目录
9-HyDE(Hypothetical Document Embeddings)假设性文档嵌入
10-Logical and Semantic routing
11-Query structuring for metadata filters
12-Multi-representation Indexing
五、Retrieval检索和Generation生成优化策略
1. 父文档检索(Parent Document Retrieval)
2. 层级检索(Hierarchical Retrieval)
4.多向量检索(Multi-Vector Retrieval)
1. CRAG(Corrective Retrieval Augmented Generation)
2. Self-RAG(Self-Reflective Retrieval Augmented Generation)
3. Adaptive-RAG(Adaptive Retrieval-Augmented Generation)
Self-consistency with CoT(CoT的自我一致性)
1. 固定大小分块(Fixed-size chunking)
3. 特定格式分块(Specialized chunking)
2. 错过超出排名范围的文档(Missed Top Ranked)
6. 不正确的具体性(Incorrect Specificity)
8. 数据摄入的可扩展性问题(Data Ingestion Scalability)
9. 结构化数据的问答(Structured Data QA)
10. 从复杂 PDF 文档提取数据(Data Extraction from Complex PDFs)
RAG的整体架构设计
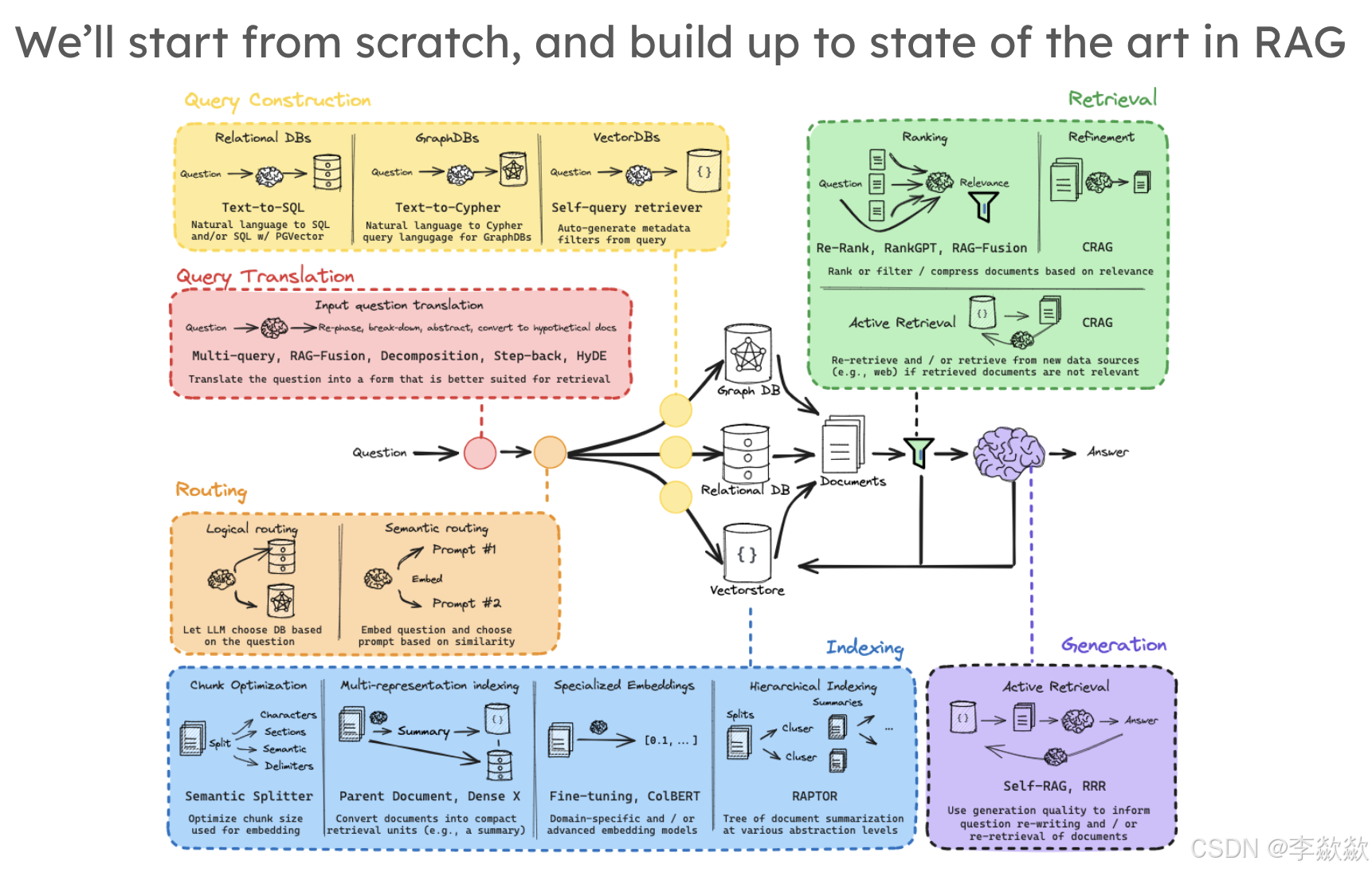
一、概览
1-Overview
RAG的流程是什么样子的?
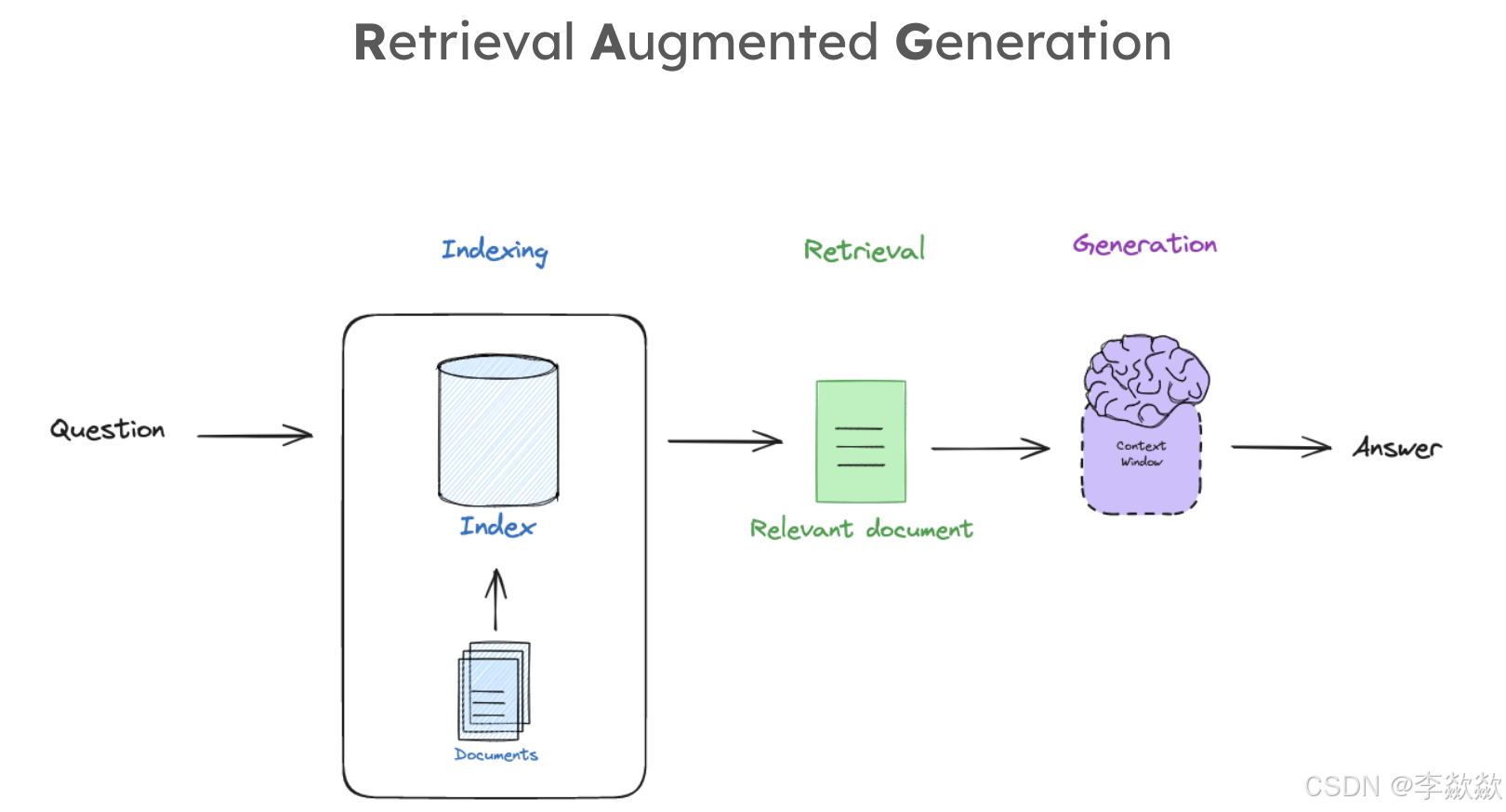
2-Indexing
第一节的Indexing工作流程是什么?
什么是HNSW算法,和余弦相似的有什么关系?
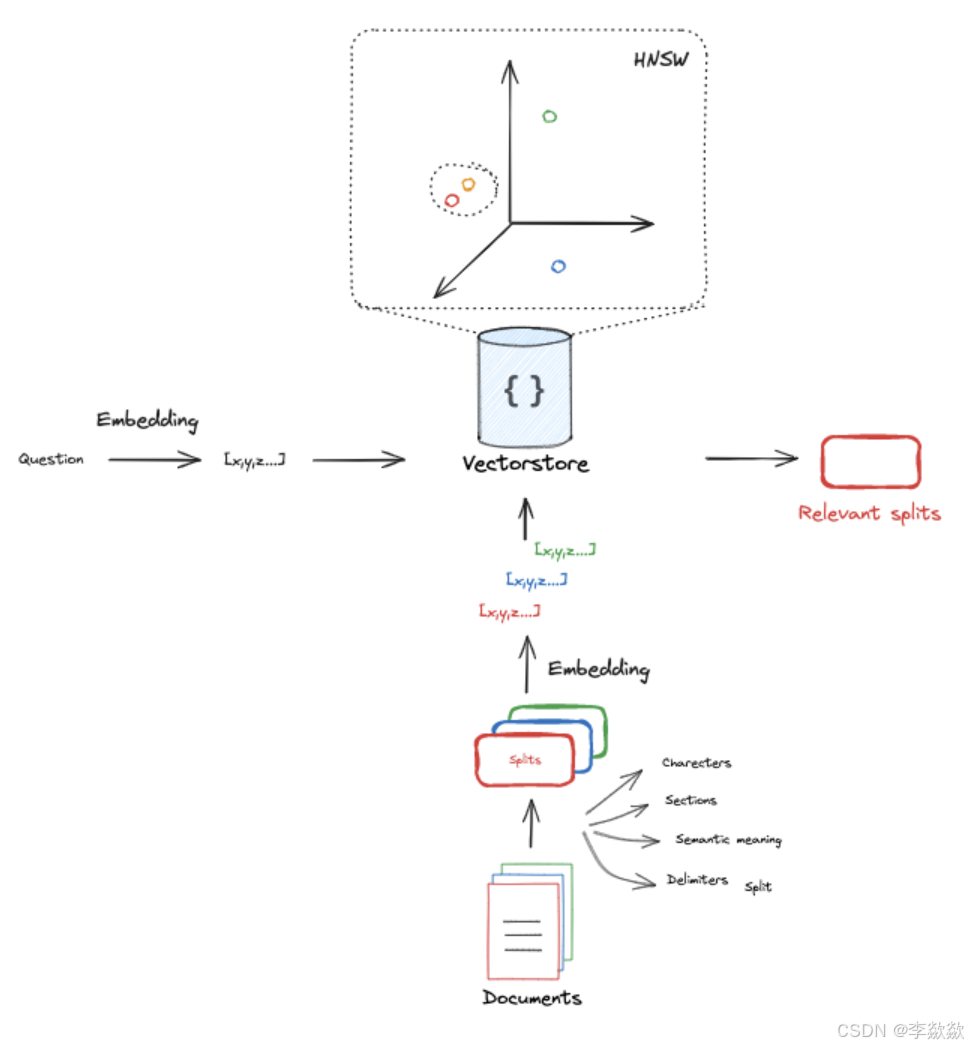
GPT:
HNSW算法(Hierarchical Navigable Small World 分层可导航小世界)是一种高效的近似最近邻搜索(Approximate Nearest Neighbor, ANN)算法,特别适用于高维向量空间中的相似性搜索问题。它通过构建分层图结构来快速搜索高维数据中相似的向量。与传统的暴力搜索(即直接计算所有点之间的距离)相比,HNSW可以大大加快搜索速度,同时保持较高的准确度。
HNSW算法的核心概念:
层次化小世界图: HNSW 构建了一个分层的图结构,最顶层的图节点较少且稀疏,而越往底层节点越多且密集。层次化的结构使得搜索从较高层次开始,能够迅速缩小候选范围,再在底层进行更细粒度的搜索。
- 上层图:较稀疏,帮助快速找到初步的相似区域。
- 底层图:较密集,保证精确搜索最近邻。
图的构建: HNSW图是动态构建的,每个向量加入时,HNSW会根据已有的图结构,选择与新向量相似的一些节点,形成连接边,最终构成近似的小世界网络(small-world graph)。这种图的结构具有较强的连通性和小世界特性,使得搜索效率很高。
搜索过程: 搜索从高层次图开始,通过找到与查询点最相似的顶层节点,逐步下降到底层图。每个层中,HNSW通过邻近节点的遍历来找到与查询点最近的节点,逐层缩小搜索范围,直到找到最相似的候选结果。
与余弦相似度的关系:
余弦相似度是衡量两个向量之间相似性的一种度量方法,通常用于高维空间中的文本、图像、嵌入向量等相似性比较。余弦相似度的公式如下:

其中 A 和 B 是两个向量,分子是它们的点积,分母是它们的模的乘积。余弦相似度的值在 [-1, 1] 之间,值越大表示两个向量越相似。
HNSW与余弦相似度的结合:
- HNSW 算法本身并不限定使用哪种相似性度量,它能够支持多种距离度量方法,包括欧氏距离、余弦相似度、杰卡德距离等。具体应用中,余弦相似度可以作为HNSW中度量向量相似性的一种方法。
- 在使用余弦相似度的场景下,HNSW通过快速查找高维空间中与查询向量在余弦相似度上接近的向量,并避免了暴力搜索的高昂计算成本。
HNSW与余弦相似度的优势:
高效性:
- 传统计算余弦相似度需要与每个数据点进行点积运算,时间复杂度为 O(n),对于大规模数据集来说代价非常高。
- HNSW通过图结构大大减少了需要计算的候选点数,典型的时间复杂度可以达到接近常数级别 O(logn)。
高维数据的近似搜索:
- HNSW适合在高维空间(如词向量、图像特征、嵌入向量)中进行近似搜索,而余弦相似度是这些高维数据常用的相似性度量之一。HNSW能够快速找到与查询点余弦相似度最大的向量。
HNSW的应用场景:
- 推荐系统:在推荐系统中,通过向量化的用户行为或商品特征,使用HNSW结合余弦相似度进行快速推荐相似用户或相似商品。
- 文本检索:在文本嵌入向量空间中,HNSW加速基于余弦相似度的检索任务,例如相似文本、文档的快速查找。
- 图像检索:在图像嵌入特征空间中,通过余弦相似度找到相似的图像,HNSW帮助提高检索效率。
总结:
HNSW算法通过构建层次化的小世界图,能够快速在高维空间中进行近似最近邻搜索。当与余弦相似度结合使用时,HNSW能够有效加速相似向量的查找过程,广泛应用于需要高维特征相似性度量的场景中,如推荐系统、文本检索和图像检索等。
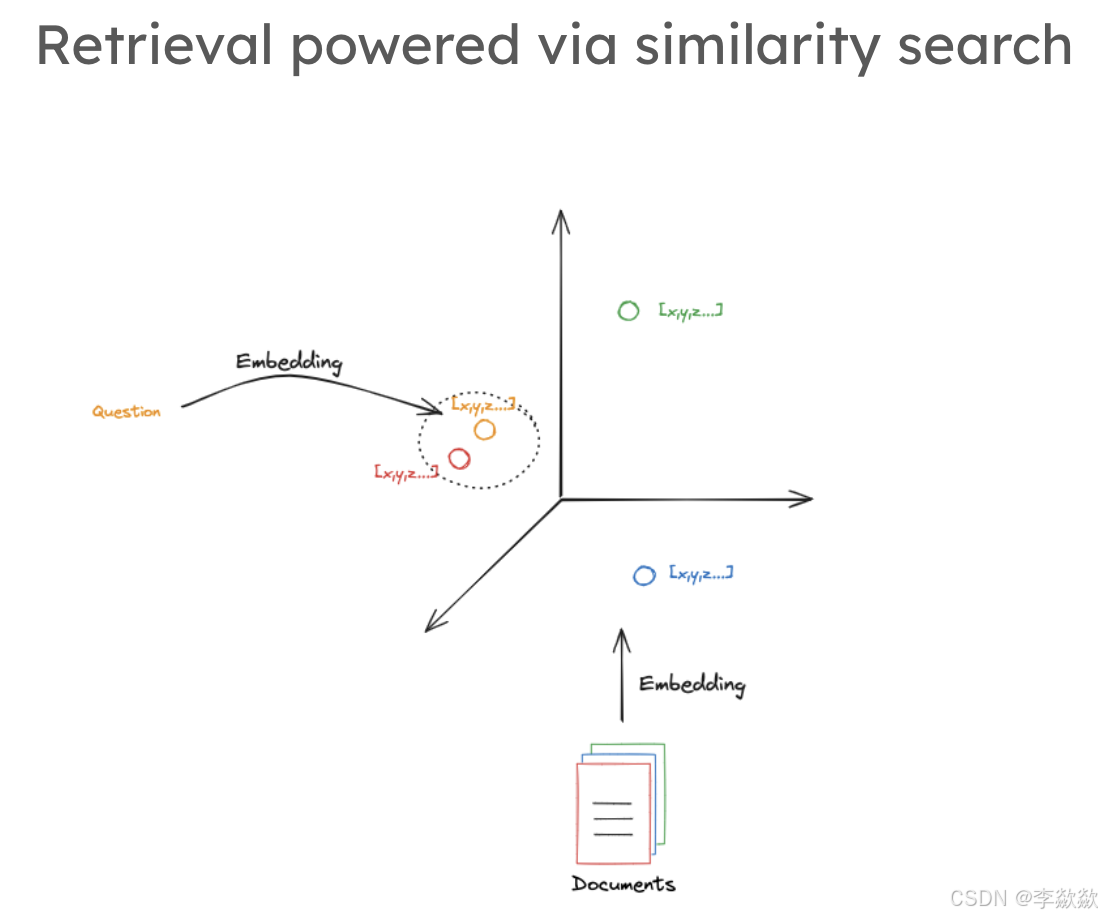
3-Retrival
如何通过矢量检索相似的内容?
4-Generation
3 中找到了与问题相似的上下文,如何使用LLM生成答案?
