任务
利用一个家庭的用电量,来预测这个家庭未来的用电量。
学会了这一个例子,如果有电网数据,就可以开发出适合各种业务需求的模型。
比如:
-
通过预测各时段各区域的用电量来协助电网更好地实现电能调度
-
用于新能源电站(光伏、风力、水电)发电量预测
数据集
数据集来源:加州大学欧文分校机器学习存储库
数据集名称:Individual household electric power consumption Data Set
下载地址:
https://archive.ics.uci.edu/ml/datasets/individual+household+electric+power+consumption
数据集分析:
该数据集是一个多变量时间序列数据集,采集了法国巴黎一个家庭近四年(2006年12月至2010年11月)的用电量,采样周期为1分钟。
date:格式dd/mm/yyyy;
time:格式hh:mm:ss;
global_active_power:每分钟的有功功率(千瓦);
global_reactive_power:每分钟的无功功率(千瓦);
voltage:每分钟的平均电压(伏特);
global_intensity:每分钟的平均电流强度(安培);
sub_metering_1:厨房有功电能(瓦时),主要包含洗碗机,烤箱和微波炉;
sub_metering_2:于洗衣房有功电能(瓦时),包含洗衣机,滚筒式烘干机,冰箱和电灯;
sub_metering_3:电热水器和空调有功电能(瓦时)。
以上数据都是间隔一分钟测得的,有功功率单位为 KW,有功电能的单位为瓦时,通过有功率乘以时间(1分钟=1/60小时)乘以1000计算得到总的有功电能消耗,单位为瓦时,减去三个sub之和,得到了家庭中其他电路的电能消耗。
sub_metering_remainder = (global_active_power * 1000 / 60) - (sub_metering_1 + sub_metering_2 + sub_metering_3)数据处理
下载后的数据是txt文件,如下图所示:
读入数据:
df = pd.read_csv('household_power_consumption.txt', sep=';',header=0,low_memory=False,infer_datetime_format=True,engine='c',parse_dates={'datetime':[0,1]},index_col=['datetime'])read_csv() 参数说明:
sep:指定列之间的分隔符为 ';',字符串格式,默认为 ‘,’;
header:指定哪一行作为列名,header=0 表示第一行数据作为列名,而不是文件的第一行作为列名;
low_memory:在内部对文件进行分块处理,从而在解析时减少了内存使用,但可能是混合类型推断。默认为 True,设置为 False 确保没有混合类型;
infer_datetime_format:设置该参数为 True 和 parse_dates 参数,pandas会推断列中日期时间字符串的格式,如果可以推断出,则切换到更快方法来解析它们。在某些情况下,这可以使解析速度提高5-10倍;
engine:要使用的解析器引擎。C引擎速度更快,而python引擎当前功能更完善;
parse_dates:{'datetime':[0,1]}将原数据中的第1、2列作为新的列名为 ‘datatime’ 的列,即将原来的日期列、时间列合并为日期时间一列;
index_col:指定’datetime’列为索引列;
看一下数据的行列数:
df.shape数据集有7个属性,一共200多万行。
看一下数据的前5行长什么样:
df.head(5)
看一下有没有缺失值:
df.isnull().sum()
电热水器和空调有功电能数据有20000多条是空值。
看一看有没有"?"的异常值:
df.loc[df.values == '?'].count()
前6个属性有15万数据是"?"。
为了提高数据处理效率,将所有标记为"?"的异常值用 np.nan 替换:
