基于机器学习的车牌识别系统
本文设计的车牌处理系统主要用于通过手机、路口监视器拍到的车牌照片进行识别。由图像处理、车牌定位、字符分割和字符识别四个模块组成,该四部分需要依次执行,其中的每一模块需要利用上一模块的结果,并为下一模块提供服务。
算法流程分为预处理、车牌定位、字符分割和字符识别四部分。在图像处理部分,主要通过高斯去噪、灰度变化、二值化等技术去除与车牌无关的背景因素,最后通过Canny算法找到各个图像的边缘。在车牌定位部分,首先通过findContours函数寻找可能存在车牌的矩形区域并且面积和长宽比筛选不符合条件的矩形;然后再通过颜色定位的方法,根据色素分布选出车牌所在的区域;最后,再次通过颜色定位的方法去除矩形区域中不包含车牌区域的杂质边框,得到最终的车牌。在字符分割部分,先要对图像进行自适应的二值化处理使字符与背景分离开,接着通过水平直方图和垂直直方图的分布,分离出单个字符。在最后的字符识别部分,首先对图像进行HOG描述处理,然后分别对汉字和数字与字母构建SVM分类器,并将待识别的图像送入指定的分类器,从而完成车牌识别。
import cv2
import numpy as np
from numpy.linalg import norm # 求向量范数
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
import sys
import os
import json
SZ = 20 # 训练图片长宽
MAX_WIDTH = 1000 # 原始图片最大宽度
Min_Area = 2000 # 车牌区域允许最小面积
PROVINCE_START = 1000
# 读取图片文件
def imreadex(filename):
return cv2.imdecode(np.fromfile(filename, dtype=np.uint8), cv2.IMREAD_COLOR)
def point_limit(point):
if point[0] < 0:
point[0] = 0
if point[1] < 0:
point[1] = 0
# 根据设定的阈值和图片直方图,找出波峰,用于分隔字符
def find_waves(threshold, histogram):
up_point = -1 # 上升点
is_peak = False
if histogram[0] > threshold:
up_point = 0
is_peak = True
wave_peaks = []
for i, x in enumerate(histogram):
if is_peak and x < threshold:
if i - up_point > 2:
is_peak = False
wave_peaks.append((up_point, i))
elif not is_peak and x >= threshold:
is_peak = True
up_point = i
if is_peak and up_point != -1 and i - up_point > 4:
wave_peaks.append((up_point, i))
return wave_peaks
# 根据找出的波峰,分隔图片,从而得到逐个字符图片
def seperate_card(img, waves):
part_cards = []
for wave in waves:
part_cards.append(img[:, wave[0]:wave[1]])
return part_cards
# 来自opencv的sample,用于svm训练
# 使用图片的二阶矩对图片进行抗扭斜处理
def deskew(img):
m = cv2.moments(img) # 获得图片的矩
if abs(m['mu02']) < 1e-2:
return img.copy()
skew = m['mu11'] / m['mu02']
M = np.float32([[1, skew, -0.5 * SZ * skew], [0, 1, 0]])
img = cv2.warpAffine(img, M, (SZ, SZ), flags=cv2.WARP_INVERSE_MAP | cv2.INTER_LINEAR) # 仿射变换 矫正车牌
return img
# 来自opencv的sample,用于svm训练
# 计算图像的hog描述符
def preprocess_hog(digits):
samples = []
for img in digits:
gx = cv2.Sobel(img, cv2.CV_32F, 1, 0)
gy = cv2.Sobel(img, cv2.CV_32F, 0, 1)
mag, ang = cv2.cartToPolar(gx, gy)
bin_n = 16
bin = np.int32(bin_n * ang / (2 * np.pi))
bin_cells = bin[:10, :10], bin[10:, :10], bin[:10, 10:], bin[10:, 10:]
