基于Seatunnel2.3.5版本分布式集群安装部署
1.环境准备
分布式集群基本环境准备,请参考我的另一篇文章dolphinscheduler分布式集群部署指南(小白版)中的环境准备小节进行配置
| IP地址 | 主机名 | 角色说明 |
|---|---|---|
| 10.10.3.10 | hadoop1001 | master节点 |
| 10.10.3.11 | hadoop1002 | slave节点 |
| 10.10.3.12 | hadoop1003 | slave节点 |
| 10.10.3.13 | hadoop1004 | slave节点 |
| 10.10.3.14 | hadoop1005 | slave节点 |
2.JDK安装
这部分跳过,很简单,基本随便找个博客文章照着配置就能搞定。
3.Maven安装
这部分跳过,很简单,基本随便找个博客文章照着配置就能搞定。
也可以不安装, 直接将Seatunnel2.3.5的源码下载到本地, 通过本地的mave把所有需要用到的连接器插件先下载下来再上传到安装目录下的$SEATUNNEL_HOME/lib目录和$SEATUNNEL_HOME/connectors/seatunnel目录下也是可以的, 这样就不需要安装Maven了。
4.Seatunnel在master节点安装部署配置
4.1.下载Seatunnel安装包
下载Seatunnel安装包上传到master节点hadoop1001的/opt/packages目录下
4.2.解压下载好的tar.gz包
tar -zxvf /opt/packages/apache-seatunnel-2.3.5-bin.tar.gz -C /opt/software
(3)查看Seatunnel使用的脚本
进入Seatunnel安装目录
cd /opt/software/apache-seatunnel-2.3.5

install-plugin.sh --安装连接器脚本
seatunnel-cluster.sh -–集群模式启动脚本
seatunnel-cluster.sh --本地模式启动脚本
start-seatunnel-flink-13-connector-v2.sh –-flink1.2-1.4版本引擎启动脚本
