分析 1996-2018 年自由骑行世界巡回赛中的极限滑雪和单板滑雪
自 1996 年以来, 自由骑行世界巡回赛 (FWT) 一直举办极限滑雪&单板滑雪赛事。在 3 月份刚刚结束 2018 赛季后,我用 r
如果你还没有听说过 FWT,这是一项令人兴奋的运动,骑手们选择崎岖不平的路线穿过悬崖、飞檐和肮脏的峡谷(就像这条路线)。没有人工跳跃或半管道,只有一个在顶部和底部的门。裁判使用五个标准(线的难度、控制、流畅性、跳跃和技术)从 0 到 100 打分。
我做这个项目的愿望主要是练习一些网络抓取,访问 Twitter API 并加强我自己对其中应用的概念的理解。当谈到体育分析时,滑雪和单板滑雪被遗忘了——我的意思是甚至网球也有一个 R 包——所以我认为这将是一个很酷的项目。
Twitter 上的#FWT18
首先,我使用 Twitter 包从 Twitter API 收集数据。为了做到这一点,我需要设置一个开发者帐户来认证来自 R 的连接(关于如何做的一个很好的教程是这里的)。
library(twitteR)# set objects
api_key <- "your api key"
api_secret <- "your api secret"
access_token <- "your access token"
access_token_secret <- "your access token secret"# authenticate
setup_twitter_oauth(api_key, api_secret, access_token, access_token_secret)
快速可视化提及#FWT18 的推文频率
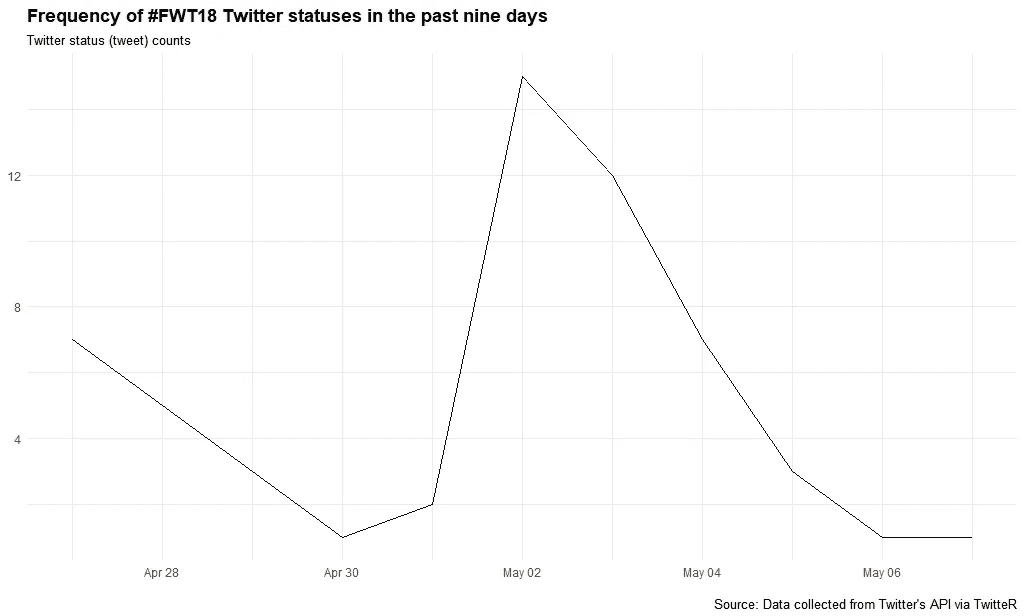
我得到一个警告,说我向 Twitter API 请求了最多 1,000 条推文,但它只返回了过去 9 天中的 58 条。
如果能有更长的历史记录就好了,但是 twitter API 只能索引几天的 tweets,不允许历史查询(有一个Python 包可以,但是我还没有试过。
世界上哪里的人在讨论#FWT18?
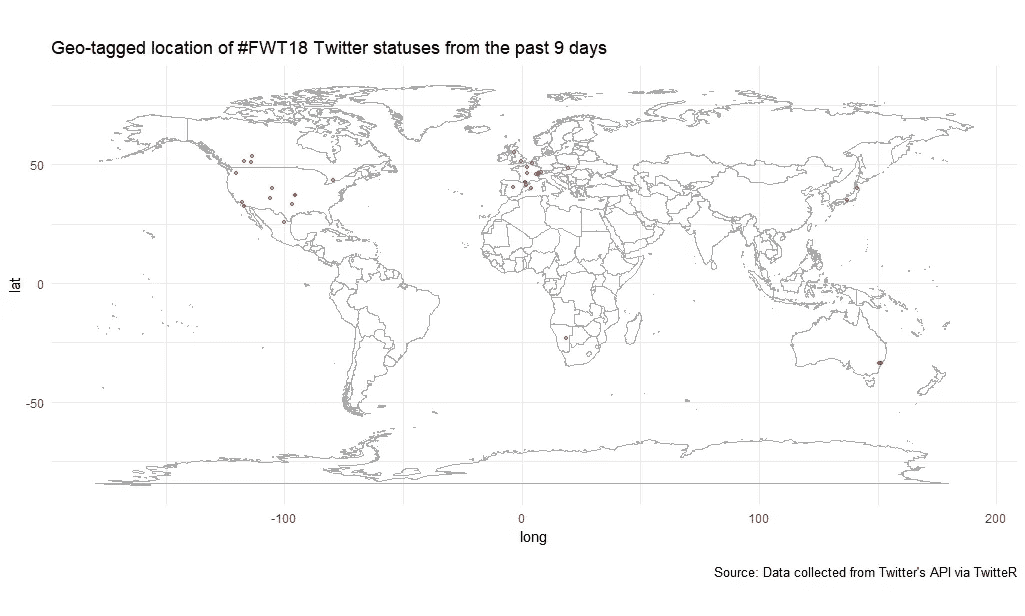
看起来大多数推文来自欧洲和北美,尽管我们看到一些来自日本、澳大利亚和非洲的推文。
请注意,地理标签推文只对那些在设置中选择了这一点的人可用,这仅占 Twitter 用户的 3%。
关于#FWT18,推特上出现的热门词汇有哪些?
这一次,我通过使用一个查找提及和散列标签的功能,将 @FreerideWTour 和几个骑手的 Twitter 句柄包括在内,然后为 #FWT18 标签中提到的最受欢迎的事物创建一个词云。

看来撞车和周末经常用。
探索 FWT18 排名
因为数据不能作为获得。txt 或 a 。网站上的 csv 文件,他们也没有提供我需要抓取的 API。
值得一提的是,管理员可能出于多种原因想要保护其网站的某些部分,“例如对未经宣布的网站进行索引、遍历需要大量服务器资源的网站部分、递归遍历无限的 URL 空间等。”
因此,应该经常检查他们是否有许可。一种方法是使用 robotstxt 包来检查你的网络机器人是否有权限访问网页的某些部分(感谢malle Salmon的提示)。
library(robotstxt)
paths_allowed("[https://www.freerideworldtour.com/rider/](https://www.freerideworldtour.com/rider/)")[1] TRUE
好的,看起来我们得到许可了。
不幸的是, FWT 2018 排名页面的代码是“花哨”的,这意味着你需要点击下拉箭头来获得每个事件的骑手分数。
我认为数据是用 JavaScript 加载的,这意味着我需要使用一个可以通过编程点击按钮的程序。我听说 splashr 或硒酸盐可以完成这个任务。但是,我是网络搜集的新手,只熟悉 rvest 所以我想出了一个(相对)快速解决办法。
我将 2018 年花名册中的名字放入一个 datase t 中,并将其作为一个对象加载。我可以通过将这些名字输入到 rvest 来自动抓取每个骑手,并使用 for 循环到https://www.freerideworldtour.com/rider/的结尾
# read in the names from 2018 roster
roster <- read_csv("[https://ndownloader.figshare.com/files/11173433](https://ndownloader.figshare.com/files/11173433)")# create a url prefix
url_base <- "[https://www.freerideworldtour.com/rider/](https://www.freerideworldtour.com/rider/)"
riders <- roster$name# Assemble the dataset
output <- data_frame()
for (i in riders) {
temp <- read_html(paste0(url_base, i)) %>%
html_node("div") %>%
html_text() %>%
gsub("\\s*\\n+\\s*", ";", .) %>%
gsub("pts.", "\n", .) %>%
read.table(text = ., fill = T, sep = ";", row.names = NULL,
col.names = c("Drop", "Ranking", "FWT", "Events", "Points")) %>%
subset(select = 2:5) %>%
dplyr::filter(
!is.na(as.numeric(as.character(Ranking))) &
as.character(Points) != ""
) %>%
dplyr::mutate(name = i)
output <- bind_rows(output, temp)
}
我打算看看每个类别(滑雪和单板滑雪)的总排名,按运动员在 2018 年每场 FWT 赛事中获得的分数划分;然而,我注意到有些奇怪的事情正在发生。
# How many riders in the roster?
unique(roster)# A tibble: 56 x 3
name sport sex
<chr> <chr> <chr>
1 aymar-navarro ski male
2 berkeley-patt~ ski male
3 carl-regner-e~ ski male
4 conor-pelton ski male
5 craig-murray ski male
6 drew-tabke ski male
7 fabio-studer ski male
8 felix-wiemers ski male
9 george-rodney ski male
10 grifen-moller ski male
# ... with 46 more rows# How many names in the output object?
unique(output$name)[1] "aymar-navarro"
[2] "berkeley-patterson"
[3] "carl-regner-eriksson"
[4] "conor-pelton"
[5] "craig-murray"
[6] "drew-tabke"
[7] "fabio-studer"
[8] "felix-wiemers"
[9] "george-rodney"
[10] "grifen-moller"
[11] "ivan-malakhov"
[12] "kristofer-turdell"
[13] "leo-slemett"
[14] "logan-pehota"
[15] "loic-collomb-patton"
[16] "markus-eder"
[17] "mickael-bimboes"
[18] "reine-barkered"
[19] "ryan-faye"
[20] "sam-lee"
[21] "stefan-hausl"
[22] "taisuke-kusunoki"
[23] "thomas-rich"
[24] "trace-cooke"
[25] "yann-rausis"
[26] "arianna-tricomi"
[27] "elisabeth-gerritzen"
[28] "eva-walkner"
[29] "hazel-birnbaum"
[30] "jaclyn-paaso"
[31] "kylie-sivell"
[32] "lorraine-huber"
[33] "rachel-croft"
[34] "blake-hamm"
[35] "christoffer-granbom"
[36] "clement-bochatay"
[37] "davey-baird"
原来第 40 行的名字elias-elhardt产生了一个问题。我不确定这是为什么,但是因为 Elias 只参加了资格赛,所以让我们简单地把他去掉,然后重新运行上面的代码。
# Remove Elias Elhardt
roster <- roster[-40,]
riders <- roster$name
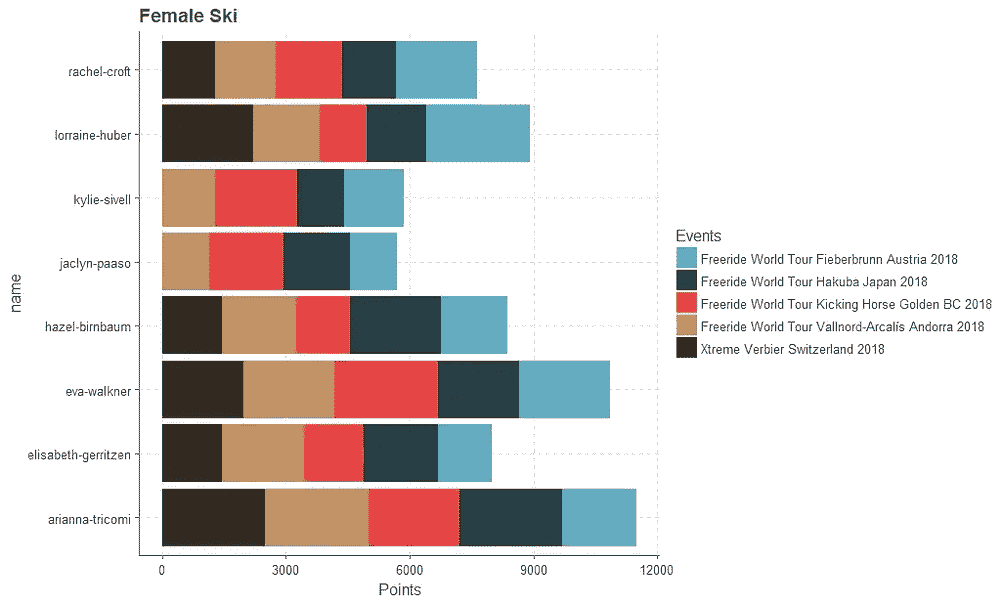
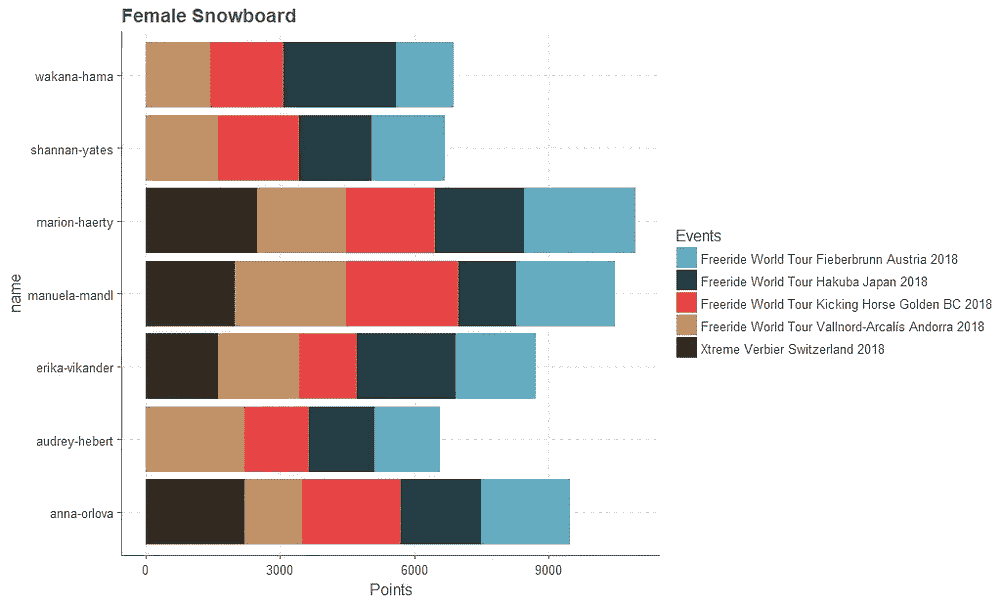
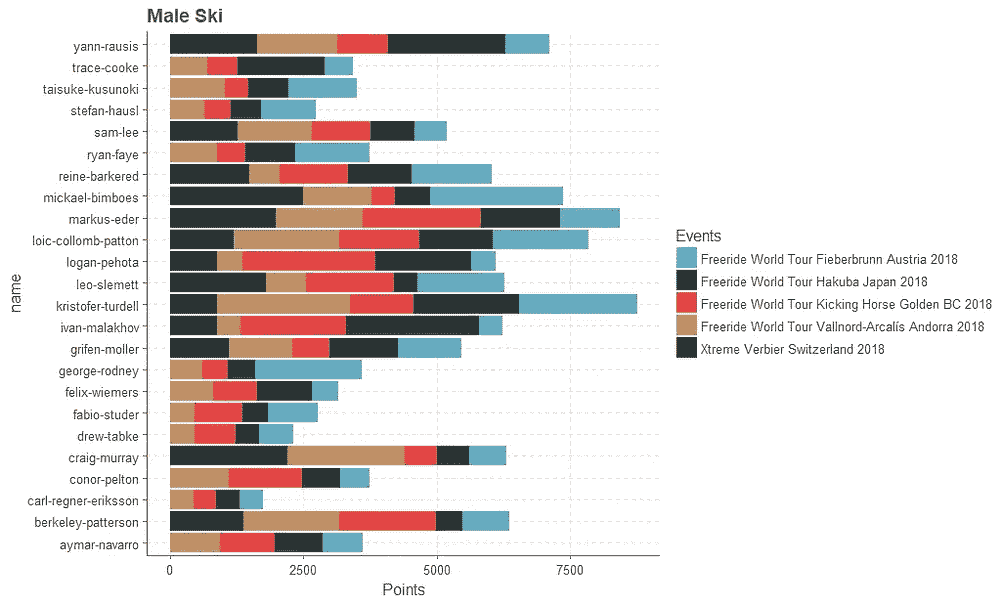
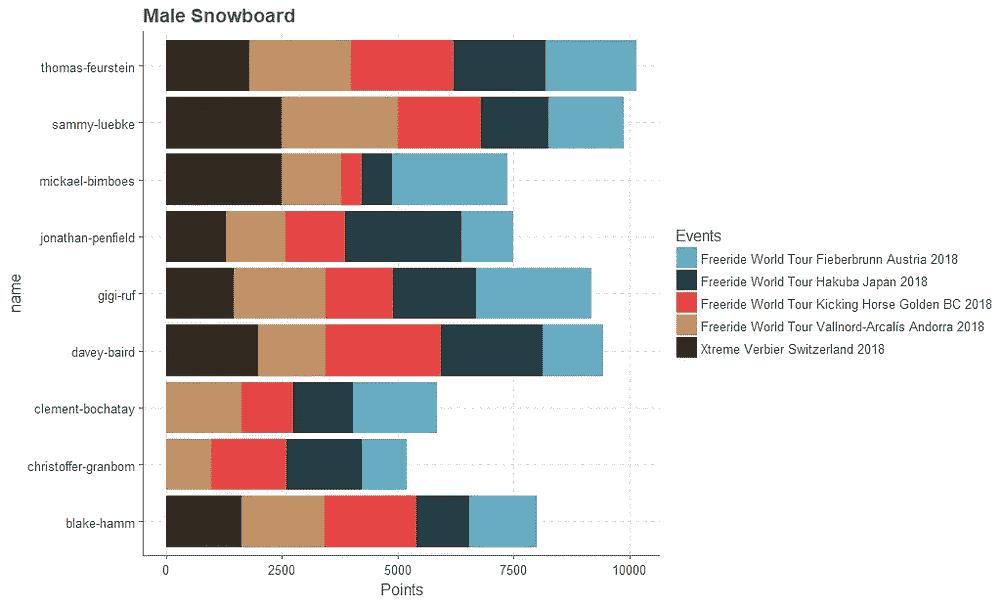
历史上的 FWT 获奖者
FWT 在他们的网站上列出了往届比赛的获胜者。我收集了 1996 年至 2018 年间 23 场巡回赛的所有获胜者的数据,并从网站或快速网络搜索中包括了他们的年龄。数据集可以在 figshare 上找到。
# load the data
df <- read_csv("[https://ndownloader.figshare.com/files/11300864](https://ndownloader.figshare.com/files/11300864)")# Get summary statistics on age of winners
df %>%
summarize(mean_age = median(age, na.rm = TRUE),
max_age = max(age, na.rm = TRUE),
min_age = min(age, na.rm = TRUE)) mean_age max_age min_age
1 29 43 15# Find minimum age of winner by sex and sport
df %>%
group_by(sex, sport) %>%
slice(which.min(age)) %>%
dplyr::select(name, sex, sport, age)# A tibble: 4 x 4
# Groups: sex, sport [4]
name sex sport age
<chr> <chr> <chr> <int>
1 Arianna Tricomi female ski 23
2 Michelle Gmitro female snowboard 16
3 George Rodney male ski 21
4 Cyril Neri male snowboard 15
骑手们赢得过多少次 FWT 赛事?
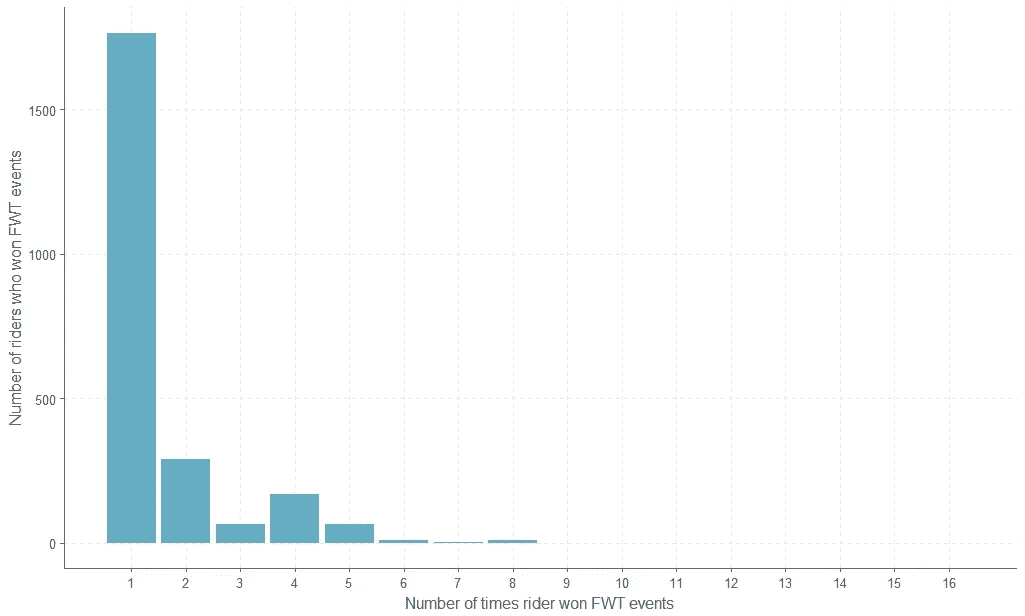
赢得至少一项 FWT 赛事的众多骑手让那些赢得大量赛事的独特运动员相形见绌。
我们可以再看一下表格中的数据。
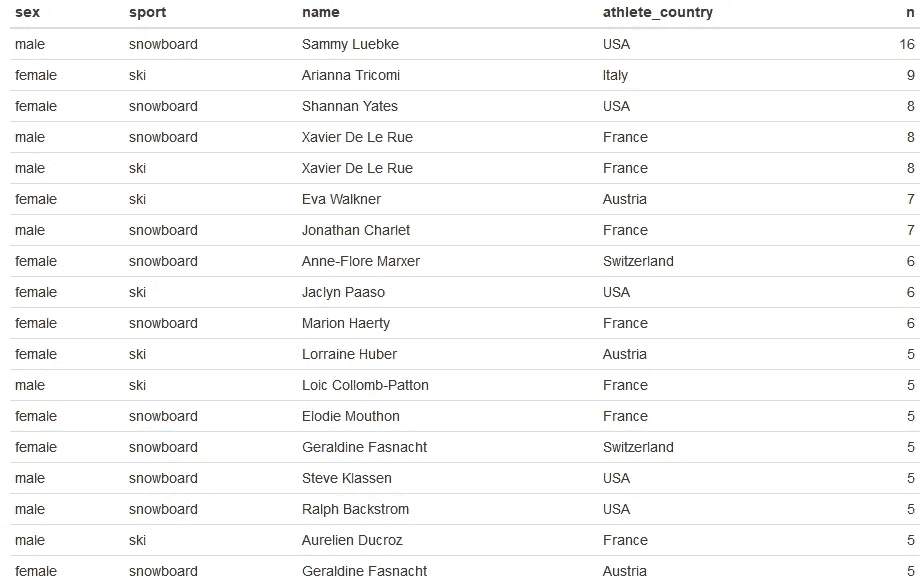
Xavier De Le Rue 以 8 分接近最高,出现在滑雪和单板滑雪两个类别中?太奇怪了。我们可以这样替换数据集中的错误。
df$sport[df$name == "Xavier De Le Rue"] <- "snowboard"
哪些国家的赢家最多?
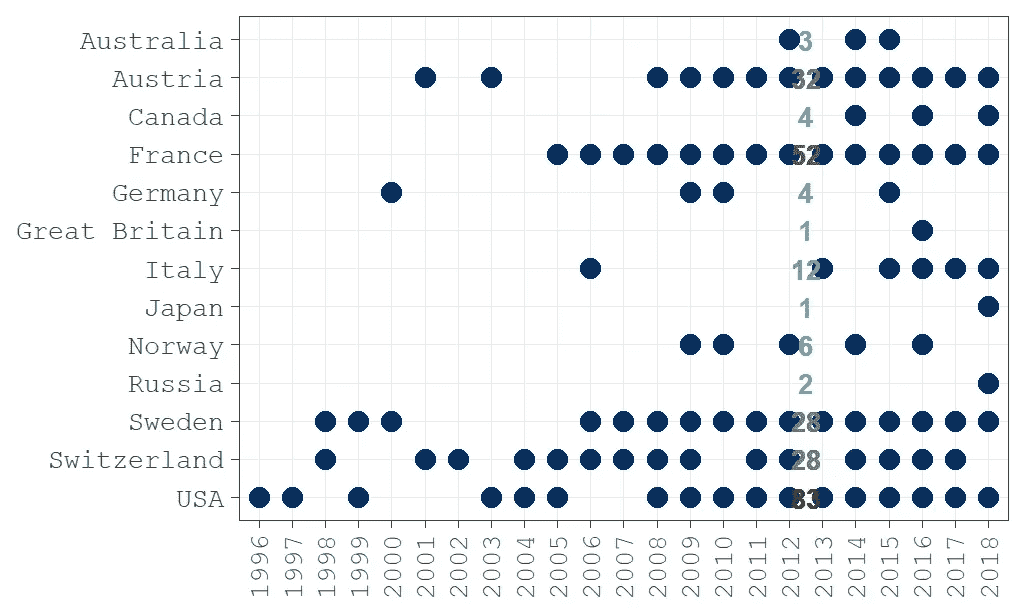
看起来美国、法国和奥地利产生了一些最好的免费搭车者。
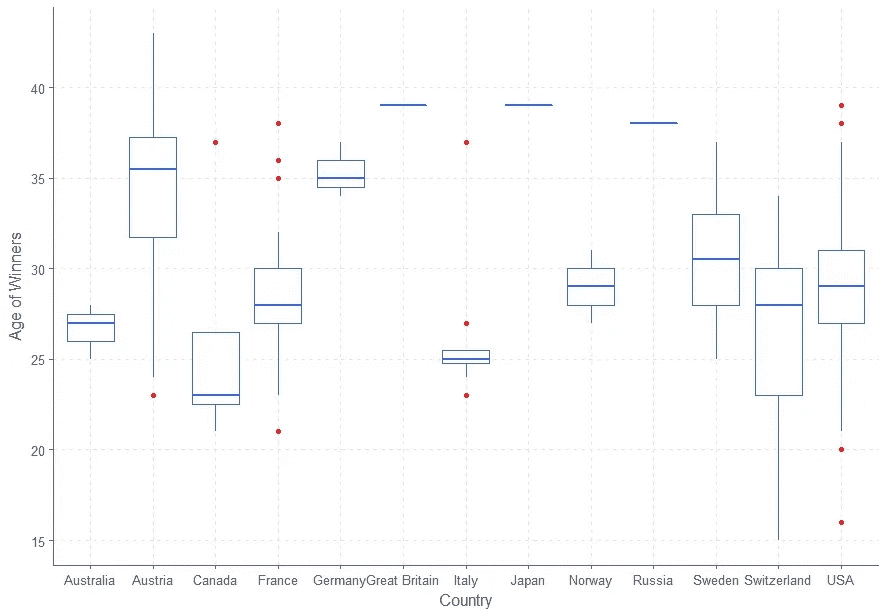
每个国家的获胜者有多大?
我们可以用箱线图来了解每个国家的年龄分布情况。
然而,一个更好的方法是用雨云图来直观地了解分布情况。因为一些国家只有一个竞争对手,所以让我们把他们去掉。
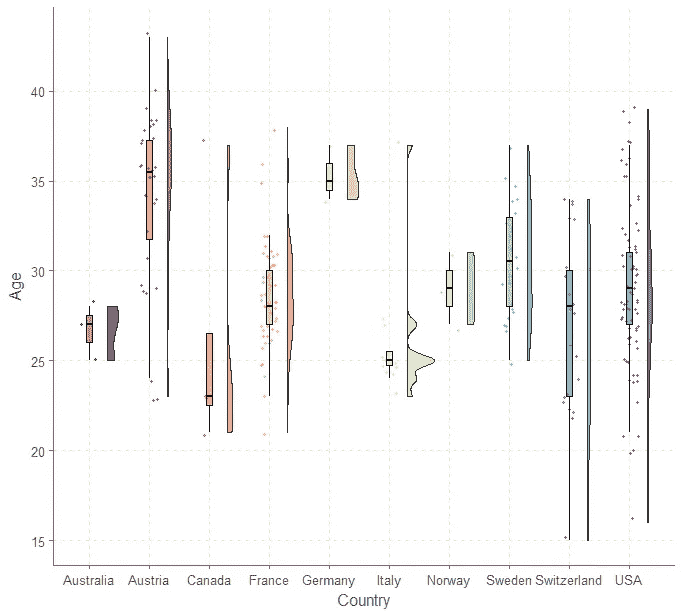
问一问获胜者的年龄在比赛的历史上是如何变化的也是很有趣的。
FWT 获奖者越来越年轻了吗?
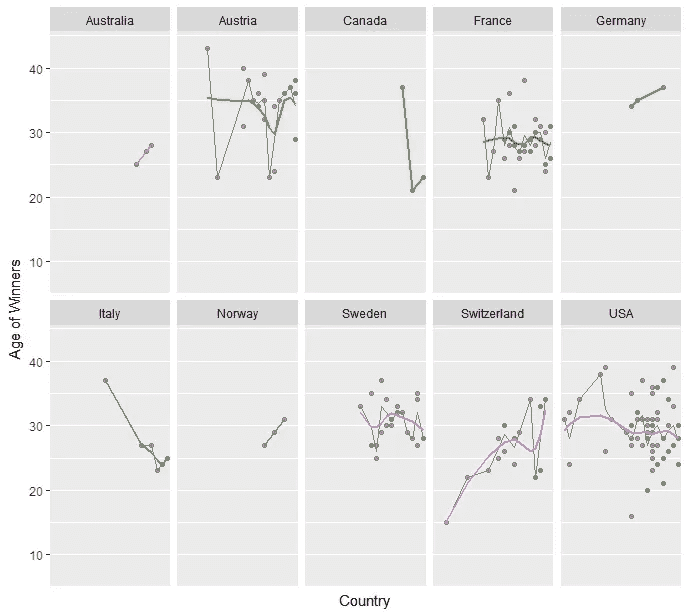
随着时间的推移,年龄和赢得 FWT 赛事似乎没有任何趋势。
这将是很好的发挥周围的数据,法官如何评分每个骑手从 0 到 100 的每一个项目的五个类别,但它看起来不像这样的信息是可用于公众在这个时候。
Python 中具有中等故事统计的数据科学
一个用于数据科学的 Python 工具包,具有中等文章统计
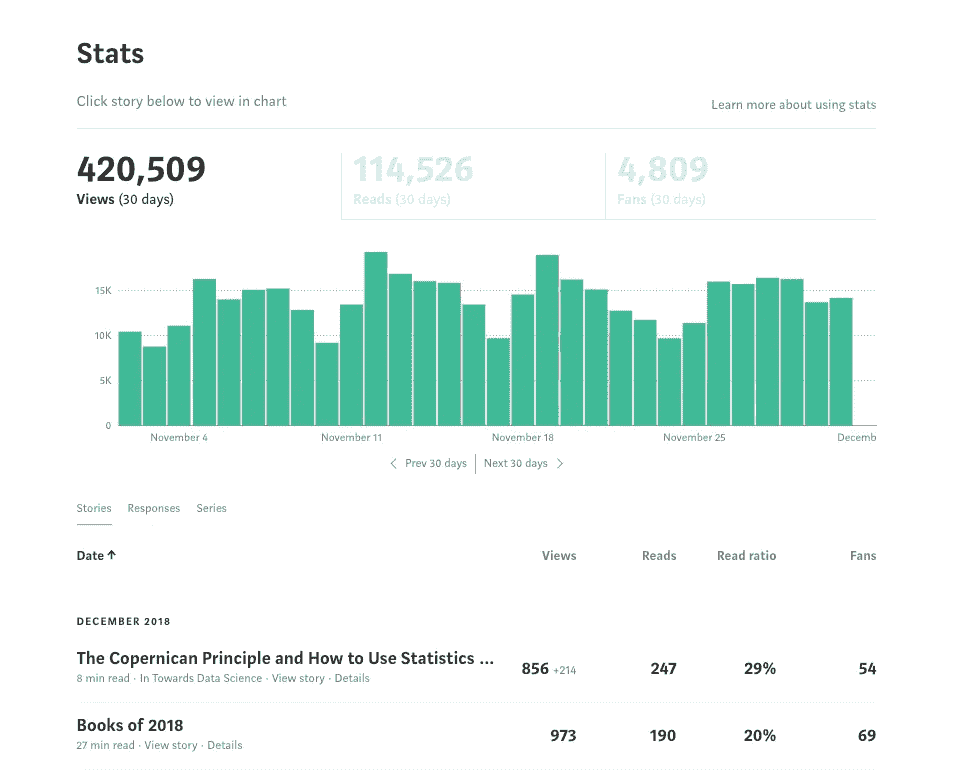
Medium 是一个写作的好地方:没有分散注意力的功能,拥有庞大但文明的读者群,最棒的是,没有广告。然而,它不足的一个方面是你可以在你的文章中看到的统计数据。当然,你可以进入统计页面,但是你看到的只是一些普通的数字和一个绿色的条形图。没有任何形式的深度分析,也没有办法理解你的文章产生的数据。
It’s nice when you reach the point where it’s more than your mom reading your articles.
这就好像 Medium 说的:“让我们建立一个伟大的博客平台,但让作者尽可能难以从他们的统计数据中获得洞察力。”虽然我不在乎使用统计数据来最大化浏览量(如果我想获得最多的浏览量,我所有的文章都是 3 分钟的列表),但作为一名数据科学家,我不能忍受数据未经检查的想法。
我决定对此做些什么,而不是仅仅抱怨媒体统计的糟糕状态,并编写了一个 Python 工具包,允许任何人快速检索、分析、解释和制作他们的媒体统计的漂亮、交互式图表。在本文中,我将展示如何使用这些工具,讨论它们是如何工作的,并且我们将从我的媒体故事统计中探索一些见解。
GitHub 上有完整的工具包供您使用。你可以在 GitHub 这里看到一个使用 Jupyter 的笔记本(不幸的是互动情节在 GitHub 的笔记本浏览器上不起作用)或者在 NBviewer 这里看到完整的互动荣耀。欢迎对这个工具包做出贡献!
Example plot from Python toolkit for analyzing Medium articles
1 分钟后开始
首先,我们需要检索一些统计数据。在编写工具包时,我花了 2 个小时试图找出如何在 Python 中自动登录到 Medium,然后决定采用下面列出的 15 秒解决方案。如果您想使用我的数据,它已经包含在工具包中,否则,请按照以下步骤使用您的数据:
- 进入你的中型统计页面。
- 向下滚动到底部,以便显示所有故事的统计数据。
- 右键单击并将页面保存为工具包
data/目录中的stats.html
下面的视频演示了这一点:

