上一篇我们简单介绍了如何简单搭建一个文本分类模型模型,但是精度不尽人意,今天为大家带来如何利用卷积神经网络实现文本情感分类
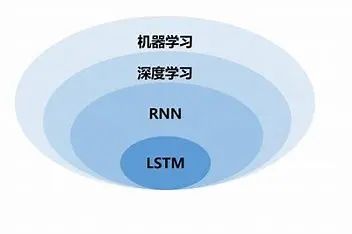
一.什么是循环神经网络?
1.循环神经网络介绍
在普通的神经网络中,信息的传递是单向的,这种限制虽然使得网络变得更容易学习,但在一定程度上也减弱了神经网络模型的能力。特别是在很多现实任务中,网络的输出不仅和当前时刻的输入相关,也和其过去一段时间的输出相关。此外,普通网络难以处理时序数据,比如视频、语音、文本等,时序数据的长度一般是不固定的,而前馈神经网络要求输入和输出的维数都是固定的,不能任意改变。因此,当处理这一类和时序相关的问题时,就需要一种能力更强的模型。
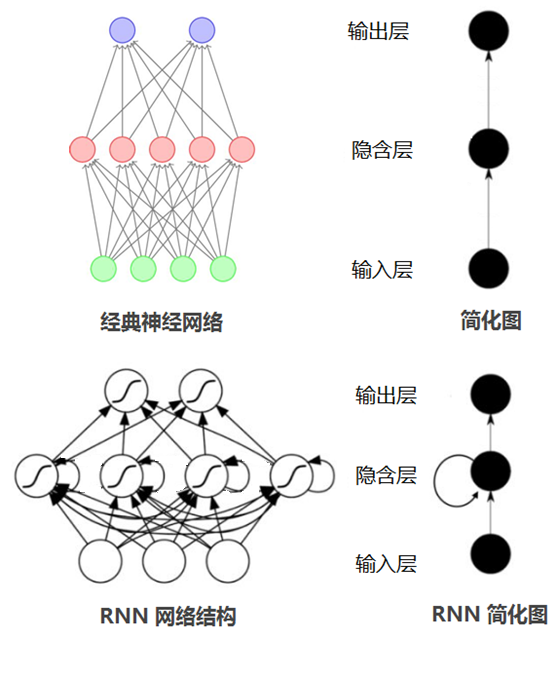
循环神经网络(Recurrent Neural Network,RNN)是一类具有短期记忆能力的神经网络。在循环神经网络中,神经元不但可以接受其它神经元的信息,也可以接受自身的信息,形成具有环路的网络结构。换句话说:神经元的输出可以在下一个时间步直接作用到自身。
通过简化图,我们看到RNN比传统的神经网络多了一个循环圈,这个循环表示的就是在下一个时间步(Time Step)上会返回作为输入的一部分,我们把RNN在时间点上展开,得到的图形如下:
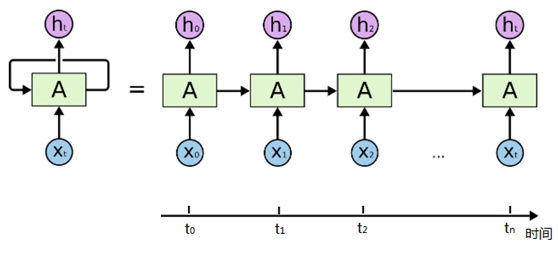
或者是:
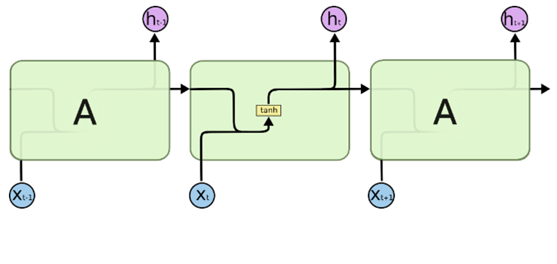
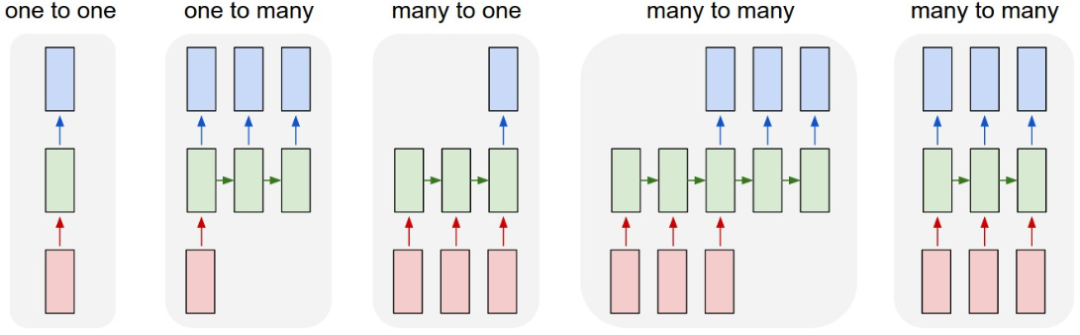
在不同的时间步,RNN的输入都将与之前的时间状态有关,t_n时刻网络的输出结果是该时刻的输入和所有历史共同作用的结果,这就达到了对时间序列建模的目的。RNN的不同表示和功能可以通过下图看出:
-
图1:固定长度的输入和输出
-
图2:序列输出
-
图3:数列输入
-
图4:异步的序列输入和输出
-
图5:同步的序列输入和输出
2.LSTM和GRU
(1). LSTM基础
假如现在有这样一个需求,根据现有文本预测下一个词语,比如天上的云朵漂浮在__,通过间隔不远的位置就可以预测出来词语是天上,但是对于其他一些句子,可能需要被预测的词语在前100个词语之前,那么此时由于间隔非常大,随着间隔的增加可能会导致真实的预测值对结果的影响变的非常小,而无法非常好的进行预测(RNN中的长期依赖问题(long-Term Dependencies))那么为了解决这个问题需要LSTM(Long Short-Term Memory网络)。一个LSMT的单元就是下图中的一个绿色方框中的内容:
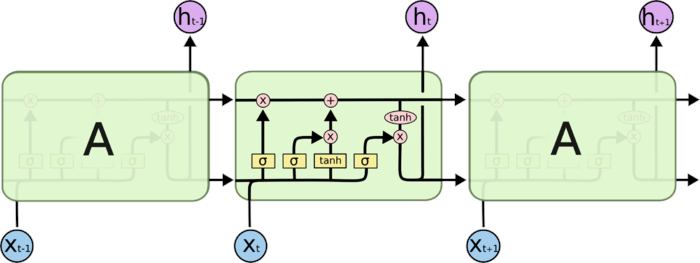
其中σ表示sigmod函数,其他符合含义如下:

(2). LSTM的核心
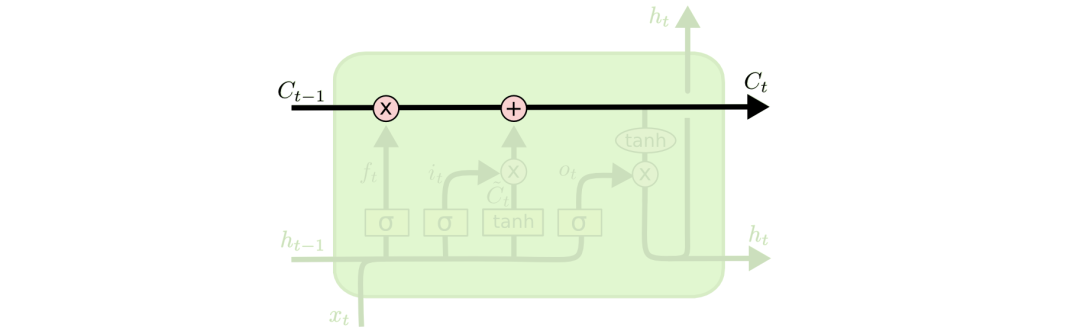
