转载地址 https://www.jianshu.com/p/c60a9c2131c3
目 录
精通细节是理解更深和更基本概念的先决条件,这一章节首先讲解了C代码、汇编代码与机器代码的关系,再次重申了汇编的承上启下的重要作用。接着从IA32的细节一步步讲起,如何存储数据、如何访问数据、如何完成运算、如何进行跳转,在了解了这些细节以后告诉你我们常用的分支语句、循环语句是怎么完成了。在如何调用函数的部分,花费的篇幅较大,详细的讲解了栈帧结构,也让我们更好的了解了递归的过程。(其他方面还对数组、结构、联合有所讲解,难度不大)通过对编译器产生的汇编代码表示,我们了解了编译器和它的优化能力,知道了编译器为我们完成了哪些工作。
[本章内容]
※c语言、汇编代码以及机器代码之间的关系;
※介绍IA32的细节;
※讲解过程的实现,包括如何维护运行栈来支持过程间数据和控制传递;
※理解存储器访问越界问题,以及缓冲区溢出攻击问题;
※IA32扩展到64位(x86-64)
[笔记]
一、c语言代码、汇编代码、机器代码之间的关系
在第一章开始的部分我们就已经讲解过这三者的关系大概顺序是:1]C预处理器扩展源代码,展开所以的#include命名的指定文件;2]编译器产生汇编代码(.s);3]汇编器将汇编代码转化成二进制目标文件(.o).二进制目标文件是很难阅读懂的,我们使用imac下的otool工具翻译如下:

图1:从左到右分别是:c语言源码、汇编源码和机器目标代码

图2:使用命令:tool -tV
我们从图1中可以看出,汇编代码起到了承上启下的作用,目前已经不再要求程序员手写汇编代码,但是理解汇编代码以及与它的源C代码之间的联系,是理解程序如何执行的关键一步,因为编译器隐藏了太多的细节如:程序计数器、寄存器(整数、条件码、浮点)等。
二、IA32指令的细节
1)区分字节与字:Intel使用术语“字”表示16位数据类型而“字节”代表的是8个位的数据。如果不习惯理解的话,可以做一个比喻“字节”相当于“字截”所以少了被截断了的嘛
2)访问信息
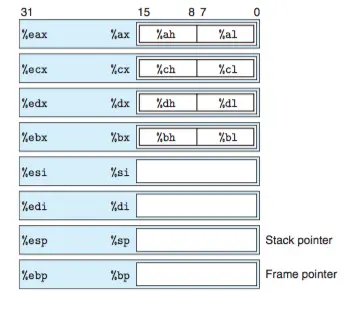
前4个寄存器可以独立访问低位字节
传送指令:move 源--> 目的地(两个操作数不能同时指向存储器,需要寄存器周转)
指针:就是地址,间接引用指针就是将指针放入一个寄存器中,然后在存储器中使用这个寄存器
栈数据的基本理解:

地址向上增大,push向下压栈
push指令相当于:sub $4, %esp 然后move %ebp, (%esp)
pop指令相当于:move (%esp), %eax 然后 add $4, %esp
栈的数据结构是向低地址方向增长的,无论如何esp都是指向栈顶顶
3)算数和逻辑操作
其实讲的就是加减乘除、与或非这一系列的指令:

加载有效地址指令:leal S, D ==> (&S-->D) 将有效地址写入到目的操作数中去
汇编代码与C语言源码中的顺序可能不同:

leal和sall组合实现了z*48
4)改变执行顺序
a.机器机制
我们这里用到的是条件码寄存器,常见的有:

4个常用的条件码寄存器
可以通过cmp和test设置条件码寄存器:
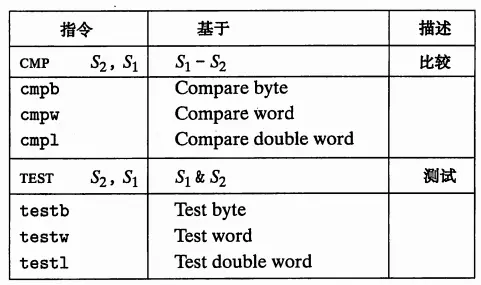
比较和测试 只修改条件码寄存器
通过set指令访问条件码,用处是设置值 or 跳转 or 传送数据:

注:set指令后缀是表示不同的操作数
跳转指令(对于理解链接非常重要):

根据条件的不同进行条件,用于改变程序的执行顺序
直接跳转用:‘.’ 间接跳转用:'*'
理解跳转指令的目标编码:

0xd并不是目标地址,而是0xd+0xa
jle跳转指令中的0d并不是目标地址,而真正的地址是通过计算0d+0a来确定的,这样做的优点是:通过使用与机器相关目标使得代码简洁,可以使目标代码移到存储器中而不是简单的地址,执行的是程序计数器与目标代码的加法。
b 翻译条件分支
通过将C代码翻译成不良好的goto语句可以方便我们理解汇编代码的执行方式。汇编程序通过条件测试和跳转来实现循环,我们常见的循环语句其实都是翻译成了do-while形式的:

do-while循环
while循环会先转成do-while形式:
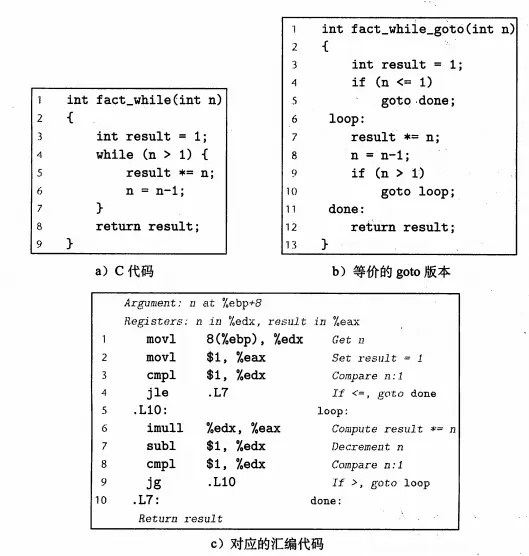
while循环
for循环也是一样的道理,先转成do-while形式:

for循环
switch语句:使用一个数组作为跳转表

着重理解跳转的创建与使用
在switch语句的汇编代码中,我们使用的是一个数组jt来表示所以可能的7种情况,使用n-100将范围缩小到了0-6区间。其中102到103中间没有break,桤木的扩展C代码中也巧妙的实现了这样的效果。
c 条件传送指令
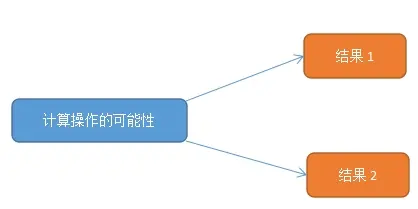
先计算出可能的多种不同结果
如条件语句:x < y ? y-x : x-y ; 就会先计算两种结果y-x和x-y的值,然后再判断x,y的大小
现代计算机CPU使用流水线方式实现性能的最优化:
举个例子,你去一家快餐店点餐,想要吃一个鸡蛋、一碗稀饭和一个包子,如果都是现场马上给你做的话,味道肯定最好,但花费的时间我估计你不会再去吃第二次了。然而真实的情况是,服务员将你的要求传达下去,宾果~~很快的时间就准备好了你需要的食物。这是因为快餐店已经从很早开始就将大家喜欢吃的都做好了,所以的结果(鸡蛋、稀饭、包子)都已经提前准备好了,这时候只需要根据你的需要(x,y的大小)马上就能给你上菜了。
在这个过程中,我们提前处理了一部分指令,如制作包子过程中的和面、包肉、上蒸笼我们成功的预测了90%的人早餐喜欢吃包子。就大大的节约了时间。记住所以的结果都提前准备好了的。
三、如何调用函数
我们如果要调用一个函数,实现将数据和控制代码从一个部分到另一个部分的跳转。我们如何来分配执行函数的变量空间,并在返回的时候释放空间,将返回值返回。用什么样的数据结构实现这一系列的操作:

单个过程分配一个栈帧结构
帧指针与栈指针的不公之处:ebp放与参数与返回地址的最下方,方便计算参数的偏移位置;而esp一直在栈顶,可以通过push将数据压入,通过pop取出,增加指针来释放空间。
1) 转移控制

常用转移控制指令
其中call先将返回地址入栈,然后跳转到函数开始的地方执行。(返回地址是开始调用者执行call的后面那条指令的地址)当遇到ret指令的时候,弹出返回地址,并跳转到该处继续执行调用者剩余部分。
2) 寄存器使用惯例
1] eax edx ecx 调用者保存,可以被调用者使用。
举个例子:这里的调用者就像很有票子的王健林一样,儿子王思聪可以无偿的使用王健林的票子
2] ebx esi edi 被调用者保存,在使用前被调用者要把这里面的值保存好,用完之后还回去
举个例子:这里就像有我有一辆豪车,可以把车子借给朋友使用,但是一定要把钥匙保存好,用完了之后还回来
3)递归的过程
我们可以理解,递归的调用其实与其他函数的调用是一样的,因为计算机使用的是栈帧结构,为每个单独的调用创建了一个栈帧,每次调用都有私有的状态信息。

