- 👏作者简介:大家好,我是爱吃芝士的土豆倪,24届校招生Java选手,很高兴认识大家
- 📕系列专栏:Spring源码、JUC源码、Kafka原理、分布式技术原理、数据库技术
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:源码溯源,一探究竟
- 📝联系方式:nhs19990716,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
Redis为什么那么快?高性能设计之epoll和IO多路复用深度解析
before
多路复用要解决的问题
并发多客户端连接,在多路复用之前最简单和典型的方案:同步阻塞网络IO模型
这种模式的特点就是用一个进程来处理一个网络连接(一个用户请求),比如一段典型的示例代码如下。
直接调用 recv 函数从一个 socket 上读取数据。
int main()
{
…
recv(sock, …) //从用户角度来看非常简单,一个recv一用,要接收的数据就到我们手里了。
}
我们来总结一下这种方式:
优点就是这种方式非常容易让人理解,写起代码来非常的自然,符合人的直线型思维。
缺点就是性能差,每个用户请求到来都得占用一个进程来处理,来一个请求就要分配一个进程跟进处理,
类似一个学生配一个老师,一位患者配一个医生,可能吗?进程是一个很笨重的东西。一台服务器上创建不了多少个进程。
结论
进程在 Linux 上是一个开销不小的家伙,先不说创建,光是上下文切换一次就得几个微秒。所以为了高效地对海量用户提供服务,必须要让一个进程能同时处理很多个 tcp 连接才行。现在假设一个进程保持了 10000 条连接,那么如何发现哪条连接上有数据可读了、哪条连接可写了 ?
我们当然可以采用循环遍历的方式来发现 IO 事件,但这种方式太低级了。
我们希望有一种更高效的机制,在很多连接中的某条上有 IO 事件发生的时候直接快速把它找出来。
其实这个事情 Linux 操作系统已经替我们都做好了,它就是我们所熟知的 IO 多路复用机制。
这里的复用指的就是对进程的复用
IO多路复用模型
是什么?
IO:网络IO
多路:多个客户端连接(连接就是套接字描述符,即socket或者channel),指的是多条TCP连接
复用:用一个进程来处理多条的连接,使用单进程就可以实现同时处理多个客户端的连接
一句话:使用单进程就实现了多个客户端的连接,IO多路复用类似于一个接口,规范、落地实现,可以从select->poll->epoll三个阶段来实现
Redis单线程如何处理那么多并发客户端连接,为什么单线程,为什么快?
Redis的IO多路复用
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,一次放到文件事件分派器,事件分派器将事件分发给事件处理器。
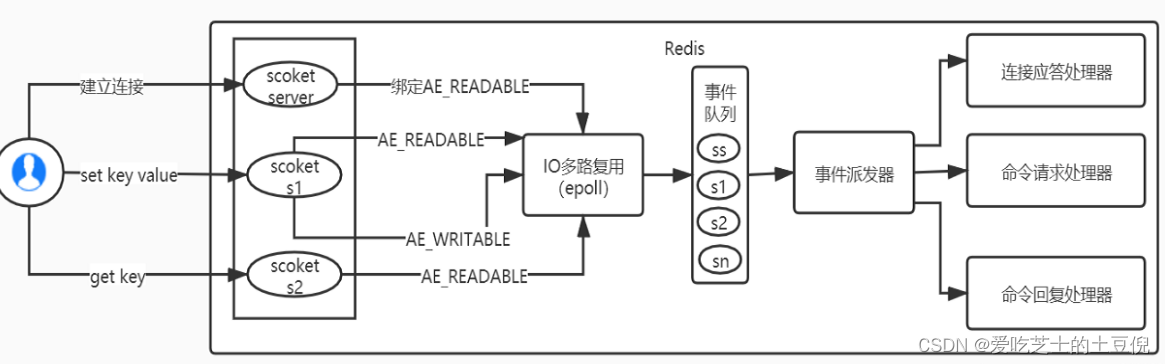
Redis 是跑在单线程中的,所有的操作都是按照顺序线性执行的,但是由于读写操作等待用户输入或输出都是阻塞的,所以 I/O 操作在一般情况下往往不能直接返回,这会导致某一文件的 I/O 阻塞导致整个进程无法对其它客户提供服务,而 I/O 多路复用就是为了解决这个问题而出现
所谓 I/O 多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。这种机制的使用需要 select 、 poll 、 epoll 来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。它的组成结构为4部分:
多个套接字、
IO多路复用程序、
文件事件分派器、
事件处理器。
因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型
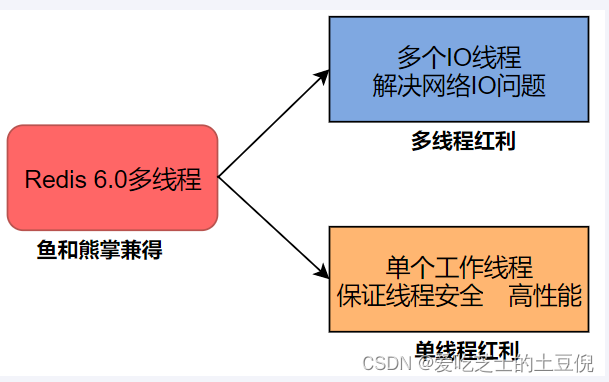
Redis设计与实现

从Redis6开始,将网络数据读写、请求协议解析通过多个IO线程的来处理 ,
对于真正的命令执行来说,仍然使用单线程操作,一举两得,便宜占尽!!! o( ̄▽ ̄)d
Unix网络编程中几种常用模型
阻塞IO
非阻塞IO
IO多路复用
从吃米线开始,读读read
上午开会,错过了公司食堂的饭点, 中午就和公司的首席架构师一起去楼下的米线店去吃米线。我们到了一看,果然很多人在排队。
架构师马上发话了:嚯,请求排队啊!你看这位收银点菜的,像不像nginx的反向代理?只收请求,不处理,把请求都发给后厨去处理。
我们交了钱,拿着号离开了点餐收银台,找了个座位坐下等餐。
架构师:你看,这就是异步处理,我们下了单就可以离开等待,米线做好了会通过小喇叭“回调”我们去取餐;
如果同步处理,我们就得在收银台站着等餐,后面的请求无法处理,客户等不及肯定会离开了。
接下里架构师盯着手中的纸质号牌。
架构师:你看,这个纸质号牌在后厨“服务器”那里也有,这不就是表示会话的ID吗?