mag_cells = mag[:10, :10], mag[10:, :10], mag[:10, 10:], mag[10:, 10:]
hists = [np.bincount(b.ravel(), m.ravel(), bin_n) for b, m in zip(bin_cells, mag_cells)]
hist = np.hstack(hists)
# transform to Hellinger kernel
eps = 1e-7
hist /= hist.sum() + eps
hist = np.sqrt(hist)
hist /= norm(hist) + eps
samples.append(hist)
return np.float32(samples)
# 不能保证包括所有省份
provinces = [
"zh_cuan", "川",
"zh_e", "鄂",
"zh_gan", "赣",
"zh_gan1", "甘",
"zh_gui", "贵",
"zh_gui1", "桂",
"zh_hei", "黑",
"zh_hu", "沪",
"zh_ji", "冀",
"zh_jin", "津",
"zh_jing", "京",
"zh_jl", "吉",
"zh_liao", "辽",
"zh_lu", "鲁",
"zh_meng", "蒙",
"zh_min", "闽",
"zh_ning", "宁",
"zh_qing", "靑",
"zh_qiong", "琼",
"zh_shan", "陕",
"zh_su", "苏",
"zh_sx", "晋",
"zh_wan", "皖",
"zh_xiang", "湘",
"zh_xin", "新",
"zh_yu", "豫",
"zh_yu1", "渝",
"zh_yue", "粤",
"zh_yun", "云",
"zh_zang", "藏",
"zh_zhe", "浙"
]
class StatModel(object):
def load(self, fn):
self.model = self.model.load(fn)
def save(self, fn):
self.model.save(fn)
class SVM(StatModel):
def __init__(self, C=1, gamma=0.5):
self.model = cv2.ml.SVM_create()
self.model.setGamma(gamma)
self.model.setC(C)
self.model.setKernel(cv2.ml.SVM_RBF)
self.model.setType(cv2.ml.SVM_C_SVC)
# 训练svm
def train(self, samples, responses):
self.model.train(samples, cv2.ml.ROW_SAMPLE, responses)
# 字符识别
def predict(self, samples):
r = self.model.predict(samples)
return r[1].ravel()
class CardPredictor:
def __init__(self):
# 车牌识别的部分参数保存在js中,便于根据图片分辨率做调整
f = open('config.js')
j = json.load(f)
for c in j["config"]:
if c["open"]:
self.cfg = c.copy()
break
else:
raise RuntimeError('没有设置有效配置参数')
def __del__(self):
self.save_traindata()
def train_svm(self):
# 识别英文字母和数字
self.model = SVM(C=1, gamma=0.5)
# 识别中文
self.modelchinese = SVM(C=1, gamma=0.5)
if os.path.exists("svm.dat"):
self.model.load("svm.dat")
else:
chars_train = []
chars_label = []
# 数据提取和打标签
for root, dirs, files in os.walk("train\\chars2"):
if len(os.path.basename(root)) > 1:
continue
root_int = ord(os.path.basename(root))
for filename in files:
filepath = os.path.join(root, filename)
digit_img = cv2.imread(filepath)
digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)
chars_train.append(digit_img)
# chars_label.append(1)
chars_label.append(root_int)
