作为一个前端,每天都需要和浏览器打交道,但是开发的过程中,我们大部分都只关注到浏览器是怎么将我们的代码渲染到浏览器的,很少会去剖析浏览器以及浏览器渲染引擎的内部原理,这使我们忽略了很多可以优化应用性能的细节,阅读这本书可以比较系统和全面的了解到前端和浏览器相关的技术,从而给我们带来更多的优化启发
第一章、浏览器和浏览器内核
浏览器发展历程
-
80年代后期90年代初期,
Berners-Lee发明了第一个浏览器WorldWideWeb,1991 公开源码- 第一个浏览器的功能比较简单,只支持文本,简单样式表,电影,声音和图片等
-
1993年,
Mosaic浏览器诞生,由忘记公司开发- 此时的浏览器页还没有js,没有css, 只支持简单的静态元素样式
-
1995年,闻名世界的IE浏览器诞生,由微软推出,受益于Windows操作系统,IE浏览器逐步取代了网景浏览器,一直到网景浏览器的消亡,至此,第一次浏览器大战结束
-
1998年,网景公司成立Mozilla基金会,开发了著名的
Firefox浏览器,拉开第二浏览器大战的序幕 -
2003年,苹果公司发布了
Safari浏览器,发起了新的开源项目webkit -
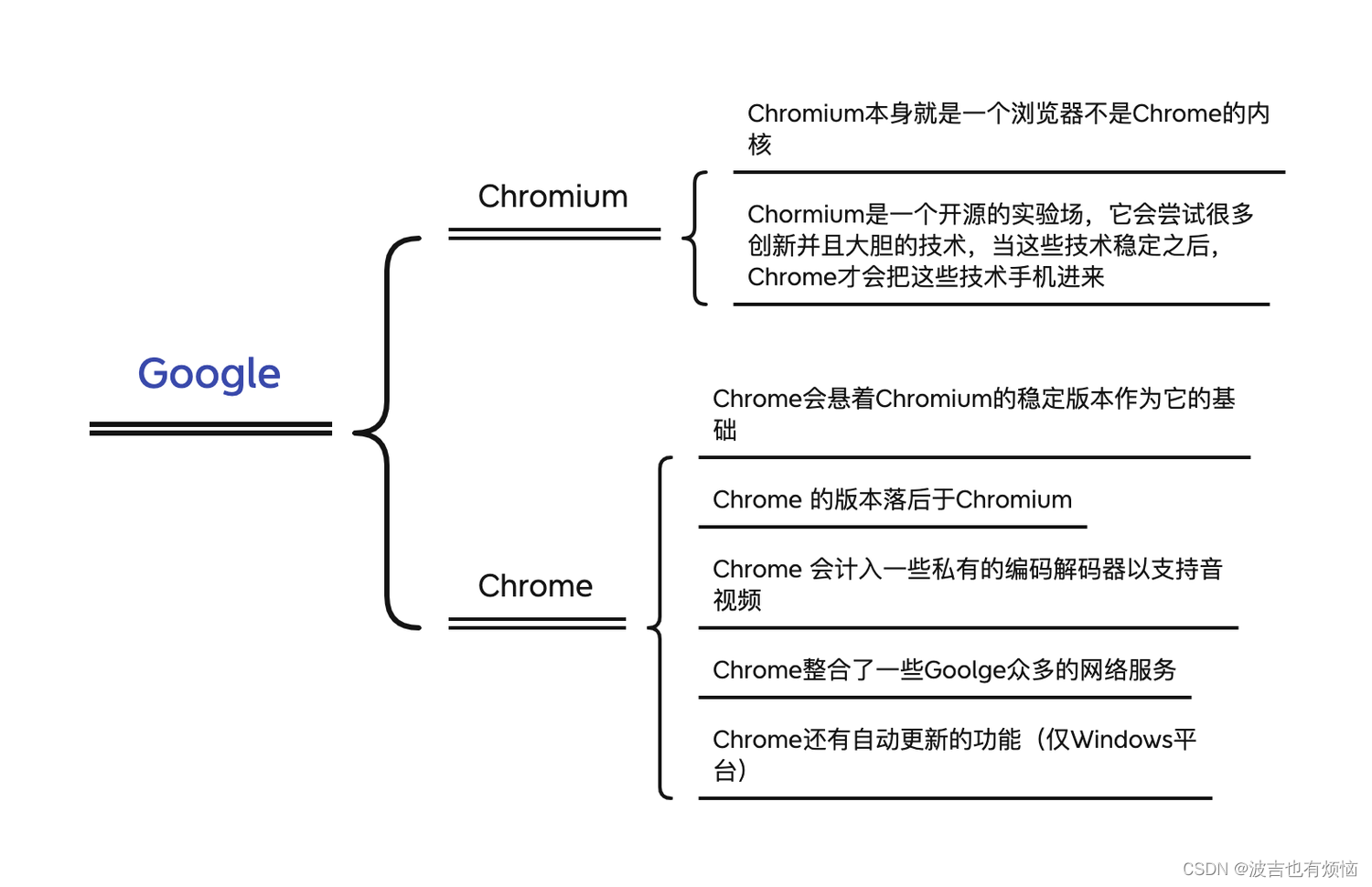
2008年,Google 公司以苹果开源的webkit作为内核,创建了一个新的项目Chromium
Chromium的目标是:创建一个快速的、支持总舵操作系统的浏览器,包括对桌面操作系统和移动操作系统的支持- 基于Chromium项目,谷歌发布了Chrome浏览器
之前在看一些博客的时候也会看到,Chromium 和 Chrome,但是很少有资料会解释两者的区别,书中详细的说明了两者之间的区别
浏览器的主要功能
<一>、 网络模块
- 浏览器通过网络模块来下载各种各样的资源
- 网络模块非常重要,因为它耗时比较长而且需要安全防卫互联网上的资源
<二>、 资源管理
- 资源管理模块用于管理从网络上下载或者从本地获取的资源
- 资源管理模块,需要高效的管理机制,需要解决如何避免重复下载资源、缓存资源等问题
<三>、网页浏览器
- 这是浏览器的和核心功能,也是最基本,最重要的功能
- 通过网络下载资源并从资源管理器获得 资源,将他们转变为可视化的结果
<四>、多页面管理
1.很多浏览器都支持多个页面同时加载的功能, 这让浏览器变得更为复杂,可以用进行和线程来绘制浏览器,比如chrome浏览器就是多进程架构的,每打开一个页面就会开启一个新的进程
<五>、账户和同步
- 将浏览器的历史记录、书签记录等信息同步到服务器
- 给用户提供了多系统的体验
<六>、 安全机制
- 给用户提供一个安全的浏览器环境,防止用户的信息被各种非法工具窃取和破坏
- 会给用户显示当前访问网站是否安全,防止浏览器被恶意代码攻击等
<七>、开发者工具
- 一个优秀的开发者工具可以帮助审查HTML元素,调试js代码,改善网页性能等等
<八>、多操作系统支持
| IE | FireFox | Chrome | Safari | |
|---|---|---|---|---|
| Windows | 是 | 是 | 是 | 是(5.1.7版本之前) |
| Mac OS | 否 | 是 | 是 | 是 |
| Linux | 否 | 是 | 是 | 否 |
| Android | 否 | 是 | 是 | 否 |
| iOS | 否 | 否 | 是 | 是 |
网页的几个革命性成果
<一>、 HTML
- HTML1.0 由 Berners-Lee 于1991年提出,经历多次版本变更之后到1994 年 4.01版本发布之后在很长的时间内都没有更新
- 直到2012年由WHATWG和W3C组织将HTML5推荐为候选规范,HTML5是以系列新的技术集合,将更多令人耳目一新的技术带入到了Web前端领域
- HTML 5 包含了以系列的标准,一共有10个类别
| 类别 | 具体规范 |
|---|---|
| 离线 | Application cache, Local Storage, Indexed DB,在/离线事件 |
| 存储 | Application cache, Local Storage, Indexed DB等 |
| 连接 | Web Sockets, Server-sent事件 |
| 文件访问 | File Api, File System, FileWriter, ProgressEvents |
| 语义 | 各种新元素,包括Media, structual, 国际化, Link relation, 属性, form 类型, microdata等方面 |
| 音频和视频 | HTML5, Video, Web, Audio, WebRTC, Video track等 |
| 3D和图形 | Canvas 2D,3D, Css变换, WebGL, SVG |
| 展示 | CSS3 2D/3D转换(transition), WebFonts等 |
| 性能 | Web Worker, HTTP caching |
| 其他 | 触控和鼠标, Shadow DOM, css masking 等 |
<二>、JAVASCRIPT 和 CSS
- 早期浏览器的网页内容是静态的,难以满足各种各样的需求,js 和 css的出现,极大的增强了显示效果并提升了开发效率
<三>、HTTP
- HTTP是构建在TCP/IP之上的应用层协议,用于传输HTML文本和所涉及的各种紫云啊,包括图片和多媒体等
- 随后诞生了HTTP的安全版HTTPS
用户代理和浏览器行为
- 用户代理: 用户代理的作用是表明浏览器的身份,使互联网的内容提供商能够知道发送请求的浏览器的身份,以及浏览器支持什么样的功能
- 有了用户代理之后,浏览器提供上就可以为不同的浏览器发送不通的网页内容,
举个例子: 互联网通常会为Chrome的桌面版和Android版本发送不通的网页内容以适应屏幕和操作系统的差别,或者因为不通的浏览器支持的标准不一样,这样做可以避免浏览器不支持的功能,获取更好的用户体验
- 因为某种浏览器的流行,很多的内容提供商和网站需要根据流行的浏览器来定制内容,当其他浏览器需要相同的内容的时候就只能是通过这些用户代理的信息来模仿获得
- 用户代理信息是在浏览器向网站服务器发送HTTP请求消息头的时候加入的,这样网站服务器就能很容易了解对方浏览器系信息
浏览器内核
- 浏览器内核是什么?有什么作用?
