目录
1 Power BI架构
Power BI是微软推出的自助商业智能分析工具,Power BI不仅仅是计算机中安装的一个软件,而是一系列的软件服务和应用,这些软件服务和应用协同工作,不管数据是简单的Excel工作簿,还是基于云的数据仓库和本地混合数据仓库的集合,Power BI都可以轻松连接到数据源,将多种的数据源转化为数据模型,形成可交互的可视化报告,并与所需的人共享。
Power BI主要由Power BI Desktop、Power BI服务以及在移动终端上也可用的Power BI移动版组成。
1.1 Power BI Desktop
Power BI Desktop是Power BI的桌面应用程序,也称为桌面版,专为分析人员设计,且完全免费!它结合了一流的交互式可视化效果和业界领先的内置数据查询和建模功能,可以创建报告并将报告发布到Power BI服务中。
Win10/Win11通过微软应用商店直接下载安装,支持应用自动更新。
如果不是Win10/Win11系统,进入Microsoft Power BI官网下载对应版本的安装包安装。
从数据准备、数据分析到数据可视化,整个流程在Power BI Desktop中一气呵成。使用Power BI Desktop制作的报告可以在本地保存成扩展名为.pbix的文件,还可以上传到Power BI服务中。
1.2 Power BI服务
Power BI服务(Power BI Service)是一个在线服务。Power BI Desktop中制作的报表发布后,就会显示在Power BI服务中,用户可以在浏览器中查看、分享、发布Power BI报表,也可以设置数据刷新计划、管理数据的安全性等。
1.3 Power BI移动版
需要在移动终端查看跟踪数据时,可以使用适用于iOS、Android的Power BI移动版。它是非常友好的Power BI移动应用程序,可以让每一个人获得触手可及的交互式数据报表。
Power BI中的一个常见工作流开始于Power BI Desktop,数据分析人员在其中创建一个报表。然后,该报表将发布到Power BI服务并在最后进行共享,Power BI移动版的用户可以随时随地查看该报表。
2 Power Query
Power BI的数据处理是通过Power Query完成的。
2.1 Power Query编辑器
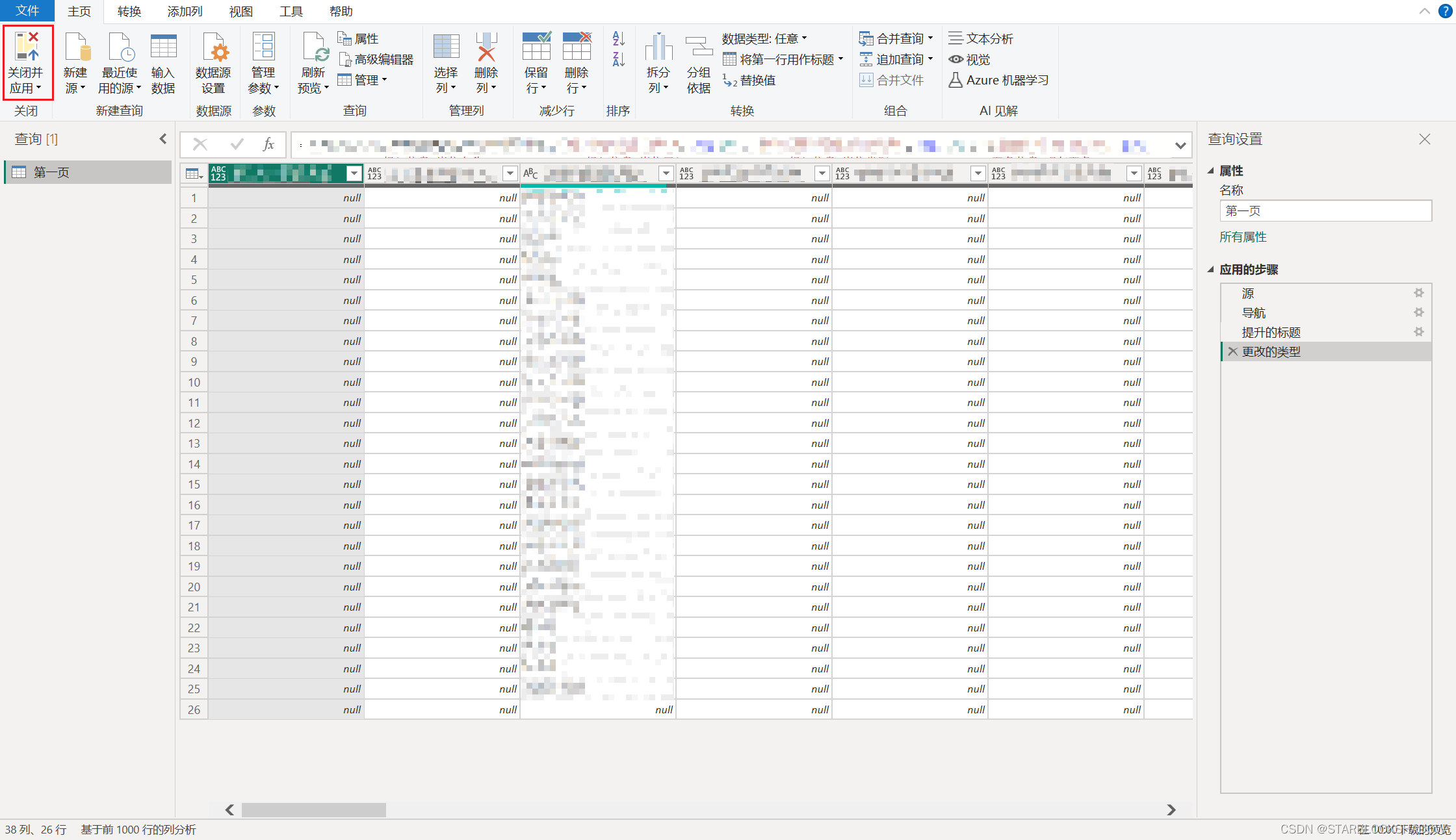
在Power BI Desktop中,如果还没有任何数据,点击“获取数据”,选择相应的数据格式导入后,就可以进入Power Query编辑器。
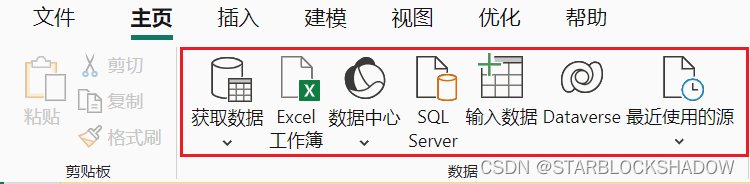
点击“转换数据”进入Power Query编辑器:
Power Query编辑器:
在Power Query编辑器中对数据处理完成后,点击左上角的“关闭并应用”将数据导入Power BI。
2.2 Power Query的优点
- 操作简单:无须掌握复杂的函数,仅使用界面上的功能即可完成大部分数据处理工作。
- 数据量不限:突破传统Excel数据行的限制。
- 自动化:处理过程全记录,每次数据源更新后刷新即可,无须重复操作。
2.3 获取数据
Power BI数据分析的第一步是获取数据,Power BI支持几乎任何来源的任何结构、任何形式的数据。
Power Query不仅能从本地获取数据,还能从网页抓取数据,比如实时抓取股票涨跌、外汇牌价等交易数据。
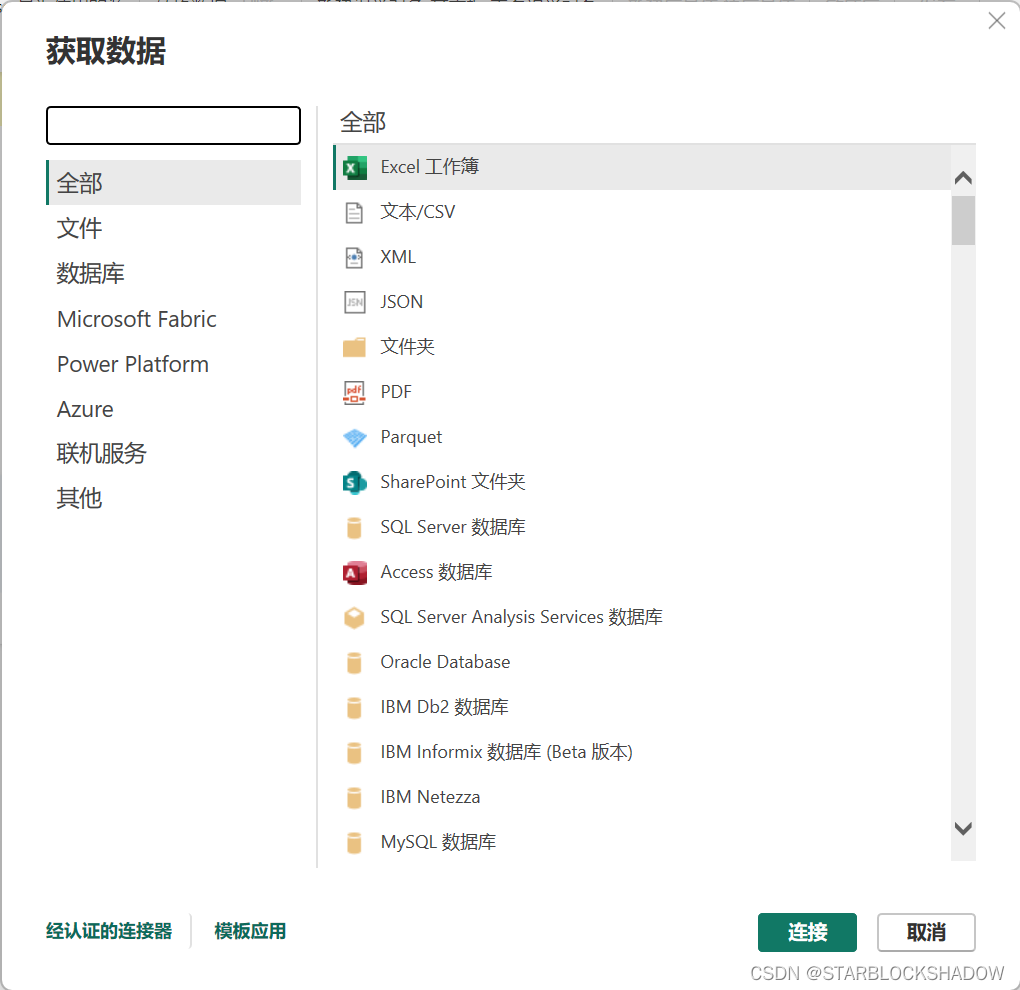
以从中国银行网站上抓取外汇牌价信息为例,点击“获取数据”,选择“Web”:
输入URL:https://www.boc.cn/sourcedb/whpj/
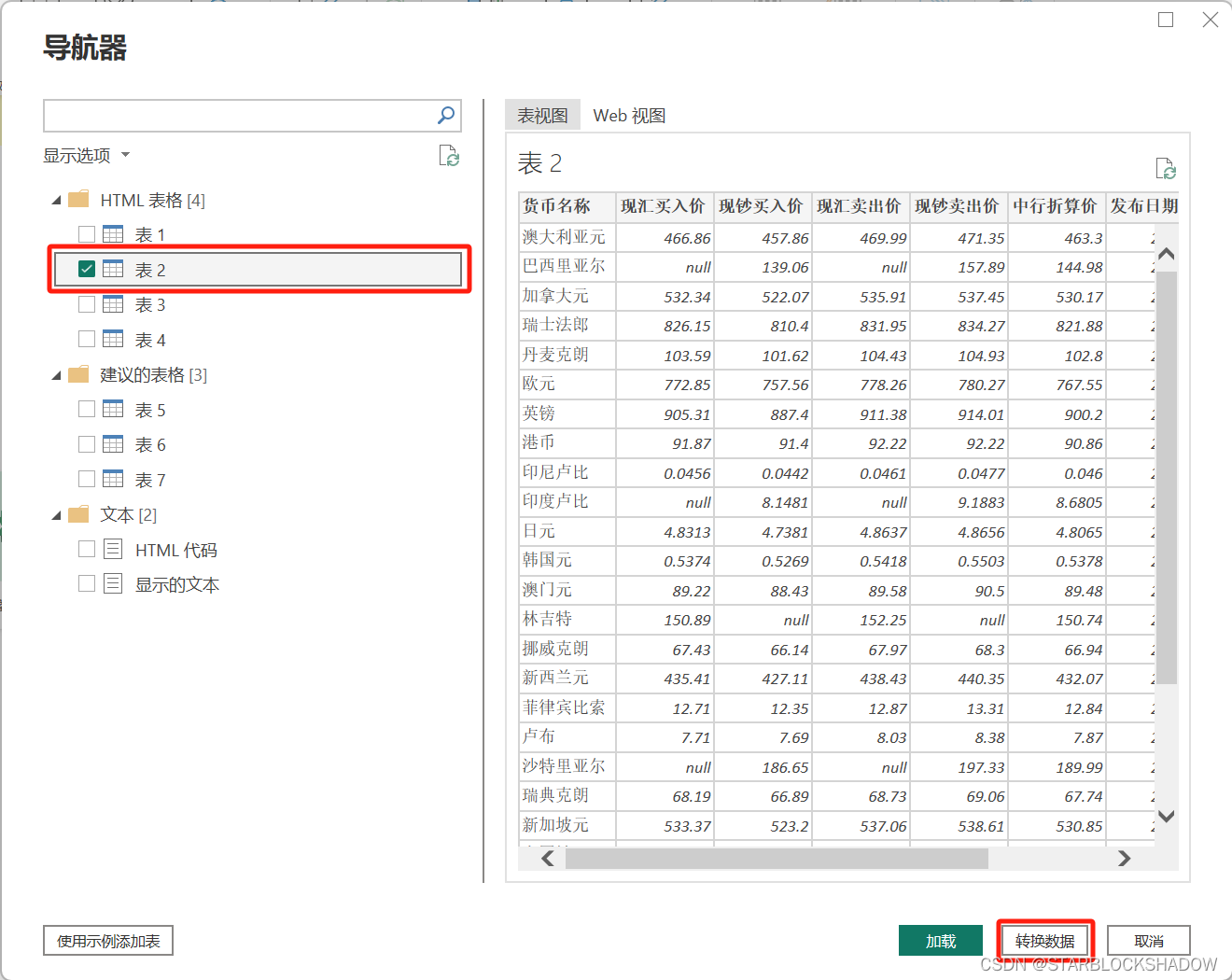
点击“确定”,等待Power BI获取网页数据,选择需要分析的表格数据并点击“转换数据”进入Power Query编辑器:

2.4 数据清洗的常用操作
在Power Query中对导入的数据进行整理的过程一般称为“数据清洗”。
2.4.1 提升标题
在Excel中第一行为标题行,从第二行开始才是数据,但在Power Query中,从第一行开始就需要是数据记录,标题在数据之上。一般情况下,Power Query会自动完成提升这个步骤,如果没有,或者需要手动设置时,单击功能栏的“将第一行用作标题”就可以了:
注:单击“将第一行用作标题”旁边的下拉按钮,还有一个“将标题作为第一行”选项,实际上就是拉低标题,这个功能也特别有用。
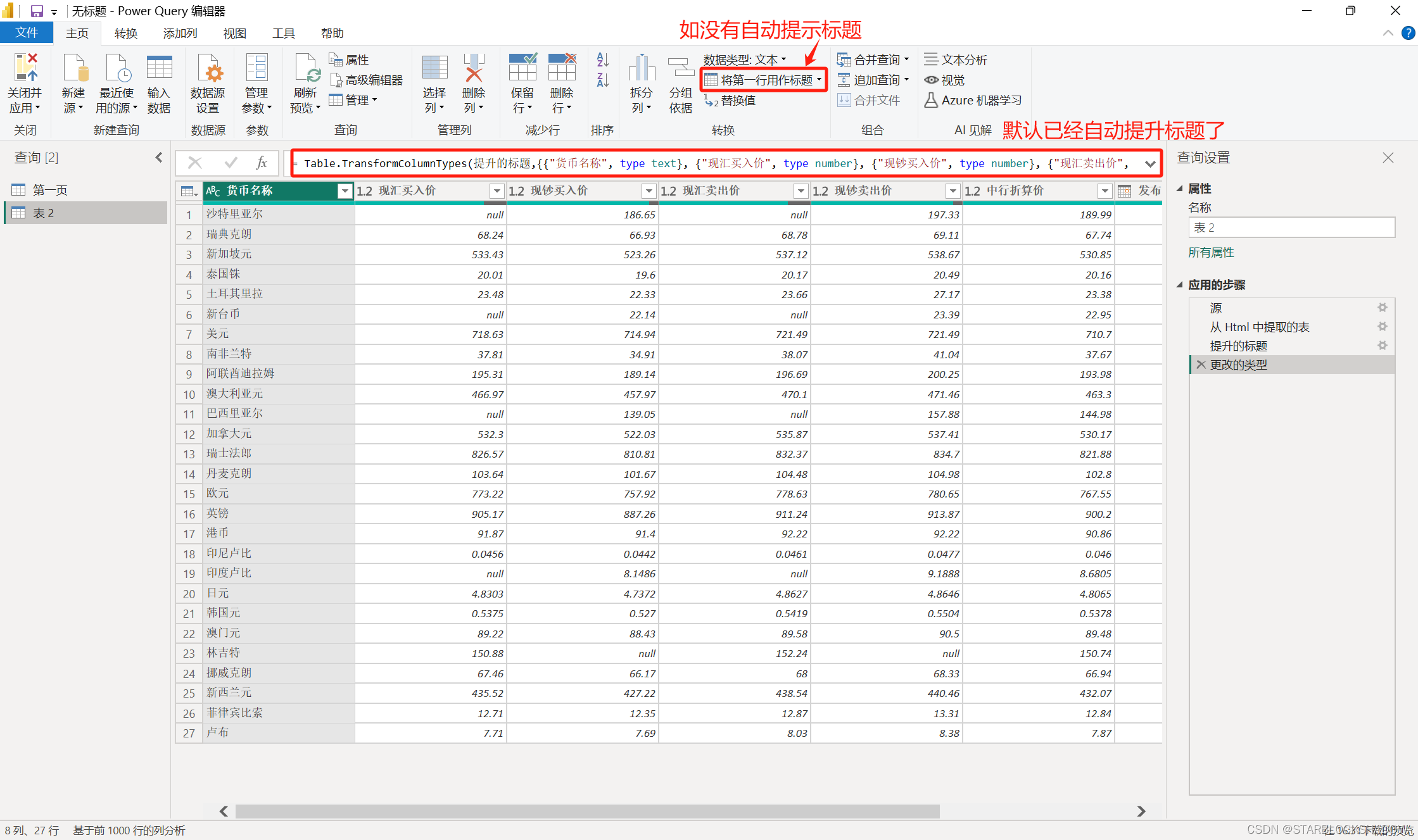
2.4.2 更改数据类型
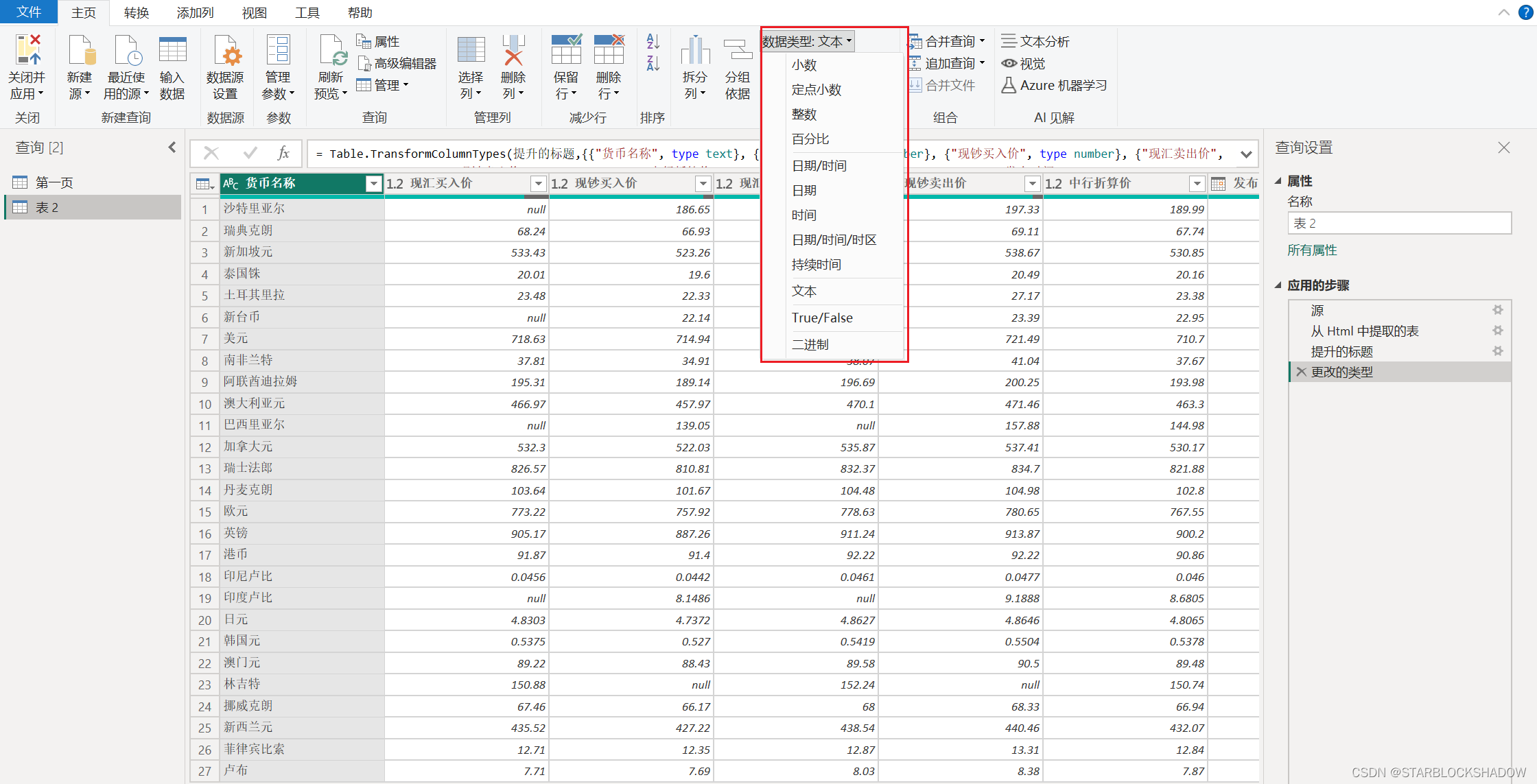
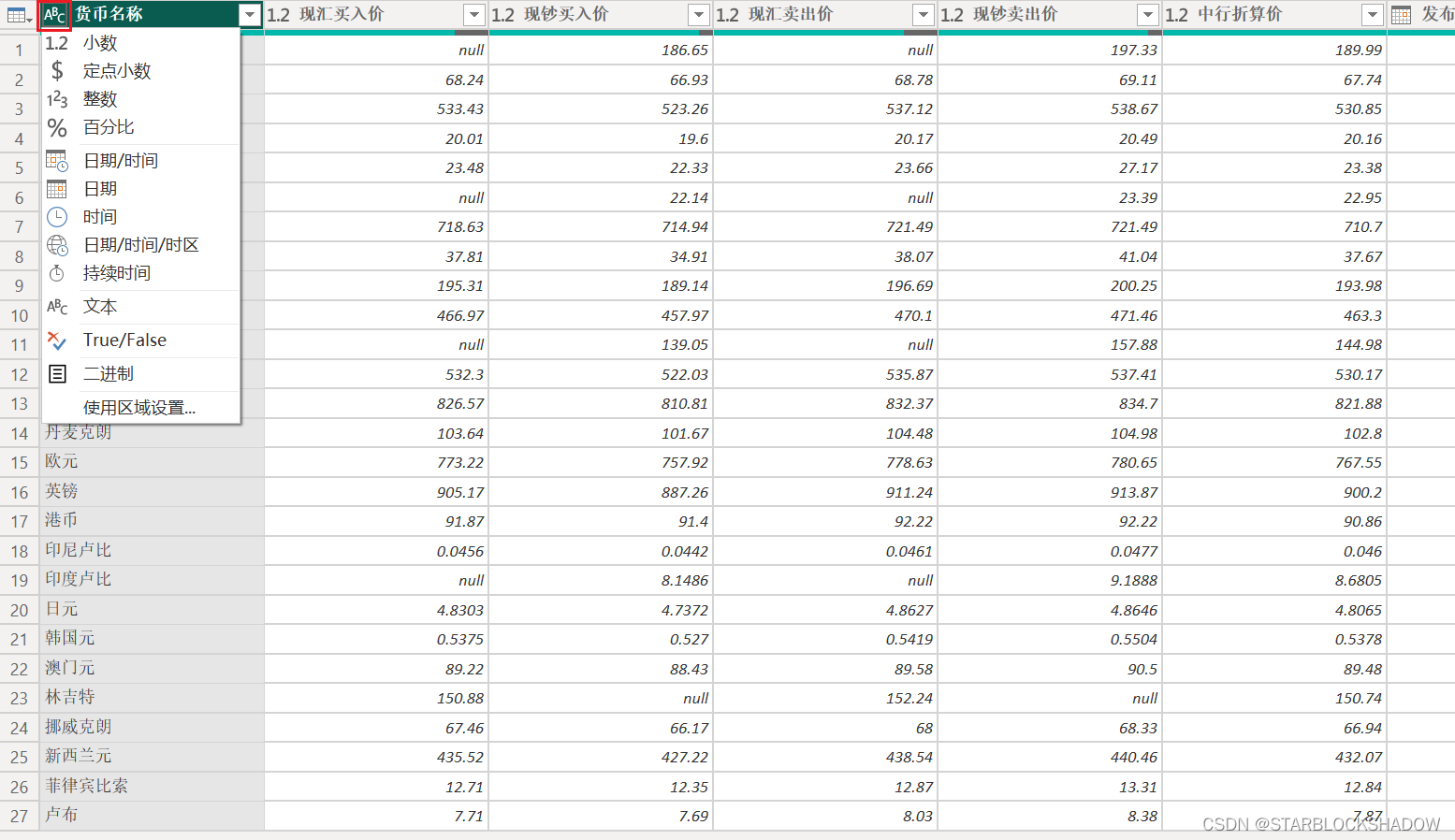
更改数据类型对数据分析也是极其重要的,有两种方式更改数据的数据类型:
