点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达来源 | AI公园
作者 | amitness
编译 | ronghuaiyang
【导读】仅使用10张带有标签的图像,它在CIFAR-10上的中位精度为78%,最大精度为84%,来看看是怎么做到的。
深度学习在计算机视觉领域展示了非常有前途的结果。但是当将它应用于实际的医学成像等领域的时候,标签数据的缺乏是一个主要的挑战。
在实际环境中,对数据做标注是一个耗时和昂贵的过程。你有很多的图片,由于资源约束,只有一小部分人可以进行标注。在这样的情况下,我们如何利用大量未标注的图像以及部分已标注的图像来提高我们的模型的性能?答案是semi-supervised学习。
FixMatch是Google Brain的Sohn等人最近开发的一种半监督方法,它改善了半监督学习(SSL)的技术水平。它是对之前的方法(例如UDA和ReMixMatch)的简单组合。在本文中,我们将了解FixMatch的概念,并看到仅使用10张带有标签的图像,它在CIFAR-10上的中位精度为78%,最大精度为84%。
FixMatch背后的直觉
假设我们正在对猫与狗进行分类,但是我们的标签数据有限,并且有很多未标签的猫狗图像。

我们通常的“监督学习”方法将是仅在标注图像上训练分类器,而忽略未标注的图像。
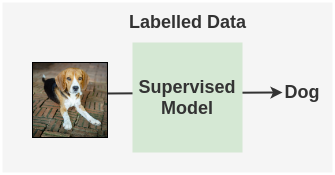
除了忽略未标注的图像,我们还可以应用以下方法。我们知道模型也应该能够处理图像的扰动,从而提高泛化能力。
如果我们对未标注的图像进行图像增强,并让监督模型预测这些图像会怎么样?由于是同一张图片,因此两者的预测的标签应该相同。
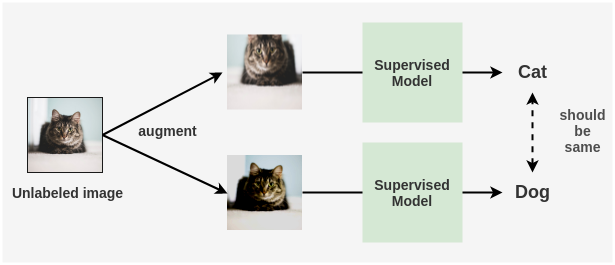
因此,即使不知道其正确的标签,我们也可以将未标注的图像用作训练流水线的一部分。这是FixMatch及其之前的许多论文背后的核心思想。
FixMatch的Pipeline
凭直觉,让我们看看如何在实践中实际应用FixMatch。下图总结了整个pipeline:
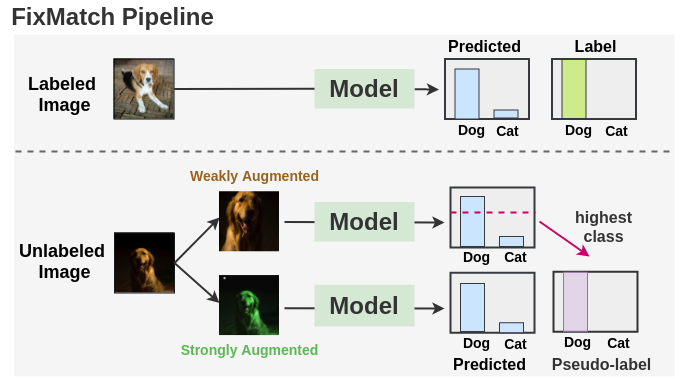
如图所示,我们使用交叉熵损失在标注的图像上训练了监督模型。对于每个未标注的图像,使用弱增强和强增强获得两个图像。弱增强图像被传递到我们的模型中,我们得到了关于类的预测。将最有信心的类别的概率与阈值进行比较。如果它高于阈值,那么我们将该类作为ground truth的标签,即伪标签。然后,将经过强增强的图像传递到我们的模型中,获取类别的预测。使用交叉熵损失将此概率分布与ground truth伪标签进行比较。两种损失组合起来进行模型的更新。
Pipeline的组件
1. 训练数据和增强