Sometimes the best solution is manual!
接下来,在工具箱的medium/目录中打开一个 Jupyter 笔记本或者 Python 终端,运行(同样,你可以使用我包含的数据):
from retrieval import get_datadf = get_data(fname='stats.html')
这不仅会解析stats.html文件并提取所有信息,还会访问每篇文章,检索整篇文章和元数据,并将结果存储在 dataframe 中。我的 121 篇,这个过程大概用了 5 秒钟!现在,我们有了一个数据框架,其中包含关于我们产品的完整信息:
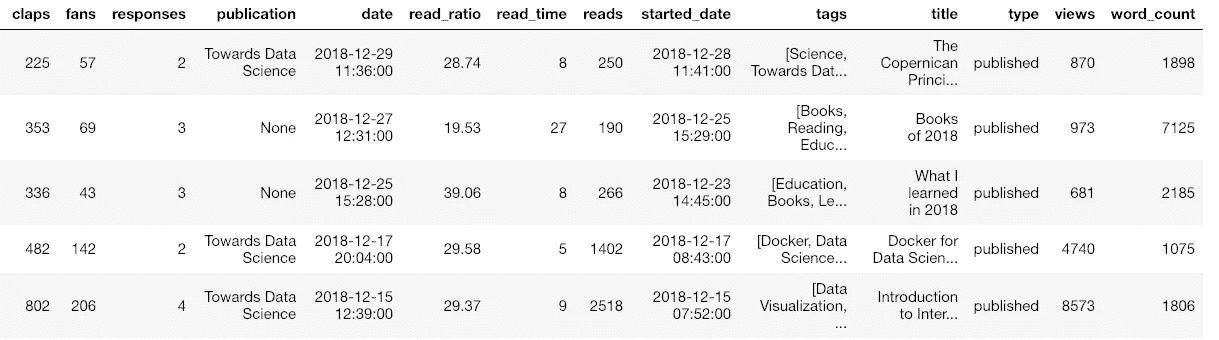
Sample of dataframe with medium article statistics
(为了显示,我已经截掉了数据帧,所以数据比显示的还要多。)一旦我们有了这些信息,我们可以使用任何我们知道的数据科学方法来分析它,或者我们可以使用代码中的工具。Python 工具包中包括制作交互式图表、用机器学习拟合数据、解释关系和生成未来预测的方法。
举个简单的例子,我们可以制作一个数据相关性的热图:
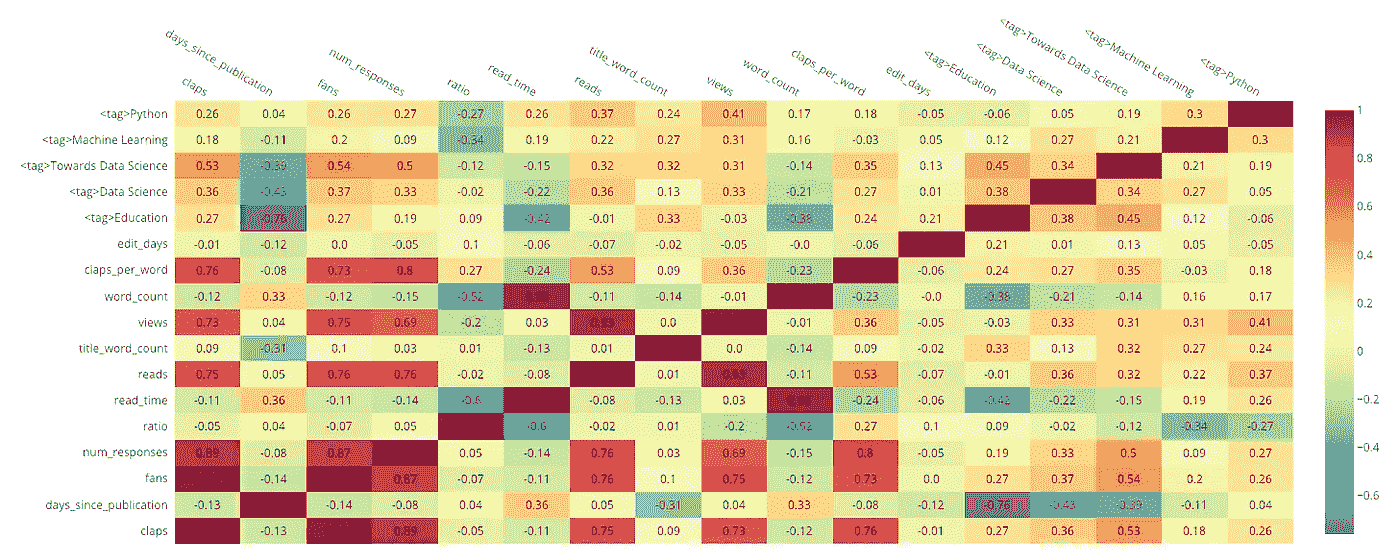
Heatmap of correlations
<tag>列表示文章是否有特定的标签。我们可以看到标签“走向数据科学”与“粉丝”的数量有 0.54 的相关性,这表明将这个标签附加到一个故事上与粉丝的数量(以及鼓掌的数量)正相关*。这些关系大多是显而易见的(掌声与粉丝正相关),但如果你想最大化故事浏览量,你也许能在这里找到一些提示。*
我们可以在单行代码中制作的另一个图是由出版物着色的散点图矩阵(也亲切地称为“splom”):
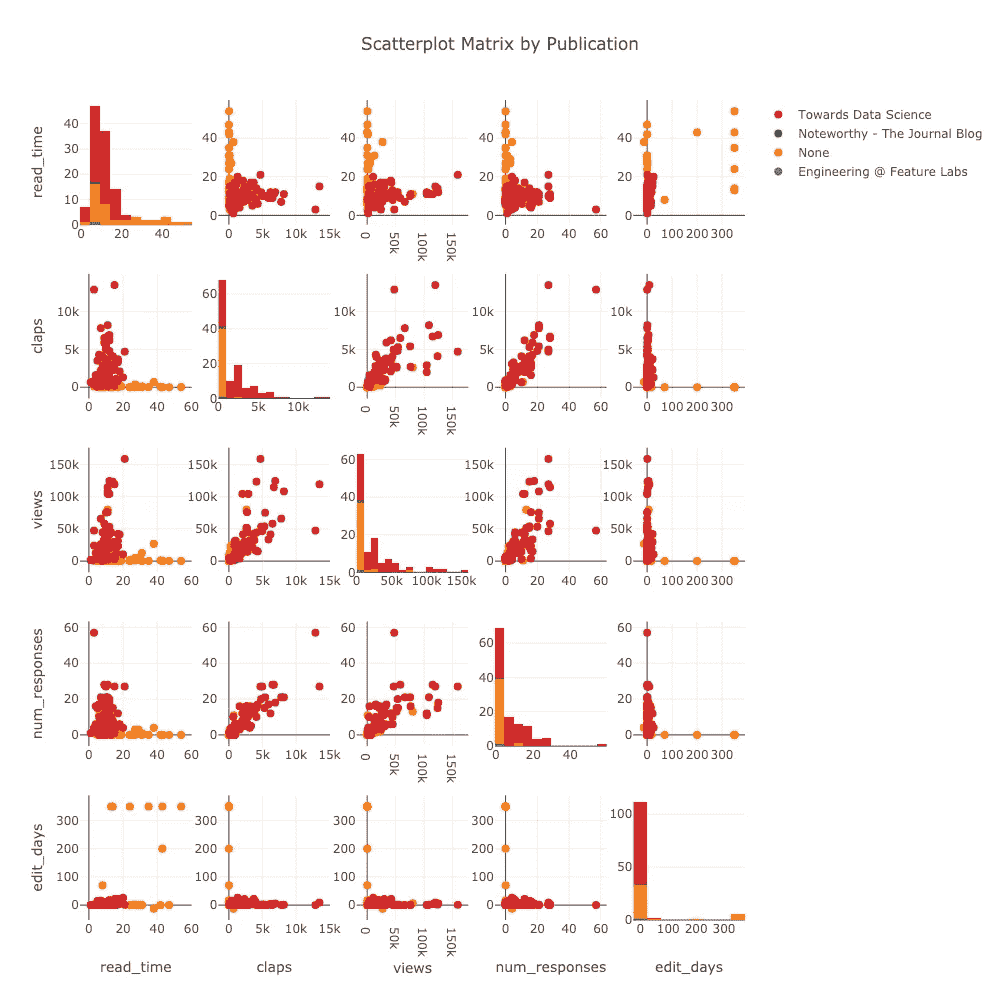
Scatterplot matrix of article stats
(这些图是交互式的,可以在 NBviewer 中的处看到)。
它是如何工作的
在我们回到分析之前(还有更多的图值得期待),有必要简要讨论一下这些 Python 工具是如何获取和显示所有数据的。代码的主力是 BeautifulSoup 、 requests 和 plotly ,在我看来,它们对于数据科学的重要性不亚于众所周知的 pandas + numpy + matplotlib 三重奏(正如我们将看到的,是时候让 matplotlib 退休了*)。*
资料检索
从第一眼看中型统计页面,它似乎不是很结构化。
然而,隐藏在互联网每一页下面的是超文本标记语言(HTML) ,一种呈现网页的结构化语言。如果没有 Python,我们可能会被迫打开 excel 并开始键入这些数字(当我在空军时,不是开玩笑,这将是公认的方法),但是,多亏了BeautifulSoup库,我们可以利用该结构来提取数据。例如,为了在下载的stats.html中找到上表,我们使用:
一旦我们有了一个soup对象,我们就遍历它,在每一点上获得我们需要的数据(HTML 有一个层次树结构,称为文档对象模型 — DOM)。从table中,我们取出一个单独的行——代表一篇文章——并提取一些数据,如下所示:
这可能看起来很乏味,当你不得不用手来做的时候。这涉及到使用谷歌 Chrome 中的开发工具在 HTML 中寻找你想要的信息。幸运的是,Python Medium stats 工具包在幕后为您完成了所有这些工作。你只需要输入两行代码!
从 stats 页面,代码提取每篇文章的元数据,以及文章链接。然后,它使用requests库获取文章本身(不仅仅是统计数据),并解析文章中的任何相关数据,同样使用BeautifulSoup。所有这些都在工具包中自动完成,但是值得看一看代码。一旦你熟悉了这些 Python 库,你就会开始意识到网络上有多少数据等着你去获取。
顺便说一句,整个代码需要大约 2 分钟的时间来连续运行,但是因为等待是无益的,所以我编写它来使用多处理,并将运行时间减少到大约 10 秒。数据检索的源代码这里是这里是。
绘图和分析
这是一个非常不科学的图表,显示了我对 Python 情节的喜爱程度:

