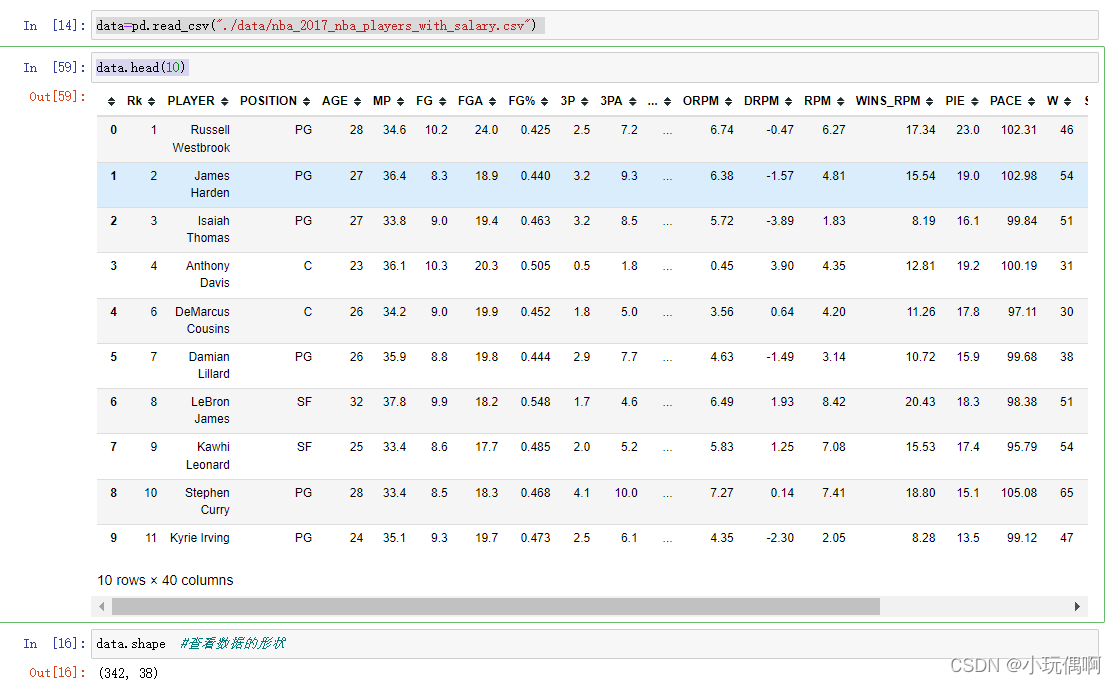
1. 获取数据
data=pd.read_csv("./data/nba_2017_nba_players_with_salary.csv")
data.head(10)
2. 数据分析
2.1 数据相关性
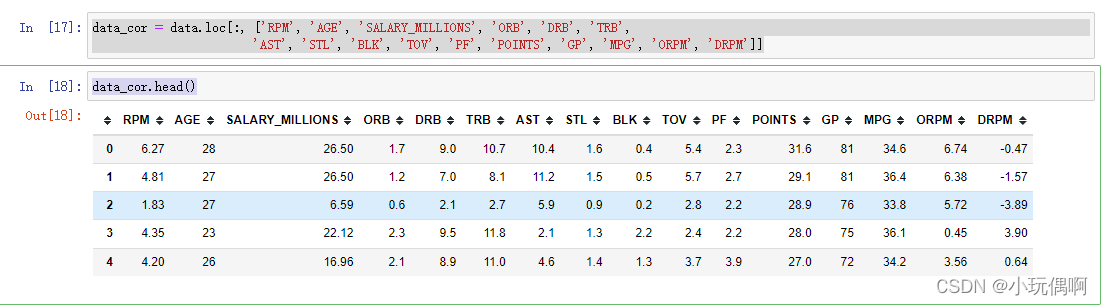
data_cor = data.loc[:, ['RPM', 'AGE', 'SALARY_MILLIONS', 'ORB', 'DRB', 'TRB',
'AST', 'STL', 'BLK', 'TOV', 'PF', 'POINTS', 'GP', 'MPG', 'ORPM', 'DRPM']]
data_cor.head()
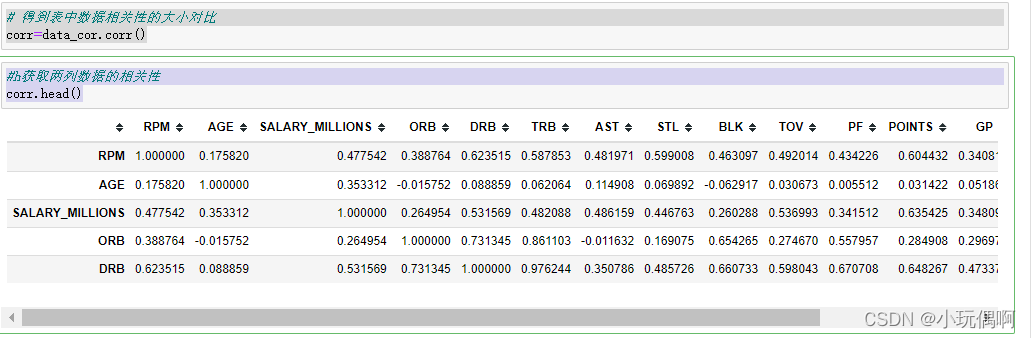
corr=data_cor.corr()
corr.head()
