文章目录
一、数据库引擎
1. 查看数据库引擎
mysql> show engines;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| ARCHIVE | YES | Archive storage engine | NO | NO | NO |
| BLACKHOLE | YES | /dev/null storage engine (anything you write to it disappears) | NO | NO | NO |
| MRG_MYISAM | YES | Collection of identical MyISAM tables | NO | NO | NO |
| FEDERATED | NO | Federated MySQL storage engine | NULL | NULL | NULL |
| MyISAM | YES | MyISAM storage engine | NO | NO | NO |
| PERFORMANCE_SCHEMA | YES | Performance Schema | NO | NO | NO |
| InnoDB | DEFAULT | Supports transactions, row-level locking, and foreign keys | YES | YES | YES |
| MEMORY | YES | Hash based, stored in memory, useful for temporary tables | NO | NO | NO |
| CSV | YES | CSV storage engine | NO | NO | NO |
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
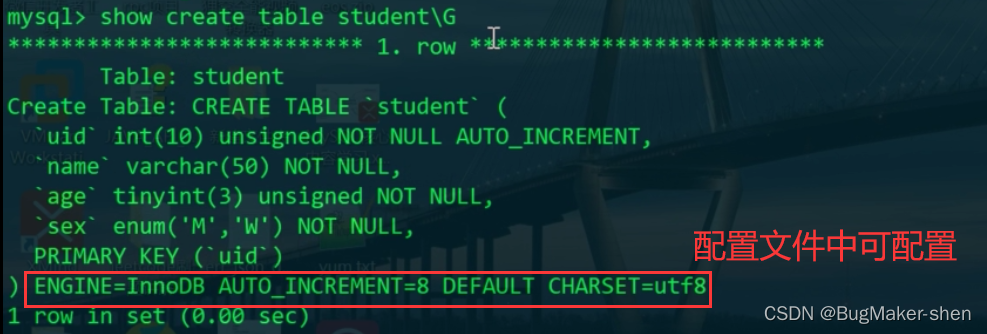
2. 查看表结构
show create table [student]:查看表结构,其中表使用的数据库引擎和字符集等可以在配置文件中修改。windows下的配置文件为安装目录下的my.ini,linux则在/etc/mysql/my.cnf
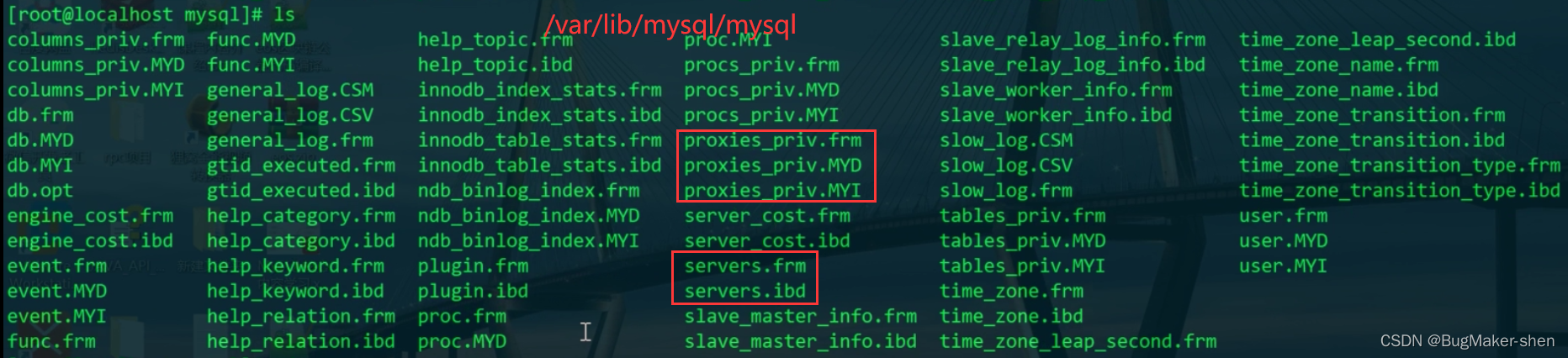
3. 查看表相关文件
表相关文件目录:/var/lib/mysql
- 使用MyISAM存储引擎的表对应的文件有三个:
*.frm,*.MYD,*.MYI,分别表示表结构、表数据、表索引 - 使用InnoDB存储引擎的表对应的文件有两个:
*.frm,*.ibd,分别表示表结构、表数据和表索引,数据和索引放在一个文件中
面试问题:为什么使用InnoDB存储引擎的表会自动生成主键,而使用MyISAM存储引擎的表不会自动生成主键?
