文章目录
- 1.1 Flume定义
- 1.2 Flume组成架构
- 1.3 Flume拓扑结构
- 1.4 Flume Agent内部原理
- 2.1 Flume安装地址
- 2.2 安装部署
- 第3章 企业开发案例
- 3.1 监控端口数据官方案例
- 3.2 实时读取本地文件到HDFS案例
- 3.3 实时读取目录文件到HDFS案例
- 3.4 单数据源多出口案例(选择器)
- 3.5 单数据源多出口案例(Sink组)
- 3.6 多数据源汇总案例
- 说下Flume事务机制
- 你是如何实现Flume数据传输的监控的
- Flume的Source,Sink,Channel的作用?你们Source是什么类型?
- Flume的Channel Selectors
- Flume参数调优
- 7.5 Flume的事务机制
- 7.6 Flume采集数据会丢失吗?
1.1 Flume定义

Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统。Flume基于流式架构,灵活简单。
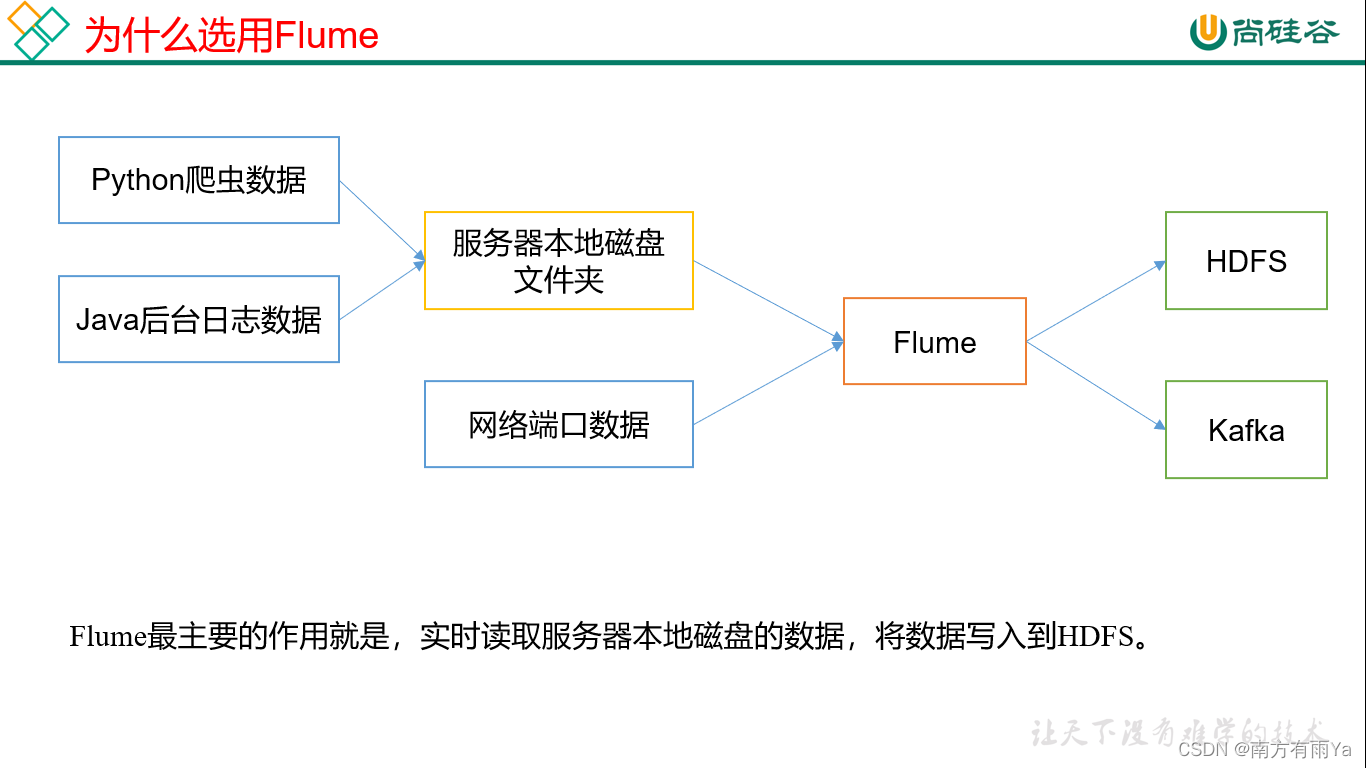
1.2 Flume组成架构
Flume组成架构如图1-1,图1-2所示:
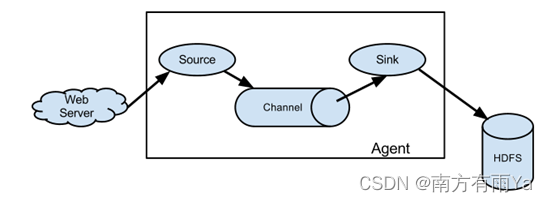
图1-1 Flume组成架构
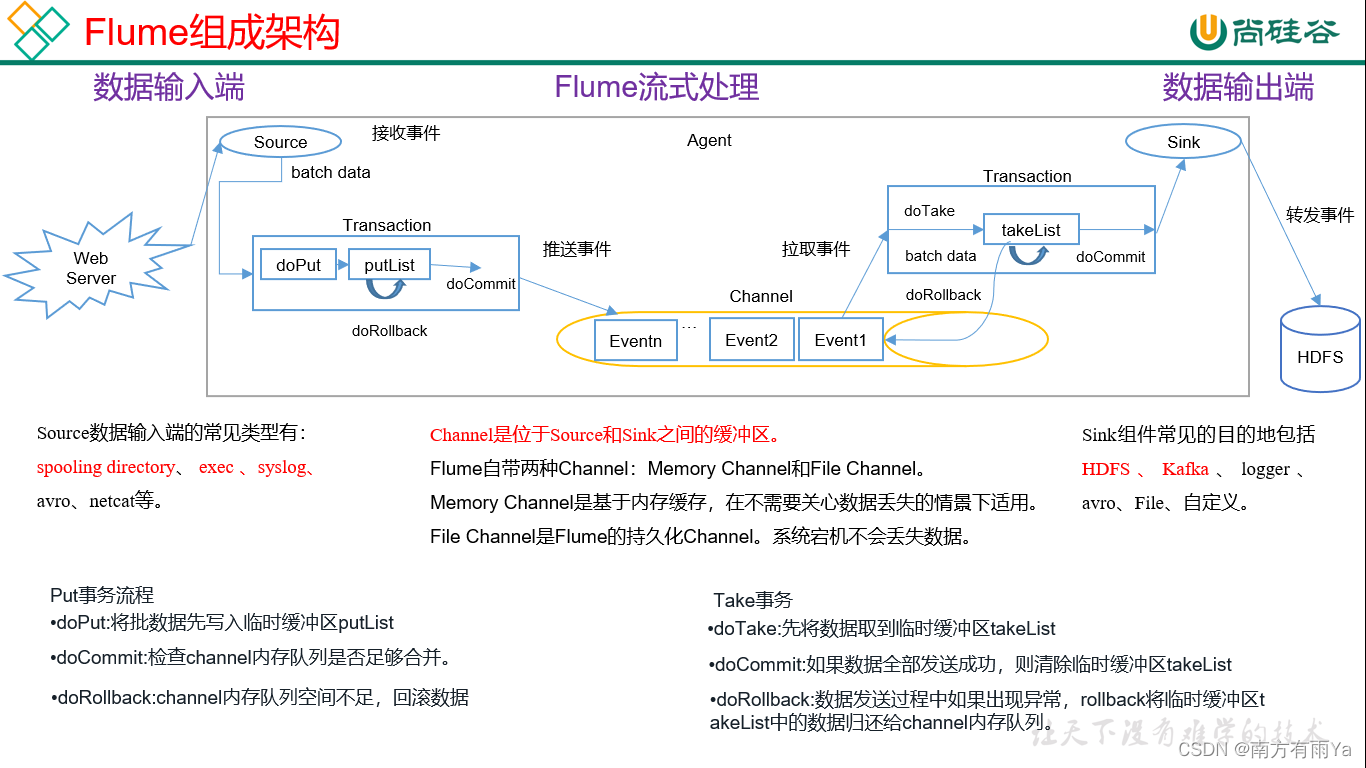
图1-2 Flume组成架构详解
下面我们来详细介绍一下Flume架构中的组件。
1.2.1 Agent
Agent是一个JVM进程,它以事件的形式将数据从源头送至目的,是Flume数据传输的基本单元。
Agent主要有3个部分组成,Source、Channel、Sink。
1.2.2 Source
Source是负责接收数据到Flume Agent的组件。Source组件可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy。
1.2.3 Channel
Channel是位于Source和Sink之间的缓冲区。因此,Channel允许Source和Sink运作在不同的速率上。Channel是线程安全的,可以同时处理几个Source的写入操作和几个Sink的读取操作。
Flume自带两种Channel:Memory Channel和File Channel。
Memory Channel是内存中的队列。Memory Channel在不需要关心数据丢失的情景下适用。如果需要关心数据丢失,那么Memory Channel就不应该使用,因为程序死亡、机器宕机或者重启都会导致数据丢失。
File Channel将所有事件写到磁盘。因此在程序关闭或机器宕机的情况下不会丢失数据。
1.2.4 Sink
Sink不断地轮询Channel中的事件且批量地移除它们,并将这些事件批量写入到存储或索引系统、或者被发送到另一个Flume Agent。
Sink是完全事务性的。在从Channel批量删除数据之前,每个Sink用Channel启动一个事务。批量事件一旦成功写出到存储系统或下一个Flume Agent,Sink就利用Channel提交事务。事务一旦被提交,该Channel从自己的内部缓冲区删除事件。
Sink组件目的地包括hdfs、logger、avro、thrift、ipc、file、null、HBase、solr、自定义。
1.2.5 Event
传输单元,Flume数据传输的基本单元,以事件的形式将数据从源头送至目的地。
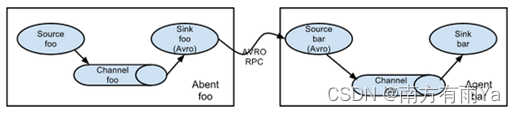
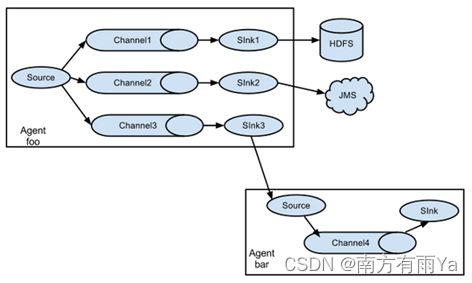
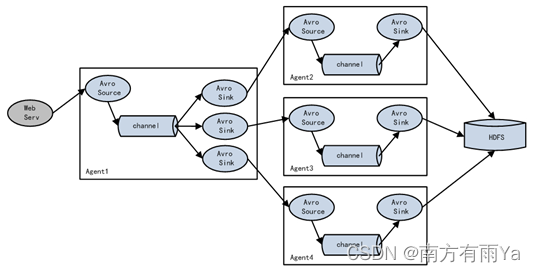
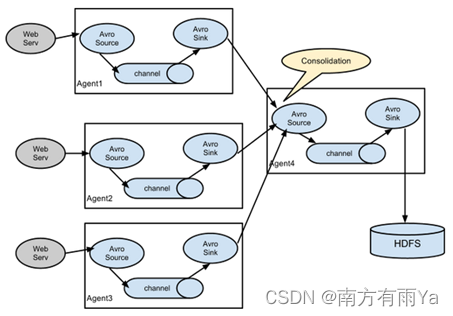
1.3 Flume拓扑结构
Flume的拓扑结构如图1-3、1-4、1-5和1-6所示:
图1-3 Flume Agent连接
图1-4 单source,多channel、sink
图1-5 Flume负载均衡
图1-6 Flume Agent聚合
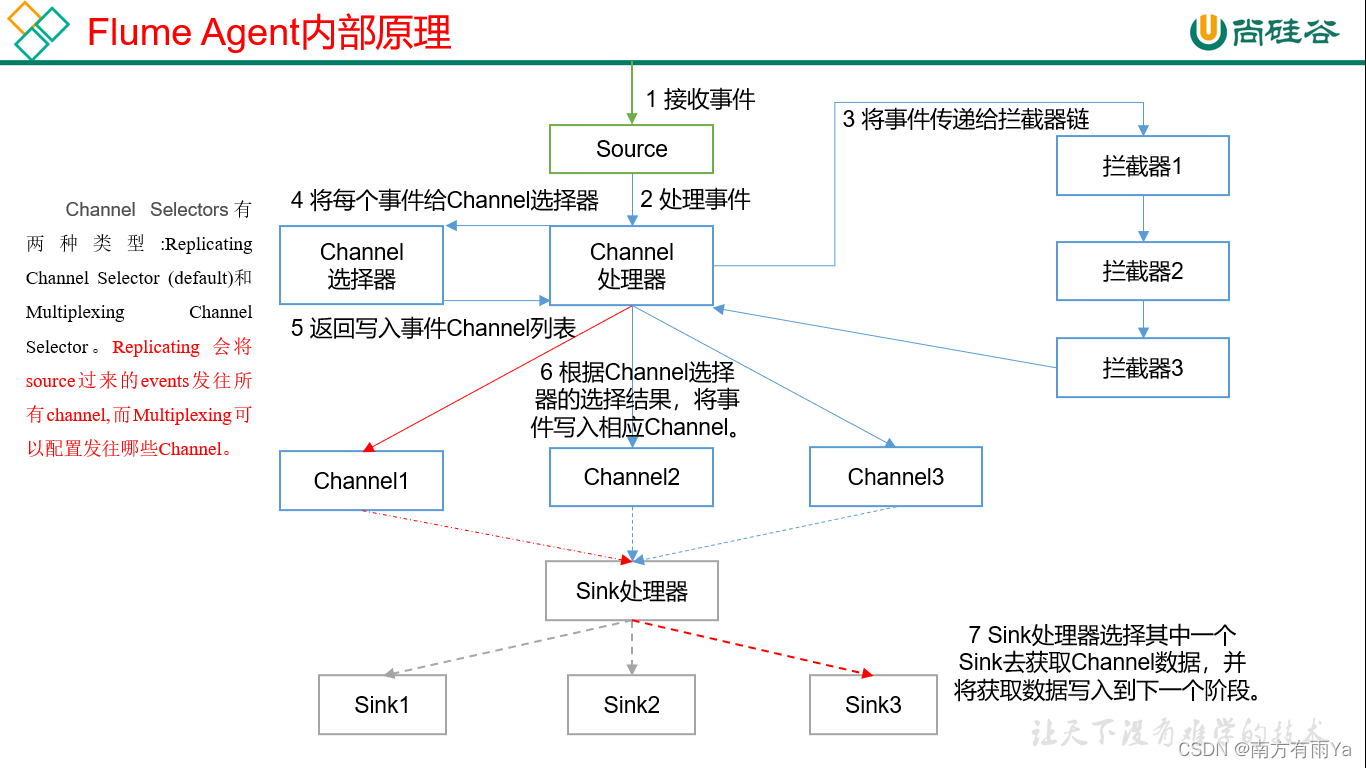
1.4 Flume Agent内部原理
2.1 Flume安装地址
1) Flume官网地址
http://flume.apache.org/
2)文档查看地址
http://flume.apache.org/FlumeUserGuide.html
3)下载地址
http://archive.apache.org/dist/flume/
2.2 安装部署
1)将apache-flume-1.7.0-bin.tar.gz上传到linux的/opt/software目录下
2)解压apache-flume-1.7.0-bin.tar.gz到/opt/module/目录下
[atguigu@hadoop102 software]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C /opt/module/
3)修改apache-flume-1.7.0-bin的名称为flume
[atguigu@hadoop102 module]$ mv apache-flume-1.7.0-bin flume
4) 将flume/conf下的flume-env.sh.template文件修改为flume-env.sh,并配置flume-env.sh文件
[atguigu@hadoop102 conf]$ mv flume-env.sh.template flume-env.sh