chars_train = list(map(deskew, chars_train))
chars_train = preprocess_hog(chars_train)
# chars_train = chars_train.reshape(-1, 20, 20).astype(np.float32)
chars_label = np.array(chars_label)
print(chars_train.shape)
self.model.train(chars_train, chars_label)
if os.path.exists("svmchinese.dat"):
self.modelchinese.load("svmchinese.dat")
else:
chars_train = []
chars_label = []
for root, dirs, files in os.walk("train\\charsChinese"):
if not os.path.basename(root).startswith("zh_"):
continue
pinyin = os.path.basename(root)
index = provinces.index(pinyin) + PROVINCE_START + 1 # 1是拼音对应的汉字
for filename in files:
filepath = os.path.join(root, filename)
digit_img = cv2.imread(filepath)
digit_img = cv2.cvtColor(digit_img, cv2.COLOR_BGR2GRAY)
chars_train.append(digit_img)
chars_label.append(1)
chars_label.append(index)
chars_train = list(map(deskew, chars_train))
chars_train = preprocess_hog(chars_train)
# chars_train = chars_train.reshape(-1, 20, 20).astype(np.float32)
chars_label = np.array(chars_label)
print(chars_train.shape)
# self.model.train(chars_train, chars_label)
self.modelchinese.train(chars_train, chars_label)
def save_traindata(self):
if not os.path.exists("svm.dat"):
self.model.save("svm.dat")
if not os.path.exists("svmchinese.dat"):
self.modelchinese.save("svmchinese.dat")
# 精确定位定位车牌
def accurate_place(self, card_img_hsv, limit1, limit2, color):
row_num, col_num = card_img_hsv.shape[:2]
xl = col_num
xr = 0
yh = 0
yl = row_num
# col_num_limit = self.cfg["col_num_limit"]
row_num_limit = self.cfg["row_num_limit"]
col_num_limit = col_num * 0.8 if color != "green" else col_num * 0.5 # 绿色有渐变
for i in range(row_num):
count = 0
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V:
count += 1
if count > col_num_limit:
if yl > i:
yl = i
if yh < i:
yh = i
for j in range(col_num):
count = 0
for i in range(row_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if limit1 < H <= limit2 and 34 < S and 46 < V :
count += 1
if count > row_num - row_num_limit:
if xl > j:
xl = j
if xr < j:
xr = j
return xl, xr, yh, yl
def predict(self, car_pic):
if type(car_pic) == type(""):
img = imreadex(car_pic)
else:
img = car_pic
pic_hight, pic_width = img.shape[:2]