因为MyISAM的数据和索引是单独存放的,手动加上主键会生成主键索引存放在*.MYI,没有主键的话*.MYI里就不用存放索引。而InnoDB会默认生成一个整型类型的索引,因为Innodb的数据和索引放在一个文件中,数据就是放在索引树上的,没有索引,数据也没有地方存放。
4. 各存储引擎的区别
| 种类 | 锁机制 | B树索引 | 哈希索引 | 外键 | 事务 | 索引缓存 | 数据缓存 |
|---|---|---|---|---|---|---|---|
| MyISAM | 表锁 | 支持 | 不支持 | 不支持 | 不支持 | 支持 | 不支持 |
| InnoDB | 行锁 | 支持 | 不支持 | 支持 | 支持 | 支持 | 支持 |
| Memory | 表锁 | 支持 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
- 锁机制:表示数据库在并发请求访问的时候,多个事务在操作时,并发操作的力度,能用行锁解决,就别用表锁,锁粒度大了降低并发度
- B树索引和哈希索引:主要是加速SQL的查询速度
- 外键:子表的字段依赖父表的主键,设置两张表的依赖关系
- 事务:多个SQL语句,保证它们共同执行的原子操作,要么成功要么失败,不能只成功一部分,失败需要回滚事务
- 索引缓存和数据缓存:和MySQL Server的查询缓存相关,索引是存放在磁盘上的,在没有对数据和索引做修改之前,重复查询可以不用进行磁盘I/O(数据库的性能提升,目的是减少磁盘I/O提升访问效率),读取上一次内存中查询的缓存就可以了
二、MySQL索引
当表中的数据量达到上百万的时候,SQL查询花费的时间会很长,需要使用索引加速SQL查询
由于 索引也是需要存储成索引文件的,因此使用索引也会涉及磁盘I/O操作。如果索引过多,使用不当,SQL查询时会造成大量无用的磁盘I/O操作,降低查询效率。
