转载:
所谓图像分割指的是根据灰度、颜色、纹理和形状等特征把图像划分成若干互不交迭的区域,并使这些特征在同一区域内呈现出相似性,而在不同区域间呈现出明显的差异性。我们先对目前主要的图像分割方法做个概述,后面再对个别方法做详细的了解和学习。
1. 图像分割算法概述
1.1 基于阈值的分割方法
阈值法的基本思想是基于图像的灰度特征来计算一个或多个灰度阈值,并将图像中每个像素的灰度值与阈值相比较,最后将像素根据比较结果分到合适的类别中。因此,该类方法最为关键的一步就是按照某个准则函数来求解最佳灰度阈值。
1.2 基于边缘的分割方法
所谓边缘是指图像中两个不同区域的边界线上连续的像素点的集合,是图像局部特征不连续性的反映,体现了灰度、颜色、纹理等图像特性的突变。通常情况下,基于边缘的分割方法指的是基于灰度值的边缘检测,它是建立在边缘灰度值会呈现出阶跃型或屋顶型变化这一观测基础上的方法。
阶跃型边缘两边像素点的灰度值存在着明显的差异,而屋顶型边缘则位于灰度值上升或下降的转折处。正是基于这一特性,可以使用微分算子进行边缘检测,即使用一阶导数的极值与二阶导数的过零点来确定边缘,具体实现时可以使用图像与模板进行卷积来完成。
1.3 基于区域的分割方法
此类方法是将图像按照相似性准则分成不同的区域,主要包括种子区域生长法、区域分裂合并法和分水岭法等几种类型。
种子区域生长法是从一组代表不同生长区域的种子像素开始,接下来将种子像素邻域里符合条件的像素合并到种子像素所代表的生长区域中,并将新添加的像素作为新的种子像素继续合并过程,直到找不到符合条件的新像素为止。该方法的关键是选择合适的初始种子像素以及合理的生长准则。
区域分裂合并法(Gonzalez,2002)的基本思想是首先将图像任意分成若干互不相交的区域,然后再按照相关准则对这些区域进行分裂或者合并从而完成分割任务,该方法既适用于灰度图像分割也适用于纹理图像分割。
分水岭法(Meyer,1990)是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一点像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆,而集水盆的边界则形成分水岭。该算法的实现可以模拟成洪水淹没的过程,图像的最低点首先被淹没,然后水逐渐淹没整个山谷。当水位到达一定高度的时候将会溢出,这时在水溢出的地方修建堤坝,重复这个过程直到整个图像上的点全部被淹没,这时所建立的一系列堤坝就成为分开各个盆地的分水岭。分水岭算法对微弱的边缘有着良好的响应,但图像中的噪声会使分水岭算法产生过分割的现象。
1.4 基于图论的分割方法
此类方法把图像分割问题与图的最小割(min cut)问题相关联。首先将图像映射为带权无向图G=<V,E>,图中每个节点N∈V对应于图像中的每个像素,每条边∈E连接着一对相邻的像素,边的权值表示了相邻像素之间在灰度、颜色或纹理方面的非负相似度。而对图像的一个分割s就是对图的一个剪切,被分割的每个区域C∈S对应着图中的一个子图。而分割的最优原则就是使划分后的子图在内部保持相似度最大,而子图之间的相似度保持最小。基于图论的分割方法的本质就是移除特定的边,将图划分为若干子图从而实现分割。目前所了解到的基于图论的方法有GraphCut,GrabCut和Random Walk等。
1.5 基于能量泛函的分割方法
该类方法主要指的是活动轮廓模型(active contour model)以及在其基础上发展出来的算法,其基本思想是使用连续曲线来表达目标边缘,并定义一个能量泛函使得其自变量包括边缘曲线,因此分割过程就转变为求解能量泛函的最小值的过程,一般可通过求解函数对应的欧拉(Euler.Lagrange)方程来实现,能量达到最小时的曲线位置就是目标的轮廓所在。按照模型中曲线表达形式的不同,活动轮廓模型可以分为两大类:参数活动轮廓模型(parametric active contour model)和几何活动轮廓模型(geometric active contour model)。
参数活动轮廓模型是基于Lagrange框架,直接以曲线的参数化形式来表达曲线,最具代表性的是由Kasset a1(1987)所提出的Snake模型。该类模型在早期的生物图像分割领域得到了成功的应用,但其存在着分割结果受初始轮廓的设置影响较大以及难以处理曲线拓扑结构变化等缺点,此外其能量泛函只依赖于曲线参数的选择,与物体的几何形状无关,这也限制了其进一步的应用。
几何活动轮廓模型的曲线运动过程是基于曲线的几何度量参数而非曲线的表达参数,因此可以较好地处理拓扑结构的变化,并可以解决参数活动轮廓模型难以解决的问题。而水平集(Level Set)方法(Osher,1988)的引入,则极大地推动了几何活动轮廓模型的发展,因此几何活动轮廓模型一般也可被称为水平集方法。
1.6 基于小波分析和小波变换的图像分割方法
小波变换是近年来得到的广泛应用的数学工具,也是现在数字图像处理必学部分,它在时间域和频率域上都有量高的局部化性质,能将时域和频域统一于一体来研究信号。而且小波变换具有多尺度特性,能够在不同尺度上对信号进行分析,因此在图像分割方面的得到了应用。
二进小波变换具有检测二元函数的局部突变能力,因此可作为图像边缘检测工具。图像的边缘出现在图像局部灰度不连续处,对应于二进小波变换的模极大值点。通过检测小波变换模极大值点可以确定图像的边缘小波变换位于各个尺度上,而每个尺度上的小波变换都能提供一定的边缘信息,因此可进行多尺度边缘检测来得到比较理想的图像边缘。
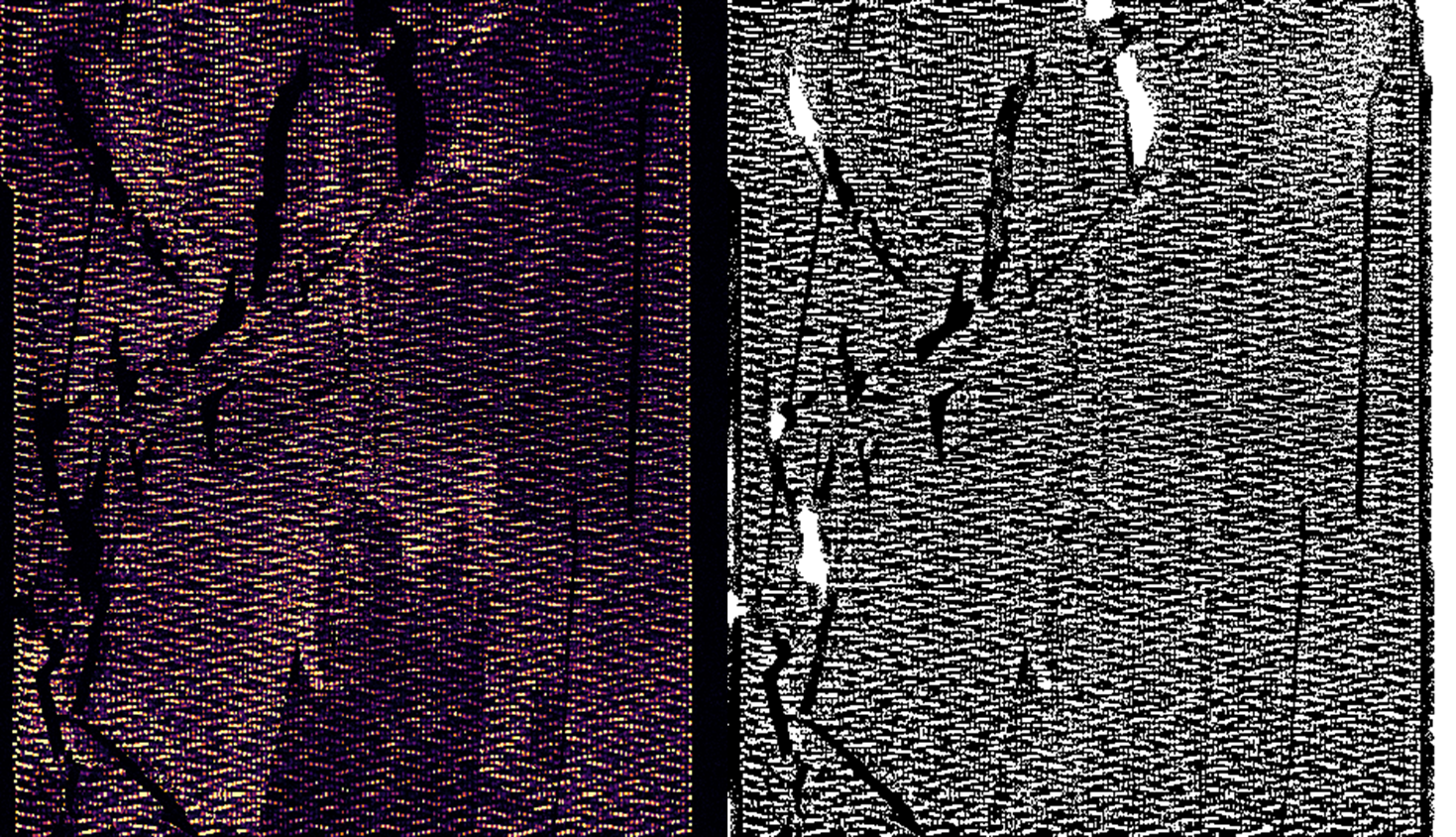
上图左图是传统的阈值分割方法,右边的图像就是利用小波变换的图像分割。可以看出右图分割得到的边缘更加准确和清晰
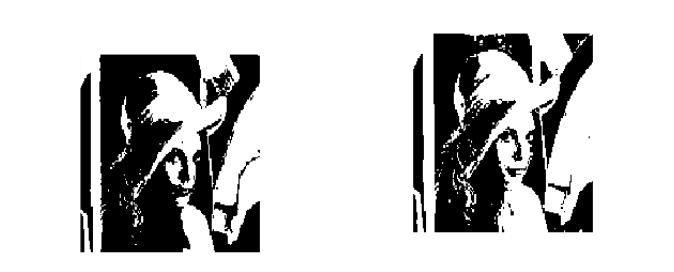
