
本系列
- 本地缓存库分析(一):golang-lru(本文)
- 本地缓存库分析(二):bigcache
- 本地缓存库分析(三):freecache(未完待续)
- 本地缓存库分析(四):fastcache(未完待续)
- 本地缓存库分析(五):groupcache(未完待续)
本地缓存概览
在业务中,一般会将极高频访问的数据缓存到本地。以减少网络IO的开销,下游服务的压力,提高性能
一般来说能放到本地的数据需要满足下面两个限制:
- 数据量不是非常大:数据量大了本地内存撑不住
- 一致性,时效性要求不是非常高:毕竟多个服务的本地缓存很难做到同步更新,及时更新
如果用go自带的map实现本地缓存,大概有两种实现方式:
sync.Mapmap + mutex.RWLock
但有以下缺点:
- 锁竞争严重
- 大量缓存写入,导致gc标记阶段占用cpu多
- 内存占用不可控
- 不支持缓存按时效性淘汰
- 不支持缓存过期
- 缓存数据可以被污染:如果缓存的V是指针,那么业务修改了V的某个值为当前请求用户自己的值,在缓存中的V就被污染了
本系列要介绍的开源缓存库如何解决上述问题?
-
将大map拆分成多个小map,每个小map使用各自的锁
-
零GC:
-
使用堆外内存,不把对象放到堆上,自然不会被gc扫描。但要注意手动管理,需要及时释放内存
-
map的非指针优化:
- 如果kv都没有指针,不会扫描map。注意常用作key的string类型含有指针,会被gc扫描
- 将hash值作为key,value在底层数组中的offset作为value,这样KV都是int,就不会被GC扫描了
-
-
内存占用可控:
- 初始化时制定好底层数组的容量,数据写满时会覆写,这样永远不会超过容量
- 或者指定好最多能放多少KV对,但如果V大小不一,极端情况下内存占用会很大
-
支持缓存按时效性淘汰,例如使用LRU算法
-
支持数据过期
- 某些库在后台启定时任务,定时清理过期的KV
- 某些库会在Get时,惰性检查KV是否过期
-
避免缓存污染:存储Value序列化后的字节数组,而不是指针
- 但cpu开销会增大,每次写入缓存都要经过序列化,每次从缓存读都要经过反序列化。内存开销也变大,每次读都相当于拷贝一份出来
- 也就是用性能换取安全性
golang-lru
本文阅读源码:https://github.com/hashicorp/golang-lru,版本:v2.0.7
该库提供了3种LRU的实现:
-
lru:标准lru -
2q:类似mysql的buffer pool,分为冷数据和热数据两部分。如果某对KV只被添加到缓存中,而没有被查询,那么只会待在冷数据区域直到被淘汰,而不会占用热数据的空间- 为啥要冷热分离?考虑这样一种场景:假设缓存中有10条热点数据,突然有用户往缓存中写10条冷数据,因为容量不够,要淘汰掉所有的热数据。如果之后也不查这些冷数据,而是继续查之前的热数据。产生的后果是所有热数据都会
cacheMiss - 如果应用了冷热分离机制,这些冷数据只会写到冷数据区,然后在冷数据区被淘汰,而不会占用热数据的空间,避免了大量热数据的cacheMiss
- 为啥要冷热分离?考虑这样一种场景:假设缓存中有10条热点数据,突然有用户往缓存中写10条冷数据,因为容量不够,要淘汰掉所有的热数据。如果之后也不查这些冷数据,而是继续查之前的热数据。产生的后果是所有热数据都会
-
expirable_lru:支持过期时间的lru
标准lru
数据结构:包含一个双向链表和hash表
