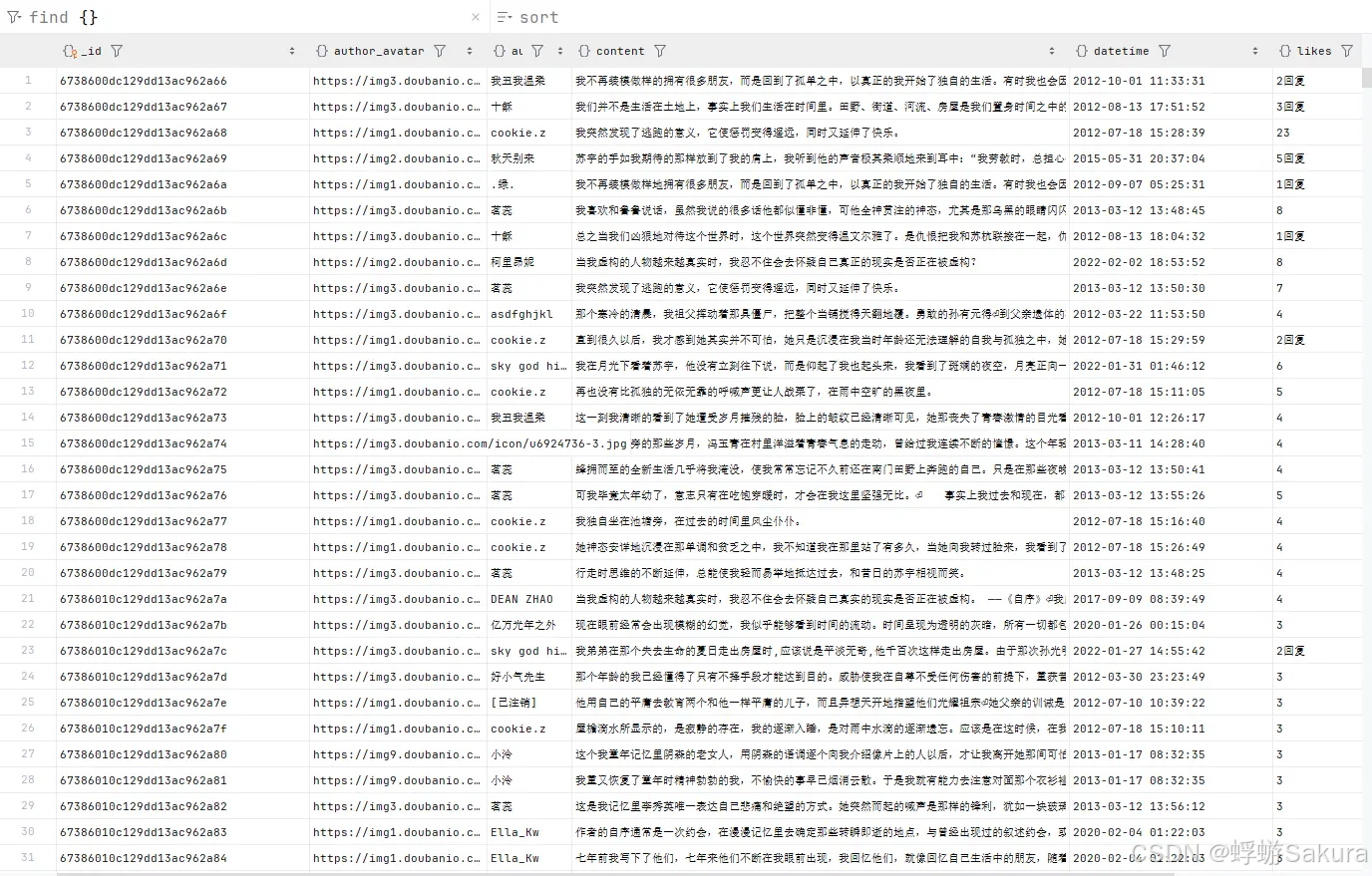
获取豆瓣书摘,存入MongoDB中。
import logging
import time
import requests
from bs4 import BeautifulSoup
from pymongo import MongoClient
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cache-control': 'max-age=0',
'priority': 'u=0, i',
'sec-ch-ua': '"Chromium";v="130", "Microsoft Edge";v="130", "Not?A_Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/130.0.0.0 Safari/537.36 Edg/130.0.0.0',
}
params = {
'sort': 'score',
'start': 0,
}
# 连接到 MongoDB 服务器(假设在本地运行,默认端口 27017)
client = MongoClient('localhost', 27017)
# 选择数据库(如果数据库不存在,MongoDB 会在插入数据时自动创建)
db = client['douban_database']
# 选择集合(如果集合不存在,MongoDB 会在插入数据时自动创建)
collection = db['blockquotes_1009393']
for start in range(0, 1260, 20):
params['start'] = start
response = requests.get('https://book.douban.com/subject/1009393/blockquotes', params=params, headers=headers)
text = response.text
soup = BeautifulSoup(text, 'lxml')
if len(soup.findAll("div", attrs={"class": "blockquote-list"})) == 0:
logging.error("blockquote-list is not exist")
exit(1)
blockquote_list = soup.findAll("div", attrs={"class": "blockquote-list"})[0]
if blockquote_list is None:
logging.error("blockquote-list None")
exit(1)
figures = blockquote_list.findAll("figure")
for figure in figures:
if figure is None:
logging.warning("figure is None")
continue
data = {
'author_avatar': None,
'author_name': None,
'likes': None,
'datetime': None,
'page_reference': None
}
try:
data['author_avatar'] = figure.find('img')['src']
except:
data['author_avatar'] = None
logging.error(figure)
try:
data['author_name'] = figure.find('a', class_='author-name').text.strip()
except:
data['author_name'] = None
logging.error(figure)
try:
data['likes'] = figure.find('span').text.strip().replace('赞', '')
except:
data['likes'] = None
logging.error(figure)
try:
data['datetime'] = figure.find('datetime').text.strip()
except:
data['datetime'] = None
logging.error(figure)
try:
data['page_reference'] = figure.find('figcaption')['title']
except:
data['page_reference'] = None
logging.error(figure)
try:
blockquote_extra = figure.find('div', class_='blockquote-extra')
a_href = figure.find('a')
blockquote_extra.decompose()
a_href.decompose()
content = figure.text.strip().replace('()', '')
# print(content)
data['content'] = content
except:
data['content'] = None
logging.error(figure)
try:
pass
collection.insert_one(data)
except Exception as e:
print(e)
time.sleep(3)
效果图: