前言:
本文为记录自己在Nerf学习道路的一些笔记,包括对论文以及其代码的思考内容。公众号: AI知识物语 B站讲解:出门吃三碗饭
本篇文章主要针对其代码来学习其内容,关于代码的理解可能会有出入,欢迎批评指正!!!
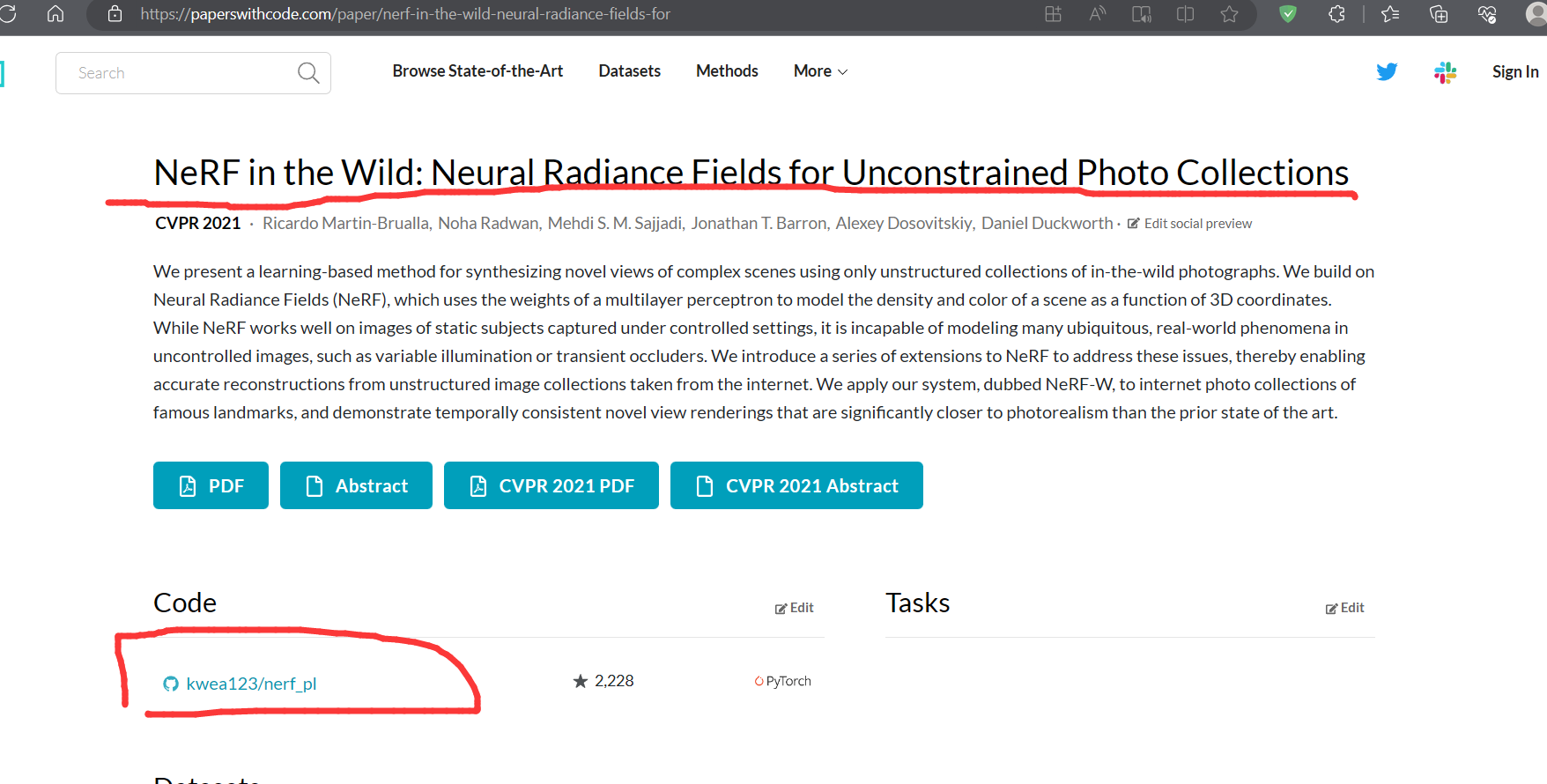
1:Paper with code 获取代码
(论文是论文:https://arxiv.org/abs/2003.08934)
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
代码地址,自取
Nerf 与unity结合

2:数据集处理
这里我们准备的llff类型的数据,具体如何制作llff数据集,看我前面的文章
Nerf如何制作自己的llff数据集
dataset下的文件负责数据的一些处理操作
(1)__init __.py
dataset_dict 变量用来存blender,llff两种类型的数据,后面根据指令的类型来选择
from .blender import BlenderDataset
from .llff import LLFFDataset
dataset_dict = {'blender': BlenderDataset,
'llff': LLFFDataset}
(2)blender.py
Blender数据集类
__init __(self, root_dir, split=‘train’, img_wh=(800, 800)):
构造函数,初始化数据集的根目录、数据集分割(默认为训练集)和图像的宽度和高度。这里需要注意图片长度和宽度需要一样!
read_meta(self):
1从元数据文件中读取场景的元数据,包括相机的角度、位置等信息,并计算焦距和光线方向。
2这里焦距的计算方式是基于长宽为800的图片。
3还会读取image的near,far和bounds、(远、近的采样距离,一个区间范围)
def define _transforms(self):
定义用于转换图像的函数。在这里,使用了T.ToTensor()将图像转换为张量。
def __len __(self):
返回数据集的长度。如果是训练集,则返回所有射线的数量;如果是验证集,则返回8(支持的GPU数量);如果是其他split类型,则返回场景的帧数self.meta[‘frames’]。
__getitem __(self, idx) :
根据给定的索引返回数据集中的样本。
如果是训练集,从预先加载的缓冲区中获取样本,包括射线和RGB值;
如果是其他split类型,为每个图像创建数据,包括射线、RGB值、相机到世界的变换矩阵和有效颜色区域的掩码。返回一个样本字典
import torch
from torch.utils.data import Dataset
import json
import numpy as np
import os
from PIL import Image
from torchvision import transforms as T
from .ray_utils import *
class BlenderDataset(Dataset):
def __init__(self, root_dir, split='train', img_wh=(800, 800)):
self.root_dir = root_dir
self.split = split
assert img_wh[0] == img_wh[1], 'image width must equal image height!'
self.img_wh = img_wh
self.define_transforms()
self.read_meta()
self.white_back = True
def read_meta(self):
with open(os.path.join(self.root_dir,
f"transforms_{self.split}.json"), 'r') as f:
self.meta = json.load(f)
w, h = self.img_wh
self.focal = 0.5*800/np.tan(0.5*self.meta['camera_angle_x']) # original focal length
# when W=800
self.focal *= self.img_wh[0]/800 # modify focal length to match size self.img_wh
# bounds, common for all scenes
self.near = 2.0
self.far = 6.0
self.bounds = np.array([self.near, self.far])
# ray directions for all pixels, same for all images (same H, W, focal) 所有像素的光线方向,所有图像相同(相同的H, W,焦点)
self.directions = \
get_ray_directions(h, w, self.focal) # (h, w, 3)
if self.split == 'train': # create buffer of all rays and rgb data
self.image_paths = []
self.poses = []
self.all_rays = []
self.all_rgbs = []
for frame in self.meta['frames']:
pose = np.array(frame['transform_matrix'])[:3, :4]
self.poses += [pose]
c2w = torch.FloatTensor(pose)
image_path = os.path.join(self.root_dir, f"{frame['file_path']}.png")
self.image_paths += [image_path]
img = Image.open(image_path)
img = img.resize(self.img_wh, Image.LANCZOS)
img = self.transform(img) # (4, h, w)
img = img.view(4, -1).permute(1, 0) # (h*w, 4) RGBA
img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
self.all_rgbs += [img]
rays_o, rays_d = get_rays(self.directions, c2w) # both (h*w, 3)
self.all_rays += [torch.cat([rays_o, rays_d,
self.near*torch.ones_like(rays_o[:, :1]),
self.far*torch.ones_like(rays_o[:, :1])],
1)] # (h*w, 8)
self.all_rays = torch.cat(self.all_rays, 0) # (len(self.meta['frames])*h*w, 3)
self.all_rgbs = torch.cat(self.all_rgbs, 0) # (len(self.meta['frames])*h*w, 3)
def define_transforms(self):
self.transform = T.ToTensor()
def __len__(self):
if self.split == 'train':
return len(self.all_rays)
if self.split == 'val':
return 8 # only validate 8 images (to support <=8 gpus)
return len(self.meta['frames'])
def __getitem__(self, idx):
if self.split == 'train': # use data in the buffers
sample = {'rays': self.all_rays[idx],
'rgbs': self.all_rgbs[idx]}
else: # create data for each image separately
frame = self.meta['frames'][idx]
c2w = torch.FloatTensor(frame['transform_matrix'])[:3, :4]
img = Image.open(os.path.join(self.root_dir, f"{frame['file_path']}.png"))
img = img.resize(self.img_wh, Image.LANCZOS)
img = self.transform(img) # (4, H, W)
valid_mask = (img[-1]>0).flatten() # (H*W) valid color area
img = img.view(4, -1).permute(1, 0) # (H*W, 4) RGBA
img = img[:, :3]*img[:, -1:] + (1-img[:, -1:]) # blend A to RGB
rays_o, rays_d = get_rays(self.directions, c2w)
rays = torch.cat([rays_o, rays_d,
self.near*torch.ones_like(rays_o[:, :1]),
self.far*torch.ones_like(rays_o[:, :1])],
1) # (H*W, 8)
sample = {'rays': rays,
'rgbs': img,
'c2w': c2w,
'valid_mask': valid_mask}
return sample
(3)depth_utils.py
读取和保存PFM(Portable Float Map)格式的图像文件
read_pfm(filename):
读取PFM文件并返回图像数据和比例因子。函数首先打开文件并解析文件头部信息,包括颜色模式、宽度、高度和比例因子。然后从文件中读取数据,并根据文件中的尺寸和颜色模式重新整形数据。最后,将数据翻转以正确显示图像,并返回数据和比例因子。
save_pfm(filename, image, scale=1):
保存图像数据为PFM格式的文件。函数首先打开文件,并根据图像数据的维度和颜色模式确定文件头部的格式。然后根据图像数据的字节顺序设置比例因子的符号。最后将图像数据写入文件,并关闭文件。
PFM格式是一种用于表示浮点数图像的文件格式。它支持灰度图像和RGB图像,并可以保存浮点数值。这段代码提供了读取和保存PFM文件的基本功能,以便在处理和分析浮点数图像时使用
import numpy as np
import re
import sys
def read_pfm(filename):
file = open(filename, 'rb')
color = None
width = None
height = None
scale = None
endian = None
header = file.readline().decode('utf-8').rstrip()
if header == 'PF':
color = True
elif header == 'Pf':
color = False
else:
raise Exception('Not a PFM file.')
dim_match = re.match(r'^(\d+)\s(\d+)\s$', file.readline().decode('utf-8'))
if dim_match:
width, height = map(int, dim_match.groups())
else:
raise Exception('Malformed PFM header.')