方法1:
方法2:
2.4.3 删除错误/空值
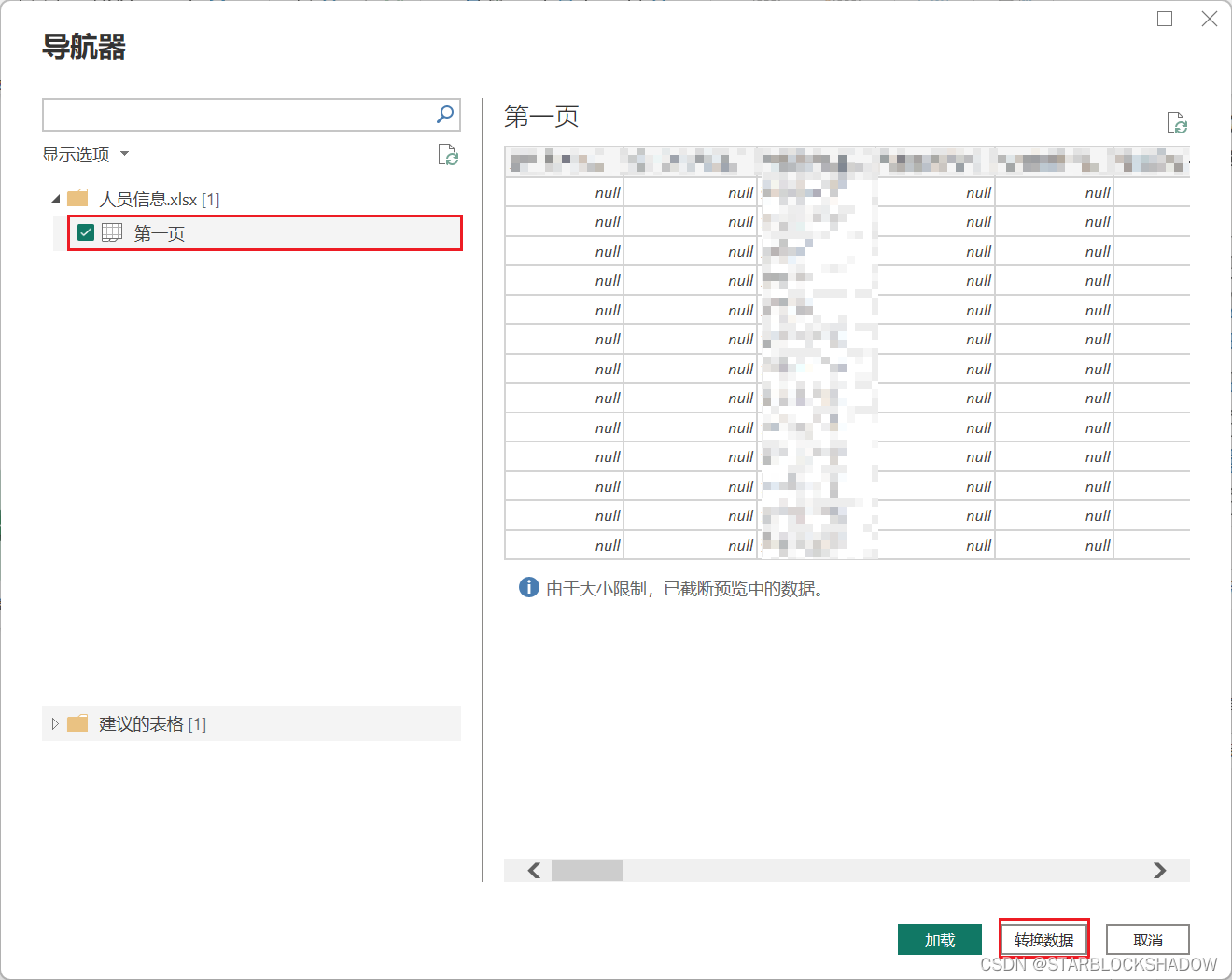
导入后的数据,有可能出现错误(Error)或者空值(null),根据分析的需要,若要删掉错误和空值,可以通过右键单击该字段选择“删除错误”,或通过单击“筛选”按钮去掉相应勾选来完成。
方式1:
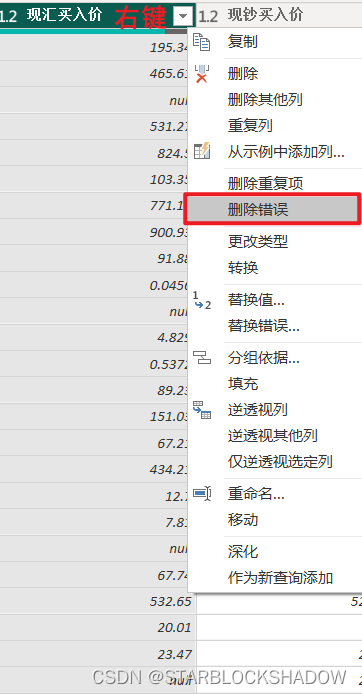
方式2:
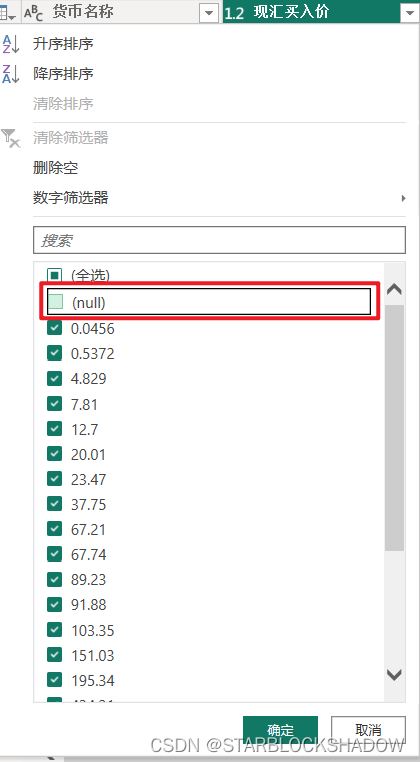
2.4.4 删除重复项
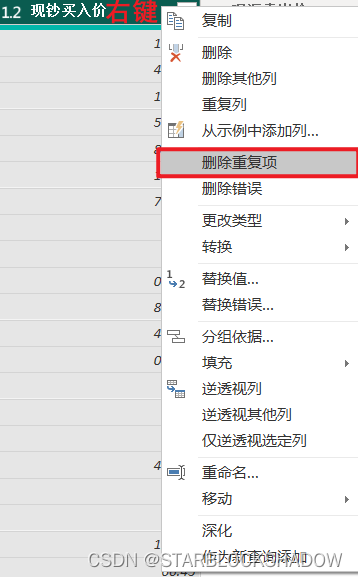
选中需要删除的列,右键单击后选择“删除重复项”。
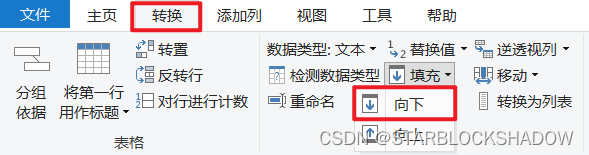
2.4.5 填充
在Excel数据中使用合并单元格的合并的单元格,导入到Power Query后其余合并的单元格会变成空值。
在Power Query中可使用向下填充将数据补全:
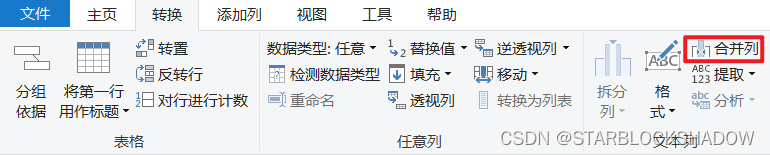
2.4.6 合并列
在Power Query中选择需要合并的列,在菜单栏中单击“合并列”,弹出合并列窗口,可以设置合并列之间的分隔符。
2.4.7 拆分列
拆分列即合并列的逆操作,可以根据按字符数、数字或字母来分列,如果列中包含多个分隔符,还可以选择按哪个位置的分隔符来拆分。
2.4.8 分组
分组即对明细数据进行汇总统计。如对所有行进行计数:

2.4.9 提取
Power Query可以按照长度、首字符、尾字符、范围等来提取字符。
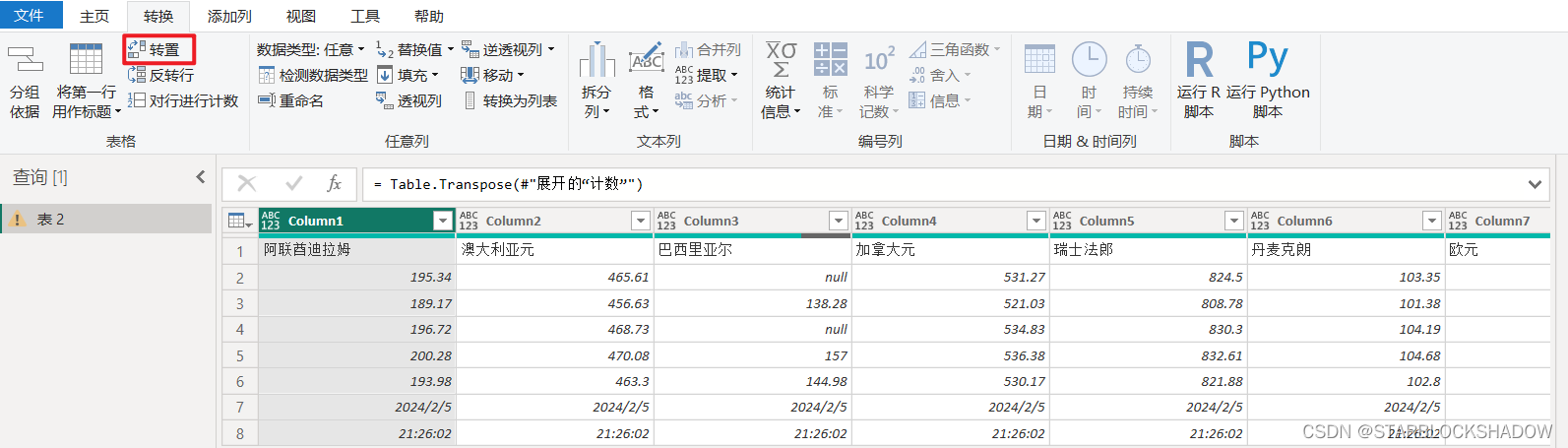
2.4.10 行列转置
数据处理中有时需要行列互相转换,直接点击行列转置实现。
一般直接转置会导致数据丢失,因此需先“将标题作为第一行”,再进行转置,最后记得再“将第一行作为标题”。
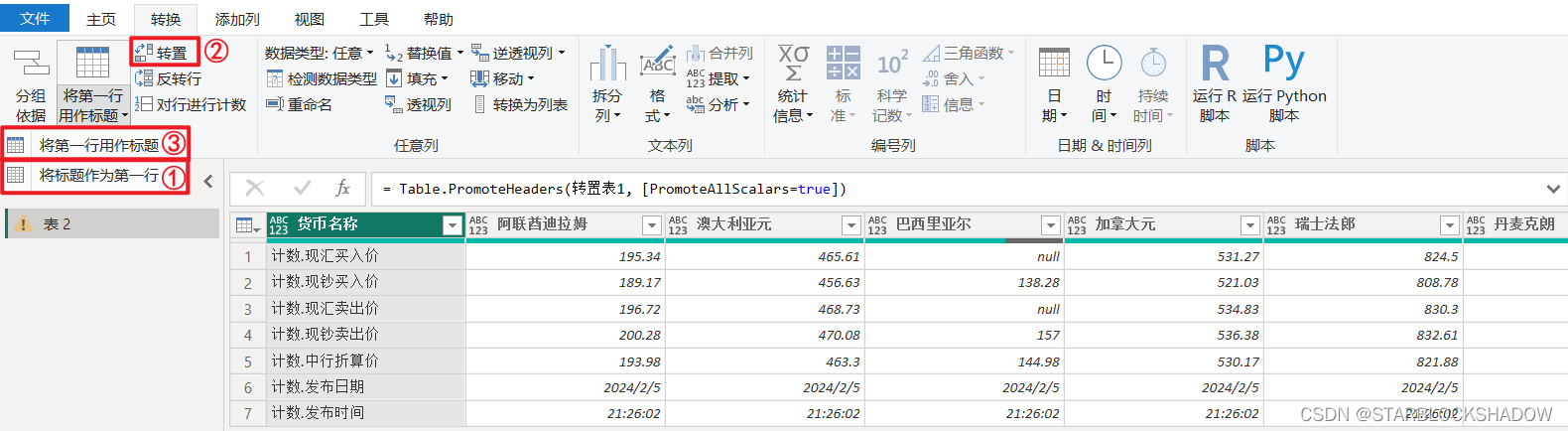
2.4.11 行列操作
Power Query的行列操作十分灵活,非常适合大规模数据操作,包括选择列、删除列、保留行和删除行:
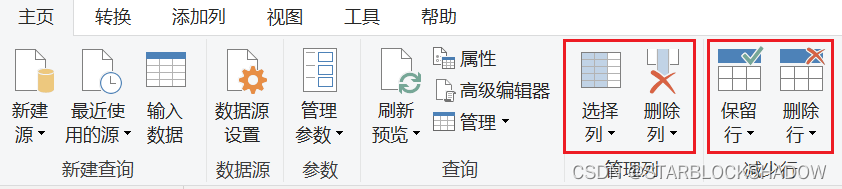
2.4.12 逆透视列
Power Query中的逆透视功能,能够一键将二维表变为一维表。
可以选中需要逆透视的列,单击“逆透视列”,或者选中不需要逆透视的列,单击“逆透视其他列”。
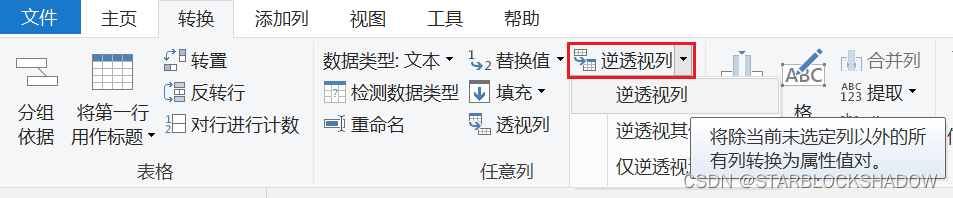
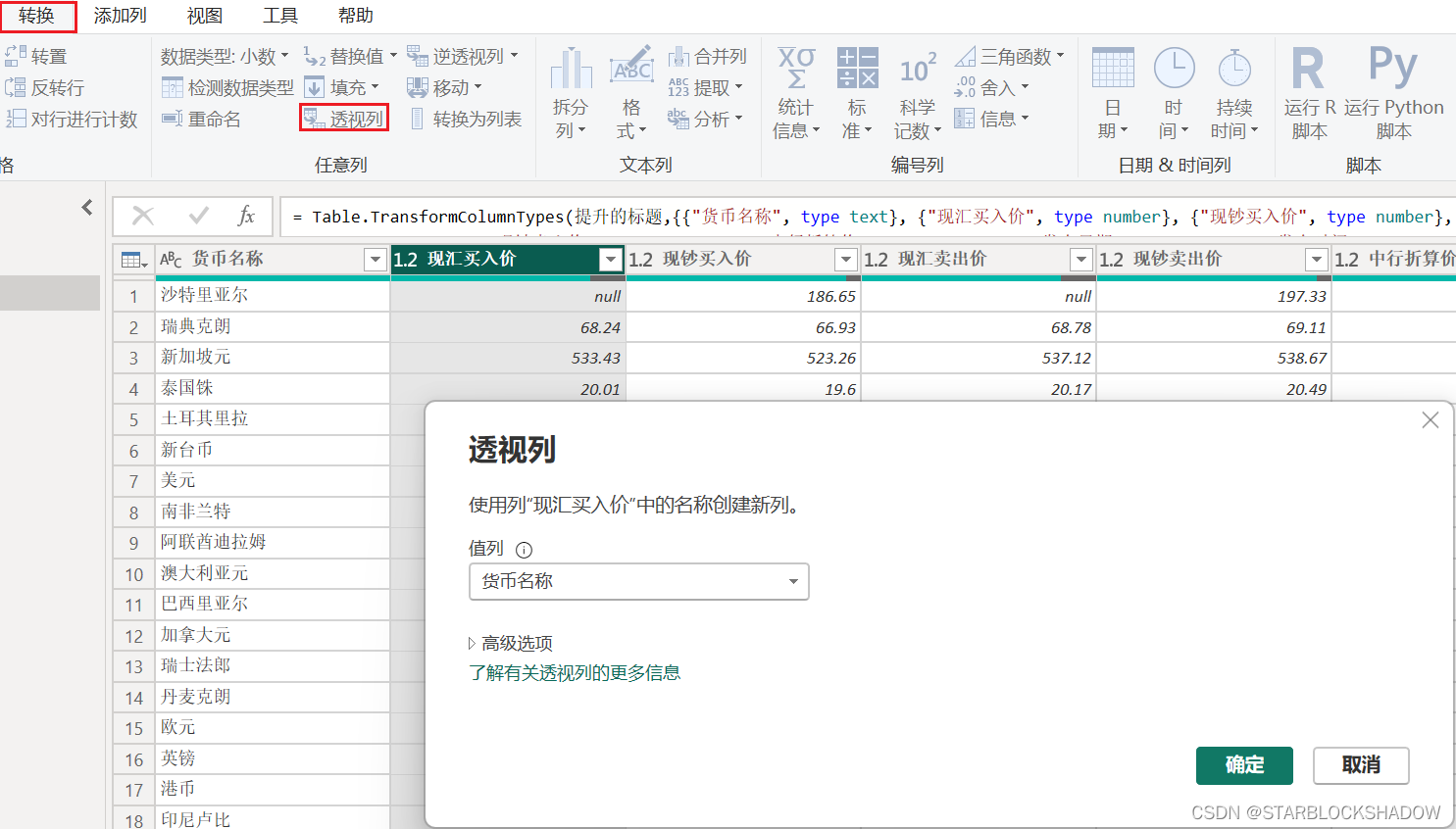
2.4.13 透视列
Power Query中的透视功能,能够一键将一维表变为二维表。
选中需要透视的列,单击“透视列”,并选择相应的值列。
2.4.14 添加列
Power Query中添加列有添加重复列、索引列、条件列、自定义列、示例中的列等形式。
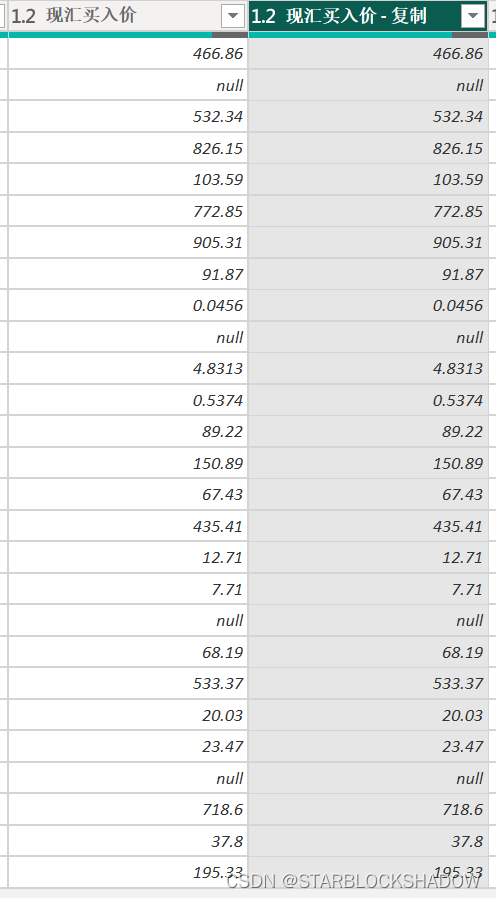
- 添加重复列
添加重复列即复制选中的某一列,以便对该列的数据进行处理而不破坏原数据。
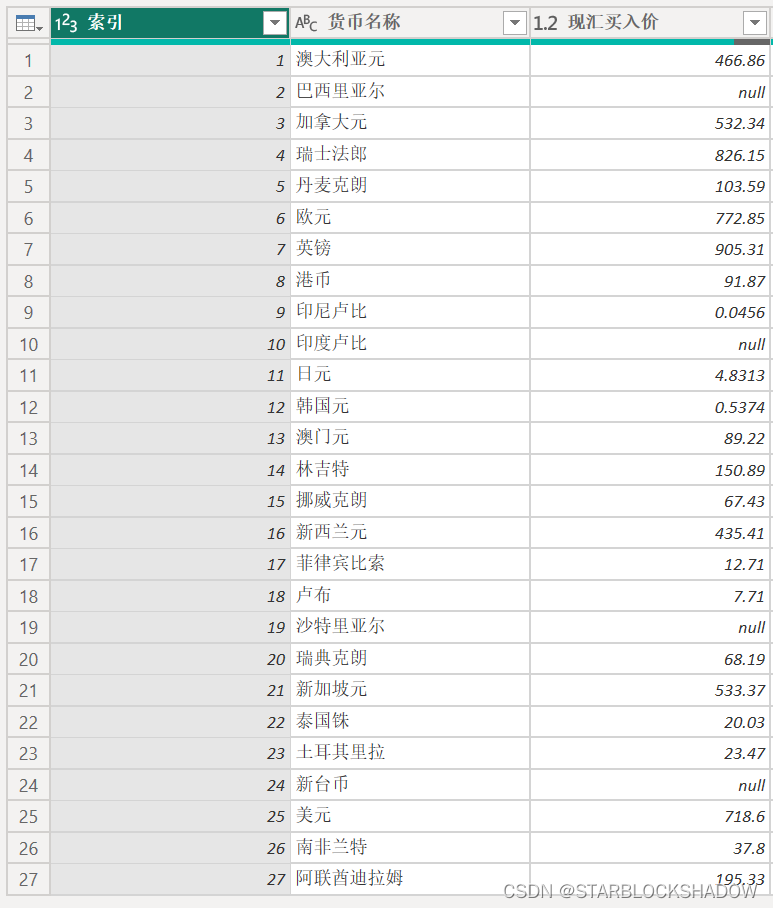
- 添加索引列
索引列即为每行增加一个序号,记录每一行所在的位置,可以选择从0或1开始。
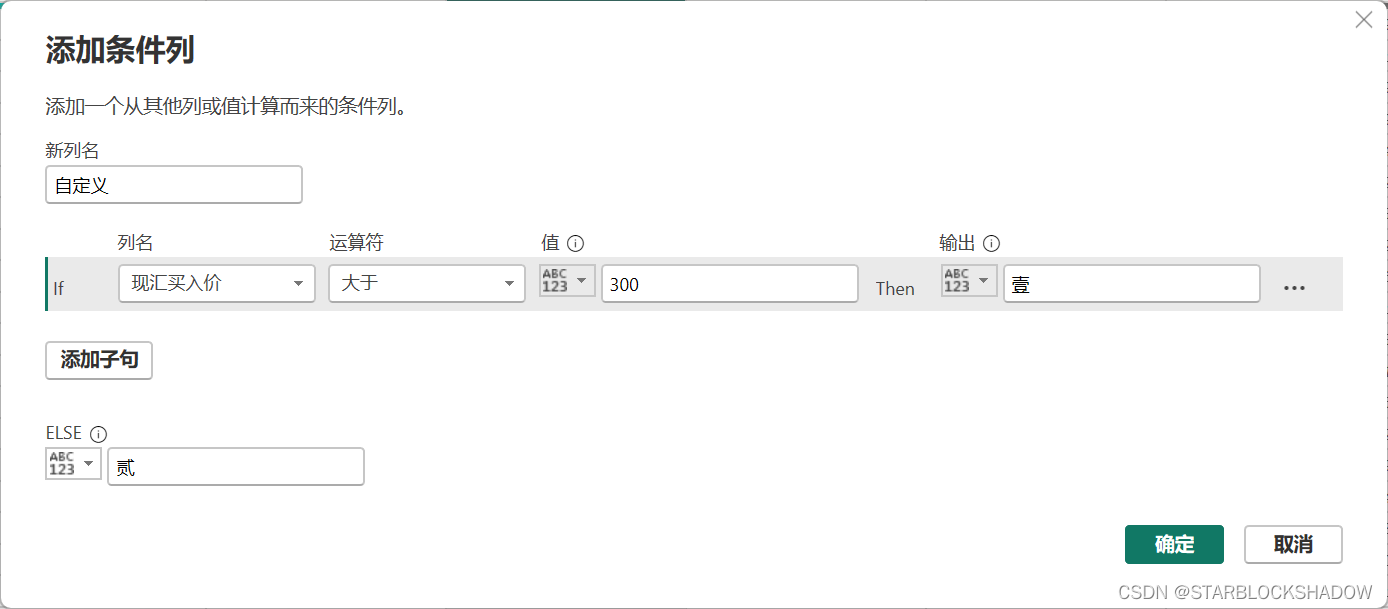
- 添加条件列
添加条件列可根据指定的条件,返回特定的值存放在条件列中。这个条件相当于Excel中的IF函数。
4.添加自定义列
自定义列即用M函数生成新的一列。
5. 添加示例中的列
添加示例中的列相当于Excel中的智能填充,单击“示例中的列”,可以选择按所选内容或者按所有列来分析,在弹出的窗口中,只要输入前两行数据,系统根据两个示例,自动分析所需要的数据,并填充到所有行。
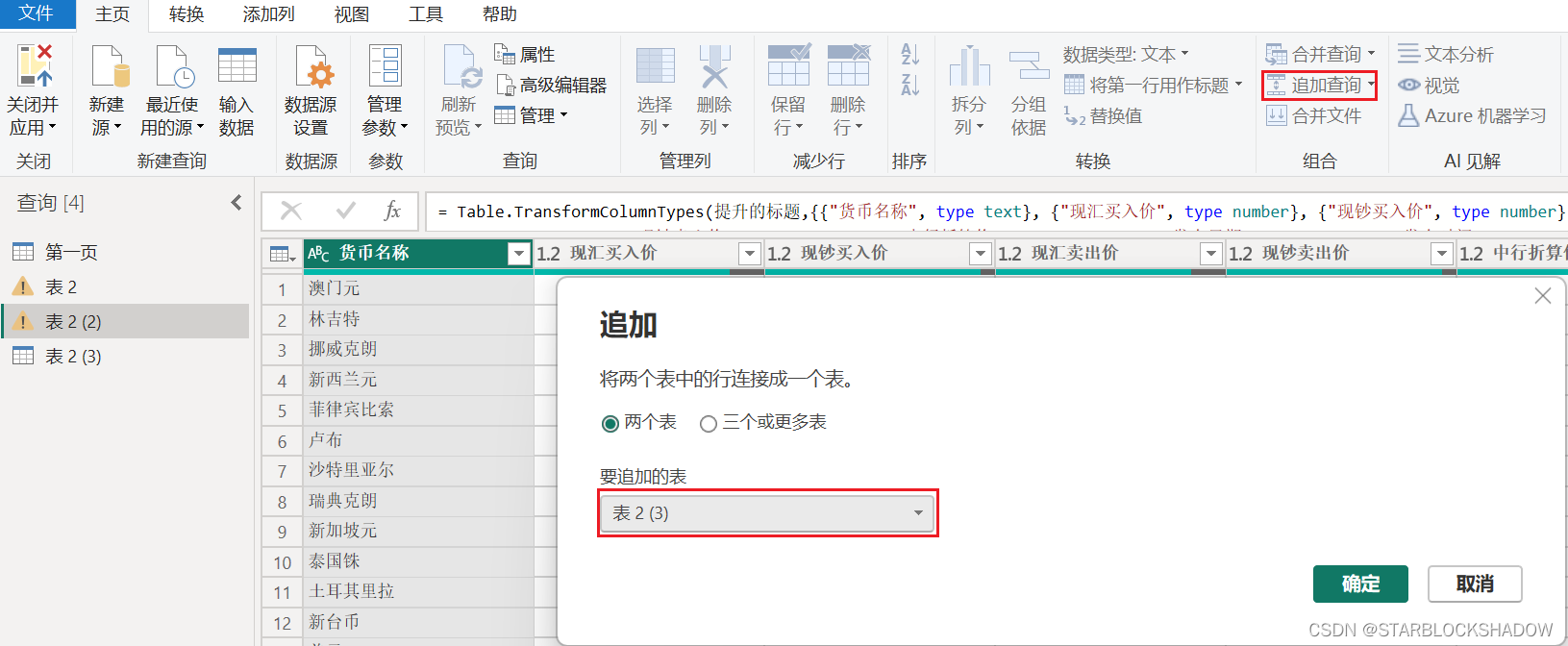
2.4.15 追加查询
追加查询是在现有记录的基础上,在下方添加新的行数据,它是一种纵向合并。
例如有两个表格式相同,需要合并为一个表,单击“追加查询”。
2.4.16 合并查询
合并查询即横向合并,它相当于Excel的VLOOKUP函数,用于匹配其他表格中的数据。
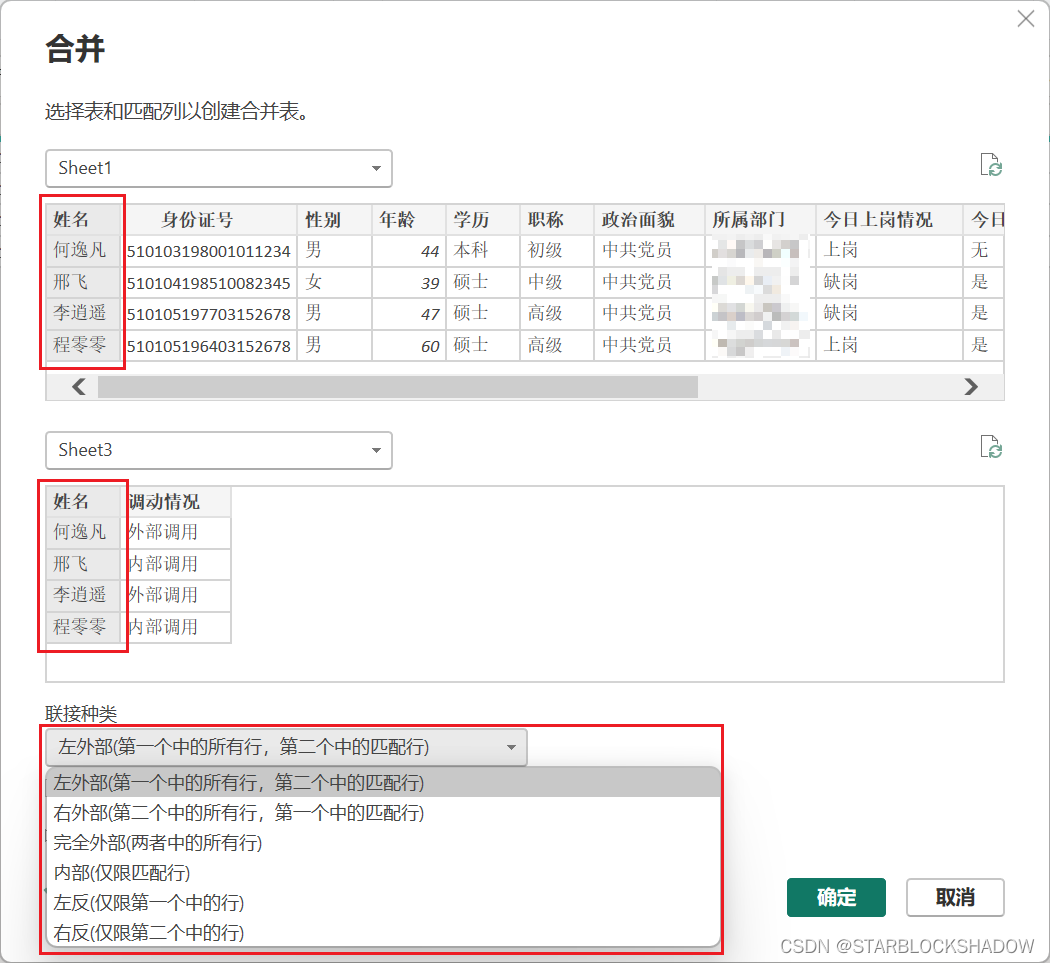
例如有两张表,一张是每个员工的调动数据表,另外一个表是包含这些员工基础信息表。现在需要在员工基础信息表中添加每个员工对应的调动情况。

点击“合并查询”,先选择两个表相互匹配的字段,点击这两个表的“姓名”列,根据需要选择联结种类。
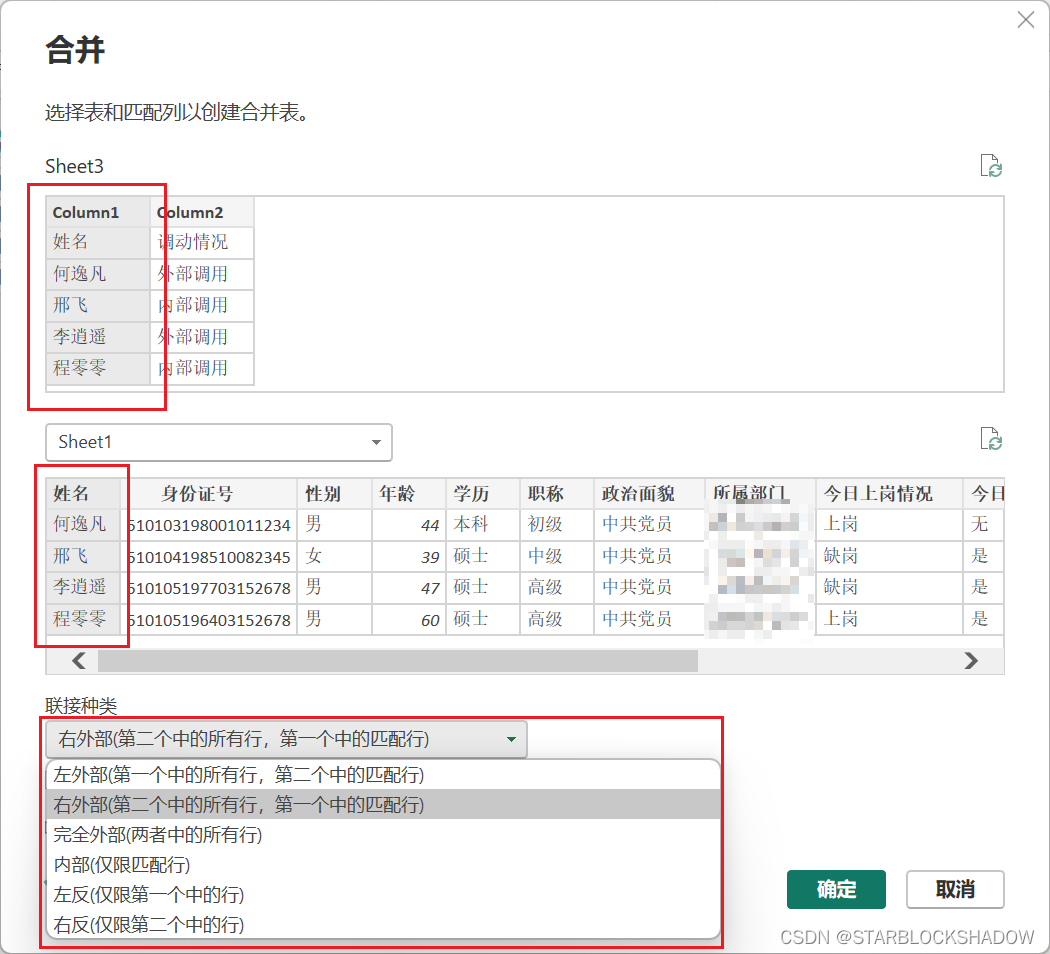
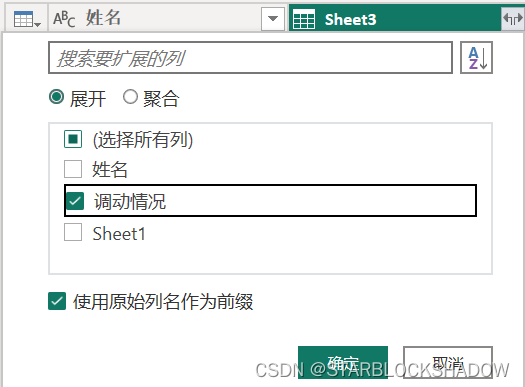