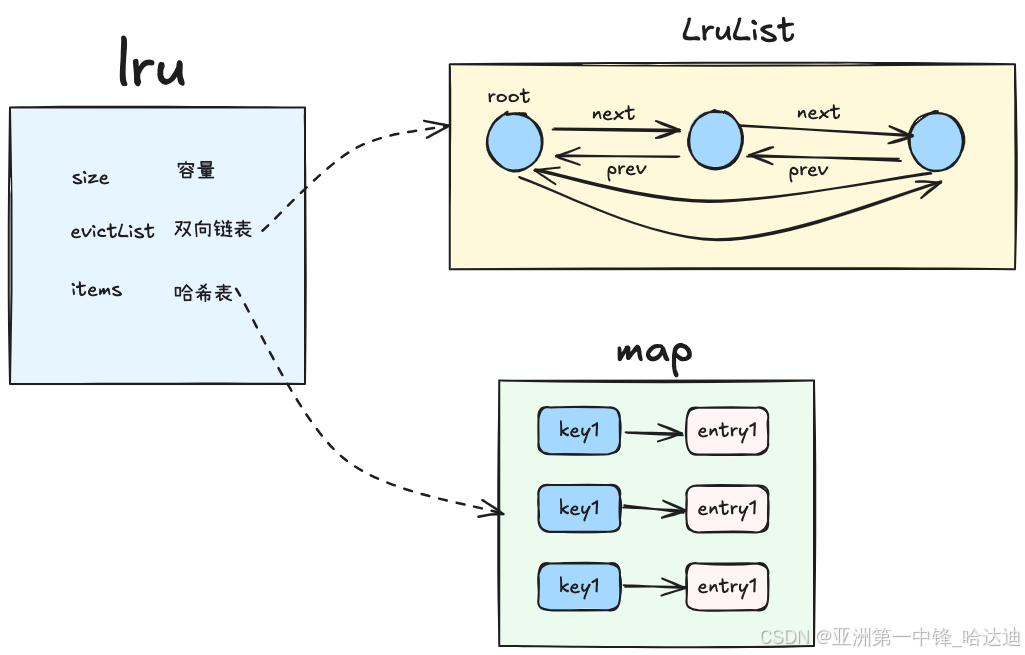
type LRU[K comparable, V any] struct {
// 容量
size int
// entry越靠近头部,越新
evictList *internal.LruList[K, V]
// hash表
items map[K]*internal.Entry[K, V]
onEvict EvictCallback[K, V]
}
LruList就是个带哨兵头节点root的双向链表,每个节点是Entry结构。哈希表items的value也是Entry机构
那么真正的头节点是root.Next
尾节点是root.Prev
type LruList[K comparable, V any] struct {
// 哨兵entry
root Entry[K, V]
// 已经放了多少entry
len int
}
entry结构如下:
type Entry[K comparable, V any] struct {
// 前后指针
next, prev *Entry[K, V]
// 属于哪个list,主要用于遍历链表时,在lru算法中没啥用
list *LruList[K, V]
Key K
Value V
}
初始化时root自己先形成一个环:
func (l *LruList[K, V]) Init() *LruList[K, V] {
l.root.next = &l.root
l.root.prev = &l.root
l.len = 0
return l
}
下面介绍一些在LRU算法中会用到的小方法
获取最后一个节点:
func (l *LruList[K, V]) Back() *Entry[K, V] {
if l.len == 0 {
return nil
}
return l.root.prev
}
将entry添加到头部:
func (l *LruList[K, V]) PushFront(k K, v V) *Entry[K, V] {
l.lazyInit()
return l.insertValue(k, v, time.Time{}, &l.root)
}
func (l *LruList[K, V]) insertValue(k K, v V, expiresAt time.Time, at *Entry[K, V]) *Entry[K, V] {
return l.insert(&Entry[K, V]{Value: v, Key: k, ExpiresAt: expiresAt}, at)
}
就是普通的双链表操作,将e插到at的后面
func (l *LruList[K, V]) insert(e, at *Entry[K, V]) *Entry[K, V] {
e.prev = at
e.next = at.next
e.prev.next = e
e.next.prev = e
e.list = l
l.len++
return e
}
将entry移动到头部:
func (l *LruList[K, V]) MoveToFront(e *Entry[K, V]) {
if e.list != l || l.root.next == e {
return
}
l.move(e, &l.root)
}
move方法:
func (l *LruList[K, V]) move(e, at *Entry[K, V]) {
if e == at {
