Unix/Linux下的五种IO模型(网络编程的角度)
重述阻塞非阻塞、同步异步(只针对IO)
-
同步IO和异步IO
- 同步:A调用B,B的处理是同步的,在处理完之前不会返回,只有处理完之后才会返回A,A需要等待B的结果才能继续执行。
- 异步:A调用B,B处理是异步的,B在接收请求后,告诉A我接收到了请求(返回),这个时候也确定了通知方式(信号/回调函数),B异步处理完A的事情,通过通知方式告诉A,A再处理针对B返回的逻辑。在等待B异步处理的时间内,A可以执行其他逻辑。
- 同步异步最大的区别是,被调用方的执行方式和返回时机。同步指的是被调用方做完事情之后再返回,异步指的是被调用方先返回,然后再做事情,做完之后再想办法通知调用方。
-
阻塞IO和非阻塞IO
- 阻塞: A调用B,A一直等待B的返回,此间A什么都干不了
- 非阻塞:A调用B,A不用一直等待B的返回,可以先去忙别的事情
- 阻塞和非阻塞最大的区别就是在被调用方返回结果之前的这段时间内,调用方是否一直等待。
阻塞IO模型(同步阻塞)
socket是阻塞模式,且内核缓冲区没有数据的话,recv会阻塞进程,如果有数据的话,会等recv将数据收完才返回。
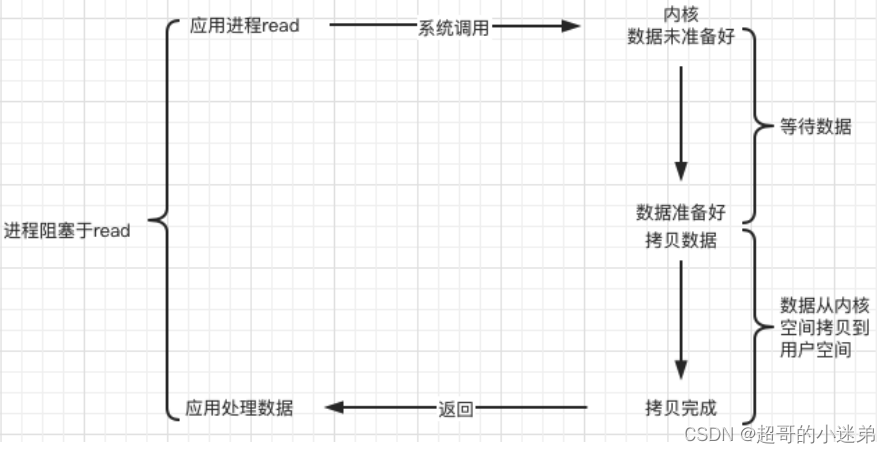
- 优点:实现简单,阻塞期间进程/线程不会占用CPU资源,如果来数据了recv拷贝数据到用户缓冲区,OS并唤醒进程/线程处理
- 缺点:
- 一个线程一个socket,如果客户端对服务端请求大量连接的话,需要开大量的线程
- 线程使用率不高,对端不发数据,导致本端内核接收缓冲区没有数据,进而使得recv会一直阻塞,从而占用线程资源。
非阻塞IO模型(同步非阻塞)
socket是非阻塞模式,内核缓冲区没有数据的话,recv直接返回(需要通过返回值判断非阻塞状态),如果内核缓冲区有数据,recv需要将内核缓冲区数据拷贝到用户缓冲区再返回,这个同步进行的。
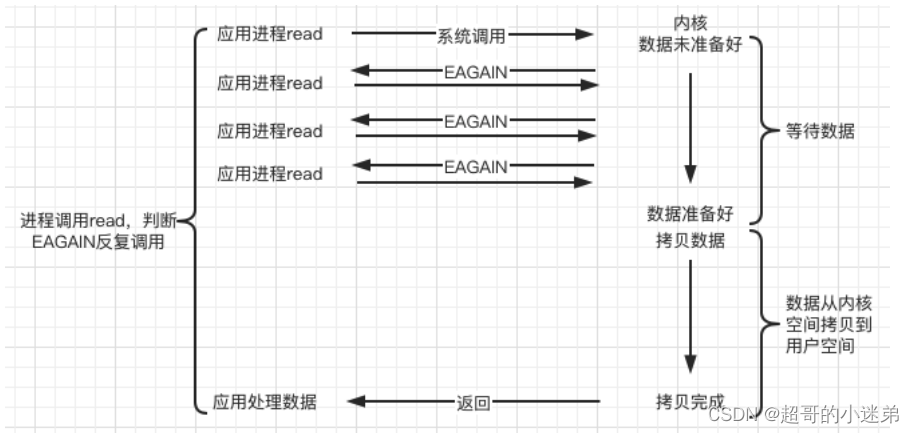
- 优点
- 没有数据的时候不需要阻塞线程,可以直接返回处理其他业务逻辑
- 缺点
- 如果内核缓冲区一直没有数据,会不断的轮询内核(while(true)),查看是不是有数据,占用大量CPU时间
- 一个线程一个socket,客户端多的时候,服务器线程数量会很大,服务器压力很大
IO复用模型
