引入
通过上一篇对HBase核心算法和数据结构的梳理,我们对于其底层设计有了更多理解。现在我们从引入篇里面提到的HBase架构出发,去看看其中不同组件是如何设计与实现。
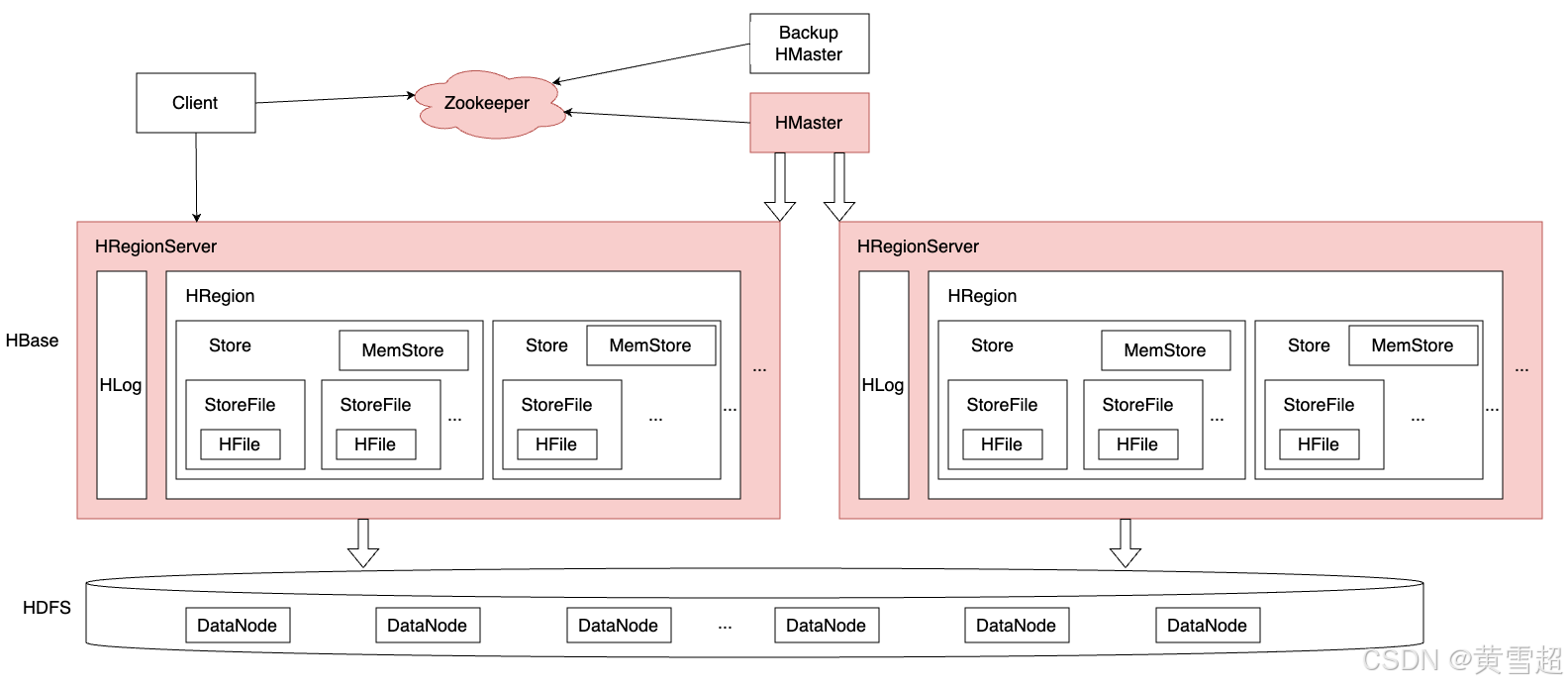
核心组件
首先,需要提到的就是HBase架构中会依赖到的Zookeeper和HDFS。
对于HDFS看过深入HDFS的小伙伴,应该都不陌生,它提供了高可靠的海量数据存储和读写能力;而对于Zookeeper,它是一个分布式协调存储服务,主要是为了解决在分布式场景下存在的一致性痛点问题。(这里挖个坑,后面会抽时间也补上深入Zookeeper专栏)
以下是它们在HBase架构中扮演的角色详细介绍:
Zookeeper
存储元数据:Zookeeper存储了HBase集群的元数据,包括Region的分布信息、表的结构信息等。客户端通过Zookeeper获取这些元数据,从而能够快速定位到存储在HBase中的数据。
协调角色:Zookeeper负责协调HBase集群中的各个组件,如HMaster和RegionServer。它确保每个RegionServer都知道其他RegionServer的存在,并且能够进行通信。当一个RegionServer失效时,Zookeeper能够快速检测到并通知HMaster进行故障转移。
一致性保障:Zookeeper提供了高可用性和一致性保障,确保HBase集群中的数据在分布式环境中的一致性。它通过ZAB协议(Zookeeper Atomic Broadcast)实现了分布式系统的数据同步和一致性,从而保证了HBase中的数据在多个节点之间的一致性和完整性。
Master故障转移:在HBase中,Master负责管理整个集群的元数据和负载均衡等任务。Zookeeper用于Master的选举和故障转移。当当前的Master节点发生故障时,Zookeeper会自动选举一个新的Master节点,确保集群的正常运行。
监控与维护:Zookeeper可以监控HBase集群中各个节点的健康状态。它通过心跳机制检测节点的存活情况,并对故障节点进行处理。此外,Zookeeper还可以用于维护集群的配置信息,如Region的拆分和合并等操作。
下面内容是HBase在ZooKeeper根节点下创建的主要子节点:
[zk: localhost:2181(CONNECTED) 2] ls /hbase [meta-region-server, backup-masters, table, region-in-transition, table-lock, master, balancer, namespace, hbaseid, online-snapshot, replication, splitWAL, recovering-regions, rs]具体说明如下:
- meta-region-server:存储HBase集群hbase:meta元数据表所在的RegionServer访问地址。客户端读写数据首先会从此节点读取hbase:meta元数据的访问地址,将部分元数据加载到本地,根据元数据进行数据路由。
- master/backup-masters:通常来说生产线环境要求所有组件节点都避免单点服务,HBase使用ZooKeeper的相关特性实现了Master的高可用功能。其中Master节点是集群中对外服务的管理服务器,backup-masters下的子节点是集群中的备份节点,一旦对外服务的主Master节点发生了异常,备Master节点可以通过选举切换成主Master,继续对外服务。需要注意的是备Master节点可以是一个,也可以是多个。
- table:集群中所有表信息。
- region-in-transition:在当前HBase系统实现中,迁移Region是一个非常复杂的过程。首先对这个Region执行unassign操作,将此Region从open状态变为off line状态(中间涉及PENDING_CLOSE、CLOSING以及CLOSED等过渡状态),再在目标RegionServer上执行assign操作,将此Region从off line状态变成open状态。这个过程需要在Master上记录此Region的各个状态。目前,RegionServer将这些状态通知给Master是通过ZooKeeper实现的,RegionServer会在region-in-transition中变更Region的状态,Master监听ZooKeeper对应节点,以便在Region状态发生变更之后立马获得通知,得到通知后Master再去更新Region在hbase:meta中的状态和在内存中的状态。
- table-lock:HBase系统使用ZooKeeper相关机制实现分布式锁。HBase中一张表的数据会以Region的形式存在于多个RegionServer上,因此对一张表的DDL操作通常都是典型的分布式操作。每次执行DDL操作之前都需要首先获取相应表的表锁,防止多个DDL操作之间出现冲突,这个表锁就是分布式锁。分布式锁可以使用ZooKeeper的相关特性来实现,在此不再赘述。
- online-snapshot:用来实现在线snapshot操作。表级别在线snapshot同样是一个分布式操作,需要对目标表的每个Region都执行snapshot,全部成功之后才能返回成功。Master作为控制节点给各个相关RegionServer下达snapshot命令,对应RegionServer对目标Region执行snapshot,成功后通知Master。Master下达snapshot命令、RegionServer反馈snapshot结果都是通过ZooKeeper完成的。
