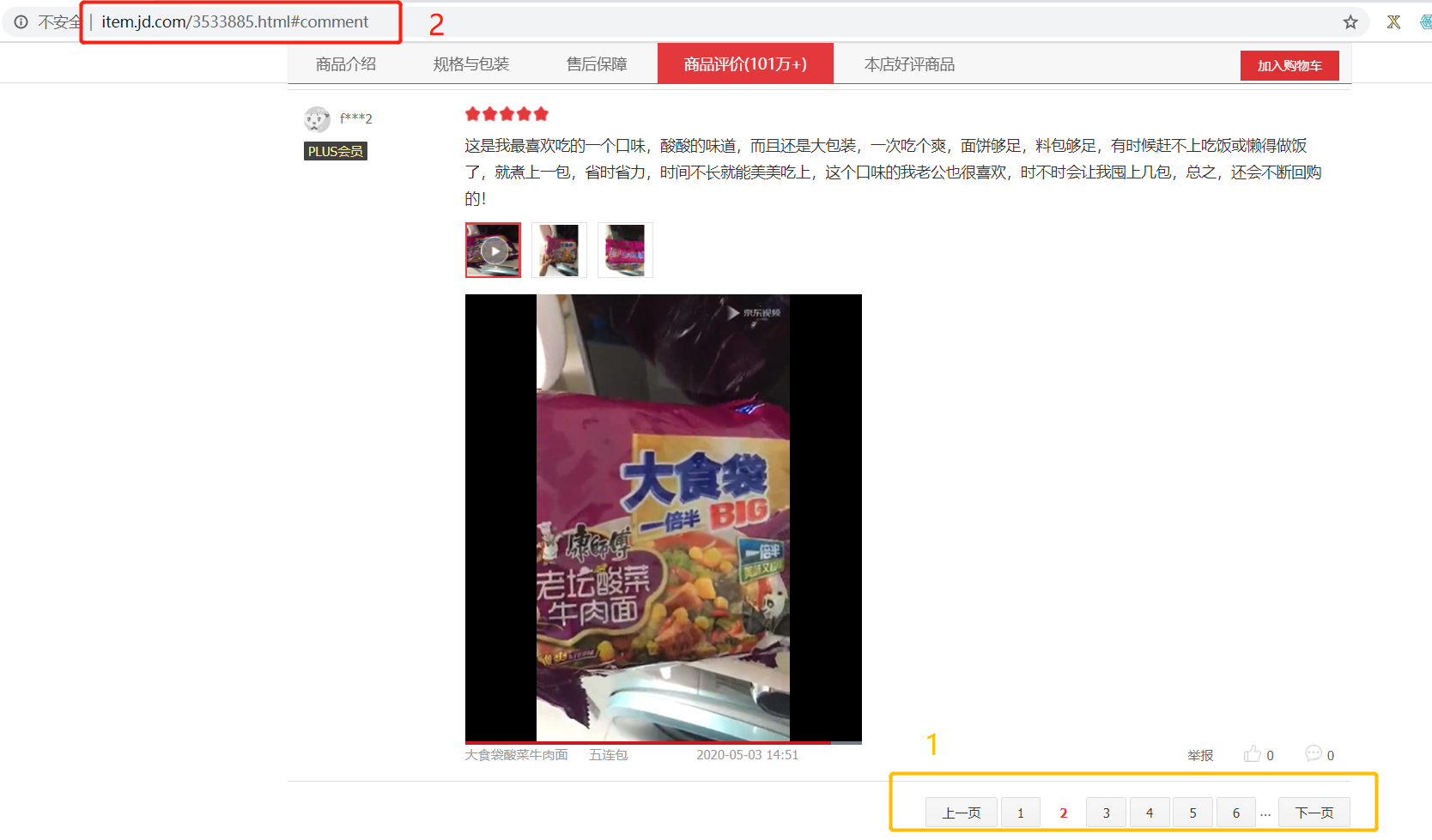
随便点击一个商品,我点的是“https://item.jd.com/3533885.html”
查看评论是否动态数据:点击改变评论页数(图中1处),网址(图中2处)不会变,说明是动态数据
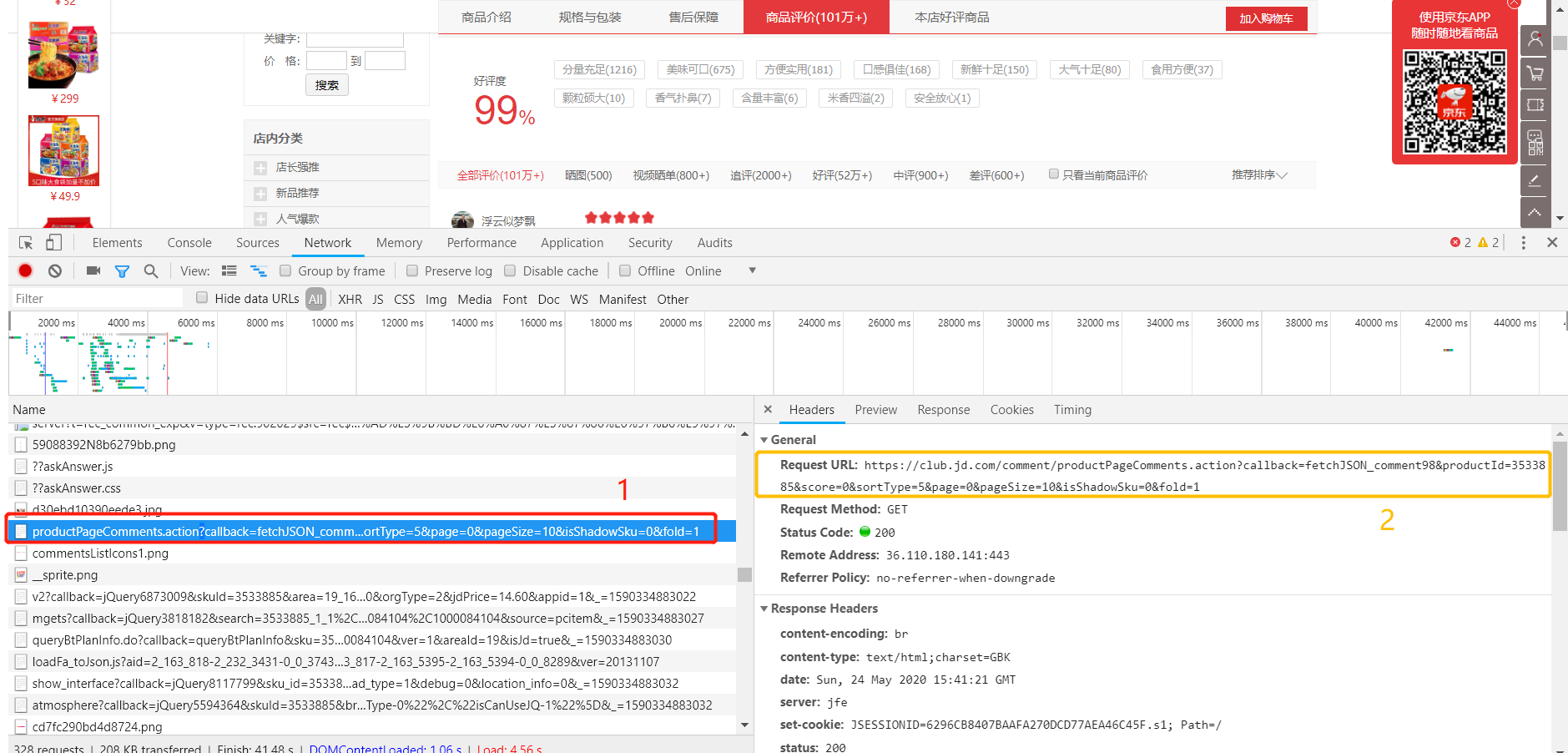
F12(或者右击检查网页源代码)->点击“Network”->F5(或ctrl+R)
点击网页“商品评价”
找到途中1,点击,复制2url:“https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=3533885&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1”
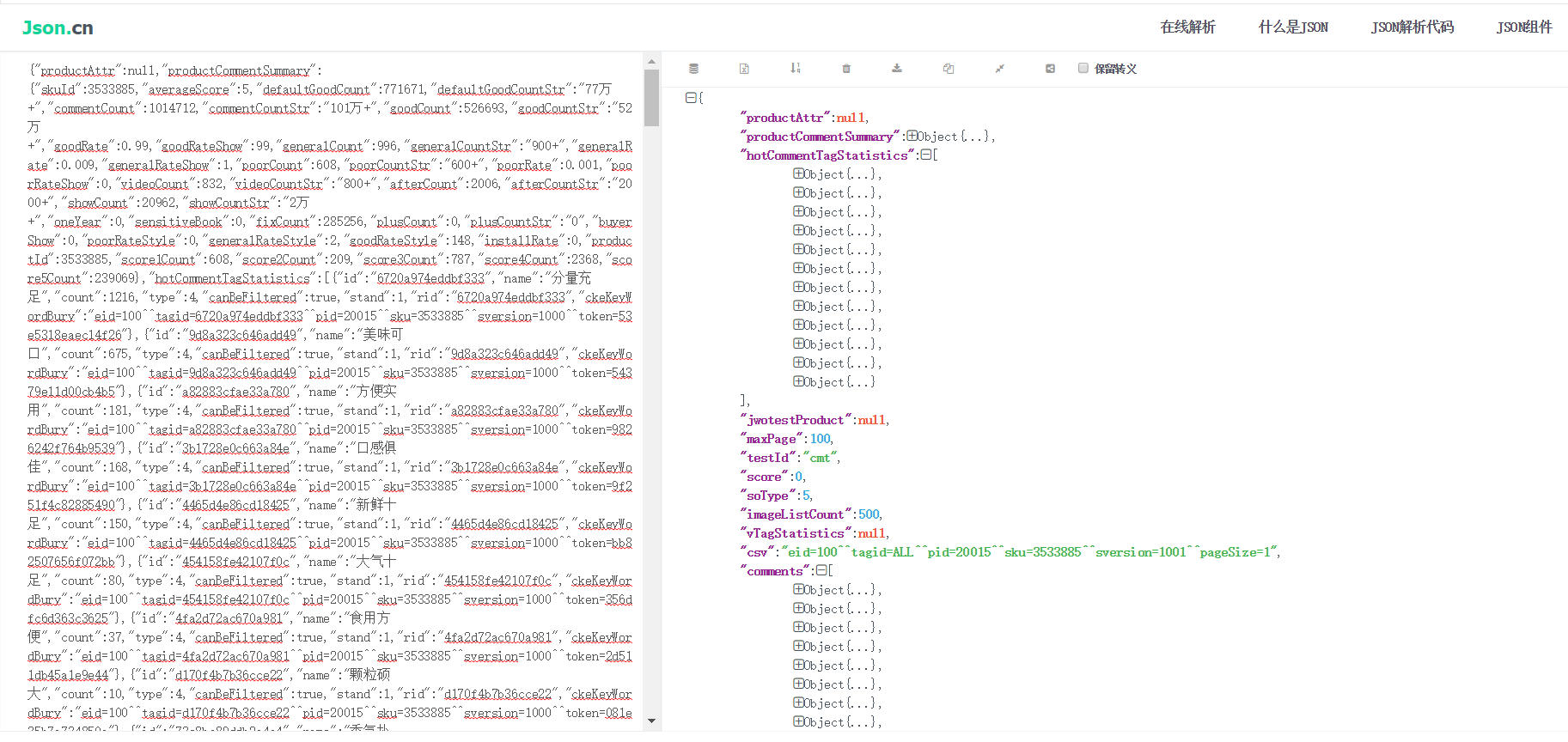
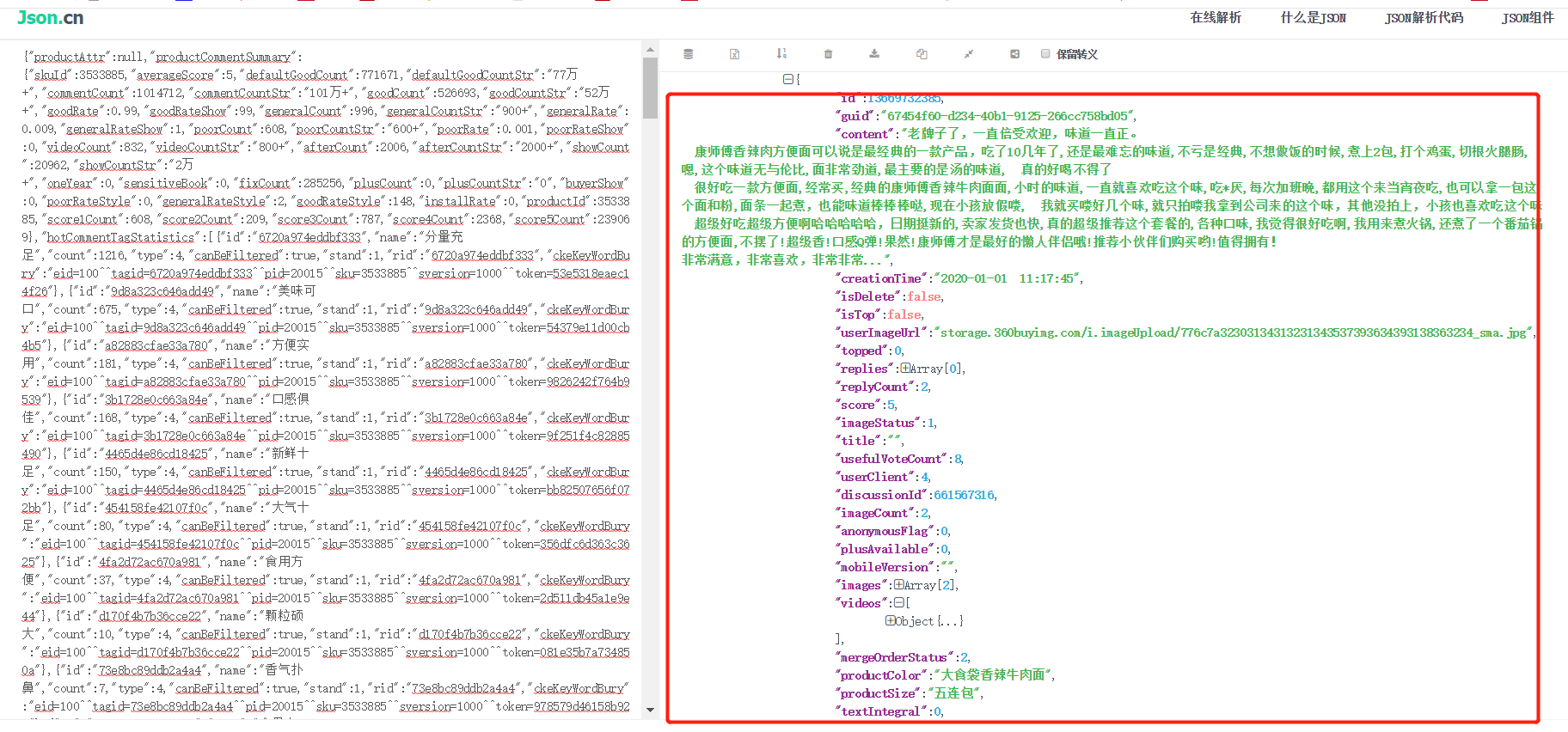
打开查看是否评论区的json数据:
把整个网页复制到“http://json.cn/”,删除前面的“fetchJSON_comment98(”和后面的“);”
就能更清晰的看出数据:

1.获取评论区的json数据
import requests
url='https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId=3533885&score=0&sortType=5&page=0&pageSize=10&isShadowSku=0&fold=1'
resp=requests.get(url)
print(resp.text)
2.获取商品评论的最大页数(根据商品编号)
import requests
import json
def get_comments(productId,page):
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(
productId, page)
resp=requests.get(url)
#print(resp.text)