# 图片裁剪为固定大小
if pic_width > MAX_WIDTH:
resize_rate = MAX_WIDTH / pic_width
img = cv2.resize(img, (MAX_WIDTH, int(pic_hight * resize_rate)), interpolation=cv2.INTER_AREA)
blur = self.cfg["blur"]
# 高斯去噪
if blur > 0:
img = cv2.GaussianBlur(img, (blur, blur), 0)
oldimg = img
cv2.imshow(" img_Gaussi", img)
cv2.waitKey(0)
img = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
cv2.imshow(" img_Gray", img)
cv2.waitKey(0)
# 开操作和加权强化对比度
kernel = np.ones((20, 20), np.uint8)
img_opening = cv2.morphologyEx(img, cv2.MORPH_OPEN, kernel)
img_opening = cv2.addWeighted(img, 1, img_opening, -1, 0);
# 找到图像边缘
ret, img_thresh = cv2.threshold(img_opening, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
img_edge = cv2.Canny(img_thresh, 100, 200)
cv2.imshow(" img_edge", img_edge)
cv2.waitKey(0)
# 使用开运算和闭运算让图像边缘成为一个整体
kernel = np.ones((self.cfg["morphologyr"], self.cfg["morphologyc"]), np.uint8)
img_edge1 = cv2.morphologyEx(img_edge, cv2.MORPH_CLOSE, kernel)
img_edge2 = cv2.morphologyEx(img_edge1, cv2.MORPH_OPEN, kernel)
cv2.imshow("img_edge2", img_edge2 )
cv2.waitKey(0)
# #去除一些小的白点
# kernelX = cv2.getStructuringElement(cv2.MORPH_RECT, (20, 1))
# kernelY = cv2.getStructuringElement(cv2.MORPH_RECT, (1, 19))
#
# # 膨胀,腐蚀
# img_edge2 = cv2.dilate(img_edge2, kernelX)
# img_edge2 = cv2.erode(img_edge2, kernelX)
# # 腐蚀,膨胀
# img_edge2 = cv2.erode(img_edge2, kernelY)
#img_edge2 = cv2.dilate(img_edge2, kernelY)
#中值滤波去除噪点
# img_edge2 = cv2.medianBlur(img_edge2, 15)
# cv2.imshow("img_edge_medianBlur", img_edge2)
# cv2.waitKey(0)
# 查找图像边缘整体形成的矩形区域,可能有很多,车牌就在其中一个矩形区域中(寻找包络)
try:
contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE )
except ValueError:
image, contours, hierarchy = cv2.findContours(img_edge2, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
contours = [cnt for cnt in contours if cv2.contourArea(cnt) > Min_Area]
# if cv2.contourArea(cnt) > Min_Area
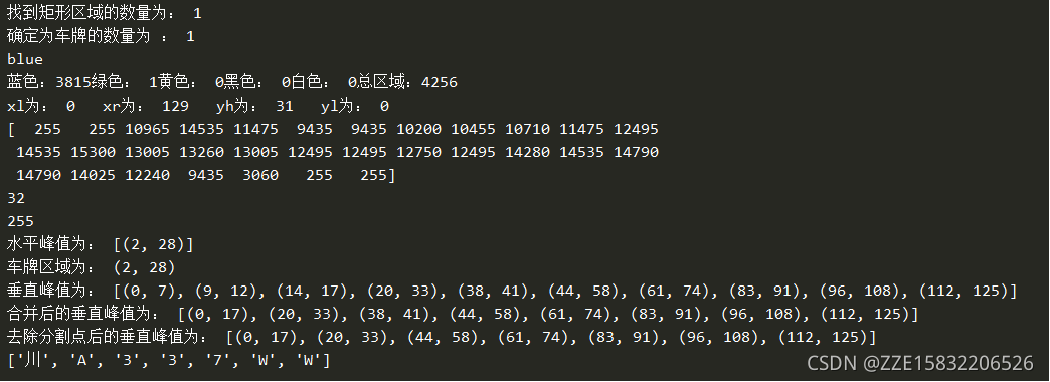
print('找到矩形区域的数量为:', len(contours))
# 一一排除不是车牌的矩形区域
car_contours = []
for cnt in contours:
rect = cv2.minAreaRect(cnt)
area_width, area_height = rect[1]
if area_width < area_height :
area_width, area_height = area_height, area_width
wh_ratio = area_width / area_height
