1、nvjpeg速度测试
在深度学习的应用场景中,常常会涉及接收来自多个相机的图像数据,例如在监控系统、自动驾驶多传感器融合等领域。然而,大量的图像数据传输会消耗大量的带宽,为了解决这一问题,在传输过程中通常会对图像进行JPEG编码。通过这种编码方式,可以在保证一定图像质量的前提下,大大减少数据量,从而加快数据传输速度。但这也带来新的问题:在对图像进行模型推理之前,我们需要先对这些JPEG编码的数据进行解码,然后再开展后续的预处理和推理工作。
图像的解码效率在很大程度上直接影响整个系统的执行速度。设想一下,如果解码过程过于缓慢,模型就不得不一直处于等待图像解码完成的停滞状态,这无疑会导致显卡性能的大量浪费,降低系统的整体性能和效率。
为了解决深度学习场景中JPEG图像解码效率的问题,NVIDIA 推出了一款专门利用显卡进行JPEG解码的库——NVJPEG。这款库针对高分辨率图像的解码进行了优化设计,能够显著提升JPEG图像的解码速度。
为了直观地感受NVJPEG解码的高效,我们进行了以下简单的测试。测试环境为Intel i7 - 12700KF处理器、NVIDIA 4070Ti显卡以及Ubuntu20.04操作系统。
首先,使用OpenCV库将一张图片编码为JPEG格式,得到JPEG编码数据 jpegBytes,相关代码如下:
// 编码为JPEG格式
std::vector<int> params;
params.push_back(cv::IMWRITE_JPEG_QUALITY);
params.push_back(85); // JPEG质量,范围是0 - 100,95是常用值
bool success = cv::imencode(".jpg", image, jpegBytes, params); // 得到jpeg编码数据
接着,使用OpenCV和NVJPEG分别对得到的编码数据进行解码测试,测试结果如下:
| 算法 | 8000*3000 | 1024*1024 |
|---|---|---|
| OpenCV | 87ms | 2.6ms |
| NVJPEG | 25ms | 0.7ms |
从测试结果可以看出,无论是大分辨率(8000*3000)还是小分辨率(1024*1024)的图像解码,NVJPEG的速度都比OpenCV解码快约3.5倍。这充分证明了NVJPEG在JPEG图像解码方面具有非常高的效率。
在实际的深度学习项目中,将NVJPEG集成进来是一个优化系统性能的有效手段,可以在不牺牲图像质量的前提下,显著提升整个系统的数据处理效率和性能,让计算资源得到更充分的利用。
2、安装nvjpeg
nvjpeg官网:nvJPEG Libraries。
文档:nvJPEG,但是注意右上角显示的CUDA版本信息,不同版本可能存在较大的变动(比如12.8之前的硬件加速仅支持A100, A30, H100显卡,而12.8版本支持Ampere (A100, A30)、Hopper、Ada、Blackwell架构的显卡)。
根据官网的说明,CUDA10.0或者9.0需要手动安装,更新的CUDA版本则已经集成nvJPEG库了。
可以通过nvjpeg头文件查询nvJPEG版本,可以看到通过cuda-11.8中的nvjpeg头文件,查询到nvjpeg版本为11.9.0.86:

cat /usr/local/cuda-11.8/include/nvjpeg.h | grep NVJPEG_VER_
#define NVJPEG_VER_MAJOR 11
#define NVJPEG_VER_MINOR 9
#define NVJPEG_VER_PATCH 0
#define NVJPEG_VER_BUILD 86
所以如果你已经安装了较新版本的CUDA,那么已经用了有nvjpeg库。
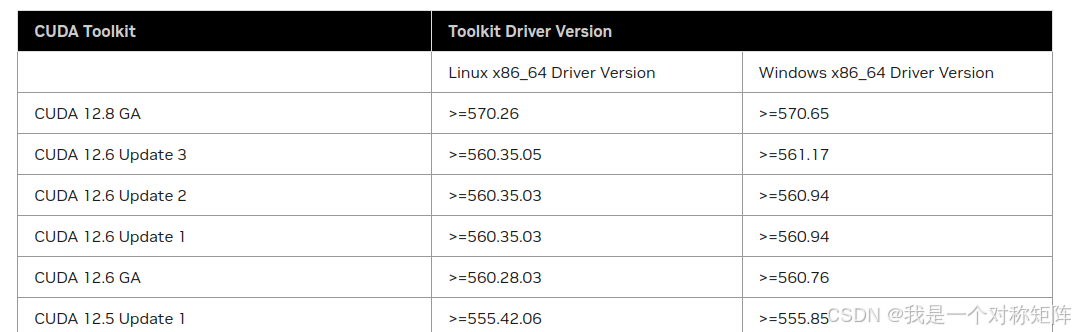
上面进行的测试是显卡软解码,效果也非常好。但如果你想使用一些nvjpeg的新特性,比如硬件加速,则需要安装指定的依赖了。根据文档描述支持硬件加速,右上角显示v12.8版本,说明需要安装CUDA12.8才可以使用具有该特性的nvjpeg库。
找到CUDA12.8的发行说明:CUDA 12.8 Release Notes,可以看到安装CUDA12.8需要的驱动版本。
至此我们知道了所需要的显卡驱动版本和CUDA版本,去搜索是否有合适自己显卡的驱动。如果没有可能就暂时没法使用指定版本的nvjpeg特性了。

3、简单的例子
如果属性CUDA或CUDA库,则使用起来非常顺手。基本流程就是创建管理对象,设置图像尺寸用于初始化接受解码后图像数据的nvjpegImage_t对象,然后解码,最后将解码数据复制到另一个显存地址。
如果使用TensorRT部署模型,模型接受的输入必须是在显存中,所以这里就很方便地将解码后的数据直接给模型推理了。如果是预处理可以使用CUDA核函数,核函数的输入(来自解码后的数据)和输出(喂给模型推理)都是在显存中,也是非常方便。
#include "nvjpeg.h"
#ifndef CUDA_CHECK
#define CUDA_CHECK(callstr) \
{ \
cudaError_t error_code = callstr; \
if (error_code != cudaSuccess) \
{ \
std::cerr << "\033[31mCUDA error code: " << error_code << "\nName: " << cudaGetErrorName(error_code) << "\nat " << __FILE__ << ":" << __LINE__ << "\033[0m" << std::endl; \
; \
throw std::runtime_error("CUDA_CHECK ERROR"); \
} \
}
#endif
int main()
{
nvjpegHandle_t handle;
nvjpegJpegState_t state;
nvjpegCreate(NVJPEG_BACKEND_DEFAULT, NULL, &handle); // 创建环境上下文
nvjpegJpegStateCreate(handle, &state); // 创建加码状态对象,管理状态
int Height = 8000; // 指定图像尺寸
int Width = 3000;
int out_step = Width;
int out_size = out_step * Height;
nvjpegImage_t out_buf; // 创建nvjpegImage_t对象,用于存放解码后图像数据
out_buf.pitch[0] = out_step;
cudaMalloc((void **)&out_buf.channel[0], out_size); // 分配显存
nvjpegDecode(handle, state, jpegBytes.data(), jpegBytes.size(), NVJPEG_OUTPUT_UNCHANGED, &out_buf, nullptr); // 解码
// 解码后数据复制到推理的显存中
cudaMemcpyAsync(decoded_cuda_buffer, out_buf.channel[0], out_size * sizeof(unsigned char), cudaMemcpyDeviceToDevice);
}