目录
MySQL体系结构和引擎
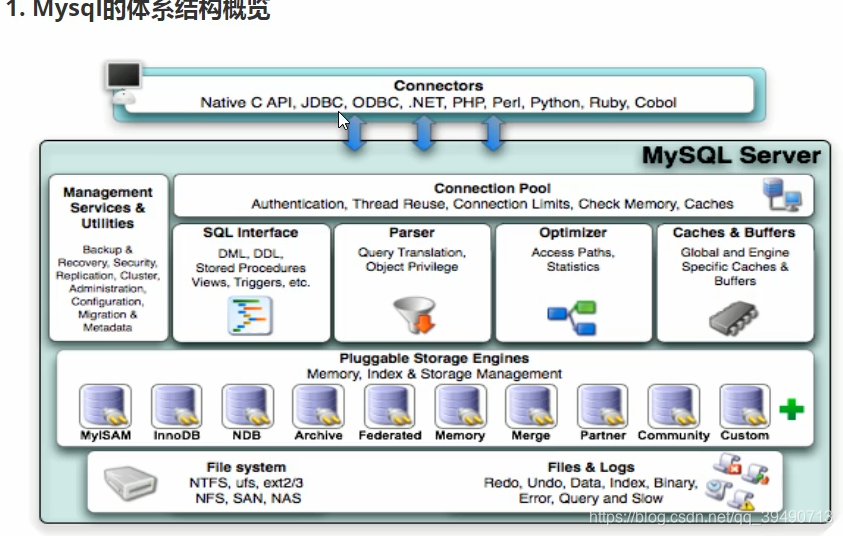
整个流程是,上层代码获取连接池连接,数据库获取sql语句,解析,自动优化,放入缓存。调用存储引擎。在底层文件系统操作数据。

存储引擎:
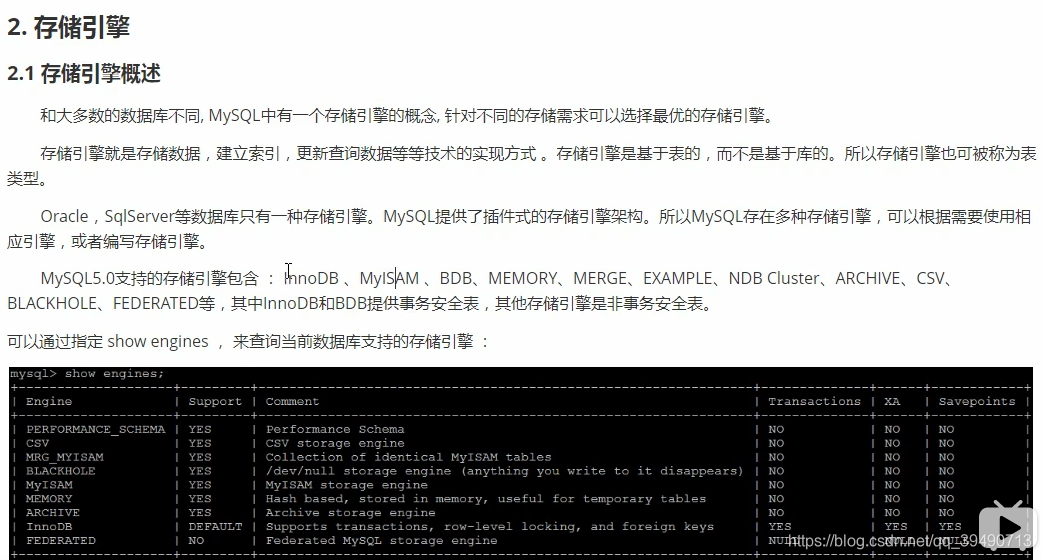
重点看InnoDB和MyISAM。都是表级的索引,而非数据库级别
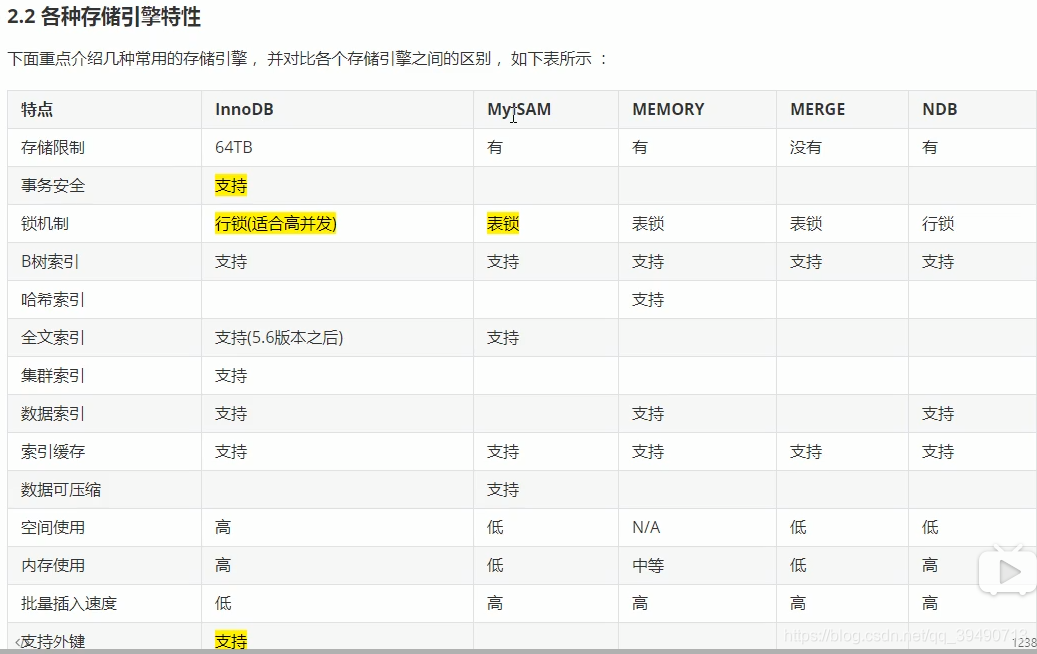
InnoDB特性:外键。
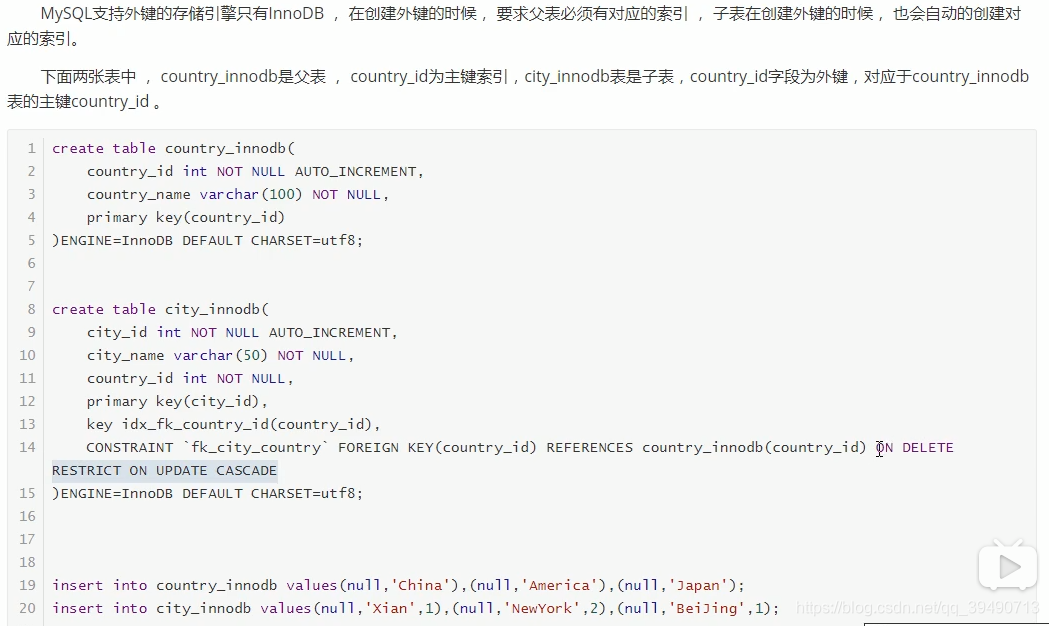

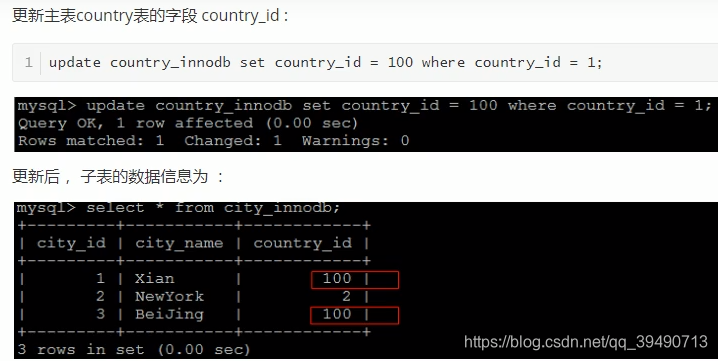
InnoDB存储方式:
InnoDB还支持事务。
MyISAM:
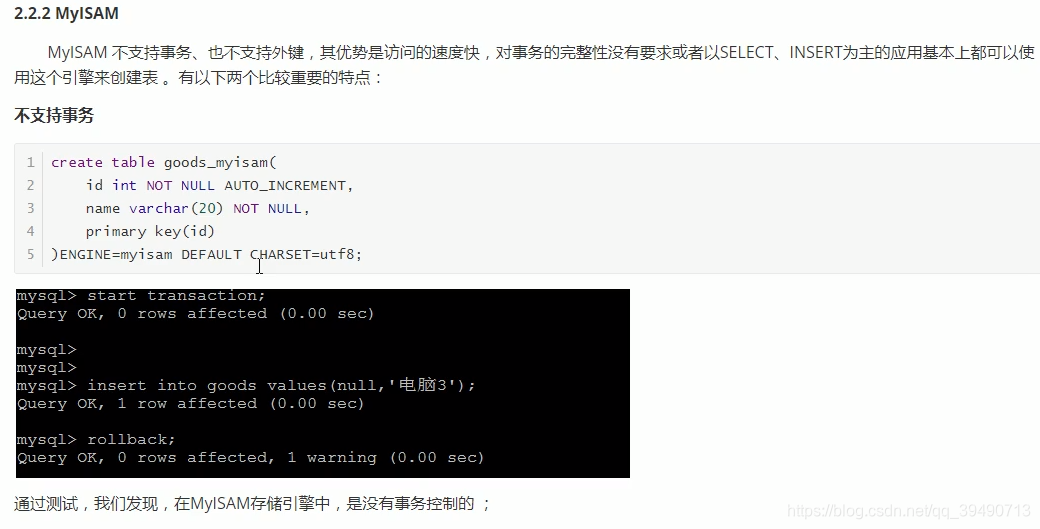
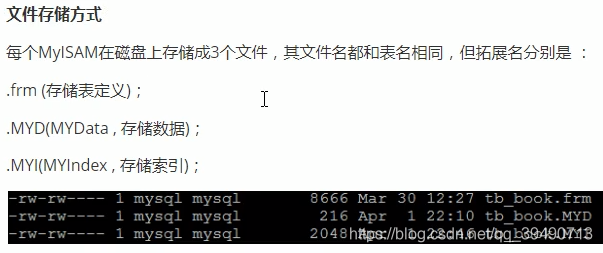
以下两个仅了解:


范式:

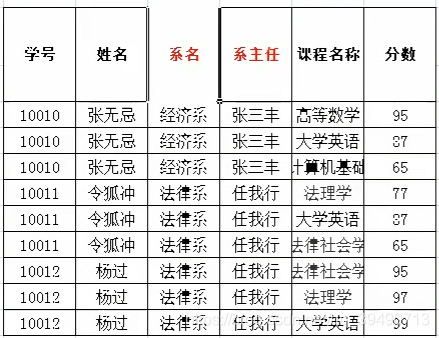
以下表为例:

系这一列不满足第一范式,因为这一列又分割成了两列,所以修改后如下:
满足第一范式之后依旧存在的问题:
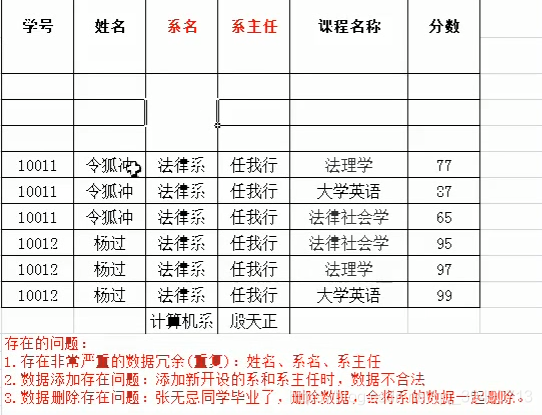
因此考虑如何满足第二范式:

因为学号和课程名称可以确定其他所有列是唯一,所以这两个接近码,不过这个码并没有实现完全依赖,即单学号就可以确定姓名,姓名不依赖于课程。所以要消除部分依赖。因此要对表进行拆分。

改造后满足第二范式,但不满足第三范式:需要消除传递依赖即系名依赖于学号,系主任依赖于系名。因此需要再拆分出一张表。
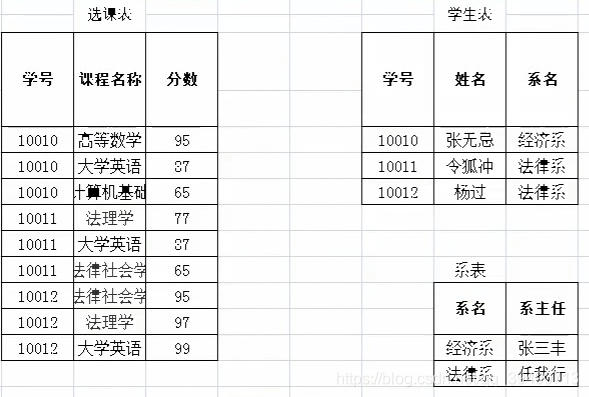
索引
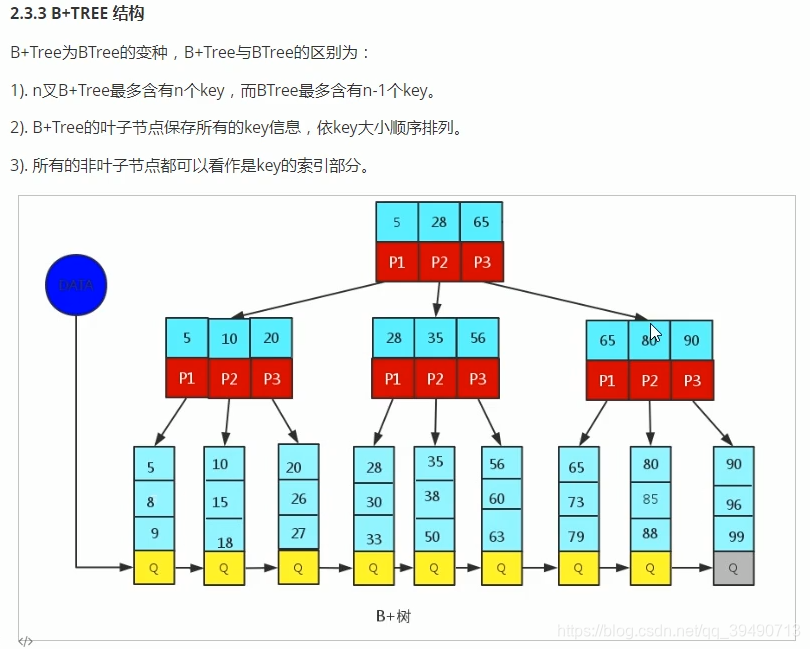
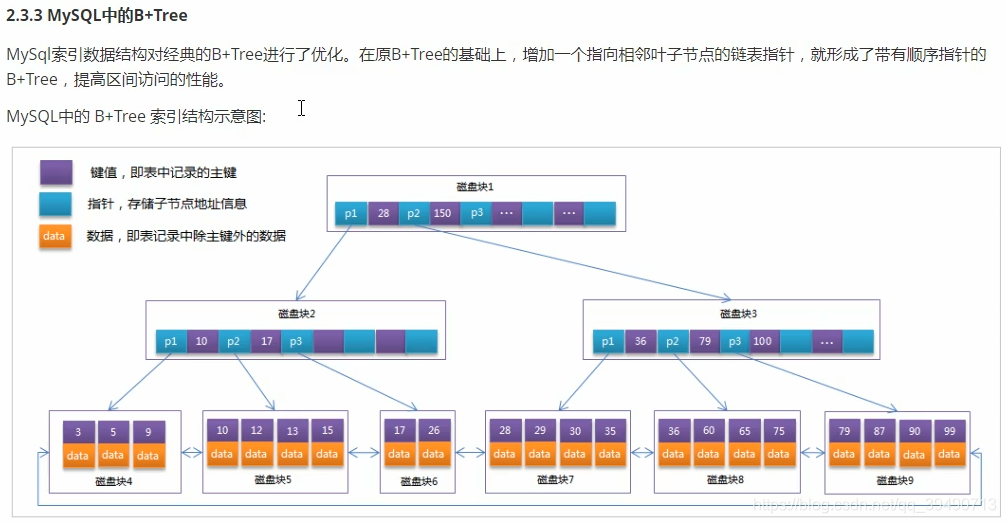
简单概念看图,索引如何加快查找。innodb底层由B+树实现。