Python plotting enjoyment over time.
plotly 库(带有袖扣包装)让用 Python 绘图再次变得有趣!它支持单行代码的完全交互式图表,制作起来非常容易,我发誓再也不写另一行 matplotlib 了。对比下面两个都是用一行代码绘制的图:
Matplotlib and plotly charts made in one line of code.
左边是matplotlib's努力——一个静态的、枯燥的图表——而右边是plotly's工作——一个漂亮的交互式图表,关键是,它能让你快速理解你的数据。
工具包中的所有绘图都是用 plotly 完成的,这意味着用更少的代码就能得到更好的图表。此外,笔记本中的绘图可以在在线绘图图表编辑器中打开,因此您可以添加自己的修改,如注释和最终编辑以供发布:
Plot from the toolkit touched up in the online editor
分析代码实现一元线性回归、一元多项式回归、多元线性回归和预测。这是通过标准的数据科学工具完成的:numpy、statsmodels、scipy和sklearn。有关完整的可视化和分析代码,请参见该脚本。
分析媒体文章
回到分析!我通常喜欢从单变量分布开始。为此,我们可以使用下面的代码:
from plotly.offline import iplot
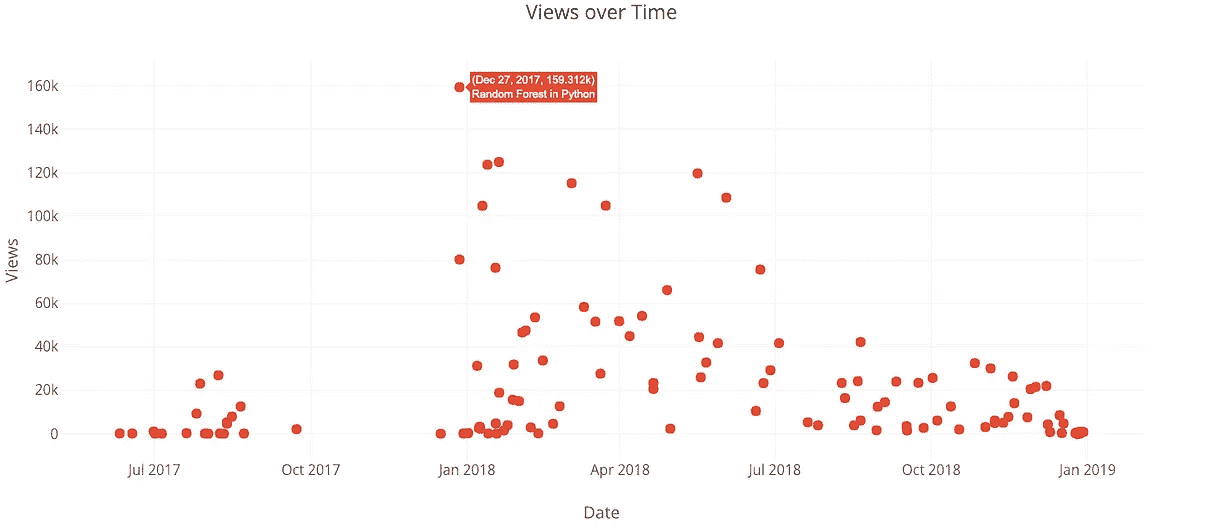
from visuals import make_histiplot(make_hist(df, x='views', category='publication'))
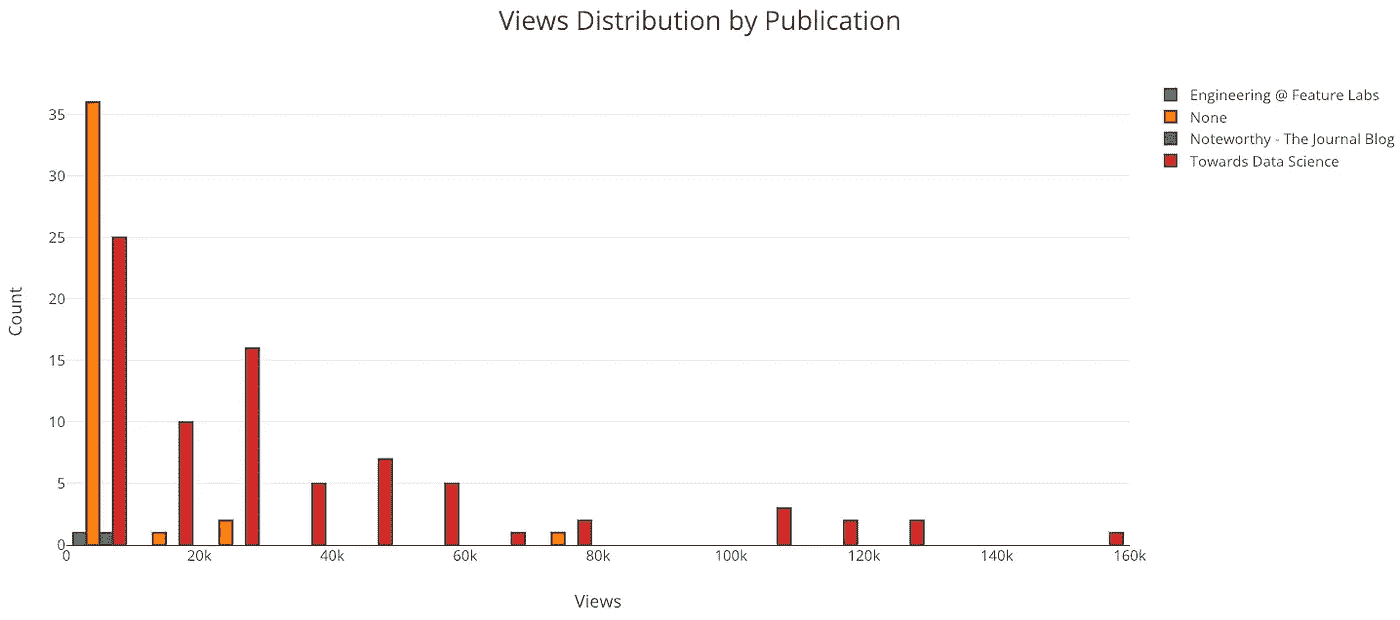
显然,我应该继续在“走向数据科学”中发表文章!我的大多数文章没有在任何出版物上发表,这意味着它们只有在你有链接的情况下才能被浏览(为此你需要在 Twitter 上关注我)。
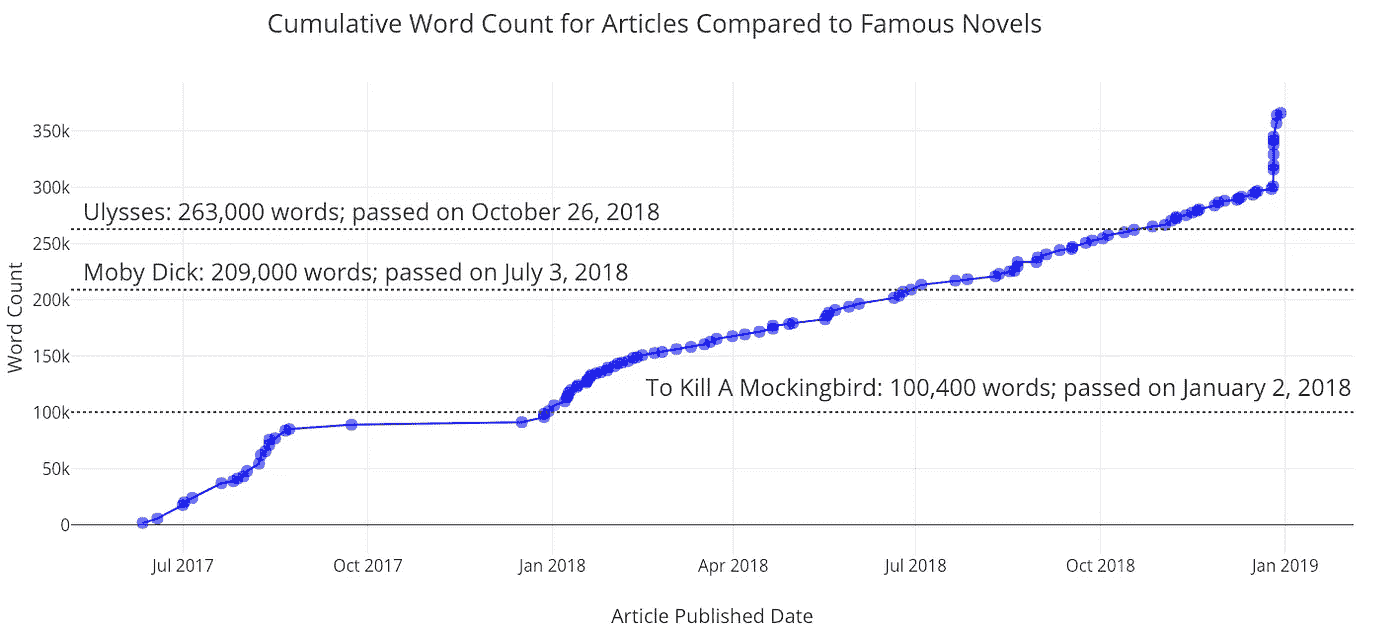
因为所有数据都是基于时间的,所以也有一种方法可以制作累积图,显示您的统计数据随时间的累积情况:
from visuals import make_cum_plotiplot(make_cum_plot(df, y=['word_count', 'views']))
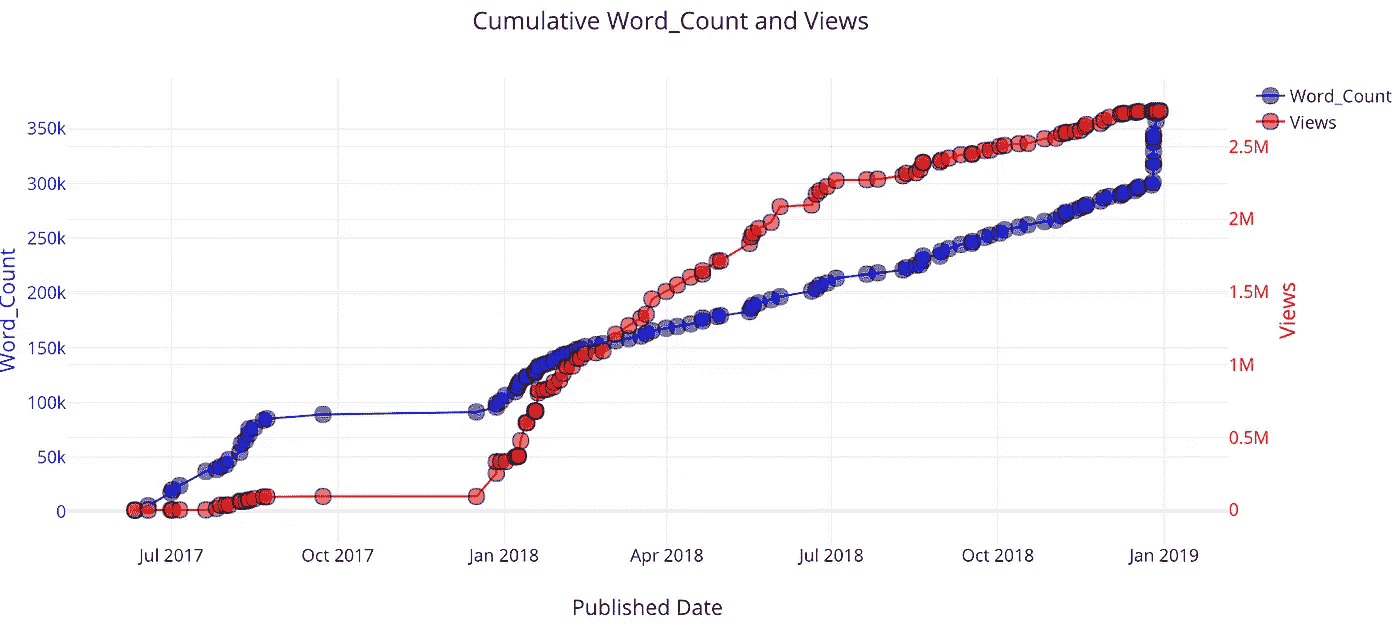
最近,我的字数激增,因为我发布了一堆我已经写了一段时间的文章。当我发表第一篇关于走向数据科学的文章时,我的观点开始流行起来。
(注意,这些视图并不完全正确,因为这是假设一篇给定文章的所有视图都出现在该文章发表的某个时间点。然而,这作为第一近似值是很好的)。
解释变量之间的关系
散点图是一种简单而有效的方法,用于可视化两个变量之间的关系。我们可能想问的一个基本问题是:阅读一篇文章的人的百分比是否随着文章长度的增加而减少?直截了当的答案是肯定的:
from visuals import make_scatter_plotiplot(make_scatter_plot(df, x='read_time', y='ratio'))
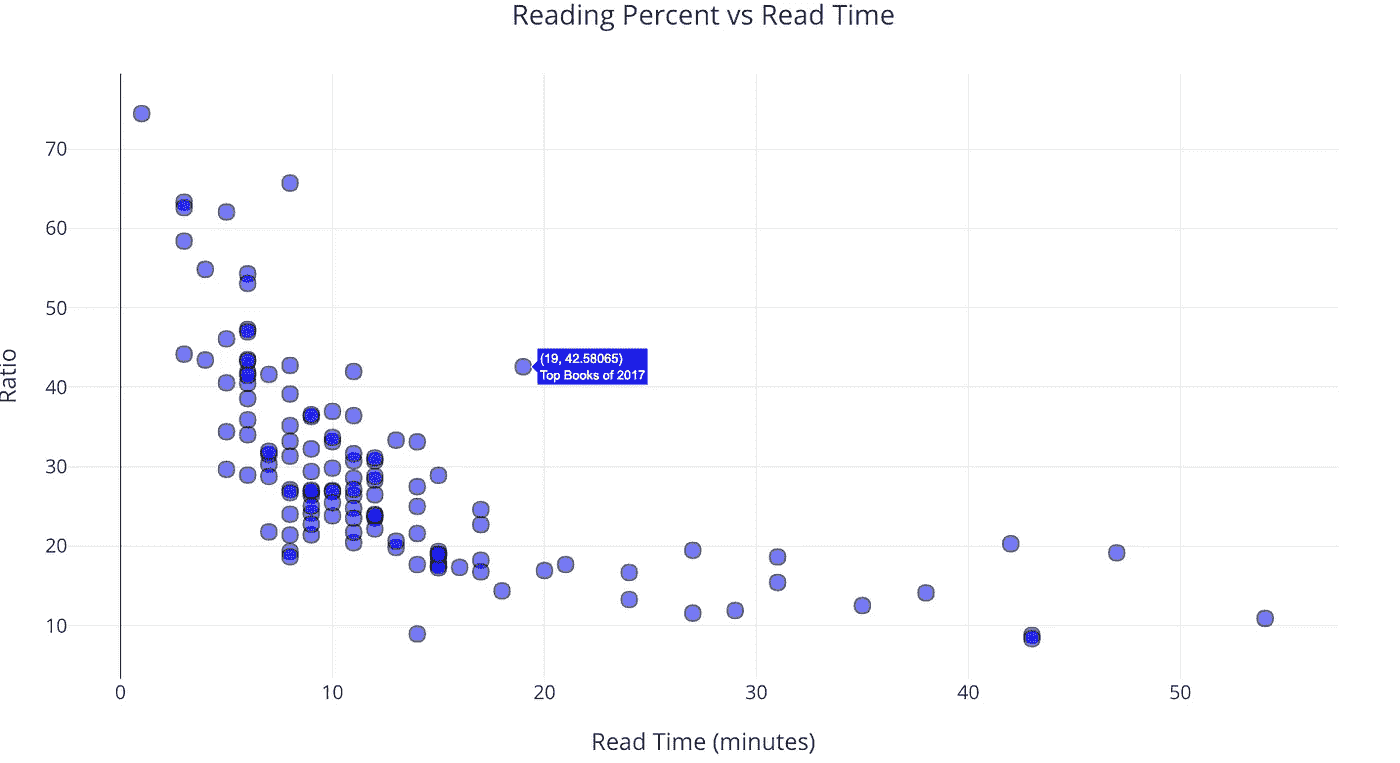
随着文章长度——阅读时间——的增加,阅读文章的人数明显减少,然后趋于平稳。
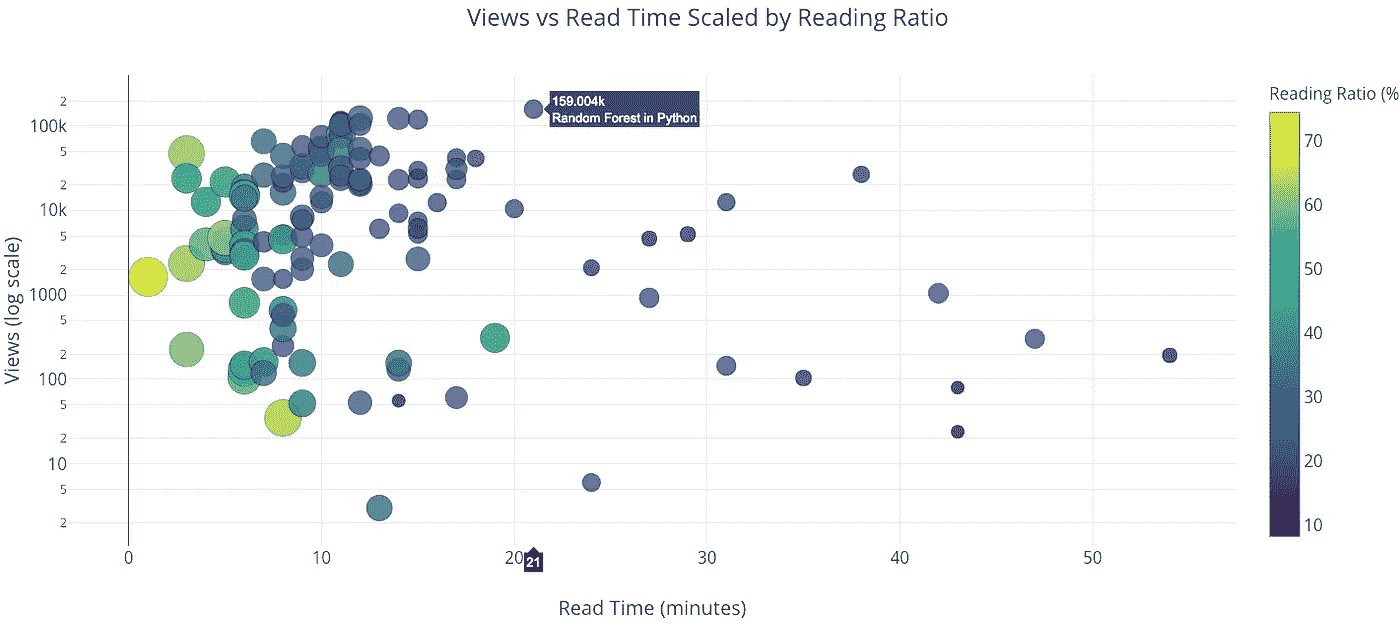
有了散点图,我们可以使任一轴为对数刻度,并通过根据数字或类别调整点的大小或给点着色,在图上包含第三个变量。这也是通过一行代码完成的:
iplot(make_scatter_plot(df, x='read_time', y='views', ylog=True,
scale='ratio'))
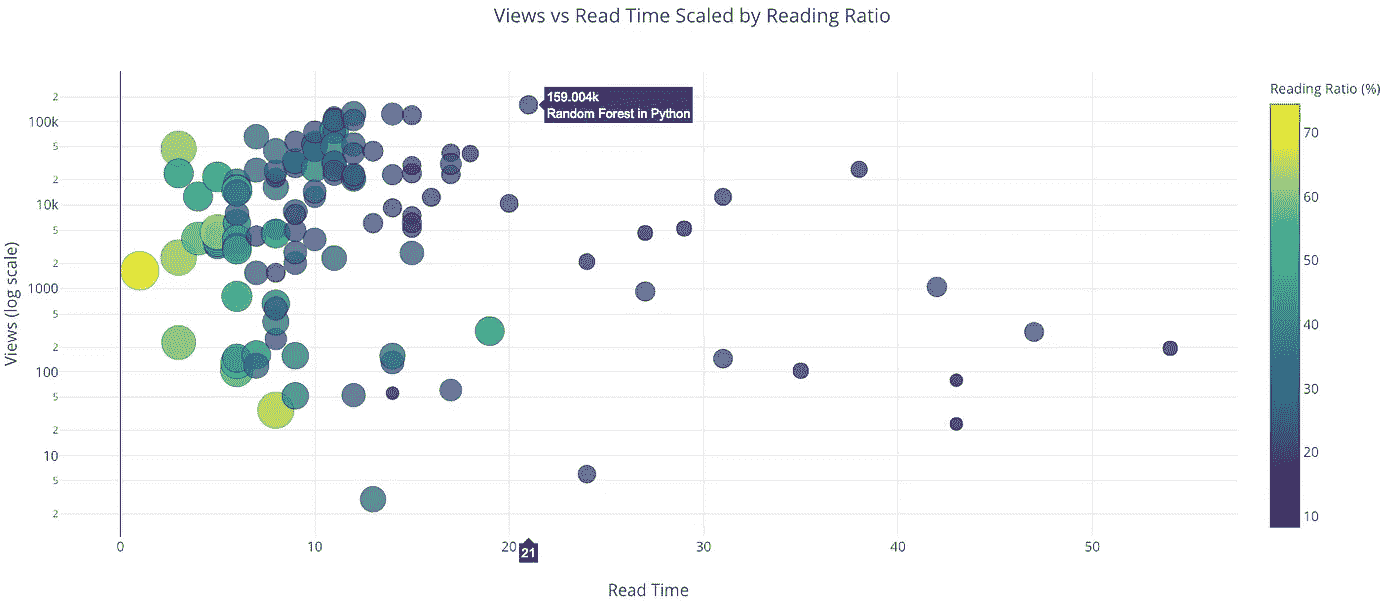
“Python 中的随机森林”这篇文章在很多方面都是一个异数。它是我所有文章中浏览量最多的,然而却花了 21 分钟才读完!
浏览量会随着文章长度减少吗?
虽然阅读率随着文章长度的增加而降低,但阅读或浏览文章的人数是否也是如此呢?虽然我们的直接答案是肯定的,但仔细分析后,似乎浏览次数*不会随着阅读时间的增加而减少。*为了确定这一点,我们可以使用工具的拟合功能。
在这个分析中,我将数据限制在我发表在《走向数据科学》杂志上的文章中,这些文章少于 5000 字,并对观点(因变量)和字数(自变量)进行了线性回归。因为视图永远不会是负数,所以截距设置为 0:
from visuals import make_linear_regressionfigure, summary = make_linear_regression(tds_clean, x='word_count',
y='views', intercept_0=True)
iplot(figure)
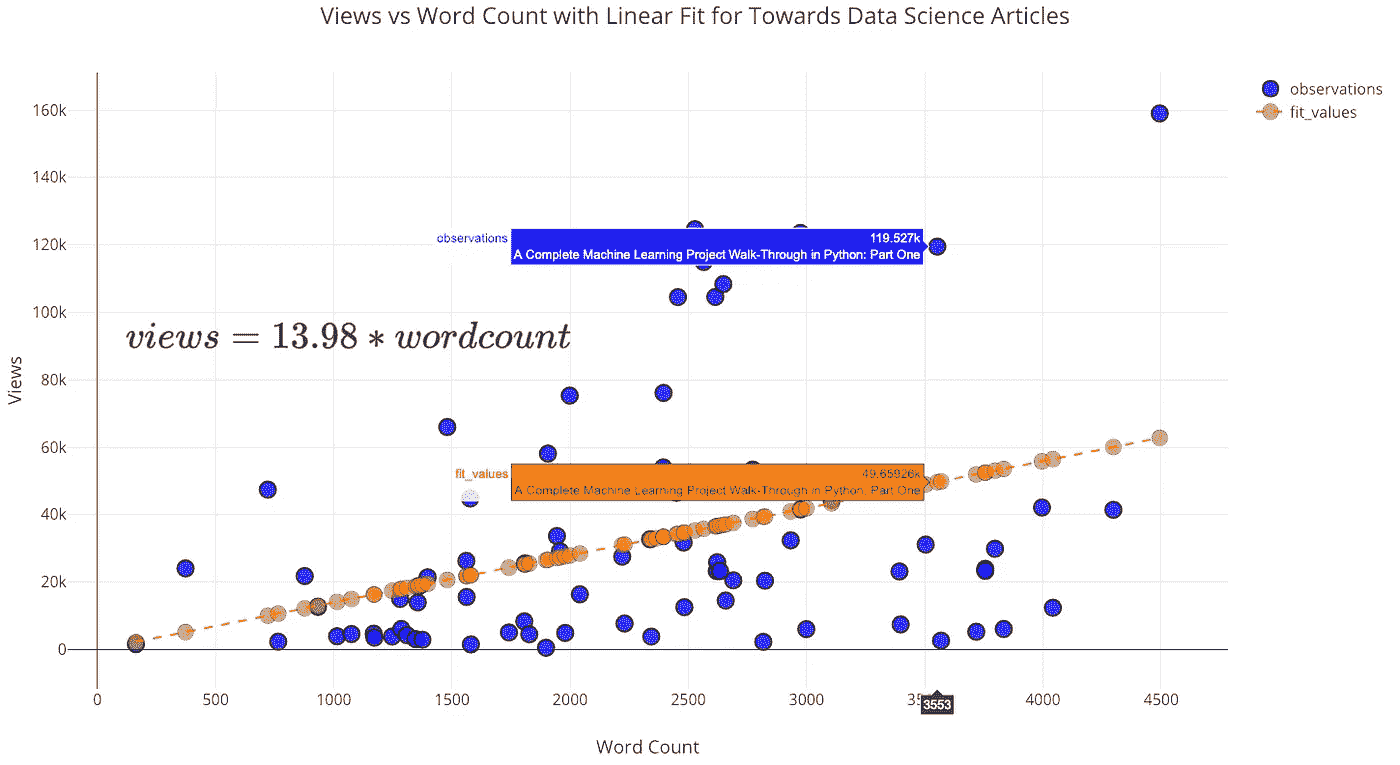
与你所想的相反,随着字数的增加(达到 5000),浏览量也会增加!该拟合的总结显示了正线性关系,并且斜率具有统计学意义:
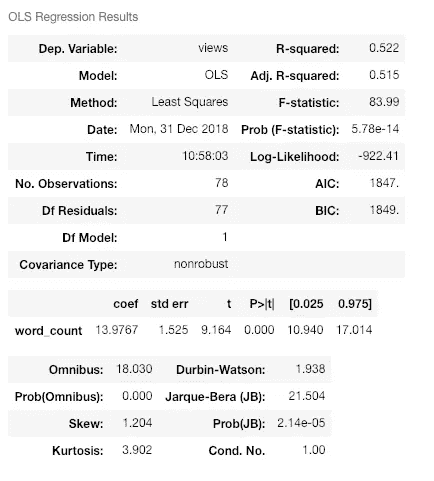
Summary statistics for linear regression.
有一次,一位非常好的女士在我的一篇文章上留下了一张私人纸条,上面写道:“你的文章写得很好,但是太长了。你应该用要点写更短的文章,而不是完整的句子。”
现在,作为一个经验法则,我假设我的读者是聪明的,能够处理完整的句子。因此,我礼貌地回复这位女士(用要点)说我会继续写非常长的文章。基于这种分析,没有理由缩短文章(即使我的目标是最大化视图),特别是对于关注数据科学的读者。事实上,我添加的每一个单词都会导致 14 次以上的浏览!
超越一元线性回归
我们不限于以线性方式将一个变量回归到另一个变量上。我们可以使用的另一种方法是多项式回归,在拟合中我们允许自变量的更高次。然而,我们要小心,因为增加的灵活性会导致过度拟合,尤其是在数据有限的情况下。要记住的一点是:当我们有一个灵活的模型时,更接近数据并不意味着对现实的准确描述!
from visuals import make_poly_fitfigure, fit_stats = make_poly_fits(tds_clean, x='word_count',
y='reads', degree=6)
iplot(figure)
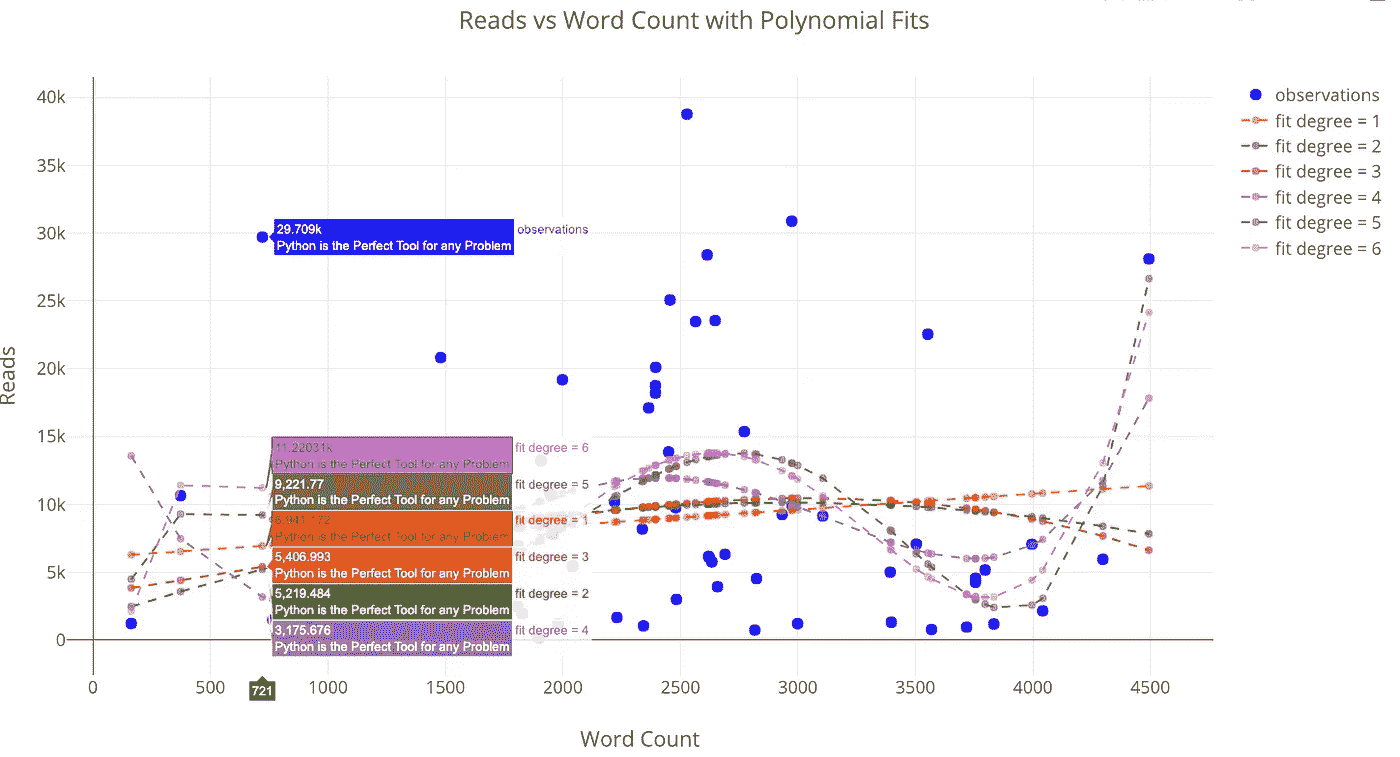
Reads versus the word count with polynomial fits.
使用任何更高程度的拟合来推断这里看到的数据是不可取的,因为预测可能是无意义的(负值或非常大)。
如果我们查看拟合的统计数据,我们可以看到均方根误差随着多项式次数的增加而减小:
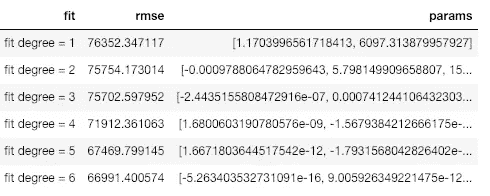
较低的误差意味着我们更好地拟合现有数据,但这并不意味着我们将能够准确地推广到新的观察结果(这一点我们稍后会看到)。在数据科学中,我们想要简约模型,即能够解释数据的最简单模型。
我们也可以在线性拟合中包含多个变量。这就是所谓的多元回归,因为有多个独立变量。
list_of_columns = ['read_time', 'edit_days', 'title_word_count',
'<tag>Education', '<tag>Data Science', '<tag>Towards Data Science',
'<tag>Machine Learning', '<tag>Python']figure, summary = make_linear_regression(tds, x=list_of_columns,
y='fans', intercept_0=False)iplot(figure)
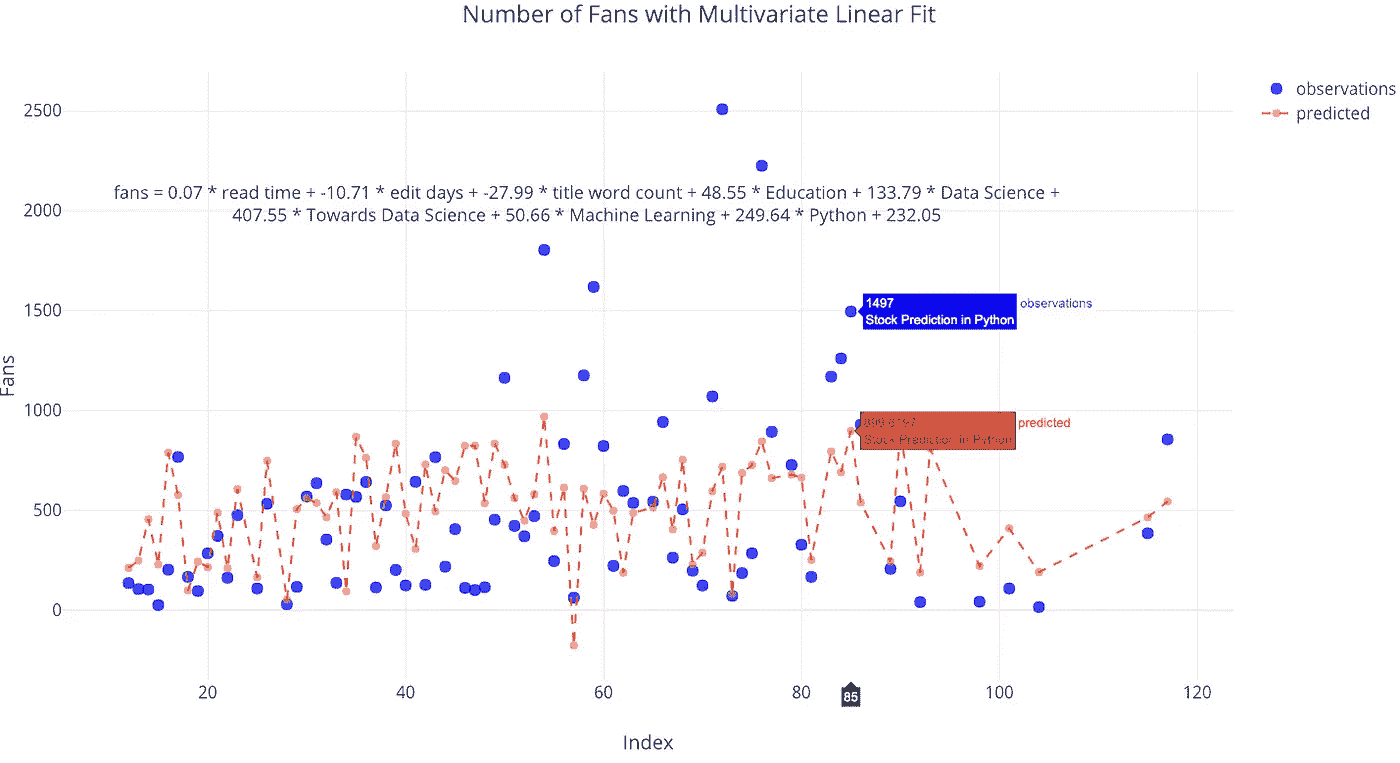
有一些独立变量,如标签 Python 和走向数据科学,有助于增加粉丝,而其他变量,如编辑花费的天数,导致粉丝数量减少(至少根据模型)。如果你想知道如何获得最多的粉丝,你可以使用这个拟合,并尝试用自由参数最大化它。
未来推断
我们工具包中的最后一个工具也是我最喜欢的:对未来的浏览量、粉丝数、阅读量或字数的外推。这可能完全是胡说八道,但这并不意味着它不令人愉快!它还强调了一点,即更灵活的拟合(更高的多项式次数)不会导致新数据更准确的概括。
from visuals import make_extrapolationfigure, future_df = make_extrapolation(df, y='word_count',
years=2.5, degree=3)
iplot(figure)
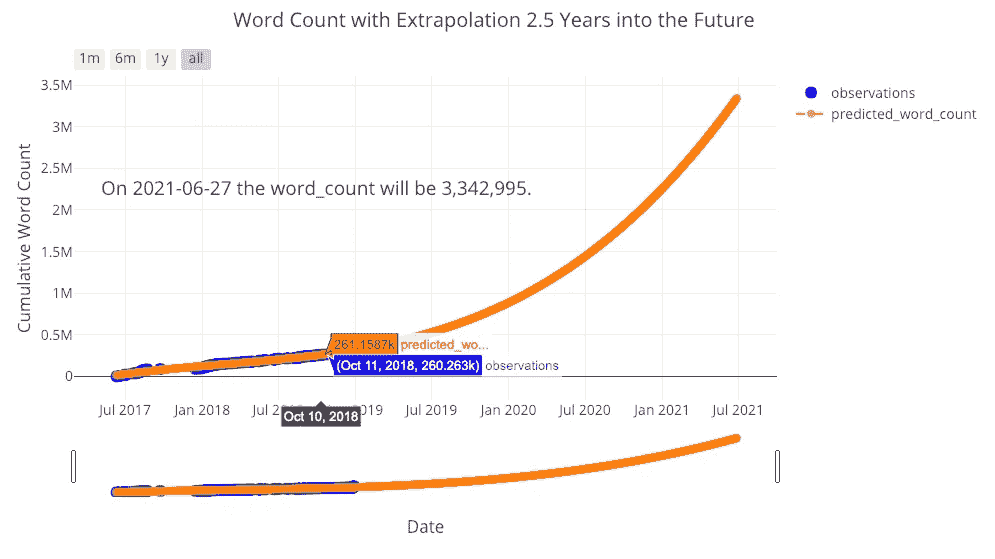
看来为了达到预期的预测,我还有很多工作要做!(底部的滑块允许您放大图表上的不同位置。你可以在全互动笔记本里玩这个)。获得合理的估计需要调整多项式拟合的次数。然而,由于数据有限,任何估计都可能在未来很长时间内失效。
让我们再做一次推断,看看我能期待多少次读取:
figure, future_df = make_extrapolation(tds, y='reads', years=1.5,
degree=3)
iplot(figure)
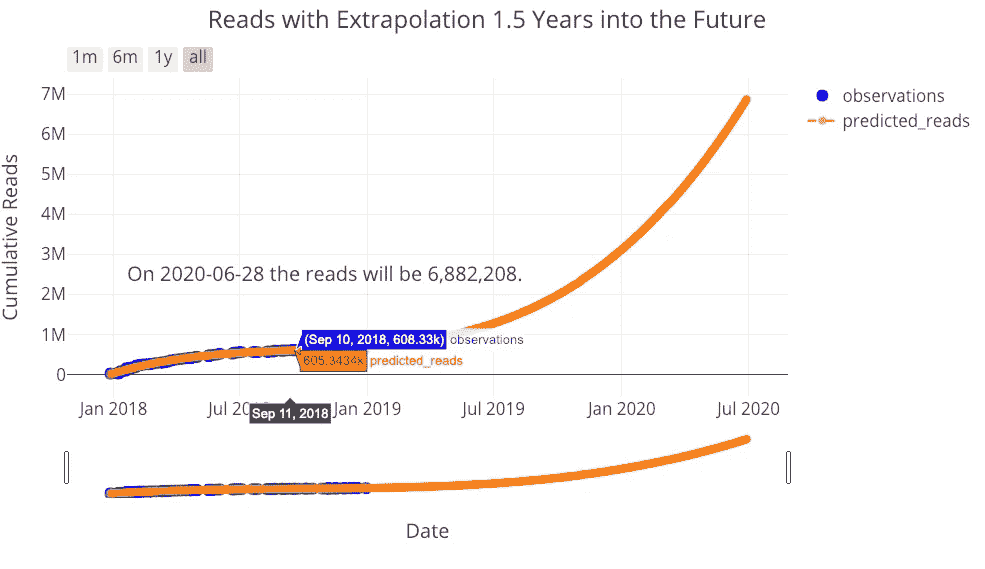
我的读者,你也有你的工作要做!我不认为这些推断是那么有用,但它们说明了数据科学中的重要观点:使模型更加灵活并不意味着它能够更好地预测未来,所有模型都是基于现有数据的近似值。
结论
Medium stats Python toolkit 是一套开发工具,允许任何人快速分析他们自己的 Medium 文章统计数据。尽管 Medium 本身不能提供对你的统计数据的深刻见解,但这并不妨碍你用正确的工具进行自己的分析!对我来说,没有什么比从数据中获取意义更令人满意的了——这也是我成为数据科学家的原因——尤其是当这些数据是个人的和/或有用的时候。我不确定这项工作有什么重要的收获——除了继续为数据科学写作——但是使用这些工具可以展示一些重要的数据科学原则。
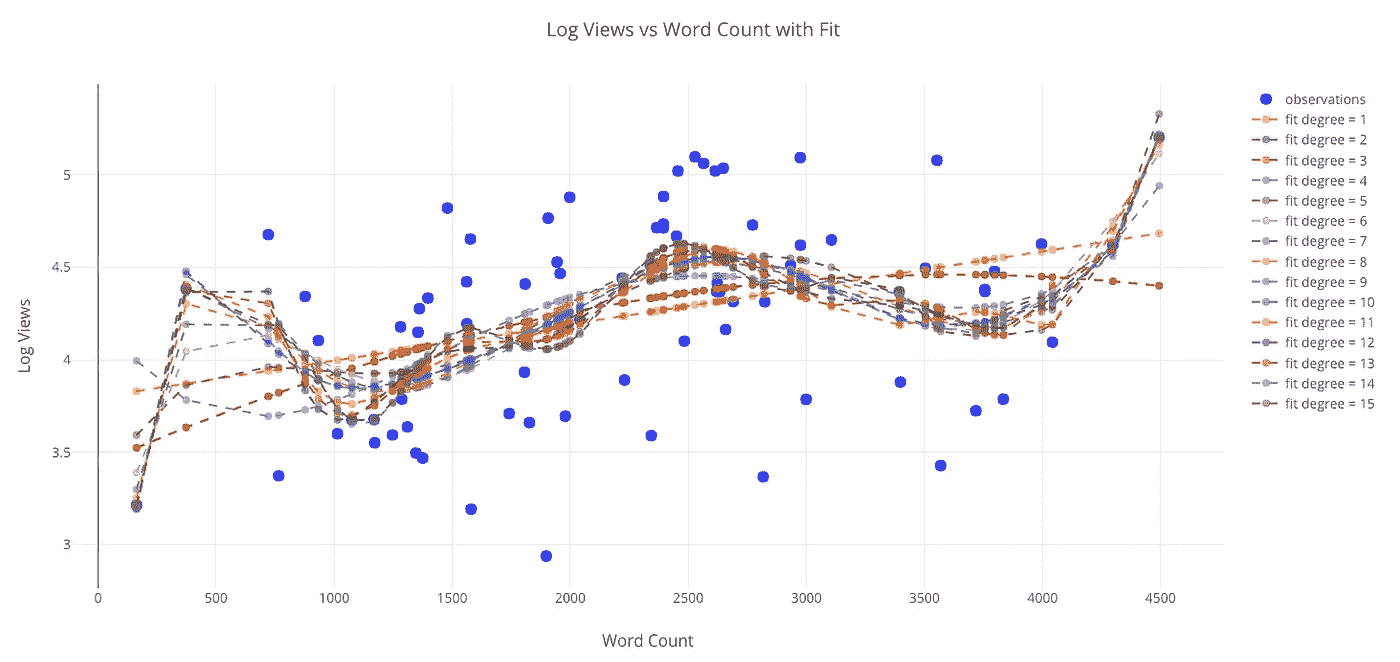
Overfitting just a little with a 15-degree fit. Remember, all models are approximations based on existing data.
开发这些工具是令人愉快的,我正在努力使它们变得更好。我将感谢任何贡献(老实说,即使这是一个 Jupyter 笔记本中的拼写错误,它会有所帮助)所以检查代码如果你想有所帮助。因为这是我今年的最后一篇文章,我想说感谢您的阅读——不管您贡献了多少统计数据,没有您我不可能完成这个分析!进入新的一年,继续阅读,继续写代码,继续做数据科学,继续让世界变得更好。
一如既往,我欢迎反馈和讨论。可以在推特上找到我。
分析我的谷歌位置历史
我最近读了这篇关于如何从你的谷歌位置历史数据创建热图的文章。我自己尝试了一下,得到了一些惊人的结果:
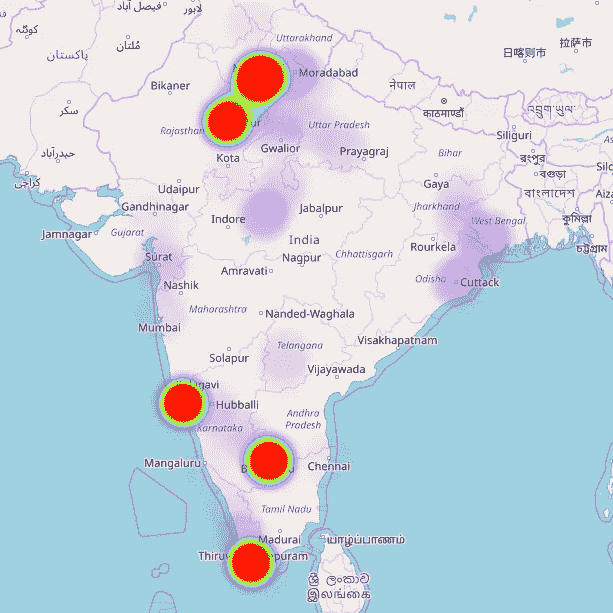
红色的大圆圈代表我待过很长时间的城市。不同地方的紫色阴影代表我坐火车旅行时去过或经过的地方。
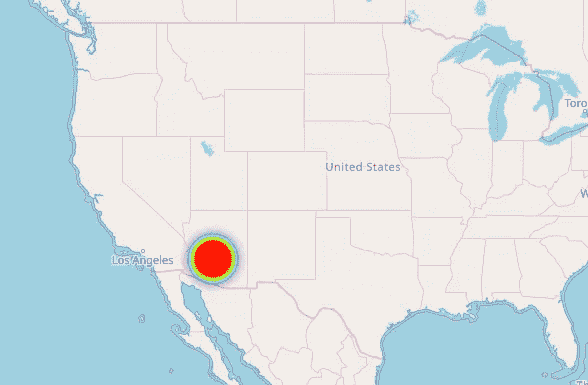
我以前的手机有一些 GPS 问题,这导致我的位置显示在美国亚利桑那州!。出人意料(还是没有?)它甚至给出了一个证明!
这一切看起来真的很酷,但我真的想深入了解这些年来我的旅行模式。
数据预处理
像大多数数据科学问题一样,数据预处理绝对是难点。数据是 JSON 格式的,不同属性的含义不是很清楚。
数据析取
{'timestampMs': '1541235389345',
'latitudeE7': 286648226,
'longitudeE7': 773296344,
'accuracy': 22,
'activity': [{'timestampMs': '1541235388609',
'activity': [{'type': 'ON_FOOT', 'confidence': 52},
{'type': 'WALKING', 'confidence': 52},
{'type': 'UNKNOWN', 'confidence': 21},
{'type': 'STILL', 'confidence': 7},
{'type': 'RUNNING', 'confidence': 6},
{'type': 'IN_VEHICLE', 'confidence': 5},
{'type': 'ON_BICYCLE', 'confidence': 5},
{'type': 'IN_ROAD_VEHICLE', 'confidence': 5},
{'type': 'IN_RAIL_VEHICLE', 'confidence': 5},
{'type': 'IN_TWO_WHEELER_VEHICLE', 'confidence': 3},
{'type': 'IN_FOUR_WHEELER_VEHICLE', 'confidence': 3}]}]},
{'timestampMs': '1541235268590',
'latitudeE7': 286648329,
'longitudeE7': 773296322,
'accuracy': 23,
'activity': [{'timestampMs': '1541235298515',
'activity': [{'type': 'TILTING', 'confidence': 100}]}]
稍微研究了一下,偶然发现了这篇文章,理清了很多东西。然而,有些问题仍然没有答案
- 活动类型
tilting是什么意思? - 我假设信心是每个任务的概率。然而,它们加起来往往不到 100。如果它们不代表概率,它们代表什么?
- 活动类型
walking和on foot有什么区别? - 谷歌怎么可能预测
IN_TWO_WHEELER_VEHICLE和IN_FOUR_WHEELER_VEHICLE之间的活动类型?!
如果有人能够解决这个问题,请在评论中告诉我。
编辑:在这个帖子中已经有一些关于这些话题的讨论。一篇关于使用智能手机数据进行人类活动识别的论文可以在这里找到。
假设
随着我继续构建我的预处理管道,我意识到我将不得不采取一些假设来考虑数据的所有属性。
- GPS 总是开着的(这是一个很强的假设,以后会考虑到)。
- 置信区间是活动类型的概率。这种假设有助于我们考虑给定实例的各种可能的活动类型,而不会低估或高估任何特定的活动类型。
- 每个日志有两种类型的时间戳。(I)对应于位置纬度和经度。㈡与活动相对应。因为两个时间戳之间的差异通常非常小(< 30 秒),所以我在分析中安全地使用了与纬度和经度相对应的时间戳
数据清理
记得我说过我的全球定位系统给出了美国亚利桑那州的位置吗?我不希望这些数据点对结果产生重大影响。利用印度的纵向边界,我过滤掉了只与印度相关的数据点。
def remove_wrong_data(data):
degrees_to_radians = np.pi/180.0
data_new = list()
for index in range(len(data)):
longitude = data[index]['longitudeE7']/float(1e7)
if longitude > 68 and longitude < 93:
data_new.append(data[index])
return data_new
特征工程
每个数据点的城市
我想获得每个给定纬度和经度对应的城市。一个简单的谷歌搜索让我得到了我曾居住过的主要城市的坐标,即德里、果阿、特里凡得琅和班加罗尔。
def get_city(latitude):
latitude = int(latitude)
if latitude == 15:
return 'Goa'
elif latitude in [12,13]:
return 'Bangalore'
elif latitude == 8:
return 'Trivandrum'
elif latitude > 27.5 and latitude < 29:
return 'Delhi'
else:
return 'Other'data_low['city'] = data.latitude.apply(lambda x:get_city(x))
距离
日志由纬度和经度组成。为了计算测井记录之间的距离,必须将这些值转换成可用于距离相关计算的格式。
from geopy.distance import vincenty
coord_1 = (latitude_1,longitude_1)
corrd_2 = (longitude_2, longitude_2)
distance = vincenty(coord_1,coord_2)
正常距
每个日志由活动组成。每个活动由一个或多个活动类型以及置信度(称为概率)组成。为了考虑测量的置信度,我设计了一个新的度量标准,叫做归一化距离,简单来说就是距离*置信度
数据分析
现在有趣的部分来了!在深入了解之前,让我简单介绍一些数据属性:-
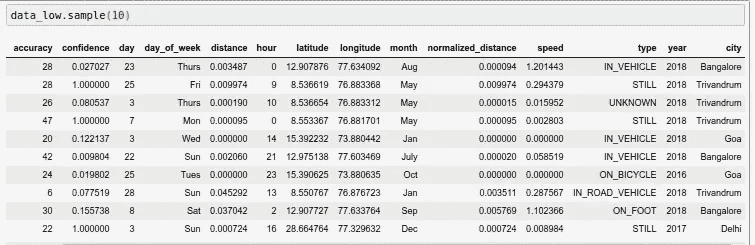
accuracy:估计数据的准确程度。小于 800 的精度通常被认为是高的。因此,我们删除了精度大于 1000 的列day:代表一个月中的某一天day_of_week:代表一周中的某一天month:代表月份year:代表年份distance:总行驶距离city:数据点对应的城市
离群点检测
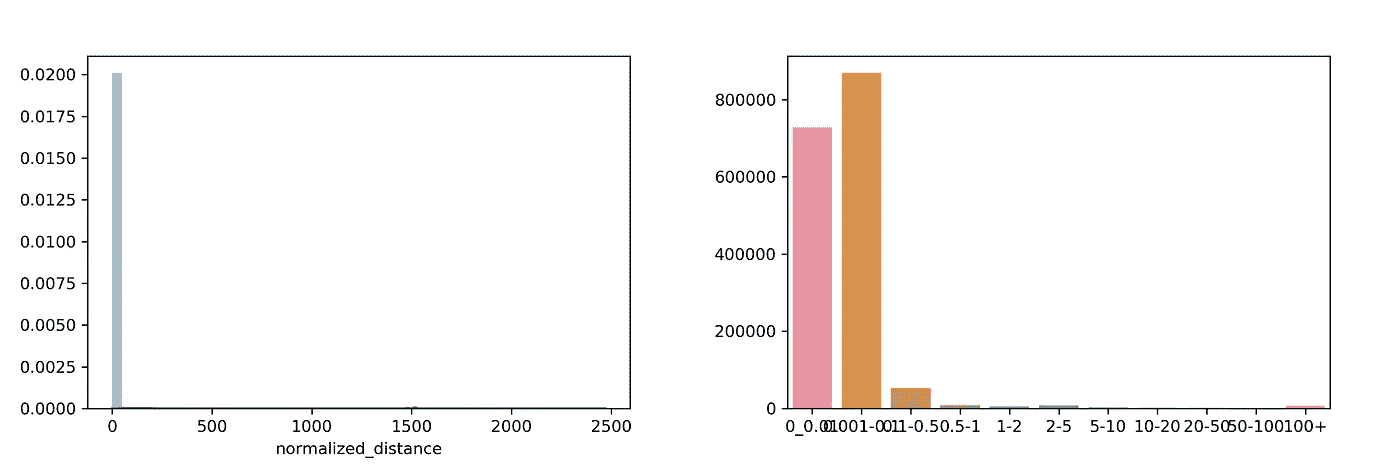
总共有 1158736 个数据点。99%的点覆盖不到 1 英里的距离。其余 1%是由于接收/飞行模式不佳而产生的异常。
为了避免 1%的数据导致我们的观察结果发生重大变化,我们将根据归一化距离将数据一分为二。
这也确保了我们删除了不符合我们在分析中所做的假设#1 的点
data_low = data[data.normalized_distance < 1]
data_large = data[data.normalized_distance > 1]
相对于城市的行驶距离
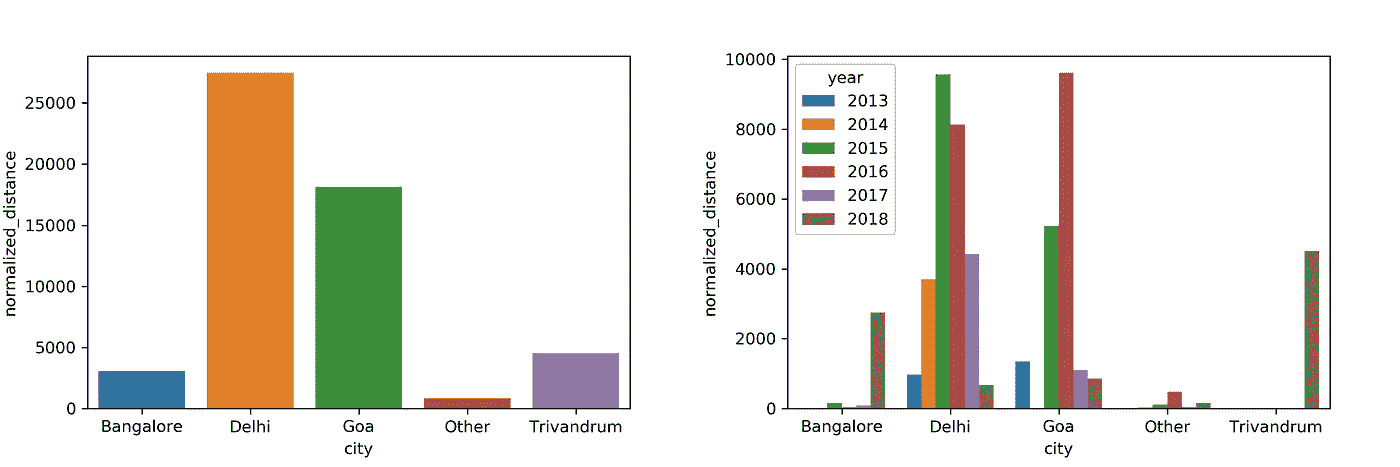
2018 年的数据正确地代表了大部分时间是在班加罗尔和特里凡得琅度过的。
我想知道在德里(我的家乡)旅行的距离怎么会超过我毕业的地方果阿。然后我突然意识到,在我大学生活的大部分时间里,我都没有移动互联网连接。
班加罗尔和特里凡得琅的旅行模式
2018 年 6 月,我完成了在原公司(Trivandrum)的实习,并加入了尼尼微公司(Bangalore)。我想知道在从一个城市过渡到另一个城市时,我的习惯是如何改变的。我对观察我的模式特别感兴趣,原因有二:
- 由于我在这些城市居住期间一直拥有移动互联网,我期望这种表现能够准确地反映现实。
- 我在两个城市呆的时间大致相同,因此数据不会偏向任何一个特定的城市。
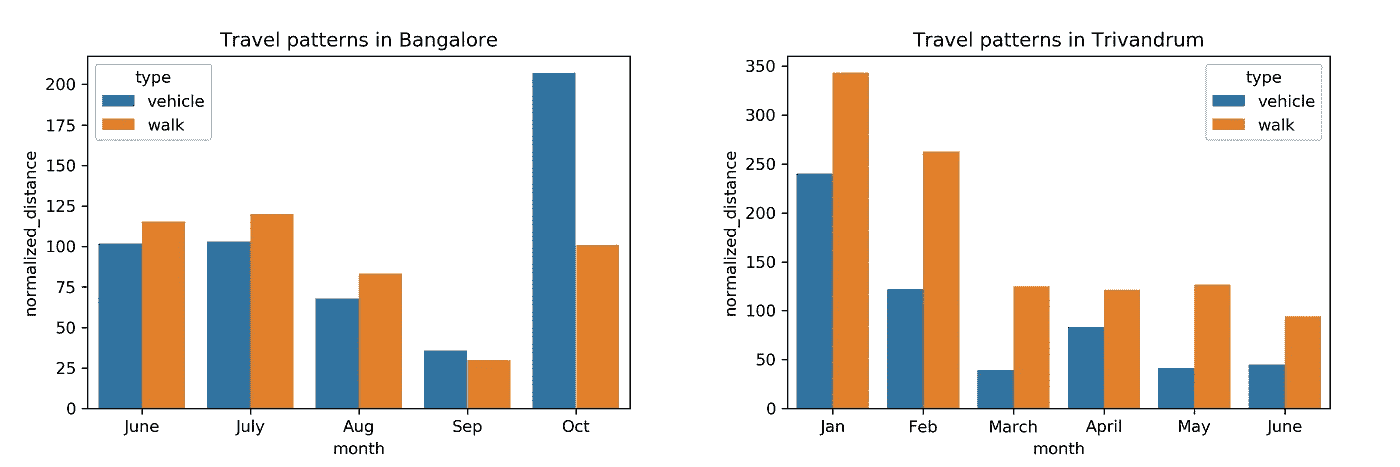
Month vs Distance travelled while in Bangalore and Trivandrum
- 10 月份,多位朋友和家人访问班加罗尔,导致车辆行驶距离大幅飙升。
- 最初,我在探索特里凡得琅。然而,随着我的注意力转向获取一个全职的数据科学机会,从 1 月到 2 月到 3 月的路程大幅缩短。