另外,将小波和其他方法结合起来处理图像分割的问题也得到了广泛研究,比如一种局部自适应阈值法就是将Hilbert图像扫描和小波相结合,从而获得了连续光滑的阈值曲线。
1.7 基于遗传算法的图像分割
遗传算法(Genetic Algorithms,简称GA)是1973年由美国教授Holland提出的,是一种借鉴生物界自然选择和自然遗传机制的随机化搜索算法。是仿生学在数学领域的应用。其基本思想是,模拟由一些基因串控制的生物群体的进化过程,把该过程的原理应用到搜索算法中,以提高寻优的速度和质量。此算法的搜索过程不直接作用在变量上,而是在参数集进行了编码的个体,这使得遗传算法可直接对结构对象(图像)进行操作。整个搜索过程是从一组解迭代到另一组解,采用同时处理群体中多个个体的方法,降低了陷入局部最优解的可能性,并易于并行化。搜索过程采用概率的变迁规则来指导搜索方向,而不采用确定性搜索规则,而且对搜索空间没有任何特殊要求(如连通性、凸性等),只利用适应性信息,不需要导数等其他辅助信息,适应范围广。
遗传算法擅长于全局搜索,但局部搜索能力不足,所以常把遗传算法和其他算法结合起来应用。将遗传算法运用到图像处理主要是考虑到遗传算法具有与问题领域无关且快速随机的搜索能力。其搜索从群体出发,具有潜在的并行性,可以进行多个个体的同时比较,能有效的加快图像处理的速度。但是遗传算法也有其缺点:搜索所使用的评价函数的设计、初始种群的选择有一定的依赖性等。要是能够结合一些启发算法进行改进且遗传算法的并行机制的潜力得到充分的利用,这是当前遗传算法在图像处理中的一个研究热点。
2. 图像分割之阈值分割
2.1 OSTU算法
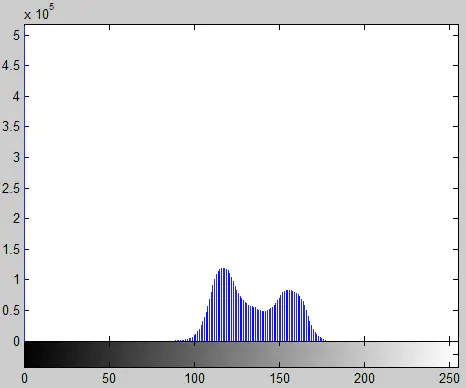
Otsu算法,也叫最大类间方差法(大津算法),是一种全局阈值的算法。
之所以称为最大类间方差法是因为,用该阈值进行的图像固定阈值二值化,类间方差最大,它是按图像的灰度特性,将图像分成背景和前景两部分,使类间方差最大的分割意味着错分概率最小。
原理:
对于图像I(x,y),前景(即目标)和背景的分割阈值记作T,属于前景的像素点数占整幅图像的比例记为ω0,其平均灰度μ0;背景像素点数占整幅图像的比例为ω1,其平均灰度为μ1。图像的总平均灰度记为μ,类间方差记为g。
假设图像的背景较暗,并且图像的大小为M×N,图像中像素的灰度值小于阈值T的像素个数记作N0,像素灰度大于阈值T的像素个数记作N1,则有:
(1) ω0=N0/ (M×N)
(2) ω1=N1/ (M×N)
(3) N0 + N1 = M×N
(4) ω0 + ω1 = 1
(5) μ = ω0 * μ0 + ω1 * μ1
(6) g = ω0 * (μ0 - μ)2 + ω1 * (μ1 - μ)2
将式(5)代入式(6),得到等价公式:
(7) g = ω0 *ω1 * (μ0 - μ1)2
采用遍历的方法得到使类间方差g最大的阈值T。
算法评价:
优点:算法简单,当目标与背景的面积相差不大时,能够有效地对图像进行分割。
缺点:当图像中的目标与背景的面积相差很大时,表现为直方图没有明显的双峰,或者两个峰的大小相差很大,分割效果不佳,或者目标与背景的灰度有较大的重叠时也不能准确的将目标与背景分开。
原因:该方法忽略了图像的空间信息,同时将图像的灰度分布作为分割图像的依据,对噪声也相当敏感。
OpenCV提供的API:
double threshold(InputArray src, OutputArray dst, double thresh, double maxval, int type)
参数:
- src:输入图,只能输入单通道,8位或32位浮点数图像。
- dst:输出图,尺寸大小、深度会和输入图相同。
- thresh:阈值。
- maxval:二值化结果的最大值。
- type:二值化操作形态,共有THRESH_BINARY、THRESH_BINARY_INV、THRESH_TRUNC、THRESH_TOZERO、THRESH_TOZERO_INV五种。type从上述五种结合CV_THRESH_OTSU就是OSTU算法,写成:THRESH_BINARY | CV_THRESH_OTSU。
2.1.1 基于OpenCV实现
#include <cstdio>
#include <opencv2/opencv.hpp>
int main() {
cv::Mat src = cv::imread("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\OSTU\\car.png");
if (src.empty()) {
return -1;
}
if (src.channels() > 1)
cv::cvtColor(src, src, cv::COLOR_RGB2GRAY);
cv::Mat dst;
threshold(src, dst, 0, 255, cv::THRESH_BINARY | cv::THRESH_OTSU); // 由于是OSTU算法,threshold这个参数无用
cv::namedWindow("src", cv::WINDOW_NORMAL);
cv::imshow("src", src);
cv::namedWindow("dst", cv::WINDOW_NORMAL);
cv::imshow("dst", dst);
cv::imwrite("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\OSTU\\car_output.png", dst);
cv::waitKey(0);
return 0;
}
我们对一张普通的车的图片进行了测试,结果如下所示:

下面我们对kitti图像和散斑结构光图像进行分割,结果如下所示:

- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka

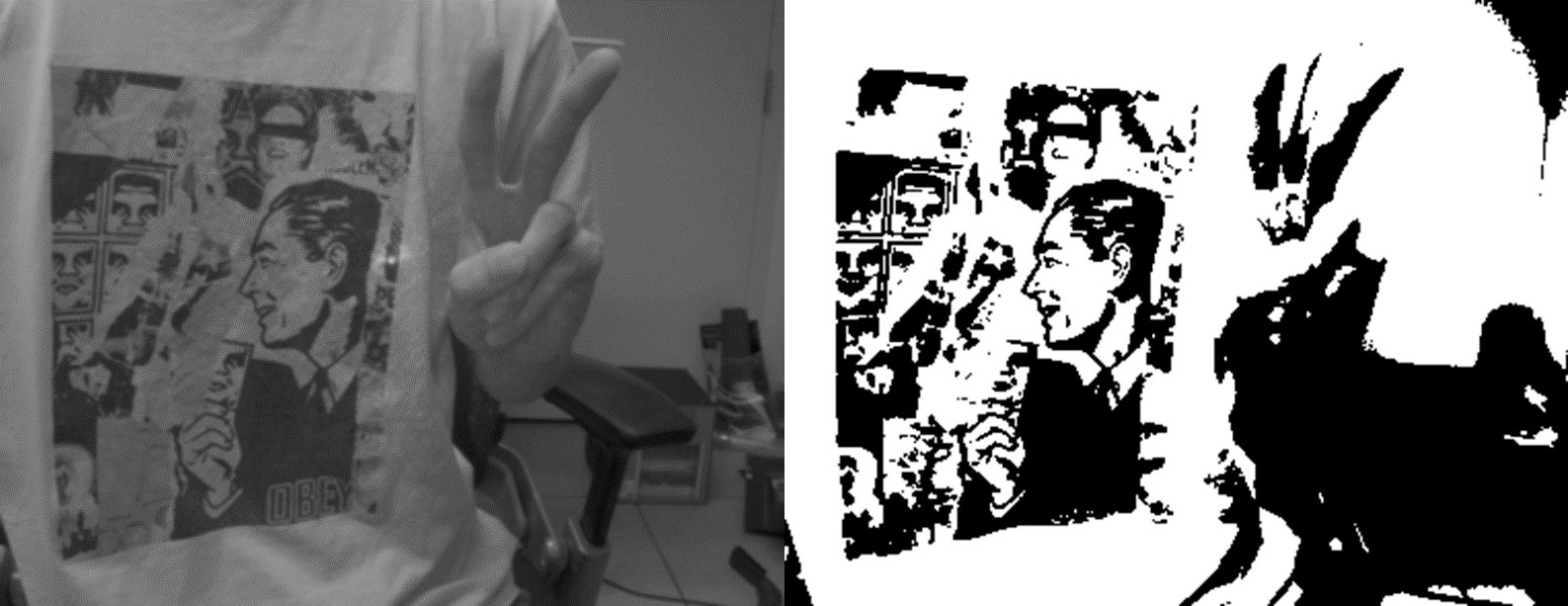





2.2 自适应阈值法
自适应阈值法(adaptiveThreshold),它的思想不是计算全局图像的阈值,而是根据图像不同区域亮度分布,计算其局部阈值,所以对于图像不同区域,能够自适应计算不同的阈值,因此被称为自适应阈值法。(其实就是局部阈值法)
如何确定局部阈值呢?可以计算某个邻域(局部)的均值、中值、高斯加权平均(高斯滤波)来确定阈值。值得说明的是:如果用局部的均值作为局部的阈值,就是常说的移动平均法。
OpenCV提供的API:
void adaptiveThreshold(InputArray src, OutputArray dst, double maxValue,
int adaptiveMethod, int thresholdType, int blockSize, double C)
参数:
- InputArray src:源图像
- OutputArray dst:输出图像,与源图像大小一致
- int adaptiveMethod:在一个邻域内计算阈值所采用的算法,有两个取值,分别为 ADAPTIVE_THRESH_MEAN_C 和 ADAPTIVE_THRESH_GAUSSIAN_C 。
- ADAPTIVE_THRESH_MEAN_C的计算方法是计算出领域的平均值再减去第七个参数double C的值。
- ADAPTIVE_THRESH_GAUSSIAN_C的计算方法是计算出领域的高斯均值再减去第七个参数double C的值。
- int thresholdType:这是阈值类型,有以下几个选择。
- THRESH_BINARY 二进制阈值化 -> 大于阈值为1 小于阈值为0
- THRESH_BINARY_INV 反二进制阈值化 -> 大于阈值为0 小于阈值为1
- THRESH_TRUNC 截断阈值化 -> 大于阈值为阈值,小于阈值不变
- THRESH_TOZERO 阈值化为0 -> 大于阈值的不变,小于阈值的全为0
- THRESH_TOZERO_INV 反阈值化为0 -> 大于阈值为0,小于阈值不变
- int blockSize:adaptiveThreshold的计算单位是像素的邻域块,这是局部邻域大小,3、5、7等。
- double C:这个参数实际上是一个偏移值调整量,用均值和高斯计算阈值后,再减这个值就是最终阈值。
注:相比OpenCV的API,我多用了一个中值法确定阈值。
2.2.1 基于OpenCV实现
#include <iostream>
#include <opencv2/core.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
enum adaptiveMethod { meanFilter, gaaussianFilter, medianFilter };
void AdaptiveThreshold(cv::Mat& src, cv::Mat& dst, double Maxval, int Subsize, double c, adaptiveMethod method = meanFilter) {
if (src.channels() > 1)
cv::cvtColor(src, src, cv::COLOR_RGB2GRAY);
cv::Mat smooth;
switch (method)
{
case meanFilter:
cv::blur(src, smooth, cv::Size(Subsize, Subsize)); //均值滤波
break;
case gaaussianFilter:
cv::GaussianBlur(src, smooth, cv::Size(Subsize, Subsize), 0, 0); //高斯滤波
break;
case medianFilter:
cv::medianBlur(src, smooth, Subsize); //中值滤波
break;
default:
break;
}
smooth = smooth - c;
//阈值处理
src.copyTo(dst);
for (int r = 0; r < src.rows; ++r) {
const uchar* srcptr = src.ptr<uchar>(r);
const uchar* smoothptr = smooth.ptr<uchar>(r);
uchar* dstptr = dst.ptr<uchar>(r);
for (int c = 0; c < src.cols; ++c) {
if (srcptr[c] > smoothptr[c]) {
dstptr[c] = Maxval;
}
else
dstptr[c] = 0;
}
}
}
int main() {
cv::Mat src = cv::imread("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\car.png");
if (src.empty()) {
return -1;
}
if (src.channels() > 1)
cv::cvtColor(src, src, cv::COLOR_RGB2GRAY);
cv::Mat dst, dst2;
double t2 = (double)cv::getTickCount();
AdaptiveThreshold(src, dst, 255, 21, 10, meanFilter); //
t2 = (double)cv::getTickCount() - t2;
double time2 = (t2 * 1000.) / ((double)cv::getTickFrequency());
std::cout << "my_process=" << time2 << " ms. " << std::endl << std::endl;
cv::adaptiveThreshold(src, dst2, 255, cv::ADAPTIVE_THRESH_MEAN_C, cv::THRESH_BINARY, 21, 10);
cv::namedWindow("src", cv::WINDOW_NORMAL);
cv::imshow("src", src);
cv::namedWindow("dst", cv::WINDOW_NORMAL);
cv::imshow("dst", dst);
cv::namedWindow("dst2", cv::WINDOW_NORMAL);
cv::imshow("dst2", dst2);
cv::imwrite("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\car_output.png", dst);
cv::waitKey(0);
}
我们对一张普通的车的图片进行了测试,结果如下所示:
左边的图像是原图,中间的图像是我们自己写的阈值分割算法的结果,右边的图像是opencv自带的阈值分割算法的结果,可以看到,两种结果是一样的。而且分割的效果都不错。

然后,我们还对kitti图像和散斑结构光图像(相当于向原图中加入了类似椒盐噪声)进行了阈值分割,先来看看结果。由于自己写的分割算法与opencv自带算法相当,由于我们写的算法还有中值滤波的选项,所以我们使用我们自己的算法。下面是结果:

- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka

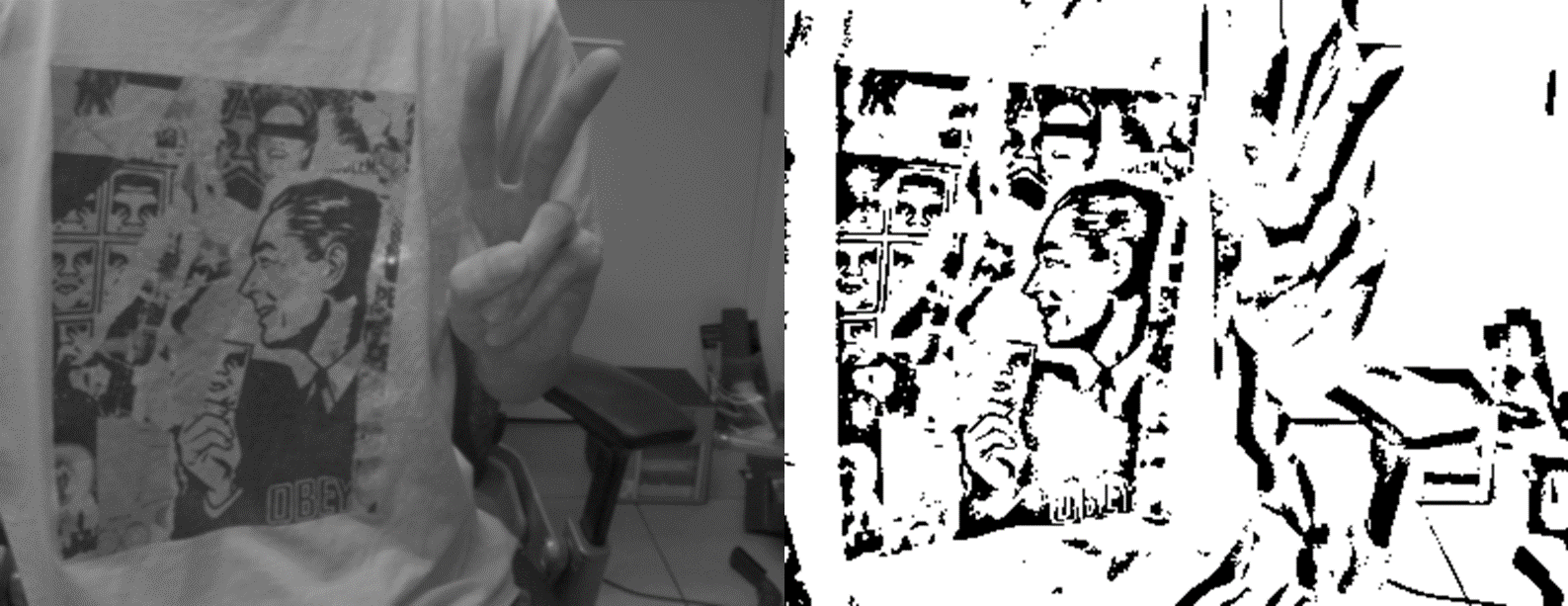




3. 基于边缘的分割方法
基于边缘检测的图像分割方法的基本思路是先确定图像中的边缘像素,然后再把这些像素连接在一起就构成所需的区域边界。
图像边缘,即表示图像中一个区域的终结和另一个区域的开始,图像中相邻区域之间的像素集合构成了图像的边缘。所以,图像边缘可以理解为图像灰度发生空间突变的像素的集合。图像边缘有两个要素,即:方向和幅度。沿着边缘走向的像素值变化比较平缓;而沿着垂直于边缘的走向,像素值则变化得比较大。因此,根据这一变化特点,通常会采用一阶和二阶导数来描述和检测边缘。
综上,图像中的边缘检测可以通过对灰度值求导数来确定,而导数可以通过微分算子计算来实现。在数字图像处理中,通常是利用差分计算来近似代替微分运算。
参考下面两篇博客:
这里只列举其中的两种算子:LoG算子和Canny算子。因为这两种算子能够较好的抑制噪声。
3.1 LoG算子