有了它就可以把大家给区分开,就不会把我的排骨米线送给别人了。过了一会, 排队的人越来越多,已经有人表示不满了,可是收银员已经满头大汗,忙到极致了。
架构师:你看他这个系统缺乏弹性扩容, 现在这么多人,应该增加收银台,可以没有其他收银设备,老板再着急也没用。
老板看到在收银这里帮不了忙,后厨的订单也累积得越来越多, 赶紧跑到后厨亲自去做米线去了。
架构师又发话了:幸亏这个系统的后台有并行处理能力,可以随意地增加资源来处理请求(做米线)。
我说:他就这点儿资源了,除了老板没人再会做米线了。
不知不觉,我们等了20分钟, 但是米线还没上来。
架构师:你看,系统的处理能力达到极限,超时了吧。
这时候收银台前排队的人已经不多了,但是还有很多人在等米线。
老板跑过来让这个打扫卫生的去收银,让收银小妹也到后厨帮忙。打扫卫生的做收银也磕磕绊绊的,没有原来的小妹灵活。
架构师:这就叫服务降级,为了保证米线的服务,把别的服务都给关闭了。
又过了20分钟,后厨的厨师叫道:237号, 您点的排骨米线没有排骨了,能换成番茄的吗?
架构师低声对我说:瞧瞧, 人太多, 系统异常了。然后他站了起来:不行,系统得进行补偿操作:退费。
说完,他拉着我,饿着肚子,头也不回地走了。
同步
调用者要一直等待调用结果的通知后才能进行后续的执行,现在就要,我可以等,等出结果为止
异步
指被调用方先返回应答让调用者返回,然后再计算调用结果,计算完最终结果后再通知并返回给调用方。
异步调用要想获得结果一般通过回调
同步和异步的理解
同步、异步的讨论对象是被调用者(服务提供者),重点在于获得调用结果的消息通知方式上
阻塞
调用方一直在等待而且别的事情什么都不做,当前进程线程被挂起,啥也不干
非阻塞
调用在发出去后,调用方先去忙别的事情,不会阻塞当前进程线程,而会立即返回
阻塞和非阻塞的理解
阻塞和非阻塞的讨论对象是调用者(服务请求者)重点在于等消息时候的行为,带哦用着是否能干其它事
JAVA实践
背景
一个redisServer + 2个Client
BIO
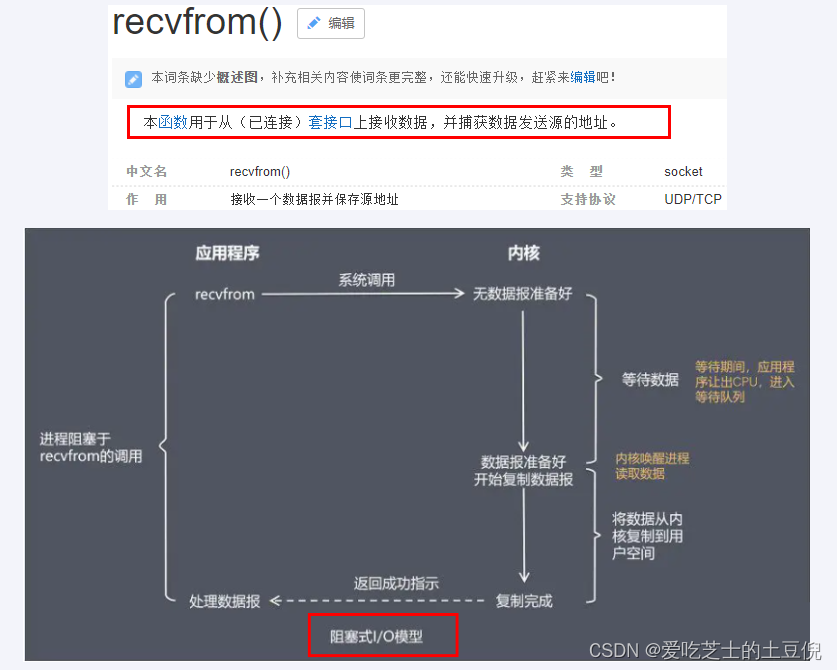
当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到操作系统内核的缓冲区中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会将数据从kernel中拷贝到用户内存,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。所以,BIO的特点就是在IO执行的两个阶段都被block了。
accept监听
RedisServer
public class RedisServer
{
public static void main(String[] args) throws IOException
{
byte[] bytes = new byte[1024];
ServerSocket serverSocket = new ServerSocket(6379);
while(true)
{
System.out.println("-----111 等待连接");
Socket socket = serverSocket.accept();
System.out.println("-----222 成功连接");
}
}
}
RedisClient01
public class RedisClient01
{
public static void main(String[] args) throws IOException
{
System.out.println("------RedisClient01 start");
Socket socket = new Socket("127.0.0.1", 6379);
}
}
RedisClient02
public class RedisClient02
{
public static void main(String[] args) throws IOException
{
System.out.println("------RedisClient02 start");
Socket socket = new Socket("127.0.0.1", 6379);
}
}
Read读取
先启动RedisServerBIO,再启动RedisClient01验证后再启动02客户端
RedisServerBIO
public class RedisServerBIO
{
public static void main(String[] args) throws IOException
{
ServerSocket serverSocket = new ServerSocket(6379);
while(true)
{
System.out.println("-----111 等待连接");
Socket socket = serverSocket.accept();//阻塞1 ,等待客户端连接
System.out.println("-----222 成功连接");
InputStream inputStream = socket.getInputStream();
int length = -1;
byte[] bytes = new byte[1024];
System.out.println("-----333 等待读取");
while((length = inputStream.read(bytes)) != -1)//阻塞2 ,等待客户端发送数据
{
System.out.println("-----444 成功读取"+new String(bytes,0,length));
System.out.println("====================");
System.out.println();
}
inputStream.close();
socket.close();
}
}
}
RedisClient01
public class RedisClient01
{
public static void main(String[] args) throws IOException
{
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
//socket.getOutputStream().write("RedisClient01".getBytes());
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
RedisClient02
public class RedisClient02
{
public static void main(String[] args) throws IOException
{
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
//socket.getOutputStream().write("RedisClient01".getBytes());
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
存在的问题
上面的模型存在很大的问题,如果客户端与服务端建立了连接,
如果这个连接的客户端迟迟不发数据,程就会一直堵塞在read()方法上,这样其他客户端也不能进行连接,
也就是一次只能处理一个客户端,对客户很不友好
知道问题所在了,请问如何解决??