- replication:用来实现HBase复制功能。
- splitWAL/recovering-regions:用来实现HBase分布式故障恢复。为了加速集群故障恢复,HBase实现了分布式故障恢复,让集群中所有RegionServer都参与未回放日志切分。ZooKeeper是Master和RegionServer之间的协调节点。
- rs:集群中所有运行的RegionServer。
HDFS
存储数据:作为HBase的底层存储系统,HDFS负责存储HBase所有的数据。HBase中的数据是以列簇(Column Family)的形式存储的,并且每个列簇对应一个或多个HDFS文件。HDFS通过分布式存储的方式,将数据存储在多个节点上,以实现数据的高可用性和高可靠性。
数据冗余与恢复:HDFS通过数据块的复制机制实现了数据的冗余存储。每个数据块会被复制到多个节点上,从而保证了数据的可靠性。如果一个节点发生故障,HDFS可以自动从其他节点上恢复数据。HBase利用这一特性,确保了数据的持久性和可用性,即使在部分节点失效的情况下,数据也不会丢失。
数据吞吐量:HDFS提供了高吞吐量的数据访问能力,这对于HBase这样的大规模数据处理系统来说至关重要。HBase可以利用HDFS的高性能读写能力,快速地读取和写入数据。HDFS的分布式特性使得数据可以并行地读写,大大提高了数据的处理效率。
存储HLog:HLog是HBase中的预写日志(Write-Ahead Log),它用于记录每一行数据的修改操作。HLog被存储在HDFS上,以确保数据的持久性和一致性。当RegionServer发生故障时,可以通过HLog中的日志恢复数据,保证数据的完整性。
支持分布式计算:HDFS与HBase的结合,使得HBase可以与Hadoop生态系统中的其他组件(如MapReduce、Spark等)进行无缝集成。HBase中的数据可以方便地被这些组件访问和处理,实现了数据的分布式计算和分析。
注意:
- HBase本身并不存储文件,它只规定文件格式以及文件内容,实际文件存储由HDFS实现。
- HBase不提供机制保证存储数据的高可靠,数据的高可靠性由HDFS的多副本机制保证。
- HBase-HDFS体系是典型的计算存储分离架构。这种轻耦合架构的好处是,一方面可以非常方便地使用其他存储替代HDFS作为HBase的存储方案;另一方面对于云上服务来说,计算资源和存储资源可以独立扩容缩容,给云上用户带来了极大的便利。
HMaster
HMaster是HBase集群的主节点,负责管理RegionServer和Region的元数据、表的创建、分区的拆分和合并、Region的分配和迁移等任务。
一个HBase集群中可以有多个 HMaster节点,由zk进行协调,保证只有一个HMaster运行,其余HMaster为Backup Master。
其主要的职责如下:
-
管理库表的元数据,如表对应Region信息,负责将Region分配给HRegionServer。
-
负责HRegionServer的负载均衡。当写入数据时负责将数据均衡的分布到各个Region上,避免HRegionServer数据存储倾斜;当读取数据时,将请求均衡的发送到各个RegionServer上,避免HRegionSever负载过大。
-
通过zk发现失效的HRegionServer并重新分配该HRegionServer上的Region。
我们下面从HBase2.6.1 源码去看看其是如何实现的,在HBase中对应的类为org.apache.hadoop.hbase.master.HMaster。
首先,还是看其备注:
HMaster is the "master server" for HBase. An HBase cluster has one active master. If many masters are started, all compete. Whichever wins goes on to run the cluster. All others park themselves in their constructor until master or cluster shutdown or until the active master loses its lease in zookeeper. Thereafter, all running master jostle to take over master role.
<p/>
The Master can be asked shutdown the cluster. See {@link #shutdown()}. In this case it will tell all regionservers to go down and then wait on them all reporting in that they are down. This master will then shut itself down.
<p/>
You can also shutdown just this master. Call {@link #stopMaster()}.
@see org.apache.zookeeper.Watcher翻译:
HMaster是HBase的“主服务器”。一个HBase集群中仅有一个处于活跃状态的主服务器。若启动了多个主服务器,它们之间将展开竞争。最终胜出者将继续负责运行该集群。其余的主服务器则在其构造函数中处于等待状态,直至主服务器或集群关闭,或者直至活跃的主服务器在Zookeeper中失去其租约。此后,所有正在运行的主服务器将竞相争夺主服务器的角色。
主服务器可以被要求关闭整个集群。参见{@link #shutdown()}。在这种情况下,它会通知所有区域服务器停止运行,然后等待它们全部报告已停止运行。随后,该主服务器将自行关闭。
此外,你还可以单独关闭当前的主服务器。调用{@link #stopMaster()}即可。
另请参阅org.apache.zookeeper.Watcher。
下面我们重点看看它的构造器函数,其对应备注如下:
Initializes the HMaster. The steps are as follows:
<p>
<ol>
<li>Initialize the local HRegionServer
<li>Start the ActiveMasterManager.
</ol>
<p>
Remaining steps of initialization occur in {@link #finishActiveMasterInitialization()} after the master becomes the active one.翻译:
初始化 HMaster。步骤如下:
1. 初始化本地 HRegionServer。
2. 启动 ActiveMasterManager。在主节点成为活动节点后,剩余的初始化步骤将在 {@link #finishActiveMasterInitialization()} 中进行。
具体源码如下:
/**
* HMaster 类的构造函数,用于初始化 HMaster 实例。
*
* @param conf HBase 配置对象,包含了 HBase 集群的各种配置信息。
* @throws IOException 当在初始化过程中发生输入输出错误时抛出该异常。
*/
public HMaster(final Configuration conf) throws IOException {
// 调用父类 HRegionServer 的构造函数,传入配置对象进行初始化
super(conf);
// 创建一个名为 "HMaster.cxtor" 的跟踪跨度,用于性能监控和调试
final Span span = TraceUtil.createSpan("HMaster.cxtor");
try (Scope ignored = span.makeCurrent()) {
// 检查配置中是否启用了维护模式
// hbase.master.maintenance_mode
if (conf.getBoolean(MAINTENANCE_MODE, false)) {
// 如果配置中启用了维护模式,记录日志
LOG.info("Detected {}=true via configuration.", MAINTENANCE_MODE);
// 设置维护模式标志为 true
maintenanceMode = true;
} else if (Boolean.getBoolean(MAINTENANCE_MODE)) {
// 如果环境变量中启用了维护模式,记录日志
LOG.info("Detected {}=true via environment variables.", MAINTENANCE_MODE);
// 设置维护模式标志为 true
maintenanceMode = true;
} else {
// 如果配置和环境变量中都未启用维护模式,设置维护模式标志为 false
maintenanceMode = false;
}
// 创建一个内存受限的日志消息缓冲区,存放来自 regionserver 的 fatal error 信息,超过 buffer 大小后会自动清理
// bug 修复:'1 * 1024 * 1024' 可被替换为 '1024 * 1024'
this.rsFatals = new MemoryBoundedLogMessageBuffer(
conf.getLong("hbase.master.buffer.for.rs.fatals", 1024 * 1024));
// 记录 HBase 根目录和集群是否为分布式模式的信息
LOG.info("hbase.rootdir={}, hbase.cluster.distributed={}", getDataRootDir(),
this.conf.getBoolean(HConstants.CLUSTER_DISTRIBUTED, false));
// 禁用 Master 中使用元数据副本
this.conf.setBoolean(HConstants.USE_META_REPLICAS, false);
// 对 Master 配置进行装饰,可能会添加或修改一些配置项
decorateMasterConfiguration(this.conf);
// Hack! Maps DFSClient => Master for logs. HDFS made this
// config param for task trackers, but we can piggyback off of it.
// 如果配置中没有设置 mapreduce.task.attempt.id,则将其设置为 hb_m_ 加上服务器名称
if (this.conf.get("mapreduce.task.attempt.id") == null) {
this.conf.set("mapreduce.task.attempt.id", "hb_m_" + this.serverName.toString());
}
// 初始化 Master 指标监控对象
this.metricsMaster = new MetricsMaster(new MetricsMasterWrapperImpl(this));
// 检查是否在启动时预加载表描述符
this.preLoadTableDescriptors = conf.getBoolean("hbase.master.preload.tabledescriptors", true);
// 获取最大平衡时间
this.maxBalancingTime = getMaxBalancingTime();
// 获取最大区域过渡百分比
this.maxRitPercent = conf.getDouble(HConstants.HBASE_MASTER_BALANCER_MAX_RIT_PERCENT,
HConstants.DEFAULT_HBASE_MASTER_BALANCER_MAX_RIT_PERCENT);
// 检查是否需要发布集群状态
boolean shouldPublish =
conf.getBoolean(HConstants.STATUS_PUBLISHED, HConstants.STATUS_PUBLISHED_DEFAULT);
// 获取集群状态发布器的类
Class<? extends ClusterStatusPublisher.Publisher> publisherClass =
conf.getClass(ClusterStatusPublisher.STATUS_PUBLISHER_CLASS,
ClusterStatusPublisher.DEFAULT_STATUS_PUBLISHER_CLASS,
ClusterStatusPublisher.Publisher.class);
// 如果需要发布集群状态
if (shouldPublish) {
// 如果发布器类未设置,记录警告日志
if (publisherClass == null) {
LOG.warn(HConstants.STATUS_PUBLISHED + " is true, but "
+ ClusterStatusPublisher.DEFAULT_STATUS_PUBLISHER_CLASS
+ " is not set - not publishing status");
} else {
// 创建集群状态发布器实例
clusterStatusPublisherChore = new ClusterStatusPublisher(this, conf, publisherClass);
// 记录调试日志,表明已创建集群状态发布器
LOG.debug("Created {}", this.clusterStatusPublisherChore);
// 将集群状态发布器添加到任务调度服务中
getChoreService().scheduleChore(clusterStatusPublisherChore);
}
}
// 创建 ActiveMasterManager 实例,用于管理主节点的选举和活动状态
this.activeMasterManager = createActiveMasterManager(zooKeeper, serverName, this);
// 创建缓存集群 ID 实例
cachedClusterId = new CachedClusterId(this, conf);
// 创建 RegionServer 跟踪器实例,用于跟踪 RegionServer 的状态
this.regionServerTracker = new RegionServerTracker(zooKeeper, this);
// 设置跟踪跨度的状态为成功
span.setStatus(StatusCode.OK);
} catch (Throwable t) {
// 记录跟踪跨度的错误信息
TraceUtil.setError(span, t);
// 记录构造 Master 失败的错误信息
LOG.error("Failed construction of Master", t);
// 抛出异常
throw t;
} finally {
// 结束跟踪跨度
span.end();
}
}
HMaster除了调用自己的构造方法,也会调用父类HRegionServer的构造方法,其中核心步骤:
- 创建 RPCServer
- 最重要的操作:初始化一个 ZKWatcher 类型的 Zookeeper 实例,用来初始化创建一些 ZNode 节点
- 启动 RPCServer
- 创建 ActiveMasterManager 用来选举和管理HMaster的状态
注意:
在2.x早期版本,因为考虑有些单元测试不需要集群,因此完全不需要 Zookeeper,相关创建ActiveMasterManager代码如下:
// Some unit tests don't need a cluster, so no zookeeper at all // 如果不是单元测试模式(不需要集群和 ZooKeeper),则创建 ActiveMasterManager 实例 if(!conf.getBoolean("hbase.testing.nocluster", false)) { // 创建 ActiveMasterManager 实例,用于管理主节点的选举和状态 this.activeMasterManager = new ActiveMasterManager(zooKeeper, this.serverName, this); } else { // 在单元测试模式下,不使用 ZooKeeper,因此将 activeMasterManager 设置为 null this.activeMasterManager = null; }在新版本的HBase中,为了确保系统的稳定性和一致性,移除了允许activeMasterManager为null的逻辑。这样做可以确保HMaster在任何情况下都能正确地与Zookeeper交互,完成必要的分布式任务。对于不需要集群的单元测试,可以通过其他方式来模拟或绕过Zookeeper的依赖,例如使用mock对象或虚拟的Zookeeper实例。
HRegionServer
HRegionServer可以看成HBase架构中的从节点,习惯上也可称为RegionServer,HBase集群中一般有多台HRegionServer,主要负责用户数据写入、读取等基础操作。
其主要的职责如下:
-
管理HMaster分配的Region,处理来自客户端的读写请求(如:put、get请求),定期向 HMaster汇报Region状态。
-
负责Region变大拆分。当一个Region的数据量增大到一定程度,HRegionServer负责将 Region拆分为两个新的Region,实现数据均衡分布。
-
负责StoreFile合并。
-
负责与HDFS交互,将数据存储到HDFS中。
我们下面接着从HBase2.6.1 源码去看看它是如何实现的,在HBase中对应的类为org.apache.hadoop.hbase.regionserver.HRegionServer。
当然还是先看其备注:
HRegionServer makes a set of HRegions available to clients. It checks in with the HMaster. There are many HRegionServers in a single HBase deployment.
翻译:
HRegionServer 为客户端提供了一组 HRegions。它会向 HMaster 进行注册。在单个 HBase 部署中存在许多 HRegionServer。
下面还是看看其构造函数,源码如下:
/**
* 构造函数,用于初始化 HRegionServer 实例。
*
* @param conf 配置对象,用于配置 HRegionServer 的各项参数。
* @throws IOException 如果在初始化过程中发生 IO 错误。
*/
public HRegionServer(final Configuration conf) throws IOException {
// 调用父类 Thread 的构造函数,设置线程名称为 "RegionServer"
super("RegionServer");
// 创建一个跟踪跨度,用于跟踪构造函数的执行时间
final Span span = TraceUtil.createSpan("HRegionServer.cxtor");
try (Scope ignored = span.makeCurrent()) {
// 获取当前时间作为服务器的启动代码
this.startcode = EnvironmentEdgeManager.currentTime();
// 保存配置对象
this.conf = conf;
// 标记数据文件系统状态为正常
this.dataFsOk = true;
// 从配置中获取是否无主节点模式
this.masterless = conf.getBoolean(MASTERLESS_CONFIG_NAME, false);
// 初始化 Netty 事件循环组配置
this.eventLoopGroupConfig = setupNetty(this.conf);
// 检查集群可用堆内存限制
MemorySizeUtil.checkForClusterFreeHeapMemoryLimit(this.conf);
// 检查 HFile 版本
HFile.checkHFileVersion(this.conf);
// 测试 hbase.regionserver.codecs 配置的编码方式是可用的
checkCodecs(this.conf);
// 初始化 userProvider 用于权限认证
this.userProvider = UserProvider.instantiate(conf);
FSUtils.setupShortCircuitRead(this.conf);
// 禁用元数据副本的使用
this.conf.setBoolean(HConstants.USE_META_REPLICAS, false);
// 从配置中获取线程唤醒频率
this.threadWakeFrequency = conf.getInt(HConstants.THREAD_WAKE_FREQUENCY, 10 * 1000);
// 从配置中获取压缩检查频率
this.compactionCheckFrequency = conf.getInt(PERIOD_COMPACTION, this.threadWakeFrequency);
// 从配置中获取刷新检查频率
this.flushCheckFrequency = conf.getInt(PERIOD_FLUSH, this.threadWakeFrequency);
// 从配置中获取消息间隔
this.msgInterval = conf.getInt("hbase.regionserver.msginterval", 3 * 1000);
// 创建一个休眠器,用于控制消息间隔
this.sleeper = new Sleeper(this.msgInterval, this);
// 设置 Nonce 标志,初始化 nonceManager
// 客户端的每次申请及重复申请使用同一个 nonce 进行描述,解决 Client 重复操作提交的情况
boolean isNoncesEnabled = conf.getBoolean(HConstants.HBASE_RS_NONCES_ENABLED, true);
// 如果启用了随机数,则创建一个服务器随机数管理器
this.nonceManager = isNoncesEnabled ? new ServerNonceManager(this.conf) : null;
// 从配置中获取操作超时时间
this.operationTimeout = conf.getInt(HConstants.HBASE_CLIENT_OPERATION_TIMEOUT,
HConstants.DEFAULT_HBASE_CLIENT_OPERATION_TIMEOUT);
// 从配置中获取短操作超时时间
this.shortOperationTimeout = conf.getInt(HConstants.HBASE_RPC_SHORTOPERATION_TIMEOUT_KEY,
HConstants.DEFAULT_HBASE_RPC_SHORTOPERATION_TIMEOUT);
// 从配置中获取重试暂停时间
this.retryPauseTime = conf.getLong(HConstants.HBASE_RPC_SHORTOPERATION_RETRY_PAUSE_TIME,
HConstants.DEFAULT_HBASE_RPC_SHORTOPERATION_RETRY_PAUSE_TIME);
// 初始化中止请求标志
this.abortRequested = new AtomicBoolean(false);
// 标记服务器未停止
this.stopped = false;
// 获取命名队列记录器实例
this.namedQueueRecorder = NamedQueueRecorder.getInstance(this.conf);
// 创建 RegionServer 的 RPC 服务端
rpcServices = createRpcServices();
// 获取要使用的主机名
useThisHostnameInstead = getUseThisHostnameInstead(conf);
// 检查是否使用 IP 地址暴露服务
boolean useIp = conf.getBoolean(HConstants.HBASE_SERVER_USEIP_ENABLED_KEY,
HConstants.HBASE_SERVER_USEIP_ENABLED_DEFAULT);
// 根据配置选择使用 IP 地址或主机名
String isaHostName =
useIp ? rpcServices.isa.getAddress().getHostAddress() : rpcServices.isa.getHostName();
// 确定最终使用的主机名
String hostName =
StringUtils.isBlank(useThisHostnameInstead) ? isaHostName : useThisHostnameInstead;
// 创建服务器名称
serverName = ServerName.valueOf(hostName, this.rpcServices.isa.getPort(), this.startcode);
rpcControllerFactory = RpcControllerFactory.instantiate(this.conf);
// RpcRetryingCaller:rpcCall() 发送请求到远程服务器
rpcRetryingCallerFactory = RpcRetryingCallerFactory.instantiate(this.conf,
clusterConnection == null ? null : clusterConnection.getConnectionMetrics());
// 登录 ZooKeeper 客户端主体
ZKAuthentication.loginClient(this.conf, HConstants.ZK_CLIENT_KEYTAB_FILE,
HConstants.ZK_CLIENT_KERBEROS_PRINCIPAL, hostName);
// 登录服务器主体
login(userProvider, hostName);
// 初始化超级用户
Superusers.initialize(conf);
// 用来记录 region server 中所有的 memstore 所占大小
regionServerAccounting = new RegionServerAccounting(conf);
// 检查是否为主节点且不承载表
boolean isMasterNotCarryTable =
this instanceof HMaster && !LoadBalancer.isTablesOnMaster(conf);
// 如果不是主节点不承载表的情况,则创建块缓存和 MOB 文件缓存
if (!isMasterNotCarryTable) {
blockCache = BlockCacheFactory.createBlockCache(conf);
mobFileCache = new MobFileCache(conf);
}
// 创建区域服务器快照验证器
rsSnapshotVerifier = new RSSnapshotVerifier(conf);
// 设置未捕获异常处理器
uncaughtExceptionHandler =
(t, e) -> abort("Uncaught exception in executorService thread " + t.getName(), e);
// hregionserver管理region,region底层就是HFile, HFile存储在HDFS,所以 hreionserver肯定会跟 HDFS打交道, 这个方法就是初始化一个 FileSystem 实例
initializeFileSystem();
// 创建配置管理器
this.configurationManager = new ConfigurationManager();
// 设置信号处理程序
setupSignalHandlers();
// 创建当前rs与zk的连接
zooKeeper = new ZKWatcher(conf, getProcessName() + ":" + rpcServices.isa.getPort(), this,
canCreateBaseZNode());
// 如果集群中没有主节点,则跳过跟踪主节点和集群状态
if (!this.masterless) {
if (
conf.getBoolean(HBASE_SPLIT_WAL_COORDINATED_BY_ZK, DEFAULT_HBASE_SPLIT_COORDINATED_BY_ZK)