OpenCV提供的API:
void GaussianBlur(InputArray src, OutputArray dst, Size ksize, double sigmaX, double sigmaY=0, int borderType=BORDER_DEFAULT )
参数:
- InputArray src: 输入图像,可以是Mat类型,图像深度为CV_8U、CV_16U、CV_16S、CV_32F、CV_64F。
- OutputArray dst: 输出图像,与输入图像有相同的类型和尺寸。
- Size ksize: 高斯内核大小,这个尺寸与前面两个滤波kernel尺寸不同,ksize.width和ksize.height可以不相同但是这两个值必须为正奇数,如果这两个值为0,他们的值将由sigma计算。
- double sigmaX: 高斯核函数在X方向上的标准偏差。
- double sigmaY: 高斯核函数在Y方向上的标准偏差,如果sigmaY是0,则函数会自动将sigmaY的值设置为与sigmaX相同的值,如果sigmaX和sigmaY都是0,这两个值将由ksize.width和ksize.height计算而来。
- int borderType=BORDER_DEFAULT: 推断图像外部像素的某种便捷模式,有默认值BORDER_DEFAULT,如果没有特殊需要不用更改,具体可以参考borderInterpolate()函数。
void Laplacian( InputArray src, OutputArray dst, int ddepth,
int ksize = 1, double scale = 1, double delta = 0,
int borderType = BORDER_DEFAULT )
参数:
- src:输入原图像,可以是灰度图像或彩色图像。
- dst:输出图像,与输入图像src具有相同的尺寸和通道数
- ddepth:输出图像的数据类型(深度),根据输入图像的数据类型不同拥有不同的取值范围,因为输入图像一般为CV_8U,为了避免数据溢出,输出图像深度应该设置为CV_16S。
- ksize:滤波器的大小,必须为正奇数。
- scale:对导数计算结果进行缩放的缩放因子,默认系数为1,表示不进行缩放。
- delta:额外加的数值,就是在卷积过程中该数值会添加到每个像素上。
- borderType:界填充方式。默认BORDER_DEFAULT,表示不包含边界值倒序填充。
3.1.1 基于OpenCV实现
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
using namespace cv;
int main()
{
//使用LoG算子做边缘检测
Mat src;
int kernel_size = 3;
src = imread("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\LoG边缘检测\\car.png");
GaussianBlur(src, src, Size(3, 3), 0, 0, BORDER_DEFAULT); //先通过高斯模糊去噪声
if (src.channels() > 1)
cv::cvtColor(src, src, cv::COLOR_RGB2GRAY);
Mat dst, abs_dst;
Laplacian(src, dst, CV_16S, kernel_size); //通过拉普拉斯算子做边缘检测
convertScaleAbs(dst, abs_dst);
namedWindow("src", WINDOW_NORMAL);
imshow("src", src);
namedWindow("dst", WINDOW_NORMAL);
imshow("dst", abs_dst);
imwrite("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\LoG边缘检测\\car_output.png", abs_dst);
waitKey(0);
//使用自定义滤波做边缘检测
//自定义滤波算子 1 1 1
// 1 -8 1
// 1 1 1
//Mat custom_src, custom_gray, Kernel;
//custom_src = imread("Lenna.jpg");
//GaussianBlur(custom_src, custom_src, Size(3, 3), 0, 0, BORDER_DEFAULT); //先通过高斯模糊去噪声
//cvtColor(custom_src, custom_gray, COLOR_RGB2GRAY);
//namedWindow("Custom Filter", WINDOW_AUTOSIZE);
//Kernel = (Mat_<double>(3, 3) << 1, 1, 1, 1, -8, 1, 1, 1, 1); //自定义滤波算子做边缘检测
//Mat custdst, abs_custdst;
//filter2D(custom_gray, custdst, CV_16S, Kernel, Point(-1, -1));
//convertScaleAbs(custdst, abs_custdst);
//imshow("Custom Filter", abs_custdst);
//waitKey(0);
return 0;
}
下面给出结果:


- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka

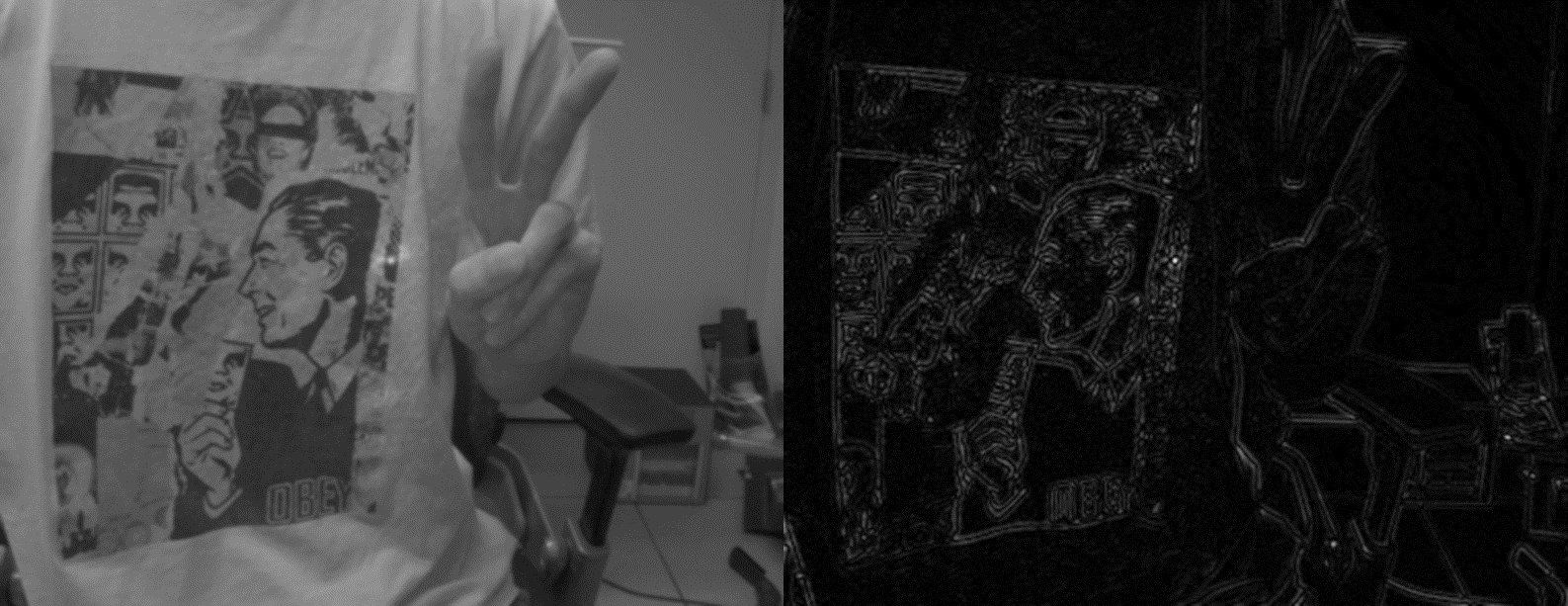





3.2 Canny算子
OpenCV提供的API:

void Canny(InputArray image,OutputArray edges, double threshold1, double threshold2, int apertureSize=3,bool L2gradient=false )
参数:
- InputArray image:输入图像,即源图像,填Mat类的对象即可,且需为单通道8位图像。
- OutputArray edges:输出的边缘图,需要和源图片有一样的尺寸和类型。
- double threshold1:第一个滞后性阈值。
- double threshold2:第二个滞后性阈值。
- int apertureSize:表示应用Sobel算子的孔径大小,其有默认值3。
- bool L2gradient:一个计算图像梯度幅值的标识,有默认值false。
3.2.1 基于Opencv实现
结果展示:


- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka







4. 图像分割之分水岭算法
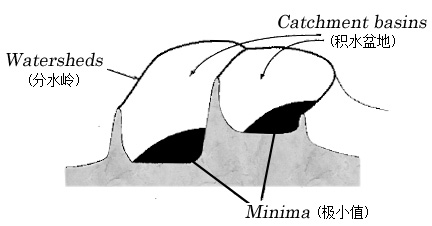
分水岭比较经典的计算方法是L.Vincent于1991年在PAMI上提出的。传统的分水岭分割方法,是一种基于拓扑理论的数学形态学的分割方法,其基本思想是把图像看作是测地学上的拓扑地貌,图像中每一像素的灰度值表示该点的海拔高度,每一个局部极小值及其影响区域称为集水盆地,而集水盆地的边界则形成分水岭。分水岭的概念和形成可以通过模拟浸入过程来说明。在每一个局部极小值表面,刺穿一个小孔,然后把整个模型慢慢浸人水中,随着浸入的加深,每一个局部极小值的影响域慢慢向外扩展,在两个集水盆汇合处构筑大坝如下图所示,即形成分水岭,下图为传统分水岭算法示意图。
然而基于梯度图像的直接分水岭算法(涨水过程都是基于梯度图)容易导致图像的过分割,产生这一现象的原因主要是由于输入的图像存在过多的极小区域(指的是梯度极小值)而产生许多小的集水盆地,从而导致分割后的图像不能将图像中有意义的区域表示出来。所以必须对分割结果的相似区域进行合并。
为了解决过分割的问题,学者们提出了基于标记(mark)图像的分水岭算法,就是通过先验知识,来指导分水岭算法,以便获得更好的图像分割效果。通常的mark图像,都是在某个区域定义了一些灰度层级,在这个区域的洪水淹没过程中,水平面都是从定义的高度开始的,这样可以避免一些很小的噪声极小值区域的分割。
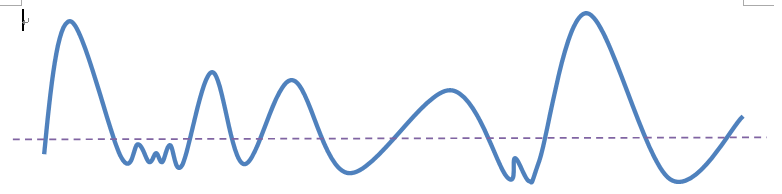
下面比较了两种分水岭的思路:
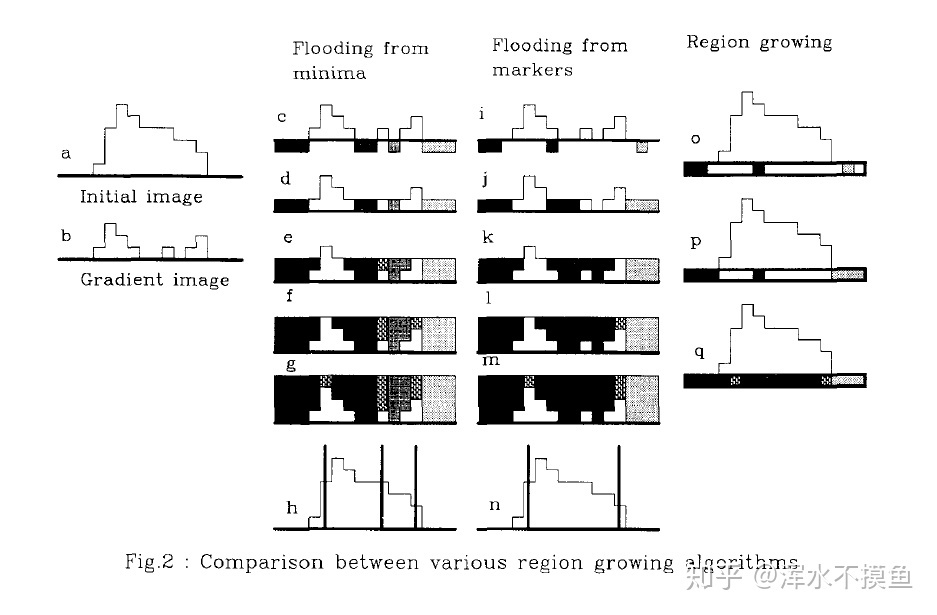
从Fig.2看,原图fig.2a,梯度图fig.2b(flooding涨水过程都是基于梯度图):
1.通过最小值构建分水岭(Flooding from minima),即从最小的灰度值开始z涨水(flooding)。步骤如下:
从b图看,得到4个局部最小区域,每一个区域都被标注为一个独立的颜色(fig.2c)(其中两块为背景)。接下来涨水过程如fig.2d-fig.2g所示,最后得到fig2.h的分割结果(当涨水到两个区域相邻时候为分水岭)。这样得到的分水岭容易过分割。
2.通过markers构建分水岭(flooding from markers),步骤如下:
如fig.2i,构建3个初始markers,涨水过程为fig.2j - fig.2m。着表明markers的选取不一定要在区域最小值位置。但是这种办法需要自己构建markers(背景也是要有一个marker)
OpenCV提供了一种改进的分水岭算法,使用一系列预定义标记来引导图像分割的定义方式。使用OpenCV的分水岭算法cv::wathershed,需要输入一个标记图像,图像的像素值为32位有符号正数(CV_32S类型),每个非零像素代表一个标签。它的原理是对图像中部分像素做标记,表明它的所属区域是已知的。分水岭算法可以根据这个初始标签确定其他像素所属的区域。
opencv提供的函数:
void watershed( InputArray image, InputOutputArray markers );
参数:
- InputArray image:输入图像,必须为8位三通道图像。
- InputOutputArray markers:标签图像。
分水岭算法其实关键是研究如何生成标签图像,关于这一点,下面给出两篇博客提供的两种不同的方法。
4.1 方法一:前景背景标签
算法步骤:
- 封装分水岭算法类
- 获取标记图像
- 获取前景像素,并用255标记前景
- 获取背景像素,并用128标记背景,未知像素,使用0标记
- 合成标记图像
- 将原图和标记图像输入分水岭算法
- 显示结果
4.1.1 基于Opencv实现
下面只给出代码,具体请看OpenCV—图像分割中的分水岭算法原理与应用
#include <opencv2/core/core.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
class WatershedSegmenter {
private:
cv::Mat markers;
public:
void setMarkers(const cv::Mat& markerImage) {
// Convert to image of ints
markerImage.convertTo(markers, CV_32S);
}
cv::Mat process(const cv::Mat& image) {
// Apply watershed
cv::watershed(image, markers);
return markers;
}
// Return result in the form of an image
cv::Mat getSegmentation() {
cv::Mat tmp;
// all segment with label higher than 255
// will be assigned value 255
markers.convertTo(tmp, CV_8U);
return tmp;
}
// Return watershed in the form of an image以图像的形式返回分水岭
cv::Mat getWatersheds() {
cv::Mat tmp;
//在变换前,把每个像素p转换为255p+255(在conertTo中实现)
markers.convertTo(tmp, CV_8U, 255, 255);
return tmp;
}
};
int main() {
// Read input image
cv::Mat image1 = cv::imread("C:\\Users\\Changming Deng\\Desktop\\飞机.png");
if (!image1.data)
return 0;
// Display the color image
cv::resize(image1, image1, cv::Size(), 0.7, 0.7);
cv::namedWindow("Original Image1");
cv::imshow("Original Image1", image1);
// Identify image pixels with object
cv::Mat binary;
cv::cvtColor(image1, binary, cv::COLOR_BGRA2GRAY);
cv::threshold(binary, binary, 30, 255, cv::THRESH_BINARY_INV);//阈值分割原图的灰度图,获得二值图像
// Display the binary image
cv::namedWindow("binary Image1");
cv::imshow("binary Image1", binary);
cv::waitKey();
// CLOSE operation
cv::Mat element5(5, 5, CV_8U, cv::Scalar(1));//5*5正方形,8位uchar型,全1结构元素
cv::Mat fg1;
cv::morphologyEx(binary, fg1, cv::MORPH_CLOSE, element5, cv::Point(-1, -1), 1);// 闭运算填充物体内细小空洞、连接邻近物体
// Display the foreground image
cv::namedWindow("Foreground Image");
cv::imshow("Foreground Image", fg1);
cv::waitKey(0);
// Identify image pixels without objects
cv::Mat bg1;
cv::dilate(binary, bg1, cv::Mat(), cv::Point(-1, -1), 4);//膨胀4次,锚点为结构元素中心点
cv::threshold(bg1, bg1, 1, 128, cv::THRESH_BINARY_INV);//>=1的像素设置为128(即背景)
// Display the background image
cv::namedWindow("Background Image");
cv::imshow("Background Image", bg1);
cv::waitKey();
//Get markers image
cv::Mat markers1 = fg1 + bg1; //使用Mat类的重载运算符+来合并图像。
cv::namedWindow("markers Image");
cv::imshow("markers Image", markers1);
cv::waitKey();
// Apply watershed segmentation
WatershedSegmenter segmenter1; //实例化一个分水岭分割方法的对象
segmenter1.setMarkers(markers1);//设置算法的标记图像,使得水淹过程从这组预先定义好的标记像素开始
segmenter1.process(image1); //传入待分割原图
// Display segmentation result
cv::namedWindow("Segmentation1");
cv::imshow("Segmentation1", segmenter1.getSegmentation());//将修改后的标记图markers转换为可显示的8位灰度图并返回分割结果(白色为前景,灰色为背景,0为边缘)
cv::waitKey();
// Display watersheds
cv::namedWindow("Watersheds1");
cv::imshow("Watersheds1", segmenter1.getWatersheds());//以图像的形式返回分水岭(分割线条)
cv::waitKey();
// Get the masked image
cv::Mat maskimage = segmenter1.getSegmentation();
cv::threshold(maskimage, maskimage, 250, 1, cv::THRESH_BINARY);
cv::cvtColor(maskimage, maskimage, cv::COLOR_GRAY2BGR);
maskimage = image1.mul(maskimage);
cv::namedWindow("maskimage");
cv::imshow("maskimage", maskimage);
cv::waitKey();
// Turn background (0) to white (255)
int nl = maskimage.rows; // number of lines
int nc = maskimage.cols * maskimage.channels(); // total number of elements per line
for (int j = 0; j < nl; j++) {
uchar* data = maskimage.ptr<uchar>(j);
for (int i = 0; i < nc; i++)
{
// process each pixel ---------------------
if (*data == 0) //将背景由黑色改为白色显示
*data = 255;
data++;//指针操作:如为uchar型指针则移动1个字节,即移动到下1列
}
}
cv::namedWindow("result");
cv::imshow("result", maskimage);
cv::waitKey();
return 0;
}
自己的思考:上面的代码中,marker分为前景(255)、背景(128)和未知(0),这个marker输入分水岭算法后,相当于规定了两个注水点(区域),分别是前景和背景两个注水区域,然后剩下的未知区域是利用分水岭的规则进行逐步的浸没,找到最终的分割边界。
4.2 方法二:轮廓标签
步骤:
- 图像灰度化、滤波、Canny边缘检测
- 查找轮廓,并且把轮廓信息按照不同的编号绘制到watershed的第二个入参merkers上,相当于标记注水点。
- watershed分水岭运算
- 绘制分割出来的区域,视觉控还可以使用随机颜色填充,或者跟原始图像融合以下,以得到更好的显示效果。
4.2.1 基于Opencv实现
下面只给出代码,详细请看:Opencv分水岭算法——watershed自动图像分割用法
#include "opencv2/imgproc/imgproc.hpp"
#include "opencv2/highgui/highgui.hpp"
#include <iostream>
using namespace cv;
using namespace std;
Vec3b RandomColor(int value); //生成随机颜色函数
int main()
{
Mat image = imread("C:\\Users\\Changming Deng\\Desktop\\美女.png"); //载入RGB彩色图像
imshow("Source Image", image);
//灰度化,滤波,Canny边缘检测
Mat imageGray;
cvtColor(image, imageGray, COLOR_RGB2GRAY);//灰度转换
GaussianBlur(imageGray, imageGray, Size(5, 5), 2); //高斯滤波
imshow("Gray Image", imageGray);
Canny(imageGray, imageGray, 80, 150);
imshow("Canny Image", imageGray);
//查找轮廓
vector<vector<Point>> contours;
vector<Vec4i> hierarchy;
findContours(imageGray, contours, hierarchy, RETR_TREE, CHAIN_APPROX_SIMPLE, Point());
Mat imageContours = Mat::zeros(image.size(), CV_8UC1); //轮廓
Mat marks(image.size(), CV_32S); //Opencv分水岭第二个矩阵参数
marks = Scalar::all(0);
int index = 0;
int compCount = 0;
for (; index >= 0; index = hierarchy[index][0], compCount++)
{
//对marks进行标记,对不同区域的轮廓进行编号,相当于设置注水点,有多少轮廓,就有多少注水点
drawContours(marks, contours, index, Scalar::all(compCount + 1), 1, 8, hierarchy);
drawContours(imageContours, contours, index, Scalar(255), 1, 8, hierarchy);
}
//我们来看一下传入的矩阵marks里是什么东西
Mat marksShows;
convertScaleAbs(marks, marksShows);
imshow("marksShow", marksShows);
imshow("轮廓", imageContours);
watershed(image, marks);
//我们再来看一下分水岭算法之后的矩阵marks里是什么东西
Mat afterWatershed;
convertScaleAbs(marks, afterWatershed);
imshow("After Watershed", afterWatershed);
//对每一个区域进行颜色填充
Mat PerspectiveImage = Mat::zeros(image.size(), CV_8UC3);
for (int i = 0; i < marks.rows; i++)
{
for (int j = 0; j < marks.cols; j++)
{
int index = marks.at<int>(i, j);
if (marks.at<int>(i, j) == -1)
{
PerspectiveImage.at<Vec3b>(i, j) = Vec3b(255, 255, 255);
}
else
{
PerspectiveImage.at<Vec3b>(i, j) = RandomColor(index);
}
}
}
imshow("After ColorFill", PerspectiveImage);
//分割并填充颜色的结果跟原始图像融合
Mat wshed;
addWeighted(image, 0.4, PerspectiveImage, 0.6, 0, wshed);
imshow("AddWeighted Image", wshed);
waitKey();
}
Vec3b RandomColor(int value)
{
value = value % 255; //生成0~255的随机数
RNG rng;
int aa = rng.uniform(0, value);
int bb = rng.uniform(0, value);
int cc = rng.uniform(0, value);
return Vec3b(aa, bb, cc);
}
自己的思考:上面的代码中,marker由多个大于零且值不同的轮廓组成,其余区域未0,这个marker输入分水岭算法后,相当于规定了多个注水点(区域)(有多少个不同值的轮廓就有多少个注水区域),然后剩下的未知区域是利用分水岭的规则进行逐步的浸没,找到最终的分割边界。
下面对车的图像、kitti图像和散斑结构光图像进行测试:


- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka






5. 图像分割之Mean shift算法
Mean shift 算法是基于核密度估计的爬山算法,可用于聚类、图像分割、跟踪等。
我们来谈谈Mean shift算法的基本思想。
此外,从公式1中可以看到,只要是落入Sh的采样点,无论其离中心x的远近,对最终的Mh(x)计算的贡献是一样的。然而在现实跟踪过程中,当跟踪目标出现遮挡等影响时,由于外层的像素值容易受遮挡或背景的影响,所以目标模型中心附近的像素比靠外的像素更可靠。因此,对于所有采样点,每个样本点的重要性应该是不同的,离中心点越远,其权值应该越小。故引入核函数和权重系数来提高跟踪算法的鲁棒性并增加搜索跟踪能力。同理,对于图像分割,离中心点空间距离越近的点,都更可能是属于同一区域,因此图像分割也需要加入核函数。

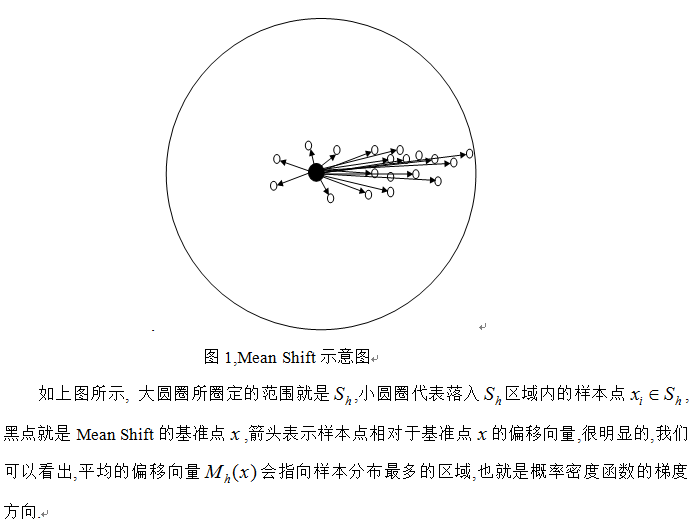
这个说的简单一点就是加入一个高斯权重,最后的漂移向量计算公式为:
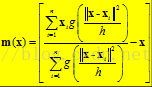
因此每次更新的圆心坐标为:
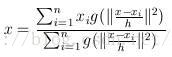
接下来,谈谈核函数:
下面我们来介绍用Mean shift进行聚类的流程:

1、在未被标记的数据点中随机选择一个点作为中心center;
2、找出离center距离在bandwidth之内的所有点,记做集合M,认为这些点属于簇c。同时,把这些求内点属于这个类的概率加1,这个参数将用于最后步骤的分类
3、以center为中心点,计算从center开始到集合M中每个元素的向量,将这些向量相加,得到向量shift。
4、center = center+shift。即center沿着shift的方向移动,移动距离是||shift||。
5、重复步骤2、3、4,直到shift的大小很小(就是迭代到收敛),记住此时的center。注意,这个迭代过程中遇到的点都应该归类到簇c。
6、如果收敛时当前簇c的center与其它已经存在的簇c2中心的距离小于阈值,那么把c2和c合并。否则,把c作为新的聚类,增加1类。
6、重复1、2、3、4、5直到所有的点都被标记访问。
7、分类:根据每个类,对每个点的访问频率,取访问频率最大的那个类,作为当前点集的所属类。
简单的说,mean shift就是沿着密度上升的方向寻找同属一个簇的数据点。
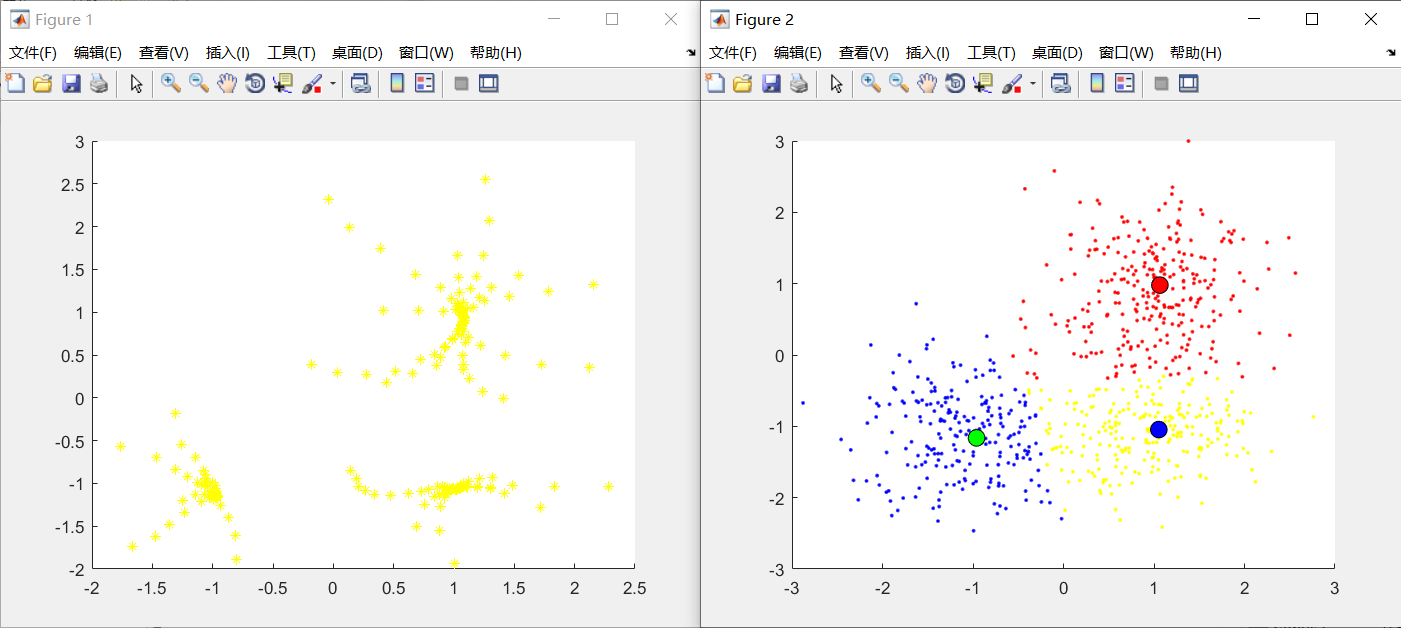
5.1 基于Matlab的Mean shift聚类
clc
close all;
clear
profile on
%生成随机数据点集
nPtsPerClust = 250;
nClust = 3;
totalNumPts = nPtsPerClust*nClust;
m(:,1) = [1 1]';
m(:,2) = [-1 -1]';
m(:,3) = [1 -1]';
var = .6;
bandwidth = .75;
clustMed = [];
x = var*randn(2,nPtsPerClust*nClust);
for i = 1:nClust
x(:,1+(i-1)*nPtsPerClust:(i)*nPtsPerClust) = x(:,1+(i-1)*nPtsPerClust:(i)*nPtsPerClust) + repmat(m(:,i),1,nPtsPerClust);
end
data=x';
% plot(data(:,1),data(:,2),'.')
%mean shift 算法
[m,n]=size(data);
index=1:m;
radius=0.75;
stopthresh=1e-3*radius;
visitflag=zeros(m,1);%标记是否被访问
count=[];
clustern=0;
clustercenter=[];
hold on;
while ~isempty(index)
cn=ceil((length(index)-1e-6)*rand);%随机选择一个未被标记的点,作为圆心,进行均值漂移迭代
center=data(index(cn),:);
this_class=zeros(m,1);%统计漂移过程中,每个点的访问频率
%步骤2、3、4、5
while 1
%计算球半径内的点集
dis=sum((repmat(center,m,1)-data).^2,2);
radius2=radius*radius;
innerS=find(dis<radius*radius);
visitflag(innerS)=1;%在均值漂移过程中,记录已经被访问过得点
this_class(innerS)=this_class(innerS)+1;
%根据漂移公式,计算新的圆心位置
newcenter=zeros(1,2);
% newcenter= mean(data(innerS,:),1);
sumweight=0;
for i=1:length(innerS)
w=exp(dis(innerS(i))/(radius*radius));
sumweight=w+sumweight;
newcenter=newcenter+w*data(innerS(i),:);
end
newcenter=newcenter./sumweight;
if norm(newcenter-center) <stopthresh%计算漂移距离,如果漂移距离小于阈值,那么停止漂移
break;
end
center=newcenter;
plot(center(1),center(2),'*y');
end
%步骤6 判断是否需要合并,如果不需要则增加聚类个数1个
mergewith=0;
for i=1:clustern
betw=norm(center-clustercenter(i,:));
if betw<radius/2
mergewith=i;
break;
end
end
if mergewith==0 %不需要合并
clustern=clustern+1;
clustercenter(clustern,:)=center;
count(:,clustern)=this_class;
else %合并
clustercenter(mergewith,:)=0.5*(clustercenter(mergewith,:)+center);
count(:,mergewith)=count(:,mergewith)+this_class;
end
%重新统计未被访问过的点
index=find(visitflag==0);
end%结束所有数据点访问
%绘制分类结果
for i=1:m
[value,index]=max(count(i,:));
Idx(i)=index;
end
figure(2);
hold on;
for i=1:m
if Idx(i)==1
plot(data(i,1),data(i,2),'.y');
elseif Idx(i)==2
plot(data(i,1),data(i,2),'.b');
elseif Idx(i)==3
plot(data(i,1),data(i,2),'.r');
elseif Idx(i)==4
plot(data(i,1),data(i,2),'.k');
elseif Idx(i)==5
plot(data(i,1),data(i,2),'.g');
end
end
cVec = 'bgrcmykbgrcmykbgrcmykbgrcmyk';
for k = 1:clustern
plot(clustercenter(k,1),clustercenter(k,2),'o','MarkerEdgeColor','k','MarkerFaceColor',cVec(k), 'MarkerSize',10)
end
结果:
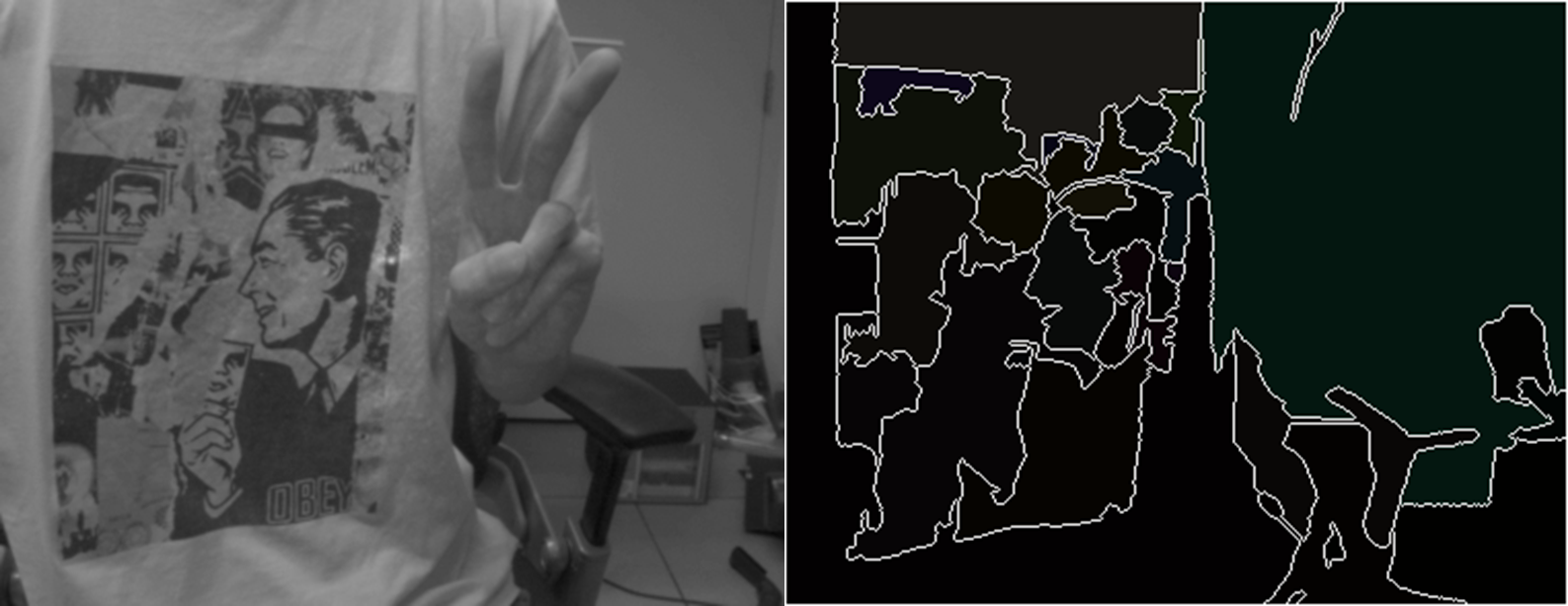
5.2 基于Opecv的Mean shift图像分割
一般而言一副图像的特征点至少可以提取出5维,即(x,y,r,g,b),众所周知,meanshift经常用来寻找模态点,即密度最大的点。所以这里同样可以用它来寻找这5维空间的模态点,由于不同的点最终会收敛到不同的峰值,所以这些点就形成了一类,这样就完成了图像分割的目的,有点聚类的意思在里面。
有一点需要注意的是图像像素的变化范围和坐标的变化范围是不同的,所以我们在使用窗口对这些数据点进行模态检测时,需要使用不同的窗口半径。
在opencv自带的meanshift分割函数pyrMeanShiftFiltering()函数中,就专门有2个参数供选择空间搜索窗口半径和颜色窗口搜索半径的。
OpenCV提供的API:
下面参考:
void pyrMeanShiftFiltering( InputArray src, OutputArray dst,
double sp, double sr, int maxLevel=1,
TermCriteria termcrit=TermCriteria(
TermCriteria::MAX_ITER+TermCriteria::EPS,5,1) );
参数:
-
src,输入图像,8位,三通道的彩色图像,并不要求必须是RGB格式,HSV、YUV等Opencv中的彩色图像格式均可;
-
dst,输出图像,跟输入src有同样的大小和数据格式;
-
sp,定义的漂移物理空间半径大小;
-
sr,定义的漂移色彩空间半径大小;
-
maxLevel,定义金字塔的最大层数;
-
termcrit,定义的漂移迭代终止条件,可以设置为迭代次数满足终止,迭代目标与中心点偏差满足终止,或者两者的结合。
在进行pyrMeanShiftFiltering滤波后,原图像的灰度级变成了中心点的数量,这就是使用了mean-shift算法滤波的结果,但是我们要的是分割图,因此需要借助另外一个漫水填充函数的进一步处理来实现,那就是floodFill:
int floodFill( InputOutputArray image, InputOutputArray mask,
Point seedPoint, Scalar newVal, CV_OUT Rect* rect=0,
Scalar loDiff=Scalar(), Scalar upDiff=Scalar(),
int flags=4 );
参数:
-
image,输入三通道8bit彩色图像,同时作为输出。
-
mask,是掩模图像,它的大小是输入图像的长宽左右各加1个像素,mask一方面作为输入的掩模图像,另一方面也会在填充的过程中不断被更新。floodFill漫水填充的过程并不会填充mask上灰度值不为0的像素点,所以可以使用一个图像边缘检测的输出作为mask,这样填充就不会填充或越过边缘轮廓。mask在填充的过程中被更新的过程是这样的:每当一个原始图上一个点位(x,y)被填充之后,该点位置对应的mask上的点(x+1,y+1)的灰度值随机被设置为1(原本该点的灰度值为0),代表该点已经被填充处理过。
-
seedPoint,是漫水填充的起始种子点。
-
newVal,被充填的色彩值。
-
rect,可选的参数,用于设置floodFill函数将要重绘区域的最小矩形区域;
-
loDiff和upDiff,用于定义跟种子点相比色彩的下限值和上限值,介于种子点减去loDiff和种子点加上upDiff的值会被填充为跟种子点同样的颜色;
-
flags定义漫水填充的模式,用于连通性、扩展方向等的定义。
#include "opencv2/highgui/highgui.hpp"
#include "opencv2/core/core.hpp"
#include "opencv2/imgproc/imgproc.hpp"
using namespace cv;
int main()
{
Mat img = imread("D:\\code\\C++\\图像分割\\image segmentation\\test_pic\\mean_shift\\草原.png"); //读入图像,RGB三通道
imshow("原图像", img);
Mat res; //分割后图像
int spatialRad = 30; //空间窗口大小
int colorRad = 30; //色彩窗口大小
int maxPyrLevel = 2; //金字塔层数
pyrMeanShiftFiltering(img, res, spatialRad, colorRad, maxPyrLevel); //色彩聚类平滑滤波
imshow("res", res);
RNG rng = theRNG();
Mat mask(res.rows + 2, res.cols + 2, CV_8UC1, Scalar::all(0)); //掩模
for (int y = 0; y < res.rows; y++)
{
for (int x = 0; x < res.cols; x++)
{
if (mask.at<uchar>(y + 1, x + 1) == 0) //非0处即为1,表示已经经过填充,不再处理
{
Scalar newVal(rng(256), rng(256), rng(256));
floodFill(res, mask, Point(x, y), newVal, 0, Scalar::all(5), Scalar::all(5)); //执行漫水填充
}
}
}
imshow("meanShift图像分割", res);
waitKey();
return 0;
}
结果:



下面将空间窗口和颜色窗口都改为20,给出对车的图像,kitti图像和散斑图像的分割结果:


- real-general

-
real-indoor1
-
real-indoor2
-
real-indoor3
-
real-outdoor
-
synthetic-intel
-
synthetic-ideal
-
synthetic-polka

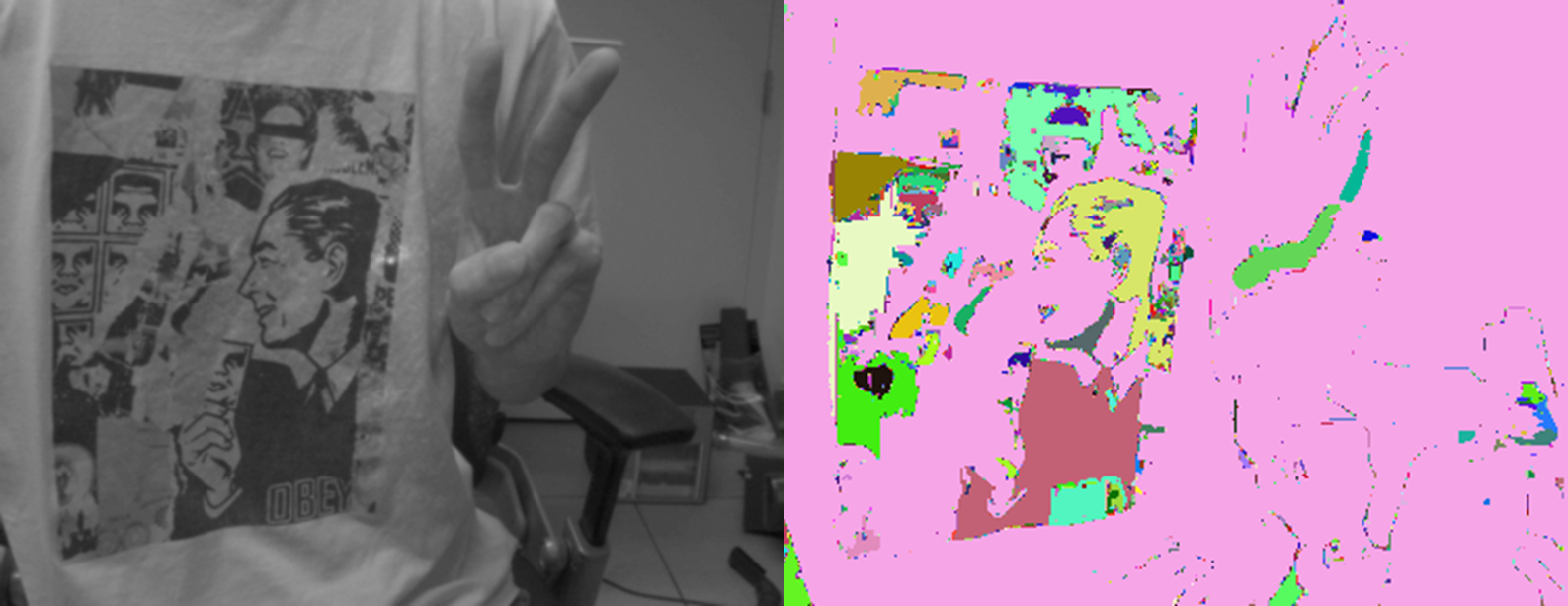





mean-shift算法可以重复使用,也就是分割完再分割,还能对分割图应用canny算子再次提取边缘。当然,这样是很耗时的。