此外,我们 改动数据以后,不仅是数据文件需要做修改,索引文件也需要修改,索引过多,修改的索引也会更多,所以索引并不是越多越好。
1. 索引分类
索引是创建在表上的,是对数据库表中一列或多列的值进行排序的一种结果,其核心就是提高查询的速度
- 物理上分为:聚集索引、非聚集索引
- 逻辑上分为:
- 普通索引:没有任何限制条件,可以给任何字段创建普通索引(一张表的一次SQL查询只能使用一个索引,比如
where age=1 and sex="man"只能使用一个索引) - 唯一性索引:使用
unique修饰的字段,值不能重复,主键索引就是一种唯一性索引 - 主键索引:使用
PRIMARY KEY修饰的索引,主键字段会自动创建索引 - 单列索引:在一个字段上创建索引
- 多列索引:在表的多个字段上创建索引 (uid+cid,age+name等,先按第一个字段排序,再按第二个字段排序),多列索引必须使用到第一个列,才能用到多列索引,否则索引用不上,比如对于uid+cid的索引,我们这样
where cid=2是无法使用该索引的 - 全文索引:使用
FULLTEXT参数可以设置全文索引,只支持CHAR,VARCHAR和TEXT类型的字段上,常用于数据量较大的字符串类型上(真实项目中使用的较少,比如我们使用百度,肯定不会在数据库搜索文本,而是使用ElasticSearch等搜索引擎加速搜索)
- 普通索引:没有任何限制条件,可以给任何字段创建普通索引(一张表的一次SQL查询只能使用一个索引,比如
- 索引的优点:提高查询效率
- 索引的缺点:索引并不是越多越好,过多的索引会导致CPU使用率居高不下,数据的改变也会造成索引文件的改变,过多的磁盘I/O造成CPU负载太重
2. 索引的创建和删除
创建表的时候指定索引字段:
CREATE TABLE student(id INT,