plt.figure(figsize=(20,8),dpi=100)
sns.heatmap(corr,square=True,linewidths=0.1,annot=True)

2.2 基本数据排名分析
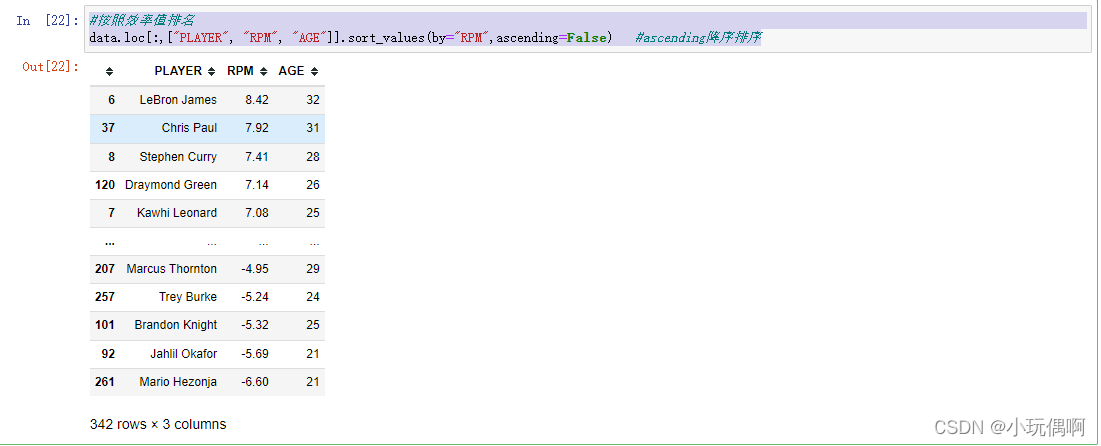
data.loc[:,["PLAYER", "RPM", "AGE"]].sort_values(by="RPM",ascending=False)
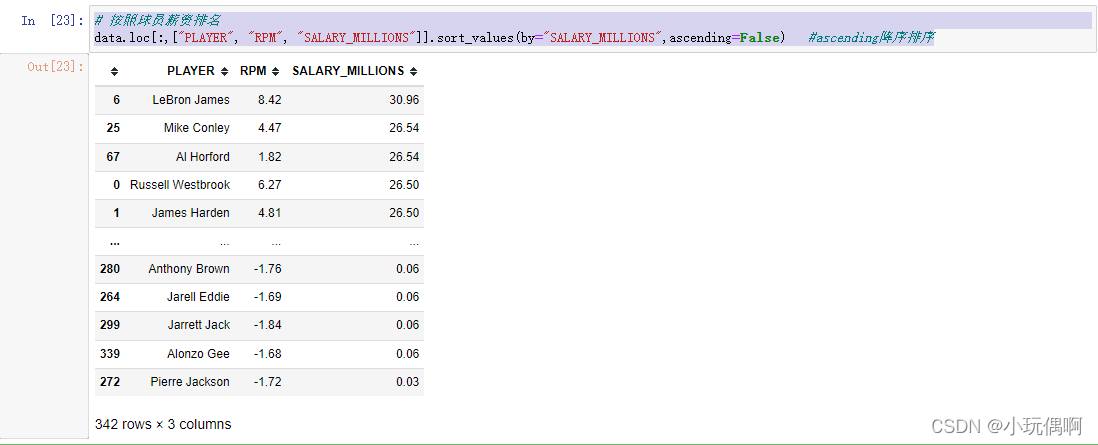
data.loc[:,["PLAYER", "RPM", "SALARY_MILLIONS"]].sort_values(by="SALARY_MILLIONS",ascending=False)
2.3 Seaborn常用的三个数据可视化方法
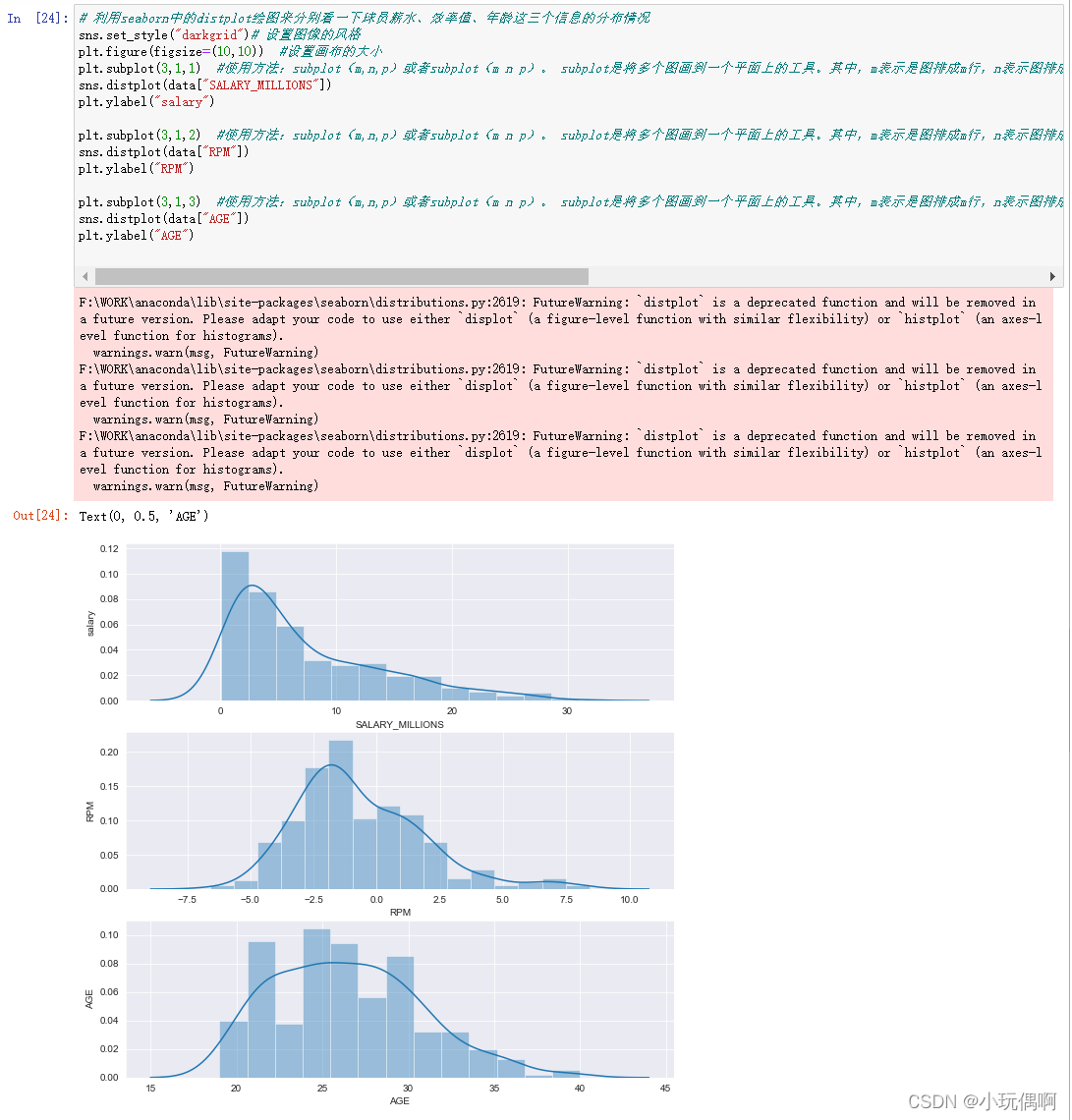
