个人总结难免疏漏,请多包涵。更多内容请查看原文。本文以及学习笔记系列仅用于个人学习、研究交流。
这篇文章是对Python对象类型-字符串的详解。内容较多需花1-2h阅读。如果你是0基础的初学者建议看这篇文章,对比其他教程会更加容易上手。
对字符串做了详解(未详细介绍Unicode文本和二进制数据)。讲解如何编写字符串常量,字符串的分片、方法调用、三重引号字符串,以及字符串操作,包括序列表达式、字符串格式化以及字符串方法调用。
本文文字较多。如果你希望快速上手,或者简明扼要,请参考其他教程如菜鸟教程等。
目录
字符串
Python字符串——一个有序的字符的集合,用来存储和表现基于文本的信息。
Python的字符串是不可变序列,字符串所包含的字符存在从左至右的位置顺序,并且不可以在原处修改。
常见字符串常量和表达式:

这里主要介绍基本的str字符串类型,该类型用来处理ASCII文本并且不管使用何种Python版本都能同样地工作。
正式地讲,ASCII是Unicode文本的一种简单形式。Python通过包含各种不同的对象类型,解决了文本和二进制数据之间的区别:
·Python 3.0中,有3种字符串类型:str用于Unicode文本(ASCII或其他),bytes用于二进制数据(包括编码的文本),bytearray是bytes的一种可变的变体。
字符串常量
Python中的字符串用起来还是相当的简单的。
·单引号:'spa"m'
·双引号:"spa'm"
·三引号:'''...spam...''',"""...spam..."""
·转义字符:"s\tp\na\0m"
·Raw字符串:r"C:\new\test.spm"
·Python 3.0中的Byte字符串:b'sp\x01am'
单引号和双引号的形式尤其常见。
单双引号字符串是一样的
Python字符串中,单引号和双引号字符是可以互换的。
字符串常量表达式可以用两个单引号或两个双引号来表示——两种形式同样有效并返回相同类型的对象。两者是等效的。
>>> 'life' == "life"
True这两种形式都能够使用是因为你不使用反斜杠转义字符就可以实现在一个字符串中包含其余种类的引号。
>>> 'life"s',"life's"
('life"s', "life's")Python自动在任意的表达式中合并相邻的字符串常量,尽管可以简单地在它们之间增加+操作符来明确地表示这是一个合并操作
>>> man = "man " 'of' " life"
>>> man
'man of life'
>>> man = "man "+'of'+" life"
>>> man
'man of life'注意,在这些字符串之间增加逗号会创建一个元组,而不是一个字符串。并且Python倾向于打印所有这些形式的字符串为单引号,除非字符串内有了单引号了。
用转义序列代表特殊字节
通过在引号前增加一个反斜杠的方式可以在字符串内部嵌入一个引号:
>>> 'kniighr\'s',"knight\"s"
("kniighr's", 'knight"s')反斜杠用来引入特殊的字节编码,是转义序列。
转义序列让我们能够在字符串中嵌入不容易通过键盘输入的字节。字符串常量中字符“\”,以及在它后边的一个或多个字符,在最终的字符串对象中会被一个单个字符所替代,这个字符通过转义序列定义了一个二进制值。
例如这里嵌入了一个换行符和一个制表符:
>>> s = 'a\nb\tc'
>>> s
'a\nb\tc'
>>> print(s)
a
b c两个字符"\n"表示一个单个字符——在字符集中包含了换行字符这个值(通常来说,ASCII编码为10)的字节。"\t"替换为制表符。这个字符串打印时的格式取决于打印的方式。
交互模式下是以转义字符的形式回显的,但是print会将其解释出来。
为了清楚地了解这个字符串中到底有多少个字节,使用内置的len函数。它会返回一个字符串中到底有多少字节,无论它是如何显示的:
>>> len(s)
5这个字符串长度为五个字节:分别包含了一个ASCII a字符,一个换行字符、一个ASCII b字符等。
注意原始的反斜杠字符并不真正和字符串一起存储在内存中;它们告诉Python字符串中保存的特殊字节值。