LSTM的核心在于单元(细胞)中的状态,也就是上图中最上面的那根线。但是如果只有上面那一条线,那么没有办法实现信息的增加或者删除,所以在LSTM是通过一个叫做门的结构实现,门可以选择让信息通过或者不通过。这个门主要是通过sigmoid和点乘(pointwise multiplication)实现的。我们都知道,sigmoid的取值范围是在(0,1)之间,如果接近0表示不让任何信息通过,如果接近1表示所有的信息都会通过
(3). 进一步理解LSTM
如果你已经大概看懂了RNN的内部原理,那么LSTM对你来说就简单了一些。LSTM(Long short-term memory),翻译过来就是长短期记忆,是RNN的一种,比普通RNN高级,基本一般情况下说使用RNN都是使用LSTM。
遗忘门:遗忘门通过sigmoid函数来决定哪些信息会被遗忘
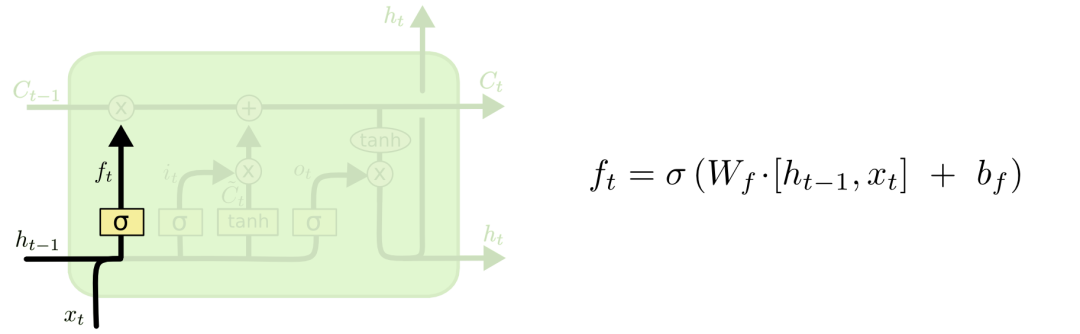
输入门:决定哪些新的信息会被保留

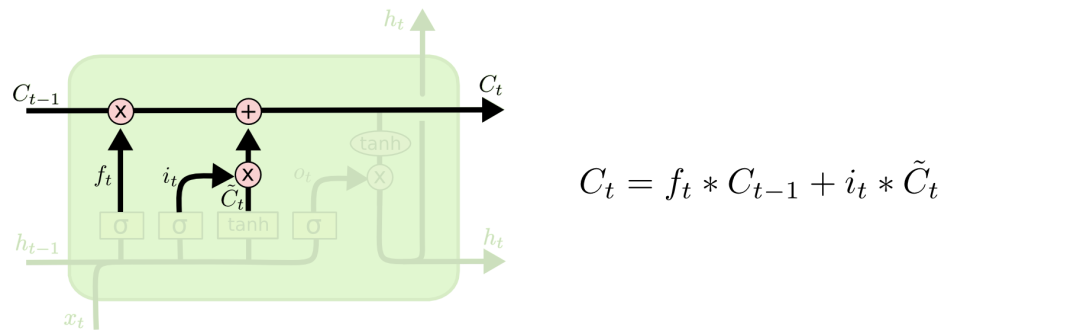
输入们更新:
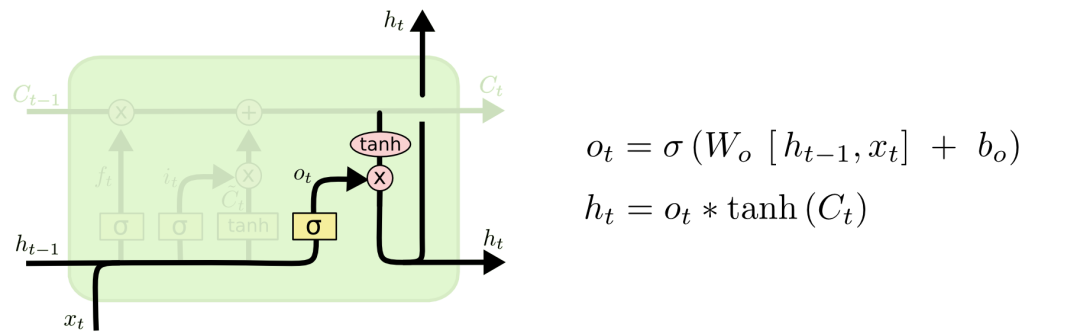
输出门:决定什么信息会被输出。
(4). GRU-LSTM的变形
GRU(Gated Recurrent Unit),是一种LSTM的变形版本, 它将遗忘和输入门组合成一个“更新门”。它还合并了单元状态和隐藏状态,并进行了一些其他更改,由于他的模型比标准LSTM模型简单,所以越来越受欢迎。

可参考:https://colah.github.io/posts/2015-08-Understanding-LSTMs/
3.双向LSTM
单向的 RNN,是根据前面的信息推出后面的,但有时候只看前面的词是不够的, 可能需要预测的词语和后面的内容也相关,那么此时需要一种机制,能够让模型不仅能够从前往后的具有记忆,还需要从后往前需要记忆。此时双向LSTM就可以帮助我们解决这个问题。
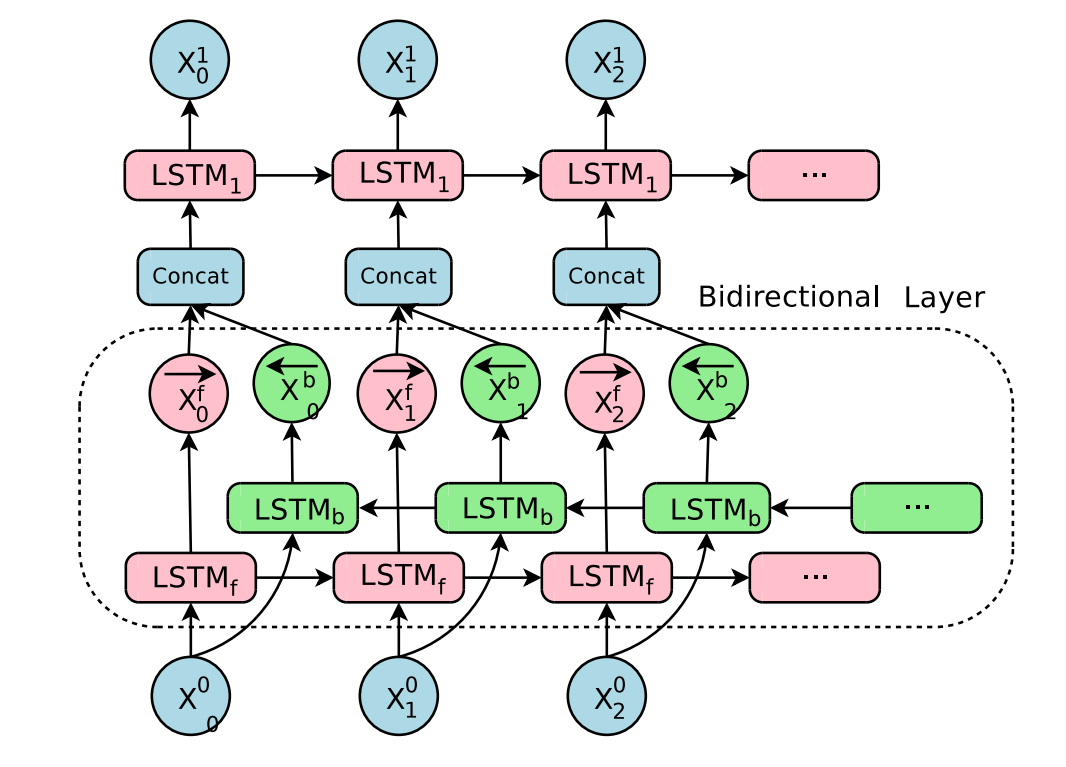
由于是双向LSTM,所以每个方向的LSTM都会有一个输出,最终的输出会有2部分,所以往往需要concat的操作。
二.循环神经网络实现文本情感分类
1.Pytorch中相关模块的使用
(1). LSTM的使用
假设数据输入为 input ,形状是[10,20],假设embedding的形状是[100,30],使用示例如下:
batch_size =10 #每个batch的大小为10
seq_len = 20 #每个输入序列长度为20
embedding_dim = 30 #词嵌入的维度为30
word_vocab = 100 #词汇表大小为100
hidden_size = 18 #隐藏层神经元的数量,即每一层有多少个LSTM单元
num_layer = 2 #RNN的中LSTM单元的层数
#准备输入数据,大小为(10,20)的张量,表示10个样本,每个样本的长度为20
input = torch.randint(low=0,high=100,size=(batch_size,seq_len))
#准备embedding,词嵌入层,由100个词汇嵌入到30维的向量空间