df.replace('?', np.nan, inplace=True)再次检查是否有"?":
df.loc[dataset.values == '?'].count()
再次查看缺失值:
df.isnull().sum()
特征工程
新增一个特征sub_metering_4:家庭中其他电路的电能消耗。
values = df.values.astype('float32')df['Sub_metering_4'] = (values[:,0] * 1000 / 60) - (values[:,4] + values[:,5] + values[:,6])
或者
df=df.astype('float32')df['Sub_metering_4'] = (df['Global_active_power'] * 1000 / 60) - (df['Sub_metering_1'] + df['Sub_metering_2'] + df['Sub_metering_3'])
保存数据
df.to_csv('household_power_consumption.csv')数据可视化
读取新保存的数据:
dataset = pd.read_csv('household_power_consumption.csv', header=0,infer_datetime_format=True, engine='c',parse_dates=['datetime'], index_col=['datetime'])
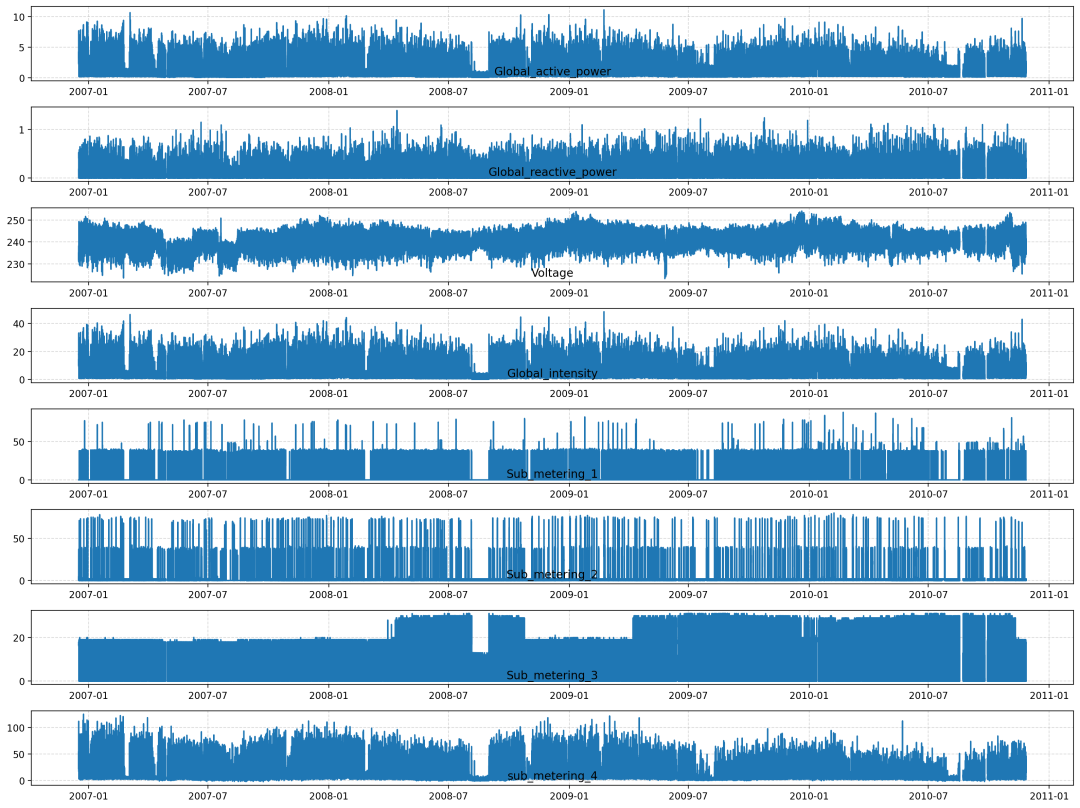
查看每一个分量的四年的趋势:
创建一个包含八个子图的图像,每个子图对应一个变量。
def plot_features(dataset):plt.figure(figsize=(16,12), dpi=200)for i in range(len(dataset.columns)):plt.subplot(len(dataset.columns), 1, i+1)feature_name = dataset.columns[i]plt.plot(dataset[feature_name])plt.title(feature_name, y=0)plt.grid(linestyle='--', alpha=0.5)plt.tight_layout()plt.show()plot_features(df)
查看每年的有功功率变化:
为每一年创建一个有功功率图,观察是否有相同的模式。
因为设置了 infer_datetime_format 参数,所以可直接使用年份索引进行截取数据。
def plot_year_gap(dataset, years_list):plt.figure(figsize=(16,12), dpi=150)for i in range(len(years_list)):ax = plt.subplot(len(years_list), 1, i+1)ax.set_ylabel(r'$KW$')year = years_list[i]year_data = dataset[str(year)]plt.plot(year_data['Global_active_power'])plt.title(str(year), y=0, loc='left')plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=45)plt.tight_layout()plt.show()years = ['2007', '2008', '2009', '2010']plot_year_gap(df, years)
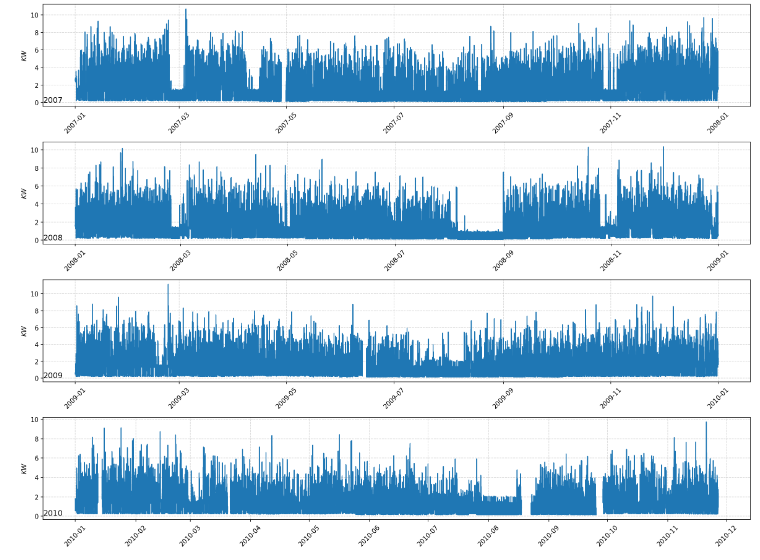
通过对以上数据进行分析可知,每年2月和8月内的某段时间耗电量有明显下降。我们似乎也看到夏季(6、7、8月)的用电量呈下降趋势,我们还可以在第1、第3和第4个图中有一些缺失的数据。
接下来查看一下每个月的用电情况:
查看2008年每个月的有功功率,有助于梳理出几个月的变化规律,如每日和每周用电状况规律。
def plot_month_gap(dataset, year, months_list):plt.figure(figsize=(16,12), dpi=150)for i in range(len(months_list)):ax = plt.subplot(len(months_list), 1, i+1)ax.set_ylabel(r'$KW$')month = str(year) + '-' + str(months_list[i])month_data = dataset[month]plt.plot(month_data['Global_active_power'])plt.title(month, y=0, loc='left')plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=0)plt.tight_layout()plt.show()year = 2008months = [i for i in range(1, 13)]plot_month_gap(df, year, months)

查看每日用电情况:
def plot_day_gap(dataset, year, month, days_list):plt.figure(figsize=(20,24), dpi=150)for i in range(len(days_list)):ax = plt.subplot(len(days_list), 1, i+1)ax.set_ylabel(r'$KW$',size=6)day = str(year) + '-0' + str(month) + '-' + str(days_list[i])day_data = dataset[day]gcp_data = day_data['Global_active_power']plt.plot(gcp_data)plt.title(day, y=0, loc='left', size=6)plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=0)plt.show()year = 2008month = 8days = [i for i in range(1, 32)]plot_day_gap(df, year, month, days)

另一个需要考虑的重要方面是变量的分布。例如,了解观测值的分布是高斯分布还是其他分布。可以通过为每个特征创建一个直方图来研究数据分布。
def dataset_distribution(dataset):plt.figure(figsize=(16,12), dpi=150)for i in range(len(dataset.columns)):ax = plt.subplot(len(dataset.columns), 1, i+1)ax.set_ylabel(r'$numbers$',size=10)feature_name = dataset.columns[i]dataset[feature_name].hist(bins=100)plt.title(feature_name, y=0, loc='right', size=20)plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=0)plt.tight_layout()plt.show()dataset_distribution(df)

可以看到有功和无功功率、强度以及分表功率都呈现偏态(左偏态/正偏态),电压数据呈高斯分布。有功功率的分布似乎是双峰的,这意味着它看起来有两组观测值。可以通过查看四年来的数据的有功功率分布来验证。
