文章目录
前言
ClickHouse通过高度协调配合的存储引擎和计算引擎,实现了令人惊叹的单机性能,但是再强的单机性能也会遇到瓶颈,此时分布式架构就成为解决单机瓶颈的一个选择。本文介绍ClickHouse分布式架构的原理及使用方法。
架构特点及对比
ClickHouse使用多主架构实现分布式表引擎,下图展示了一个典型的ClickHouse集群示意:
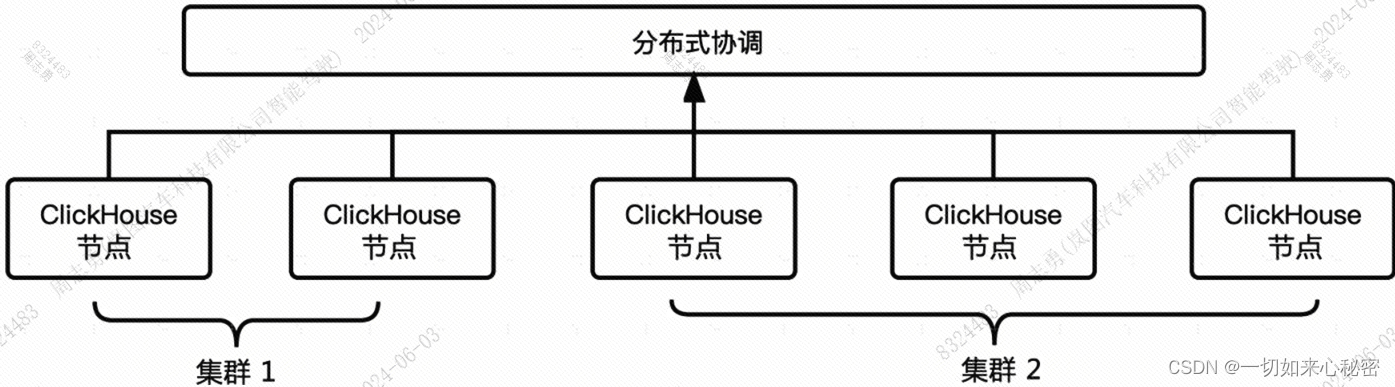
- 中5个ClickHouse节点通过一个分布式协调组件组成了2个逻辑集群,每个节点都可以独立对外提供服务,分布式协调组件只是用于ClickHouse内部节点的协调,不负责对外提供服务。
- 集群中每个节点都可以独立对外提供服务。
- 节点之间无共享,同步由第三方分布式协调组件提供。
- 无主节点或所有节点都是主节点。
ClickHouse分布式架构的优点
实现简单
ClickHouse使用多主架构实现分布式引擎,由于多主架构不需要在节点之间共享信息,因此实现非常简单。在实现分布式表引擎时,按照本地表的代理方式实现即可,实现逻辑相对简单。可以引入一个外部的分布式协调组件复制表引擎,不需要复杂的同步机制。
另外,ClickHouse不支持数据修改,不会对内部数据进行再平衡,这意味着ClickHouse不需要复杂的集群间协调,可以使用较为简单的多主架构实现。
响应速度快,提升查询性能
ClickHouse分布式表引擎使用MPP架构,每一台节点都是对等的,查询时任意一台节点都可以响应用户请求。ClickHouse没有复杂的调度过程,不需要将任务按照调度策略调度到其他节点上计算。由于节点收到查询请求后可以立即进行计算,因此ClickHouse的响应速度非常快,对于ClickHouse擅长的查询操作,节省的调度时间是非常可观的。
可用性高
ClickHouse使用MPP架构,所有节点之间没有共享信息,这意味着ClickHouse不会由于单点故障导致整个集群无法响应。在ClickHouse中,单个节点的故障最多只会引起某些数据失效,并不会将单点故障扩散到整个集群。
ClickHouse分布式架构的缺点
存在木桶效应
数据由每个节点自己管理,如果某个节点的性能比较低,那么运行在该节点上的计算程序会变慢,从而拖慢整个集群的计算速度。
此时,增加节点也无法解决该问题,使得集群出现瓶颈。对于ClickHouse集群,最好选择相同的节点配置。
无法支持复杂的SQL优化
由于ClickHouse的多主架构没有统一的任务调度器,因此只能实现简单的任务调度能力,无法支持复杂的SQL优化。
ClickHouse目前的任务执行逻辑不具备Shuffle能力,导致其只能使用效率比较低的Broadcast Join算法。这种算法在执行Join操作时会将其中一个表的数据广播到所有的计算节点,只有在右表数据量比较小的前提下才能达到很高的性能。
对于左表和右表数据量都很大的场景来说,这种算法会带来非常大的网络I/O,降低查询速度。而效率更高的Shuffle Join算法需要更复杂的任务调度和资源调度,现阶段的ClickHouse任务执行逻辑因分布式架构较为简单,暂时无法支撑Shuffle Join的实现。
运维复杂,扩容缩容需要用户进行额外操作
ClickHouse采用多主架构,没有统一的资源管理,在扩容时,新加入的节点是空的,ClickHouse不会自动在集群间再平衡数据,这给运维带来了挑战。集群扩容后需要将数据进行重新分布。
同样地,ClickHouse集群在缩容时,也需要用户自行将数据迁移到集群的节点上,这样的设计给运维带来了复杂度。
ClickHouse与Hadoop的分布式架构对比
数据管理
- Hadoop数据存储于HDFS,HDFS是主从架构,数据由主节点统一管理,由主节点负责将数据切分并分配到底层数据节点中。元数据也由主节点统一管理,数据节点只负责存储数据。
- ClickHouse数据由各个节点自行管理,其分布式表只是代理,不具备数据管理的能力,元数据也都分布在各个节点中。
调度
- Hadoop调度使用了一个统一的yarn调度器。yarn是一个支持异构资源框架的多租户抢占式分布式资源调度器,负责调度任务、重试失败任务、收集任务结果、基于调度策略抢占低优先级任务的资源、统一管理集群中的资源。Hadoop通过yarn调度器,可以实现很多复杂的功能。
- ClickHouse没有统一的调度器,其多主架构支持任意一个节点接收查询任务。简单的调度策略使得ClickHouse更适合执行需要快速得出响应结果的分析任务。