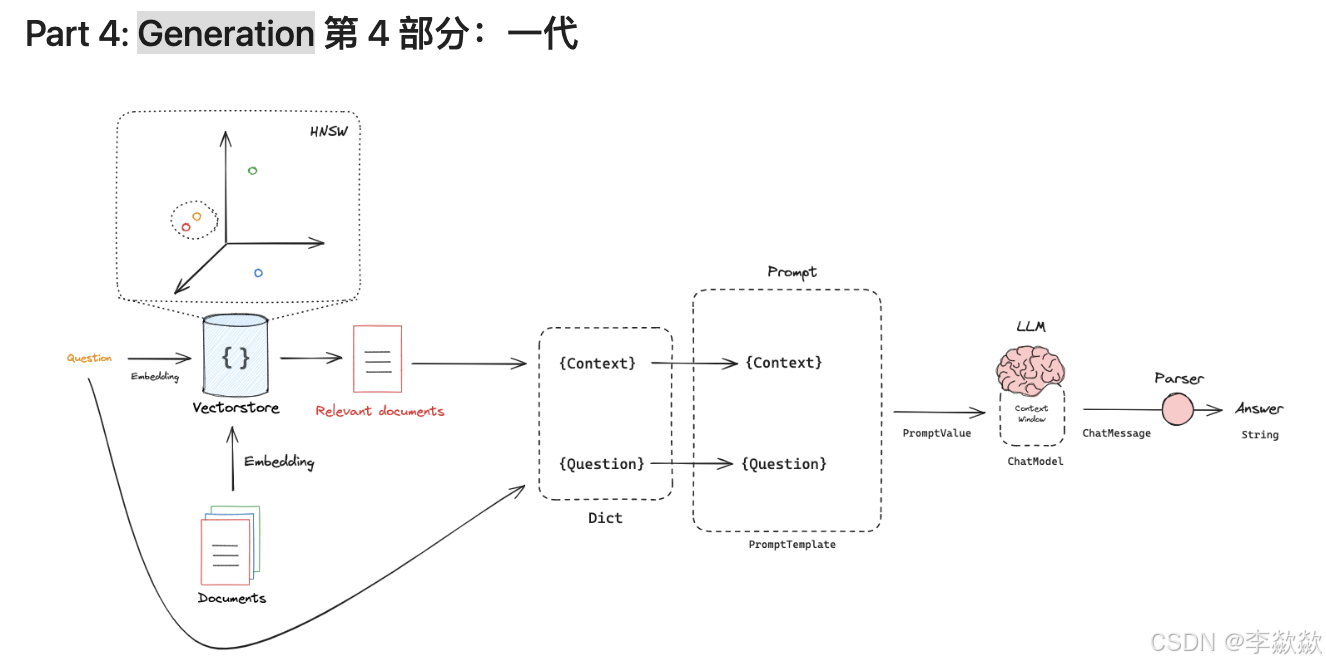
二、优化元素提问
Query Translation查询转换侧重于重写和/或修改问题,使得问题转换为更好解决的问题,更方便检索。
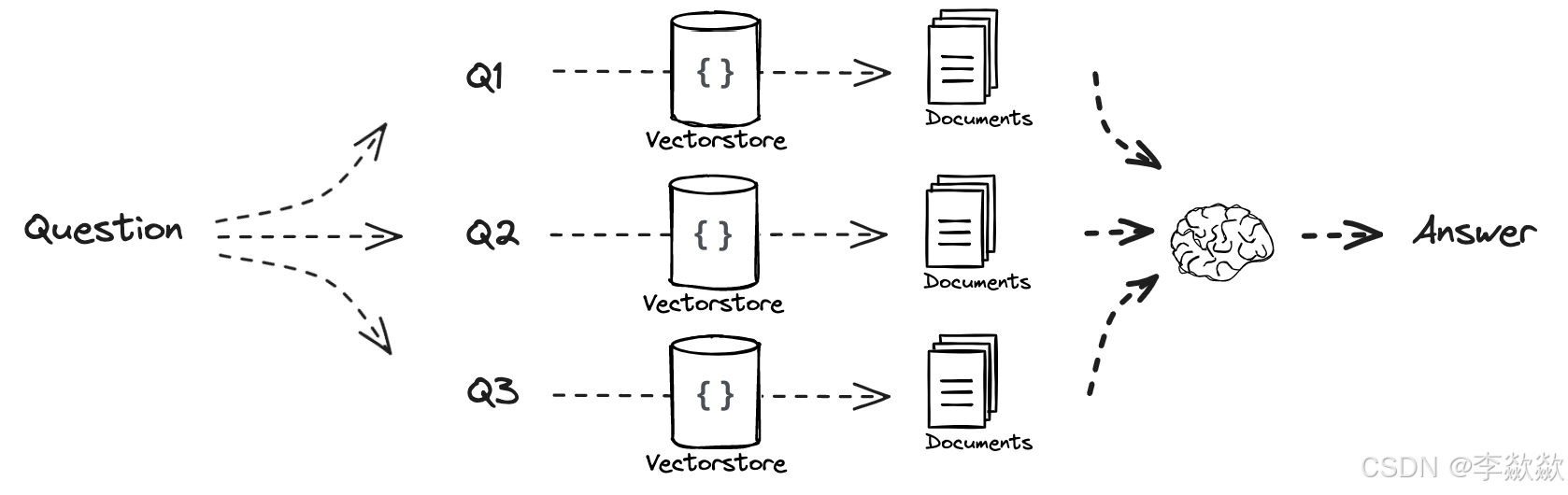
5-Multi Query多查询策略
在同一维度,根据用户输入的问题生成多个子问题,对同一问题生成多个视角的提问,然后依次进行检索,最后将检索到的文档合并返回。
Docs:
6-RAG-Fusion多查询结果融合策略
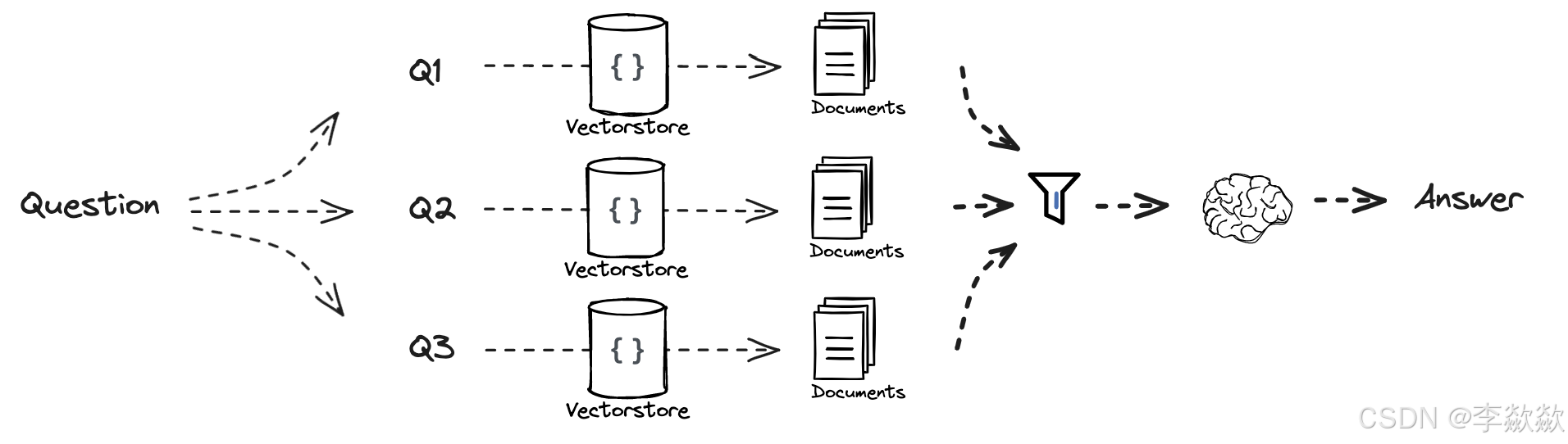
RAG Fusion 和 MultiQueryRetriever 基于同样的思路,在5生成子问题并检索的基础上,它对检索结果执行 倒数排名融合(Reciprocal Rank Fusion,RRF) 算法【后面再讲】,使得检索效果更好。
Docs:
Blog / repo:
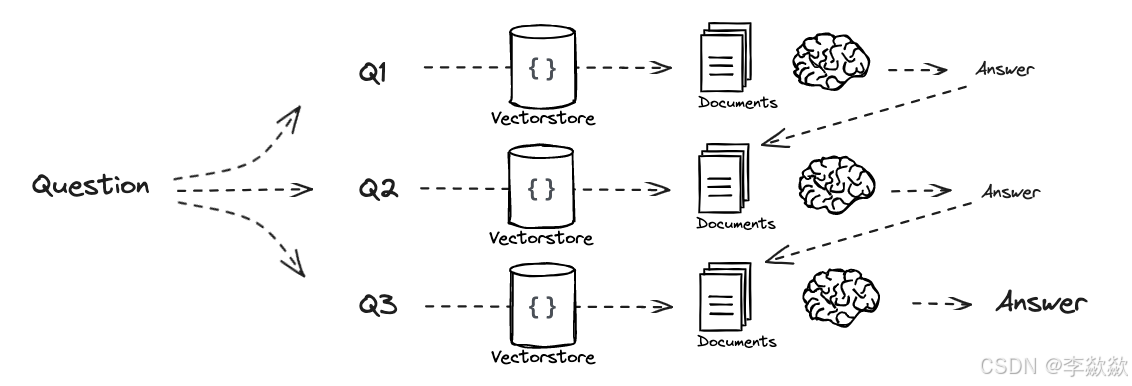
7-Decomposition问题分解策略
在下一个更简单维度,将一个复杂问题分解成多个子问题,将问题分解为一组子问题。之后解决这些子问题再进行合并。有两种类型:Answer recursively和Answer individually
Answer recursively
使用第一个问题的答案+检索来回答第二个问题,以此类推。
Papers:
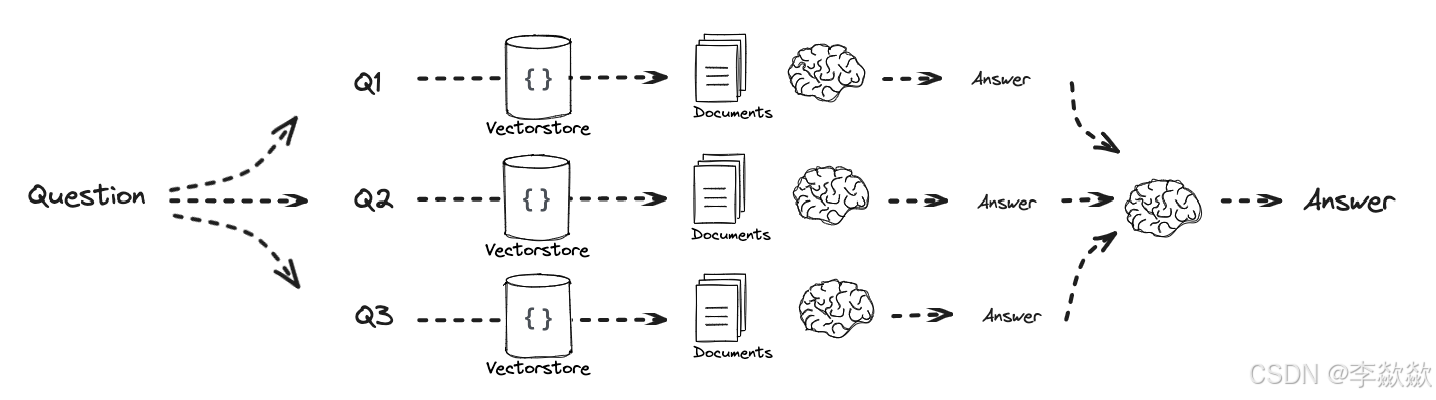
Answer individually
独立解决每一个问题,最后将每个答案合并为最终答案。
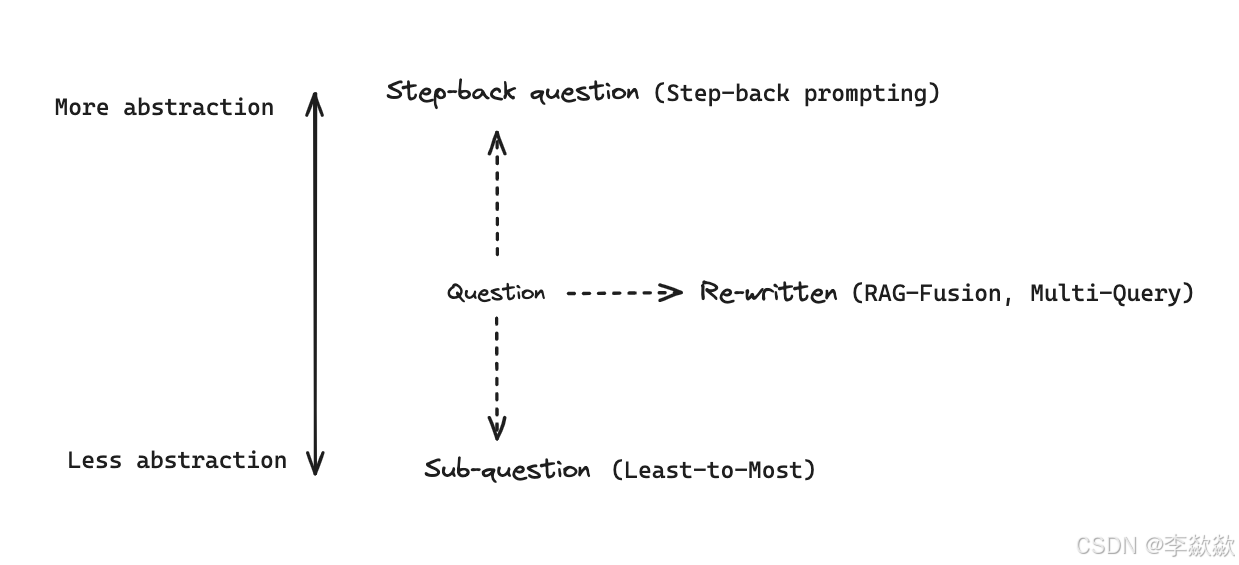
8-Step Back问答回退策略
在更简单的维度,基于用户的原始问题生成一个后退问题,后退问题相比原始问题具有更高级别的概念或原则,从而提高解决复杂问题的效果。
构成上包括抽象abstraction和推理reasoning两个步骤,比如给定一个问题,需要提示大模型,找到回答该问题的一个前置问题,得到前置问题及其答案后,再将其整体与当前问题进行合并,最后送入大模型进行问答,得到最终答案。例如一个关于物理学的问题可以后退为一个关于该问题背后的物理原理的问题,然后对原始问题和后退问题进行检索。
Paper:
9-HyDE(Hypothetical Document Embeddings)假设性文档嵌入
使用基于相似性的向量检索时,在原始问题上进行检索可能效果不佳,因为它们的嵌入可能与相关文档的嵌入不太相似,但是,如果让大模型生成一个假设的相关文档,然后使用它来执行相似性检索可能会得到意想不到的结果。这就是 假设性文档嵌入(Hypothetical Document Embeddings,HyDE) 背后的关键思想。

Docs:
Paper:
HyDE 可能出现的两个失败场景:
- 在没有上下文的情况下,HyDE 可能会对原始问题产出误解,导致检索出误导性的文档;比如用户问题是 “What is Bel?”,由于大模型缺乏上下文,并不知道 Bel 指的是 Paul Graham 论文中提到的一种编程语言,因此生成的内容和论文完全没有关系,导致检索出和用户问题没有关系的文档;
- 对开放式的问题,HyDE 可能产生偏见;比如用户问题是 “What would the author say about art vs. engineering?”,这时大模型会随意发挥,生成的内容可能带有偏见,从而导致检索的结果也带有偏见;
其他方法
查询重写(Query Rewriting),处理表达不清的用户输入,和处理聊天场景中的后续问题(Follow Up Questions)。
查询压缩(Query Compression),用户可能是以聊天对话的形式与系统交互的,为了正确回答用户的问题,我们需要考虑完整的对话上下文,为了解决这个问题,可以将聊天历史压缩成最终问题以便检索。
三、路由优化和问题构建策略
Routing(路由)
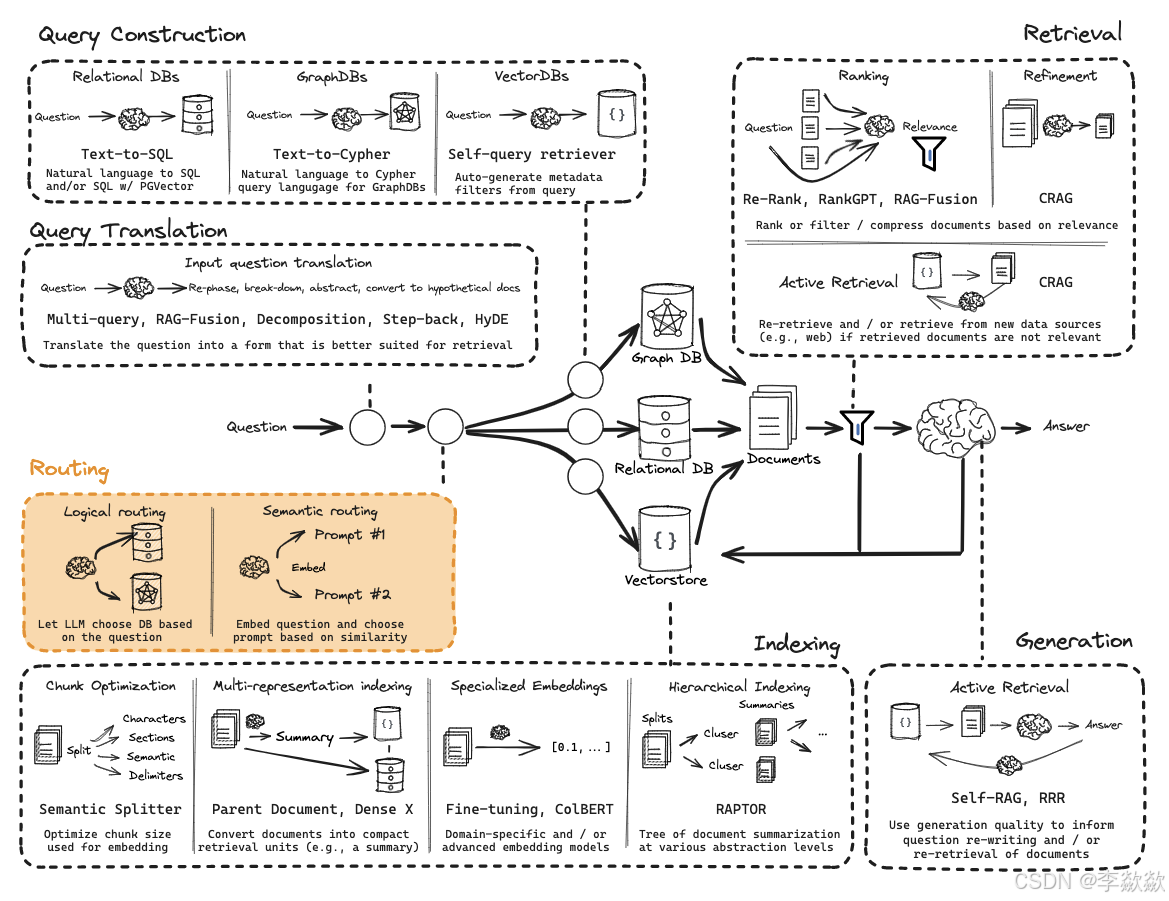
主要解决的是从获取query之后,所选择问题域的方案,包括Logical routing and Semantic routing,基于逻辑路由和语义路由的分发。数据源选择,Prompt选择。
10-Logical and Semantic routing
Logical routing(数据源路由)
配置不同的数据源以供选择。
Use function-calling for classification.
Flow:
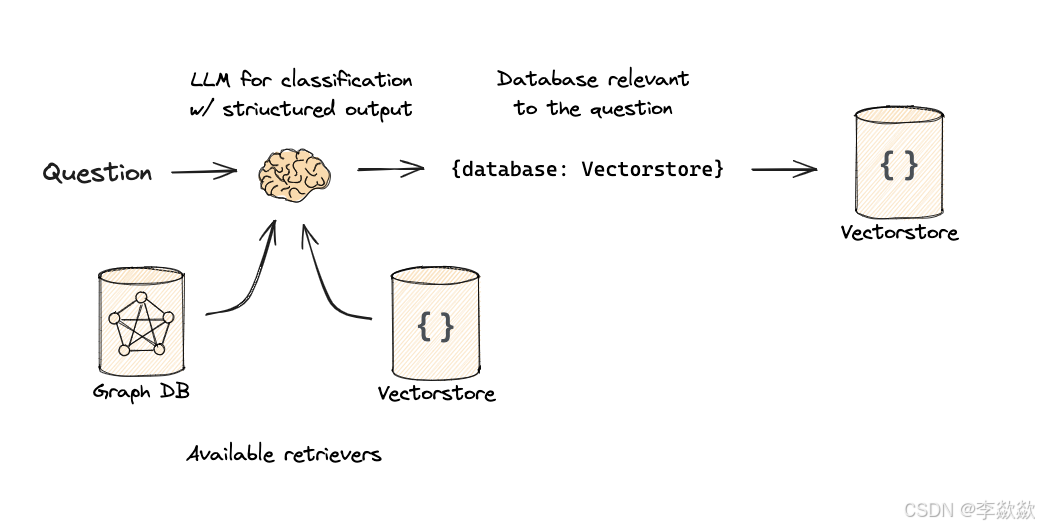
Docs:
Note: we used function calling to produce structured output.

