无监督学习(弱监督学习)
让模型对输入的数据进行特征提取,从而实现无标签学习(无监督学习)
本质是编码,解码的过程。让模型在卷积编码(下采样)、卷积解码(上采样)的过程中。自我总结特征
目前常用于图像分割
(ps:图像分割又分为三种:普通分割、 语义分割、实例分割。此处的无监督学习现用于普通分割)
编码解码器的结构,可以类似为一种无监督神经网络,每层结构类似(顺序不能变):
卷积 +
BtachNormal +
ReLU+
Pool(未定)+
Dropout
(同时这一结构也是后期大部分卷积网络的基本结构)
代码实现:
nn.Conv2d(16, 32, 3, 1, padding=1, padding_mode="reflect", bias=False), # 普通卷积层,这里选择"3卷积核/1步长/1padding"的模板,不改变输入内容的尺寸,只进行特征提取
#注意: bias=False,是因为BatchNorm2d相当于进行了bias的操作(只不过是做乘法),所以手动去掉bias
nn.BatchNorm2d(32),
# 常规的Relu,
# 也可以换为LeakyReLU。但就要加上nn.Dropout(0.2)去掉一些多余的数据
nn.ReLU(),
# !!!最大池化/平均池化 的输入值都是“池化区大小”,别调太大!!!
nn.MaxPool2d(3),
由于编码(下采样)会丢失数据,所以需要在解码(上采样)里补充特征
如果编码(下采样)时压缩率过高,损失太高,解码(上采样)可能会失败
通道混洗(Group编组)
在不增加计算量的情况下,使通道充分融合
简而言之,即改形状(reshape)后转置/换轴(transpose),再改回来。实现打乱顺序,重新排序
注意:实现混洗的基础是,“上一个卷积层进行了分组”
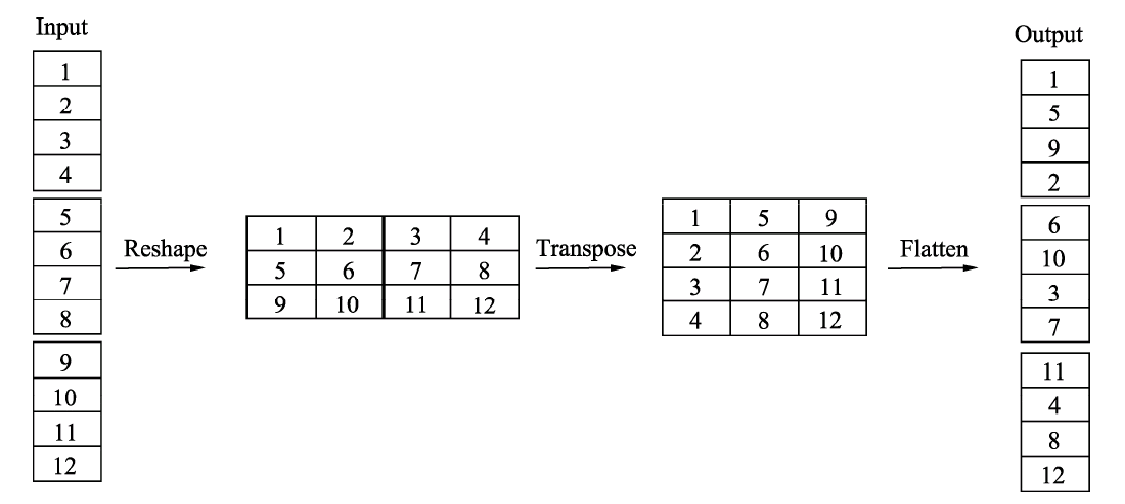
layer1 = nn.Conv2d(12, 12, 3, 1, padding=1, groups=6) # 深度可分离卷积
out = layer1(x)
print(out.shape) # 1, 12, 32, 32
# 通道混洗(reshape)
out = out.reshape(1, 3, 4, 32, 32)
# 换轴
out = torch.permute(out, (0, 2, 1, 3, 4))
print(out.shape) # 1, 4, 3, 32, 32
# 再换回来
out = out.reshape(1, 12, 32, 32)
print(out.shape) # 1, 12, 32, 32
UNET(U型网络)
一种全卷积神经网络,用于图像分割
UNET本身就是编解码过程,下采样+上采样就是编解码。整体的结构类似↘↗
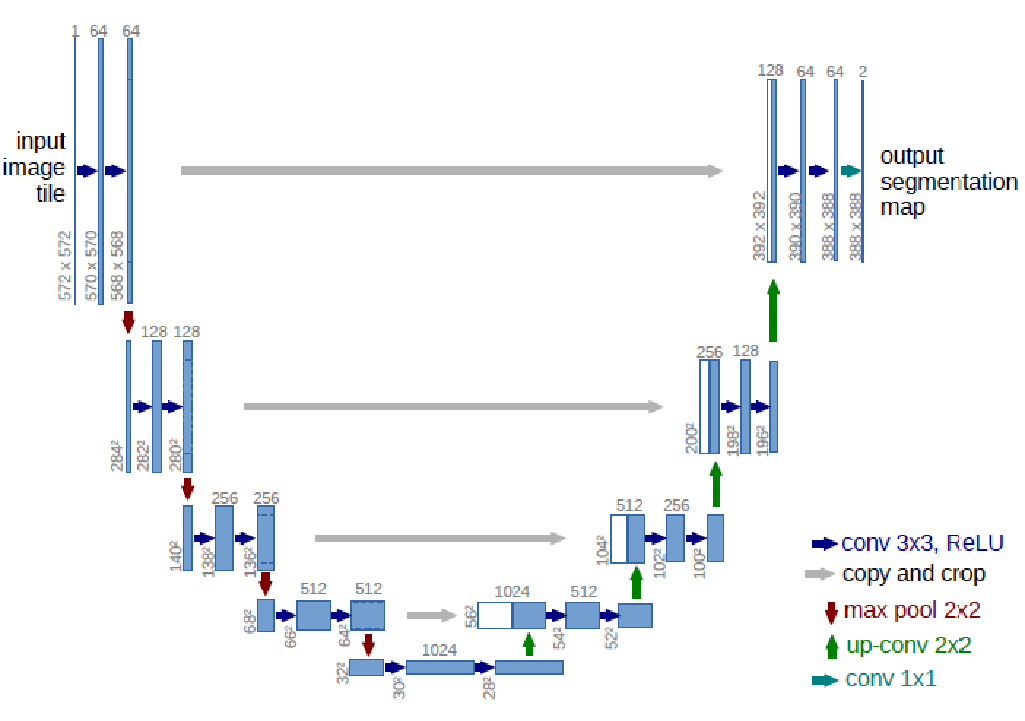
注意:LeakyReLU(在>0处有输出的relu)添加不少参数,需要Dropout出更多参数
注意:11的卷积核没有特征提取,还是推荐用33的
注意:构造序列器写起来简单,但不灵活(没办法加参数之类的)
注意:做数据集训练的过程,即为特征提取的过程
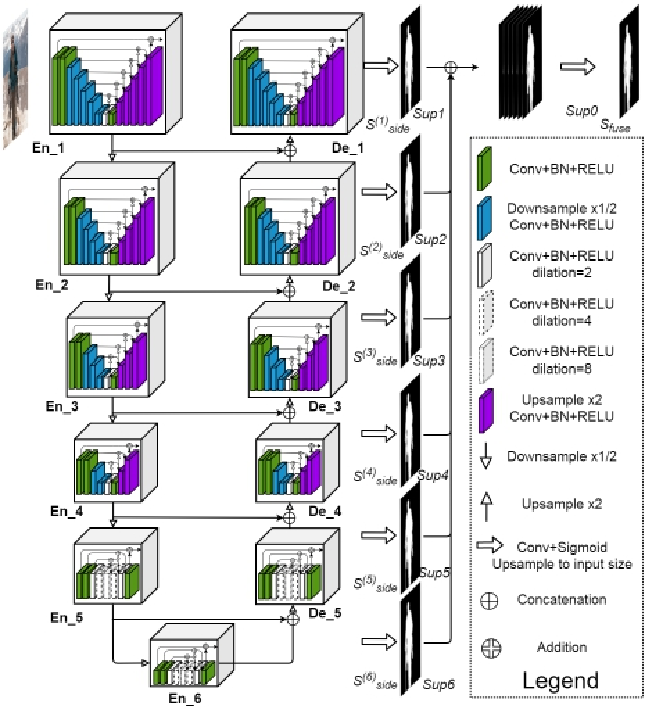
U2NET(复合型U型网络)
一种复合型的U型网络
主要用于显著目标检测(RSU)。可以自动识别输入图片中最大的物体
每一层都有
性能比UNET更强一些
一些小知识
batchSize:学生机可以设置4~8,建议4
VOC训练集-数据33260,训练集-标签2913
VOC数据集缺点:噪声大、背景复杂、标签不细致(效果不好)
优点:免费!样本多3w
训练集/对标签的要求
训练集必须:数据+标签
测试集可以不要标签,直接看效果就行
如何开启附加线程
batchSize旁边加一个num_workers=True开启附加线程
获取列表/元祖/矩阵中最大值的方法
argmax(获取列表/元祖最大值的索引)
宝可梦属性分类项目的实现思路
残差卷积+全连接,实现18分类,905数据