- 班加罗尔的车辆使用率在 20:00–00:00 之间要高得多。我想我以后会离开班加罗尔的办公室。
- 我在特里凡得琅走得更多!从 10:00 到 20:00 的步行距离差异表明,我是如何在办公室每隔一两个小时散步一次,从而过上更健康的生活的。
结论
有更多(像这个和这个)与您的位置历史有关。您也可以探索您的推特/脸书/铬数据。尝试浏览数据集时的一些便捷技巧:
- 花大量时间预处理您的数据。这很痛苦,但值得。
- 当处理大量数据时,预处理的计算量很大。不要每次都重新运行 Jupyter Cells,而是将预处理后的数据转储到一个 pickle 文件中,并在您再次启动时简单地导入数据。
- 最初,你可能很惨(像我一样)找不到任何模式。列出您的观察结果,并继续从不同角度探索数据集。如果您曾经想知道是否存在任何模式,请问自己三个问题: (i)我是否对数据的各种属性有透彻的理解?(ii)我能做些什么来改进我的预处理步骤吗?(iii)我是否使用了所有可能的可视化/统计工具探索了所有属性之间的关系?
开始时,您可以在这里使用我的 Jupyter 笔记本。
如果你有任何问题/建议,请随意发表评论。
你可以在 LinkedIn 上联系我,或者发邮件到 [email protected] 找我。
使用 R 分析股票
对亚马逊(Amazon)股票的一般和技术分析,以及使用随机漫步和蒙特卡罗方法的价格模拟。用 plotly 和 ggplot 完成的可视化。
亚马逊(Amazon)的股票在过去一年上涨了 95.6%(918.93 美元),这使得亚马逊成为许多投资者的理想选择。许多分析师还认为,亚马逊(Amazon)的价值将在未来几年继续增长。虽然购买股票听起来很诱人,但应该进行详细的深入分析,以避免基于投机购买股票。
我落实了我在统计学和 R 技能方面的知识,从技术面分析它的表现,预测它未来的价格。我非常依赖量化金融中常用的软件包,如 quant mod 和 xts 来实现我的目标。
以下是我使用的软件包的完整列表:
library(quantmod)
library(xts)
library(rvest)
library(tidyverse)
library(stringr)
library(forcats)
library(lubridate)
library(plotly)
library(dplyr)
library(PerformanceAnalytics)
我从获得亚马逊股票从 2008 年 8 月 1 日到 2018 年 8 月 17 日的日志回报开始分析:
getSymbols("AMZN",from="2008-08-01",to="2018-08-17")AMZN_log_returns<-AMZN%>%Ad()%>%dailyReturn(type='log')
日志返回在这个阶段没有意义,但它实际上是我分析的基础。我稍后会解释。
技术分析
我首先对亚马逊的股票进行了技术分析:
AMZN%>%Ad()%>%chartSeries()AMZN%>%chartSeries(TA='addBBands();addVo();addMACD()',subset='2018')
第一个图表系列图很简单,因为它显示了亚马逊的价格图表:
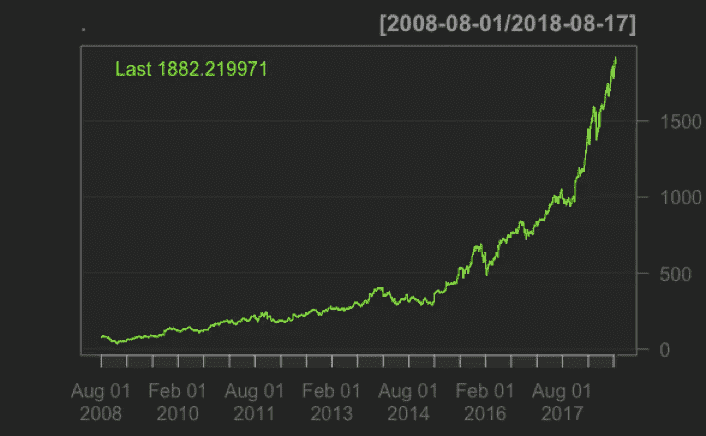
Price Chart
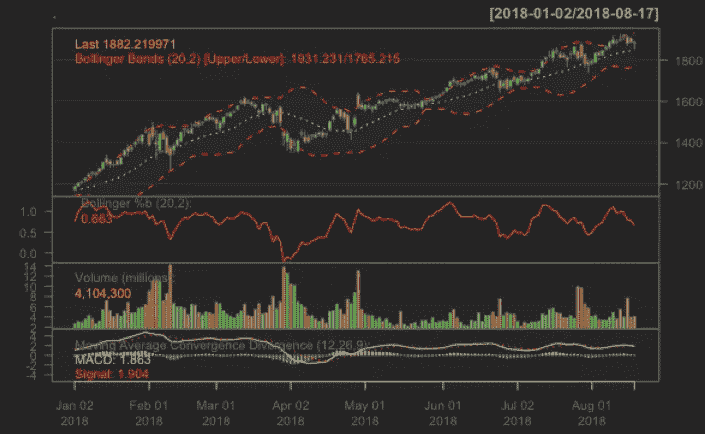
第二个图表系列显示了仅在 2018 年的布林线图、布林线百分比变化、成交量和移动平均线收敛趋势:
Technical Analysis
均线对于理解亚马逊(Amazon)的技术图表非常重要。它通过平均股票价格来平滑每日价格波动,并有效地识别潜在趋势。
布林线图表绘制了两个远离移动平均线的标准偏差,用于衡量股票的波动性。成交量图显示了其股票每天的交易情况。均线收敛背离给技术分析师买入/卖出信号。经验法则是:如果跌破该线,就该卖出了。如果它上升到线以上,它正在经历一个上升的势头。
上面的图表通常用来决定是否买/卖股票。由于我不是一个认证的金融分析师,我决定做额外的研究来说服自己。
比较
我实现了公开比较的基本原则。我想看看亚马逊(Amazon)与其他热门科技股如脸书(Alibaba)、谷歌(Google)和苹果(Apple)相比表现如何。
我首先比较了每只股票的风险/回报率。我取了对数回报的平均值和对数回报的标准差。均值被认为是一致的回报率,而标准差是购买股票带来的风险。我用 plotly,一个交互式可视化工具,来说明我的发现。
Risk vs Reward chart
谷歌(GOOGL)股票风险最低,回报也最低。脸书(Alibaba)和亚马逊(Amazon)的风险一样大,但后者的回报更高。如果你喜欢冒险,特斯拉(TSLA)是一个很好的投资,因为它有高风险和高回报。但如果你像我一样厌恶风险,苹果(AAPL)是最好的选择。
一个流行的投资原则是分散投资:不要把所有的鸡蛋放在一个篮子里。购买股票时,你应该尽量购买相关性小的股票,因为你想最大化总回报率。
library(PerformanceAnalytics)data<-cbind(diff(log(Cl(AMZN))),diff(log(Cl(GOOGL))),diff(log(Cl(AAPL))),diff(log(Cl(FB))))chart.Correlation(data)
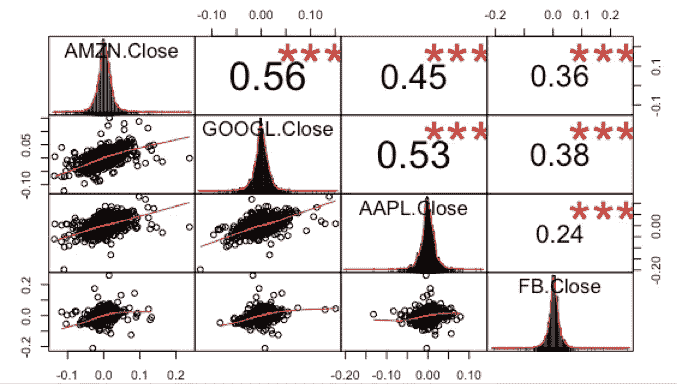
Correlation Chart
脸书(FB)和苹果(AAPL)的相关性最小,为 0.24,而亚马逊(Amazon)和谷歌(Google)的相关性最高,为 0.56。每只股票之间的相关性很高,因为它们都是科技股。最好购买不同行业的股票,以真正实现风险最小化和回报率最大化。
价格预测
我接着预测了亚马逊(Amazon)股票的价格。我通过随机漫步理论和蒙特卡罗方法实现了这一点。
随机游走理论适合于股票的价格预测,因为它植根于这样一种信念,即过去的表现不是未来结果的指标,价格波动无法准确预测。
我模拟了亚马逊(Amazon)股票 252*4 个交易日的价格(因为一年有大约 252 个交易日)。这是 4 年的交易价值!
我使用我之前从对数收益中获得的数据生成价格,并使用指数增长率来预测股票每天将增长多少。增长率是随机生成的,取决于 mu 和 sigma 的输入值。
mu<-AMZN_mean_log # mean of log returns
sig<-AMZN_sd_log # sd of log returns price<-rep(NA,252*4)#start simulating pricesfor(i in 2:length(testsim)){
price[i]<-price[i-1]*exp(rnorm(1,mu,sig))
}random_data<-cbind(price,1:(252*4))
colnames(random_data)<-c("Price","Day")
random_data<-as.data.frame(random_data)random_data%>%ggplot(aes(Day,Price))+geom_line()+labs(title="Amazon (AMZN) price simulation for 4 years")+theme_bw()

Price Preidction with Random Walk
上图显示了大约 1000 个交易日的模拟价格。如果你注意我的代码,我没有包含 set.seed()。模拟价格将会改变,并取决于我的种子。为了得出稳定的预测,价格模拟需要使用蒙特卡罗方法,在这种方法中,价格被重复模拟以确保准确性。
N<-500
mc_matrix<-matrix(nrow=252*4,ncol=N)
mc_matrix[1,1]<-as.numeric(AMZN$AMZN.Adjusted[length(AMZN$AMZN.Adjusted),])for(j in 1:ncol(mc_matrix)){
mc_matrix[1,j]<-as.numeric(AMZN$AMZN.Adjusted[length(AMZN$AMZN.Adjusted),])
for(i in 2:nrow(mc_matrix)){
mc_matrix[i,j]<-mc_matrix[i-1,j]*exp(rnorm(1,mu,sig))
}
}name<-str_c("Sim ",seq(1,500))
name<-c("Day",name)final_mat<-cbind(1:(252*4),mc_matrix)
final_mat<-as.tibble(final_mat)
colnames(final_mat)<-namedim(final_mat) #1008 501final_mat%>%gather("Simulation","Price",2:501)%>%ggplot(aes(x=Day,y=Price,Group=Simulation))+geom_line(alpha=0.2)+labs(title="Amazon Stock (AMZN): 500 Monte Carlo Simulations for 4 Years")+theme_bw()
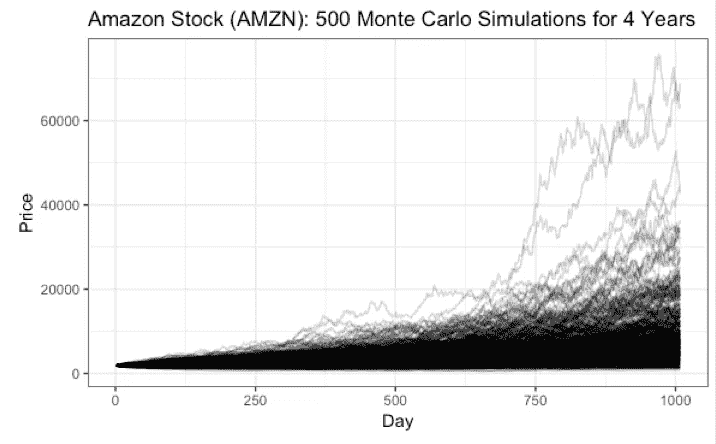
Price Prediction with Monte Carlo
上面的图表并不直观,所以我在四年后用亚马逊(Amazon)的价格百分比最终确定了我的发现。
final_mat[500,-1]%>%as.numeric()%>%quantile(probs=probs)
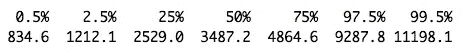
不要相信我的话,但从我的模拟结果来看,亚马逊(Amazon)的股票可能会在四年内达到 11198.10 美元的价格,或者跌至 834.60 美元的低点。你可以将我的发现与亚马逊(Amazon)的 CAGR 进行比较,看看我的发现是否有意义。但是如果有机会,我会马上买下这只股票!
感谢阅读!如果你有任何反馈/想聊天,请告诉我。你可以打电话给我
推特:@joygraceeya
电子邮件:[email protected]
你可以在这里看我的完整代码和参考文献。
解析伦敦 2018 艺术博览会,第一部分
第一部分:5.6k Instagram 和 3.2k Twitter 帖子的探索性数据分析

Frieze Masters Art Fair on the left and Nan Golding on the right
Frieze 是一家国际艺术商业特许经营公司,1991 年以杂志起家,但后来发展成为一家组织一些年度日历上最重要的艺术博览会和活动的机构。
自 2003 年以来,每年 10 月,Frieze 都会在伦敦摄政公园的中央组织一次大型当代艺术展,吸引成千上万的人。来自 20 多个国家的 150 多家画廊通常会参加盈利性艺术博览会。
然而,Frieze 现在已经不仅仅是一个艺术博览会。
“楣周”已经成为一个文化娱乐周,人们纯粹是为了观赏而参加,这里有一个雕塑公园,甚至主要的拍卖行也举办他们的中期当代拍卖会,以配合楣周。

Imaged taken from bulanlifestyleblog
本文的目的是通过分析 5.6k Instagram 和 3.2k Twitter 帖子,展示一些关于艺术博览会的社交媒体数据的探索性数据分析,从而更好地了解 Frieze London 2018。请向下滚动,通过交互式数据可视化查看我的分析!
数据和方法
在节日期间,我使用 Twitter API 收集了 3200 条推文,使用 Instagram API 收集了 5600 条包含标签 #frieze 的 Instagram 帖子。值得注意的是,我只收集了包含标签 #frieze 的帖子;当然,有许多关于 Frieze London 2018 的推文不包含这个标签。
在我收集了数据之后,我在一个 python 笔记本中对这些推文进行了预处理和分析。你可以在这里查看我的 Kaggle 内核对这篇文章的分析。
【本文不解释如何获取数据;这是我的发现的介绍。关于如何使用 API 从 Twitter 获取数据的更多信息,请阅读这篇文章作者 Michael Galarnyk

Photo I took at Frieze London 2018
分析推文和 Instagram 帖子
我分析的主要内容来自我通过 Twitter 和 Instagram APIs 收集的 9000 条帖子。下面,我报告对以下三个指标的一些初步分析:
- 每天的帖子数量;
- 每小时的帖子数量(四天的平均值);
- Tweeters 和 Instagrammers 前 10 名(按发帖频率)。
每天的帖子数量
下面的条形图显示,2018 年伦敦 Frieze 最受欢迎的一天是第一天,即 10 月 4 日星期四,使用 #frieze 在两个平台上发布了 1786 条帖子。然后从周四到周一逐渐下降。
Figure 1: Bar chart showing the number of posts by day during Frieze London 2018
然而,如果我们将这些数字按平台分开,我们会发现 Instagram 主导了大部分在线活动,平均占 #frieze 一周内*所有每日帖子的 72%。*事实上,随着“Frieze Week”的发展,更多的在线用户开始在 Instagram 上用#frieze 发帖,而不是在 Twitter 上。
这完全有意义,因为 Instagram 是一个非常视觉化的内容平台,使其完全符合 Frieze art fair,人们通常在那里发布艺术品的图像。在第 3 部分中,我将更详细地看看这些图片。
Figure 2: Bar chart showing the % of posts by platform per day
按小时计算的帖子数量
早在早上 6 点(格林威治时间)就有活动,而且活动迅速加快。上午 11 时和下午 3 时最繁忙,分别有 541 个和 542 个职位;然而,在上午 9 点到下午 5 点之间有非常高且稳定的活动。
Figure 3: Bar chart showing the average tweets per hour
同样,如果我们按平台划分每小时的帖子,我们可以清楚地看到 Instagram 的优势,平均占所有每小时帖子的 71%。
Figure 4: Bar chart showing the % of posts by platform per hour
前 10 名 Instagrammers 和 Tweeters
下面的条形图显示了按帖子数量排名的前 10 名 Instagrammers 和 Tweeters,分别是左图和右图。
在 Instagram 上, gusgracey 使用 #frieze 总共发布了 56 条帖子,而 aservais1 在 Twitter 上发布了 59 条帖子。只有一个用户(使用相同的手柄)在两个平台上都进入了前 10 名: cordy_86 。
Figure 5: Top 10 Instagrammers and Tweeters by the frequency of posts
结论
所以你有它!我在 11000 条关于伦敦设计节 2018 的推文中展示了一些 EDA。如果你有任何想法或建议,请在下面留下你的评论,或者在我的 Kaggle 内核上留下你的评论——如果能在 Kaggle 上投上一票,我将不胜感激:)。

Photo I took at Frieze London 2018
下次…
在我的下一篇文章(第 2 部分)中,我将展示我的自然语言处理(NLP)分析的发现。期待看到推文的文本分析和情感分析。敬请关注。
感谢阅读!
Vishal
在你离开之前…
如果你觉得这篇文章有帮助或有趣,请按住👏请在推特、脸书或 LinkedIn 上分享这篇文章,这样每个人都能从中受益。
Vishal 是一名文化数据科学家,也是伦敦 UCL 学院的研究生。他对城市文化的经济和社会影响感兴趣。你可以在Twitter或者LinkedIn上与他取得联系。在insta gram或他的 网站 上看到更多 Vishal 的作品。
解析 2018 伦敦设计节(上)
第 1 部分:对 11,000 条推文的探索性数据分析

“世界设计之都”是伦敦设计节的组织者自豪地宣传伦敦的方式。鉴于上个月在 9 月 15 日(周六)至 9 月 23 日(周日)为期七天的设计节期间,估计有超过 50 万人参观了这座城市,这种说法可能是正确的。
伦敦设计节 2018 (LDF18)有一个非常活跃的活动计划,横跨伦敦 11 个不同的“设计区”、5 个“设计目的地”和 3 条“设计路线”。这是伦敦作为一个建筑环境的灵活性的另一个极好的例子,作为一个画布来展示创造性的想法。

Image of Es Devlin’s Please Feed the Lions, taken by David Holt and downloaded from Flick
本文的目的是通过分析 11,000 条推文,展示一些关于音乐节的社交媒体数据的探索性数据分析,从而更好地理解 LDF18。请向下滚动,通过交互式数据可视化查看我的分析!
数据和方法
组织者推广的官方标签是# ldf 18——在电影节期间,我使用 Twitter API 收集了 11000 条包含该标签的推文。值得注意的是,我只收集了包含标签# LDF18 的推文。当然,有许多关于 2018 年伦敦设计节的推文不包含该标签。
在我收集了数据之后,我在一个 python 笔记本中对这些推文进行了预处理和分析。你可以在这里查看我的 Kaggle 内核对这篇文章的分析。
【本文不解释如何获取数据;这是我的发现的介绍。关于如何使用 API 从 Twitter 获取数据的更多信息,请阅读这篇文章作者 Michael Galarnyk

Picture of Waugh Thistleton Architects: MultiPly taken by the US Embassy in the UK and downloaded from Flickr
分析推文
我分析的主要内容来自我通过 Twitter API 收集的 11000 条推文。下面,我报告对以下四个指标的一些初步分析:
- 每天的推文数量;
- 每小时的推文数量(一周的平均值);
- 前 10 名 tweeters(按关注人数);
- 前 10 名推文(按推文频率)。
每天的推文数量
下面的条形图显示,在 LDF18 上最受欢迎的一天是 9 月 20 日星期四,有 1491 条使用#LDF18 的推文。令人惊讶的是,节日前后的周末都不是最忙的;也许周四有一个特别的活动——我会在第二部分的推文中看得更深入一些——或者,也许这最终证实了周四是伦敦的新周五。
Figure 1: Bar chart showing the number of tweets by day during the festival
每小时的推文数量
伦敦人早早起床去看 LDF18 的比赛!上午和下午是最忙的时候,从上午 10 点到下午 1 点活动量几乎是一致的,然后到下午 3 点活动量有所下降。
Figure 2: Bar chart showing the average tweets per hour
前 10 名推特用户
近 5000 名不同的 Twitter 用户使用#LDF18 发布了关于这个节日的推文。如果我们按照关注者数量来看前 10 名推特用户,只有三个用户占据主导地位——T2、金融时报、设计博物馆和伦敦 NMH,如下表所示。但是,这不是一个有用的衡量标准,所以,我们来看看前 10 名用户使用#LDF18 发微博的次数。
Table 1: Top 10 tweets by the number of followers
按推文频率排名的前 10 名推文者
下面的条形图显示了前 10 名推特用户发出的推文数量,包括转发和不转发,分别为左图和右图。
官方推特账号@L_D_F 使用#LDF18 发了近 295 条推文,其中 70 条被转发。而且,虽然“@designledreview”发出了 193 条推文,但几乎都是 RTs。有趣的是,维多利亚阿尔伯特博物馆的高级设计策展人奥利维亚·霍斯福尔·特纳( @ 霍斯福尔·特纳)疯狂地用#LDF18 发了 83 条推特!
Figure 3: Top 10 tweeters by the frequency of tweets
A tweet from the official @L_D_F twitter account
结论
所以你有它!我在 11000 条关于伦敦设计节 2018 的推文中展示了一些 EDA。如果你有任何想法或建议,请在下面留下你的评论,或者,在我的 Kaggle 内核上——对 Kaggle 投赞成票将不胜感激:)。
下次…
在我的下一篇文章(第 2 部分)中,我将展示我的自然语言处理(NLP)分析的发现。期待看到推文的文本分析和情感分析。敬请关注。
感谢阅读!
Vishal
在你离开之前…
如果你觉得这篇文章有帮助或有趣,请按住👏请在推特、脸书或 LinkedIn 上分享这篇文章,这样每个人都能从中受益。
Vishal 是一名文化数据科学家,也是伦敦 UCL 学院的研究生。他对城市文化的经济和社会影响感兴趣。你可以在Twitter或者LinkedIn上与他取得联系。在insta gram或他的 网站 上看到更多 Vishal 的作品。
琉米爱尔伦敦 2018:探索性数据分析(第一部分)
第 1 部分:对 11,000 条推文的探索性数据分析

介绍
琉米爱尔伦敦 2018 是今年早些时候在伦敦举行的大型灯光节。从 1 月 18 日(星期四)到 1 月 21 日(星期日)的四天时间里,53 位艺术家的 50 多件公共艺术品在伦敦的六个区展出,超过 100 万人参加了此次艺术节!
琉米爱尔 2018 是协调和交付的史诗般的例子,向伦敦市民公开展示艺术和文化。它是免费参加的,受伦敦市长的委托,由艺术慈善机构朝鲜蓟信托策划、制作和策划。节日期间,威斯敏斯特教堂、伦敦眼等建筑都会被点亮。
你可以在这里阅读更多关于琉米爱尔及其创始伙伴的信息。

Westminster Abbey in London illuminated by Patrice Warrener with his work The Light of the Spirit.
本文的目的是通过分析 11,000 条推文,展示一些关于 2018 年琉米爱尔伦敦奥运会社交媒体数据的探索性数据分析。请向下滚动,通过交互式数据可视化查看我的分析!
数据和方法
组织者推广的官方标签是#LumiereLDN。在节日期间,我使用 Twitter API 收集了 11000 条包含这个标签的推文。需要注意的是,我只收集了包含# LumiereLDN 的推文。当然,有许多关于琉米爱尔伦敦 2018 的推文没有包含这个标签。
在我收集了数据之后,我在一个 python 笔记本中对这些推文进行了预处理和分析。你可以点击查看我的 Kaggle 内核,了解这篇文章的分析。
【本文不解释如何获取数据;这是我的发现的介绍。有关如何使用 API 从 Twitter 获取数据的更多信息,您可以阅读迈克尔·加拉内克的文章
装置的位置
总共有 54 个公共艺术装置,分布在伦敦市中心的六个不同区域——国王十字车站、菲茨罗维亚、梅菲尔、西区、维多利亚和威斯敏斯特以及南岸和滑铁卢。下图显示了这些装置是如何分布在各个地区的:

This map was taken from the official Lumiere London leaflet.
下面的饼状图按位置显示了公共艺术装置的频率——它是交互式的,就像所有其他图表一样,所以请悬停并点击它!
伦敦西区是人口最多的地区,有 15 个公共艺术装置——这是有道理的,因为伦敦西区历史上是一个旅游区——有趣的是,国王十字车站以 11 个装置位居第二。
Figure 1: Pie chart showing the number of public art installations by location
仔细查看官方合作伙伴页面将西区和国王十字商圈列为“主要合作伙伴”。

Waterlicht by Daan Roosegaarde at King’s Cross - taken by Ian Woodhead and downloaded from Flickr
分析推文
我分析的主要内容来自我通过 Twitter API 收集的 11000 条推文。下面,我报告对以下三个指标的一些初步分析:
- 每天的推文数量;
- 每小时的推文数量(四天的平均值);
- 前 10 名推特用户(按关注人数)。
每天的推文数量
下面的条形图显示,2018 年伦敦琉米爱尔最受欢迎的一天是 1 月 19 日星期五,有2449 条推文包含标签#LumiereLDN。令人惊讶的是,周四 18+周五 19比周末,周六 20+周日 21更受欢迎。
Figure 2: Bar chart showing the number of tweets by day during the festival
每小时的推文数量
一天中最繁忙的时间(整个节日的所有日子)是在晚上 6 点到 10 点之间——晚上 9 点是最繁忙的时间,总共有 769 条推文。据推测,人们在晚上下班和放学后参观这个节日。该事件也是针对夜间事件的
Figure 3: Bar chart showing the average tweets per hour
前 10 名推特用户
在节日期间,超过 6000 名不同的人使用#LumiereLDN 发推文,但一些有趣的人物突然出现。下表显示了根据粉丝数量排名的前 10 名推特用户。
像 BBC 新闻实验室、商业内幕、推特视频和超时这样的媒体果然出现在名单中,但是像迈克·彭博、戈登·拉姆齐和戴维娜·迈克考这样的名人也在推特上发了关于这个事件的消息!
Table 1: Top 10 tweets by the number of followers

The Wave by Vertigo at Southbank in London
结论
所以你有它!我在 11,000 条关于琉米爱尔伦敦 2018 灯光节的推文中展示了一些 EDA。如果你有任何想法或建议,请在下面留下你的评论,或者在我的 Kaggle 内核上留下你的评论——如果能给 Kaggle 投上一票,我将不胜感激:)。
下次…
在我的下一篇文章(第 2 部分)中,我将展示我的自然语言处理(NLP)分析的发现。期待看到推文的文本分析和情感分析。敬请关注。
感谢阅读!
Vishal
在你离开之前…
如果你觉得这篇文章有帮助或有趣,请按住👏请在推特、脸书或 LinkedIn 上分享这篇文章,这样每个人都能从中受益。
Vishal 是一名文化数据科学家,也是伦敦 UCL 学院的研究生。他对城市文化的经济和社会影响感兴趣。你可以在Twitter或者LinkedIn上与他取得联系。在insta gram或他的 网站 上看到更多 Vishal 的作品。
解析琉米爱尔伦敦 2018 灯光节(下)
第二部分:11,000 条推文的自然语言处理

介绍
在本系列的第 1 部分中,我展示了一份关于琉米爱尔伦敦 2018 的 11,000 条推文的探索性数据分析,这是今年 1 月早些时候在伦敦举行的一个大型灯光节。
从 1 月 18 日(星期四)到 1 月 21 日(星期日)的四天时间里,53 位艺术家的 50 多件公共艺术品在伦敦的六个区展出,超过 100 万人参加了此次艺术节!
本文的目的是展示我的自然语言处理分析对这 11,000 条推文的研究结果,以了解人们对 2018 年琉米爱尔伦敦奥运会的看法。
请向下滚动,通过交互式数据可视化查看我的分析!
Control No Control by Daniel Iregul at Whitfield Gardens in Fitzrovia — my photo
数据和方法
这一事件的官方标签是#LumiereLDN。在通过 Twitter API 在事件发生时收集了 11000 条包含这个标签的推文之后,我首先在 Python 笔记本中预处理和清理了文本数据。
然后,我使用谷歌的 langdetect 库 过滤掉非英语推文,并从 NLP 分析中删除所有转发,这样就不会出现重复。经过这些步骤,我剩下了 4600 条独特的推文。接下来,我使用谷歌云自然语言 API 来获取每条推文的情感。
最后,我使用 gensim 库的 Word2Vec 模型来获取整个 tweets 语料库中与单词“LumiereLDN”相关的每个单词的单词嵌入向量。Word2Vec 用于从大型文本语料库中计算单词之间的相似度— Kavita Ganesan 的文章是一个很好的解释。
一旦我有了每个单词的向量,我就使用 scikitlearn 库来执行主成分分析(PCA)以进行降维,并绘制出与“LumiereLDN”最相似的单词(最近邻)。
你可以在这里查看我的 Kaggle 内核对这篇文章的所有分析。
分析
在这一节中,我将展示我的自然语言处理(NLP)分析的发现。下面,我报告以下三个指标:
- 每日推文的情感分析;
- 词频和标签频率分析;
- Word2Vec 模型的输出:主成分分析(PCA)和最近邻分析。

