点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达论文代码是否应该公开已是争论已久的问题,有从业者呼吁通过代码提交减少当下各类论文中的「水分」,也有研发人员表示「代码提交」类问题得因「研究」而异。不过单从我们最关心的各类顶会而言,似乎可以简单从三个角度去看待此问题:如果评审能够拿到底层代码或者数据,是否能更好地做评审工作?开放代码对作者有好处吗?对读者有好处吗?
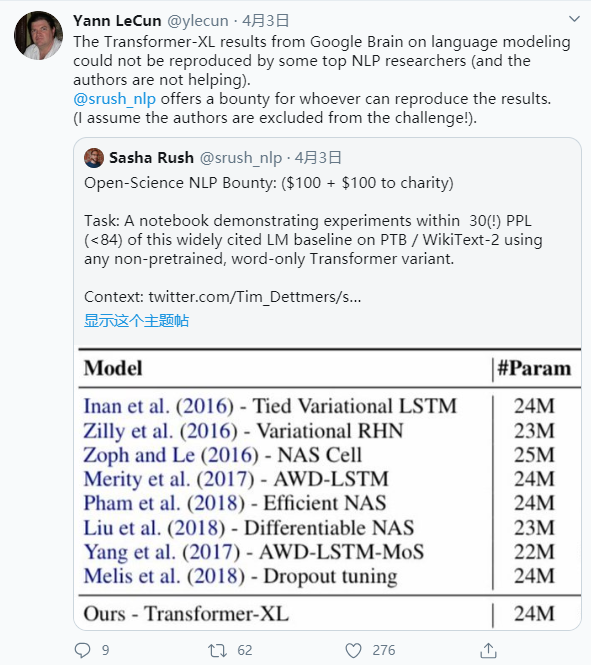
上周,图灵奖得主 Yann LeCun 公开质疑谷歌大脑的论文无法复现,引起了社区热议。Lecun 表示,即使是 NLP 的一些顶级研究人员也无法复现谷歌大脑的语言模型 Transformer-XL 所得到的结果。此外,有人还面向广大研发人员发出了「江湖悬赏令」,称成功复现者将获得「酬劳」。
迄今为止,行业内仍有相当数量的优质研究未能复现,这也使得后来的研究工作多多少少受到影响。但由于各项研究的本质各不相同,所以这类问题需要多维度地去看待。例如,一篇偏理论的论文其算法可能不是核心,又或者由于研究所用数据涉及所有权问题,因此代码无法公开,从而导致可复现性受到阻碍。
那么研究论文的代码是否应该「开源」?我们来看开发者们的观点。
论文代码是否应该【强制】开源?
近日,一位网友在 Reddit 社区呼吁,希望所有研究者都能在发表论文的同时公开自己的代码,否则应该被直接拒绝。

发起人认为,任何形式的研究行为均可看做对知识体系的贡献,并终将造福于人类社会。在他看来,不将论文代码公开阻碍了这一进程,这样的行为不应受到鼓励。
他表示自己经常听到类似这样的评论:「如果我需要用代码申请专利并用它赚钱怎么办?」发起人给出了如下解决方案:不要写研究论文,而是为专利准备相关项目和文档。
此外也有这样的评论:「如果有人剽窃我的想法怎么办?」发起人建议,可以将论文先上传到 arXiv 这样的论文预印版平台上。
发起人同时表示,审稿人在论文代码没有公开的情况下就接收论文,这点让他感到理解无能。难道科学领域的审稿过程不应该确保其研究结果的可复现性吗?审稿人是如何做到在论文代码未公开的情况下进行测试的呢?