解决
利用多线程
只要连接了一个socket,操作系统分配一个线程来处理,这样read()方法堵塞在每个具体线程上而不堵塞主线程,
就能操作多个socket了,哪个线程中的socket有数据,就读哪个socket,各取所需,灵活统一。
程序服务端只负责监听是否有客户端连接,使用 accept() 阻塞
客户端1连接服务端,就开辟一个线程(thread1)来执行 read() 方法,程序服务端继续监听
客户端2连接服务端,也开辟一个线程(thread2)来执行 read() 方法,程序服务端继续监听
客户端3连接服务端,也开辟一个线程(thread3)来执行 read() 方法,程序服务端继续监听
。。。。。。
任何一个线程上的socket有数据发送过来,read()就能立马读到,cpu就能进行处理。
RedisServerBIOMultiThread
public class RedisServerBIOMultiThread
{
public static void main(String[] args) throws IOException
{
ServerSocket serverSocket = new ServerSocket(6379);
while(true)
{
//System.out.println("-----111 等待连接");
Socket socket = serverSocket.accept();//阻塞1 ,等待客户端连接
//System.out.println("-----222 成功连接");
new Thread(() -> {
try {
InputStream inputStream = socket.getInputStream();
int length = -1;
byte[] bytes = new byte[1024];
System.out.println("-----333 等待读取");
while((length = inputStream.read(bytes)) != -1)//阻塞2 ,等待客户端发送数据
{
System.out.println("-----444 成功读取"+new String(bytes,0,length));
System.out.println("====================");
System.out.println();
}
inputStream.close();
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
},Thread.currentThread().getName()).start();
System.out.println(Thread.currentThread().getName());
}
}
}
RedisClient01
public class RedisClient01
{
public static void main(String[] args) throws IOException
{
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
//socket.getOutputStream().write("RedisClient01".getBytes());
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
RedisClient02
public class RedisClient02
{
public static void main(String[] args) throws IOException
{
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
//socket.getOutputStream().write("RedisClient01".getBytes());
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
存在问题
多线程模型
每来一个客户端,就要开辟一个线程,如果来1万个客户端,那就要开辟1万个线程。
在操作系统中用户态不能直接开辟线程,需要调用内核来创建的一个线程,
这其中还涉及到用户状态的切换(上下文的切换),十分耗资源。
知道问题所在了,请问如何解决??
第一个办法:使用线程池
这个在客户端连接少的情况下可以使用,但是用户量大的情况下,你不知道线程池要多大,太大了内存可能不够,也不可行。
第二个办法:NIO(非阻塞式IO)方式
因为read()方法堵塞了,所有要开辟多个线程,如果什么方法能使read()方法不堵塞,这样就不用开辟多个线程了,这就用到了另一个IO模型,NIO(非阻塞式IO)
tomcat7之前就是用BIO多线程来解决多连接
两个痛点
accept
read
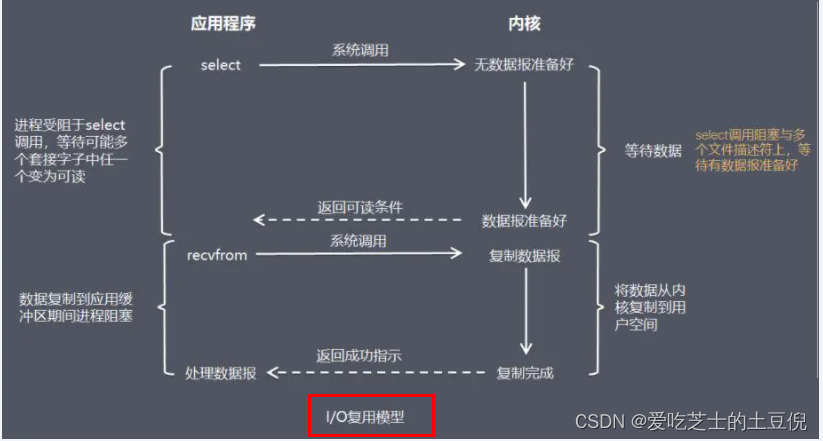
在阻塞式IO模型中,应用程序在从调用recvfrom开始到它返回有数据报准备好这段时间是阻塞的,recvfrom返回成功后,应用进程才能开始处理数据报。
思考:每个线程分配一个连接,必然会产生多个,既然是多个socket连接必然需要放入容器,纳入统一管理
NIO
当用户进程发出read操作时,如果kernel中的数据还没有准备好,那么它并不会block用户进程,而是立刻返回一个error。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回。所以,NIO特点是用户进程需要不断的主动询问内核数据准备好了吗?一句话,用轮询替代阻塞!