- 浏览器内核也成称为渲染引擎
- 主要作用是将HTML/CSS/JS文本及其他资源文件转换成图像结果的模块
经常说渲染,却不明白渲染的真正含义:渲染就是根据描述或者定义构建数学模型,然后通过数学模型生成图像
- 几个主流的渲染引擎
- Trident
- Gecko
- Webkit(由苹果发起的开源项目)
- 2013 年Chrome宣布了Blink内核,Blink内核是从Webkit复制出去的
| Trident | Gecko | Webkit | |
|---|---|---|---|
| 基于渲染引擎的浏览器或者Web平台 | IE | Firefox | Safari、Chromium/Chrome, Android 浏览器, ChromeOS, WebOS |
- 现在已经有了基于Webkit开发的Web平台,包括ChromeOS和WebOS,它们利用HTML5 强大的能力,具有前瞻性地尝试开发了支持HTML5的Web操作系统
内核特征(渲染主要提供的功能)
- 一个渲染引擎主要包括HTML解释器、CSS解释器、布局、Javascrpt引擎、绘图模块,网络等
- 描述渲染引擎的功能模块
HTML解释器: 解释HTML文本的解释器,主要作用是将HTML文本解析成DOM(文档对象模型)树,DOM是一种文档的表示方法CSS解释器:级联样式表的解释器,它的作用是为DOM中的各个元素对象计算出样式信息,从而为计算最后网页的布局提供基础设施布局:在DOM创建之后,Webkit 需要将器中的元素对象同样式信息结合起来,计算它们的大小位置等布局信息形成一个能够表示这所有信息的内部表示模型Javascript引擎:使用javascript代码可以修改网页的内容,也能修改css信息,javascript引擎能够解释javascript代码,并且通过接口来修改网页内容和样式信息,从而改变渲染的结果绘图: 使用图形库将布局计算后的各个网页的节点绘制成图像结果
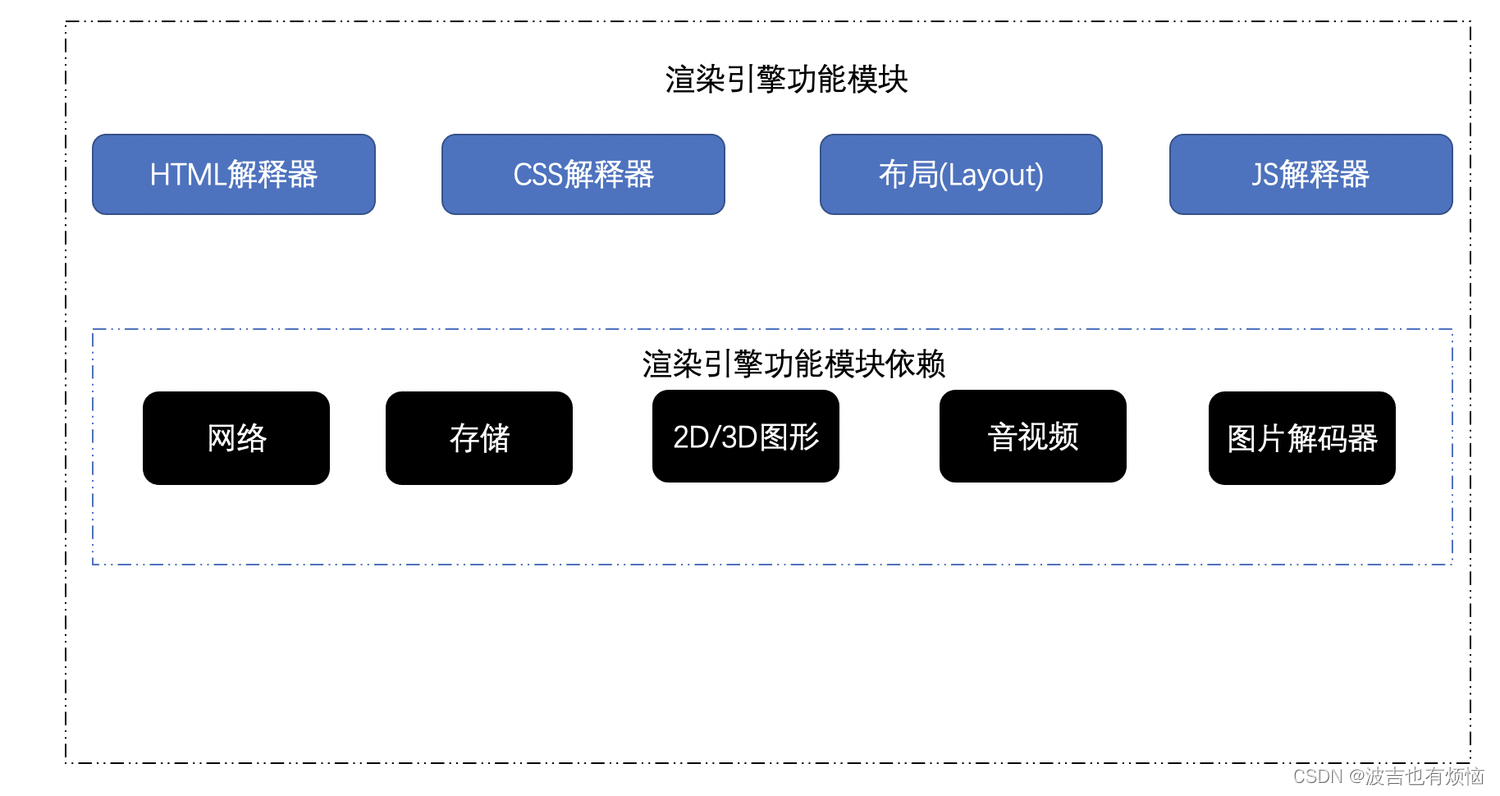
- 浏览器的这写功模块依赖了很多其他的基础模块:网络、存储、2D/3D图形、音视频和图片解码器等
- 在渲染引擎中还包括了如何使用这些依赖模块的部分
举例子:利用2D/3D图形库来实现高性能的网页绘制和网页的3D渲染
渲染引擎工作的核心过程
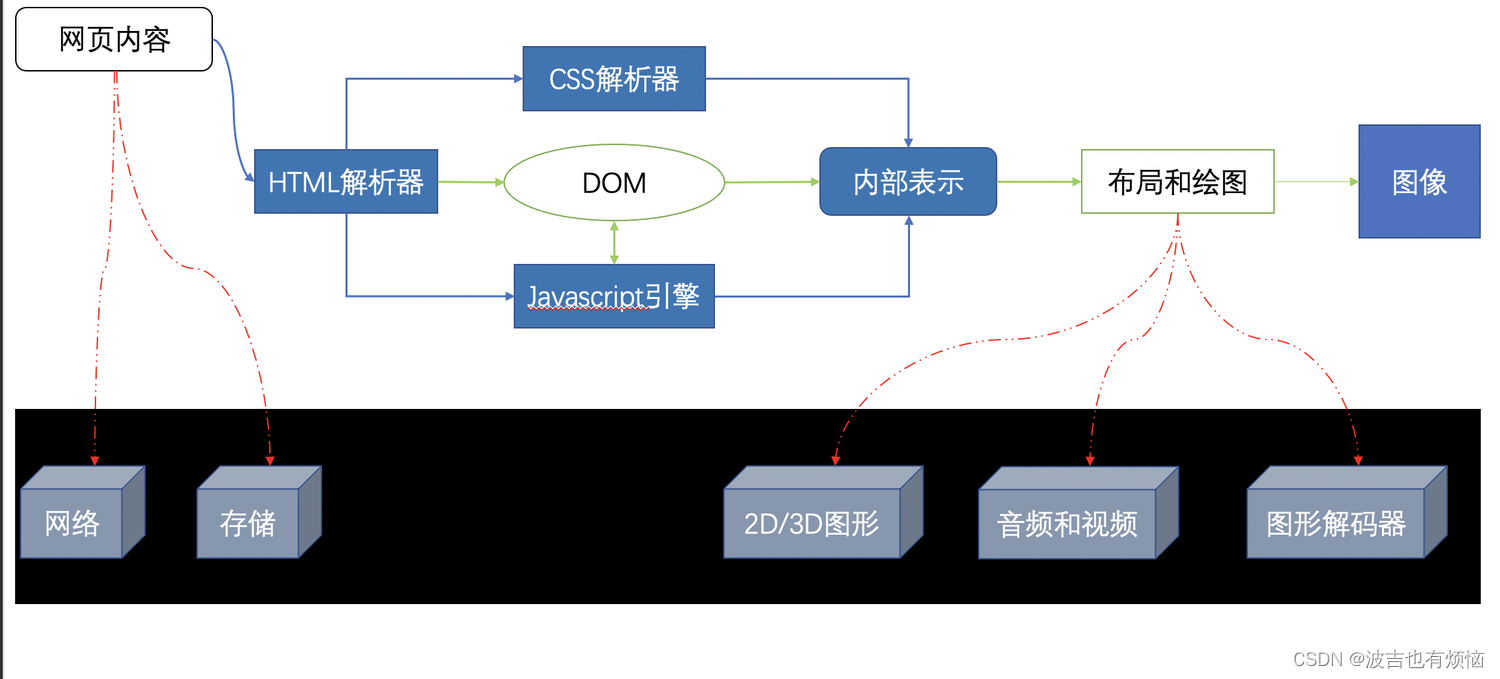
网页内容渲染过程:
- 从网页内容开始,在网页内容下载的过程中需要使用到网络和存储模块
- 网页内容输入到HTML解析器中,HTML解析器会将HTML内容解析成一个DOM树;在解析的过程中,如果遇到了Javascript代码则将js代码交给js引擎进行解析;如果解析HTML的过程中遇到了CSS代码,则将CSS代码交个CSS解析器进行解析
- 当DOM树建立的时候,渲染引擎会接收来自CSS解析器的样式信息,构建一个新的内部绘图模型。
- 内部绘图模型由布局模块计算模型内部各个元素的位置信息和大小信息,最后由绘图模块完成从该模型到图像的绘制。在绘制的过程中,计算布局和绘制图形的时候,需要使用2D/3D的图形模块,同时因为要生成最后的可视化结果,这是需要开始解码音频、视频和图片,和其他内容一起绘制到最后的图像中
- 渲染完成之后,用户可能需要跟渲染的结果进行狡猾,或者网页自身有动画操作,一般而言,这需要持续的重复渲染过程
Webkit 内核
Webkit 发展历程
- 1998 年,苹果公司参与了由KDE开源社区发起的网页渲染引擎KHTML的开源项目
- 由于提交的代码庞大并且没有合适的文档注释、描述, 于2001年,苹果公司从KHTML的源代码树中复制代码出来,成立了一个新的项目,这个项目就是Webkit
Webkit 的含义
-
广义Webkit:
- webkit 项目
-
狭义Webkit(Webkit嵌入式接口):
- WebCore(HTML解析器、CSS解析器、布局模块等)和JS引擎之上的一层绑定和嵌入式编成接口,这个接口可以被各种浏览器调用
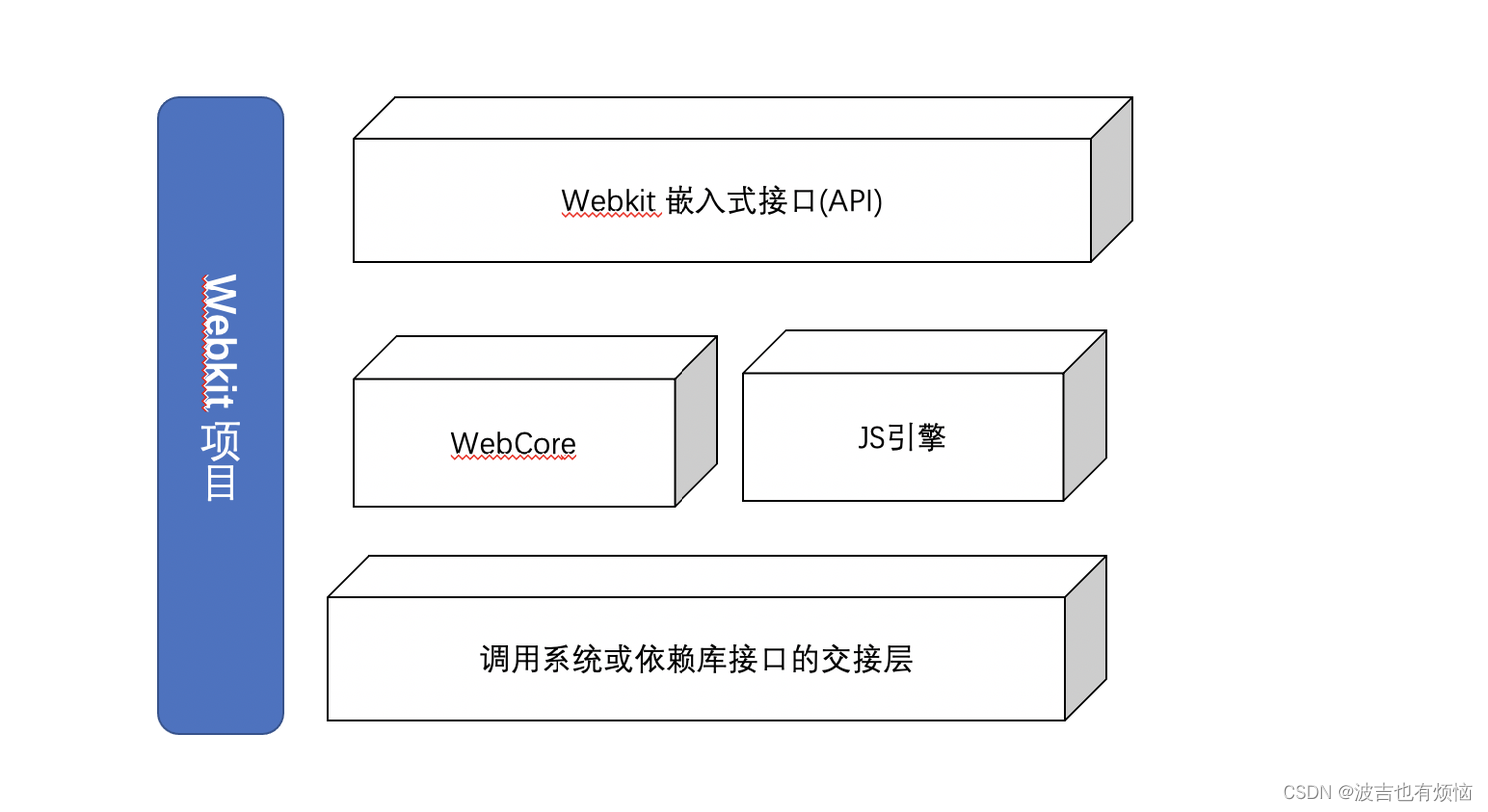
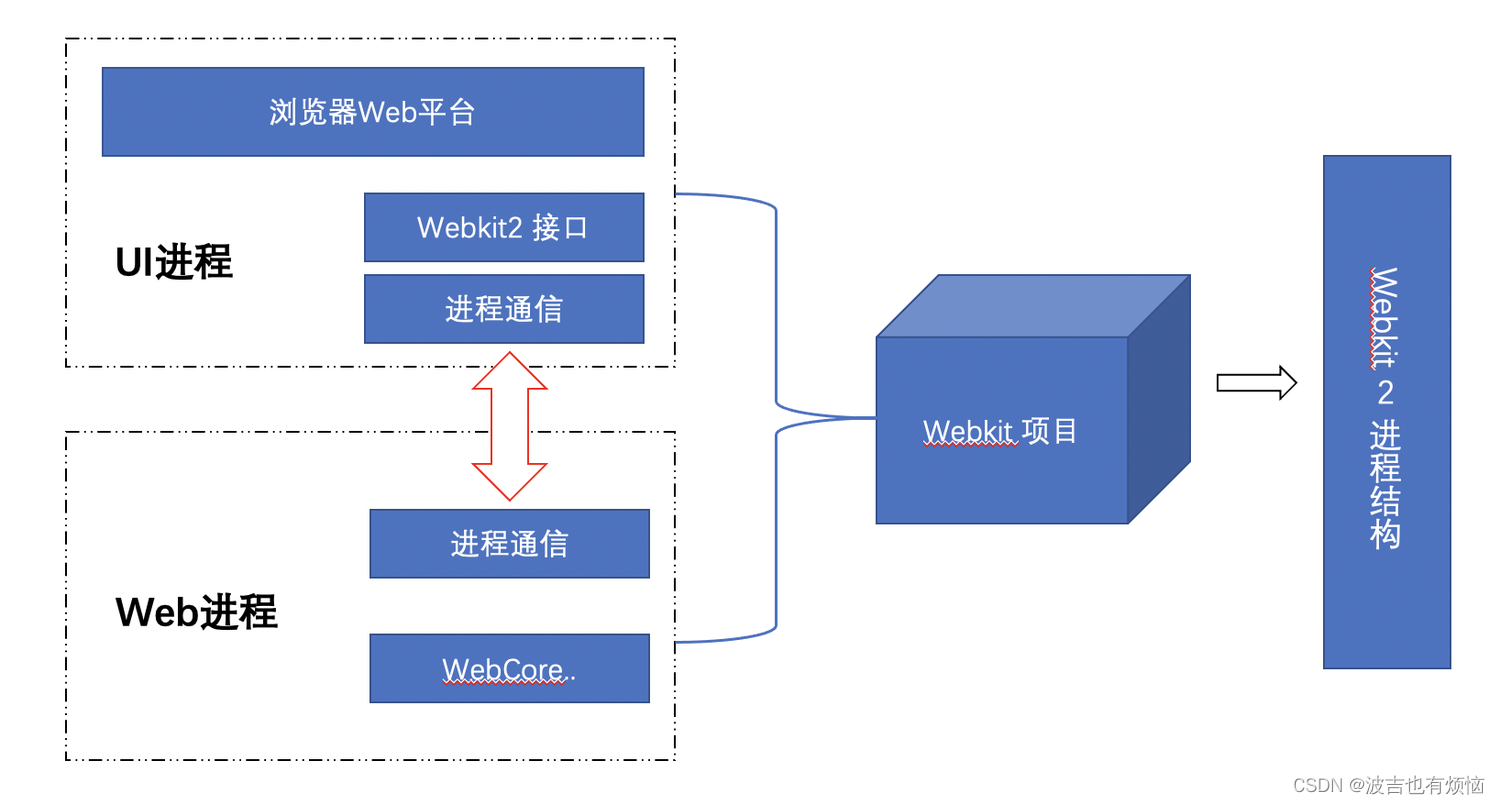
Webkit 2 (狭义的Webkit)
webkit 2是苹果公司于2010年4月宣布的,目标是抽象出一组新的编程接口webkit 2接口和调用者代码与网页的渲染工作代码不在同一个进程, 拥有多进程的有优点webkit 2接口的使用者不需要理解和接触背后的多进程和进程间通信等复杂机制webkit 2的部分代码也属于webkit 项目Webkit 2多进程结构- UI进程
- Web进程
Chromium 内核 Blink
- 2013 年 4 月goolge 宣布了从Webkit复制并且独立运行的项目Blink, 之后, Webkit 就将与Google Chromium 浏览器相关的代码移除了,Blink将除Chromium 浏览器需要之外的代码都移除了
- Google 希望未来在Blink中加入很多新的技术:
- 实现跨进程的iframe
- 重新整理和修改Webkit关于网络方面的架构和接口
- 将DOM树引入JS引擎中(目前的状态是DOM树和js引擎是分开的, js引擎访问DOM树需要较高的代价)
- 针对各种技术进行性能优化,包括但是不限于图形、js引擎、内存使用、编译的二进制文件大小等
第二章、HTML 网页和结构
了解HTML网页和结构可以帮助我们更好的理解浏览器内核的渲染过程和渲染原理
HTML
- HTML 是一种半结构化的数据表现方式
- HTML 的特征可以归纳为三种:
- 树状结构
- 层次结构
- 框结构
网页构成
动态网页(Dynamic HTML): 可以出现动画,可以和用户进行交互
基本元素和树状结构
-
网页的基本元素
- HTML
- CSS - 描述网页信息
- Javascrit - 控制网页内部逻辑
- 各种各样的资源文件
-
树形结构(DOM 树形结构)
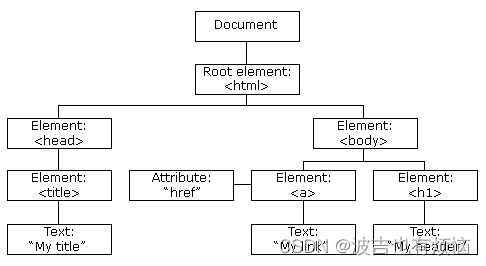
网页结构
- 框结构

- 框结构的概念很早之前就被引入了,用来对网页的布局进行分割,将网页分割成几个框
- 通过 ‘iframe’、‘frame’、‘frameset’可以用来在当前网页中嵌入其他新的框结构
- 每个框结构都包含一个HTML 文档
- 层次结构
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-IAIjJIKn-1679640439734)(/download/attachments/1265403381/%E6%88%AA%E5%B1%8F2021-12-08%20%E4%B8%8B%E5%8D%888.42.06.png?version=1&modificationDate=1638967517795&api=v2)]](/image/aHR0cHM6Ly9pbWctYmxvZy5jc2RuaW1nLmNuLzliYjZhODNmMjkzOTQ1MTdhYWE4NDc3YmUyZjBlOWQ4LnBuZw%3D%3D)
- 网页中的不通元素可能会分布在不同的层次中,某些元素可能不同于它的父元素所在的层次,因为某些原因,webkit 需要为改元素和它的子女建立一个新的层
- 对于层次结构而言,不要太深,一般都是建议三级以内,首页为一级,栏目页与分类页为一级,资讯详情页与产品详情页为一级,这种三级页便于蜘蛛快速抓取页面以及内容,网站代码一定要精简,便于蜘蛛快速爬行。
Webkit 网页渲染的过程
加载和渲染
- 网页加载过程: 从’URL’ 到构建DOM树
- 网页渲染过程:从DOM 树到生成可视化图像的过程
加载和渲染有时有也会重叠,无法清晰的去区分他们,将加载和渲染统称为渲染过程
渲染过程
了解浏览器的渲染过程就是了解浏览器各个具体的模块在渲染过程中的作用
- 渲染数据: 网页内容、DOM、内部表示和图像
- 渲染涉及的具体模块: HTML解释器、CSS解释器、Javascript 引擎、布局模块(Layout模块)、绘图模块
渲染的三个阶段*
第一阶段:从网页的URL到构建完DOM树
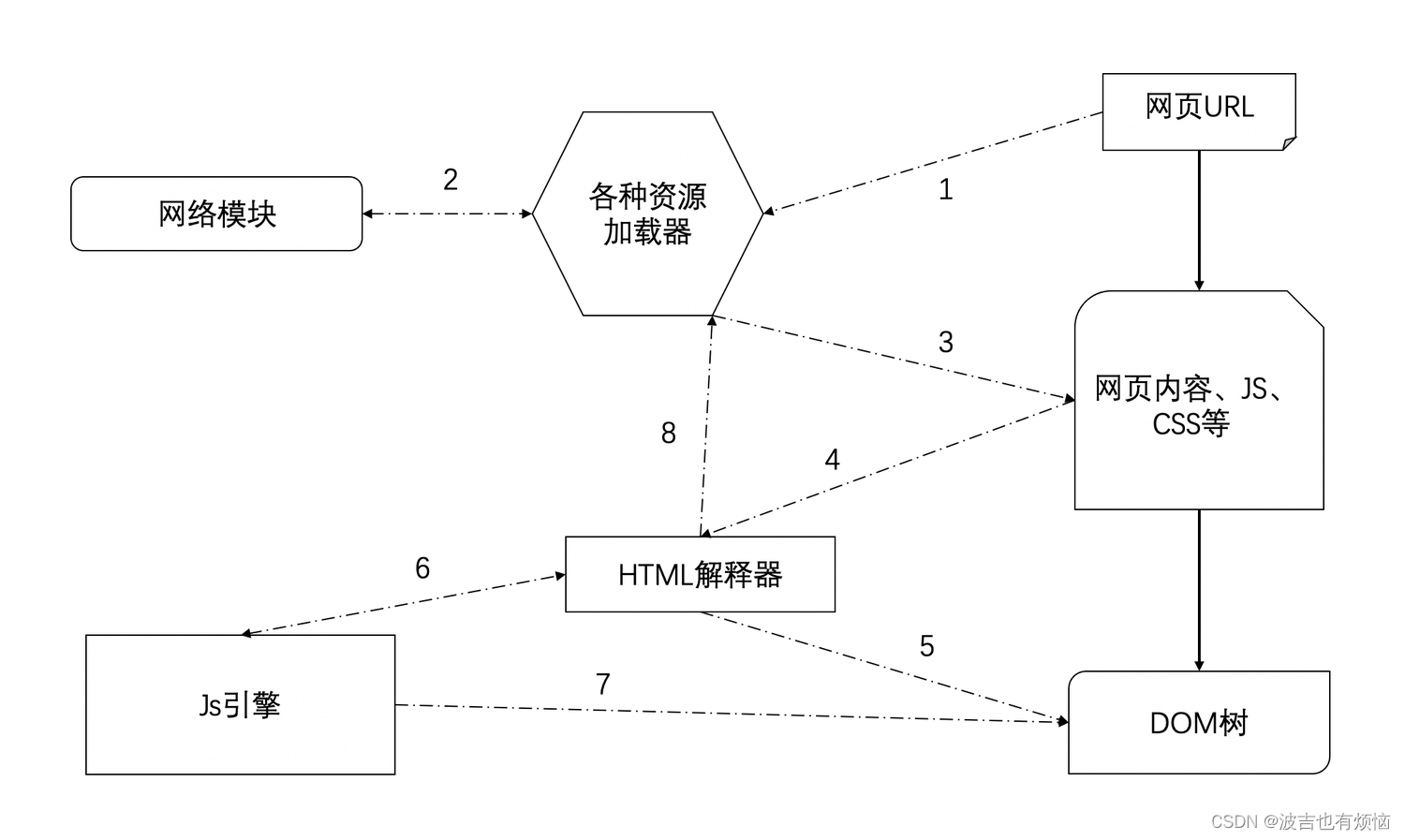
- 当用户输入网页的URL地址的时候,Webkit 调用其资源加载器加载URL对应的网页
- 加载器以来网络模块建立连接,发送请求并接收答复
- Webkit接收各种网页或者资源数据,其中某些资源可能是同步的也可能是异步获取的
- 网页被交给HTML解析器进行解析,将网页内容转换成一系列的词句
- 解释器的根据词句构建节点(Node), 形成DOM树
- 如果节点是js代码,就会调用js引擎解析并执行
- js可能会修改DOM的树形结构
- 如果节点以来其他资源(图片、css、视频等),调用资源加载器来加载他们,这个过程是异步的,不会阻碍当前DOM树的继续创建,如果是js资源的url(咩有标记异步的情况下),需要停止当前dom树的创建,直到js资源被加载并且执行完毕后才会继续创建DOM树。
网页在加载和渲染的过程中会发出DOMContent和 DOM的onload事件, 这两个事件分贝额在DOM树构建完之后和DOM树构建完并且网页所依赖的资源加载完成之后发生的。 由于某些资源的加载并不会阻碍DOM树的创建,所以两个时间多数时候不是同事发生的
第二阶段: 从 CSS 和 DOM 树到绘图上下文
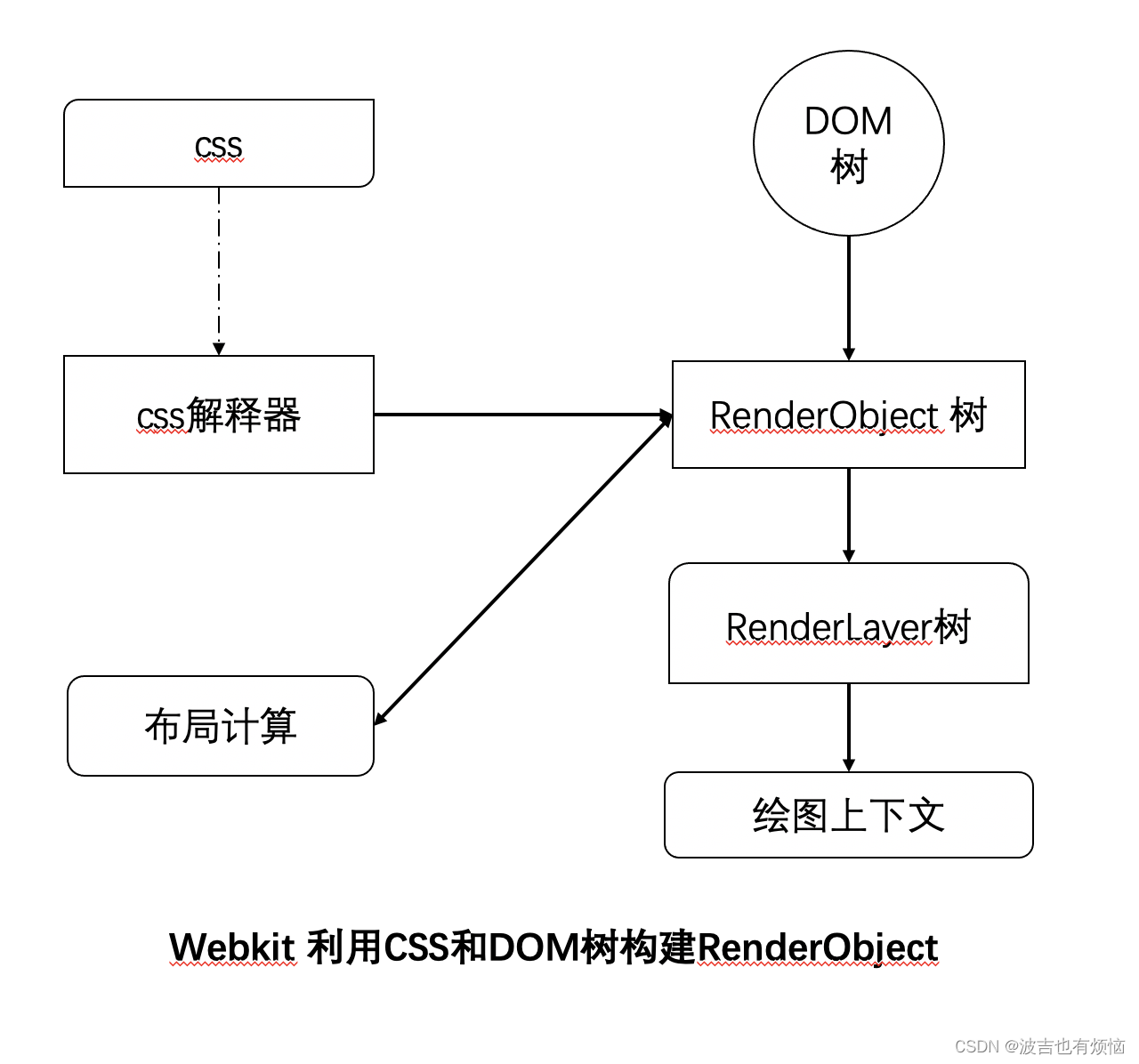
- CSS被CSS解析器解析成内部表示结构
- CSS解释器工作结束之后,在DOM树上附加解释后的样式信息,这就是RenderObject树
- ReaderObject 节点在创建的同时,Webkit会根据网页的层次结构创建RenderLayer树,同时构建一个虚拟的绘图上下文。
RenderObject 树的建立并不表示DOM树会被销毁,事实上,DOM树、RenderObject、RenderLayer、绘图上下文这四个内部表示结构一直存在,知道网页被销毁,因为它们对于网页的渲染起了非常大的作用
第三阶段:根据绘图上下文来生成最终的图像(主要依赖2D和3D图形库)
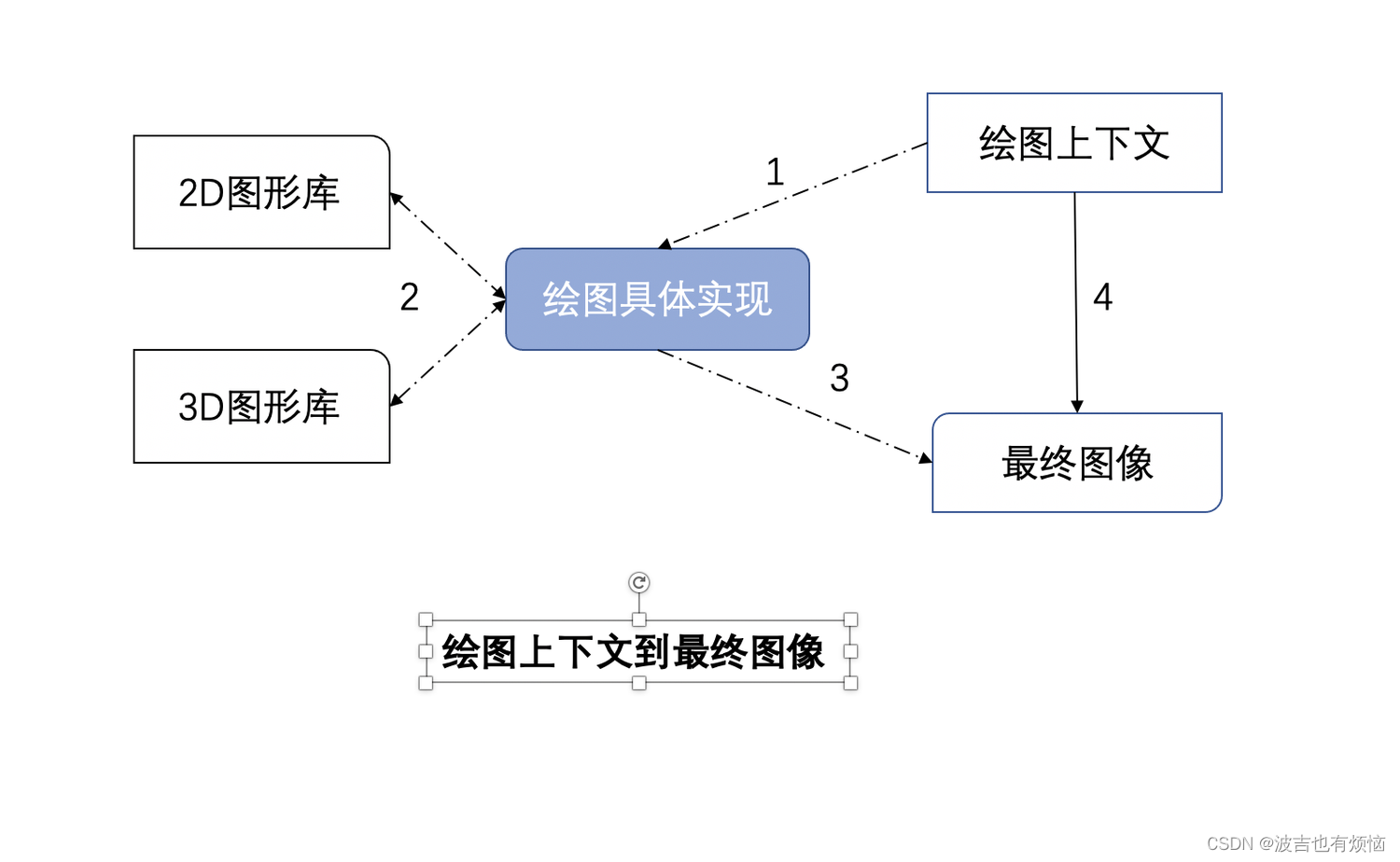
- 绘图上下文是一个与平台无关的
抽象类, 它的每个绘图操作桥接到不通的具体实现类,页就是绘图具体实现类 - 绘图实现类也可能有简单的实现,也可能有复杂的实现。在Chromium中,它的实现相当复杂,需要Chromium的合成器来完成复杂的多进程和GPU加速机制
- 绘图实现类将2D图形和3D图形库绘制的结果保存下来,交给浏览器界面一起显示
** 思考: 通过对Webkit网页的渲染过程的学习,有以下几点启发: **
** *1. 我们理解‘onload’ 和 ‘DOMContent’ 事件的触发时机,可以在javascript代码中注册相应的回调函数 * **
** *2. 在DOM构建的过程中需要执行js代码,所以需要特别注意这部分代码对网页Dom的访问问题,因为这个时候DOM可能还未创建完成,因此js代码不能访问DOM结构 * **
第三章、Webkit架构和模块
Webkit 最显著的特征就是它支持不同的浏览器,不同的浏览器的需求不同,所以在Webkit中一些代码是各个浏览器之间可以共享的,一些代码是不可以共享的(Webkit移植Ports)
Webkit 架构
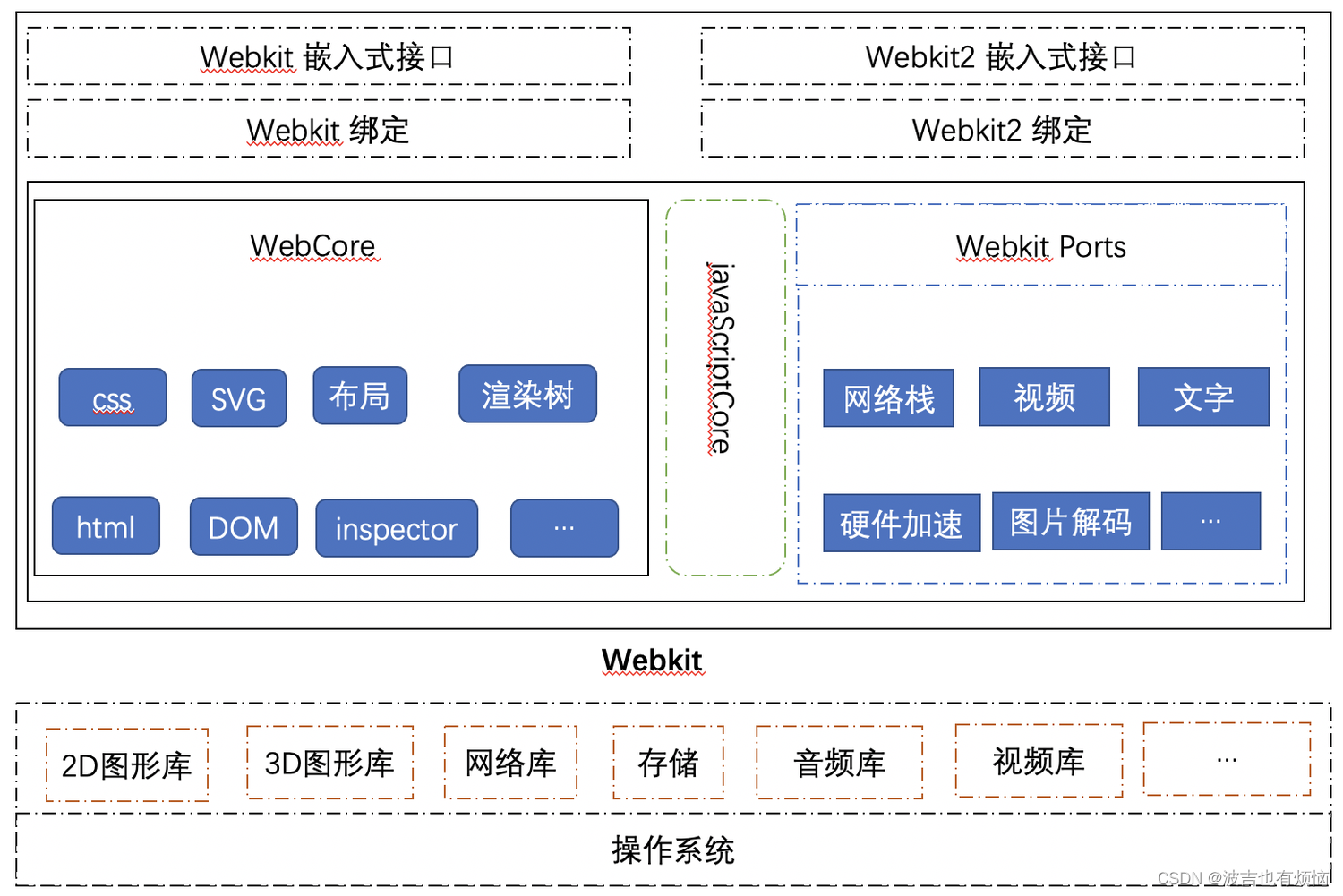
- 使用虚线框表示该部分模块在不同浏览器使用的webkit内核中的实现是不一样的,虚线框中的内容不是普遍共享的
- 使用实线框标记的模块基本上是共享的(实线框中的一些特性是不能共享的,而且可以通过不同的编译配置改变它们的行为)