就目前的情况而言,公开代码并不是研究者发表论文时的「硬性规定」。在这一话题的评论区,许多人表达了自己的观点:
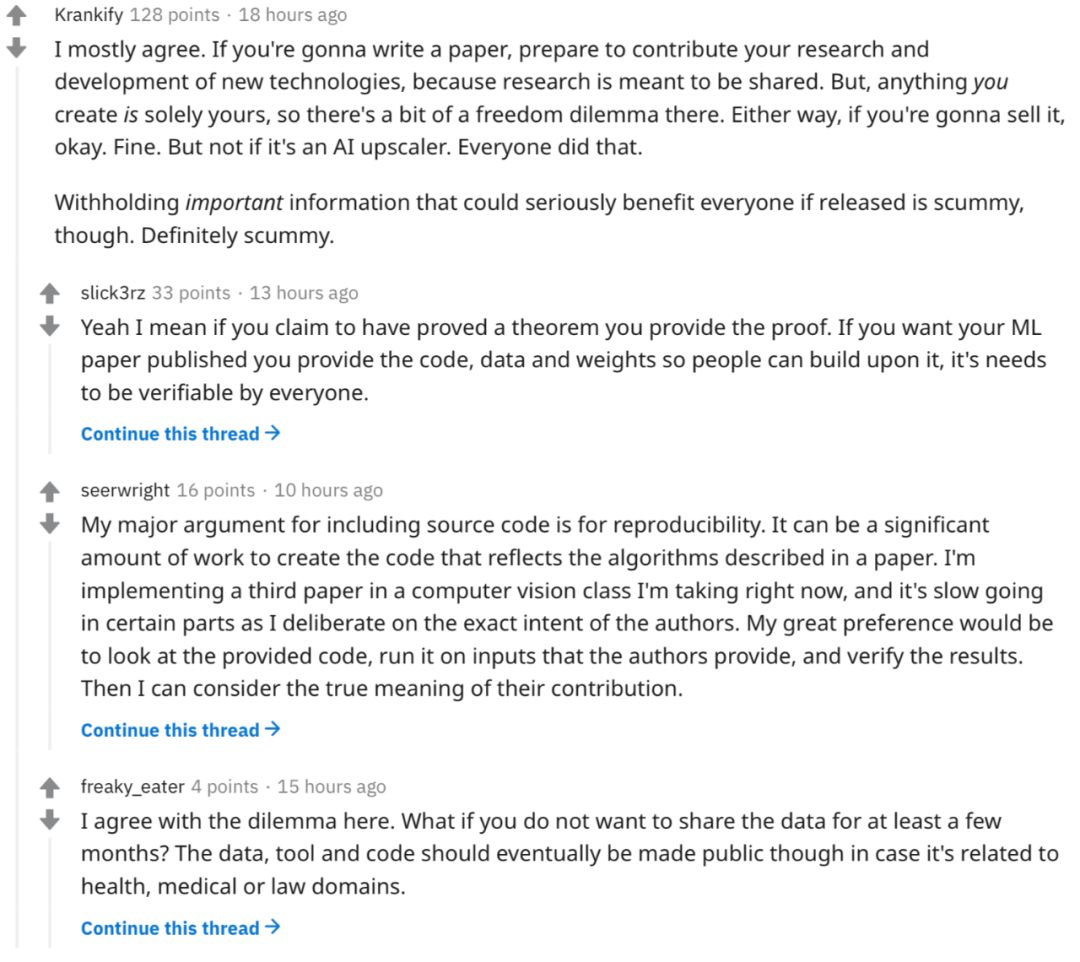
观点 1:研究本来就是要共享
写论文之前,就要准备好为新技术的研究和开发做贡献,因为研究本来就是要共享的。隐瞒那些公开后能够造福大众的重要信息,这样的行为是卑劣的。
观点 2:有些数据、代码是保密的,不能也不愿公开
我在石油领域做 ML 工作,这个领域的数据和代码都没有人公开,因为这些东西是保密的。那些论文的作者仅抛出一些方程来「解释」他们的神经网络是如何工作的。这些方法都是使用 Keras、PyTorch 等框架基于现有方法实现的,但作者仍然选择不公开他们的代码。
为什么会这样?很大程度上是为了避免别人仔细检查他们所提出的方法。每个人都会在论文中写道「我们进行了超参数调整并选择了最优的参数」。但这些超参数到底是多少,谁又知道呢?
