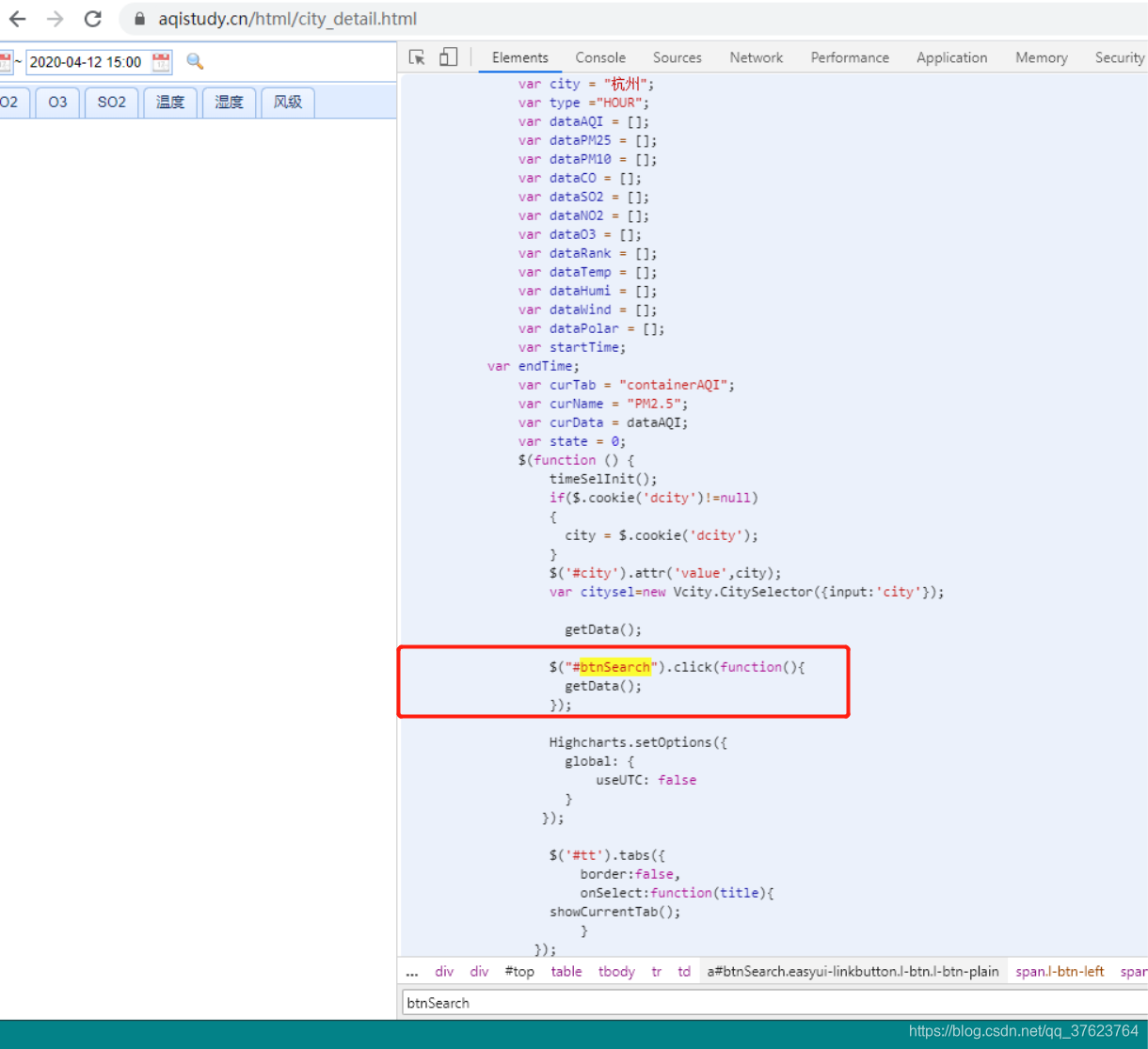
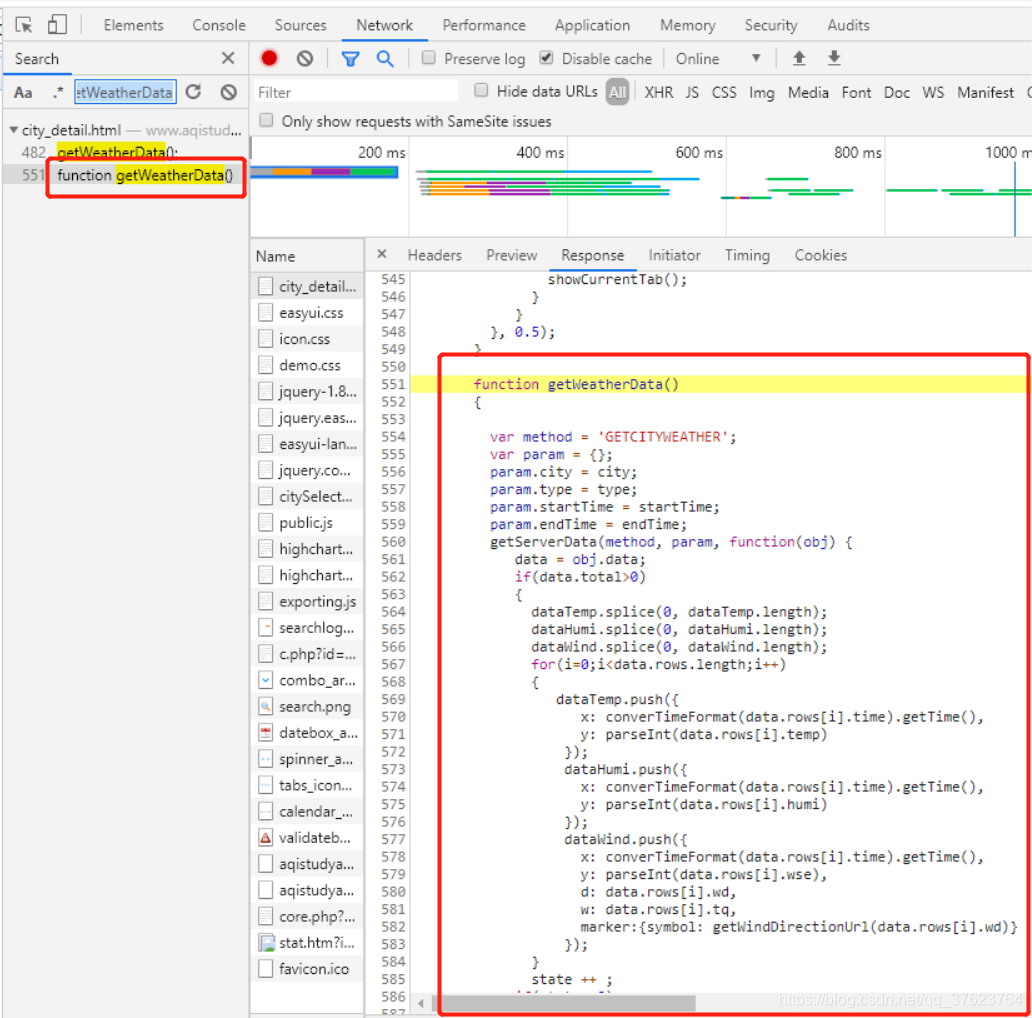
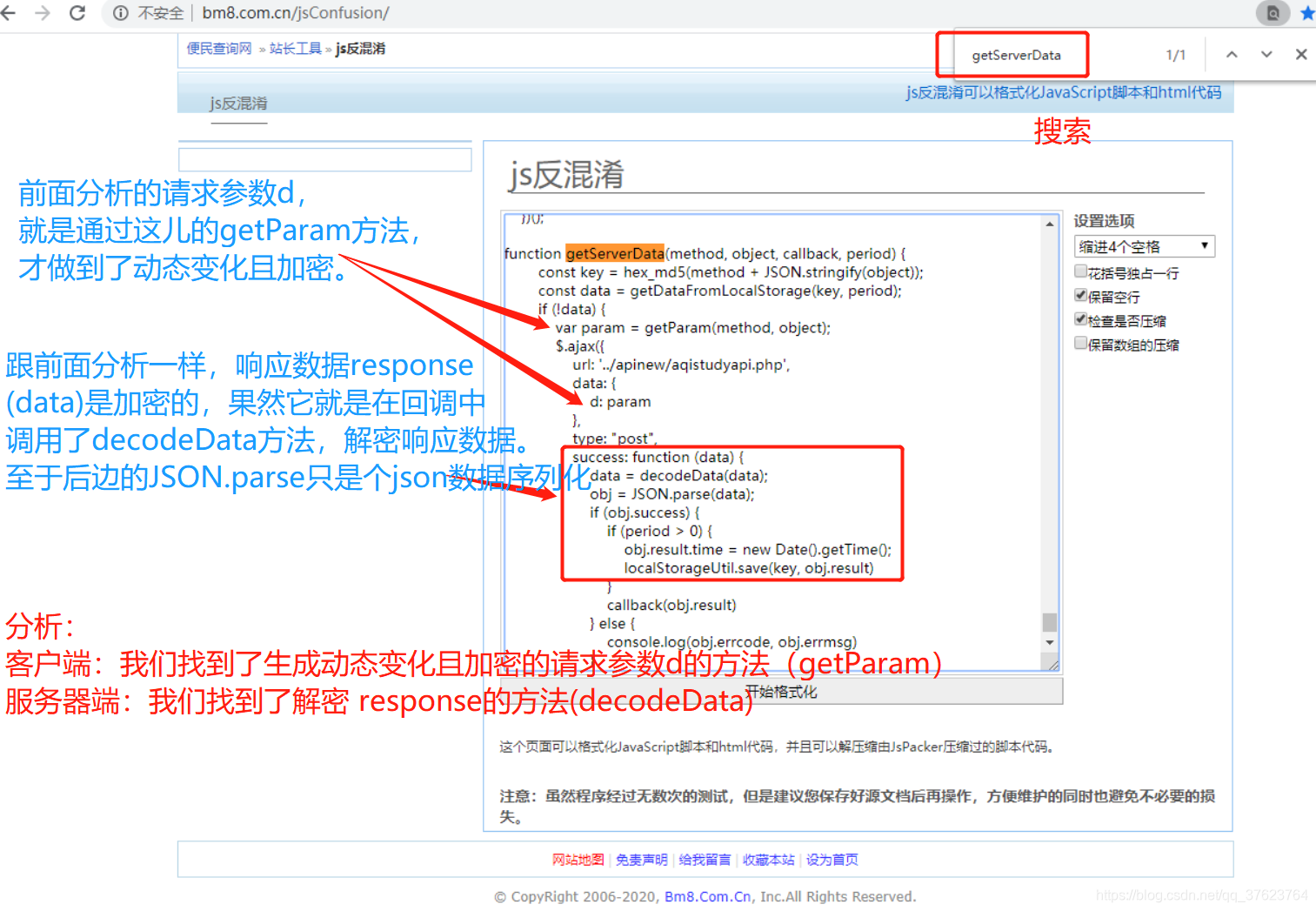
我们找到了用于绑定点击搜索图标的事件函数,就是这个getData(),因为ajax请求就是放在绑定事件中。所以去全局搜getdata,其他的好多个getdata不要管,我们只需要getdata的内部实现。
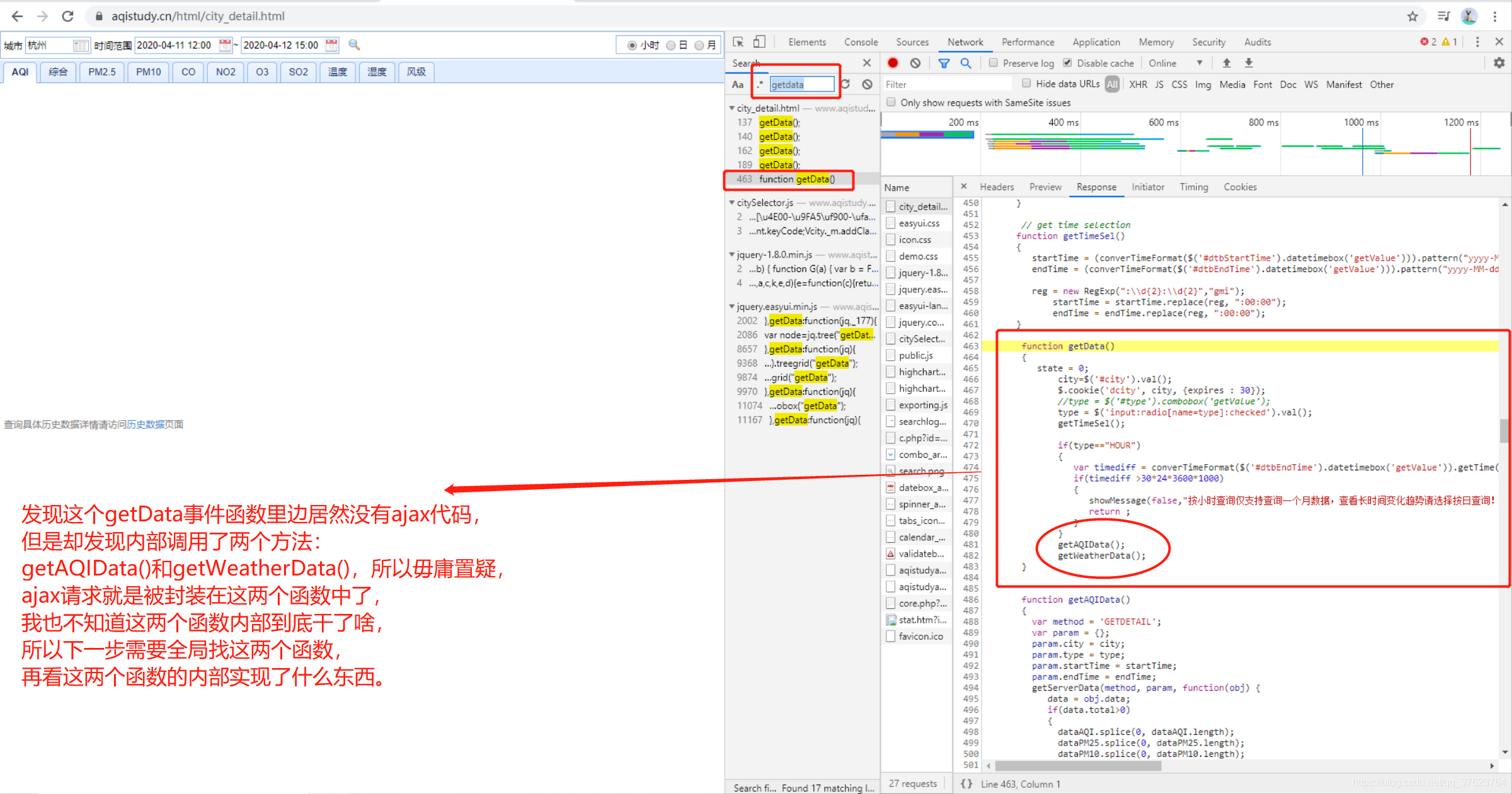
getAQIData:
getWeatherData:
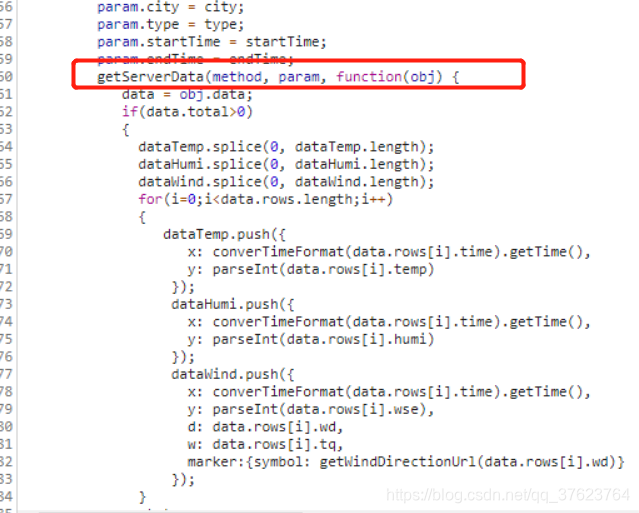
上面的两个函数是挨在一起的,但内部竟然都没有ajax请求代码,但是它们两个函数内部都调用了这个方法:
都调用了getServerData函数,那么getServerData内部一定是发起了ajax请求的。那我们就全局搜索getServerData:
结果复制之后一看:
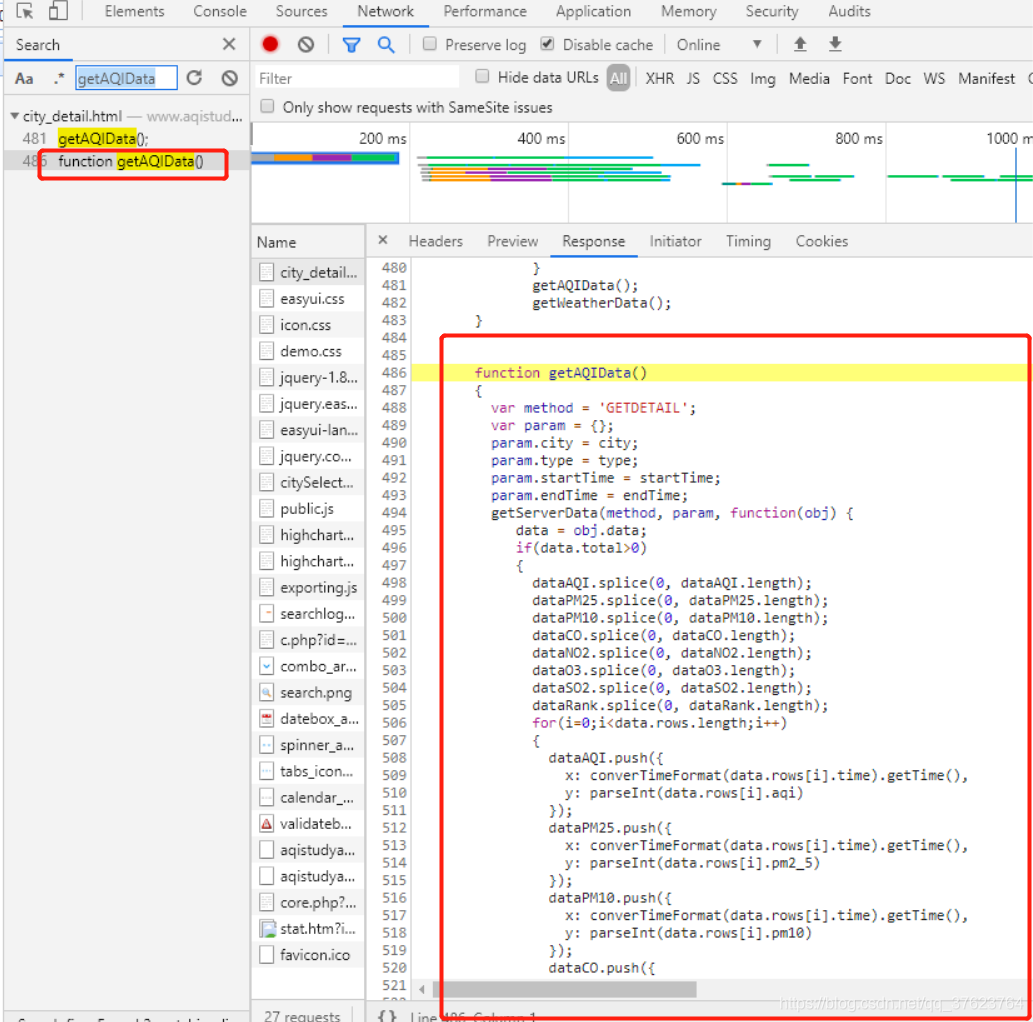
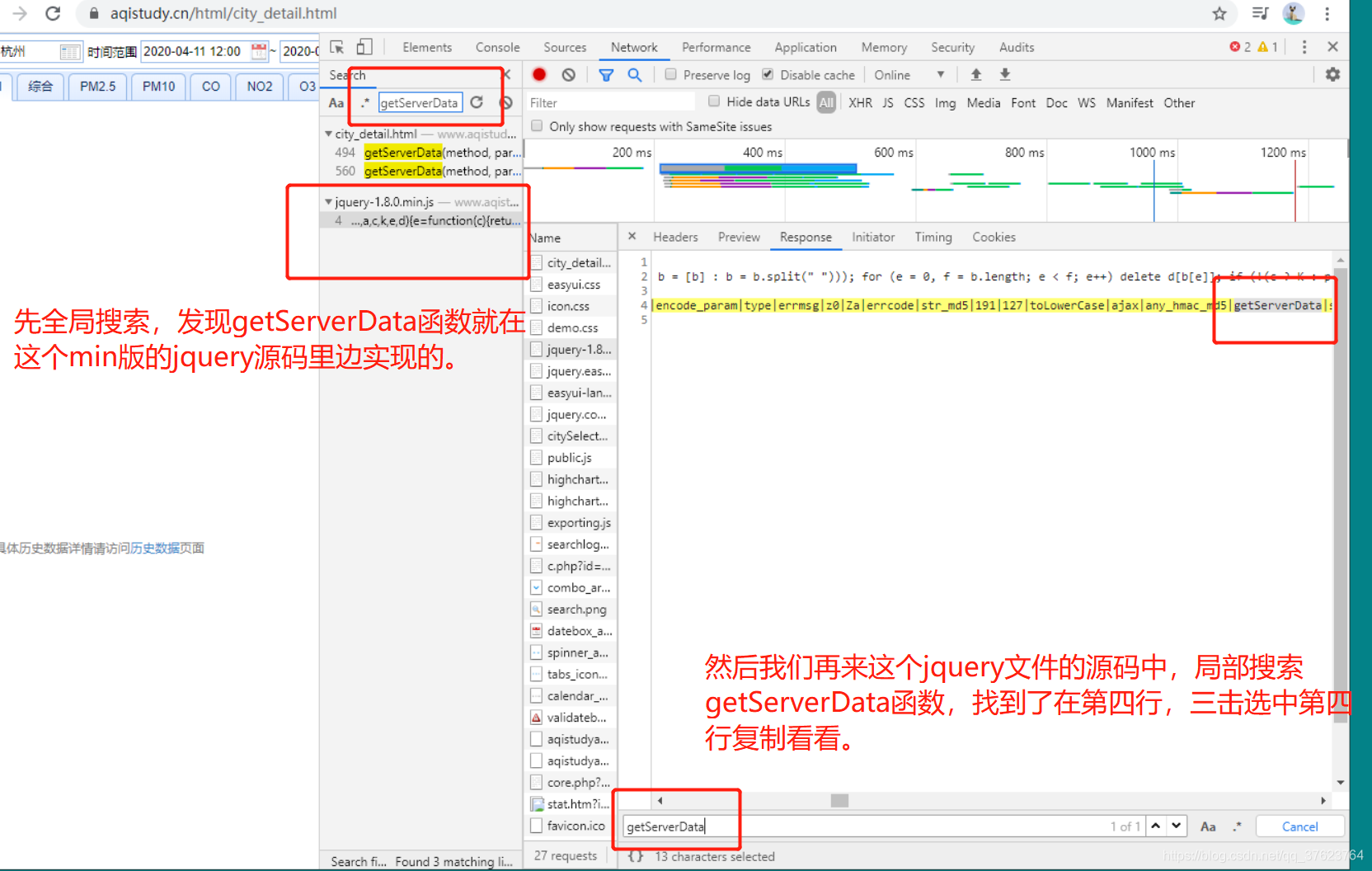
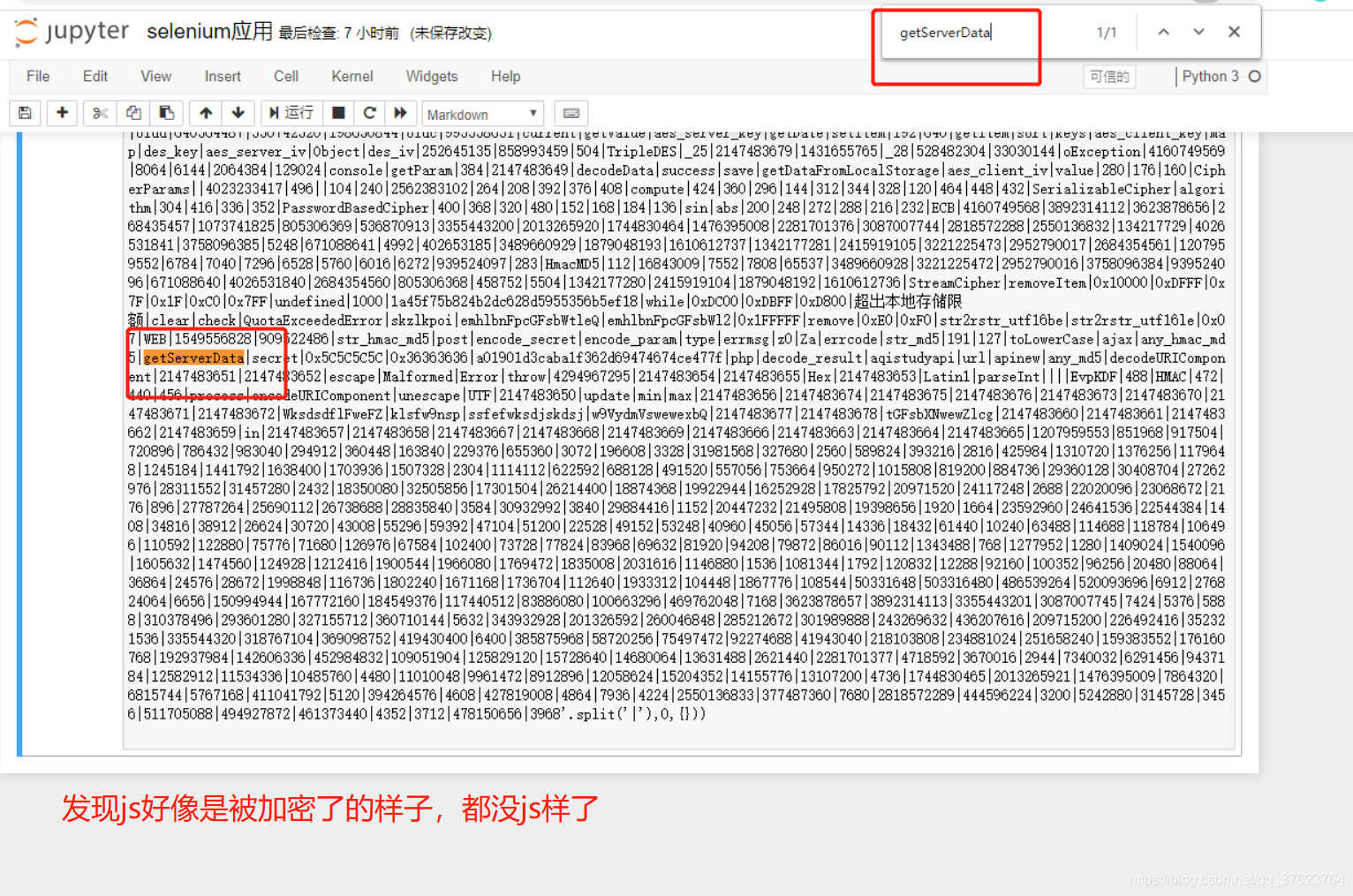
其实这就是js混淆,在web开发中,前端三件套html,css,js代码是用户能看到的或者查到的,因为它们是静态文件。不像后台接口是隐蔽的。所以,有一些牛x的js实现功能不想让别人知道,就会做js的混淆。所以我们需要对js进行反混淆。
反混淆网站:
https://www.bm8.com.cn/jsConfusion/
现在有个问题:上诉两个函数是js函数,我们现在是在python中伪造请求参数(需要用getParam)来发起ajax请求,拿到响应数据还要解密(需要用到decodeData)Response。它们都在上图中,直接搜就能搜到。
那怎样在python中调用这两个js函数呢(js逆向)?