A lady looking very happy at Lumiere London! Illumaphonium by Michael David, at Mount Street in Mayfair
情感分析
每条推文的情绪是使用谷歌的云 NLP API 计算的。下面的条形图显示了每天推文的平均情绪,其中-1 表示非常消极的情绪,+1 表示非常积极的情绪。
我们看到,琉米爱尔伦敦 2018 年奥运会开始时情绪相对较高,然后在 1 月 17 日星期三下降,直到再次达到良好的情绪;我将不得不检查推文进一步了解下降。总体而言,琉米爱尔全天的平均情绪为 0.47。
Figure 1: Line chart showing the average sentiment of the tweets per day
下表显示了按情感分类的前五条(绿色)和后五条(红色)推文。你可以通过左边的推文清楚地看到,积极的语言被云 NLP API 检测到,类似地,负面的推文在右边。
一些人表示灯光“不太优雅”,而另一些人则认为它们是“灯光和声音的有力庆祝”,并将其描述为“辉煌”和“令人印象深刻”。云 NLP API 做的很好!
Table 1: Tabel showing the top five (left) and bottom five (right) tweets by sentiment score
文本频率分析
下面的条形图显示了一个词出现的次数,还有一个标签出现在所有推文中,分别在左边和右边。不出所料,“卢米埃尔登”出现的次数最多。
然而,这些结果在告诉我们人们对事件的真实想法方面并不十分有用,因为标签的频率显然是单词频率的一个混淆变量。在未来的分析中,我将尝试从文本频率分析中删除 hashtag word。
Figure 2: Bar graphs showing the count of words and hashtags appearing in all the tweets
最近的邻居
Word2Vec 是一个神经语言机器学习模型。它将大量文本(在本例中,来自 11,000 条推文的文本)作为输入,并产生一个向量空间,通常有数百个维度,每个唯一的单词对应于空间中的一个向量——单词嵌入。
重要的是,它用于计算和捕捉 11,000 条推文中单词之间的相似性和关系。具体来说,空间中距离较近的物体意味着它们是相似的——被称为最近邻。我的目标是找到所有与“ LumiereLDN ”紧密相关的单词。
主成分分析用于将 Word2Vec 空间的维度降低到 x 和 y 坐标,其输出显示在下面的散点图中。似乎有一些聚类,但是,很乱,很难找到与“ LumiereLDN ”紧密相关的词。
Figure 3: PCA output of the words embedding vector space from the Word2Vec model
我们需要进一步放大。
最近邻是来自 Word2Vec 模型的少数几个基于余弦度量相似性得分与“ LumiereLDN ”最相似的单词。下面的散点图显示了“ LumiereLDN ”的最近邻居。
拉近镜头,我们发现伦敦的区域——“维多利亚”、“梅菲尔”、“菲茨罗维亚”、国王十字”——这些艺术品被安装的地方,似乎就在附近。
但重要的是,“神奇的”、“奇妙的”和“好玩的”这些词也近在咫尺。一个非常积极的结果!统计表明,这些词最能代表人们在推特上谈论琉米爱尔伦敦 2018 时的感受。
Figure 4: PCA output of the nearest neighbours of #LumiereLDN from the Word2Vec model

Love Motion by Rhys Coren at The Royal Academy in the West End— my photo
结论
所以你有它!我已经在 11000 条关于琉米爱尔伦敦 2018 灯光节的推文中展示了我的 NLP 的发现。尽管有一些关于琉米爱尔伦敦的负面推文和情绪,但 Word2Vec 模型的输出显示人们对该活动持积极态度。
如果你有任何想法或建议,请在下面或在我的 Kaggle 内核上留下评论——非常感谢你对 Kaggle 的支持:)
有这么多 NLP 库,很可能以后我会用 GloVe 、 Tensorflow 或者 Bert 重新审视这个分析。
下次…
在我的下一篇文章(第 3 部分)中,我将展示我的计算机视觉分析的发现。期待看到哪些艺术品出现的次数最多。敬请关注。
感谢阅读!
Vishal
Vishal 是一名文化数据科学家,也是伦敦 UCL 学院的研究生。他对城市文化的经济和社会影响感兴趣。
一目分析的效用分析
Ichimoku trading 是一种理解和开发感兴趣股票的买卖信号的有趣方式,也是我试图在自己的股票分析中融入的一种方式。在这篇文章中,我想解释我是如何发现这些分析的,以及我是如何将这些信号整合到我自己的预测分析中的。
那么市目是什么呢?“Ichimoku Kinko Hyo”是对股票动力、阻力和支撑的分析,根据最近的表现产生交易信号。有五条绘制的线构成了分析的基础:
**Tenkan-sen(转换线)😗*9 日最高价和最低价的平均值
**Kijun-sen(基线)😗*26 天最高价和最低价的平均值
森口跨度 A(领先跨度 A): 换算与基线的平均值
**森口跨度 B(领先跨度 B)😗*52 天高低点平均值
**迟口跨度(滞后跨度)😗*26 天前的收盘价
这两个寇森跨越了所谓的“库莫云”的界限,即价格高于、低于或低于我。下面是标准普尔 500 的 Ichimoku 分析图像(来自 ichimokutrader.com)。
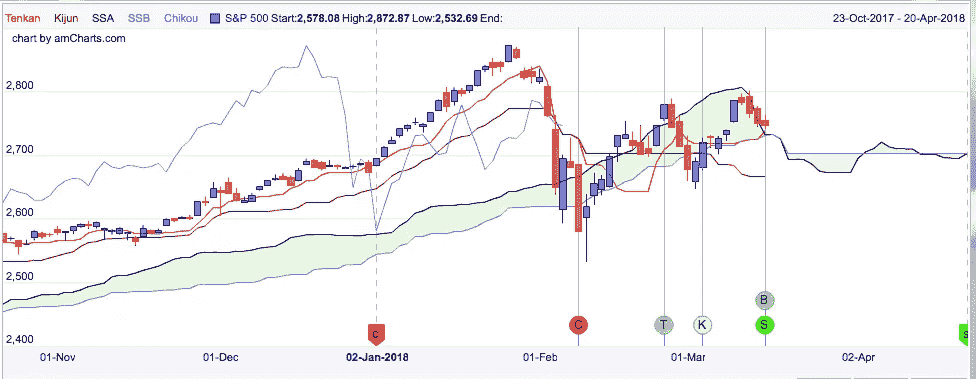
绿色和红色的区域代表 Kumo,而线条代表前面提到的每个跨度和线条。线交叉产生的信号有几种类型。其中包括:
天坎/基君十字:
Tenkan 从 Kijun 下方到上方时的看涨信号(Kumo 云下方时弱,内侧时中性,上方时强)。
Tenkan 从 Kijun 上方到 belw 时的看跌信号(Kumo 云上方时弱,内部时中性,下方时强)。
价格交叉 Kijun 森:
当价格从下方上涨到上方时,是看涨信号(当价格低于 Kumo 时是弱势,当价格在内部时是中性,当价格在上方时是强势)。
当价格从上方下跌到下方时,熊市信号(当价格在 Kumo 上方时是弱势,当价格在内部时是中性,当价格在下方时是强势)。
库莫突围:
当价格脱离库莫云顶部时,是看涨信号。
当价格脱离库莫云底部时,是看跌信号。
寇森跨越:
森口跨度 A 从下方移动到森口跨度 B 上方时的看涨信号(库莫下方时弱,内侧时中性,上方时强)。
当森口跨度 A 从上方移动到森口跨度 B 下方时的看跌信号(Kumo 上方时弱,内侧时中性,下方时强)。
池口跨度穿越价格:
当 Chikou Span 从价格下方移动到价格上方时的看涨信号(当低于 Kumo 时为弱,当在内部时为中性,当在上方时为强)。
当 Chikou Span 从价格上方移动到价格下方时,是看跌信号(Kumo 上方是弱信号,Kumo 内部是中性信号,Kumo 下方是强信号)。
整合这种分析的下一步是对信号进行编码。有两种选择:
- 使用图像处理来识别出现的信号。
- 手动对线进行编码,并通过识别线何时从大于彼此变为小于彼此来找到交叉点。
因为对图像识别不太熟悉,所以选择了后者。这导致我使用 if-then 语句寻找交叉点的许多繁琐而全面的代码序列,但这最终是可行的。我给信号赋值,范围从-3(强烈看跌信号)到 0(没有信号)到 3(强烈看涨信号)。每一个都将成为我的算法中的数据点(在介绍文章中描述),最终提高准确性。下表说明了这些影响:

Accuracy Analysis of KNN Algorithm Predicting S&P 500 Stock Price Direction
这里我们可以看到 Ichimoku 信号提高了整体算法的精度。5 天和 10 天的预测准确率提高了不到 11%,而 15 天、30 天和 60 天的预测准确率提高了约 9%。随着我们进入 90 天的时间框架,这些准确性的增加似乎会减少,甚至可能超过 90 天,这可能说明信号在短期内的效用。
总的来说,我想确定信号在创建更准确的预测算法中的效用,我觉得我在这方面是成功的。虽然我不能说信号的有效性是做交易决定的唯一因素,但很明显,在预测分析中包含信号会使分析更有效。
注来自《走向数据科学》的编辑: 虽然我们允许独立作者根据我们的 规则和指导方针 发表文章,但我们不认可每个作者的贡献。你不应该在没有寻求专业建议的情况下依赖一个作者的作品。详见我们的 读者术语 。
分析熊猫的时间序列数据

在我之前的教程中,我们考虑过数据准备和可视化工具,如 Numpy 、 Pandas 、Matplotlib 和 Seaborn。在本教程中,我们将学习时间序列,为什么它很重要,我们需要应用时间序列的情况,更具体地说,我们将学习如何使用 Pandas 分析时间序列数据。
什么是时间序列
时间序列是在特定时间通常以相等的间隔(例如每小时、每天、每周、每季度、每年等)获取的一组数据点或观察值。时间序列通常用于根据以前观察到的事件或值来预测未来的事件。预测明天股票市场将会发生什么,在接下来的一周将会售出的货物量,一个项目的价格是否会在 12 月暴涨,一段时间内优步乘坐的次数等;是我们可以用时间序列分析做的一些事情。
为什么我们需要时间序列
时间序列有助于我们理解过去的趋势,因此我们可以预测和规划未来。例如,你拥有一家咖啡店,你可能看到的是你每天或每月销售多少咖啡,当你想看到你的店在过去六个月的表现时,你可能会添加所有六个月的销售额。现在,如果您希望能够预测未来六个月或一年的销售额,该怎么办呢?在这种情况下,您唯一知道的变量是时间(秒、分、天、月、年等),因此您需要时间序列分析来预测其他未知变量,如趋势、季节性等。
因此,重要的是要注意,在时间序列分析中,唯一已知的变量是— 时间。
为什么 pandas 使处理时间序列变得容易
事实证明,Pandas 作为处理时间序列数据的工具非常成功。这是因为 Pandas 有一些内置的datetime函数,这使得处理时间序列分析变得很容易,并且由于时间是我们在这里处理的最重要的变量,这使得 Pandas 成为执行这种分析的非常合适的工具。
时间序列的组成部分
一般来说,包括金融领域之外的时间序列通常包含以下特征:
- 趋势:这是指一个序列在一个长时期内相对较高或较低的值的移动。例如,当时间序列分析显示一个向上的模式时,我们称之为上升趋势,当模式向下时,我们称之为下降趋势,如果根本没有趋势,我们称之为水平或静止趋势。需要注意的一点是,趋势通常会持续一段时间,然后消失。
- 季节性:这是指在一个固定的时间段内重复的模式。虽然这些模式也可以向上或向下摆动,但是,这与趋势有很大的不同,因为趋势会持续一段时间,然后消失。然而,季节性在固定的时间段内持续发生。例如,当圣诞节时,你会发现卖了更多的糖果和巧克力,这种情况每年都会发生。
- 不规则性:这也叫噪音。不规则性发生的时间很短,而且不会耗尽。一个很好的例子是埃博拉病毒。在那段时期,洗手液的需求量很大,但这种需求是不稳定的/系统的,没有人能预测到,因此没有人能知道销售了多少,也不知道下一次会有什么爆发。
- 周期性的:这是当一系列重复向上和向下运动时。它通常没有固定的模式。它可能发生在 6 个月后,然后两年后,然后 4 年,然后 1 年后。这种模式很难预测。
何时不应用 TS
还记得我们说过这里的主要变量是时间吗?同样,必须指出的是,在以下情况下,我们不能对数据集进行时间序列分析:
- 变量/值是常量。例如,去年圣诞节和前年圣诞节售出了 5000 盒糖果。因为两个值相同,所以我们不能应用时间序列来预测今年圣诞节的销售额。

2.函数形式的值:当您可以简单地使用公式或函数来计算值时,对数据集应用时间序列分析是没有意义的。
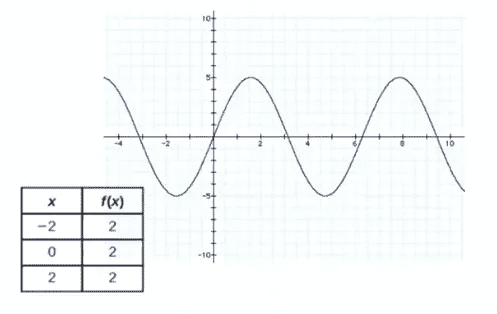
现在我们对时间序列有了基本的了解,让我们继续做一个例子来完全掌握如何分析时间序列数据。
预测航空旅行公司的未来
在这个例子中,我们被要求建立一个模型来预测特定航空公司的机票需求。我们将使用国际航空公司的乘客数据集。你也可以从 kaggle 这里下载。
导入包和数据
首先,我们需要做的第一件事是导入我们将用来执行分析的包:在这种情况下,我们将利用pandas来准备我们的数据,并访问datetime函数和matplotlib来创建我们的可视化:

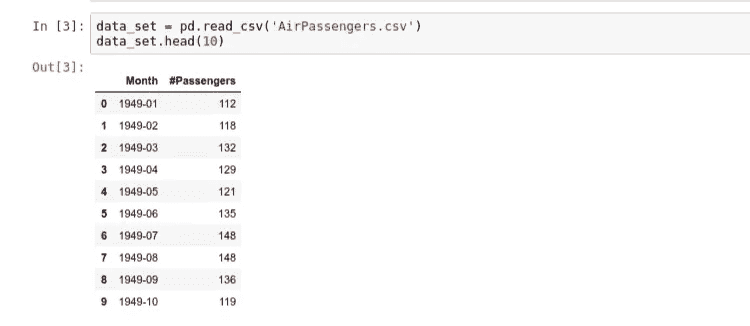
现在,让我们读取数据集,看看我们有什么样的数据。如我们所见,数据集被分为两列;月和每月旅客人数。
我通常喜欢获取数据集的摘要,以防有一行的值为空。让我们继续执行以下操作进行检查:

正如我们所看到的,我们的数据集中没有任何空值,所以我们可以自由地继续我们的分析。现在,我们要做的是确认Month列是datetime格式,而不是字符串。熊猫.dtypes功能让这一切成为可能:

我们可以看到Month列是一个通用的对象类型,可能是一个字符串。因为我们想要对这些数据执行与时间相关的操作,所以我们需要将它转换成一种datetime格式,然后它才能对我们有用。让我们继续使用to_datetime()助手函数来完成这项工作,让我们将月份列转换为一个datetime对象,而不是一个通用对象:
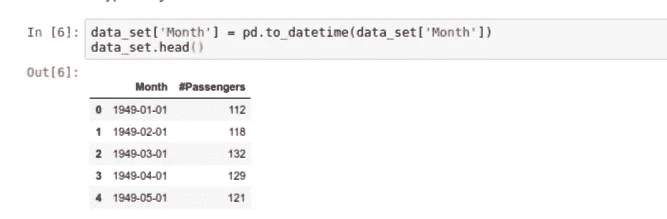
请注意,我们现在已经生成了作为月份列一部分的date字段。默认情况下,“日期”字段假定每月的第一天来填写未提供的日期值。现在,如果我们返回并确认类型,我们可以看到它现在的类型是datetime:

现在,我们需要将datetime对象设置为 dataframe 的索引,以允许我们真正探索我们的数据。让我们使用.set_index()方法来完成:
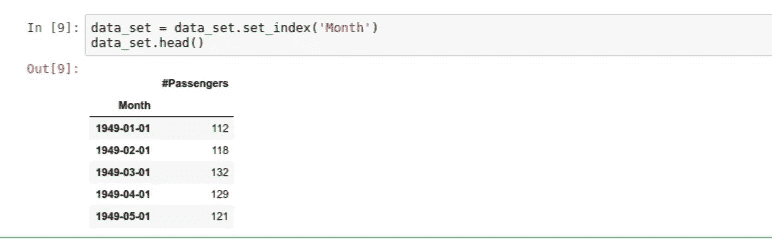
我们现在可以看到,Month列是我们的数据帧的索引。让我们继续创建我们的图,看看我们的数据看起来像什么:
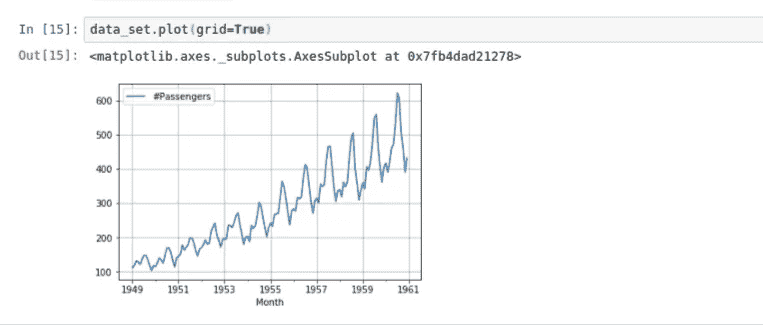
注意,在时间序列图中,时间通常绘制在
x-axis上,而y-axis通常是数据的大小。
请注意Month列是如何被用作x-axis的,因为我们之前已经将Month列转换为datetime,所以year被专门用于绘制图形。
现在,你应该注意到一个上升的趋势,表明随着时间的推移,航空公司将有更多的乘客。虽然在每个时间点都有起伏,但通常我们可以观察到趋势是增加的。我们还可以注意到起伏似乎有点规律,这意味着我们可能也在观察一种季节性模式。让我们通过观察某年的数据来仔细了解一下:
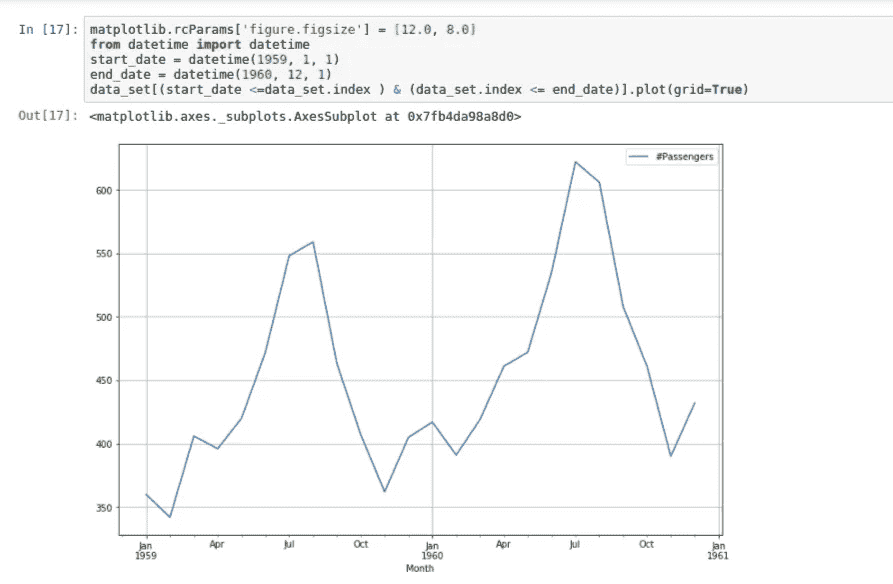
正如我们在图中看到的,通常在 7 月和 9 月之间有一个高峰,到 10 月开始下降,这意味着更多的人在 7 月和 9 月之间旅行,可能从 10 月开始旅行减少。
还记得我们提到过在我们的观察中有一个上升趋势和一个季节性模式吗?在大多数时间序列分析中,通常有许多组成部分[向上滚动查看时间序列组成部分的解释]。因此,我们现在需要做的是使用分解技术将我们的观察解构为几个组件,每个组件代表一个基本的模式类别。
时间序列的分解
在时间序列数据的分解过程中,有几个模型需要考虑。
1。加法模型:当趋势的变化不随时间序列水平而变化时,使用这种模型。这里,时间序列的组成部分简单地用公式相加:
y(t) = Level(t) + Trend(t) + Seasonality(t) + Noise(t)
2。乘法模型:如果趋势与时间序列的级别成比例,则使用乘法模型。这里,时间序列的组成部分简单地用公式相乘:
y(t) = Level(t) * Trend(t) * Seasonality(t) *Noise(t)
出于本教程的目的,我们将使用加法模型,因为它开发速度快,训练速度快,并且提供可解释的模式。我们还需要导入[statsmodels](https://www.statsmodels.org/stable/index.html),它有一个tsa(时间序列分析)包以及我们需要的seasonal_decompose()功能:
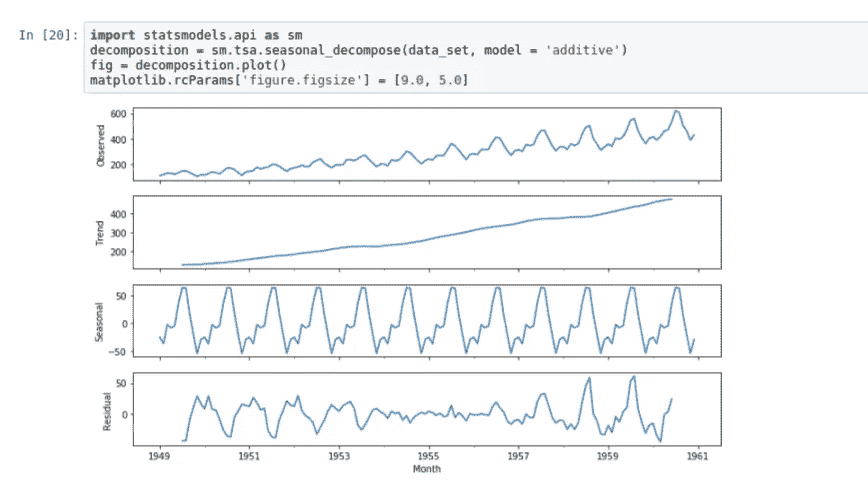
现在我们有了一个更清晰的图表,显示趋势在上升,季节性遵循一个规律。
我们要做的最后一件事是绘制观察到的时间序列的趋势图。为此,我们将使用 Matplotlib 的.YearLocator()函数将每个year设置为从一月month=1开始,并将month设置为每 3 个月(intervals=3)显示一次刻度的次要定位器。然后,我们使用数据帧的索引x-axis和y-axis的乘客数量来绘制数据集(并赋予其蓝色)。
我们对趋势观察做了同样的处理,用红色绘制。
import matplotlib.pyplot as plt
import matplotlib.dates as mdatesfig, ax = plt.subplots()
ax.grid(True)year = mdates.YearLocator(month=1)
month = mdates.MonthLocator(interval=3)
year_format = mdates.DateFormatter('%Y')
month_format = mdates.DateFormatter('%m')ax.xaxis.set_minor_locator(month)ax.xaxis.grid(True, which = 'minor')
ax.xaxis.set_major_locator(year)
ax.xaxis.set_major_formatter(year_format)plt.plot(data_set.index, data_set['#Passengers'], c='blue')
plt.plot(decomposition.trend.index, decomposition.trend, c='red')
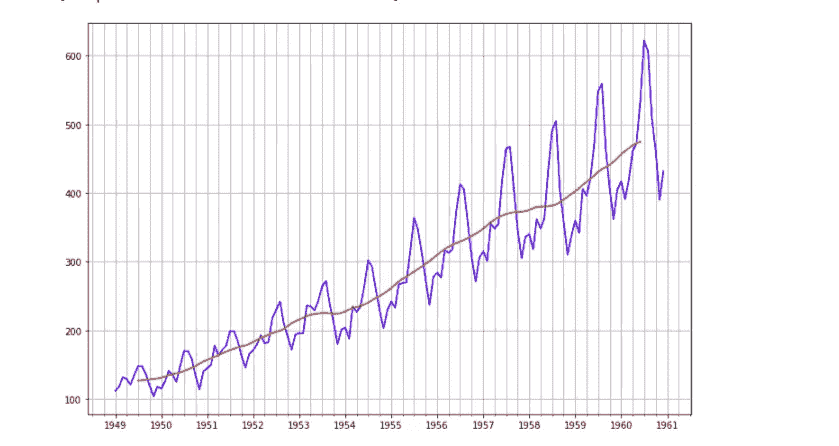
同样,我们可以看到趋势与个别观察结果相反。
结论
我希望这篇教程能帮助你理解什么是时间序列,以及如何开始分析时间序列数据。
分析新加坡的火车旅行时间和票价
我试图了解新加坡不同火车站的可达性,以及不同车站的旅行时间和票价是如何变化的。分析的目的是在火车作为唯一运输方式的基础上,确定更方便的地区。有许多方法可以进行分析:
-查看 X 分钟内可到达的站点数量
-查看行程时间的范围/分布
-查看旅行费用的范围/分布
我对每个站都给予了同等的重视,即每个站都与另一个站一样重要。这可能不太现实,因为有些位置的访问频率不如其他位置。然而,这是一个很好的起点,也是一种通用的方法。我还更加关注使用旅行时间而不是旅行费用作为比较的基础,因为票价将于 2018 年 12 月 29 日发生变化。还需要注意的是,这里的行程时间不包括等待和换乘时间,也不包括延误时间。这可能不是微不足道的,但我假设每个站发生的概率相等,这可能不是真的。在我们建立这个先验之前,需要分析延迟事件的概率,目前我没有这个数据。我如何收集旅行时间和费用数据可以在之前的帖子中找到。
因此,我为用户设计了一个仪表板,让他们在一定时间内比较某个特定站点与另一个站点的覆盖范围,以帮助他们建议重叠区域内可能的会合点。有趣的是,小印度拥有最多 15 分钟内可到达的车站。对于在 8 到 18 分钟内可到达的大多数车站,前 3 名车站是 Dhoby Ghaut、Bugis 和小印度。Serangoon 成为 19 分钟内可到达车站最多的车站。这有助于房产购买的计划,因为便利是一个主要的考虑因素。将这种可及性与房地产价格联系起来也很有意思。
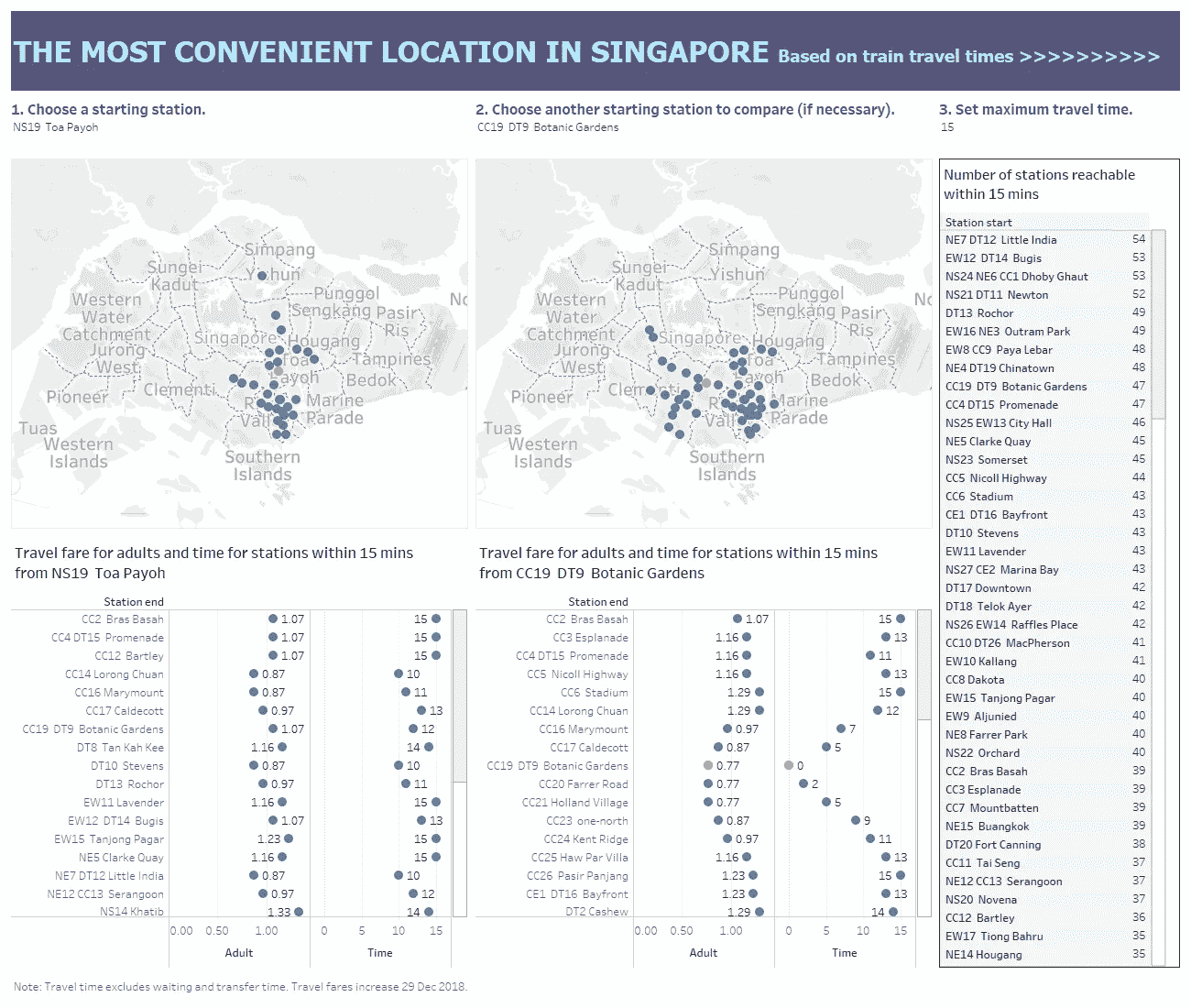
The interactive dashboard can be accessed here.
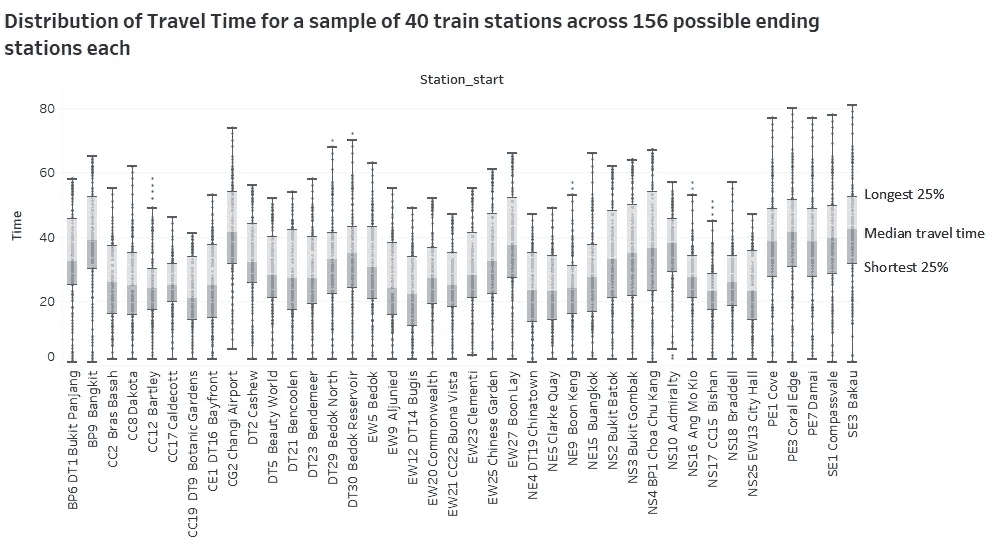
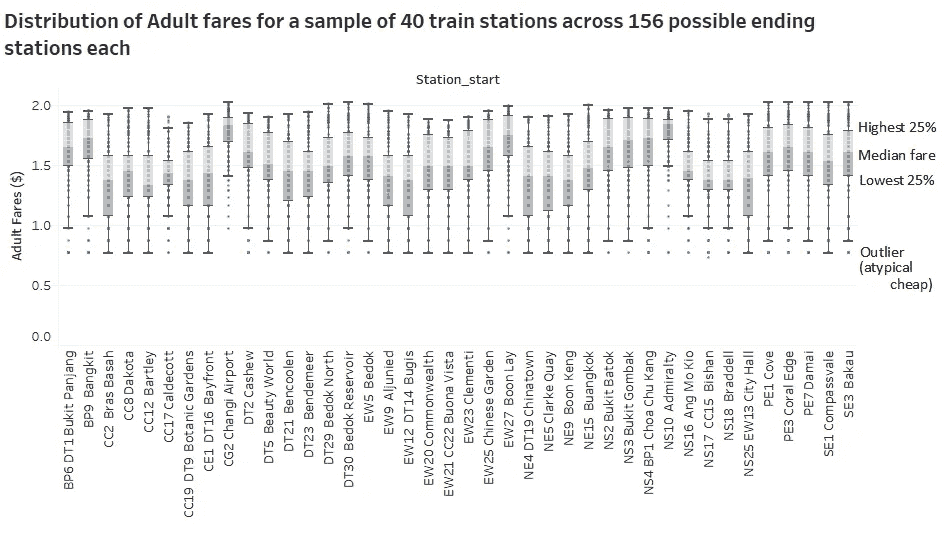
我做了第二个仪表板来呈现旅行时间和费用分布的宏观和微观视图。似乎有一种向花哨的可视化发展的趋势,我不太赞同这一点。大多数情况下,简单的图表,如条形图、线形图或散点图,能够有效地展示调查结果。尽管如此,我还是决定尝试一下辐射图。如果你看它,它真的只有在我们有兴趣看大局,而不是依赖它的统计数据或数字时才有用。我们可以看到不同火车线路的旅行时间的总体分布,用不同的颜色表示(我将一些组合在一起,例如 SW 和 SE,PW 和 PE,CE 和 CG)。此外,我们可以看出 BP 线(用灰色表示)的站点数量最少,紧随其后的是 ne 线(用紫色表示)。此外,西南/东南线(由粉红色表示)和 PW/ PE 线(由蓝绿色表示)上的站点具有非常相似的行程时间分布,而东西线(由绿色表示)具有最大的差异,其分布看起来像一个心形图形。更均匀的分布类似于三角形,更类似于 BP 线(用灰色表示)。通过调整最大旅行时间,我发现 CC 线上的所有车站(用黄色表示)都能够在 62 分钟内到达所有其他车站。同样,这样的图表也有很多局限性。不清楚 15 分钟内有多少(或多少比例)的电台可以到达,也很难筛选出一个特定的电台来查看。因此,这真的取决于一个人在设计可视化时要达到的目标。
从径向图开始,旁边的两个图表提供了逐站旅行时间和票价的细分。更容易看到每条线路和每个站的分布。旅行费用的分布非常有趣。每一种都有独特的形状,尤其是不同的线条。票价肯定不是正态分布的,因此计算某个人从特定车站出发的平均票价可能没有意义。研究每个地区的人在火车旅行上的花费是有益的,这可能会更好地影响不同层次的福利包的设计,以补充运输成本。当然,有很多方法可以做到这一点,无论是通过上限或每次乘坐的百分比折扣;就实施而言,这可能必须与一张可识别的卡联系在一起。