B树的构造:

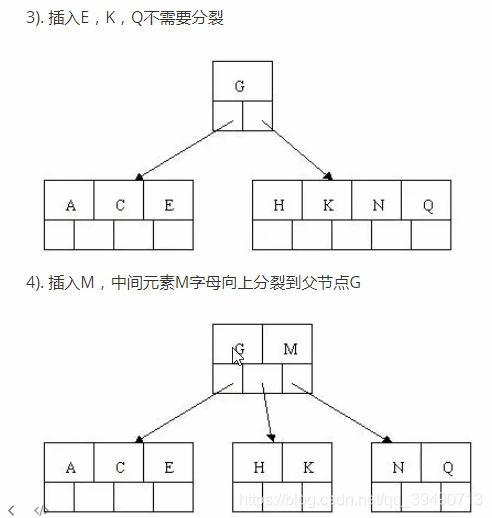
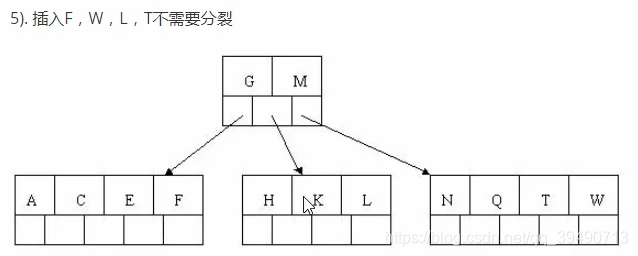
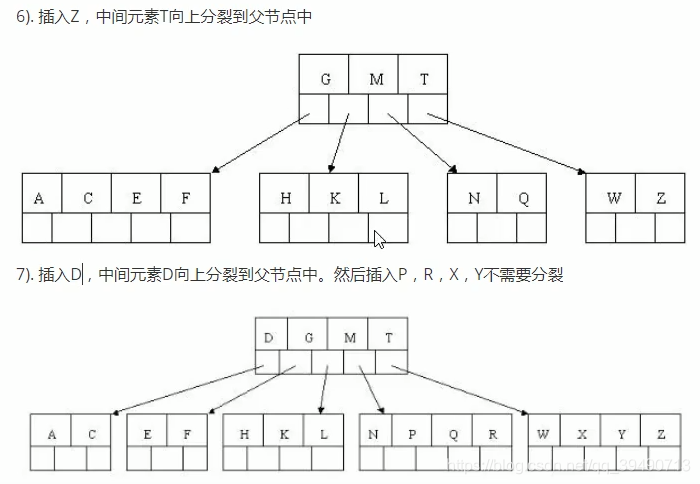
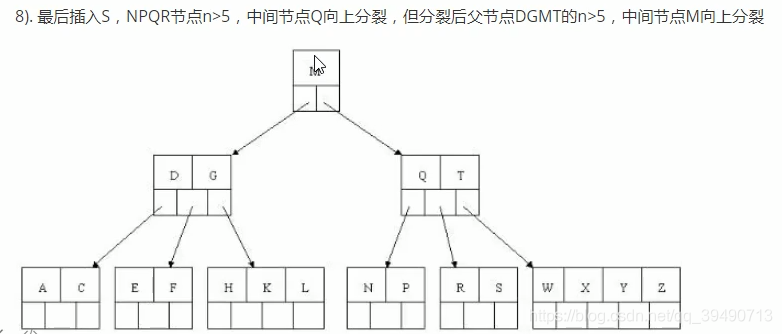
B+树
索引的分类:

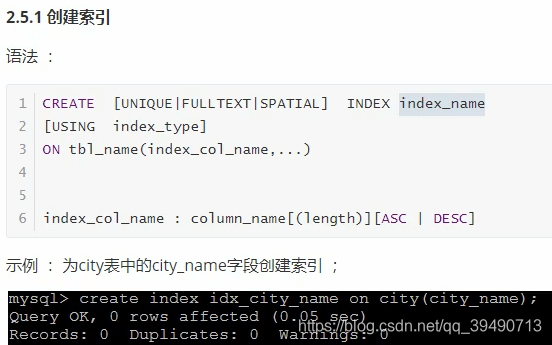
创建索引:默认自动创建主键索引的
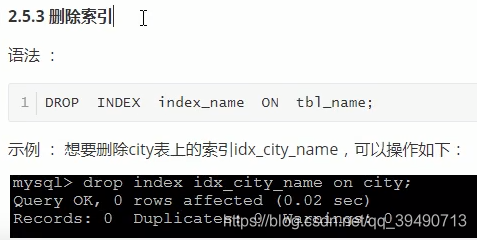

索引设计原则:

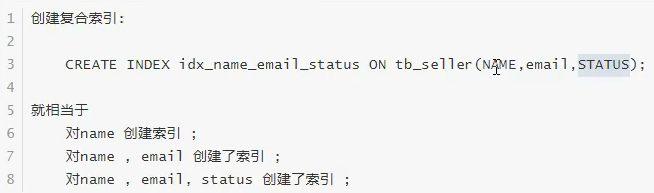
索引的使用:
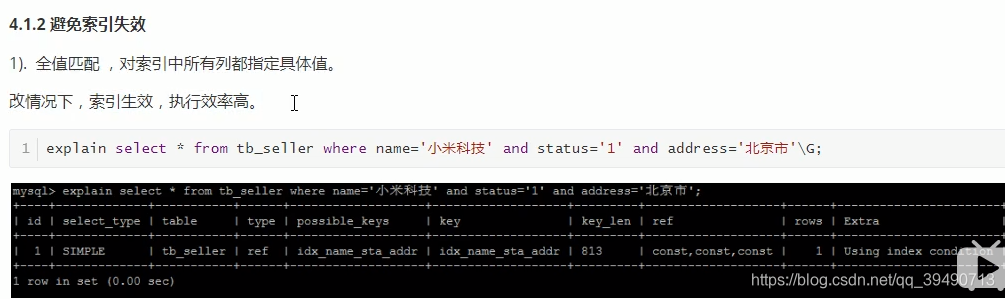
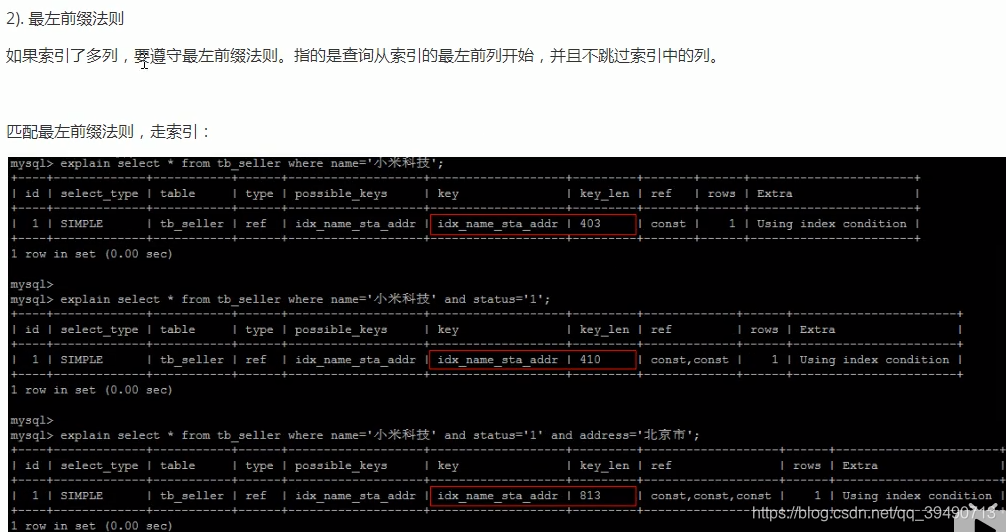
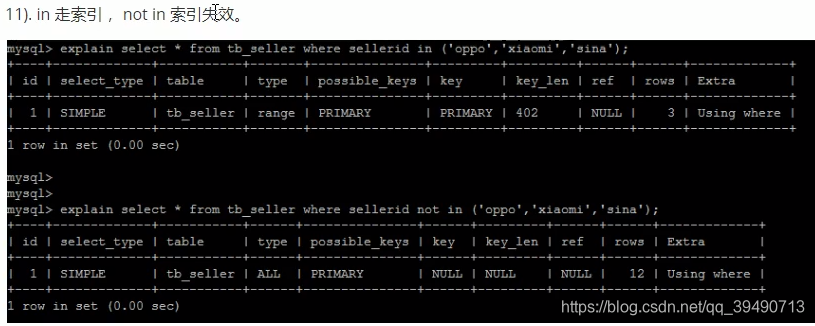
注意查询复合索引时的具体列。最左原则,必须要复合索引的第一个列才会使用索引。
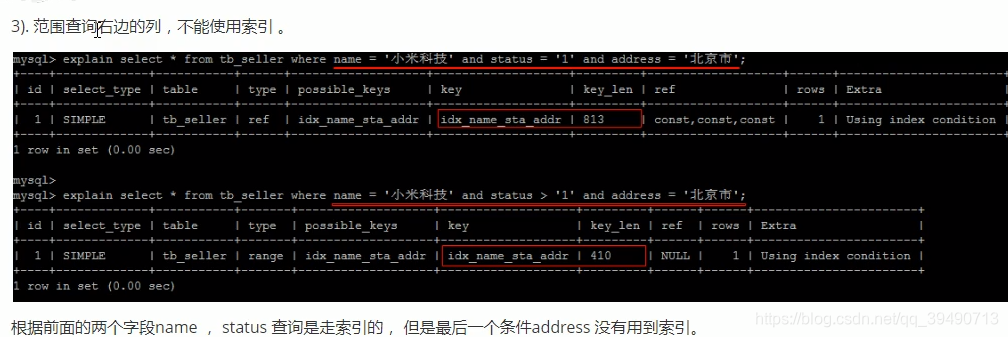
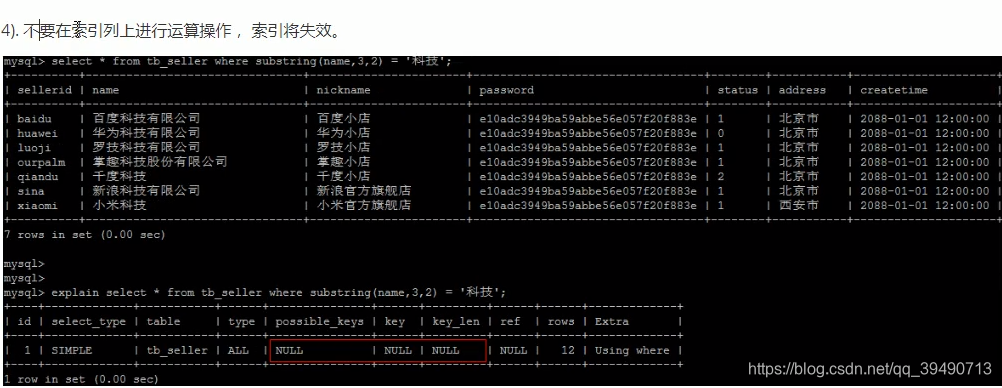

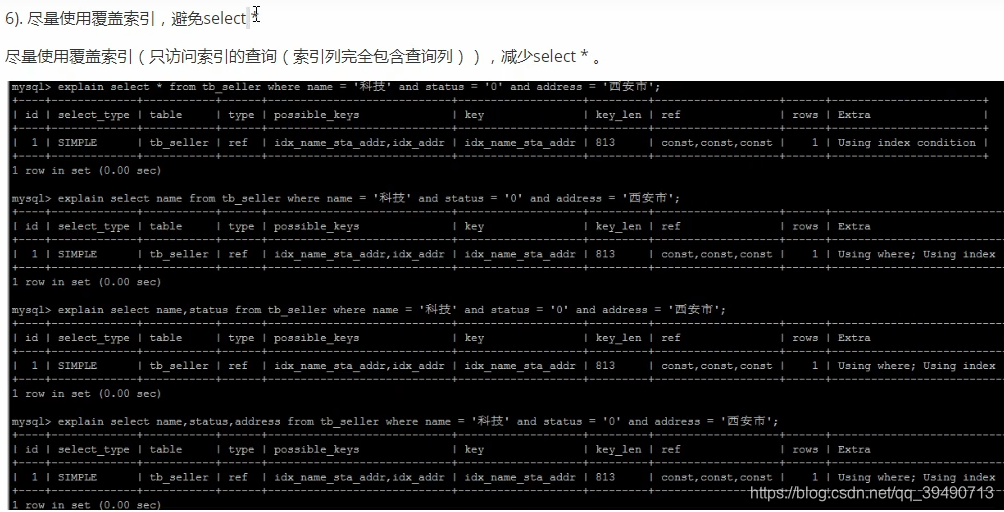
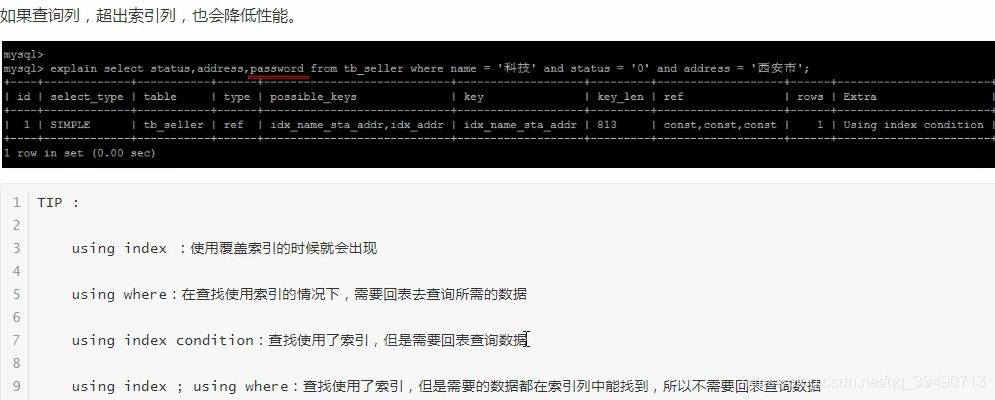
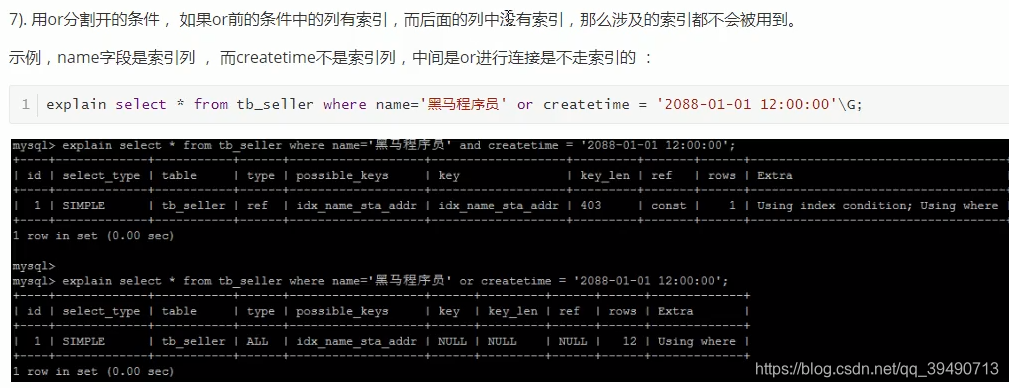
解决方案:仅查找索引内的列:覆盖索引