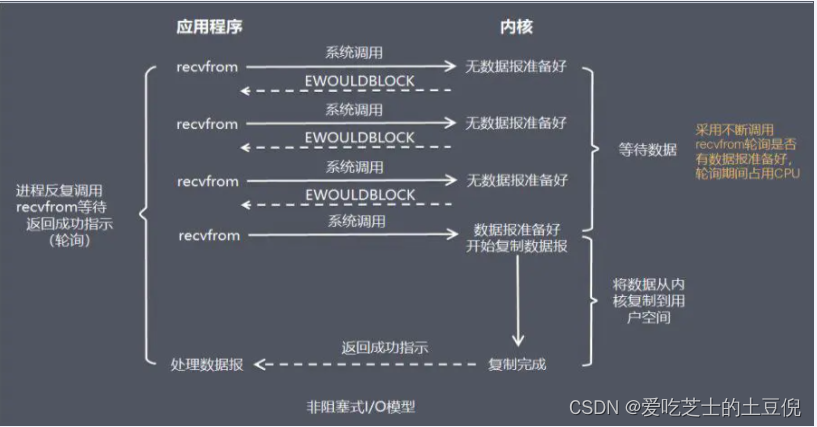
在NIO模式中,一切都是非阻塞的:
accept()方法是非阻塞的,如果没有客户端连接,就返回无连接标识
read()方法是非阻塞的,如果read()方法读取不到数据就返回空闲中标识,如果读取到数据时只阻塞read()方法读数据的时间
在NIO模式中,只有一个线程:
当一个客户端与服务端进行连接,这个socket就会加入到一个数组中,隔一段时间遍历一次,
看这个socket的read()方法能否读到数据,这样一个线程就能处理多个客户端的连接和读取了
code
上述以前的socket是阻塞的,所以需要另外开发一套
ServerSocketChannel
RedisServerNIO
public class RedisServerNIO
{
static ArrayList<SocketChannel> socketList = new ArrayList<>();
static ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
public static void main(String[] args) throws IOException
{
System.out.println("---------RedisServerNIO 启动等待中......");
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.bind(new InetSocketAddress("127.0.0.1",6379));
serverSocket.configureBlocking(false);//设置为非阻塞模式
while (true)
{
for (SocketChannel element : socketList)
{
int read = element.read(byteBuffer);
if(read > 0)
{
System.out.println("-----读取数据: "+read);
byteBuffer.flip();
byte[] bytes = new byte[read];
byteBuffer.get(bytes);
System.out.println(new String(bytes));
byteBuffer.clear();
}
}
SocketChannel socketChannel = serverSocket.accept();
if(socketChannel != null)
{
System.out.println("-----成功连接: ");
socketChannel.configureBlocking(false);//设置为非阻塞模式
socketList.add(socketChannel);
System.out.println("-----socketList size: "+socketList.size());
}
}
}
}
RedisClient01
public class RedisClient01
{
public static void main(String[] args) throws IOException
{
System.out.println("------RedisClient01 start");
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
RedisClient02
public class RedisClient02
{
public static void main(String[] args) throws IOException
{
System.out.println("------RedisClient02 start");
Socket socket = new Socket("127.0.0.1",6379);
OutputStream outputStream = socket.getOutputStream();
while(true)
{
Scanner scanner = new Scanner(System.in);
String string = scanner.next();
if (string.equalsIgnoreCase("quit")) {
break;
}
socket.getOutputStream().write(string.getBytes());
System.out.println("------input quit keyword to finish......");
}
outputStream.close();
socket.close();
}
}
NIO成功的解决了BIO需要开启多线程的问题,NIO中一个线程就能解决多个socket,但是还存在2个问题。
问题一:
这个模型在客户端少的时候十分好用,但是客户端如果很多,
比如有1万个客户端进行连接,那么每次循环就要遍历1万个socket,如果一万个socket中只有10个socket有数据,也会遍历一万个socket,就会做很多无用功,每次遍历遇到 read 返回 -1 时仍然是一次浪费资源的系统调用。
问题二:
而且这个遍历过程是在用户态进行的,用户态判断socket是否有数据还是调用内核的read()方法实现的,这就涉及到用户态和内核态的切换,每遍历一个就要切换一次,开销很大因为这些问题的存在。
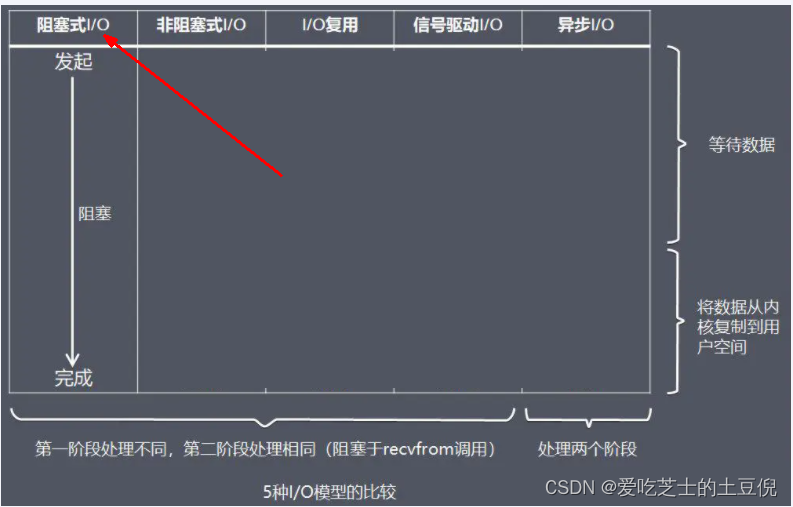
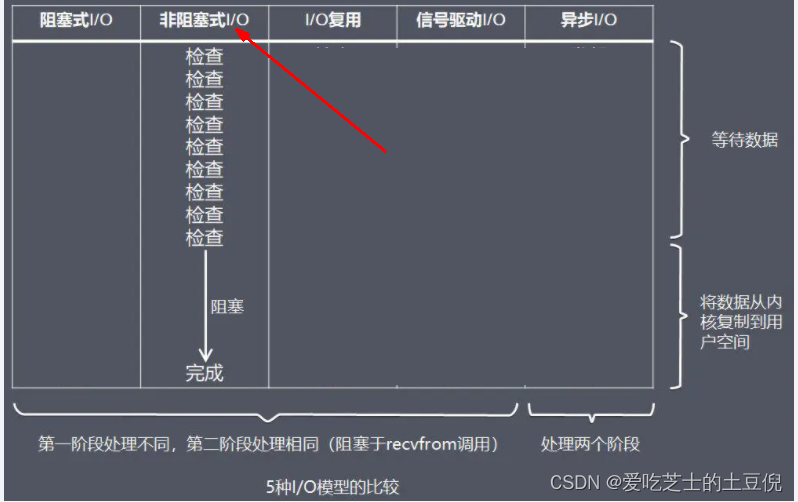
优点:不会阻塞在内核的等待数据过程,每次发起的 I/O 请求可以立即返回,不用阻塞等待,实时性较好。
缺点:轮询将会不断地询问内核,这将占用大量的 CPU 时间,系统资源利用率较低,所以一般 Web 服务器不使用这种 I/O 模型。
结论:让Linux内核搞定上述需求,我们将一批文件描述符通过一次系统调用传给内核由内核层去遍历,才能真正解决这个问题。IO多路复用应运而生,也即将上述工作直接放进Linux内核,不再两态转换而是直接从内核获得结果,因为内核是非阻塞的。
问题升级:如何让单线程处理大量连接
IO多路复用
是什么?
