运行环境
- linux-CentOS6.8
- hadoop-2.7.5
- Scala-2.11.6
- jdk-1.8
- flink-1.7.1-bin-hadoop27-scala_2.11.tgz
flink搭建
1.下载
下载地址:http://flink.apache.org/downloads.html
根据自己集群环境的情况,下载相应的flink版本。
上面描述我的集群环境是hadoop2.7.5,Scala2.11,所以下载:flink-1.7.1-bin-hadoop27-scala_2.11.tgz
2.下载方式
2.1 直接从网页上下载,上传至集群上。
2.2wget下载: wget flink-1.7.1-bin-hadoop27-scala_2.11.tgz(推荐使用)
3.解压
tar -zxvf flink-1.7.1-bin-hadoop27-scala_2.11.tgz
4.设置环境变量
vi /etc/profile
#flink
export FLINK_HOME=/usr/local/flink-1.7.1
export PATH=$FLINK_HOME/bin:$PATH
刷新使之生效 source /etc/profile
5.配置
cd /usr/local/flink-1.7.1/conf
5.1配置文件说明
这里面需要我们配置的有:slaves和flink-conf.yaml文件,这里面masters文件是用来配置HA的,只要我们不配置HA的话,就不需要配置masters文件(flink也是master/slave结构,但是对于此时master的选择是执行启动脚本的机器为master)。但是slave需要我们配置,配置对应的主机名即可(伪分布式和分布式的区别也就是实际上slave节点的个数,以及分布式在多个节点上而已)。接下来需要我们配置的就是flink-conf.yaml,flink和spark还是有区别的,spark配置文件分spark-env.sh和spark-default.conf文件,而flink的配置都在flink-conf.yaml中完成配置。
5.2修改flink-conf.yaml配置文件,先配置一个简单版本,standalone的模式
# JobManager runs.
jobmanager.rpc.address: cdh1
# The RPC port where the JobManager is reachable.
jobmanager.rpc.port: 6123
# The heap size for the JobManager JVM
jobmanager.heap.size: 1024m
# The heap size for the TaskManager JVM
taskmanager.heap.size: 1024m
# The number of task slots that each TaskManager offers. Each slot runs one parallel pipeline.
taskmanager.numberOfTaskSlots: 1
# The parallelism used for programs that did not specify and other parallelism.
parallelism.default: 1
#配置是否在Flink集群启动时候给TaskManager分配内存,默认不进行预分配,这样在我们不适用flink集群时候不会占用集群资源
taskmanager.memory.preallocate: false
# 用于未指定的程序的并行性和其他并行性,默认并行度
parallelism.default: 2
#指定JobManger的可视化端口,尽量配置一个不容易冲突的端口
jobmanager.web.port: 5566
#配置checkpoint目录
state.backend.fs.checkpointdir: hdfs://cdh1:9000/flink-checkpoints
#配置hadoop的配置文件
fs.hdfs.hadoopconf: /usr/local/hadoop/etc/hadoop/
#访问hdfs系统使用的
fs.hdfs.hdfssite: /usr/local/hadoop/etc/hadoop/hdfs-site.xml
5.3修改slaves和masters2个文件,用来配置taskManager和JobManager信息
[hadoop@cdh1 conf]$ cat slaves
cdh2
cdh3
cdh4
cdh5
[hadoop@cdh1 conf]$ cat masters
cdh1:8081
5.4配置内容注意
flink-conf.yaml中配置key/value时候在“:”后面需要有一个空格,否则配置不会生效。
#sloves文件配置,填写从节点的ip地址即可
同步信息
将flink安装所有信息已经环境信息同步到其他机器上面,这里有几台机器就要执行几次
scp /etc/profile root@cdh3:etc/profile
scp -r ./flink-1.7.1 root@cdh3:/usr/local
source /etc/proflie
flink集群的开启
1.启动flink集群
start-cluster.sh
[root@cdh1 bin]# start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host cdh1 .