合并查询匹配过来的是一个表,所以每行都显示为Table,为了得到某一列,可以单击右上角的展开,选择需要的字段以完成合并查询。可以观察到表中增加了每个员工对应的调动情况。
通过这种方式可以一次性匹配多列,在展开时,选择需要的列就可以了,而VLOOKUP函数一次只能匹配一列。

2.5 二维表转一维表
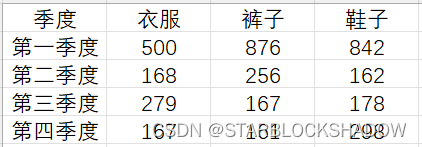
二维表更符合人们日常的阅读习惯,信息更浓缩,展现效果更好,但作为源数据进行数据分析时,一维表更合适。
以下是一个二维表的示例:
而一维表每一列是一个维度,列名就是该列值的共同属性;每一行是一条独立的记录。
以下是一个一维表的示例:
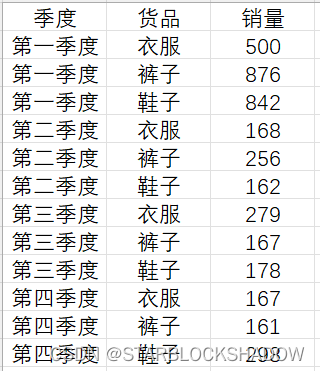
根据二维表结构的不同,转换成一维表的方式也有所不同。
2.5.1 行列标题均为单层的二维表
直接使用Power Query中的逆透视功能。
选中“季度”列,点击“逆透视列”下的“逆透视其他列”。
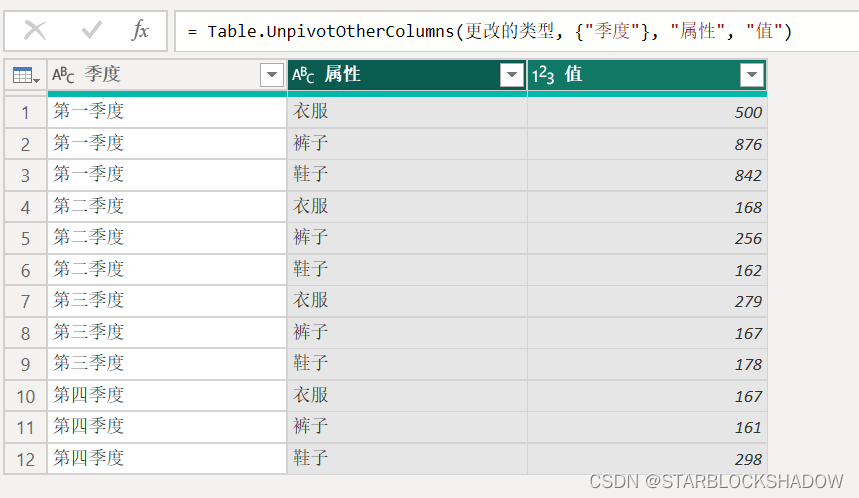
注:透视/逆透视等操作,生成的结果表的列名,需自己手动更改。
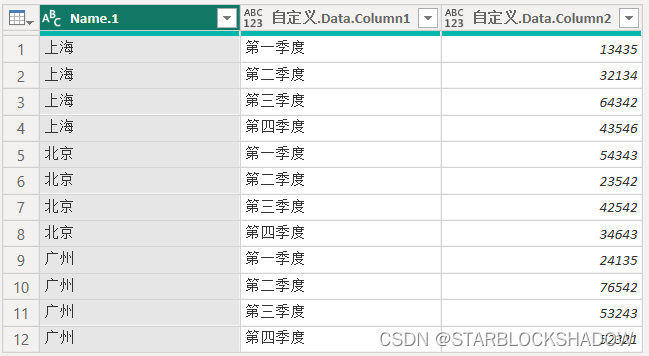
2.5.2 行标题有多层的二维表
行标题带有层级结构的二维表,有两层行标题,如下表所示:
将该表导入Power Query编辑器后,合并单元格的内容会显示为null。
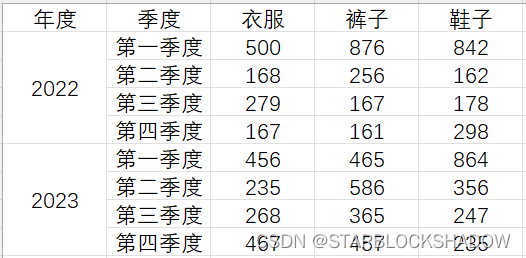
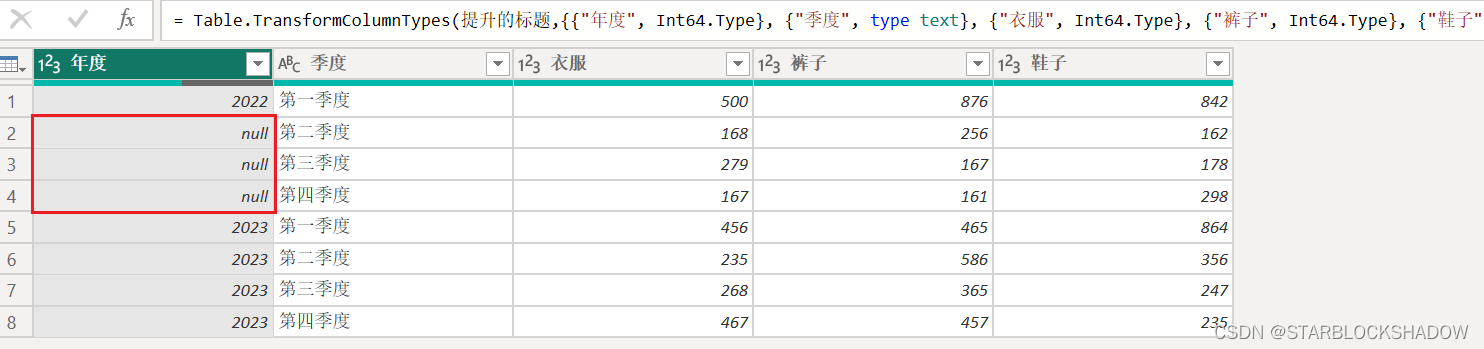
首先把年度列向下填充,将年度数据补齐:
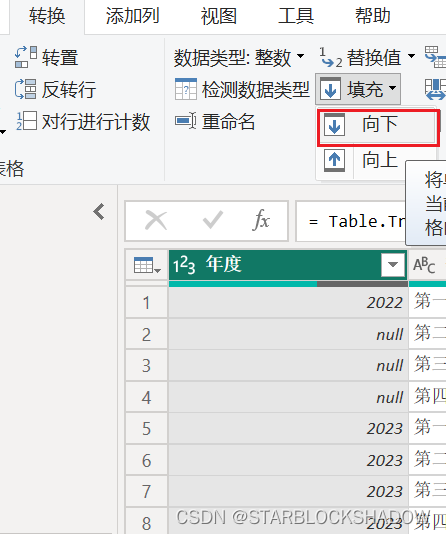
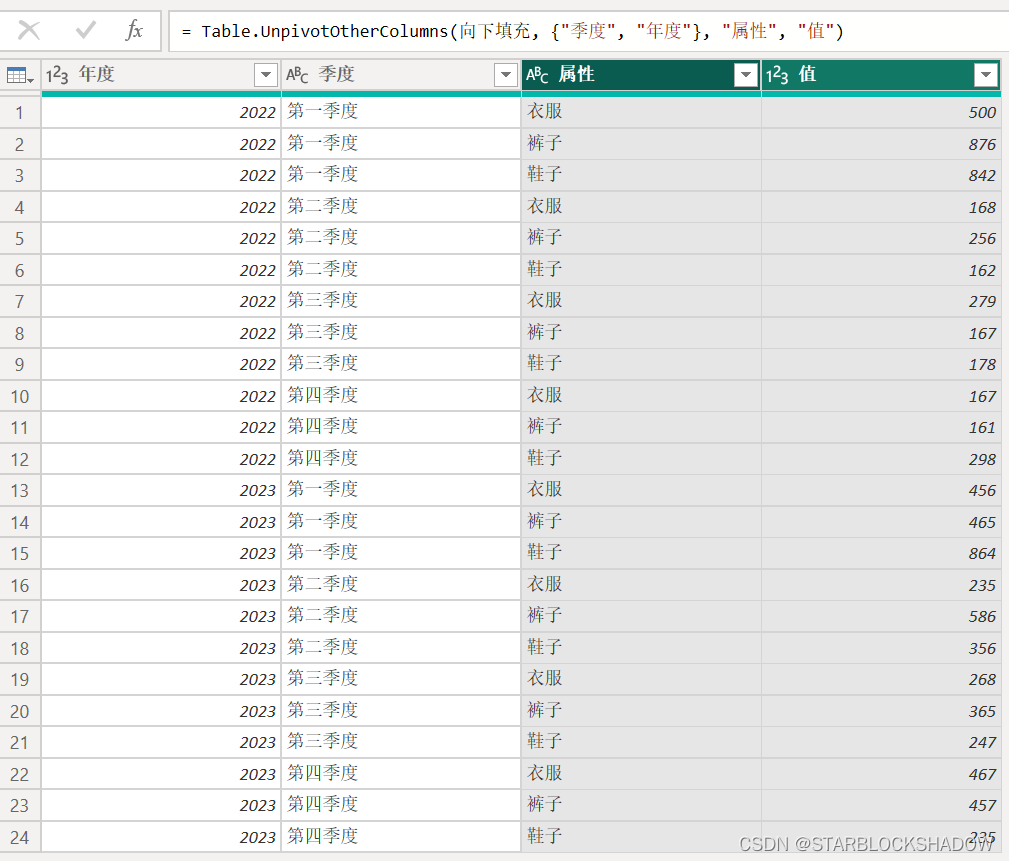
接着选中“年度”和“季度”列,点击“逆透视其他列”,完成一维表的转换。
2.5.3 列标题有多层的二维表
列标题带有层级结构的二维表,有两层列标题,如下表所示:
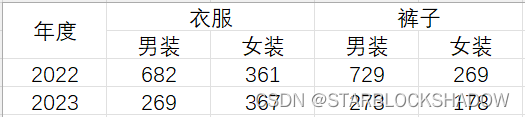
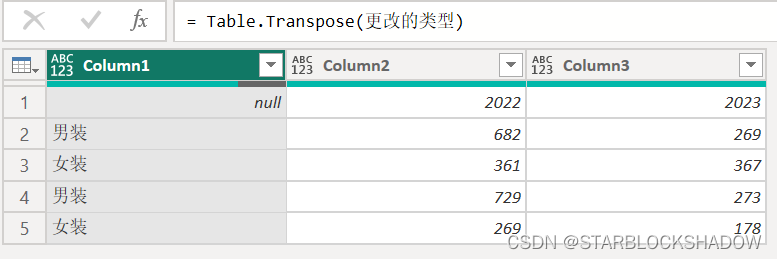
将该表导入Power Query编辑器后,点击“转置”,即可将这种类型的二维表转换为行标题有多层的二维表类型,接着“将第一行用作标题”,选中第一列,“逆透视其他列”即可。
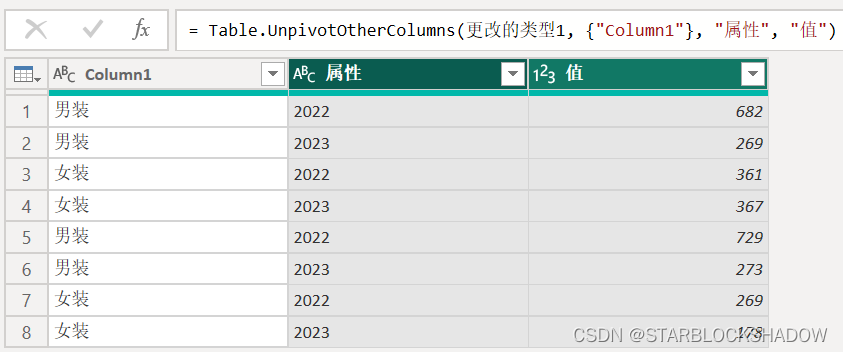
2.5.4 行、列标题均有多层的二维表
行标题和列标题均带有层级结构,如下表所示:
将该表导入Power Query编辑器:
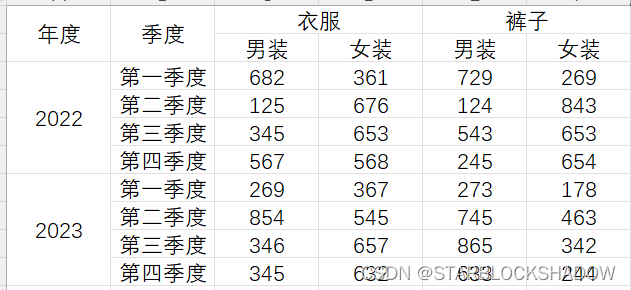
- 将“年度”列向下填充:
- 将“年度”列和“季度”列合并,生成年度季度列:
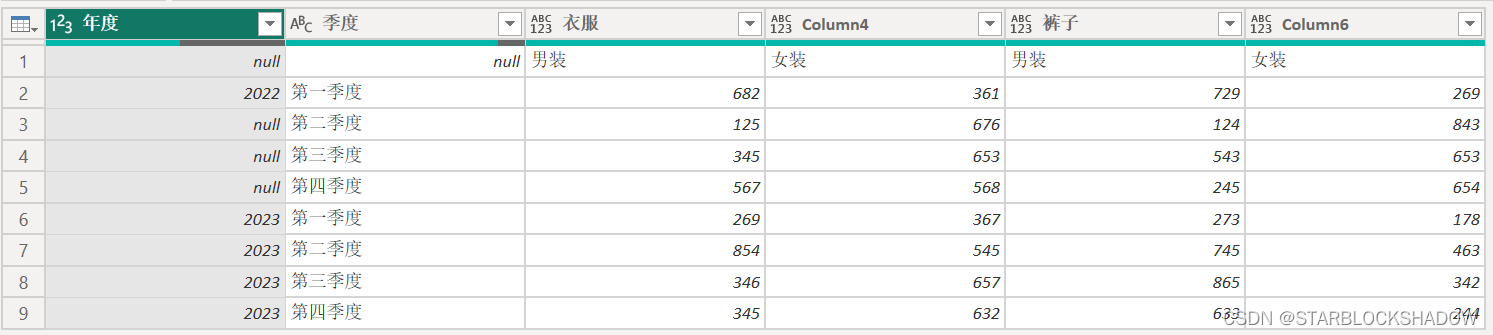
“将标题作为第一行”:
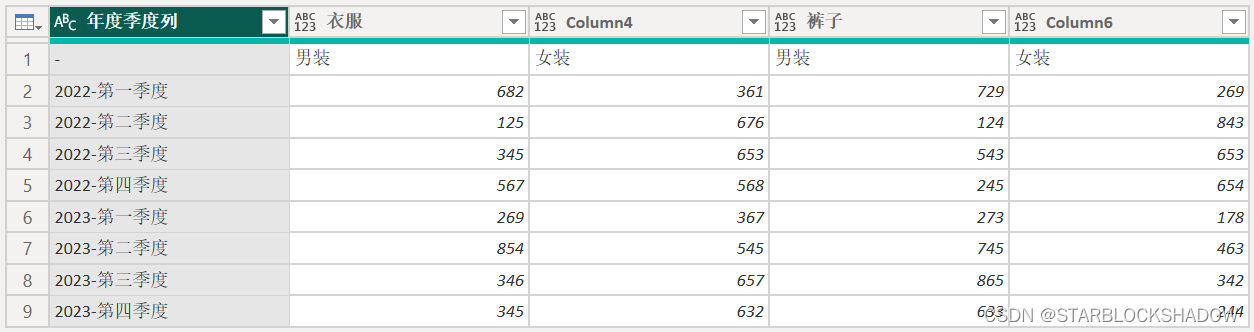
此时,该二维表已转换为列标题有多层的二维表。
-
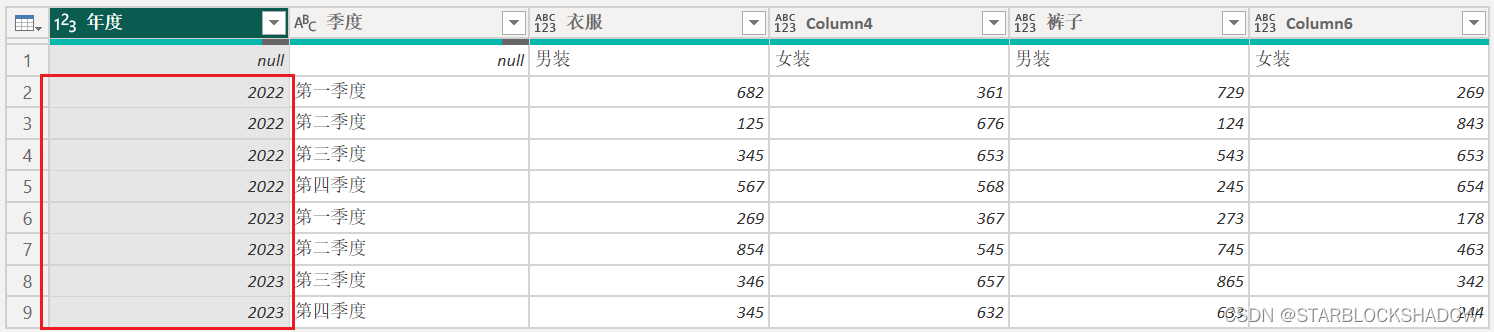
“转置”表,并“将第一行用作标题”,“替换值”,就转换成了行标题有多层的二维表:
-
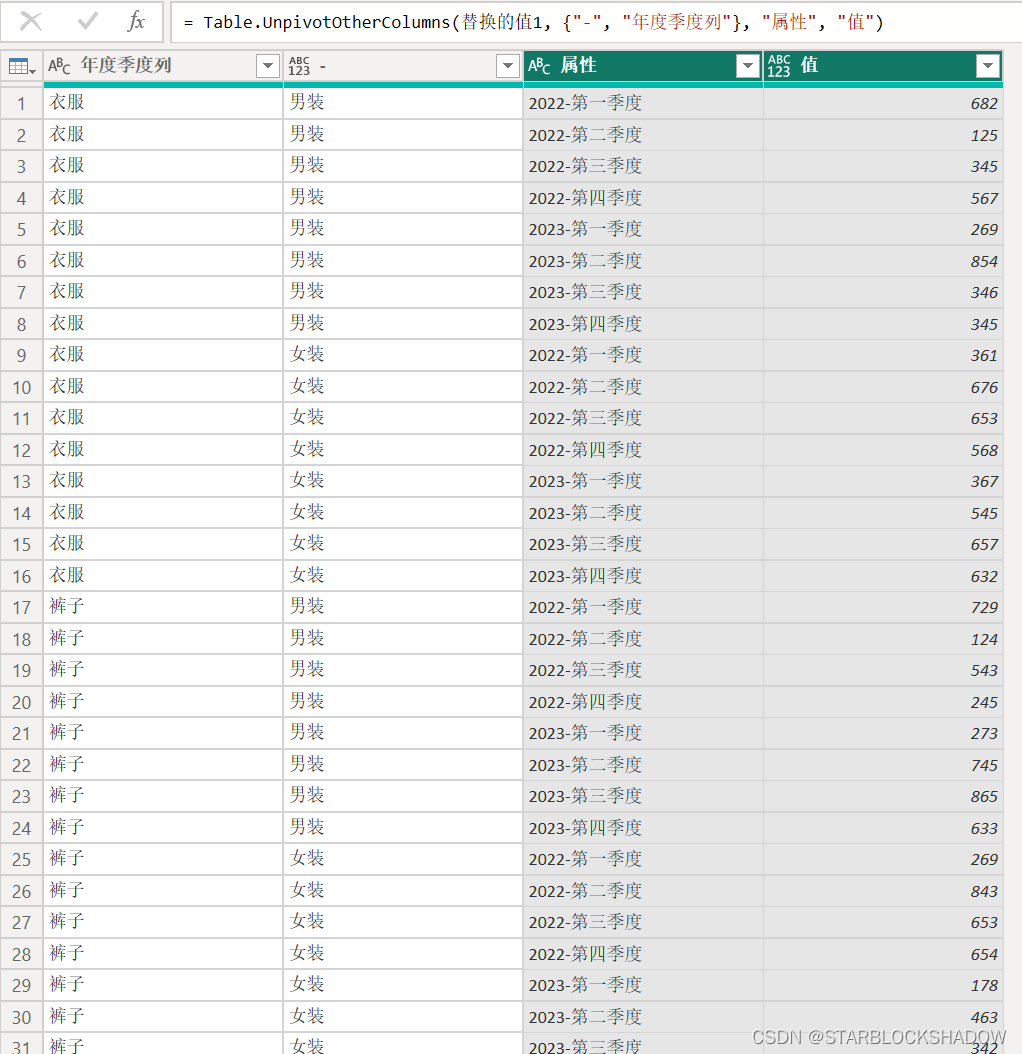
选中前两列,逆透视其他列,就转换成了一维表:

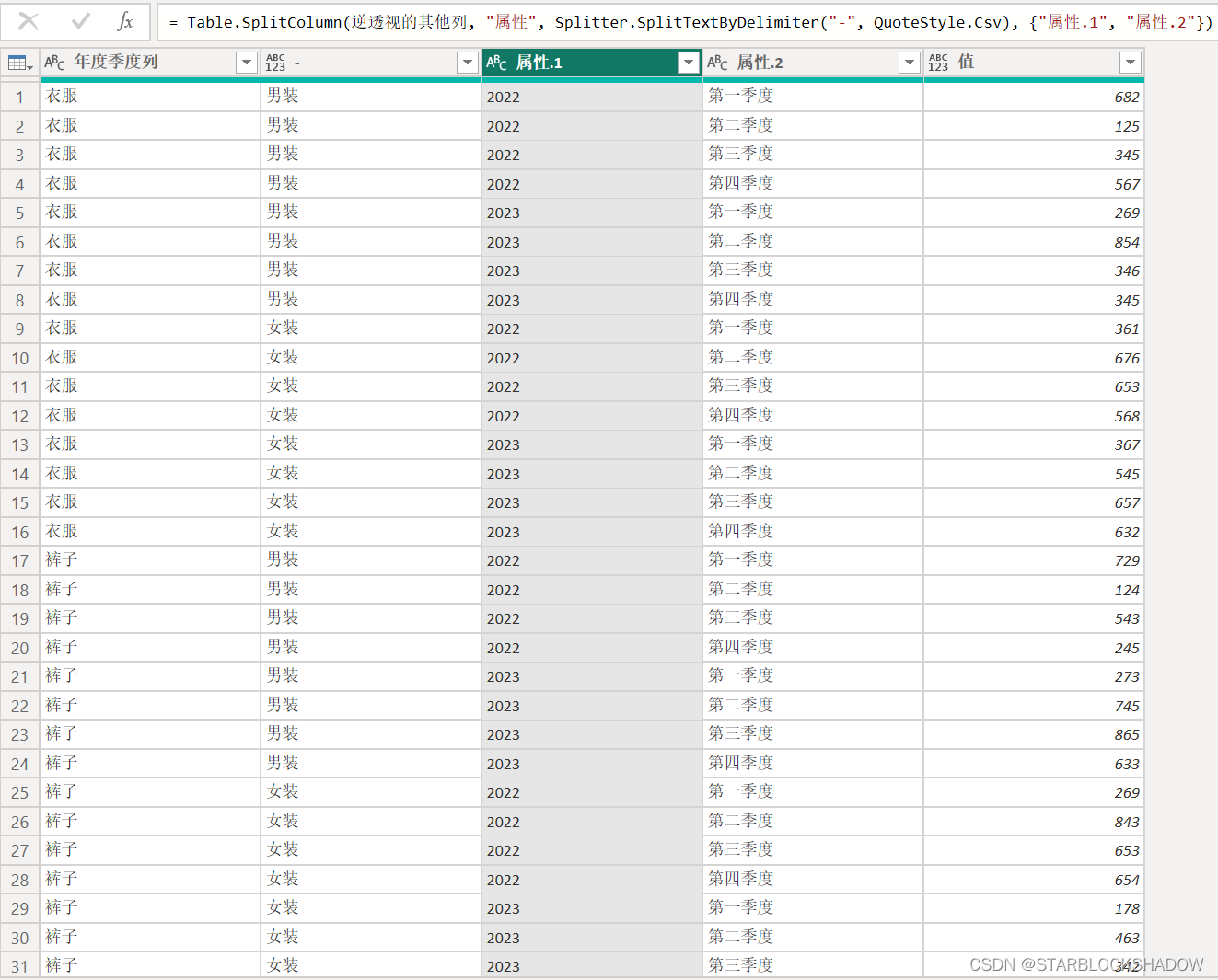
5. 为了和源数据维度一致,将年度季度列进行分列,得到最终的一维表:
2.6 M函数
Power Query中的函数称为M函数,可实现更复杂的操作。
数据清洗的每一个步骤,都是使用M函数实现的,只是Power Query将一些常用操作简化成了键鼠操作。
打开菜单栏视图→高级编辑器,可查看M函数实现的数据清洗的每一步操作:
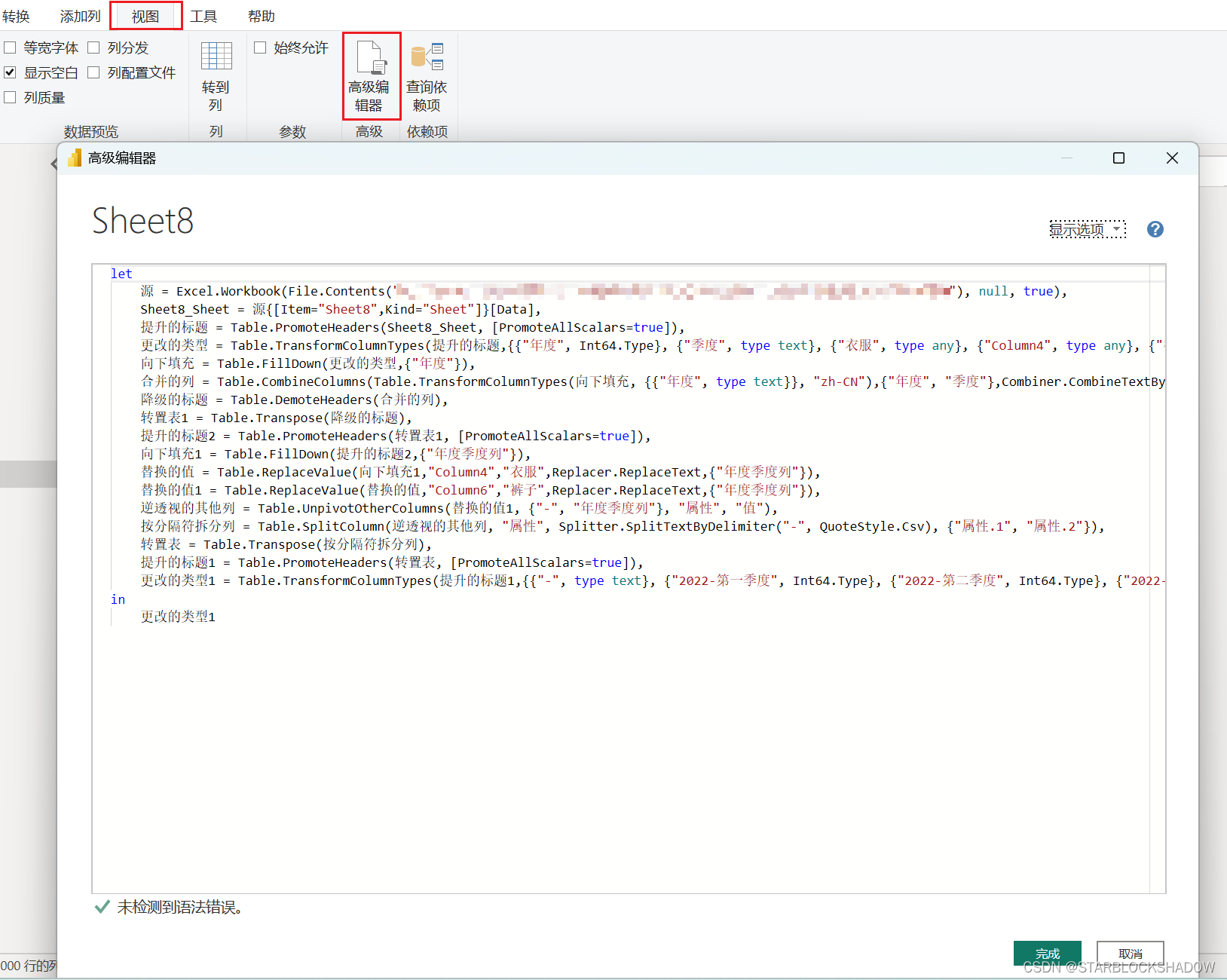
2.6.1 M函数的基本规范
- 严格区分大小写,每一个字母必须按函数规范书写,第一个字母都是大写的。
- 表被称为Table,每行的内容是一个Record,每列的内容是一个List。
- 行标是大括号
{},比如取第一行的内容:=表{0};列标用中括号[],比如提取自定义列的内容:=表[自定义]。取第一行自定义列的内容:=表{0}[自定义]。
注:Power Query的第一行从0开始。
2.6.2 常用的M函数
- 聚合函数
- 求和:List.Sum()
- 求最小值:List.Min()
- 求最大值:List.Max()
- 求平均值:List.Average()
- 文本函数
- 求文本长度:Text.Length()
- 去文本空格:Text.Trim()
- 取前n个字符:Text.Start()
- 取后n个字符:Text.End()