start-seatunnel-flink-15-connector-v2.sh –-flink1.5-1.6版本引擎启动脚本
start-seatunnel-spark-2-connector-v2.sh –-saprk2.x版本引擎启动脚本
start-seatunnel-spark-3-connector-v2.sh –-saprk3.x版本引擎启动脚本
4.3.下载连接器
这里可以直接将Seatunnel2.3.5的源码下载到本地,
修改install-plugin.cmd脚本,通过调用本地的mave把所有需要用到的连接器插件先下载下来再上传到安装目录下的$SEATUNNEL_HOME/lib目录和$SEATUNNEL_HOME/connectors/seatunnel目录下也可以
进入Seatunnel安装目录
cd /opt/software/apache-seatunnel-2.3.5
修改install-plugin.sh脚本, 切换成本地自定义安装的maven进行插件下载安装。
注意,如果你需要使用这种方式需要保证你的本地已经安装了apache-maven(>=3.6.3),并且已经给maven配置了系统环境变量。
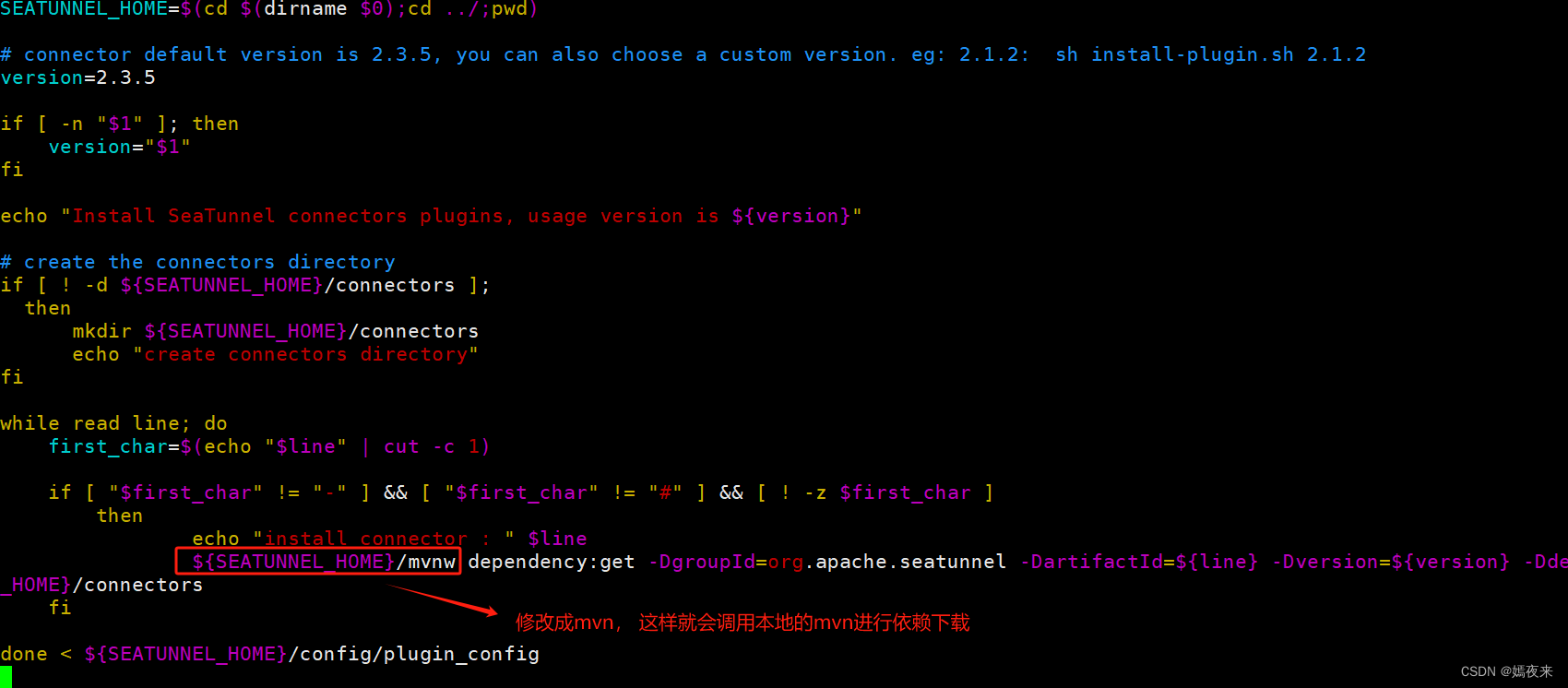
下载完成之后将/opt/software/seatunnel-2.3.5/connectors下的所有的jar包都拷贝到·/opt/software/seatunnel-2.3.5/connectors/seatunnel目录下以及/opt/software/seatunnel-2.3.5/lib目录下
mkdir -p /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/
cp /opt/software/apache-seatunnel-2.3.5/connectors/*.jar /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/
cp /opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/* /opt/software/seatunnel-2.3.5/lib/