2.然后jps查看一下进程:
分别可以看到JobManager和TaskManager的2个进程
[root@cdh1 bin]$ jps
3876 StandaloneSessionClusterEntrypoint
[root@cdh2 ~]$ jps
3544 TaskManagerRunner
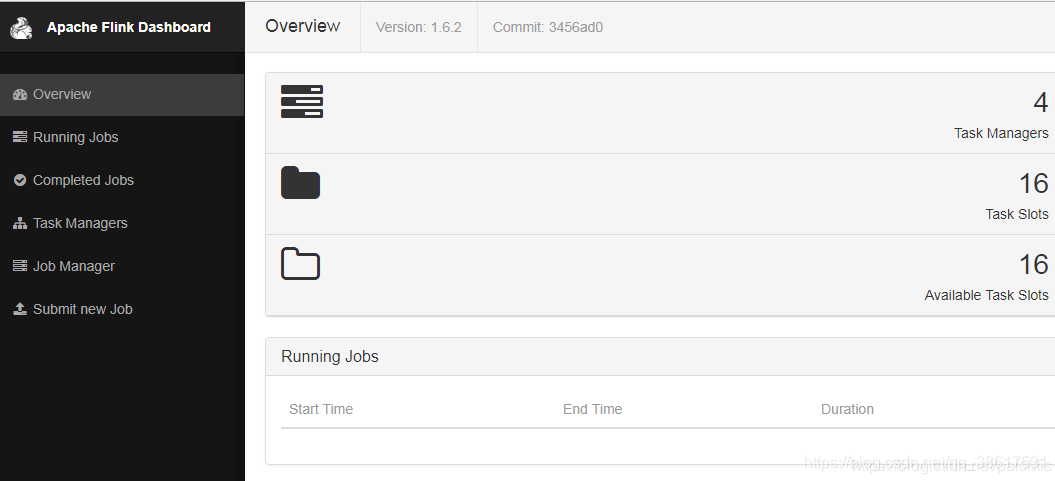
3.登录JobManager的地址查看web界面 http://192.168.10.3:8081
已经表示搭建完成了,现在我们开始验证一下集群
运行模式介绍
使用start-scala-shell.sh来验证
${FLINK_HOME}/bin/start-scala-shell.sh是flink提供的交互式clinet,可以用于代码片段的测试,方便开发工作,它有两种启动方式,一种是工作在本地,另一种是工作到集群。本例中因为机器连接非常方便,就直接使用集群进行测试,在开发中,如果集群连接不是非常方便,可以连接到本地,在本地开发测试通过后,再连接到集群进行部署工作。如果程序有依赖的jar包,则可以使用 -a <path/to/jar.jar> 或 --addclasspath <path/to/jar.jar>参数来添加依赖。
1.本地连接
${FLINK_HOME}/bin/start-scala-shell.sh local
2.集群连接
${FLINK_HOME}/bin/start-scala-shell.sh remote <hostname> <portnumber>
3.带有依赖包的格式
${FLINK_HOME}/bin/start-scala-shell.sh [local|remote<host><port>] --addclasspath<path/to/jar.jar>
4.查看帮助
${FLINK_HOME}/bin/start-scala-shell.sh --help
[root@cdh2 bin]$ ./start-scala-shell.sh --help
Flink Scala Shell
Usage: start-scala-shell.sh [local|remote|yarn] [options] <args>...
Command: local [options]
Starts Flink scala shell with a local Flink cluster
-a, --addclasspath <path/to/jar>
Specifies additional jars to be used in Flink
Command: remote [options] <host> <port>
Starts Flink scala shell connecting to a remote cluster
<host> Remote host name as string
<port> Remote port as integer
-a, --addclasspath <path/to/jar>
Specifies additional jars to be used in Flink
Command: yarn [options]
Starts Flink scala shell connecting to a yarn cluster
-n, --container arg Number of YARN container to allocate (= Number of TaskManagers)
-jm, --jobManagerMemory arg
Memory for JobManager container
-nm, --name <value> Set a custom name for the application on YARN
-qu, --queue <arg> Specifies YARN queue
-s, --slots <arg> Number of slots per TaskManager
-tm, --taskManagerMemory <arg>
Memory per TaskManager container
-a, --addclasspath <path/to/jar>
Specifies additional jars to be used in Flink
--configDir <value> The configuration directory.