- 移除文本:Text.Remove()
- 提取文本:Text.Select()
| 提取字符类型 | M函数 |
|---|---|
| 提取数字 | Text.Select([文本数据],{“0”…“9”}) |
| 提取大写英文字符 | Text.Select([文本数据],{“A”…“Z”}) |
| 提取小写英文字符 | Text.Select([文本数据],{“a”…“z”}) |
| 提取全部英文字符 | Text.Select([文本数据],{“A”…“z”}) |
| 提取全部中文字符 | Text.Select([文本数据],{“一”…“龟”}) |
Text.Remove()函数同样可以使用上表,不同的是结果变为移除这些字符。
- 提取数据函数
- 从Excel表中提取数据:Excel.Workbook()
- 从Csv/Txt中提取数据:Csv.Document()
- 条件函数
- If then else(相当于Excel中的IF函数)
2.7 分列技巧
2.7.1 常规分列
最常见的是有固定分隔符的规范数据,这种数据按照分隔符拆分即可。
若没有分隔符,还可以考虑“按字符数”、“按位置”、“按照从小写到大写的转换”、“按照从大写到小写的转换”、“按照从数字到非数字的转换”、“按照从非数字到数字的转换”。
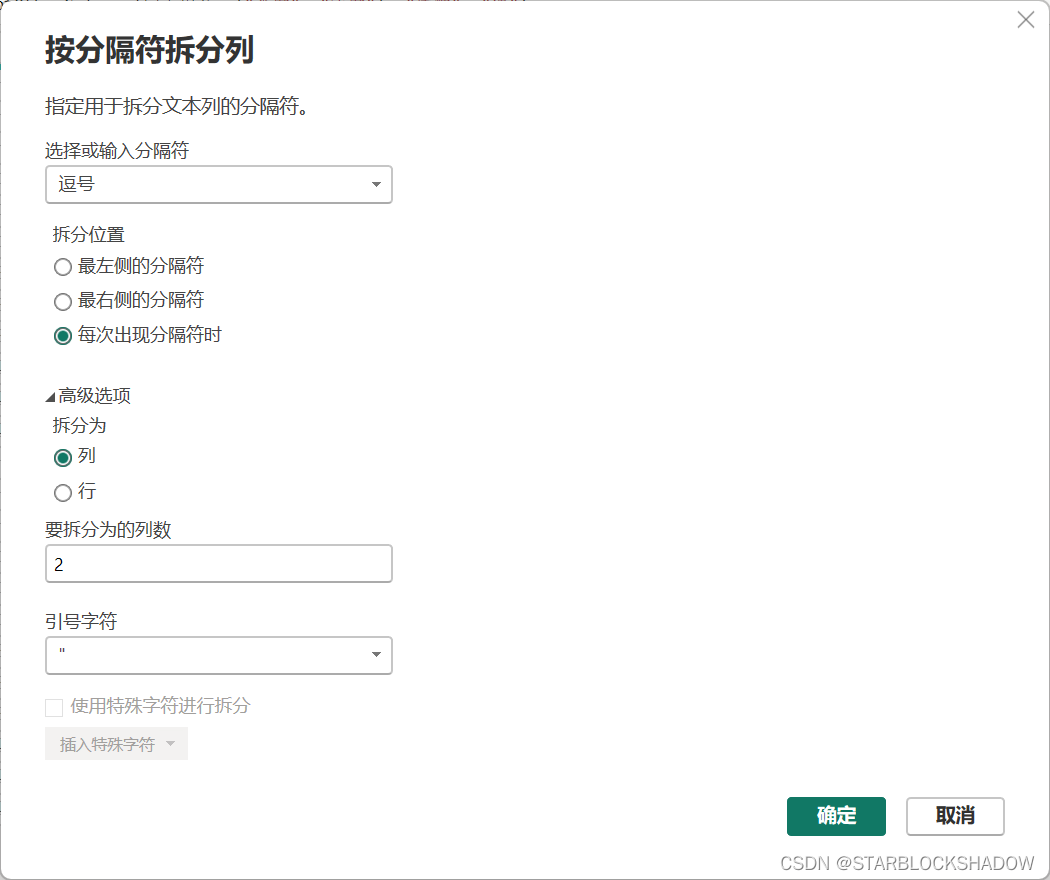
高级选项中还能将一个单元格中的内容拆分为多行。
2.7.2 多种分隔符
如果分隔符有多种,那么可以使用M函数进行分列:
=Table.SplitColumn(
提升的标题, "区号",
Splitter.SplitTextByAnyDelimiter(
{",",";","-","+","。"},
QuoteStyle.Csv
)
)
其中提升的标题是上一个步骤的名称,使用时要更改为实际的步骤名,字符替换为实际数据的分隔符。
2.8 批量汇总
批量汇总即将多个表的内容汇总到一个表中。
2.8.1 批量汇总多表数据
一个工作薄有多张工作表:
-
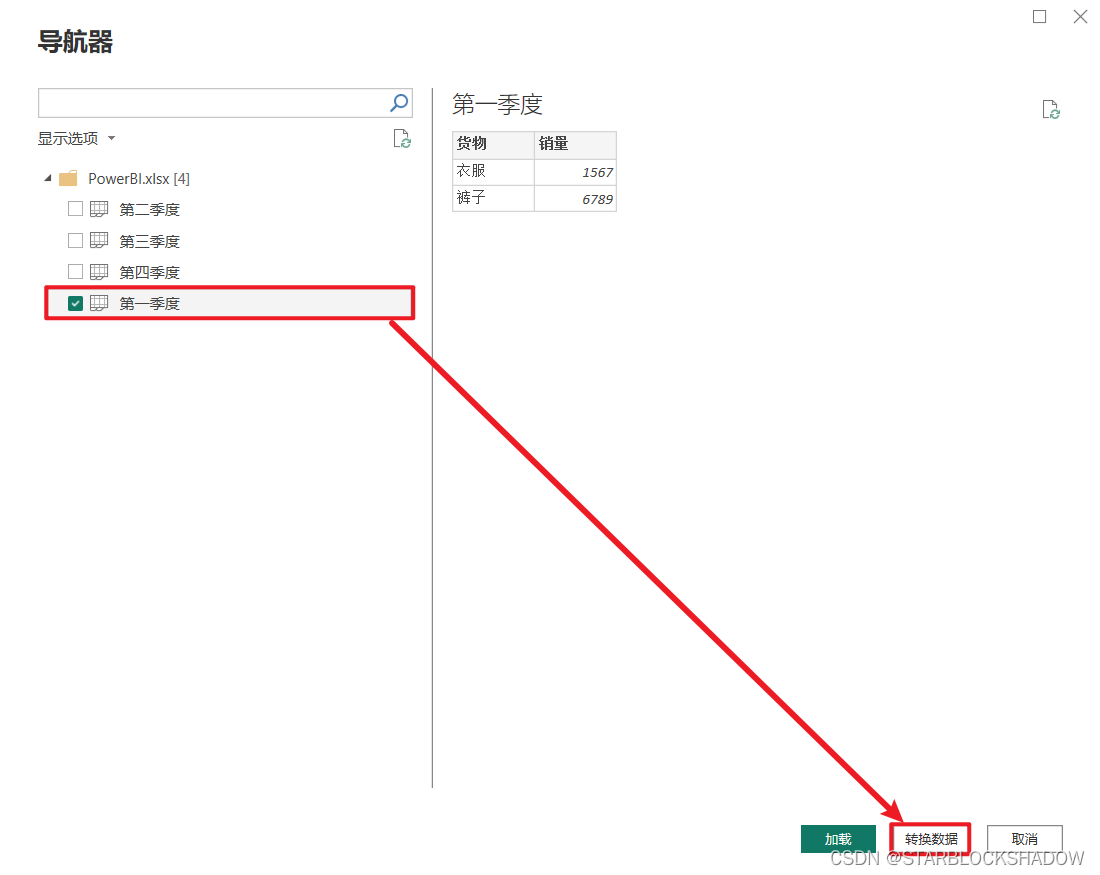
将该工作薄导入Power BI,选择任意一个工作表,单击“转换数据”:
-
在Power Query编辑器窗口中,在右侧的步骤栏删掉“源”之后的所有步骤:
-
筛选Name列,选择需要合并的工作表,如果不选择,就是合并所有的工作表数据。
-
展开Data列的数据,得到合并所有工作表的效果:
-
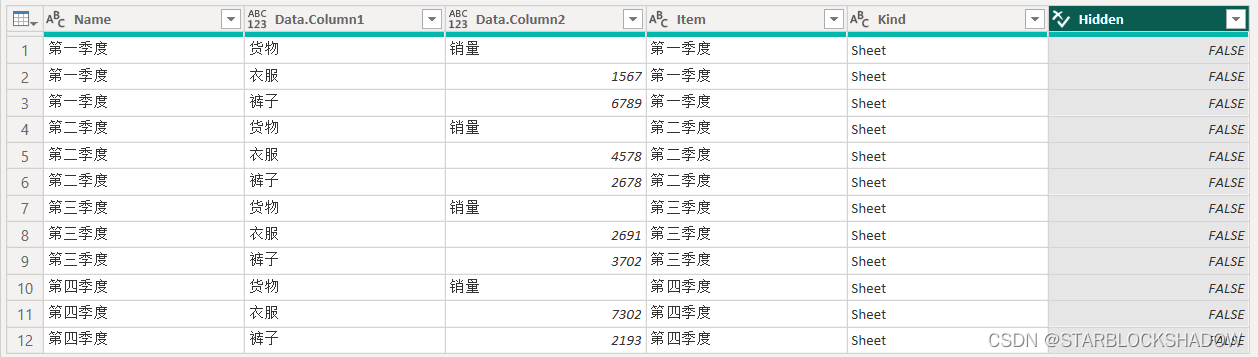
对数据表进行相应的数据处理,得到最终的表格:


2.8.2 批量合并多工作簿数据
-
将需要合并的多个工作簿放在同一个文件夹中:
-
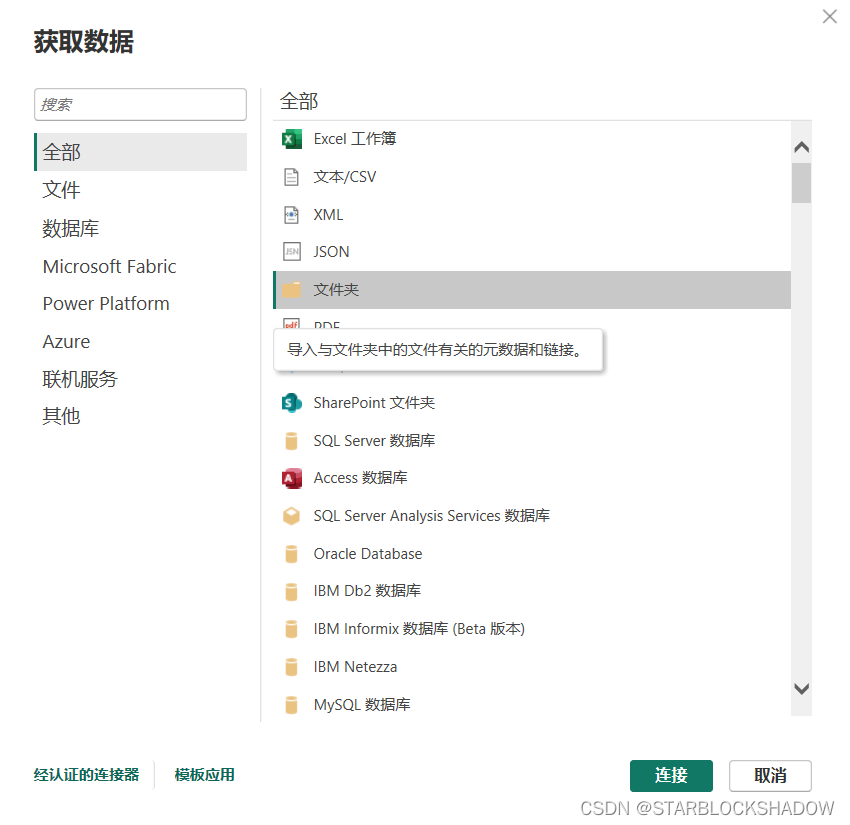
在Power BI中选择“获取数据”→“全部”→“文件夹”,选择文件夹所在位置:
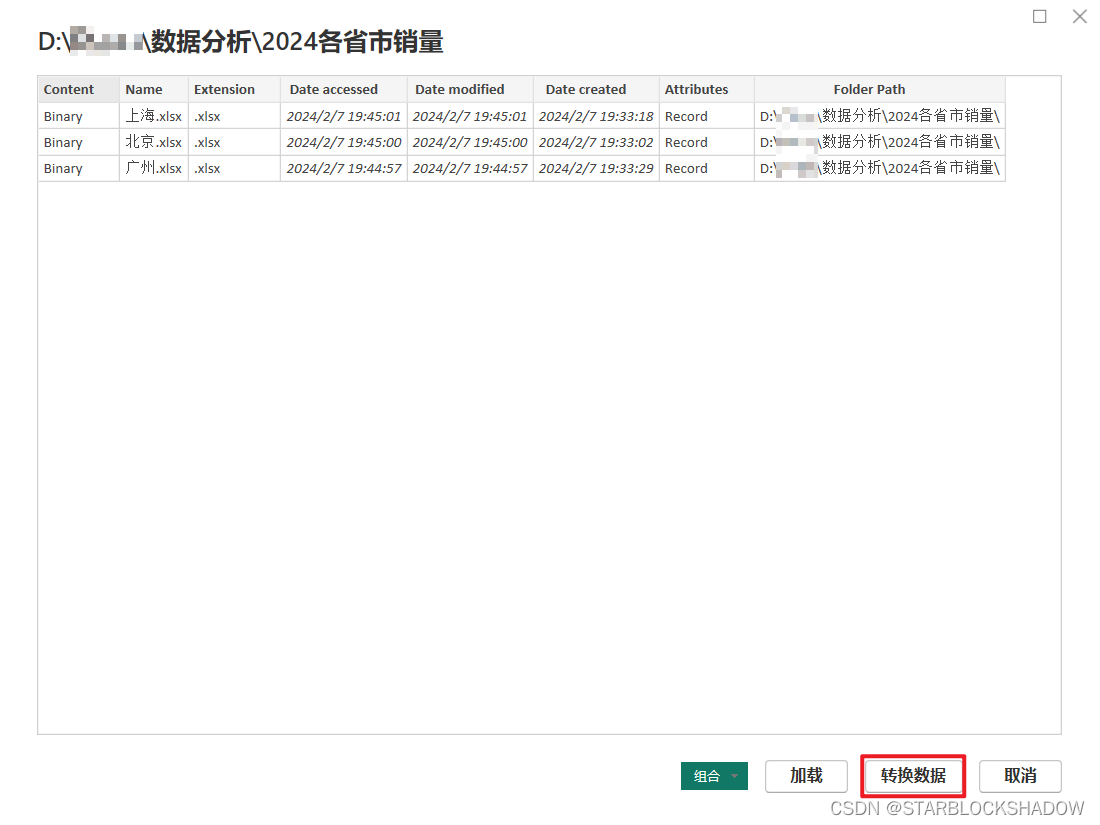
-
在预览界面中点击“转换数据”:
-
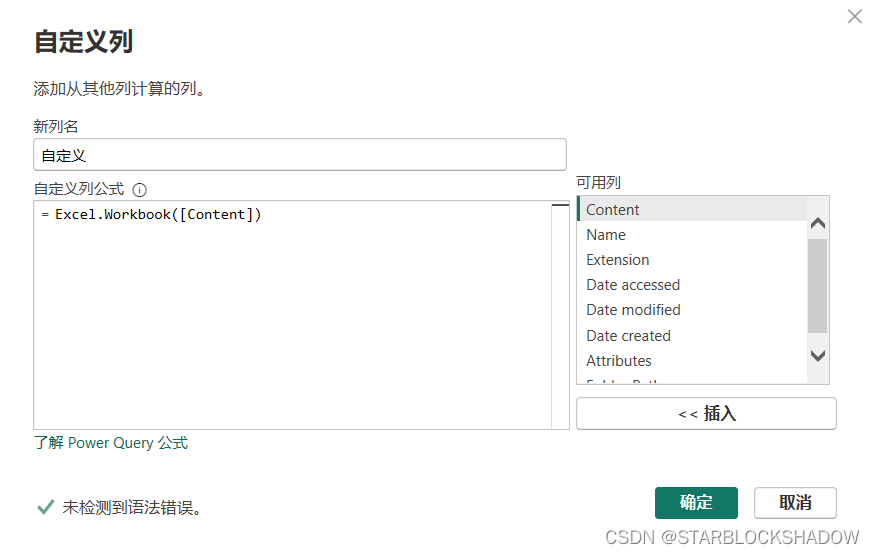
进入Power Query编辑器,添加自定义列
=Excel.Workbook([Content]):
Excel.Workbook是一个M函数,用于将Power Query导入数据自动生成的二进制工作表转换成可读的table文件。 -
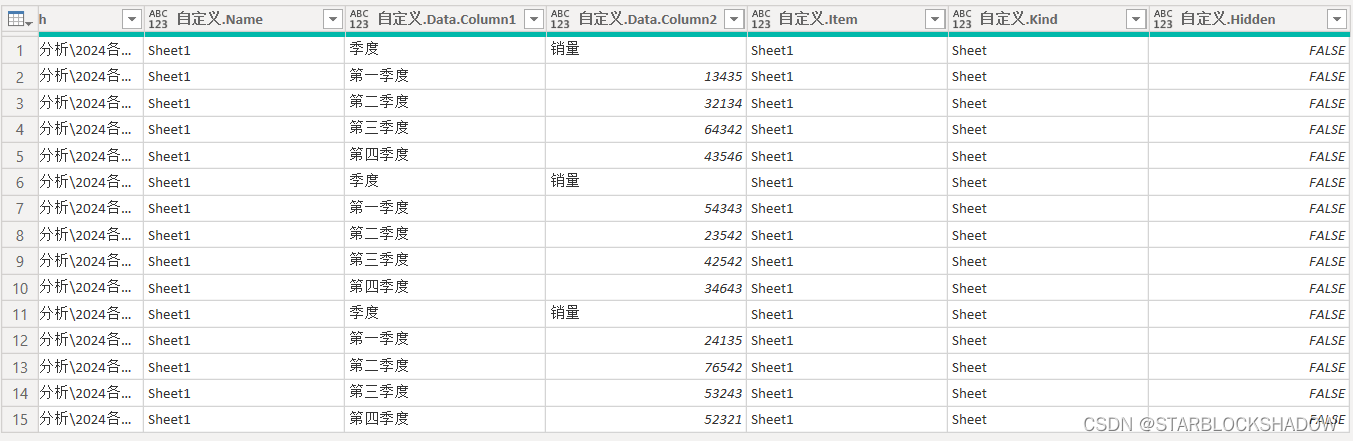
展开自定义列,所有Excel工作簿的每个工作表都会显示出来:
展开之后,会有一列是所有工作簿中的工作表列表,如果只想合并部分工作表,可以在这里通过筛选实现,如果不做任何筛选,就是合并每一个工作簿中的所有数据。 -
展开Data列,把合并的数据展示出来:
-
经过数据整理,得到最终的数据表:

3 数据建模
根据数据分析的需求,在多个表之间建立合适的关系,将多个分散的表格变成一个协同的模型,以便能按不同的维度、不同的逻辑来聚合分析数据,这个过程称为数据建模。
3.1 基本概念
3.1.1 字段
字段是表的一列,只包含一种信息,列名就是字段名。
在Power BI中,选中某个字段,功能区上方自动出现“列工具”选项卡。在进行数据分析之前,最好对字段进行如下设置:

- 检查字段的数据类型是否正确,比如数值型、文本型等。
- 设置字段的显示格式,比如百分比、千分比等。
- 检查字段的默认汇总方式,比如求和、计数、不汇总等。
- 检查字段的数据类别,比如地理字段,可以设置为国家、城市、经纬度等。
3.1.2 计算列
计算列也是一个字段,它是在数据模型中使用DAX新建的列。在数据视图中,选择需要新建列的表,单击功能区中的“新建列”即可输入DAX,在该表中添加一个新列,这个新建的列可以同源数据的其他列一样使用。


计算列仅当刷新表数据时才执行计算所使用的DAX,计算列的生成值存储在数据模型中,占用内存,如果在很大的表中添加列可能会对数据模型的内存大小产生显著影响,因此非必需的情况下,一般不建议使用计算列。