[atguigu@hadoop102 conf]$ vi flume-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
第3章 企业开发案例
3.1 监控端口数据官方案例
1)案例需求:首先,Flume监控本机44444端口,然后通过telnet工具向本机44444端口发送消息,最后Flume将监听的数据实时显示在控制台。
2)需求分析:
3)实现步骤:
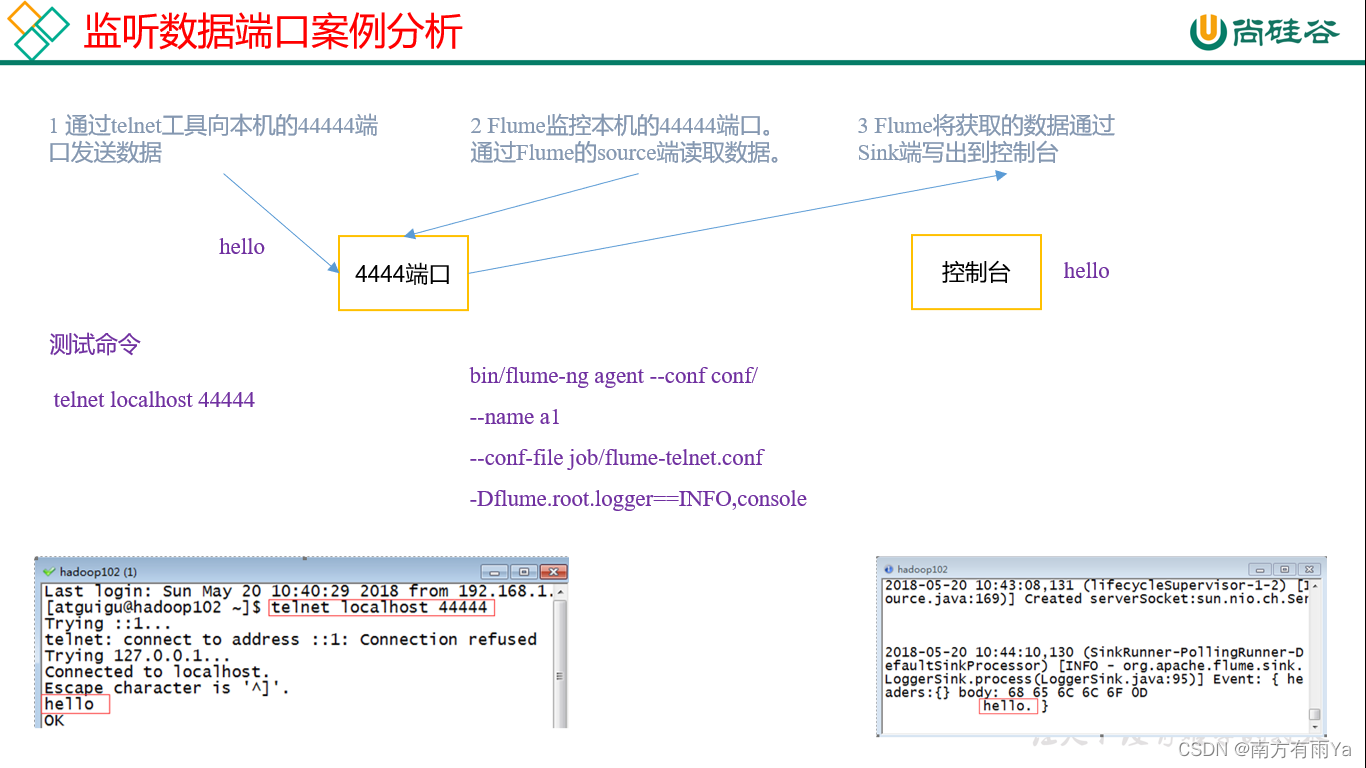
- 安装telnet工具
将rpm软件包(xinetd-2.3.14-40.el6.x86_64.rpm、telnet-0.17-48.el6.x86_64.rpm和telnet-server-0.17-48.el6.x86_64.rpm)拷入/opt/software文件夹下面。执行RPM软件包安装命令:
[atguigu@hadoop102 software]$ sudo rpm -ivh xinetd-2.3.14-40.el6.x86_64.rpm
[atguigu@hadoop102 software]$ sudo rpm -ivh telnet-0.17-48.el6.x86_64.rpm
[atguigu@hadoop102 software]$ sudo rpm -ivh telnet-server-0.17-48.el6.x86_64.rpm
- 判断44444端口是否被占用
[atguigu@hadoop102 flume-telnet]$ sudo netstat -tunlp | grep 44444
功能描述:netstat命令是一个监控TCP/IP网络的非常有用的工具,它可以显示路由表、实际的网络连接以及每一个网络接口设备的状态信息。
基本语法:netstat [选项]
选项参数:
-t或--tcp:显示TCP传输协议的连线状况;
-u或--udp:显示UDP传输协议的连线状况;
-n或--numeric:直接使用ip地址,而不通过域名服务器;
-l或--listening:显示监控中的服务器的Socket;
-p或--programs:显示正在使用Socket的程序识别码和程序名称;
3.创建Flume Agent配置文件flume-telnet-logger.conf
在flume目录下创建job文件夹并进入job文件夹。
[atguigu@hadoop102 flume]$ mkdir job
[atguigu@hadoop102 flume]$ cd job/
在job文件夹下创建Flume Agent配置文件flume-telnet-logger.conf。
[atguigu@hadoop102 job]$ touch flume-telnet-logger.conf
在flume-telnet-logger.conf文件中添加如下内容。
[atguigu@hadoop102 job]$ vim flume-telnet-logger.conf
添加内容如下:
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
注:配置文件来源于官方手册http://flume.apache.org/FlumeUserGuide.html

- 先开启flume监听端口
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/flume-telnet-logger.conf -Dflume.root.logger=INFO,console
参数说明:
--conf conf/ :表示配置文件存储在conf/目录
--name a1 :表示给agent起名为a1
--conf-file job/flume-telnet.conf :flume本次启动读取的配置文件是在job文件夹下的flume-telnet.conf文件。
-Dflume.root.logger==INFO,console :-D表示flume运行时动态修改flume.root.logger参数属性值,并将控制台日志打印级别设置为INFO级别。日志级别包括:log、info、warn、error。
- 使用telnet工具向本机的44444端口发送内容
[atguigu@hadoop102 ~]$ telnet localhost 44444
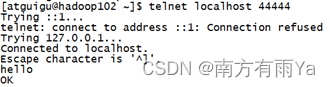
6.在Flume监听页面观察接收数据情况

3.2 实时读取本地文件到HDFS案例
1)案例需求:实时监控Hive日志,并上传到HDFS中
2)需求分析:
3)实现步骤:
-
Flume要想将数据输出到HDFS,必须持有Hadoop相关jar包
将commons-configuration-1.6.jar、
hadoop-auth-2.7.2.jar、
hadoop-common-2.7.2.jar、
hadoop-hdfs-2.7.2.jar、
commons-io-2.4.jar、
htrace-core-3.1.0-incubating.jar
拷贝到/opt/module/flume/lib文件夹下。 -
创建flume-file-hdfs.conf文件
创建文件
[atguigu@hadoop102 job]$ touch flume-file-hdfs.conf
注:要想读取Linux系统中的文件,就得按照Linux命令的规则执行命令。由于Hive日志在Linux系统中所以读取文件的类型选择:exec即execute执行的意思。表示执行Linux命令来读取文件。
[atguigu@hadoop102 job]$ vim flume-file-hdfs.conf
添加如下内容
# Name the components on this agent
a2.sources = r2
a2.sinks = k2