基本概念
集群
- Clickhouse 的集群是逻辑上的,必须借助分布式协调组件,将逻辑集群中的计算节点连接。
- 分布式协调组件可以和ClickHouse节点共用服务器,也可以使用完全独立的服务器,需要用户按照实际情况进行选择。一般对于数据量较小且预算较少的场景,可以复用ClickHouse的节点。
副本
数据副本可以保证ClickHouse集群中多个节点的数据一致。ClickHouse中的数据副本经常容易混淆,需要注意的是,ClickHouse的数据副本有3种内涵。
分片中的副本
- 分片在狭义上只是配置文件中的逻辑概念,本身并没有任何能力,只是对服务器进行了逻辑上的划分,分片中的副本也只是逻辑上的概念。分片必须配合ClickHouse的分布式表引擎才能发挥作用。
复制表引擎中的副本
- ClickHouse复制表引擎中的副本是一个真实存在的表,每一个复制表引擎中的副本都对应着ClickHouse集群中的一个物理表。这些物理表互为副本,复制表引擎会保证这些表中的数据时刻同步。
分布式表引擎中的副本
- 分布式表引擎中的副本也是一个逻辑概念,具体实现时按照底层物理表的不同而产生不同的影响
- ClickHouse中的副本指的是不同数据库的两张表中的数据保持一致。副本的具体行为会依据底层不同的实现而有所不同。
分片
ClickHouse的副本并不会直接提高查询能力,只是通过数据冗余间接提高了集群性能,这并没有解决ClickHouse单机瓶颈的问题。要解决单机瓶颈,需要依靠ClickHouse的分片(shard)。
分片指的是数据表中的数据分布在不同的物理服务器上,类似于数据库中的分库,从而解决ClickHouse的单机瓶颈的问题。数据分布可以按照业务的实际需求,使用多种策略,可以按照业务进行分片,例如按照性别,将所有男性的数据放置于分片1上,将所有女性的数据放置于分片2上;也可以按照字段进行随机分布,以避免出现数据倾斜。
分片可以和副本一起使用,即利用分片分散数据表的数据,结合副本将分片中的数据复制到另一台节点上以提高查询能力。
下列代码展示了配置分片的示例,定义了一个名为cluster_1的集群,集群中有2个分片,每个分片有2个副本。

ClickHouse的复制表引擎
通过ClickHouse提供的Replicated*MergeTree表引擎,可以在ClickHouse集群中创建副本,保证多台节点的表数据保持一致。
创建复制表
下列代码展示了配置副本的操作方式。首先在每一个节点的配置文件中配置好#1宏替换占位符,必须保证代码中的配置项shard在每个ClickHouse节点上不同。接下来在每一个需要创建副本的ClickHouse节点上执行#2建表语句,建表语句中的占位符会被ClickHouse用宏替换。

复制表复制
副本的复制是多主异步的,对副本中任意一个节点的操作都会同步到副本中的所有节点。由于复制是异步的,因此可能存在不一致的窗口,ClickHouse会保证数据的最终一致性。
在数据复制的过程中,ClickHouse会通过简单的事务提供有限的原子性保障。ClickHouse保证单个数据块的写入是原子和唯一的,数据块的大小可以通过max_insert_block_size进行配置,默认大小是1048576(220)条。
复制表查询
复制表的查询和本地表一致,直接对表进行查询即可。复制表不会直接提高查询的性能,ClickHouse的任务调度不会通过复制表来加速查询。复制表最大的作用在于避免数据丢失。
用户可以自行利用复制表实现读写分离、提高ClickHouse集群的并发能力,从而间接提高ClickHouse的性能。这些功能需要用户自行实现,ClickHouse并没有原主提供这样的能力。
从ClickHouse对副本的实现来看,副本只是在本地表的基础上增加了数据同步的能力,会自动将数据在副本间进行同步,本质上还是本地表。
ClickHouse分布式表引擎
ClickHouse的分布式表引擎本身并不存储数据,只是对多台节点上的物理表进行代理。通过ClickHouse的分布式表引擎可以在多台服务器上进行分布式查询,从而解决单机性能瓶颈。
ClickHouse的分布式表引擎必须依赖前边介绍的分片配置才能运行,下边介绍ClickHouse分布式表引擎的使用方法及运作机制。

分布式表查询原理
ClickHouse可以对分布式表中的任意一个节点发起查询。在查询分布式表时,接收用户查询语句的节点被称为发起节点,发起节点会将SELECT语句发送到每一个分片上执行,各个分片将结果汇总至发起查询的节点。