scale = float(file.readline().rstrip())
if scale < 0: # little-endian
endian = '<'
scale = -scale
else:
endian = '>' # big-endian
data = np.fromfile(file, endian + 'f')
shape = (height, width, 3) if color else (height, width)
data = np.reshape(data, shape)
data = np.flipud(data)
file.close()
return data, scale
def save_pfm(filename, image, scale=1):
file = open(filename, "wb")
color = None
image = np.flipud(image)
if image.dtype.name != 'float32':
raise Exception('Image dtype must be float32.')
if len(image.shape) == 3 and image.shape[2] == 3: # color image
color = True
elif len(image.shape) == 2 or len(image.shape) == 3 and image.shape[2] == 1: # greyscale
color = False
else:
raise Exception('Image must have H x W x 3, H x W x 1 or H x W dimensions.')
file.write('PF\n'.encode('utf-8') if color else 'Pf\n'.encode('utf-8'))
file.write('{} {}\n'.format(image.shape[1], image.shape[0]).encode('utf-8'))
endian = image.dtype.byteorder
if endian == '<' or endian == '=' and sys.byteorder == 'little':
scale = -scale
file.write(('%f\n' % scale).encode('utf-8'))
image.tofile(file)
file.close()
(4)llff.py
normalize(v):将向量v归一化,即将其长度除以其模长。
average_poses(poses):
计算平均姿态,用于将所有姿态居中。计算过程如下:1. 计算中心点:所有姿态中心点的平均值;2. 计算Z轴方向:所有姿态Z轴方向的平均值,并进行归一化;3. 计算Y轴方向的平均值;4. 计算X轴方向:通过Y轴方向和Z轴方向的叉乘得到,并进行归一化;5. 计算Y轴方向:通过Z轴方向和X轴方向的叉乘得到。最后返回平均姿态。
center_poses(poses):
将所有姿态居中,以便在渲染时使用归一化设备坐标。计算过程如下:1. 调用average_poses函数计算平均姿态;2. 将平均姿态转换为齐次坐标形式;3. 将所有姿态转换为齐次坐标形式;4. 使用平均姿态的逆矩阵将所有姿态居中;5. 返回居中的姿态和平均姿态的逆矩阵。
create_spiral_poses(radii, focus_depth, n_poses=120):
创建螺旋路径的相机姿态。计算过程如下:对于给定的旋转角度范围,计算螺旋路径上每个姿态的中心点;计算每个姿态的Z轴方向:从焦点平面指向中心点;根据average_poses函数的计算过程,计算每个姿态的X轴和Y轴方向;将每个姿态的X轴、Y轴、Z轴和中心点组合成姿态矩阵。最后返回所有姿态。
create_spheric_poses(radius, n_poses=120):
创建环绕Z轴的圆形路径上的相机姿态。计算过程如下:1对于给定的旋转角度范围,2计算圆形路径上每个姿态的中心点;3根据给定的半径、旋转角度和倾斜角度,4计算每个姿态的姿态矩阵。5最后返回所有姿态。
另外,llffDataset 和上面的BlenderDataset功能类似,此处略过
def normalize(v):
"""Normalize a vector."""
return v/np.linalg.norm(v)
def average_poses(poses):
"""
Calculate the average pose, which is then used to center all poses
using @center_poses. Its computation is as follows:
1. Compute the center: the average of pose centers.
2. Compute the z axis: the normalized average z axis.
3. Compute axis y': the average y axis.
4. Compute x' = y' cross product z, then normalize it as the x axis.
5. Compute the y axis: z cross product x.
Note that at step 3, we cannot directly use y' as y axis since it's
not necessarily orthogonal to z axis. We need to pass from x to y.
Inputs:
poses: (N_images, 3, 4)
Outputs:
pose_avg: (3, 4) the average pose
"""
# 1. Compute the center
center = poses[..., 3].mean(0) # (3)
# 2. Compute the z axis
z = normalize(poses[..., 2].mean(0)) # (3)
# 3. Compute axis y' (no need to normalize as it's not the final output)
y_ = poses[..., 1].mean(0) # (3)
# 4. Compute the x axis
x = normalize(np.cross(y_, z)) # (3)
# 5. Compute the y axis (as z and x are normalized, y is already of norm 1)
y = np.cross(z, x) # (3)
pose_avg = np.stack([x, y, z, center], 1) # (3, 4)
return pose_avg
def center_poses(poses):
"""
Center the poses so that we can use NDC.
See https://github.com/bmild/nerf/issues/34
Inputs:
poses: (N_images, 3, 4)
Outputs:
poses_centered: (N_images, 3, 4) the centered poses
pose_avg: (3, 4) the average pose
"""
pose_avg = average_poses(poses) # (3, 4)
pose_avg_homo = np.eye(4)
pose_avg_homo[:3] = pose_avg # convert to homogeneous coordinate for faster computation
# by simply adding 0, 0, 0, 1 as the last row
last_row = np.tile(np.array([0, 0, 0, 1]), (len(poses), 1, 1)) # (N_images, 1, 4)
poses_homo = \
np.concatenate([poses, last_row], 1) # (N_images, 4, 4) homogeneous coordinate
poses_centered = np.linalg.inv(pose_avg_homo) @ poses_homo # (N_images, 4, 4)
poses_centered = poses_centered[:, :3] # (N_images, 3, 4)
return poses_centered, np.linalg.inv(pose_avg_homo)
def create_spiral_poses(radii, focus_depth, n_poses=120):
"""
Computes poses that follow a spiral path for rendering purpose.
See https://github.com/Fyusion/LLFF/issues/19
In particular, the path looks like:
https://tinyurl.com/ybgtfns3
Inputs:
radii: (3) radii of the spiral for each axis
focus_depth: float, the depth that the spiral poses look at
n_poses: int, number of poses to create along the path
Outputs:
poses_spiral: (n_poses, 3, 4) the poses in the spiral path
"""
poses_spiral = []
for t in np.linspace(0, 4*np.pi, n_poses+1)[:-1]: # rotate 4pi (2 rounds)
# the parametric function of the spiral (see the interactive web)
center = np.array([np.cos(t), -np.sin(t), -np.sin(0.5*t)]) * radii
# the viewing z axis is the vector pointing from the @focus_depth plane
# to @center
z = normalize(center - np.array([0, 0, -focus_depth]))
# compute other axes as in @average_poses
y_ = np.array([0, 1, 0]) # (3)
x = normalize(np.cross(y_, z)) # (3)
y = np.cross(z, x) # (3)
poses_spiral += [np.stack([x, y, z, center], 1)] # (3, 4)
return np.stack(poses_spiral, 0) # (n_poses, 3, 4)
def create_spheric_poses(radius, n_poses=120):
"""
Create circular poses around z axis.
Inputs:
radius: the (negative) height and the radius of the circle.
Outputs:
spheric_poses: (n_poses, 3, 4) the poses in the circular path
"""
def spheric_pose(theta, phi, radius):
trans_t = lambda t : np.array([
[1,0,0,0],
[0,1,0,-0.9*t],
[0,0,1,t],
[0,0,0,1],
])
rot_phi = lambda phi : np.array([
[1,0,0,0],
[0,np.cos(phi),-np.sin(phi),0],
[0,np.sin(phi), np.cos(phi),0],
[0,0,0,1],
])
rot_theta = lambda th : np.array([
[np.cos(th),0,-np.sin(th),0],
[0,1,0,0],
[np.sin(th),0, np.cos(th),0],
[0,0,0,1],
])
c2w = rot_theta(theta) @ rot_phi(phi) @ trans_t(radius)
c2w = np.array([[-1,0,0,0],[0,0,1,0],[0,1,0,0],[0,0,0,1]]) @ c2w
return c2w[:3]
spheric_poses = []
for th in np.linspace(0, 2*np.pi, n_poses+1)[:-1]:
spheric_poses += [spheric_pose(th, -np.pi/5, radius)] # 36 degree view downwards
return np.stack(spheric_poses, 0)
(5) ray_utils.py
这段代码实现了将光线从世界坐标系转换为归一化设备坐标(NDC)的操作。
具体步骤如下:
(1)将光线的原点平移到近平面:根据光线的深度和方向,计算光线与近平面的交点,将光线的原点平移到近平面上。
(2)计算中间的齐次坐标结果:将光线的原点在x、y方向上除以z坐标,得到齐次坐标的中间结果。
投影变换:根据相机的焦距和图像大小,对光线的原点和方向进行投影变换,得到归一化设备坐标系中的光线原点和方向。
(3)最终返回归一化设备坐标系中的光线原点和方向。
具体详情可以见代码以及对应注释
import torch
from kornia import create_meshgrid
def get_ray_directions(H, W, focal):
"""
Get ray directions for all pixels in camera coordinate.
Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
ray-tracing-generating-camera-rays/standard-coordinate-systems
Inputs:
H, W, focal: image height, width and focal length
Outputs:
directions: (H, W, 3), the direction of the rays in camera coordinate
"""
# 获取相机坐标中所有像素的光线方向。
#
# 参考: https: // www.scratchapixel.com / lessons / 3
# d - basic - rendering /
#
# ray - tracing - generating - camera - rays / standard - coordinate - systems
#
# 输入:
# H、W、焦距: 图像高度、宽度和焦距
# 输出:
# 方向为(H, W, 3),为光线在相机坐标中的方向
grid = create_meshgrid(H, W, normalized_coordinates=False)[0]
i, j = grid.unbind(-1)
# the direction here is without +0.5 pixel centering as calibration is not so accurate
# see https://github.com/bmild/nerf/issues/24
directions = \
torch.stack([(i-W/2)/focal, -(j-H/2)/focal, -torch.ones_like(i)], -1) # (H, W, 3)
return directions
def get_rays(directions, c2w):
"""
Get ray origin and normalized directions in world coordinate for all pixels in one image.
Reference: https://www.scratchapixel.com/lessons/3d-basic-rendering/
ray-tracing-generating-camera-rays/standard-coordinate-systems
Inputs:
directions: (H, W, 3) precomputed ray directions in camera coordinate
c2w: (3, 4) transformation matrix from camera coordinate to world coordinate
Outputs:
rays_o: (H*W, 3), the origin of the rays in world coordinate
rays_d: (H*W, 3), the normalized direction of the rays in world coordinate
"""
rays_d = directions @ c2w[:, :3].T # (H, W, 3)
rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
# The origin of all rays is the camera origin in world coordinate
rays_o = c2w[:, 3].expand(rays_d.shape) # (H, W, 3)
rays_d = rays_d.view(-1, 3)
rays_o = rays_o.view(-1, 3)
return rays_o, rays_d
def get_ndc_rays(H, W, focal, near, rays_o, rays_d):
"""
Transform rays from world coordinate to NDC.
NDC: Space such that the canvas is a cube with sides [-1, 1] in each axis.
For detailed derivation, please see:
http://www.songho.ca/opengl/gl_projectionmatrix.html
https://github.com/bmild/nerf/files/4451808/ndc_derivation.pdf
In practice, use NDC "if and only if" the scene is unbounded (has a large depth).
See https://github.com/bmild/nerf/issues/18
Inputs:
H, W, focal: image height, width and focal length
near: (N_rays) or float, the depths of the near plane
rays_o: (N_rays, 3), the origin of the rays in world coordinate
rays_d: (N_rays, 3), the direction of the rays in world coordinate
Outputs:
rays_o: (N_rays, 3), the origin of the rays in NDC
rays_d: (N_rays, 3), the direction of the rays in NDC
"""
# 将光线从世界坐标转换为NDC。
#
# NDC: 这样的空间,画布是一个立方体,每个轴的边都是[- 1, 1]。
#
# 有关详细的推导,请参阅:
#
# http: // www.songho.ca / opengl / gl_projectionmatrix.html
#
# https: // github.com / bmild / nerf / files / 4451808 / ndc_derivation.pdf
#
# 在实践中,使用NDC“当且仅当”场景是无界的(有很大的深度)。
#
# 参见https: // github.com / bmild / nerf / issues / 18
#
# 输入:
#
# H、W、焦距: 图像高度、宽度和焦距
#
# near: (N_rays)
# 或float,近平面的深度
#
# rays_o: (N_rays, 3),世界坐标中射线的原点
#
# rays_d: (N_rays, 3),射线的世界坐标方向
#
# 输出:
#
# rays_o: (N_rays, 3), NDC中射线的原点
#
# rays_d: (N_rays, 3), NDC中的射线方向
# Shift ray origins to near plane
t = -(near + rays_o[...,2]) / rays_d[...,2]
rays_o = rays_o + t[...,None] * rays_d
# Store some intermediate homogeneous results
ox_oz = rays_o[...,0] / rays_o[...,2]
oy_oz = rays_o[...,1] / rays_o[...,2]
# Projection
o0 = -1./(W/(2.*focal)) * ox_oz
o1 = -1./(H/(2.*focal)) * oy_oz
o2 = 1. + 2. * near / rays_o[...,2]
d0 = -1./(W/(2.*focal)) * (rays_d[...,0]/rays_d[...,2] - ox_oz)
d1 = -1./(H/(2.*focal)) * (rays_d[...,1]/rays_d[...,2] - oy_oz)
d2 = 1 - o2
rays_o = torch.stack([o0, o1, o2], -1) # (B, 3)
rays_d = torch.stack([d0, d1, d2], -1) # (B, 3)
return rays_o, rays_d
nerf.py Nerf网络结构
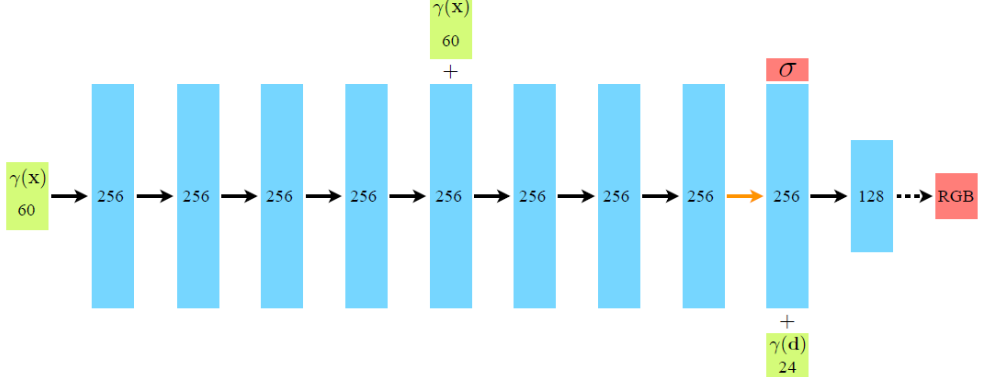
这段代码实现了一个名为NeRF的神经网络模型,用于将输入的位置(xyz)和方向(dir)编码为输出的颜色(rgb)和密度(sigma)。
具体实现如下:
定义了一个Embedding类,用于将输入的位置和方向嵌入到多维空间中。参考Nerf的Positional Encoding作用。
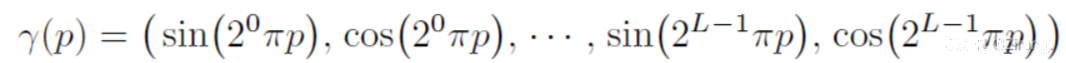
定义了一个NeRF类,包含了多个全连接层。通过将输入的位置和方向分别输入到不同的编码层中,得到编码后的特征。然后将编码后的特征输入到输出层中,得到最终的颜色和密度输出。
forward方法实现了神经网络的前向传播过程,将输入的位置和方向编码为颜色和密度输出。
import torch
from torch import nn
class Embedding(nn.Module):
def __init__(self, in_channels, N_freqs, logscale=True):
"""
Defines a function that embeds x to (x, sin(2^k x), cos(2^k x), ...)
in_channels: number of input channels (3 for both xyz and direction)
"""
# 定义一个函数,将x嵌入到(x, sin(2 ^ k x), cos(2 ^ k x),…)
# In_channels: 输入通道的数量(xyz和方向都是3)
super(Embedding, self).__init__()
self.N_freqs = N_freqs
self.in_channels = in_channels
self.funcs = [torch.sin, torch.cos]
self.out_channels = in_channels*(len(self.funcs)*N_freqs+1)
if logscale:
self.freq_bands = 2**torch.linspace(0, N_freqs-1, N_freqs)
else:
self.freq_bands = torch.linspace(1, 2**(N_freqs-1), N_freqs)
def forward(self, x):
"""
Embeds x to (x, sin(2^k x), cos(2^k x), ...)
Different from the paper, "x" is also in the output
See https://github.com/bmild/nerf/issues/12
Inputs:
x: (B, self.in_channels)
Outputs:
out: (B, self.out_channels)
"""
# ”“”
# 将x嵌入到(x, sin(2 ^ k x) cos(2 ^ k x),…) 与论文不同的是,“x”也在输出中
# 参见https: // github.com / bmild / nerf / issues / 12
# 输入:
# x: (B, self.in_channels)
# 输出:
# out: (B, self.out_channels)
# ”“”
out = [x]
for freq in self.freq_bands:
for func in self.funcs:
out += [func(freq*x)]
return torch.cat(out, -1)
class NeRF(nn.Module):
def __init__(self,
D=8, W=256,
in_channels_xyz=63, in_channels_dir=27,
skips=[4]):
"""
D: number of layers for density (sigma) encoder
W: number of hidden units in each layer
in_channels_xyz: number of input channels for xyz (3+3*10*2=63 by default)
in_channels_dir: number of input channels for direction (3+3*4*2=27 by default)
skips: add skip connection in the Dth layer
D:密度(sigma)编码器的层数
W:每层隐藏单位的数量
In_channels_xyz: xyz的输入通道数(默认为3+3*10*2=63)
In_channels_dir:方向的输入通道数(默认为3+3*4*2=27)
skip:在第d层增加skip连接
"""
super(NeRF, self).__init__()
self.D = D
self.W = W
self.in_channels_xyz = in_channels_xyz
self.in_channels_dir = in_channels_dir
self.skips = skips
# xyz encoding layers
for i in range(D):
if i == 0:
layer = nn.Linear(in_channels_xyz, W)
elif i in skips:
layer = nn.Linear(W+in_channels_xyz, W)
else:
layer = nn.Linear(W, W)
layer = nn.Sequential(layer, nn.ReLU(True))
setattr(self, f"xyz_encoding_{i+1}", layer)
self.xyz_encoding_final = nn.Linear(W, W)
# direction encoding layers
self.dir_encoding = nn.Sequential(
nn.Linear(W+in_channels_dir, W//2),
nn.ReLU(True))
# output layers
self.sigma = nn.Linear(W, 1)
self.rgb = nn.Sequential(
nn.Linear(W//2, 3),
nn.Sigmoid())
def forward(self, x, sigma_only=False):
"""
Encodes input (xyz+dir) to rgb+sigma (not ready to render yet).
For rendering this ray, please see rendering.py
Inputs:
x: (B, self.in_channels_xyz(+self.in_channels_dir))
the embedded vector of position and direction
sigma_only: whether to infer sigma only. If True,
x is of shape (B, self.in_channels_xyz)
Outputs:
if sigma_ony:
sigma: (B, 1) sigma
else:
out: (B, 4), rgb and sigma
"""
# ”“”
# 将输入(xyz + dir)
# 编码为rgb + sigma(尚未准备好渲染)。
# 要渲染该光线,请参阅rendering.py
# 输入:
# (B, self.in_channels_xyz(+self.in_channels_dir))
# 位置和方向的嵌入向量
# Sigma_only: 是否只推断sigma。如果这是真的,
# x的形状是(B, self.in_channels_xyz)
# 输出:
# 如果sigma_ony:
# (B, 1)
# 其他:
# out: (B, 4), rgb和sigma
# ”“”
if not sigma_only:
input_xyz, input_dir = \
torch.split(x, [self.in_channels_xyz, self.in_channels_dir], dim=-1)
else:
input_xyz = x
xyz_ = input_xyz
for i in range(self.D):
if i in self.skips:
xyz_ = torch.cat([input_xyz, xyz_], -1)
xyz_ = getattr(self, f"xyz_encoding_{i+1}")(xyz_)
sigma = self.sigma(xyz_)
if sigma_only:
return sigma
xyz_encoding_final = self.xyz_encoding_final(xyz_)
dir_encoding_input = torch.cat([xyz_encoding_final, input_dir], -1)
dir_encoding = self.dir_encoding(dir_encoding_input)
rgb = self.rgb(dir_encoding)
out = torch.cat([rgb, sigma], -1)
return out
render.py
这段代码实际上是一个渲染函数的实现。首先,根据输入的参数和模型,将粗糙模型和嵌入层从列表中提取出来。
然后,对于每个光线,通过嵌入方向信息和采样深度,计算出采样点的坐标。如果在测试模式下,只计算权重值并返回,否则计算RGB颜色值、深度和权重值,并返回结果。
如果N_importance大于0,还会在粗糙模型的基础上采样额外的深度点,并使用精细模型计算RGB颜色值、深度和权重值,并将结果存储在字典中。最后返回字典结果。
注释翻译(输入、输出):
“”"
该函数通过计算模型在光线上的输出来渲染光线。
输入:
models: 包含粗糙模型和精细模型的列表
embeddings: 包含位置嵌入和方向嵌入的列表
rays: 光线的张量,形状为(N_rays, 8),表示光线的起点、方向、近平面和远平面
N_samples: 采样深度点的数量
use_disp: 是否使用视差进行采样
perturb: 采样深度点时的扰动程度
noise_std: 输入噪声的标准差
N_importance: 用于精细模型的采样深度点的数量
chunk: 模型推理时的批次大小
white_back: 是否使用白色背景
test_time: 是否在测试模式下运行
输出为一个字典,包含粗糙模型的rgb_coarse(颜色结果)、depth_coarse(深度结果)、opacity_coarse(不透明度结果)等键值对,如果N_importance大于0,则还包含精细模型的rgb_fine、depth_fine和opacity_fine的键值对。
“”"
import torch
from torch import searchsorted
__all__ = ['render_rays']
"""
Function dependencies: (-> means function calls)
@render_rays -> @inference
@render_rays -> @sample_pdf if there is fine model
"""
def sample_pdf(bins, weights, N_importance, det=False, eps=1e-5):
"""
Sample @N_importance samples from @bins with distribution defined by @weights.