The interactive dashboard can be found here.
另外,在我收集完所有 157 个站点的数据之前,我决定在收集了 40 个站点的数据之后对分布进行初步分析。箱线图在评估范围/分布时非常有用,在这种情况下,中值对异常值更稳健,从而使比较更有意义。也很容易看出哪些车站的平均旅行时间和票价比其他车站低。同样,这是基于每个站同等重要的假设。如果我们给某些电台更高的权重,分布将会改变。
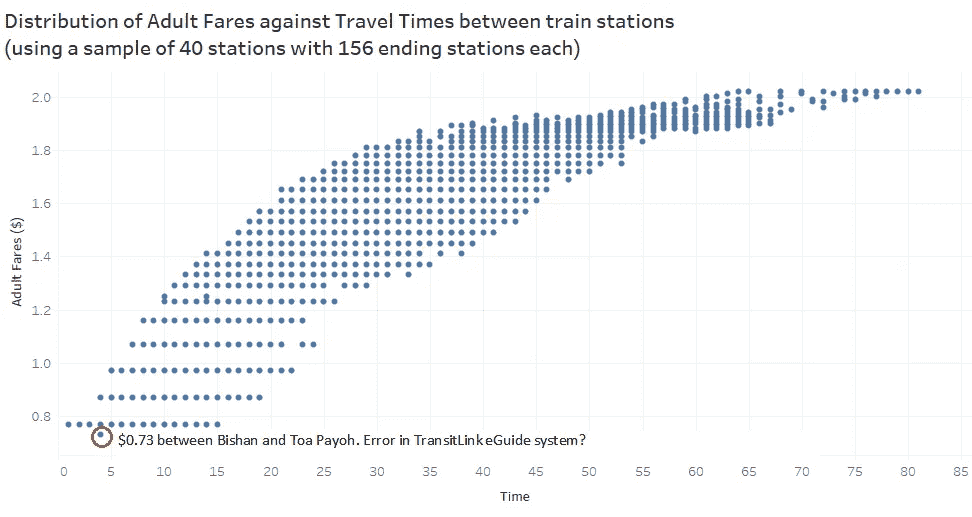
另一方面,散点图有助于我们理解总体趋势,也有助于识别异常值(和可能的数据输入错误?).我们可以看到具有平台效应的对数关系。研究不同定价策略对收入的影响肯定是有潜力的,例如阶梯式增长或基于时间而不是基于距离的费用结构。这将使票价估算更容易,但我也认为这将转化为通勤者更高的成本。
原载于 2018 年 11 月 5 日【projectosyo.wixsite.com】。
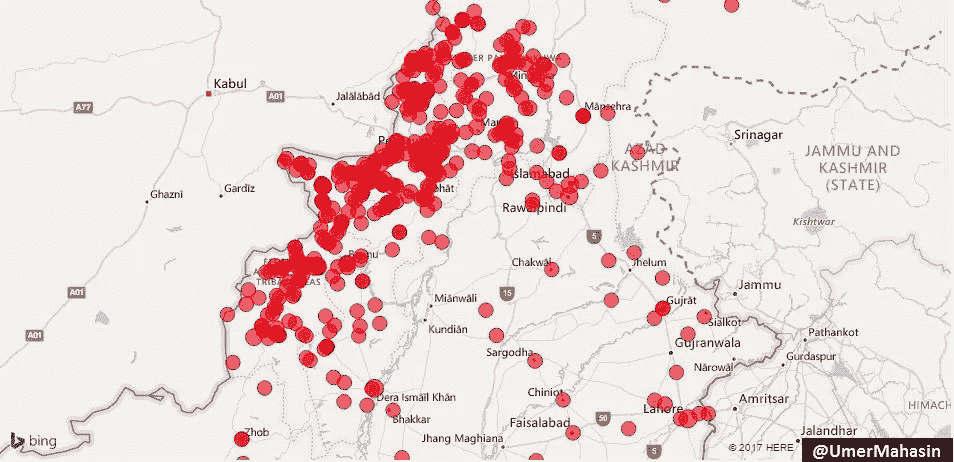
分析和可视化巴基斯坦和印度的恐怖袭击(2002–2015)
我目前正在学习数据科学,所以最好的学习方法是实时学习,作为一名巴基斯坦人,我会查看来自我自己国家的数据进行分析和可视化,不幸的是,我脑海中闪现的第一件事是巴基斯坦的恐怖袭击。
所以,我开始寻找巴基斯坦恐怖袭击的数据库,我在马里兰大学的全球恐怖主义数据库找到了一个。
在讨论数据之前,我想强调一下数据中我认为缺失的一个重要元素。GTD 使用了城市的坐标,而不是事件发生的实际地点,这使得它在分析数据时效率较低。如果我们有事件发生地点的实际坐标,至少我们将能够分析城市的哪个部分更容易受到攻击,以及可能的原因,我们还可以通过运行预测分析模型或在机器学习的帮助下了解即将到来的攻击。
在我们继续之前,最后一件事,我不是数据分析或可视化方面的专家。所以,原谅我,如果它可以更好,或者我的分析是薄弱的。
我分析了巴基斯坦和印度。为什么是印度?因为我们是爱情鸟,我们一直都这样。我这么做的原因和这个印度人试图在ka ggle找到**“克什米尔的恐怖事件和巴基斯坦的牵连”**一样。
我有几句话要对 Anshul 先生说:你可以更好地为你的国家和这个社区服务,提出印度的真正问题,而不是把时间浪费在最不重要的事情上。
以下可视化是使用至少有 1 个因果关系的数据作为恐怖袭击的结果。
巴基斯坦恐怖袭击概述
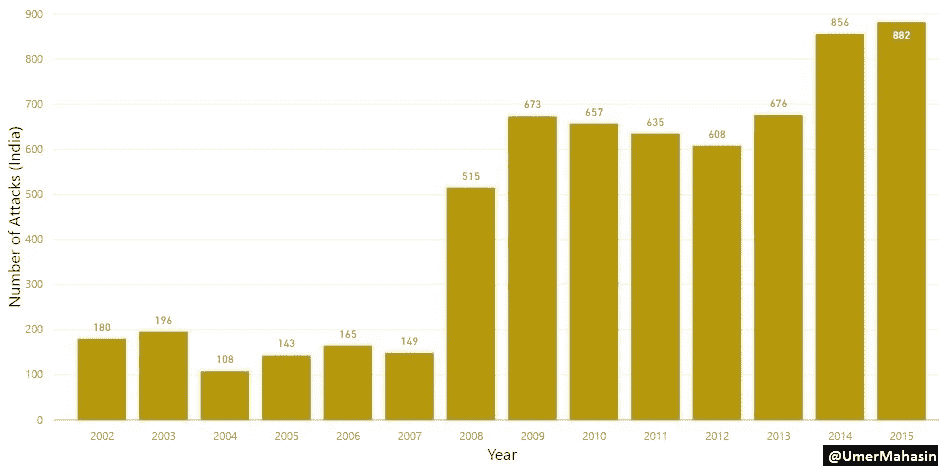
该数据中分析的年份为 2002 年至 2015 年:根据 GTD 的数据,巴基斯坦发生了超过 10,000 起恐怖袭击,其中略多于 18,000 人死亡,超过 30,000 人受伤。

Overview of terrorist attacks in Pakistan
看起来整个巴基斯坦都受到了影响,这是真的,但大多数袭击发生在俾路支,FATA 和 KPK。
这三个地区位于阿富汗边境!
印度恐怖袭击概述
这就是印度恐怖袭击在地图上的样子。
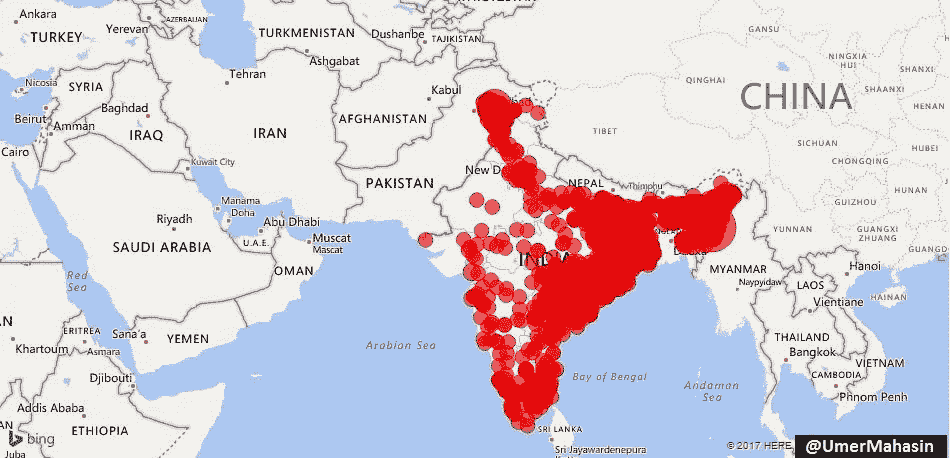
它从克什米尔开始,深入到印度的东部、南部、北部和东南部。
如果巴基斯坦在印度输出恐怖主义,为什么我们没有看到任何跨越 2900 多公里边界的活动?为什么只有克什米尔有麻烦?因为这是印巴之间有争议的领土,克什米尔人民正在为自由而战,这也是 GTD 数据库中的恐怖主义。
根据 GTD 的数据,2002 年至 2015 年期间,印度记录了 6488 起恐怖袭击事件。超过 7600 人死亡,超过 14400 人受伤。329 起袭击是由“伊斯兰”组织实施的,在过去的 15 年里造成了 1119 起伤亡,其余的则是由“非伊斯兰”组织实施的。正如我们在下面所看到的,超过 95%的“伊斯兰组织”的袭击发生在克什米尔,同样是自由运动活跃的争议地区。
这是印度“伊斯兰”组织的所有袭击,看起来像是在地图上…
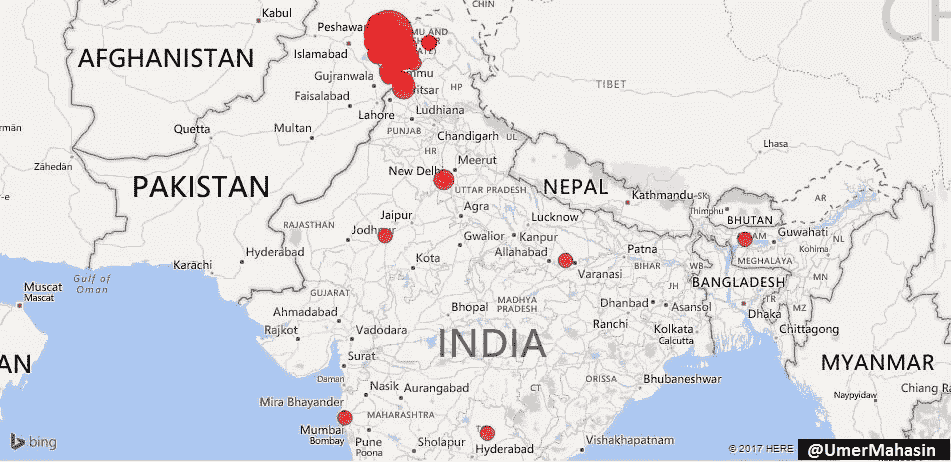
Attacks by “Islamic” groups in India
亲爱的印度!你的问题既不是巴基斯坦也不是穆斯林。
巴基斯坦受影响最严重的地区
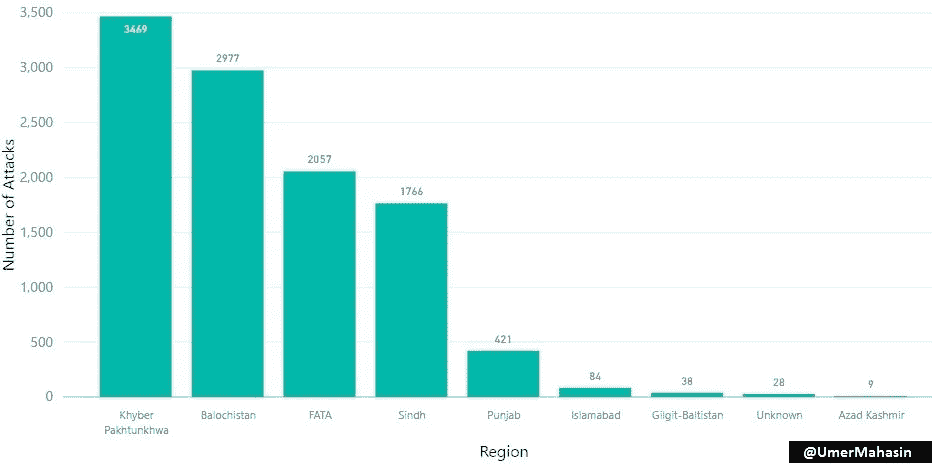
FATA 碰巧是像 TTP 这样的恐怖组织的大本营,但就袭击数量而言,它在名单上排名第三,这显然是因为没有多少“有价值”的目标。从 FATA 崛起后,第一个受到影响的地区是 KPK。
俾路支斯坦和阿富汗之间没有任何东西,所以即使俾路支斯坦的总人口不超过巴基斯坦的 5%,进入第二个国家也是显而易见的。
旁遮普是巴基斯坦人口最多的地区,人口占总人口的 50%以上。如果我们假设恐怖主义的根源在巴基斯坦内部,我们应该已经看到旁遮普、信德和伊斯兰堡的最大数量的袭击,但是**我们看到袭击数量和受影响最严重地区的地理位置(与阿富汗接壤)**之间存在正相关。还有一个原因导致了这些地区更多的恐怖活动。与这个国家的其他地区相比,这些地区被忽视并且不发达。
信德省并不与阿富汗接壤,但是阿富汗发生大量袭击事件的原因是相互之间以及与安全部队之间的政治和种族战争。
这是 FATA/KPK &旁遮普袭击的特写镜头。
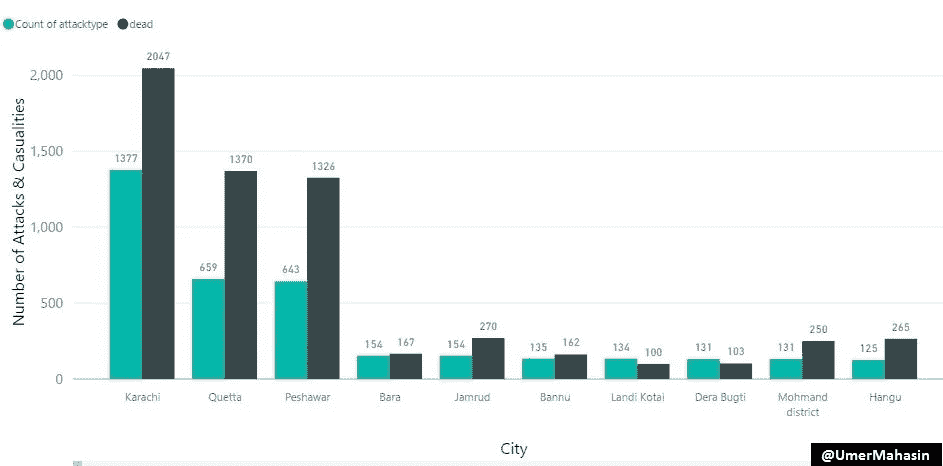
袭击数量&各城市的伤亡人数
卡拉奇是巴基斯坦最大的城市,人口超过 2000 万。因此,奎达和白沙瓦名列榜首。
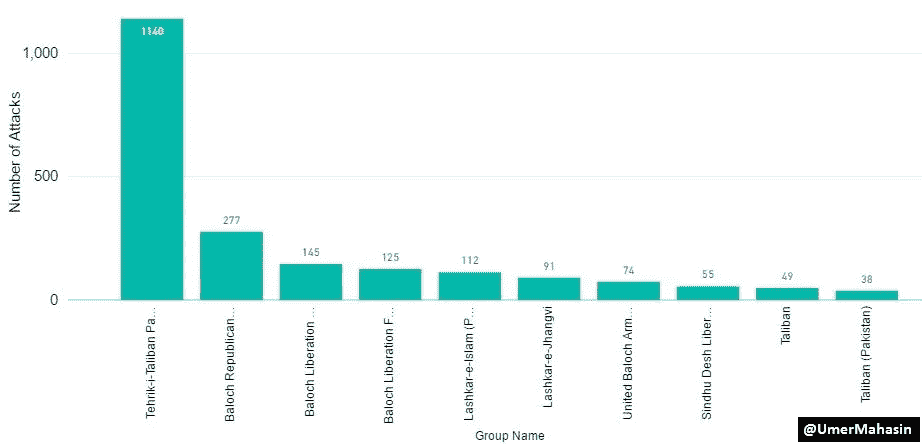
按团体划分的攻击次数
有趣的是,当我们看到 TTP 在 FATA 崛起时,我们也看到俾路支省的俾路支恐怖组织崛起。
如果我们看看印度不同组织的袭击次数。很明显,巴泰虔诚军(LeT)T1 和 T2 伊斯兰圣战者组织 T3 分别位于 T4 的第 6 位、T42 的第 6 位和第 7 位,这使得他们对印度的威胁很小(至少除非他们先对付其他组织)。
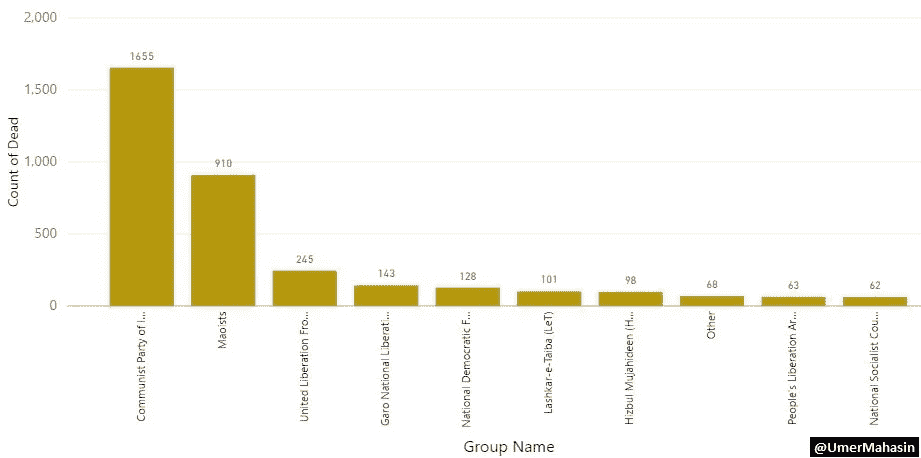
前 5 名是…
1.印度共产党(毛派)
2.毛派
3.阿萨姆联合解放阵线(ULFA)
4.加罗民族解放军
5.波多兰全国民主阵线(NDFB)
每年的攻击次数

2007 年巴基斯坦恐怖袭击激增。以下是 2007 年及之前发生的几起助长巴基斯坦恐怖主义的重大事件。
**1。**印度沿巴基斯坦边境在阿富汗开设领事馆。
**2。**巴基斯坦开始报道印度干涉 FATA &俾路支省。

这篇报道发表于2006 年 4 月 24 日,四个月后巴基斯坦于2006 年 8 月 26 日在俾路支省杀死了俾路支叛军首领阿克巴·布格提,这进一步助长了俾路支省的叛乱。

1。恐怖分子接管了伊斯兰堡的拉尔清真寺,拉尔清真寺被围困是 2007 年 7 月伊斯兰原教旨主义武装分子和巴基斯坦政府之间的对抗。
2。拉尔清真寺的行动被用来助长斯瓦特地区的叛乱。TNSM 在 2007 年接管了斯瓦特的大部分地区。
**3。**2007 年 12 月,大约 13 个组织在巴伊图拉·马哈苏德的领导下联合起来,成立了巴基斯坦塔利班运动(TTP)。
但好的一面是;过去几年,巴基斯坦似乎赢得了反恐战争的胜利。
多年来印度的攻击次数
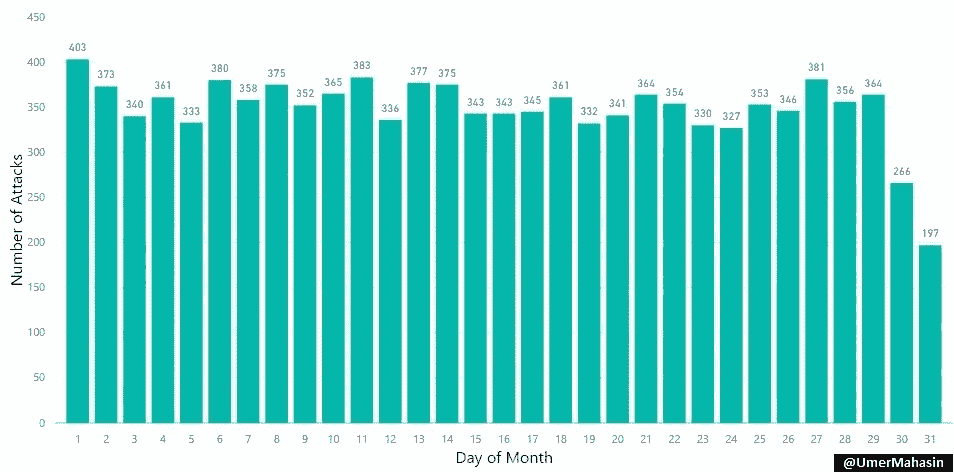
每月各天的攻击次数
恐怖分子在每月的第一天最活跃,在每月的最后一天最不活跃。
为什么?嗯,我想不出一个可靠的理由,所以你能帮我理解吗?
以下是 TTP 每月每天发动的攻击数量。
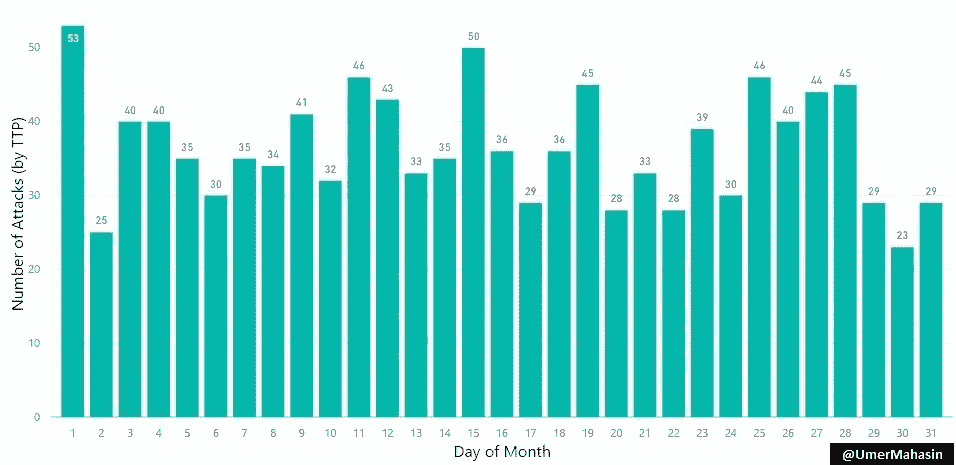
有趣的是,他们在每月的 1 号和 15 号进行了大部分的攻击。
为什么?也许是因为他们根据“表现”得到了双周刊的报酬,谁知道呢?😄
恐怖袭击中广泛使用的武器类型
恐怖分子使用了爆炸物/炸弹/炸药(61.81%) 其次是火器(31.98%)
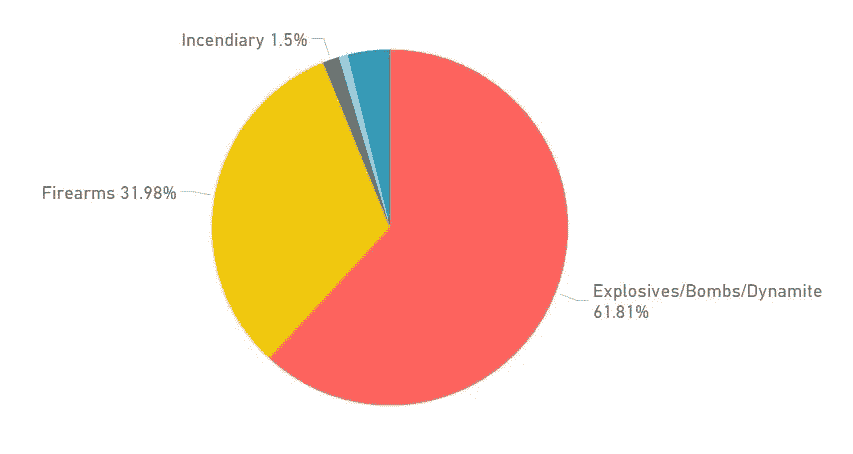
每月攻击次数
恐怖分子喜欢在五月发动袭击。我不是军事专家,但我肯定有人能得出结论,为什么五月发生的袭击最多,为什么九月发生的袭击最少。
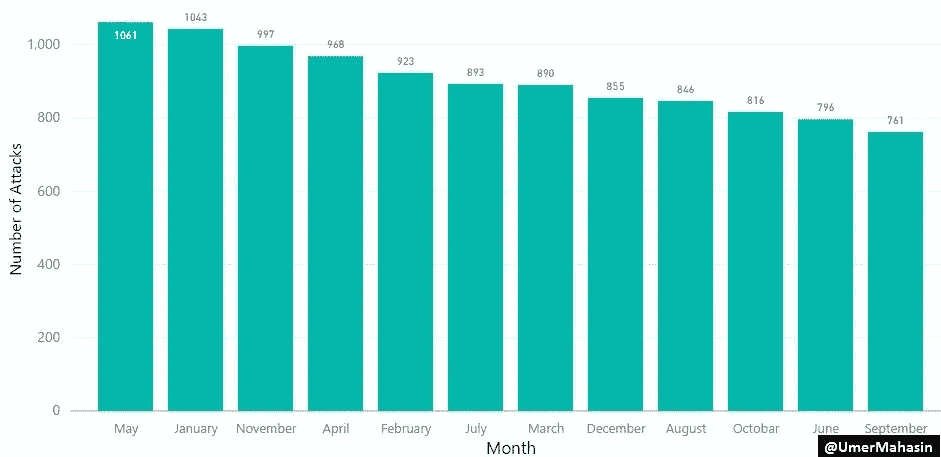
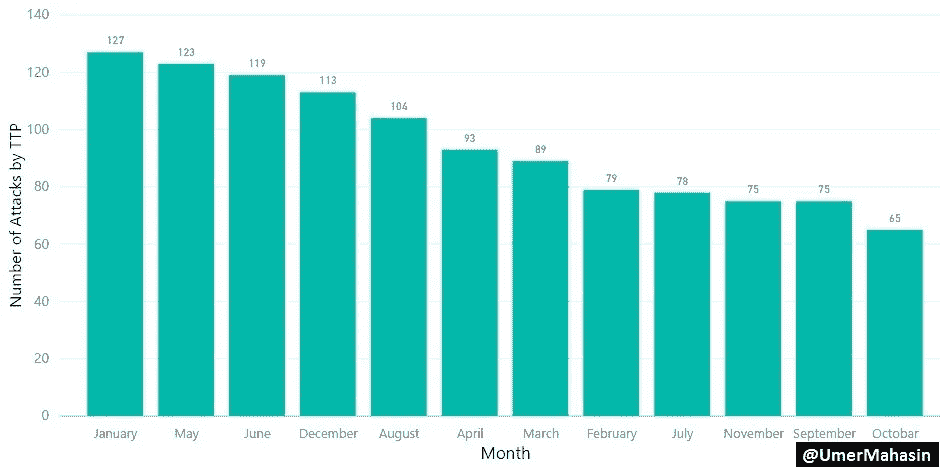
而 TTP 似乎在一月最活跃,十月最不活跃。
外国公民在巴基斯坦遇害
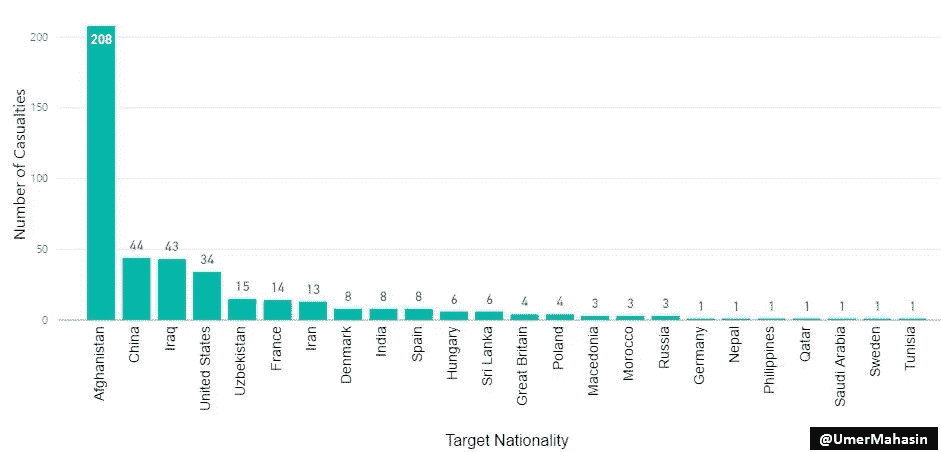
从 2002 年到 2015 年,共有 427 名外国公民在巴基斯坦被杀,其中大部分是阿富汗人这是显而易见的,因为阿富汗人生活在恐怖袭击地区,如 FATA,KPK &俾路支省,他们也和巴基斯坦人一样成为受害者。
这还不是全部!
巴基斯坦将有许多出色的数据科学家,他们可以从这个数据库中提取更有价值的信息,并与我们分享。
在花了几天时间研究这些数据后,我得出结论,巴基斯坦和印度应该花更多的时间提高他们自己人民的生活水平,把更多的注意力放在被忽视的领域,而不是互相攻击。恐怖主义马上就会减少 70%。
爱与和平!
人们在理发上花费多少?
男生还是女生在头发上花费更多?