词牌
模型
I/O多路复用在英文中其实叫 I/O multiplexing
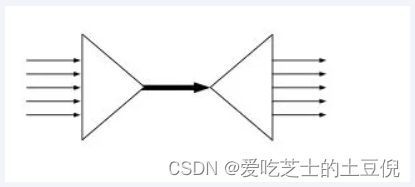
多个Socket复用一根网线这个功能是在内核+驱动层实现的
I/O multiplexing 这里面的 multiplexing 指的其实是在单个线程通过记录跟踪每一个Sock(I/O流)的状态来同时管理多个I/O流. 目的是尽量多的提高服务器的吞吐能力。
大家都用过nginx,nginx使用epoll接收请求,ngnix会有很多链接进来, epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁,然后调用相应的代码处理。redis类似同理
FileDescriptor
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开。但是文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
IO multiplexing就是我们说的select,poll,epoll,有些技术书籍也称这种IO方式为event driven IO事件驱动IO。就是通过一种机制,一个进程可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或者写就绪),能够通知程序进行相应的读写操作。可以基于一个阻塞对象并同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程,每次new一个线程),这样可以大大节省系统资源。所以,I/O 多路复用的特点是通过一种机制一个进程能同时等待多个文件描述符而这些文件描述符(套接字描述符)其中的任意一个进入读就绪状态,select,poll,epoll等函数就可以返回。
简单总结
模拟一个tcp服务器处理30个客户socket,一个监考老师监考多个学生,谁举手就应答谁。
假设你是一个监考老师,让30个学生解答一道竞赛考题,然后负责验收学生答卷,你有下面几个选择:
第一种选择:按顺序逐个验收,先验收A,然后是B,之后是C、D。。。这中间如果有一个学生卡住,全班都会被耽误,你用循环挨个处理socket,根本不具有并发能力。
第二种选择:你创建30个分身线程,每个分身线程检查一个学生的答案是否正确。 这种类似于为每一个用户创建一个进程或者线程处理连接。
第三种选择,你站在讲台上等,谁解答完谁举手。这时C、D举手,表示他们解答问题完毕,你下去依次检查C、D的答案,然后继续回到讲台上等。此时E、A又举手,然后去处理E和A。。。这种就是IO复用模型。Linux下的select、poll和epoll就是干这个的。
将用户socket对应的fd注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻塞模式。这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阻塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor反应模式。
能干嘛?