s = resp.text.replace('fetchJSON_comment98(', '')
s = s.replace(');', '')
#将str类型的数据转成json格式的数据
json_data=json.loads(s)
return json_data
#获取最大页数
def get_max_page(productId):
dic_data=get_comments(productId,0) #调用get_comments函数,向服务器发送请求,获取字典数据
return dic_data['maxPage']
if __name__ == '__main__':
productId="3533885"
print(get_max_page(productId))
100
3.根据json数据确定自己要获取的数据
import requests
import json
import time
import openpyxl #用于操作Excel文件的
def get_comments(productId,page):
url = 'https://club.jd.com/comment/productPageComments.action?callback=fetchJSON_comment98&productId={0}&score=0&sortType=5&page={1}&pageSize=10&isShadowSku=0&fold=1'.format(
productId, page)
resp=requests.get(url)
#print(resp.text)
s = resp.text.replace('fetchJSON_comment98(', '')
s = s.replace(');', '')
#将str类型的数据转成json格式的数据
json_data=json.loads(s)
return json_data
#提取数据
def get_info(productId):
#调用函数获取商品的最大评论页数
#max_page=get_max_page(productId)
max_page=20
lst=[] #用于存储提取到的商品数据
for page in range(1,max_page+1): #循环执行次数
#获取每页的商品评论
comments=get_comments(productId,page)
comm_lst=comments['comments'] #根据key获取value,根据comments获取到评论的列表(每页有10条评论)
#遍历评论列表,分别获取每条评论的中的内容,颜色,商品的类型
for item in comm_lst: #每条评论又分别是一个字典,再继续根据key获取值
content=item['content'] #获取评论中的内容
color=item['productColor'] #获取评论购买商品的口味
lst.append([content,color]) #将每条评论的信息添加到列表中
time.sleep(3) #延迟时间,防止程序执行速度太快,被封IP
save(lst) #调用自己编写的函数,将列表中的数据进行存储
#用于将爬取到的数据存储到Excel中
def save(lst):
wk=openpyxl.Workbook () #创建工作薄对象
noodles=wk.active #获取活动表
#遍历列表,将列表中的数据添加到工作表中,列表中的一条数据,在Excel中是 一行
for item in lst:
sheet.append(item)
#保存到磁盘上
wk.save('销售数据.xlsx')
if __name__ == '__main__':
productId='3533885'
#print(get_max_page(productId))
get_info(productId)

4.简单分析
(1)查看表格几行几列
import openpyxl
#从Excel中读取数据
wk=openpyxl.load_workbook('销售数据.xlsx')
noodles=wk.active #获取活动sheet表
#获取最大行数和最大列数
rows=noodles.max_row #200行
cols=noodles.max_column #2列
print(rows,cols)
200 2
(2)统计口味数据(简单对excel表格进行处理)
import openpyxl
