
前言
在上一篇文章Golang 怎么高效处理ACM模式输入输出中提到了用bufio来高效处理输入输出,本文来分析bufio高效的原理
主要看bufio.Reader和bufio.Writer如何包装缓冲区和真正的reader,writer,实现高效IO
阅读的go版本:1.22.6
简介
为啥要用bufio?我认为有以下两个方面:
-
提高性能:通过开辟一块缓冲区,减少系统调用的次数
- bufio.Reader:先调一次真正的reader读取一批数据到缓冲区,接下来的read就直接从缓冲区读,无需再调真正的reader发起系统调用
- bufio.Writer:大部分写把数据写到缓冲区就可以返回了,等缓冲区写不下,或调Flush时才把数据往真正的writer写
-
提供易于使用的api:例如调ReadLine,reader会读取并返回一行完整的数据,免去自己手动处理换行符的操作
下面简单介绍下api怎么使用
bufio.Reader
假设要从标准输入读两行文本:
func main() {
reader := bufio.NewReader(os.Stdin)
datas := []string{}
for i := 0; i < 2; i++{
data, _, _ := reader.ReadLine()
datas = append(datas, string(data))
}
}
标准输入:
hello
world
输出结果如下:
[hello world]
bufio.Writer
假设要往控制台输出hello world:
func main() {
w := bufio.NewWriter(os.Stdout)
fmt.Fprint(w, "Hello, ")
fmt.Fprint(w, "world!")
w.Flush() // Don't forget to flush!
}
输出结果:
Hello, world!
bufio.Reader
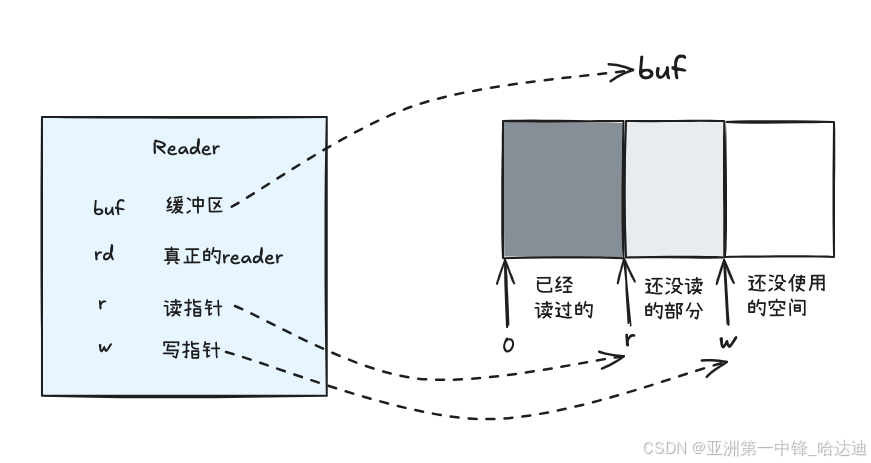
type Reader struct {
// 缓冲区
buf []byte
// 真正的reader
rd io.Reader
// 读,写位置
r, w int
err error
lastByte int
lastRuneSize int
}
其中:
- r:下次从哪来开始读
- w:下次从真正的reader读取数据后,往缓冲区的哪个位置写
构造
构造reader:主要是分配一个缓冲区
func NewReader(rd io.Reader) *Reader {
return NewReaderSize(rd, defaultBufSize)
}
func NewReaderSize(rd io.Reader, size int) *Reader {
// (可以不关心)如果已经是bufio.Reader了,
b, ok := rd.(*Reader)
if ok && len(b.buf) >= size {
return b
}
r := new(Reader)
r.reset(make([]byte, max(size, minReadBufferSize)), rd)
return r
}
默认值defaultBufSize为4096,也可以调bufio.NewReaderSize自己指定缓冲区长度
reset:设置buf,reader字段
func (b *Reader) reset(buf []byte, r io.Reader) {
*b = Reader{
buf: buf,
rd: r,
lastByte: -1,
lastRuneSize: -1,
}
}
Buffered:返回缓冲区有多少数据可以读
func (b *Reader) Buffered() int { return b.w - b.r }
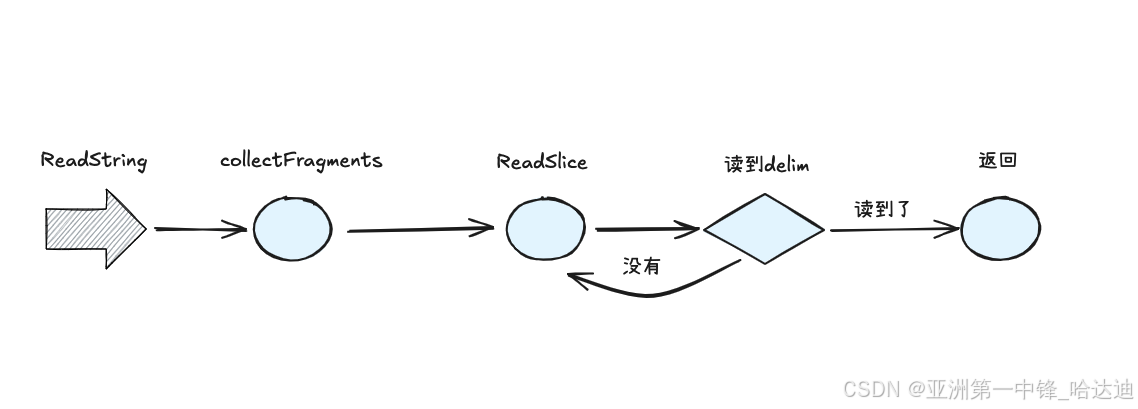
ReadString
该方法读直到delim为止的所有字符串
例如传delim = '\n’时,表示读一行数据
func (b *Reader) ReadString(delim byte) (string, error) {
/**
读数据,直到遇到delim字符为止
full, frag都是读到的数据
*/
full, frag, n, err := b.collectFragments(delim)
// 将读到的[]byte数据转换成字符串
var buf strings.Builder
buf.Grow(n)
for _, fb := range full {
buf.Write(fb)
}
// 写最后一段
buf.Write(frag)
