一、AlexNet网络详解
AlexNet是2012年ISLVRC 2012(ImageNet Large Scale Visual Recognition Challenge)竞赛的冠军网络,分类准确率由传统的 70%+提升到 80%+。 它是由Hinton和他的学生Alex Krizhevsky设计的。也是在那年之后,深 度学习开始迅速发展。
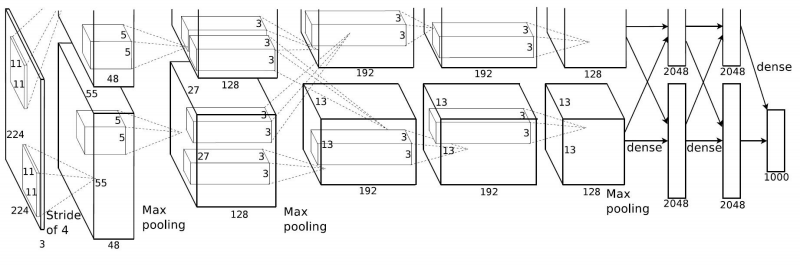
该网络的亮点在于:
(1)首次利用 GPU 进行网络加速训练。
(2)使用了 ReLU 激活函数,而不是传统的 Sigmoid 激活函数以及 Tanh 激活函数。
(3)使用了 LRN 局部响应归一化。
(4)在全连接层的前两层中使用了 Dropout 随机失活神经元操作,以减少过拟合。
1.ReLU激活函数
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1gefuR8T-1648692034025)(watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L3FxXzMxMjc4OTAz,size_16,color_FFFFFF,t_70.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvZjgxNWMxOTg5OThiMWRlOWZiY2UzYzEwYWY2Yzg2NGMucG5n)
针对sigmoidsigmoid梯度饱和导致训练收敛慢的问题,在AlexNet中引入了ReLU。ReLU是一个分段线性函数,小于等于0则输出为0;大于0的则恒等输出。相比于sigmoidsigmoid,ReLU有以下有点:
- 计算开销小。sigmoidsigmoid的正向传播有指数运算,倒数运算,而ReLu是线性输出;反向传播中,sigmoidsigmoid有指数运算,而ReLU有输出的部分,导数始终为1.
- 梯度饱和问题
- 稀疏性。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生
2.使用Dropout
过拟合:根本原因是特征维度过多,模型假设过于复杂,参数 过多,训练数据过少,噪声过多,导致拟合的函数完美的预测 训练集,但对新数据的测试集预测结果差。 过度的拟合了训练 数据,而没有考虑到泛化能力。
引入Dropout主要是为了防止过拟合。在神经网络中Dropout通过修改神经网络本身结构来实现,对于某一层的神经元,通过定义的概率将神经元置为0,这个神经元就不参与前向和后向传播,就如同在网络中被删除了一样,同时保持输入层与输出层神经元的个数不变,然后按照神经网络的学习方法进行参数更新。在下一次迭代中,又重新随机删除一些神经元(置为0),直至训练结束。
Dropout应该算是AlexNet中一个很大的创新,现在神经网络中的必备结构之一。Dropout也可以看成是一种模型组合,每次生成的网络结构都不一样,通过组合多个模型的方式能够有效地减少过拟合,Dropout只需要两倍的训练时间即可实现模型组合(类似取平均)的效果,非常高效。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UMVwFUoq-1648692034029)(image-20220330145132257.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvZTAxYmU3ZThkZmY3ZmJmN2Y5YmUyOGRhMDg4YWJiNjcucG5n)
3.经卷积后的矩阵尺寸大小计算公式为:
N = (W − F + 2P ) / S + 1
① 输入图片大小 W×W
② Filter大小 F×F
③ 步长 S
④ padding的像素数 P
4.每一层网络详解
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UuJwtrKl-1648692034031)(image-20220330150550517.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvOGYxNTNjNmI4NzE2OGNlNmZlZjUxOTdjODhiZGVkZjQucG5n)
| Conv1: | Maxpool1: | Conv2: | Maxpool2: | Conv3: | Conv4: |
|---|---|---|---|---|---|
| kernels:96 | kernels:256 | kernels:=384 | kernels:384 | ||
| kernel_size:11 | kernel_size:3 | kernel_size:5 | kernel_size:3 | kernel_size:3 | kernel_size:3 |
| padding: [1, 2] | pading: 0 | padding: [2, 2] | pading: 0 | padding: [1, 1] | padding: [1, 1] |
| stride:4 | stride:2 | stride:1 | stride:2 | stride:1 | stride:1 |
| output_size: | output_size: | output_size: | output_size: | output_size: | output_size: |
| [55, 55, 96] | [27, 27, 96] | [27, 27, 256] | [13, 13, 256] | [13, 13, 384] | [13, 13, 384] |
| layer_name | kernel_size | kernel_num | padding | stride |
|---|---|---|---|---|
| Conv1 | 11 | 96 | [1, 2] | 4 |
| Maxpool1 | 3 | None | 0 | 2 |
| Conv2 | 5 | 256 | [2, 2] | 1 |
| Maxpool2 | 3 | None | 0 | 2 |
| Conv3 | 3 | 384 | [1, 1] | 1 |
| Conv4 | 3 | 384 | [1, 1] | 1 |
| Conv5 | 3 | 256 | [1, 1] | 1 |
| Maxpool3 | 3 | None | 0 | 2 |
| FC1 | 2048 | None | None | None |
| FC2 | 2048 | None | None | None |
| FC3 | 1000 | None | None | None |
二、训练测试
首先说明,本模型采用的是5分类的花数据集,如果想要可以私信我
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pdoKbcWu-1648692034033)(image-20220330151020207.png)]](/image/aHR0cHM6Ly9pLWJsb2cuY3NkbmltZy5jbi9ibG9nX21pZ3JhdGUvZmZlYWRjNWU1ZjIwODUxYzQxNDU1YmE5NDU5MWVkOTAucG5n)
1.编写模型代码net.py
import torch
from torch import nn
import torch.nn.functional as F
class MyAlexNet(nn.Module):
def __init__(self):
super(MyAlexNet, self).__init__()
self.c1 = nn.Conv2d(in_channels=3, out_channels=48, kernel_size=11, stride=4, padding=2)
self.ReLU = nn.ReLU()
self.c2 = nn.Conv2d(in_channels=48, out_channels=128, kernel_size=5, stride=1, padding=2)
self.s2 = nn.MaxPool2d(2)
