一、zookeeper高可用
- 关闭之前的服务,并清理环境
[hadoop@server1 hadoop]$ sbin/stop-yarn.sh
[hadoop@server1 hadoop]$ sbin/stop-dfs.sh
[hadoop@server1 hadoop]$ jps
16432 Jps
##1-4server都执行
[hadoop@server1 hadoop]$ rm -fr /tmp/*
- 搭建zookeeper(在任意一个节点作都可以)
[hadoop@server2 ~]$ tar zxf zookeeper-3.4.9.tar.gz
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ cd conf/
- 添加从节点信息
[hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@server2 conf]$ vim zoo.cfg
server.1=172.25.14.2:2888:3888
server.2=172.25.14.3:2888:3888
server.3=172.25.14.4:2888:3888
- 各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入一个唯一的数字,取值范围在 1-255
[hadoop@server2 conf]$ mkdir /tmp/zookeeper
[hadoop@server3 conf]$ mkdir /tmp/zookeeper
[hadoop@server4 conf]$ mkdir /tmp/zookeeper
[hadoop@server2 conf]$ echo 1 > /tmp/zookeeper/myid
[hadoop@server3 conf]$ echo 2 > /tmp/zookeeper/myid
[hadoop@server4 conf]$ echo 3 > /tmp/zookeeper/myid
- 开启服务
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh start
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh start
并查看各节点状态
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower ##从
##3是主
[hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader ##主
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower ##从
- 在server2进入命令行
[hadoop@server2 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server2 bin]$ pwd
/home/hadoop/zookeeper-3.4.9/bin
[hadoop@server2 bin]$ ./zkCli.sh 连接zookeeper
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[quota]
[zk: localhost:2181(CONNECTED) 2] ls /zookeeper/quota
[]
[zk: localhost:2181(CONNECTED) 3] get /zookeeper/quota
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
- 进行hadoop的配置详解
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
##指定 hdfs 的 namenode 为 masters (名称可自定义)
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
##指定 zookeeper 集群主机地址
<property>
<name>ha.zookeeper.quorum</name>
<value>172.25.14.2:2181,172.25.14.3:2181,172.25.14.4:2181</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
##指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一致
<property>
<name>dfs.nameservices</name>
<value>masters</value>
</property>
##masters 下面有两个 namenode 节点,分别是 h1 和 h2
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
##指定 h1 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.14.1:9000</value>
</property>
##指定 h1 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.14.1:9870</value>
</property>
##指定 h2 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.14.5:9000</value>
</property>
##指定 h2 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.14.5:9870</value>
</property>
##指定 NameNode 元数据在 JournalNode 上的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.14.2:8485;172.25.14.3:8485;172.25.14.4:8485/masters</value>
</property>
##指定 JournalNode 在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
##开启 NameNode 失败自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
##配置失败自动切换实现方式
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
##配置隔离机制方法,每个机制占用一行
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
##使用 sshfence 隔离机制时需要 ssh 免密码
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
##配置 sshfence 隔离机制超时时间
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
- 启动 hdfs 集群(按顺序启动)在三个 DN 上依次启动 zookeeper 集群
[hadoop@server2 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server2 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server2 hadoop]$ jps
12948 Jps
12775 QuorumPeerMain
12909 JournalNode
[hadoop@server3 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server3 hadoop]$ jps
13105 Jps
13066 JournalNode
12926 QuorumPeerMain
[hadoop@server4 hadoop]$ bin/hdfs --daemon start journalnode
[hadoop@server4 hadoop]$ jps
13011 Jps
12980 JournalNode
12879 QuorumPeerMain
- 传递配置文件搭建高可用
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.14.5:/tmp
[hadoop@server5 ~]$ ls /tmp
hadoop-hadoop
- 格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
[zk: localhost:2181(CONNECTED) 1] get /hadoop-ha/masters/ActiveBreadCrumb
mastersh1server1 �F(�>
- 启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
Starting namenodes on [server1 server5]
server5: Warning: Permanently added 'server5' (ECDSA) to the list of known hosts.
Starting datanodes
Starting journal nodes [172.25.14.2 172.25.14.3 172.25.14.4]
172.25.14.2: journalnode is running as process 12909. Stop it first.
172.25.14.4: journalnode is running as process 12980. Stop it first.