Semantic routing(Prompt路由)
配置不同的Prompt进行选择。
Flow:
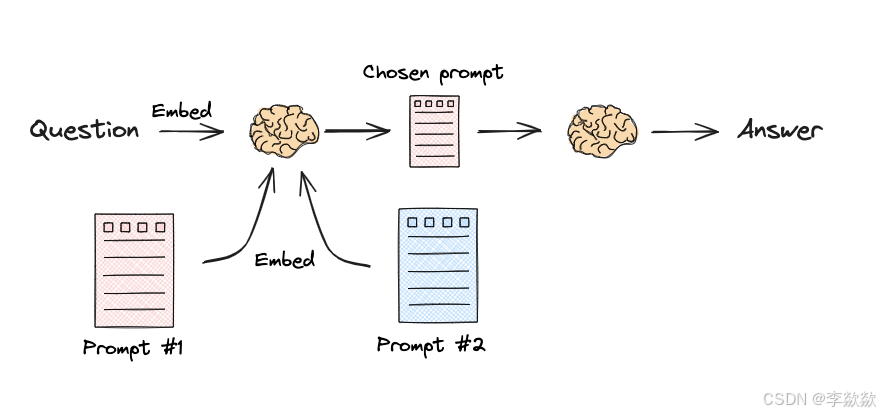
Docs:
Route logic based on input | 🦜️🔗 LangChain
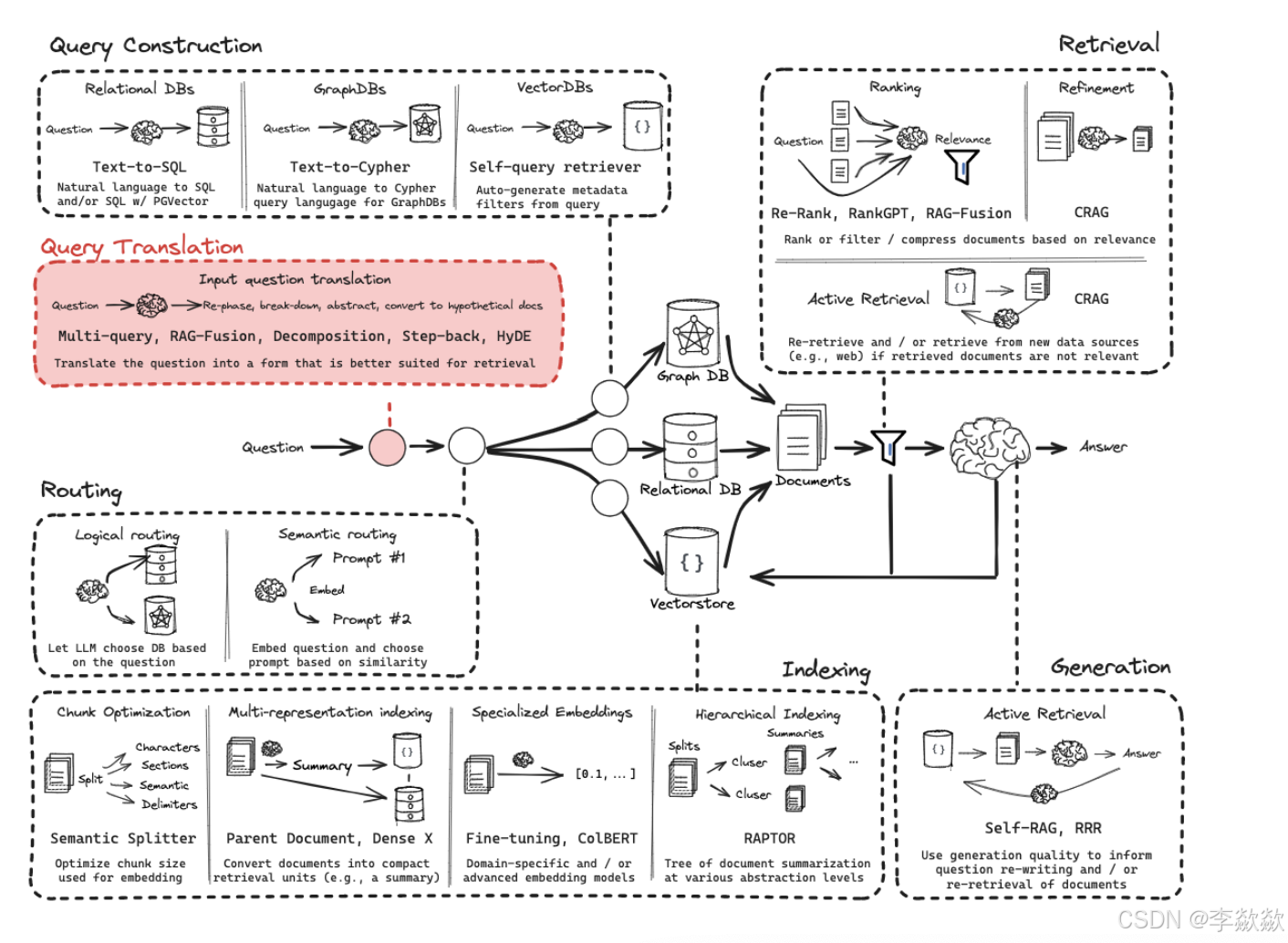
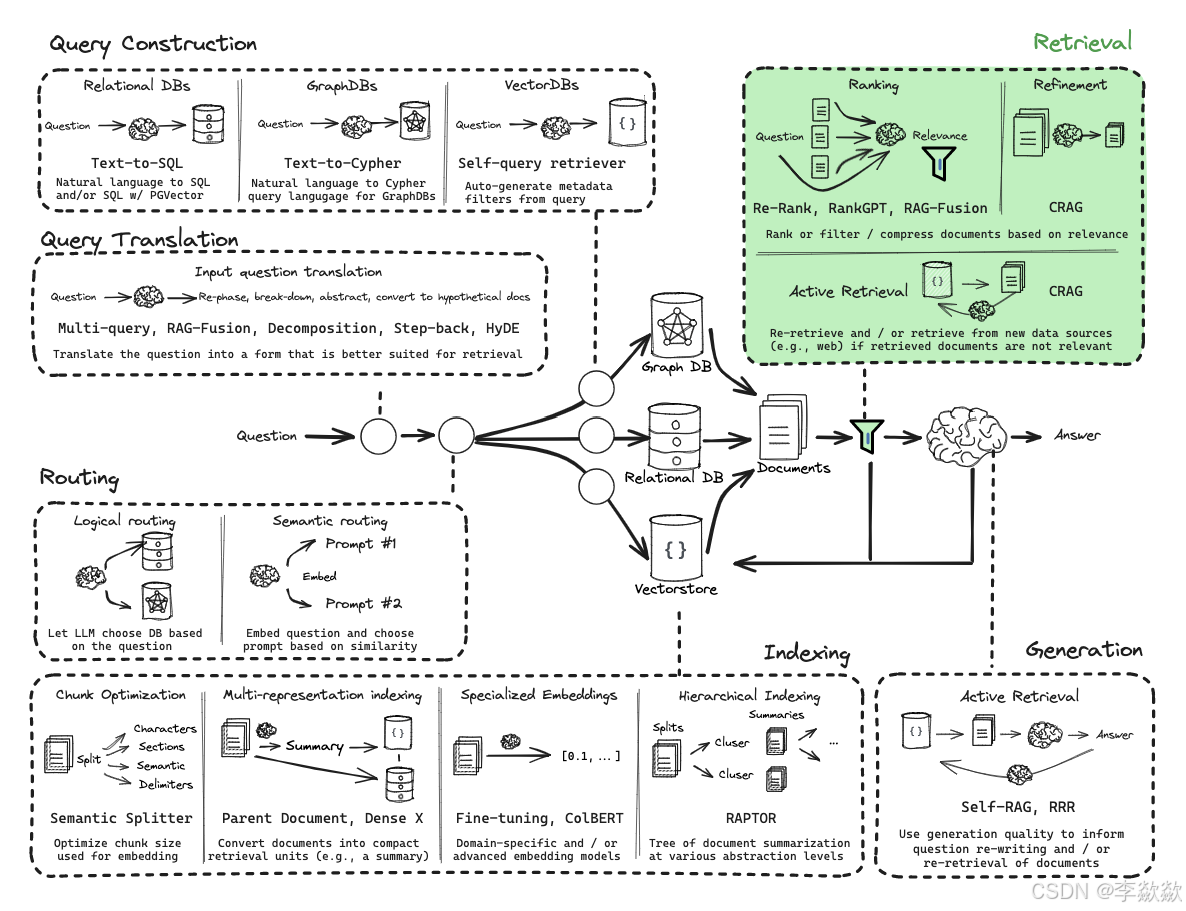
Query Construction问题构建优化策略
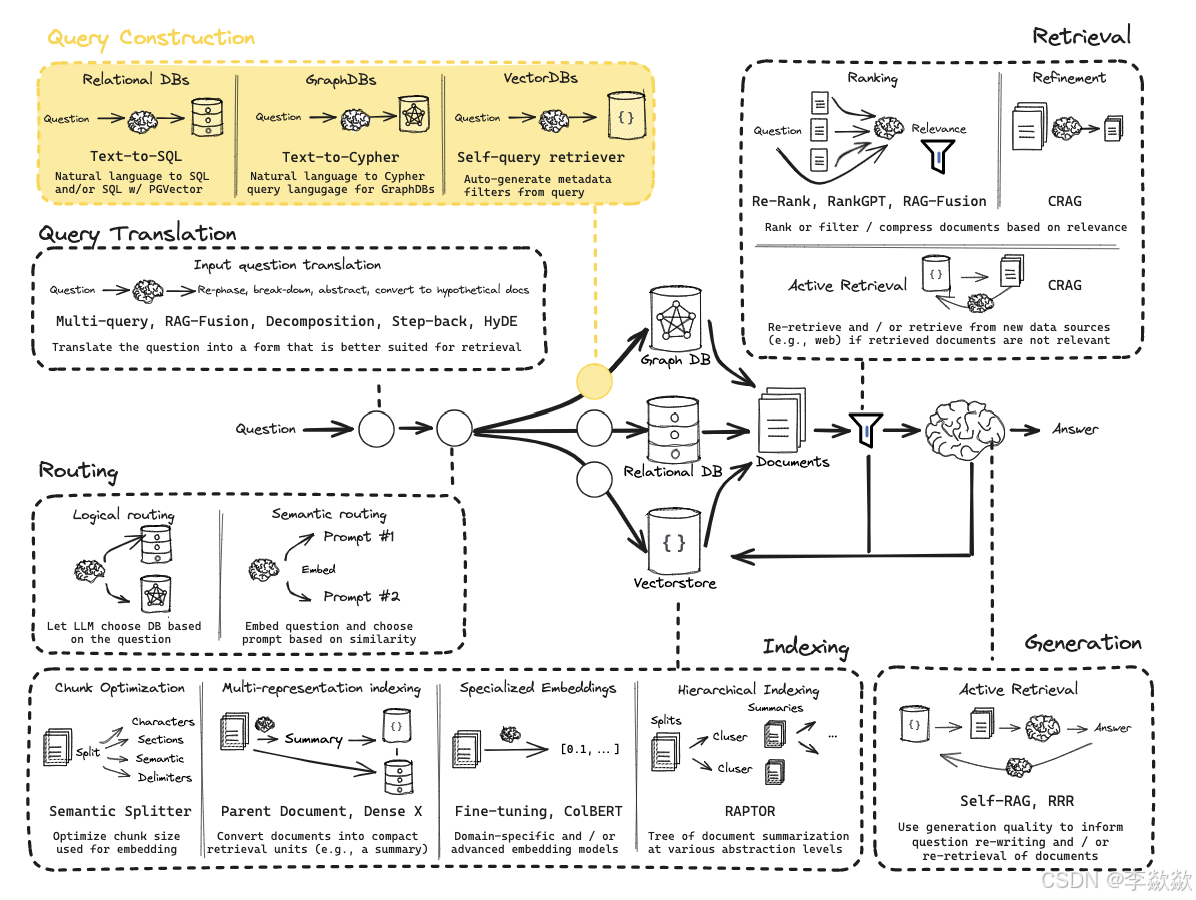
在上一步中的Logical routing中,我们知道数据可能存储在关系型数据库或图数据库中,根据数据的类型,我们将其分为结构化(SQL 或图数据库)、半结构化(将结构化元素与非结构化元素)和非结构化(向量数据库)三大类。
将自然语言与各种类型的数据无缝连接是一件极具挑战的事情。要从这些库中检索数据,必须使用特定的语法,而用户问题通常都是用自然语言提出的,所以我们需要将自然语言转换为特定的查询语法。这个过程被称为查询构造(Query Construction)。
查询构造主要有上图中的三种:Text-to-SQL(关系型数据库)、Text-to-Cypher(图数据库)、Self-Query rertriver(向量数据库),除此之外还有半结构化数据(Text-to-SQL + Semantic)。
其中向量数据库中常用的是基于元数据过滤器。
11-Query structuring for metadata filters
Flow:

许多向量库都包含元数据字段。这使得基于元数据过滤特定块成为可能。
元数据过滤器是基于某些特定的元数据属性(如时间、类别、语言、标签等)来限定查询的范围,从而缩小搜索空间,提高检索的精度。
Docs:
四、索引生成优化
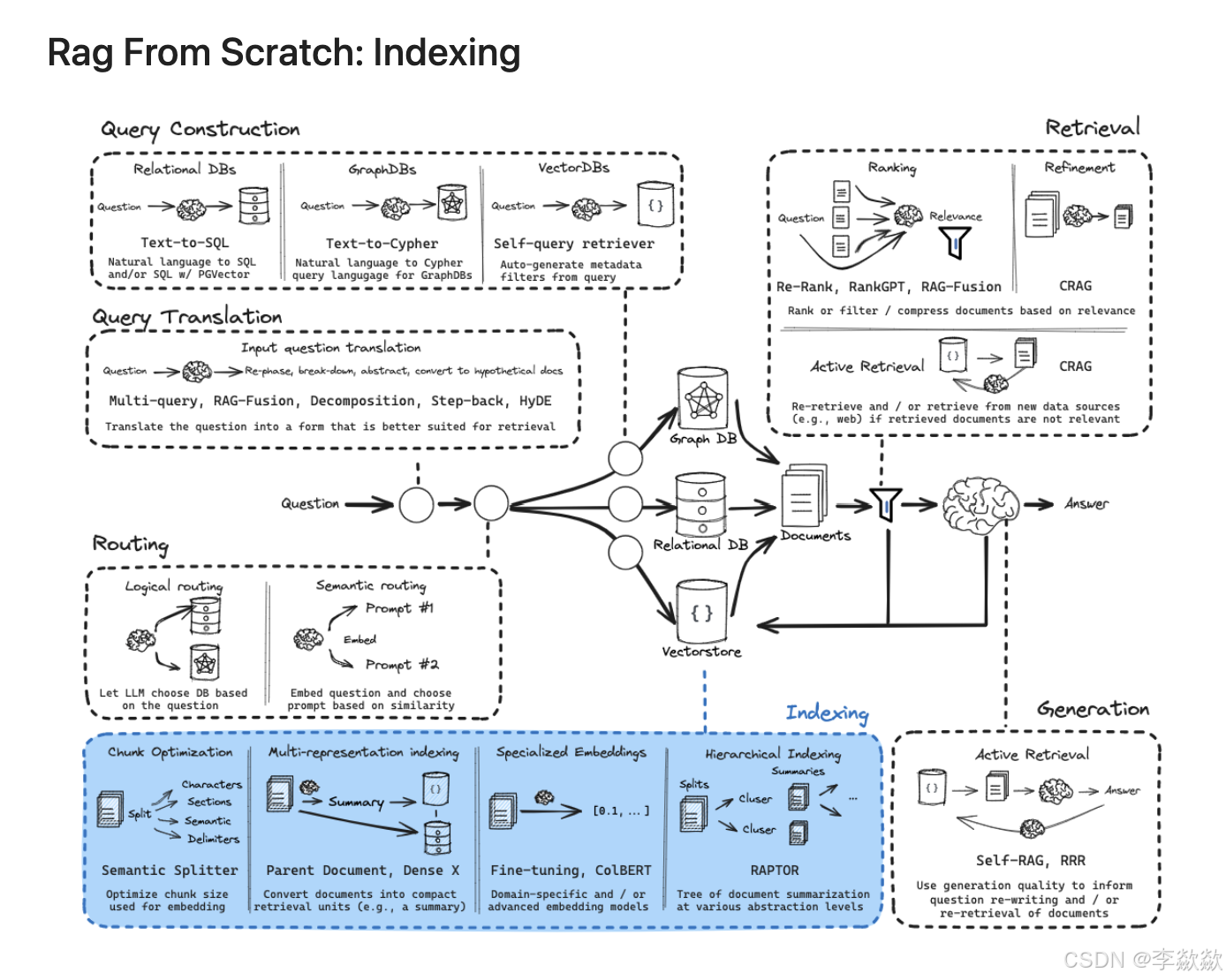
解释不同的生成索引的方式,概要如下:
- 分块策略(Chunking)简单,更好的存储数据split,chunk,overlap(简单而直观的数据分割存储方法)。有多种分块方法,可以分解多种格式的文件,以及Embedding模型。
- 多重表示索引(Multi-representation Indexing),先生成文档摘要(“命题”)。再进行进行相似性搜索,但将完整文档返回给LLM进行生成
- 专用嵌入(Specialized Embeddings),为文档生成特定的向量嵌入,便于高效的相似性计算。例如使用Colbert专一领域的生成索引的方式。
- 分层索引(Hierarchical Indexing),构建多层次的摘要索引树,将文档在不同抽象层次上进行摘要。
12-Multi-representation Indexing
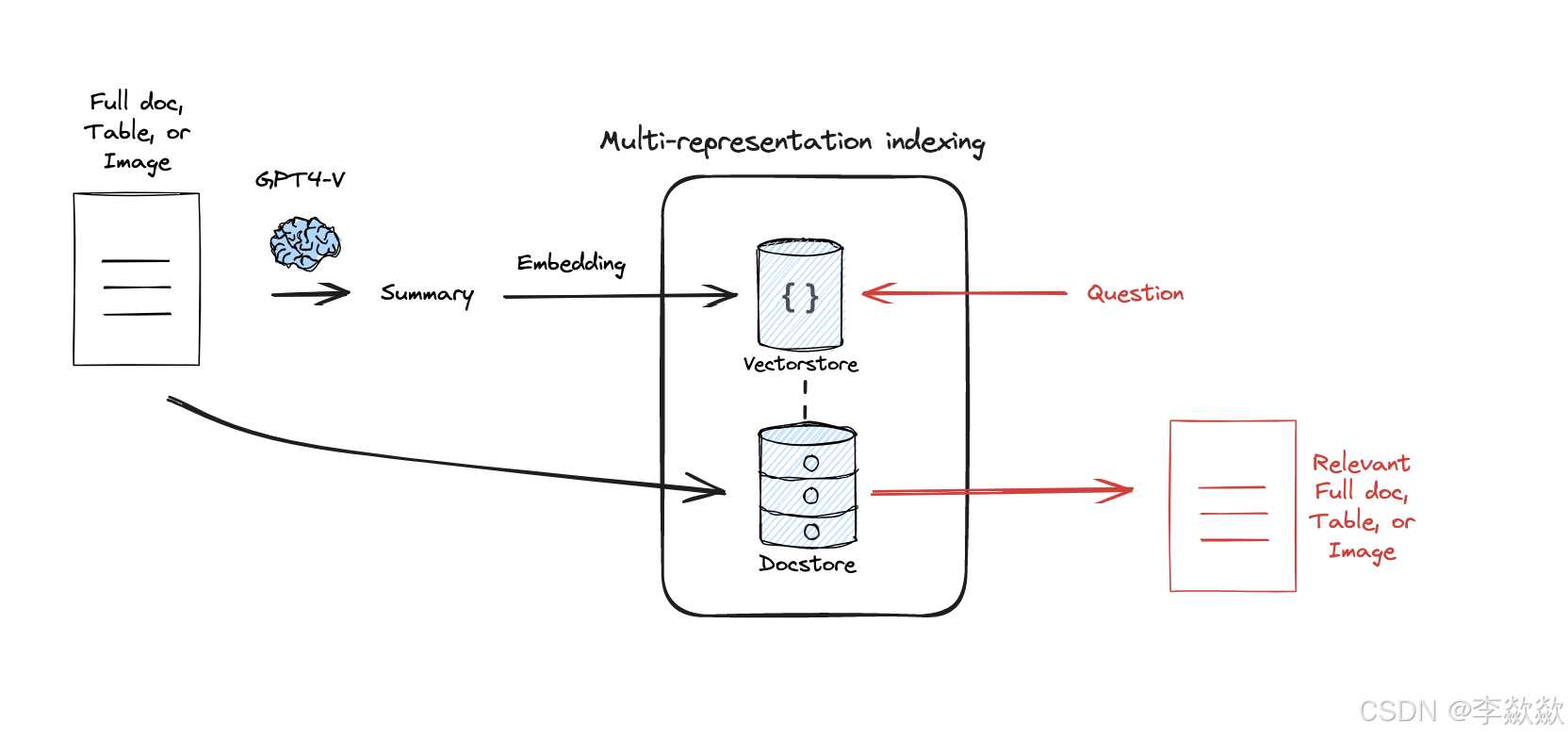
除了存储文本的向量,图片和表格会生成对于的summary进行向量存储【可以使用多模态模型进行生成或者将图片/表格原文的相关上下文进行摘要选取】,同时保留原文件(图像和表格)及其对应关系,例如parent-document-retrival。Multi-representation Indexing,使用LLM生成针对检索进行优化的文档摘要(“命题”)。嵌入这些摘要以进行相似性搜索,但将完整文档返回给LLM进行生成。
Flow:
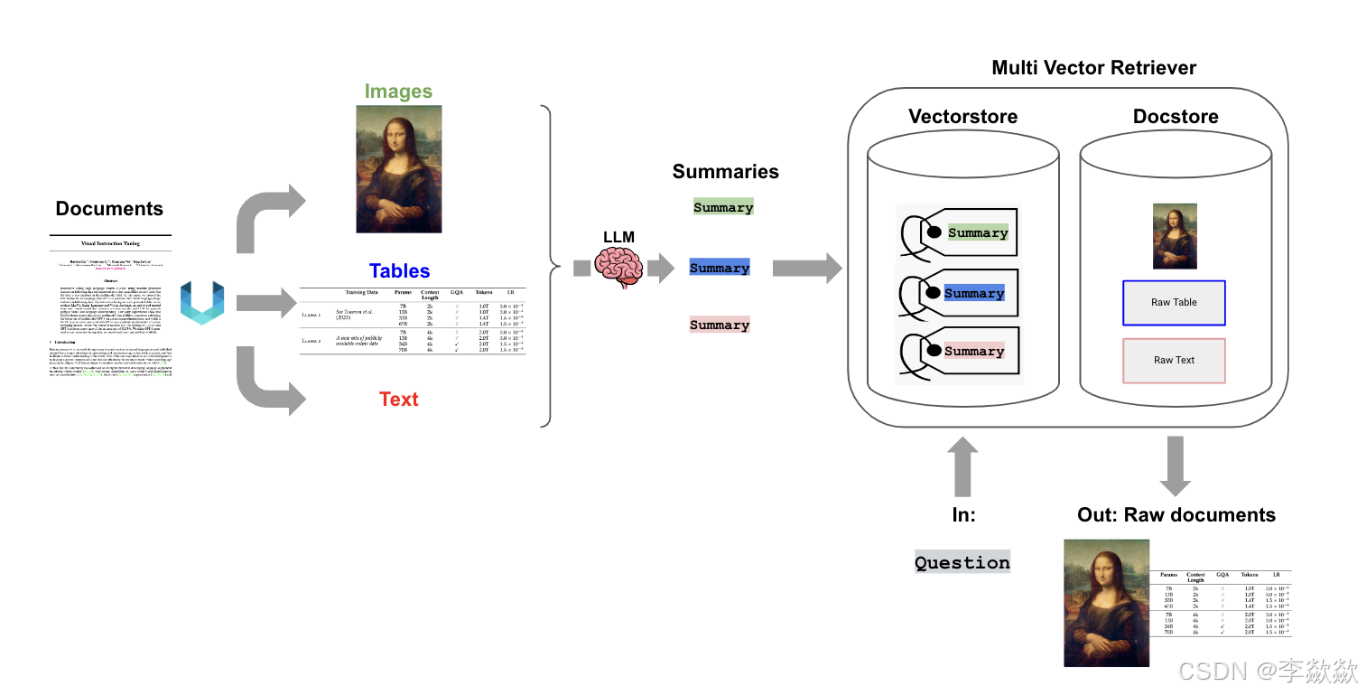
Docs:
Multi-Vector Retriever for RAG on tables, text, and images
MultiVector Retriever | 🦜️🔗 LangChain
Paper:
https://arxiv.org/abs/2312.06648
13-RAPTOR
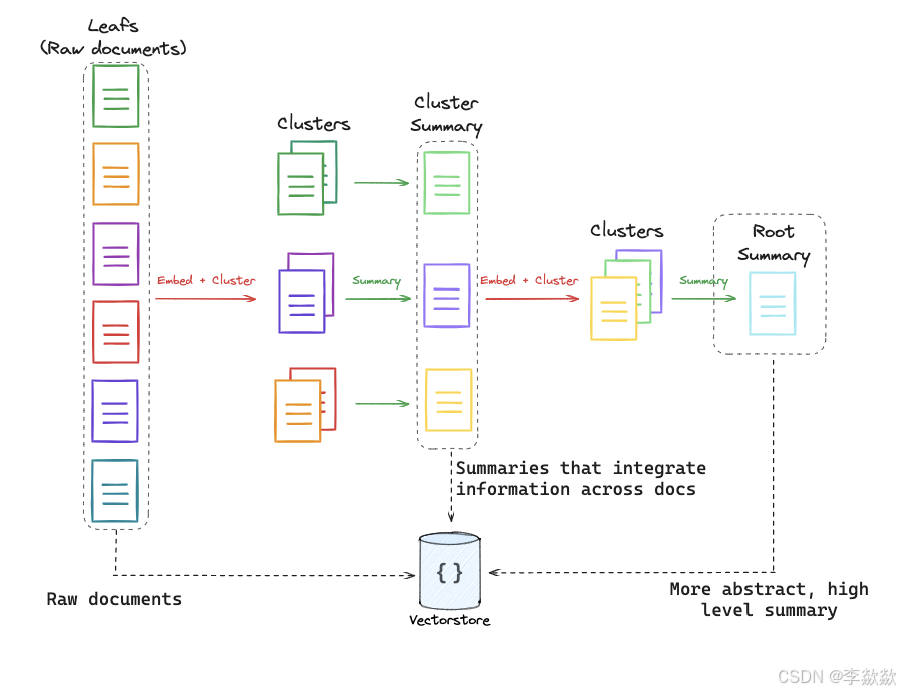
传统的RAG方法通常仅检索较短的连续文本块,这限制了对整体文档上下文的全面理解。散乱的内容详略不一致的很多文档,如何进行有效分类和整理?RAPTOR(Recursive Abstractive Processing for Tree-Organized Retrieval)通过递归嵌入、聚类和总结文本块,构建一个自底向上的树形结构,在推理时从这棵树中检索信息,从而在不同抽象层次上整合长文档的信息。
这是层级性索引的方案其思想在于对文档进行生成聚类摘要,然后将设计成层级性。
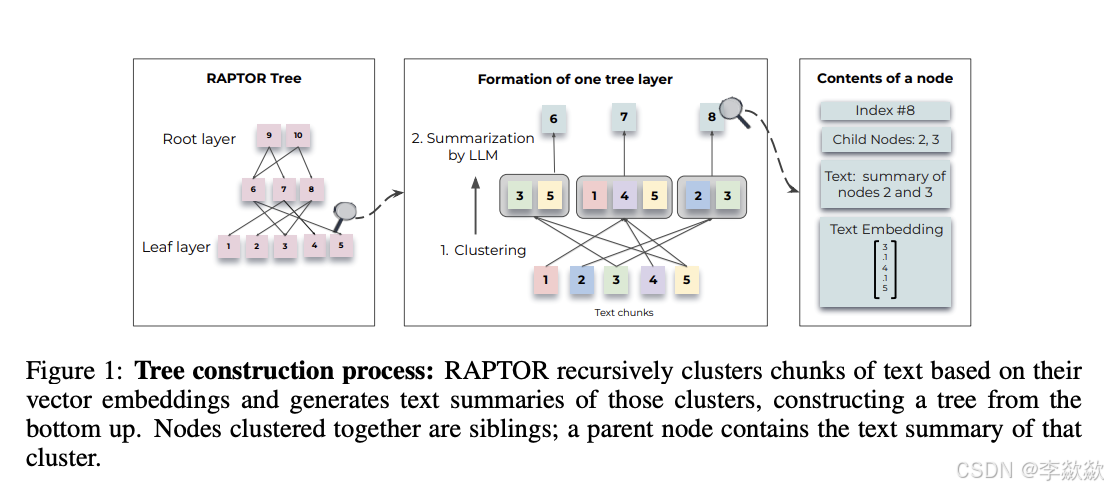
1. 树形结构构建:
-
文本分块:首先将检索语料库分割成短的、连续的文本块。
-
嵌入和聚类:使用SBERT(基于BERT的编码器)将这些文本块嵌入,然后使用高斯混合模型(GMM)进行聚类。
-
摘要生成:对聚类后的文本块使用语言模型生成摘要,这些摘要文本再重新嵌入,并继续聚类和生成摘要,直到无法进一步聚类,最终构建出多层次的树形结构。
Flow:
2. 查询方法:
-
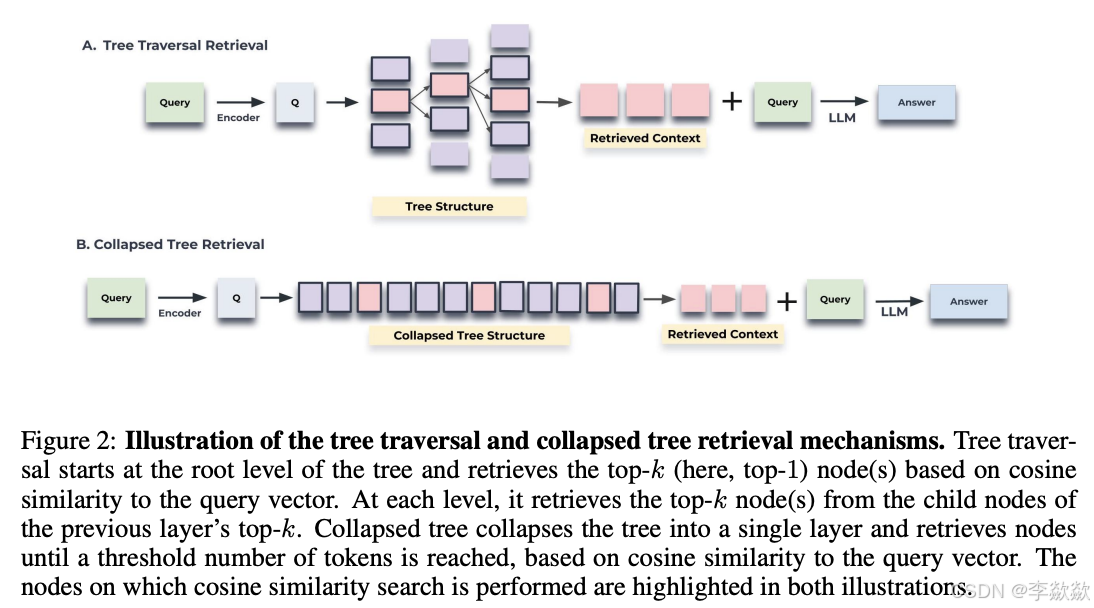
树遍历:从树的根层开始,逐层选择与查询向量余弦相似度最高的节点,直到到达叶节点,将所有选中的节点文本拼接形成检索上下文。
-
平铺遍历:将整个树结构平铺成一个单层,将所有节点同时进行比较,选出与查询向量余弦相似度最高的节点,直到达到预定义的最大token数。
3. 实验结果:RAPTOR在多个任务上显著优于传统的检索增强方法,特别是在涉及复杂多步推理的问答任务中。RAPTOR与GPT-4结合后,在QuALITY基准上的准确率提高了20%。
-
代码:RAPTOR的源代码将在GitHub上公开。
-
数据集:实验中使用了NarrativeQA、QASPER和QuALITY等问答数据集。
Deep dive video:
https://www.youtube.com/watch?v=jbGchdTL7d0
Paper:
https://arxiv.org/pdf/2401.18059.pdf
Full code:
https://github.com/langchain-ai/langchain/blob/master/cookbook/RAPTOR.ipynb
14-ColBERT

RAGatouille使ColBERT的使用变得非常简单。ColBERT为段落中的每个标记生成一个受上下文影响的向量。ColBERT类似地为查询中的每个令牌生成向量。然后,每个文档的得分是每个查询嵌入与任何文档嵌入的最大相似性的总和。
特定化的Embedding,之前的方法停留在文本层级,ColBERT做到了token级,为段落中的每个token生成一个受上下文影响的向量,ColBERT同样为查询中的每个token生成向量,然后,每个文档的得分就是每个查询嵌入与任意文档嵌入的最大相似度之和,这块可以看:
https://hackernoon.com/how-colbert-helps-developers-overcome-the-limits-of-rag
https://til.simonwillison.net/llms/colbert-ragatouille
五、Retrieval检索和Generation生成优化策略
Retrieval检索优化策略
完成对问题的改写、不同知识库查询的构建以及路由分发、查询构建和索引生成优化之后可以进一步优化Retrieval检索。包括Ranking、Refinement以及Adaptive retrival。
Retrieval检索
首先需要先检索,之后再进行后面的Ranking、Refinement和Adaptive retrival操作。先来说一下检索:检索是在索引的基础上进行查询的,所以检索方式和索引结构分不开。构建索引的目的是为了更快的检索,检索器可以针对单个索引,也可以组合不同检索技术,比主要有以下的几种类型:
1. 父文档检索(Parent Document Retrieval)
当我们对文档进行分块的时候,我们可能希望每个分块不要太长,因为只有当文本长度合适,嵌入才可以最准确地反映它们的含义,太长的文本嵌入可能会失去意义;但是在将检索内容送往大模型时,我们又希望有足够长的文本,以保留完整的上下文。为了实现二者的平衡,有以下三种方式实现父文档检索:
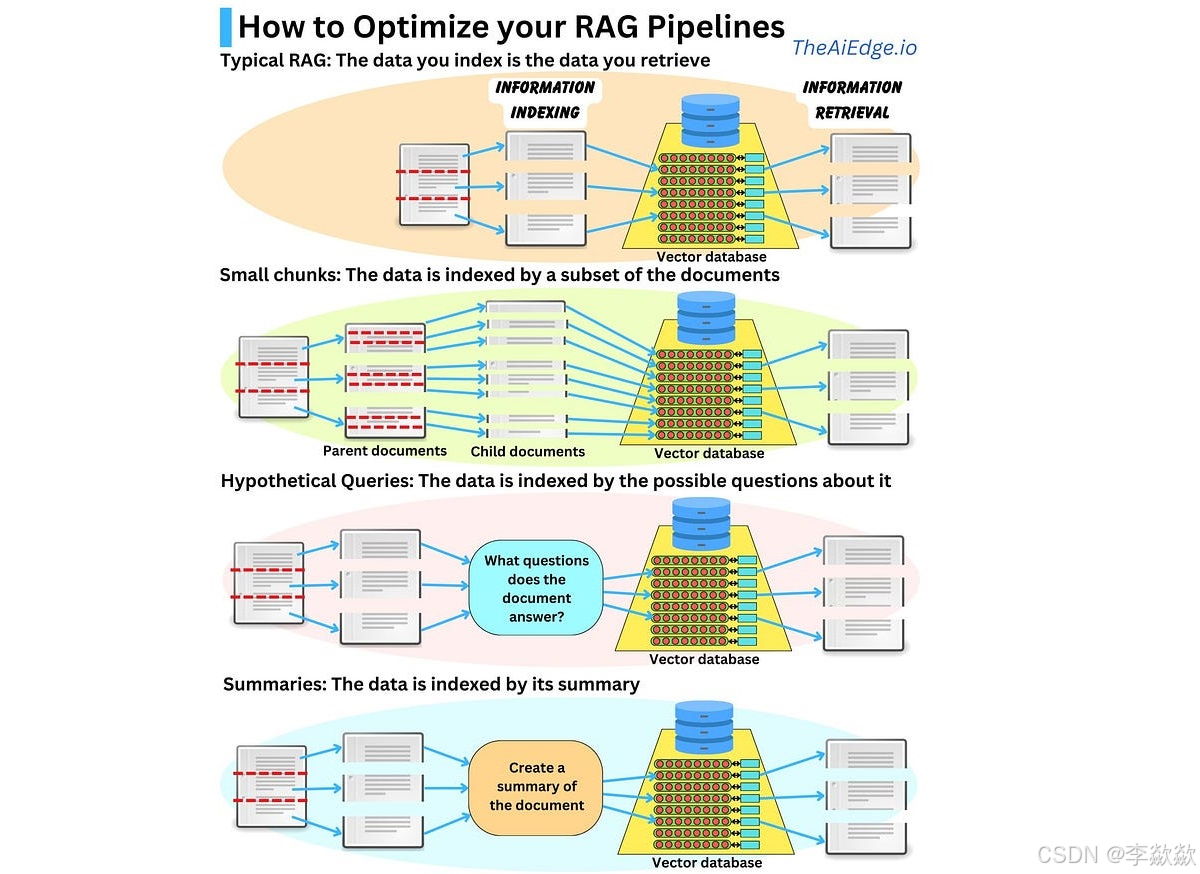
- 可以在检索过程中,首先获取小的分块,然后查找这些小分块的父文档,并返回较大的父文档,这里的父文档指的是小分块的来源文档,可以是整个原始文档,也可以是一个更大的分块。
- 使用大模型对文档进行摘要,然后对摘要进行嵌入和检索,这种方法对处理包含大量冗余细节的文本非常有效,这里的原始文档就相当于摘要的父文档。【在四的part12中有使用】
- 通过大模型为每个文档生成 假设性问题(Hypothetical Questions),【在二的part9中有使用】然后对问题进行嵌入和检索,也可以结合问题和原文档一起检索,这种方法提高了搜索质量,因为与原始文档相比,用户查询和假设性问题之间的语义相似性更高。
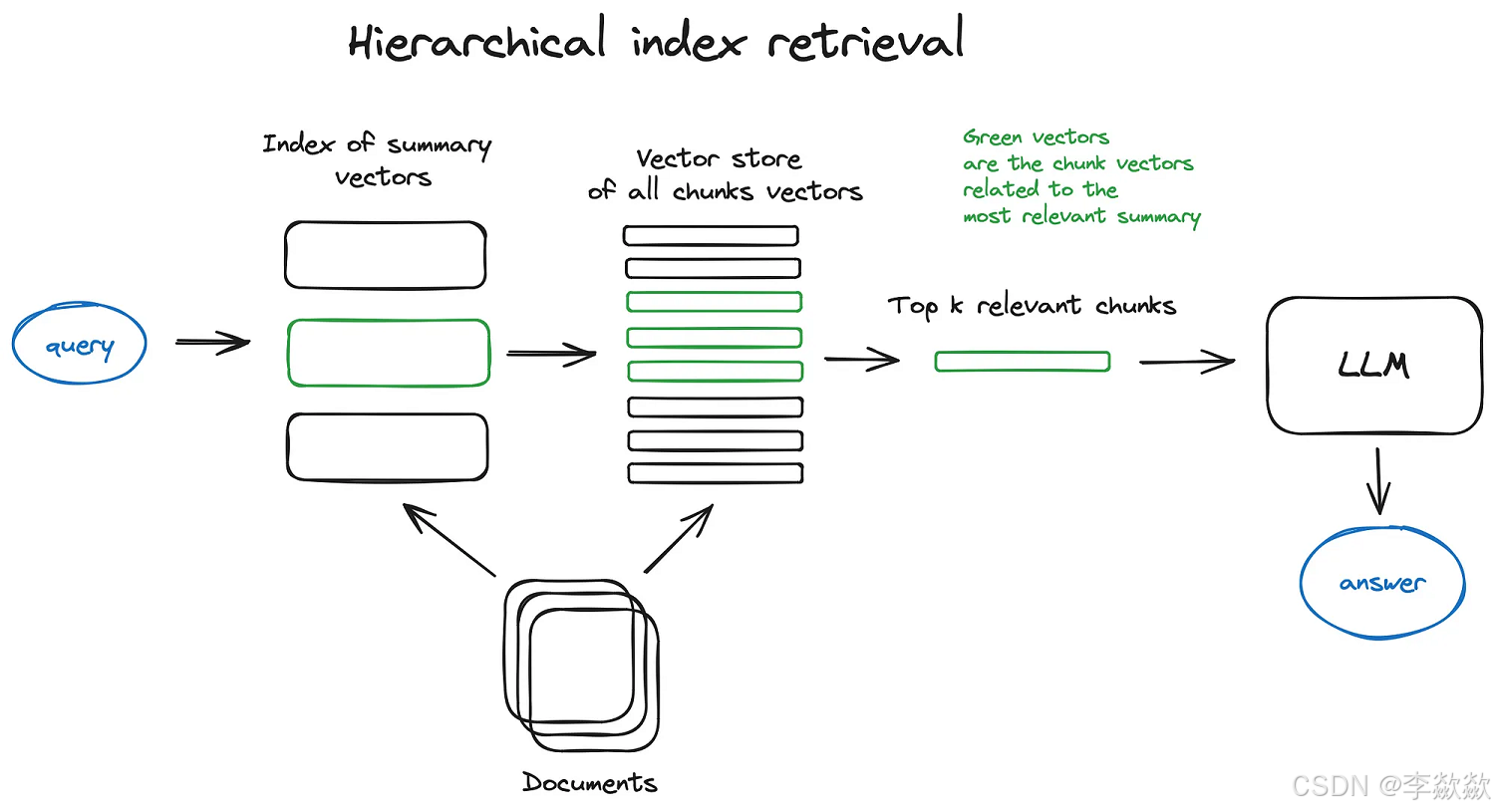
2. 层级检索(Hierarchical Retrieval)
有大量的文档需要检索,为了高效地在其中找到相关信息,一种高效的方法是创建两个索引:一个由摘要组成,另一个由文档块组成,然后分两步搜索,首先通过摘要筛选出相关文档,然后再在筛选出的文档中搜索。【在part四中投提到,RAPTOR是其中的一种实现方式】
3. 混合检索(Fusion Retrieval)
【在二的part 6】有提到 RAG 融合(RAG Fusion) 技术,它根据用户的原始问题生成意思相似但表述不同的子问题并检索。其实,还可以结合不同的检索策略,最常见的做法是将基于关键词的老式搜索和基于语义的现代搜索结合起来。
- 基于关键词的搜索又被称为 稀疏检索器(sparse retriever),通常使用 BM25、TF-IDF 等传统检索算法;
- 基于语义的搜索又被称为 密集检索器(dense retriever),使用的是现在流行的 Embedding 算法。
通常结合了稀疏检索(Sparse Retrieval)和稠密检索(Dense Retrieval)的策略,通常可以兼顾两种检索方式的优势,提高检索的效果和效率。两种方法的详细解释如下:
- 稀疏检索(Sparse Retrieval):这种方法通常基于倒排索引(Inverted Index),对文本进行词袋(Bag-of-Words)、BM25或者TF-IDF表示,然后按照关键词的重要性对文档进行排序。稀疏检索的优点是速度快,可解释性强,但在处理同义词、词语歧义等语义问题时效果有限。
- 稠密检索(Dense Retrieval):这种方法利用深度神经网络,将查询和文档映射到一个低维的稠密向量空间,然后通过向量相似度(如点积、余弦相似度)来度量查询与文档的相关性。稠密检索能更好地捕捉语义信息,但构建向量索引的成本较高,检索速度也相对较慢。
关键词搜索和向量搜索各有其优势和局限性:
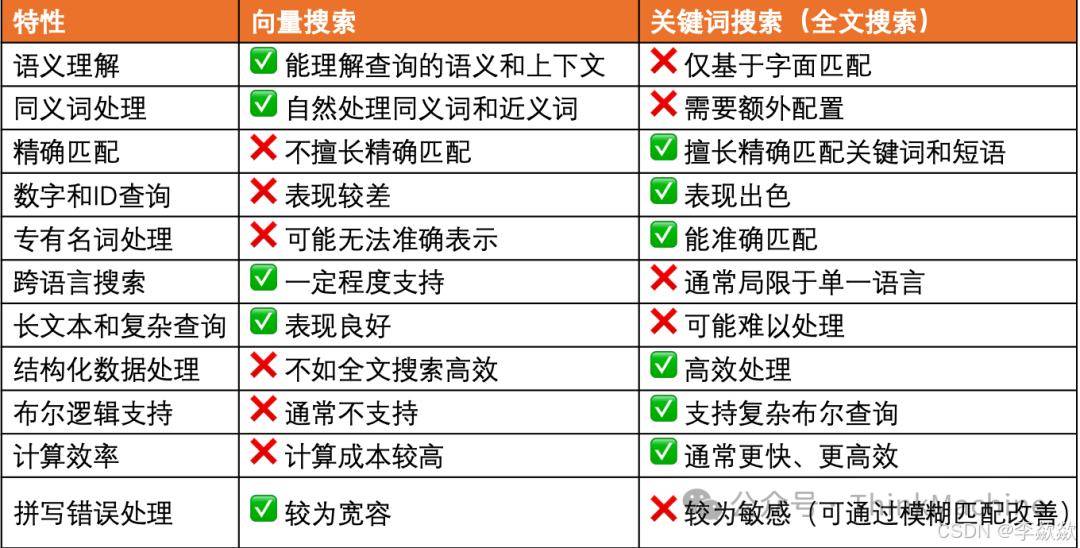
在实际RAG系统的开发中,现实通常是各种情况都有,难以使用一种搜索方法解决全部问题。用户的查询可能涵盖广泛的类型,从精确的关键词匹配到抽象的概念探索,再到专业领域的术语搜索。同时,知识库中的数据也可能是多样化的,包含结构化和非结构化信息、数字数据、专有名词等。面对这些复杂的需求,仅依赖向量搜索或全文搜索中的一种往往会导致检索结果的不准确。这就是为什么在现代RAG系统中,混合搜索方法变得越来越重要的原因。
混合搜索的工作原理:
1、并行执行:
- 对每个查询,系统同时执行向量搜索和全文搜索。
- 向量搜索捕捉查询的语义内容。
- 全文搜索处理关键词匹配和精确查找。
2、结果融合:
- 使用特定算法将两种搜索的结果合并成一个统一的结果集。
- 最常用的方法之一是倒数排名融合(Reciprocal Rank Fusion,RRF)算法。
并行执行的实现并不复杂,它的关键技巧是结果融合,这个问题通常是通过 倒数排名融合(Reciprocal Rank Fusion,RRF) 算法来解决的,RRF 算法对检索结果重新进行排序从而获得最终的检索结果。
RRF 是滑铁卢大学和谷歌合作开发的一种算法,它可以将具有不同相关性指标的多个结果集组合成单个结果集,这里是 它的论文地址,其中最关键的部分就是下面这个公式:

k 是一个常量,默认值为 60。RRF 不依赖于每次检索分配的绝对分数,而是依赖于相对排名,这使得它非常适合组合来自可能具有不同分数尺度或分布的查询结果。
实现权重平衡的办法,可以通过直接调整经典RRF公式中的k值来实现。在经典RRF公式中,K为常数,建议设为60。实际这个K是可调的,通过调整k值,我们可以有效地改变关键词搜索和向量搜索的相对重要性权重,从而使RRF算法获得更好的性能。
直接修改k值是对RRF公式增加权重平衡的最简单方法,易于实施和调整,适合快速优化和实验。2023年5月,来自向量数据库初创企业Pinecone和伯克利的研究人员共同发表了论文,提出了一种新的混合搜索算法,称为TM2C2(Theoretical Min-Max Convex Combination),论文中,我们看到TM2c2算法有如下几个优势:
- 稳定性:相比传统的 min-max 归一化,TM2C2 更稳定。
- 性能:在大多数数据集上,TM2C2 优于 RRF 和其他基线方法。
- 可解释性:α 参数直观地表示了语义搜索和关键词搜索的相对重要性。
- 样本效率:只需要很少的训练样本就能调整到较好的性能。
我们可以发现,TM2c2算法实际上是RRF引入权重参数和归一函数后的变体。这一变化为特定场景下,混合搜索的性能提升提供了更多的可能性。
4.多向量检索(Multi-Vector Retrieval)
对于同一份文档,可以有多种嵌入方式,也就是为同一份文档生成几种不同的嵌入向量,这在很多情况下可以提高检索效果,这被称为多向量检索器(Multi-Vector Retriever)。为同一份文档生成不同的嵌入向量有很多策略可供选择,上面所介绍的父文档检索就是比较典型的方法。
当我们处理包含文本和表格的半结构化文档时,多向量检索器也能派上用场,在这种情况下,可以提取每个表格,为表格生成适合检索的摘要,但生成答案时将原始表格送给大模型。有些文档不仅包含文本和表格,还可能包含图片,随着多模态大模型的出现,我们可以为图像生成摘要和嵌入。
LangChain 的 这篇博客 对多向量检索做了一个全面的描述,并提供了大量的示例,用于表格或图片等多模任务的检索。
注意:父文档检索和层级检索很相似,其区别在于父文档检索只检索一次摘要,然后由摘要扩展出原始文档,而层级检索是通过检索摘要筛选出一批文档,然后在筛选出的文档中执行二次检索。
5. 后处理
RAG 系统的最后一个问题,如何将检索出来的信息丢给大模型?
检索出来的信息可能过长,或者存在冗余(比如从多个来源进行检索),我们可以在后处理步骤中对其进行上下文压缩、排序、去重等。LangChain 中并没有专门针对后处理的模块,文档也是零散地分布在各个地方,比如 Contextual compression、Cohere reranker 等。
15-Re-ranking
检索得到的数据直接提交给LLM去生成答案,但这样存在检索出来的chunks并不一定完全和上下文相关的问题,最后导致大模型生成的结果质量不佳。
这个问题很大程度上是因为召回相关性不够或者是召回数量太少导致的,从扩大召回这个角度思考,借鉴推荐系统做法,引入粗排或重排的步骤来改进效果。
重排越来越popular,在上面的过滤策略中,我们经常会用到 Embedding 来计算文档的相似性,然后根据相似性来对文档进行排序(包括Fusion),这里的排序被称为 粗排,我们还可以使用一些专门的排序引擎对文档进一步排序和过滤,这被称为 精排。每个子问题检索到的文档根据设定的权重进行排序(每个子问题都用到的文档权重更高)。再基于这个权重,在选择top-k的文档。
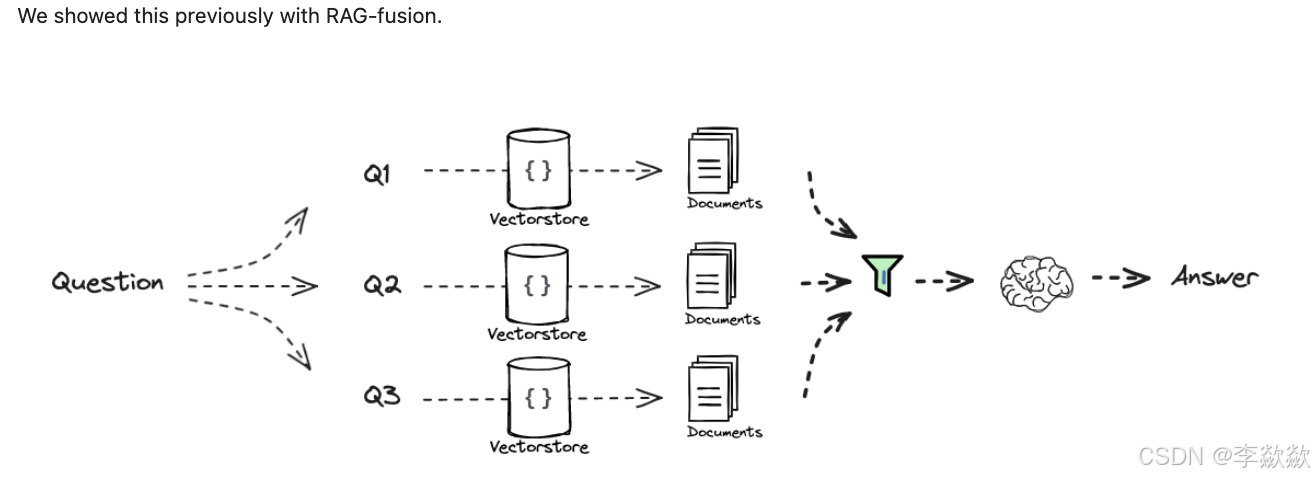
解决召回数量太少的方法是原有的top-k向量检索召回扩大召回数目;
Rerank主要有两种实现方式:
- 使用一些专门的排序引擎对文档进一步排序和过滤
- 使用大模型来做重排序
1. 使用Cohere 的Re-Rank方案
We can also use Cohere Re-Rank.