FixMatch借鉴了UDA和ReMixMatch的这一思想,应用不同的增强方法,即在未标注的图像上进行弱增强以生成伪标签,同时在未标注图像上进行强增强以进行预测。
a. 弱增强
对于弱增强,本文使用标准的翻转和平移策略。它包括两个简单的增强:
Random Horizontal Flip

应用此增强的概率为50%。对于SVHN数据集,将跳过此步骤,因为那些图像包含与水平翻转无关的数字。在PyTorch中,可以使用transforms执行以下操作:
from PIL import Image
import torchvision.transforms as transforms
im = Image.open('dog.png')
weak_im = transforms.RandomHorizontalFlip(p=0.5)(im)随机水平和垂直移动
12.5%,在PyTorch中,可以使用以下代码来实现,其中32是图像的大小:

import torchvision.transforms as transforms
from PIL import Image
im = Image.open('dog.png')
resized_im = transforms.Resize(32)(im)
translated = transforms.RandomCrop(size=32,
padding=int(32*0.125),
padding_mode='reflect')(resized_im)b. 强增强
其中包括输出严重失真的输入图像的增强版本。FixMatch应用RandAugment或CTAugment,然后应用CutOut增强。
1. Cutout

这种增强会随机删除图像的正方形部分,并用灰色或黑色填充。PyTorch没有内置的Cutout函数,但是我们可以重用其RandomErasing函数来达到CutOut的效果。
import torch
import torchvision.transforms as transforms
# Image of 520*520
im = torch.rand(3, 520, 520)
# Fill cutout with gray color
gray_code = 127
# ratio=(1, 1) to set aspect ratio of square
# p=1 means probability is 1, so always apply cutout
# scale=(0.01, 0.01) means we want to get cutout of 1% of image area
# Hence: Cuts out gray square of 52*52
cutout_im = transforms.RandomErasing(p=1,
ratio=(1, 1),
scale=(0.01, 0.01),