一种方法是将js函数改写为python函数达到js逆向的效果。另一种方法是使用python的相关模块进行js逆向(推荐这一种):
1、
# 一个可以使用python来模拟运行javascript的python库
pip install PyExecJS
2、除了安装PyExecJS包之外,还需要跑一个node.js的环境。安装node.js,不会安装就百度,就下载一个安装包文件就好了。
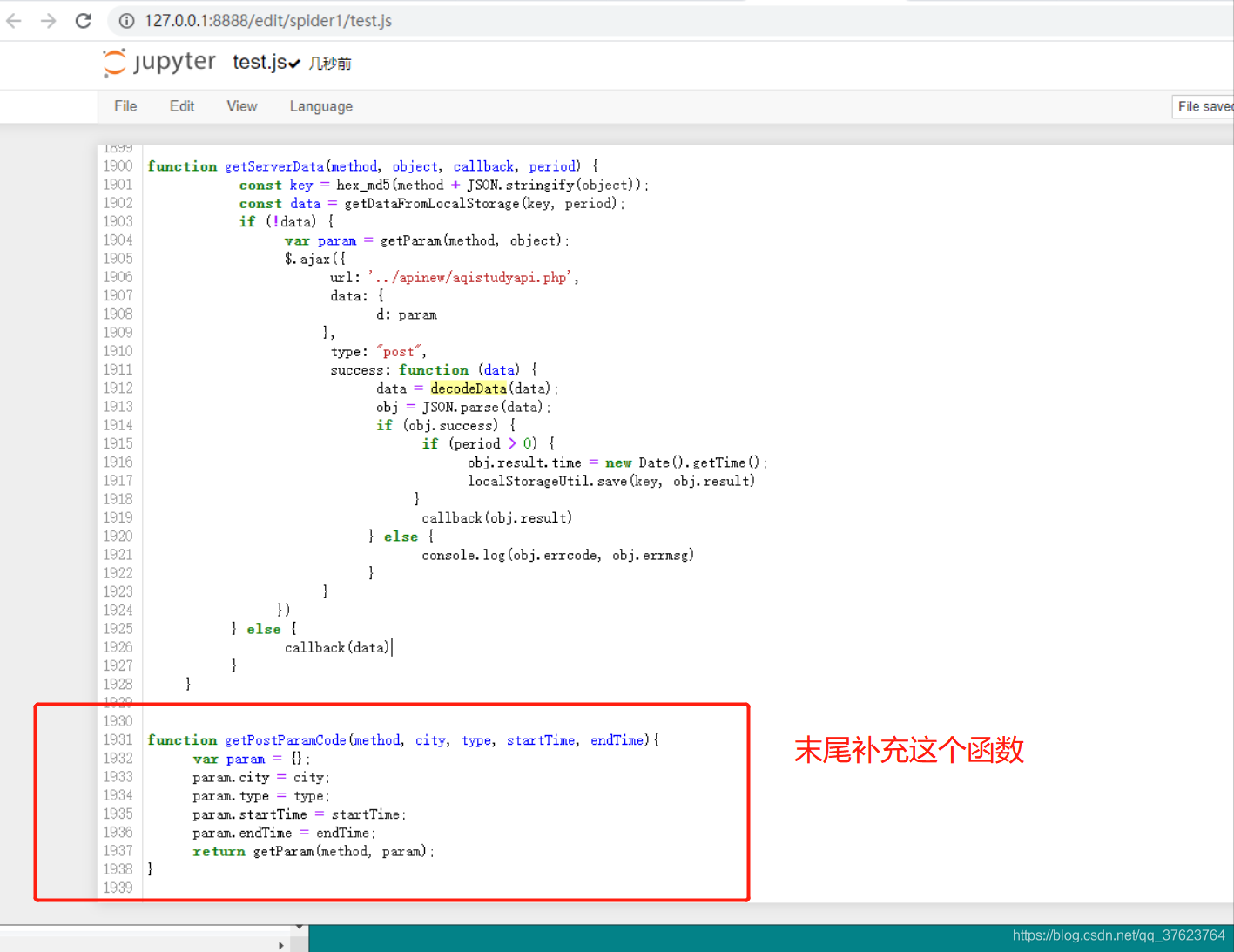
3、需要把待执行的js函数的全部定义存储到一个js源文件中。按理我们只需要把getParam和decodeData放进去,但是有可能存在调用其他的js函数,所以我们把反混淆的js代码全放进这个js源文件。起名叫test.js:
4、还需要在test.js末尾加一个函数,加这个getPostParamCode函数的作用是为了模拟执行js源文件中的js函数。
function getPostParamCode(method, city, type, startTime, endTime){
var param = {};
param.city = city;
param.type = type;
param.startTime = startTime;
param.endTime = endTime;
return getParam(method, param);
}
然后就可以js逆向了,完成我们的目的一:生成动态变化并加密的请求参数d。目的二:解密response,服务器返回给我们的加密数据。
先看目的一的js逆向代码:
# 使用这个模块进行js逆向,模拟来生成参数d和解密response
import execjs
#实例化一个对象
node = execjs.get()
# Params
method = 'GETDETAIL'
city = '北京'
type = 'HOUR'
start_time = '2018-01-25 00:00:00'
end_time = '2018-01-25 23:00:00'
# 待加载的js源文件test.js
file = 'test.js'
# 加载编译js源文件中的js代码
ctx = node.compile(open(file,encoding='utf-8').read())
# 传五个参数进getPostParamCode函数
js = 'getPostParamCode("{0}", "{1}", "{2}", "{3}", "{4}")'.format(method, city, type, start_time, end_time)