# 要求矩形区域长宽比在2到5.5之间,2到5.5是车牌的长宽比,其余的矩形排除
if wh_ratio > 2 and wh_ratio < 5.5 :
car_contours.append(rect)
box = cv2.boxPoints(rect)
box = np.int0(box)
#oldimg = cv2.drawContours(oldimg, [box], 0, (0, 0, 255), 2)
# cv2.imshow("edge4", oldimg)
#cv2.waitKey(0)
#print(rect)
print('确定为车牌的数量为 :',len(car_contours))
#print("精确定位")
card_imgs = []
# 矩形区域可能是倾斜的矩形,需要矫正,以便使用颜色定位
for rect in car_contours:
if rect[2] > -1 and rect[2] < 1: # 创造角度,使得左、高、右、低拿到正确的值
angle = 1
else:
angle = rect[2]
rect = (rect[0], (rect[1][0] + 5, rect[1][1] + 5), angle) # 扩大范围,避免车牌边缘被排除
box = cv2.boxPoints(rect)
heigth_point = right_point = [0, 0]
left_point = low_point = [pic_width, pic_hight]
for point in box:
if left_point[0] > point[0]:
left_point = point
if low_point[1] > point[1]:
low_point = point
if heigth_point[1] < point[1]:
heigth_point = point
if right_point[0] < point[0]:
right_point = point
if left_point[1] <= right_point[1]: # 正角度
new_right_point = [right_point[0], heigth_point[1]]
pts2 = np.float32([left_point, heigth_point, new_right_point]) # 字符只是高度需要改变
pts1 = np.float32([left_point, heigth_point, right_point])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))
point_limit(new_right_point)
point_limit(heigth_point)
point_limit(left_point)
card_img = dst[int(left_point[1]):int(heigth_point[1]), int(left_point[0]):int(new_right_point[0])]
card_imgs.append(card_img)
# cv2.imshow("card", card_img)
# cv2.waitKey(0)
elif left_point[1] > right_point[1]: # 负角度
new_left_point = [left_point[0], heigth_point[1]]
pts2 = np.float32([new_left_point, heigth_point, right_point]) # 字符只是高度需要改变
pts1 = np.float32([left_point, heigth_point, right_point])
M = cv2.getAffineTransform(pts1, pts2)
dst = cv2.warpAffine(oldimg, M, (pic_width, pic_hight))
point_limit(right_point)
point_limit(heigth_point)
point_limit(new_left_point)
card_img = dst[int(right_point[1]):int(heigth_point[1]), int(new_left_point[0]):int(right_point[0])]
card_imgs.append(card_img)
# cv2.imshow("card", card_img)
# cv2.waitKey(0)
# 开始使用颜色定位,排除不是车牌的矩形,目前只识别蓝、绿、黄车牌
colors = []
for card_index, card_img in enumerate(card_imgs):
green = yello = blue = black = white = 0
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
# 有转换失败的可能,原因来自于上面矫正矩形出错
if card_img_hsv is None:
print(1111111111111111111)
continue
row_num, col_num = card_img_hsv.shape[:2]
card_img_count = row_num * col_num
for i in range(row_num):
for j in range(col_num):
H = card_img_hsv.item(i, j, 0)
S = card_img_hsv.item(i, j, 1)
V = card_img_hsv.item(i, j, 2)
if 11 < H <= 34 and S > 34: # 图片分辨率调整
yello += 1
elif 35 < H <= 99 and S > 34 : # 图片分辨率调整
green += 1
elif 99 < H <= 124 and S > 43 and V > 46 : # 图片分辨率调整
blue += 1
if 0 < H < 180 and 0 < S < 255 and 0 < V < 46:
black += 1
elif 0 < H < 180 and 0 < S < 43 and 221 < V < 225:
white += 1
color = "no"
# rgbs=[yello,green,blue,black,white]
# print(rgbs)
# rgbs_max=max(rgbs)
# limit1 = limit2 = 0
# if yello == rgbs_max:
# color = "yello"
# limit1 = 11
# limit2 = 34
# elif green == rgbs_max:
# color = "green"
# limit1 = 35
# limit2 = 99
# elif blue == rgbs_max:
# color = "blue".0
# limit1 = 100
# limit2 = 124 # 有的图片有色偏偏紫
limit1 = limit2 = 0
if yello * 2 >= card_img_count:
color = "yello"
limit1 = 11
limit2 = 34 # 有的图片有色偏偏绿
elif green * 2 >= card_img_count:
color = "green"
limit1 = 35
limit2 = 99
elif blue * 2 >= card_img_count:
color = "blue"
limit1 = 100
limit2 = 124 # 有的图片有色偏偏紫
#elif black + white >= card_img_count * 0.7: # TODO
# color = "bw"
print(color)
colors.append(color)
print('蓝色:' + str(blue) +'绿色: ' +str(green)+'黄色: ' +str(yello)+'黑色: ' +str(black)+'白色: ' + str(white)+'总区域:' + str(card_img_count))
cv2.imshow("color", card_img_hsv)
cv2.waitKey(0)
# if limit1 == 0:
# continue
# 以上为确定车牌颜色
# 根据车牌颜色再定位,缩小边缘非车牌边界(根据颜色重新裁剪筛选)
xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)
print('xl为: '+str(xl)+' xr为: '+str(xr)+' yh为: '+str(yh)+' yl为: '+str(yl))
if yl == yh and xl == xr:
continue
need_accurate = False
if yl >= yh:
yl = 0
yh = row_num
need_accurate = True
if xl >= xr:
xl = 0
xr = col_num
need_accurate = True
card_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh - yl) // 4 else card_img[ yl - (yh - yl) // 4:yh, xl:xr]
if need_accurate: # 可能x或y方向未缩小,需要再试一次
card_img = card_imgs[card_index]
card_img_hsv = cv2.cvtColor(card_img, cv2.COLOR_BGR2HSV)
xl, xr, yh, yl = self.accurate_place(card_img_hsv, limit1, limit2, color)
if yl == yh and xl == xr:
continue
if yl >= yh:
yl = 0
yh = row_num
if xl >= xr:
xl = 0