这意味着ClickHouse不会自动依据数据分布对查询进行优化,例如继续某次查询的数据量比较小而集中在某一个分片上时,ClickHouse依然会将SELECT语句分发到所有的集群中运行,这样非常浪费服务器资源。这是没有CBO和资源调度器导致的,遇到这类问题时,用户需要自行对数据分布进行优化。
如果分片配置了副本,ClickHouse会依据load_balancing中的设置选择副本,默认使用随机模型。目前最新版本的ClickHouse支持5种负载均衡配置,分别是随机、最邻近主机名、按顺序查询、第一次或随机、轮询(Round Robin)。
随机
-
计算每个副本的错误次数,选择错误最少的1个副本提供服务。如果有多个副本的错误次数相同,且都是最小的,则随机选择一个副本提供服务。
例如,发起查询的服务器主机名为example-01,某次查询时,example-02、example-03、example-04这3个服务器的错误数都是0,依据随机原则,随机选择其中一个提供服务。
最邻近主机名 -
计算每个副本的错误次数,选择错误最少的1个副本提供服务。如果有多个副本的错误次数相同,且都是最小的,ClickHouse根据主机名,选择与发起查询的服务器的配置文件中主机名最相似的副本提供服务。
例如,发起查询的服务器主机名为example-01,某次查询时,example-02、example-03、example-04这3个服务器的错误次数都是0,依据按顺序查询的原则,选择配置文件中的第一个服务器,即example-02提供服务。
按顺序查询 -
计算每个副本的错误次数,选择错误最少的1个副本提供服务。如果有多个副本的错误次数相同,且都是最小的,ClickHouse按照配置文件中副本的配置顺序,选择第一个提供服务。第一个发生错误时,按顺序选择第二个。
例如,发起查询的服务器主机名为example-01,某次查询时,example-02、example-03、example-04这3个服务器的错误次数都是0,依据按顺序查询的原则,选择配置文件中的第一个服务器,即example-02提供服务。
第一个或随机 -
计算每个副本的错误次数,选择错误最少的1个副本提供服务。如果有多个副本的错误次数相同,且都是最小的,ClickHouse按照配置文件中副本的配置顺序,选择第一个提供服务。第一个发生错误时,在剩余的机器中随机选择一个进行查询。
轮询
- 计算每个副本的错误次数,选择错误最少的1个副本提供服务。如果有多个副本的错误次数相同,且都是最小的,ClickHouse会使用Round Robin算法依次将查询分摊到每一个副本服务器上执行,充分利用服务器资源。
分布式表的数据写入方案
直接写入
- 直接对ClickHouse的分布式表执行写入操作时,ClickHouse会按照分片键和权重通过网络向各个分片写入数据。权重表示每个分片接收数据的概率,默认为1,越大表示接收的数据越多。
- 当新的节点加入集群时,可以通过调大权重的方式迅速将数据写满节点,而不必对ClickHouse集群进行再平衡。
自行决定数据分布并直接将数据写入本地表
- 由于ClickHouse的分布式表引擎只是本地表的代理,因此也可以将数据直接写入本地表。也就是说,用户按照自己的业务需求自行决定数据如何分布,并直接对本地表执行写入操作。
分布式表中副本的处理方式
分布式表是本地表的一个代理,是建立在底层本地表之上的。底层本地表的一些特性会影响分布式表对副本的处理方式。
底层表为普通表
- 当分布式底层表为普通表时,由分布式表负责将数据复制到所有的副本上。分布式表引擎并不会检查数据的一致性,如果有查询语句没有通过分布式表而是直接对本地表进行操作,这些操作不会被分布式表捕获而复制到副本上,此时会出现副本数据不一致的情况,导致查询结果出错。
底层表为复制表
- 当分布式底层表为复制表时,由复制表负责将数据同步到副本上,分布式表会忽略副本的数据复制过程。
- ClickHouse官方建议用户使用该方式实现副本的数据同步。使用该方式时,用户需要在配置分片时显式地将internal_replication设置为true,该参数默认为false。
总结
本文介绍了ClickHouse的分布式架构及其运作机制。ClickHouse的强项并不在分布式架构上,其自身的分布式能力也只是聊胜于无。应当将ClickHouse应用到其擅长的领域,不用过分追求强大的分布式能力。