同时,计算列不涉及用户交互,其类型和格式等设置与字段的设置相同。
3.1.3 度量值
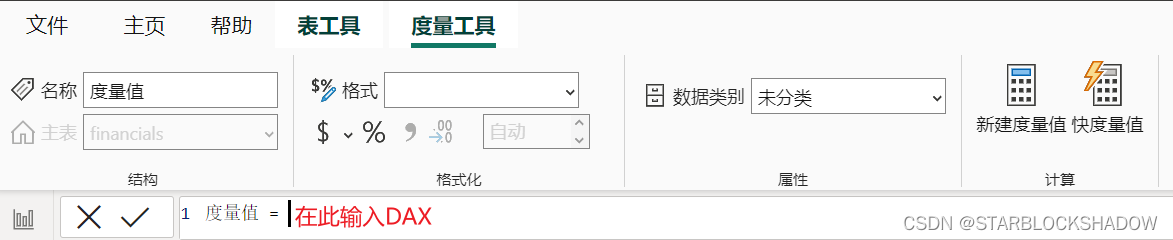
度量值与计算列一样是使用DAX建立的一个公式,但它不属于任何表。新建的度量值保持休眠状态,不执行计算,直到其被用于视觉对象中。
度量值计算出的结果是动态的,在不同的上下文中执行不同的计算,也被称为移动的公式。它可以响应用户交互,可以快速重新计算,但不将输出存储在数据模型中,对数据模型的物理大小没有影响,因此度量值计算是数据分析的首选方式。
点击功能区中的“新建度量值”,即可在编辑框中输入DAX建立度量值。建立好的度量值会显示在字段区中的某个表中,但它与该表并没有关系。当度量值比较多,可以将度量值专门收纳到一个文件夹中。点击某个度量值,在功能区会出现“度量工具”选项卡,可以设置该度量值的显示格式等,与字段的设置类似。

3.1.4 事实表
在Power BI中并没有事实表和维度表的区分,此处引用数据库中的相关概念,以便更容易解释数据模型。
事实表,又叫明细表,表示业务开展而产生的结果记录,比如订单表,如果有10000次销售,理论上,订单表包含10000行。
一个事实表最好只包含一种业务记录,比如订单表只含有销售记录,采购表只含有采购记录。
3.1.5 维度表
维度表,又叫查找表,通常用来作为分析问题的角度。比如按照产品分析,应该制作一个产品维度表,包含所有产品的不重复列表;按客户分析,应制作一个客户维度表,包含所有客户的不重复列表。
切片器的字段、图表的轴都应来自于维度表。数据模型的好坏取决于维度表的设计好坏和维度的质量好坏。
3.1.6 关系
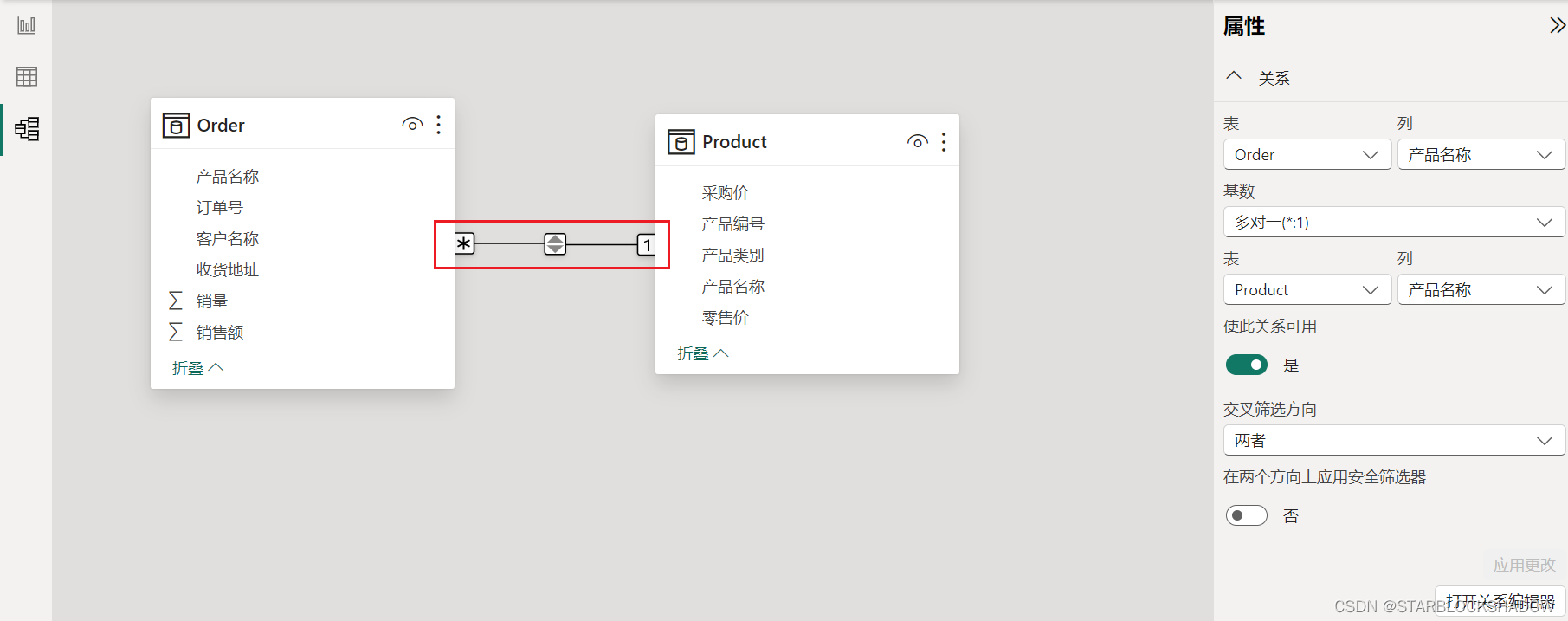
两个表之间的联系称为关系,它是数据建模最基础也是最重要的概念。从建模视图直观来看,关系就是一条线,关系线的中间带有箭头,两端还有1或者*的符号,这些都是关系的属性。
在建模视图中,拖动一个表的字段到另一个表的字段上,Power BI会自动分析检测数据,以便判断哪端是1,哪端是多(*),箭头一般是从1端指向多端的方向。当然前提是两个表确实有共同的关系列。
模型中可能有多个表,但一个关系仅存在于两个表之间,可以单击关系线查看建立模型的相关参数。
3.1.7 基数与交叉筛选器方向
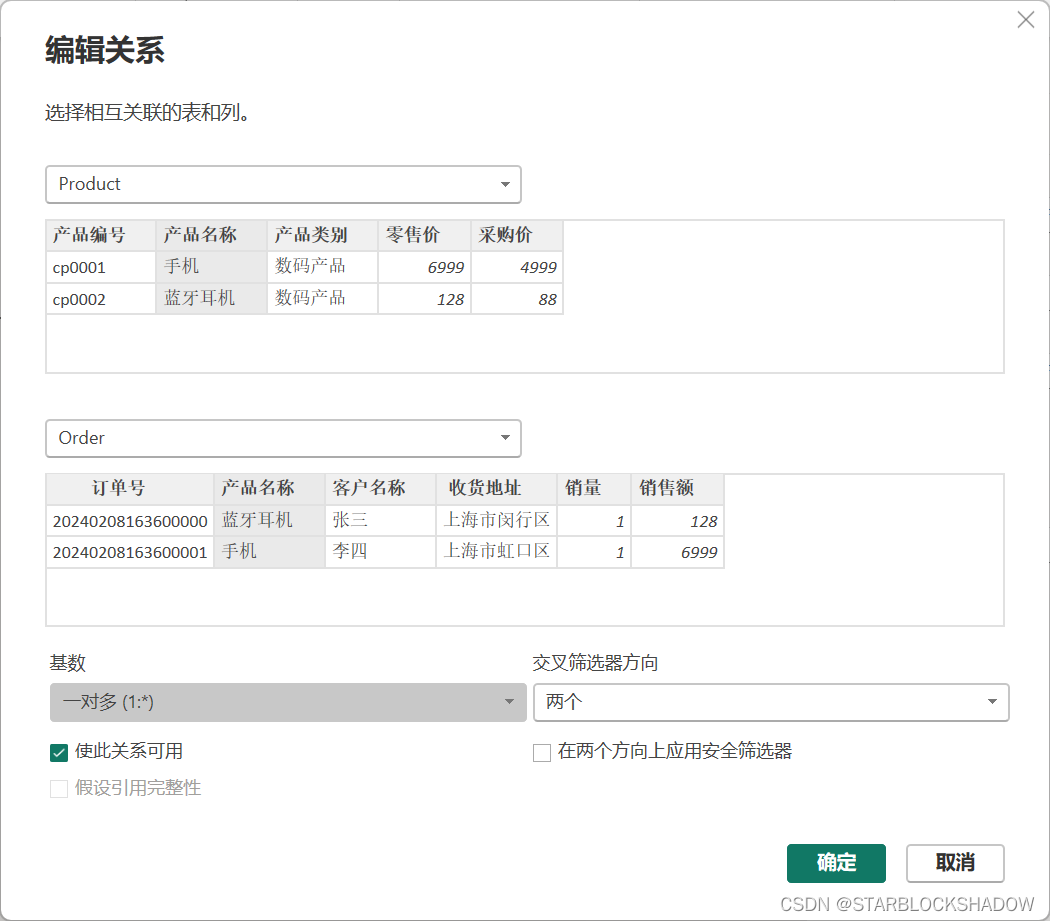
基数是两个表的对应关系,关系是有次序的,分为左表和右表,两个表之间有多对一、一对一、一对多和多对多四种关系:
- 多对一(* : 1):最常见的类型,代表左表中的关系列有重复值,而在右表中是单一值。
- 一对一(1 : 1):左表和右表关系列中的值都是唯一的。
- 一对多(1 : *):与多对一正好相反。
- 多对多(* : *):左表和右表关系列中均有重复值,尽量避免使用这种关系。
在关系的“一”端的表通常是维度表,而在关系的“多”端的表为事实表。
交叉筛选器方向表示数据筛选的流向,在关系线上用箭头标示,有如下两种类型。
- 单一:单项关系,一个表会沿着箭头的方向对另一个表筛选,而不能反向。
- 两个:双向关系,两个表可以互相筛选。
对于建立关系有如下几个建议:
(1)尽量避免多对多关系。
(2)尽量避免双向关系。
(3)避免在事实表之间创建关系。
3.1.8 数据模型
在Power BI中,字段、度量值、事实表、维度表、关系的集合构成了数据模型。
直观来看,数据建模就是在表之间建立关系。数据模型是进行数据分析的基础,数据模型能够处理更大量级的数据,并且速度很快。
3.2 DAX
DAX(Data Analysis Expression)即数据分析表达式,专门用来进行数据分析,在Power BI中可用于新建度量值,新建列和新建表。
3.2.1 DAX函数基本语法
- 表达式以等号开始。
- 等号前面是表达式名称。
- 如果DAX建立的是度量值,它就是度量值名称;若是用于建立计算列,就是计算列名;若是建立一个新表,它就是表名。
- 函数后都用双括号
()括上参数,参数之间用逗号,分割。 - 表名用单引号
''包裹。 - 列字段用中括号
[]包裹,前面跟上表名,如'订单表'[销售额]。 - 度量值用中括号
[]包裹,如DIVIDE([本年累计销售额],[上年累计销售额])。
注:DAX函数不区分大小写,较M函数要灵活很多。但为了DAX的简洁和统一,建议DAX函数都用大写字母。
3.2.2 DAX格式规范
- 如果函数只有1个参数,则和函数放在同一行。
- 如果函数具有2个或更多参数,则将每1个参数都另起一行。
- 如果函数及其参数写在多行上:
- 左括号
(与函数在同一行; - 参数是新行,从该函数对齐位开始缩进4字符;
- 右括号
)与函数开头对齐; - 分隔两个参数的逗号位于前一个参数的同一行;
- 如果必须将表达式拆分为更多行,则运算符作为新行中的首字符。
- 左括号