Redis单线程如何处理那么多并发客户端连接?为什么单线程,为什么这么快?
Redis的IO多路复用
Redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到事件分派器,事件分派器将事件分发给事件处理器。
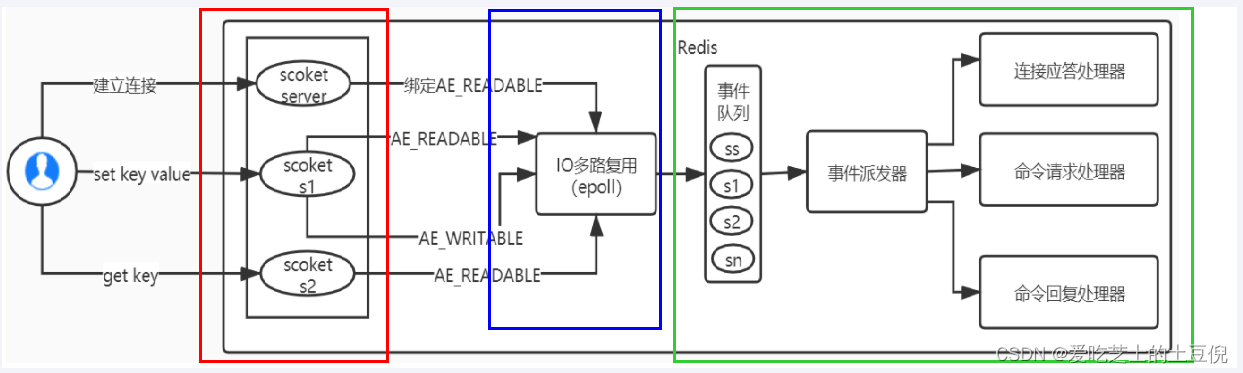
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
所谓 I/O 多路复用机制,就是说通过一种机制,可以监视多个描述符,一旦某个描述符就绪(一般是读就绪或写就绪),能够通知程序进行相应的读写操作。这种机制的使用需要 select 、 poll 、 epoll 来配合。多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
所谓 I/O 多路复用机制,就是说通过一种考试监考机制,一个老师可以监视多个考生,一旦某个考生举手想要交卷了,能够通知监考老师进行相应的收卷子或批改检查操作。所以这种机制需要调用班主任(select/poll/epoll)来配合。多个考生被同一个班主任监考,收完一个考试的卷子再处理其它人,无需等待所有考生,谁先举手就先响应谁,当又有考生举手要交卷,监考老师看到后从讲台走到考生位置,开始进行收卷处理。
Reactor设计模式
基于 I/O 复用模型:多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象上等待,无需阻塞等待所有连接。当某条连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
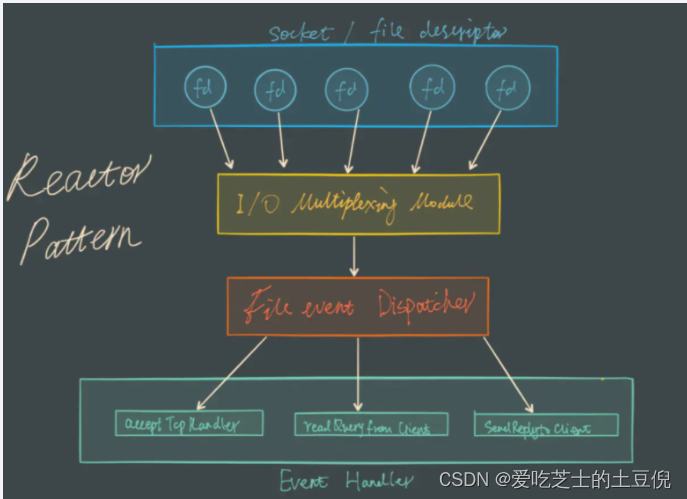
Reactor 模式,是指通过一个或多个输入同时传递给服务处理器的服务请求的事件驱动处理模式。服务端程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫 Dispatcher 模式。即 I/O 多了复用统一监听事件,收到事件后分发(Dispatch 给某进程),是编写高性能网络服务器的必备技术。
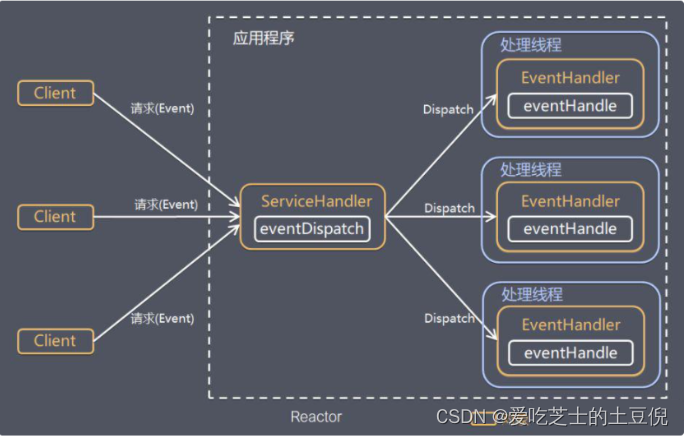
Reactor 模式中有 2 个关键组成:
1)Reactor:Reactor 在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对 IO 事件做出反应。 它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人;
2)Handlers:处理程序执行 I/O 事件要完成的实际事件,类似于客户想要与之交谈的公司中的实际办理人。Reactor 通过调度适当的处理程序来响应 I/O 事件,处理程序执行非阻塞操作。
每个网络连接其实都对应着一个文件描述符
Redis 服务采用 Reactor 的方式来实现文件事件处理器(每一个网络连接其实都对应一个文件描述符)
Redis基于Reactor模式开发了网络事件处理器,这个处理器被称为文件事件处理器。