- 由于不同浏览器使用的webkit架构不同,所以不同浏览器回表现出不同的行为
-
操作系统:
- webkit 可以在不同的操作系统上工作
- 不同浏览器可能会依赖不同的操作系统
- 同一个浏览器可能依赖不通的操作系统
-
第三方库(2D、3D图形库,网络库…)
- 这些第三方库是浏览工作是需要依赖的基础模块
- 如何高效的使用这些基础模块,是各大浏览器厂商的一个重大课题(如何设计一个良好的架构利用它们以获得高性能)
-
webCore
- webCore部分包含了目前被各个浏览器所使用的Webkit共享部分,这些都是加载和渲染网页的基础部分
- 具体包括: HTML解析器、CSS解析器、SVG、DOM、渲染树(RenderObject 树、RenderLayer树等),以及Inspector(Web Inspector、调试网页)
-
javaScriptCore 引擎
javaScriptCore引擎是webkit中默认的js引擎javaScriptCore并不是唯一不可替代的- 在webkit中,对js引擎的调用时独立于引擎的
- 在Google的Chromium开源项目中,
javaScriptCore被替换为V8引擎
-
Webkit ports
- webkit ports 是webkit的非共享部分
- 对于不同的浏览器而言,这些模块由于平台差异、依赖的第三方库不通、需求不同,浏览器厂商往往按照自己的方式设计和实现,这是导致webkit版本行为并非一致的重要原因
-
嵌入式编程接口
- 这些嵌入式接口是提供给浏览器调用的(用两个接口,广义的Webkit接口和狭义的Webkit接口)
- 接口与具体移植有关,所以需要一与浏览器相关的绑定层
-
Webkit 测试用例(包含大量的测试用例和期望结果)
- 布局测试用例
- 性能测试用例
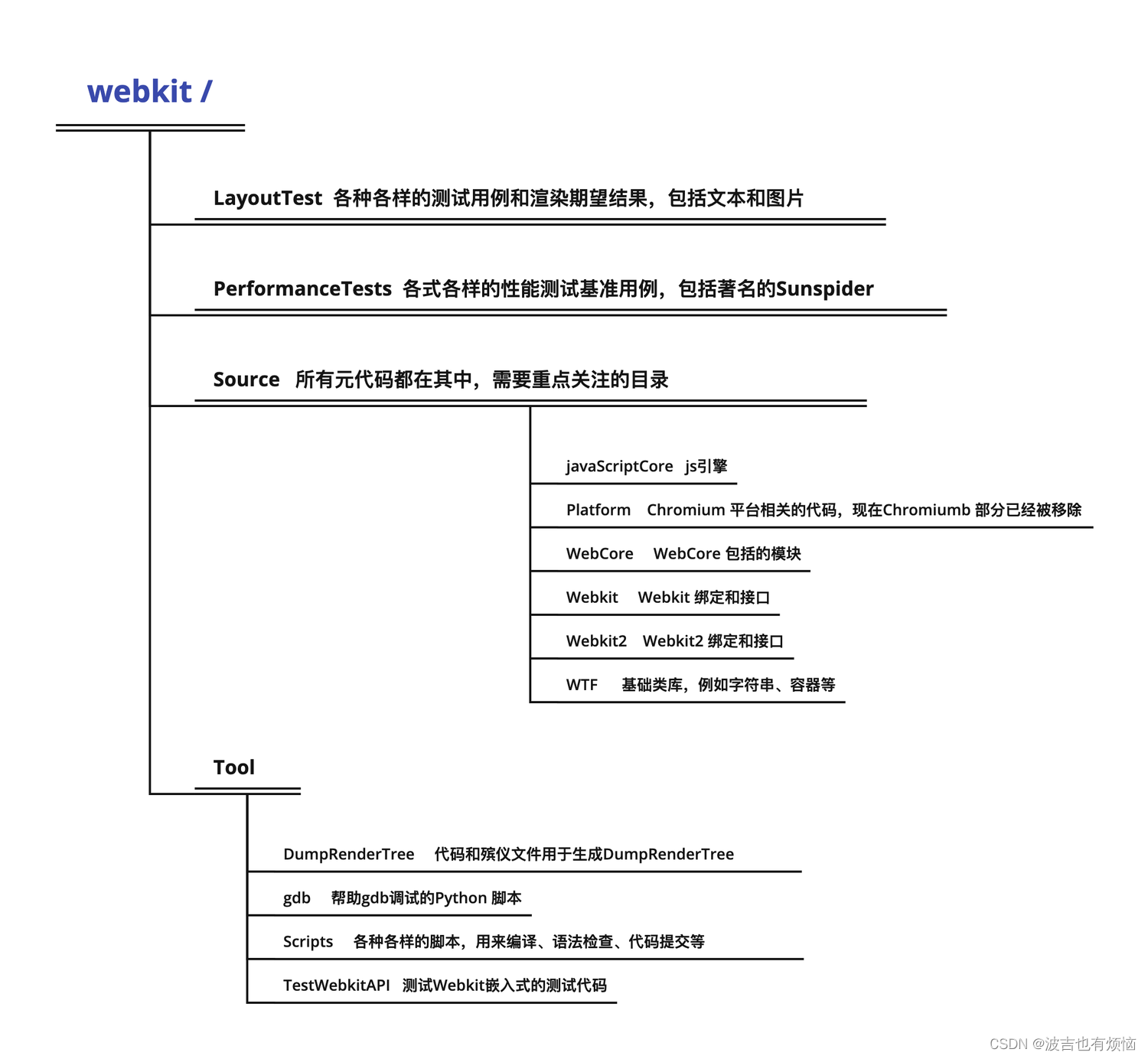
Webkit 源代码目录结构
基于Blink的Chromium浏览器结构
通过Chromiumk可以了解如何基于Webkit构建浏览器
Chromium 架构及包含的模块
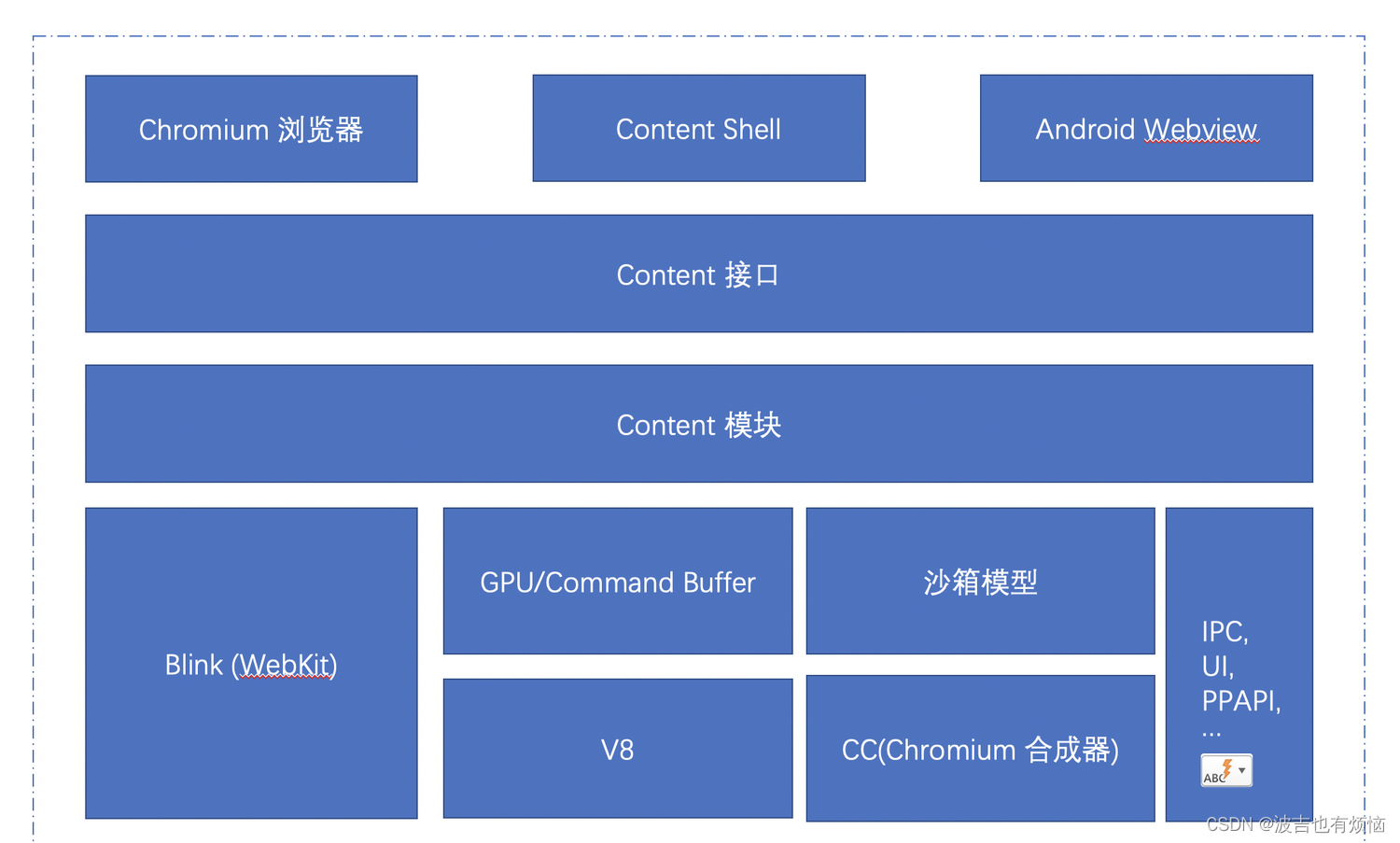
Content模块和Content API将下面的渲染机制、安全机制和插件机制等盈仓起来,提供一个接口层- 由
Content 模块和Content API提供的接口,可以被上层模块或者其他项目调用,内部调用者包括Chromium浏览器、Content Shell等,外部包括CEF(Chromium Embedded Framework)、Opera浏览器等 - Chromium 浏览器是我们编译出来能看到的浏览器的式样, Chromium 的源码没有完全开源
- Content Shell 是使用Content API 来包装的一层简单的‘壳’,但是它也是一根简单的‘浏览器’,用户可以使用Content 模块来寻渲染和显示网页内容
- Content Shell 可以用来测试Content模块很多功能的正确性(渲染、硬件加速)
- Content Shell 可以被很多外部项目参考来开发基于‘Content API’的浏览器或者各种类型的项目
- Android WebView 是为了满足Android 系统上的WebView而设计的,其思想是利用Chromium的实现来替换原来Android系统默认的WebView
多进程模型
- Chromium 多进程架构的优势:
- 避免单个页面不相应或者崩溃而影响整个页面的或者浏览器的稳定性,特别是对用户界面的影响
- 当第三方插件崩溃时不会影响页面或者浏览器的稳定性,这是因为第三方插件也是使用单独的进程来运行的
- 方便了安全模型的实施,沙箱模型是基于多进程架构的
- 使用资源换取浏览器的稳定
- Chromium 浏览器主要包括的进程