return
}
// 先将e从list删除
e.prev.next = e.next
e.next.prev = e.prev
// 再将e插到at后面
e.prev = at
e.next = at.next
e.prev.next = e
e.next.prev = e
}
lru的操作
主要看看Get和Put这两大流程
原则:每次操作完,都要将KV所在的entry移动到list头部,表示该entry实效性最好,最不应该过期
Put
func (c *LRU[K, V]) Add(key K, value V) (evicted bool) {
// 如果已存在,将entry移到链表头部,更新value
if ent, ok := c.items[key]; ok {
c.evictList.MoveToFront(ent)
ent.Value = value
return false
}
// 新元素,加入头部
ent := c.evictList.PushFront(key, value)
c.items[key] = ent
evict := c.evictList.Length() > c.size
// 如果容量超了,需要移除最老的
if evict {
c.removeOldest()
}
return evict
}
removeOldest:删除最老的entry
func (c *LRU[K, V]) removeOldest() {
// 找到列表末尾的entry
if ent := c.evictList.Back(); ent != nil {
c.removeElement(ent)
}
}
// 把entry从链表和map中删除
func (c *LRU[K, V]) removeElement(e *internal.Entry[K, V]) {
c.evictList.Remove(e)
delete(c.items, e.Key)
if c.onEvict != nil {
c.onEvict(e.Key, e.Value)
}
}
Get
如果key存在,将key所在的entry移动到list头部
func (c *LRU[K, V]) Get(key K) (value V, ok bool) {
if ent, ok := c.items[key]; ok {
c.evictList.MoveToFront(ent)
return ent.Value, true
}
return
}
2q:冷热分离lru
2q在用了3个lru
recent:保存冷数据,默认容量为size的1/4frequent:保存热数据,默认容量为size的3/4recentEvict:保存最近从冷数据中被删除的key,默认容量为size的1/2
数据加到缓存时,首先被添加到冷数据区,如果后续没有操作,就会在冷数据区被淘汰。如果在还没被淘汰时执行了Put或Get,就会提升到热数据区
在Put时,如果某个key在冷热数据都没有,但在recentEvict中有,说明是最近被删除的,也当做热数据处理,加到冷数据区
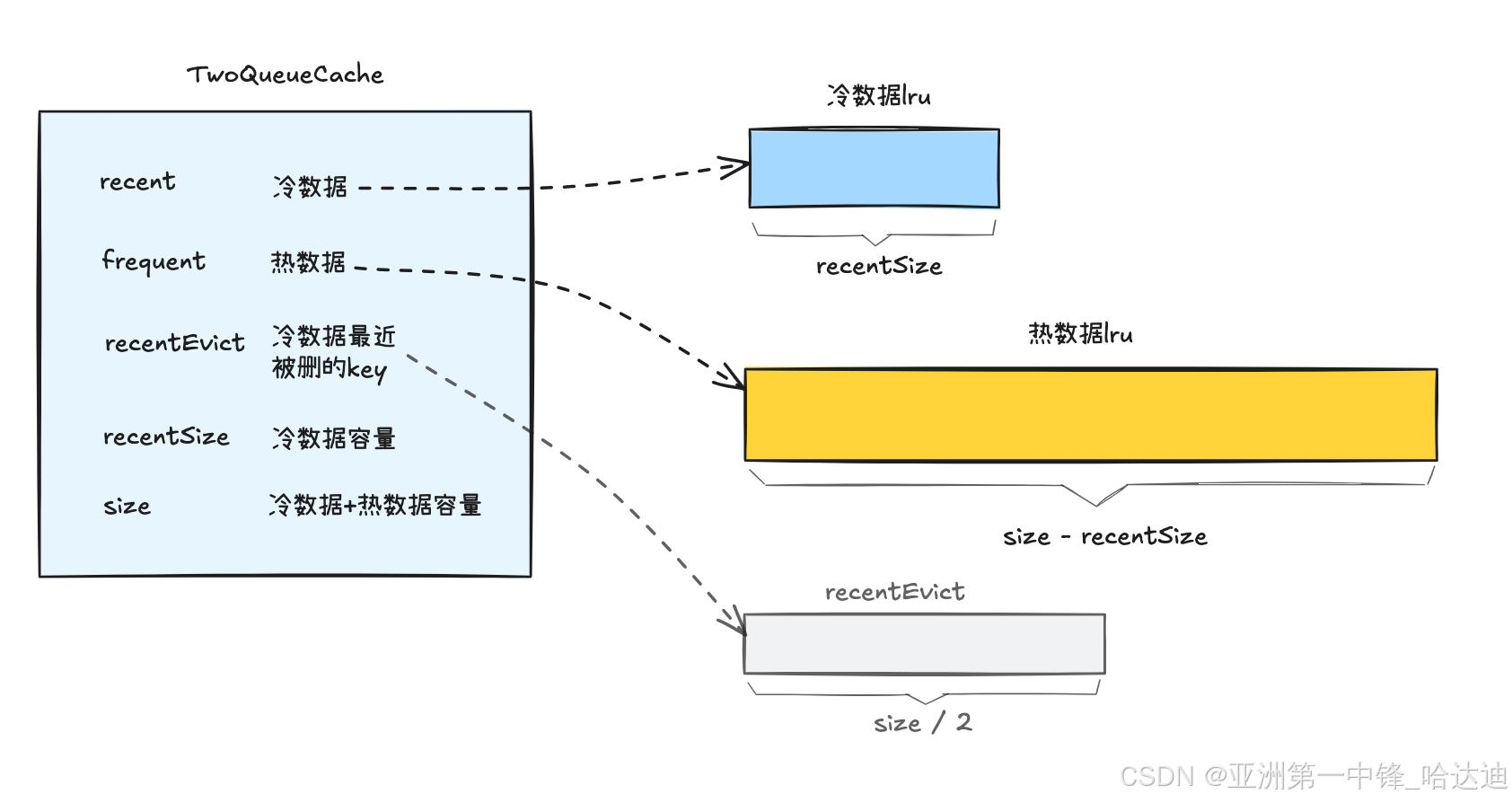
type TwoQueueCache[K comparable, V any] struct {
size int
// size * 0.25
recentSize int
// 0.25
recentRatio float64
// 0.5