Inputs:
bins: (N_rays, N_samples_+1) where N_samples_ is "the number of coarse samples per ray - 2"
weights: (N_rays, N_samples_)
N_importance: the number of samples to draw from the distribution
det: deterministic or not
eps: a small number to prevent division by zero
Outputs:
samples: the sampled samples
从@bins中抽取@N_importance样本,其分布由@weights定义。
输入:
bins:(N_rays, N_samples_+1)其中N_samples_为“每条射线的粗样本数- 2”
weights: (N_rays, N_samples_)
N_importance:从分布中抽取的样本数量
Det:确定与否
Eps:一个小的数字,以防止被零除
输出:
样本:采样的样本
"""
N_rays, N_samples_ = weights.shape
weights = weights + eps # prevent division by zero (don't do inplace op!)
pdf = weights / torch.sum(weights, -1, keepdim=True) # (N_rays, N_samples_)
cdf = torch.cumsum(pdf, -1) # (N_rays, N_samples), cumulative distribution function
cdf = torch.cat([torch.zeros_like(cdf[: ,:1]), cdf], -1) # (N_rays, N_samples_+1)
# padded to 0~1 inclusive
if det:
u = torch.linspace(0, 1, N_importance, device=bins.device)
u = u.expand(N_rays, N_importance)
else:
u = torch.rand(N_rays, N_importance, device=bins.device)
u = u.contiguous()
inds = searchsorted(cdf, u, side='right')
below = torch.clamp_min(inds-1, 0)
above = torch.clamp_max(inds, N_samples_)
inds_sampled = torch.stack([below, above], -1).view(N_rays, 2*N_importance)
cdf_g = torch.gather(cdf, 1, inds_sampled).view(N_rays, N_importance, 2)
bins_g = torch.gather(bins, 1, inds_sampled).view(N_rays, N_importance, 2)
denom = cdf_g[...,1]-cdf_g[...,0]
denom[denom<eps] = 1 # denom equals 0 means a bin has weight 0, in which case it will not be sampled
# anyway, therefore any value for it is fine (set to 1 here)
samples = bins_g[...,0] + (u-cdf_g[...,0])/denom * (bins_g[...,1]-bins_g[...,0])
return samples
def render_rays(models,
embeddings,
rays,
N_samples=64,
use_disp=False,
perturb=0,
noise_std=1,
N_importance=0,
chunk=1024*32,
white_back=False,
test_time=False
):
def inference(model, embedding_xyz, xyz_, dir_, dir_embedded, z_vals, weights_only=False):
N_samples_ = xyz_.shape[1]
# Embed directions
xyz_ = xyz_.view(-1, 3) # (N_rays*N_samples_, 3)
if not weights_only:
dir_embedded = torch.repeat_interleave(dir_embedded, repeats=N_samples_, dim=0)
# (N_rays*N_samples_, embed_dir_channels)
# Perform model inference to get rgb and raw sigma
B = xyz_.shape[0]
out_chunks = []
for i in range(0, B, chunk):
# Embed positions by chunk
xyz_embedded = embedding_xyz(xyz_[i:i+chunk])
if not weights_only:
xyzdir_embedded = torch.cat([xyz_embedded,
dir_embedded[i:i+chunk]], 1)
else:
xyzdir_embedded = xyz_embedded
out_chunks += [model(xyzdir_embedded, sigma_only=weights_only)]
out = torch.cat(out_chunks, 0)
if weights_only:
sigmas = out.view(N_rays, N_samples_)
else:
rgbsigma = out.view(N_rays, N_samples_, 4)
rgbs = rgbsigma[..., :3] # (N_rays, N_samples_, 3)
sigmas = rgbsigma[..., 3] # (N_rays, N_samples_)
# Convert these values using volume rendering (Section 4)
deltas = z_vals[:, 1:] - z_vals[:, :-1] # (N_rays, N_samples_-1)
delta_inf = 1e10 * torch.ones_like(deltas[:, :1]) # (N_rays, 1) the last delta is infinity
deltas = torch.cat([deltas, delta_inf], -1) # (N_rays, N_samples_)
# Multiply each distance by the norm of its corresponding direction ray
# to convert to real world distance (accounts for non-unit directions).
deltas = deltas * torch.norm(dir_.unsqueeze(1), dim=-1)
noise = torch.randn(sigmas.shape, device=sigmas.device) * noise_std
# compute alpha by the formula (3)
alphas = 1-torch.exp(-deltas*torch.relu(sigmas+noise)) # (N_rays, N_samples_)
alphas_shifted = \
torch.cat([torch.ones_like(alphas[:, :1]), 1-alphas+1e-10], -1) # [1, a1, a2, ...]
weights = \
alphas * torch.cumprod(alphas_shifted, -1)[:, :-1] # (N_rays, N_samples_)
weights_sum = weights.sum(1) # (N_rays), the accumulated opacity along the rays
# equals "1 - (1-a1)(1-a2)...(1-an)" mathematically
if weights_only:
return weights
# compute final weighted outputs
rgb_final = torch.sum(weights.unsqueeze(-1)*rgbs, -2) # (N_rays, 3)
depth_final = torch.sum(weights*z_vals, -1) # (N_rays)
if white_back:
rgb_final = rgb_final + 1-weights_sum.unsqueeze(-1)
return rgb_final, depth_final, weights
# Extract models from lists
model_coarse = models[0]
embedding_xyz = embeddings[0]
embedding_dir = embeddings[1]
# Decompose the inputs
N_rays = rays.shape[0]
rays_o, rays_d = rays[:, 0:3], rays[:, 3:6] # both (N_rays, 3)
near, far = rays[:, 6:7], rays[:, 7:8] # both (N_rays, 1)
# Embed direction
dir_embedded = embedding_dir(rays_d) # (N_rays, embed_dir_channels)
# Sample depth points
z_steps = torch.linspace(0, 1, N_samples, device=rays.device) # (N_samples)
if not use_disp: # use linear sampling in depth space
z_vals = near * (1-z_steps) + far * z_steps
else: # use linear sampling in disparity space
z_vals = 1/(1/near * (1-z_steps) + 1/far * z_steps)
z_vals = z_vals.expand(N_rays, N_samples)
if perturb > 0: # perturb sampling depths (z_vals)
z_vals_mid = 0.5 * (z_vals[: ,:-1] + z_vals[: ,1:]) # (N_rays, N_samples-1) interval mid points
# get intervals between samples
upper = torch.cat([z_vals_mid, z_vals[: ,-1:]], -1)
lower = torch.cat([z_vals[: ,:1], z_vals_mid], -1)
perturb_rand = perturb * torch.rand(z_vals.shape, device=rays.device)
z_vals = lower + (upper - lower) * perturb_rand
xyz_coarse_sampled = rays_o.unsqueeze(1) + \
rays_d.unsqueeze(1) * z_vals.unsqueeze(2) # (N_rays, N_samples, 3)
if test_time:
weights_coarse = \
inference(model_coarse, embedding_xyz, xyz_coarse_sampled, rays_d,
dir_embedded, z_vals, weights_only=True)
result = {'opacity_coarse': weights_coarse.sum(1)}
else:
rgb_coarse, depth_coarse, weights_coarse = \
inference(model_coarse, embedding_xyz, xyz_coarse_sampled, rays_d,
dir_embedded, z_vals, weights_only=False)
result = {'rgb_coarse': rgb_coarse,
'depth_coarse': depth_coarse,
'opacity_coarse': weights_coarse.sum(1)
}
if N_importance > 0: # sample points for fine model
z_vals_mid = 0.5 * (z_vals[: ,:-1] + z_vals[: ,1:]) # (N_rays, N_samples-1) interval mid points
z_vals_ = sample_pdf(z_vals_mid, weights_coarse[:, 1:-1],
N_importance, det=(perturb==0)).detach()
# detach so that grad doesn't propogate to weights_coarse from here
z_vals, _ = torch.sort(torch.cat([z_vals, z_vals_], -1), -1)
xyz_fine_sampled = rays_o.unsqueeze(1) + \
rays_d.unsqueeze(1) * z_vals.unsqueeze(2)
# (N_rays, N_samples+N_importance, 3)
model_fine = models[1]
rgb_fine, depth_fine, weights_fine = \
inference(model_fine, embedding_xyz, xyz_fine_sampled, rays_d,
dir_embedded, z_vals, weights_only=False)
result['rgb_fine'] = rgb_fine
result['depth_fine'] = depth_fine
result['opacity_fine'] = weights_fine.sum(1)
return result
eval.py
这段代码是用于在给定的数据集上进行渲染和评估的。代码首先解析命令行参数,包括数据集路径、场景名称、分割数据集类型、图像分辨率等。
然后,根据参数初始化数据集对象,并初始化嵌入层和模型。使用预训练的checkpoint加载模型参数,并将模型移动到GPU上。
接下来,使用批处理方法对每个样本进行渲染和评估。首先从数据集中获取光线信息,并调用batched_inference函数对光线进行渲染。该函数使用模型和嵌入层对光线进行批处理渲染,并返回渲染结果。
然后将渲染结果保存为图像文件,并计算PSNR评估指标。
最后将渲染的图像序列保存为动态图像文件,并打印平均PSNR评估指标(如果有)。
总的来说,这段代码的作用是在给定的数据集上进行渲染和评估,并保存结果。
import torch
import os
import numpy as np
from collections import defaultdict
from tqdm import tqdm
import imageio
from argparse import ArgumentParser
from models.rendering import render_rays
from models.nerf import *
from utils import load_ckpt
import metrics
from datasets import dataset_dict
from datasets.depth_utils import *
torch.backends.cudnn.benchmark = True
def get_opts():
parser = ArgumentParser()
parser.add_argument('--root_dir', type=str,
default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
help='root directory of dataset')
parser.add_argument('--dataset_name', type=str, default='blender',
choices=['blender', 'llff'],
help='which dataset to validate')
parser.add_argument('--scene_name', type=str, default='test',
help='scene name, used as output folder name')
parser.add_argument('--split', type=str, default='test',
help='test or test_train')
parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
help='resolution (img_w, img_h) of the image')
parser.add_argument('--spheric_poses', default=False, action="store_true",
help='whether images are taken in spheric poses (for llff)')
parser.add_argument('--N_samples', type=int, default=64,
help='number of coarse samples')
parser.add_argument('--N_importance', type=int, default=128,
help='number of additional fine samples')
parser.add_argument('--use_disp', default=False, action="store_true",
help='use disparity depth sampling')
parser.add_argument('--chunk', type=int, default=32*1024*4,
help='chunk size to split the input to avoid OOM')
parser.add_argument('--ckpt_path', type=str, required=True,
help='pretrained checkpoint path to load')
parser.add_argument('--save_depth', default=False, action="store_true",
help='whether to save depth prediction')
parser.add_argument('--depth_format', type=str, default='pfm',
choices=['pfm', 'bytes'],
help='which format to save')
return parser.parse_args()
@torch.no_grad()
def batched_inference(models, embeddings,
rays, N_samples, N_importance, use_disp,
chunk,
white_back):
"""Do batched inference on rays using chunk."""