Browser 进程:浏览器的主要进程,负责浏览器界面的现实,各个页面的管理,是所有其他类型进程的祖先,负责它们的创建和销毁等工作,有且仅有一个Renderer 进程:网页的渲染进程,负责页面的渲染工作,Blink/Webkit 的渲染工作主要在这个进程中完成,可能有多个,但是Renderer进程的数量不一定和用户打开的网页数量一致,原因是Chromium 设计了灵活了机制,允许用户配置,同时在沙箱模型启动的情况下,该进程可能会发生一些改变NPAPI 插件进程:这个进程是为NPAPI类型的插件而创建的,其穿件的基本原则是每种类型的插件只会被创建一次,而且仅当使用时才会被创建。当有多个网页需要使用同一类型的插件时,插件进程是被共享的(例: 多个网页使用Flash插件,Flash插件的进程会为每个使用者创建一个实例)Pepper 插件进程:与NPAPI插件进程类似,不同的是为Pepper插件而创建的进程其他类型的进程:Linux 下的‘Zygote’进程(创建Renderere进程), ‘Sandbox’进程(安全相关)
- 桌面系统(Widows、Linux、Mas OS)中的Chromium浏览器,进程模型的特征
- Browser 进程和页面的渲染是分开的,者保证了页面的渲染导致的崩溃不会导致浏览器主界面的崩溃
- 每个网页是独立的进程,保证了页面之间不相互影响
- 插件进程也是独立的,插件本身的问题不会影响浏览器主界面和网页
- GPU硬件加速进程也是独立的
- Chromium Android 版
- Android 版不支持插件,没有插件进程
- GPU进程演变成Browser进程的一个线程,即GPU线程(节省资源)
- Renderer进程演变成Android的服务进程
- 由于Android的局限性,Renderer进程的数目被严格限制
影子标签: 浏览器会将后台的网页所使用的渲染设施都清除,只留下之前的一个影子,当前用户再次切换的时候,网页需要重新加载和渲染
- 多进程模型的模型类型
Process-per-site-instance: 该类型的含义是为每一个页面创建一个独立的Render进程,不管这些页面是否是来自于同一个域(每个页面互不影响,浪费资源)Process-per-site: 该类型的含义是属于同一个域的页面共享同一个进程,而不同属于一个域的页面则分属不通的进程(进程可以共享,内存消耗较小,但是可能会出现特别大的Renderer进程)Process-per-tab: 该类型的含义是Chromium为每个标签页都创建一个独立的进程,而不管他们是否是不是同域的不同的实例,这也是Chromium的默认行为,虽然会浪费资源Single process(试验性的,不稳定): 该类型的含义是,Chromium 不为页面页面创建人和独立的进程,所有渲染工作都在Browser 进程中进行,它们是Browser 进程中的多个线程,在Android WebView 系统中被采用
Browser 进程和 Renderer 进程
Browser 进程和 Renderer 进程都是在Webkit 接口之外由Chromium引入的
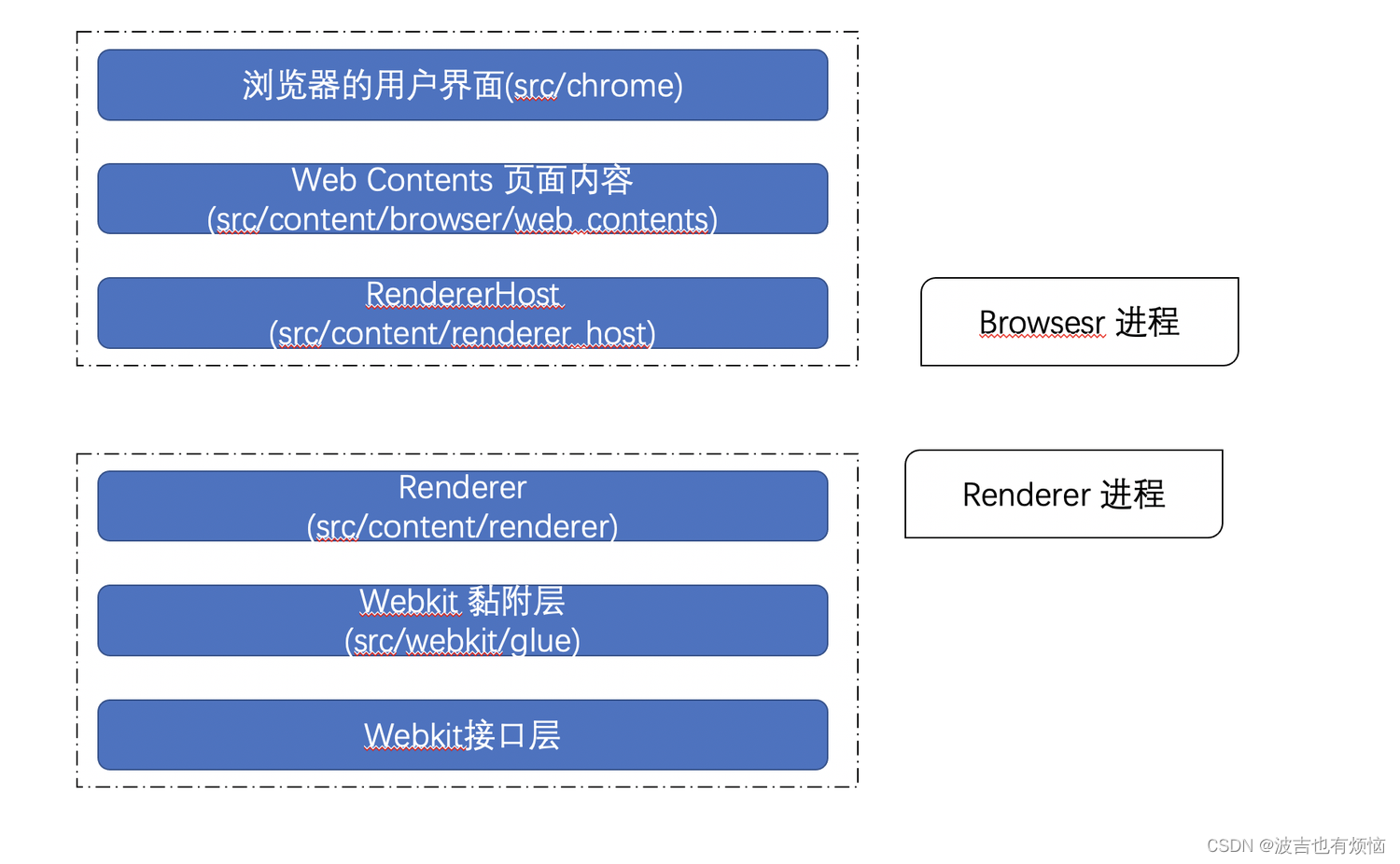
从下往上
-
Renderer 进程:
webkit 接口层:一般基于webkit接口层的浏览器是直接在上面构建的,没有引入复杂的多进程结构webkit 黏附层:这是chromium基于webkit的接口引入的,它的出现,主要是因为Chromium中的一些类型和webkit内部不一致,所以需要引入一个简单的桥接层renderer: 主要用于处理进程之间的通信,接收来自Browser进程的请求,并调用相应的webkit接口层,同时将webkit的处理结果发送回去
-
Browser进程:
RendererHost: 处理同Renderer之间的通信,给Renderer进程发送请求并接收来自Renderer进程的结果web contents: 表示网页内容
多线程模型
** * 每个进程内部都有很多线程* **
-
为什么要使用多线程?