3.2.3 DAX函数类别
3.2.3.1 聚合函数
- SUM
- AVERAGE
- MIN
- MAX
这几个函数和Excel中的一样,其用法和功能也类似,DAX中还有一类特有的函数非常有用,和这几个函数很像,只是在后面加了一个X:
- SUMX
- AVERAGEX
- MINX
- MAXX
- RANKX
这几个函数可以循环访问表的每一行,并执行计算,所以也被称为迭代函数。
其他常见的聚合函数及功能如下:
- COUNT:计数
- COUNTROWS:计算行数
- DISTINCTCOUNT:计算不重复值的个数
3.2.3.2 时间智能函数
- PREVIOUSYEAR/Q/M/D:上一年/季/月/日
- NEXTYEAR/Q/M/D:下一年/季/月/日
- TOTALYTD/QTD/MTD:年/季/月初至今
- SAMEPERIODLASTYEAR:上年同期
- PARALLELPERIOD:上一期
- DATESINPERIOD:指定期间的日期
- DATEADD:移动一定间隔的日期
3.2.3.3 筛选函数
- FILTER:筛选
- ALL:所有值,可以清除筛选
- ALLEXCEPT:保留指定列
- VALUES:返回不重复值
这几个函数是典型的DAX筛选函数,它们通过筛选来控制上下文的范围。
3.2.3.4 CALCULATE函数
CALCULATE函数用于在由过滤器修改的上下文中计算表达式。
CALCULATE函数语法如下:
CALCULATE(表达式,[过滤器1,过滤器2,……])
其中,
第一个参数(必须):返回的计算类型,一般为聚合函数。
第二个参数/第三个参数……(可选):可以没有过滤器,也可以有多个过滤器。
返回值:根据第二个及之后的过滤器筛选后的上下文,返回第一个表达式计算的值。
CALCULATE函数是从第二个参数开始,将所有过滤条件的交集形成最终的筛选数据集合,对最终的筛选数据集合执行第一个参数的聚合运算后,返回运算结果。
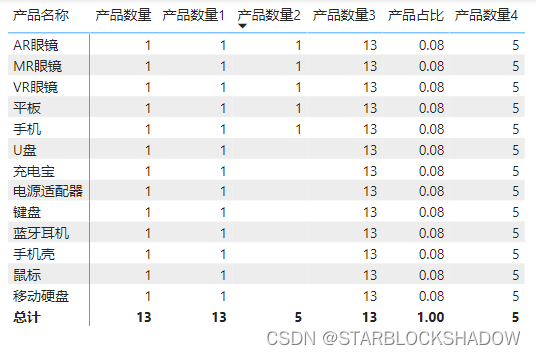
以产品明细表为例,将该表导入Power BI中。
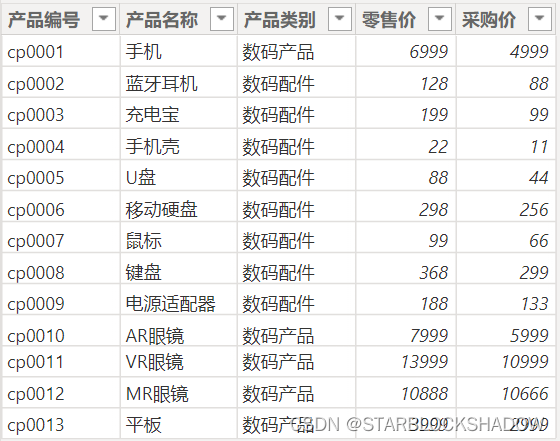
新建一个度量值求每种产品的数量:
产品数量 = COUNTROWS('产品明细')
由于每种产品的只有1行,因此求产品明细表的行数(除标题行外)就相当于求各种产品的数量,新建一个矩阵图表,将产品名称和该度量值拖曳入矩阵表,如下图所示:
以CALCULATE函数的角度来看,这里外部上下文就是表格每行的行标签,即产品名称,每个产品名称在产品表中对应的只有一行数据,所以全部返回值都是1。

以下是具体的CALCULATE计算示例:
- 筛选条件为空,不影响外部上下文
用CALCULATE函数新建一个度量值:
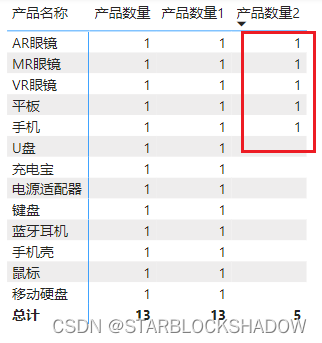
该度量值因为没有内部筛选,所以完全依赖外部上下文,运行结果也和原度量值一致。产品数量1 = CALCULATE([产品数量]) - 添加限制条件,缩小上下文
新建一个度量值“产品数量2”,限制计算时的产品类别:
将该度量值拖拽到上述的矩阵图表中,发现只有类别为“数码产品”的产品计数正常显示,而其他产品的数据没有显示。产品数量2 = CALCULATE([产品数量],'产品明细'[产品类别]="数码产品")
这是因为CALCULATE的第二个参数的限制,只筛选类别为“数码产品”的产品,限制了外部的上下文,非数码产品的产品都不再运算。
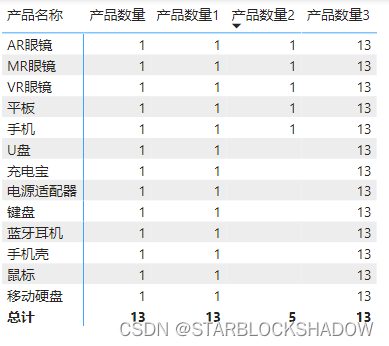
3.结合ALL函数,扩大上下文
新建度量值“产品数量3”,筛选条件使用ALL函数:产品数量3 = CALCULATE([产品数量],ALL('产品明细'))
这里筛选条件使用了ALL函数,ALL('产品表')表示清除产品表里的所有外部上下文,外部筛选器不起作用了,每行统计的都是该产品表中的所有产品的行数,因此每行的数据都是13。
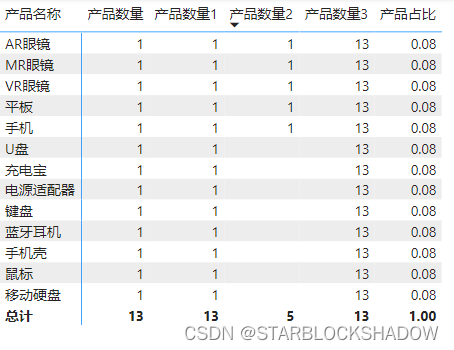
ALL函数可以用于计算每个产品的数量占总产品数量的比例:产品占比=DIVIDE([产品数量],[产品数量3])
4.重置上下文
新建度量值“产品数量4”:
这里用ALL函数清除行标签的外部筛选后,从全部产品中统计品类为“数码产品”的产品的数量,所以每行都返回5。产品数量4 = CALCULATE([产品数量],ALL('产品明细'),'产品明细'[产品类别]="数码产品")
3.2.4 常用的DAX函数
3.2.4.1 FILTER函数
FILTER函数用于筛选,参与CALCULATE函数第二个及之后的参数计算。
FILTER函数的语法如下:
FILTER(表,筛选条件)
其中,
第一个参数:一定是表,是不能放入列或者值的;
第二个参数:筛选条件。如果是多条件筛选,可以用&&符号或者||符号连接起来。