B = rays.shape[0]
chunk = 1024*32
results = defaultdict(list)
for i in range(0, B, chunk):
rendered_ray_chunks = \
render_rays(models,
embeddings,
rays[i:i+chunk],
N_samples,
use_disp,
0,
0,
N_importance,
chunk,
dataset.white_back,
test_time=True)
for k, v in rendered_ray_chunks.items():
results[k] += [v]
for k, v in results.items():
results[k] = torch.cat(v, 0)
return results
if __name__ == "__main__":
args = get_opts()
w, h = args.img_wh
kwargs = {'root_dir': args.root_dir,
'split': args.split,
'img_wh': tuple(args.img_wh)}
if args.dataset_name == 'llff':
kwargs['spheric_poses'] = args.spheric_poses
dataset = dataset_dict[args.dataset_name](**kwargs)
embedding_xyz = Embedding(3, 10)
embedding_dir = Embedding(3, 4)
nerf_coarse = NeRF()
nerf_fine = NeRF()
load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
nerf_coarse.cuda().eval()
nerf_fine.cuda().eval()
models = [nerf_coarse, nerf_fine]
embeddings = [embedding_xyz, embedding_dir]
imgs = []
psnrs = []
dir_name = f'results/{args.dataset_name}/{args.scene_name}'
os.makedirs(dir_name, exist_ok=True)
for i in tqdm(range(len(dataset))):
sample = dataset[i]
rays = sample['rays'].cuda()
results = batched_inference(models, embeddings, rays,
args.N_samples, args.N_importance, args.use_disp,
args.chunk,
dataset.white_back)
img_pred = results['rgb_fine'].view(h, w, 3).cpu().numpy()
if args.save_depth:
depth_pred = results['depth_fine'].view(h, w).cpu().numpy()
depth_pred = np.nan_to_num(depth_pred)
if args.depth_format == 'pfm':
save_pfm(os.path.join(dir_name, f'depth_{i:03d}.pfm'), depth_pred)
else:
with open(f'depth_{i:03d}', 'wb') as f:
f.write(depth_pred.tobytes())
img_pred_ = (img_pred*255).astype(np.uint8)
imgs += [img_pred_]
imageio.imwrite(os.path.join(dir_name, f'{i:03d}.png'), img_pred_)
if 'rgbs' in sample:
rgbs = sample['rgbs']
img_gt = rgbs.view(h, w, 3)
psnrs += [metrics.psnr(img_gt, img_pred).item()]
imageio.mimsave(os.path.join(dir_name, f'{args.scene_name}.gif'), imgs, fps=30)
if psnrs:
mean_psnr = np.mean(psnrs)
print(f'Mean PSNR : {mean_psnr:.2f}')
extract_color_mesh.py
(1)函数get_opts,该函数用于解析命令行参数并返回参数对象。
(2)函数f,用于对光线进行批处理的推理。
首先,通过@torch.no_grad()装饰器,表示在函数内部不需要计算梯度。
然后,根据输入的参数和模型,对光线进行批处理的推理。首先根据批处理的大小将光线分成若干个chunk,然后调用render_rays函数对每个chunk的光线进行渲染。渲染的结果保存在rendered_ray_chunks字典中。
接下来,将每个chunk的渲染结果按照键值进行合并,得到最终的渲染结果。
(3)接着生成和融合3D模型的颜色信息。
首先,根据命令行参数创建数据集对象。然后定义了两个嵌入层,分别用于表示3D点的空间坐标和方向。接下来创建了一个NeRF模型对象,并加载预训练模型。
然后,根据输入的参数和网格的大小,定义了一个密集的查询网格。通过调用嵌入层将网格点的空间坐标和方向进行嵌入,并将嵌入后的数据传递给NeRF模型进行预测。预测得到的结果包括光线的颜色和密度信息。
接下来,根据预测得到的密度信息,使用Marching Cubes算法提取出模型的顶点和三角面片。然后对顶点进行坐标变换,根据预定义的图像宽度、高度和相机内参将顶点转换为世界坐标系下的坐标。
接着,根据输入的参数,决定使用作者建议的法线向量方法还是自定义的颜色平均方法。如果使用法线向量方法,则根据顶点法线计算射线方向,并根据顶点和法线计算射线原点。然后将射线方向和原点数据传递给f函数进行批处理的渲染。如果使用颜色平均方法,则创建缓冲区来存储最终的颜色信息。
最后,根据渲染结果进行颜色融合。根据作者建议的方法,通过融合多个颜色样本,计算非遮挡颜色的平均值。如果使用自定义的颜色平均方法,则根据每个顶点的颜色样本计算颜色和。
(4)最后生成和融合3D模型的颜色信息。
首先,根据命令行参数创建数据集对象。然后定义了两个嵌入层,分别用于表示3D点的空间坐标和方向。接下来创建了一个NeRF模型对象,并加载预训练模型。
然后,根据输入的参数和网格的大小,定义了一个密集的查询网格。通过调用嵌入层将网格点的空间坐标和方向进行嵌入,并将嵌入后的数据传递给NeRF模型进行预测。预测得到的结果包括光线的颜色和密度信息。
接下来,根据预测得到的密度信息,使用Marching Cubes算法提取出模型的顶点和三角面片。然后对顶点进行坐标变换,根据预定义的图像宽度、高度和相机内参将顶点转换为世界坐标系下的坐标。
接着,根据输入的参数,决定使用作者建议的法线向量方法还是自定义的颜色平均方法。如果使用法线向量方法,则根据顶点法线计算射线方向,并根据顶点和法线计算射线原点。然后将射线方向和原点数据传递给f函数进行批处理的渲染。如果使用颜色平均方法,则创建缓冲区来存储最终的颜色信息。
最后,根据渲染结果进行颜色融合。根据作者建议的方法,通过融合多个颜色样本,计算非遮挡颜色的平均值。如果使用自定义的颜色平均方法,则根据每个顶点的颜色样本计算颜色和。
import torch
import os
import numpy as np
import cv2
from PIL import Image
from collections import defaultdict
from tqdm import tqdm
import mcubes
import open3d as o3d
from plyfile import PlyData, PlyElement
from argparse import ArgumentParser
from models.rendering import *
from models.nerf import *
from utils import load_ckpt
from datasets import dataset_dict
torch.backends.cudnn.benchmark = True
def get_opts():
parser = ArgumentParser()
parser.add_argument('--root_dir', type=str,
default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
help='root directory of dataset')
parser.add_argument('--dataset_name', type=str, default='blender',
choices=['blender', 'llff'],
help='which dataset to validate')
parser.add_argument('--scene_name', type=str, default='test',
help='scene name, used as output ply filename')
parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
help='resolution (img_w, img_h) of the image')
parser.add_argument('--N_samples', type=int, default=64,
help='number of samples to infer the acculmulated opacity')
parser.add_argument('--chunk', type=int, default=32*1024,
help='chunk size to split the input to avoid OOM')
parser.add_argument('--ckpt_path', type=str, required=True,
help='pretrained checkpoint path to load')
parser.add_argument('--N_grid', type=int, default=256,
help='size of the grid on 1 side, larger=higher resolution')
parser.add_argument('--x_range', nargs="+", type=float, default=[-1.0, 1.0],
help='x range of the object')
parser.add_argument('--y_range', nargs="+", type=float, default=[-1.0, 1.0],
help='x range of the object')
parser.add_argument('--z_range', nargs="+", type=float, default=[-1.0, 1.0],
help='x range of the object')
parser.add_argument('--sigma_threshold', type=float, default=20.0,
help='threshold to consider a location is occupied')
parser.add_argument('--occ_threshold', type=float, default=0.2,
help='''threshold to consider a vertex is occluded.
larger=fewer occluded pixels''')
#### method using vertex normals ####
parser.add_argument('--use_vertex_normal', action="store_true",
help='use vertex normals to compute color')
parser.add_argument('--N_importance', type=int, default=64,
help='number of fine samples to infer the acculmulated opacity')
parser.add_argument('--near_t', type=float, default=1.0,
help='the near bound factor to start the ray')
return parser.parse_args()
@torch.no_grad()
def f(models, embeddings, rays, N_samples, N_importance, chunk, white_back):
"""Do batched inference on rays using chunk."""
B = rays.shape[0]
results = defaultdict(list)
for i in range(0, B, chunk):
rendered_ray_chunks = \
render_rays(models,
embeddings,
rays[i:i+chunk],
N_samples,
False,
0,
0,
N_importance,
chunk,
white_back,
test_time=True)
for k, v in rendered_ray_chunks.items():
results[k] += [v]
for k, v in results.items():
results[k] = torch.cat(v, 0)
return results
if __name__ == "__main__":
args = get_opts()
kwargs = {'root_dir': args.root_dir,
'img_wh': tuple(args.img_wh)}
if args.dataset_name == 'llff':
kwargs['spheric_poses'] = True
kwargs['split'] = 'test'
else:
kwargs['split'] = 'train'
dataset = dataset_dict[args.dataset_name](**kwargs)
embedding_xyz = Embedding(3, 10)
embedding_dir = Embedding(3, 4)
embeddings = [embedding_xyz, embedding_dir]
nerf_fine = NeRF()
load_ckpt(nerf_fine, args.ckpt_path, model_name='nerf_fine')
nerf_fine.cuda().eval()
# define the dense grid for query
N = args.N_grid
xmin, xmax = args.x_range
ymin, ymax = args.y_range
zmin, zmax = args.z_range
# assert xmax-xmin == ymax-ymin == zmax-zmin, 'the ranges must have the same length!'
x = np.linspace(xmin, xmax, N)
y = np.linspace(ymin, ymax, N)
z = np.linspace(zmin, zmax, N)
xyz_ = torch.FloatTensor(np.stack(np.meshgrid(x, y, z), -1).reshape(-1, 3)).cuda()
dir_ = torch.zeros_like(xyz_).cuda()
# sigma is independent of direction, so any value here will produce the same result
# predict sigma (occupancy) for each grid location
print('Predicting occupancy ...')
with torch.no_grad():
B = xyz_.shape[0]
out_chunks = []
for i in tqdm(range(0, B, args.chunk)):
xyz_embedded = embedding_xyz(xyz_[i:i+args.chunk]) # (N, embed_xyz_channels)
dir_embedded = embedding_dir(dir_[i:i+args.chunk]) # (N, embed_dir_channels)
xyzdir_embedded = torch.cat([xyz_embedded, dir_embedded], 1)
out_chunks += [nerf_fine(xyzdir_embedded)]
rgbsigma = torch.cat(out_chunks, 0)
sigma = rgbsigma[:, -1].cpu().numpy()
sigma = np.maximum(sigma, 0).reshape(N, N, N)
# perform marching cube algorithm to retrieve vertices and triangle mesh
print('Extracting mesh ...')
vertices, triangles = mcubes.marching_cubes(sigma, args.sigma_threshold)
##### Until mesh extraction here, it is the same as the original repo. ######
vertices_ = (vertices/N).astype(np.float32)
## invert x and y coordinates (WHY? maybe because of the marching cubes algo)
x_ = (ymax-ymin) * vertices_[:, 1] + ymin
y_ = (xmax-xmin) * vertices_[:, 0] + xmin
vertices_[:, 0] = x_
vertices_[:, 1] = y_
vertices_[:, 2] = (zmax-zmin) * vertices_[:, 2] + zmin
vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
face['vertex_indices'] = triangles
PlyData([PlyElement.describe(vertices_[:, 0], 'vertex'),
PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
# remove noise in the mesh by keeping only the biggest cluster
print('Removing noise ...')
mesh = o3d.io.read_triangle_mesh(f"{args.scene_name}.ply")
idxs, count, _ = mesh.cluster_connected_triangles()
max_cluster_idx = np.argmax(count)
triangles_to_remove = [i for i in range(len(face)) if idxs[i] != max_cluster_idx]
mesh.remove_triangles_by_index(triangles_to_remove)
mesh.remove_unreferenced_vertices()
print(f'Mesh has {len(mesh.vertices)/1e6:.2f} M vertices and {len(mesh.triangles)/1e6:.2f} M faces.')
vertices_ = np.asarray(mesh.vertices).astype(np.float32)
triangles = np.asarray(mesh.triangles)
# perform color prediction
# Step 0. define constants (image width, height and intrinsics)
W, H = args.img_wh
K = np.array([[dataset.focal, 0, W/2],
[0, dataset.focal, H/2],
[0, 0, 1]]).astype(np.float32)
# Step 1. transform vertices into world coordinate
N_vertices = len(vertices_)
vertices_homo = np.concatenate([vertices_, np.ones((N_vertices, 1))], 1) # (N, 4)
if args.use_vertex_normal: ## use normal vector method as suggested by the author.
