论文地址:
https://arxiv.org/abs/2203.11082
代码地址:
https://github.com/MCG-NJU/MixFormer
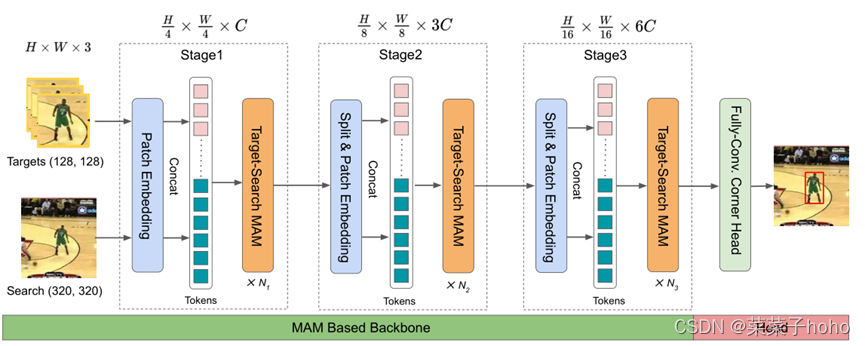
端到端的MixFormer跟踪整体框架
它只由一个基于MAM的主干和一个定位头组成,MAM为混合注意模块(Mixed Attention Module),用来完成特征提取和目标信息合并的过程。Stage i有Ni个MAM和MLP层定义。
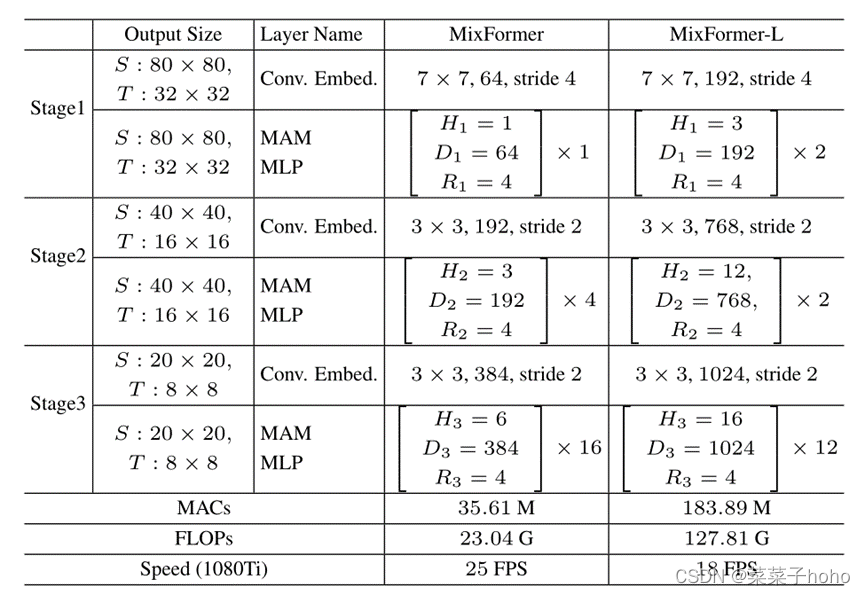
MixFormer和MixFormer-L的基于MAM的主干架构。输入是形状为128×128×3的目标模板和形状为320×320×3的搜索区域。S和T代表搜索区域和模板。Hi和Di是第i阶段的头数和嵌入特征维数。Ri是MLP层中的特征尺寸扩展比。
Mixed attention module (MAM)
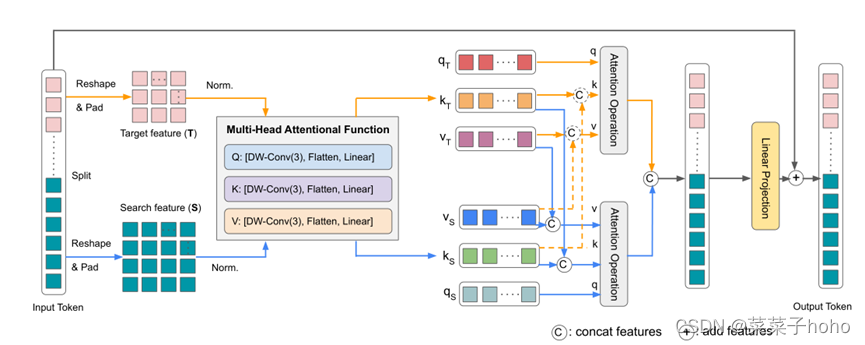
MAM的输入是目标模板和搜索区域。其目的是同时提取它们各自的long-range特征,并融合它们之间的相互作用信息。与最初的多头注意力
(https://blog.csdn.net/qq_41442511/article/details/124277219?spm=1001.2014.3001.5501)相反,MAM在目标模板和搜索区域的两个独立的标记序列上执行双重注意力操作。它对每个序列中的标记进行自我关注,以捕捉目标或搜索特定信息。同时,在两个序列的标记之间进行交叉注意,以允许目标模板和搜索区域之间的通信。
理解来讲,MAM首先输入一整个Token,该Token首先被Split为模板特征和搜索特征两个部分,此时这两部分的特征是被展平的序列,Reshape后变成2D特征图,特征图先经过归一化后被输入Multi-Head Attention Function部分,该部分负责通过线性投影将特征图展平并产生QKV三个值,随后,目标特征和搜索特征同时计算自注意和交叉注意,得到的目标注意特征和搜索注意特征同时包含自注意和交叉注意,先cat后输出。
