出于科研原因,最近需要部署一些大语言模型。这次部署的是北京智源人工智能研究院发布的悟道·天鹰(Aquila)大语言模型。
据官方说该模型在技术上继承了 GPT-3、LLaMA 等的架构设计优点,替换了一批更高效的底层算子实现、重新设计实现了中英双语的 tokenizer,升级了 BMTrain 并行训练方法等等。咱也不懂,但是该模型完全开源真的挺香的,那闲话少叙,直接开始部署吧!
一、部署环境
首先是部署环境,我采用的是高校的服务器,配置信息是:
| 模型:AquilaChat-7B |
| GPU:A800(80GB) |
| 内存:500G |
| Python版本:3.11.3 |
| CUDA版本:12.0 |
| PyTorch版本:2.0.0 |
二、下载开源代码和模型
方法一:
这里模型可以直接在命令行里pip下载FlagAI(FlagAI就是悟道的算法工具包)。
pip install flagai如果下载太慢或者无法下载,那就上清华镜像下载,懂的都懂。
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple flagai如果下载完成,应该会在本地(如果你是在本地部署的话),或者服务器上有一个FlagAI文件夹出现。
这个时候检查一下,FlagAl/examples/Aquila/Aquila-chat路径下这些文件是不是都在,在的话,恭喜你部署成功!
方法二:
如果上述这些文件不在的话也不要担心,咱们还有plan B!
首先命令行克隆FlagAI github仓库(前提是你要事先安装了git工具):
git clone https://github.com/FlagAI-Open/FlagAI.git如果你不会克隆也没关系,直接去GitHub下载压缩包解压也可以的,但是要注意,解压路径不要有中文哦!