#从Excel中读取数据
wk=openpyxl.load_workbook('销售数据.xlsx')
noodles=wk.active #获取活动sheet表
#获取最大行数和最大列数
rows=noodles.max_row #200行
cols=noodles.max_column #2列
lst=[] #用于存储方便面口味
for i in range(1,rows+1):
color=noodles.cell(i,2).value
lst.append(color)
'''for item in lst:
print(item)
'''
'''从Excel中将方便面口味数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同口味的方便面销售'''
'''Python中有一种数据结构叫字典,使用口味作key,使用销售数量作value'''
dic_color={}
for item in lst:
dic_color[item]=0
for item in lst:
for color in dic_color: #遍历字典
if item==color:
dic_color[color]+=1
break
'''for item in dic_color:
print(item,dic_color[item])'''
lst_total=[]
for item in dic_color:
lst_total.append([item,dic_color[item],dic_color[item]/200*1.0])
for item in lst_total:
print(item)
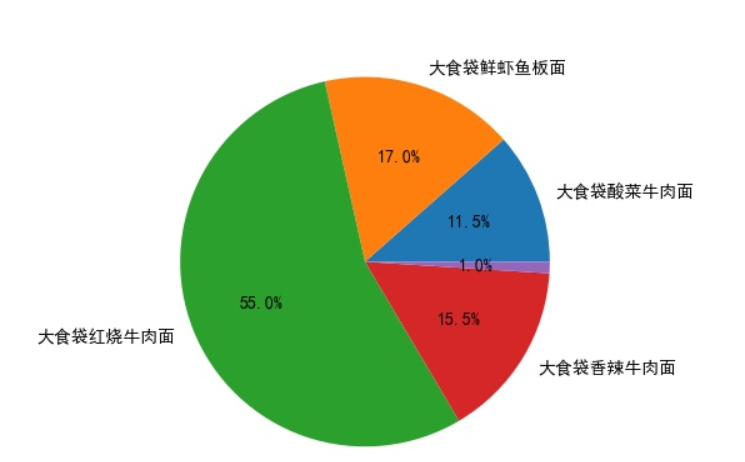
[‘大食袋酸菜牛肉面’, 23, 0.115]
[‘大食袋鲜虾鱼板面’, 34, 0.17]
[‘大食袋红烧牛肉面’, 110, 0.55]
[‘大食袋香辣牛肉面’, 31, 0.155]
[None, 2, 0.01]
(3)生成饼图
import openpyxl
import matplotlib.pyplot as pit
#从Excel中读取数据