因为它们属于 ML 应用研究,严格来说并不是 ML 本身,所以这些研究全部基于现有实现是没有问题的,但是这类研究也没有什么价值。
很多时候情况确实非常荒谬——「未完全解释的方法」使用「未公开的数据」在「未共享的模型」上取得了 98%的准确率。这就像是一篇删除了你想知道的所有研究重点的 Medium 文章。
神回复:
我做了一个准确率为 100% 的人脸识别项目。来源:相信我就好了,哥们儿。

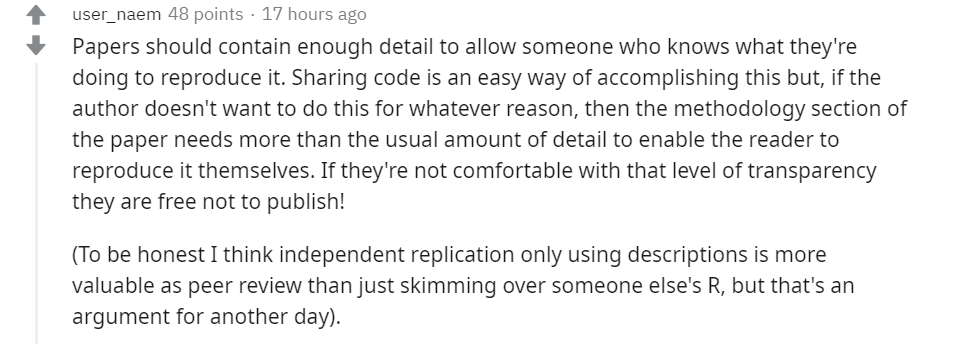
观点 3:论文本身应该包含足够多的细节,但是否开源是各人的自由
论文本身就应该包含足够多的细节,这样其他人才能了解如何复现。分享代码可以让他人轻松地复现,但如果论文作者不愿分享的话,则需要在方法部分提供更多的细节,这样读者才能自行复现。决定是否分享代码是研究者的自由,别人无权干涉。
观点 4:是否公开代码需根据研究类型而定
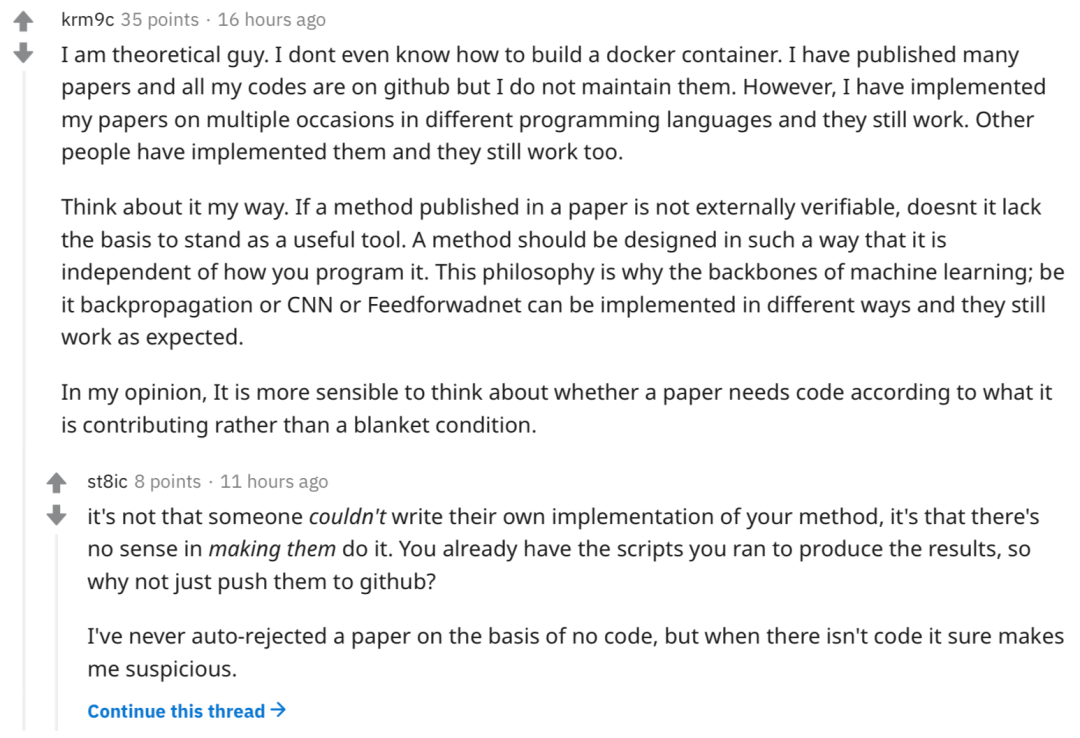
我是做理论研究的,甚至不知道如何创建 docker 容器。我发表了很多论文,并在 GitHub 上公开了所有的代码。有时候我会使用不同的编程语言来实现我的论文,那些方法依然有效。
如果论文所提出的方法无法从外部验证,那么它是否缺乏作为有用工具的依据?方法的设计应独立于其编程方式。在我看来,决定论文是否需要公开代码时,根据论文的具体贡献来做判断是更明智的做法,而不是一概而论。
观点 5:不会拒绝没有代码的论文,但会有疑虑
他们并不是不能写方法实现,但是「令」他们这么做可能毫无意义。你已经有了可以生成结果的脚本,为什么不直接把它们放到 GitHub 上呢?