value=gray_code)(im)2. AutoAugment的变体
以前的SSL使用的是AutoAugment,这个工具训练了一个强化学习算法来寻找让代理任务(例如CIFAR-10)得到最佳准确性的增强方法。这是有问题的,因为我们需要一些标注的数据集来学习增强,并且还受到使用RL的资源限制。
因此,FixMatch使用了AutoAugment的两个变体之一:
a. RandAugment
Random Augmentation(RandAugment) 思想是非常简单的。
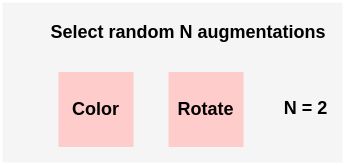
首先,你有一个14种可能的增强的列表,以及一系列可能的幅度。

你从这个列表里随机选出N个增强,这里我们从列表里选出两种。
然后我们选择一个随机的幅度M,从1到10。我们可以选择一个幅度5,这意味着以百分比表示的幅度为50%,因为最大可能的M为10,所以百分比= 5/10 = 50%。
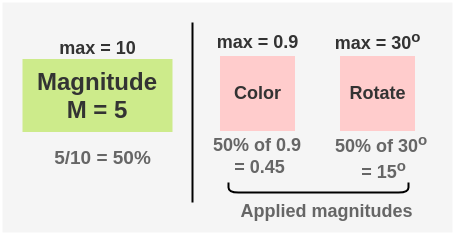
现在,将所选的增强应用于序列中的图像。每种增强都有50%的可能性被应用。

N和M的值可以通过在验证集上使用网格搜索的超参数优化来找到。在本文中,在每个训练步骤使用预定义范围内的随机幅度,而不是固定幅度。
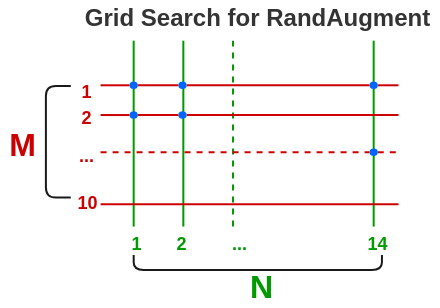
b. CTAugment
CTAugment是ReMixMatch论文中引入的一种增强技术,它使用控制理论中的思想来消除对AutoAugment中增强学习的需求。运作方式如下:
我们有一组18种可能的变换,类似于RandAugment
变换的幅度值被划分为bin,每个bin被分配一个权重。最初,所有bin的权重均为1。
现在从该集合中以相等的概率随机选择两个变换,它们的序列形成了一条管道。这类似于RandAugment。
对于每个变换,根据归一化的bin权重随机选择一个幅值bin
现在,带有标记的样本通过这两个转换得到了增强,并传递给模型以进行预测
根据模型预测值与实际标签的接近程度,更新这些变换的bin权重。
因此,它学会选择具有较高的机会来预测正确的标签的模型,从而在网络容差范围内进行增强。
因此,我们看到,与RandAugment不同,CTAugment可以在训练过程中动态学习每个变换的幅度。因此,我们无需在某些受监督的代理任务上对其进行优化,并且它没有敏感的超参数可优化。因此,这非常适合缺少标签数据的半监督环境。
2. 模型结构
本文使用称为Wide Residual Networks的ResNet的更广和更浅的变体作为基础体系结构。使用的确切变体是Wide-Resnet-28-2,深度为28,扩展因子为2。因此,此模型的宽度是ResNet的两倍。它总共有150万个参数。该模型与输出层堆叠在一起,输出层的节点等于所需的类数(例如,用于猫/狗分类的2个类)。