172.25.14.3: journalnode is running as process 13066. Stop it first.
Starting ZK Failover Controllers on NN hosts [server1 server5]
[hadoop@server1 hadoop]$ jps
17074 DFSZKFailoverController
16725 NameNode
17125 Jps
[hadoop@server5 ~]$ jps
12227 DFSZKFailoverController
12165 NameNode
12312 Jps
-
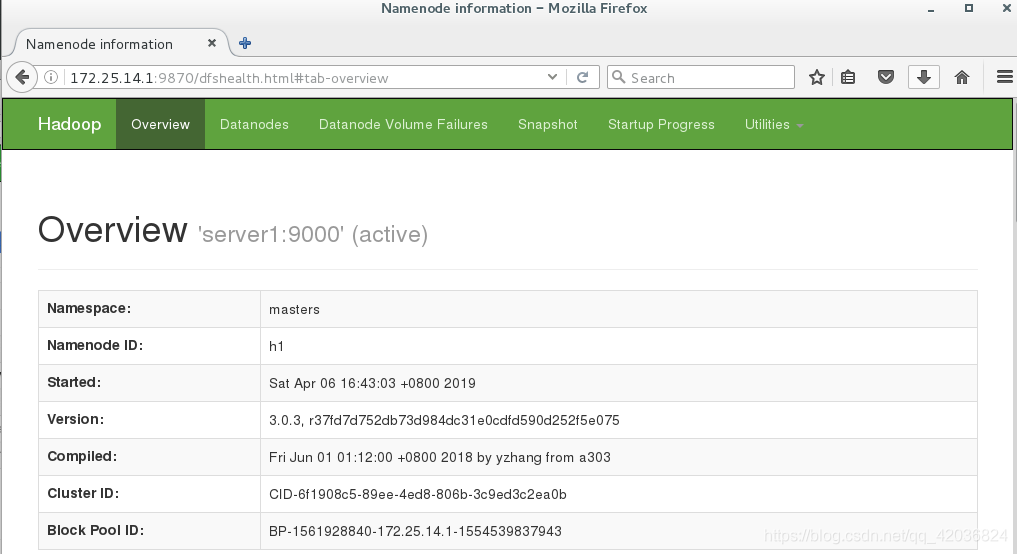
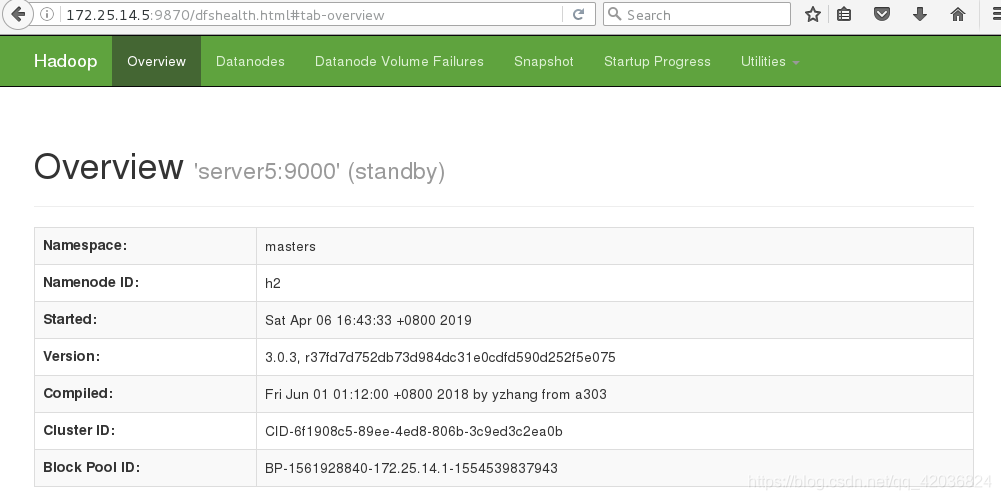
浏览器测试显示1上是active,5是standby
-
停掉server1,server5的状态就变成了active
[hadoop@server1 hadoop]$ jps
17074 DFSZKFailoverController
16725 NameNode
17142 Jps
[hadoop@server1 hadoop]$ kill 16725
[hadoop@server1 hadoop]$ jps
17074 DFSZKFailoverController
17160 Jps

- 1虽然关了,但是还是可以上传,是通过5上传的
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ bin/hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ bin/hdfs dfs -put etc/hadoop/* input
- 5上看到已经上传了
- 重新打开1.变成standby

[hadoop@server1 hadoop]$ bin/hdfs --daemon start namenode
[hadoop@server1 hadoop]$ jps
17074 DFSZKFailoverController
17442 NameNode
17509 Jps

二、yarn 的高可用
- 配置
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
- 启动服务
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
172.25.14.4: Warning: Permanently added '172.25.14.4' (ECDSA) to the list of known hosts.