a2.channels = c2
# Describe/configure the source
a2.sources.r2.type = exec
a2.sources.r2.command = tail -F /opt/module/hive/logs/hive.log
a2.sources.r2.shell = /bin/bash -c
# Describe the sink
a2.sinks.k2.type = hdfs
a2.sinks.k2.hdfs.path = hdfs://hadoop102:9000/flume/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k2.hdfs.filePrefix = logs-
#是否按照时间滚动文件夹
a2.sinks.k2.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k2.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k2.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k2.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k2.hdfs.batchSize = 1000
#设置文件类型,可支持压缩
a2.sinks.k2.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k2.hdfs.rollInterval = 600
#设置每个文件的滚动大小
a2.sinks.k2.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k2.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k2.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a2.channels.c2.type = memory
a2.channels.c2.capacity = 1000
a2.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r2.channels = c2
a2.sinks.k2.channel = c2

3.执行监控配置
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/flume-file-hdfs.conf
4.开启Hadoop和Hive并操作Hive产生日志
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
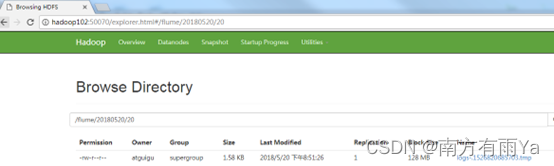
5.在HDFS上查看文件。
3.3 实时读取目录文件到HDFS案例
1)案例需求:使用Flume监听整个目录的文件
2)需求分析:
3)实现步骤:
1.创建配置文件flume-dir-hdfs.conf
创建一个文件
[atguigu@hadoop102 job]$ touch flume-dir-hdfs.conf
打开文件
[atguigu@hadoop102 job]$ vim flume-dir-hdfs.conf
添加如下内容
a3.sources = r3
a3.sinks = k3
a3.channels = c3
# Describe/configure the source
a3.sources.r3.type = spooldir
a3.sources.r3.spoolDir = /opt/module/flume/upload
a3.sources.r3.fileSuffix = .COMPLETED
a3.sources.r3.fileHeader = true
#忽略所有以.tmp结尾的文件,不上传
a3.sources.r3.ignorePattern = ([^ ]*\.tmp)
# Describe the sink
a3.sinks.k3.type = hdfs
a3.sinks.k3.hdfs.path = hdfs://hadoop102:9000/flume/upload/%Y%m%d/%H
#上传文件的前缀
a3.sinks.k3.hdfs.filePrefix = upload-
#是否按照时间滚动文件夹
a3.sinks.k3.hdfs.round = true
#多少时间单位创建一个新的文件夹
a3.sinks.k3.hdfs.roundValue = 1
#重新定义时间单位
a3.sinks.k3.hdfs.roundUnit = hour
#是否使用本地时间戳
a3.sinks.k3.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a3.sinks.k3.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a3.sinks.k3.hdfs.fileType = DataStream
#多久生成一个新的文件
a3.sinks.k3.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a3.sinks.k3.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a3.sinks.k3.hdfs.rollCount = 0
#最小冗余数
a3.sinks.k3.hdfs.minBlockReplicas = 1