embedding = torch.nn.Embedding(word_vocab,embedding_dim)
# LSTM模型,输入为embedding_dim维度的词嵌入向量,输出为hidden_size维度的隐藏状态,LSTM层数为num_layer
lstm = torch.nn.LSTM(embedding_dim,hidden_size,num_layer)
#进行mebed操作,通过embedding层将input中的词转换成30维的向量,大小为(20,10,30)的张量
embed = embedding(input) #[10,20,30]
#转化数据为batch_first=False,将张量的维度改为(20,10,30)
embed = embed.permute(1,0,2) #[20,10,30]
# h_0和c_0:LSTM的初始隐藏状态和细胞状态,大小同output即(2,10,18)
h_0 = torch.rand(num_layer,batch_size,hidden_size)
c_0 = torch.rand(num_layer,batch_size,hidden_size)
output,(h_1,c_1) = lstm(embed,(h_0,c_0))
# output大小为(20,10,18)的张量,表示20个时间步的每个样本所对应的18维隐藏状态
# h_1,c_1:output的最后一个时间步的隐藏状态和细胞状态,大小同h_0和c_0即(2,10,18)(2). GRU的使用
GRU模块torch.nn.GRU,和LSTM的参数相同,含义相同,具体可参考文档
但是输入只剩下gru(input,h_0),输出为output, h_n。
(3). 双向LSTM的使用
如果需要使用双向LSTM,则在实例化LSTM的过程中,需要把LSTM中的bidriectional设置为True,同时h_0和c_0使用num_layer*2。
# 定义batch大小为10
batch_size = 10
# 定义序列长度为20
seq_len = 20
# 定义嵌入维度为30
embedding_dim = 30
# 定义单词词汇表大小为100
word_vocab = 100
# 定义隐藏层大小为18
hidden_size = 18
# 定义LSTM层数为2
num_layer = 2
# 生成一个大小为[10, 20]的、取值范围在[0, 100)的随机整数张量
input = torch.randint(low=0, high=100, size=(batch_size, seq_len))
# 定义一个维度为[100, 30]的嵌入矩阵
embedding = torch.nn.Embedding(word_vocab, embedding_dim)
# 定义一个包含双向LSTM的LSTM对象,输入维度为30,隐藏层大小为18,LSTM层数为2
lstm = torch.nn.LSTM(embedding_dim, hidden_size, num_layer, bidirectional=True)