See here:
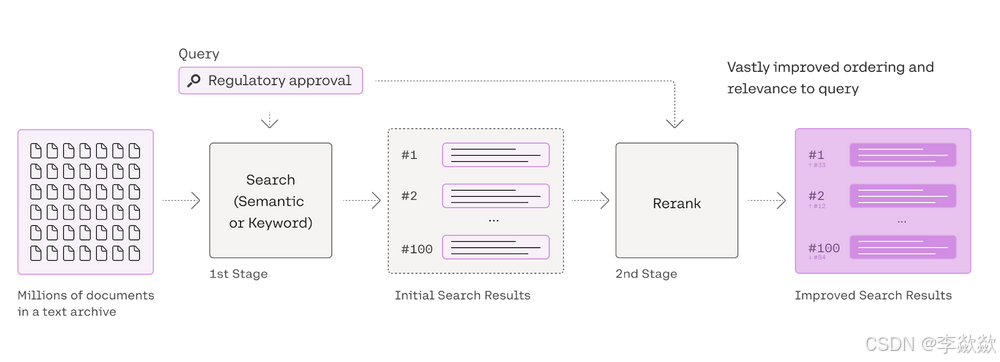
除此之外,排序引擎还有JinaRerank 、SentenceTransformerRerank、Colbert Reranker:
- Jina AI 总部位于柏林,是一家领先的 AI 公司,提供一流的嵌入、重排序和提示优化服务,实现先进的多模态人工智能。可以使用 Jina 提供的 Rerank API 来对文档进行精排。
- 除了使用商业服务,我们也可以使用一些本地模型来实现重排序。比如 sentence-transformer 包中的 交叉编码器(Cross Encoder) 可以用来重新排序节点。LlamaIndex 默认使用的是
cross-encoder/ms-marco-TinyBERT-L-2-v2模型,这个是速度最快的。为了权衡模型的速度和准确性,请参考 sentence-transformer 文档,以获取更完整的模型列表。 - 另一种实现本地重排序的是 ColBERT 模型,它是一种快速准确的检索模型,可以在几十毫秒内对大文本集合进行基于 BERT 的搜索。
2. 大模型做重排序
使用大模型来做重排序,将文档丢给大模型,然后让大模型对文档的相关性进行评分,从而实现文档的重排序。
使用 LLM 来决定哪些文档/文本块与给定查询相关。prompt由一组候选文档组成,这时LLM 的任务是选择相关的文档集,并用内部指标对其相关性进行评分。为了避免因为大文档chunk化带来的内容分裂,在建库阶段也可做了一定优化,利用summary index对大文档进行索引。
下面是 LlamaIndex 内置的用于重排序的 Prompt:
DEFAULT_CHOICE_SELECT_PROMPT_TMPL = (
"A list of documents is shown below. Each document has a number next to it along "
"with a summary of the document. A question is also provided. \n"
"Respond with the numbers of the documents "
"you should consult to answer the question, in order of relevance, as well \n"
"as the relevance score. The relevance score is a number from 1-10 based on "
"how relevant you think the document is to the question.\n"
"Do not include any documents that are not relevant to the question. \n"
"Example format: \n"
"Document 1:\n<summary of document 1>\n\n"
"Document 2:\n<summary of document 2>\n\n"
"...\n\n"
"Document 10:\n<summary of document 10>\n\n"
"Question: <question>\n"
"Answer:\n"
"Doc: 9, Relevance: 7\n"
"Doc: 3, Relevance: 4\n"
"Doc: 7, Relevance: 3\n\n"
"Let's try this now: \n\n"
"{context_str}\n"
"Question: {query_str}\n"
"Answer:\n"
)基于LLM召回或重排存在一些缺陷,首先就是慢,第二就是增加了LLM的调用成本,第三,由于打分是分批进行的,存在着无法全局对齐的问题。
除此之外,使用LLM进行排序的相关论文方法还有:
- RankGPT 是 Weiwei Sun 等人在论文 Is ChatGPT Good at Search? Investigating Large Language Models as Re-Ranking Agents 中提出的一种基于大模型的 zero-shot 重排方法,它采用了排列生成方法和滑动窗口策略来高效地对段落进行重排序,具体内容可以参考 RankGPT 的源码。
- RankLLM 和 RankGPT 类似,也是利用大模型来实现重排,只不过它的重点放在与 FastChat 兼容的开源大模型上,比如 Vicuna 和 Zephyr 等,并且对这些开源模型专门为重排任务进行了微调,比如 RankVicuna 和 RankZephyr 等。
16-Retrieval (CRAG)
其本质上是一种Adaptive-RAG策略,实现方式为在循环单元测试中自我纠正检索错误,以确定文档相关性并返回到网络搜索,即纠对检索文档的自我反思/自我评分,主要采用如下步骤:
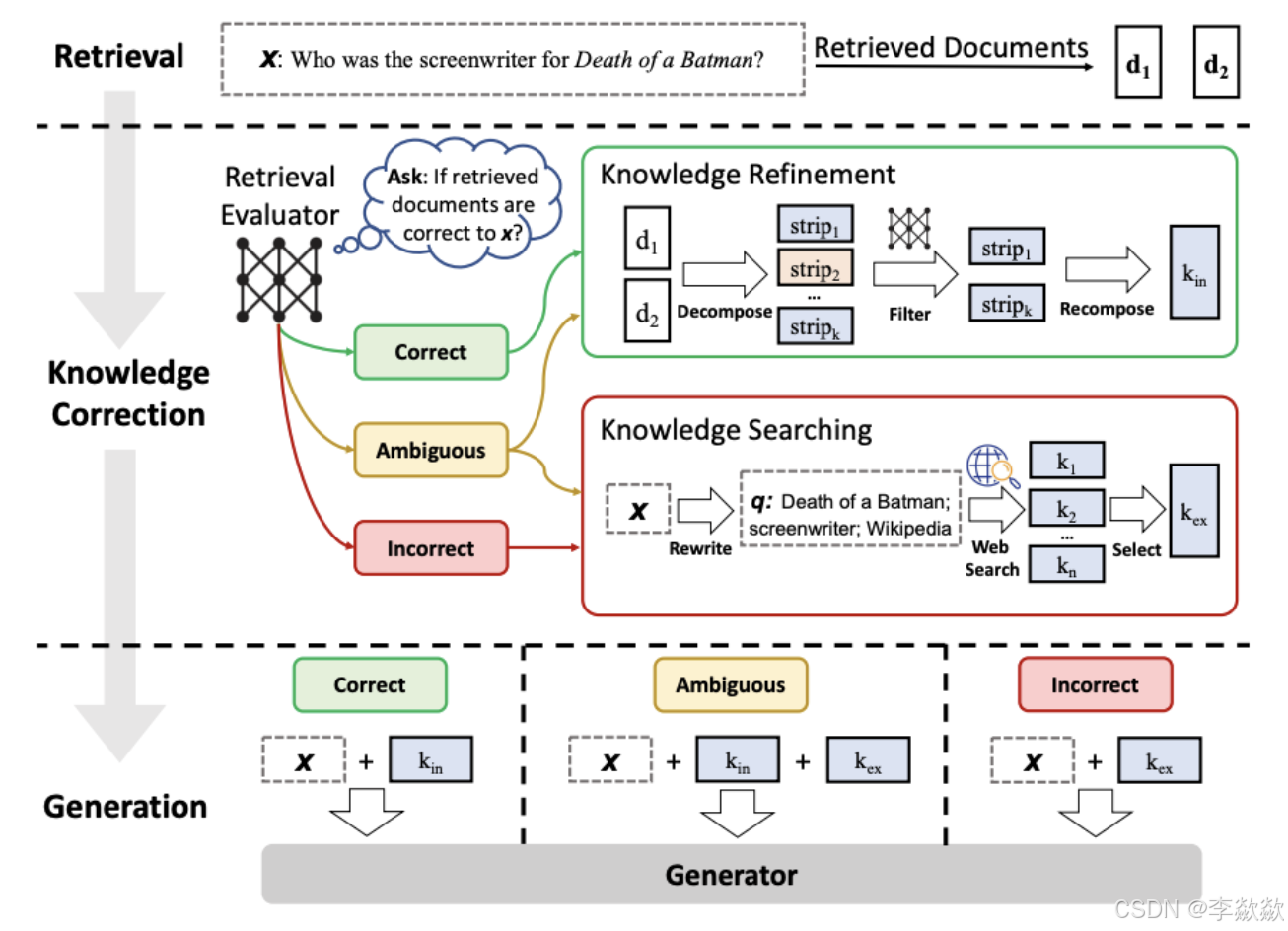
首先需要知道的是CRAG的特色发生在retrieval阶段的最后,即当我们获得到了近似的document(或者说relevant snippets)之后。
然后会进入一个额外的环节,叫Knowledge Correction。在这里呢我们会先对retrieval得到的每一个相关切片snippets进行evaluate,评估一下我们获取到的snippet是不是对问的问题有效?(此处重点:evaluator也是一个LLM)
然后会有三种情况:
- Correct:那就直接进行RAG的正常流程。(不过图中是加了进一步的优化)
- Incorrect:那就直接丢弃掉原来的document,直接去web里搜索相关信息
- Ambiguous:对于模糊不清的,就两种方式都要
那么在最后的generation部分,也是根据三种不同的情况分别做处理。
- 之前是correct,那现在就直接拼接问题和相关文档
- 之前是incorrect,那现在就直接拼接问题和web获取的信息
- 之前是ambiguous,那现在就拼接三个加起来
以上是CRAG的原始大概逻辑,但在langchain中对此进行了简化:
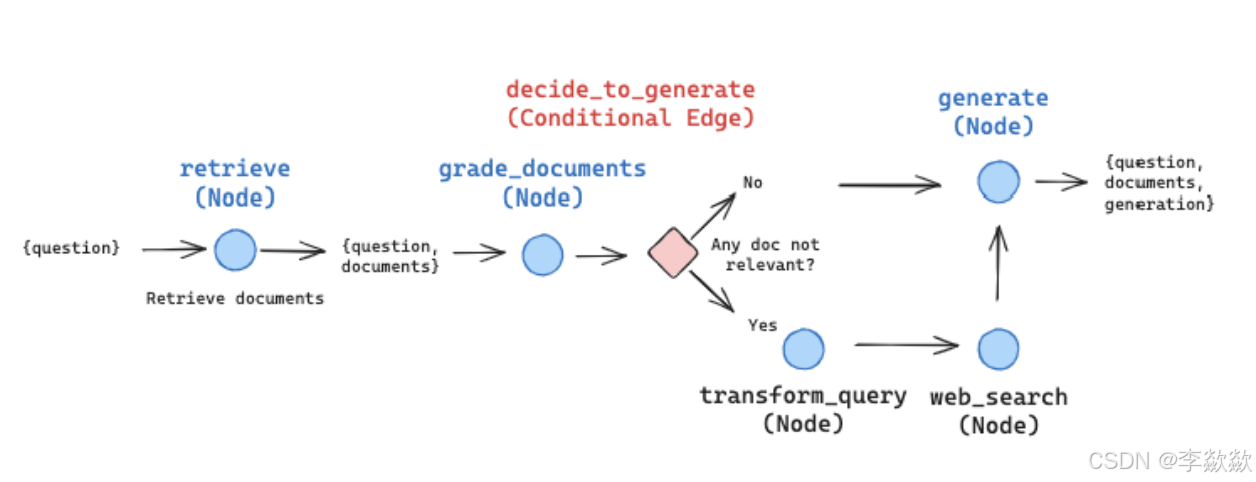
在Langchain中只存在两种情况,即:
- 当incorrect的时候,直接就去web上search了(先经过一个transform_query对问题进行重写,变成更适合web搜索的形式)。
- 如果至少有一个文档超过了相关性阈值(correct),则进入生成阶段。在生成之前,进行知识细化将文档划分为知识条带(knowledge strip) , 对每个知识条进行分级,过滤不相关的知识条,如果所有文档都低于相关性阈值,或者分级者不确定,那么框架就会寻找额外的数据源,并使用网络搜索来补充检索。
Deep Dive
https://www.youtube.com/watch?v=E2shqsYwxck
Notebooks
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag.ipynb
https://github.com/langchain-ai/langgraph/blob/main/examples/rag/langgraph_crag_mistral.ipynb
Self-Reflective RAG with LangGraph
Generation生成优化策略
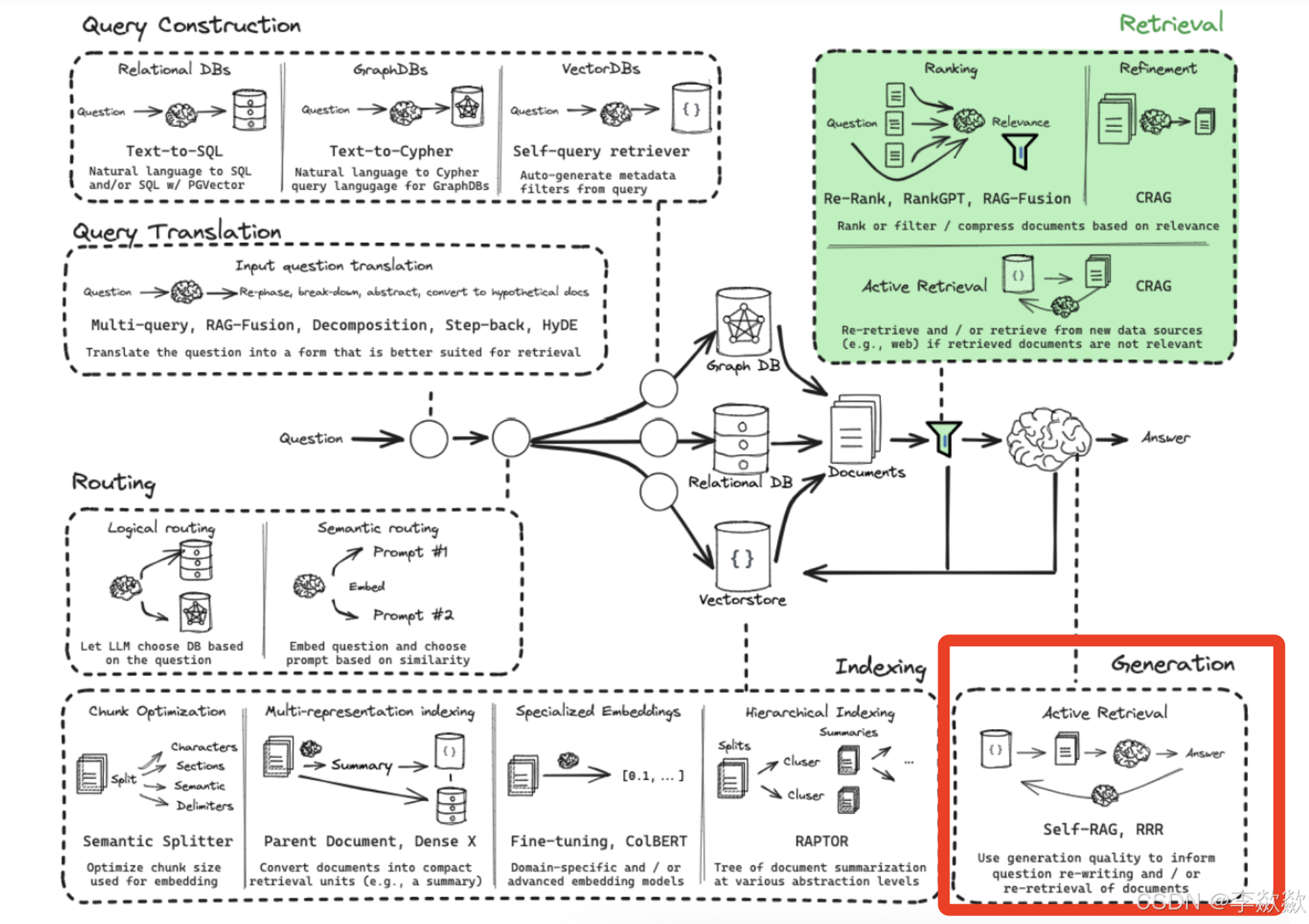
17-Retrieval (Self-RAG)
和CRAG的核心一样,都是self-reflective,即当发现结果不是那么有效时,要通过环回溯到之前的步骤去优化。其基本思想在于:使用循环单元测试自行纠正RAG错误,以检查文档相关性、答案幻觉和答案质量。
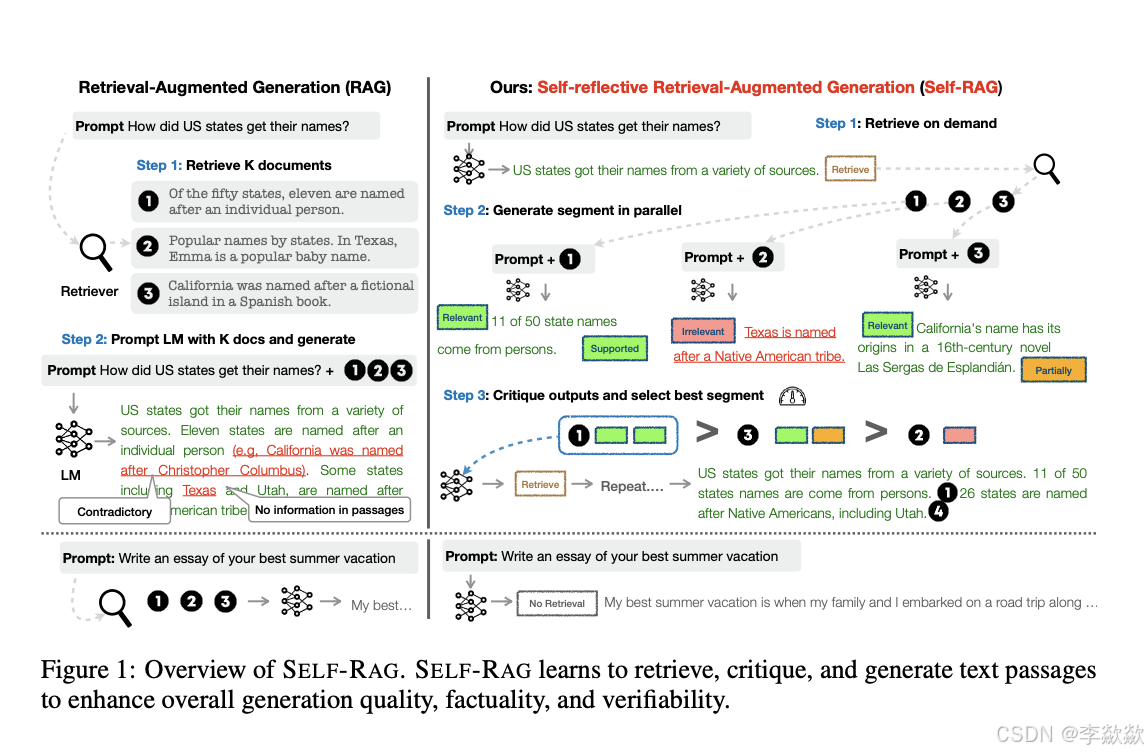
和CRAG不一样的是,selfRAG的流程是从最开始进行的,评估三次,大概流程:
- 首先先判断问题是不是需要retrieval,如上图右下角,此处的问题是写一篇essay,那其实根本没必要去retrieval,直接放入LLM就行
- 当问题需要检索的时候,我们会将得到的每个document snippet分别判断,是否检索到了有关relevant:
- 如果无关,那就不进行下一步。
- 如果有关,那是否支持support 生成相关内容,或者部分支持partial support,或者不支持。
- 当我们对所有snippets都判断后,按照相关性进行排序,然后依次送到LLM中去进行最后的步骤。
- 在最后生成后还有一次评估,评估生成的内容是否是有效的,总共三次。
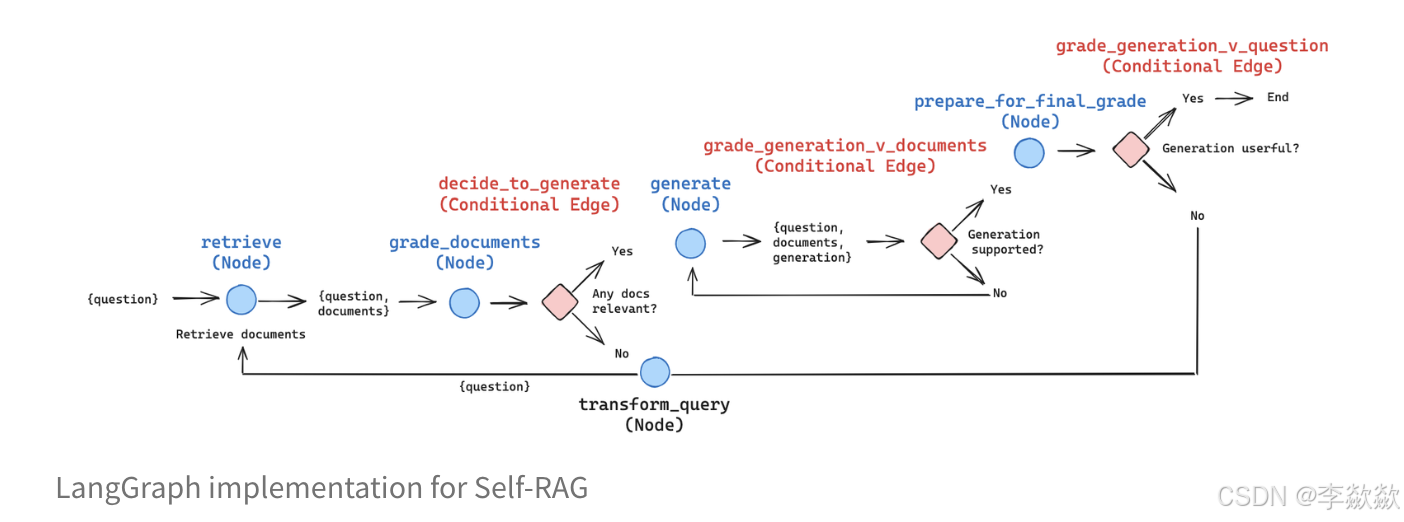
在Langchain中的self-RAG的流程图如上图所示,流程如下:
- 检索阶段判断:Self-RAG 首先确定检索到的文档是否与问题相关。将检索到的信息添加到响应是否有帮助。相关如果是,它会发出一个检索过程的信号,并要求外部检索模块找到相关文档。
- 生成阶段判断:如果不需要检索,Self-RAG 会像常规语言模型一样预测响应的下一个部分。如果需要检索,它首先评估检索到的文档是否支持生成内容(能否基于检索到的文档生成内容),然后根据所发现的内容生成响应的下一个部分。
- 最终结果判断:如果检索到的文档能支持生成内容,则生成内容。并且评估生成响应的整体质量。如果整体质量好,则结束本次响应,否则,再次从头开始检索。
Notebooks
langgraph/examples/rag at main · langchain-ai/langgraph · GitHub
https://arxiv.org/pdf/2310.11511
六、其他
RAG出现的原因
知识的局限性(实时性、离线数据无法解答):模型自身的知识完全源于它的训练数据,而现有的主流大模型(ChatGPT、文心一言、通义千问…)的训练集基本都是构建于网络公开的数据,对于一些实时性的、非公开的或离线的数据是无法获取到的,这部分知识也就无从具备。
幻觉问题:所有的AI模型的底层原理都是基于数学概率,其模型输出实质上是一系列数值运算,大模型也不例外,所以它有时候会一本正经地胡说八道,尤其是在大模型自身不具备某一方面的知识或不擅长的场景。而这种幻觉问题的区分是比较困难的,因为它要求使用者自身具备相应领域的知识。
数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。这也导致完全依赖通用大模型自身能力的应用方案不得不在数据安全和效果方面进行取舍。
RAG发展阶段
Yunfan Gao 等人在 Retrieval-Augmented Generation for Large Language Models: A Survey 中详细考察了 RAG 范式的演变和发展,将其分成三个阶段:朴素 RAG、高级 RAG 和模块化 RAG:
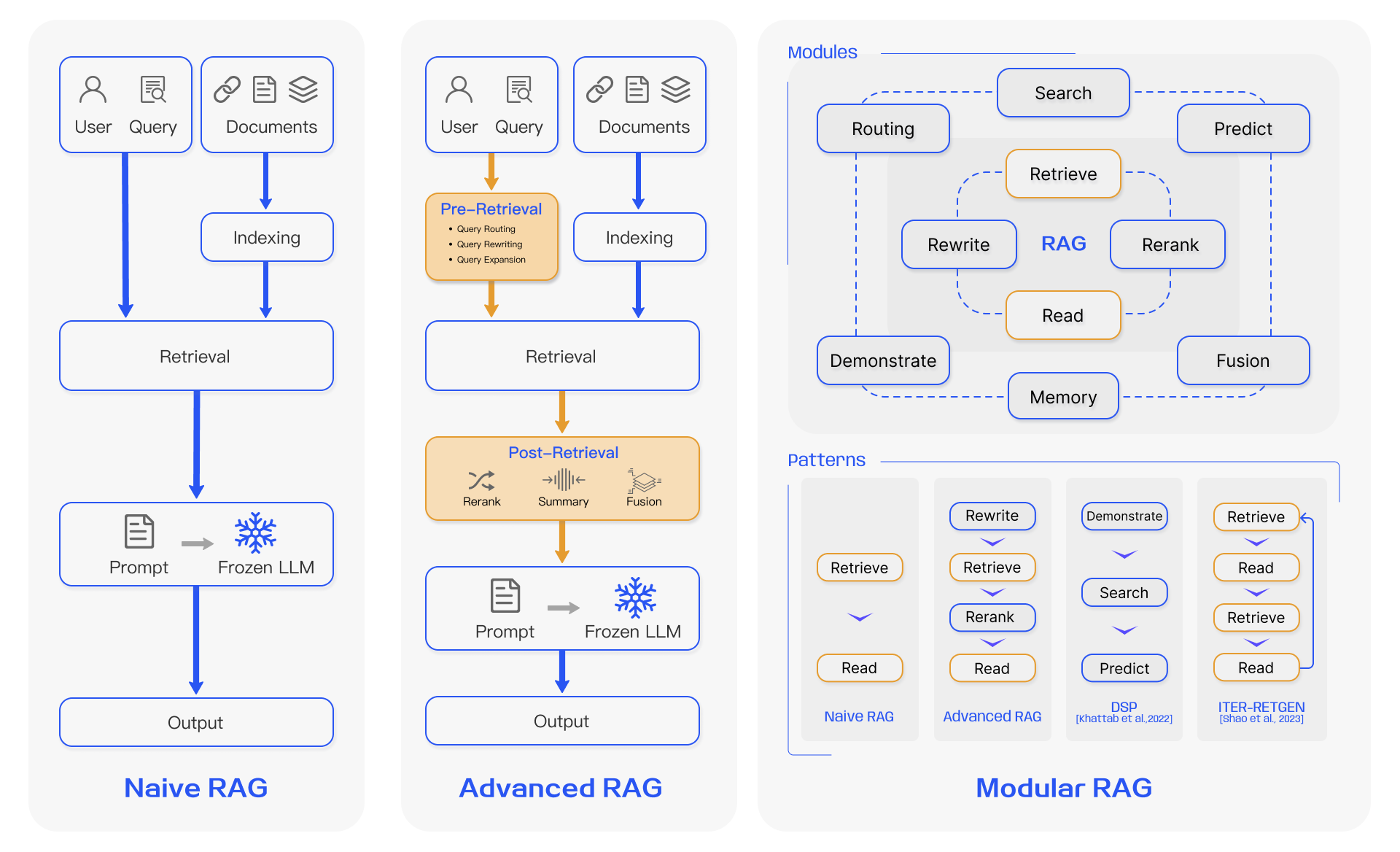
朴素 RAG 最早出现,包括索引、检索和生成三部分:
- 索引 — 将文档库分割成较短的 Chunk,并通过编码器构建向量索引。
- 检索 — 根据问题和 chunks 的相似度检索相关文档片段。
- 生成 — 以检索到的上下文为条件,生成问题的回答。
虽然朴素 RAG 简单易懂,但是在检索质量、响应生成质量以及增强过程中存在多个挑战。
- 首先,在检索阶段,精确性和召回率往往是一个难题,既要避免选择无关片段,又要避免错过关键信息;
- 其次,如何将检索到的信息整合在一起也是一个挑战,面对复杂问题,单个检索可能不足以获取足够的上下文信息;对检索的结果,我们要确定段落的重要性和相关性,对段落进行排序,并对冗余段落进行处理;
- 最后,在生成回复时,模型可能会面临幻觉问题,即产生与检索到的上下文不符的内容;此外,模型可能会过度依赖上下文信息,导致只生成检索到的内容,而缺乏自己的见解;同时我们又要尽量避免模型输出不相关、有毒或有偏见的信息。
为了解决朴素 RAG 遗留的问题,高级 RAG 引入了一些改进措施,增加了 预检索过程(Pre-Retrieval Process) 和 后检索过程(Post-Retrieval Process) 两个阶段,提高检索质量:
- 在预检索过程这个阶段,主要关注的是 索引优化(index optimization) 和 查询优化(query optimization);