IO复用也是同步的,需要调用方通过调用来判断是不是有事件发生,没有人会给调用发通知。IO复用可以通过设置超时时间来决定阻塞多久一般有三种情况:NULL(没有事件永久等待)、>0(等待相应时间)、0(立即返回)
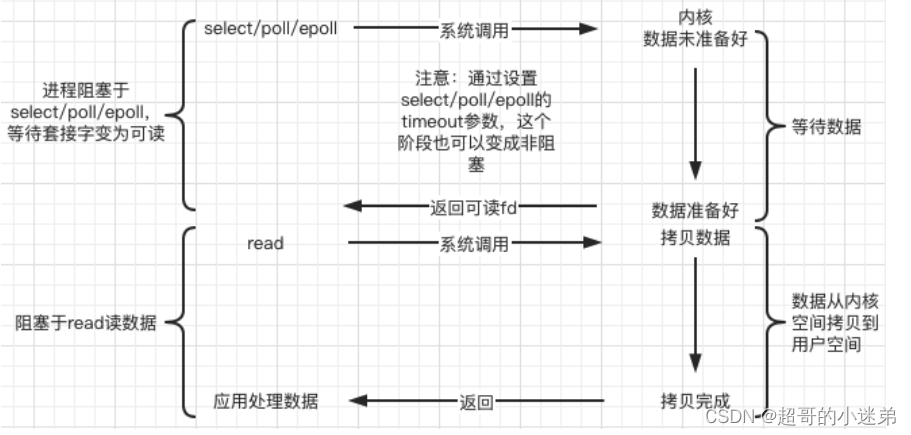
- 优点:
- 可以解决阻塞IO和非阻塞IO一个线程一个socket不能实现高并发的问题。一个线程中的IO复用函数可以挂载多个socketfd句柄,来检测具体哪个socket有事件。
- 应用:非阻塞IO机会和IO复用一起使用
- 为什么和非组IO绑定: 单独的非组塞IO,会不断进行轮询,检测内核数据是不是准备好了,并且是一个线程一个socket,浪费线程资源并且占用CPU时间片
- IO为什么不和阻塞IO绑定:阻塞IO可能会阻塞当前线程的执行,这样子就没办法通过IO复用处理其他socket上的事件。
- epoll边缘模式+阻塞IO: 需要while一直到recv收完数据,如果是阻塞recv,收完后会阻塞进程
- epoll水平模式+非阻塞IO:可以搭配,但是不能用while来收,防止阻塞
信号驱动IO模型
socket为非阻塞的时候,通过注册信号,协商异步的通知方式,如果数据准备好了,OS会通过信号告诉进程处理数据,也就是调用recv,如果数据没准备好,也不需要轮询检测内核缓冲区是不是有数据
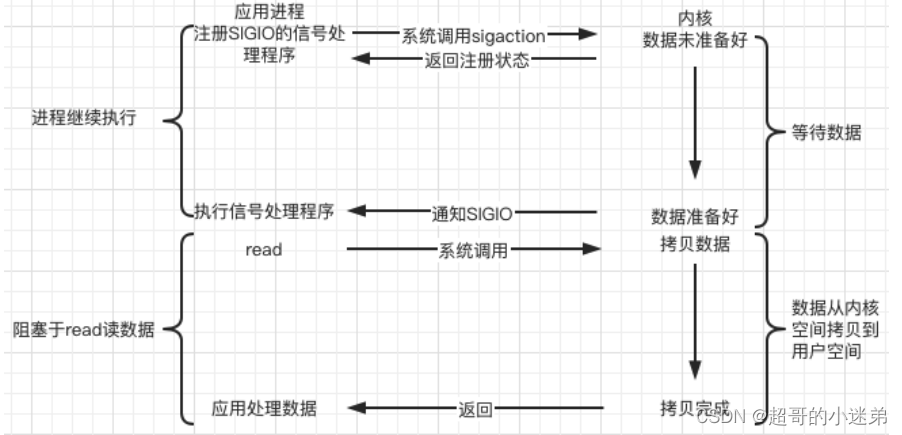
- 内核在第一阶段是异步(异步非阻塞),第二阶段是同步(同步非阻塞);与非阻塞IO的区别在于提供消息处理机制,不需要用户不断的轮询检测有没有数据到来,减少了系统API调用次数,提高了效率
- 但是需要注意的是,这个模型和异步IO的区别就在第二阶段,调用的是同步IO接口读取数据,读数据没返回的时候线程是阻塞的,但是这个时间很短
异步IO模型
在异步IO模型中,应用只需要向内核发送一个请求,告诉内核它要读取数据后即刻返回;内核收到请求后会建立一个信号联系,当数据准备就绪,内核会主动把数据从内核复制到用户空间(而信号驱动是告诉应用程序何时可以开始拷贝数据),异步IO模型真正的做到了完完全全的非阻塞;
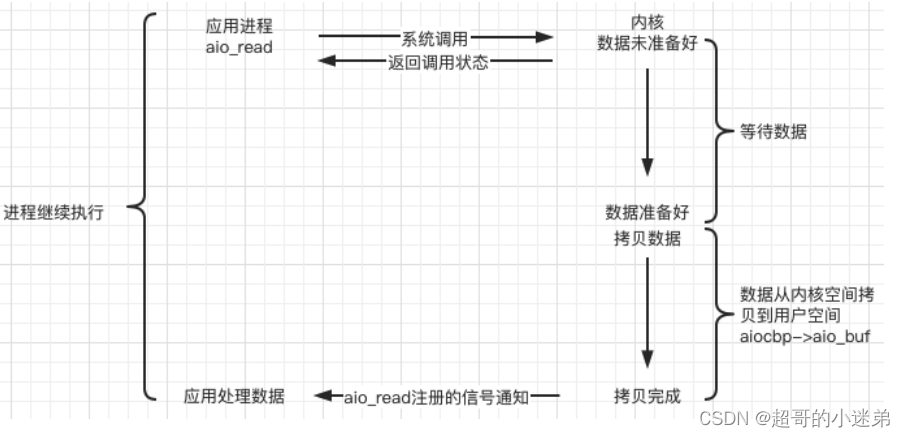
- 线程调用异步IO的具体实现过程都是OS完成,OS检测有没有数据准备好,OS将数据从内核缓冲区拷贝到用户缓冲区,再告诉线程数据接收完成了,只需要进行业务处理了