# Use a channel which buffers events in memory
a3.channels.c3.type = memory
a3.channels.c3.capacity = 1000
a3.channels.c3.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r3.channels = c3
a3.sinks.k3.channel = c3
- 启动监控文件夹命令
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/flume-dir-hdfs.conf
说明: 在使用Spooling Directory Source时
(1) 不要在监控目录中创建并持续修改文件
(2)上传完成的文件会以.COMPLETED结尾
(3)被监控文件夹每500毫秒扫描一次文件变动
- 向upload文件夹中添加文件
在/opt/module/flume目录下创建upload文件夹
[atguigu@hadoop102 flume]$ mkdir upload
向upload文件夹中添加文件
[atguigu@hadoop102 upload]$ touch atguigu.txt
[atguigu@hadoop102 upload]$ touch atguigu.tmp
[atguigu@hadoop102 upload]$ touch atguigu.log
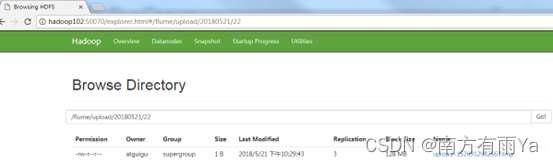
-
查看HDFS上的数据
-
等待1s,再次查询upload文件夹
[atguigu@hadoop102 upload]$ ll
总用量 0
-rw-rw-r–. 1 atguigu atguigu 0 5月 20 22:31 atguigu.log.COMPLETED
-rw-rw-r–. 1 atguigu atguigu 0 5月 20 22:31 atguigu.tmp
-rw-rw-r–. 1 atguigu atguigu 0 5月 20 22:31 atguigu.txt.COMPLETED
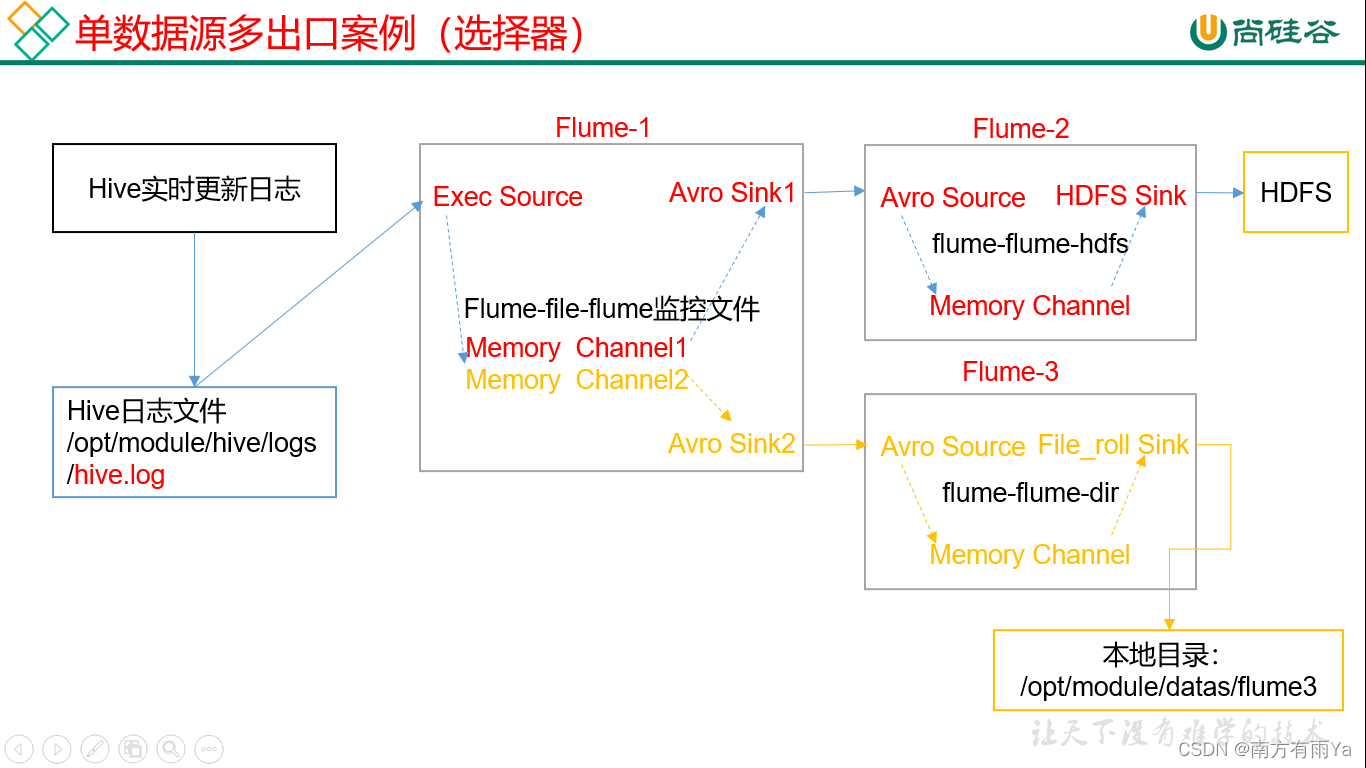
3.4 单数据源多出口案例(选择器)
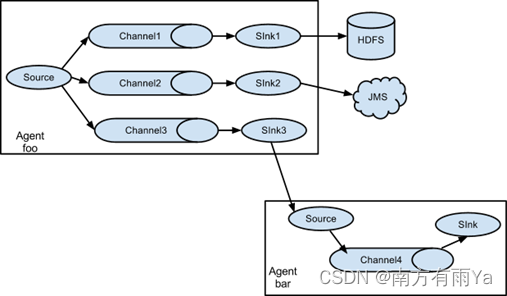
单Source多Channel、Sink如图7-2所示。
图7-2 单Source多Channel、Sink
1)案例需求:使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3负责输出到Local FileSystem。
2)需求分析:
3)实现步骤:
- 准备工作
在/opt/module/flume/job目录下创建group1文件夹
[atguigu@hadoop102 job]$ cd group1/
在/opt/module/datas/目录下创建flume3文件夹
[atguigu@hadoop102 datas]$ mkdir flume3 - 创建flume-file-flume.conf
配置1个接收日志文件的source和两个channel、两个sink,分别输送给flume-flume-hdfs和flume-flume-dir。
创建配置文件并打开
[atguigu@hadoop102 group1]$ touch flume-file-flume.conf
[atguigu@hadoop102 group1]$ vim flume-file-flume.conf
添加如下内容
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# 将数据流复制给所有channel
a1.sources.r1.selector.type = replicating
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/hive/logs/hive.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000
a1.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架。
注:RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
- 创建flume-flume-hdfs.conf
配置上级Flume输出的Source,输出是到HDFS的Sink。
创建配置文件并打开
[atguigu@hadoop102 group1]$ touch flume-flume-hdfs.conf
[atguigu@hadoop102 group1]$ vim flume-flume-hdfs.conf
添加如下内容
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = hdfs
a2.sinks.k1.hdfs.path = hdfs://hadoop102:9000/flume2/%Y%m%d/%H
#上传文件的前缀
a2.sinks.k1.hdfs.filePrefix = flume2-
#是否按照时间滚动文件夹
a2.sinks.k1.hdfs.round = true
#多少时间单位创建一个新的文件夹
a2.sinks.k1.hdfs.roundValue = 1
#重新定义时间单位
a2.sinks.k1.hdfs.roundUnit = hour
#是否使用本地时间戳
a2.sinks.k1.hdfs.useLocalTimeStamp = true
#积攒多少个Event才flush到HDFS一次
a2.sinks.k1.hdfs.batchSize = 100
#设置文件类型,可支持压缩