self.c3 = nn.Conv2d(in_channels=128, out_channels=192, kernel_size=3, stride=1, padding=1)
self.s3 = nn.MaxPool2d(2)
self.c4 = nn.Conv2d(in_channels=192, out_channels=192, kernel_size=3, stride=1, padding=1)
self.c5 = nn.Conv2d(in_channels=192, out_channels=128, kernel_size=3, stride=1, padding=1)
self.s5 = nn.MaxPool2d(kernel_size=3, stride=2)
self.flatten = nn.Flatten()
self.f6 = nn.Linear(4608, 2048)
self.f7 = nn.Linear(2048, 2048)
self.f8 = nn.Linear(2048, 1000)
self.f9 = nn.Linear(1000, 5)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.ReLU(self.c2(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s3(x)
x = self.ReLU(self.c4(x))
x = self.ReLU(self.c5(x))
x = self.s5(x)
x = self.flatten(x)
x = self.f6(x)
x = F.dropout(x, p=0.5)
x = self.f7(x)
x = F.dropout(x, p=0.5)
x = self.f8(x)
x = F.dropout(x, p=0.5)
x = self.f9(x)
return x
if __name__ == '__mian__':
x = torch.rand([1, 3, 224, 224])
model = MyAlexNet()
y = model(x)
2.编写模型train.py
import os
import json
import torch
from PIL import Image
from torchvision import transforms
from model_v3 import mobilenet_v3_large
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
# 指向需要遍历预测的图像文件夹
imgs_root = r"D:/other/ClassicalModel/data/flower_datas/train/tulips"
assert os.path.exists(imgs_root), f"file: '{imgs_root}' dose not exist."
# 读取指定文件夹下所有jpg图像路径
img_path_list = [os.path.join(imgs_root, i) for i in os.listdir(imgs_root) if i.endswith(".jpg")]
# read class_indict
json_path = r"D:/other/ClassicalModel/ResNet/class_indices.json"
assert os.path.exists(json_path), f"file: '{json_path}' dose not exist."
json_file = open(json_path, "r")
class_indict = json.load(json_file)
# create model
model = mobilenet_v3_large(num_classes=5).to(device)
# load model weights
weights_path = r"D:/other/ClassicalModel/MobileNet/runs12/mobilenet_v3_large.pth"
assert os.path.exists(weights_path), f"file: '{weights_path}' dose not exist."
model.load_state_dict(torch.load(weights_path, map_location=device))
#save predicted img
filename = 'record.txt'
save_path = 'detect'
path_num = 1
while os.path.exists(save_path + f'{path_num}'):
path_num += 1
os.mkdir(save_path + f'{path_num}')
f = open(save_path + f'{path_num}/' + filename, 'w')
f.write("imgs_root:"+imgs_root+"\n")
f.write("weights_path:"+weights_path+"\n")
actual_classes="tulips"
acc_num=0
all_num=len(img_path_list)
# prediction
model.eval()
batch_size = 8 # 每次预测时将多少张图片打包成一个batch
with torch.no_grad():
for ids in range(0, len(img_path_list) // batch_size):
img_list = []
for img_path in img_path_list[ids * batch_size: (ids + 1) * batch_size]:
assert os.path.exists(img_path), f"file: '{img_path}' dose not exist."
img = Image.open(img_path)
img = data_transform(img)
img_list.append(img)
# batch img
# 将img_list列表中的所有图像打包成一个batch
batch_img = torch.stack(img_list, dim=0)
# predict class
output = model(batch_img.to(device)).cpu()
predict = torch.softmax(output, dim=1)
probs, classes = torch.max(predict, dim=1)
for idx, (pro, cla) in enumerate(zip(probs, classes)):
print("image: {} class: {} prob: {:.3}".format(img_path_list[ids * batch_size + idx],
class_indict[str(cla.numpy())],
pro.numpy()))
f.write("image: {} class: {} prob: {:.3}\n".format(img_path_list[ids * batch_size + idx],
class_indict[str(cla.numpy())],
pro.numpy()))
if class_indict[str(cla.numpy())]==actual_classes:
acc_num+=1
print("classes:{},acc_num:{:d},all_num:{:d},accuracy: {:.3f}".format(actual_classes,acc_num,all_num,acc_num/all_num))
f.write("classes:{},acc_num:{:d},all_num:{:d},accuracy: {:.3f}".format(actual_classes,acc_num,all_num,acc_num/all_num))
f.close()
if __name__ == '__main__':
main()