理发的时候想着理发
我坐在 Dazzle’s salon 的椅子上,看着迈克尔把我头上的豪猪变成一件稍微像样的东西,这时我意识到,“哇,我在理发上花了一大笔钱”。
每次去 Dazzle 要花我 30 美元,我大概每个月都会去一次。这意味着我每年要在理发上花费大约 360 美元。这比我花在其他服务上的钱还多,我认为这些服务是我生活中不可或缺的(如互联网、电力、亚马逊 Prime)。
一系列的想法和问题冒了出来:
每个人都在理发上花这么多钱吗?
我为女孩感到难过,她们肯定比我花得多。
等等,女孩理发的花费真的比我多吗?
我的女性朋友经常抱怨说,女性理发的费用比男性高是多么令人愤慨。我抗议这种不公正,就像我抗议所有对我的生活没有影响的不公正一样:保持沉默,希望它消失。因为这个价格差距,我一直认为女性在理发上的花费比男性多。
但是当我开始做一些计算时,我不太确定了。我无法想象大多数女孩需要像男孩一样频繁地理发。基于我有限的观察能力,女性一年理发两到三次——明显少于男性。因此,我不清楚到底是谁在理发上花费更多。
现在你可能会想,在这个世界上留下的所有未解之谜和未回答的问题中,男性或女性在理发上的花费更多是一个极其狭隘和毫无意义的问题,不值得深入研究。
你可能是对的。

这是为了科学,我保证!
我首先对我的朋友做了一个粗略的调查,以更好地了解一般的理发习惯。
如果有一本书叫做如何失去朋友并让人们认为你在暗地里是一个连环黑仔,询问人们关于他们的护发习惯应该有自己的一章。
在得到预期的“你为什么需要知道”“为什么?”我个人最喜欢的“…”,我的男性朋友说他们每一到两个月理发一次,每次 20-30 美元,而我的女性朋友每三个月到每两年理发一次,每次 50-100 美元。
显然,还有“附加服务”,如直发、染发和所谓的巴西式发型。
然而,要真正回答哪个性别花费更多的问题,我需要一个更大的样本量。
如果是调查就没那么毛骨悚然了…也许吧
我招募了 202 个人,给他们一份调查。
我问他们多久去一次发廊/理发店,每次去多少钱。我还特意询问了他们的理发习惯,以及他们是否为任何额外服务付费。
虽然调查参与者偏向女性(30%男性,70%女性),但结果仍然很有趣。
那么什么是理发呢?
那么谁在理发上花费更多呢?
简短的回答是,看情况而定;你如何定义一个发型?
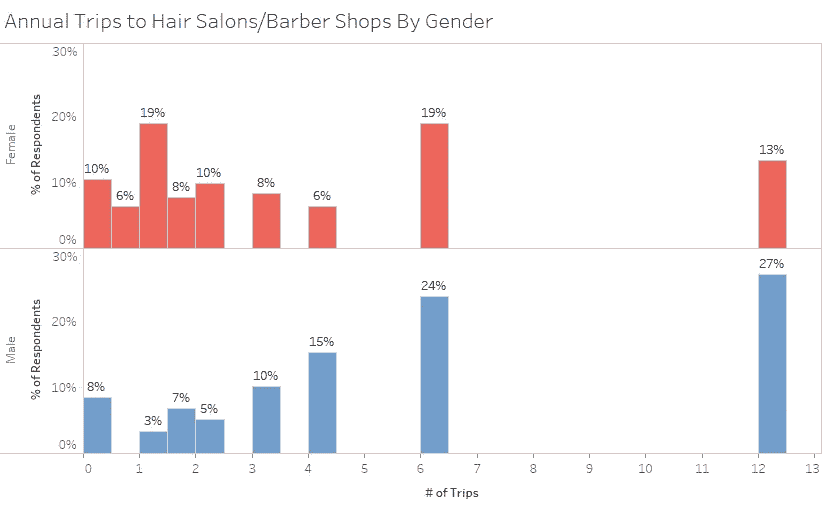
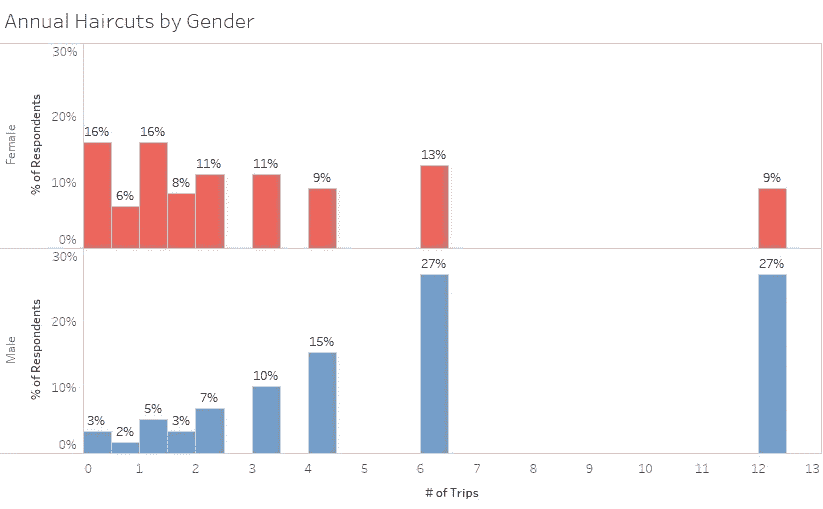
平均而言,男人一年去发廊或理发店 5.84 次,或每 8 周多一点,而女人一年去 3.81 次,或每 13 周半。男性每次旅行的花费约为 22.93 美元,而女性每次旅行的花费是男性的两倍多,为 54.34 美元。
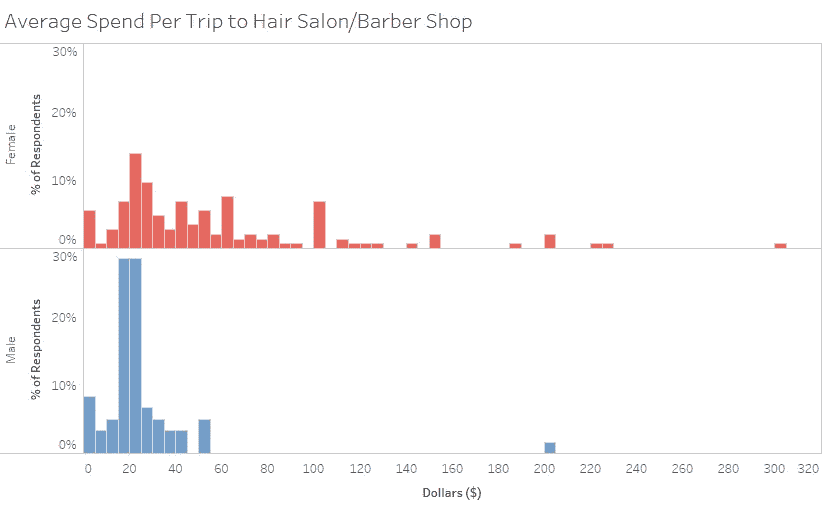
将每位受访者的年度旅行次数乘以他/她每次旅行的花费,男性平均每年在发廊/理发店的花费约为 154.44 美元,而女性平均为 257.42 美元。
乍一看,女人在头发上花的钱比男人多得多。然而,这些数字还包括花在染发、拉直、巴西吹等方面的钱。
只看花在剪刀剪头发,头发在地上理发上的钱,男人平均每次理发花费 22.74 美元,而女人平均花费 29.55 美元。尽管女性理发仍然比男性理发贵,但差别已经不那么明显了。
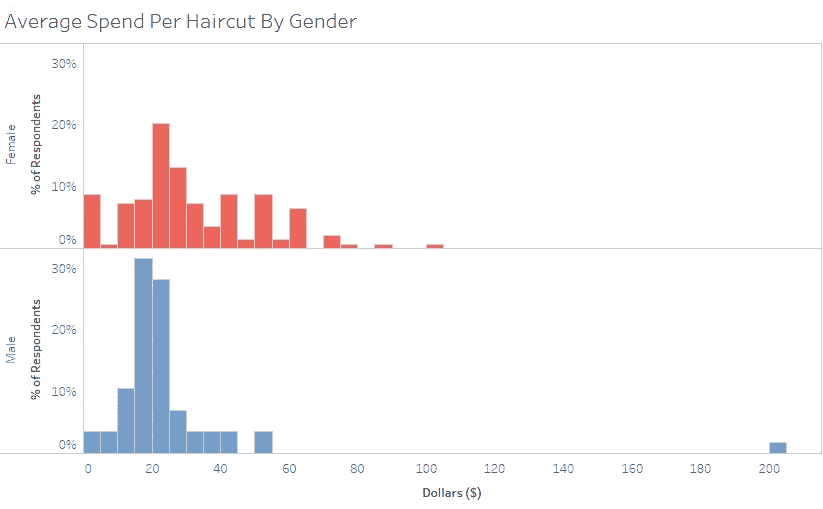
如果你把男性理发的频率(每两个月一次)和女性理发的频率(一年四次)考虑在内,男性平均每年花费 158.90 美元,而女性花费 104.21 美元。因此,从纯粹理发的角度来看,男性每年在理发上的花费实际上比女性多。
男人就是不为额外的服务付费。
在女性每年在发廊花费的 257.42 美元中,只有 40%真正用于理发——剩下的 154.45 美元用于支付额外的服务——染发、拉直、吹发等。
花在男性额外服务上的钱接近于零。乍一看,男性在理发上的花费(158.90 美元)似乎比他们在沙龙/理发店的花费(154.44 美元)要多。我有点困惑这怎么可能,直到我看到评论——几个家伙自己剪了头发。这些人拉低了发廊/理发店的平均频率和花费,而没有影响理发频率和花费。

所以我的直觉是对的…也是错的。
我同情外面所有的女人。头发护理可不是闹着玩的,可笑的是,即使是简单的理发,女孩也要比男孩多付 50%左右。
然而,仍然有意思的是,普通男生在纯理发上的花费实际上比普通女生多。女性护发费用过高的主要原因是“附加服务”,这些服务可以说是可选的。
我想过用这些事实来安慰我的女性朋友,并向她们展示她们在理发上的花费实际上比我少。但是,我其实很喜欢有女性朋友。
更有可能的是,我会保持沉默,希望有人会像我一样对这个分析感兴趣
你可能喜欢的其他文章
如果你喜欢这篇文章,请访问 LateNightFroyo.com 的,阅读关于爱情、生活等话题的话题。
什么时候去参加聚会比较合适?
阅读法律案例文件,如专业指南和分析。

Type, type, type, done!
在印度,税务案件分为直接和间接。直接税包括所得税、财产税、利息税、赠与税等。间接税包括 GST (自 2017 年生效)、增值税(仍适用于酒类、黄金、珠宝等)、关税等。我有机会分析了223k direct tax cases。最老的一个在January, 1950,而最近的一个在August, 2018。在一系列的帖子中,我很乐意从这个庞大的语料库中得出见解。就本文而言,这些是每个法院的案件数量,考虑到:
- 最高法院:
**3145** (1.4%) - 高等法院:
**64847** (29%) - 所得税上诉法庭(ITAT):
**154963** (69.6%)
解剖
法律案例文档是一个人应该如何组织任何文本的主要例子。它是*(读起来应该是)*有说服力的,而且重要的是,它沿着一条线索将读者从一点平稳地带到另一点。理解构成判决的要素及其特征对任何读者都是有用的,更不用说律师和从业者了。 此外,即使在知道大小写之前就知道一个元素的大概位置,也能加快阅读过程。
撇开创作自由、不必要的冗长和无根据的重复不谈,法律判决似乎遵循这种普遍的未明说的格式,正如一个不在法律领域的人所理解的那样:
1。开始 -对案例的快速介绍、最初提交案例的详细信息以及其他先决条件信息。
这些是 2007-08 课税年度针对劳工处的命令而提出的交叉上诉。CIT(A)-XX,新德里,2013 年 3 月 6 日。
二(一)。问题- 手头的事情,是利益点和案件的基石。争议是对法律或事实的争论。基石。问题提出了,法庭欠我们答案。
被评人提出的第一个问题是反对劳工处的行动。CIT(A)确认增加 10,747 卢比,由 AO 作为捐赠和订阅账户。
2(b)。理由- 根据当事人的观点,理由是问题。理由是问题的问题。它们是一个案件的为什么的为什么。
在编号为 921/JP/2011 的 2004-05 年度 ITA 中,税务局基于以下理由提起上诉:1 .那是身份证。CIT (A)在删除《1961 年信息技术法》第 10(23c)(iiiad)条拒绝豁免请求的规定时,在法律上以及在本案的事实和情况上都犯了错误。
2©。祈祷文 -祈祷文是对法庭的呼吁。
上诉人请求许可在审理时或之前补充、更改、修正和/或变更上诉理由。
一起,理由,问题和祈祷可以被称为提交给法院。
3。事实是案件中发生的事情。案件的论证和推理依赖于事实。虽然双方通常对事实意见一致,但如果有争议,就会产生事实问题,法院必须解决这一问题。事实包括被评人的业务/行业、进行的交易、争议的金额及/或交易等。
这个问题的简单事实是,被评估人是一家从事向其集团公司提供营销服务的公司。
4。辩护律师为自己一方辩护时提出的论点或辩护。这些论点由陈述支持,这些陈述被称为案例的推理要素。律师引用法律和判例来支持他们的主张。法官或成员也将在进行辩论时提供必要的支持。
经询问,被评估人认为这些费用实际上是在本年度发生的。
是 ld 提交的。被评税者认为 CIT(A)通过的受质疑命令是作为被评税者的单方面行为。
5。控股- 裁决,包括双方将采取的指令部分。“指令部分”表示各方要采取的行动。
有鉴于此,现阶段不需要对案件的是非曲直作出裁决。
6。结局- 以一种浓缩的控股形式作为裁决,来概括这个案子。
参考资料被相应地处置,没有关于费用的命令。
结果,被评人在 2008-09 及 2009-10 课税年度的上诉部分获得批准,而税务局在 2009-10 课税年度的上诉则被驳回。
理想情况下,在涉及一个以上法律问题的情况下,应重复第 2 点至第 5 点,直到所有问题都得到解决。
洞察力
平均判决长度为6.87 pages。平均来说,一个判断有2015 words呈现在69.27 sentences中,合并成22.89 paragraphs.
文本分类模型被用来预测所有判断中的这些元素。在超过 10 万个预测句子的聚合语料库中,观察到以下趋势。
这些元素的平均字符长度如下:
- 投稿:
307.09字符 - 参数
276.12字符 - 手持:
202.97字符 - 结果:
95.15字符
意见书和论辩书明显比持有和判决长。这是因为这两个要素-意见书和论点需要阐述。论元句是那些包含明确陈述的句子,如上面的例子所示。预测每一个推理/论证句子,往好里说是尝试,往坏里说是不可能。
在至少预测到一个提交的情况下,判决平均包含3.74 submissions、7.44 arguments、1.07 holdings和1.91 outcome个句子。
机器学习笔记
考虑到统计数据,一个判断将由70 sentences组成,其中只有~14 sentences属于任何一个类别。这大约发生在案件的20%左右。这是不平衡学习的一个典型例子,可以通过以下一种或多种方式来处理:欠采样、过采样、使用类似 SMOTE 的方法创建类的伪示例,或者调整模型的参数来惩罚这种不平衡。在我们的例子中,对少数类进行过采样是一个更好的方法,因为 这些元素的结构彼此非常相似。对少数类进行欠采样会导致信息丢失。
为了验证上述说法,我在训练数据中随机抽取了一个案例的问题,得到了以下结果:
1.判决是否应该在摘要中报道?
根据本案的事实和情况,同时考虑到 KSBC 禁止在外服役,法庭允许塞尔维亚共和国的开支在法律和事实上是否正确。
2。了解到的下级机构是否有材料和在法律上正确认定法案第 269D(2)(b)条包含的法定要求得到遵守?
3。这种利益是否符合为外国游客提供服务的利润,这是个问题。
4。为了支出的目的,是否提取了任何资本,或者,换句话说,发生支出的目的是否是使用作为业务资本而获得的资本。
(高亮显示的单词和短语是在表示怀疑或询问某事时使用的假设情景的经典例子。所有这些元素都可以单独评估它们的词类和其他语言特征,但那是以后的事了。)
通常,一个元素可以属于两个类(不是互斥的),而multi-label classification是合适的。然而,从上述类的一个元素开始比从其他元素开始更容易
因为一个类的大多数元素在结构上是相似的,所以一个bag of words或者一个TF-IDF方法可以很好地用于建模。Word vectors在不太大的训练集中表现不佳,而前者表现良好。
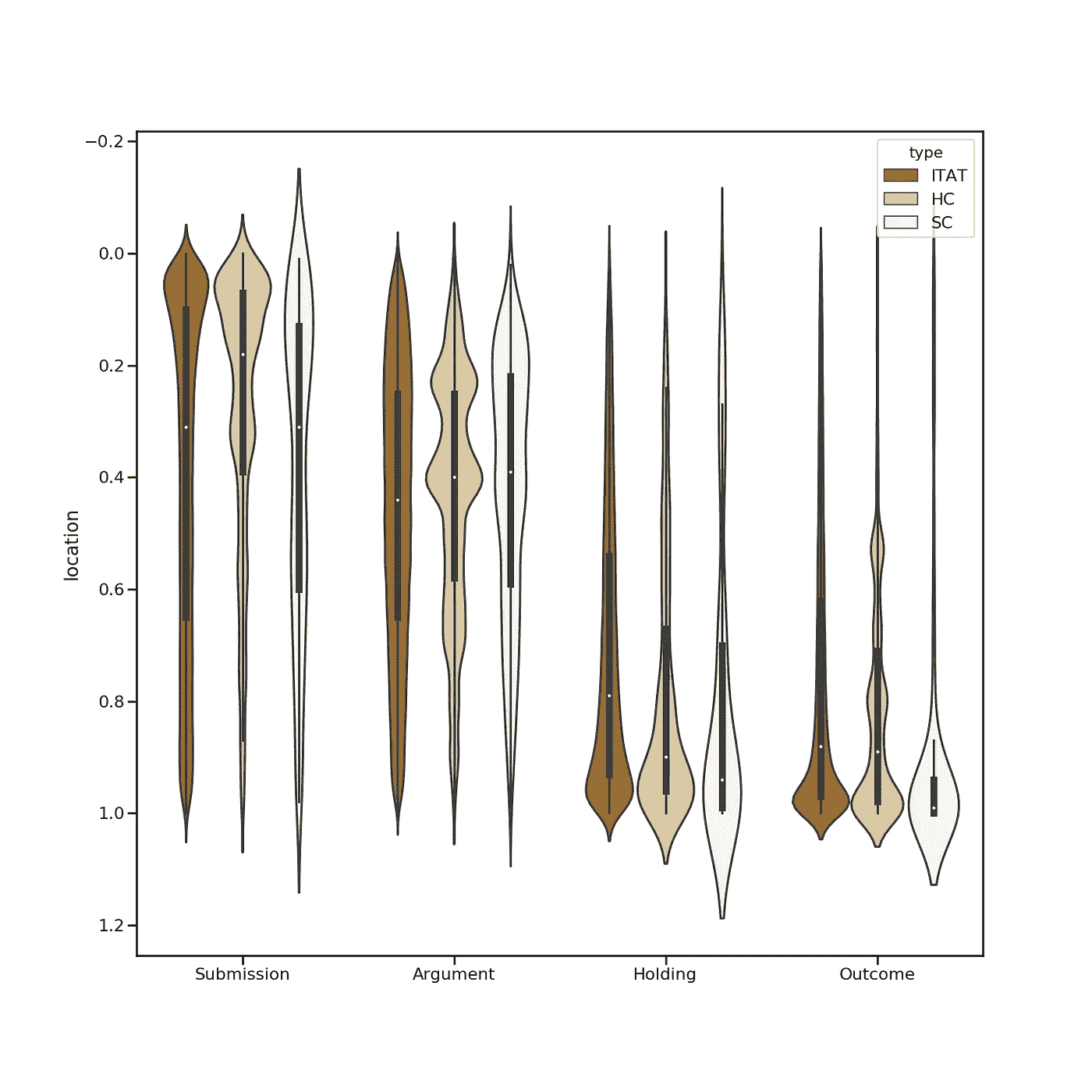
如下图所示,位置也是该车型的一个突出特点。
案件中这些要素的分布
Where’s what?
注意事项:
在 x 轴上,我们有一个案件的各种元素。为了便于理解图表, y 轴已经倒置。在 y 轴上,我们有一个案例中的位置,即从第一行开始,要到达文本中的特定行(0.2 =案例中的 20%)必须穿过案例的范围。
例如,显而易见,提交的案例(问题和理由)位于案例正文的前 40% 处。该分布持续存在并最终收敛。
分析和见解:
- 提交、支持、结果——这些要素清楚地位于案件的某些特定点上,而论点和理由几乎均匀地散布在整个案件中。
- 控股公司紧随其后的是结果声明。
- 另一方面,提交的材料和论点更多地是在高级委员会和高级委员会中提出的。这些在上面的图表中显示为块状。经分析,HC 和 SC 评委的写作风格连贯清晰。他们从清楚地描述一个问题开始,然后在继续另一个问题之前详细地讨论它。另一方面,在没有这种固定模式的 ITAT 判决中存在着一种混乱状态。
- 持有和结果声明显示了法院几乎相似的趋势。
- 事实*(上面没有显示)*分散在整个案件中。
- 这些元素的平均位置如下:
- 提交:
0.29 - 论据:
0.46 - 原因:
0.53 - 控股:
0.76 - 结果:
0.82
这个顺序验证了我们之前关于理想判断顺序的假设。
看了几年,下图小提琴情节具体化。
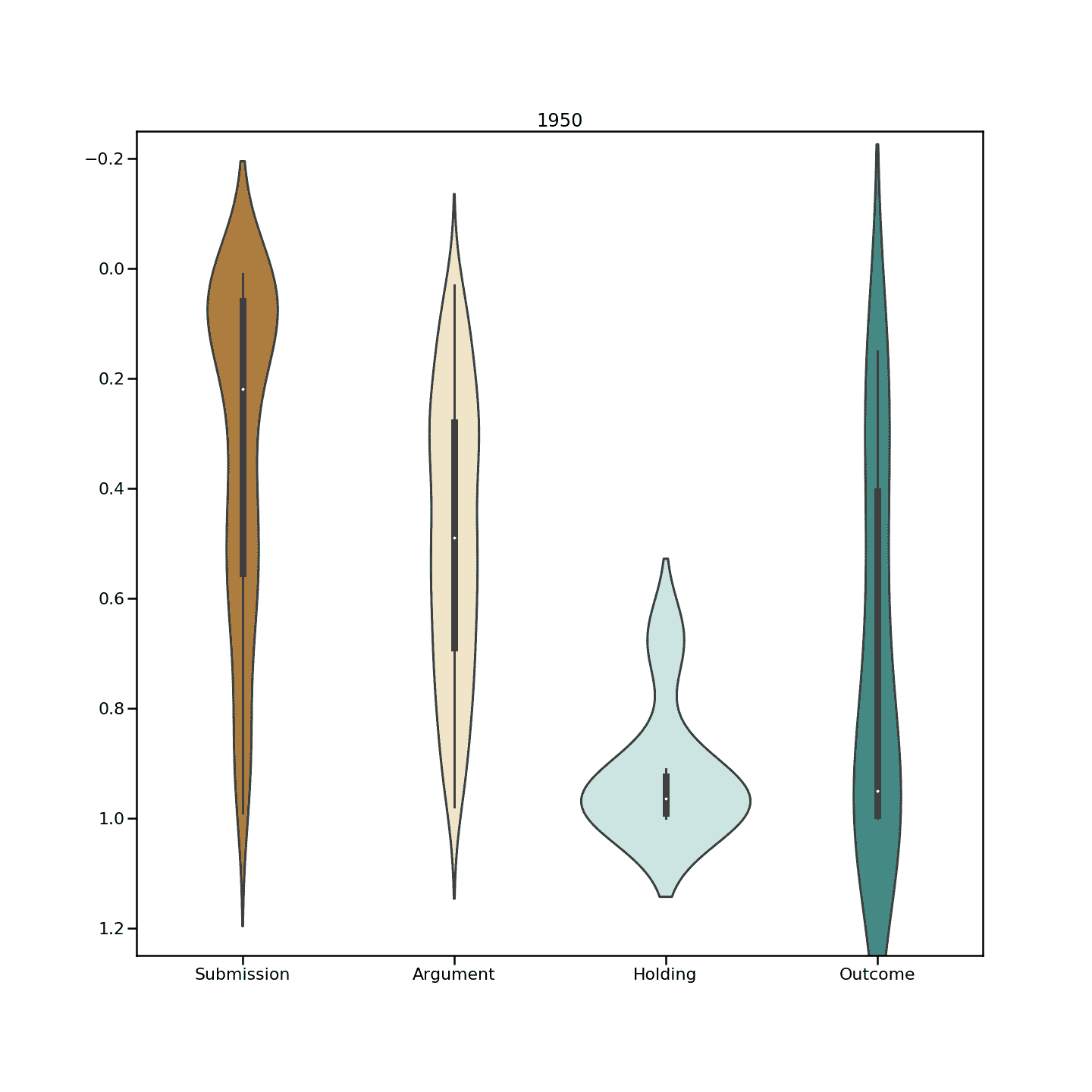
What’s where, when?
有一个明显的趋势表明,随着时间的推移,判断已经从相当结构化的要素转变为更加松散的结构。在上图中,小提琴的球形度表示判断中特定位置的元素密度。我们可以看到,这种进展是从被严重描绘(更多球状)到更分散的集中(更少球状),表明元素现在在判断中的位置方面更加分散。
虽然许多人说撰写判决书是一门艺术,但通常阅读判决书也是一门艺术。如果这种艺术形式至少在核心上是一致的,那肯定是有帮助的。
结尾注释:
- 临时命令、诉讼记录和其他非最后文件不在此分析之列,因为它们包含缺乏这些核心要素的琐碎信息。
- 数据来源-我在 Riverus 工作,一家致力于为从业者和普通民众简化法律的法律技术公司。
锚盒——质量目标检测的关键
在学习用于对象检测的卷积神经网络时,最难理解的概念之一是锚盒的概念。它也是可以优化以提高数据集性能的最重要的参数之一。事实上,如果锚盒没有正确调整,你的神经网络甚至永远不会知道某些小的、大的或不规则的对象的存在,也永远不会有机会检测到它们。幸运的是,你可以采取一些简单的步骤来确保你不会落入这个陷阱。
什么是锚盒?
当你使用像 YOLO 或 SDD 这样的神经网络来预测一张图片中的多个对象时,网络实际上正在进行成千上万次预测,并且只显示它确定为对象的那些。多个预测以下列格式输出:
预测一:(X,Y,高度,宽度),类
…。
预测~8 万:(X,Y,高度,宽度),类
其中(X,Y,高度,宽度)被称为“边界框”,或包围对象的框。这个框和 object 类由人工注释者手动标记。
在一个极其简单的示例中,假设我们有一个模型,它有两个预测,并接收到以下图像:
我们需要告诉我们的网络它的每一个预测是否正确,以便它能够学习。但是我们告诉神经网络 it 预测应该是什么呢?预测的类别应该是:
预测一:梨
预测二:苹果
或者应该是:
预测一:苹果
预测二:梨
如果网络预测:
预测一:苹果
预测二:苹果
我们需要我们网络的两个预测者能够分辨出他们的工作是预测梨还是苹果。要做到这一点,有几种工具。预测器可以专注于特定大小的对象、具有特定纵横比(高与宽)的对象或图像不同部分的对象。大多数网络使用所有三个标准。在梨/苹果图像的示例中,我们可以让预测 1 针对图像左侧的对象,预测 2 针对图像右侧的对象。那么我们就有了网络应该预测的答案:
预测一:梨
预测二:苹果
实践中的锚箱
现有技术的物体检测系统目前做以下工作:
1.为每个预测器创建数千个“锚框”或“先验框”,代表它专门预测的对象的理想位置、形状和大小。
2.对于每个锚定框,计算哪个对象的边界框具有最高的重叠除以非重叠。这被称为并集上的交集或 IOU。
3.如果最高 IOU 大于 50%,告诉锚盒它应该检测给出最高 IOU 的对象。
4.否则,如果 IOU 大于 40%,则告诉神经网络真实检测是不明确的,并且不要从该示例中学习。
5.如果最高 IOU 低于 40%,那么主播框应该预测没有对象。
这在实践中效果很好,数以千计的预测器在决定他们的对象类型是否出现在图像中方面做得非常好。看一看 RetinaNet 的开源实现,这是一个最先进的对象检测器,我们可以可视化锚框。太多了,无法一次全部形象化,然而这里只是其中的 1%:

使用默认的锚框配置可以创建太过专门化的预测器,并且出现在图像中的对象可能无法实现带有任何锚框的 50% IOU。在这种情况下,神经网络将永远不会知道这些对象的存在,也永远不会学会预测它们。我们可以将锚盒调整得更小,比如这个 1%的样本:

在 RetinaNet 配置中,最小的锚盒大小为 32x32。这意味着许多比这更小的物体将无法被探测到。这里有一个来自 WiderFace 数据集(杨,硕和罗,平和洛伊,陈变和唐,小欧)的例子,其中我们将边界框与它们各自的锚框进行匹配,但有些没有被发现:

Source: WIDER FACE
在这种情况下,只有四个基本事实边界框与任何锚框重叠。神经网络永远不会学会预测其他面孔。我们可以通过改变默认的锚盒配置来解决这个问题。减小最小的锚框尺寸,所有的脸至少与我们的锚框之一对齐,我们的神经网络可以学习检测它们!

Source: WIDER FACE
改进锚箱配置
一般来说,在开始训练模型之前,您应该问自己以下关于数据集的问题:
- 我希望能够检测到的最小尺寸的盒子是什么?
- 我希望能够检测到的最大尺寸的盒子是什么?
- 这个盒子可以有哪些形状?例如,只要汽车或摄像机不会侧翻,汽车检测器可能有短而宽的锚盒。
您可以通过实际计算数据集中最极端的大小和长宽比来获得粗略的估计。另一个物体检测器 YOLO v3 使用 K 均值来估计理想的边界框。另一个选择是学习锚箱配置。
一旦你想通了这些问题,你就可以开始设计你的锚盒了。一定要对它们进行测试,方法是对你的基本事实边界框进行编码,然后对它们进行解码,就好像它们是来自你的模型的预测一样。您应该能够恢复地面真实边界框。
此外,请记住,如果边界框和定位框的中心不同,这将减少 IOU。即使你有小的锚盒,如果锚盒之间的跨度很大,你可能会错过一些地面真相盒。改善这种情况的一种方法是将 IOU 阈值从 50%降至 40%。
David Pacassi Torrico 最近的一篇文章比较了当前人脸检测的 API 实现,强调了正确指定锚盒的重要性。你可以看到算法做得很好除了对于小脸。下面是一些 API 根本无法检测到任何人脸的图片,但我们的新模型检测到了许多人脸:


如果你喜欢这篇文章,你可能会喜欢阅读没有锚盒的对象检测*。*
锚定你的模型

“top view of two white yachts” by Tom Grimbert on Unsplash
模型解释意味着提供原因和背后的逻辑,以实现模型的可问责性和透明性。正如之前的博客(模型解释简介和 SHAP 所提到的,模型解释对于数据科学获得管理层和客户的信任非常重要。
LIME 的作者提到,LIME 在某些情况下无法正确解释模型。因此,他们提出了一种新的模型解释方法,即锚。
看完这篇文章,你会明白:
- 石灰解释的局限性
- 新方法:锚
石灰解释的局限性
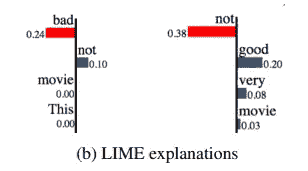
From Ribeiro, Singh, and Guestrin 2018
虽然我们可以用简单函数来局部解释复杂性,但它只能解释特定的情况。这意味着它可能不适合看不见的情况。
从以上对情绪预测的解释来看,“不”在左手边提供了积极的影响,而在右手边提供了严重的消极影响。如果我们只看其中一种解释,这是没问题的,但是如果我们把两种解释放在一起看,我们就会感到困惑。
新方法:锚
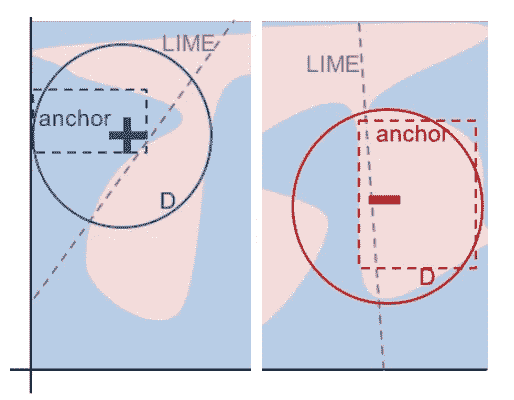
From Ribeiro, Singh, and Guestrin 2018
通过学习直线(或斜率),LIME 解释了预测结果。与 LIME 不同,Anchors 使用“局部区域”来学习如何解释模型。为了解释,“局部区域”是指生成数据集的更好构造。
有两种方法可以找到锚点。第一种是自下而上的方法,这种方法简单,但需要更多的时间来计算结果。第二种是“锚”库中采用的波束搜索。
自下而上的方法

From Ribeiro, Singh, and Guestrin 2018
该方法从空集开始。在每次迭代中,它将生成一组候选项,并且每次将添加一个新的特征谓词(特征输入)。如果规则达到精度并满足等式 3 的标准,它将停止寻找下一个特征谓词。因为它的目标是找到最短的锚点,因为他们注意到短锚点可能具有更高的覆盖率。
直觉上,有两个主要问题。一次只能添加一个功能。同样,贪婪搜索的主要目的是识别最短路径。
光束搜索方法

From Ribeiro, Singh, and Guestrin 2018
这种方法解决了贪婪搜索的局限性。它使用 KL-LUCB 算法来选择那些最佳候选。预期的结果是,这种方法比自底向上搜索更有可能识别具有更高覆盖率的锚点。
履行
explainer = anchor_text.AnchorText(spacy_nlp, labels, use_unk_distribution=True)
exp = explainer.explain_instance(x_test[idx], estimator, threshold=0.8, use_proba=True, batch_size=30)max_pred = 2
print('Key Singal from Anchors: %s' % (' AND '.join(exp.names())))
print('Precision: %.2f' % exp.precision())
print()exp.show_in_notebook()
当调用“解释实例”时,我们需要提供
- x _ test[idx]:x 的目标
- 评估者:你的模型
- 阈值:锚点使用此阈值来查找包含锚点(特征)的最小精度
- batch_size:要生成的批的数量。更多的批处理意味着生成更多可能的数据集,但也需要更长的时间
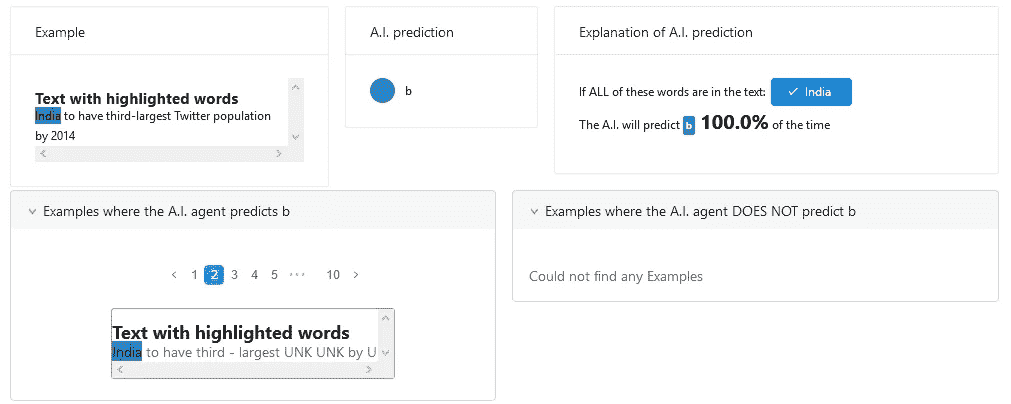
根据上面的解释,Anchors 规定“印度”是将输入分类为“b”类别的输入锚点。
外卖食品
要访问所有代码,你可以访问我的 github repo。
- 与 SHAP 相比,计算时间更少。
- 在我之前的文章中,我用 SHAP 和锚来解释这个预测。你也可以考虑使用多模型解释器。
- 标签只能接受整数。意味着不能传递准确的分类名称,只能传递编码的类别。
关于我
我是湾区的数据科学家。专注于数据科学、人工智能,尤其是 NLP 和平台相关领域的最新发展。你可以通过媒体博客、 LinkedIn 或 Github 联系我。
参考
里贝罗·m·t·辛格·s·格斯特林·C…“我为什么要相信你?”解释任何分类器的预测。2016.https://arxiv.org/pdf/1602.04938.pdf
里贝罗·m·t·辛格·s·格斯特林·C…锚:高精度模型不可知的解释。2018.https://homes.cs.washington.edu/~marcotcr/aaai18.pdf
Kaufmann E .,Kalyanakrishnan s .“Bandit 子集选择中的信息复杂性”,2013 年。http://proceedings.mlr.press/v30/Kaufmann13.pdf
奥斯卡奖颁给…数据分析?