[hadoop@server1 hadoop]$ jps
14085 NameNode
15628 Jps
14303 SecondaryNameNode
15327 ResourceManager ##多出这个
##所有节点都有NodeManager
[hadoop@server2 ~]$ jps
11959 DataNode
12346 NodeManager
12446 Jps
- 配置server5
[root@server5 ~]# useradd -u 1000 hadoop
[root@server5 ~]# yum install -y nfs-utils
[root@server5 ~]# systemctl start rpcbind
[root@server5 ~]# mount 172.25.14.1:/home/hadoop /home/hadoop
[hadoop@server5 ~]$ cd hadoop
[hadoop@server5 hadoop]$ sbin/yarn-daemon.sh start
[hadoop@server5 hadoop]$ jps
14085 NameNode
15628 Jps
14303 SecondaryNameNode
15327 ResourceManager
- 配置yarn的高可用
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ vim yarn-site.xml
<configuration>
配置可以在 nodemanager 上运行 mapreduce 程序
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
激活 RM 高可用
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
指定 RM 的集群 id
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>RM_CLUSTER</value>
</property>
定义 RM 的节点
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
指定 RM1 的地址
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>172.25.14.1</value>
</property>
指定 RM2 的地址
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>172.25.14.5</value>
</property>
激活 RM 自动恢复
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
配置 RM 状态信息存储方式,有 MemStore 和 ZKStore
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
配置为 zookeeper 存储时,指定 zookeeper 集群的地址
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>172.25.14.2:2181,172.25.14.3:2181,172.25.14.4:2181</value>
</property>
</configuration>
- 启动 yarn 服务
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-yarn.sh
[hadoop@server1 hadoop]$ jps
1606 NameNode
2409 Jps
1900 DFSZKFailoverController
2335 ResourceManager
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
2762 Jps
2020 NameNode
2711 ResourceManager
- 浏览器输入172.25.14.1:8088(active),或者172.25.14.5:8088(standby)
- 在server2的命令行查看当前master:


[hadoop@server2 zookeeper-3.4.9]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0]
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, yarn-leader-election, hadoop-ha, rmstore]
[zk: localhost:2181(CONNECTED) 1] ls /yarn-leader-election
[RM_CLUSTER]
[zk: localhost:2181(CONNECTED) 2] ls /yarn-leader-election/RM_CLUSTER
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election/RM_CLUSTER/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election/RM_CLUSTER/ActiveBreadCrumb
[]
[zk: localhost:2181(CONNECTED) 4] get /yarn-leader-election/RM_CLUSTER/ActiveBreadCrumb
RM_CLUSTERrm1 ##rm1
cZxid = 0x100000016
ctime = Tue Aug 28 11:58:18 CST 2018
mZxid = 0x100000016
mtime = Tue Aug 28 11:58:18 CST 2018
pZxid = 0x100000016
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 17
numChildren = 0
- 进行故障切换检测
[hadoop@server1 hadoop]$ jps
1606 NameNode
2409 Jps
1900 DFSZKFailoverController
2335 ResourceManager
[hadoop@server1 hadoop]$ kill -9 2335 ##结束当前master进程
[hadoop@server1 hadoop]$ jps
1606 NameNode
2839 Jps
1900 DFSZKFailoverController