xr = col_num
card_imgs[card_index] = card_img[yl:yh, xl:xr] if color != "green" or yl < (yh - yl) // 4 else card_img[yl - (yh - yl) // 4:yh,xl:xr]
# 以上为车牌定位
# 以下为识别车牌中的字符
predict_result = []
roi = None
card_color = None
for i, color in enumerate(colors):
if color in ("blue", "yello", "green"):
card_img = card_imgs[i]
gray_img = cv2.cvtColor(card_img, cv2.COLOR_BGR2GRAY)
# 黄、绿车牌字符比背景暗、与蓝车牌刚好相反,所以黄、绿车牌需要反向
if color == "green" or color == "yello":
gray_img = cv2.bitwise_not(gray_img)
ret, gray_img = cv2.threshold(gray_img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# 查找水平直方图波峰
# cv2.imshow("gray_img", gray_img)
# cv2.waitKey(0)
x_histogram = np.sum(gray_img, axis=1)
print(x_histogram)
print(len(x_histogram)+1)
# l = []
# for i in range(len(x_histogram)+1):
# l.append(i)
# print(l)
# x=range(len(x_histogram))
# plt.plot(x, x_histogram)
# plt.show()
x_min = np.min(x_histogram)
print(x_min)
x_average = np.sum(x_histogram) / x_histogram.shape[0]
x_threshold = (x_min + x_average) / 2
wave_peaks = find_waves(x_threshold, x_histogram)
print("水平峰值为:",wave_peaks)
if len(wave_peaks) == 0:
print("水平波峰未找到!( Error ! peak less 0)")
continue
# 认为水平方向,最大的波峰为车牌区域
wave = max(wave_peaks, key=lambda x: x[1] - x[0])
print("车牌区域为:", wave)
gray_img = gray_img[wave[0]:wave[1]]
# 查找垂直直方图波峰
row_num, col_num = gray_img.shape[:2]
# 去掉车牌上下边缘1个像素,避免白边影响阈值判断
gray_img = gray_img[1:row_num - 1]
y_histogram = np.sum(gray_img, axis=0)
# y = range(len(y_histogram))
# plt.plot(y, y_histogram)
# plt.show()
y_min = np.min(y_histogram)
y_average = np.sum(y_histogram) / y_histogram.shape[0]
y_threshold = (y_min + y_average) / 9 # U和0要求阈值偏小,否则U和0会被分成两半
wave_peaks = find_waves(y_threshold, y_histogram)
print("垂直峰值为:", wave_peaks)
# for wave in wave_peaks:
# cv2.line(card_img, pt1=(wave[0], 5), pt2=(wave[1], 5), color=(0, 0, 255), thickness=2)
# 车牌字符数应大于6
if len(wave_peaks) <= 6:
print("错误! 车牌字符小于6!识别的数量为:(error !peak less :)", len(wave_peaks))
continue
wave = max(wave_peaks, key=lambda x: x[1] - x[0])
max_wave_dis = wave[1] - wave[0]
# 判断是否是左侧车牌边缘
if wave_peaks[0][1] - wave_peaks[0][0] < max_wave_dis / 2 and wave_peaks[0][0] == 0:
wave_peaks.pop(0)
# 组合分离汉字
cur_dis = 0
#组合汉字
for i, wave in enumerate(wave_peaks):
