ICML 2024
1 背景
- 在传统LLM训练过程中,为了提高效率,通常会将多个输入文档拼接在一起,然后将这些拼接的文档分割成固定长度的序列。
- ——>会造成一个重大问题——文档截断(document truncation),损害了数据完整性(data integrity)
- 此外,文档截断减少了每个序列中的上下文量,可能导致下一个词的预测与上文不相关,从而使模型更容易产生幻觉 (hallucination)。
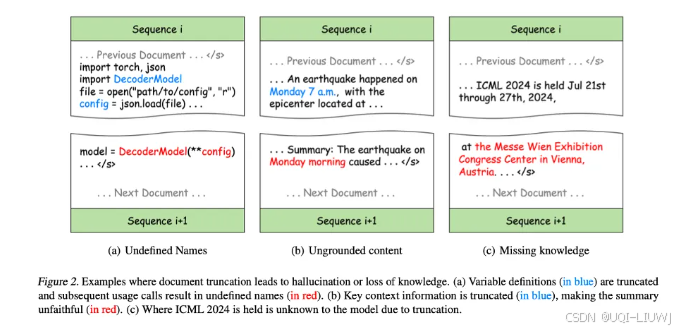
- (a):将变量定义与使用分割到不同的训练序列
- ——>使得模型学习到错误的模式,并可能在下游任务中产生幻觉。
- (b):摘要中的“Monday morning”无法与训练序列中的任何上下文匹配,导致内容失实
- ——>显著降低模型对上下文信息的敏感度,导致生成的内容与实际情况不符,即所谓的不忠实生成 (unfaithful generation)。
- (c):阻碍训练期间的知识获取,因为知识在文本中的表现形式通常依赖完整的句子或段落
- (a):将变量定义与使用分割到不同的训练序列
- ——>论文提出了最佳适配打包 (Best-fit Packing)
- 使用长度感知的组合优化技术,有效地将文档打包到训练序列中,从而完全消除不必要的截断。
- 不仅保持了传统方法的训练效率,而且通过减少数据的片段化,实质性地提高了模型训练的质量