ghostRatio float64
// 保存冷数据
recent simplelru.LRUCache[K, V]
// 正常热数据
frequent simplelru.LRUCache[K, V]
// 最近从冷数据删除的key
recentEvict simplelru.LRUCache[K, struct{}]
lock sync.RWMutex
}
构造方法,就是初始化3个lru,以及每个lru的容量
const (
// 默认冷数据的容量 = size * 0.25
Default2QRecentRatio = 0.25
// 默认被删除数据的容量 = size * 0.5
Default2QGhostEntries = 0.50
)
func New2Q[K comparable, V any](size int) (*TwoQueueCache[K, V], error) {
return New2QParams[K, V](size, Default2QRecentRatio, Default2QGhostEntries)
}
func New2QParams[K comparable, V any](size int, recentRatio, ghostRatio float64) (*TwoQueueCache[K, V], error) {
recentSize := int(float64(size) * recentRatio)
evictSize := int(float64(size) * ghostRatio)
// 初始化3个lru
recent, err := simplelru.NewLRU[K, V](size, nil)
if err != nil {
return nil, err
}
frequent, err := simplelru.NewLRU[K, V](size, nil)
if err != nil {
return nil, err
}
recentEvict, err := simplelru.NewLRU[K, struct{}](evictSize, nil)
if err != nil {
return nil, err
}
c := &TwoQueueCache[K, V]{
size: size,
recentSize: recentSize,
recentRatio: recentRatio,
ghostRatio: ghostRatio,
recent: recent,
frequent: frequent,
recentEvict: recentEvict,
}
return c, nil
}
重点还是看Put和Get
Put
流程为:
- 如果key在热数据中有,那就在热数据的lru中执行Put,更新其value,返回
- 如果在冷数据中有,那么本次不是第一次操作,说明该key不再是冷数据了,将其移动到热数据的lru中,返回
- 到这一步说明在冷热两个lru中都没有,再看看
recentEvict中有没有,如果有,说明是最近才从冷数据被删除的,那么也算作是热数据,在热数据lru中新增 - 否则就在冷数据lru中新增
func (c *TwoQueueCache[K, V]) Add(key K, value V) {
c.lock.Lock()
defer c.lock.Unlock()
// 如果在热数据中有,在热数据的lru中执行Put
if c.frequent.Contains(key) {