name VARCHAR(50),
sex ENUM('male', 'female'),
INDEX(id));
在已经创建的表上添加索引:
CREATE [UNIQUE] INDEX 索引名 ON 表名(属性名(length) [ASC | DESC]);
length表示用该字段的前length个字符建索引,如果字段很长,索引文件就会很大,搜索也慢,如果前length个字符可以区分该字段,就可以使用前length个字符建立索引
删除索引:
DROP INDEX 索引名 ON 表名;
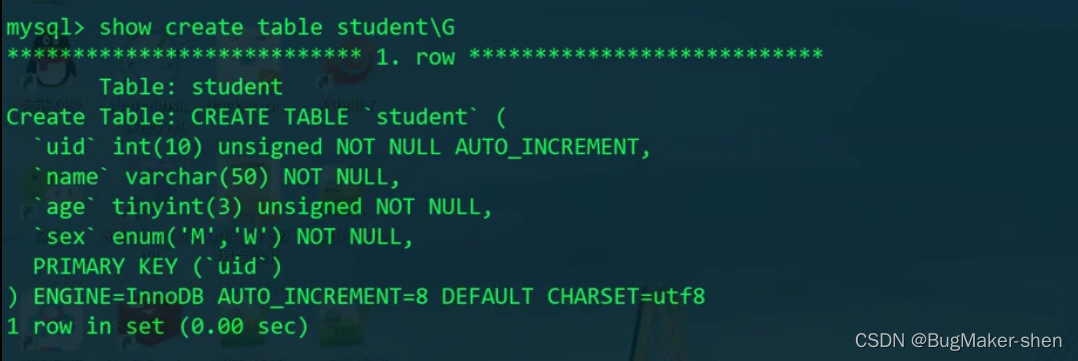
此时表结构如下:
show create table student \G
使用具有主键索引的id进行过滤查找:
explain select * from student where uid=3;
从索引树上直接获取数据,并没有整表扫描,对于当前uid创建了索引,无论查询uid是多少的信息,都能在索引树上取得,直接命中

使用没有索引的name属性扫描
explain select * from student where name="zhangsan";
就算zhangsan排在第一个,也需要整表扫描,不扫描完,不知道其他行有没有zhangsan

给name添加索引
create index nameidx on student(name);
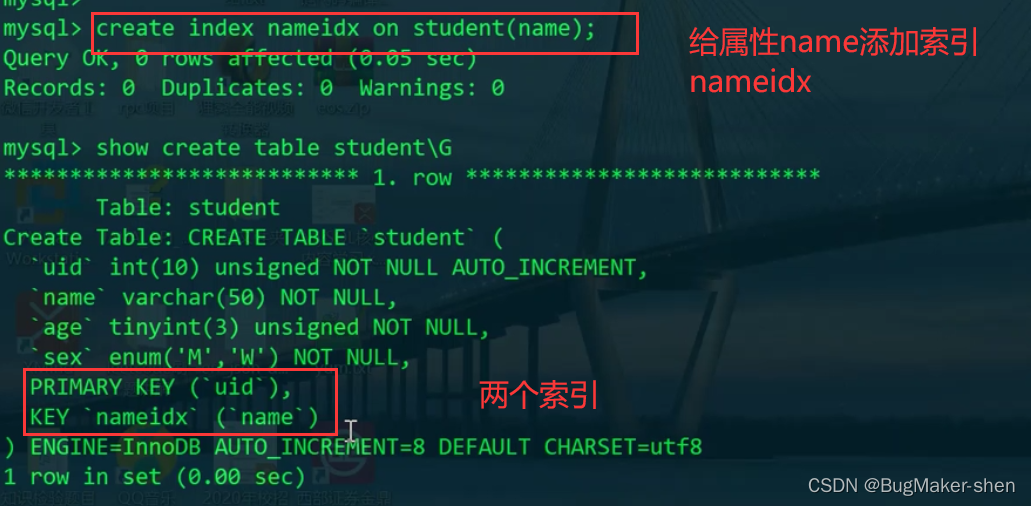
用name索引加速搜索

- type为ref,表示在扫描索引树;若type为const,表示使用主键索引或唯一性索引,直接精确匹配
- key_len这里是152,对于给字符串类型数据建立索引的时候,一般会限制索引长度。若前面一部分字符区可以用于区分不同的数据,没必要使用很长长度的索引(key_len很大)。因为索引长了,索引文件会变大,就会使用更多的磁盘IO,应尽量避免