使用多线程模型的主要目的就是为了保持用户界面的高度响应,保证UI线程(Browser中的主线程)不会被其他的耗时操作(读取本地文件、socket读写、数据库操作等…),阻碍从而影响了对用户操作的影响
为了利用多核的优势,Chromium渲染过程管线化,这样可以让渲染的不同阶段在不同的线程执行 -
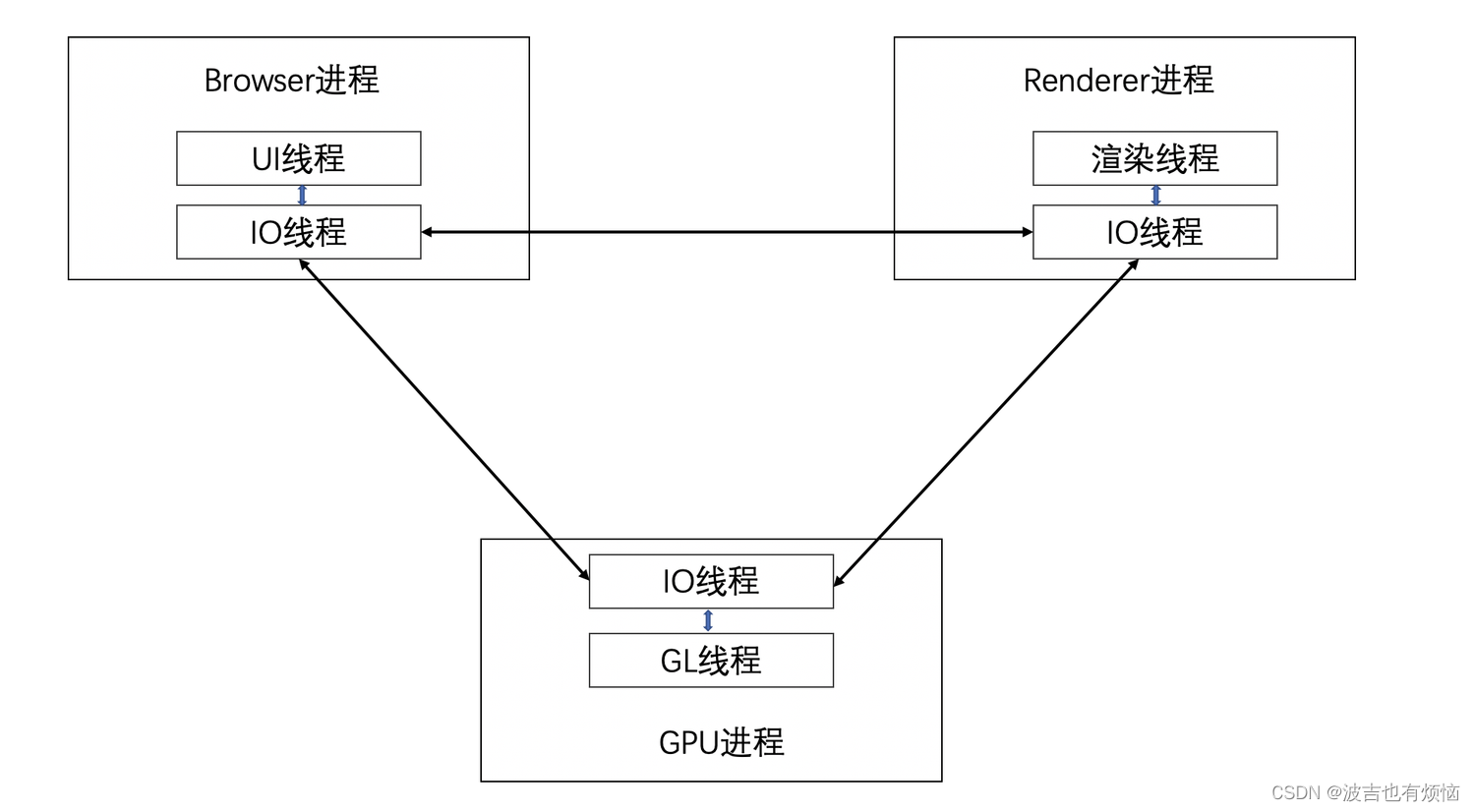
Chromium多线程模型
-
网页加载和渲染在多线程模型下的工作方式
1)、 Browser进程收到用户请求,首先有UI线程处理,随即将任务转给IO线程,IO线程再讲任务传递给Renderer进程
2)、Renderer进程的IO线程经过简单解释只有交给渲染线程,渲染进程接受请求,加载网页并渲染网页,这个过程可能需要Browser进程获取资源和需要GPU进程来帮助渲染;最后Renderer进程将结果由IO线程传递给Browser进程
3)、Browser接收到结果并讲结果绘制出来
Content 接口
Content 不仅提供了一层对多进程进行渲染的抽象接口,而且从它诞生以来一个重要的目标就是支持所有的HTML5功能、GPU硬件加速功能和沙箱机制
Content接口的相关定义文件均在content/public上,按照功能可以分为六个部分:
- App
- 这部分主要与应用程序或者进程的创建和初始化有关,它被所有的进程使用,用来处理一些进程的公共操作,具体包括两种类型:
- 进程创建的初始化函数,即Content模块的初始化和关闭动作;
- 各种毁掉函数,用来告诉嵌入者启动完成,进程启动、推出,沙盒模型初始化开始和结束等
- 这部分主要与应用程序或者进程的创建和初始化有关,它被所有的进程使用,用来处理一些进程的公共操作,具体包括两种类型:
- Browser
- 第一类包括对一些HTML5功能和其他一些高级功能实现的参与,因为这些实现需要Chromium的不同平台实现,同时需要例如:Notification、Speech recognition、Web worker、Download、Geolocation等这些Content层提供的接口,Content模块需要调用它们来实现HTML5功能
- 第二类的典型接口类是ContentBrowserCLIENT,主要实现部分的逻辑,被Browser进程调用,还有就是一些时间的函数回调
- Common
- 主要定义一些公共的,这些被Renderer和Browser共享,例如一些进程相关、参数、GPU相关等
- Plugin
- 仅有一个接口类,同志嵌入者Plugin进程何时被创建
- Renderer
- 第一类包含获取RendererThread的消息虚循环、注册V8 Extension、计算Javascript表达式等
- 第二类包括ContentRendererClient,主要是实现部分逻辑,被Browser端调用,还有就是一些时间的函数毁掉
- Utility
- 工具类接口,主要包括嵌入者参与Content接口中的线程创建和消息的过滤
Webkit 2
webkit 2是一套全新的结构和接口,而不是一个简单的升级版本
Webkit 2 架构及模块
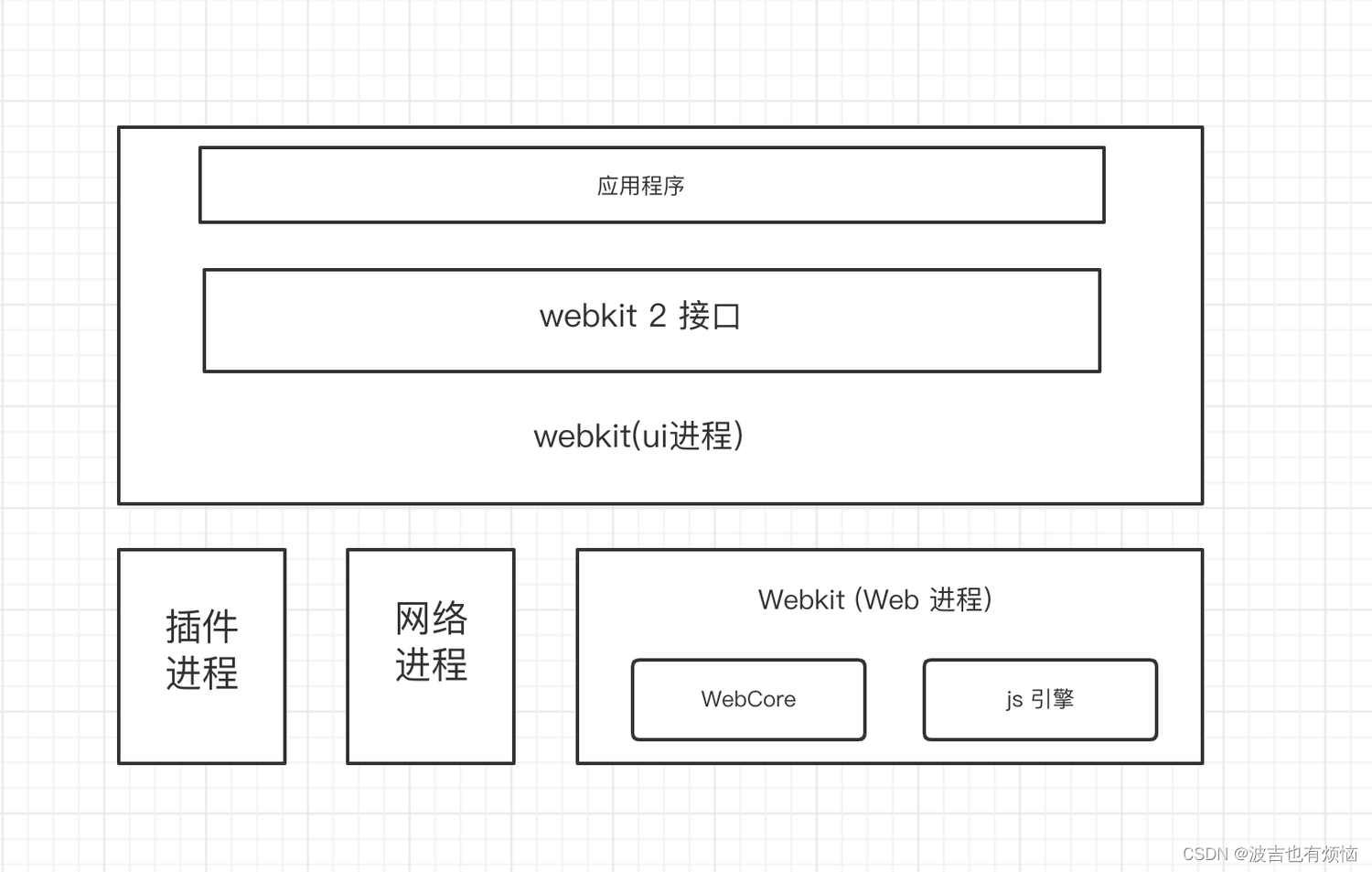
- 在webkit2 中引入了插件进程,网络进程
- web进程对应于Chromium中的Renderer 进程,主要是渲染网页
- 进程对阴雨Chromium中的Browser进程,接口就暴露在该进程中,饮用程序可以直接调用这些接口
Webkit 和 Webkit 2 嵌入式接口
-
嵌入式接口是指,通过改接口,可以将网页渲染的程序嵌入在应用程序中
-
按功能分类可以将这些接口分为6种类型:
- 第一类: 设置加载网页、获取加载速度、停止加载、重加载等;
- 第二类: 遍历前后浏览记录,可以前进、后退等;
- 第三类:网页的很多设置,比如缩放、主题、背景、模式、编码等;
- 第四类: 查找网页内容、高亮等;
- 第五类: 触控事件、鼠标事件处理;
- 第六类: 查看网页元代码,显示调试窗口等与开发者相关的接口
-
webkit 和 webkit 2 接口是不兼容的,但是他们实现的功能目标是差不多的
比较Webkit 2 和 Chromium多进程模型以及接口
一、第一点
- Chromium 使用的是Webkit 接口,而不是Webkit 2 接口
- Chromium 是在webkit接口之上构建的多进程模型
二、第二点
- Webkit 2希望将尽可能多的进程结构隐藏起来,这样可以让应用程序不必纠结于内部的细节
- 对Chromium来说,它的主要目的是给Chromium提供Content接口以便构建浏览器,本身目标不是提供嵌入式的接口,虽然有CEF项目基于它构建了嵌入式接口
三、 第三点
- Chromium 中每个进程都从相同的二进制文件可执行文件启动
- 基于Webkit 2的进程不一定是从相同的二进制文件可执行文件启动的
第四章、 资源加载和网络栈