# 对输入进行嵌入操作,将其从[batch_size, seq_len]转化为[batch_size, seq_len, embedding_dim]
embed = embedding(input) #[10,20,30]
# 将嵌入数据转化为batch_first=False形式,即[seq_len, batch_size, embedding_dim]
embed = embed.permute(1, 0, 2) #[20,10,30]
# 初始化LSTM层的初始隐状态和细胞状态,大小为[num_layer*2, batch_size, hidden_size]
h_0 = torch.rand(num_layer*2, batch_size, hidden_size)
c_0 = torch.rand(num_layer*2, batch_size, hidden_size)
# 对输入数据进行LSTM计算,输出output和最终状态(h_1, c_1)
output, (h_1, c_1) = lstm(embed, (h_0, c_0))在单向LSTM中,最后一个time step的输出的前hidden_size个和最后一层隐藏状态h_1的输出相同。双向LSTM中:output按照正反计算的结果顺序在第2个维度进行拼接,正向第一个拼接反向的最后一个输出;hidden state按照得到的结果在第0个维度进行拼接,正向第一个之后接着是反向第一个。前向的LSTM中,最后一个time step的输出的前hidden_size个和最后一层向前传播h_1的输出相同。后向LSTM中,最后一个time step的输出的后hidden_size个和最后一层后向传播的h_1的输出相同。
2. LSTM实现文本情感分类
上一篇实现了初级文本情感分类,详细代码见:文本情感分类模型的初级实现
现在在模型中添加上LSTM层,观察分类效果。
(1).修改模型(model.py)
import torch.nn as nn
import config
import torch.nn.functional as F
import torch
class ImdbModel(nn.Module):
def __init__(self):
super(ImdbModel,self).__init__()
self.hidden_size = 64
self.embedding_dim = 200
self.num_layer = 2
self.bidriectional = True
self.bi_num = 2 if self.bidriectional else 1
self.dropout = 0.5
#以上部分为超参数,可以自行修改
self.embedding = nn.Embedding(len(config.ws), self.embedding_dim, padding_idx=config.ws.PAD) # [N,300]
self.lstm = nn.LSTM(self.embedding_dim, self.hidden_size, self.num_layer, bidirectional=True,