上诉是对称的结构,计算公式如下:
但作者认为从目标查询到搜索区域的交叉注意并不重要,并且可能由于潜在的干扰物而带来负面影响。为了降低MAM的计算成本,从而允许有效地使用多个模板来处理对象变形,作者进一步通过修剪不必要的目标-搜索区域交叉注意来提出定制的非对称混合注意方案。也就是上图中橙色虚线部分不在使用(如果使用该部分的就意味着每个模板都需要与搜索图片计算交叉注意特征,这就大大提升的计算成本,所以去掉后更利用多个模板图片的使用),这种不对称混合注意的定义如下:
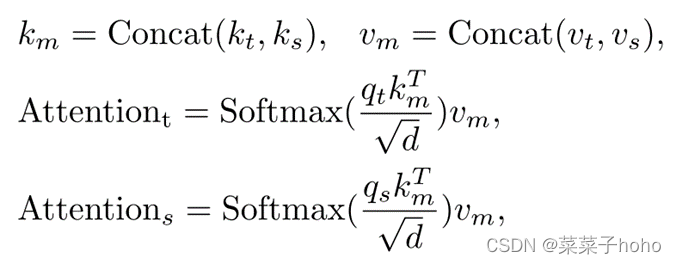
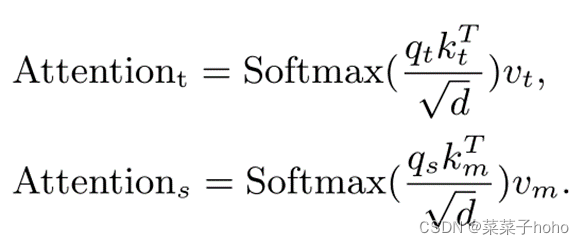
基于角的定位头
受STARK中的角点检测头的启发,采用了一个完全可选的基于角点的定位头来直接估计被跟踪对象的边界框,仅使用几个Conv-BN-ReLU层分别用于左上角和右下角的预测。最后,我们可以通过计算角概率分布的期望来获得包围盒。与STARK的区别在于,我们的是完全卷积头,而STARK高度依赖于编码器和解码器,设计更复杂。(定位这部分没有理解)
基于查询的定位头
受DETR的启发,我们提出使用一个简单的基于查询的定位头。这种稀疏定位头可以验证我们的MAM主干的泛化能力,并产生一个纯基于变压器的跟踪框架。具体来说,我们在最后阶段的序列中添加了一个额外的可学习的回归标记,并使用该标记作为锚来聚集来自整个目标和搜索区域的信息。最后,采用三个完全连接的层的FFN来直接回归包围盒坐标。这个框架也不使用任何后处理技术。(定位这部分没有理解)
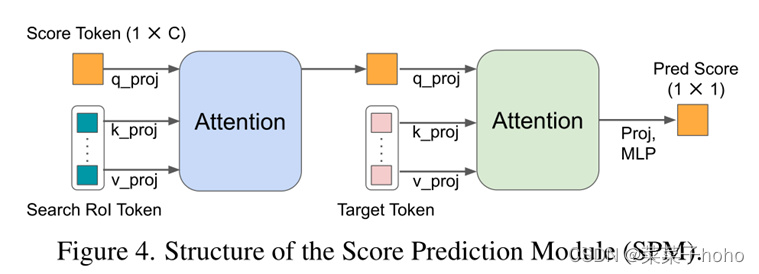
分数预测模块(SPM)
由于目标在线更新就需要一个分数预测模块(SPM),SPM由两个注意块和一个三层感知器组成。首先,一个可学习的score Token作为Q来参加搜索ROI标记。它使score Token能够对挖掘的目标信息进行编码。接下来,score Token关注初始目标Token的所有位置,以隐式地将挖掘的目标与第一个目标进行比较。最后,分数由MLP层和sigmoid激活产生。当在线模板的预测得分低于0.5时,该模板被视为负面的。