然而添加索引后,不一定就能使用到索引,因为MySQL server有优化,它会先进行分析,如果发现使用索引需要扫描的数据基本上是所有数据的大概百分之七八十左右,其实是不会使用索引的,因为如果花费差不多,读索引文件花费磁盘I/O,还要扫描索引树,还不如直接整张表搜索取数据
3. 关于缓存问题
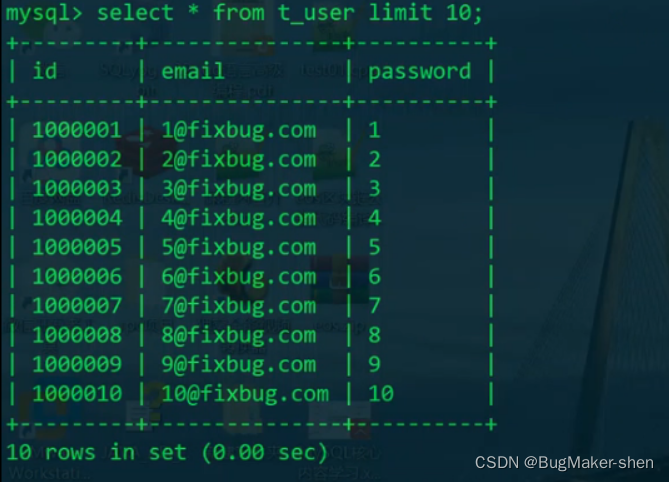
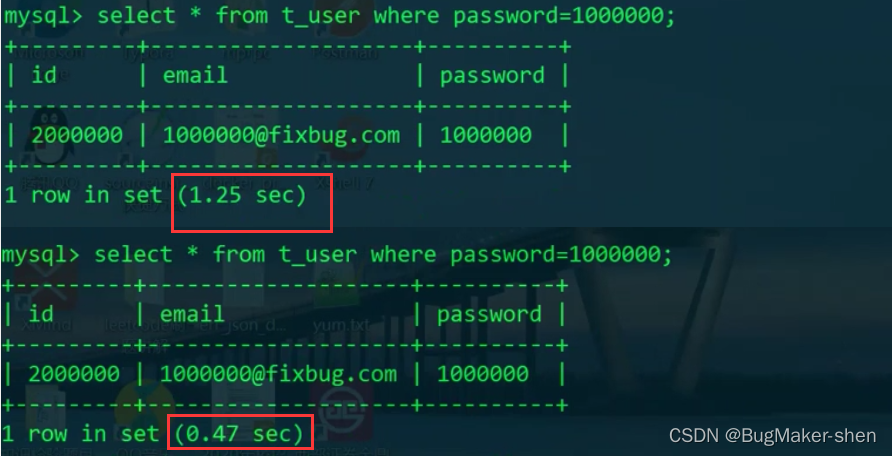
对于相同的操作,若中间没有更新数据(insert/delete/update),则第一次花费时间长,第二次花费时间短,这是因为存储引擎对索引和数据进行了缓存。 第一次查询后的结果会放在数据缓存或者索引缓存里,第二次就不用花费磁盘I/O从磁盘读取索引了。
4. 过滤条件字段涉及类型转换则无法使用索引
查看表结构后发现,password属性是varchar,然而查询的时候使用的是int,这就涉及到了类型转换,所以不会使用索引。此外,如果用到了mysql的聚集函数或表达式计算,也不会用到索引
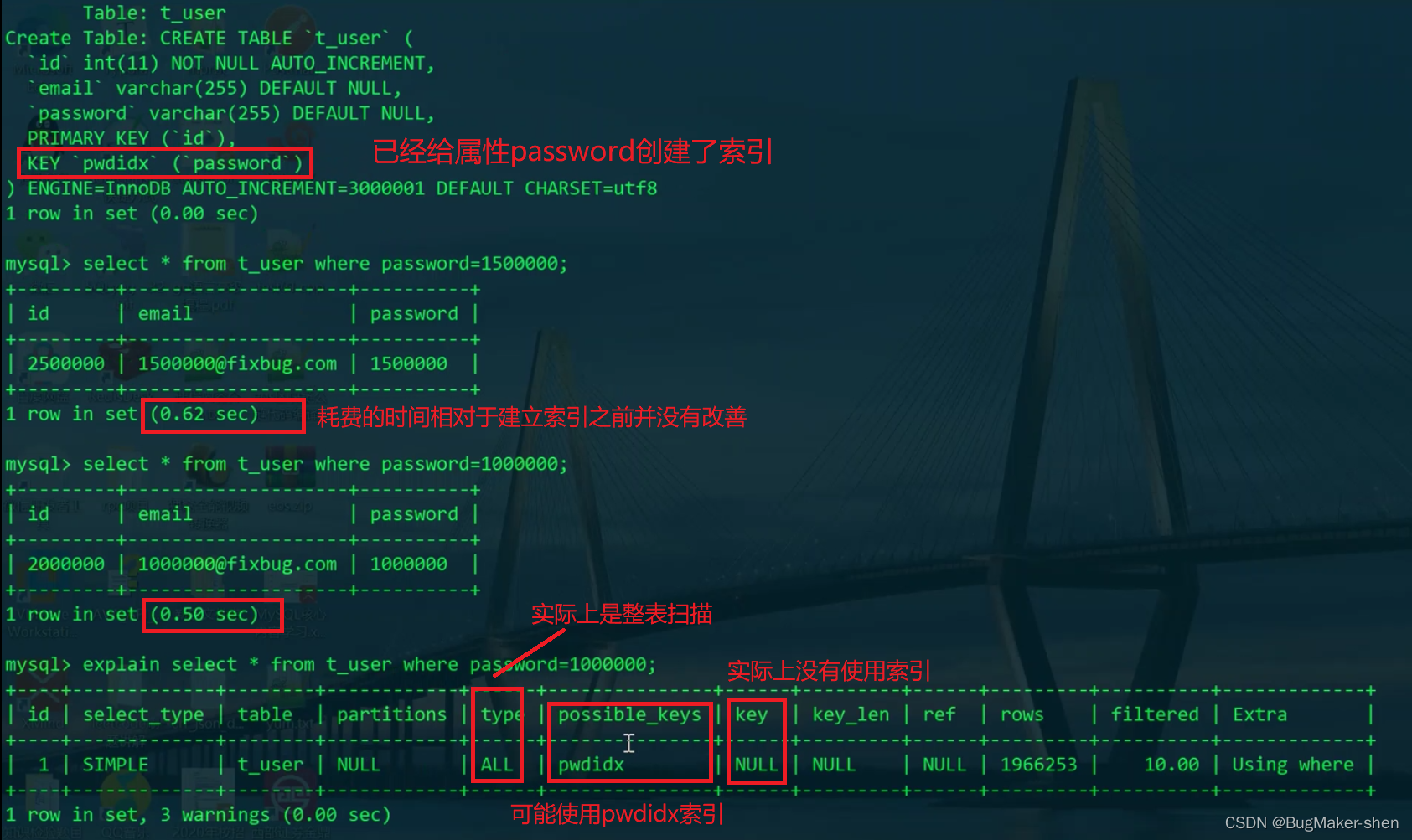

5. 删除索引
drop index pwdidx on t_user;
6. explain字段含义
-
select_type
-
table
-
type
-
ref
-
Extra





7. 加索引优化原则
- 若经常作为过滤条件(where)的属性,需要加上索引
- 给字符串属性添加索引的时候,最好根据字段前面一部分字符创建索引即可,即限制索引的长度(key_len)
- where过滤条件使用的索引字段涉及类型强转、mysql聚合函数调用、表达式计算等,则不会使用索引