def plot_year_dist(dataset, years_list):plt.figure(figsize=(16,12), dpi=150)for i in range(len(years_list)):ax = plt.subplot(len(years_list), 1, i+1)ax.set_ylabel(r'$numbers$')ax.set_xlim(0, 5)year = years_list[i]year_data = dataset[str(year)]year_data['Global_active_power'].hist(bins=100, histtype='bar')plt.title(str(year), y=0, loc='right', size=10)plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=0)plt.tight_layout()plt.show()years = ['2007', '2008', '2009', '2010']plot_year_dist(df, years)
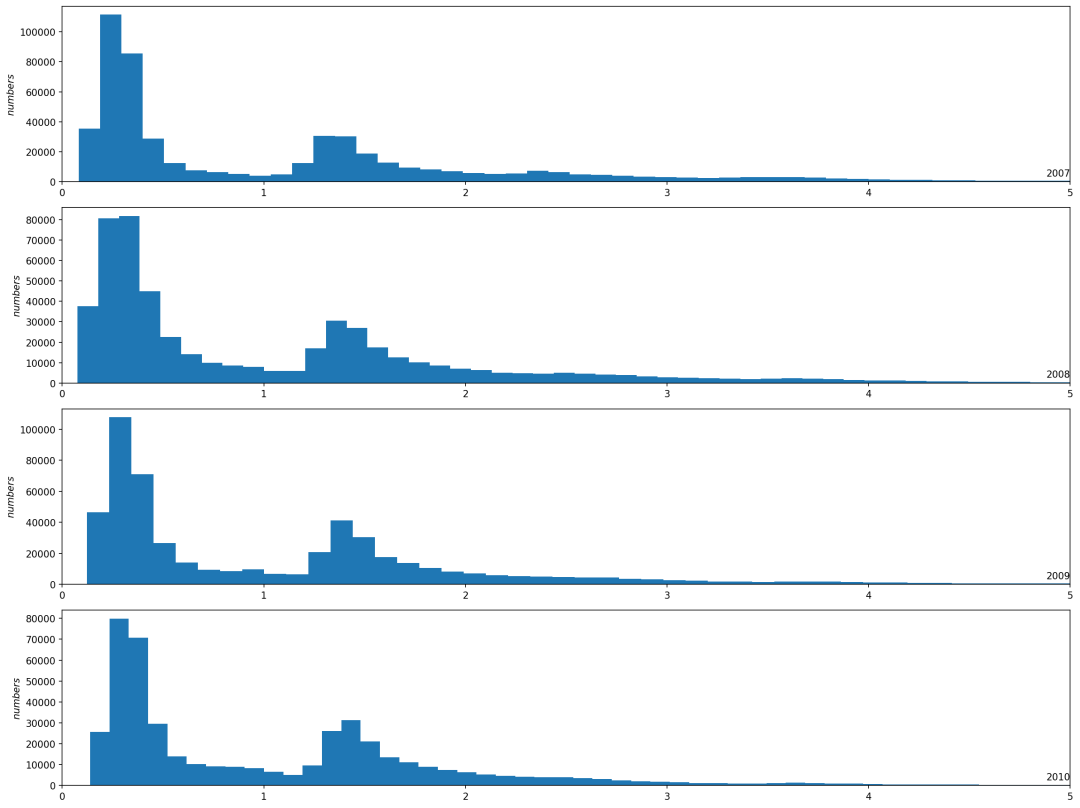
可以看到,有功功率分布看起来非常相似。这种分布确实是双峰的,一个峰值约为0.3kw,另一个峰值约为1.3kw。随着有功功率(x轴)的增加,高功率用电时间点的数量越来越少。
可以通过查看一年中每个月的有功功率分布来对一年中不同季节的用电情况进行调查。
def plot_month_dist(dataset, year, months_list):plt.figure(figsize=(16,12), dpi=150)for i in range(len(months_list)):ax = plt.subplot(len(months_list), 1, i+1)ax.set_ylabel(r'$KW$')ax.set_xlim(0, 5)month = str(year) + '-' + str(months_list[i])month_data = dataset[month]month_data['Global_active_power'].hist(bins=100, histtype='bar')plt.title(month, y=0, loc='right', size=10)plt.grid(linestyle='--', alpha=0.5)plt.xticks(rotation=0)plt.tight_layout()plt.show()year = 2008months = [i for i in range(1, 13)]plot_month_dist(df, year, months)

可以看到,在北半球法国巴黎较暖的月份,有功功率比较大的点少,而在较冷的月份,有功功率比较大的点多。在12月到3月的较冷月份,可以看到有更大的千瓦值(大约 3.7~4kW)。
业务需求
对于我们使用的家庭用电量数据集来说,可以提出很多建模问题,比如:
-
预测一天内每小时的耗电量;
-
预测一周内每天的耗电量;
-
预测一月内每天的耗电量;
-
预测一年内每天的耗电量。
以上四类预测问题称为多步预测。利用所有特征进行预测的模型称为多变量多步预测模型。每个模型都不局限于日期的大小,还可以根据需求对更细粒度的问题进行建模,比如一天内某各时段每分钟的耗电量预测问题。这有助于电力公司进行电能调度,是一个广泛研究的重要问题。
特征工程
-
每日差异可能有用,以调整数据中的每日周期。
-
年度差异可能有助于调整数据中的任何年度周期。
-
标准化可能有助于将不同单位的变量减少到相同的比例
-
表示一天中的时间,以说明人们是否有可能在家。
-
指示一天是工作日还是周末。
-
表示一天是否为北美公共假日。这些因素对预测月度数据的重要性可能会大大降低,在一定程度上对周数据的重要性可能也会降低。
-
更一般的特征可能包括:表示季节,这可能导致使用的环境控制系统的类型或数量。
建模方法
-
朴素方法(明天和今天一样,明天和去年的今天一样,明天是过去几天的平均值)
-
经典线性方法(SARIMA季节自回归综合移动平均、ETS三重指数平滑)
-
机器学习方法(K近邻算法、SVM、决策树、随机森林、GBM)
-
深度学习方法(LSTM长短期记忆网络)