a2.sinks.k1.hdfs.fileType = DataStream
#多久生成一个新的文件
a2.sinks.k1.hdfs.rollInterval = 600
#设置每个文件的滚动大小大概是128M
a2.sinks.k1.hdfs.rollSize = 134217700
#文件的滚动与Event数量无关
a2.sinks.k1.hdfs.rollCount = 0
#最小冗余数
a2.sinks.k1.hdfs.minBlockReplicas = 1
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 创建flume-flume-dir.conf
配置上级Flume输出的Source,输出是到本地目录的Sink。
创建配置文件并打开
[atguigu@hadoop102 group1]$ touch flume-flume-dir.conf
[atguigu@hadoop102 group1]$ vim flume-flume-dir.conf
添加如下内容
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = file_roll
a3.sinks.k1.sink.directory = /opt/module/datas/flume3
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
提示:输出的本地目录必须是已经存在的目录,如果该目录不存在,并不会创建新的目录。
- 执行配置文件
分别开启对应配置文件:flume-flume-dir,flume-flume-hdfs,flume-file-flume。
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group1/flume-flume-dir.conf
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group1/flume-flume-hdfs.conf
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group1/flume-file-flume.conf
- 启动Hadoop和Hive
[atguigu@hadoop102 hadoop-2.7.2]$ sbin/start-dfs.sh
[atguigu@hadoop103 hadoop-2.7.2]$ sbin/start-yarn.sh
[atguigu@hadoop102 hive]$ bin/hive
hive (default)>
-
检查HDFS上数据
-
检查/opt/module/datas/flume3目录中数据
[atguigu@hadoop102 flume3]$ ll
总用量 8
-rw-rw-r–. 1 atguigu atguigu 5942 5月 22 00:09 1526918887550-3
3.5 单数据源多出口案例(Sink组)
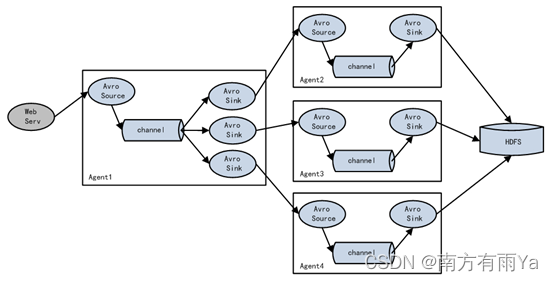
单Source、Channel多Sink(负载均衡)如图7-3所示。
图7-3 单Source、Channel多Sink
1)案例需求:使用Flume-1监控文件变动,Flume-1将变动内容传递给Flume-2,Flume-2负责存储到HDFS。同时Flume-1将变动内容传递给Flume-3,Flume-3也负责存储到HDFS
2)需求分析:
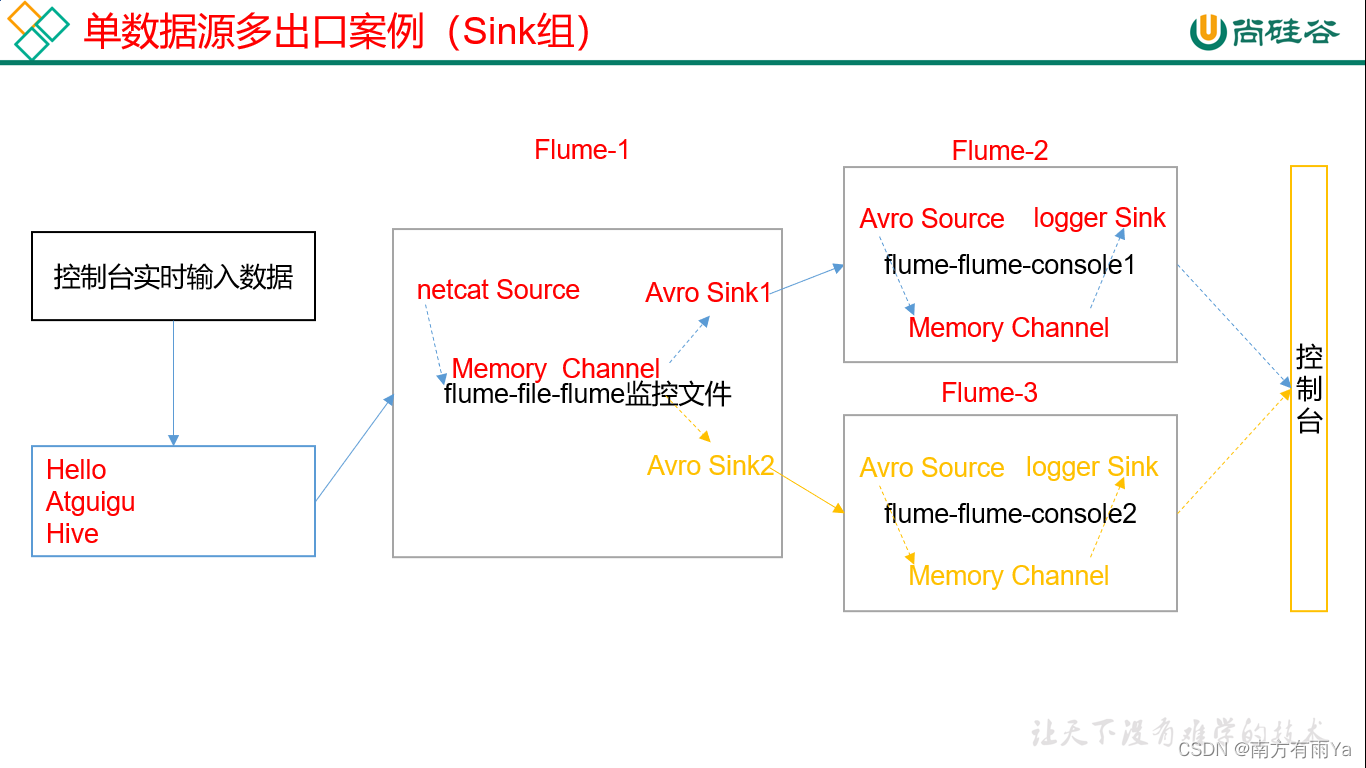
3)实现步骤:
- 准备工作
在/opt/module/flume/job目录下创建group2文件夹
[atguigu@hadoop102 job]$ cd group2/ - 创建flume-netcat-flume.conf
配置1个接收日志文件的source和1个channel、两个sink,分别输送给flume-flume-console1和flume-flume-console2。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-netcat-flume.conf
[atguigu@hadoop102 group2]$ vim flume-netcat-flume.conf
添加如下内容
# Name the components on this agent
a1.sources = r1
a1.channels = c1
a1.sinkgroups = g1
a1.sinks = k1 k2
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = round_robin
a1.sinkgroups.g1.processor.selector.maxTimeOut=10000
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop102
a1.sinks.k1.port = 4141
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop102
a1.sinks.k2.port = 4142
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c1
注:Avro是由Hadoop创始人Doug Cutting创建的一种语言无关的数据序列化和RPC框架。
注:RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。
- 创建flume-flume-console1.conf