如果查的列,某一条数据占用的比例较大,比如99%都是,则不走索引。
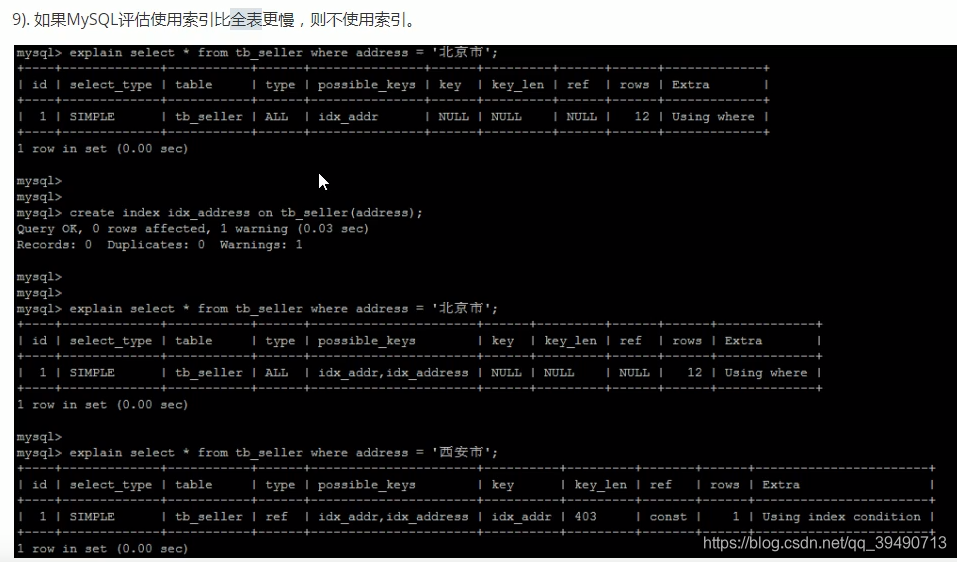
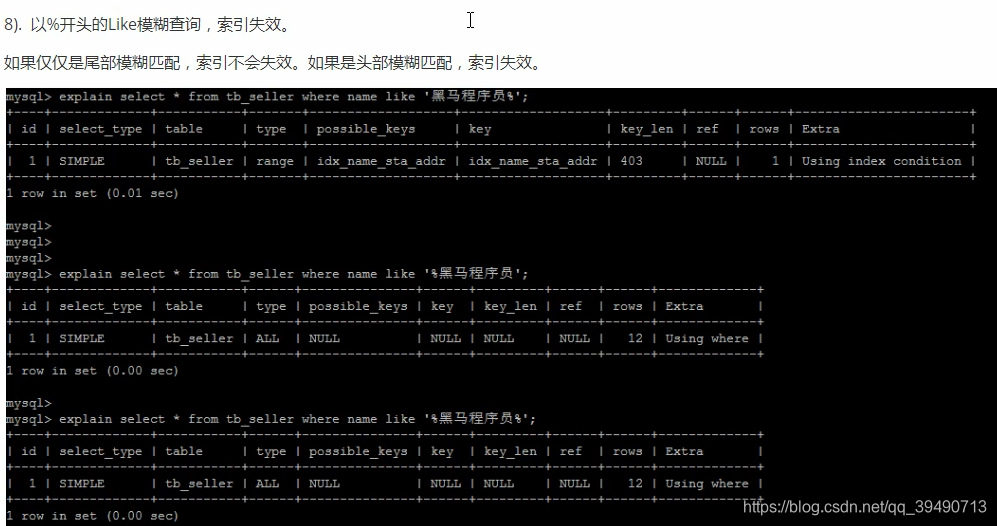
底层会自动判断走不走,主要看数据占数据表的比例。多则不走索引。
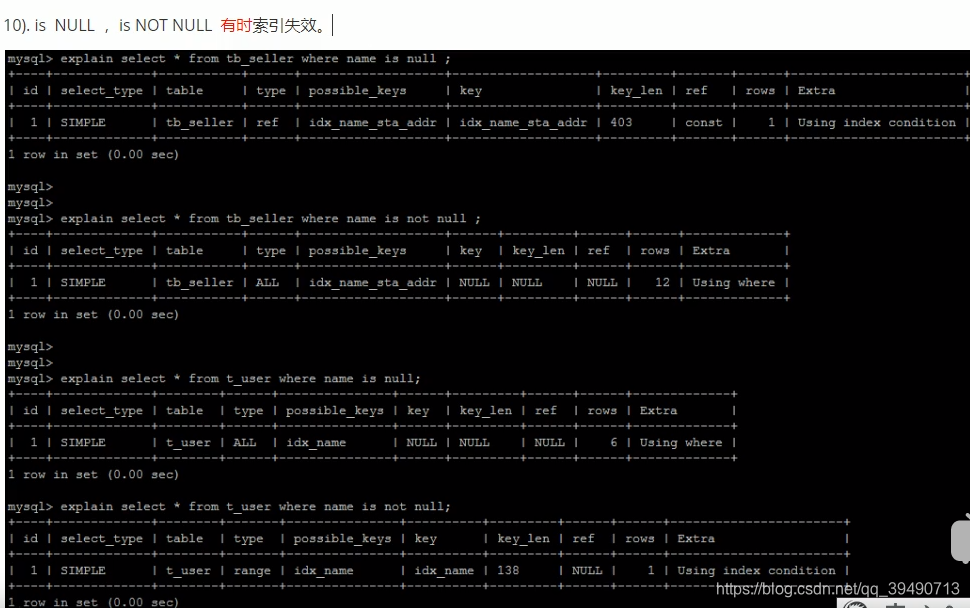

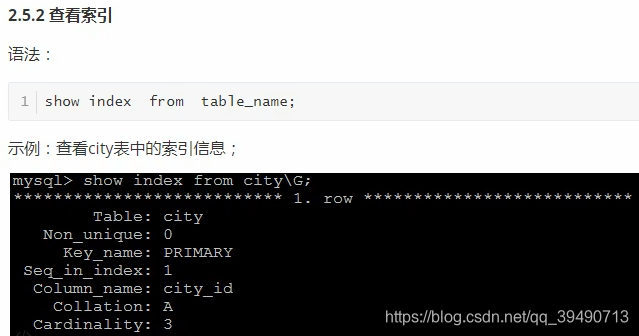
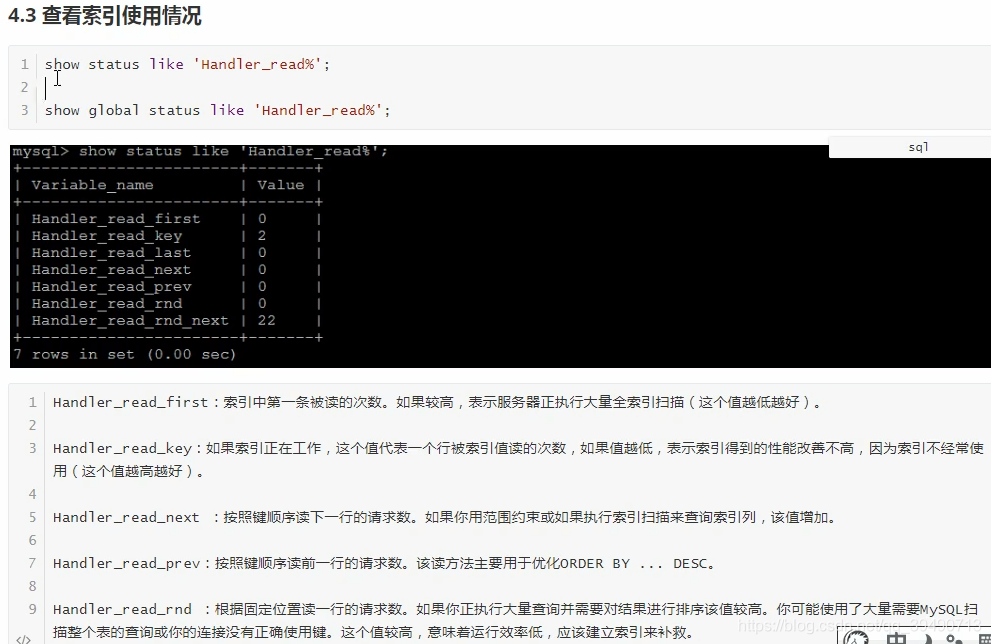
查看索引使用情况:
视图:

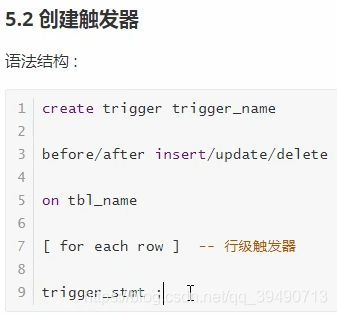
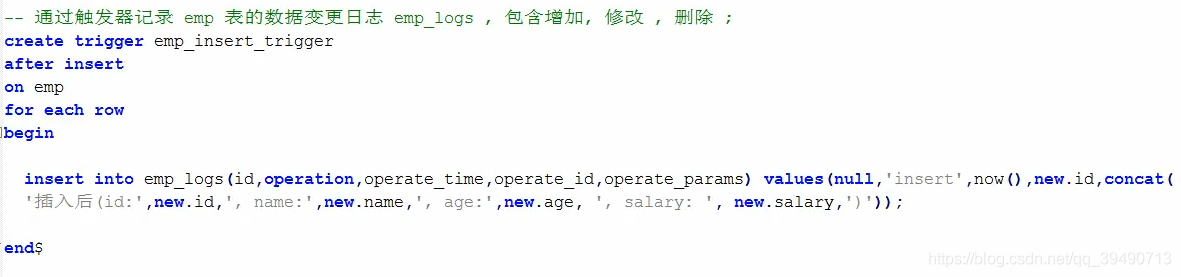
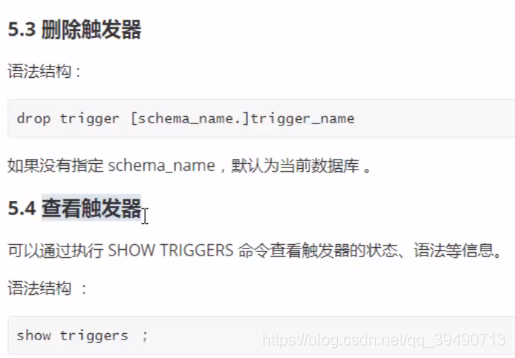
触发器:



SQL优化步骤:
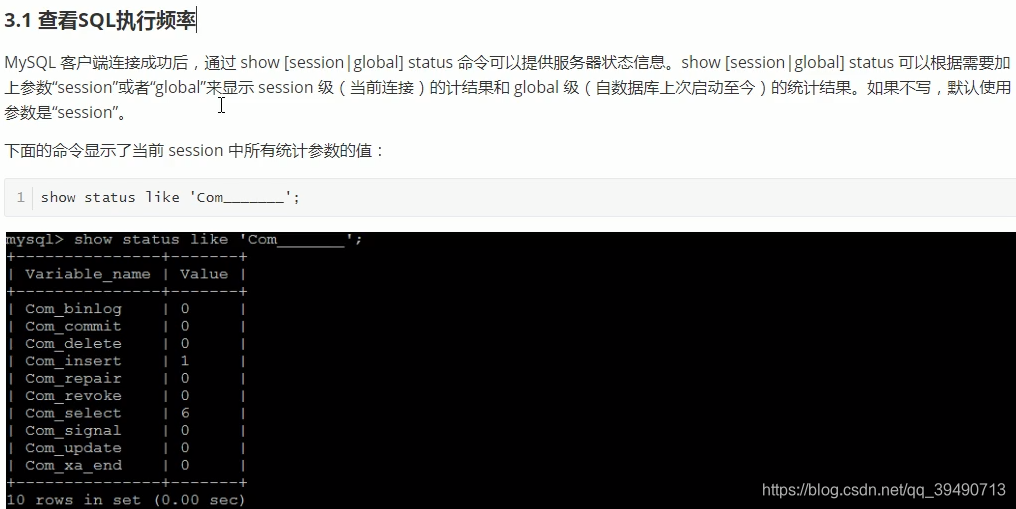
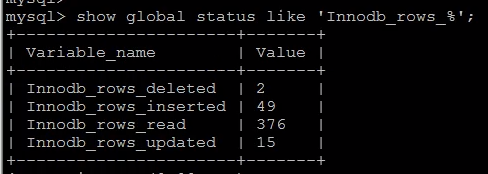
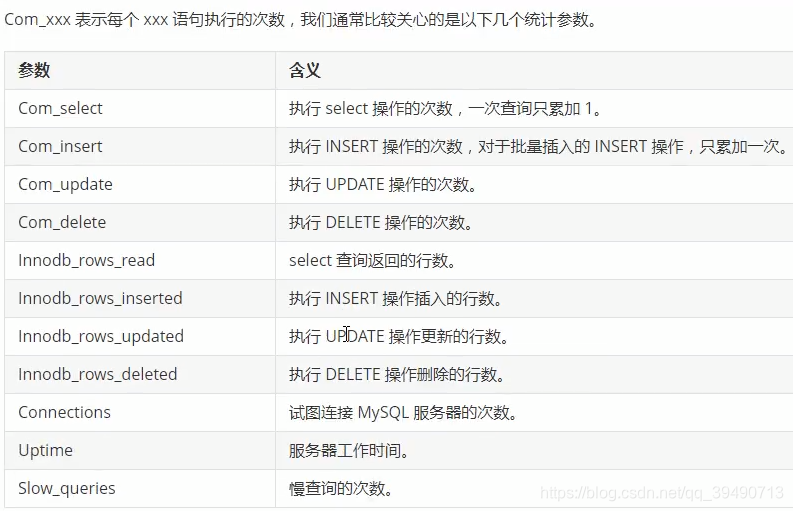
查询特定表的影响的行数:global是历史以来,不加为当前连接。