- 索引优化的目标是提高被索引内容的质量,常见的方法有:提高数据粒度(enhancing data granularity)、优化索引结构(optimizing index structures)、添加元数据(adding metadata)、对齐优化(alignment optimization) 和 混合检索(mixed retrieval);
- 查询优化的目标是使用户的原始问题更清晰、更适合检索任务,常见的方法有:查询重写(query rewriting)、查询转换(query transformation)、查询扩展(query expansion) 等技术。
- 后检索过程关注的是,如何将检索到的上下文有效地与查询整合起来。直接将所有相关文档输入大模型可能会导致信息过载,使关键细节与无关内容混淆,为了减轻这种情况,后检索过程引入的方法包括:重新排序块(rerank chunks) ; 上下文压缩(context compressing)和上下文筛选缩短窗口长度等。
可以看出,尽管高级 RAG 在检索前和检索后提出了多种优化策略,但是它仍然遵循着和朴素 RAG 一样的链式结构,架构的灵活性仍然收到限制。
模块化 RAG(Retrieval-Augmented Generation) 是一种将 RAG 系统的不同功能组件模块化的设计方式,使系统更易于管理、扩展和优化。模块化 RAG 的架构超越了前两种 RAG 范式,增强了其适应性和功能性,可以灵活地引入特定功能模块或替换现有模块,整个过程不仅限于顺序检索和生成,还包括迭代和自适应检索等方法。
模块化 RAG 并不是突然出现的,三个范式之间是继承与发展的关系。Advanced RAG 是 Modular RAG 的一种特例形式,而 Naive RAG 则是 Advanced RAG 的一种特例。关于这些 RAG 技术的细节,推荐研读 Yunfan Gao 等人的 论文,写的非常详细。
RAG应用流程
完整的RAG应用流程主要包含两个阶段:
-
数据准备阶段:数据提取——>文本分割——>向量化(embedding)——>数据入库
-
应用阶段:用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
下面我们详细介绍一下各环节的技术细节和注意事项:
数据准备阶段
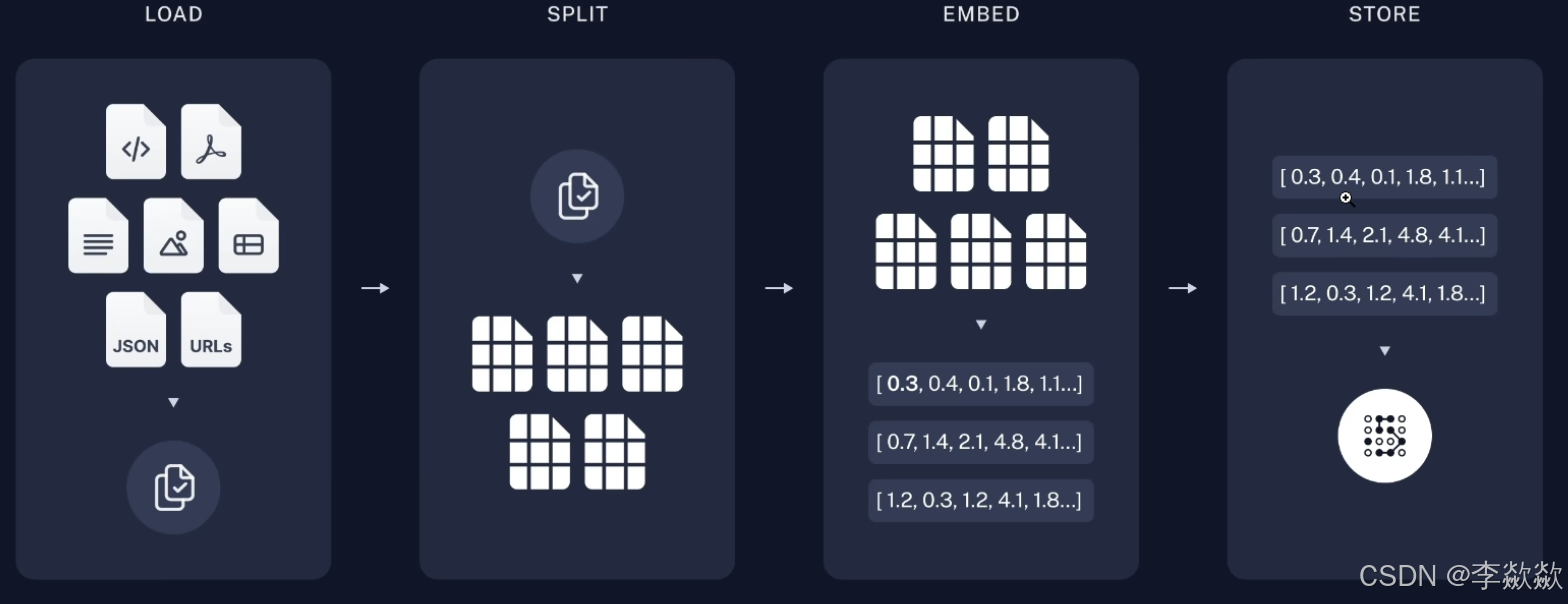
数据准备一般是一个离线的过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等环节。
数据准备
数据提取
- 数据加载:包括多格式数据加载、不同数据源获取等,根据数据自身情况,将数据处理为同一个范式。
- 数据处理:包括数据过滤、压缩、格式化等。
- 元数据获取:提取数据中关键信息,例如文件名、Title、时间等 。
文本分割
文本分割主要考虑两个因素:1)embedding模型的Tokens限制情况;2)语义完整性对整体的检索效果的影响。一些常见的文本分割方式如下:
- 句分割:以”句”的粒度进行切分,保留一个句子的完整语义。常见切分符包括:句号、感叹号、问号、换行符等。
- 固定长度分割:根据embedding模型的token长度限制,将文本分割为固定长度(例如256/512个tokens),这种切分方式会损失很多语义信息,一般通过在头尾增加一定冗余量来缓解。
向量化(embedding)
向量化是一个将文本数据转化为向量矩阵的过程,该过程会直接影响到后续检索的效果。目前常见的embedding模型如下所示,这些embedding模型基本能满足大部分需求,但对于特殊场景(例如涉及一些罕见专有词或字等)或者想进一步优化效果,则可以选择开源Embedding模型微调或直接训练适合自己场景的Embedding模型。
| ChatGPT-Embedding | ChatGPT-Embedding由OpenAI公司提供,以接口形式调用。 |
| ERNIE-Embedding V1 | ERNIE-Embedding V1由百度公司提供,依赖于文心大模型能力,以接口形式调用。 |
| M3E | M3E是一款功能强大的开源Embedding模型,包含m3e-small、m3e-base、m3e-large等多个版本,支持微调和本地部署。 |
| BGE | BGE由北京智源人工智能研究院发布,同样是一款功能强大的开源Embedding模型,包含了支持中文和英文的多个版本,同样支持微调和本地部署。 |
数据入库
数据向量化后构建索引,并写入数据库的过程可以概述为数据入库过程,适用于RAG场景的数据库包括:FAISS、Chromadb、ES、milvus等。一般可以根据业务场景、硬件、性能需求等多因素综合考虑,选择合适的数据库。
应用阶段
在应用阶段,我们根据用户的提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成相应的答案。关键环节包括:用户提问、数据检索、注入Prompt、LLM生成答案。
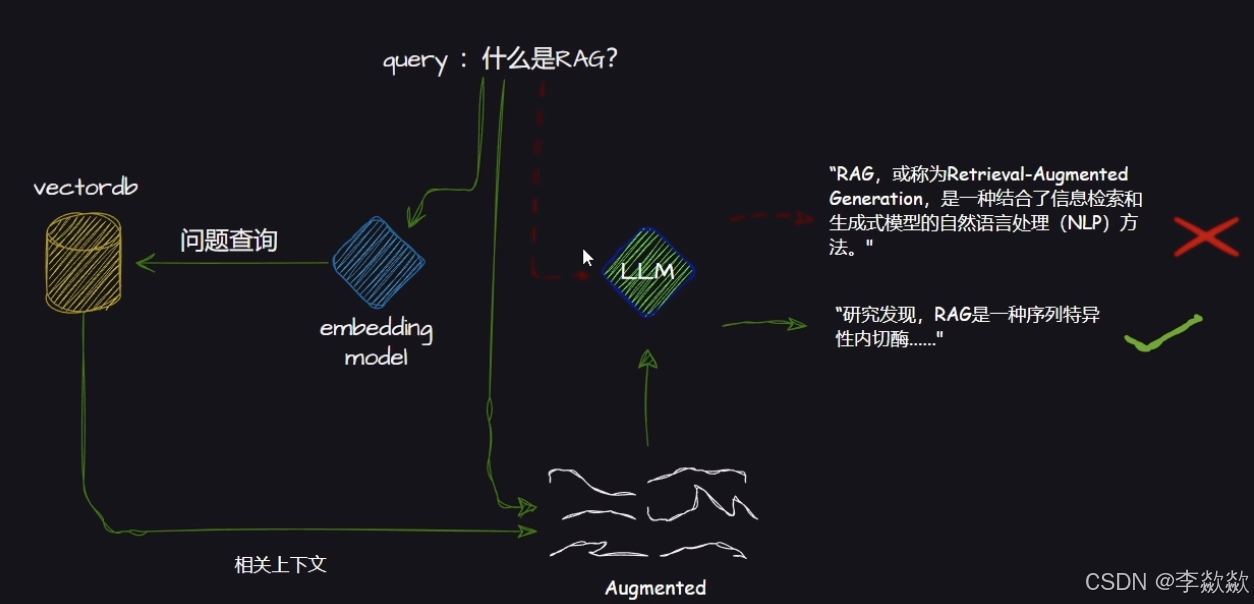
用户提问
在这一阶段,用户通过自然语言的方式向系统提出问题或查询。这些问题可以是开放性的,也可以是具体的,涉及各个领域的知识。
数据检索
常见的数据检索方法包括:相似性检索(语义检索、密集检索)、全文检索(关键词检索、稀疏检索)等,根据检索效果,一般可以选择多种检索方式融合,提升召回率。
- 相似性检索:即计算查询向量与所有存储向量的相似性得分,返回得分高的记录。常见的相似性计算方法包括:余弦相似性、欧氏距离、曼哈顿距离等。
- 全文检索:全文检索是一种比较经典的检索方式,在数据存入时,通过关键词构建倒排索引;在检索时,通过关键词进行全文检索,找到对应的记录。
注入Prompt
Prompt作为大模型的直接输入,是影响模型输出准确率的关键因素之一。在检索到相关数据后,系统会将这些数据作为Prompt(提示词)注入到LLM(大语言模型)中。Prompt可以是一段文本、一个查询语句或者一组关键词,用于引导LLM理解和生成答案。作用是Prompt为LLM提供了额外的上下文信息,使得LLM在生成答案时能够参考这些信息,从而生成更加准确、相关的答案。
LLM生成答案
在注入Prompt后,LLM会基于其强大的语言生成能力,结合Prompt中的信息,生成并输出最终的答案。这个答案既可以是文本形式,也可以是其他形式(如图像、语音等),具体取决于系统的设计和需求。
RAG优化方法
在文本预处理、文本分块、嵌入、检索和生成等环节依次介绍各个优化方法。
数据处理
不管RAG系统结构怎样复杂,由于其数据驱动的特性,高信噪比的数据仍然是十分重要的。在检索之前对原始数据的优化包括以下方法:
-
实体解析:消除实体和术语的歧义以实现一致的引用。例如,将“LLM”、“大语言模型”和“大模型”标准化为通用术语。
-
增加元数据:增加内容摘要、时间戳、用户可能提出的问题等附加信息来丰富知识库。
-
数据增强:使用同义词、释义甚至其它语言的翻译来增加知识库的多样性。
-
文档划分:合理地划分不同主题的文档。不同主题的文档是集中在一处还是分散在多处?如果人类都不能轻松地判断出需要查阅哪个文档才能回答提问,那么检索系统也无法做到。
-
处理特殊数据:例如时间敏感数据,对于经常更新的主题,实施一种机制来使过时的文档失效或更新。
文本分割
通常被检索知识库中的数据量是远超于LLM所能接受的输入长度的,因此合理的分块(Chunking)应尽可能做到在不超出LLM输入长度限制的情况下,保证块之间的差异性和块内部的一致性。当然这是最理想的状态,在实际应用中,可能有一篇文档像散文一般,不同段落之间没有明显内容区别,段落内部又特别地“散”,整篇文档又特别地长。当然我们不可能先验地将文本按内容完美分块,毕竟下游还有LLM这样智能的模型可以发挥其“智慧”来回答用户问题,我们提供的块不过是“提示”。但我们仍然还是需要尽可能提供有用的信息给LLM,而不是提供无关的信息分散其注意力。因此,可以采用以下高级的分块方法:
-
句分割:使用NLTK或者spaCy库提供的句子分割功能,主流开发框架如langchain都有集成。
-
递归分割:通过重复地应用分块规则来递归地分解文本。例如,在langchain中会先通过段落换行符(
\n\n)进行分割。然后检查这些块的大小,如果大小不超过一定阈值,则该块被保留。对于超过阈值的块,使用单换行符(\n)再次分割。以此类推,不断根据块大小更新更小的分块规则(如空格,句号)。这种方法可以灵活地调整块的大小。例如,对于文本中的密集信息部分,可能需要更细的分割来捕捉细节;而对于信息较少的部分,则可以使用更大的块。 -
语义分割:通过计算向量化后的文本的相似度来进行语义层面的分割。
-
特殊结构分割:针对特定结构化内容(例如Markdown、LaTex、JSON等)的专门分割器。这些分割器特别设计来处理这些类型的文档,以确保正确地保留其结构。
分块还有一个因素比较重要,就是块的大小。除了嵌入模型,文档的类型和用户查询的长度及复杂性也是决定分块大小的重要因素。处理长篇文章或书籍时,较大的分块有助于保留更多的上下文和主题连贯性;而对于社交媒体帖子,较小的分块可能更适合捕捉每个帖子的精确语义。如果用户的查询通常是简短和具体的,较小的分块可能更为合适;相反,如果查询较为复杂,可能需要更大的分块。实际场景中,我们可能还是需要不断实验调整,在一些测试中,128大小的分块往往是最佳选择,在无从下手时,可以从这个大小作为起点进行测试。
向量化(embedding)
接下来就是数据处理的最后一个环节,相当于数据的类型转换,即对文本数据使用嵌入(Embedding)模型进行向量化(Vectorization),以便于在检索阶段使用向量检索(Vector Retrieval)。嵌入阶段有以下几个可以优化的点:
-
尽量使用动态嵌入:动态嵌入相较于静态嵌入更能够处理一词多义的情况。例如:我买了一张光盘”,这里“光盘”指的是具体的圆形盘片,而在“光盘行动”中,“光盘”则指的是把餐盘里的食物吃光,是一种倡导节约的行为。语义完全不一样的词使用静态嵌入其向量是固定的。相比之下,引入自注意力机制的模型,如BERT,能够提供动态的词义理解。这意味着它可以根据上下文动态地调整词义,使得同一个词在不同语境下有不同的向量表示。
-
微调嵌入:大多数嵌入模型都是在通用语料上进行训练的,有些项目为了让模型对垂直领域的词汇有更好的理解,会对嵌入模型进行微调。使模型能够对垂直领域词汇和通用词汇一视同仁,不被分散注意力。
-
混合嵌入:对用户问题和知识库文本使用不同的嵌入模型。
用户提问
在实际环境中,可能由于用户的表述多样性亦或是模糊的,导致在检索阶段召回率和准确率较低,这时就需要对查询做一个优化,能够规范和丰富查询所包含的信息,便于在系统中检索到与用户相关的文档。对查询的优化方法有以下几个:
-
查询重写:通过提示LLM或者使用专门的“问题重写器”(通常是经过微调的小型Transformer)来对用户的问题进行改写。
-
后退提示:提示LLM提出一个关于高层次概念或原则的抽象通用问题(称之为“后退”问题)。后退问题的抽象程度需要根据特定任务进行调整。最终后退问题和原始问题一起进行检索。例如,对于问题“Estella Leopold在1954年8月至11月期间上了哪所学校?”这个问题很难直接解决,因为有时间范围的详细限制。在这两种情况下,提出一个后退问题“Estella Leopold的教育经历怎么样的?”则有助于系统的检索。
-
Follow Up Questions/查询问题压缩:使用LLM针对历史对话和当前问题生成一个独立问题。这个方法主要针对以下情况:a. 后续问题建立在前一次对话的基础上,或引用了前一次谈话。例如,如果用户先问“我在意大利能做什么”,然后问“那里有什么类型的食物”——如果只嵌入“那里有哪种类型的食物“,LLM就不知道“那里”在哪里。b.嵌入整个对话(或最后k条消息)。如果后续问题与之前的对话完全无关,那么它可能会返回完全无关的结果,从而在生成过程中分散LLM的注意力。
-
HyDE:用LLM生成一个“假设”答案,将其和问题一起进行检索。HyDE的核心思想是接收用户提问后,先让LLM在没有外部知识的情况下生成一个假设性的回复。然后,将这个假设性回复和原始查询一起用于向量检索。假设回复可能包含虚假信息,但蕴含着LLM认为相关的信息和文档模式,有助于在知识库中寻找类似的文档。
-
多问题查询:基于原始问题,提示LLM从不同角度产生多个新问题或者子问题,并使用每一个新问题进行检索,在后续阶段使用RRF或者rerank合并来自不同问题的检索结果。例如,对于原始问题:谁最近赢得了总冠军,红袜队还是爱国者队?,可以生成两个子问题:a. 红袜者队上一次赢得总冠军是什么时候?b. 爱国者队上一次赢得总冠军是什么时候?
