HA概述
H(high)A(avilable): 高可用,意味着必须有容错机制,不能因为集群故障导致不可用!
- 实现高可用最关键的策略是消除单点故障(SPOF)。HA严格来说应该分成各个组件的HA机制:HDFS的HA和YARN的HA
- 实现hadoop的HA,必须保证在NN和RM故障时,采取容错机制,可以让集群继续使用
HDFS-HA
工作机制
HDFS HA功能通过配置Active/Standby两个NameNode实现在集群中对NameNode的热备来解决问题,通过双NameNode消除单点故障。
使用active状态来标记主节点,使用standby状态标记备用节点
工作要点
-
元数据管理方式需要改变
内存中各自保存一份元数据; Edits日志只有Active状态的NameNode节点可以做写操作 两个NameNode都可以读取Edits,共享的Edits放在一个共享存储中管理 -
需要一个状态管理功能模块
实现了一个zkfc进程(zookeeper failover control)常驻在每一个namenode所在的节点,每一个zkfc负责监控自己所在NameNode节点, 利用ZK进行状态标识,当需要进行状态切换时,由zkfc来负责切换,切换时需要防止脑裂(brain split)现象的发生脑裂:(brain-split) 运行过程中出现两个 namenode 同时服务于整个集群,这种情况称之为脑裂
-
必须保证两个NameNode之间能够ssh无密码登录
-
隔离(Fence),即同一时刻仅仅有一个NameNode对外提供服务
元数据同步
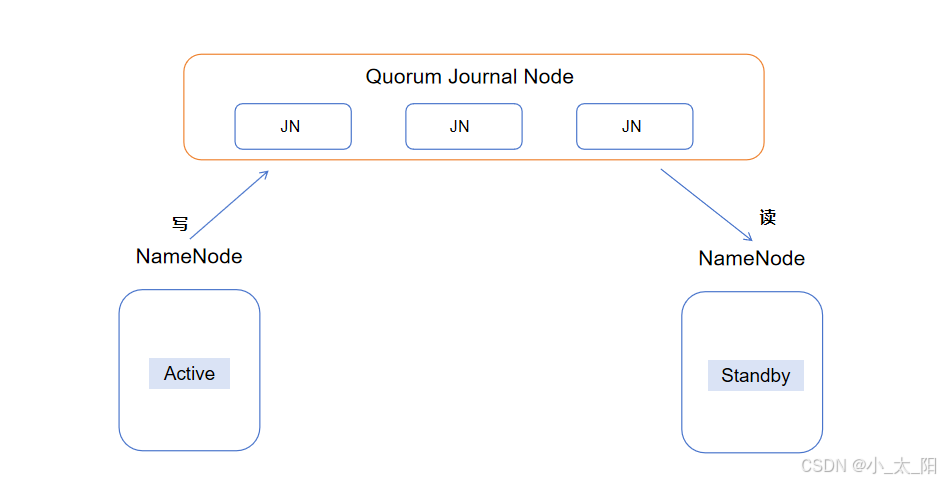
- 集群启动后,standby NameNode和active NameNode同时与JournalNodes(JNS)进程保持通信
- 每次active NameNode写 EditLog 的时候,除了向本地磁盘写入 EditLog 之外,也会并行地向JournalNode集群之中的每一个JournalNode发送写请求,只要大多数 (majority) 的JournalNode节点返回成功就认为向JournalNode集群写入 EditLog 成功
- standby NameNode周期性的从JNS中获取 EditLog 并应用到本地namespace
- 在failover发生时,standby节点会在转变为active之前从JNS中读取并处理所有editlog,以此保持与active NameNode的状态完全同步
- 另一方面,为了failover后standy节点快速提供服务,所有的DateNode节点同时向主备两个NameNode报告block信息
journode是基于paxos协议实现的
参数配置
参考实例:
高可用集群hdfs-site.xml配置_CSDN
手动故障转移
在原active的namenode节点上执行下面命令,强制转换nn2为active节点
hdfs haadmin -transitionToActive --forceactive nn2
自动故障转移工作机制
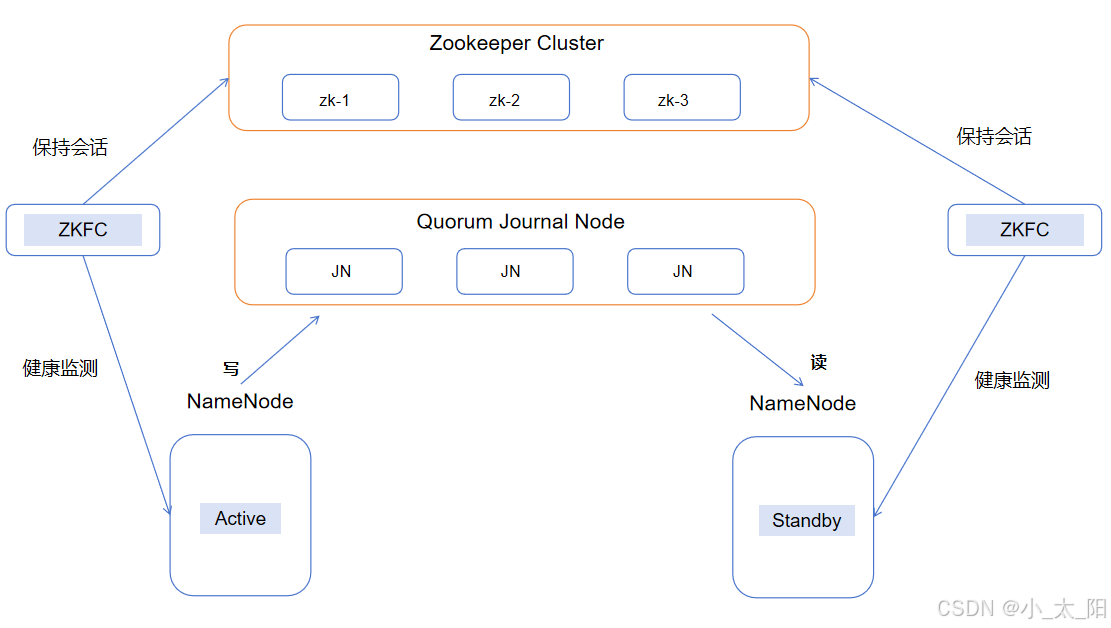