返回值:一个表。不能直接用于建立度量值,但可以新建表,最常用的就是作为CALCULATE的参数,返回表中符合筛选条件的行,接着交给CALCULATE的第一个参数执行聚合运算。
3.2.4.2 ALL函数
ALL函数的参数可以是一个表,也可以是一个或多个列,但它返回的数据类型都是表。其用法如下:
1.可单独用于创建表,参数为一个表,相当于复制表
2.可单独用于创建表,参数为一列,返回该列的不重复列表
3.可作为度量值中的参数,清除外部上下文
3.2.4.3 VALUES函数
VALUES函数的参数只有一个,即表的一列,但返回的数据类型是表,为该列的不重复值的列表,其语法如下:
VALUES(表[列])
注:如果某函数需要的参数是表,但想提供的是列,可以使用VALUES函数转换一下。
VALUES函数的用法如下:
1.返回某列的不重复列表,常用于通过事实表构建维度表(与ALL函数参数为一列时的功能相同)
2.保持外部上下文筛选(该功能正好与ALL函数清除外部上下文功能相反)
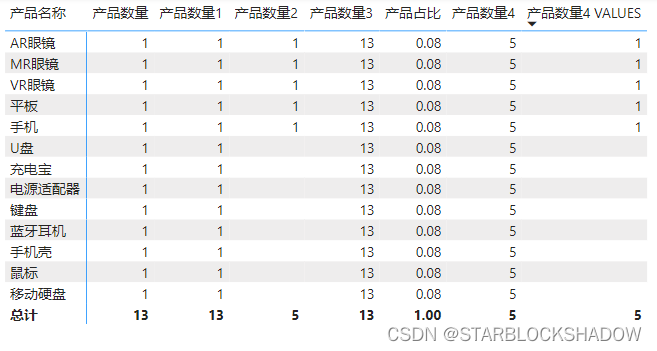
如3.2.3.4节中的度量值“产品数量4”利用ALL函数重置上下文,所有行返回了数码产品的数量5,如果想保持上下文的筛选,除了修改ALL函数之外,还可以加个VALUES函数:
产品数量4 VALUES =
CALCULATE(
[产品数量],
ALL('产品明细'),
'产品明细'[产品类别]="数码产品",
VALUES('产品明细'[产品名称])
)
将该度量值拖拽至矩阵图表中,如下图所示:
可以看到在CALCULATE函数内部添加了VALUES('产品名称'[产品名称])以后,计算结果又恢复了产品名称的筛选。
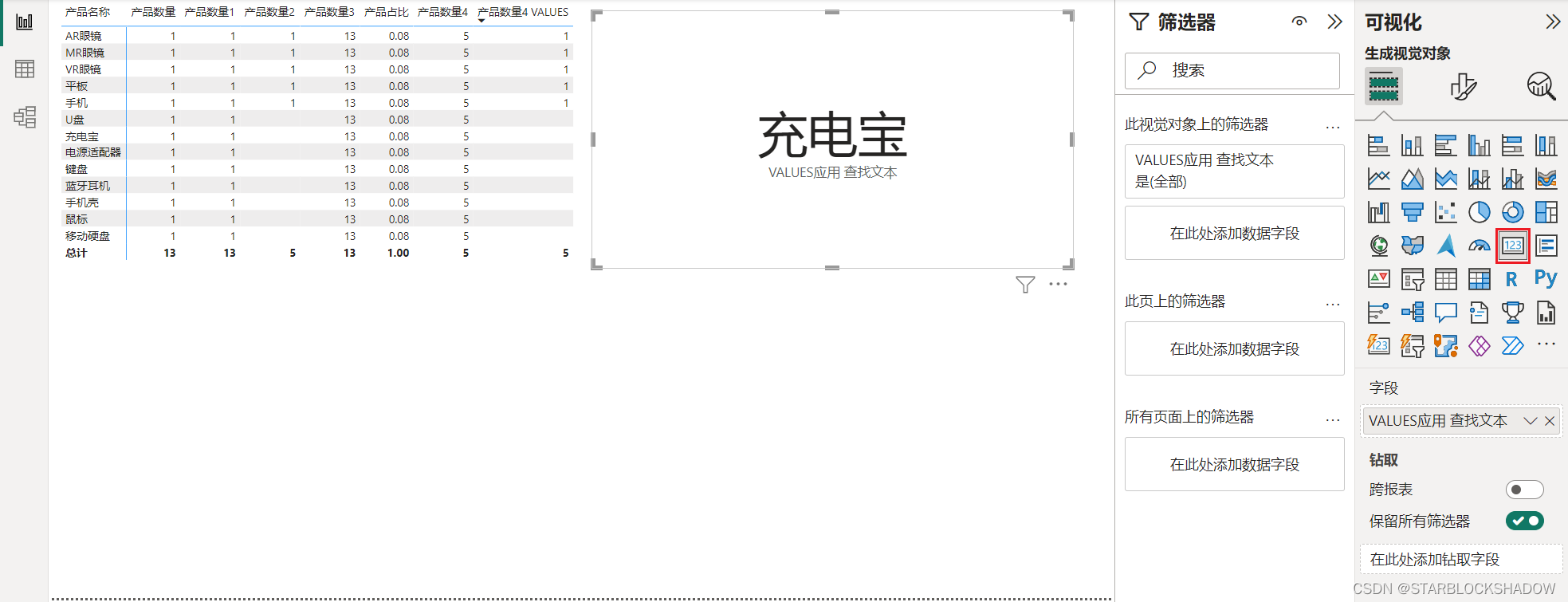
3.查找文本型的数据
如从产品明细表中找出零售价为199元的产品名称是什么,新建度量值如下:
VALUES应用 查找文本 =
CALCULATE(VALUES('产品明细'[产品名称]),'产品明细'[零售价]=199)
使用卡片来表示查找到的结果:
DAX有一个重要的特征:如果一个表只有一行一列,它同时也可以作为值使用。因此此处VALUES函数返回的是一个只有一行一列的表,在卡片中显示为一个查找结果值。
3.2.4.4 HASONEVALUE函数
HASONEVALUE(has one value)函数的英文意思是“有一个值”,它的参数为表的列,语法如下:
HASONEVALUE(表[列])
HASONEVALUE函数判断某列是否被过滤为仅有一个值,如果是一个值,返回TRUE;如果没有值或者有多个值,则返回FALSE。
HASONEVALUE函数一般作为IF函数的第一个参数使用,判断交叉筛选后是否为一个值。
例如,新建一个度量值,如果产品名称被筛选后只有一个值,返回这个产品名称,否则返回空值:
IF ( HASONEVALUE ('产品明细'[产品名称]),VALUES ('产品明细' [产品名称] ) )
注:IF函数的第三个参数可以省略,如果省略,当第一个参数,也就是判断条件为FALSE时,默认返回BLANK()。
又如,3.2.4.3节中使用VALUES函数筛选出产品明细表中零售价为199元的产品名称:
VALUES应用 查找文本 =
CALCULATE(VALUES('产品明细'[产品名称]),'产品明细'[零售价]=199)
如果产品明细表中零售价为199的产品不止一个,那么上述度量值将会发生错误。

为了防止错误的情况发生,可以利用IF和HASONEVALUE函数进行错误拦截,新建一个度量值:
HASONEVALUE应用 =
IF(
HASONEVALUE('产品明细'[产品名称]),
CALCULATE(
VALUES('产品明细'[产品名称]),
'产品明细'[零售价]=199
)
)

3.2.4.5 时间智能函数
时间智能函数是一类函数的统称,也是数据分析中最常用的独立变量,在进行时间相关的分析时十分有用。
1.Power BI中的时间智能函数
| 时间智能函数 | 说明 |
|---|---|
| DATESMTD/DATESQTD/DATESYTD | 月/季/年初至今 |
| FIRSTDATE/LASTDATE | 第一个日期/最后一个日期 |
| PREVIOUSDAY/MONTH/QUARTER/YEAR | 上一日/月/季/年 |
| NEXTDAY/MONTH/QUARTER/YEAR | 次日/月/季/年 |
| ENDOFMONTH/QUARTER/YEAR | 月/季/年度的最后一天 |
| STARTOFMONTH/QUARTER/YEAR | 月/季/年度的第一天 |
| SAMEPERIODLASTYEAR | 上年同期 |
| DATEADD | 移动一定间隔后的时间段 |
| DATESBETWEEN | 从起始日到结束日的时间段 |
| DATESINPERIOD | 从指定日期移动一定间隔的时间段 |
| PARALLELPERIOD | 移动指定间隔的完整粒度的时间段 |