return buf.String(), err
}
内部调collectFragments读数据,其两个返回值都是读到的数据:
- fullBuffers:没有delim的部分
- finalFragment:最后一段有delim的部分
为啥会有两部分?因为可能缓冲区满了都没遇到delim,于是会把已经读到的部分塞到fullBuffers中,然后清空buf,进行下一次读取。最后读到delim的部分放到finalFragment返回
func (b *Reader) collectFragments(delim byte) (fullBuffers [][]byte, finalFragment []byte, totalLen int, err error) {
var frag []byte
for {
var e error
// 调ReadSlice读,一直遇到delim字符为止
frag, e = b.ReadSlice(delim)
if e == nil {
break
}
// 遇到非ErrBufferFull的err,也就是非预期的err,break返回
if e != ErrBufferFull {
err = e
break
}
// 到这说明buf都读满了,还没遇到delim
buf := bytes.Clone(frag)
// 先把本次读到的暂存到fullBuffers,再继续读
fullBuffers = append(fullBuffers, buf)
totalLen += len(buf)
}
totalLen += len(frag)
return fullBuffers, frag, totalLen, err
}
内部调ReadSlice方法:
- 如果从buf中能找到
delim,就返回这一段 - 如果缓冲区buf满了也没读到
delim,返回给上游特殊错误ErrBufferFull,并把缓冲区中所有暂时读到的数据返回 - 缓冲区没满,也没读到
delim,调fill方法从真正的reader中读数据,填充到缓冲区
func (b *Reader) ReadSlice(delim byte) (line []byte, err error) {
s := 0
for {
// 看已读到的数据中有没有特殊字符delim
if i := bytes.IndexByte(b.buf[b.r+s:b.w], delim); i >= 0 {
// 如果有,截取从b.r到delim的部分,返回
i += s
line = b.buf[b.r : b.r+i+1]
b.r += i + 1
break
}
// 读到err,返回
if b.err != nil {
line = b.buf[b.r:b.w]
b.r = b.w
err = b.readErr()
break
}
// 缓冲区满了也没读到,先将缓冲区中所有数据返回
// 并用ErrBufferFull告诉调用方缓冲区满了也没读到
if b.Buffered() >= len(b.buf) {
b.r = b.w
line = b.buf
err = ErrBufferFull
break
}
// 没找到,且缓冲区没满的情况下,b.w - b.r就是这次扫描过的长度
// 下次要从b.r+s位置开始扫描,因为已扫描过的不用再扫描了
s = b.w - b.r
// 调真正的reader读数据,并放到缓冲区中
b.fill()
}
// 设置最后一个字节
if i := len(line) - 1; i >= 0 {
b.lastByte = int(line[i])
b.lastRuneSize = -1
}
return
}
fill方法:调真正的reader读数据,并填充缓冲区中
- 将已有的数据移动buf头部,此时buf中的数据为:
[b.r : b.w],其中b.r被置为0 - 调真正的reader读数据到
b.buf中,从b.w位置开始写
func (b *Reader) fill() {
// 将已有的数据移动slice头部
if b.r > 0 {
copy(b.buf, b.buf[b.r:b.w])
b.w -= b.r
b.r = 0
}
if b.w >= len(b.buf) {
panic("bufio: tried to fill full buffer")
}
for i := maxConsecutiveEmptyReads; i > 0; i-- {
// 调真正的reader读数据,到b.buf中
// 从b.w位置开始写
n, err := b.rd.Read(b.buf[b.w:])
if n < 0 {
panic(errNegativeRead)