3. 模型训练和损失函数
步骤1: 准备batches
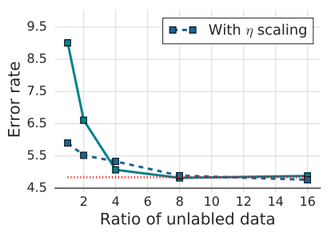
我们准备了批大小为B的标记图像和批大小为μB的未标记图像。μ是一个超参数,它决定批中未标注图像的相对大小。例如,μ=2意味着我们使用的未标注图像数量是标注图像的两倍。

该论文尝试增加μ的值,发现随着我们增加未标注图像的数量,错误率会降低。本文将μ=7用于验证数据集。
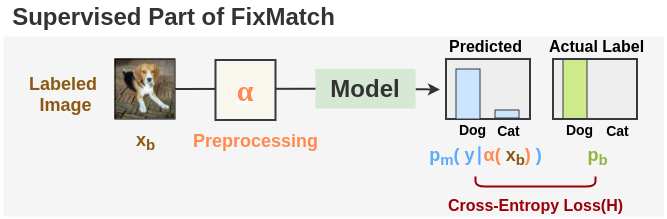
步骤2: 监督学习
对于在标注图像上训练的监督部分,我们将常规的交叉熵损失H()用于分类任务。batch的总损失由定义,并通过取batch中每个图像的交叉熵损失的平均值来计算。
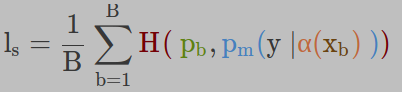
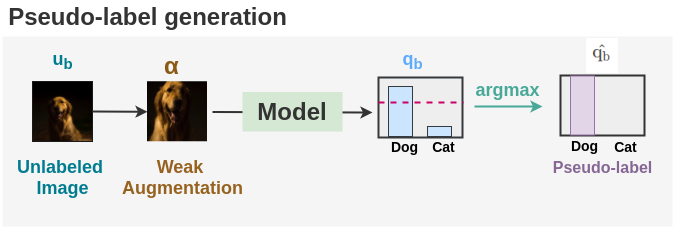
步骤3: 伪标签
对于未标注的图像,首先我们对未标注的图像应用弱增强,并通过argmax获得最高概率的预测类别。这就是伪标签,将与强增强图像上的模型输出进行比较。
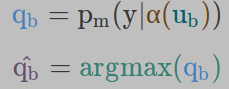
步骤4: 一致性正则化
现在,同一张未标注的图片进行了强增强,并将其输出与我们的伪标签进行比较以计算交叉熵损失H()。未标注的总batch损失由表示,并由下式给出:
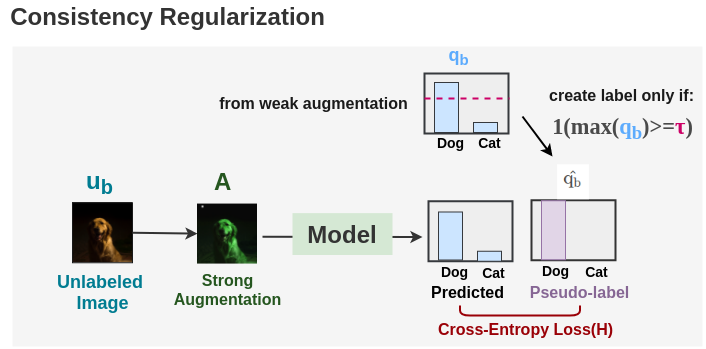
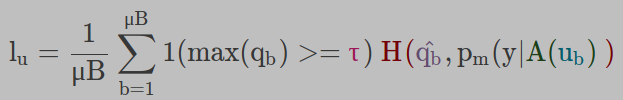
这里τ表示阈值,在该阈值之上我们采用伪标签。该损失类似于伪标签损失。不同之处在于,我们使用弱增强来生成标签,而强增强则用于损失。
步骤5: 课程学习
最后,我们将这两个损失相结合,以获得总损失,我们可以对其进行优化以改进模型。是一个固定的标量超参数,它决定了未标注图像损失相对于标注损失的贡献量。
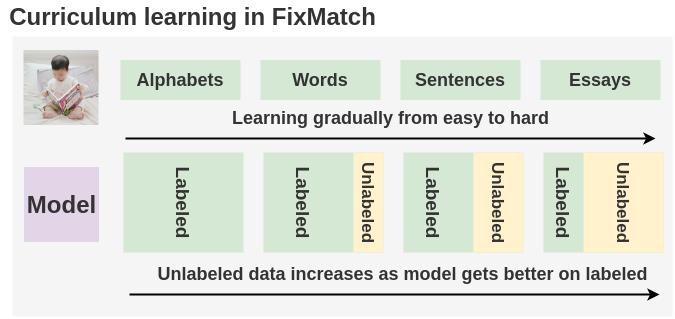
有趣的结果来自。以前的工作表明,在训练过程中增加权重是很好的。但是,在FixMatch中,这是自动内置的。由于最初,该模型对标注的数据没有把握,因此其对未标注的数据的输出预测将低于阈值。这样,将仅在标注的数据上训练模型。但是随着训练的进行,模型对标注的数据变得更加自信,因此,对未标注数据的预测也将开始超过阈值。这样,损失将很快也开始包含对未标注图像的预测。这为我们提供了一种免费的课程学习形式。
从直觉上讲,这类似于我们在儿童时期的教学方式。在早期,我们先学习一些简单的概念,例如字母表及其代表的含义,然后再继续学习复杂的主题,例如构词,句子和文章。
论文中的直觉
1. 我们可以每个类别只学习一张图片吗?