wk=openpyxl.load_workbook('销售数据.xlsx')
noodles=wk.active #获取活动sheet表
#获取最大行数和最大列数
rows=noodles.max_row #200行
cols=noodles.max_column #2列
lst=[] #用于存储方便面口味
for i in range(1,rows+1):
color=noodles.cell(i,2).value
lst.append(color)
'''for item in lst:
print(item)
'''
'''从Excel中将方便面口味数据读取完毕,添加到列表中,以下操作,开始数据统计,统计不同口味的方便面销售'''
'''Python中有一种数据结构叫字典,使用口味作key,使用销售数量作value'''
dic_color={}
for item in lst:
dic_color[item]=0
for item in lst:
for color in dic_color: #遍历字典
if item==color:
dic_color[color]+=1
break
'''for item in dic_color:
print(item,dic_color[item])'''
lst_total=[]
for item in dic_color:
lst_total.append([item,dic_color[item],dic_color[item]/200*1.0])
'''for item in lst_total:
print(item)
'''
'''数据统计完毕,开始进行数据可视化'''
labels=[item[0] for item in lst_total] #使用列表生成式,得到饼图的标签
fraces=[item[2] for item in lst_total] #饼图中的数据源
pit.rcParams['font.family']=['SimHei']
pit.pie(x=fraces,labels=labels,autopct='%1.1f%%')
#pit.show()
pit.savefig('饼图.jpg')