) {
// 如果使用 ZooKeeper 协调 WAL 拆分,则创建协调状态管理器
this.csm = new ZkCoordinatedStateManager(this);
}
// 创建主节点地址跟踪器并启动
masterAddressTracker = new MasterAddressTracker(getZooKeeper(), this);
masterAddressTracker.start();
// 创建集群状态跟踪器并启动
clusterStatusTracker = new ClusterStatusTracker(zooKeeper, this);
clusterStatusTracker.start();
} else {
// 如果是无主节点模式,则不使用主节点地址跟踪器和集群状态跟踪器
masterAddressTracker = null;
clusterStatusTracker = null;
}
// 启动 RPC 服务
this.rpcServices.start(zooKeeper);
// 创建元数据区域位置缓存
this.metaRegionLocationCache = new MetaRegionLocationCache(zooKeeper);
// 繁杂服务:1、封装了线程池,负责周期性的调度任务;2、心跳、检查compact、compact完成后hfile清理
// ChoreService 里面包装了一个线程池,用来处理 hmaster 或者 hregionserver自己的一些内部服务的定时调度
// 这违反了“构造函数中不启动服务”的原则,但主节点依赖于以下任务和执行器的创建
// 主节点和区域服务器有很多重叠代码,需要重构以减少重复
// 主节点期望构造函数启动 Web 服务器
int choreServiceInitialSize =
conf.getInt(CHORE_SERVICE_INITIAL_POOL_SIZE, DEFAULT_CHORE_SERVICE_INITIAL_POOL_SIZE);
// 创建任务服务
this.choreService = new ChoreService(getName(), choreServiceInitialSize, true);
// 初始化rs处理任务的线程池,同master的任务线程池
// ExecutorService 同样也是包装了一个线程池,用来处理其他的 RpcClient 发送过来的请求
this.executorService = new ExecutorService(getName());
// 启动 jetty,Region Server WebUI
putUpWebUI();
// 设置跟踪跨度状态为成功
span.setStatus(StatusCode.OK);
} catch (Throwable t) {
// 确保记录异常信息
TraceUtil.setError(span, t);
LOG.error("Failed construction RegionServer", t);
// 抛出异常
throw t;
} finally {
// 结束跟踪跨度
span.end();
}
}
相比2.x早期源码版本,新版本的做了以下优化迭代:
- 功能增强
引入 Span 和 NamedQueueRecorder,提升性能监控和调试能力。
增加 RSSnapshotVerifier 和 ClusterId 支持,增强数据的可靠性和集群管理能力。
引入 EOF 和新的线程池管理逻辑,提升系统的并发处理能力和资源利用率。 - 性能优化
移除对 numRetries 和部分配置参数的支持,减少不必要的计算和资源消耗。
优化线程池和 ChoreService 的初始化,提升系统的响应速度和稳定性。 - 安全性和稳定性提升
使用 final 和 AtomicBoolean,增强代码的稳定性和可读性。
引入 ZKAuthentication 和 Superusers 的管理,增强系统的安全性和权限控制。
使用 try-finally 和 Scope,确保资源的正确释放和异常信息的完整记录。
HRegionServer组件是一个综合体系,包含多个各司其职的核心模块:HLog、MemStore、HFile以及BlockCache。
一个RegionServer由一个(或多个)HLog、一个BlockCache以及多个Region组成。其中,HLog用来保证数据写入的可靠性;BlockCache可以将数据块缓存在内存中以提升数据读取性能;Region是HBase中数据表的一个数据分片,一个RegionServer上通常会负责多个Region的数据读写。一个Region由多个Store组成,每个Store存放对应列簇的数据,比如一个表中有两个列簇,这个表的所有Region就都会包含两个Store。每个Store包含一个MemStore和多个HFile,用户数据写入时会将对应列簇数据写入相应的MemStore,一旦写入数据的内存大小超过设定阈值,系统就会将MemStore中的数据落盘形成HFile文件。HFile存放在HDFS上,是一种定制化格式的数据存储文件,方便用户进行数据读取。
下面我们分别看看这些核心模块:
HLog
HBase中系统故障恢复以及主从复制都基于HLog实现。默认情况下,所有写入操作(写入、更新以及删除)的数据都先以追加形式写入HLog,再写入MemStore。大多数情况下,HLog并不会被读取,但如果RegionServer在某些异常情况下发生宕机,此时已经写入MemStore中但尚未f lush到磁盘的数据就会丢失,需要回放HLog补救丢失的数据。此外,HBase主从复制需要主集群将HLog日志发送给从集群,从集群在本地执行回放操作,完成集群之间的数据复制。
HLog生命周期包含4个阶段:
- HLog构建:HBase的任何写入操作都会先将记录追加写入到HLog文件中。
- HLog滚动:HBase后台启动一个线程,每隔一段时间(由参数'hbase.regionserver. logroll.period'决定,默认1小时)进行日志滚动。日志滚动会新建一个新的日志文件,接收新的日志数据。日志滚动机制主要是为了方便过期日志数据能够以文件的形式直接删除。
- HLog失效:写入数据一旦从MemStore中落盘,对应的日志数据就会失效。为了方便处理,HBase中日志失效删除总是以文件为单位执行。查看某个HLog文件是否失效只需确认该HLog文件中所有日志记录对应的数据是否已经完成落盘,如果日志中所有日志记录已经落盘,则可以认为该日志文件失效。一旦日志文件失效,就会从WALs文件夹移动到oldWALs文件夹。注意此时HLog并没有被系统删除。
- HLog删除:Master后台会启动一个线程,每隔一段时间(参数'hbase.master.cleaner. interval',默认1分钟)检查一次文件夹oldWALs下的所有失效日志文件,确认是否可以删除,确认可以删除之后执行删除操作。
确认条件主要有两个:- 该HLog文件是否还在参与主从复制。对于使用HLog进行主从复制的业务,需要继续确认是否该HLog还在应用于主从复制。
- 该HLog文件是否已经在OldWALs目录中存在10分钟。为了更加灵活地管理HLog生命周期,系统提供了参数设置日志文件的TTL(参数'hbase.master.logcleaner.ttl',默认10分钟),默认情况下oldWALs里面的HLog文件最多可以再保存10分钟。
MemStore
MemStore是HBase中用于存储内存中数据修改的一个关键组件。每个HStore(对应一个列簇)都有一个MemStore,它类似于一个写缓冲区,用于暂存对HBase表的写入操作,而不会立刻将这些变更持久化到磁盘。当MemStore达到一定的大小限制或满足其他条件时,其内容会被刷新到磁盘,存储为一个HFile。
下面还是看看对应源码,首先其注释如下:
The MemStore holds in-memory modifications to the Store. Modifications are {@link Cell}s.
The MemStore functions should not be called in parallel. Callers should hold write and read locks. This is done in {@link HStore}.翻译:
MemStore 保存对 Store 的内存修改。修改是 {@link Cell}。
不应并行调用 MemStore 的函数。调用者应持有写锁和读锁。这在 {@link HStore} 中完成。
其具体源码如下:
@InterfaceAudience.Private
public interface MemStore extends Closeable {
/**
* 创建当前内存存储的快照。
* 快照必须通过调用 {@link #clearSnapshot(long)} 方法进行清理。
*
* @return 一个表示当前内存存储快照的 {@link MemStoreSnapshot} 对象。
*/
MemStoreSnapshot snapshot();
/**
* 清理当前内存存储的快照。
* 此方法与 {@link #snapshot()} 方法配合使用。
*
* @param id 要清理的快照的唯一标识符。
* @throws UnexpectedStateException 如果清理过程中出现意外状态。
*/
void clearSnapshot(long id) throws UnexpectedStateException;
/**
* 执行刷新操作。
* 刷新操作首先会清理快照中的数据(如果有),若快照为空,则会刷新当前的 Cell 集合。
*
* @return 刷新操作将清理的内存大小。
*/
MemStoreSize getFlushableSize();
/**
* 返回内存存储快照的大小(如果有)。
*
* @return 内存存储快照的大小。
*/
MemStoreSize getSnapshotSize();
/**
* 向内存存储中写入一个更新。
*
* @param cell 要写入的 Cell 对象。
* @param memstoreSizing 用于传递内存存储大小变化的对象,包含数据大小和堆开销的变化。
*/
void add(final Cell cell, MemStoreSizing memstoreSizing);
/**
* 向内存存储中写入多个更新。
*
* @param cells 要写入的 Cell 对象的可迭代集合。
* @param memstoreSizing 用于传递内存存储大小变化的对象,包含数据大小和堆开销的变化。
*/
void add(Iterable<Cell> cells, MemStoreSizing memstoreSizing);
/**
* 返回内存存储中所有 Cell 的最旧时间戳。
*
* @return 最旧时间戳。
*/
long timeOfOldestEdit();
/**
* 更新或插入指定的 Cell 集合。
* 对于每个 Cell,将其插入到内存存储中。这将原子地更新或插入该行/族/限定符的值。
* 如果 Cell 已经存在,则会先将其移除。
* 目前,内存存储时间戳(memstoreTS)保持为 0,因此每次插入都会立即可见。
* 此方法在行锁下调用,因此 Get 操作仍能原子地看到更新。扫描操作只能看到每个 KeyValue 的更新是原子的。
*
* @param readpoint 读取点,低于该读取点的重复 Cell 可以安全地移除。
* @param memstoreSizing 用于传递内存存储大小变化的对象,包含数据大小和堆开销的变化。
*/
void upsert(Iterable<Cell> cells, long readpoint, MemStoreSizing memstoreSizing);
/**
* 获取内存存储的扫描器。
* 如果存在快照,扫描器可能会包含对快照的扫描。
*
* @param readPt 读取点。
* @return 一个包含 KeyValueScanner 的列表。
* @throws IOException 如果在获取扫描器时发生 I/O 错误。
*/
List<KeyValueScanner> getScanners(long readPt) throws IOException;
/**
* 返回此内存存储占用的总内存。
* 此方法不包括快照占用的任何大小,因为假设快照会很快被清理。
* 此方法不是线程安全的,在计算大小时内存存储可能会被修改。调用者有责任确保不会发生这种情况。
*
* @return 内存存储占用的总内存。
*/
MemStoreSize size();
/**
* 在执行刷新操作之前调用此方法。
*
* @return 刷新操作执行后,内存存储中未刷新的序列号的估计值(下限)。
* 如果内存存储将被清理,则返回 {@code HConstants.NO_SEQNUM}。
*/
long preFlushSeqIDEstimation();
/**
* 判断内存存储是否可能使用一些额外的内存空间。
*
* @return 如果内存存储可能使用额外的内存空间,则返回 true;否则返回 false。
*/
boolean isSloppy();
/**
* 通知内存存储接下来的更新将是从 WAL 中重放编辑的一部分。
*/
default void startReplayingFromWAL() {
return;
}
/**
* 通知内存存储从 WAL 中重放编辑的操作已完成。
*/
default void stopReplayingFromWAL() {
return;
}
/**
* 关闭内存存储。
* 通常,只有在内存存储中没有数据时才应调用此方法,除非要进行自我终止操作。
* 对于正常情况,此方法仅用于修复引用计数,参见 HBASE-27941。
*/
@Override
void close();
}
我们知道,MemStore底层采用了跳跃表这种数据结构。当然HBase实现的时候,自然是不会直接使用原始跳跃表,而是使用了JDK自带的数据结构ConcurrentSkipListMap。
ConcurrentSkipListMap底层使用跳跃表来保证数据的有序性,并保证数据的写入、查找、删除操作都可以在O(logN)的时间复杂度完成。除此之外,ConcurrentSkipListMap有个非常重要的特点是线程安全,它在底层采用了CAS原子性操作,避免了多线程访问条件下昂贵的锁开销,极大地提升了多线程访问场景下的读写性能。
MemStore由两个ConcurrentSkipListMap(称为A和B)实现,写入操作(包括更新删除操作)会将数据写入ConcurrentSkipListMap A,当ConcurrentSkipListMap A中数据量超过一定阈值之后会创建一个新的ConcurrentSkipListMap B来接收用户新的请求,之前已经写满的ConcurrentSkipListMap A会执行异步flush操作落盘形成HFile。
这个具体见如下源码:
/**
* 构造一个新的 CellSet 实例,使用指定的 CellComparator 来对 Cell 进行排序。
* HBase 的 Memstore 使用 ConcurrentSkipListMap 作为数据结构,它是一个基于跳表实现的、线程安全的有序哈希表,
* 兼顾了查询和插入删除操作的性能平衡。
*
* @param c 用于比较 Cell 的 CellComparator 对象
*/
CellSet(final CellComparator c) {
this.delegatee = new ConcurrentSkipListMap<>(c.getSimpleComparator());
this.numUniqueKeys = UNKNOWN_NUM_UNIQUES;
}
注意:
MemStore从本质上来看就是一块缓存,可以称为写缓存。而在Java系统中,大内存系统总会面临GC问题,MemStore本身会占用大量内存,因此GC的问题不可避免。不仅如此,HBase中MemStore工作模式的特殊性更会引起严重的内存碎片,存在大量内存碎片会导致系统看起来似乎还有很多空间,但实际上这些空间都是一些非常小的碎片,已经分配不出一块完整的可用内存,这时会触发长时间的Full GC。
HBase解决方案:
HBase引入了MSLAB(MemStore-Local Allocation Buffers)来解决内存碎片问题。MSLAB是一种基于Slab分配器的实现,通过分配连续的定长内存块来减少内存碎片。MSLAB为每个MemStore分配一个固定的内存区域,当数据写入MemStore时,会直接分配到这些预分配的内存块中,从而避免了JVM堆内存的频繁分配和回收。
HFile
MemStore中数据落盘之后会形成一个文件写入HDFS,这个文件称为HFile。HFile参考BigTable的SSTable和Hadoop的TFile实现。
其源码注释如下:
File format for hbase. A file of sorted key/value pairs. Both keys and values are byte arrays.
<p>
The memory footprint of a HFile includes the following (below is taken from the <a href=https://issues.apache.org/jira/browse/HADOOP-3315>TFile</a> documentation but applies also to HFile):
<ul>
<li>Some constant overhead of reading or writing a compressed block.
<ul>
<li>Each compressed block requires one compression/decompression codec for I/O.
<li>Temporary space to buffer the key.
<li>Temporary space to buffer the value.
</ul>
<li>HFile index, which is proportional to the total number of Data Blocks. The total amount of memory needed to hold the index can be estimated as (56+AvgKeySize)*NumBlocks.
</ul>
Suggestions on performance optimization.
<ul>
<li>Minimum block size. We recommend a setting of minimum block size between 8KB to 1MB for general usage. Larger block size is preferred if files are primarily for sequential access.However, it would lead to inefficient random access (because there are more data to decompress).Smaller blocks are good for random access, but require more memory to hold the block index, and may be slower to create (because we must flush the compressor stream at the conclusion of each data block, which leads to an FS I/O flush). Further, due to the internal caching in Compression codec, the smallest possible block size would be around 20KB-30KB.
<li>The current implementation does not offer true multi-threading for reading. The implementation uses FSDataInputStream seek()+read(), which is shown to be much faster than positioned-read call in single thread mode. However, it also means that if multiple threads attempt to access the same HFile (using multiple scanners) simultaneously, the actual I/O is carried out sequentially even if they access different DFS blocks (Reexamine! pread seems to be 10% faster than seek+read in my testing -- stack).
<li>Compression codec. Use "none" if the data is not very compressable (by compressable, I mean a compression ratio at least 2:1). Generally, use "lzo" as the starting point for experimenting. "gz" overs slightly better compression ratio over "lzo" but requires 4x CPU to compress and 2x CPU to decompress, comparing to "lzo".
</ul>
For more on the background behind HFile, see <a
href=https://issues.apache.org/jira/browse/HBASE-61>HBASE-61</a>.
<p>
File is made of data blocks followed by meta data blocks (if any), a fileinfo block, data block index, meta data block index, and a fixed size trailer which records the offsets at which file changes content type.
<pre>
<data blocks><meta blocks><fileinfo>< data index><meta index><trailer>
</pre>
Each block has a bit of magic at its start. Block are comprised of key/values. In data blocks, they are both byte arrays. Metadata blocks are a String key and a byte array value. An empty file looks like this:
<pre>
<fileinfo><trailer>
</pre>
. That is, there are not data nor meta blocks present.
<p>
TODO: Do scanners need to be able to take a start and end row? TODO: Should BlockIndex know the name of its file? Should it have a Path that points at its file say for the case where an index lives apart from an HFile instance?
翻译:
HBase的文件格式。一个由排序的键值对组成的文件。键和值都是字节数组。
HFile的内存占用包括以下部分(以下内容摘自 [HADOOP-3315] 新的二进制文件格式 的TFile文档,但同样适用于HFile):
读取或写入压缩块的一些常量开销:
每个压缩块需要一个压缩/解压缩编解码器用于I/O。
临时空间用于缓冲键。
临时空间用于缓冲值。
HFile索引,与数据块的总数成正比。存储索引所需的总内存可以估计为 (56 + 平均键大小) * 块数。
性能优化建议:
最小块大小。我们建议一般使用时将最小块大小设置在8KB到1MB之间。如果文件主要用于顺序访问,则建议使用较大的块大小。然而,这会导致随机访问效率低下(因为需要解压缩更多的数据)。较小的块有利于随机访问,但需要更多的内存来存储块索引,并且可能创建速度较慢(因为必须在每个数据块结束时刷新压缩流,这会导致文件系统I/O刷新)。此外,由于压缩编解码器内部的缓存,最小的块大小约为20KB-30KB。
当前实现不提供真正的多线程读取。实现使用FSDataInputStream的seek()+read()方法,这在单线程模式下比定位读取调用快得多。然而,这也意味着,如果多个线程同时尝试访问同一个HFile(使用多个扫描器),即使它们访问不同的DFS块,实际的I/O操作也是顺序进行的(重新检查!在我的测试中,pread比seek+read快10%——stack)。
压缩编解码器。如果数据不太可压缩(可压缩是指至少2:1的压缩比),则使用“none”。通常,以“lzo”作为实验的起点。“gz”比“lzo”提供稍好的压缩比,但压缩需要4倍的CPU,解压缩需要2倍的CPU,相比之下“lzo”则更优。
关于HFile的背景信息,详见 [HBASE-61] [hbase] 创建HBase特定的MapFile实现。
文件由数据块组成,后面跟着元数据块(如果有)、文件信息块、数据块索引、元数据块索引,以及一个固定大小的尾部,记录文件内容类型变化的偏移量。
<data blocks><meta blocks><fileinfo><data index><meta index><trailer>每个块的开头都有一些标识信息。块由键值对组成。在数据块中,它们都是字节数组。元数据块是一个字符串键和一个字节数组值。一个空文件看起来是这样的:
<fileinfo><trailer>也就是说,没有数据块或元数据块。
待办事项:扫描器是否需要能够接受起始行和结束行?块索引是否应该知道其文件的名称?它是否应该有一个指向其文件的路径,例如,当索引与HFile实例分开存在时?
具体源码就不在深入,感兴趣小伙伴可以深入阅读看看。
BlockCache
为了提升读取性能,HBase实现了一种读缓存结构——BlockCache。客户端读取某个Block,首先会检查该Block是否存在于Block Cache,如果存在就直接加载出来,如果不存在则去HFile文件中加载,加载出来之后放到Block Cache中,后续同一请求或者邻近数据查找请求可以直接从内存中获取,以避免昂贵的IO操作。
BlockCache是RegionServer级别的,一个RegionServer只有一个BlockCache,在RegionServer启动时完成BlockCache的初始化工作。到目前为止,HBase先后实现了3种BlockCache方案,LRUBlockCache是最早的实现方案,也是默认的实现方案;HBase 0.92版本实现了第二种方案SlabCache,参见HBASE-4027;HBase 0.96之后官方提供了另一种可选方案BucketCache,参见HBASE-7404。
这3种方案的不同之处主要在于内存管理模式,其中LRUBlockCache是将所有数据都放入JVM Heap中,交给JVM进行管理。而后两种方案采用的机制允许将部分数据存储在堆外。这种演变本质上是因为LRUBlockCache方案中JVM垃圾回收机制经常导致程序长时间暂停,而采用堆外内存对数据进行管理可以有效缓解系统长时间GC。
总结
今天深入了HBase的核心组件的设计与实现,其中还有很多有趣的地方没有提到,比如最后的BlockCache读写实现等,感兴趣的小伙伴可以深入源码探索一下。