使用网络栈来下载网页和网页资源是渲染引擎工作的第一步
Webkit 资源和加载机制
一、资源
网页本身就是一种资源、网页还需要依赖很多其他的资源(图片、视频)
-
HTML 支持的资源主要包括以下几种类型:
- HTML 页面,包括各式各样的HTML元素
- JavaScript
- CSS
- 图片
- SVG
- CSS Shader
- 音频、视频、文字
- 字体文件
- XSL样式表:使用XSLT语言编写的XSLT代码文件
-
在webkit种通过不同的类来表示这些资源,webkit为这些资源提供了一个公共基类
CachedResource -
Webkit 资源类
CachedRawResource 是HTML文本对应的资源
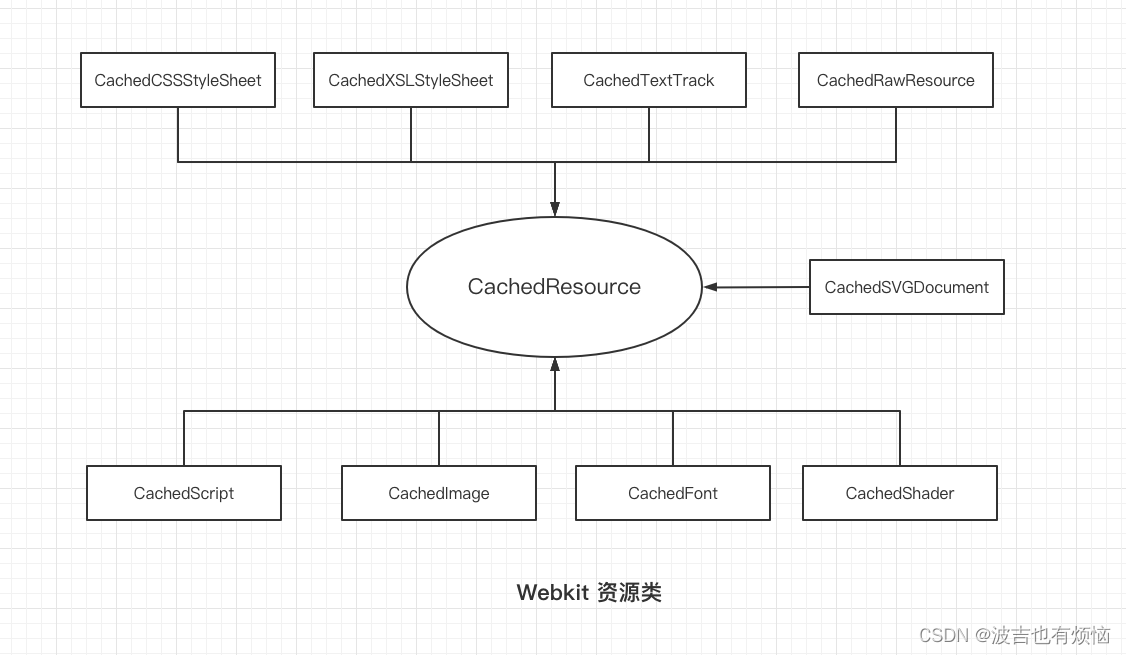
二、资源缓存
- 使用资源缓存是为了提高资源的利用率
- 资源缓存的基本思想:
- 建立一个资源的缓存池
- 需要资源时先从缓存池中获取,如果缓存池中没有,webkit就回创建一个新的CachedResource子类的对象,并发送真正的请真正的请求给服务器,服务器返回资源之后,webkit就会将接收到的资源设置到该资源类的对象中去,并缓存下载方便下次使用
- 缓存池是建立在内存中的
- 资源缓存基本原理
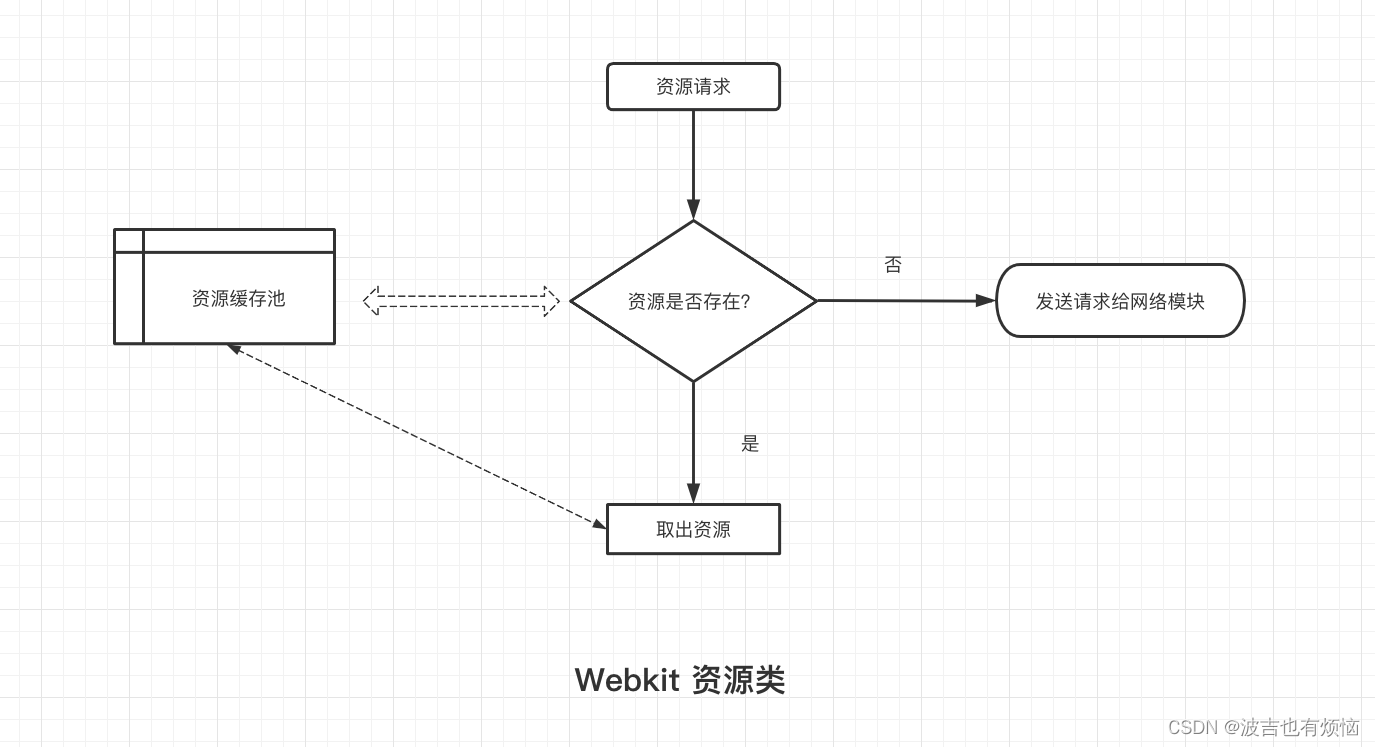
- webkit从资源池中查找资源的关键字是URL(标记资源唯一性的特征就是资源的URL)
- 即使是两个资源有完全相同的内容,如果URL不同也会被认为是完全不同的资源
资源加载器
- webkit 总共有三种类型的资源加载器:
- 第一种是针对每种资源类型的特定加载器,这种加载器的特点是仅加载一种资源
- 第二种:资源缓存机制的资源加载器的特点是所有特定加载器都更想它来查找并插入缓存资源 - CachedResourceLoader类,特定资源加载器是通过缓存机制的资源加载器来查找是否有资源缓存,属于HTML文档对象
- 第三种: 通用资源加载器 - ResourceLoader类,是在webkit需要从网络或者文件系统获取资源的时候使用该类只负责获得资源的数据,因此被所有特定资源加载器所共享
资源池的生命周期
资源池的大小是有先的,必须要使用相应的机制来替换资源池中的资源,以便加入新的资源, 资源池中替换、更新资源的机制就是资源池的生命周期
- 资源池采用什么机制来更新资源?
- 采用LRU(Least Recent Used)最近最少使用算法
- webkit 如何判断下次使用的时候是否需要更行该资源而重新从服务器请求?
- 当一个资源被加载之后,通常就会被放入资源池,当用户打开网页后他想刷新当前页面,资源池并不会清除所有的资源,重新请求服务器,也不会直接利用当前的资源
- webkit的做法是,首先会判断资源是否在资源池中,如果资源在资源池中,那么会向服务器发送一个请求,告诉服务器资源池中的信息(过期时间,修改时间等), 服务器会更具这行信息作出判断,如果没有更新,服务器则会返回304的状态码,表示不需要更新,直接利用资源池中的资源,如果资源不在资源池中,webkit会向服务器发送加载资源的请求
Chromium 多进程资源加载
Chromium采用的是多进程资源加载机制
网络栈
网络栈的基本组成
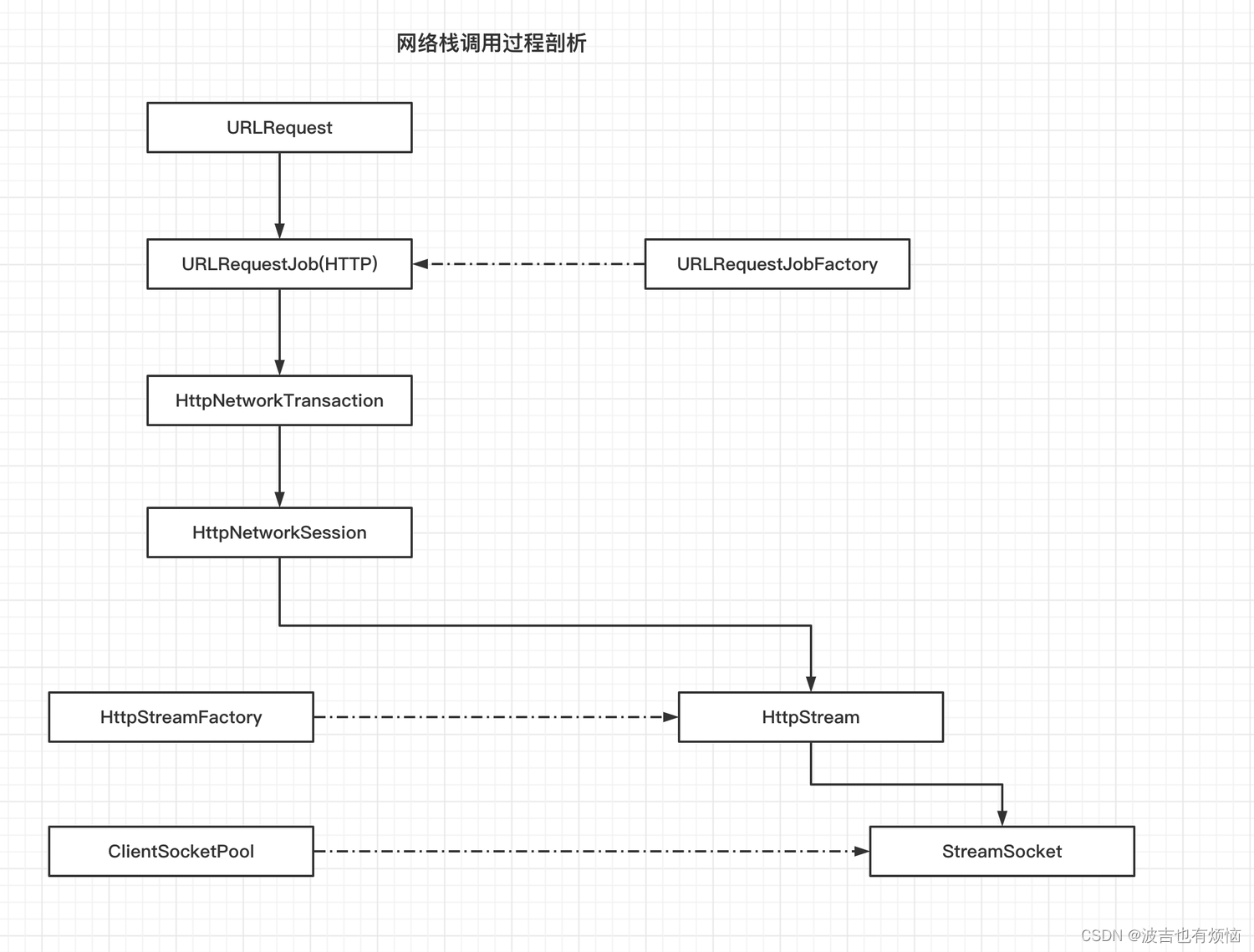
以HTTP协议为例,建立TCP的socket连接过程中涉及到的类
- URLRequest类被上层调用并请求的时候,会根据URL的’scheme’来决定需要创建什么类型的请求
- ‘scheme’ 就是URL的协议类型(http:// , file://),还可以是自定义的scheme
- URLRequestJob 类和它的工厂类URLRequestJobFactory的管理工作都是由URLRequestJobManager类负责,主要思路就是用户可以在该类中注册入多个工厂,当有URLRequest请求时,先由工厂检查是否需要处理该scheme,如果没有,就交给下一工厂类来处理,最后如果没有可以处理的工厂函数,Chromium则交给内置的工厂函数检查和处理为“http://”, "file://“或"ftp://”
- 当’URLRequestJob’被创建止呕,改对象首先从Cookie管理器中或者去与改URL相关联的信息
HTTPTransactionFactory对象可以创建一个HttpTransaction对象表示HTTP连接的事物- `HttpNetwork类使用HttpSession类来管理会话
- HttpSession类时通过它的成员HttpStreamFactory对象将网络之间的数据读写交给自己新创建的一个HttpSteam子类的对象来处理
- 最后时套接字的建立,Chromium中与服务器建立套接字的时StreamSocket类
- StreamSocket 是一个抽象类,早POSIX系统和Windows系统上有着分别不同的实现