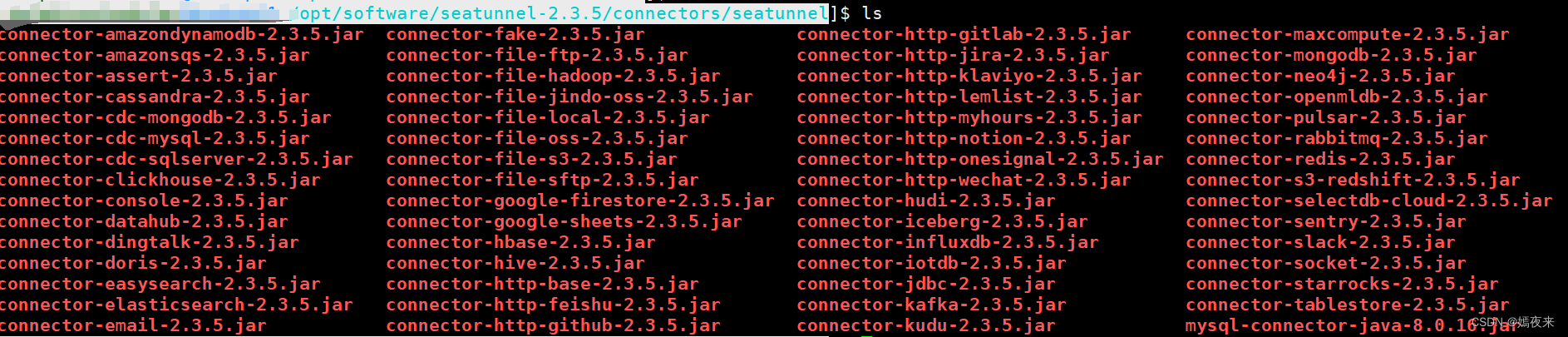
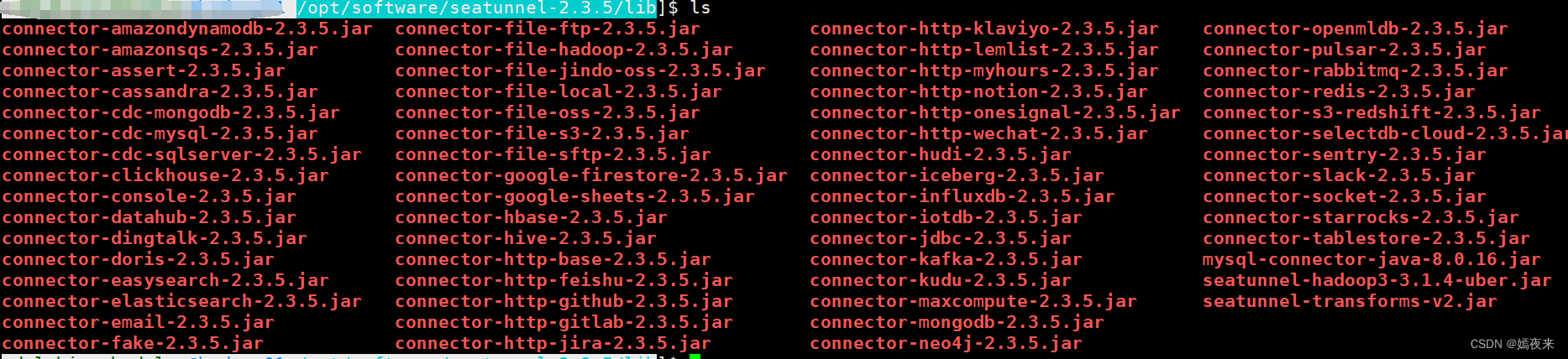
操作完成结果如下:
/opt/software/apache-seatunnel-2.3.5/connectors/seatunnel/目录下如下图:
/opt/software/seatunnel-2.3.5/lib/目录下如下图:
4.4.配置Seatunnel的系统环境变量
- 编辑
/etc/profile.d/seatunnel.sh
vim /etc/profile.d/seatunnel.sh
- 在文件中添加以下内容配置环境变量
export SEATUNNEL_HOME=/opt/software/apache-seatunnel-2.3.5
export PATH=$PATH:$SEATUNNEL_HOME/bin
wq!保存退出, 一定要保存退出。
- 系统环境变量立即生效
source /etc/profile
- 验证系统环境变量是否生效
echo $SEATUNNEL_HOME
命令行输出如下,说明配置成功

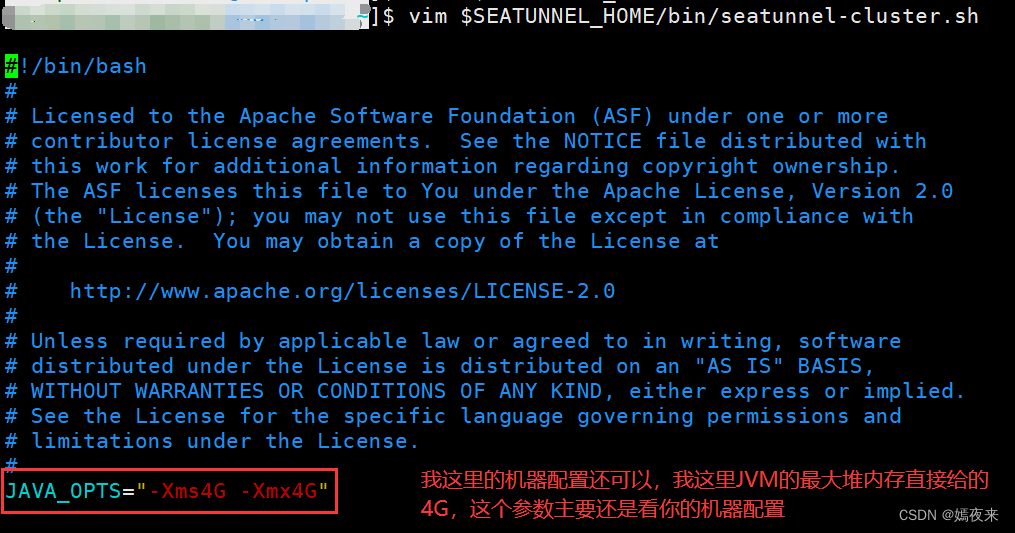
4.5.配置 SeaTunnel Engine服务 JVM参数
将 JVM 参数选项添加到$SEATUNNEL_HOME/bin/seatunnel-cluster.sh文件的开头
JAVA_OPTS="-Xms2G -Xmx2G"
4.6.配置文件中集群相关参数修改
主要针对``$SEATUNNEL_HOME/config/`以下三个文件进行修改
修改具体说明一下每个文件都要修改的配置项
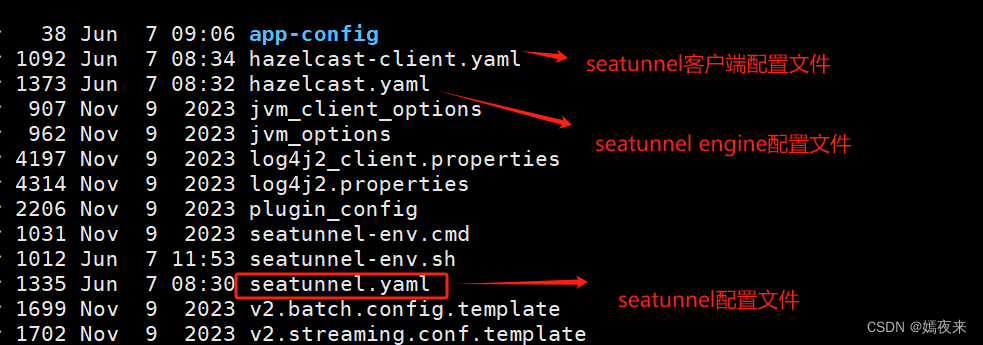
现在seatunnel的官方已经出了中文版本的文档, 如果觉得我写的很乱,或者有问题,可以直接查看官方文档 Apache Seatunnel官网中文文档传送门
4.6.1.SEATUNNEL配置文件修改
SEATUNNEL配置$SEATUNNEL_HOME/config/seatunnel.yaml文件