}
b.w += n
if err != nil {
b.err = err
return
}
// 读到数据就返回
if n > 0 {
return
}
}
b.err = io.ErrNoProgress
}
ReadLine
ReadLint方法的作用是:读一行完整的数据返回,也就是一直读,直到遇到换行符为止
流程为:
- 内部调
ReadSlice - 如果缓冲区满了也没读到
换行符,就先把读到的部分返回,并返回isPrefix=true表示该case - 否则读到了,去除末尾的换行符返回
func (b *Reader) ReadLine() (line []byte, isPrefix bool, err error) {
line, err = b.ReadSlice('\n')
// 如果缓冲区满了还没读到
if err == ErrBufferFull {
// 处理\r\n跨越缓冲块的边界情况
if len(line) > 0 && line[len(line)-1] == '\r' {
// 将\r放回去
b.r--
line = line[:len(line)-1]
}
return line, true, nil
}
if len(line) == 0 {
if err != nil {
line = nil
}
return
}
err = nil
// 去除末尾的换行符
if line[len(line)-1] == '\n' {
drop := 1
if len(line) > 1 && line[len(line)-2] == '\r' {
drop = 2
}
line = line[:len(line)-drop]
}
return
}
bufio.Writer
构造
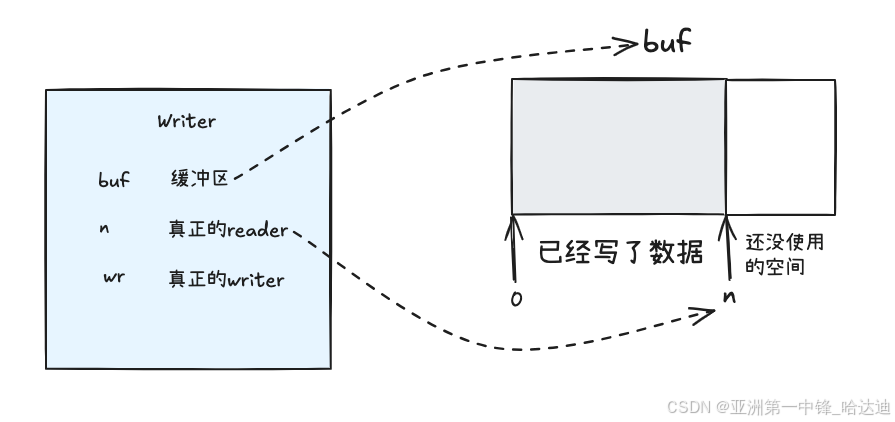
type Writer struct {
err error
// 输出缓冲区
buf []byte
// 缓冲区写到哪了
n int
// 被包装的writer
wr io.Writer
}
buf是缓冲区,其中buf[0:n]表示装已经写了的数据,buf[n:] 表示还可以写的空间
Available:缓冲区是否还有剩余空间可写
如果n到最后了,说明没位置可写了
func (b *Writer) Available() int { return len(b.buf) - b.n }
WriteString
整体流程比较直白:
- 如果缓冲区够写,就把字符串s写到缓冲区,返回
- 否则剩下的缓冲区不够写完整的s,就先写一部分,把缓冲区填满,调Flush方法把缓冲区的全部数据写到真正的writer中
- 再把s剩下的部分写到缓冲区中
func (b *Writer) WriteString(s string) (int, error) {
var sw io.StringWriter
tryStringWriter := true
nn := 0
// 剩余的缓冲区不够写s了
for len(s) > b.Available() && b.err == nil {
var n int
// 先把s的一部分拷贝到buf中
n = copy(b.buf[b.n:], s)
b.n += n
// 调真正的writer把buf的数据写出去
b.Flush()
nn += n
// 扣减本次写过的部分,for循环下次写剩下的部分
s = s[n:]
}
if b.err != nil {
return nn, b.err
}
// 到这说明缓存空间还够写s,那就把s完整复制到buf中
n := copy(b.buf[b.n:], s)
b.n += n
nn += n
return nn, nil
}
Flush
将缓冲区中的所有数据调真正的writer写出去,然后清空缓冲区
func (b *Writer) Flush() error {
if b.err != nil {
return b.err
}
if b.n == 0 {
return nil
}
// 调真正的writer,写buf中的所有数据
n, err := b.wr.Write(b.buf[0:b.n])
if n < b.n && err == nil {
err = io.ErrShortWrite
}
if err != nil {
// 返回err,但写成功了一部分,写成功的这部分从缓冲区移除
if n > 0 && n < b.n {
copy(b.buf[0:b.n-n], b.buf[n:b.n])
}
b.n -= n
b.err = err
return err
}
// 写完后清空buf
b.n = 0
return nil
}