2.3.1 单变量
sns.set_style("darkgrid")
plt.figure(figsize=(10,10))
plt.subplot(3,1,1)
sns.distplot(data["SALARY_MILLIONS"])
plt.ylabel("salary")
plt.subplot(3,1,2)
sns.distplot(data["RPM"])
plt.ylabel("RPM")
plt.subplot(3,1,3)
sns.distplot(data["AGE"])
plt.ylabel("AGE")
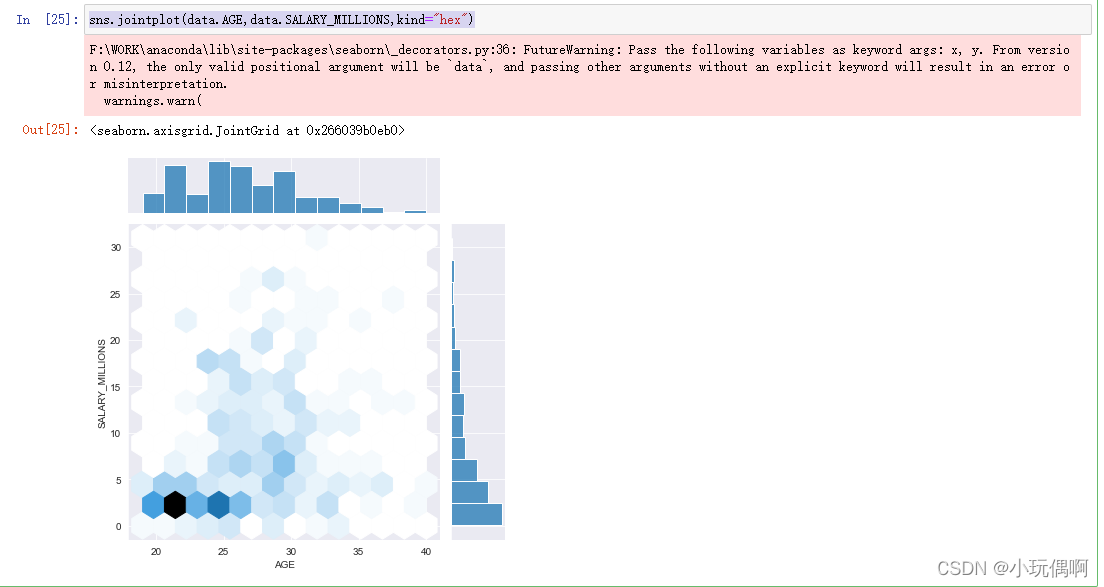
2.3.2 双变量
sns.jointplot(data.AGE,data.SALARY_MILLIONS,kind="hex")
2.3.3 多变量