配置上级Flume输出的Source,输出是到本地控制台。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-flume-console1.conf
[atguigu@hadoop102 group2]$ vim flume-flume-console1.conf
添加如下内容
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = avro
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 4141
# Describe the sink
a2.sinks.k1.type = logger
# Describe the channel
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 创建flume-flume-console2.conf
配置上级Flume输出的Source,输出是到本地控制台。
创建配置文件并打开
[atguigu@hadoop102 group2]$ touch flume-flume-console2.conf
[atguigu@hadoop102 group2]$ vim flume-flume-console2.conf
添加如下内容
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c2
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop102
a3.sources.r1.port = 4142
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c2.type = memory
a3.channels.c2.capacity = 1000
a3.channels.c2.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c2
a3.sinks.k1.channel = c2
- 执行配置文件
分别开启对应配置文件:flume-flume-console2,flume-flume-console1,flume-netcat-flume。
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group2/flume-flume-console2.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group2/flume-flume-console1.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group2/flume-netcat-flume.conf
-
使用telnet工具向本机的44444端口发送内容
$ telnet localhost 44444 -
查看Flume2及Flume3的控制台打印日志
3.6 多数据源汇总案例
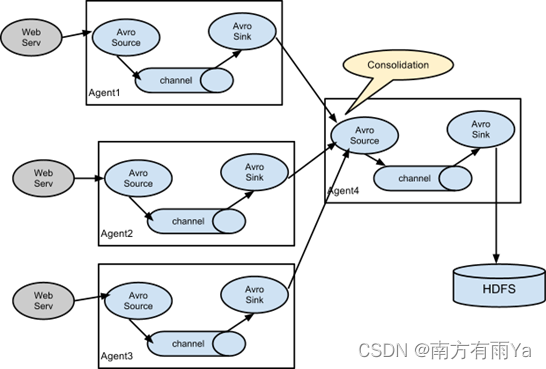
多Source汇总数据到单Flume如图7-4所示。
图7-4多Flume汇总数据到单Flume
1) 案例需求:
hadoop103上的Flume-1监控文件/opt/module/group.log,
hadoop102上的Flume-2监控某一个端口的数据流,
Flume-1与Flume-2将数据发送给hadoop104上的Flume-3,Flume-3将最终数据打印到控制台。
2)需求分析:
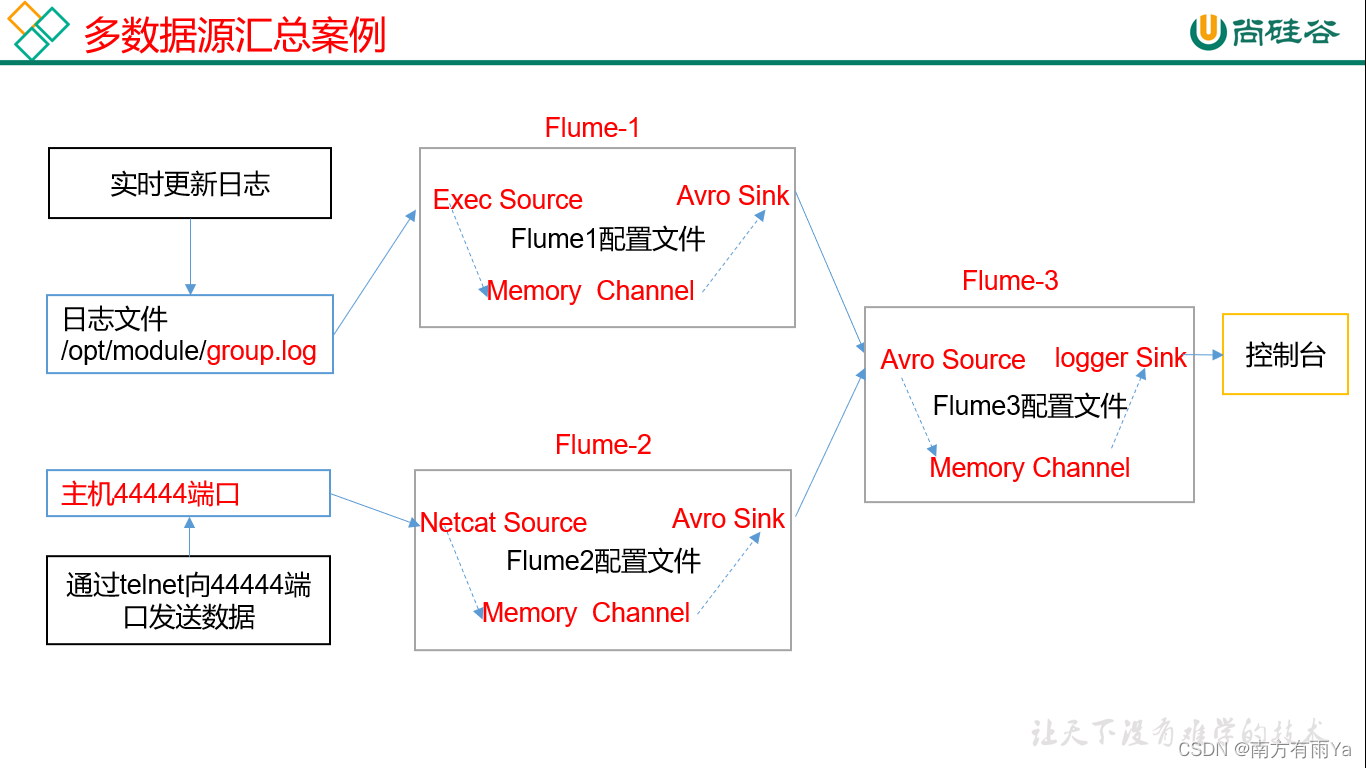
3)实现步骤:
-
准备工作
分发Flume
[atguigu@hadoop102 module]$ xsync flume
在hadoop102、hadoop103以及hadoop104的/opt/module/flume/job目录下创建一个group3文件夹。
[atguigu@hadoop102 job]$ mkdir group3
[atguigu@hadoop103 job]$ mkdir group3
[atguigu@hadoop104 job]$ mkdir group3 -
创建flume1-logger-flume.conf
配置Source用于监控hive.log文件,配置Sink输出数据到下一级Flume。
在hadoop103上创建配置文件并打开
[atguigu@hadoop103 group3]$ touch flume1-logger-flume.conf
[atguigu@hadoop103 group3]$ vim flume1-logger-flume.conf
添加如下内容
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /opt/module/group.log
a1.sources.r1.shell = /bin/bash -c
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop104
a1.sinks.k1.port = 4141
# Describe the channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
- 创建flume2-netcat-flume.conf
配置Source监控端口44444数据流,配置Sink数据到下一级Flume:
在hadoop102上创建配置文件并打开
[atguigu@hadoop102 group3]$ touch flume2-netcat-flume.conf