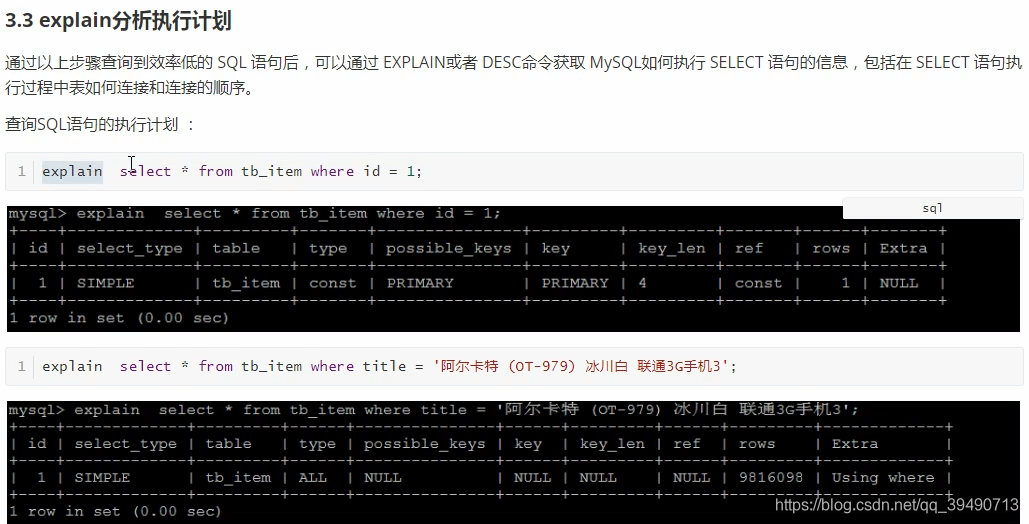

这个id指定了表实际的查询顺序。
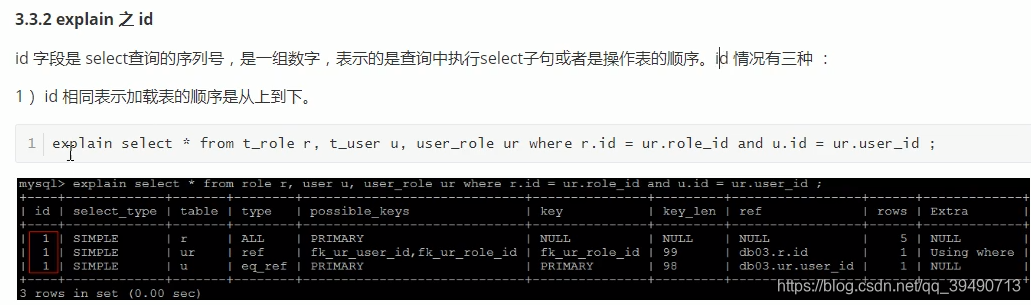
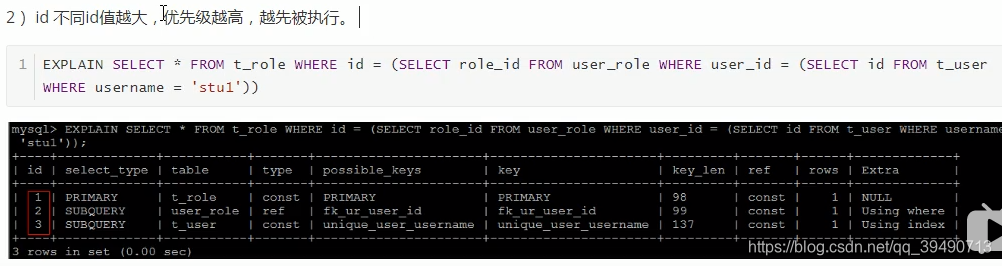
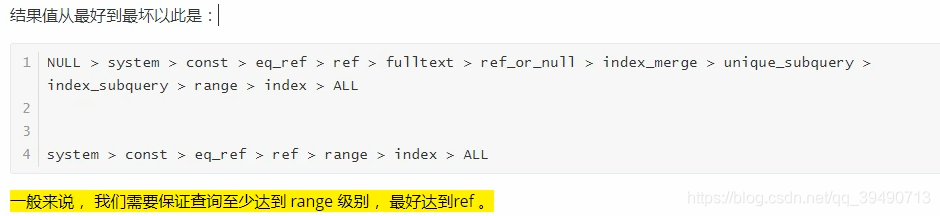
从上往下,效率越来越低。

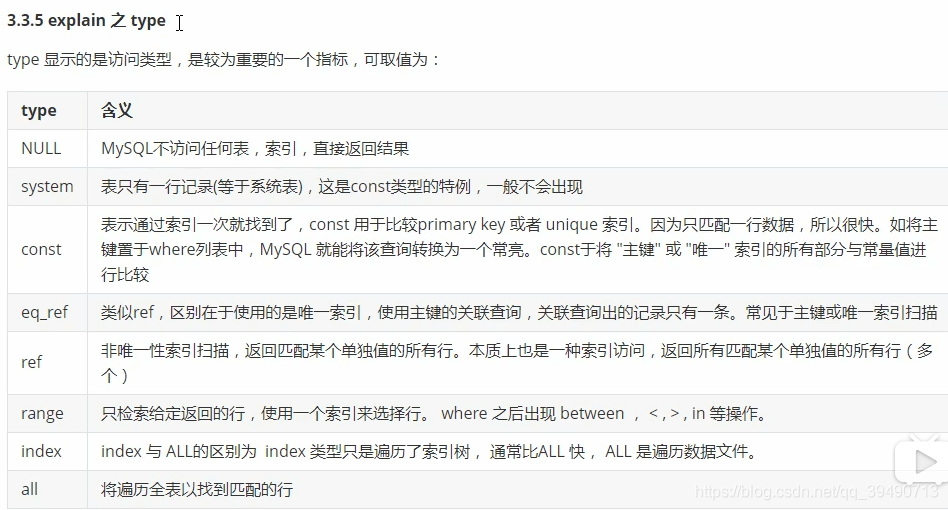

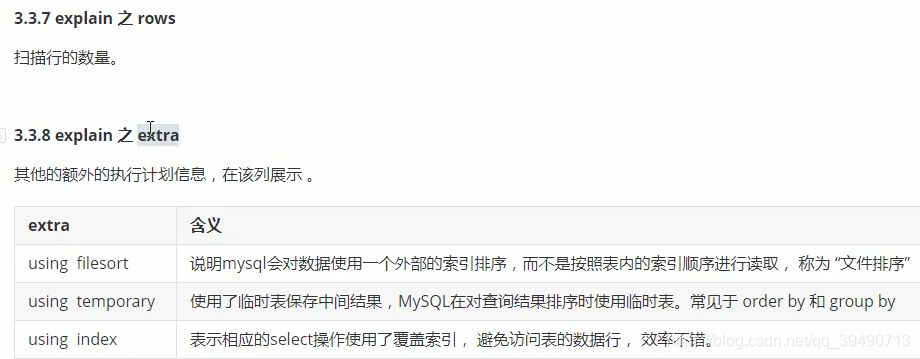
filesort和temporary需要优化。

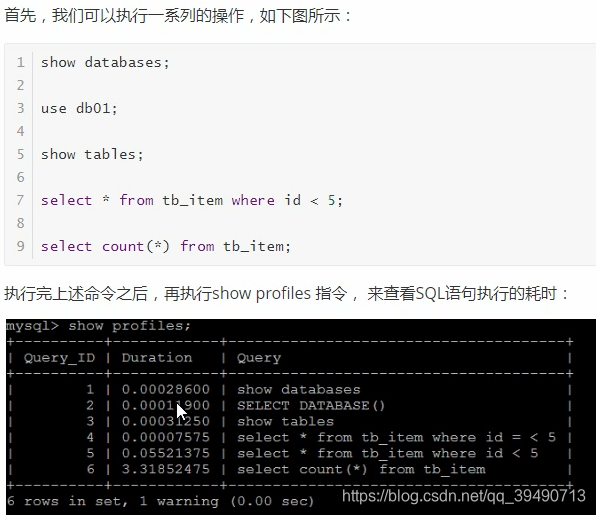
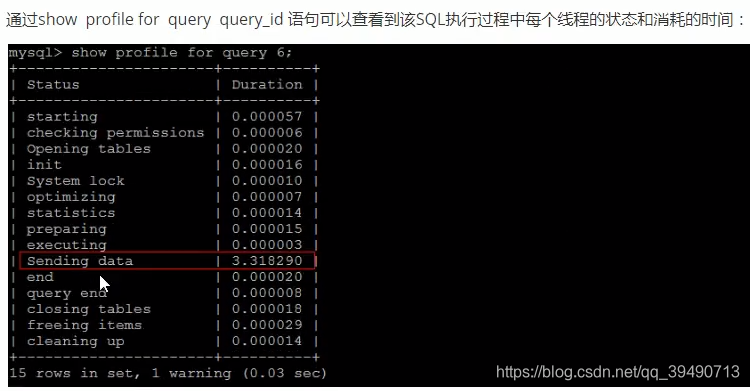

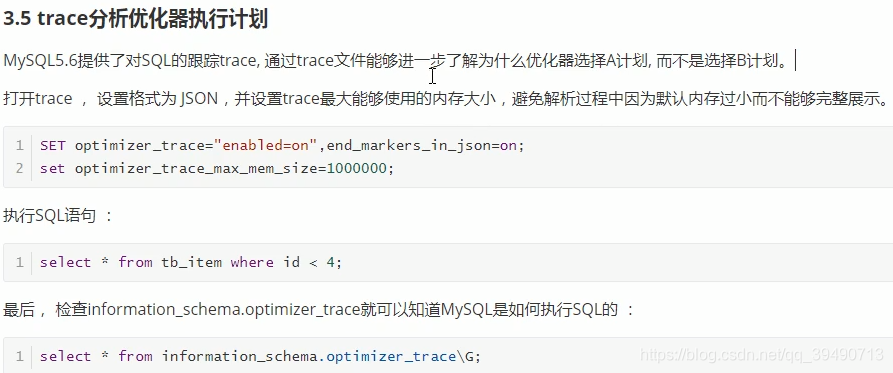
trace分析优化器:
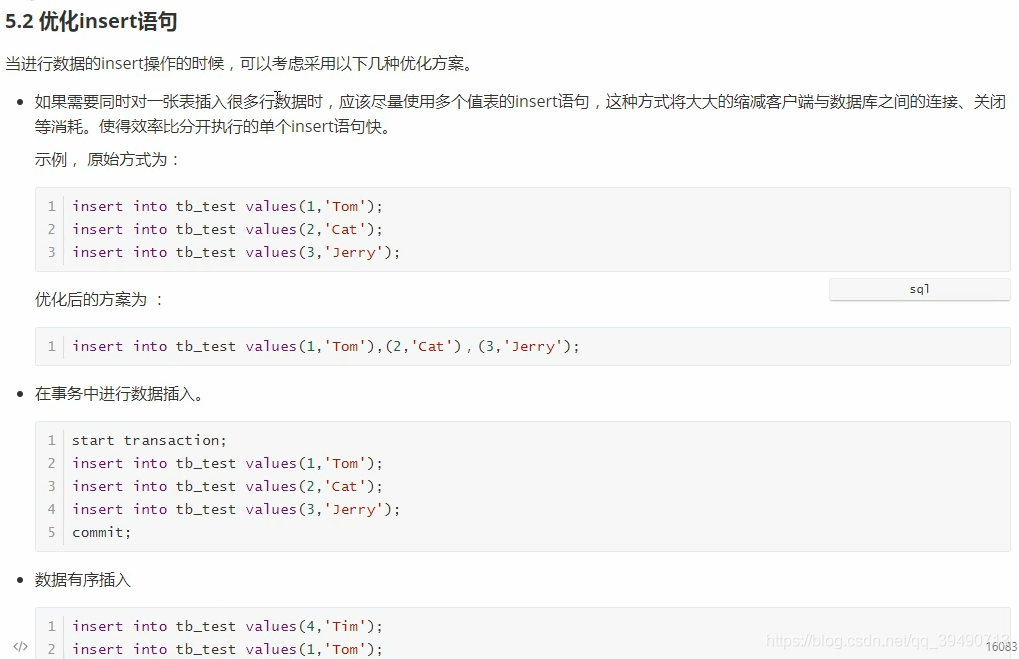
SQL优化:



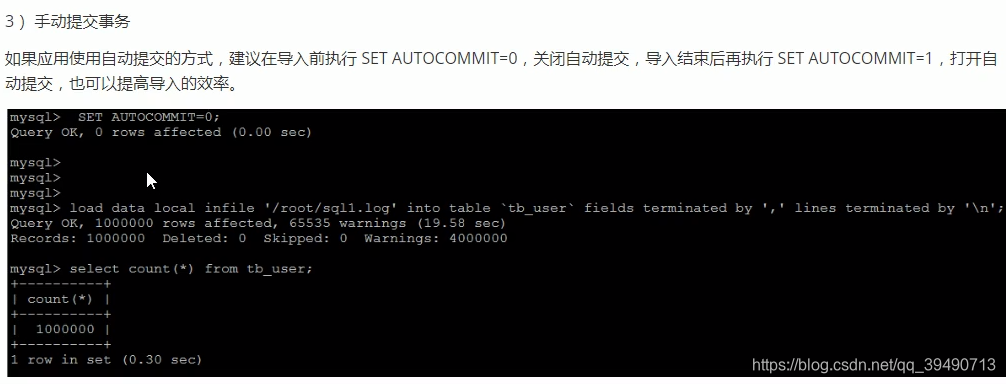
如果建表有唯一索引,默认会启用唯一性校验。手动关闭可加速。


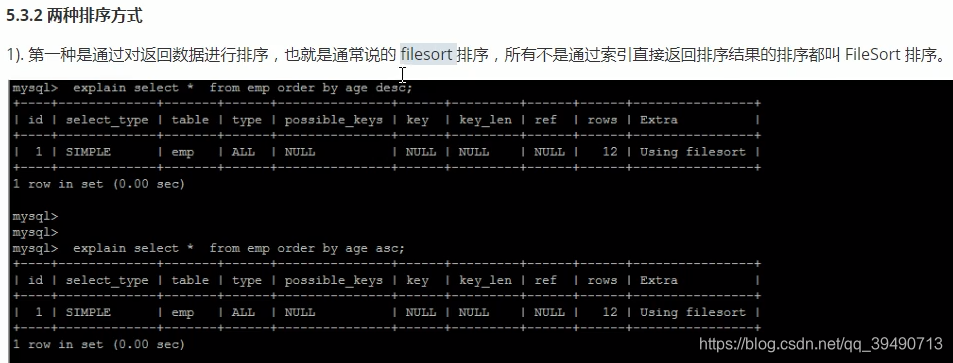
order by优化:
用到的还是索引覆盖。如果查询的数据在索引内会有用。
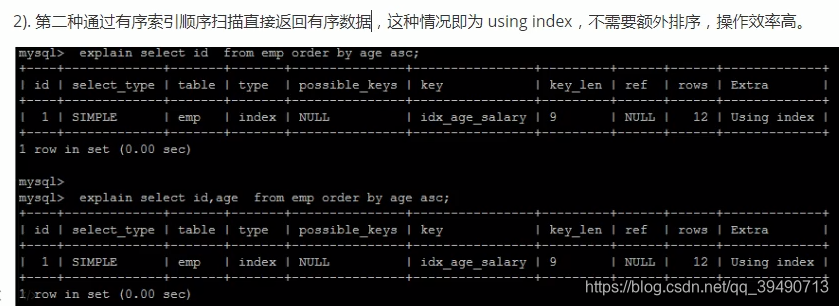
多字段排序,如果一个升序,一个降序不会走索引。