一些转义序列允许一个字符串的字节中嵌入绝对的二进制值。
有一个五个字符的字符串,其中嵌入了两个二进制零字符(将八进制编码转义为一个数字):
>>> s = 'a\0b\0c'
>>> s
'a\x00b\x00c'
>>> print(s)
abc
>>> len(s)
5Python在内存中保持了整个字符串的长度和文本。
这里有一个完全由绝对的二进制转义字符编码的字符串——一个二进制1和2(以八进制编码)以及一个二进制3(以十六进制编码):
>>> s = '\001\002\x03'
>>> s
'\x01\x02\x03'
>>> len(s)
3
Python以十六进制显示非打印的字符。
我们可以自由地组合上表列的绝对值转义和更多符号转义类型。
>>> s = 's\tp\na\x00m'
>>> s
's\tp\na\x00m'
>>> len(s)
7
>>> print(s)
s p
am当使用Python处理二进制数据文件时,了解这些知识显得格外重要。
如果Python没有作为一个合法的转义编码识别出在“\”后的字符,它就直接在最终的字符串中保留反斜杠。
>>> x = 'C:\py\code'
>>> x
'C:\\py\\code'
>>> len(x)
10如果希望在脚本中编写明确的常量反斜杠,重复两个反斜杠(“\\”是“\”的转义字符)或者使用raw字符串。
如果你对二进制数据文件特别感兴趣的话,其主要的不同就在于它们是你在二进制模式下打开的(使用open模式的标志位b,例如'rb','wb'等)。在Python 3.0中,二进制文件的内容是一个bytes字符串,带有一个类似于常规字符串的接口。
raw字符串抑制转义
转义序列用来处理嵌入在字符串中的特殊字节编码是很合适的。
但是Python新手有时会像下面这样使用文件名参数去尝试打开一个文件:
>>> myfile = open('C:\new\text.dat','w')认为这将会打开一个在C:\new目录下名为text.dat的文件。问题是这里有"\n",它会识别为一个换行字符,并且"\t"会被一个制表符所替代。结果就是,这个调用是尝试打开一个名为C:(换行)ew(制表符)ext.dat的文件。
使用raw字符串可以解决。如果字母r(大写或小写)出现在字符串的第一引号的前面,它将会关闭转义机制。这个结果就是Python会将反斜杠作为常量来保持,就像输入的那样。
myfile = open(r'C:\new\text.dat','w')还有一种办法:因为两个反斜杠是一个反斜杠的转义序列,能够通过简单地写两个反斜线去保留反斜杠:
myfile = open('c:\\new\\text.dat','w')实际上,当打印一个嵌入了反斜杠字符串时,Python自身也会使用这种写两个反斜杠的方法:
>>> path = r'C:\new\text.dat'
>>> path
'C:\\new\\text.dat'
>>> print(path)
C:\new\text.dat
>>> len(path)
15除了在Windows下的文件夹路径,raw字符串也在正则表达式(文本模式匹配,re模块支持)中常见。注意Python脚本会自动在Windows和UNIX的路径中使用斜杠表示字符串路径,因为Python试图以可移植的方法解释路径(例如,打开文件的时候,'C:/new/text.dat'也有效)。尽管这样,如果你编写的路径使用Windows的反斜杠,raw字符串是很有用处的。
注意:一个raw字符串不能以单个的反斜杠结尾。r"...\"不是一个有效的字符串常量,一个raw字符串不能以奇数个反斜杠结束。
如果需要用单个的反斜杠结束一个raw字符串,手动添加一个反斜杠(r'1\nb\tc'+'\\'),或者忽略raw字符串语法并在常规字符串中把反斜杠改为双反斜杠('1\\nb\\tc\\')。
三重引号编写多行字符串块
Python还有一种三重引号内的字符串常量格式,有时候称作块字符串,这是一种对编写多行文本数据来说很便捷的语法。
以三重引号开始(单引号和双引号都可以),并紧跟任意行数的文本,并且以开始时的同样的三重引号结尾。嵌入在这个字符串文本中的单引号和双引号也会,但不是必须转义——直到Python看到和这个常量开始时同样的三重引号,这个字符串才会结束。
>>> mo = """中
... 国
... 乒乓
... 球
... 队"""
>>> mo
'中\n\t国\n\t乒乓\n\t球\n\t队'Python把所有在三重引号之内的文本收集到一个单独的多行字符串中,并在代码折行处嵌入了换行字符(\n),以及制表符(\t)。
>>> print(mo)
中
国
乒乓
球
队三重引号字符串在程序需要输入多行文本的任何时候都是很有用的。它们往往是可以用作多行注释的。
三重引号字符串经常在开发过程中作为常规的惯例去废除一些代码。
如果希望让一些行的代码不工作,之后再次运行代码,可以简单地在这几行前、后加入三重引号,就像这样。