(image credit: BRIDGEi2i.com)
第 89 届奥斯卡颁奖典礼最近在好莱坞的杜比剧院落下帷幕。魅力四射的吉米·基梅尔主持了这场活动,其结局令人想起 2015 年环球小姐选美大赛上的史蒂夫·哈维事件。
在提名预告之后,费·唐纳薇和沃伦·比蒂宣布《拉拉之地》为最佳影片。不久之后,这部电影的全体演员和工作人员冲上舞台,庆祝并准备发表演讲。
然而,唯一的问题是啦啦土地不是赢家。显然,贝蒂拿错了信封。真正的赢家是由巴里·詹金斯执导的剧情片《T4 月光》。在道歉和相当尴尬的“交流”中,错误得到了纠正。双关语。
分析公司在体育和娱乐领域做出预测的趋势每年都在增长。数据分析解决方案能够预测很多事情;然而,尴尬的时刻不在其中。
也就是说,一些分析初创公司和数据公司不时会发布对各种公众感兴趣的事件的预测——游戏、选举、电影和音乐奖项等等——主要是为了在炫耀数字技能之外找点乐子。
就奥斯卡而言,一般来说,分析公司利用的一些信息来源包括:
- 主要颁奖典礼(DGA、PGA、BAFTA、SAG 等。)
- 批评家的选择
- 以前的提名和获奖
- 流派和票房表现
- 被提名者的个人资料(年龄、记录等。)
- 社交媒体(公众情绪数据)
- 奥斯卡奖投票者的人口统计
2017 年奥斯卡颁奖典礼已经过去,许多才华横溢的艺术家获得了认可和荣誉。让我们仔细看看数据公司在奥斯卡上对各种奖项的预测。
以色列科技公司 Taykey 根据社交媒体上的对话和情绪对奥斯卡进行了预测。该公司专门从事实时情绪分析,每天跟踪数亿个数据点。
Taykey 的首席执行官 Amit Avner 说,当第 88 届奥斯卡颁奖典礼即将到来时,莱昂纳多迪卡普里奥对互联网用户的影响最大。迪卡普里奥在 80%关于他的网上聊天中得到了积极的回应。据报道,这位才华横溢的演员将制作 星球队长电影,并凭借荒野猎人获得最佳男演员奖。此外,在同一类别中失败的马特·达蒙(Matt Damon)仅获得 57%的积极回应。
Taykey 使用其专有方法确定安德鲁·加菲尔德和伊莎贝尔·于佩尔的积极情绪评级最高,分别为 86%和 76%。另一方面,艾玛·斯通的得分为 67%。
所以,这是泰基对四个主要类别的预测:
- 最佳男演员——安德鲁·加菲尔德
- 最佳女演员——伊莎贝尔·于佩尔
- 最佳男配角——马赫沙拉·阿里
- 最佳女配角——维奥拉·戴维斯
有趣的是,这些预测只有一半是真的,卡西·阿弗莱克和艾玛·斯通分别获得了最佳男演员和最佳女演员。我个人并不介意阿弗莱克击败加菲猫获得最佳男演员,因为《神奇蜘蛛侠 2》太混乱了。一个真正的漫画迷永远不会忘记。但是我跑题了。
移动大数据和人工智能解决方案提供商 Disrupted Logic Interactive 使用了奥斯卡奖数据中 17 年的数据点。这些数据点被输入该公司的软件,然后该软件使用专有的概率和关系算法来确定最佳影片的获胜者。
据报道,该软件的准确率“超过 100%”,预测学院 66%的投票者(超过 6000 人)会选择啦啦地。有那么一会儿,全世界都以为这部电影赢了,但事实并非如此。再说一次,这是一个我并不介意的结果,因为的《啦啦地》,尽管有一些令人惊叹的电影摄影,但几乎让我在影院里睡着了。(本来就是这样。)
专注于自然语言处理的人工智能初创公司 Luminoso Technologies 预测,娜塔莉·波特曼主演杰姬可能会赢得最佳影片。该公司利用 84,058 条 IMDb 评论进行了预测,报告称,“摄影”、“视觉”、“震撼”、“体验”和“杰作”等术语与获得提名的电影直接相关。然而,是月光夺走了梦寐以求的奥斯卡小金人。
总之,许多数据公司在今年的奥斯卡颁奖典礼上弄错了(尤其是最佳影片类别)。这可以归因于这样一个事实,即并不总是可能考虑到某些关键因素,如每个电影制片厂在活动开始前开展的活动。虽然有些因素可以考虑,但其他因素很难确定,更不用说研究和“借鉴”了。因此,任何分析软件都很难做出正确的预测。
现在是今年的裁决:
奥斯卡颁给了…数据分析。不是。(看到我在那里做了什么吗?)
这篇特写最早出现在 BRIDGEi2i 博客 上。
吴恩达的 Python(线性回归)机器学习教程

Machine Learning — Andrew Ng
我是一名药学本科生,一直想做的远不止是一名临床药师。我曾试图在我对它的热爱和我拥有的医疗保健知识之间找到某种融合,但在当今这个时代,人们真的会感到迷失在丰富的信息中。
6 个月前,我偶然发现了数据科学的概念及其在医疗保健行业的应用。鉴于数据和计算能力的进步,利用计算机来识别、诊断和治疗疾病不再是梦想。在更高级的层面上,计算机视觉可以帮助使用射线照相图像识别疾病,而在更简单的层面上,算法可以检测改变生活的潜在药物相互作用。
带着进入医疗 IT 行业的目标,我为那些没有技术背景的人设计了一个数据科学课程,我在这里展示了它。
斯坦福大学在 Coursera(https://www.coursera.org/learn/machine-learning)开设的吴恩达机器学习是数据科学社区强烈推荐的课程之一。经过 6 个月的基础数学和 python 培训,我开始了这门课程,以步入机器学习的世界。你们很多人都知道,这门课是在 Octave 或 Matlab 中进行的。虽然学习一些 Octave 编程并完成编程任务是很好的,但我想测试我的 python 知识,并尝试从头开始完成 python 的任务。
本文将是我撰写的系列文章的一部分,记录我在课程中编程作业的 python 实现。这绝不是其他人的指南,因为我也在不断学习,但可以作为那些希望做同样事情的人的起点。也就是说,我很高兴从你们那里收到一些建设性的反馈。
首先将使用数据集 **ex1data1.txt**进行一元线性回归
首先,我将导入所有相关的库并将数据集加载到 jupyter 笔记本中
import numpy as np
import matplotlib.pyplot as plt
import pandas as pddata=pd.read_csv("Uni_linear.txt", header=None)
为了养成良好的习惯,我会经常看数据,并对数据有良好的感觉
data.head()
data.describe()

绘制数据,以显示因变量(y)和自变量(X)之间的关系
plt.scatter(data[0],data[1])
plt.xticks(np.arange(5,30,step=5))
plt.yticks(np.arange(-5,30,step=5))
plt.xlabel("Population of City (10,000s)")
plt.ylabel("Profit ($10,000")
plt.title("Profit Vs Population")
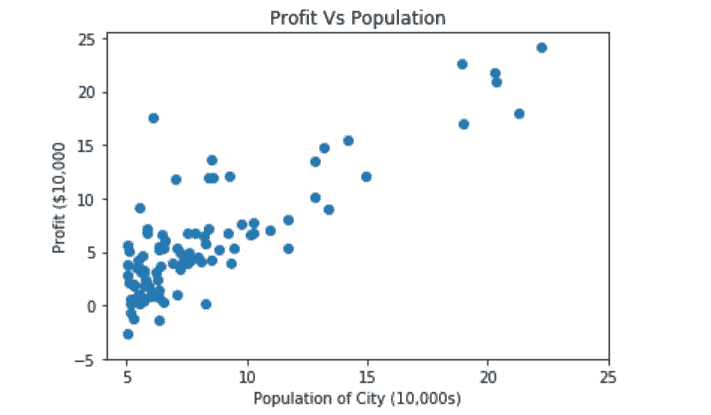
我已经习惯了这种绘制图形的方式,但是我意识到使用 matplotlib 有一种面向对象的方式,我将在本作业的其他一些图形中使用这种方式
接下来计算成本函数 J(θ)
def computeCost(X,y,theta):
"""
Take in a numpy array X,y, theta and generate the cost function of using theta as parameter in a linear regression model
"""
m=len(y)
predictions=X.dot(theta)
square_err=(predictions - y)**2
return 1/(2*m) * np.sum(square_err)
初始化 X,y 并计算使用θ=(0,0)的成本
data_n=data.values
m=len(data_n[:,-1])
X=np.append(np.ones((m,1)),data_n[:,0].reshape(m,1),axis=1)
y=data_n[:,1].reshape(m,1)
theta=np.zeros((2,1))computeCost(X,y,theta)
这可能不是最好的方法,但这是我找到的唯一一个为₀.增加一列 1 的解决方案这里的computeCost函数将给出32.072733877455676
现在通过最小化成本函数 J(θ)来实现梯度下降以优化θ
def gradientDescent(X,y,theta,alpha,num_iters):
"""
Take in numpy array X, y and theta and update theta by taking num_iters gradient steps
with learning rate of alpha
return theta and the list of the cost of theta during each iteration
"""
m=len(y)
J_history=[]
for i in range(num_iters):
predictions = X.dot(theta)
error = np.dot(X.transpose(),(predictions -y))
descent=alpha * 1/m * error
theta-=descent
J_history.append(computeCost(X,y,theta))
return theta, J_historytheta,J_history = gradientDescent(X,y,theta,0.01,1500)print("h(x) ="+str(round(theta[0,0],2))+" + "+str(round(theta[1,0],2))+"x1")
print 语句将打印出假设:*h*(*x*) = -3.63 + 1.17x₁,显示四舍五入到小数点后两位的优化θ值
为了使任务更加完整,我还尝试将标准单变量情况下的成本函数可视化
from mpl_toolkits.mplot3d import Axes3D#Generating values for theta0, theta1 and the resulting cost valuetheta0_vals=np.linspace(-10,10,100)
theta1_vals=np.linspace(-1,4,100)
J_vals=np.zeros((len(theta0_vals),len(theta1_vals)))for i in range(len(theta0_vals)):
for j in range(len(theta1_vals)):
t=np.array([theta0_vals[i],theta1_vals[j]])
J_vals[i,j]=computeCost(X,y,t)#Generating the surface plot
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
surf=ax.plot_surface(theta0_vals,theta1_vals,J_vals,cmap="coolwarm")
fig.colorbar(surf, shrink=0.5, aspect=5)
ax.set_xlabel("$\Theta_0$")
ax.set_ylabel("$\Theta_1$")
ax.set_zlabel("$J(\Theta)$")#rotate for better angle
ax.view_init(30,120)
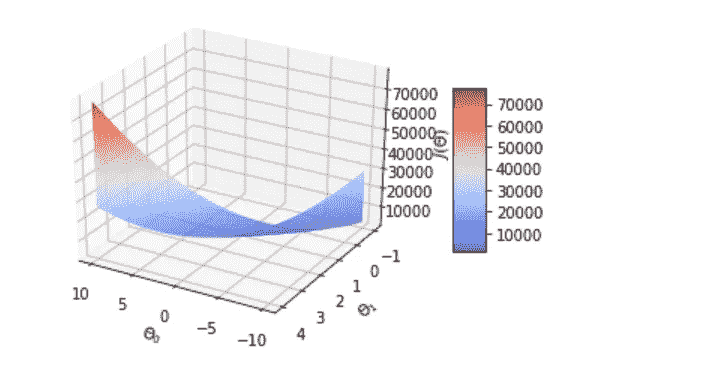
上面的代码块生成如图所示的 3d 表面图。正如在讲座中提到的,成本函数是一个凸函数,只有一个全局最小值,因此,梯度下降将总是导致找到全局最小值
顺便说一下,我使用了 mplot3d 教程来帮助我进行 3d 绘图。(https://matplotlib.org/mpl_toolkits/mplot3d/tutorial.html)
plt.plot(J_history)
plt.xlabel("Iteration")
plt.ylabel("$J(\Theta)$")
plt.title("Cost function using Gradient Descent")
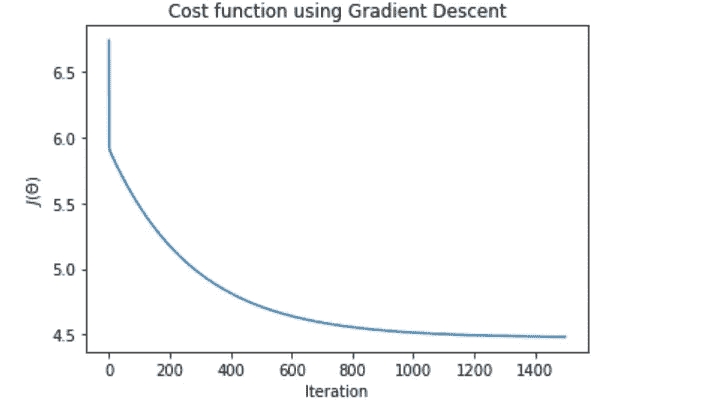
相对于迭代次数绘制成本函数给出了良好的下降趋势,表明梯度下降实现在降低成本函数方面起作用
现在,有了优化的θ值,我将把预测值(最佳拟合线)一起绘制成图
plt.scatter(data[0],data[1])
x_value=[x for x in range(25)]
y_value=[y*theta[1]+theta[0] for y in x_value]
plt.plot(x_value,y_value,color="r")
plt.xticks(np.arange(5,30,step=5))
plt.yticks(np.arange(-5,30,step=5))
plt.xlabel("Population of City (10,000s)")
plt.ylabel("Profit ($10,000")
plt.title("Profit vs Population")
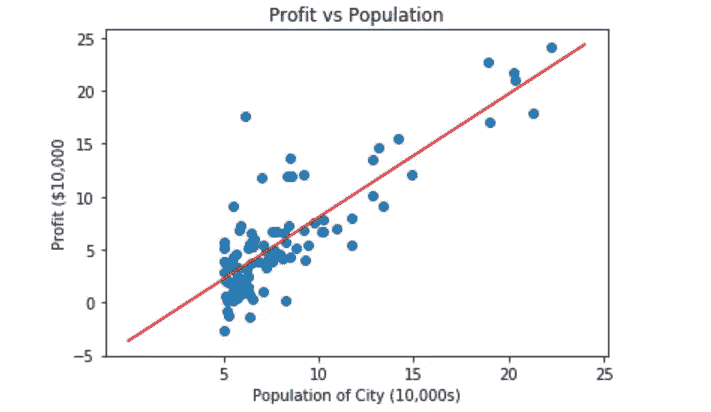
同样,这可能不是基于θ生成直线的最佳方式,如果有更好的方式,请告诉我
作业的最后一部分包括根据你的模型做出预测
def predict(x,theta):
"""
Takes in numpy array of x and theta and return the predicted value of y based on theta
"""
predictions= np.dot(theta.transpose(),x)
return predictions[0]predict1=predict(np.array([1,3.5]),theta)*10000print("For population = 35,000, we predict a profit of $"+str(round(predict1,0)))
打印报表打印:For population = 35,000, we predict a profit of $4520.0
predict2=predict(np.array([1,7]),theta)*10000
print("For population = 70,000, we predict a profit of $"+str(round(predict2,0)))
打印报表打印:For population = 70,000, we predict a profit of $45342.0

Machine Learning – Andrew Ng
现在使用数据集 **ex1data2.txt**进行多元线性回归
与所有数据集一样,我首先加载数据并查看数据
data2=pd.read_csv("Multi_linear.txt", header=None)
data2.head()
data2.describe()
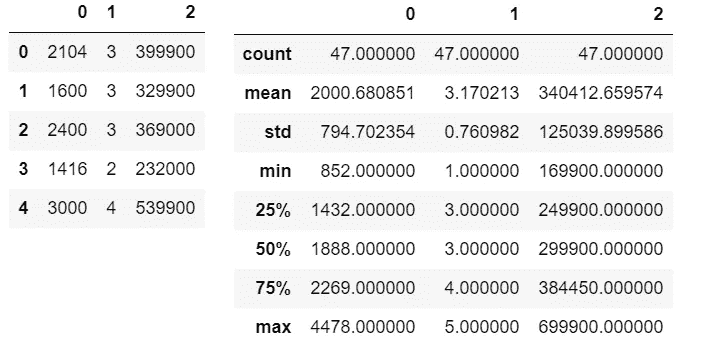
如你所见,现在 X 有两个特征,使它成为一个多元问题
# Create 2 subplot, 1 for each variable
fig, axes = plt.subplots(figsize=(12,4),nrows=1,ncols=2)axes[0].scatter(data2[0],data2[2],color="b")
axes[0].set_xlabel("Size (Square Feet)")
axes[0].set_ylabel("Prices")
axes[0].set_title("House prices against size of house")
axes[1].scatter(data2[1],data2[2],color="r")
axes[1].set_xlabel("Number of bedroom")
axes[1].set_ylabel("Prices")
axes[1].set_xticks(np.arange(1,6,step=1))
axes[1].set_title("House prices against number of bedroom")# Enhance layout
plt.tight_layout()
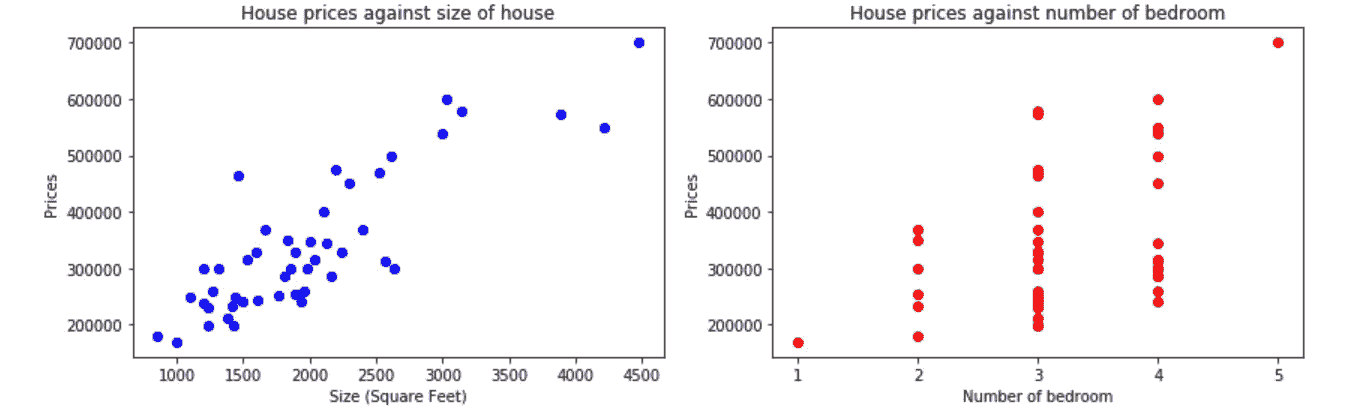
针对每个功能绘制价格图显示了它们之间的关系。仅仅通过看这个图,我们就应该期望因变量和自变量之间有某种程度的正相关。
对于使用梯度下降的多变量问题优化,需要特征归一化来加速优化过程。
def featureNormalization(X):
"""
Take in numpy array of X values and return normalize X values,
the mean and standard deviation of each feature
"""
mean=np.mean(X,axis=0)
std=np.std(X,axis=0)
X_norm = (X - mean)/std
return X_norm , mean , stddata_n2=data2.values
m2=len(data_n2[:,-1])
X2=data_n2[:,0:2].reshape(m2,2)
X2, mean_X2, std_X2 = featureNormalization(X2)
X2 = np.append(np.ones((m2,1)),X2,axis=1)
y2=data_n2[:,-1].reshape(m2,1)
theta2=np.zeros((3,1))
接下来是测试我们之前的函数,computeCost(X, y, theta)和gradientDescent(X, y, theta, alpha, num_iters)是否适用于多特征输入
使用computeCost(X2,y2,theta2)给出65591548106.45744,这是使用θ(0,0,0)作为参数的成本
theta2, J_history2 = gradientDescent(X2,y2,theta2,0.01,400)
print("h(x) ="+str(round(theta2[0,0],2))+" + "+str(round(theta2[1,0],2))+"x1 + "+str(round(theta2[2,0],2))+"x2")
打印语句 print: h(x) =334302.06 + 99411.45x1 + 3267.01x2,它是优化后的θ值,四舍五入到小数点后两位
plt.plot(J_history2)
plt.xlabel("Iteration")
plt.ylabel("$J(\Theta)$")
plt.title("Cost function using Gradient Descent")

绘制J(θ)与迭代次数的关系图给出了一个下降趋势,证明我们的gradientDescent 函数也适用于多元情况
最后,使用优化后的θ值对一栋 1650 平方英尺、有 3 间卧室的房子进行预测。
*#feature normalisation of x values
x_sample = featureNormalization(np.array([1650,3]))[0]
x_sample=np.append(np.ones(1),x_sample)
predict3=predict(x_sample,theta2)
print("For size of house = 1650, Number of bedroom = 3, we predict a house value of $"+str(round(predict3,0)))*
此打印声明打印:For size of house = 1650, Number of bedroom = 3, we predict a house value of $430447.0
第一个练习到此为止。希望你能像我写它一样喜欢阅读它。请随时给我留下一些意见,告诉我如何改进。如果你想访问 Jupyter 笔记本来完成这个任务,我已经上传了 Github 中的代码(https://Github . com/Ben lau 93/Machine-Learning-by-Andrew-Ng-in-Python)。
对于本系列中的其他 python 实现,
感谢阅读。
吴恩达的 Python(逻辑回归)机器学习课程

Machine Learning – Andrew Ng
继续这个系列,这将是吴恩达关于逻辑回归的机器学习课程的 python 实现。
与标签为连续变量的线性回归相比,逻辑回归用于标签为离散类别数的分类问题。
和往常一样,我们从导入库和数据集开始。这个数据集包含 2 个不同的学生考试成绩和他们的大学录取状态。我们被要求根据学生的考试成绩来预测他们是否被大学录取。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pddf=pd.read_csv("ex2data1.txt",header=None)
理解数据
df.head()
df.describe()
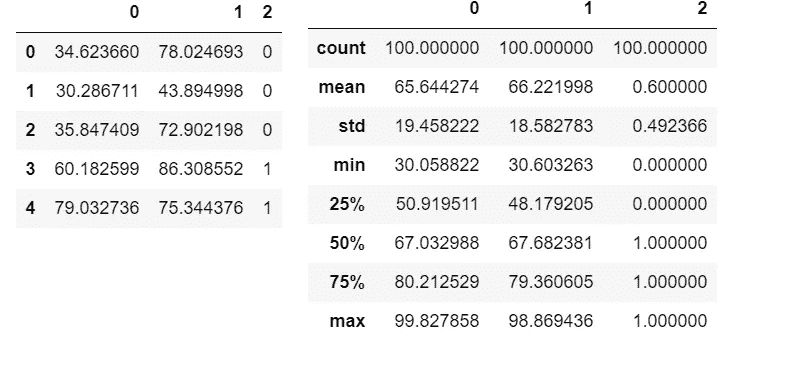
数据绘图
pos , neg = (y==1).reshape(100,1) , (y==0).reshape(100,1)
plt.scatter(X[pos[:,0],0],X[pos[:,0],1],c="r",marker="+")
plt.scatter(X[neg[:,0],0],X[neg[:,0],1],marker="o",s=10)
plt.xlabel("Exam 1 score")
plt.ylabel("Exam 2 score")
plt.legend(["Admitted","Not admitted"],loc=0)
由于这不是标准的散点图或线图,为了便于理解,我将逐步分解代码。对于分类问题,我们将独立变量彼此相对绘制,并识别不同的类别以观察它们之间的关系。因此,我们需要区分导致大学录取的 x1 和 x2 的组合和没有导致大学录取的组合。变量pos和neg就是这样做的。通过用不同的颜色和标记画出被大学录取的 x1 和 x2 的组合,我们成功地将这种关系可视化。
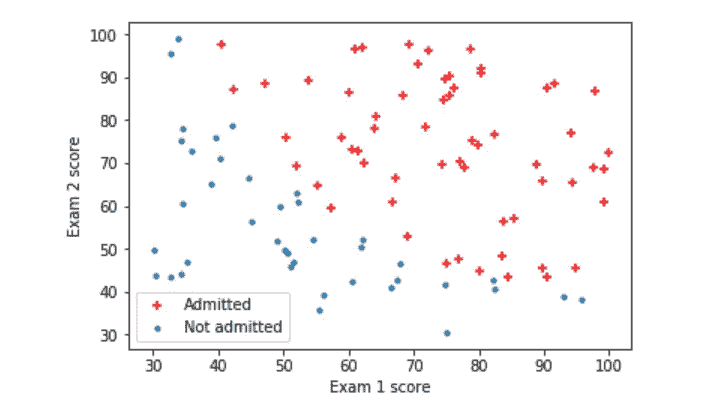
两次考试分数都较高的学生果然被大学录取了。
区分逻辑回归和线性回归的 sigmoid 函数
def sigmoid(z):
"""
return the sigmoid of z
"""
return 1/ (1 + np.exp(-z))# testing the sigmoid function
sigmoid(0)
运行sigmoid(0)功能返回 0.5
计算成本函数 J(θ)和梯度(J(θ)相对于每个θ的偏导数)
def costFunction(theta, X, y):
"""
Takes in numpy array theta, x and y and return the logistic regression cost function and gradient
"""
m=len(y)
predictions = sigmoid(np.dot(X,theta))
error = (-y * np.log(predictions)) - ((1-y)*np.log(1-predictions))cost = 1/m * sum(error)
grad = 1/m * np.dot(X.transpose(),(predictions - y))
return cost[0] , grad
设置 initial_theta 并测试成本函数
m , n = X.shape[0], X.shape[1]
X= np.append(np.ones((m,1)),X,axis=1)
y=y.reshape(m,1)
initial_theta = np.zeros((n+1,1))
cost, grad= costFunction(initial_theta,X,y)
print("Cost of initial theta is",cost)
print("Gradient at initial theta (zeros):",grad)
打印语句将打印:初始角增量的成本是0.693147180559946初始角增量处的梯度(零):[-0.1],[-12.00921659],[-11.26284221]
现在是优化算法。在任务本身中,我们被告知使用 Octave 中的fminunc函数来寻找无约束函数的最小值。至于 python 实现,有一个库可以用于类似的目的。你可以在这里找到官方文档。有各种各样优化方法可供选择,在我之前,许多其他人都在他们的 python 实现中使用过这些方法。在这里,我决定使用梯度下降来进行优化,并将结果与 Octave 中的fminunc进行比较。
在进行梯度下降之前,永远不要忘记对多元问题进行特征缩放。
def featureNormalization(X):
"""
Take in numpy array of X values and return normalize X values,
the mean and standard deviation of each feature
"""
mean=np.mean(X,axis=0)
std=np.std(X,axis=0)
X_norm = (X - mean)/std
return X_norm , mean , std
正如讲座中提到的,梯度下降算法与线性回归非常相似。唯一的区别是假设 h(x) 现在是 g(θ^tx)其中 g 是 sigmoid 函数。
def gradientDescent(X,y,theta,alpha,num_iters):
"""
Take in numpy array X, y and theta and update theta by taking num_iters gradient steps
with learning rate of alpha
return theta and the list of the cost of theta during each iteration
"""
m=len(y)
J_history =[]
for i in range(num_iters):
cost, grad = costFunction(theta,X,y)
theta = theta - (alpha * grad)
J_history.append(cost)
return theta , J_history
我一直很喜欢干(不要重复自己)在编码上的说法。由于我们之前已经有了一个计算梯度的函数,我们就不重复计算了,在这里添加一个α项来更新θ。
由于作业没有实现梯度下降,我不得不测试一些 alpha 和 num_iters 值来找到最佳值。
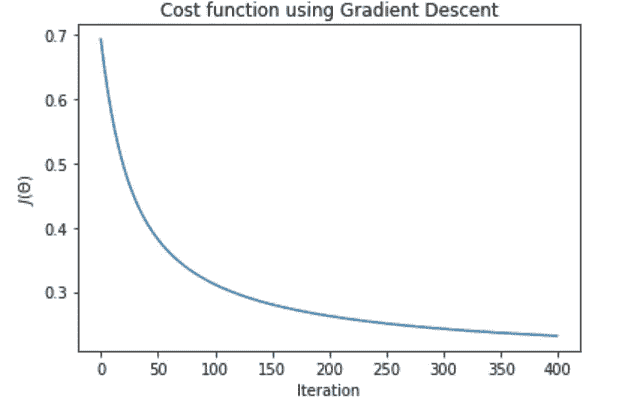
使用alpha=0.01, num_iters=400,

梯度下降在每次迭代中降低成本函数,但是我们可以做得更好。用alpha = 0.1, num_iters =400,
好多了,但我会尝试另一个值,只是为了确保。与alpha=1, num_iters=400,
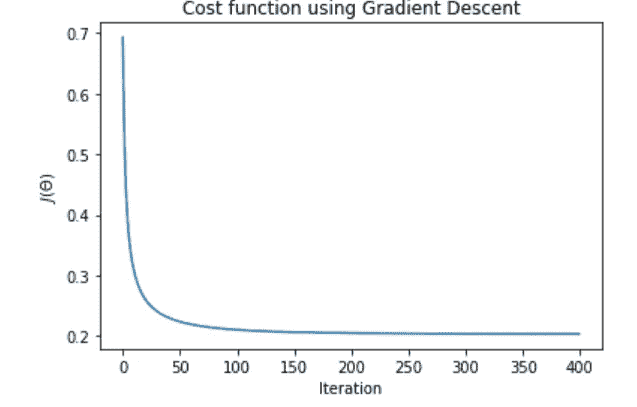
下降更剧烈,并且成本函数在 150 次迭代左右达到平稳。使用这个 alpha 和 num_iters 值,优化的θ是[1.65947664],[3.8670477],[3.60347302],结果成本是0.20360044248226664。与最初的0.693147180559946相比有了显著的改进。与 Octave 中使用fminunc的优化成本函数相比,它与任务中获得的0.203498相差不远。
接下来是使用优化的θ绘制决策边界。在课程资源中有关于如何绘制决策边界的逐步解释。链接可以在这里找到。
plt.scatter(X[pos[:,0],1],X[pos[:,0],2],c="r",marker="+",label="Admitted")
plt.scatter(X[neg[:,0],1],X[neg[:,0],2],c="b",marker="x",label="Not admitted")
x_value= np.array([np.min(X[:,1]),np.max(X[:,1])])
y_value=-(theta[0] +theta[1]*x_value)/theta[2]
plt.plot(x_value,y_value, "r")
plt.xlabel("Exam 1 score")
plt.ylabel("Exam 2 score")
plt.legend(loc=0)
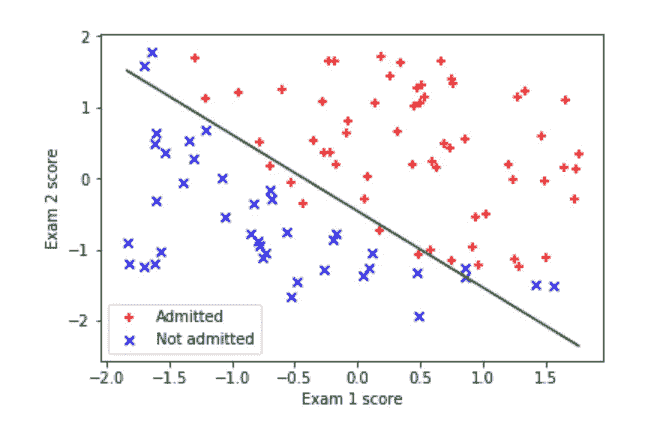
使用优化的 theta 进行预测
x_test = np.array([45,85])
x_test = (x_test - X_mean)/X_std
x_test = np.append(np.ones(1),x_test)
prob = sigmoid(x_test.dot(theta))
print("For a student with scores 45 and 85, we predict an admission probability of",prob[0])
打印语句将打印:对于一个分数为 45 和 85 的学生,我们预测录取概率为0.7677628875792492。使用fminunc非常接近0.776291。
为了找到分类器的准确性,我们计算训练集上正确分类的百分比。
def classifierPredict(theta,X):
"""
take in numpy array of theta and X and predict the class
"""
predictions = X.dot(theta)
return predictions>0p=classifierPredict(theta,X)
print("Train Accuracy:", sum(p==y)[0],"%")
如果被大学录取的概率大于 0.5,函数classifierPredict 返回一个带有True的布尔数组,否则返回False。取sum(p==y)将所有正确预测 y 值的实例相加。
print 语句 print: Train Accuracy: 89 %,表明我们的分类器正确预测了 89 %的训练集。
这都是为了逻辑回归。像往常一样,Jupyter 笔记本上传到我的 GitHub,网址是(https://GitHub . com/Ben lau 93/Machine-Learning-by-Andrew-Ng-in-Python)。
对于本系列中的其他 python 实现,
感谢您的阅读。