dropout=self.dropout)
# 使用两个全连接层,中间使用relu激活函数
self.fc = nn.Linear(self.hidden_size * self.bi_num, 20)
self.fc2 = nn.Linear(20, 2)
def forward(self, x):
x = self.embedding(x)
x = x.permute(1,0,2) # 进行轴交换
h_0,c_0 = self.init_hidden_state(x.size(1))
_,(h_n,c_n) = self.lstm(x,(h_0,c_0))
#只要最后一个lstm单元处理的结果,这里多去的hidden state
out = torch.cat([h_n[-2, :, :], h_n[-1, :, :]], dim=-1)
out = self.fc(out) # 进行全连接
out = F.relu(out) # 进行relu
out = self.fc2(out) # 全连接
return F.log_softmax(out,dim=-1)
def init_hidden_state(self,batch_size):
h_0 = torch.rand(self.num_layer * self.bi_num, batch_size, self.hidden_size).to(config.device)
c_0 = torch.rand(self.num_layer * self.bi_num, batch_size, self.hidden_size).to(config.device)
return h_0,c_0(2).加入GPU(config.py)
为了提高程序的运行速度,可以考虑把模型放在gup上运行,涉及计算的所有tensor都需要转化为CUDA的tensor,首先需要对配置文件进行修改。
import pickle
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_batch_size = 512
test_batch_size = 500
ws = pickle.load(open("./models/ws.pkl","rb"))
max_len = 50(3).进行训练(train.py)
import torch
from model import ImdbModel
from dataset import get_dataloader
from torch.optim import Adam
from tqdm import tqdm
import torch.nn.functional as F
import config
model = ImdbModel().to(config.device) # 在gpu上运行,提高运行速度
optimizer = Adam(model.parameters())
def train(epoch):
print("epcoh:{}".format(epoch))