对于大段的代码,这也比手动在每一行之前加入井号,之后再删除它们要容易得多。如果使用没有对编辑Python代码有特定支持的文本编辑器时尤其如此。在Python中,实用往往会胜过美观。
实际应用中的字符串
这里会介绍字符串的基础知识、格式以及方法,这是Python语言中文本处理的首要工具。
基本操作
字符串可以通过+操作符进行合并并且可以通过*操作符进行重复:
>>> len('abc')
3
>>> 'abc' + 'def'
'abcdef'
>>> 'hi' * 4
'hihihihi'两个字符串对象相加创建了一个新的字符串对象,这个对象就是两个操作的对象内容相连。
重复就像在字符串后再增加一定数量的自身。
在Python中没有必要去做任何预声明,包括数据结构的大小。内置的len函数返回了一个字符串(或任意有长度的对象)的长度。
Python会使用引用值计数的垃圾收集策略,自动回收无用对象的内存空间。每个对象都会记录引用其的变量名、数据结构等的次数,一旦计数值到了零,Python就会释放该对象的空间。这种方式意味着Python不用停下来扫描所有内存,从而寻找要释放的无用空间(一个额外的垃圾组件也会收集循环对象)。
重复最初看起来有些费解,然而在相当多的场合使用起来十分顺手。例如,为了打印包含80个横线的一行,你可以一个一个数到80,或者让Python去帮你数:
>>> print('________________________________________________________________________________')
________________________________________________________________________________
>>> print('_' * 80)
________________________________________________________________________________注意:Python不允许在+表达式中混合数字和字符串:'abc'+9会抛出一个错误而不会自动地将9加载到个字符串上。
可以使用for语句在一个字符串中进行循环迭代,并使用in表达式操作符对字符和子字符串进行成员关系的测试。对于子字符串,in返回一个布尔结果而不是子字符串的位置:
>>> job = 'test'
>>> for c in job: print(c,end=' ')
...
t e s t >>>
>>> 'k' in job
False
>>> 't' in job
True
>>> 'te' in job
Truefor循环指派了一个变量去获取一个序列(对应这里的是一个字符串)其中的元素,并对每一个元素执行一个或多个语句。实际上,这里变量c成为了一个在这个字符串中步进的指针。
索引和分片
字符串定义为字符的有序集合,所以我们能够通过其位置获得他们的元素。在Python中,字符串中的字符是通过索引(通过在字符串之后的方括号中提供所需要的元素的数字偏移量)提取的。
Python偏移量是从0开始的,并比字符串的长度小1。一个个负偏移与这个字符串的长度相加后得到这个字符串的正的偏移值。能够将负偏移看做是从结束处反向计数。
>>> s = 'life'
>>> s[0],s[-2]
('l', 'f')
>>> s[1:3],s[1:],s[:-1]
('if', 'ife', 'lif')第一行定义了有一个四个字符的字符串,并将其赋予变量名s。下一行用两种方法对其进行索引:S[0]获取了从最左边开始偏移量为0的元素(单字符的字符串'l'),并且s[-2]获取了从尾部开始偏移量为2的元素[或等效的,在从头来算偏移量为(4+(-2))的元素]。
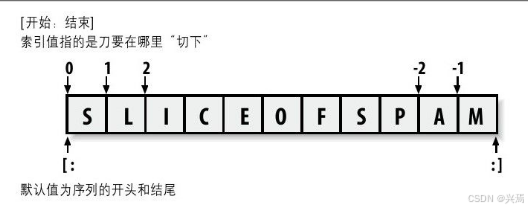
偏移和分片:位置偏移从左至右(偏移0为第一个元素),而负偏移是由末端右侧开始计算(偏移-1为最后一个元素)。这两种偏移均可以在索引及分片中作为所给出的位置
理解分片最好的办法就是将其看做解析(分析结构)的一种形式,特别是当你对字符串应用分片时——它让我们能够从一整个字符串中分离提取出一部分内容(子字符串)。分片可以用作提取部分数据,分离出前、后缀等场合。
当使用一对以冒号分隔的偏移来索引字符串这样的序列对象时,Python将返回一个新的对象,其中包含了以这对偏移所标识的连续的内容。
记住,如果你不确定分片的意义,可以交互地试验一下。
下面概括一些细节:
·索引(S[i])获取特定偏移的元素:
—第一个元素的偏移为0。
—负偏移索引意味着从最后或右边反向进行计数。
—S[0]获取了第一个元素。
—S[-2]获取了倒数第二个元素(就像S[len(s)-2]一样)。
·分片(S[i:j])提取对应的部分作为一个序列:
—上边界并不包含在内。
—分片的边界默认为0和序列的长度,如果没有给出的话。
—S[1:3]获取了从偏移为1的元素,直到但不包括偏移为3的元素。
—S[1:]获取了从偏移为1直到末尾(偏移为序列长度)之间的元素。
—S[:3]获取了从偏移为0直到但是不包括偏移为3之间的元素。
—S[:-1]获取了从偏移为0直到但是不包括最后一个元素之间的元素。
—S[:]获取了从偏移0到末尾之间的元素,这有效地实现顶层S拷贝。
最后一项成为了一个非常常见的技巧:它实现了一个完全的顶层的序列对象的拷贝——一个有相同值,但是是不同内存片区的对象。对于像字符串这样的不可变对象并不是很有用,但对于可以在原地修改的对象来说却很实用,例如列表。
扩展分片:第三个限制值
分片表达式增加了一个可选的第三个索引,用作步进(有时称为是stride)。
步进添加到每个提取的元素的索引中。完整形式的分片现在变成了X[I:J:K],这表示“索引X对象中的元素,从偏移为I直到偏移为J-1,每隔K元素索引一次”。
第三个限制——K,默认为1,这也就是通常在一个切片中从左至右提取每一个元素的原因。如果你定义了一个明确的值,那么能够使用第三个限制去跳过某些元素或反向排列它们的顺序。
>>> s = 'abcdefghijklmnopq'
>>> s[1:10:2] #取出偏移值1~9之间,间隔了一个元素的元素
'bdfhj'
>>> s[::2] #取出序列从头到尾、每隔一个元素的元素
'acegikmoq'
>>> s[::-1] #反转,从左到右变为从右到左
'qponmlkjihgfedcba'
>>> s[5:1:-1] #以反转的顺序获取从2到5的元素
'fedc'像这样使用三重限制的列表来跳过或者反序输出是很常见的情况。
分片等同于用一个分片对象进行索引。
>>> s[1:3]
'bc'
>>> s[slice(1,3)]
'bc'
>>> s[::-1]
'qponmlkjihgfedcba'
>>> s[slice(None,None,-1)]
'qponmlkjihgfedcba'为什么使用分片
目前没有遇到真实应用场景。
下面是一个实际例子:一个系统命令行中启动Python程序时罗列出的参数,这使用了内置的sys模块中的argv属性:

通常,你只对跟随在程序名后边的参数感兴趣。这就是一个分片的典型应用:一个分片表达式能够返回除了第一项之外的所有元素的列表。这里,sys.argv[1:]返回所期待的列表['-a','-b','-c']。
分片也常常用作清理输入文件的内容。如果知道一行将会以行终止字符(\n换行字符标识)结束,你就能够通过一个简单的表达式,例如,line[:-1],把这行除去最后一个字符之外的所有内容提取出来(默认的左边界为0)。无论是以上哪种情况,分片都表现出了比底层语言的实现更明确直接的逻辑关系。
为了去掉换行字符常常推荐采用line.rstrip方法,因为这个调用将会留下没有换行字符那行的最后一个字符,而这在一些文本编辑器工具中是很常见的。当你确定每一行都是通过换行字符终止时适宜使用分片。
字符串转换工具
在Python中不能够让数字和字符串相加,甚至即使字符串看起来像是数字也不可以:
>>> '1' + 1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str如果脚本从文件或用户界面得到了一个作为文本字符串出现的数字该怎么办?这里的技巧就是,需要使用转换工具预先处理,把字符串当作数字,或者把数字当作字符串。例如:
>>> int('1'),str(1)
(1, '1')
>>> repr(1)
'1'int函数将字符串转换为数字,str函数将数字转换为字符串表达形式。repr函数也能够将一个对象转换为其字符串形式。
对于字符串来说,如果是使用print语句进行显示的话,其结果需用引号括起来。
混合字符串和数字类型进行像+这样的加法要在之前做转换:
>>> s = '1'
>>> i = 1
>>> s+i
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only concatenate str (not "int") to str
>>> int(s) + i
2
>>> s + str(i)
'11'类似的内置函数可以把浮点数转换成字符串,或者把字符串转换成浮点数:
>>> str(3.1415),float('1.55')
('3.1415', 1.55)
>>> text = '1.23445789E-20'
>>> float(text)
1.23445789e-20eval函数。它将会运行一个包含了Python表达式代码的字符串,并能够将一个字符串转换为任意类型的对象。
函数int和float只能够对数字进行转换,然而这样的约束意味着它往往要更快一些(并且更安全,因为它不能够接受那些随意的表达式代码)。
字符串代码转换
单个的字符也可以通过将其传给内置的ord函数转换为其对应的ASCII码——这个函数实际上返回的是这个字符在内存中对应的字符的二进制值。
而chr函数将会执行相反的操作,获取ASCII码并将其转化为对应的字符:
>>> ord('s')
115
>>> chr(115)
's'这样的转换可以与循环语句一起配合使用,可以将一个表示二进制数的字符串转换为等值的整数。每次都将当前的值乘以2,并加上下一位数字的整数值:
>>> b = '1101'
>>> i = 0
>>> while b != '':
... i = i*2 +(ord(b[0]) - ord('0'))
... b = b[1:]
...
>>> i
13int和bin在Python 中用来处理二进制转换任务
>>> int('1101',2)
13
>>> bin(13)
'0b1101'修改字符串
字符串是不可变序列,不可变的意思就是不能在原地修改一个字符串(例如,给一个索引进行赋值):
>>> s = 'life'
>>> s[0] = 'x'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'str' object does not support item assignment如何在Python中改变文本信息?
若要改变一个字符串,需要利用合并、分片这样的工具来建立并赋值给一个新的字符串,倘若必要的话,还要将这个结果赋值给字符串最初的变量名:
>>> s = 'life'
>>> s = s + 'Life'
>>> s
'lifeLife'
>>>
>>> s = s[:4] + 'jacket'
>>> s
'lifejacket'第一个例子在S后面加了一个子字符串,这的确是通过合并创建了一个新的字符串并赋值给S,然而你也可以把它看做是对原字符串的“修改”。
第二个例子通过分片、合并将4个字符变为6个字符。
这一结果同样可以通过像replace这样的字符串方法来实现:
>>> s = 'splot'
>>> s = s.replace('pl','pamal')
>>> s
'spamalot'像每次操作生成新的字符串的值那样,字符串方法都生成了新的字符串对象,如果愿意保留那些对象,你可以将其赋值给新的变量名。
可以通过字符串格式化表达式来创建新的文本值。下面的两种方式都把对象替换为字符串,在某种意义上,是把对象转换为字符串并且根据指定的格式来改变最初的字符串:
>>> 'That is %d %s brid' % (1,'beautiful')
'That is 1 beautiful brid'
>>> 'That is {0} {1} brid'.format(1,'beautiful')
'That is 1 beautiful brid'格式化的结果是一个新的字符串对象,而不是修改后的对象。
字符串方法
除表达式运算符之外,字符串还提供了一系列的方法去实现更复杂的文本处理任务。方法就是与特定的对象相关联在一起的函数。
更详细一点,函数也就是代码包,方法调用同时进行了两次操作(一次获取属性和一次函数调用):
属性读取
具有object.attribute格式的表达式可以理解为“读取object对象的属性attribute的值”。
函数调用表达式
具有函数(参数)格式的表达式意味着“调用函数代码,传递零或者更多用逗号隔开的参数对象,最后返回函数的返回值”。
将两者合并可以让我们调用一个对象方法。方法调用表达式对象,方法(参数)从左至右运行,也就是说Python首先读取对象方法,然后调用它,传递参数。如果一个方法计算出一个结果,它将会作为整个方法调用表达式的结果被返回。
表7-3概括了Python 3.0中内置字符串对象的方法及调用模式;这些经常有变化,因此,确保查看Python的标准库手册以获取最新的列表,或者在交互模式下在任何字符串上调用help。