我从未因为论文没有代码而拒绝一篇论文,但是没有代码会让我产生很多疑虑。

强制提交代码可能不切实际
ICML、ICLR 和 NeurIPS 都在努力推进将实验代码和数据作为评审材料的一部分提交,并鼓励作者在评审或出版过程中提交代码以帮助结果可复现。
以机器之心近期报道的 NeurIPS 为例:NeurIPS 组委会从 2019 年起就鼓励论文作者提交代码(非强制),而且成效显著。在 NeurIPS 2019 的最后提交阶段,有 75% 的被接收论文附带了代码。今年,NeuIPS 将代码提交从「鼓励」变成了「强烈建议」(仍不强制),还提供了提交代码的准则和模板。
目前依然有很多研究结果缺乏可复现性,很多优秀研究没有提供对应的代码。从可复现性层面看,每一年相较上一年都有不错的进步,同时也受到越来越多的关注。从研究角度来说,很多后来的研究者会基于先驱工作做一些新的探索,而缺乏可复现性将使其变得举步维艰。
此外,秉承着辩证思考的观点,有些研究者会对前沿工作有些怀疑,认为其研究结果存在水分。而提供可复现的代码能在一定程度上消除这样的质疑。
但不公开代码就直接拒绝未免过于「一刀切」,毕竟,可复现性并不是评价论文的唯一标准。
可复现性是重要的属性,但不是唯一的属性
如果对强制要求可复现性进行「一刀切」,将导致非常糟糕的后果。举例而言,部分研究真正有价值的部分是展示可能性,「什么是可能的?」这个问题也很关键,部分研究连代码也未发布,如果将可复现性作为绝对价值来看待,那么就会大概率错失这类研究成果。
采用「放之四海皆准」的策略是一种错误,要求每一篇论文都是可编程复现的会降低各类研究社区的活力与创新。机器之心早期报道过微软研究院 John Langford 的观点,值得借鉴。
从机器学习角度出发,John Langford 认为其研究类型至少有三种:
算法:研究目标是发现一些更好的算法以解决各种学习问题,是顶会中最典型的类型。
理论:研究目标是一般性地理解哪些学习算法是可能的,哪些是不可能的。虽然这些论文同样可能提出算法,但它们通常并不要求一定要实现,因为这会浪费作者、评审者和读者的时间。
应用:这些研究的目标是解决特定的任务。AlphaGoZero 就是一个例子,它在围棋领域中用算法击败了世界冠军。对于这类研究而言,由于计算量大、数据所有权等特点,编程的可复现性可能不切实际。
而另一种可行方案是将代码作为补充资料进行定位,例如像附录那样查看代码(和数据)的提交,以便于评审探究和使用。而对于作者本人而言,提供额外的代码也便于说服那些善于质疑的评审。
值得肯定的是,各大顶会的组委会都在积极尝试探索针对提交代码的「平衡」,没有所谓的「一刀切」,从 19 年的尝试到今年初看效果,还是能感受到长足的进步。找到最适合各社区的「平衡」才是长久之道。
参考链接:https://www.reddit.com/r/MachineLearning/comments/fzss9t/d_if_a_paper_or_project_doesnt_publicly_release/
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~