if wave[1] - wave[0] + cur_dis > max_wave_dis * 0.8:
break
else:
cur_dis += wave[1] - wave[0]
if i > 0:
wave = (wave_peaks[0][0], wave_peaks[i][1])
wave_peaks = wave_peaks[i + 1:]
wave_peaks.insert(0, wave)
print("合并后的垂直峰值为:", wave_peaks)
# 去除车牌上的分隔点
point = wave_peaks[2]
if point[1] - point[0] < max_wave_dis / 3:
point_img = gray_img[:, point[0]:point[1]]
cv2.imshow(" point_img", point_img)
cv2.waitKey(0)
if np.mean(point_img) < 255 / 5:
wave_peaks.pop(2)
print("去除分割点后的垂直峰值为:", wave_peaks)
if len(wave_peaks) <= 6:
print("错误! 去除分割点后的字符数量为:(peak less 2 :)", len(wave_peaks))
continue
part_cards = seperate_card(gray_img, wave_peaks)
# for i in range(7):
# title = "The " + str(i + 1) + "th Number "
# # 行,列,索引
# plt.subplot(3, 3, i + 1)
# plt.imshow(part_cards[i])
# plt.title(title, fontsize=8)
# plt.xticks([])
# plt.yticks([])
# plt.show()
#
# mluti_part_cards = np.vstack(part_cards)
# # 展示多个
# for i in range(7):
# cv2.imshow(" the "+i+" img", part_cards[i])
# cv2.waitKey(0)
for i, part_card in enumerate(part_cards):
# 可能是固定车牌的铆钉
if np.mean(part_card) < 255 / 5:
print("发现铆钉。")
continue
part_card_old = part_card
w = abs(part_card.shape[1] - SZ) // 2
part_card = cv2.copyMakeBorder(part_card, 0, 0, w, w, cv2.BORDER_CONSTANT, value=[0, 0, 0])
part_card = cv2.resize(part_card, (SZ, SZ), interpolation=cv2.INTER_AREA)
# part_card = deskew(part_card)
part_card = preprocess_hog([part_card])
if i == 0:
resp = self.modelchinese.predict(part_card)
charactor = provinces[int(resp[0]) - PROVINCE_START]
else:
resp = self.model.predict(part_card)
charactor = chr(resp[0])
# 判断最后一个数是否是车牌边缘,假设车牌边缘被认为是1
if charactor == "1" and i == len(part_cards) - 1:
if part_card_old.shape[0] / part_card_old.shape[1] >= 7: # 1太细,认为是边缘
continue
predict_result.append(charactor)
roi = card_img
card_color = color
break
return predict_result, roi, card_color # 识别到的字符、定位的车牌图像、车牌颜色
if __name__ == '__main__':
c = CardPredictor()
c.train_svm()
r, roi, color = c.predict("car08.jpg")
print(r)
成果展示

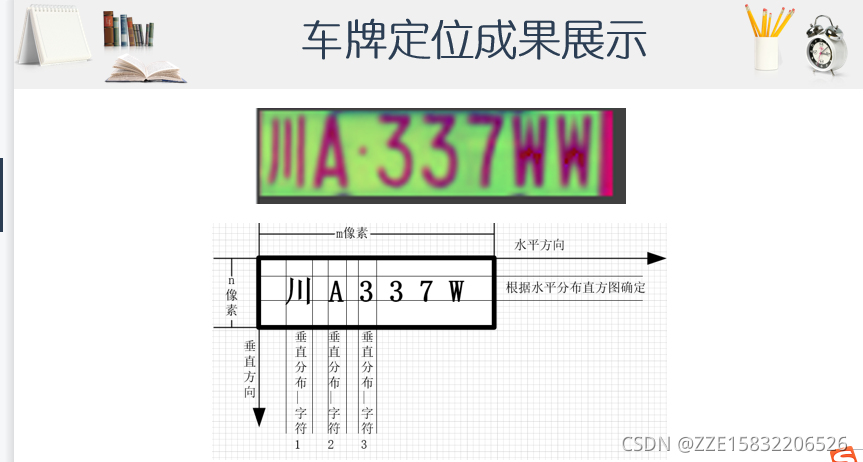
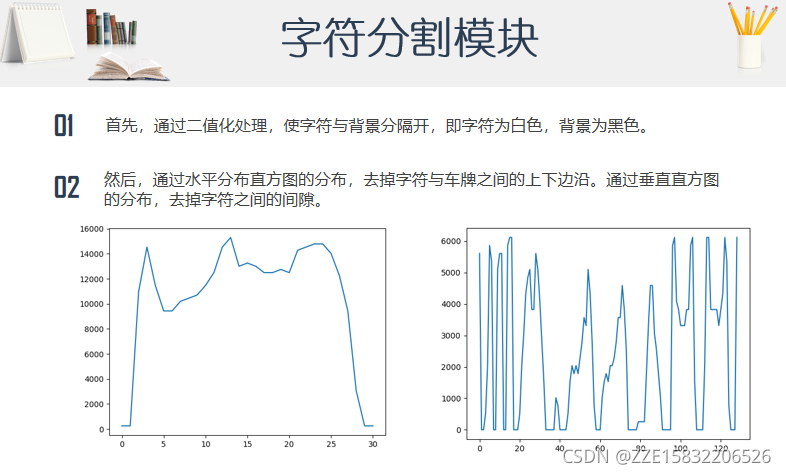
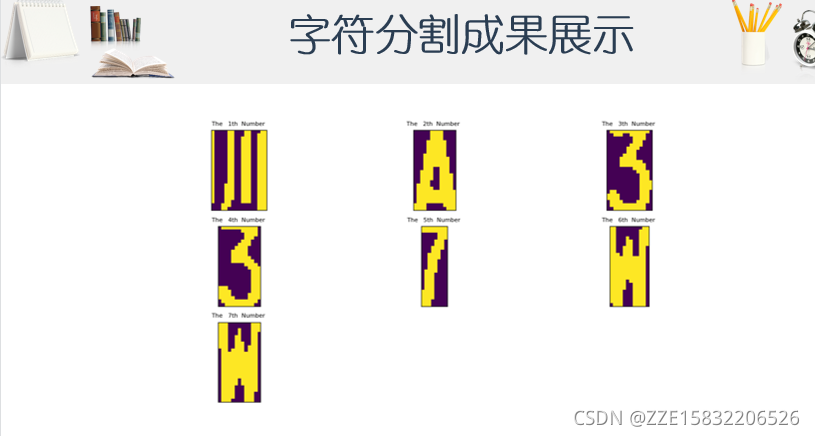
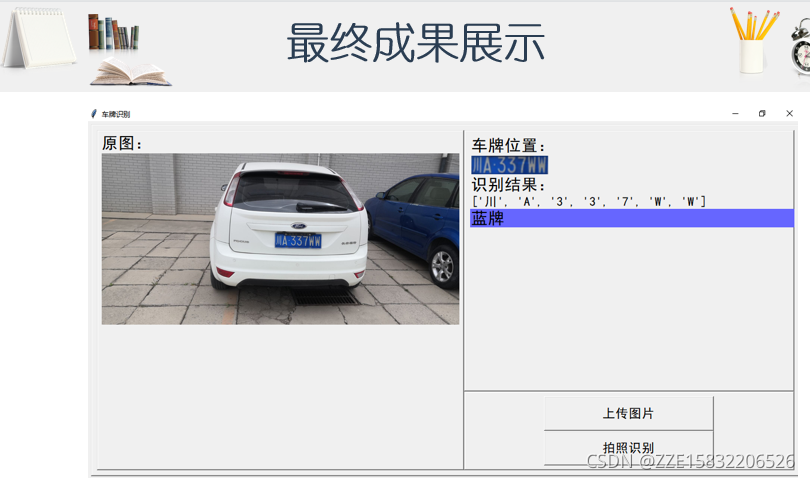
目前方向
在研究表面缺陷检测,对车牌识别系统改进可以联系[email protected]