multi_data = data.loc[:, ['RPM','SALARY_MILLIONS','AGE','POINTS']]
multi_data.head()
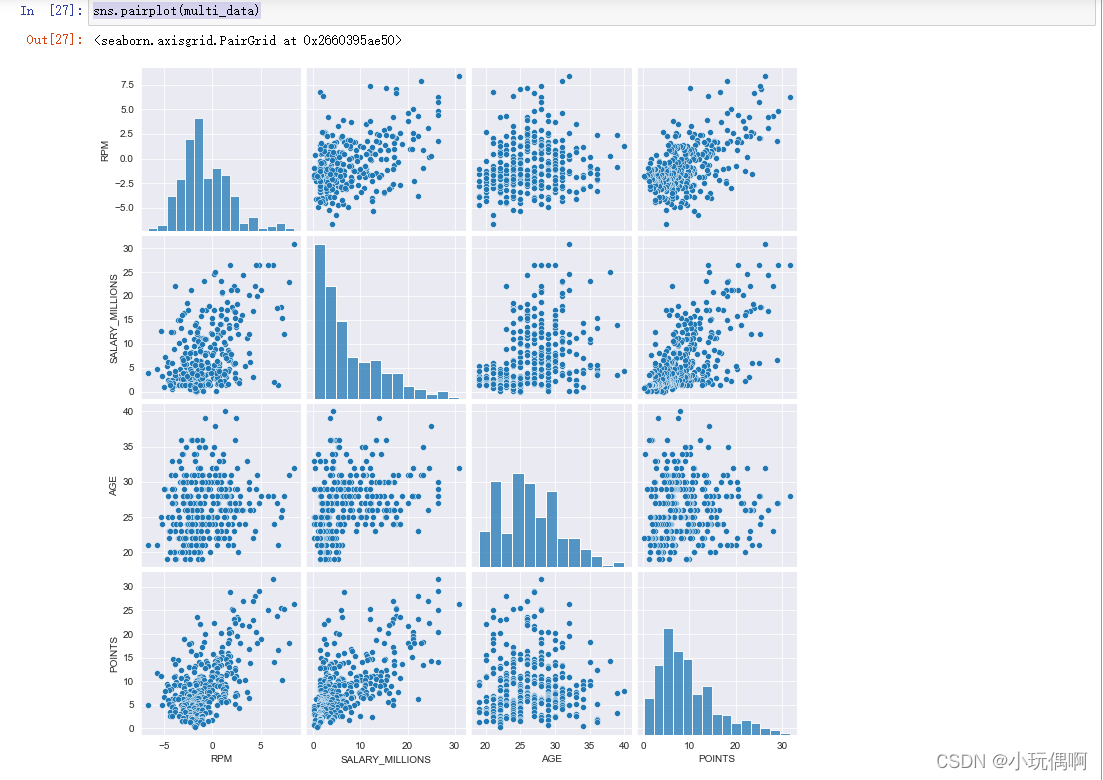
sns.pairplot(multi_data)
2.3.4 衍生变量的一些可视化实践-以年龄为例
def age_cut(df):
'''年龄划分'''
if df.AGE<=24:
return "young"
elif df.AGE>=30:
return "old"
else:
return "best"
data["age_cut"]=data.apply(lambda x:age_cut(x),axis=1)
data.head()
data["cut"]=1
data.loc[data.age_cut=="best"].SALARY_MILLIONS.head()

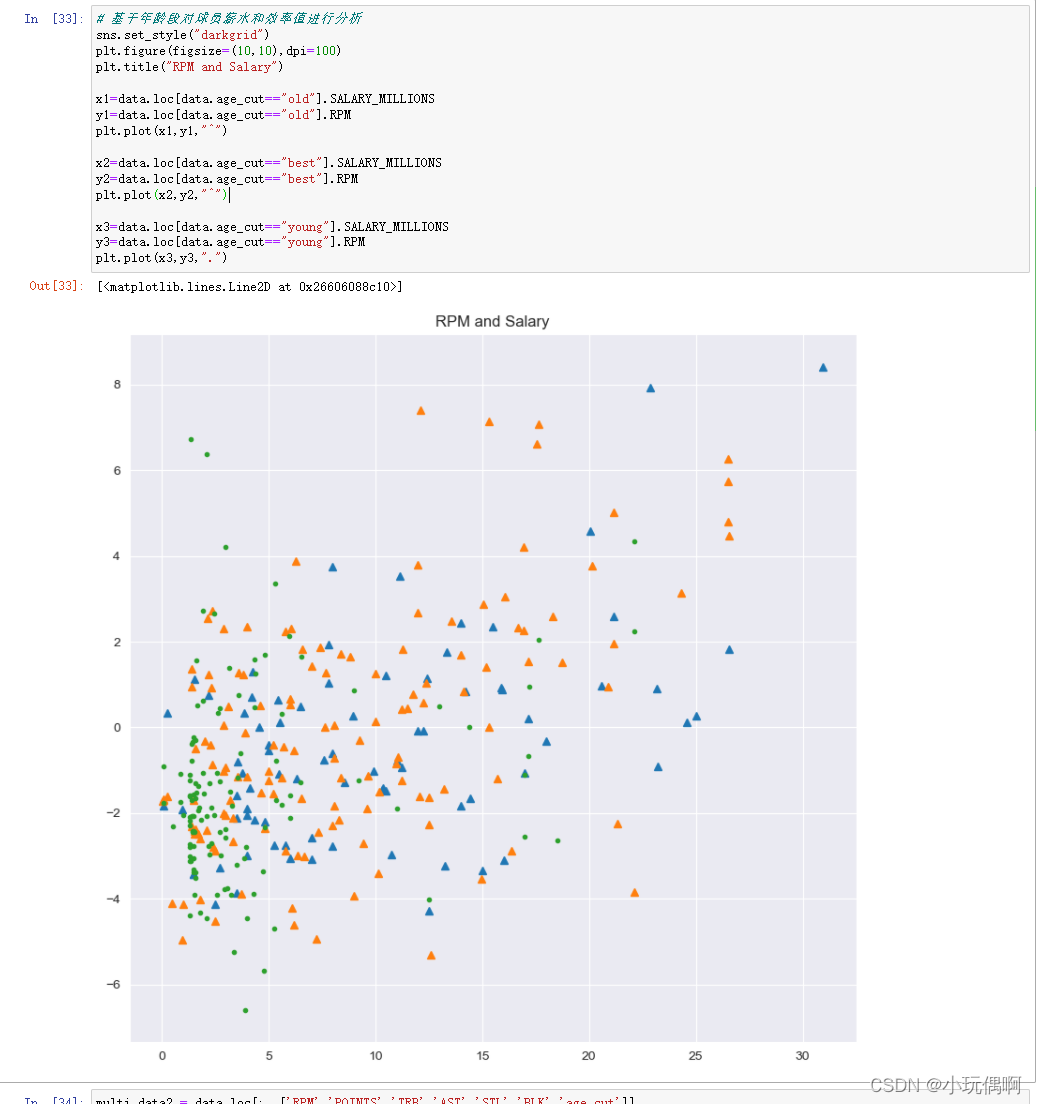
sns.set_style("darkgrid")
plt.figure(figsize=(10,10),dpi=100)
plt.title("RPM and Salary")
x1=data.loc[data.age_cut=="old"].SALARY_MILLIONS
y1=data.loc[data.age_cut=="old"].RPM
plt.plot(x1,y1,"^")
x2=data.loc[data.age_cut=="best"].SALARY_MILLIONS
y2=data.loc[data.age_cut=="best"].RPM
plt.plot(x2,y2,"^")
x3=data.loc[data.age_cut=="young"].SALARY_MILLIONS
y3=data.loc[data.age_cut=="young"].RPM
plt.plot(x3,y3,".")