作者对CIFAR-10数据集进行了一个非常有趣的实验。他们仅使用10个标注图像(即每个类别1个标注样本)在CIFAR-10上训练了模型。
他们通过从数据集中从每个类中随机选择一个样本来创建4个数据集,并对每个数据集进行4次训练。他们达到了48.58%至85.32%的测试准确度,中位准确率为64.28%。准确性的这种差异是由于标注样本的质量所致。当模型提供低质量的样本时,很难有效地学习每个类别。

为了测试这一点,他们创建了8个训练数据集,其样本范围从最有代表性的到最不代表性的。他们遵循了本文的顺序并分为8个bin。第一个bin包含最具代表性的图像,而最后一个bin包含离群值。然后,他们从每个bin中随机抽取每个类别的一个样本,以创建8个标注过的训练集并训练FixMatch模型。结果是:
最具代表性的bin:中位数精度为78%,最大精度为84%
中等代表性的bin:准确度达65%
离群值:仅仅有10%的精度无法完全收敛
评估和结果
作者对常用的SSL的数据集(例如CIFAR-10,CIFAR-100,SVHN,STL-10和ImageNet)进行了评估。
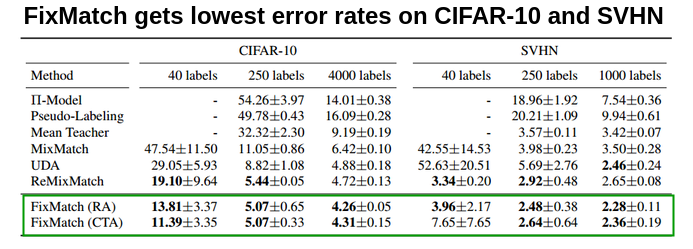
CIFAR-10和SVHN:
FixMatch在CIFAR-10和SVHN基准测试中获得了state of the art的结果。
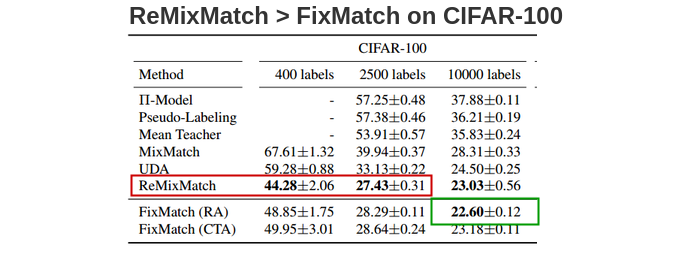
CIFAR-100:
在CIFAR-100上,ReMixMatch优于FixMatch。为了理解原因,作者从ReMixMatch中借用了各种组件到FixMatch上,并测量了它们对性能的影响。他们发现,*Distribution Alignment(DA)*组件促使模型以相同的概率预测所有类,这就是原因。因此,当他们将FixMatch与DA结合使用时,他们实现了40.14%的错误率,而ReMixMatch的错误率为44.28%。
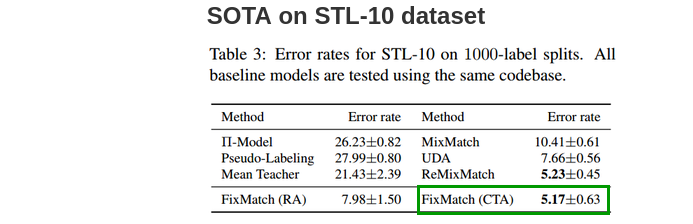
STL-10:
STL-10数据集由100,000个未标注图像和5000个标注图像组成。我们需要预测10类(飞机,鸟,汽车,猫,鹿,狗,马,猴子,船,卡车)。它是半监督学习的更具代表性的评估方法,因为其未标注的集合具有分布以外的图像。在所有方法中,对1000张带标签的图像进行5折评估时,FixMatch的CTAugment可以实现最低的错误率。
ImageNet:
作者还评估了ImageNet上的模型,以验证其是否适用于大型和复杂的数据集。他们将训练数据的10%作为标记的图像,其余的90%作为未标记的图像。同样,所使用的体系结构是ResNet-50而不是WideResNet,并且RandAugment被用作增强。他们的top-1错误率达到28.54%±0.52,比UDA高2.68%。top5的错误率是10.87%±0.28%。
代码实现
官方实现,TensorFlow:https://github.com/google-research/fixmatch。
PyTorch的的非官方实现:
1、https://github.com/kekmodel/FixMatch-pytorch
2、https://github.com/CoinCheung/fixmatch
3、https://github.com/valencebond/FixMatch_pytorch
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~