[atguigu@hadoop102 group3]$ vim flume2-netcat-flume.conf
添加如下内容
# Name the components on this agent
a2.sources = r1
a2.sinks = k1
a2.channels = c1
# Describe/configure the source
a2.sources.r1.type = netcat
a2.sources.r1.bind = hadoop102
a2.sources.r1.port = 44444
# Describe the sink
a2.sinks.k1.type = avro
a2.sinks.k1.hostname = hadoop104
a2.sinks.k1.port = 4141
# Use a channel which buffers events in memory
a2.channels.c1.type = memory
a2.channels.c1.capacity = 1000
a2.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a2.sources.r1.channels = c1
a2.sinks.k1.channel = c1
- 创建flume3-flume-logger.conf
配置source用于接收flume1与flume2发送过来的数据流,最终合并后sink到控制台。
在hadoop104上创建配置文件并打开
[atguigu@hadoop104 group3]$ touch flume3-flume-logger.conf
[atguigu@hadoop104 group3]$ vim flume3-flume-logger.conf
添加如下内容
# Name the components on this agent
a3.sources = r1
a3.sinks = k1
a3.channels = c1
# Describe/configure the source
a3.sources.r1.type = avro
a3.sources.r1.bind = hadoop104
a3.sources.r1.port = 4141
# Describe the sink
# Describe the sink
a3.sinks.k1.type = logger
# Describe the channel
a3.channels.c1.type = memory
a3.channels.c1.capacity = 1000
a3.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a3.sources.r1.channels = c1
a3.sinks.k1.channel = c1
- 执行配置文件
分别开启对应配置文件:flume3-flume-logger.conf,flume2-netcat-flume.conf,flume1-logger-flume.conf。
[atguigu@hadoop104 flume]$ bin/flume-ng agent --conf conf/ --name a3 --conf-file job/group3/flume3-flume-logger.conf -Dflume.root.logger=INFO,console
[atguigu@hadoop102 flume]$ bin/flume-ng agent --conf conf/ --name a2 --conf-file job/group3/flume2-netcat-flume.conf
[atguigu@hadoop103 flume]$ bin/flume-ng agent --conf conf/ --name a1 --conf-file job/group3/flume1-logger-flume.conf
-
在hadoop103上向/opt/module目录下的group.log追加内容
[atguigu@hadoop103 module]$ echo ‘hello’ > group.log -
在hadoop102上向44444端口发送数据
[atguigu@hadoop102 flume]$ telnet hadoop102 44444 -
检查hadoop104上数据
说下Flume事务机制
1.事务
Flume使用两个独立的事务分别负责从soucrce到channel,以及从channel到sink的事件传递。一旦事务中所有的事件全部传递到channel且提交成功,那么source就将该文件标记为完成。同理,事务以类似的方式处理从channel到sink的传递过程,如果因为某种 原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到channel中,等待重新传递。
Flume的事务机制,总的来说,保证了source产生的每个事件都会传送到sink中。这样就造成每个source产生的事件至少到达sink一次,换句话说就是同一事件有可能重复到达。
2.Channel配置
Flume中提供的Channel实现主要有三个:
Memory Channel event保存在Java Heap中。如果允许数据小量丢失,推荐使用。(宕机可能丢失数据)
File Channel event保存在本地文件中,可靠性高,但吞吐量低于Memory Channel
JDBC Channel event保存在关系数据中,一般不推荐使用
你是如何实现Flume数据传输的监控的
使用第三方框架Ganglia实时监控Flume。
Flume的Source,Sink,Channel的作用?你们Source是什么类型?