- ZooKeeper会话管理:每个运行的NameNode主机也运行了一个ZKFC进程,ZKFC进程会在NameNode上实例一个Zookeeper客户端,保持一个在ZooKeeper中打开的会话
- 现役NameNode选择:会话打开后ZKFC会将节点信息写入Zookeeper,谁先在Zookeeper中写入成功,且ZKFC发现没有其它的节点当前持有znode锁,它将为自己获取该锁,如果成功,则它已经赢得了选择,并负责运行故障转移进程以使它的本地NameNode为Active
- 如果本地NameNode处于active状态,ZKFC也保持一个特殊的znode锁,该锁使用了ZooKeeper对短暂节点的支持,如果会话终止,锁节点将自动删除
- 健康监测:ZKFC使用一个健康检查命令定期地ping与之在相同主机的NameNode,只要该NameNode及时地回复健康状态,ZKFC认为该节点是健康的。如果该节点崩溃,健康监测器标识该节点为非健康的
- 故障检测:集群中的每个NameNode在ZooKeeper中维护了一个持久会话,如果机器崩溃,ZKFC会释放对Zookeeper节点的所有权,ZooKeeper中的会话将终止,因为节点是临时节点,会话终止临时节点也就消失了
- 隔离:目前现役NameNode崩溃,另一个节点可能从ZooKeeper获得特殊的排外锁以表明它应该成为现役NameNode,在成为现役之前,需要先把假死的NameNode进程杀掉,避免出现脑裂问题
- NameNode的standby节点会重新在Zookeeper上写入新的节点,并将自己提升为active

相关命令
- hdfs查看nn状态命令
hdfs haadmin -getAllServiceState

- hdfs切换为active命令
hdfs haadmin -transitionToActive --forcemanual <Namenode Id>
- hdfs切换为standby命令
hdfs haadmin -transitionToStandby --forcemanual <Namenode Id>
YARN-HA
参数配置
参考实例:
高可用集群yarn-site.xml配置_CSDN
自动故障转移机制
ResourceManager中基于zookeeper的ActiveStandbyElector组件来选举哪个RM作为activeRM。
active RM关闭或故障时自动选举standby状态的RM作为新的active RM接管工作
与HDFS的HA不同的是,YARN的HA方案不需要单独的ZKFC程序, 基于zk的ActiveStandbyElector作为RM内部组件进行故障检测和active选举
相关命令
- yarn查看rm状态命令
yarn rmadmin -getAllServiceState

- yarn切换为active状态
yarn rmadmin -transitionToActive --forcemanual <rm id>
- yarn切换为standby状态
yarn rmadmin -transitionToStandby --forcemanual <rm id>
附录
Zookeeper详解
- 参考链接
zookeeper详解_CSDN