它的组成结构为4部分:
多个套接字、
IO多路复用程序、
文件事件分派器、
事件处理器。因为文件事件分派器队列的消费是单线程的,所以Redis才叫单线程模型
select、poll、epoll都是IO多路复用的具体实现
select

select 函数监视的文件描述符分3类,分别是readfds、writefds和exceptfds,将用户传入的数组拷贝到内核空间
调用后select函数会阻塞,直到有描述符就绪(有数据 可读、可写、或者有except)或超时(timeout指定等待时间,如果立即返回设为null即可),函数返回。
当select函数返回后,可以通过遍历fdset,来找到就绪的描述符。
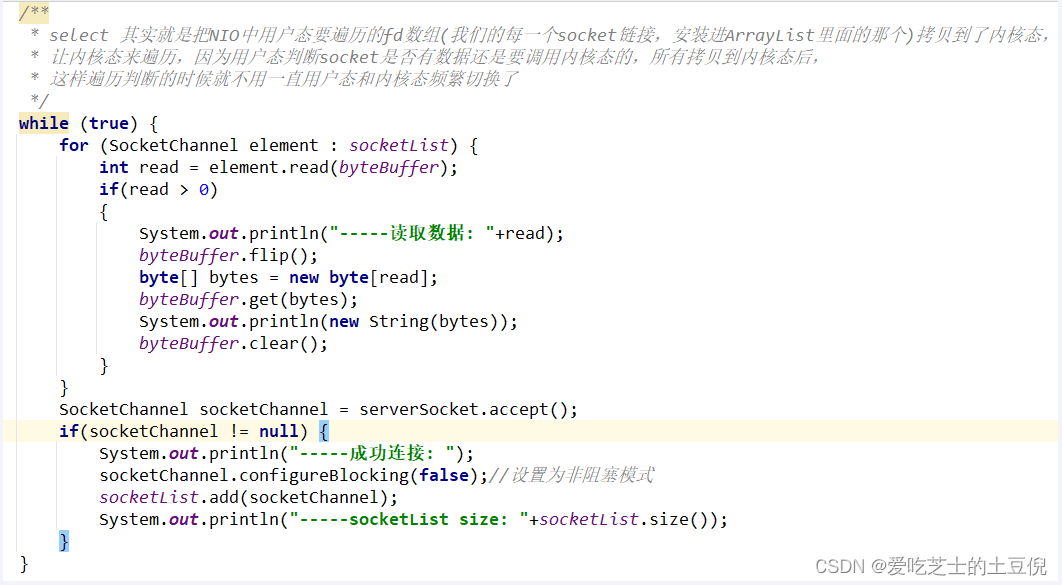
用户态我们自己写的java代码思想
C语言代码
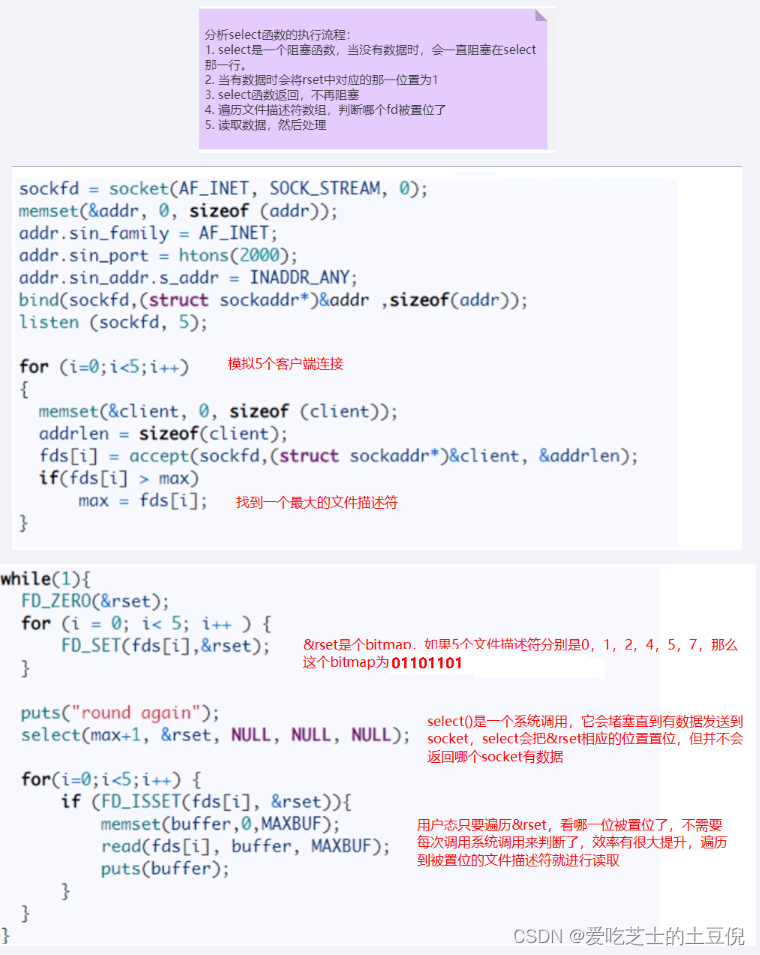
优点
select 其实就是把NIO中用户态要遍历的fd数组(我们的每一个socket链接,安装进ArrayList里面的那个)拷贝到了内核态,让内核态来遍历,因为用户态判断socket是否有数据还是要调用内核态的,所有拷贝到内核态后,这样遍历判断的时候就不用一直用户态和内核态频繁切换了
从代码中可以看出,select系统调用后,返回了一个置位后的&rset,这样用户态只需进行很简单的二进制比较,就能很快知道哪些socket需要read数据,有效提高了效率

缺点
1、bitmap最大1024位,一个进程最多只能处理1024个客户端
2、&rset不可重用,每次socket有数据就相应的位会被置位
3、文件描述符数组拷贝到了内核态(只不过无系统调用切换上下文的开销。(内核层可优化为异步事件通知)),仍然有开销。select 调用需要传入 fd 数组,需要拷贝一份到内核,高并发场景下这样的拷贝消耗的资源是惊人的。(可优化为不复制)
4、select并没有通知用户态哪一个socket有数据,仍然需要O(n)的遍历。select 仅仅返回可读文件描述符的个数,具体哪个可读还是要用户自己遍历。(可优化为只返回给用户就绪的文件描述符,无需用户做无效的遍历)
我们自己模拟写的是,RedisServerNIO.java,只不过将它内核化了。
总结
select方式,既做到了一个线程处理多个客户端连接(文件描述符),又减少了系统调用的开销(多个文件描述符只有一次 select 的系统调用 + N次就绪状态的文件描述符的 read 系统调用
poll

c语言代码
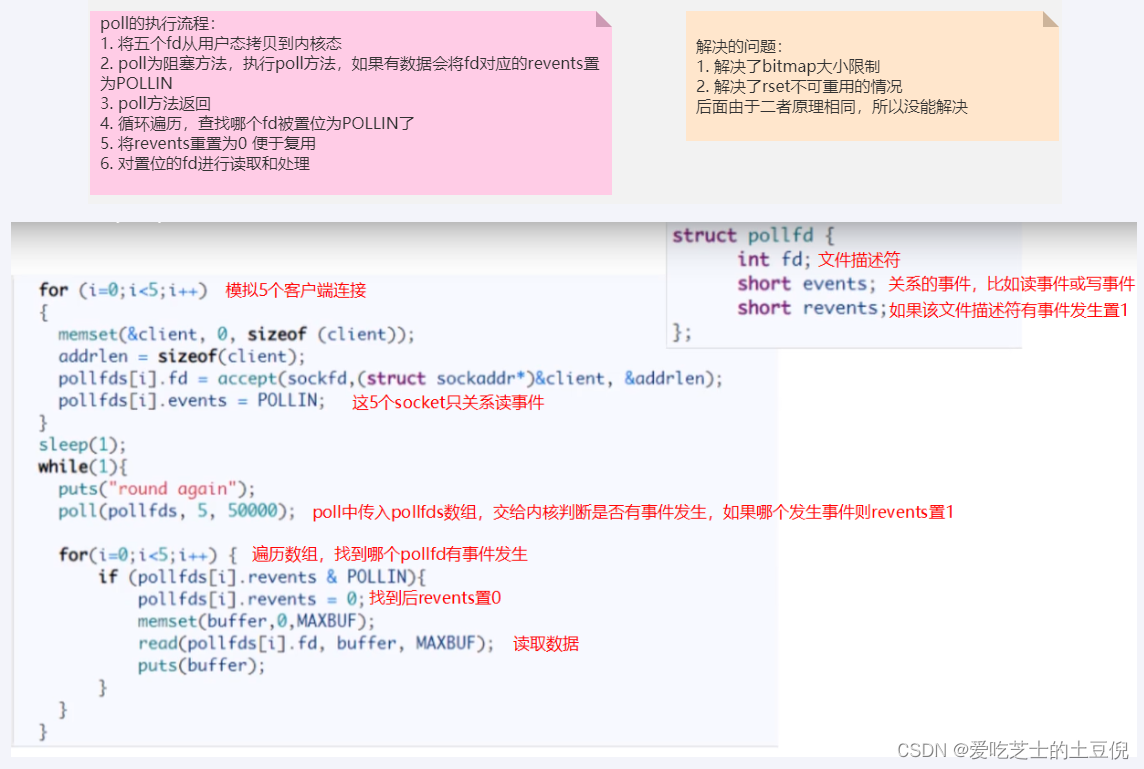
优点
1、poll使用pollfd数组来代替select中的bitmap,数组没有1024的限制,可以一次管理更多的client。它和 select 的主要区别就是,去掉了 select 只能监听 1024 个文件描述符的限制。
2、当pollfds数组中有事件发生,相应的revents置位为1,遍历的时候又置位回零,实现了pollfd数组的重用
缺点
poll 解决了select缺点中的前两条,其本质原理还是select的方法,还存在select中原来的问题