train_dataloader = get_dataloader(train=True)
bar = tqdm(train_dataloader, total=len(train_dataloader))
correct = 0
total = 0
for idx, (input, target) in enumerate(bar):
input = input.to(config.device)
target = target.to(config.device)
optimizer.zero_grad()
output = model(input)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
# 计算准确率
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.shape[0]
acc = correct / total
bar.set_description("Train:idx:{} loss:{:.6f} acc:{:.4f}".format(idx, loss.item(), acc))
# 加上测试集代码
def test():
test_dataloader = get_dataloader(train=False)
bar = tqdm(test_dataloader, total=len(test_dataloader))
correct = 0
total = 0
for idx, (input, target) in enumerate(bar):
with torch.no_grad():
input = input.to(config.device)
target = target.to(config.device)
output = model(input)
loss = F.nll_loss(output, target)
# 计算准确率
pred = output.argmax(dim=1, keepdim=True)
correct += pred.eq(target.view_as(pred)).sum().item()
total += target.shape[0]
acc = correct / total
bar.set_description("Test:idx:{} loss:{:.6f} acc:{:.4f}".format(idx, loss.item(), acc))
if __name__ == '__main__':
for i in range(10):
train(i)
test()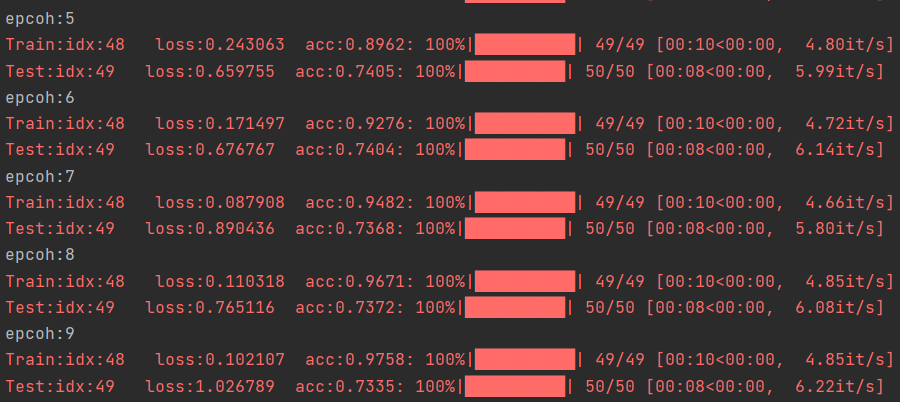
观察结果,相比之前60%的acc,加入LSTM后,提升了约10个百分点。关于GRU和多层LSTM,可根据前面理论部分进行修改。对于LSTM模型,matlab中有自带的函数库,只需要简单的调用即可实现,如果需要可参考:
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!