字符串方法实例:修改字符串
字符串是不可变的,所以不能在原处直接对其进行修改。为了在已存在的字符串中创建新的文本值,我们可以通过分片和合并这样的操作来建立新的字符串。上方有讲述过。
replace方法比这一段代码所表现的更具有普遍性。它的参数是原始子字符串(任意长度)和替换原始子字符串的字符串(任意长度),之后进行全局搜索并替换:
>>> 'aa$bb$cc'.replace('$','HI')
'aaHIbbHIcc'replace可以当作实现模板(例如,一定格式的信件)替换的工具来使用。
如果需要在任何偏移时都能替换一个固定长度的字符串,可以再做一次替换,或者使用字符串方法find搜索的子字符,之后使用分片:
>>> s = 'aaHIbbHIcc'
>>> wee = s.find('HI')
>>> wee
2
>>> s = s[:wee] + 'xxxx' + s[(wee+4):]
>>> s
'aaxxxxHIcc'find方法返回在子字符串出现处的偏移(默认从前向后开始搜索)或者未找到时返回-1。
>>> s = 'aaHIbbHIcc'
>>> s.replace('HI','xxxx')
'aaxxxxbbxxxxcc'
>>> s.replace('HI','xxxx',1)
'aaxxxxbbHIcc'注意:replace每次返回一个新的字符串对象。由于字符串是不可变的,因此每一种方法并不是真正在原处修改了字符串。
合并操作和replace方法每次运行会产生新的字符串对象,实际上利用它们去修改字符串是一个潜在的缺陷。
如果你不得不对一个超长字符串进行许多的修改,为了优化脚本的性能,可能需要将字符串转换为一个支持原处修改的对象。
>>> s = 'life'
>>> l = list(s)
>>> l
['l', 'i', 'f', 'e']内置的list函数(或一个对象构造函数调用)以任意序列中的元素创立一个新的列表——在这个例子中,它将字符串的字符“打散”为一个列表。这样无需在每次修改后进行复制就可以对其进行多次修改:
>>> l[3] = 'x'
>>> l
['l', 'i', 'f', 'x']修改之后,如果你需要将其变回一个字符串(例如,写入一个文件时),可以用字符串方法join将列表“合成”一个字符串:
>>> s = ''.join(l)
>>> s
'lifx'join将列表字符串连在一起,并用分隔符隔开。这个例子中使用一个空的字符串分隔符将列表转换为字符串。
对任何字符串分隔符和可迭代字符串都会是这样的结果:
>>> 'SPAM'.join(['eggs','sausage','ham','toast'])
'eggsSPAMsausageSPAMhamSPAMtoast'实际上,像这样一次性连接子字符串比单独地合并每一个要快很多。
字符串方法实例:文本解析
另外一个字符串方法的常规角色是以简单的文本解析的形式出现的——分析结构并提取子串。为了提取固定偏移的子串,我们可以利用分片技术:

这一技术称为解析,只要你所需要的数据组件有固定的偏移。
有些分割符分开了数据组件,你就可以使用split提取出这些组件。在字符串中,数据出现在任意位置,这种方法都能够工作:
>>> line = 'aaa bbb ccc'
>>> col = line.split()
>>> col
['aaa', 'bbb', 'ccc']字符串的split方法将一个字符串分割为一个子字符串的列表,以分隔符字符串为标准。默认的分隔符为空格。
下面这个例子使用逗号分隔(因此有时分解)一个字符串,这个字符串是使用某些数据库工具返回的由逗号分隔开的数据:
>>> line = 'bob,test,40'
>>> line.split(',')
['bob', 'test', '40']分隔符也可以比单个字符更长,比如:
>>> line = 'alifeblifeclifed'
>>> line.split('life')
['a', 'b', 'c', 'd']实际应用中的其他常见字符串方法
例如,为了清除每行末尾的空白,执行大小写转换,测试内容以及检测末尾或起始的子字符串:

与字符串方法相比,其他的技术有时也能够达到相同的结果——例如,成员操作符in能够用来检测一个子字符串是否存在,并且length和分片操作能够用来做字符串末尾的检测:

字符串格式化表达式
Python还提供了一种更高级的方法来组合字符串处理任务——字符串格式化允许在一个单个的步骤中对一个字符串执行多个特定类型的替换。
如今的Python中的字符串格式化可以以两种形式实现:
字符串格式化表达式
这是从Python诞生的时候就有的最初的技术;这是基于C语言的"printf"模型,并且在大多数现有的代码中使用。
字符串格式化方法调用
是Python独有的方法,并且和字符串格式化表达式的功能有很大重叠。
Python在对字符串操作的时候定义了%二进制操作符,当应用在字符串上的时候,%提供了简单的方法对字符串的值进行格式化,这一操作取决于格式化定义的字符串。
格式化字符串:
1.在%操作符的左侧放置一个需要进行格式化的字符串,这个字符串带有一个或多个嵌入的转换目标,都以%开头(例如,%d)。
2.在%操作符右侧放置一个(或多个,嵌入到元组中)对象,这些对象将会插入到左侧想让Python进行格式化字符串的一个(或多个)转换目标的位置上去。
>>> 'That is %d %s brid' % (1,'beautiful')
'That is 1 beautiful brid'
>>> 'That is {0} {1} brid'.format(1,'beautiful')
'That is 1 beautiful brid'字符串的格式化表达式往往是可选的——通常你可以使用多次的多字符串的合并和转换达到类似的目的。格式化允许我们将多个步骤合并为一个简单的操作:
>>> exl = 'NI'
>>> 'The knights who say %s' % exl
'The knights who say NI'
>>> '%d %s %d you' % (1,'life',3)
'1 life 3 you'
>>> '%s -- %s -- %s' % (1,3.1415,[1,2,3,4])
'1 -- 3.1415 -- [1, 2, 3, 4]'第一个例子中,在左侧目标位置插入字符串'Ni',代替标记%s。在第二个例子中,在目标字符串中插入三个值。
需要注意的是当不止一个值待插入的时候,应该在右侧用括号把它们括起来(也就是说,把它们放到元组中去)。%格式化表达式操作符在其右边期待一个单独的项或者一个或多个项的元组。
第三个例子同样是插入三个值:一个整数、一个浮点数对象和一个列表对象。但是注意到所有目标左侧都是%s,这就表示要把它们转换为字符串。
除非你要做特殊的格式化,一般你只需要记得用%s这个代码来格式化表达式。
高级字符串格式化表达式
Python字符串格式化支持C语言中所有常规的printf格式的代码(但是并不像printf那样显示结果,而是返回结果)。表中的一些格式化代码为同一类型的格式化提供了不同的选择。例如,%e、%f和%g都可以用于浮点数的格式化。

在格式化字符串中,表达式左侧的转换目标支持多种转换操作,这些操作自有一套相当严谨的语法。转换目标的通用结构看上去是这样的:

表7-4中的字符码出现在目标字符串的尾部,在%和字符码之间,你可以进行以下的任何操作:放置一个字典的键;罗列出左对齐(-)、正负号(+)和补零(0)的标志位;给出数字的整体长度和小数点后的位数等。width和percision都可以编码为一个*,以指定它们应该从输入值的下一项中取值。
举例:
首先是对整数进行默认格式化,随后进行了6位的左对齐格式化,最后进行了6位补零的格式化:
>>> x = 1234
>>> res = 'integers:..%d..%-6d..%06d' % (x,x,x)
>>> res
'integers:..1234..1234 ..001234'%e、%f和%g格式对浮点数的表示方法有所不同,正如下面的交互模式下所显示的那样(%E和%e相同,只不过指数是大写表示的):
>>> '%e|%f|%g' % (x,x,x)
'1.234567e+00|1.234567|1.23457'
>>> '%E' % x
'1.234567E+00'对浮点数来讲,通过指定左对齐、补零、正负号、数字位数和小数点后的位数,你可以得到各种各样的格式化结果。对于较简单的任务来说,你可以通过利用简单的格式化表达式进行字符串转换
>>> '%-6.2f | %05.2f | %+06.1f' % (x,x,x)
'1.23 | 01.23 | +001.2'字典的字符串格式化
字符串的格式化同时也允许左边的转换目标来引用右边字典中的键来提取对应的值。
>>> '%(n)d %(x)s' % {'n':1,'x':'life'}
'1 life'格式化字符串里(n)和(x)引用了右边字典中的键,并提取它们相应的值。
生成类似HTML或XML的程序往往利用这一技术。你可以建立一个数值字典,并利用一个基于键的引用的格式化表达式一次性替换它们:
>>> reply = '''NGreetings...
... hello %(name)s,
... age is %(age)s
... '''
>>> va = {'name':'bob','age':40}
>>> print(reply % va)
NGreetings...
hello bob,
age is 40这样的小技巧也常与内置函数vars配合使用,这个函数返回的字典包含了所有在本函数调用时存在的变量:
>>> food = 'spam'
>>> age = 40
>>> vars()
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <class '_frozen_importlib.BuiltinImporter'>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, 'food': 'spam', 'age': 40}当字典用在一个格式化操作的右边时,它会让格式化字符串通过变量名来访问变量(也就是说,通过字典中的键):
>>> '%(age)d %(food)s' % vars()
'40 spam'字符串格式化调用方法
基础知识
python的新的字符串对象的format方法使用主体字符串作为模板,并且接受任意多个表示将要根据模板替换的值的参数。在主体字符串中,花括号通过位置(例如,{1})或关键字(例如,{food})指出替换目标及将要插入的参数。