1、作用
(1)Source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy
(2)Channel组件对采集到的数据进行缓存,可以存放在Memory或File中。
(3)Sink组件是用于把数据发送到目的地的组件,目的地包括Hdfs、Logger、avro、thrift、ipc、file、Hbase、solr、自定义。
2、我公司采用的Source类型为:
(1)监控后台日志:exec
(2)监控后台产生日志的端口:netcat
Exec spooldir
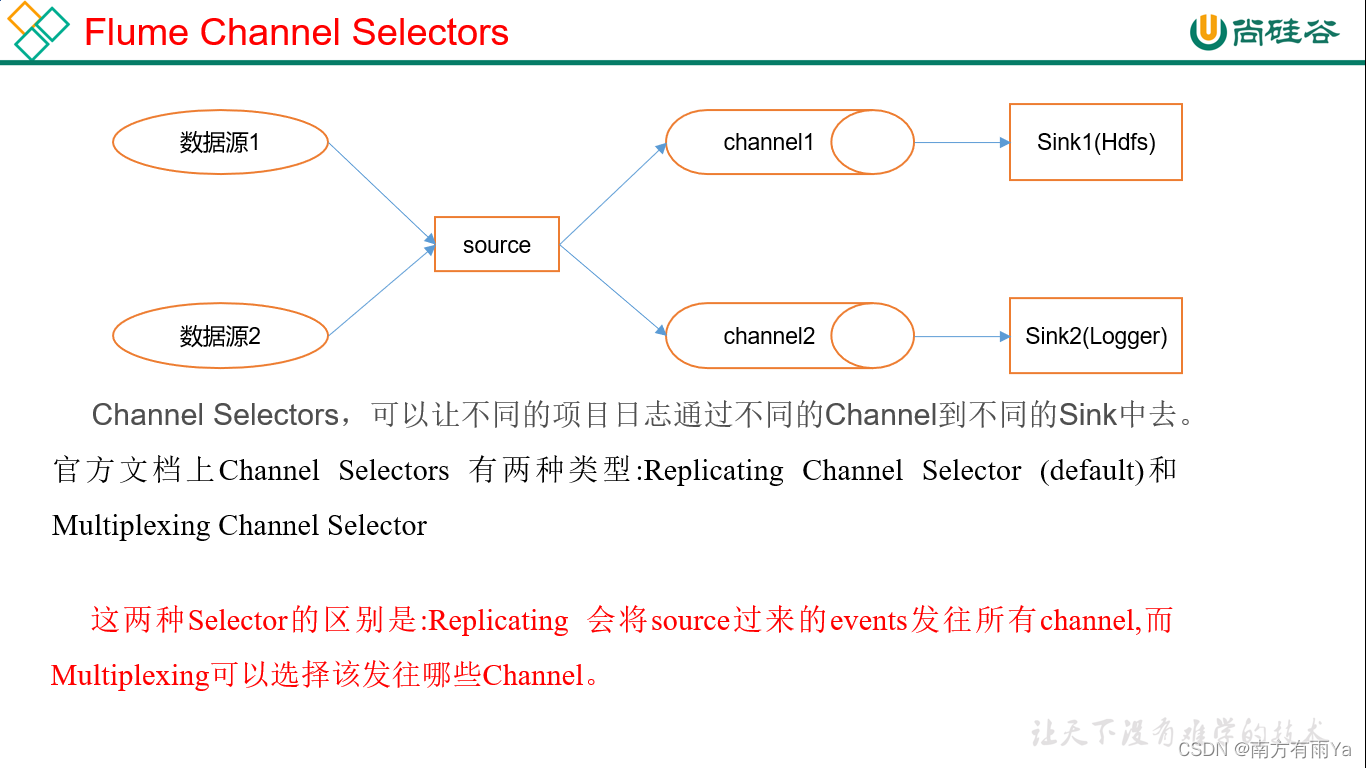
Flume的Channel Selectors
Flume参数调优
1. Source
增加Source个(使用Tair Dir Source时可增加FileGroups个数)可以增大Source的读取数据的能力。例如:当某一个目录产生的文件过多时需要将这个文件目录拆分成多个文件目录,同时配置好多个Source 以保证Source有足够的能力获取到新产生的数据。
batchSize参数决定Source一次批量运输到Channel的event条数,适当调大这个参数可以提高Source搬运Event到Channel时的性能。
2. Channel
type 选择memory时Channel的性能最好,但是如果Flume进程意外挂掉可能会丢失数据。type选择file时Channel的容错性更好,但是性能上会比memory channel差。
使用file Channel时dataDirs配置多个不同盘下的目录可以提高性能。
Capacity 参数决定Channel可容纳最大的event条数。transactionCapacity 参数决定每次Source往channel里面写的最大event条数和每次Sink从channel里面读的最大event条数。transactionCapacity需要大于Source和Sink的batchSize参数。
3. Sink
增加Sink的个数可以增加Sink消费event的能力。Sink也不是越多越好够用就行,过多的Sink会占用系统资源,造成系统资源不必要的浪费。
batchSize参数决定Sink一次批量从Channel读取的event条数,适当调大这个参数可以提高Sink从Channel搬出event的性能。
7.5 Flume的事务机制
Flume的事务机制(类似数据库的事务机制):Flume使用两个独立的事务分别负责从Soucrce到Channel,以及从Channel到Sink的事件传递。比如spooling directory source 为文件的每一行创建一个事件,一旦事务中所有的事件全部传递到Channel且提交成功,那么Soucrce就将该文件标记为完成。同理,事务以类似的方式处理从Channel到Sink的传递过程,如果因为某种原因使得事件无法记录,那么事务将会回滚。且所有的事件都会保持到Channel中,等待重新传递。
7.6 Flume采集数据会丢失吗?
不会,Channel存储可以存储在File中,数据传输自身有事务。