| TOTALMTD/TOTALQTD/TOTALYTD | 月/季/年初至今,内置CALCULATE |
| CLOSINGBALANCEMONTH/QUARTER/YEAR | 月/季/年度的期末数据,内置CALCULATE |
| OPENINGBALANCEMONTH/QUARTER/YEAR | 月/季/年度的期初数据,内置CALCULATE |
根据时间智能函数返回的结果,可以时间智能函数分为两类。
- 返回表的时间智能函数。
- 返回值的时间智能函数。
2.返回表的时间智能函数
- DATESMTD/DATESQTD/DATESYTD:月/季/年初至今
- FIRSTDATE/LASTDATE:第一个日期/最后一个日期
- PREVIOUSDAY/MONTH/QUARTER/YEAR:上一日/月/季/年
- NEXTDAY/MONTH/QUARTER/YEAR:次日/月/季/年
- ENDOFMONTH/QUARTER/YEAR:月/季/年度的最后一天
- STARTOFMONTH/QUARTER/YEAR:月/季/年度的第一天
- SAMEPERIODLASTYEAR:上年同期
- DATEADD:移动一定间隔后的时间段
- DATESBETWEEN:从起始日到结束日的时间段
- DATESINPERIOD:从指定日期移动一定间隔的时间段
- PARALLELPERIOD:移动指定间隔的完整粒度的时间段
以上大部分函数只需要使用一个日期参数就可以,返回对应的时间区间,一般结合CALCULATE函数使用。
3.返回值的时间智能函数
- TOTALMTD/TOTALQTD/TOTALYTD:月/季/年初至今,内置CALCULATE
- CLOSINGBALANCEMONTH/QUARTER/YEAR:月/季/年度的期末数据,内置CALCULATE
- OPENINGBALANCEMONTH/QUARTER/YEAR:月/季/年度的期初数据,内置CALCULATE
以上函数可以对重置后的下上文执行运算,省掉了CALCULATE函数。
例如求年初至今的销量,使用TOTALYTD函数:
=TOTALYTD([数量],日期表[日期])
与使用DATESYTD函数的效果等同:
=CALCULATE([数量],DATESYTD(日期表[日期]))
4.涉及年度的时间智能函数的特殊用法
- DATESYTD:年初至今
- PREVIOUSYEAR:上一年
- NEXTYEAR:次年
- ENDOFYEAR:年度的最后一天
- STARTOFYEAR:年度的第一天
- TOTALYTD:年初至今,内置CALCULATE
- CLOSINGBALANCEYEAR:年度的期末数据,内置CALCULATE
- OPENINGBALANCEYEAR:年度的期初数据,内置CALCULATE
以上8个函数的参数中最后都有一个可选参数<year_end_date>,意思是年度结束日期,默认情况下就是自然年度的结束日期12月31日,可以省略,在特定的分析中,若年度结束日期不是12月31日,可以使用这个参数来界定。
5.时间智能函数和普通函数的区别
- 日期函数直接依赖当前行上下文,一般作为新建列使用,比如YEAR函数,提取日期列的年度;
- 时间智能函数会重置上下文,一般新建度量值时使用,可以快速移动到指定区间。
3.3 VAR变量
VAR是VARIABLE的缩写,意为变量。
3.3.1 VAR语法
VAR的语法规范就是把一个表达式定义为一个名称:
VAR 变量名=表达式
其中变量名不能和模型中现有的表名、字段名相同,也不能使用数字作为第一个字符,不能使用空格、不能使用中文等。
定义变量是为了使用,可以使用RETURN来返回结果。
3.4 常用的数据分析
3.4.1 占比问题
计算个体占总体的比例是一个很常见的分析方式,即两个数字相除。可以用ALL函数计算出汇总数据作为分母。
以某网上商城的电子产品的销售记录数据为例,根据销售额指标来计算某产品的占总体或者类别的比例。
首先写一个基础的销售金额度量值:
销售金额 = SUM('订单'[销售额])
3.4.1.1 总体占比
计算总体占比,就是用每一个类别的销售额除以总计销售额。计算总计销售额,可以用ALL函数清除外部上下文的筛选,先单独计算出总计销售额:
销售额总计= CALCULATE([销售金额],ALL('产品表'))
新建一个度量值,用于计算占总体比例:
总体占比 =
DIVIDE(
[销售金额],
CALCULATE([销售金额],ALL('产品表'))
)
将产品名称和产品类别放入矩阵的行中,度量值“销售金额”和“总体占比”放入矩阵的值中:
3.4.1.2 分类占比
每一种产品相对于总体的比例计算出来了,但是如果还需要知道每一种产品占所属分类的比例,新建一个度量值表示分类占比:
分类占比 =
DIVIDE(
[销售金额],
CALCULATE([销售金额],ALL('产品表'[产品名称]))
)
将这个度量值放入矩阵中,得到分类占比:
未完待续