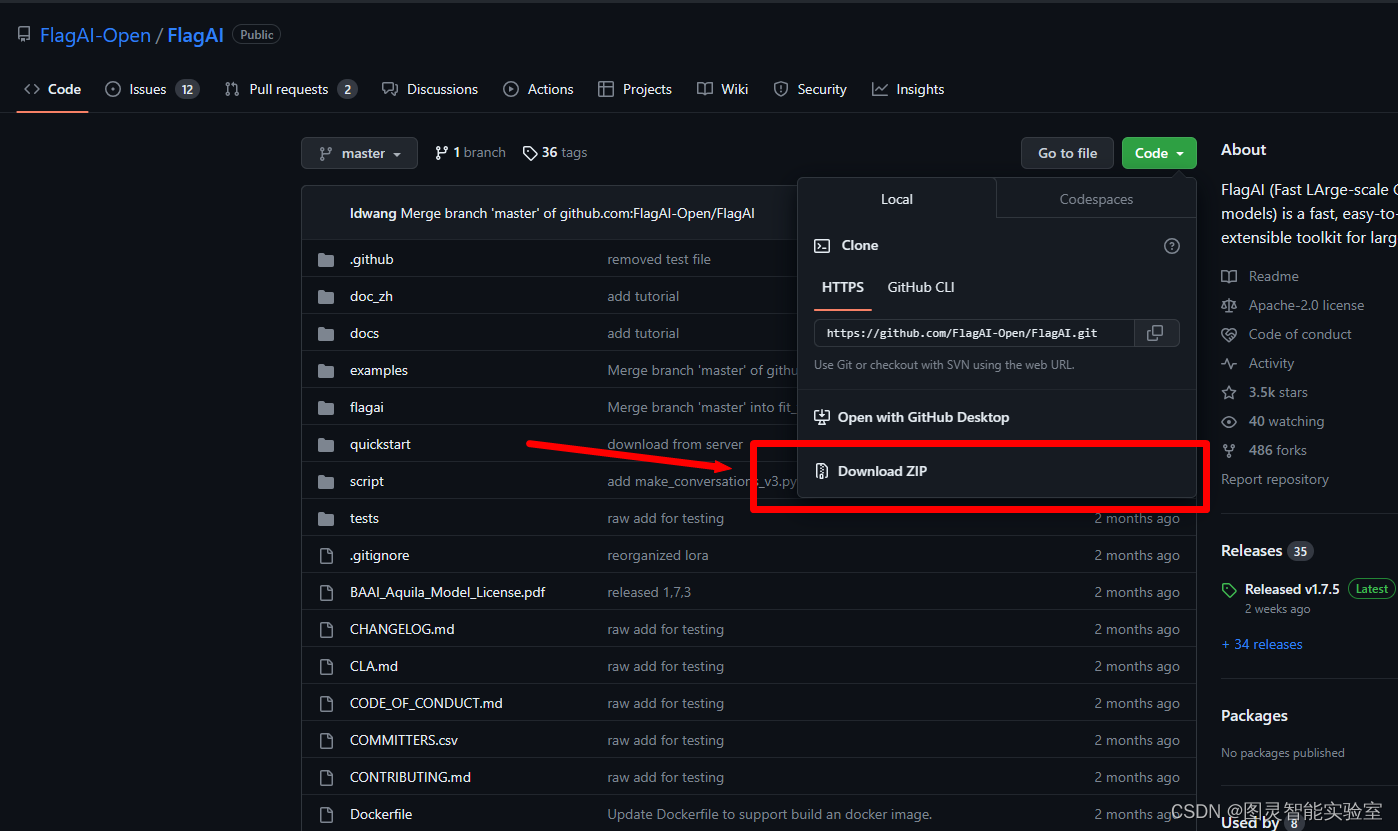
然后在命令行中进入安装脚本的路径,从源码安装FlagAI:
cd FlagAI python setup.py install等待安装即可。
三、运行模型
首先在命令行中进入到对话模型的路径下:
cd FlagAI/examples/Aquila/Aquila-chat然后运行脚本文件即可:
python generate_chat.py上述是单轮对话,如果是多轮对话则运行:
python generate_chat_multiround.py如果想进行低资源推理(适合配置较低的用户),则运行:
python generate_chat_bminf.py其实到这里已经可以进行人机对话了,大家按照步骤到这一步应该已经拥有了自己的ChatGPT了。但是我还是做了些个性化的改动。因为我是在服务器上部署的,而且还要做一些测试,所以推理脚本我在jupyter notebook里面重新写了,具体做法是:
第一步:进入FlagAI/examples/Aquila/Aquila-chat路径下:
cd FlagAI/examples/Aquila/Aquila-chat
第二步:去FlagAI/examples/Aquila/Aquila-chat路径下找到generate_chat.py文件并打开,把代码copy到jupyter notebook中。
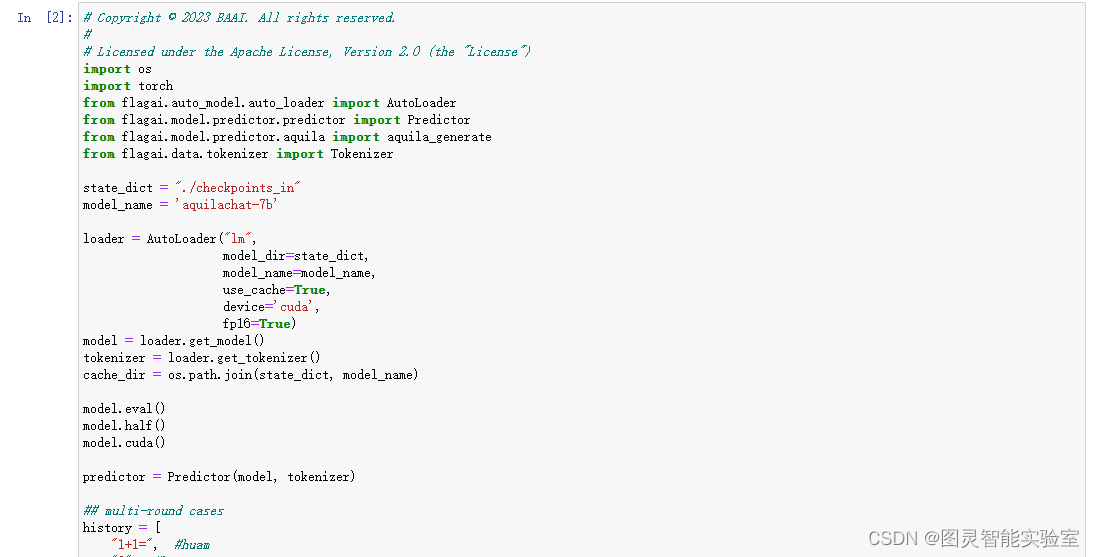
第三步:修改第二步代码中的texts后面的文字,改成你要问的问题,可以问很多问题,但是要注意格式为:
texts = ["请问中国的首都为什么是北京","请介绍蔡徐坤",]
四 测试结果
完成上述后,直接运行所有代码块,得到结果:

可以看到,回答还算不错。
最后,欢迎大家关注微信公众号:图灵智能实验室。不定期更新人工智能前沿算法与应用!