因为我这里已经按照了hadoop的集群, 可以直接使用HDFS api 读写文件,存储直接使用默认的HDFS,当然你也可以使用其他的存储类型,具体的参数配置可以参考官网说明。
修改参数如下:
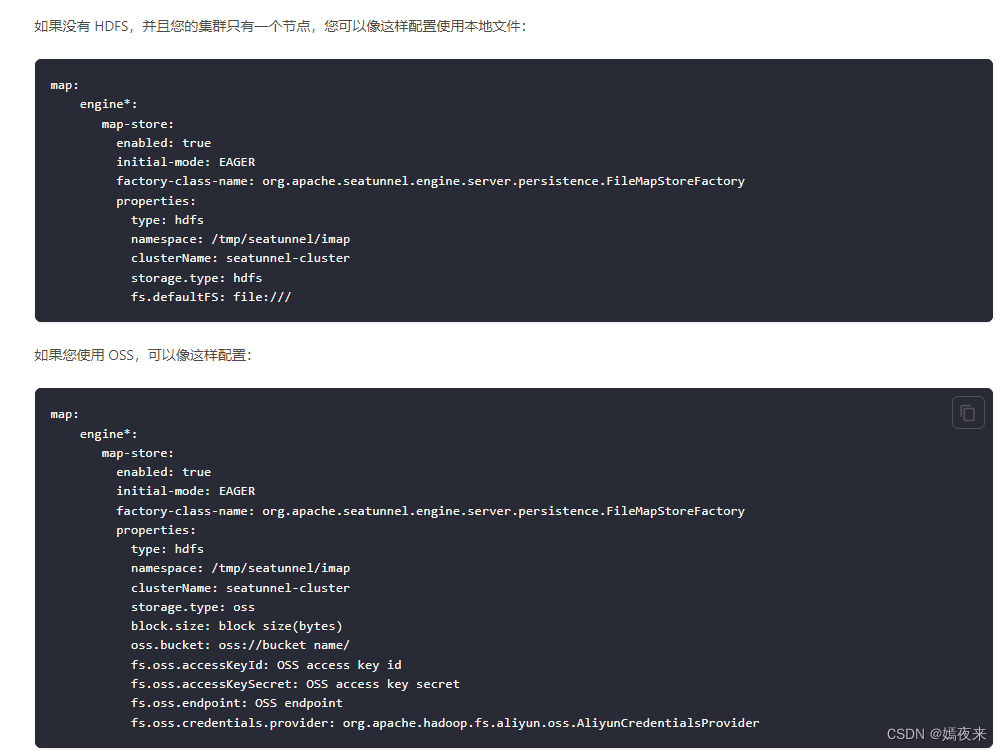
seatunnel:
engine:
history-job-expire-minutes: 1440
backup-count: 1
queue-type: blockingqueue
print-execution-info-interval: 60
print-job-metrics-info-interval: 60
slot-service:
dynamic-slot: true
checkpoint:
interval: 10000
timeout: 60000
storage:
type: hdfs
max-retained: 3
plugin-config:
namespace: /tmp/seatunnel/checkpoint_snapshot
storage.type: hdfs
# 主要就是修改了hdfs的URI,其它参数使用了系统默认参数
fs.defaultFS: hdfs://hadoop1001:8020
4.6.2.SEATUNNEL Engine服务配置文件修改
SEATUNNEL Engine配置$SEATUNNEL_HOME/config/hazelcast.yaml文件
具体的配置项的解释说明请查看 配置 SeaTunnel Engine 服务
hazelcast:
# seatunnel集群的名称, 这这个集群名称需要和SEATUNNEL Engine客户端配置文件中集群名称保持一致
cluster-name: st-etl
network:
rest-api:
enabled: true
endpoint-groups:
CLUSTER_WRITE:
enabled: true
DATA:
enabled: true
join:
tcp-ip:
enabled: true
# 需要部署Seatunnel集群的主机列表
member-list:
- hadoop1001
- hadoop1002
- hadoop1003
- hadoop1004
- hadoop1005
port:
auto-increment: false
# 默认的端口是5801,需要确认这个端口未被系统占用
port: 5801
properties:
hazelcast.invocation.max.retry.count: 20
hazelcast.tcp.join.port.try.count: 30
hazelcast.logging.type: log4j2
hazelcast.operation.generic.thread.count: 50
4.6.3.SEATUNNEL Engine客户端配置文件修改
SEATUNNEL Engine配置$SEATUNNEL_HOME/config/hazelcast-client.yaml文件
具体的配置项的解释说明请查看 配置 SeaTunnel Engine 客户端
hazelcast-client:
# seatunnel集群的名称, 这这个集群名称需要和SEATUNNEL Engine服务配置文件中集群名称保持一致
cluster-name: st-etl
properties:
hazelcast.logging.type: log4j2
connection-strategy:
connection-retry:
cluster-connect-timeout-millis: 3000
network:
# SEATUNNEL Engine服务列表
cluster-members:
- hadoop1001:5801
- hadoop1002:5801
- hadoop1003:5801
- hadoop1004:5801
- hadoop1005:5801
通过以上操作, 单台机器上的seatunnel服务就安装配置完成了。现在我们进行分布式集群部署。
5.分布式集群安装部署
5.1.创建日志目录
我们提前在seatunnel的安装目录下创建一个日志目录,后续seatunnel集群启动之后日志文件会保存再改目录下,在seatunnel服务分发到其他节点之前,先进行该操作。
mkdir -p /opt/software/apache-seatunnel-2.3.5/logs
5.2.添加服务分发集群脚本
这个脚本可以生效需要满足以下三点:
- 需要分发服务的每台主机上都已经安装了