c.frequent.Add(key, value)
return
}
// 如果在冷数据中有,移动到frequent中
if c.recent.Contains(key) {
c.recent.Remove(key)
c.frequent.Add(key, value)
return
}
// 在两个lru中都没有,但最近移除过这个key,加到frequent中
if c.recentEvict.Contains(key) {
c.ensureSpace(true)
c.recentEvict.Remove(key)
c.frequent.Add(key, value)
return
}
// 否则加到recent中
c.ensureSpace(false)
c.recent.Add(key, value)
}
当需要新增时,需要确保容量足够,如果容量超了,需要淘汰老数据,给新数据腾位置
ensureSpace方法干这个活,淘汰规则为:
-
如果recent和frequent的len加起来不够size,判定为还有容量,不淘汰
- 也就是说,在容量没满时,冷热数据区分别都可以用到size个空间,有很大的灵活性
-
否则看冷数据区frequent有没有超过容量限制,超过了就从frequent中淘汰一个
-
否则从热数据区中淘汰一个
func (c *TwoQueueCache[K, V]) ensureSpace(recentEvict bool) {
// 如果还有空间,返回
recentLen := c.recent.Len()
freqLen := c.frequent.Len()
if recentLen+freqLen < c.size {
return
}
/**
recent超过了限制, 从recent移除最老的entry,将key加到recentEvict中
*/
if recentLen > 0 && (recentLen > c.recentSize || (recentLen == c.recentSize && !recentEvict)) {
k, _, _ := c.recent.RemoveOldest()
c.recentEvict.Add(k, struct{}{})
return
}
// 否则就是frequent超过限制了,从frequent中移除最老的entry
c.frequent.RemoveOldest()
}
Get
- 先看热数据有没有该key,如果有返回对应的value
- 再看冷数据有没有,如果有,说明本次不是第一次操作该key,将其提升到热数据中
- 否则在冷热数据中都没有,返回空
func (c *TwoQueueCache[K, V]) Get(key K) (value V, ok bool) {
c.lock.Lock()
defer c.lock.Unlock()
// 先看热数据有没有
if val, ok := c.frequent.Get(key); ok {
return val, ok
}
// 在看冷数据有没有
if val, ok := c.recent.Peek(key); ok {
c.recent.Remove(key)
c.frequent.Add(key, val)
return val, ok
}
// No hit
return
}
expirable_lru:支持过期时间的lru
其结构就是在标准LRU的基础上,增加过期时间ttl和过期桶(固定为100个)
所有KV都应用相同的过期时间ttl
每次Put后,会把key加到最新的过期桶中
后台有定时任务,每ttl/100时间执行一次,把即将过期的桶nextCleanupBucket 中的数据清空
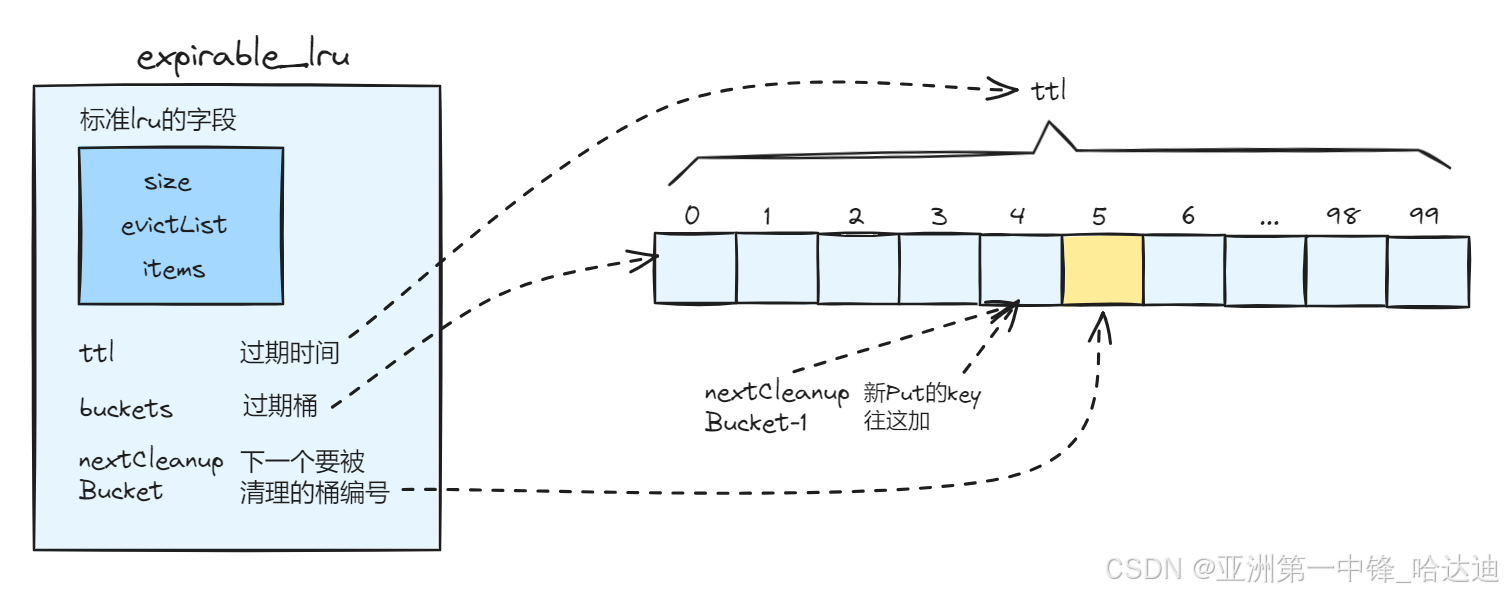
type LRU[K comparable, V any] struct {
// 标准LRU结构
size int
evictList *internal.LruList[K, V]
items map[K]*internal.Entry[K, V]
onEvict EvictCallback[K, V]
mu sync.Mutex
// LRU中的所有kv都用这个过期时间
ttl time.Duration
done chan struct{}
// 存储所有过期的key,
buckets []bucket[K, V]
// 下次要清除的bucket索引
nextCleanupBucket uint8
}
bucket定义如下
type bucket[K comparable, V any] struct {
// 所有过期的key
entries map[K]*internal.Entry[K, V]
// enteied中的所有key,最晚在啥时候过期
newestEntry time.Time
}
Put
在标准LRU的基础上,新增了对过期桶的操作
func (c *LRU[K, V]) Add(key K, value V) (evicted bool) {
c.mu.Lock()
defer c.mu.Unlock()
now := time.Now()
// key存在
if ent, ok := c.items[key]; ok {
c.evictList.MoveToFront(ent)
// 将entry从过期桶移除
c.removeFromBucket(ent)
ent.Value = value
ent.ExpiresAt = now.Add(c.ttl)
// 加入最新的过期桶
c.addToBucket(ent)
return false
}
// key不存在
ent := c.evictList.PushFrontExpirable(key, value, now.Add(c.ttl))
c.items[key] = ent
c.addToBucket(ent)
// 容量超了,移除最老的元素
evict := c.size > 0 && c.evictList.Length() > c.size
if evict {
c.removeOldest()
}
return evict
}
看看怎么将entry加入过期桶:
func (c *LRU[K, V]) addToBucket(e *internal.Entry[K, V]) {
// 加到nextCleanupBucket-1对应的bucket里,也就是最新的bucket
bucketID := (numBuckets + c.nextCleanupBucket - 1) % numBuckets
e.ExpireBucket = bucketID
c.buckets[bucketID].entries[e.Key] = e
// 更新桶中最新的entry过期时间
if c.buckets[bucketID].newestEntry.Before(e.ExpiresAt) {