数据检索
检索(Retrieval)最终的目标就是获取最相关的文档或者保证最相关的文档在获取的文档列表中存在。为了达成这个目标,该环节有以下几个优化方法:
-
上下文压缩:当文档块过大时,可能包含太多不相关的信息,传递这样的文档块可能导致更昂贵的LLM调用和更差的响应。上下文压缩的思想就是通过LLM的帮助根据上下文对单个文档内容进行压缩,或者对返回结果进行一定程度的过滤仅返回相关信息。
-
句子窗口搜索:相反,文档文块太小会导致上下文的缺失。其中一种解决方案就是窗口搜索,该方法的核心思想是当提问匹配好文档块后,将该文档块周围的块作为上下文一并交给LLM进行输出,来增加LLM对文档上下文的理解。
-
父文档搜索:父文档搜索也是一种很相似的解决方案,父文档搜索先将文档分为尺寸更大的主文档,再把主文档分割为更短的子文档两个层级,用户问题会与子文档匹配,然后将该子文档所属的主文档发送给LLM。
-
自动合并:自动合并是在父文档搜索上更进一步的复杂解决方案。同样地,我们先对文档进行结构切割,比如将文档按三层树状结构进行切割,顶层节点的块大小为1024,中间层的块大小为512,底层的叶子节点的块大小为128。而在检索时只拿叶子节点和问题进行匹配,当某个父节点下的多数叶子节点都与问题匹配则将该父节点作为结果返回。
-
混合检索:RAG系统从根本上来说是作为开放域、基于自然语言的问答系统。为了获得开放式用户查询的高事实召回率,概括和聚焦应用场景以选择合适的检索模式或组合至关重要。在大多数文本搜索场景中,主要目标是确保最相关的结果出现在候选列表中。混合检索通过混合多个检索方法来实现不同检索技术的协同作用从而能够最大化事实召回率。例如,可以采用向量检索+关键词检索的组合来构建RAG系统的检索模块。
-
路由机制:当建立了多个针对不同数据类型和查询需求的索引后,例如,可能有一个索引专门处理摘要类问题,另一个专门应对直接寻求具体答案的问题,还有一个专门针对需要考虑时间因素的问题。这时就需要使用路由机制来选择最合适的索引进行数据检索,从而提升检索质量和响应速度。
-
使用Agent:该方法就是使用Agent来决定应该采用什么样的检索方法,从不同的检索方法中选取一种或多种进行召回。同时组合方式也是灵活的,是垂直关系还是平行关系。例如:对于查询“最新上映的科幻电影推荐”,Agent可能首先将其路由至专门处理当前热点话题的索引,然后利用专注于娱乐和影视内容的索引来生成相关推荐。
检索后处理
检索后处理这个概念还是很宽泛的,是对检索结果进行进一步的处理以便于后续LLM更好的生成,比较典型的就是重排序(Rerank)。向量检索其实就是计算语义层面的相似性,但语义最相似并不总是代表最相关。重排模型通过对初始检索结果进行更深入的相关性评估和排序,确保最终展示给用户的结果更加符合其查询意图。实现重排序除了可以提示LLM进行重排,更多的是使用了专门的重排序模型(例如闭源的有Cohere,开源有BAAI和IBM发布的模型)。这些模型会考虑更多的特征,如查询意图、词汇的多重语义、用户的历史行为和上下文信息,从而保证最相关的文档排在结果列表的最前面。
生成
在生成(Generation)阶段的优化更多的是考虑用户体验,有以下几点可以供参考:
-
多轮对话:也就是带聊天历史的RAG,以AI搜索为例,明星产品perplexity就是支持多轮对话的,这样用户可以通过连续对话来深入了解解决某个问题。
-
增加追问机制:在prompt中加入“如果无法从背景知识回答用户的问题,则根据背景知识内容,对用户进行追问,问题限制在3个以内”。这个机制并没有什么技术含量,主要依靠大模型的能力。不过大大改善了用户体验,用户在多轮引导中逐步明确了自己的问题,从而能够得到合适的答案。
-
prompt优化:RAG系统中的prompt应明确指出回答仅基于搜索结果,不要添加任何其他信息。例如,可以设置prompt:“你是一名智能客服。你的目标是提供准确的信息,并尽可能帮助提问者解决问题。你应保持友善,但不要过于啰嗦。请根据提供的上下文信息,在不考虑已有知识的情况下,回答相关查询。”当然也可以根据场景需要,适当让模型的回答融入一些主观性或其对知识的理解。此外,使用Few-shot的方法指导LLM如何利用检索到的知识,也是提升LLM生成内容质量的有效方法。
-
用户反馈循环:基于现实世界用户的反馈不断更新数据库,标记它们的真实性。
Adaptive-RAG
首先回顾两种RAG系统的重要变体,CRAG和Self-RAG。
1. CRAG(Corrective Retrieval Augmented Generation)
CRAG,即纠正性检索增强生成,主要关注于在检索阶段后引入一个额外的知识精炼(Knowledge Correction)环节。这个环节会对检索到的每一个相关切片(snippets)进行评估,判断其是否对问题有效。如果评估结果为不正确(Incorrect),则会丢弃原来的文档,并可能通过网络搜索获取新的相关信息。CRAG的特色在于其自我评估和自我修正的能力,旨在提高生成结果的准确性和质量。
2. Self-RAG(Self-Reflective Retrieval Augmented Generation)
Self-RAG,即自我反思式检索增强生成,强调通过自我反思能力来调整自身的检索和生成结果。它会在生成内容的过程中进行自我评分,以识别和减少可能出现的幻觉(即与事实不符的生成内容)。Self-RAG的流程从问题判断开始,根据需要选择是否进行检索;并对检索到的文档进行评估和排序,检索到的文档是否能支撑生成内容。最后送入语言模型进行生成,生成的内容进行评估,判断是否结束响应或者重新生成。其重点在于通过反思评分来优化检索和生成过程,提高整体性能。
3. Adaptive-RAG(Adaptive Retrieval-Augmented Generation)
Adaptive-RAG是一种更加灵活和动态的RAG变体,它根据查询的复杂度自适应地选择最合适的检索策略。这包括使用一个小型的语言模型作为分类器来预测查询的复杂度,并根据复杂度级别选择相应的检索策略(如迭代式、单步式或无检索方法)。Adaptive-RAG的核心思想在于通过动态调整来平衡处理简单查询和复杂查询时的效率和准确性。
接下来重点讲诉Adaptive-RAG。
论文:Adaptive-RAG: Learning to Adapt Retrieval-Augmented Large Language Models through Question Complexity
Code:github.com/starsuzi/Adaptive-RAG
Adaptive-RAG 方案能够自适应地根据 user query 的难度选择合适的 RAG 模型来解决。比如对于直接性的 query,就可以直接让 LLM 回答;对于简单的 query,只需要一轮 retrieval 就可以让 LLM 完成回答;而对于复杂的需要 multi-hop 的 query,则需要多轮 retrieval 才能让 LLM 完成回答。
论文概要
在论文中,作者指出了以下两个观察到的现象:
- 用户大多数的问题都是简单的问题,少数情况下才是需要多条推理的复杂问题
- 简单的问题使用复杂的 RAG 模型存在开销的浪费,而复杂的问题又无法用简单的 RAG 模型来解决
为此,本论文才提出了如下的方案(最右边的 C 就是本论文提出的 Adaptive-RAG 的思路):
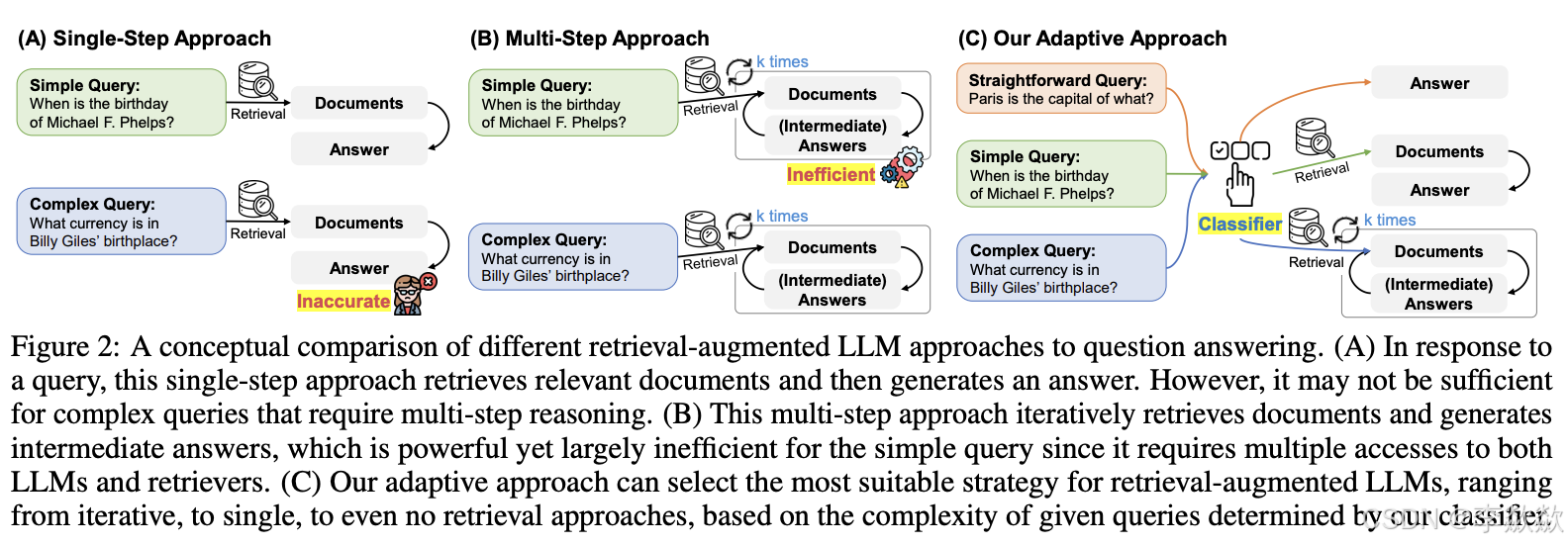
如上图,在 C 所示的思路中,存在一个 classifier 来对 user query 做困难度分类,然后再交由三种用于处理不同复杂的 RAG 模型的其中一个来完成解决。
实现细节
本工作将 user query 的难度分为了三种,并给出了三种对应的解决策略:
- Non Retrieval for QA:对于 Straightforward Query,不需要经过检索,直接由 LLM 回答即可。
- Single-step Approach for QA:对于 Simple Query,只需要经过一轮检索即可获取支持 LLM 回复的 doc
- Multi-step Approach for QA:对于 Complex Query,需要多步、复杂的检索才能得到答案
对于一个具体的 user query,如何将其分类呢?
这里就是训练了一个小语言模型作为 classifier,输入是 user query,输出是 query 的难度。原论文使用了 T5-large 并再训练得到的 classifier。
但是,目前并没有可用的 query-complexity pairs 数据集,因此,论文介绍了该工作是如何收集到用于训练 classifier 数据集的。query-complexity paris 是借助于已有的 QA 数据集来构建,为已有的 QA 数据集的 pair 标注 complexity label 来构建本实验所需的数据集。该数据集的收集主要包括两个过程:
- Generate silver data from predicted outcomes of models:意思是说,假如难度分成 [A, B, C] 三个等级,A 最简单,C 最困难,那么给定一个 query,首先先让 LLM 直接回答,如果 LLM 回答正确,则将 query 标记为 A;如果 LLM 经过一轮检索后生成正确答案,则将 query 标记为 B;如果 LLM 经过多轮检索后生成正确答案,则将 query 标记为 C。
- Utilize inductive bias in datasets:经过第一个过程,有些 query 仍然无法被标记,因为可能三种 RAG 模型都没有生成正确答案,这个时候只能利用这个过程来完成标注。这时候利用一个特点:这些 benchmark datasets 的数据都有一定的偏向性,比如一个 dataset 可能都比较偏 single-hop,而另一个 dataset 可能就都比较偏 multi-hop,对于偏 single-hop 的则直接标为 B,否则直接标为 C。
经过以上两个过程,我们的数据集就构建出来了。
补充讨论
-
多次查询确实是有问题的,有些查询可能并不需要那么多,可能是多余的甚至是反效果的,本文的自适应确实是有一定收益。
-
新增一种划分策略的思路,可以通过难度来划分应对策略,这个不仅在处理性能上有收益,在最终效果上也有收益。
-
分类这块,可以看到这个分类的效果确实比较差,个人感觉原因主要是在分类问题的定义上,难度和大模型、和知识库支持、和问题领域之类的差异会比较大,本身分类效果不好应该是意料之中,不过好奇是这个分类器的优化会给RAG整体效果带来多大收益仍未可知。
-
self-rag被放进来进行对比,结果发现非常拉胯,有些让人出乎意外。感觉这里有打开方式、适应场景等的问题,有展开分析的价值。
ReAct 与 CoT、ToT 的区别
当下提高大模型推理能力的几个主要技术,从CoT(Chain of Thought)到TOT(Tree of Thought),再到ReAct。
CoT(Chain of Thought,思维链)
第一次接触到CoT是在Prompt工程中,其作为Prompt高级技巧的一部分,可以显著提高大模型在推理方面的能力,尤其是解决数学等具有逻辑性的问题时。
区别于传统的 Prompt 从输入直接到输出的映射 <input——>output> 的方式,CoT 完成了从输入到思维链再到输出的映射,即 <input——>reasoning chain——>output>。
例如,如果问题是“纽约到洛杉矶的距离是多少?”,模型可能首先检索纽约和洛杉矶的坐标,然后计算两点之间的距离,最后给出答案。在这个过程中,模型不仅提供了答案,还展示了其推理过程,增强了答案的可信度。
原论文:https://arxiv.org/pdf/2201.11903.pdf
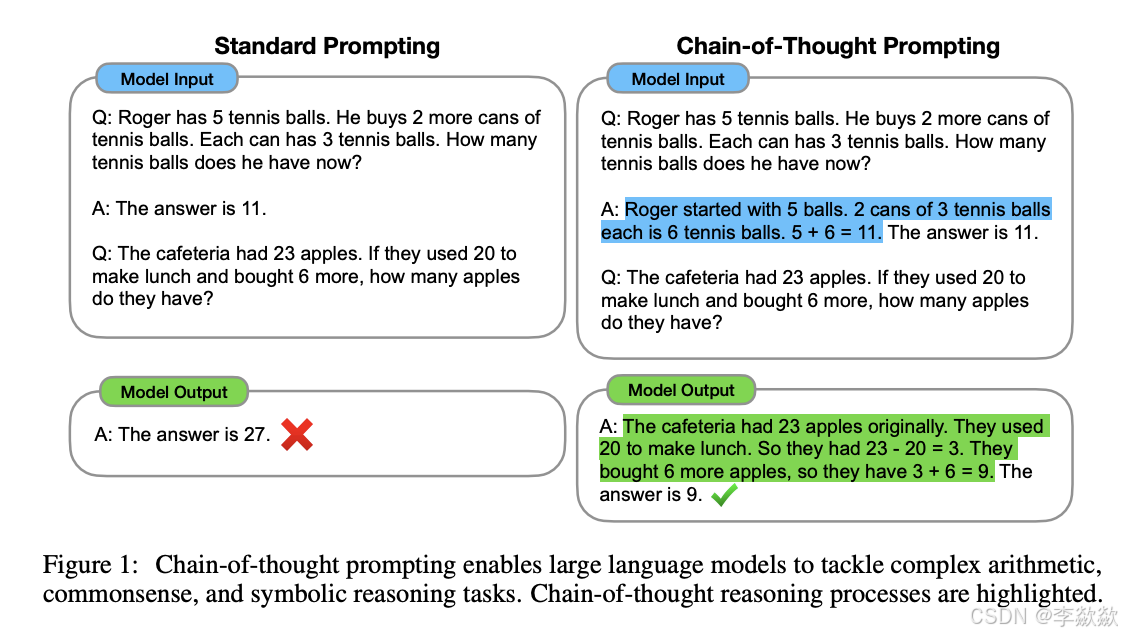
关于使用COT:在现在应该是大模型本身就应该具备的能力,只需要在Prompt 中添加了一句 “Let's Step by Step” 就让大模型在推理上用到了思维链。然后使用就可以了,并不需要自己去写代码写逻辑去亲自实现CoT。
Self-consistency with CoT(CoT的自我一致性)
一种CoT在实际应用中的方案是:Self-consistency with CoT(CoT的自我一致性)。简单地要求模型对同一提示进行多次回答,并将多数结果作为最终答案。 它是CoT(Chain of Thought)的后续方法。示例代码如下:对同一个Prompt,重复调用5次,然后取其中多数结果作为最终答案。
ToT(Tree of Thought,思维树)
在CoT的基础上,有人指出其存在的缺陷:
-
对于局部,没有探索一个思考过程下的不同延续——树的分支。
-
对于全局,没有利用任何类型的规划,前瞻以及回溯去帮助评估不同抉择——而启发式的探索正式人类解决问题的特性。
针对以上缺陷,他提出了ToT(Tree of Thought,思维树)的概念。
原论文:https://arxiv.org/pdf/2305.10601.pdf
具体结构图如下:虚线左边为基本Prompt、CoT以及CoT Self Consisitency,虚线右边为ToT。
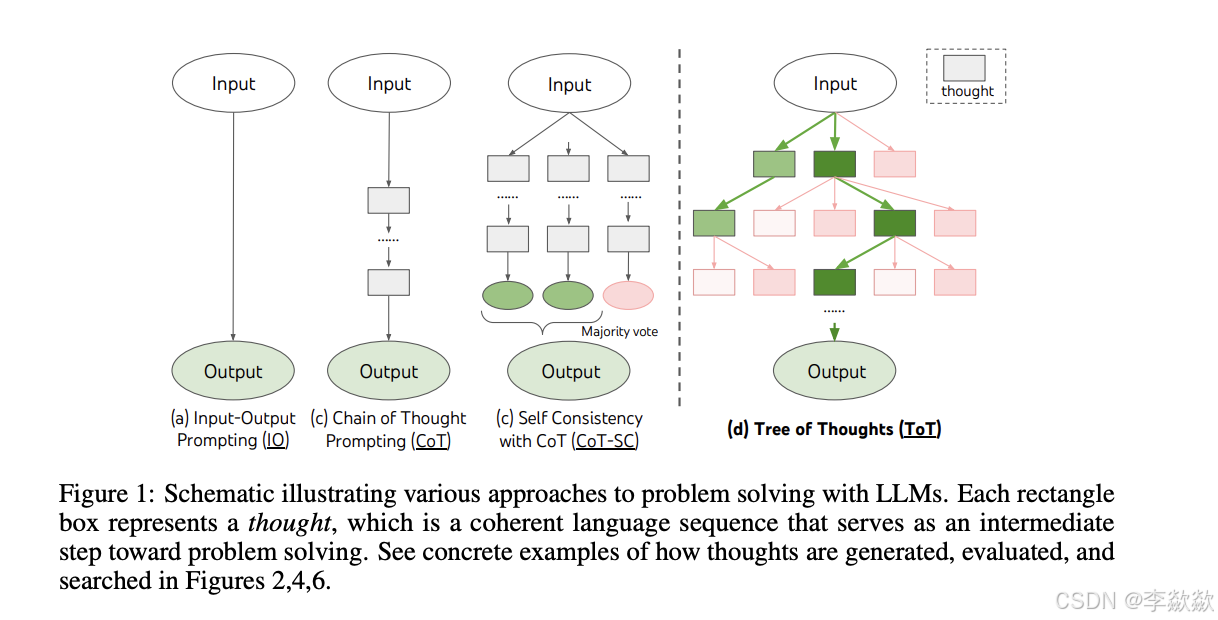
从原始输入开始,在思维链的每一步,采样多个分支。逐渐形成树状结构,对每一个分支进行评估,然后在合适的分支上进行搜索。这就是ToT思维树的基本过程。
它以树状图的形式展示思考的层次和分支。在决策制定、问题解决、创意生成等场景中,思维树可以帮助人们系统地探索各种可能性,评估不同选项,从而做出更明智的决策。
在思维树中:
- 根节点:通常代表问题或决策的起点,即需要解决的核心问题。
- 分支:从根节点开始,每个分支代表一个可能的思考方向或解决方案。分支可以进一步细分,形成更详细的子分支,代表更具体的思考步骤或子问题。
- 叶节点:树的末端,代表思考过程的最终结果或结论。
通过构建思维树,人们可以:
- 系统地探索确保所有可能的思考方向都被考虑,避免遗漏重要的信息或解决方案。
- 评估和比较:通过比较不同分支的结果,评估各种选项的优劣,做出更合理的决策。
- 增强理解:通过可视化思考过程,增强对问题的理解,使复杂的决策过程变得清晰。
目前针对TOT我们还没有得到特别好的效果,可能是在构建当中还有不合理的定义或者解析问题不精准的存在。但从对于资源的合理性投入,供应链的管理,提高决策质量和效率它应该是有天然的优势存在。
ReAct
个人理解一下:CoT、ToT 都是作用在大模型本身的内在推理(Reason)过程上,而 ReAct 则是统筹整个系统,从推理过程,结合外部工具共同实现最终的目标(Reason + Action)。
原论文:https://arxiv.org/pdf/2210.03629
以ReAct论文中那张图来看,可以更清晰的理解ReAct与CoT、ToT的区别:

对于ReAct这个框架可以理解为是一种结合了推理和行动的新型人工智能框架,主要用于增强AI系统在复杂环境中的决策能力和执行效率。ReAct框架的核心思想是通过实时检索相关信息和执行基于这些信息的行动,来辅助AI系统进行更准确的推理和决策。
在ReAct框架中,AI系统不仅依赖于其预训练的知识,还会在遇到新情况时,主动检索外部信息(如数据库、网络资源等),并将这些信息整合到其决策过程中。这一过程可以看作是AI系统在“思考”(Reasoning)和“行动”(Acting)之间的循环,其中:
- 思考(Reasoning):AI系统基于当前状态和目标,进行推理和规划,确定下一步需要采取的行动或需要检索的信息。
- 行动(Acting):根据推理结果,AI系统执行相应的行动,如检索信息、执行任务等。
- 反馈:AI系统根据行动的结果,更新其状态和知识,然后再次进入思考阶段,形成一个闭环。
ReAct框架的优势在于,它使AI系统能够适应不断变化的环境,处理之前未见过的情况,而不仅仅是依赖于预训练数据。通过实时检索和整合新信息,AI系统可以做出更准确、更灵活的决策,提高其在复杂任务中的表现。
总结
CoT目前来看已经集成进了大模型内部,通过在Prompt中加入一些提示词(Let's think step by step)即可唤醒大模型的CoT思考能力。对于ToT,有实现代码参考,就是在思维链的基础上,每一步不再是只有一个结果,而是采样多个分支,综合评估。对于ReAct,则是从推理过程,结合外部工具共同实现最终目标。ReAct不止在推理,还在利用外部工具实现目标,Reason + Action,而Cot、ToT 则只是 Reason。
Chunking优化
整理自:
Chunking Strategies for LLM Applications | Pinecone
https://blog.csdn.net/EnjoyEDU/article/details/141038019
高级 RAG 技术学习笔记 - aneasystone's blog