rsync服务 - 集群的域名都已经进行映射
- 脚本执行的主机上已经设置了SSH免密登录其他节点
在hadoop1001主机上添加集群服务分发脚本,直接添加到/usr/bin目录(免得还需要配合子系统环境变量)
vim /usr/bin/data_rsync
脚本内容如下:
#!/bin/bash
#1 获取输入参数个数,如果没有参数,直接退出
pcount=$#
if((pcount==0)); then
echo no args;
exit;
fi
#2 获取文件名称
p1=$1
fname=`basename $p1`
echo fname=$fname
#3 获取上级目录到绝对路径
pdir=`cd -P $(dirname $p1); pwd`
echo pdir=$pdir
#4 获取当前用户名称
user=`whoami`
#5 循环()
for((host=2; host<=5; host++)); do
echo ------------------- hadoop$host --------------
rsync -av $pdir/$fname $user@hadoop100$host:$pdir
done
配置脚本的执行权限
chmod 777 /usr/bin/data_rsync
5.3.Seatunnel服务分发到集群其他主机
执行以下命令完成服务分发
data_rsync /opt/software/seatunnel-2.3.5
如下图说明同步分发完成
检查hadoop1001~1005的主机上/opt/software/目录下是否成功同步了seatunnel-2.3.5安装包
5.4.Seatunnel服务系统环境配置文件分发到集群其他主机
执行以下命令完成服务分发
data_rsync /etc/profile.d/seatunnel.sh
分发完成之后, 登录依次ssh登录到每台服务(hadoop1001~hadoop1004)上,让Seatunnel的系统环境变量立即生效。


- 系统环境变量立即生效
source /etc/profile
- 验证系统环境变量是否生效
echo $SEATUNNEL_HOME
命令行输出如下,说明配置成功
通过以上操作,我们的Seatunnel分布式集群基本就安装完毕了,下面我们继续完成spark引擎和flink引擎配置。