c.buckets[bucketID].newestEntry = e.ExpiresAt
}
}
解释下为啥加到下标为nextCleanupBucket-1的桶里:nextCleanupBucket为即将失效的桶,那么nextCleanupBucket-1就是在当前时刻来说,最晚失效的桶
Get
在标准LRU的Get流程上,多了一步校验key是否过期
func (c *LRU[K, V]) Get(key K) (value V, ok bool) {
c.mu.Lock()
defer c.mu.Unlock()
var ent *internal.Entry[K, V]
if ent, ok = c.items[key]; ok {
// 校验是否过期
if time.Now().After(ent.ExpiresAt) {
return value, false
}
c.evictList.MoveToFront(ent)
return ent.Value, true
}
return
}
过期
缓存数据怎么实现过期呢?在初始化LRU时,起了后台任务:
go func(done <-chan struct{}) {
ticker := time.NewTicker(res.ttl / numBuckets)
defer ticker.Stop()
for {
select {
case <-done:
return
case <-ticker.C:
res.deleteExpired()
}
}
}(res.done)
每隔一段时间执行deleteExpired方法:
- 准备将下标为nextCleanupBucket的中的所有KV过期
- sleep直到时间到
newestEntry,因为桶中最晚过期的key在这个时候,不能提前过期 - 将该桶中所有KV删除
- 推进nextCleanupBucket,让
nextCleanupBucket++
func (c *LRU[K, V]) deleteExpired() {
c.mu.Lock()
//
bucketIdx := c.nextCleanupBucket
timeToExpire := time.Until(c.buckets[bucketIdx].newestEntry)
// sleep直到newestEntry到来
if timeToExpire > 0 {
c.mu.Unlock()
time.Sleep(timeToExpire)
c.mu.Lock()
}
// 将里面所有kv删除
for _, ent := range c.buckets[bucketIdx].entries {
c.removeElement(ent)
}
// 推进nextCleanupBucket
c.nextCleanupBucket = (c.nextCleanupBucket + 1) % numBuckets
c.mu.Unlock()
}
总结
最后看看golang-lru解决了哪些原生缓存的问题:
| 问题 | 解决 |
|---|---|
| 锁竞争严重 | 没有解决,只有一把大锁,锁竞争依然严重 |
| 大量缓存写入,导致gc标记阶段占用cpu多 | 没有解决 |
| 内存占用不可控 | 有改善,在KV个数的层面可用,在总内存占用量的层面依然不可用 |
| 不支持缓存按时效性淘汰 | 解决了,支持按LRU算法淘汰 |
| 不支持缓存过期 | 解决了,expirable_lru支持 |
| 缓存数据可以被污染 | 没有解决,还是存指针 |