本质上,字符串也可以是创建一个临时字符串的常量,并且任意的对象类型都可以替换:
>>> '{motto},{0} and {food}'.format(42,motto=3.14,food=[1,2])
'3.14,42 and [1, 2]'就像%表达式和其他字符串方法一样,format创建并返回一个新的字符串对象,它可以立即打印或保存起来方便以后使用(别忘了,字符串是不可变的,因此,format必须创建一个新的对象)。
字符串格式化不只是用来显示:

添加键、属性和偏移量
格式化调用可以变得更复杂以支持更多高级用途。
格式化字符串可以指定对象属性和字典键——就像在常规的Python语法中一样,方括号指定字典键,而点表示位置或关键字所引用的一项的对象属性。
>>> import sys
>>> 'My {1[spam]} runs {0.platform}'.format(sys,{'spam':'laptop'})
'My laptop runs win32'
>>> 'My {config[spam]} runs {sys.platform}'.format(sys = sys , config = {'spam':'lap
top'})
'My laptop runs win32'格式化字符串中的方括号可以指定列表(及其他的序列)偏移量以执行索引。但是,只有单个的正的偏移才能在格式化字符串的语法中有效。
和%表达式一样,要指定负的偏移或分片,或者使用任意表达式,必须在格式化字符串自身之外运行表达式:
>>> somelist = list('SPAM')
>>> 'frst = {0[0]},third = {0[2]}'.format(somelist)
'frst = S,third = A'
>>> 'first={0},last={1}'.format(somelist[0],somelist[-1])
'first=S,last=M'
>>> parts=somelist[0],somelist[-1],somelist[1:3]
>>> parts
('S', 'M', ['P', 'A'])
>>> 'first={0},last={1},middle={2}'.format(*parts)
"first=S,last=M,middle=['P', 'A']"添加具体格式化
另一种和%表达式类似的是,可以在格式化字符串中添加额外的语法来实现更具体的层级。
对于格式化方法,我们在替换目标的标识之后使用一个冒号,后面跟着可以指定字段大小、对齐方式和一个特定类型编码的格式化声明。如下是可以在一个格式字符串中作为替代目标出现的形式化结构:

·fieldname是指定参数的一个数字或关键字,后面跟着可选的".name"或"[index]"成分引用。
·Conversionflag可以是r、s,或者a分别是在该值上对repr、str或ascii内置函数的一次调用。
·Formatspec指定了如何表示该值,包括字段宽度、对齐方式、补零、小数点精度等细节,并且以一个可选的数据类型编码结束。
冒号后的formatspec组成形式上的描述如下(方括号表示可选的组成,并且不能编写为常量):
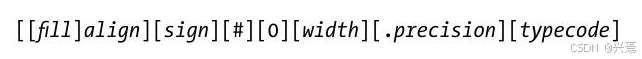
align可能是<、>、=或^,分别表示左对齐、右对齐、一个标记字符后的补充或居中对齐。Formatspec也包含嵌套的、只带有{}的格式化字符串,它从参数列表动态地获取值(和格式化表达式中的*很相似)。
参见Python的库手册可以了解关于替换语法的更多信息和可用的类型编码的列表,它们几乎与前面表7-4中列出的以及%表达式中使用的那些完全重合。
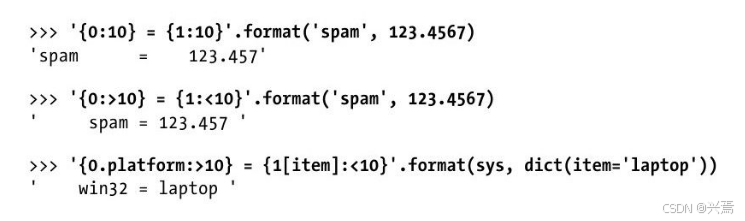
例如,下面的{0:10}意味着一个10字符宽的字段中的第一个位置参数,{1:<10}意味着第2个位置参数在一个10字符宽度字段中左对齐,{0.platform:>10}意味着第一个参数的platform属性在10字符宽度的字段中右对齐:
与%格式化表达式比较
对于位置的引用和字典键,字符串格式化方法看上去和%格式化表达式很像,特别是提前使用类型代码和额外的格式化语法。
实际上,在通常的使用情况下,格式化表达式可能比格式化方法调用更容易编写,特别是当使用通用的%s打印字符串替代目标的时候:

更复杂的格式化倾向于降低复杂性(复杂的任务通常都很困难,不管用什么方法),并且某些人把格式化方法看做是很大程度的冗余。
格式化方法还提供了一些潜在的优点。例如,最初的%表达式无法处理关键字、属性引用和二进制类型代码,尽管%格式化字符串中的字典键引用常常能够达到类似的目标。要看看两种技术是如何重合的,把如下的%表达式与前面显示的对等的格式化方法调用进行比较:

当较为复杂的格式化应用两种技术方法进行复杂性的比较的时候,把如下的代码与前面列出的对等的格式化方法调用比较,你将会发现%表达式往往能够更简单一些并且更简练:


格式化方法拥有%表达式所没有的很多高级功能,但是,更复杂的格式化似乎看起来也能从根本上降低复杂性。
如下的代码展示了用两种技术产生同样的结果,带有字段大小和对齐以及各种参数引用方法:

格式化方法和%表达式之间的比较更加直接(这里方法调用中的**数据是特殊的语法,它把键和值的一个字典包装到单个的"name=value"关键字参数中,以便可以在格式化字符串中用名字来引用它们):
>>> data = dict(platform = sys.platform,spam = 'laptop')
>>> 'My {spam:<8} runs {platform:>8}'.format(**data)
'My laptop runs win32'
>>> 'My %(spam)-8s runs %(platform)8s' % data
'My laptop runs win32'为什么用新的格式化方法
为什么有时可能想要考虑使用格式化方法。简而言之,尽管格式化方法有时候需要更多的代码,它还是:
·拥有%表达式所没有的一些额外功能。
·可以更明确地进行替代值引用。
·考虑到操作符会有一个更容易记忆的方法名。
·不支持用于单个和多个替代值大小写的不同语法。
额外功能
方法调用支持表达式所没有的一些额外功能,例如二进制类型编码和千分位分组。此外,方法调用支持直接的键和属性引用。正如我们已经见到的,格式化表达式通常可以以其他方法实现同样的效果:

格式化方法存在一个颇具争议的使用情况——很多值都要替换到格式化字符串中。这样看起来方法{i}的位置标签比表达式的%更易读。

方法名和通用参数
格式化表达式接受一个单个替换值,或者一项或多项的元组。单个项可以独自给定,也可以在元组中给定,要格式化的元组必须作为嵌套的元组提供:

格式化方法通过在两种情况下接受通用的函数参数,把这两种情况绑定到一起:

通常意义下的类型分类
同样分类的类型共享其操作集合
字符串是不可改变的序列:它们不能在原处进行改变(不可变部分),并且它们是位置相关排序好的集合,可以通过偏移量读取(序列部分)。
所有的序列都可以使用这里对于字符串的序列操作——合并、索引、迭代等。
正式的来说,在Python中有三个主要类型(以及操作)的分类:
数字(整数、浮点数、二进制、分数等)
支持加法和乘法等。
序列(字符串、列表、元组)
支持索引、分片和合并等。
映射(字典)
支持通过键的索引等。
集合是自成一体的一个分类(它们不会把键映射到值,并且没有逐位的排序顺序)。
我们遇到的很多其他类型都与数字和字符串类似,对于任意的序列对象X和Y:
·X+Y将会创建一个包含了两个操作对象内容的新的序列对象。
·X*N将会创建一个包含操作对象X内容N份拷贝的新的序列对象。
这些操作工作起来对于任意一种序列对象都一样,包括字符串、列表、元组以及用户定义的对象类型。唯一的区别就是,你得到的新的最终对象是根据操作对象X和Y来决定的——如果你合并的是列表,那么你将得到一个新的列表而不是字符串。索引、分片以及其他的序列操作对于所有的序列来说都是同样有效的,对象的类型将会告诉Python去执行什么样的任务。
可变类型能够在原处修改
Python中的主要核心类型划分为如下两类:
不可变类型(数字、字符串、元组、不可变集合)
不可变的分类中没有哪个对象类型支持原处修改,尽管我们总是可以运行表达式来创建新的对象并将其结果分配给变量。
可变类型(列表、字典、可变集合)
相反,可变的类型总是可以通过操作原处修改,而不用创建新的对象。尽管这样的对象可以复制,但原处修改支持直接修改。
一般来说,不可变类型有某种完整性,保证这个对象不会被程序的其他部分改变。