几乎所有的大模型或嵌入模型,输入长度都是受限的,因此,需要将文档进行分块,通过分块可以确保嵌入的内容尽可能少地包含噪音,同时嵌入内容和用户查询之间具有更高的语义相关性。
有很多种不同的分块策略,比如按长度进行分割,保证每个分块大小适中;也可以按句子或段落进行分割,防止将完整的句子切成两半;每种分块策略可能适用于不同的情况,需要仔细斟酌这些策略的优点和缺点,确定他们的适用场景,这篇博客 对常见的分块策略做了一个总结。
文本切割的主要观点:
-
文本切割是优化语言模型应用性能的关键步骤。切割策略应根据数据类型和语言模型任务的性质来定制。
-
传统的基于物理位置的切割方法(如字符级切割和递归字符切割)虽简单,但可能无法有效地组织语义相关的信息。
-
语义切割和基因性切割是更高级的方法,它们通过分析文本内容的语义来提高切割的精确度。
-
使用多向量索引可以提供更丰富的文本表示,从而在检索过程中提供更相关的信息。多向量索引是一种将文本数据以多个向量的形式进行表示和索引的技术。这些向量可能来源于不同的向量化技术或算法,但更重要的是它们能够共同反映文本的多维度特征和信息。
-
工具和技术的选择应基于对数据的深入理解以及最终任务的具体需求。
文本切割的主要策略:
1. 固定大小分块(Fixed-size chunking)
字符级切割, 简单粗暴地按字符数量固定切割文本。
这是最常见也是最直接的分块策略,文档被分割成固定大小的分块(chunk_size),分块之间可以保留一些重叠(chunk_overlap),以确保不会出现语义相关的内容被不自然地拆分的情况。在大多数情况下,固定大小分块都是最佳选择,与其他形式的分块相比,它既廉价又简单易用,而且不需要使用任何自然语言处理库。
分块大小是一个需要深思熟虑的参数,它取决于你所使用的嵌入模型的 token 容量,比如,基于 BERT 的 sentence-transformer 最多只能处理 512 个 token,而 OpenAI 的 ada-002 能够处理 8191 个;另外这里也需要权衡大模型的 token 限制,由于分块大小直接决定了我们加载到大模型上下文窗口中的信息量,这篇博客 中对不同的分块大小进行了实验,可以看到不同的分块大小可以得到不同的性能表现。
递归字符切割: 考虑文本的物理结构,如换行符、段落等,逐步递归切割。
它可以接受一组分隔符,比如 ["\n\n", "\n", " ", ""],它首先使用第一个分隔符对文本进行分块,如果第一次分块后长度仍然超出分块大小,则使用第二个,以此类推,通过这种递归迭代的过程,直到达到所需的块大小。
大模型的上下文限制是 token 数量,而不是文本长度,因此当我们将文本分成块时,建议计算分块的 token 数量,比如使用 OpenAI 的 tiktoken 库。
2. 句子拆分(Sentence splitting)
很多模型都针对句子级内容的嵌入进行了优化,所以,如果我们能将文本按句子拆分,可以得到很好的嵌入效果。常见的句子拆分方法有下面几种:
- 直接按英文句号(
.)、中文句号(。)或换行符等进行分割
这种方法快速简单,但这种方法不会考虑所有可能的边缘情况,类似上面字符级切割的递归字符切割可能会破坏句子的完整性。
NLTK 是一个流行的自然语言工具包,它提供了一个句子分词器(sentence tokenizer),可以将文本分割成句子
spaCy 是另一个强大的用于自然语言处理任务的 Python 库,它提供了复杂的句子分割功能,可以高效地将文本分割成单独的句子,从而在生成的块中更好地保留上下文。
3. 特定格式分块(Specialized chunking)
文档特定切割,有很多文本文件具有特定的结构化内容,比如 Markdown、LaTeX、HTML 或 各种源码文件等,针对这种格式的内容可以使用一些专门的分块方法。
- Markdown:LangChain 的 MarkdownHeaderTextSplitter 就是基于这一想法实现的分块方法,它通过 Markdown 的标题来组织分组,然后再在特定标题组中创建分块。
- HTML:LangChain 中的 HTMLHeaderTextSplitter 根据标题来实现 HTML 的分块,HTMLSectionSplitter 能够在元素级别上分割文本,它基于指定的标签和字体大小进行分割,将具有相同元数据的元素组合在一起,以便将相关文本语义地分组,并在文档结构中保留丰富的上下文信息。
- LaTeX:通过解析 LaTeX 可以创建符合内容逻辑组织的块(例如章节、子章节和方程式),从而产生更准确和上下文相关的结果。LangChain 的
LatexTextSplitter实现了 LaTex 格式的分块。 - JSON:需要考虑嵌套的 JSON 对象的完整性,通常按照深度优先的方式遍历 JSON 对象,并构建出较小的 JSON 块,参考 LangChain 的 RecursiveJsonSplitter 。
-
PDF:使用pypdf按照page逐页解析pdf;使用 pyplumber 将pdf逐页进行解析, 但是文本结构在分栏的时候存在混淆,解析不完全;使用 PDFMiner ,将整个文档解析成一个完整的文本。文本结构可以自行认为定义;使用非结构化 Unstructured;
4. 语义分块(Semantic chunking)
利用语言模型的嵌入向量来分析文本的意义和上下文,以确定切割点。
这是一种实验性地分块技术,最初由 Greg Kamradt 提出,它在 The 5 Levels Of Text Splitting For Retrieval 这个视频中将分块技术划分为 5 个等级,其中 语义分块(Semantic chunking) 是第 4 级。它的基本原理如下:
- 首先将文本划分成一个个句子,并计算第一个句子的向量;
- 接着计算第二个句子的向量,并和第一个句子进行比较,得到相似度;
- 接着计算第三个句子的向量,并和第二个句子进行比较,得到相似度,以此类推;
- 当句子之间的相似度高于某个阈值时,说明这里的话题可能存在转折,可以将这个地方作为分块的临界点。
这里 是对应的代码实现。
LangChain 的 SemanticChunker 和 LlamaIndex 的 SemanticSplitterNodeParser 都实现了语义分块。
5. 智能切割
创建一个Agent,使用Agent来决定如何切割文本,以更智能地组织信息。
句子窗口检索
在介绍句子窗口检索之前,我们先简单介绍一下普通的 RAG 检索,下面是普通 RAG 检索的流程:
-
先将文档切片成大小相同的块
-
将切片后的块进行 Embedding 并保存到向量数据库
-
根据问题检索出 Embedding 最相似的 K 个文档库
-
将问题和检索结果一起交给 LLM 生成答案
普通 RAG 检索的问题是如果文档切片比较大的话,检索结果可能会包含很多无关信息,从而导致 LLM 生成的结果不准确。
我们再来看下句子窗口检索的流程:
-
和普通 RAG 检索相比,句子窗口检索的文档切片单位更小,通常以句子为单位
-
在检索时,除了检索到匹配度最高的句子,还将该句子周围的上下文也作为检索结果一起提交给 LLM
父文档检索一节中,我们提到,通过检索更小的块可以获得更好的搜索质量,然后通过扩大上下文范围可以获取更好的推理结果。句子窗口检索 使用的也是这个思想,句子窗口检索让检索内容更加准确,同时上下文窗口又能保证检索结果的丰富性。
原理
句子窗口检索的原理其实很简单,首先在文档切分时,将文档以句子为单位进行切分,一句话相比于一段话来说,语义可能要更接近于用户的问题,同时进行 Embedding 并保存数据库。然后在检索时,通过问题检索到相关的句子,但并不只是将检索到的句子作为检索结果,而是将该句子前面和后面的句子一起作为检索结果放到一个窗口中,窗口包含的句子数量可以通过参数来进行设置,最后将检索结果再一起提交给 LLM 来生成答案。可以看到整个过程和父文档检索几乎是一样的,但是 LlamaIndex 为了区别其实现方式,将其放在了后处理模块,而不是检索模块。

Embedding发展
有很多嵌入模型可供选择,比如 BAAI 的 bge-large,微软的 multilingual-e5-large,OpenAI 的 text-embedding-3-large 等,可以在 MTEB 排行榜 上了解最新的模型更新情况。
词嵌入技术经历了一个从静态到动态的发展过程,静态嵌入为每个单词使用单一向量,而动态嵌入根据单词的上下文进行调整,可以捕获上下文理解。排行榜上排名靠前的基本上都是动态嵌入模型。
此外,关于嵌入模型的优化,通常围绕着嵌入模型的微调展开,将嵌入模型定制为特定领域的上下文,特别是对于术语不断演化或罕见的领域,可以参考下面的一些教程:
- Training and Finetuning Embedding Models with Sentence Transformers v3
- Using LangSmith to Support Fine-tuning
值得一提的是,嵌入不仅仅限于文本,我们还可以创建图像或音频的嵌入,并将其与文本嵌入进行比较,这个概念适用于强大的图像或音频搜索、分类、描述等系统。
RAG效果评估
RAGAS:
Evaluating RAG pipelines with Ragas + LangSmith、AI大模型探索之路-应用篇11:AI大模型应用智能评估(Ragas)-CSDN博客
TruLens:使用 Trulens 评估 RAG 应用
开发 RAG 系统面临的 12 个问题
Paper:https://arxiv.org/pdf/2401.05856
在论文中,作者提出了7个 RAG 系统中可能会面临的问题:
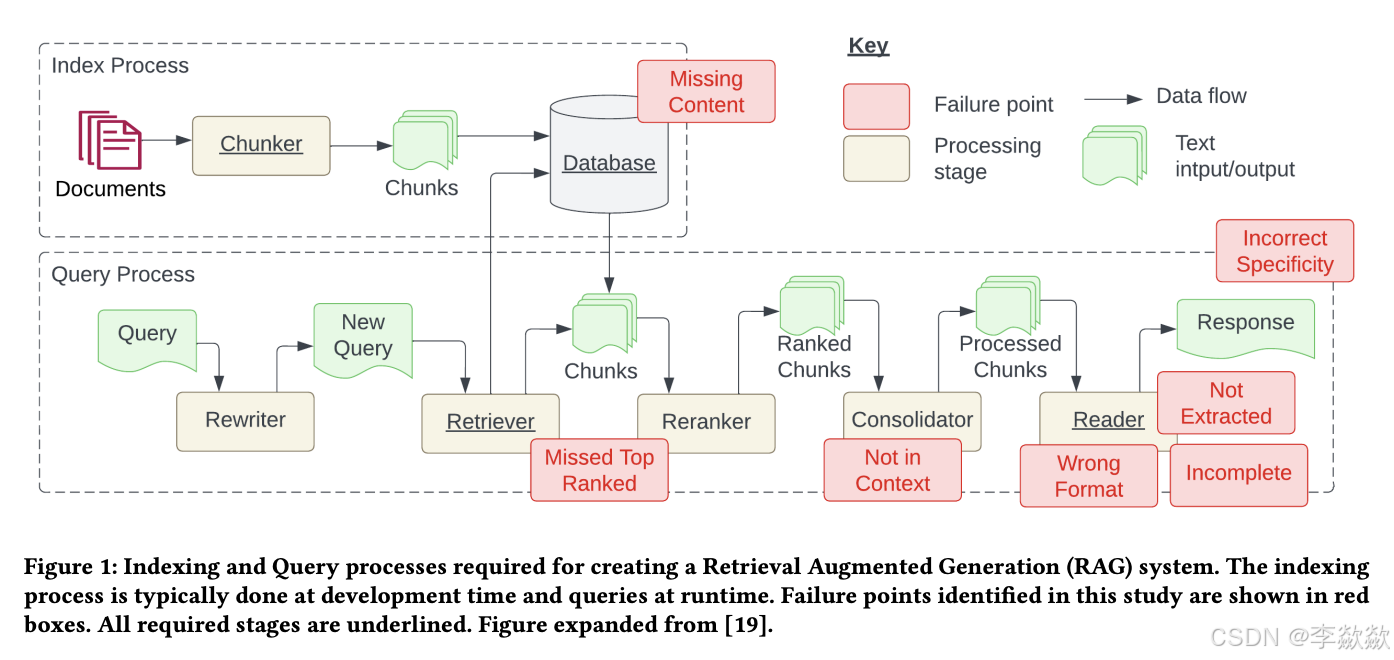
1. 缺失内容(Missing Content)
当用户的问题无法从文档库中检索到时,可能会导致大模型的幻觉现象。理想情况下,RAG 系统可以简单地回复一句 “抱歉,我不知道”,然而,如果用户问题能检索到文档,但是文档内容和用户问题无关时,大模型还是可能会被误导。
2. 错过超出排名范围的文档(Missed Top Ranked)
由于大模型的上下文长度限制,我们从文档库中检索时,一般只返回排名靠前的 K 个段落,如果问题答案所在的段落超出了排名范围,就会出现问题。
3. 不在上下文中(Not In Context)
包含答案的文档已经成功检索出来,但却没有包含在大模型所使用的上下文中。当从数据库中检索到多个文档,并且使用合并过程提取答案时,就会出现这种情况。
4. 未提取(Not Extracted)
答案在提供的上下文中,但是大模型未能准确地提取出来,这通常发生在上下文中存在过多的噪音或冲突信息时。
5. 错误的格式(Wrong Format)
问题要求以特定格式提取信息,例如表格或列表,然而大模型忽略了这个指示。
6. 不正确的具体性(Incorrect Specificity)
尽管大模型正常回答了用户的提问,但不够具体或者过于具体,都不能满足用户的需求。不正确的具体性也可能发生在用户不确定如何提问,或提问过于笼统时。
7. 不完整的回答(Incomplete Answers)
考虑一个问题,“文件 A、B、C 包含哪些关键点?”,直接使用这个问题检索得到的可能只是每个文件的部分信息,导致大模型的回答不完整。一个更有效的方法是分别针对每个文件提出这些问题,以确保全面覆盖。
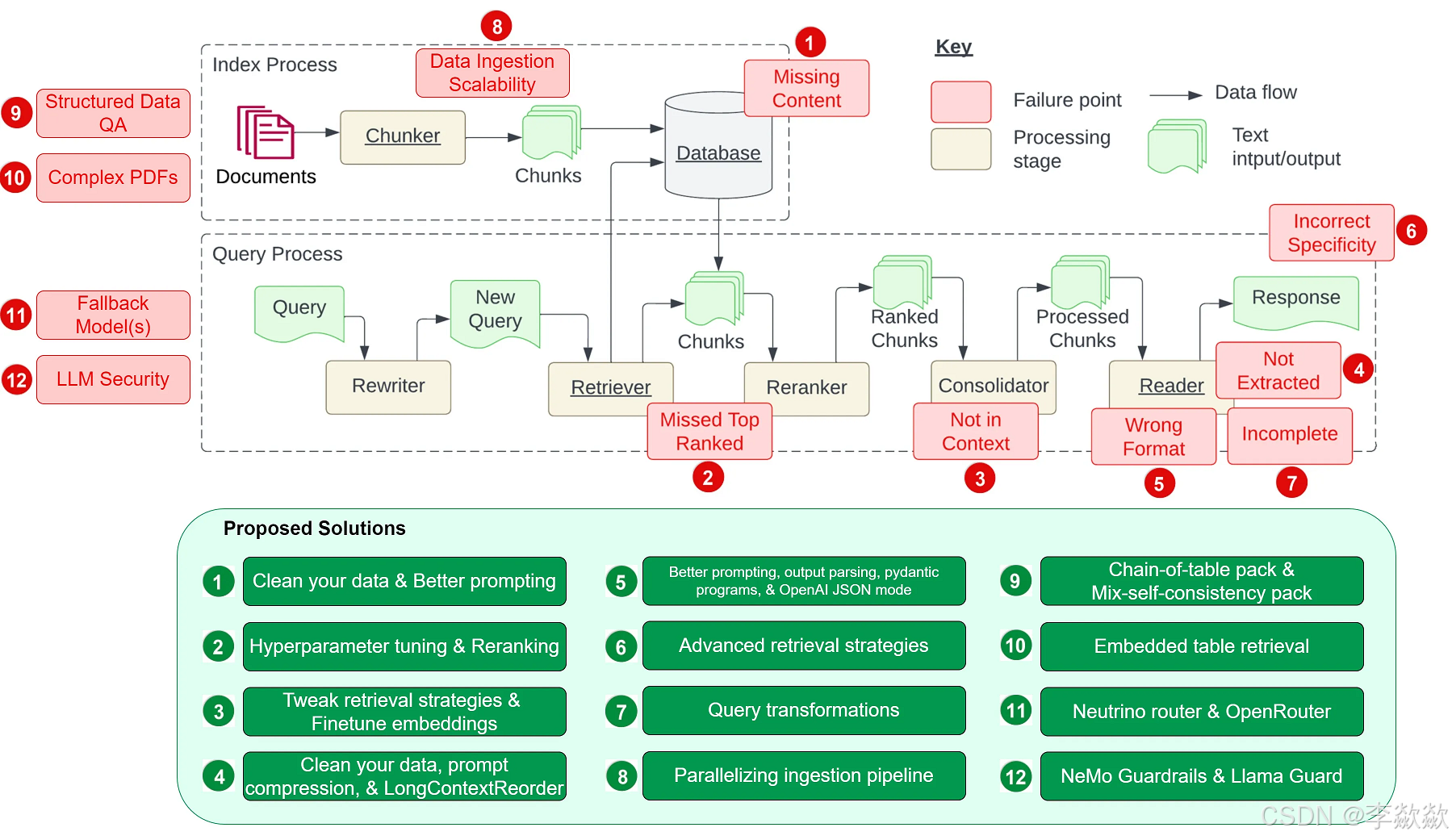
Wenqi Glantz 在他的博客 12 RAG Pain Points and Proposed Solutions 中又扩充了另 5 个问题:
8. 数据摄入的可扩展性问题(Data Ingestion Scalability)
当数据规模增大时,系统可能会面临如数据摄入时间过长、系统过载、数据质量下降以及可用性受限等问题,这可能导致性能瓶颈甚至系统故障。
9. 结构化数据的问答(Structured Data QA)
根据用户的问题准确检索出所需的结构化数据是一项挑战,尤其是当用户的问题比较复杂或比较模糊时。这是由于文本到 SQL 的转换不够灵活,当前大模型在处理这类任务上仍然存在一定的局限性。
10. 从复杂 PDF 文档提取数据(Data Extraction from Complex PDFs)
复杂的 PDF 文档中可能包含有表格、图片等嵌入内容,在对这种文档进行问答时,传统的检索方法往往无法达到很好的效果。我们需要一个更高效的方法来处理这种复杂的 PDF 数据提取需求。
11. 备用模型(Fallback Model(s))
在使用单一大模型时,我们可能会担心模型遇到问题,比如遇到 OpenAI 模型的访问频率限制错误。这时候,我们需要一个或多个模型作为备用,以防主模型出现故障。
12. 大语言模型的安全性(LLM Security)
如何有效地防止恶意输入、确保输出安全、保护敏感信息不被泄露等问题,都是我们需要面对的重要挑战。
在 Wenqi Glantz 的博客中,他不仅整理了这些问题,而且还对每个问题给出了对应的解决方案,整个 RAG 系统的蓝图如下:
上下文压缩
在问题优化,检索到的文档以及生成的答案阶段都可以进行压缩。
- 问题优化阶段,将聊天历史压缩成最终问题以便检索。
- 检索阶段,不要立即按原样返回检索到的文档,可以对查询到的上下文对其进行压缩。
- 答案生成阶段,对生成的答案进行压缩。
敏感信息处理
检索的文档中可能含有如用户名、身份证、手机号等敏感信息,这类信息统称为 PII(Personal Identifiable Information、个人可识别信息),如果将这类信息丢给大模型生成回复,可能存在一定的安全风险,所以需要在后处理步骤中将 PII 信息删除。LlamaIndex 提供了两种方式来 删除 PII 信息:使用大模型(PIINodePostprocessor)和使用专用的 NER 模型(NERPIINodePostprocessor)。
引用来源
一个基于 RAG 的应用不仅要提供答案,还要提供答案的引用来源,这样做有两个好处,首先,用户可以打开引用来源对大模型的回复进行验证,其次,方便用户对特定主体进行进一步的深入研究。
这里是 Perplexity 泄露出来的 Prompt 可供参考,这里是 WebLangChain 对其修改后的实现。在这个 Prompt 中,要求大模型在生成内容时使用 [N] 格式表示来源,然后在客户端解析它并将其呈现为超链接。
七、自我总结
- 上下文压缩:使用上下文压缩历史对话和问题和结果。
- 路由配置:路由配置备用的大模型,不同的Prompts和助手(艺术专业助手、计算机专业助手)。两种路由选择方式:一种是根据用户输入返回对应的链(手动,例如根据当前登陆用户判断需要什么助手);一种是计算的一个提示词与问题的相似度,选择相似度高的路由(自动,LLM判断选择哪个路由)。
- 元数据:在文件级别、段落级别添加元数据,根据元数据进行过滤,可以加快检索,元数据例如:where={"metadata_field": "is_equal_to_this"},# 元数据过滤条件 where_document={"$contains": "search_string"} # 文档内容过滤条件
- 查询sql的问题:大模型调用SQL可能会有错(需要知道表结构,工作量大),而且直接访问数据库,可能影响数据库性能。直接查询接口相对来说会好一点,接口有容灾。
- 集成/混合检索器:多种检索器结合,使用RRF对检索的结果进行Fusion,再进行精排。
- text-embedding-3-small 8000 4000 200和gpt-3.5-turbo-16k 16000
- 数据处理阶段:增加元数据、数据增强;文档太大,上下文压缩;文档太小,句子窗口搜索;index时候英语文档翻译成中文,查询时候的中文翻译成英语
参考
一文详看Langchain框架中的RAG多阶段优化策略:从问题转换到查询路由再到生成优化
高级 RAG 技术学习笔记 - aneasystone's blog
LLM大模型技术实战:一文讲透专补大模型短板的RAG_大模型提升搜索召回率-CSDN博客
一文详谈20多种RAG优化方法 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI
【AI开发】CRAG、Self-RAG、Adaptive-RAG_corrective rag 和 self rag-CSDN博客
https://zhuanlan.zhihu.com/p/680265210
3.2 ReAct 与 CoT、ToT 的区别 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI【AI大模型应用开发】从CoT到ToT,再到ReAct,提升大模型推理能力的方式探索(含代码)_react cot-CSDN博客
改进召回(Retrieval)和引入重排(Reranking)提升RAG架构下的LLM应用效果_cohere rerank-CSDN博客
《设计 RAG 系统时需要考虑的七个失败点 》论文 AI 解读 - 大模型知识库|大模型训练|开箱即用的企业大模型应用平台|智能体开发|53AI