-h, --help Prints this usage text
测试
我们 使用集群模式去验证
[root@cdh1 bin]$ ./start-scala-shell.sh remote 192.168.10.3 8081
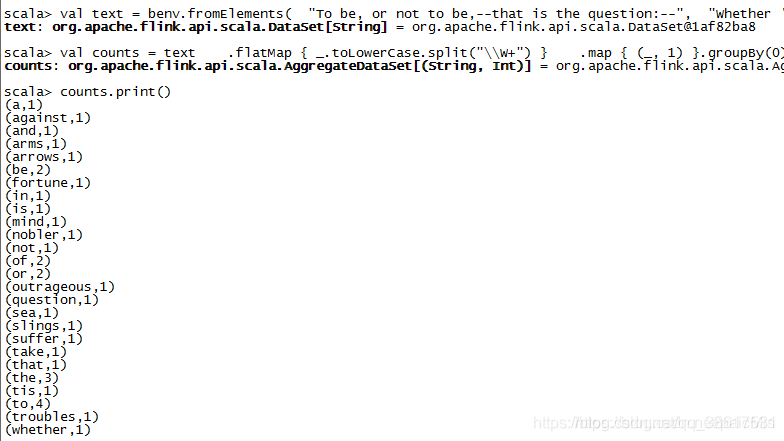
运行如下案例代码
Scala> val text = benv.fromElements(
"To be, or not to be,--that is the question:--",
"Whether 'tis nobler in the mind to suffer",
"The slings and arrows of outrageous fortune",
"Or to take arms against a sea of troubles,")
Scala> val counts = text
.flatMap { _.toLowerCase.split("\\W+") }
.map { (_, 1) }.groupBy(0).sum(1)
Scala> counts.print()
运行结果
web url也可以看到详细的信息
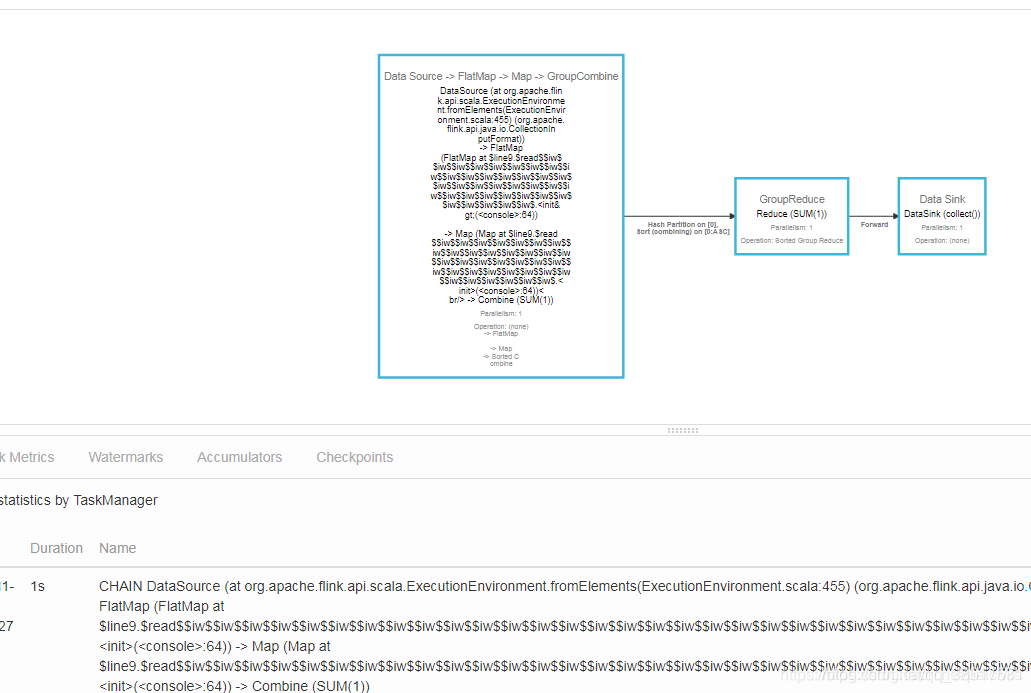
遇到异常情况:
我们这边是因为安装了Scala导致通信失败,将Scala的环境信息去掉就可以了。
停止flink集群
stop-cluster.sh
[root@cdh1 conf]# stop-cluster.sh
参考链接
(1)https://blog.csdn.net/paicMis/article/details/84642263
(2)https://blog.csdn.net/aa518189/article/details/82749899