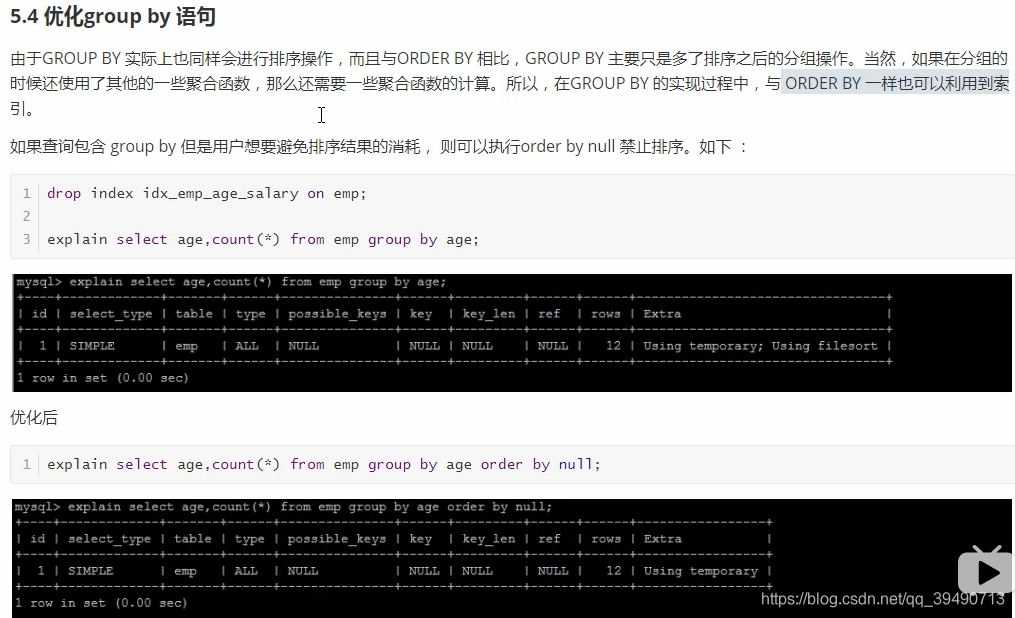
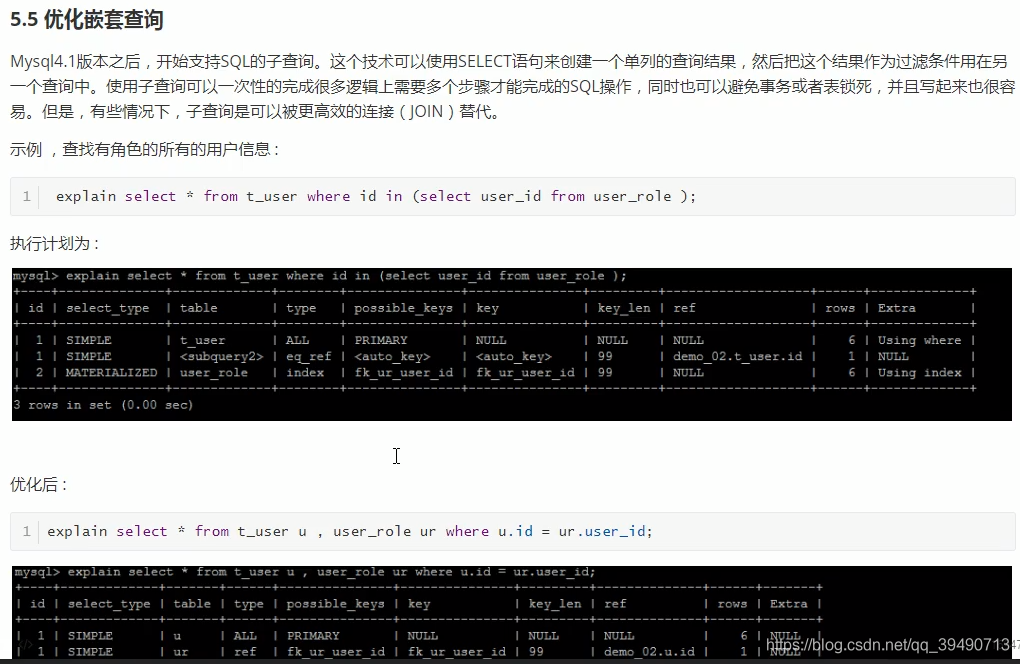
建议使用union来替换:求并集。


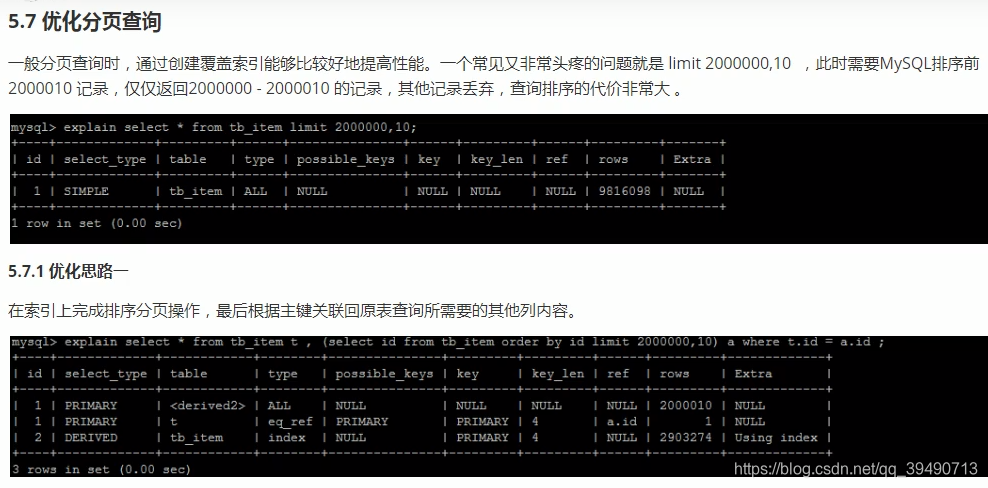
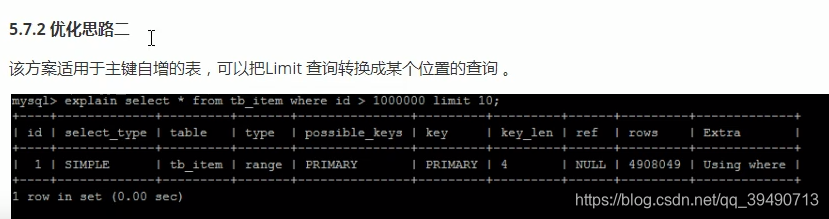
思路二需要主键自增,且不能出现断层。
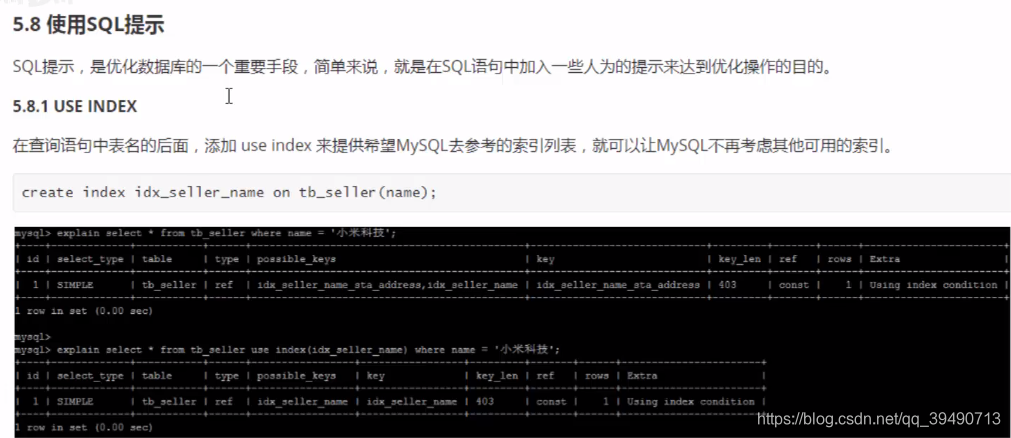
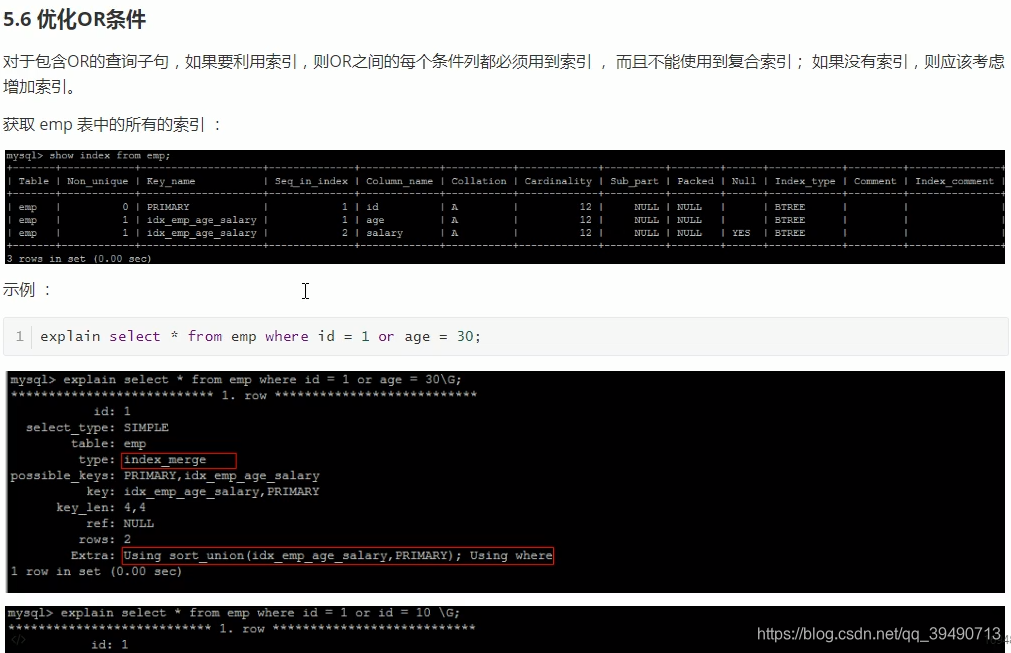
忽略索引:
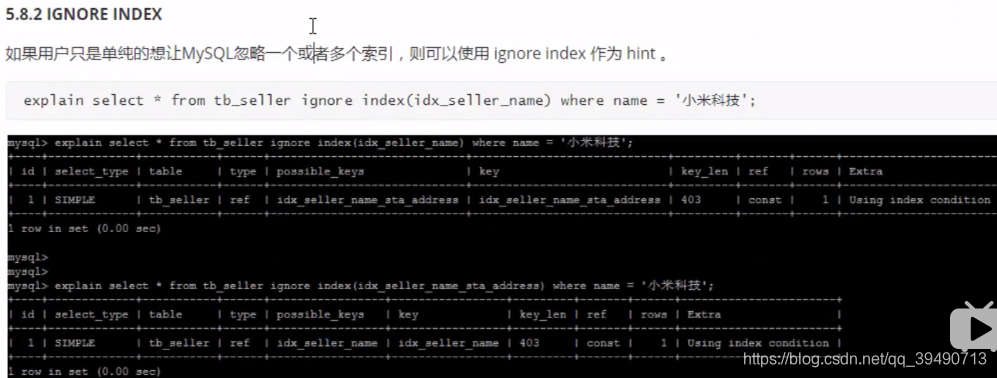

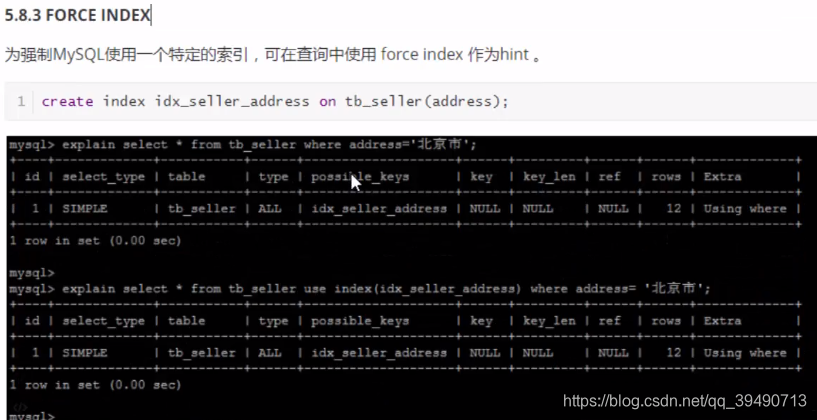
注意和use index的区别。force是强制使用的。
应用优化:

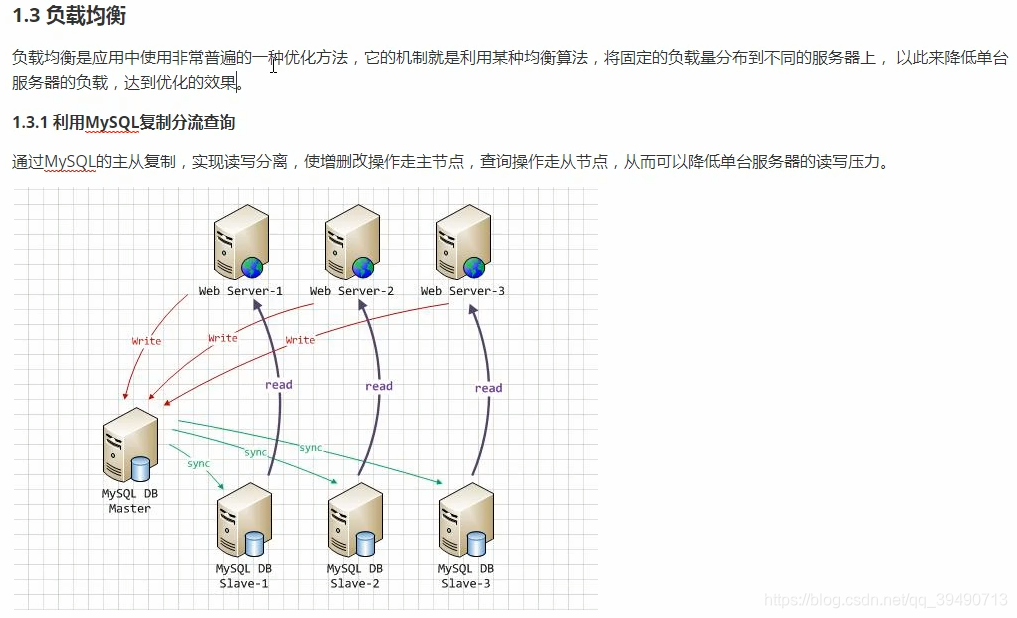

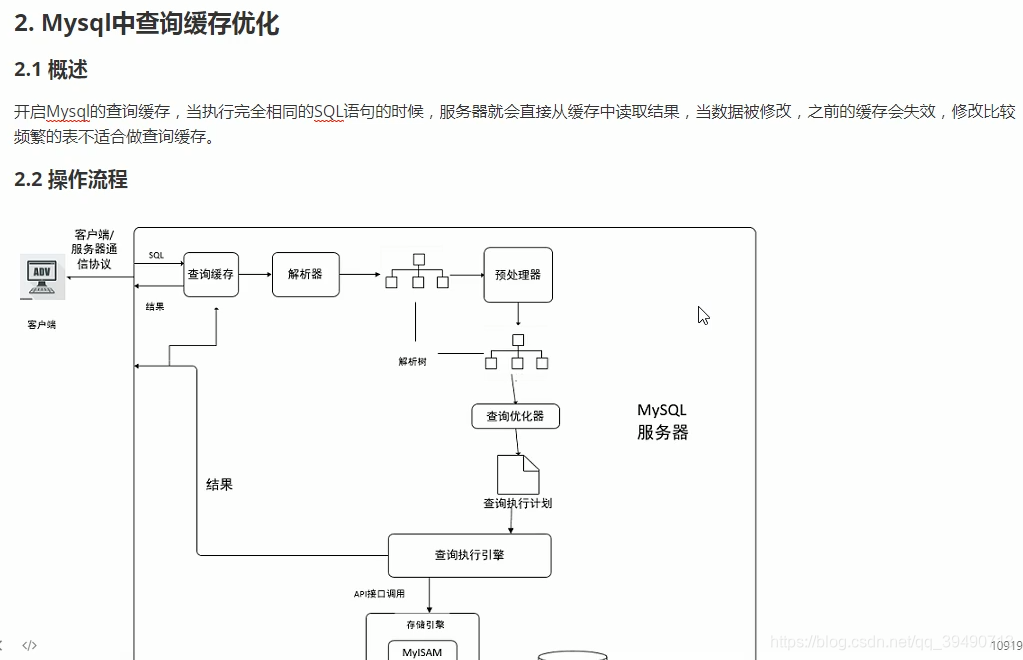
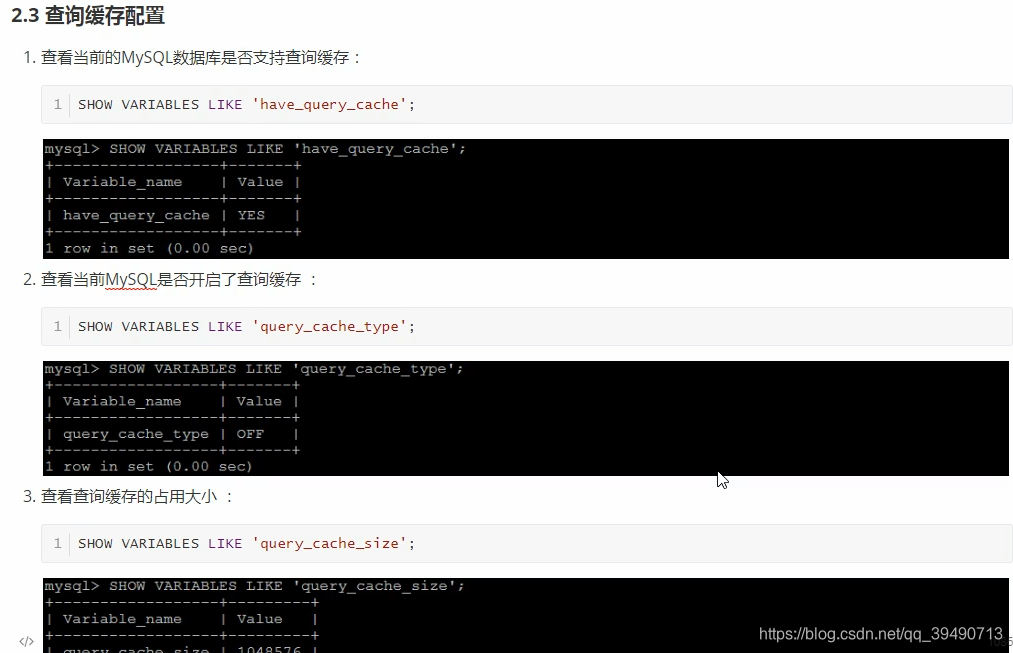
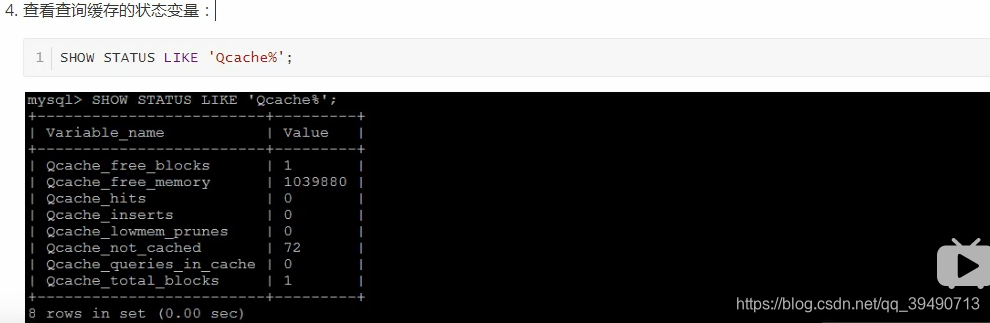
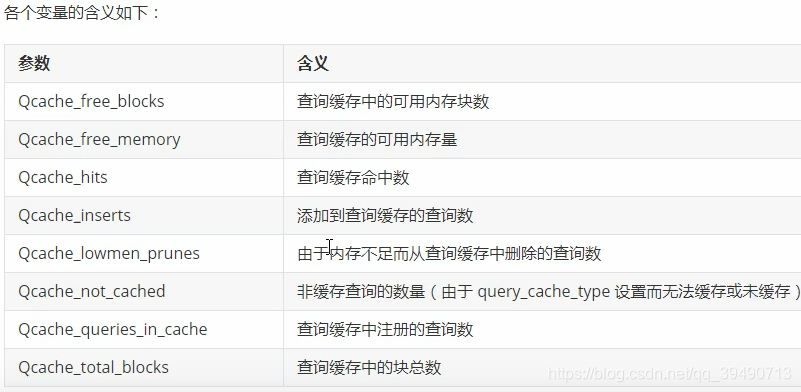
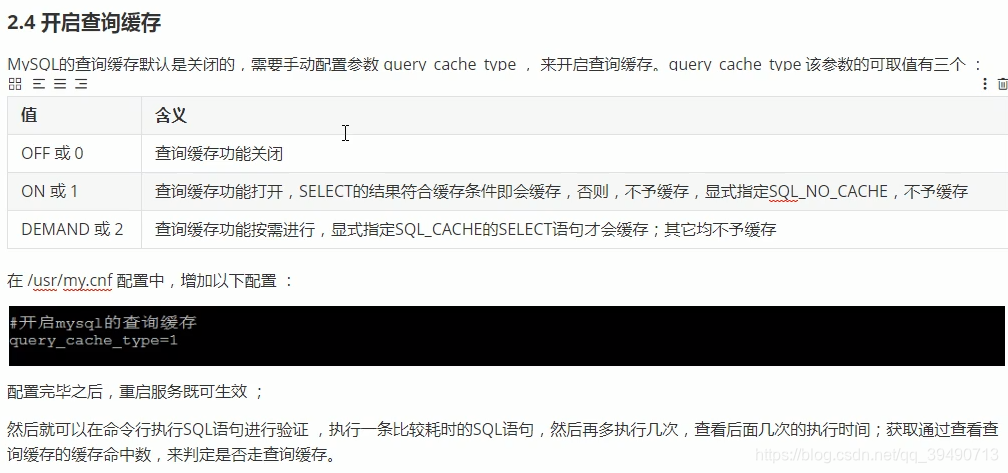

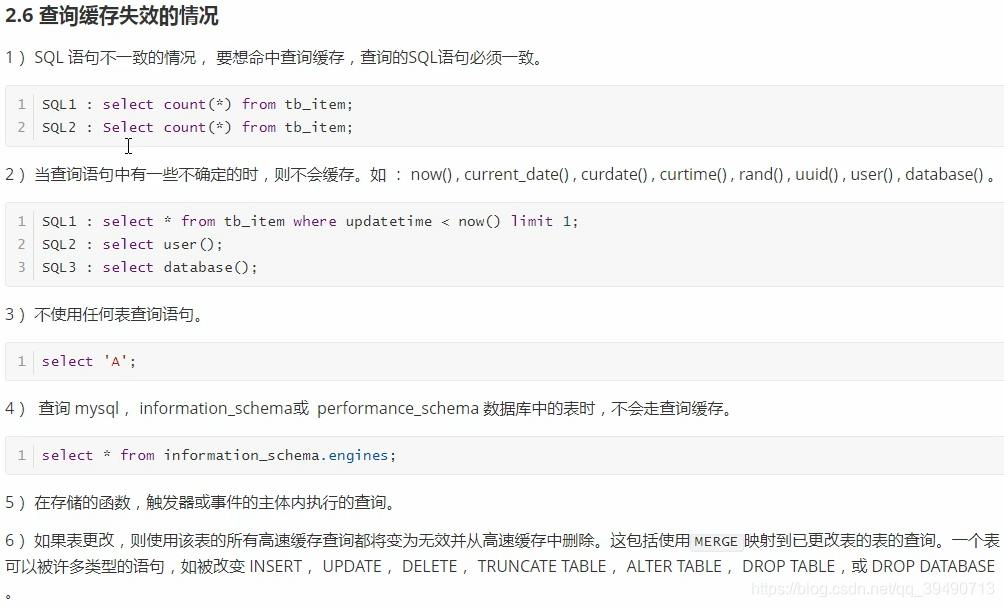
内存管理及优化:
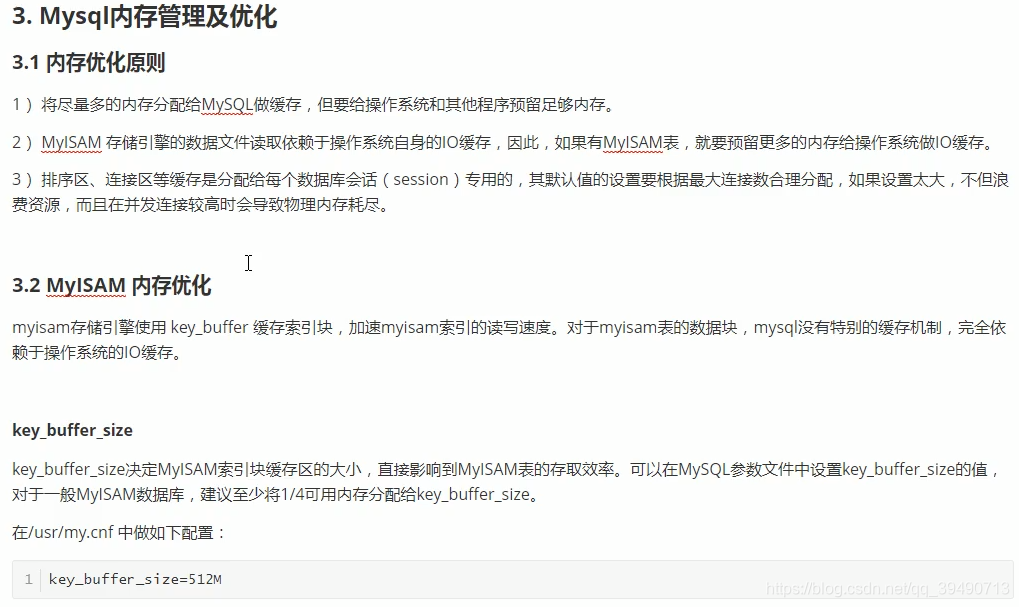