## see https://github.com/bmild/nerf/issues/44
mesh.compute_vertex_normals()
rays_d = torch.FloatTensor(np.asarray(mesh.vertex_normals))
near = dataset.bounds.min() * torch.ones_like(rays_d[:, :1])
far = dataset.bounds.max() * torch.ones_like(rays_d[:, :1])
rays_o = torch.FloatTensor(vertices_) - rays_d * near * args.near_t
nerf_coarse = NeRF()
load_ckpt(nerf_coarse, args.ckpt_path, model_name='nerf_coarse')
nerf_coarse.cuda().eval()
results = f([nerf_coarse, nerf_fine], embeddings,
torch.cat([rays_o, rays_d, near, far], 1).cuda(),
args.N_samples,
args.N_importance,
args.chunk,
dataset.white_back)
else: ## use my color average method. see README_mesh.md
## buffers to store the final averaged color
non_occluded_sum = np.zeros((N_vertices, 1))
v_color_sum = np.zeros((N_vertices, 3))
# Step 2. project the vertices onto each training image to infer the color
print('Fusing colors ...')
for idx in tqdm(range(len(dataset.image_paths))):
## read image of this pose
image = Image.open(dataset.image_paths[idx]).convert('RGB')
image = image.resize(tuple(args.img_wh), Image.LANCZOS)
image = np.array(image)
## read the camera to world relative pose
P_c2w = np.concatenate([dataset.poses[idx], np.array([0, 0, 0, 1]).reshape(1, 4)], 0)
P_w2c = np.linalg.inv(P_c2w)[:3] # (3, 4)
## project vertices from world coordinate to camera coordinate
vertices_cam = (P_w2c @ vertices_homo.T) # (3, N) in "right up back"
vertices_cam[1:] *= -1 # (3, N) in "right down forward"
## project vertices from camera coordinate to pixel coordinate
vertices_image = (K @ vertices_cam).T # (N, 3)
depth = vertices_image[:, -1:]+1e-5 # the depth of the vertices, used as far plane
vertices_image = vertices_image[:, :2]/depth
vertices_image = vertices_image.astype(np.float32)
vertices_image[:, 0] = np.clip(vertices_image[:, 0], 0, W-1)
vertices_image[:, 1] = np.clip(vertices_image[:, 1], 0, H-1)
## compute the color on these projected pixel coordinates
## using bilinear interpolation.
## NOTE: opencv's implementation has a size limit of 32768 pixels per side,
## so we split the input into chunks.
colors = []
remap_chunk = int(3e4)
for i in range(0, N_vertices, remap_chunk):
colors += [cv2.remap(image,
vertices_image[i:i+remap_chunk, 0],
vertices_image[i:i+remap_chunk, 1],
interpolation=cv2.INTER_LINEAR)[:, 0]]
colors = np.vstack(colors) # (N_vertices, 3)
## predict occlusion of each vertex
## we leverage the concept of NeRF by constructing rays coming out from the camera
## and hitting each vertex; by computing the accumulated opacity along this path,
## we can know if the vertex is occluded or not.
## for vertices that appear to be occluded from every input view, we make the
## assumption that its color is the same as its neighbors that are facing our side.
## (think of a surface with one side facing us: we assume the other side has the same color)
## ray's origin is camera origin
rays_o = torch.FloatTensor(dataset.poses[idx][:, -1]).expand(N_vertices, 3)
## ray's direction is the vector pointing from camera origin to the vertices
rays_d = torch.FloatTensor(vertices_) - rays_o # (N_vertices, 3)
rays_d = rays_d / torch.norm(rays_d, dim=-1, keepdim=True)
near = dataset.bounds.min() * torch.ones_like(rays_o[:, :1])
## the far plane is the depth of the vertices, since what we want is the accumulated
## opacity along the path from camera origin to the vertices
far = torch.FloatTensor(depth) * torch.ones_like(rays_o[:, :1])
results = f([nerf_fine], embeddings,
torch.cat([rays_o, rays_d, near, far], 1).cuda(),
args.N_samples,
0,
args.chunk,
dataset.white_back)
opacity = results['opacity_coarse'].cpu().numpy()[:, np.newaxis] # (N_vertices, 1)
opacity = np.nan_to_num(opacity, 1)
non_occluded = np.ones_like(non_occluded_sum) * 0.1/depth # weight by inverse depth
# near=more confident in color
non_occluded += opacity < args.occ_threshold
v_color_sum += colors * non_occluded
non_occluded_sum += non_occluded
# Step 3. combine the output and write to file
if args.use_vertex_normal:
v_colors = results['rgb_fine'].cpu().numpy() * 255.0
else: ## the combined color is the average color among all views
v_colors = v_color_sum/non_occluded_sum
v_colors = v_colors.astype(np.uint8)
v_colors.dtype = [('red', 'u1'), ('green', 'u1'), ('blue', 'u1')]
vertices_.dtype = [('x', 'f4'), ('y', 'f4'), ('z', 'f4')]
vertex_all = np.empty(N_vertices, vertices_.dtype.descr+v_colors.dtype.descr)
for prop in vertices_.dtype.names:
vertex_all[prop] = vertices_[prop][:, 0]
for prop in v_colors.dtype.names:
vertex_all[prop] = v_colors[prop][:, 0]
face = np.empty(len(triangles), dtype=[('vertex_indices', 'i4', (3,))])
face['vertex_indices'] = triangles
PlyData([PlyElement.describe(vertex_all, 'vertex'),
PlyElement.describe(face, 'face')]).write(f'{args.scene_name}.ply')
print('Done!')
loss.py
这段代码定义了一个自定义的MSELoss类,并将其添加到了一个名为loss_dict的字典中。该MSELoss类继承自nn.Module类,重写了forward函数,用于计算均方误差损失。
在构造函数中,通过调用父类的构造函数初始化MSELoss类,并将nn.MSELoss作为损失函数对象进行实例化。损失函数的reduction参数被设置为’mean’,表示返回的损失值是对所有元素求平均。
在forward函数中,首先计算输入inputs和目标targets之间的均方误差损失。如果inputs字典中包含键为’rgb_fine’的项,则继续计算输入inputs[‘rgb_fine’]和目标targets之间的均方误差损失,并将两个损失值相加。最终返回计算得到的总损失。
loss_dict字典是用于存储不同类型的损失函数,其中键为损失函数的名称,值为对应的损失函数类。这样可以方便地通过名称来获取对应的损失函数类,并进行实例化和使用。
class MSELoss(nn.Module):
def __init__(self):
super(MSELoss, self).__init__()
self.loss = nn.MSELoss(reduction='mean')
def forward(self, inputs, targets):
loss = self.loss(inputs['rgb_coarse'], targets)
if 'rgb_fine' in inputs:
loss += self.loss(inputs['rgb_fine'], targets)
return loss
loss_dict = {'mse': MSELoss}
metrics.py
这段代码定义了三个函数:mse、psnr和ssim,用于计算均方误差(MSE)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。
mse函数用于计算均方误差。给定预测图像image_pred和目标图像image_gt,通过将它们逐元素相减并平方,得到差的平方项。如果提供了有效掩码valid_mask,则仅考虑掩码为True的像素。最后,根据指定的减少(reduction)方式,返回平均值或未减少的值。
psnr函数用于计算峰值信噪比。通过调用mse函数计算均方误差,并使用-10乘以以10为底的对数将均方误差转换为分贝单位的峰值信噪比。返回的值越高,表示图像质量越好。
ssim函数用于计算结构相似性指数。使用了来自kornia库的ssim函数。该函数接受预测图像image_pred和目标图像image_gt,并返回一个范围在[0, 1]的相似性值。最后,将相似性值转换为[-1, 1]的范围,以与其他指标保持一致。
这些函数可以在计算机视觉任务中用于评估模型的性能和图像质量。
import torch
from kornia.losses import ssim as dssim
def mse(image_pred, image_gt, valid_mask=None, reduction='mean'):
value = (image_pred-image_gt)**2
if valid_mask is not None:
value = value[valid_mask]
if reduction == 'mean':
return torch.mean(value)
return value
def psnr(image_pred, image_gt, valid_mask=None, reduction='mean'):
return -10*torch.log10(mse(image_pred, image_gt, valid_mask, reduction))
def ssim(image_pred, image_gt, reduction='mean'):
"""
image_pred and image_gt: (1, 3, H, W)
"""
dssim_ = dssim(image_pred, image_gt, 3, reduction) # dissimilarity in [0, 1]
return 1-2*dssim_ # in [-1, 1]
get_opts.py
定义命令参数
import argparse
def get_opts():
parser = argparse.ArgumentParser()
parser.add_argument('--root_dir', type=str,
default='/home/ubuntu/data/nerf_example_data/nerf_synthetic/lego',
help='root directory of dataset')
parser.add_argument('--dataset_name', type=str, default='blender',
choices=['blender', 'llff'],
help='which dataset to train/val')
parser.add_argument('--img_wh', nargs="+", type=int, default=[800, 800],
help='resolution (img_w, img_h) of the image')
parser.add_argument('--spheric_poses', default=False, action="store_true",
help='whether images are taken in spheric poses (for llff)')
parser.add_argument('--N_samples', type=int, default=64,
help='number of coarse samples')
parser.add_argument('--N_importance', type=int, default=128,
help='number of additional fine samples')
parser.add_argument('--use_disp', default=False, action="store_true",
help='use disparity depth sampling')
parser.add_argument('--perturb', type=float, default=1.0,
help='factor to perturb depth sampling points')
parser.add_argument('--noise_std', type=float, default=1.0,
help='std dev of noise added to regularize sigma')
parser.add_argument('--loss_type', type=str, default='mse',
choices=['mse'],
help='loss to use')
parser.add_argument('--batch_size', type=int, default=1024,
help='batch size')
parser.add_argument('--chunk', type=int, default=32*1024,
help='chunk size to split the input to avoid OOM')
parser.add_argument('--num_epochs', type=int, default=16,
help='number of training epochs')
parser.add_argument('--num_gpus', type=int, default=1,
help='number of gpus')
parser.add_argument('--ckpt_path', type=str, default=None,
help='pretrained checkpoint path to load')
parser.add_argument('--prefixes_to_ignore', nargs='+', type=str, default=['loss'],
help='the prefixes to ignore in the checkpoint state dict')
parser.add_argument('--optimizer', type=str, default='adam',
help='optimizer type',
choices=['sgd', 'adam', 'radam', 'ranger'])
parser.add_argument('--lr', type=float, default=5e-4,
help='learning rate')
parser.add_argument('--momentum', type=float, default=0.9,
help='learning rate momentum')
parser.add_argument('--weight_decay', type=float, default=0,
help='weight decay')
parser.add_argument('--lr_scheduler', type=str, default='steplr',
help='scheduler type',
choices=['steplr', 'cosine', 'poly'])
#### params for warmup, only applied when optimizer == 'sgd' or 'adam'
parser.add_argument('--warmup_multiplier', type=float, default=1.0,
help='lr is multiplied by this factor after --warmup_epochs')
parser.add_argument('--warmup_epochs', type=int, default=0,
help='Gradually warm-up(increasing) learning rate in optimizer')
###########################
#### params for steplr ####
parser.add_argument('--decay_step', nargs='+', type=int, default=[20],
help='scheduler decay step')
parser.add_argument('--decay_gamma', type=float, default=0.1,
help='learning rate decay amount')
###########################
#### params for poly ####
parser.add_argument('--poly_exp', type=float, default=0.9,
help='exponent for polynomial learning rate decay')
###########################