6.基于Spark/flink引擎的Seatunnel集群配置
首先需要部署spark和Flink集群, 这个应该也挺简单了,不会可以自行百度, 实在搞不定私信留言我再输出一个spark和Flink集群安装部署的文章。
我这里已经安装部署了spark和Flink集群, 所以不需要再进行spark集群的部署配置了,这里直接说明如何完成基于spark/Flink引擎的Seatunnel集群配置。
其他这个也很简单, 我们只需要修改seatunnel的环境配置脚本即可,将里面的spark的安装目录路径修改成我们本地的spark安装目录即可
vim $SEATUNNEL_HOME/config/seatunnel-env.sh
脚本内容如下:
#设置spark分布式集群的安装目录
SPARK_HOME=${SPARK_HOME:-/opt/software/spark}
#设置flink分布式集群的安装目录
FLINK_HOME=${FLINK_HOME:-/opt/software/flink}
保存退出。
然后将这个配置文件的修改同步到集群其他主机
data_rsync /opt/software/seatunnel-2.3.5/config/seatunnel-env.sh
重启Seatunnel集群即可。
7.Seatunnel集群常用管理命令
- 1)启动集群(需要在集群每台节点上都执行)
nohup $SEATUNNEL_HOME/bin/seatunnel-cluster.sh 2>&1 &
- 2)停止集群(需要在集群每台节点上都执行)
$SEATUNNEL_HOME/bin/stop-seatunnel-cluster.sh
3)默认引擎任务提交命令
$SEATUNNEL_HOME/bin/seatunnel.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
4)spark2.X版本引擎任务提交命令
$SEATUNNEL_HOME/bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
5)spark3.X版本引擎任务提交命令