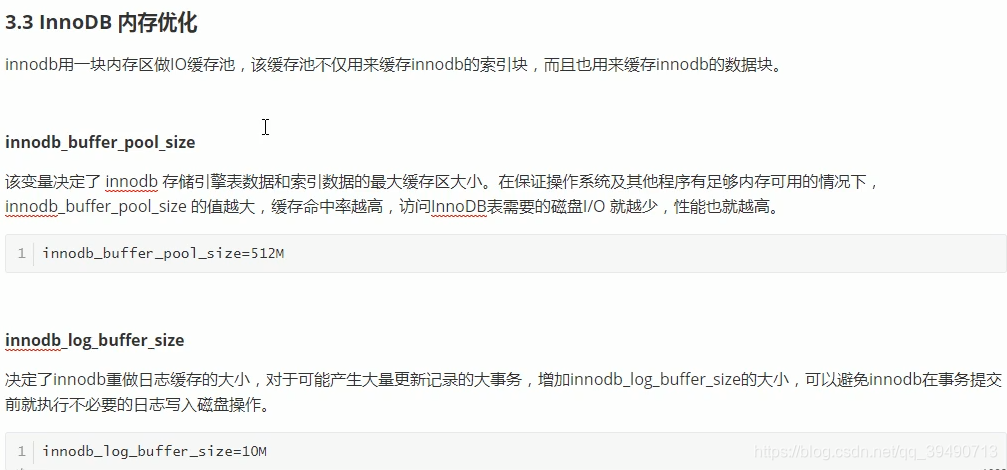
注意两者区别,Innodb还缓存数据块和索引块,myisam只缓存索引块。


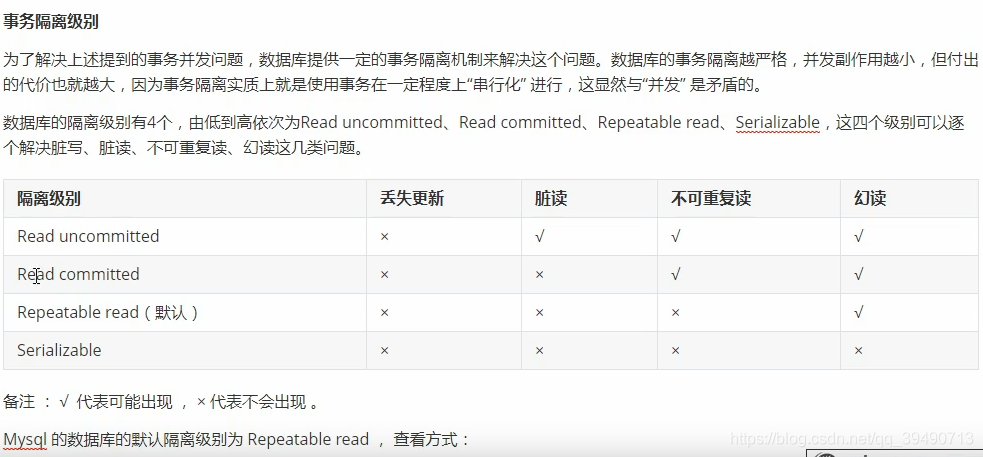
Mysql锁

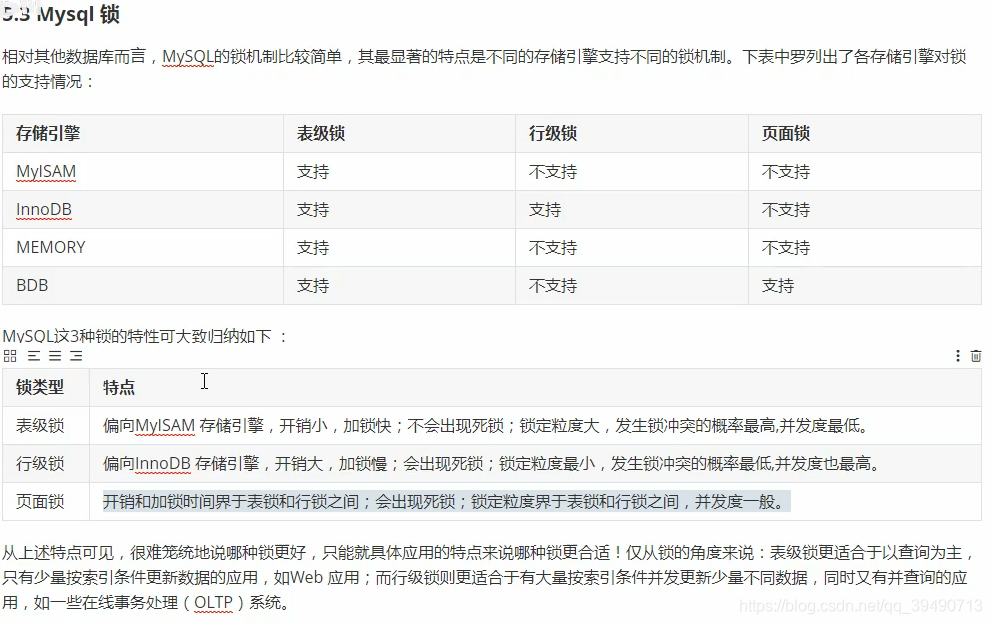

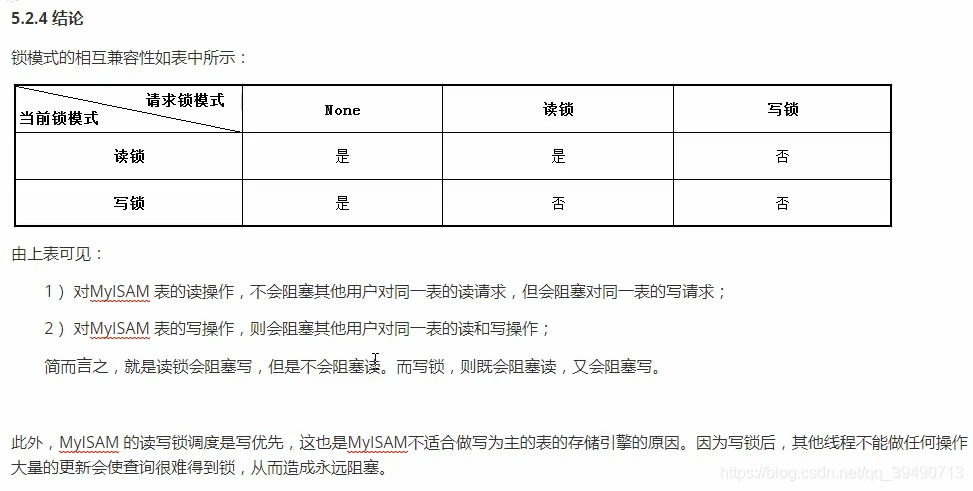
加了写锁,其他事务读写都得等。
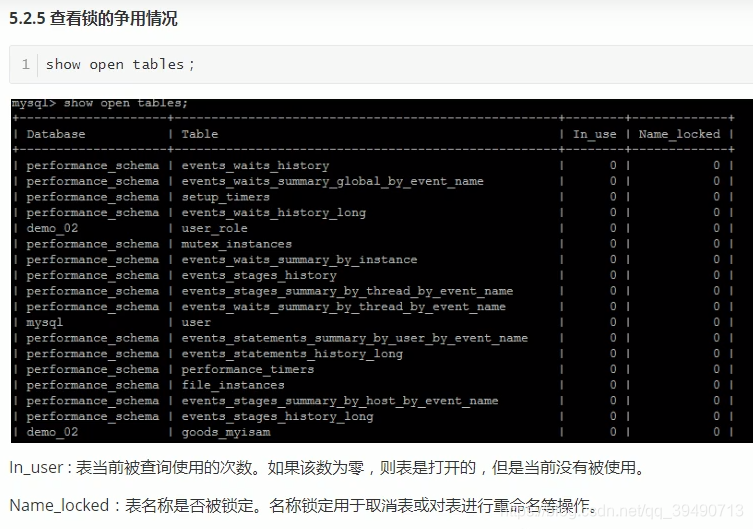
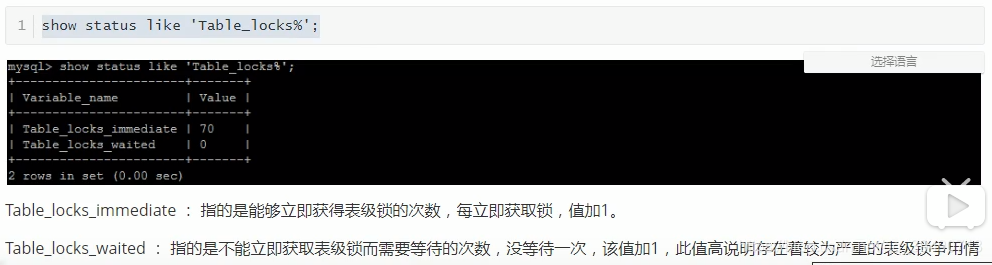
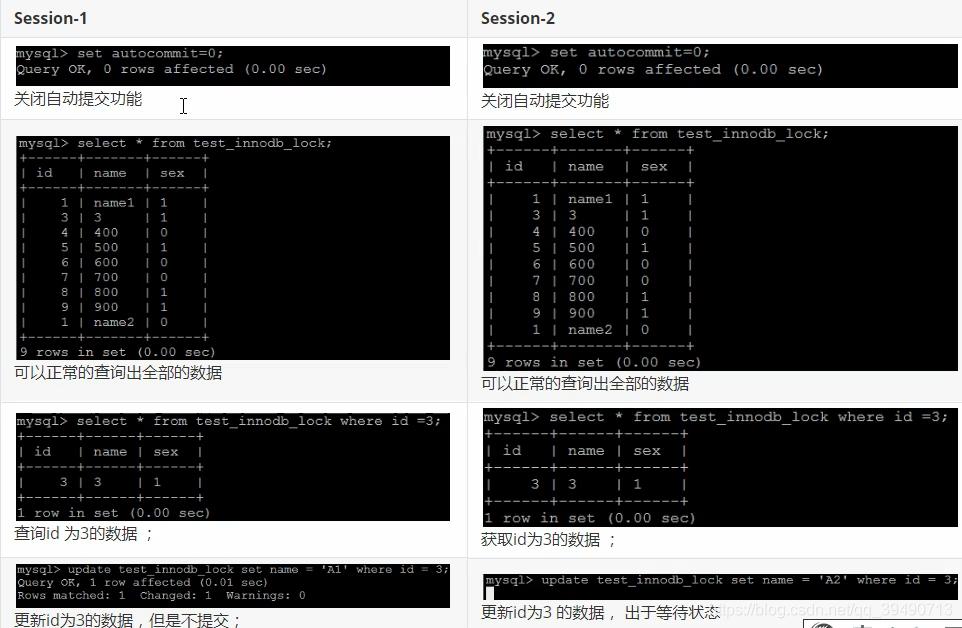
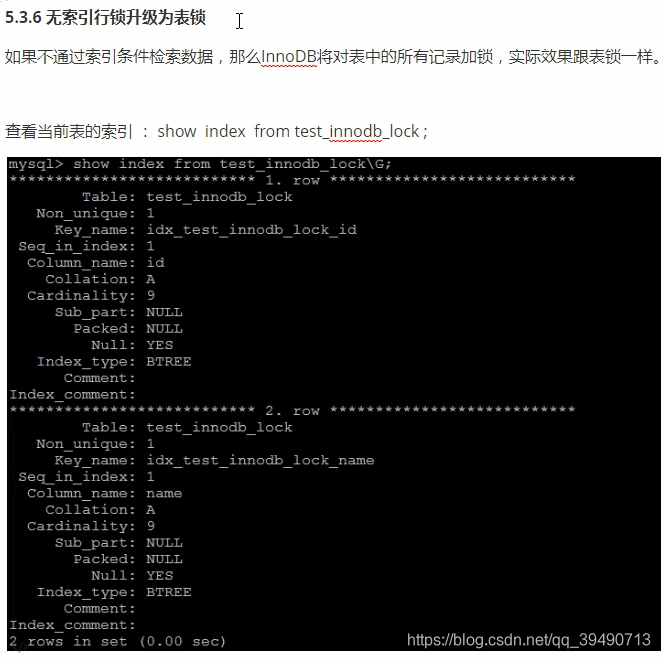
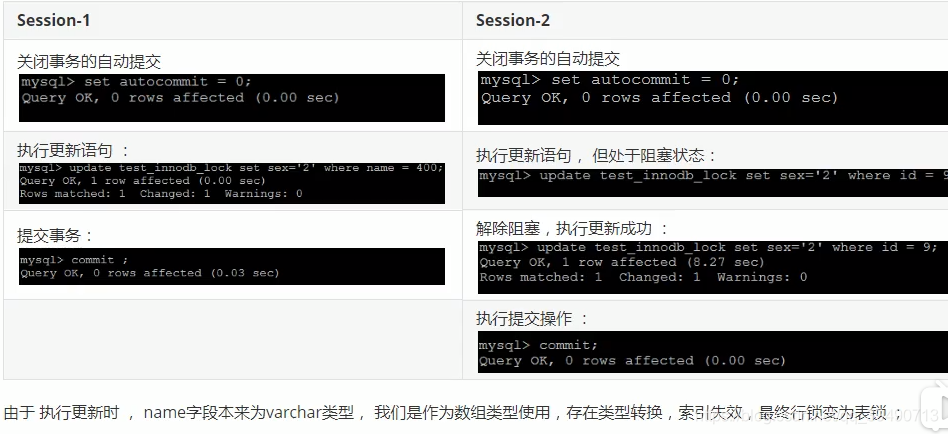
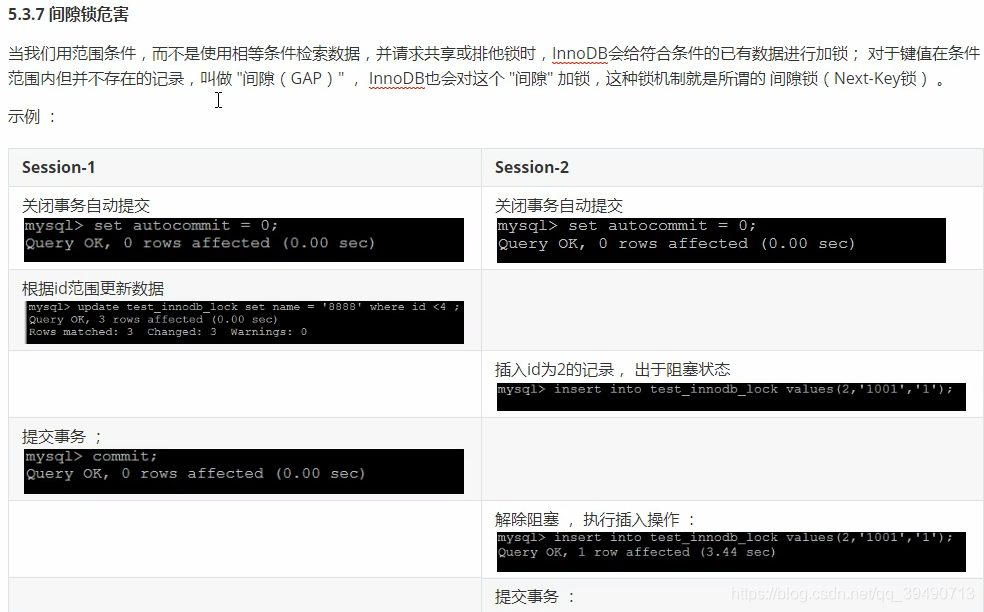
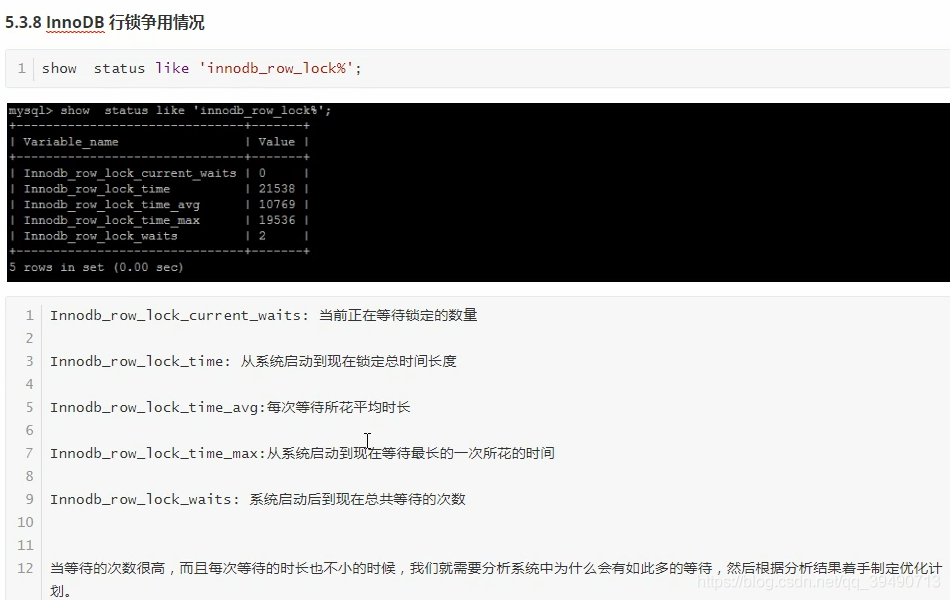
InnoDB行锁:


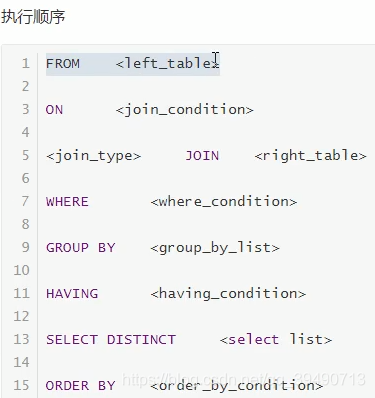
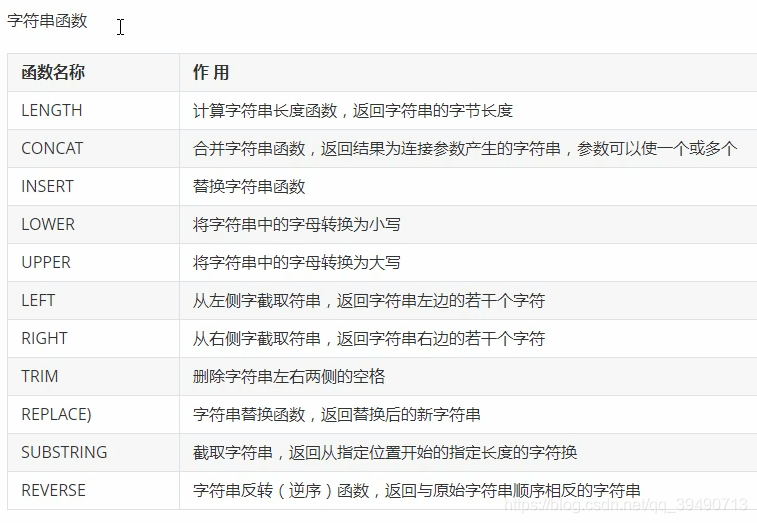
SQL技巧:

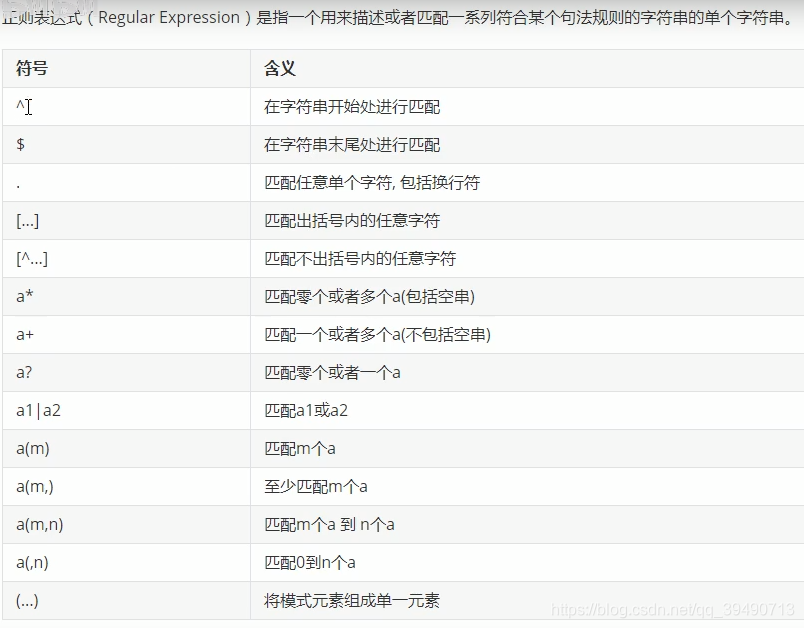
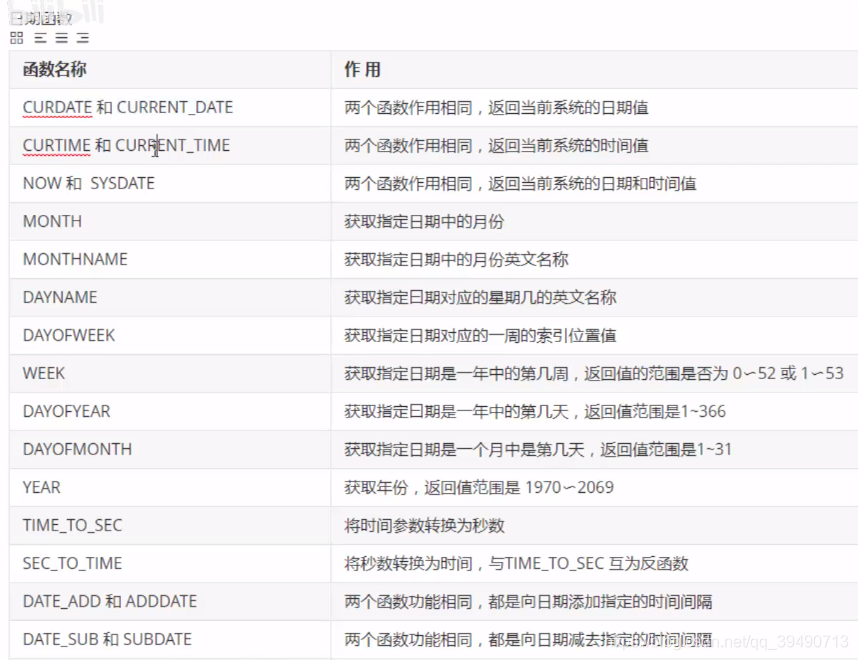
日期函数:
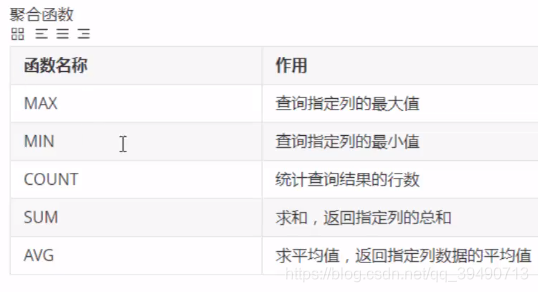
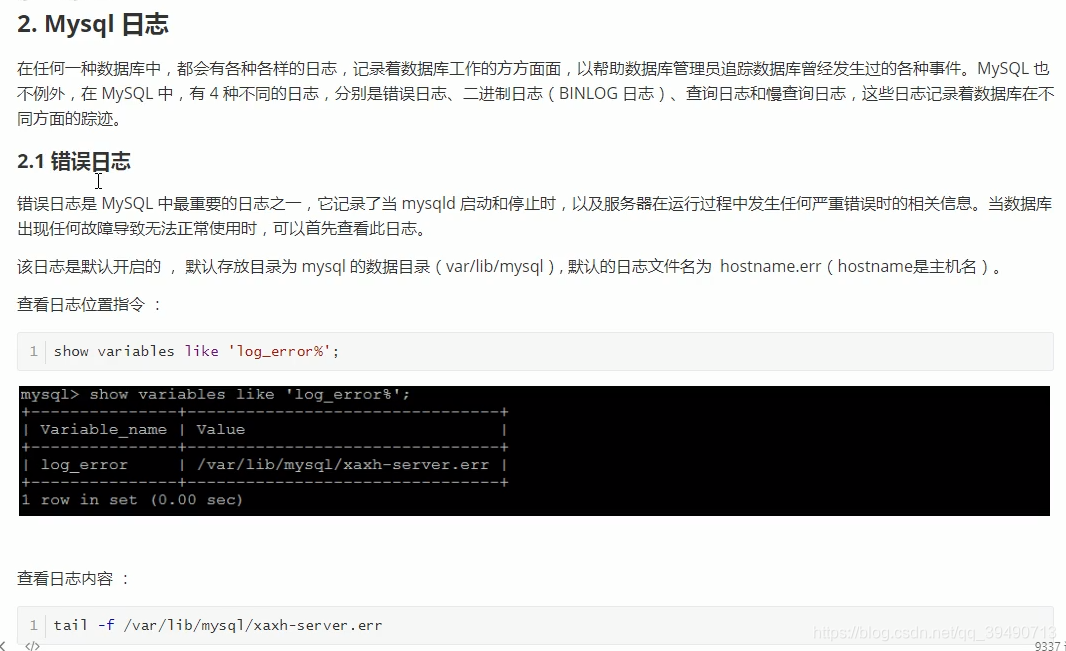
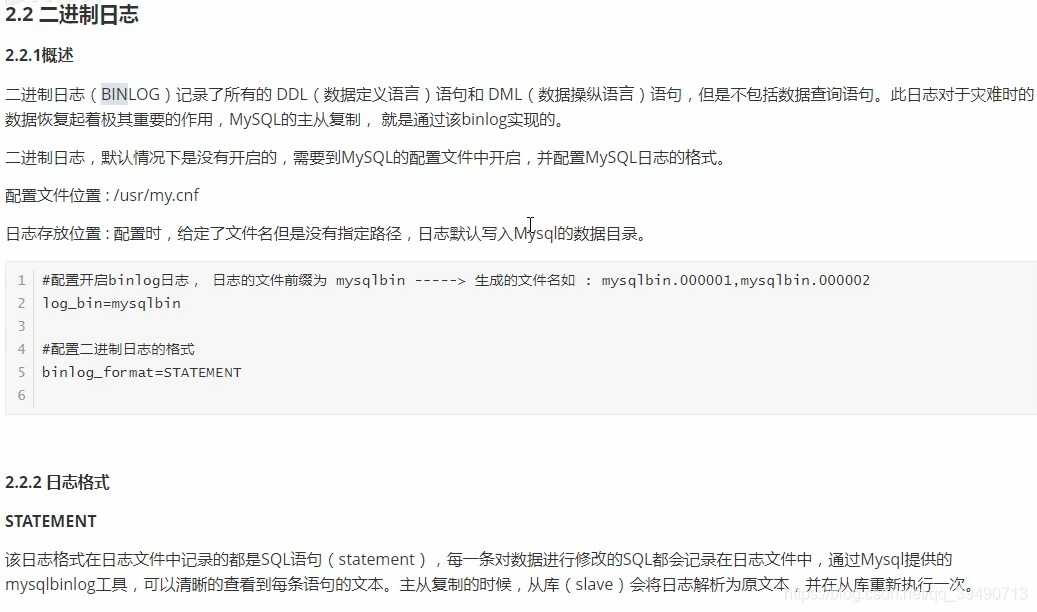
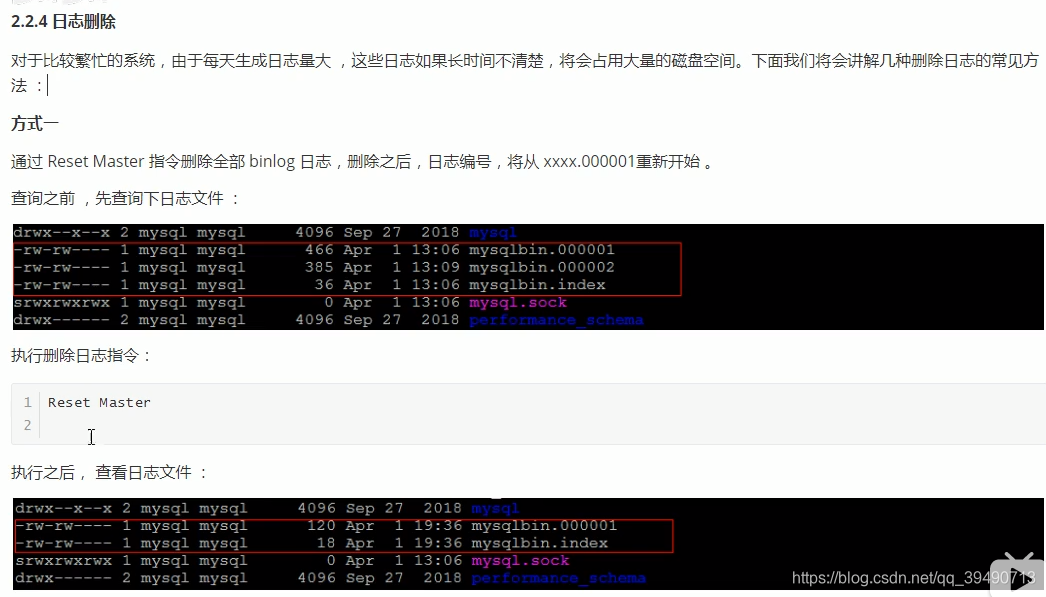
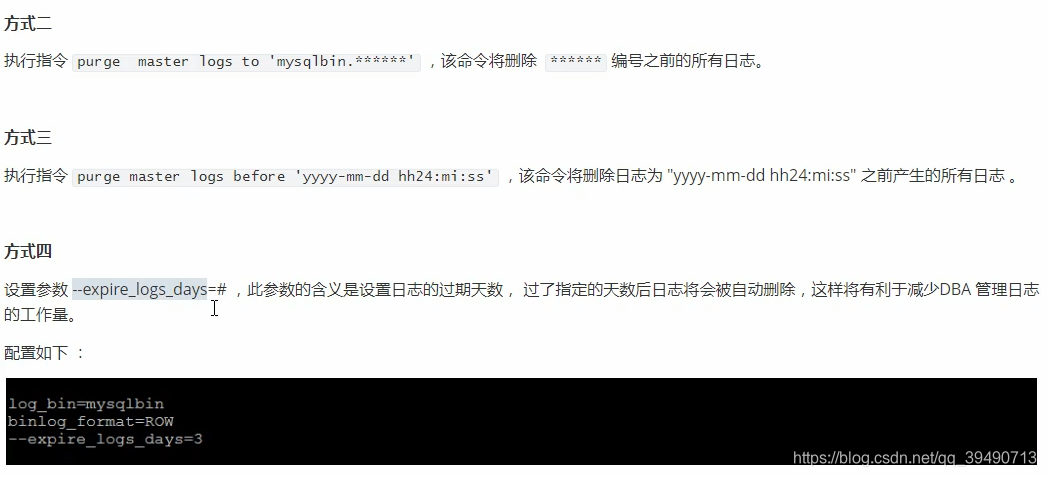
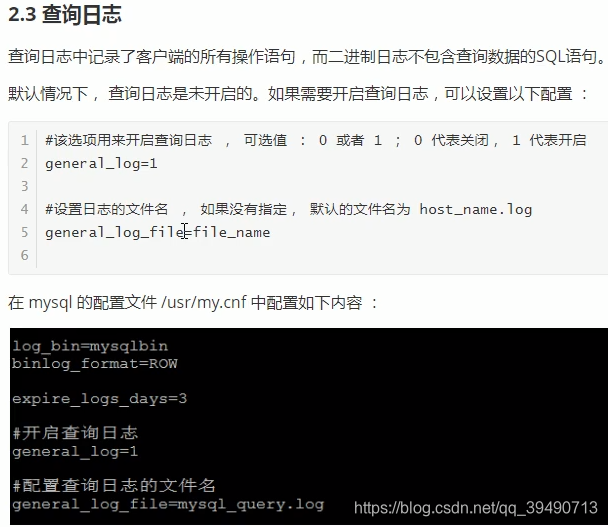
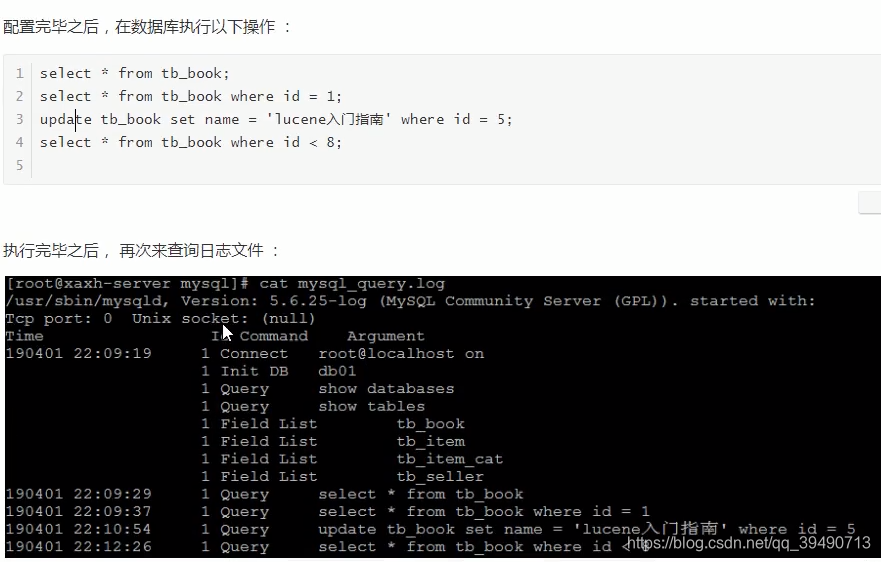
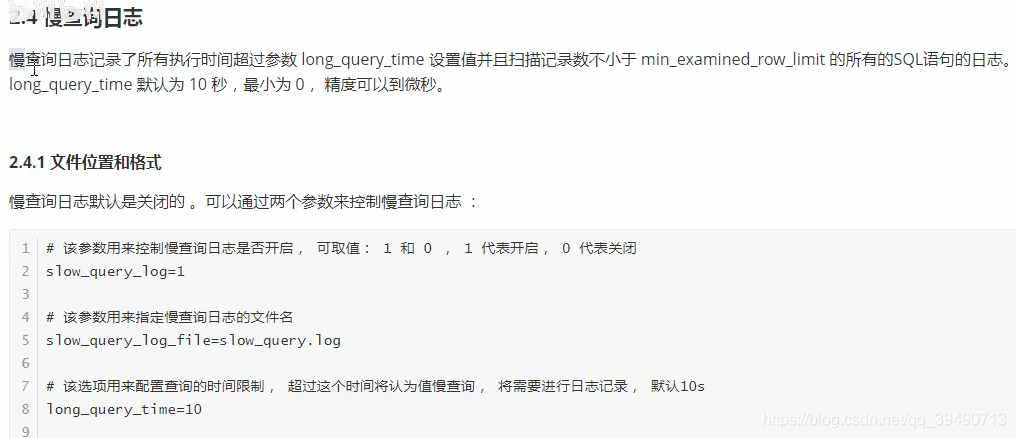
Mysql日志:

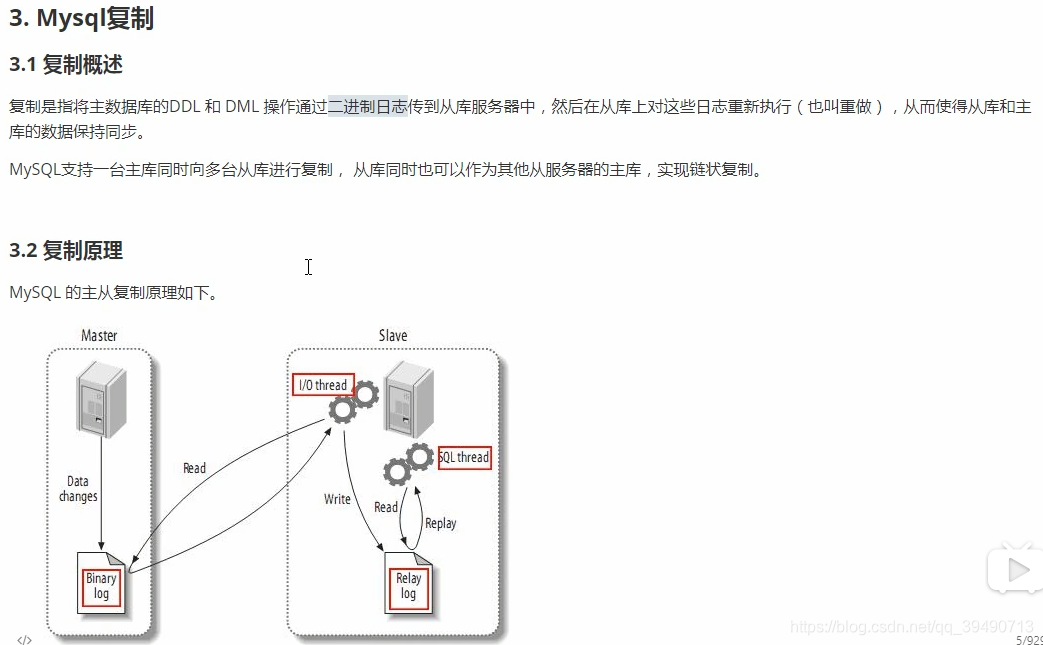
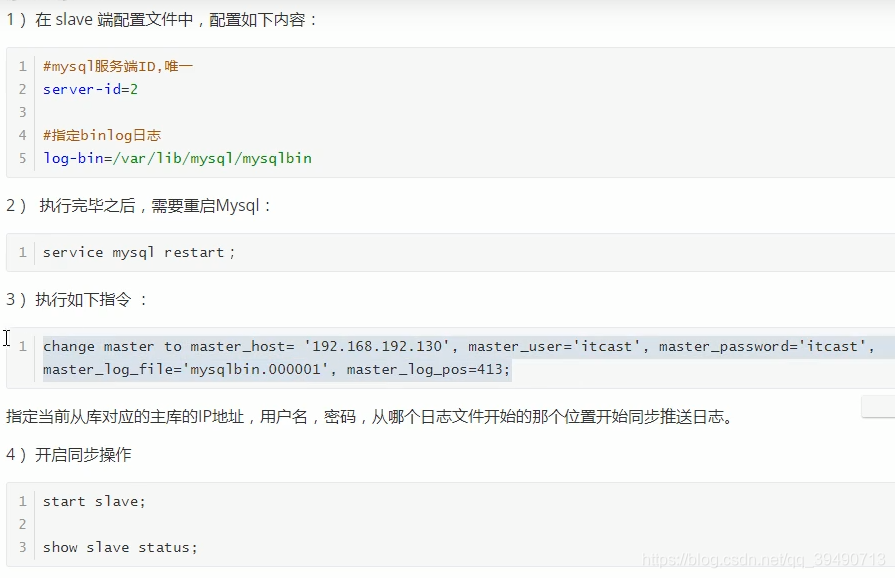
Mysql复制: