每日Attention学习19——Convolutional Multi-Focal Attention
模块出处
[ICLR 25 Submission] [link] UltraLightUNet: Rethinking U-shaped Network with Multi-kernel Lightweight Convolutions for Medical Image Segmentation
模块名称
Convolutional Multi-Focal Attention (CMFA)
模块作用
轻量解码器
模块结构
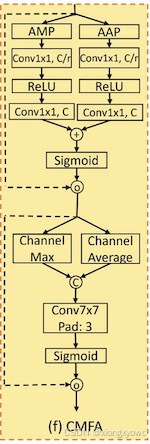
模块特点
- 使用最大池化与平均池化构建通道注意力
- 使用Channel Max与Channel Average构建空间注意力
- 核心思想与CBAM较为类似,串联通道注意力与空间注意力
模块代码
import torch
import torch.nn as nn
import torch.nn.functional as F
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7, 11), 'kernel size must be 3 or 7 or 11'
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_out = torch.mean(x, dim=1, keepdim=True)
max_out, _ = torch.max(x, dim=1, keepdim=True)
x = torch.cat([avg_out, max_out], dim=1)
x = self.conv(x)
return self.sigmoid(x)
class ChannelAttention(nn.Module):
def __init__(self, in_planes, out_planes=None, ratio=16):
super(ChannelAttention, self).__init__()
self.in_planes = in_planes
self.out_planes = out_planes
if self.in_planes < ratio:
ratio = self.in_planes
self.reduced_channels = self.in_planes // ratio
if self.out_planes == None:
self.out_planes = in_planes
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.activation = nn.ReLU(inplace=True)
self.fc1 = nn.Conv2d(in_planes, self.reduced_channels, 1, bias=False)
self.fc2 = nn.Conv2d(self.reduced_channels, self.out_planes, 1, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_pool_out = self.avg_pool(x)
avg_out = self.fc2(self.activation(self.fc1(avg_pool_out)))
max_pool_out= self.max_pool(x)
max_out = self.fc2(self.activation(self.fc1(max_pool_out)))
out = avg_out + max_out
return self.sigmoid(out)
class CMFA(nn.Module):
def __init__(self, in_planes, out_planes=None,):
super(CMFA, self).__init__()
self.ca = ChannelAttention(in_planes=64, out_planes=64)
self.sa = SpatialAttention()
def forward(self, x):
x = x*self.ca(x)
x = x*self.sa(x)
return x
if __name__ == '__main__':
x = torch.randn([1, 64, 44, 44])
cmfa = CMFA(in_planes=64, out_planes=64)
out = cmfa(x)
print(out.shape) # [1, 64, 44, 44]