每个调用都有独立的栈帧结构
五、数组的分配与访问
1)基本原则
数组的声明就不用多说了,来看看声明过后数组的具体位置

Xa代表的是起始地址
汇编代码使用move指令来简化访问:
movl (%edx , %ecx, 4), %eax
假设E是一个int类型的数组,我们要计算E[i]的值,在此,E的地址放于edx中,而i放于ecx中,我们通过上面的指令就完成了Xe + 4i来读取其中的值,放在了eax中去。
2)指针运算:对指针的运算其实际是按照相应的数据大小进行了伸缩
point + i = Xp + (数据大小)L * i
如何计算二维数组的大小呢?
我们定义一个int D[5][3]的数组,形如:

数组D
如果我们要计算D[4,2]的地址,就可以使用
D[i][j] = Xd + L(C * i + j) = D[0,0] + 4 * (3 * 4 + 2)
由于每组有3个数据,所以跳过一组就要乘以3,跳过4组就12个,再加上偏移的2,就是最后一个数据的地址了。
3)理解指针:数组与指针关系密切
①指针用&符号创造、用*符号间接引用
②指针从一个类型 转为另外一个类型,只是伸缩因子变化,不改变它的值
③指针可以指向函数:int (*f)(int *)从f开始由内往外阅读,首先f代表的是一个指向函数的指针,这个函数的参数是int * 返回值是int
六、结构与联合
1)结构:所有的组成部分在存储器中连续存放,指向结构的指针指向结构的第一个字节;结构的各个字段的选取是在编译时处理,机器代码不包含字段的声明或字段名字的信息。
2)联合:一个联合的总大小等于它最大字段的大小,而指向一个联合的指针,引用的是数据结构的起始位置。应用在:
a.如果两个数据互斥,减少空间;
b.访问不同数据的位模式;

使用不同的位模式访问数据
用有符号数据存储,而返回的确实无符号的数据。特别注意的是,如果用联合将不同大小的数据组合到一起的时候要注意字节的顺序。
3)数据对齐:要求某个类型对象的数据地址必须是(2.4.8)的倍数

其中的.align 4要求数组开始的位置为4的倍数,由于每单个数据的长度也是4的倍数,也就保证了后续的数据是4的倍数,数据对齐了。这种设计简化了,处理器与存储器之间接口的硬件设计。这种设计,编译器甚至会在字段中间、后面插入间隙,以保证每个结构满足上述要求。如下图所示:

结构的中间插入间隙,保证数据对齐
七、存储器越界引用和缓冲区溢出
由于C对于数组不进行边界检查,在栈帧结构中局部变量和状态信息,特别是返回地址也是在栈中存放的,对越界数据的访问和修改将破坏掉这些数据,当ret试图返回的时候,错误的地址(甚至是被修改的恶意目的地地址)会带来严重的安全隐患。

越界访问
上图两段代码展示了一个get函数在只有8个字节的空间中,存入了太多的数据,使得栈数据不断被破坏的过程。

在计算机中存储的 顺序

被破坏的过程
常见的攻击方式是覆盖返回地址,使得程序跳转到所插入的恶意代码部分。
对抗方式:
① 栈随机化:在程序开始时,随机分配一段0-n的空间,使得栈的位置每次运行都不同。栈地址随机化,即使在一台机器上运行同样的程序,地址都是不同的。
② 栈破坏检测:插入栈保护者,俗称金丝雀的一段随机大小
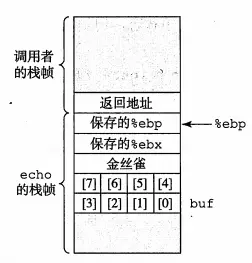
在数组buf和保存状态之间放入一个特殊的金丝雀,代码检查该值,确定栈状态是否被改变
③ 限制可执行代码区域
八、x86-64:将IA32扩展到64位
1)数据类型的比较:

指针和长整数是64位
2)访问信息:

callee被调用者保存,caller调用者保存
注:pc相对寻址-立即数+下条指令地址
3)算术指令:当大小不同的操作数混在一起的时候,必须进行正确的扩展
4)控制指令:增加了cmpq 、testq指令
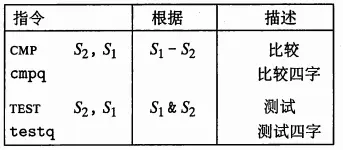
增加cmpq与testq指令
a 过程
由于寄存器翻了一倍,64位中不需要栈帧来存储参数,而是直接使用寄存器:

主要不同的地方
b 栈帧
以下原因会使用栈帧结构:

c 寄存器保存惯例:
被调用者保存:rbx rbp 12 13 14 15号寄存器
调用者保存: 10 11 号寄存器
d 数据结构:严格对齐要求