multi_data2 = data.loc[:, ['RPM','POINTS','TRB','AST','STL','BLK','age_cut']]
sns.pairplot(multi_data2,hue="age_cut")
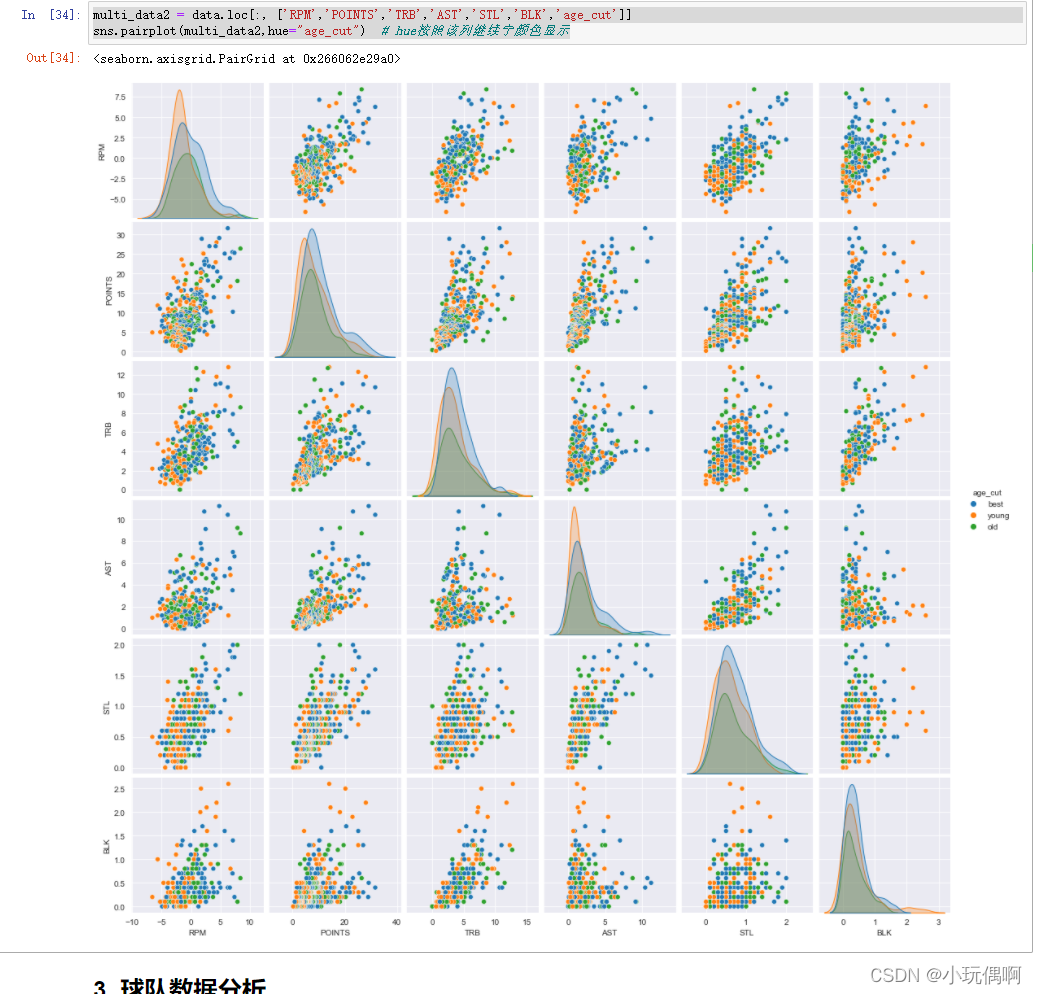
3. 球队数据分析
3.1 球队薪资排行
data.groupby(by="age_cut").agg({"SALARY_MILLIONS":np.mean})

data_team=data.groupby(by="TEAM").agg({"SALARY_MILLIONS":np.mean})
data_team.sort_values(by="SALARY_MILLIONS",ascending=False).head()

3.2 按照分球队 分年龄段,上榜球员数相同,则按照效率值降序排列
data_RMP=data.groupby(by=["TEAM","age_cut"]).agg({"SALARY_MILLIONS":np.mean,"RPM":np.mean,"PLAYER":np.size})
data_RMP.head()
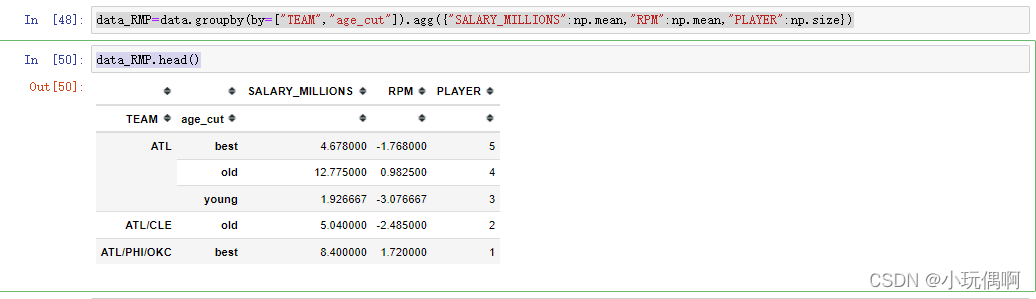