parser.add_argument('--exp_name', type=str, default='exp',
help='experiment name')
return parser.parse_args()
train.py
这段代码用于训练和评估NeRF模型。
NeRFSystem类是一个继承自LightningModule的类,用于定义NeRF模型的训练和评估过程。在__init__方法中,定义了NeRF模型的各个组件,如嵌入层、编码器和解码器等。在forward方法中,实现了对输入光线的批量推理。prepare_data方法用于准备训练和验证数据集。
configure_optimizers方法用于定义优化器和学习率调度器。在训练过程中,使用train_dataloader方法加载训练数据集,并使用training_step方法计算损失和指标。在验证过程中,使用val_dataloader方法加载验证数据集,并使用validation_step方法计算验证指标。validation_epoch_end方法用于计算验证集的平均损失和指标。
在if name == ‘main’:代码块中,首先通过get_opts函数获取命令行参数。然后创建NeRFSystem对象和ModelCheckpoint回调函数,用于保存训练过程中的最佳模型。接下来创建TestTubeLogger对象,用于保存训练日志。最后,创建Trainer对象并调用其fit方法开始训练。
import os, sys
from opt import get_opts
import torch
from collections import defaultdict
from torch.utils.data import DataLoader
from datasets import dataset_dict
# models
from models.nerf import Embedding, NeRF
from models.rendering import render_rays
# optimizer, scheduler, visualization
from utils import *
# losses
from losses import loss_dict
# metrics
from metrics import *
# pytorch-lightning
from pytorch_lightning.callbacks import ModelCheckpoint
from pytorch_lightning import LightningModule, Trainer
from pytorch_lightning.logging import TestTubeLogger
class NeRFSystem(LightningModule):
def __init__(self, hparams):
super(NeRFSystem, self).__init__()
self.hparams = hparams
self.loss = loss_dict[hparams.loss_type]()
self.embedding_xyz = Embedding(3, 10) # 10 is the default number
self.embedding_dir = Embedding(3, 4) # 4 is the default number
self.embeddings = [self.embedding_xyz, self.embedding_dir]
self.nerf_coarse = NeRF()
self.models = [self.nerf_coarse]
if hparams.N_importance > 0:
self.nerf_fine = NeRF()
self.models += [self.nerf_fine]
def decode_batch(self, batch):
rays = batch['rays'] # (B, 8)
rgbs = batch['rgbs'] # (B, 3)
return rays, rgbs
def forward(self, rays):
"""Do batched inference on rays using chunk."""
B = rays.shape[0]
results = defaultdict(list)
for i in range(0, B, self.hparams.chunk):
rendered_ray_chunks = \
render_rays(self.models,
self.embeddings,
rays[i:i+self.hparams.chunk],
self.hparams.N_samples,
self.hparams.use_disp,
self.hparams.perturb,
self.hparams.noise_std,
self.hparams.N_importance,
self.hparams.chunk, # chunk size is effective in val mode
self.train_dataset.white_back)
for k, v in rendered_ray_chunks.items():
results[k] += [v]
for k, v in results.items():
results[k] = torch.cat(v, 0)
return results
def prepare_data(self):
dataset = dataset_dict[self.hparams.dataset_name]
kwargs = {'root_dir': self.hparams.root_dir,
'img_wh': tuple(self.hparams.img_wh)}
if self.hparams.dataset_name == 'llff':
kwargs['spheric_poses'] = self.hparams.spheric_poses
kwargs['val_num'] = self.hparams.num_gpus
self.train_dataset = dataset(split='train', **kwargs)
self.val_dataset = dataset(split='val', **kwargs)
def configure_optimizers(self):
self.optimizer = get_optimizer(self.hparams, self.models)
scheduler = get_scheduler(self.hparams, self.optimizer)
return [self.optimizer], [scheduler]
def train_dataloader(self):
return DataLoader(self.train_dataset,
shuffle=True,
num_workers=4,
batch_size=self.hparams.batch_size,
pin_memory=True)
def val_dataloader(self):
return DataLoader(self.val_dataset,
shuffle=False,
num_workers=4,
batch_size=1, # validate one image (H*W rays) at a time
pin_memory=True)
def training_step(self, batch, batch_nb):
log = {'lr': get_learning_rate(self.optimizer)}
rays, rgbs = self.decode_batch(batch)
results = self(rays)
log['train/loss'] = loss = self.loss(results, rgbs)
typ = 'fine' if 'rgb_fine' in results else 'coarse'
with torch.no_grad():
psnr_ = psnr(results[f'rgb_{typ}'], rgbs)
log['train/psnr'] = psnr_
return {'loss': loss,
'progress_bar': {'train_psnr': psnr_},
'log': log
}
def validation_step(self, batch, batch_nb):
rays, rgbs = self.decode_batch(batch)
rays = rays.squeeze() # (H*W, 3)
rgbs = rgbs.squeeze() # (H*W, 3)
results = self(rays)
log = {'val_loss': self.loss(results, rgbs)}
typ = 'fine' if 'rgb_fine' in results else 'coarse'
if batch_nb == 0:
W, H = self.hparams.img_wh
img = results[f'rgb_{typ}'].view(H, W, 3).cpu()
img = img.permute(2, 0, 1) # (3, H, W)
img_gt = rgbs.view(H, W, 3).permute(2, 0, 1).cpu() # (3, H, W)
depth = visualize_depth(results[f'depth_{typ}'].view(H, W)) # (3, H, W)
stack = torch.stack([img_gt, img, depth]) # (3, 3, H, W)
self.logger.experiment.add_images('val/GT_pred_depth',
stack, self.global_step)
log['val_psnr'] = psnr(results[f'rgb_{typ}'], rgbs)
return log
def validation_epoch_end(self, outputs):
mean_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
mean_psnr = torch.stack([x['val_psnr'] for x in outputs]).mean()
return {'progress_bar': {'val_loss': mean_loss,
'val_psnr': mean_psnr},
'log': {'val/loss': mean_loss,
'val/psnr': mean_psnr}
}
if __name__ == '__main__':
hparams = get_opts()
system = NeRFSystem(hparams)
checkpoint_callback = ModelCheckpoint(filepath=os.path.join(f'ckpts/{hparams.exp_name}',
'{epoch:d}'),
monitor='val/loss',
mode='min',
save_top_k=1,)
logger = TestTubeLogger(
save_dir="logs",
name=hparams.exp_name,
debug=False,
create_git_tag=False
)
trainer = Trainer(max_epochs=hparams.num_epochs,
checkpoint_callback=checkpoint_callback,
resume_from_checkpoint=hparams.ckpt_path,
logger=logger,
early_stop_callback=None,
weights_summary=None,
progress_bar_refresh_rate=1,
gpus=hparams.num_gpus,
distributed_backend='ddp' if hparams.num_gpus>1 else None,
num_sanity_val_steps=1,
benchmark=True,
profiler=hparams.num_gpus==1)
trainer.fit(system)
optimizers.py
这段代码是定义了几个优化算法的类,包括RAdam、PlainRAdam和AdamW。这些优化算法都是用于神经网络训练中的优化方法。
RAdam是一种基于Adam的优化算法,它在Adam的基础上做了一些改进,使得训练更加稳定和高效。
PlainRAdam是RAdam的一个简化版本,去掉了一些不必要的计算。
AdamW是一种基于Adam的带权重衰减的优化算法,它在Adam的基础上添加了一个权重衰减项,可以控制模型的复杂度。
import math
import torch
from torch.optim.optimizer import Optimizer, required
import itertools as it
class RAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=True):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
self.degenerated_to_sgd = degenerated_to_sgd
if isinstance(params, (list, tuple)) and len(params) > 0 and isinstance(params[0], dict):
for param in params:
if 'betas' in param and (param['betas'][0] != betas[0] or param['betas'][1] != betas[1]):
param['buffer'] = [[None, None, None] for _ in range(10)]
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay, buffer=[[None, None, None] for _ in range(10)])
super(RAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(RAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('RAdam does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = group['buffer'][int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
# more conservative since it's an approximated value
if N_sma >= 5:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
elif self.degenerated_to_sgd:
step_size = 1.0 / (1 - beta1 ** state['step'])
else:
step_size = -1
buffered[2] = step_size
# more conservative since it's an approximated value
if N_sma >= 5:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
p.data.copy_(p_data_fp32)
elif step_size > 0:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
return loss
class PlainRAdam(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, degenerated_to_sgd=True):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
self.degenerated_to_sgd = degenerated_to_sgd
defaults = dict(lr=lr, betas=betas, eps=eps, weight_decay=weight_decay)
super(PlainRAdam, self).__init__(params, defaults)
def __setstate__(self, state):
super(PlainRAdam, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('RAdam does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
# more conservative since it's an approximated value
if N_sma >= 5:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
step_size = group['lr'] * math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size, exp_avg, denom)
p.data.copy_(p_data_fp32)
elif self.degenerated_to_sgd:
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
step_size = group['lr'] / (1 - beta1 ** state['step'])
p_data_fp32.add_(-step_size, exp_avg)
p.data.copy_(p_data_fp32)
return loss
class AdamW(Optimizer):
def __init__(self, params, lr=1e-3, betas=(0.9, 0.999), eps=1e-8, weight_decay=0, warmup = 0):
if not 0.0 <= lr:
raise ValueError("Invalid learning rate: {}".format(lr))
if not 0.0 <= eps:
raise ValueError("Invalid epsilon value: {}".format(eps))
if not 0.0 <= betas[0] < 1.0:
raise ValueError("Invalid beta parameter at index 0: {}".format(betas[0]))
if not 0.0 <= betas[1] < 1.0:
raise ValueError("Invalid beta parameter at index 1: {}".format(betas[1]))
defaults = dict(lr=lr, betas=betas, eps=eps,
weight_decay=weight_decay, warmup = warmup)
super(AdamW, self).__init__(params, defaults)
def __setstate__(self, state):
super(AdamW, self).__setstate__(state)
def step(self, closure=None):
loss = None
if closure is not None:
loss = closure()
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Adam does not support sparse gradients, please consider SparseAdam instead')
p_data_fp32 = p.data.float()
state = self.state[p]
if len(state) == 0:
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
state['step'] += 1
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
exp_avg.mul_(beta1).add_(1 - beta1, grad)
denom = exp_avg_sq.sqrt().add_(group['eps'])
bias_correction1 = 1 - beta1 ** state['step']
bias_correction2 = 1 - beta2 ** state['step']
if group['warmup'] > state['step']:
scheduled_lr = 1e-8 + state['step'] * group['lr'] / group['warmup']
else:
scheduled_lr = group['lr']
step_size = scheduled_lr * math.sqrt(bias_correction2) / bias_correction1
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * scheduled_lr, p_data_fp32)
p_data_fp32.addcdiv_(-step_size, exp_avg, denom)
p.data.copy_(p_data_fp32)
return loss
#Ranger deep learning optimizer - RAdam + Lookahead combined.
#https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer
#Ranger has now been used to capture 12 records on the FastAI leaderboard.
#This version = 9.3.19
#Credits:
#RAdam --> https://github.com/LiyuanLucasLiu/RAdam
#Lookahead --> rewritten by lessw2020, but big thanks to Github @LonePatient and @RWightman for ideas from their code.
#Lookahead paper --> MZhang,G Hinton https://arxiv.org/abs/1907.08610
#summary of changes:
#full code integration with all updates at param level instead of group, moves slow weights into state dict (from generic weights),
#supports group learning rates (thanks @SHolderbach), fixes sporadic load from saved model issues.
#changes 8/31/19 - fix references to *self*.N_sma_threshold;
#changed eps to 1e-5 as better default than 1e-8.
class Ranger(Optimizer):
def __init__(self, params, lr=1e-3, alpha=0.5, k=6, N_sma_threshhold=5, betas=(.95, 0.999), eps=1e-5, weight_decay=0):
#parameter checks
if not 0.0 <= alpha <= 1.0:
raise ValueError(f'Invalid slow update rate: {alpha}')
if not 1 <= k:
raise ValueError(f'Invalid lookahead steps: {k}')
if not lr > 0:
raise ValueError(f'Invalid Learning Rate: {lr}')
if not eps > 0:
raise ValueError(f'Invalid eps: {eps}')
#parameter comments:
# beta1 (momentum) of .95 seems to work better than .90...
#N_sma_threshold of 5 seems better in testing than 4.
#In both cases, worth testing on your dataset (.90 vs .95, 4 vs 5) to make sure which works best for you.
#prep defaults and init torch.optim base
defaults = dict(lr=lr, alpha=alpha, k=k, step_counter=0, betas=betas, N_sma_threshhold=N_sma_threshhold, eps=eps, weight_decay=weight_decay)
super().__init__(params,defaults)
#adjustable threshold
self.N_sma_threshhold = N_sma_threshhold
#now we can get to work...
#removed as we now use step from RAdam...no need for duplicate step counting
#for group in self.param_groups:
# group["step_counter"] = 0
#print("group step counter init")
#look ahead params
self.alpha = alpha
self.k = k
#radam buffer for state
self.radam_buffer = [[None,None,None] for ind in range(10)]
#self.first_run_check=0
#lookahead weights
#9/2/19 - lookahead param tensors have been moved to state storage.
#This should resolve issues with load/save where weights were left in GPU memory from first load, slowing down future runs.
#self.slow_weights = [[p.clone().detach() for p in group['params']]
# for group in self.param_groups]
#don't use grad for lookahead weights
#for w in it.chain(*self.slow_weights):
# w.requires_grad = False
def __setstate__(self, state):
print("set state called")
super(Ranger, self).__setstate__(state)
def step(self, closure=None):
loss = None
#note - below is commented out b/c I have other work that passes back the loss as a float, and thus not a callable closure.
#Uncomment if you need to use the actual closure...
#if closure is not None:
#loss = closure()
#Evaluate averages and grad, update param tensors
for group in self.param_groups:
for p in group['params']:
if p.grad is None:
continue
grad = p.grad.data.float()
if grad.is_sparse:
raise RuntimeError('Ranger optimizer does not support sparse gradients')
p_data_fp32 = p.data.float()
state = self.state[p] #get state dict for this param
if len(state) == 0: #if first time to run...init dictionary with our desired entries
#if self.first_run_check==0:
#self.first_run_check=1
#print("Initializing slow buffer...should not see this at load from saved model!")
state['step'] = 0
state['exp_avg'] = torch.zeros_like(p_data_fp32)
state['exp_avg_sq'] = torch.zeros_like(p_data_fp32)
#look ahead weight storage now in state dict
state['slow_buffer'] = torch.empty_like(p.data)
state['slow_buffer'].copy_(p.data)
else:
state['exp_avg'] = state['exp_avg'].type_as(p_data_fp32)
state['exp_avg_sq'] = state['exp_avg_sq'].type_as(p_data_fp32)
#begin computations
exp_avg, exp_avg_sq = state['exp_avg'], state['exp_avg_sq']
beta1, beta2 = group['betas']
#compute variance mov avg
exp_avg_sq.mul_(beta2).addcmul_(1 - beta2, grad, grad)
#compute mean moving avg
exp_avg.mul_(beta1).add_(1 - beta1, grad)
state['step'] += 1
buffered = self.radam_buffer[int(state['step'] % 10)]
if state['step'] == buffered[0]:
N_sma, step_size = buffered[1], buffered[2]
else:
buffered[0] = state['step']
beta2_t = beta2 ** state['step']
N_sma_max = 2 / (1 - beta2) - 1
N_sma = N_sma_max - 2 * state['step'] * beta2_t / (1 - beta2_t)
buffered[1] = N_sma
if N_sma > self.N_sma_threshhold:
step_size = math.sqrt((1 - beta2_t) * (N_sma - 4) / (N_sma_max - 4) * (N_sma - 2) / N_sma * N_sma_max / (N_sma_max - 2)) / (1 - beta1 ** state['step'])
else:
step_size = 1.0 / (1 - beta1 ** state['step'])
buffered[2] = step_size
if group['weight_decay'] != 0:
p_data_fp32.add_(-group['weight_decay'] * group['lr'], p_data_fp32)
if N_sma > self.N_sma_threshhold:
denom = exp_avg_sq.sqrt().add_(group['eps'])
p_data_fp32.addcdiv_(-step_size * group['lr'], exp_avg, denom)
else:
p_data_fp32.add_(-step_size * group['lr'], exp_avg)
p.data.copy_(p_data_fp32)
#integrated look ahead...
#we do it at the param level instead of group level
if state['step'] % group['k'] == 0:
slow_p = state['slow_buffer'] #get access to slow param tensor
slow_p.add_(self.alpha, p.data - slow_p) #(fast weights - slow weights) * alpha
p.data.copy_(slow_p) #copy interpolated weights to RAdam param tensor
return loss
save_wights_only.py
将指定路径下的PyTorch模型加载到内存中,并将模型的参数保存为一个新的文件。
import torch
import argparse
def get_opts():
parser = argparse.ArgumentParser()
parser.add_argument('--ckpt_path', type=str, required=True,
help='checkpoint path')
return parser.parse_args()
if __name__ == "__main__":
args = get_opts()
checkpoint = torch.load(args.ckpt_path, map_location=torch.device('cpu'))
torch.save(checkpoint['state_dict'], args.ckpt_path.split('/')[-2]+'.ckpt')
print('Done!')
visualization.py
定义了一个名为visualize_depth的函数,用于可视化深度图。
import torchvision.transforms as T
import numpy as np
import cv2
from PIL import Image
def visualize_depth(depth, cmap=cv2.COLORMAP_JET):
"""
depth: (H, W)
"""
x = depth.cpu().numpy()
x = np.nan_to_num(x) # change nan to 0
mi = np.min(x) # get minimum depth
ma = np.max(x)
x = (x-mi)/(ma-mi+1e-8) # normalize to 0~1
x = (255*x).astype(np.uint8)
x_ = Image.fromarray(cv2.applyColorMap(x, cmap))
x_ = T.ToTensor()(x_) # (3, H, W)
return x_
warmup_scheduler.py
定义了一个名为GradualWarmupScheduler的自定义学习率调度器类,用于在优化器中逐渐增加学习率(warm-up)
from torch.optim.lr_scheduler import _LRScheduler
from torch.optim.lr_scheduler import ReduceLROnPlateau
class GradualWarmupScheduler(_LRScheduler):
""" Gradually warm-up(increasing) learning rate in optimizer.
Proposed in 'Accurate, Large Minibatch SGD: Training ImageNet in 1 Hour'.
Args:
optimizer (Optimizer): Wrapped optimizer.
multiplier: target learning rate = base lr * multiplier
total_epoch: target learning rate is reached at total_epoch, gradually
after_scheduler: after target_epoch, use this scheduler(eg. ReduceLROnPlateau)
"""
def __init__(self, optimizer, multiplier, total_epoch, after_scheduler=None):
self.multiplier = multiplier
if self.multiplier < 1.:
raise ValueError('multiplier should be greater thant or equal to 1.')
self.total_epoch = total_epoch
self.after_scheduler = after_scheduler
self.finished = False
super().__init__(optimizer)
def get_lr(self):
if self.last_epoch > self.total_epoch:
if self.after_scheduler:
if not self.finished:
self.after_scheduler.base_lrs = [base_lr * self.multiplier for base_lr in self.base_lrs]
self.finished = True
return self.after_scheduler.get_lr()
return [base_lr * self.multiplier for base_lr in self.base_lrs]
return [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
def step_ReduceLROnPlateau(self, metrics, epoch=None):
if epoch is None:
epoch = self.last_epoch + 1
self.last_epoch = epoch if epoch != 0 else 1 # ReduceLROnPlateau is called at the end of epoch, whereas others are called at beginning
if self.last_epoch <= self.total_epoch:
warmup_lr = [base_lr * ((self.multiplier - 1.) * self.last_epoch / self.total_epoch + 1.) for base_lr in self.base_lrs]
for param_group, lr in zip(self.optimizer.param_groups, warmup_lr):
param_group['lr'] = lr
else:
if epoch is None:
self.after_scheduler.step(metrics, None)
else:
self.after_scheduler.step(metrics, epoch - self.total_epoch)
def step(self, epoch=None, metrics=None):
if type(self.after_scheduler) != ReduceLROnPlateau:
if self.finished and self.after_scheduler:
if epoch is None:
self.after_scheduler.step(None)
else:
self.after_scheduler.step(epoch - self.total_epoch)
else:
return super(GradualWarmupScheduler, self).step(epoch)
else:
self.step_ReduceLROnPlateau(metrics, epoch)