# eval表示模拟执行编译好的js函数
params = ctx.eval(js)
# 返回的这个params就是我们想要的动态变化并且加密的参数d
print(params)
结果:
再看目的二:

现在有了参数d,我们就可以对这个ajax的请求接口发请求拿加密的Response:
url = 'https://www.aqistudy.cn/apinew/aqistudyapi.php'
data = {
# 这个d就是我们js逆向生成的动态变化的请求参数
"d":"tdgHOYxwKdDSgYXe+RLPzYCgLvrddahasI5XXklB4gVLYqab+XRPpMD/oSqnJ/aEmFwzVEUhLnPzRy03+X1BIzLvxQKwu4A3YsqR3OemYgNnHqPdBwvJlbxia99YeK+x3eSy71iD/0QbX9El/nHhrPfFwTgdOu3ftz9Oa5qIemvgwtydVGKXJoGoy8TgtplwUBZwozfi5FFYErfUGu5AAL8k1ylBNgrJkXmFS+CbzQ/20hqCD3KDsahRL3gRTVv/Gn7Pfrhiy1oLPLrOYIFrG5e980ktfX4ecd6UbX79iK4Vtd7jHncnMbfQdgrMchMPEWs9cyYUm3b6HBMNPMpqCZVMMtI2Mc9hzPJZS/9/0hBLiI8lKDTfNsc4uZ6h9IpM/8AdLpe6O0FuY+yfGtNsN0kMWiSHYg2TbePR/EZztAzITAsgYS/IyNks96tcKJNRqssZjOEZjqvf8cJ7exRBeA=="
}
response_text = requests.post(url, data=data).content.decode()
print(response_text)
拿到密文Response:
我们拿密文response在js逆向中使用decodeData解密:

# 对加密的响应数据进行解密
js = 'decodeData("{0}")'.format(response_text)
decrypted_data = ctx.eval(js)
print(decrypted_data)
结果为空或者报错,原因是这个天气网站服务器其实已经崩了,不能返回给我们数据或者返回的其他数据,浏览器上都是空的,所以才会出现这两种问题,如果返回了真实数据就不会报错,会解密出response数据。重点是为了搞清楚js加密,混淆,js逆向。