data_RMP.sort_values(by=["PLAYER","RPM"],ascending=False).head(10)
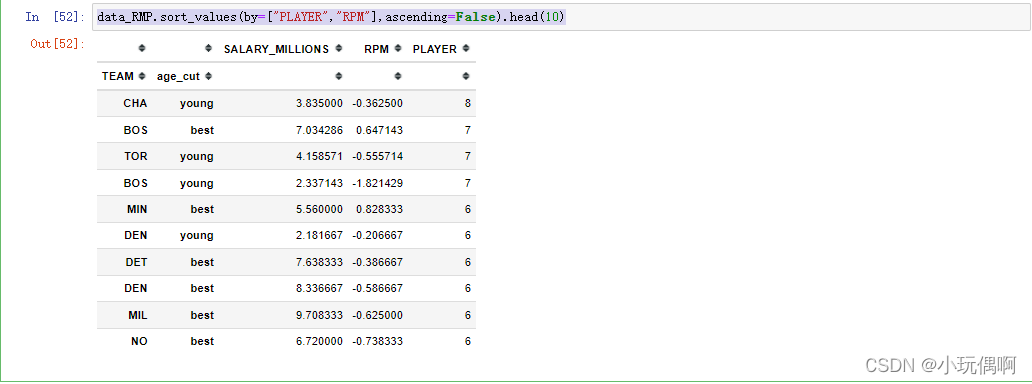
3.3 按照球队综合实力排名
data_rpm2=data.groupby(by=["TEAM"],as_index=False).agg({"SALARY_MILLIONS":np.mean,
"RPM":np.mean,
"PLAYER":np.size,
"POINTS":np.mean,
"eFG%":np.mean,
"MPG":np.mean,
"AGE":np.mean})
data_rpm2.head()
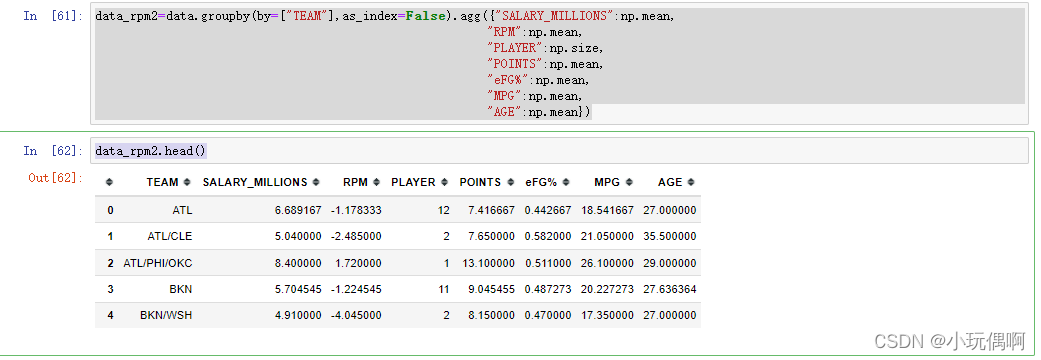
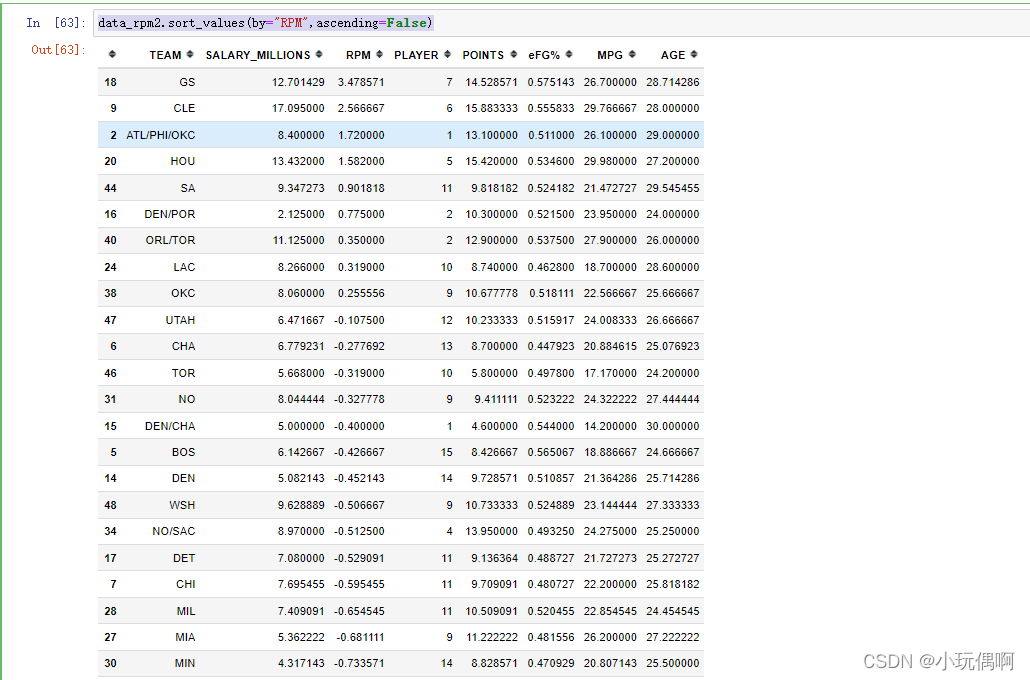
data_rpm2.sort_values(by="RPM",ascending=False)
3.4 利用箱线图和小提琴图进行数据分析
sns.set_style("whitegrid")
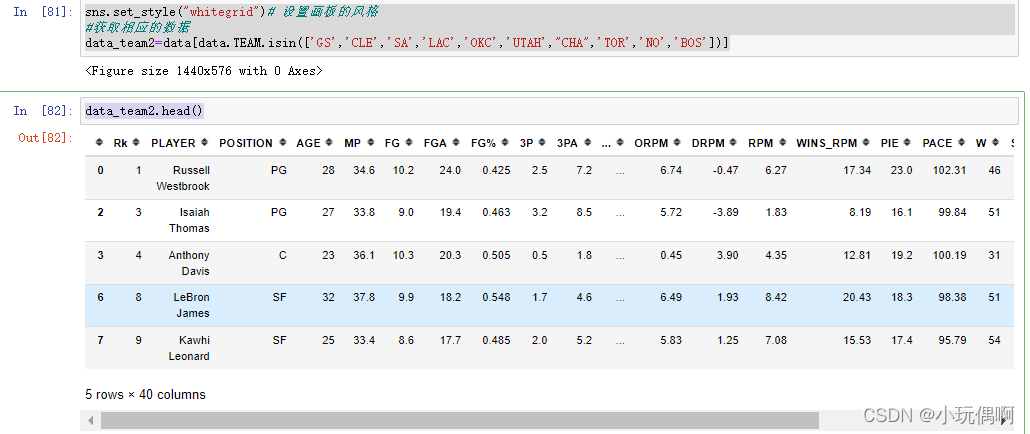
data_team2=data[data.TEAM.isin(['GS','CLE','SA','LAC','OKC','UTAH',"CHA",'TOR','NO','BOS'])]