- 浏览器输入172.25.14.5:8088,显示active
- 恢复server1的服务
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/yarn-daemon.sh start resourcemanager
starting resourcemanager, logging to /home/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-server1.out
[hadoop@server1 hadoop]$ jps
2897 ResourceManager
1606 NameNode
1900 DFSZKFailoverController
2926 Jps
- 网页查看server1的状态为standby,作为备用节点
三、Hbase高可用
[hadoop@server1 ~]$ tar zxf hbase-1.2.4-bin.tar.gz 解压包
[hadoop@server1 ~]$ cd hbase-1.2.4
[hadoop@server1 hbase-1.2.4]$ cd conf/
[hadoop@server1 conf]$ vim hbase-env.sh
export JAVA_HOME=/home/hadoop/java 指定 jdk
export HBASE_MANAGES_ZK=false
##默认值时 true,hbase 在启动时自动开启 zookeeper,如需自己维护 zookeeper集群需设置为 false
export HADOOP_HOME=/home/hadoop/hadoop
##指定 hadoop 目录,否则 hbase无法识别 hdfs 集群配置。
[hadoop@server1 conf]$ vim hbase-site.xml
指定 region server 的共享目录,用来持久化 HBase。这里指定的 HDFS 地址
是要跟 core-site.xml 里面的 fs.defaultFS 的 HDFS 的 IP 地址或者域名、端口必须一致
<property>
<name>hbase.rootdir</name>
<value>hdfs://masters/hbase</value>
</property>
启用 hbase 分布式模式
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
Zookeeper 集群的地址列表,用逗号分割。默认是 localhost,是给伪分布式用
的。要修改才能在完全分布式的情况下使用。
<property>
<name>hbase.zookeeper.quorum</name>
<value>172.25.14.2,172.25.14.3,172.25.14.4</value>
</property>
指定 hbase 的 master
<property>
<name>hbase.master</name>
<value>h1</value>
</property>
</configuration>
[hadoop@server1 conf]$ vim regionservers
[hadoop@server1 conf]$ cat regionservers
172.25.14.2
172.25.14.3
172.25.14.4
启动 hbase主备节点运行
[hadoop@server1 hbase-1.2.4]$ bin/start-hbase.sh
[hadoop@server1 hbase-1.2.4]$ jps
2379 HMaster
2897 ResourceManager
1606 NameNode
3451 Jps
1900 DFSZKFailoverController
[hadoop@server5 hbase-1.2.4]$ bin/hbase-daemon.sh start master
[hadoop@server5 hbase-1.2.4]$ jps
2457 HMaster
1479 DFSZKFailoverController
2020 NameNode
2711 ResourceManager
3978 Jps
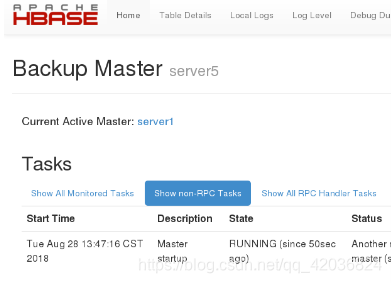
- 在网页查看server1为master,server5为backup master
- HBase Master 默认端口时 16000,还有个 web 界面默认在 Master 的 16010 端口上,HBase RegionServers 会默认绑定 16020 端口,在端口 16030 上有一个展示信息的界面

[hadoop@server1 ~]$ cd hbase-1.2.4
[hadoop@server1 hbase-1.2.4]$ ls
bin conf hbase-webapps lib logs README.txt
CHANGES.txt docs LEGAL LICENSE.txt NOTICE.txt
[hadoop@server1 hbase-1.2.4]$ bin/hbase shell 打开一个shell
hbase(main):004:0> create 'linux', 'cf'
0 row(s) in 18.6610 seconds
=> Hbase::Table - linux
hbase(main):005:0> list 'linux'
TABLE
linux
1 row(s) in 0.0290 seconds
=> ["linux"]
hbase(main):006:0> put 'linux', 'row1', 'cf:a', 'value1'
0 row(s) in 1.6750 seconds
hbase(main):007:0> put 'linux', 'row2', 'cf:b', 'value2'
0 row(s) in 0.1740 seconds
hbase(main):008:0> put 'linux', 'row3', 'cf:c', 'value3'
0 row(s) in 0.0470 seconds
hbase(main):009:0> scan 'linux' 创建字段信息
ROW COLUMN+CELL
row1 column=cf:a, timestamp=1535435781214, value=value1
row2 column=cf:b, timestamp=1535435793162, value=value2
row3 column=cf:c, timestamp=1535435801252, value=value3
3 row(s) in 0.2010 seconds