$SEATUNNEL_HOME/bin/start-seatunnel-spark-3-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
6)flink低版本引擎任务提交命令(Flink版本1.12.x到1.14.x)
$SEATUNNEL_HOME/bin/start-seatunnel-flink-13-connector-v2.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.streaming.conf.template
7)flink高版本引擎任务提交命令(Flink版本1.15.x到1.16.x)
$SEATUNNEL_HOME/bin/start-seatunnel-flink-15-connector-v2.sh --config /opt/software/seatunnel-2.3.5/config/app-config/v2.streaming.conf.template
8.Seatunnel集群任务测试验证
在hadoop1001上执行基于spark引擎的任务提交进行测试验证, 验证之前需要保证集群服务正常启动
ps -ef|grep seatunnel
如下图,说明集群正常启动
提交测试任务

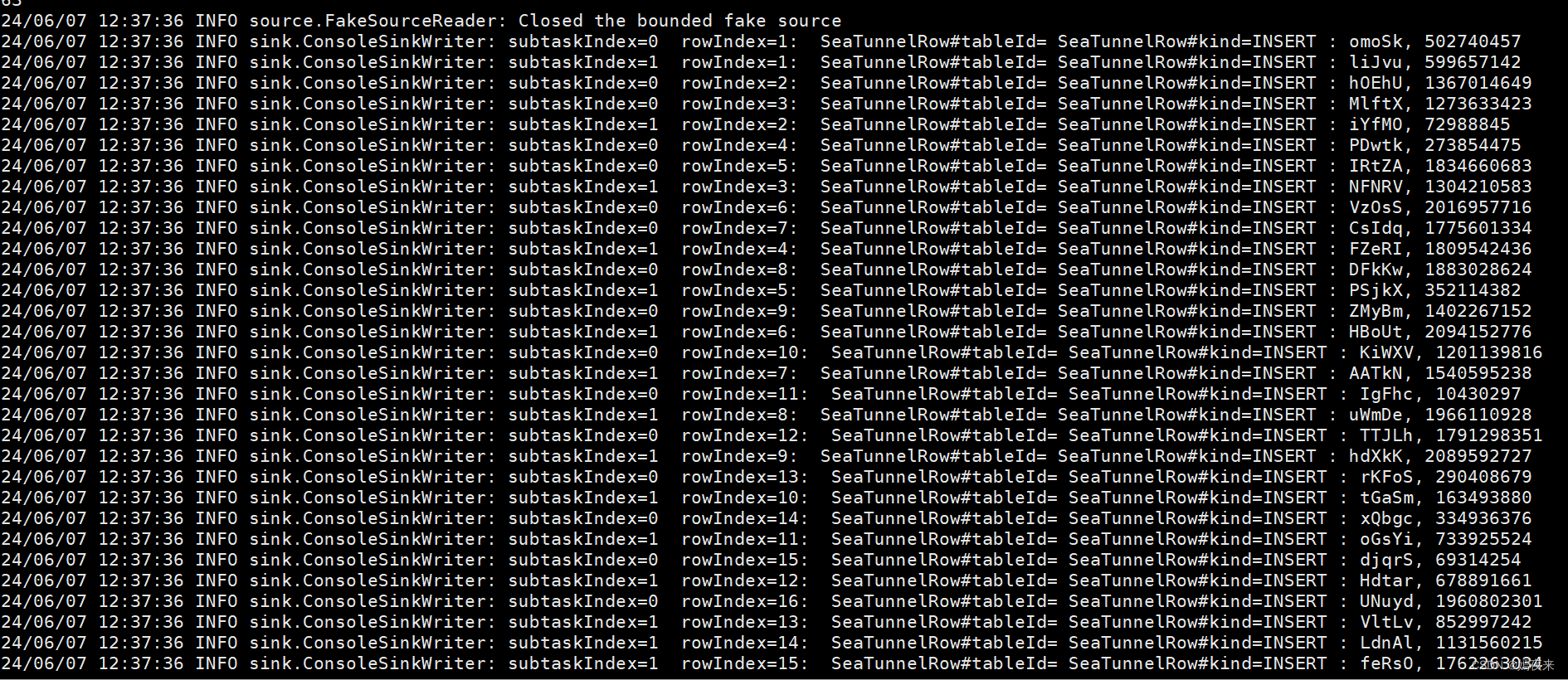
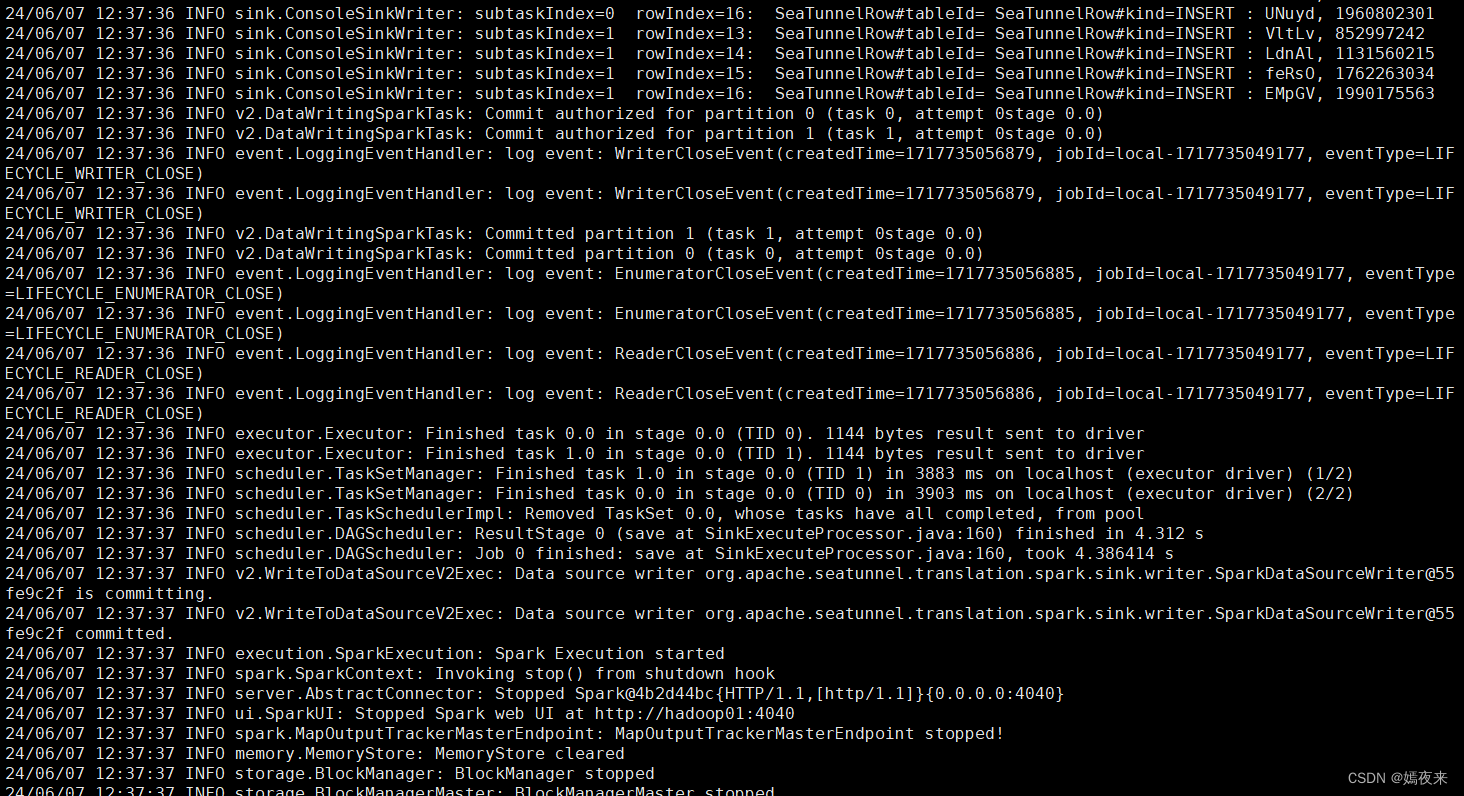
$SEATUNNEL_HOME/bin/start-seatunnel-spark-2-connector-v2.sh --master local[4] --deploy-mode client --config /opt/software/seatunnel-2.3.5/config/app-config/v2.batch.config.template
任务处理过程打印如下日志,说明集群配置正常,就可以创建其他数据处理的任务。
通过以上部署及验证,Seatunnel集群已经全部安装配置好了, 用起来吧。后续计划把Seatunnel结合Dolphinscheduler任务调度在实际业务中的使用再输出一篇文章。
如果觉得文章写的还不错,喜欢的童鞋们请点赞收藏,送你一送小红花哈。~