data_team2.head()
plt.figure(figsize=(20,10))
plt.subplot(3,1,1)
sns.boxplot(x="TEAM",y="SALARY_MILLIONS",data=data_team2)
plt.subplot(3,1,2)
sns.boxplot(x="TEAM",y="AGE",data=data_team2)
plt.subplot(3,1,3)
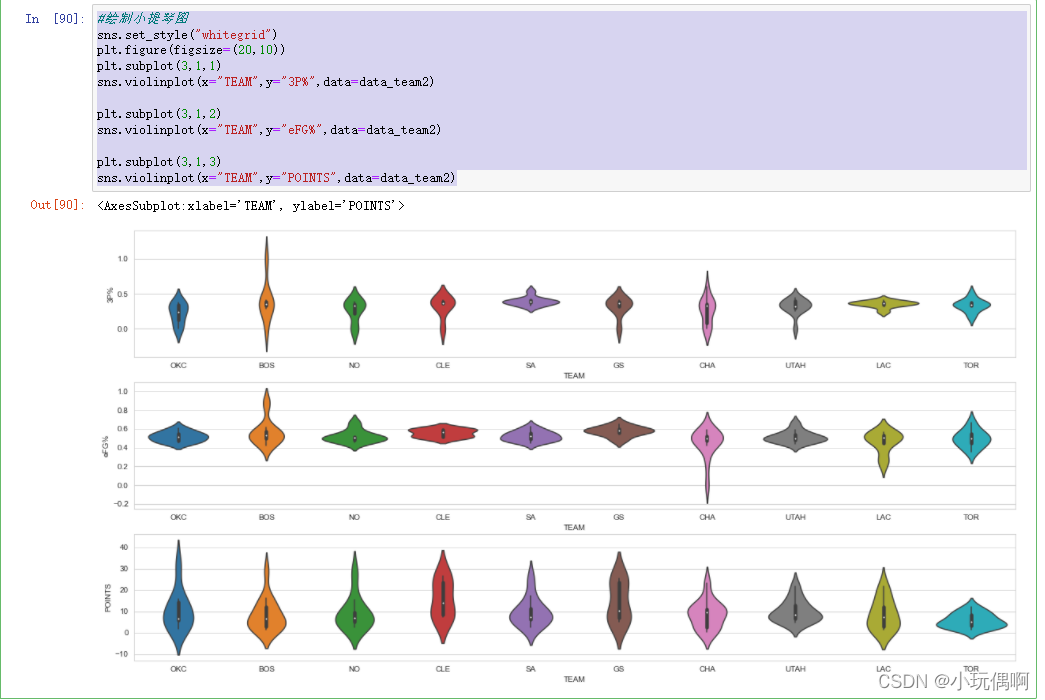
sns.boxplot(x="TEAM",y="MPG",data=data_team2)

sns.set_style("whitegrid")
plt.figure(figsize=(20,10))
plt.subplot(3,1,1)
sns.violinplot(x="TEAM",y="3P%",data=data_team2)
plt.subplot(3,1,2)
sns.violinplot(x="TEAM",y="eFG%",data=data_team2)
plt.subplot(3,1,3)
sns.violinplot(x="TEAM",y="POINTS",data=data_team2)