1、pollfds数组拷贝到了内核态,仍然有开销
2、poll并没有通知用户态哪一个socket有数据,仍然需要O(n)的遍历
epoll
分为三步调用
epoll_create:创建一个epoll句柄
epoll_ctl:向内核添加、修改或删除要监控的文件描述符
epoll_wait:类似发起了select调用
c语言代码
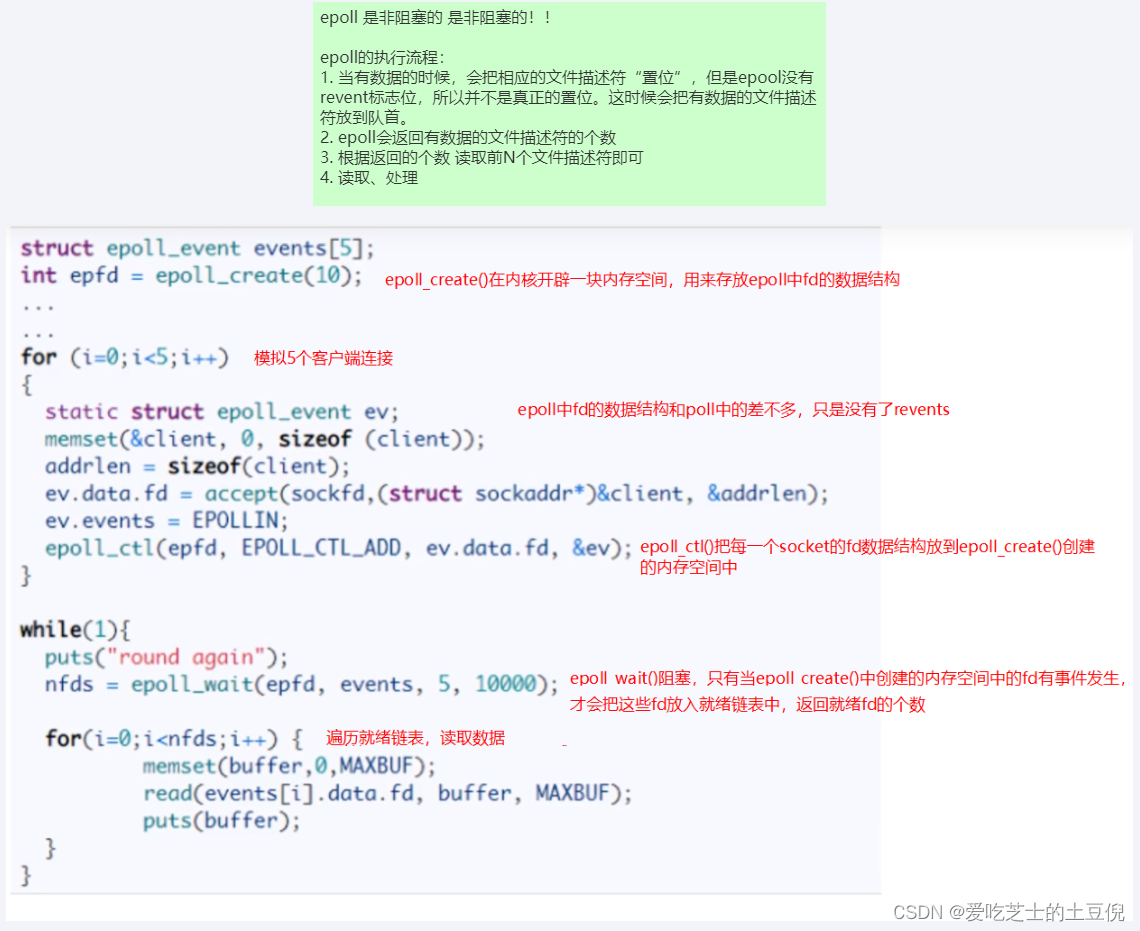
结论
多路复用快的原因在于,操作系统提供了这样的系统调用,使得原来的 while 循环里多次系统调用,
变成了一次系统调用 + 内核层遍历这些文件描述符。
epoll是现在最先进的IO多路复用器,Redis、Nginx,linux中的Java NIO都使用的是epoll。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。
1、一个socket的生命周期中只有一次从用户态拷贝到内核态的过程,开销小
2、使用event事件通知机制,每次socket中有数据会主动通知内核,并加入到就绪链表中,不需要遍历所有的socket
在多路复用IO模型中,会有一个内核线程不断地去轮询多个 socket 的状态,只有当真正读写事件发送时,才真正调用实际的IO读写操作。因为在多路复用IO模型中,只需要使用一个线程就可以管理多个socket,系统不需要建立新的进程或者线程,也不必维护这些线程和进程,并且只有真正有读写事件进行时,才会使用IO资源,所以它大大减少来资源占用。多路I/O复用模型是利用 select、poll、epoll 可以同时监察多个流的 I/O 事件的能力,在空闲的时候,会把当前线程阻塞掉,当有一个或多个流有 I/O 事件时,就从阻塞态中唤醒,于是程序就会轮询一遍所有的流(epoll 是只轮询那些真正发出了事件的流),并且只依次顺序的处理就绪的流,这种做法就避免了大量的无用操作。 采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络 IO 的时间消耗),且 Redis 在内存中操作数据的速度非常快,也就是说内存内的操作不会成为影响Redis性能的瓶颈
三个方法对比

epoll_ctl一次用户态转移内核态调用
在使用 epoll 的时候,当我们通过 epoll_ctl 将文件描述符(fd)添加到内核事件表中时,内核会将该 fd 相关的事件信息保存在内核态的数据结构中,以便后续监听和处理事件。
一旦将 fd 添加到 epoll 中,内核会监视该 fd 上的事件,并在事件发生时通知用户态。这意味着,每当有事件发生时,内核都会将事件通知送达给用户态,而不需要用户态重复的系统调用。
如果 fd 发生变化(如可读、可写等事件状态的变化),内核会自动更新内部的事件状态,不需要用户态再次调用 epoll_ctl。当有新的事件发生时,内核会将事件信息保存在内核态的数据结构中,等待用户态进程主动调用 epoll_wait 等待事件的发生。
所以,一次调用 epoll_ctl 只是将 fd 添加到内核的事件表中,而不是只能进行一次。内核会实时监视 fd 的状态变化,并在需要时通知用户态。这样做的好处是避免了频繁的系统调用,提高了性能和效率。